(WIP) Distributed Training (Parallelism, ZeRO and so on)
04 Oct 2023< 목차 >
- Motivation
- Parallelism
- Zero Redundancy Optimizer (ZeRO)
- Summry of ZeRO and Advanced ZeROs
- Other Techniques for Large Scale Modeling
- Library/Frameworks for Distributed Training
- Key Elements of a GPU
- References
Deep Learning 분야의 model size가 점점 더 large scale로 가고있습니다. 수십~수백 billion (B)단위의 large model을 학습하기 위해서는 다양한 technique들이 요구됩니다. 이번 post에서는 병렬화 (prallelism) 부터 ZeRO, activation checkpointing 등 각종 large scale modeling에 관한 technique들에 대해 알아보려고 합니다.
Motivation
분산 학습 (Distributed Training) 이란 하나의 main process만 이용해서 model을 학습하는 것이 아니라 여러개의 mini process를 사용해서 학습하는것을 말합니다.
왜 분산 학습을 해야 하는 걸까요?
Deep learning model을 학습하기 위해 1,000,000개의 sample로 이루어진 dataset을 구축했다고 생각해 봅시다.
가장 간단한 idea는 모든 data를 보고 각각의 loss를 계산한 다음에 gradient를 구해서 model parameter를 update하는 겁니다.
하지만 이는 불가능하기 때문에 우리는 dataset의 일부분만을 sampling하면서 update를 하며 결국 dataset을 다 보게 되는데, 이 때 얼만큼의 data sample을 한번에 쓸 것이냐?를 Batch Size라고 하며 dataset을 한 번 전부 순회 (iteration) 하는 단위를 epoch이라고 합니다.
이렇게 학습하는 방식은 Batch learning이 아닌 Mini-batch learning 이라고 하거나 이런 알고리즘을 일반적으로 몇 개씩 무작위로 학습하기 때문에 sampling Stochastic Gradient Descent (SGD) 혹은 Online Gradient Descent라고도 부릅니다.
그런데 학습 하려는 model size가 너무 크면 어떻게 할까요? GPU memory의 대부분을 model이 차지하게 될 것이고, 우리는 Adam 같은 momentum을 사용하는 optimizer를 일반적으로 사용하기 때문에 이 optimizer state들 까지 생각하면 GPU memory가 tight한 상황이 발생합니다. 당연하게도 batch size를 256, 128, … 8, 4 이렇게 줄여나감으로써 문제를 해결하게 될텐데, 일반적으로 large batch size를 사용하는것이 모델 성능면에서도, 학습 시간 면에서도 이득이기 때문에 다른 방법을 강구해야합니다.
Parallelism
Data Parallelism (DP)
그 다른 방법은 별 게 없는데, 바로 GPU를 더 쓰는 것입니다.
어떤 workstation에 GPU가 8개 박혀있다고 생각해 봅시다.
이 때 GPU 1개 당 batch size 4를 쓸 수 있었다고 치면, dataset 1,000,000개를 84로 나누어 31,250개 씩 각 GPU에 할당합니다.
(어떤 data가 어떤 GPU로 가는지는 일반적으로 매 epoch마다 random shuffle 됩니다)
만약 dataset이 1,000,135개 였다면 135개는 딱 나눠떨어지지 않기에 (not evenly divisible) 324=128개를 제외한 7개를 버리던지, 32*5=160개가 되도록 기존의 data들을 random하게 25개 정도 upsampling을 해서 나눠줍니다.
이런식으로 하면 GPU 1개당 4개의 gradient를 계산하므로 batch size를 32로 설정한 것과 다름이 없게 되며 모든 gradient는 main process로 모아서 처리하게 됩니다.
