(WIP) Communication Overlap and Gradient/Parameter Bucketing (and Some Profiling and Debugging Logs)
27 Nov 2024< 목차 >
- Overview of Gradient Bucketing and Overlapping
- My Profiling Results for ZeRO-3 (FSDP)
- My Debugging Log on Megatron-LM
- References
Overview of Gradient Bucketing and Overlapping
Gradient Bucketing
Parameter, Gradient bucketing과 communication overlapping은 분산 학습에서 매우 중요한 기술이다.
먼저 gradient bucketing은 Data Parallel (DP)를 한다고 칠 때 서로 다른 mini-batch로 부터 얻은 averaged gradient를 합치는 모든 process가 나눠가져야 하는 All-Reduce (AR)을 할 때,
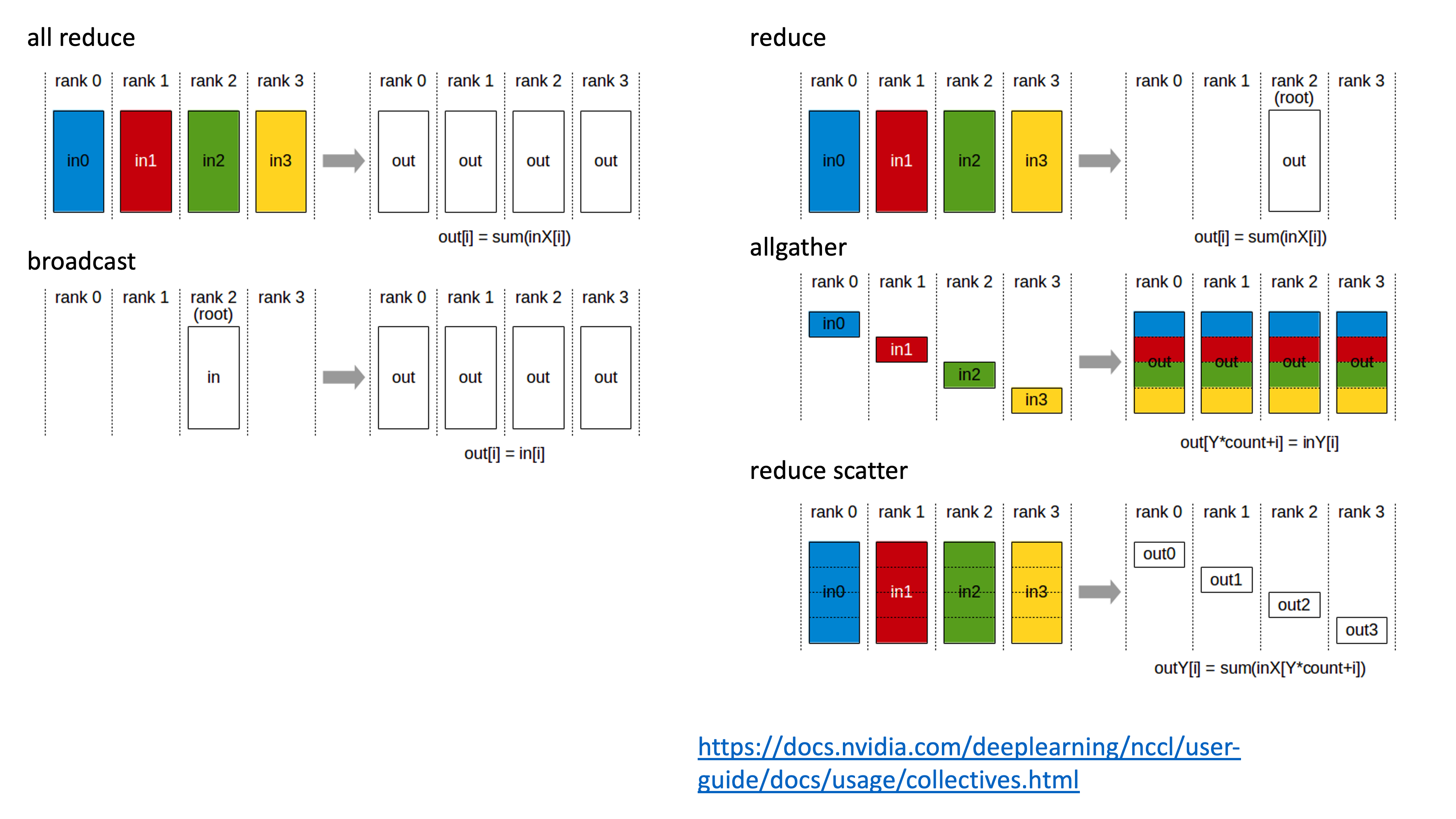 Fig. Overview of Communication Operations
Fig. Overview of Communication Operations
예를 들어 layer가 96개인데 매 layer의 gradient가 생길 대 마다 통신하는 것은 비효율적이기 때문에 50~100MB정도 사용자가 정의한 message size가 찰 때 까지 기다렸다가 통신하는 것을 의미한다.
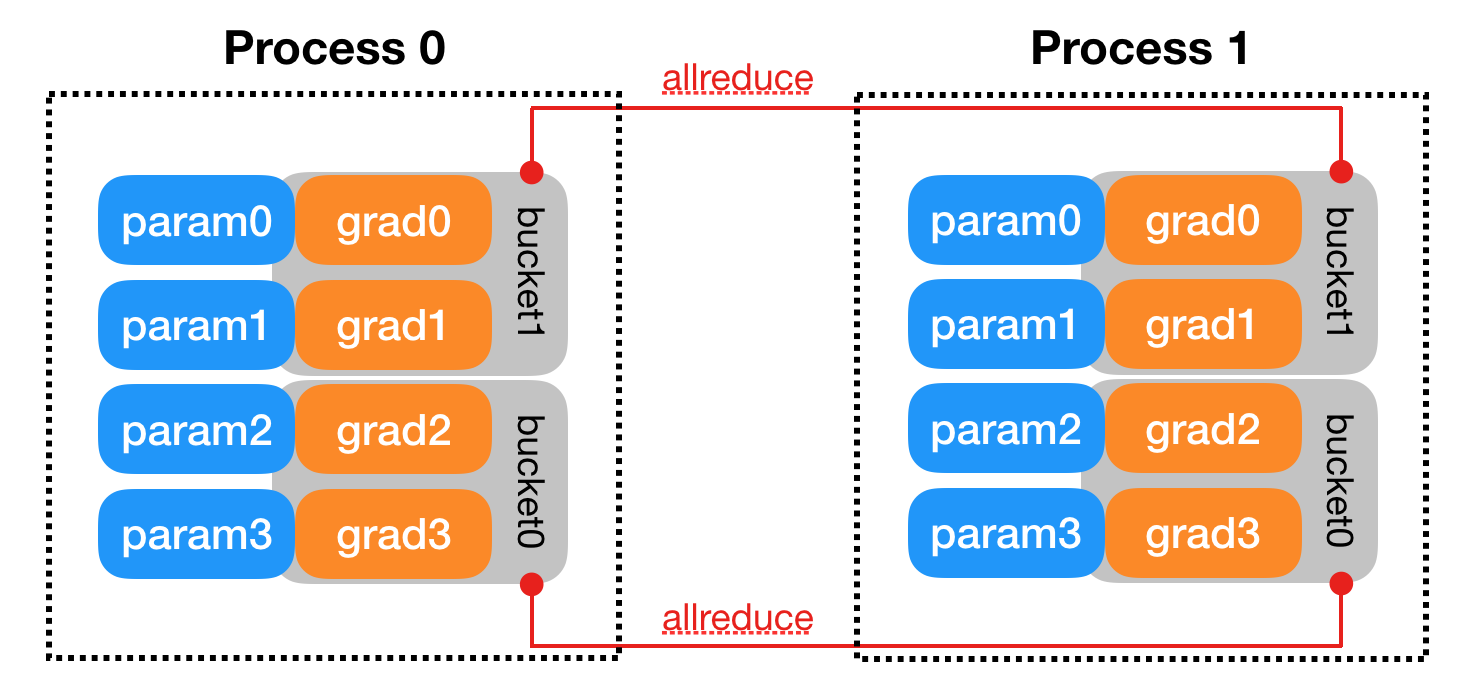 Fig.
Fig.
Communication Overlapping
이 때 gradient bucket이 찼으면 이를 통신하는것과 backpropagation을 통해 각 layer의 gradient를 순차적으로 구하는 것은 겹칠 수가 있는데,
왜냐하면 통신을 하는 것은 GPU core를 쓰는 것이 아니기 때문에 문제가 되지 않기 때문이며,
이를 Communication Overlapping이라고 한다.
 Fig.
Fig.
Overlapping은 축구에서도 많이 쓰이는 용어인데, 예를 들어 왼쪽 풀백 수비수가 왼쪽 윙어 공격수가 있는 지점까지 올라가 둘의 포지션을 겹쳐 순간적으로 2:1을 만들어 돌파하는 전략을 의미한다. Distributed training에서는 overlap을 구현하려면 CUDA stream이 통신용, GPU operation용 두 개가 만들어야 한다.
 Fig.
Fig.
일반적인 DP를 넘어 Zero Redundancy Optimizer (ZeRO)에 대해 생각해보자. gpt-2 xl size의 LLM만 돼도 그냥 DP로는 학습할 수 없기 때문에 optimizer state를 sharding해야 하며, llama 정도의 크기가 되면 (2B~7B 이상) parameter까지 sharding해야 한다.