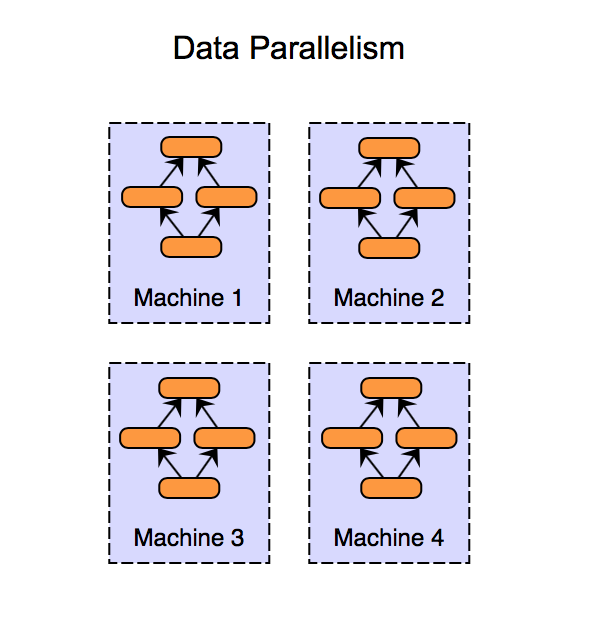 Fig. DP는 예를 들어 GPU 4개에 full size model이 copy되고 각 GPU가 서로 다른 batch를 처리한다. Source from link
Fig. DP는 예를 들어 GPU 4개에 full size model이 copy되고 각 GPU가 서로 다른 batch를 처리한다. Source from link
만약 우리가 GPU 8대 workstation을 8개 가지고 있다면 우리는 64개 GPU로 256 batch size learning을 하는 효과를 누리게 되는데, 한 machine당 GPU 8대가 한계인데 machine을 하나만 쓰는 것을 multi-gpu, single-node상황 이라고 하며 machine을 8개 쓴 후자의 경우를 multi-node상황 이라고 합니다.
Multi-node의 경우 각 machine의 각 GPU가 계산한 gradient를 main process로 모으는 것은 node간 통신 (communication)이 필요합니다.
초당 data를 얼마나 보내는지를 결정하는 memory bandwidth는 GPU hardware마다 다르고 당연하게도 장비가 비쌀수록 좋아집니다.
이렇게 모든 GPU에 각각 동일한 model 을 띄우고 개별적으로 gradient를 계산하고 모으는 방식은 data만 나눴기 때문에 Data Parallelism (DP)라고 부릅니다.
DP방식은 모든 GPU에 같은 크기의 Model parameter를 전부 Copy하는 방식이기 때문에 Memory Efficiency는 떨어지는 방법이지만 model size가 그렇게 크지 않다면 선택할 수 있는 방법 중 가장 간단하고 시간적으로 큰 낭비가 없는 (후에 말씀드리겠지만 MP, PP 등은 idle time이 발생할 수 있습니다) 방법입니다.
Model Parallelism (MP)
그런데, 만약 GPU 1대에 Model 하나가 아예 올라가지도 못 하는 상황이 발생하면 어떻게 해야할까요?
Large Transformer 시대에 상대적으로 작은 규모인 10 Billion parameters의 model 의 경우 Floating Point 16 (FP16)을 쓸 경우 약 20GB의 memory가 필요한데, 학습을 하려면 mixed precision 등의 technique을 쓰더라도 paramter당 20 bytes로 총 200GB memory를 필요로 하게 됩니다.
이는 구매 가능한 현존 최고 spec인 A100 GPU의 Memory 가 80GB인 상황을 생각하더라도 1대에도 다 올릴 수 없는 양 입니다.
이런 경우는 model 의 각 layer를 쪼개서 각 GPU에 올리는 방식으로 해결을 할 수 있는데, 단순히 model을 쪼개서 올리는것 만으로는 부족합니다. 즉 추가로 어떤 방식들들이 더 필요한데요, 어떤 방식들에는 Zero Redundancy Optimizer (ZeRO) 같은 방법이 있는데 이는 후술 하도록 하겠습니다.
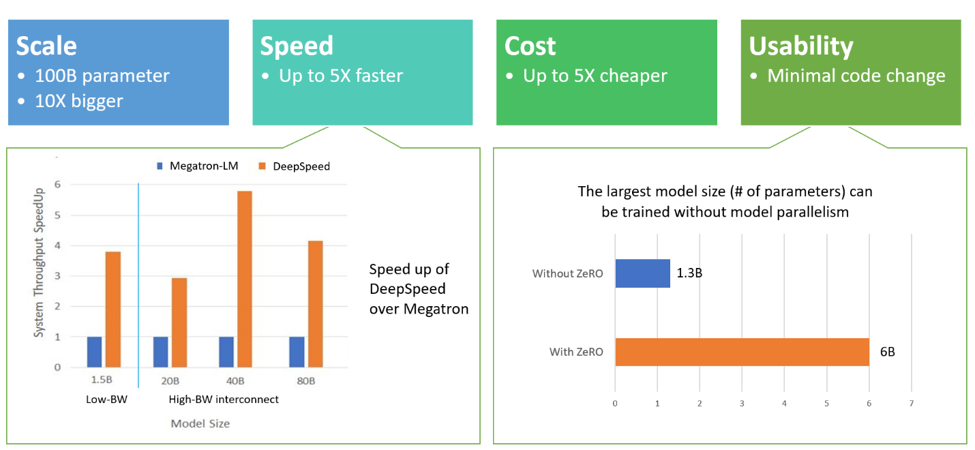 Fig. multi GPU일 경우 model을 쪼개지 않아도 ZeRO를 쓰는 것만으로 4~5배 size의 model을 학습할 수 있다. Source from link
Fig. multi GPU일 경우 model을 쪼개지 않아도 ZeRO를 쓰는 것만으로 4~5배 size의 model을 학습할 수 있다. Source from link
일단 model을 쪼개는 (partitioning) 방식만 생각해봅시다.