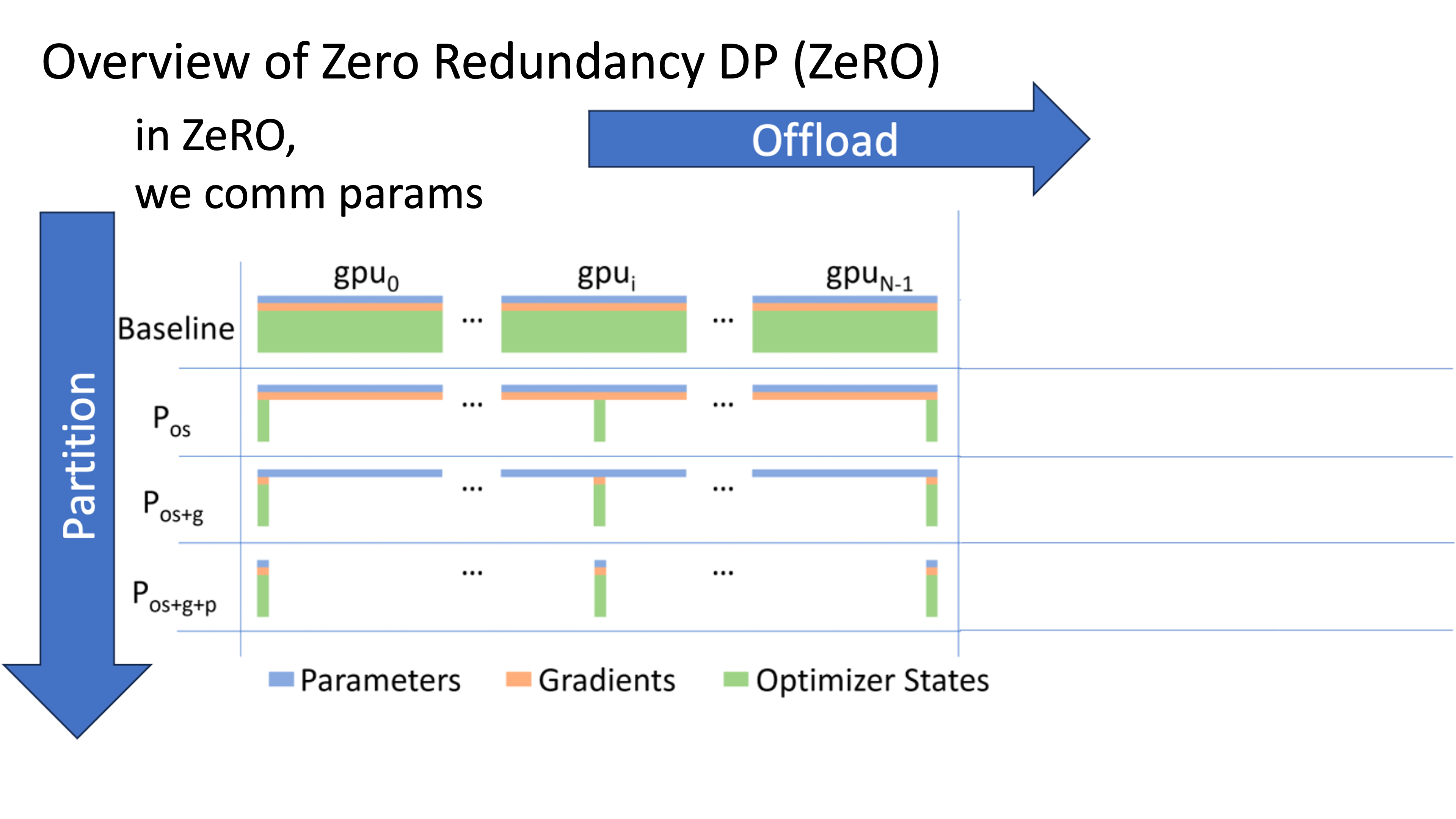 Fig.
Fig.
이 경우 예를 들어 GPU 갯수가 128개라면 parameter, optim state모두 128등분이 된다 (hybrid를 안쓰고 vanilla를 쓴다는 가정). 경우 forward시에도 communication overlap이 가능하게 된다. 아래 slide를 보자.
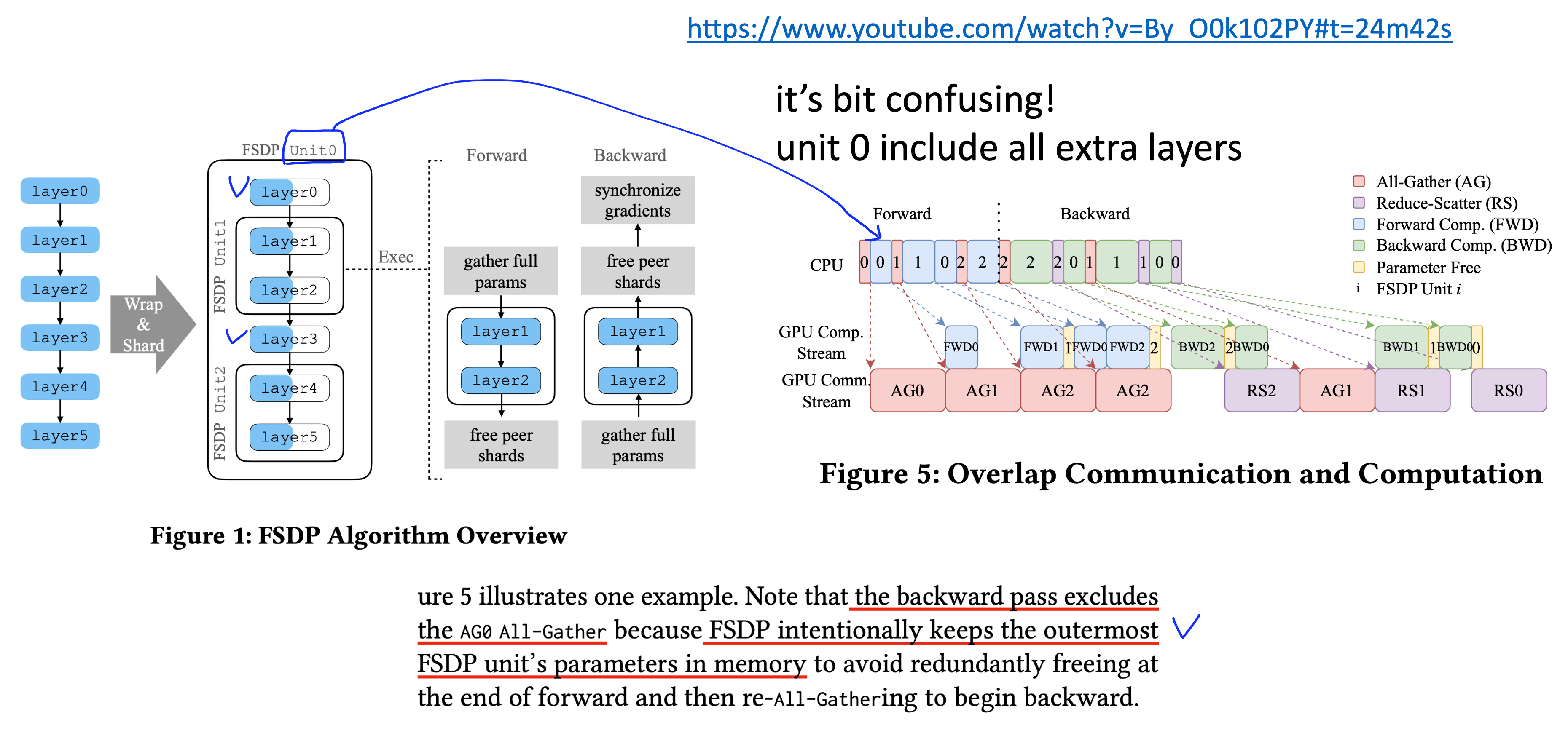 Fig.
Fig.
slide의 내용은 PyTorch FSDP: Experiences on Scaling Fully Sharded Data Parallel에서 가져온 것인데, Microsoft의 ZeRO, torch의 FSDP는 아예 같은 기술을 의미한다. FSDP-1의 경우 layer 0~5번에 대해서 communication을 위한 bucketing 전략을 layer 1, 2를 하나로 묶고 layer 4, 5를 또 하나로 묶고, 나머지는 outer most bucket으로 정의해 하나로 묶는다. 위의 stream을 보면 쪼개져있는 parameter를 하나로 묶는 All-Gather (AG)작업을 해야 parameter forward를 할 수 있는 zero의 특성을 반영해, 가장 첫 layer는 어쩔 수 없이 AG와 forward를 겹치지 못했지만 그 뒤 부터는 다음 param group에 대한 AG를 현재 group의 forward와 겹쳐 미리 수행해놓은 뒤 forward는 시간 지연 없이 진행하는 모습을 볼 수 있다. 그리고 backward에서의 AR은 우리가 아는 대로 진행된다.
이 때 AG를 한없이 미리 해둘 수는 없는데, 그 이유는 ZeRO가 애초에 parameter를 전체 다 들고 있으면 memory가 부족하다는 것을 해소하는 철학으로 디자인 됐기 때문이다. 즉 FSDP unit-1을 forward하는데 unit 2,3,4,5,6,…. 을 다 하면 안되고, unit-2만 하거나 memory 여유가 있으면 unit-2, 3 정도만 겹쳐야 한다.
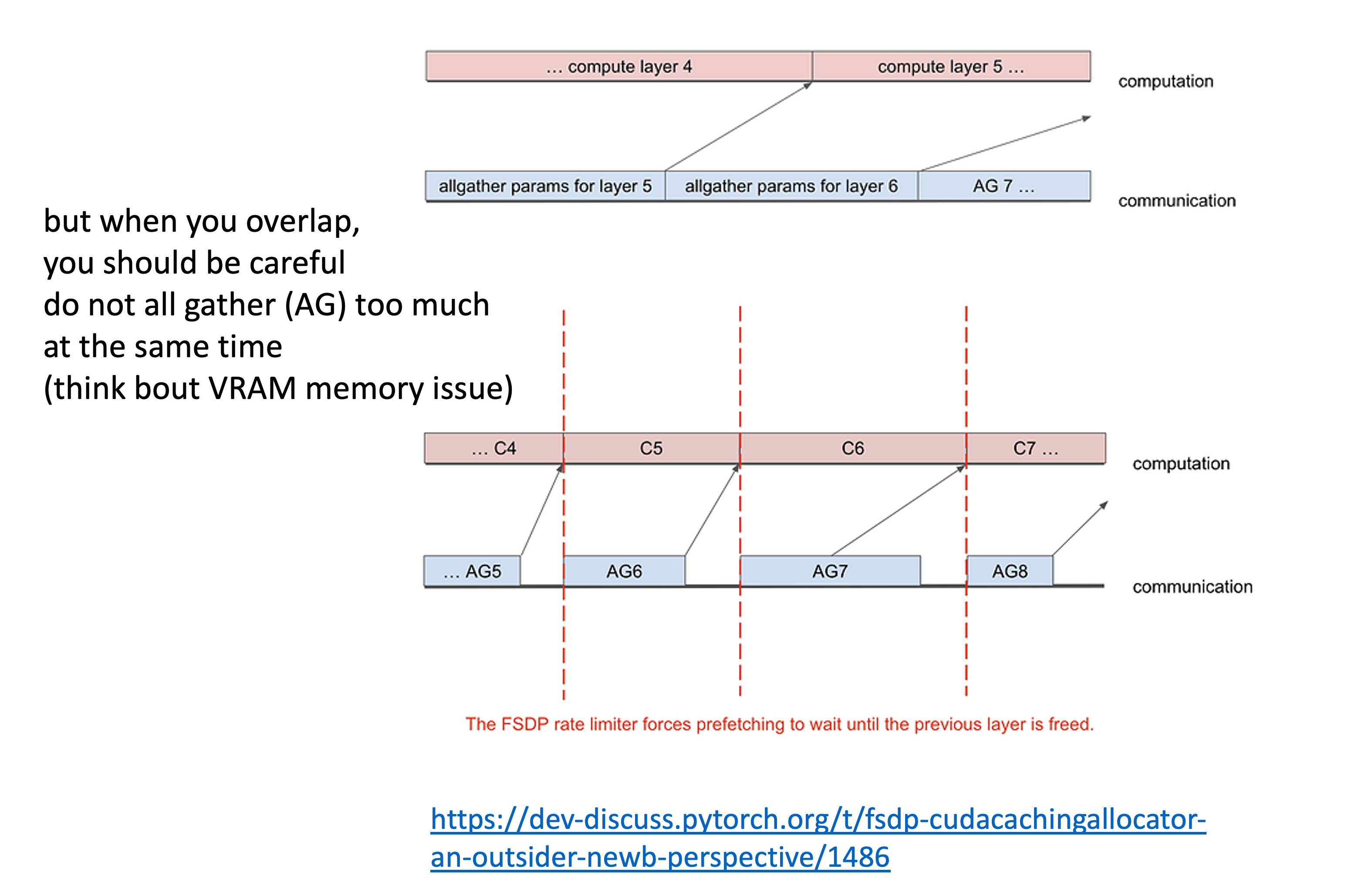 Fig.
Fig.
Comm Overlap is one of key factor but not silver bullet
하지만 communication overlap이 만능은 아니다. 왜냐하면 hardware가 발전할수록 초당 연산횟수 (FLOPs)는 증가하는데 반해 memory bandwidth는 그렇지 않기 때문이다. 그리고 GPU cluster 수가 늘어날수록 communication cost가 지배적으로 되기 때문에 overlap으로 이득을 보기가 쉽지 않아진다.
 Fig.
Fig.
근데 그런 상황이 아니라면 overlapping은 distributed training에 핵심인 요소중 하나인 것은 나의 경험적으로 맞는 것 같다. 그리고 communication overlap은 ZeRO offload이나 asynchronous Tensor Parallel (TP)같은 상황에서도 중요하다.
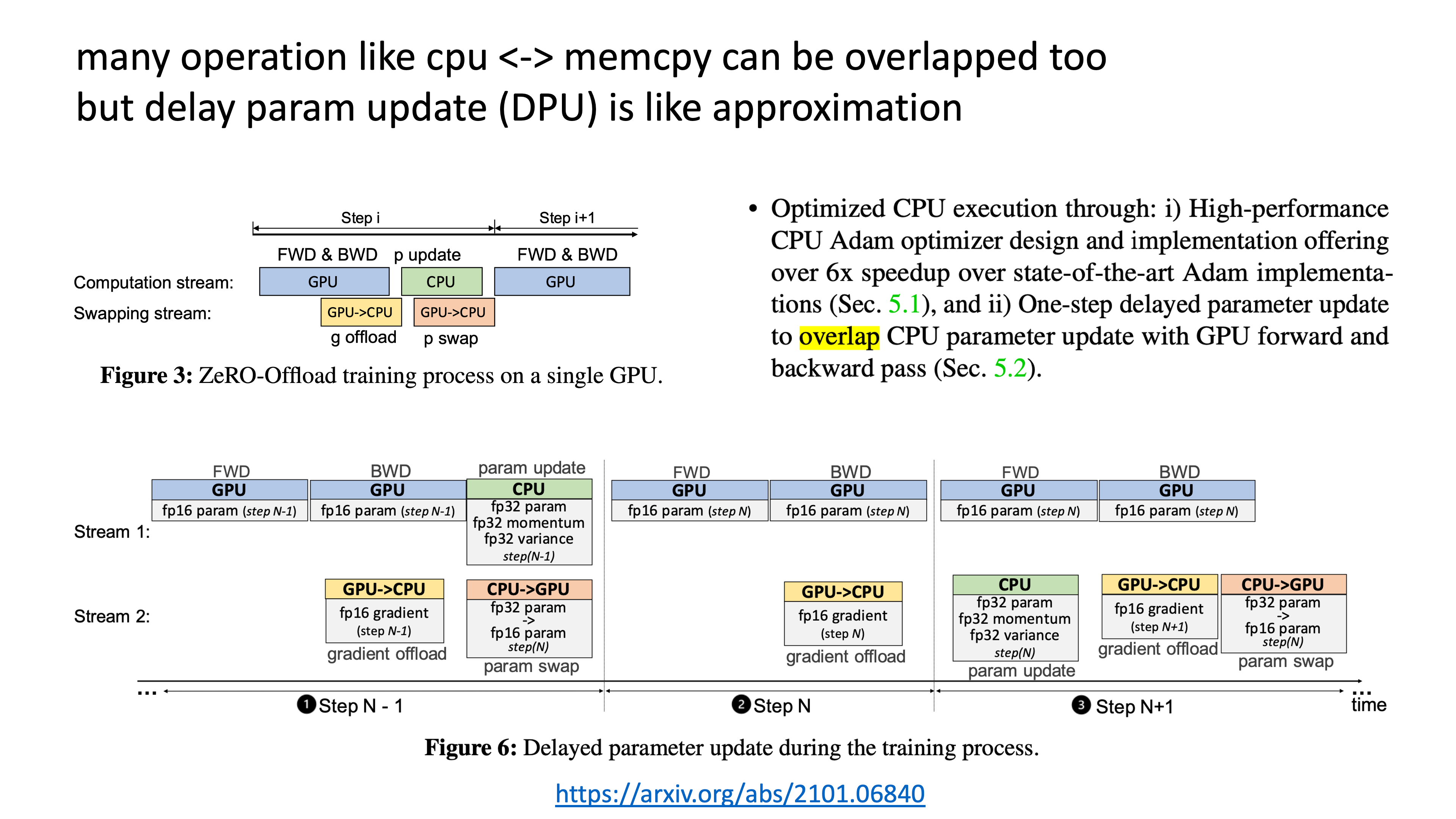 Fig.
Fig.
ZeRO offload는 parameter, optim state를 CPU offload하고 필요할 때만 GPU로 가져오는 것을 의마하는데, 이 GPU, CPU swap (memory copy)도 GPU operation과 잘 겹쳐야 Machin FLOPs Utilization (MFU)를 손해보지 않을 수 있다.
개인적으로 deep learning system을 공부하다보면 idea들은 간단한데 어떻게 이 communication operation들을 hiding 할 수 있는가가 핵심인 것 같다.
My Profiling Results for ZeRO-3 (FSDP)
먼저 현재 존재하는 distributed training 중 ZeRO라는 technology (torch의 fsdp, google의 mesh transformer)로 유명한 deepspeed를 사용해서 Qwen-72B model을 학습한 경우를 살펴보자. training setup은 다음과 같다.
- 72B model
- 8k batch tokens
- 4 node A100-80GB
- zero-3
- offload or not
- liger
(여기서 liger kernel을 적용한 이유는 Qwen 2.5 series의 vocab size가 150k를 넘기 때문에 fp32 logit을 만들 때 매우 많은 memory가 생기는 것을 피하기 위해서이며, 당연히 triton fused kernel을 적용하면 더 빨라지기 때문에 썼다.)
이 경우 offload에 따라 Machine FLOPs Utilization (MFU)는 아래 정도 차이가 나는데, 우리는 둘 다 어떻게 overlap이 진행되고 있는지? 어떤 연산들이 실제로 수행되고 있는지에 대해 간단하게 살펴보려고 한다.