말 그대로 각 GPU에 부분 부분 layer를 올리는 방식으로 Model이 32개 layer를 갖고 있고 8 GPU 1 node 상황에서 각 GPU별로 딱 나눠 떠러지게 나눴다고 (evenly partitioning) 치면 각 GPU당 4개의 layer가 올라가 있는 상황이 됩니다.
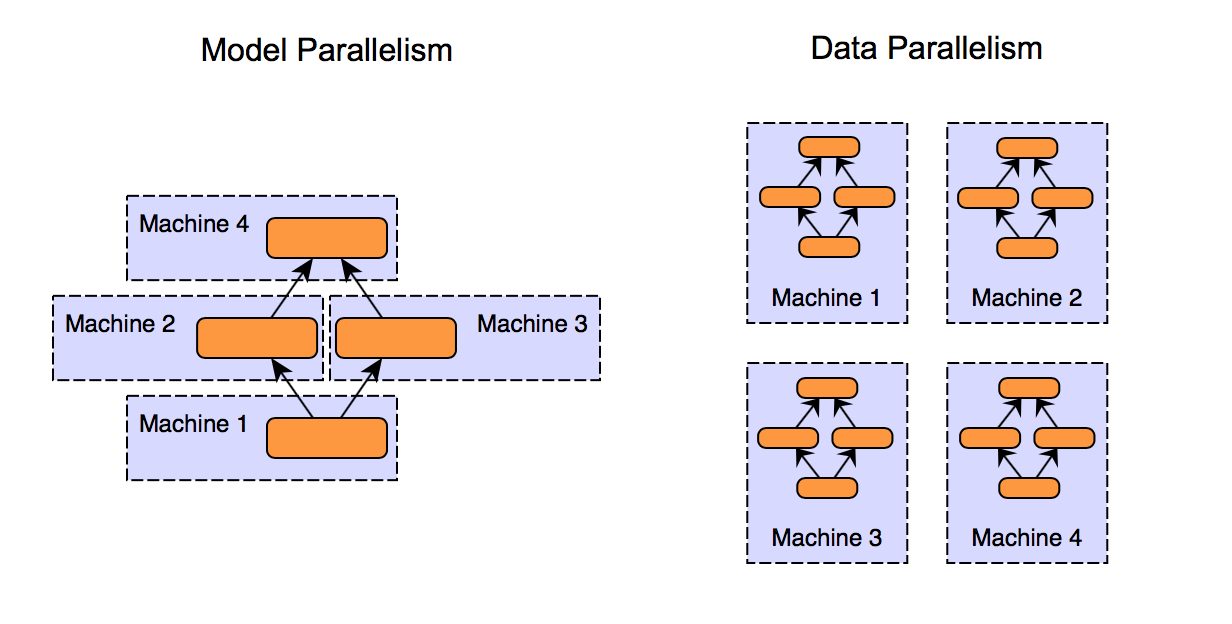 Fig. MP vs DP. DP는 GPU 4개에 full size model이 copy되어있고, MP는 일부가 나눠져 올라가 있다. Source from link
Fig. MP vs DP. DP는 GPU 4개에 full size model이 copy되어있고, MP는 일부가 나눠져 올라가 있다. Source from link
문제는 Neural Network (NN)는 이전 layer의 output이 다음 layer의 output이 되어야 하기 때문에
어떤 GPU들은 대기상태에 들어가는 문제가 발생할 수 밖에 없습니다.
즉 병렬 처리 (Parallel Process)를 할 수 없게 되는겁니다.