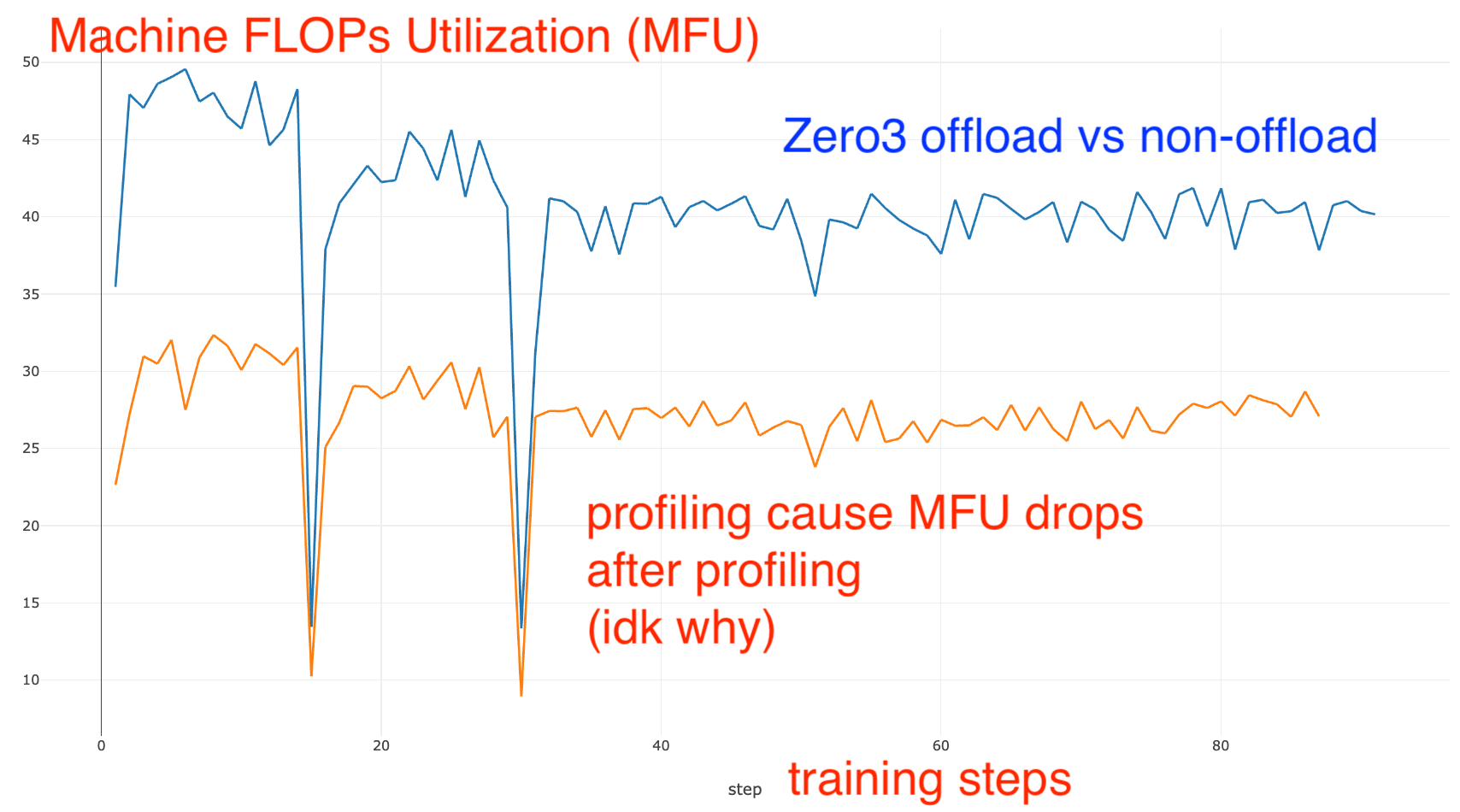
(Torch Profiler의 각 정보들이 어떤 것을 의미하는지 알고싶다면 link를 참고하길 바란다)
Qwen-72B 4-node A100-80GB ZeRO-3 (no offload)
먼저 ZeRO-3를 parameter, optimizer state offload 없이 학습한 model의 profiling results를 살펴보도록 하자. 먼저 overview는 다음과 같다.

전체 profiling step 동안 GPU kernel 연산에 쓰인 시간이 대부분을 차지하고,
communication 이나 memory copy, cpu execution 등에 걸린 시간은 거의 없다는 걸 알 수 있는데,
step time breakdown이 의미하는 바와 계산이 된 방식은 다음과 같다.

즉 위의 설명에 따르면 대부분의 communication 등이 hiding이 된 것으로 생각할 수 있다.
이제 trace를 보도록 하자. trace는 ml system 이나 gpu programming 전문가가 아니라면 꽤 보기 어렵지만 guide에 따르면 대충 아래와 같은 내용을 담고 있다는 걸 알 수 있다.

위 figure를 보면 설명에서도 쓰여있지만 CPU thread가 존재하고,
CPU가 gpu kernel launch를 하면 steam 7이라는 GPU stream에서 matmul같은 연산이 실제로 수행되거나,
htod, dtoh (cpu <-> gpu) 나 dtod (gpu <-> gpu) memory copy등도 여기서 일어나게 된다.
지금은 torch profiler에 대해 알아가는 post가 아니기 때문에 이런 저런 내용을 다 다룰 순 없지만,
여기서 중요하게 봐야할 것은 GPU utilization과 SM Efficiency (Streaming Multiprocessor Efficiency)라는 것 정도는 알아야 한다.
GPU Utilization은 GPU device 전체가 얼마나 오랜 시간 동안 ‘활성 상태 (kerne이 실행 중; activation)’에 있었는지를 의미하는데,
이 수치는 GPU가 완전히 놀고 있는 시간 대비 작업 중인 시간이 어느 정도 되는지를 대충 알려주는 metric이다.
그러나 이는 앞서 설명한 MFU와 같은 개념은 아니다.
이는 보통 nvidia-smi를 찍어보면 대충 100%를 찍는 GPU util을 볼 수 있는데 이것이 실제 GPU 연산을 의미하지 않고 다른 process를 기다리는 중인 경우도 있는 경우와 비슷할 것 같기 때문에,
내 생각에 전체 process time중에서 util이 100인 부분을 다 100이라고 오해하면 안될 것 같다.
반면 SM Efficiency (Streaming Multiprocessor Efficiency)는 GPU 내부에 있는 각종 multiprocessor (SM)가 실제 연산에 얼마나 빈틈없이 동원되고 있는지를 알려주는 것으로, 이 값은 GPU가 단순히 “일을 하고 있다”는 것을 넘어, 해당 일이 얼마나 효율적으로 각 SM에 분배되어 실행되고 있는지를 보여준다. 즉, SM Efficiency가 높다면 GPU가 내부적으로 멀티프로세서를 거의 빈틈없이 활용하고 있어, 단위 시간당 더 많은 연산을 수행할 수 있음을 의미한다.
정리하자면 GPU Utilization은 GPU가 얼마나 자주 “일하고 있나?”라는 큰 틀의 관점이고, SM Efficiency는 “GPU가 일하고 있을 때, 내부 연산 자원을 얼마나 빽빽하게 활용하나?”를 보여주는 보다 세부적인 효율성을 측정하는 metric으로, 이 두가지가 높아야 우리는 training시 GPU를 놀리지 않고 효율적으로 썼다는 것이 된다.
말이 길어졌는데 이제 qwen 72b training의 trace view를 보자. 안타깝게도 내가 예전에 발표할 때 쓰던 screenshot에 annotation을 달아둔 것이 있기 때문에 이걸 쓰려고 하는데, 이는 2node에 cpu offloading zero-3를 썼던 실험에 대한 것이다 (근데 설명하는데는 무리가 없으니 그냥 쓰겠다).

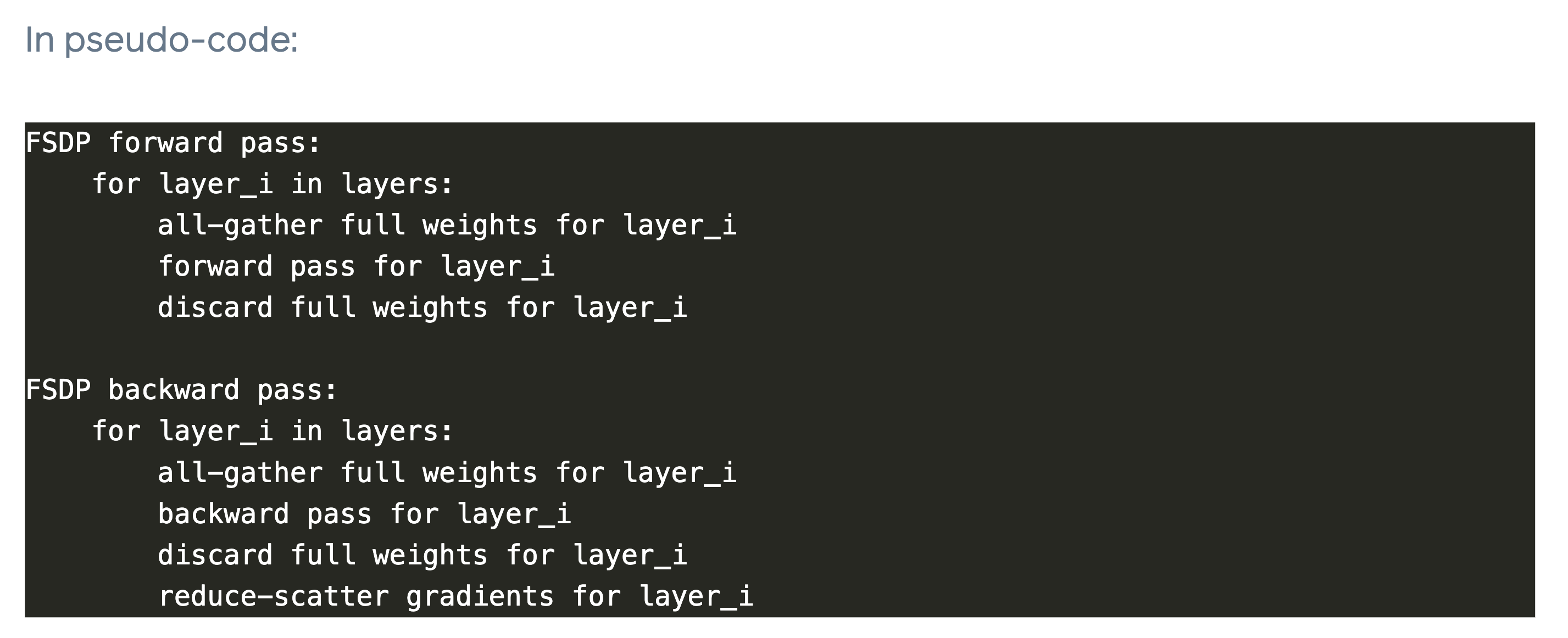
all-reduce는 reduce-scatter, all-gather로 분리될 수 있다 (can be decomposed). 아래 figure를 보자.

만약에 overlap이 안되면 어떻게 될까. overlap이 안되면 아래 issue처럼 all-gather나 reduce comm을 할 때 그 시간동안은 device들이 놀게된다.
 Fig. issue link
Fig. issue link
실제로 overlapping이 잘 됐는지를 확인하는 또 다른 방법이 있다.
바로 Distributed View를 보는 것이고 이는 다음과 같이 left panel, right panel 두 가지로 구성되어 있으며,
left panel을 보면 overlapping time을 확인할 수 있다.
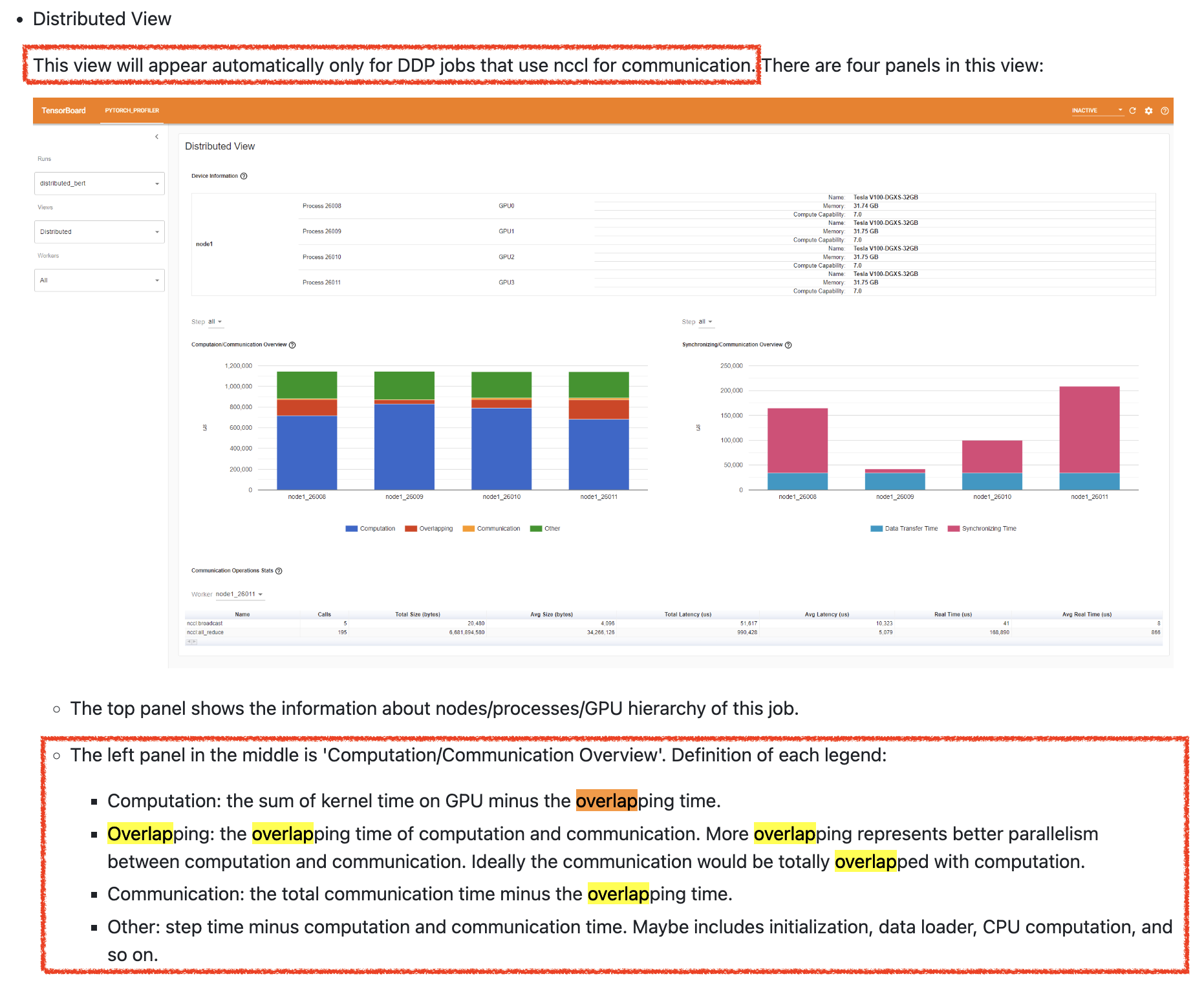



Qwen-72B 4-node A100-80GB ZeRO-3 (offload)




My Debugging Log on Megatron-LM
What Communication Can Be Overlapped in Megatron-LM (DP + TP/PP)
이제 내가 겪었던 overlap 관련된 megatron-lm issue에 대해 간단하게만 얘기해보자. 먼저 megatron-lm이 뭔지 아는 것이 중요한데, 내가 현재까지 파악한바로 megatorn-lm의 핵심은 아래와 같다.
- DP (zero-1)/ TP/ PP/ EP/ CP 등 parallel state module
- 관리가 매우 효율적으로 짜여져있음
- (layernorm + linear), (swiglu), (fused rope) 등 fused kernel 제공
- TransformerEngine library를 갖다 쓰는 것으로 바뀜
- efficient data builder (sequence packing, binarized)
- MoE 등 highly scalable model architecture 들의 구현
이 중에서 ZeRO-3와 다르게 TP, PP가 들어가면 상황이 매우 복잡해지는데, TP, PP는 ZeRO-3와는 다른 철학을 가지고 있다. ZeRO-3는 parameter를 sharding해서 가지고 있다가 forward, backward시 parameter 자체를 broadcasting (all-gather) 하는데 반해, TP, PP는 model parameter를 쪼개서 가지고 있긴 하나 activation을 all-reduce나 p2p 통신 한다.
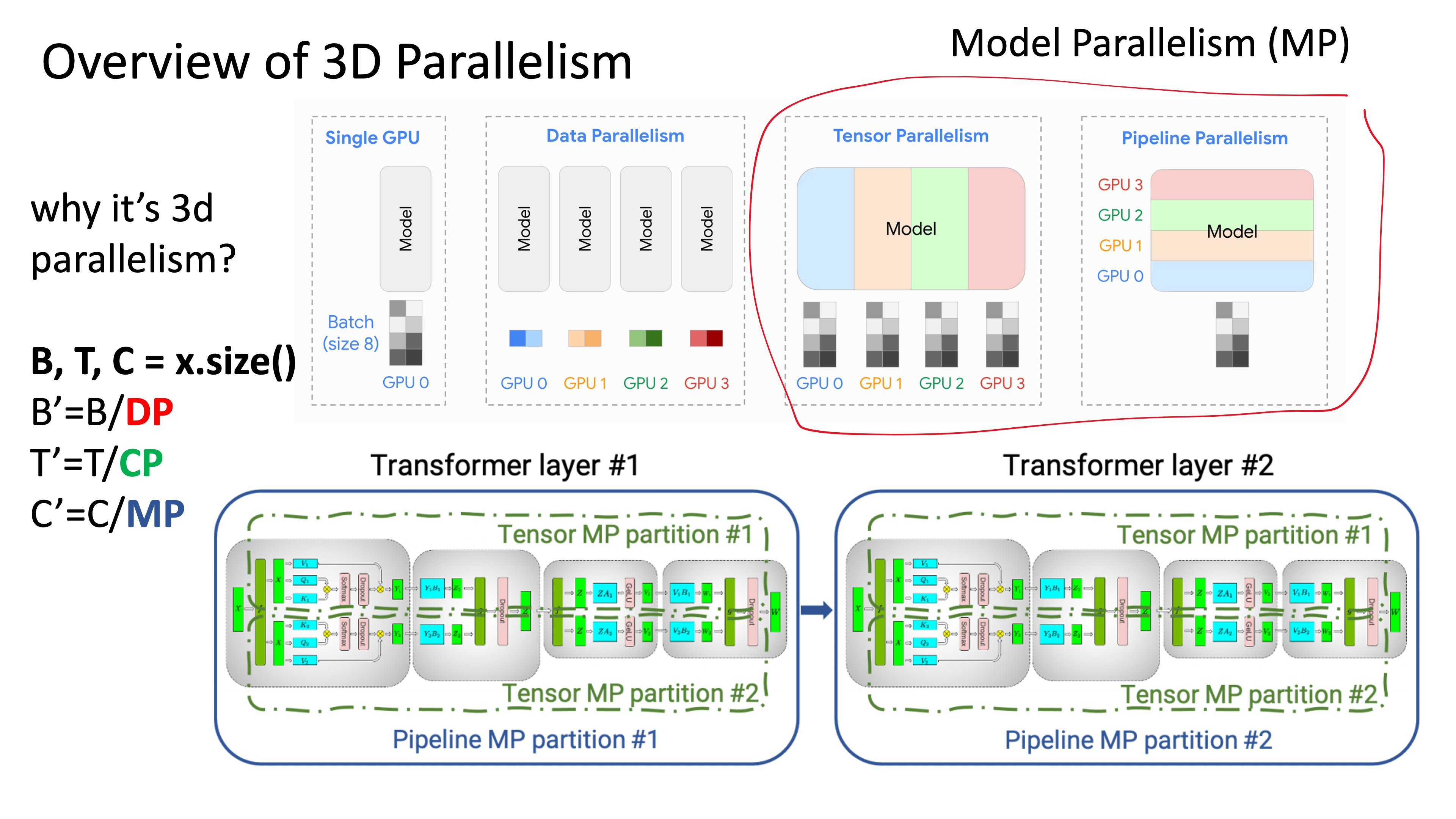 Fig.
Fig.
즉 TP를 예로 들면 all-gahter를 할 것이 없어 보이지만 마냥 그렇지는 않다. 왜냐면 modern llm은 TP, PP만으로 학습이 가능하지 않고 매우 큰 optim state나 gradient 만이라도 zero partition을 하긴 해야 하기 때문에 zero-1을 같이 쓰게 되고, 이 경우 gpu가 가령 256개라고 치고 TP degree가 8, PP degree는 1이라고 칠 때 gpu 8개 (node 1개)에 model 1개가 fitting되어 DP degree가 32가 되어 optimizer state는 32등분이 된다. (좀 더 알아보니 256등분이 될 수도 있는 것 같다, 이 부분이 메모리는 덜 들 것이다)
뭐 만약 zero-1과 TP를 같이 쓰지 않을 수도 있다.
이 경우 model이 TP=8, PP=1이기 때문에 각 device는 model, optim state, gradient를 8등분 해서 가지고 있을 것이기 때문에 어느정도 save는 되지만 앞선 qwen 72b의 경우를 예로 들면 model param + state에 72e9/8*18/1024/1024=154,495 MB가 필요하기 때문에 이는 말이 되지 않는다.
그래서 zero-1을 쓰긴 쓰는데,
megatron-lm도 당연히 deepspeed처럼 여러 overlap을 도입해서 성능을 끌어올렸다.
하나는 forward and all-gahter overlap이고,
나머지 하나는 backward and reduce-scatter overlap이다.
 Fig.
Fig.
 Fig.
Fig.
그리고 여기에 TP/PP시 bucketing에 대한 heuristic까지 고려하여 more scalable하도록 만들었다고 한다.