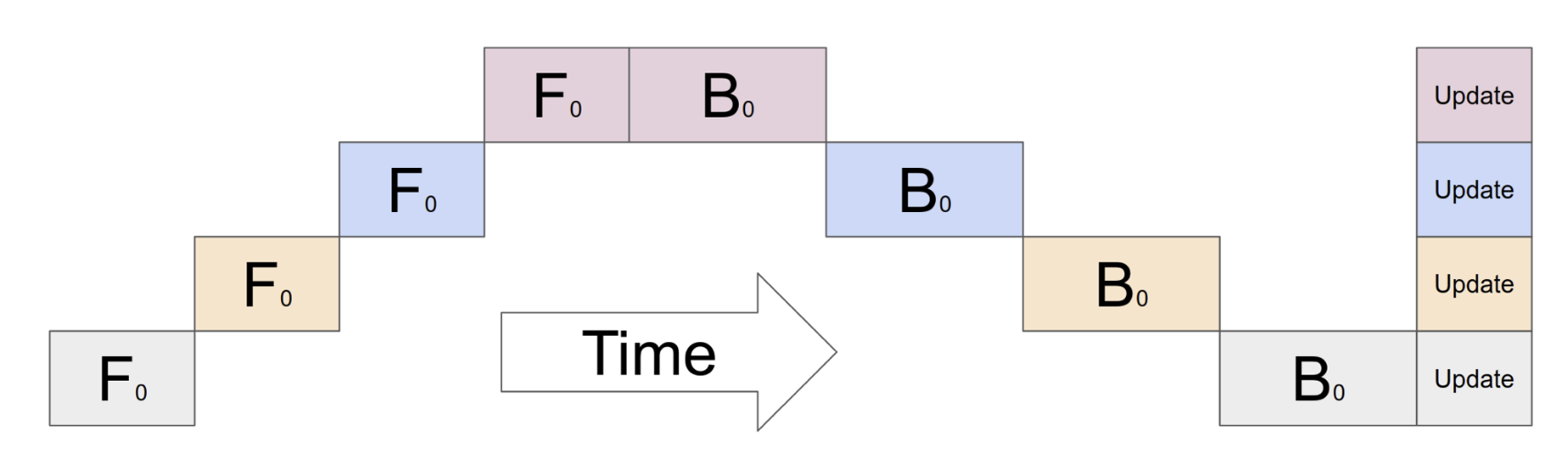 Fig.
Fig.
Pipeline (Model) Parallelism (PP)
앞서 말씀드린 것 처럼 MP가 NN의 sequential dependency 때문에 idle time이 생기기 때문에 효율적인 Pipelining 필요하게 되었습니다.
Pipleline Parallelism (PP)는 Gpipe라는 Paper에서 최초로 제안되었는데
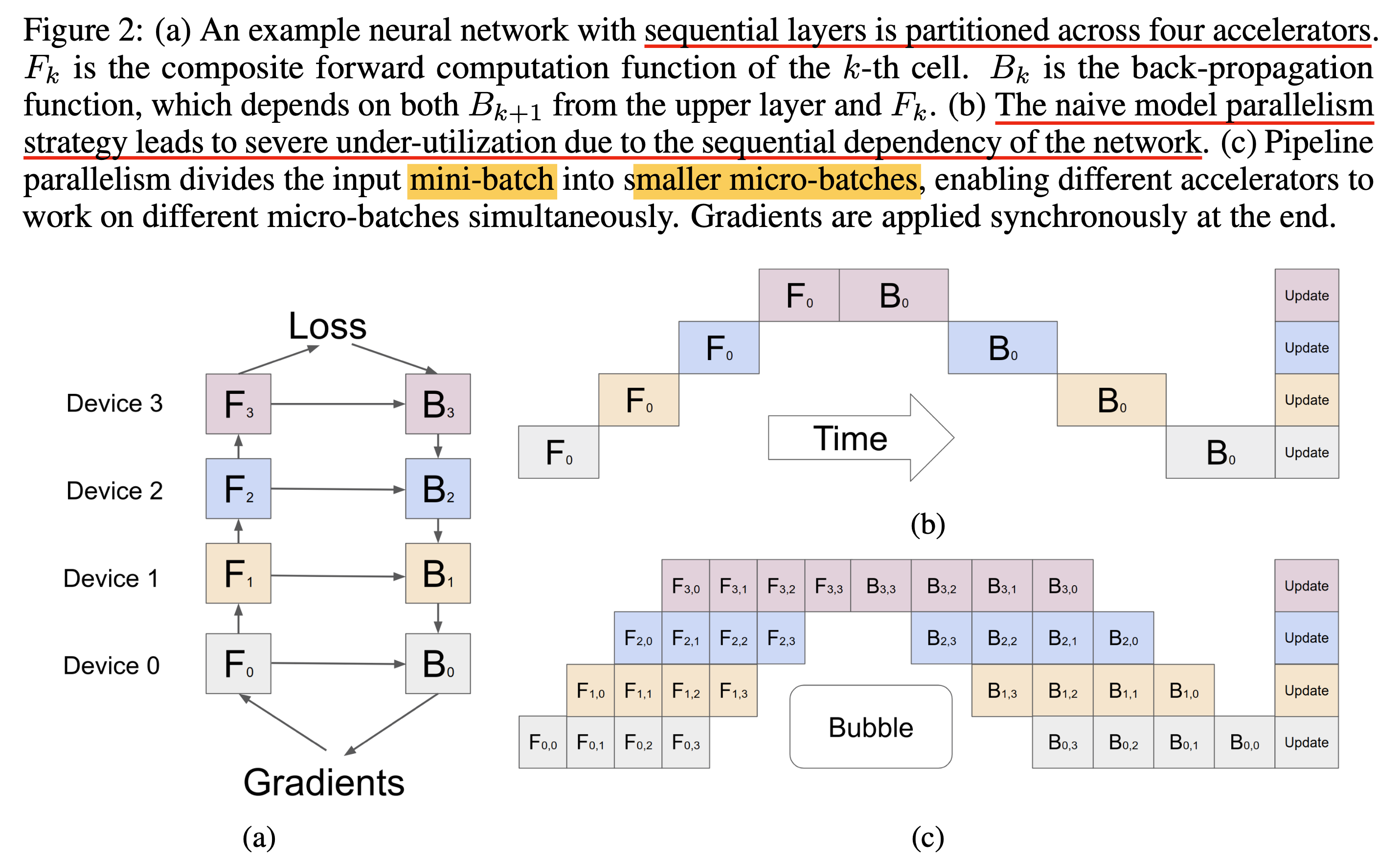 Fig.
Fig.
Figure에서 처럼 mini batch를 micro batch로 더 개념을 세분화해서 pipelining을 하게 됩니다. 이렇게 하면 동시에 처리할 수 있는 job이 늘어나면서 MP의 idle time을 최소화 할 수 있게 되는겁니다.
 Fig. Source from link
Fig. Source from link
아래의 animation을 보시면 micro batch를 세분화 할수록 Idle time (bubble time)이 줄어드는걸 볼 수 있습니다.