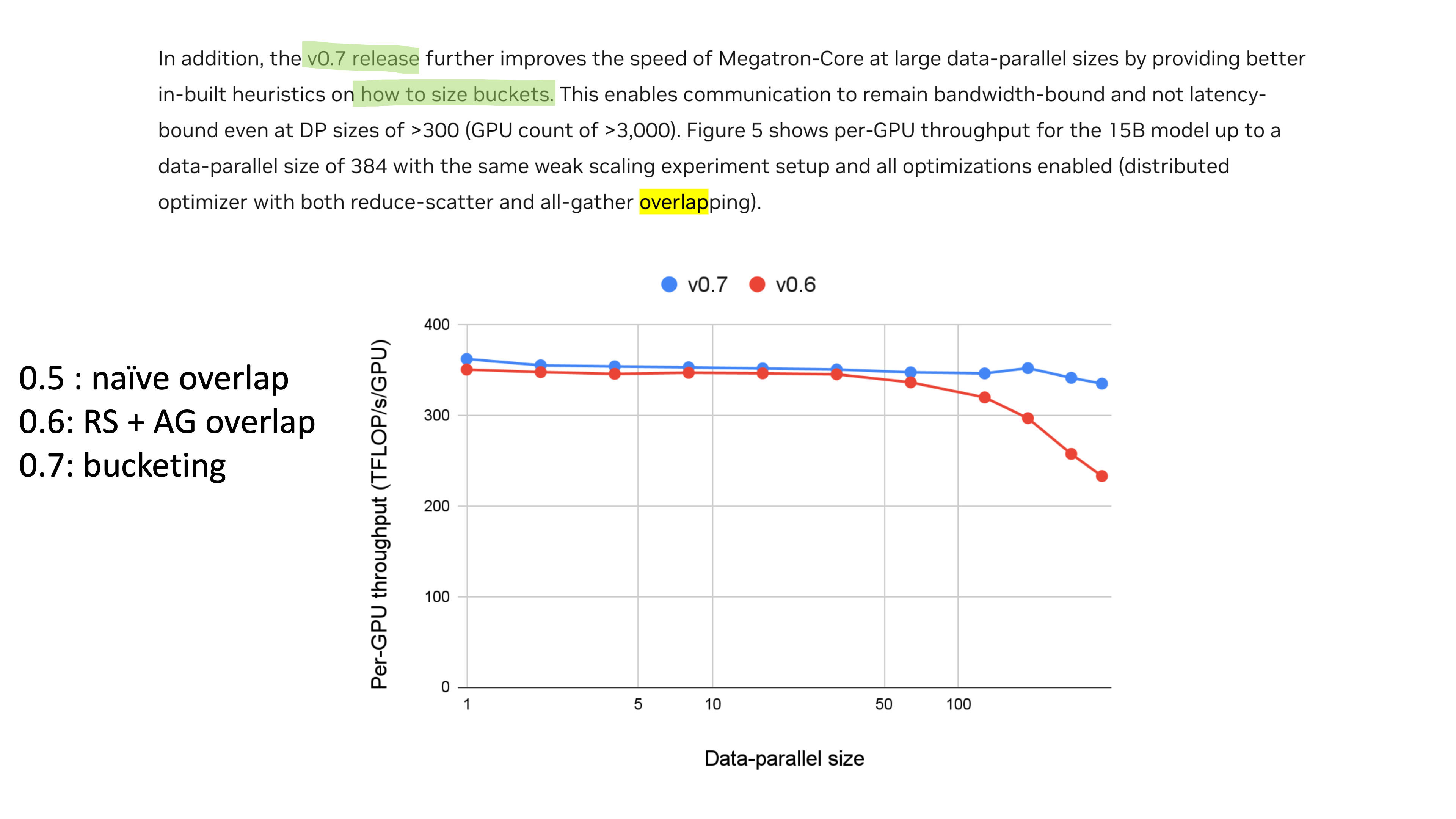 Fig.
Fig.
Bucketing and Overlap is Implemented in Reverse Order of Param Ibit (Backprop Order)
근데 나는 뭐가 이슈였을까? (my megatron-lm issue 참고) 결론부터 말하자면 megatron-lm의 bucketing-overlap은 model forward 순서에 맞도록 구성되어야 했는데 내가 이를 지키지 않았기 때문이다. 보통 bucketing은 예를 들어 layer당 weight이 5개고 layer가 6개라면 6*5=30개의 weight이 있다고 칠 때 backprop order로 bucketing을 한다.
 Fig.
Fig.
하지만 나는 아래와 같이 기존 noam architecture (llama-3 구조라 보면 됨)에 training stability를 위해 여기저기 rmsnorm을 끼워넣는 실험을 하고 있었고, 여기서 model.init 이 잘못됐기 때문에 bucketing 순서가 꼬이게 됐다.
 Fig.
Fig.
결과적으로 나는 아래와 같은 error를 얻었는데, 이를 이해하기 위해서는 먼저 megatron-lm에 대해 알아야 한다.
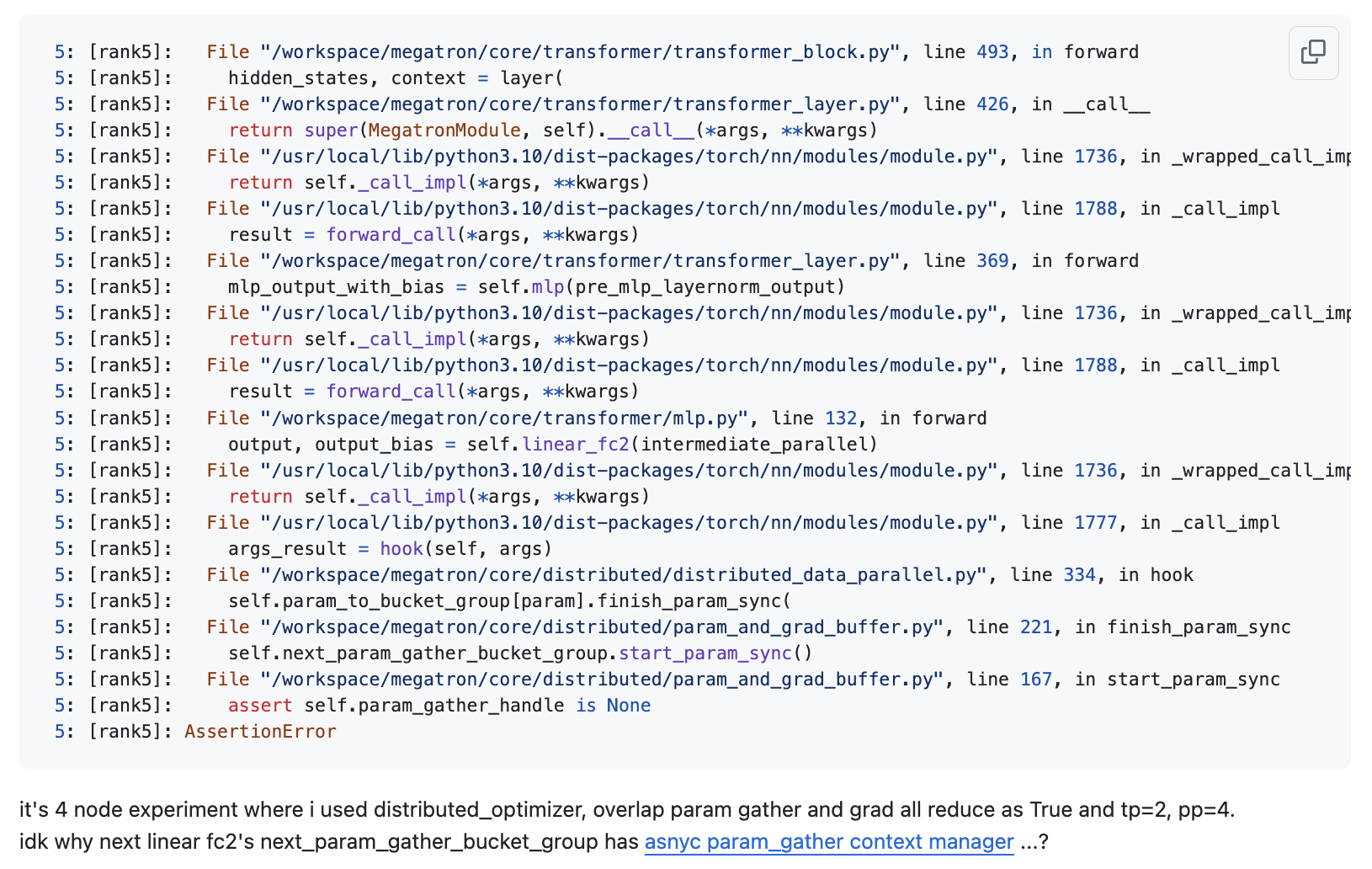 Fig.
Fig.
대충 megatron-lm은 weight들이 생성된 순서가 model forward과 align되도록 되어있다 (내가 rmsnorm을 막 넣기 전까지). 그리고 bucketing은 생성된 순서대로 된다고 했다. 하지만 나는 rmsnorm 2개를 아래와 같이 기존 코드 맨 아래에 넣었다.
 Fig.
Fig.
하지만 각 rmsnorm은 내가 맨 뒤에 넣은 것과는 다르게, 하나는 맨 뒤에서 실행되지만 다른 하나는 중간에 self attention이후 발동한다.
 Fig.
Fig.
그런데 megatron-lm의 forward and all-gather overlap logic은 다음과 같다.
- 대충 weight들을 순회하면서 bucket size만큼 weight들을 담아 여러 bucket을 만든다.
- 각 bucket들을 backprop order로 서로 연결한다 (bucket[i-1].next = bucket[i-2]).
- 각 module에 forward hook을 걸어 현재 module이 forward될 때 overlap이 되도록 한다.
- 이 때 overlap은 다른 cuda stream에서 수행되므로 gpu kernel operation과 async
- 이 경우 아마 gpu device 가 담당하는 optim state는 매우 작은 부분이기 때문에 forward하면서 optim state update를 위해 미리 all-gather하는게 memory에 큰 부담은 아닐듯
- all-gather을 할 때 next bucket도 all-gather 명령을 한다.
- 다음 layer로 forward graph가 넘어갔을 때 또 async all-gather를 시도하겠으나 현재 module이 이미 all-gather 되어있다면 (dispatched) 넘어간다.