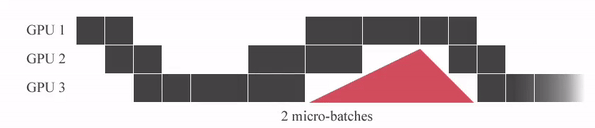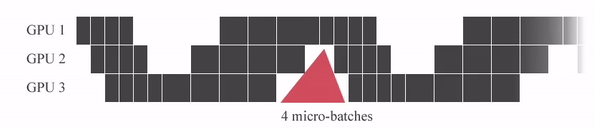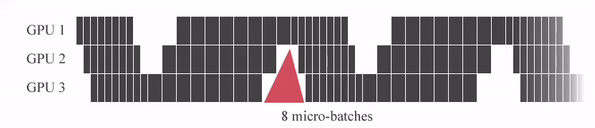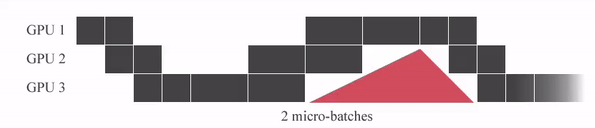 Fig. Source from link
Fig. Source from link
그럼 micro batch로 bubble time을 얼마나 줄일 수 있는가? Gpipe paper에서는
- batch size: N
- micro batch size: M
- #GPU: K
라고 했을 때 bubble time을 아래와 같이 정량화 했습니다.
\[O(\frac{K-1}{\color{red}{M}+K-1})\]즉 M이 커질수록 이를 줄일 수 있게 되는 것인데, paper의 실험에서는 \(M \geq 4 \times K\) 일 때 bubble은 무시할 수준이 되었다고 합니다 (backward, activation checkpoint를 모두 고려했을 때).
PP구현체들을 보면 GPU 8대에 예를 들어 model을 얼마의 단위로 등분할 것인가? (MP degree), 얼마나 data 병렬화를 할 것인가? (DP degree)라는 두 개의 개념이 있고, 이 둘을 곱한 수만큼의 GPU가 총 필요한 GPU 수가 됩니다.