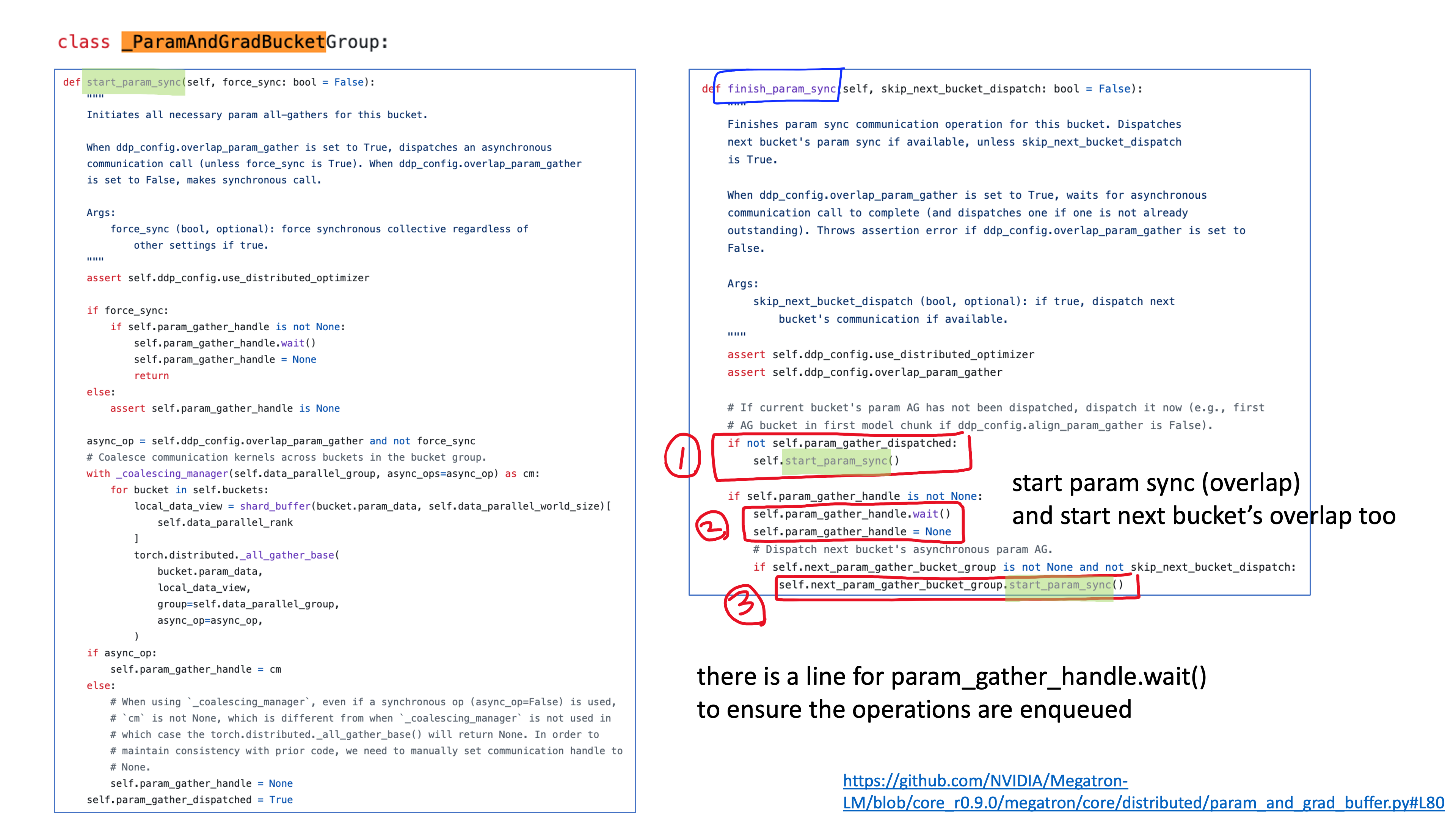 Fig.
Fig.
근데 문제가 발생한 이유는 위의 code를 보면 아래와 같이 current bucket이 all-gather되어있는지는 확인하면서, 그것과 연결된 다음 bucket은 all-gather 했는지는 확인하지 않는다는 것이다. (혹은 그냥 내가 forward 순서대로 module 선언을 하면 됐을 일이다)
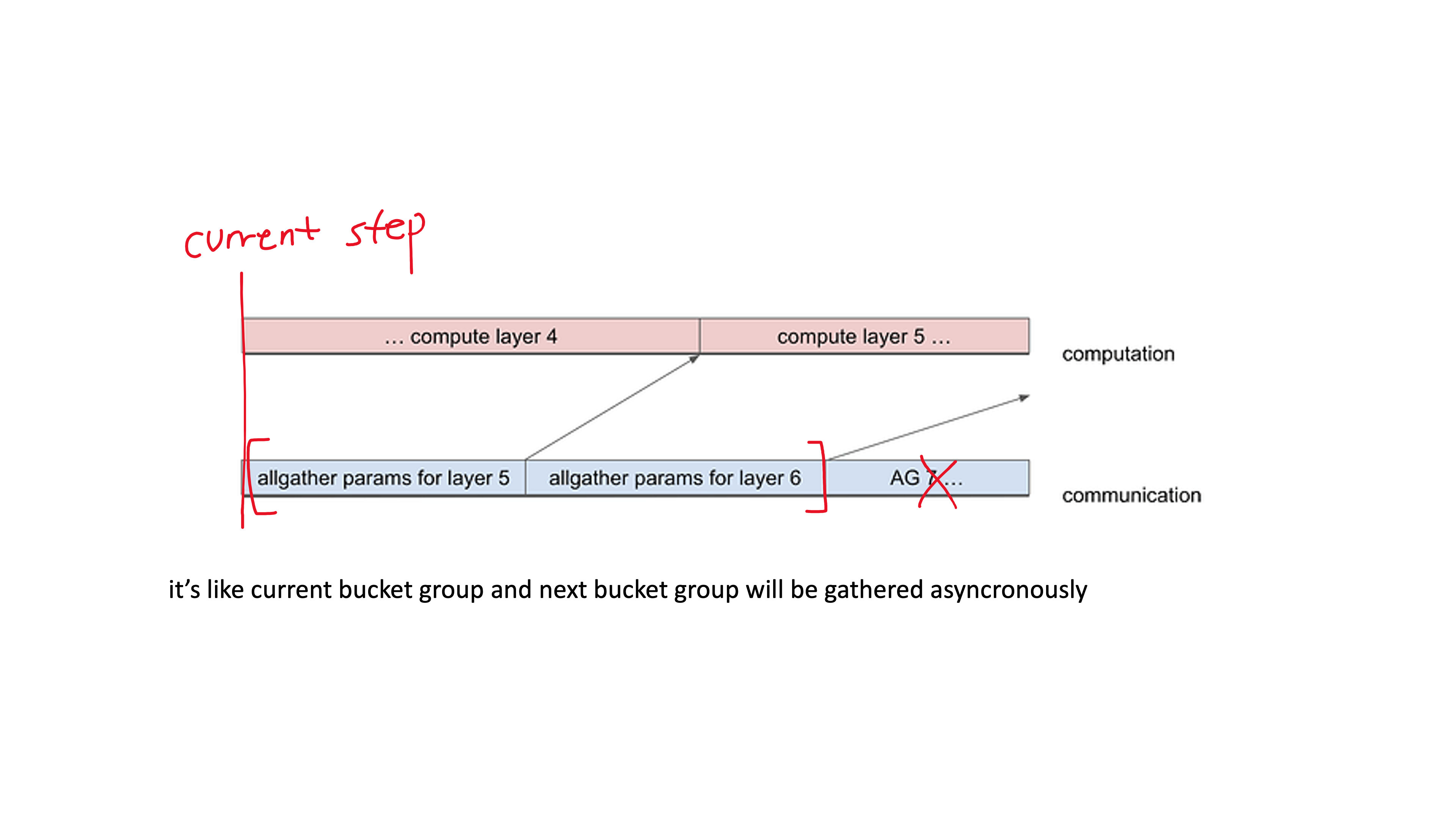 Fig.
Fig.
그렇기 때매 예를들어 아래와 같은 순서로 model forward이 될 때,
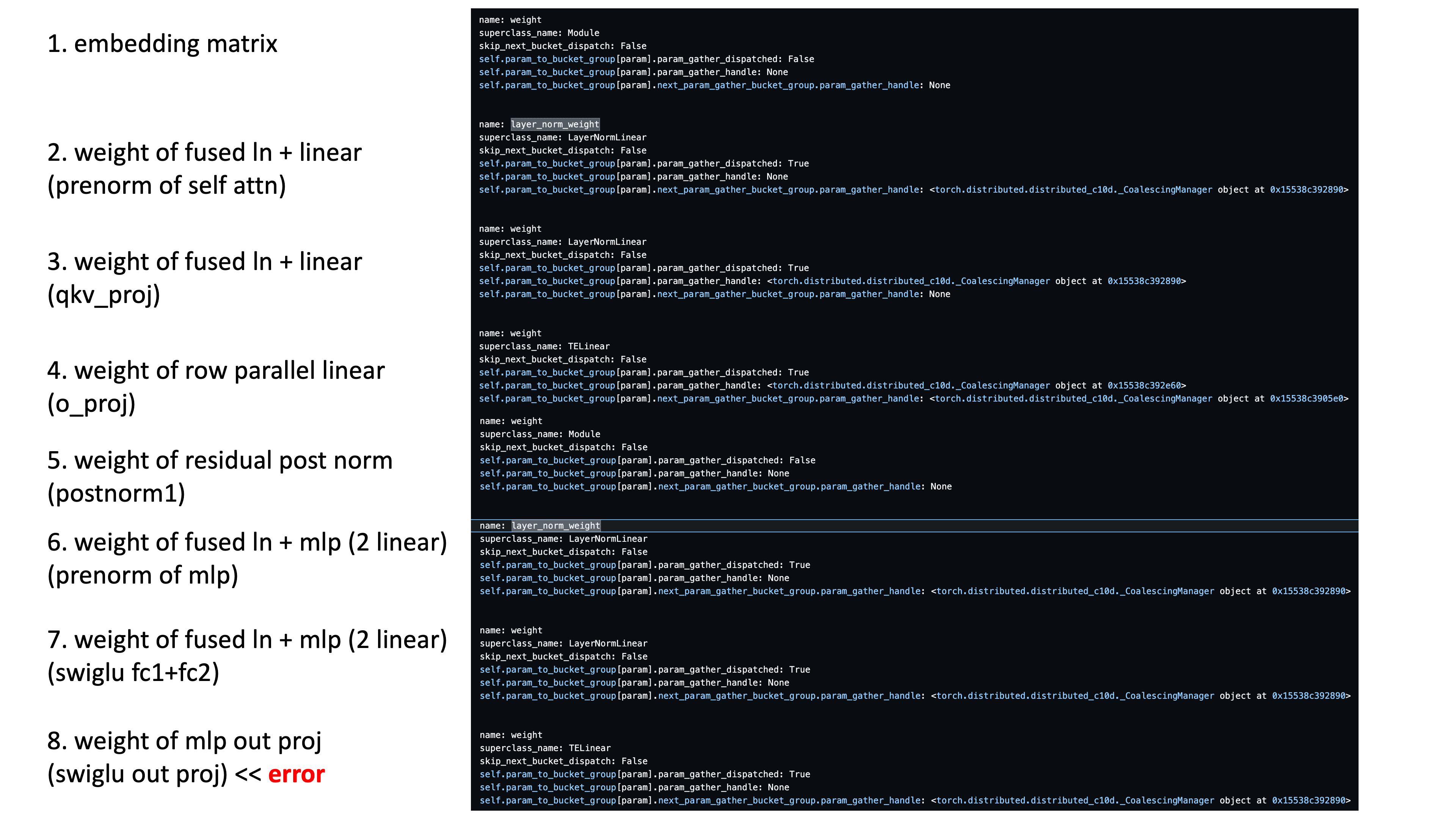 Fig.
Fig.
아래와 같이 bucket 순서가 꼬여 에러가 나는 것이다.
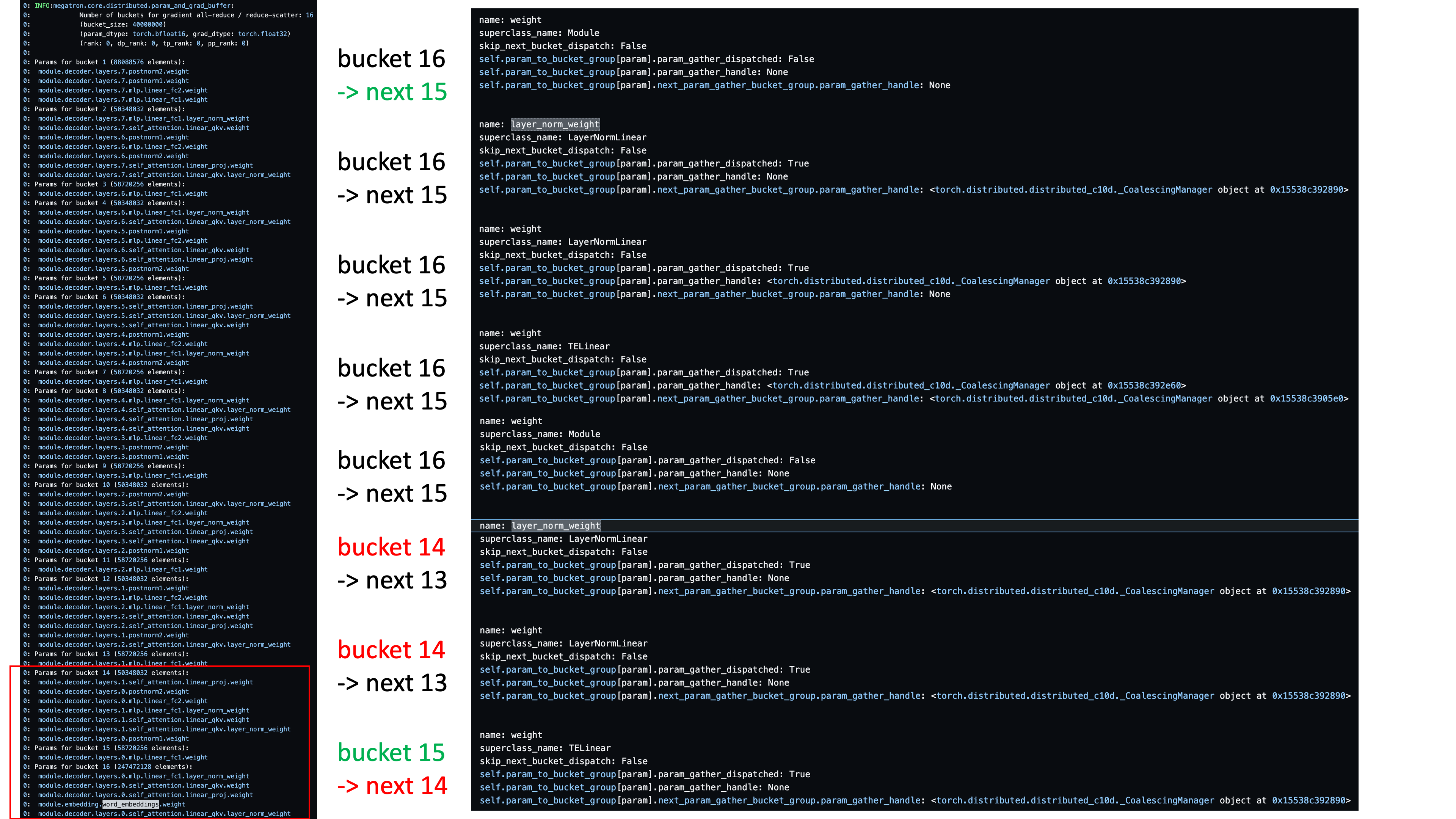 Fig.
Fig.
module을 어디 선언하는지에 따라 bucket group이 갖는 model weight들이 바뀌는 것을 볼 수 있다.
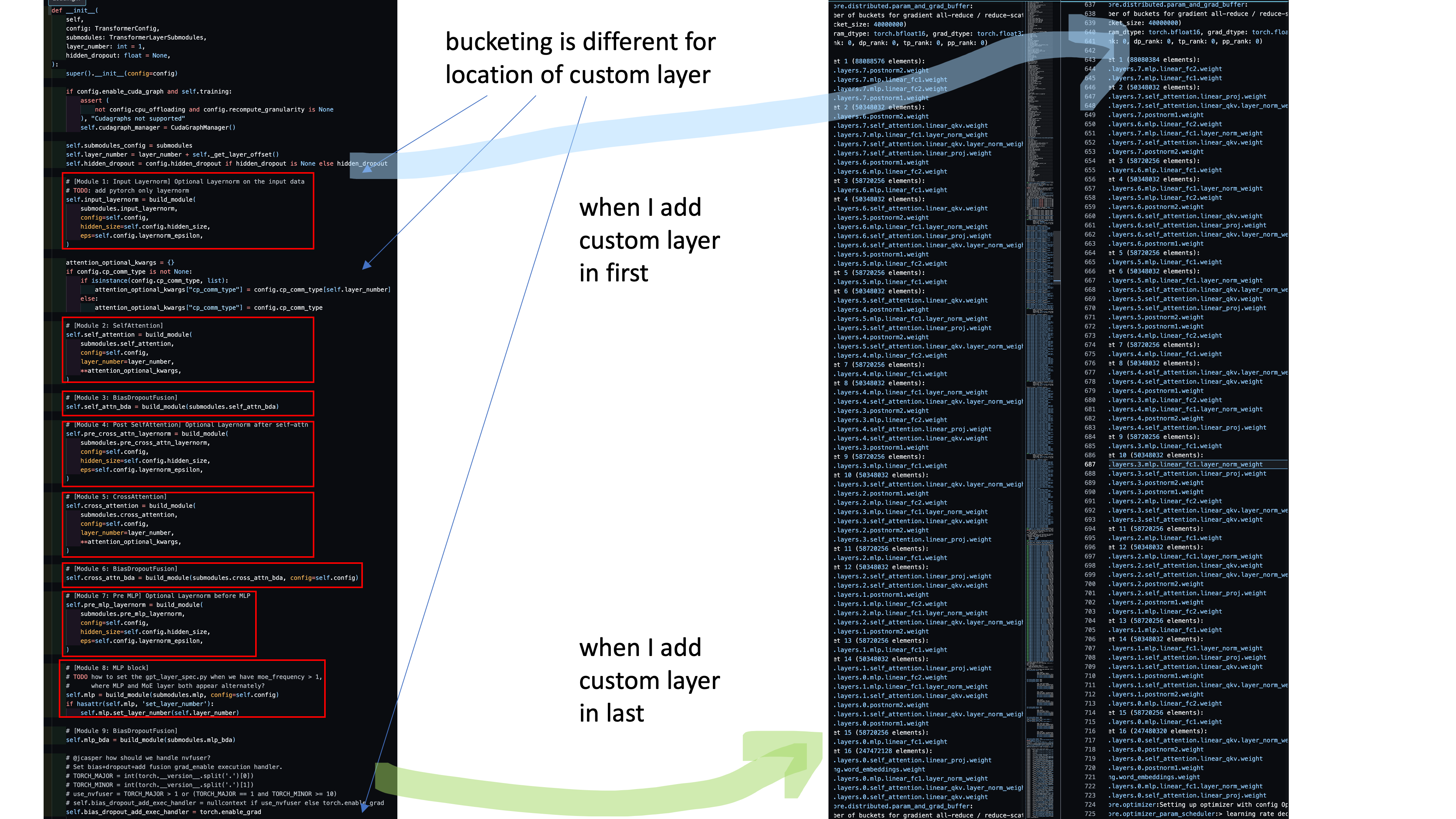 Fig.
Fig.
p.s. megatron-lm docs 중에 model customizing하는 예제가 있는데, 예시로는 falcon 같이 parallel layer를 사용하는 경우를 들고 있으나 (fusion이 잘 안된거같지만) 어느 시점부터 이렇게 naive하게 선언하면 all-gather overlap과 충돌이 생기는 것 같다.
References
- Distributed Data Parallel Docs
- PyTorch FSDP: Experiences on Scaling Fully Sharded Data Parallel
- FSDP & CUDACachingAllocator: an outsider newb perspective
- Per-Parameter-Sharding FSDP #114299
- How Fully Sharded Data Parallel (FSDP) works?
- PyTorch Data Parallel Best Practices on Google Cloud from pytorch
- PyTorch Profiler TensorBoard Plugin
- A guide on good usage of non_blocking and pin_memory() in PyTorch