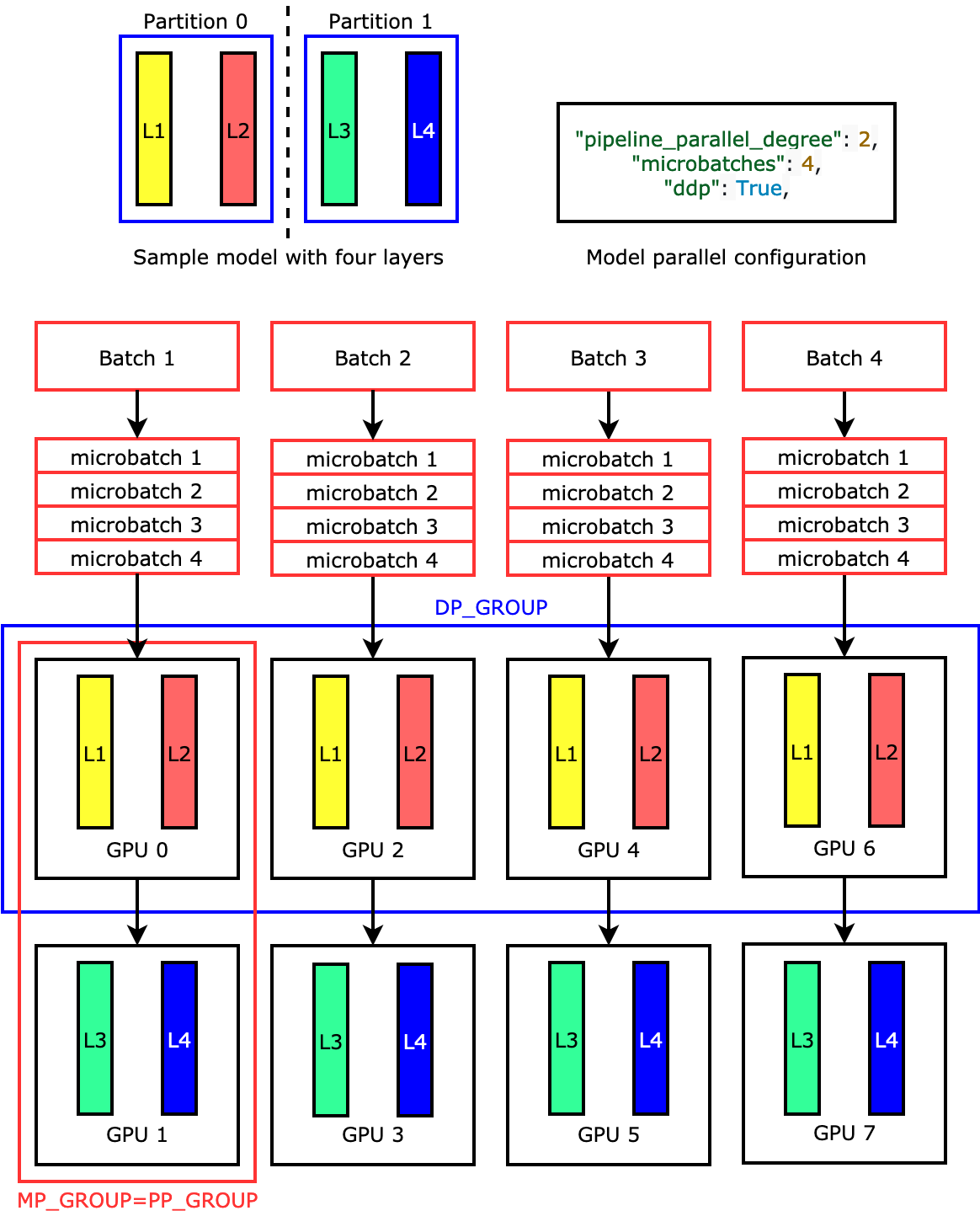 Fig. Source from link
Fig. Source from link
- PP configuration example)
- world size: 2*8=16 (총 process 수)
- node: 2 (machine 수)
- #GPU per node: 8 (machine 당 GPU 수)
- Degree
- DP Degree 4 (total batch를 4등분)
- MP Degree 2 (2GPU에 model을 등분)
- total batch size per iteration: 256
- mini batch size: 32 (2gpu 당 32)
- micro batch size: 2 (32를 2씩, 즉 16개가 나옴)
- world size: 2*8=16 (총 process 수)
한 편, 이런 pipeline 방식도 더 디테일하게 구현을 할 수 있는데, forwarding을 먼저 하고 backward를 순차적으로 하는 것이 일반적인 method라면
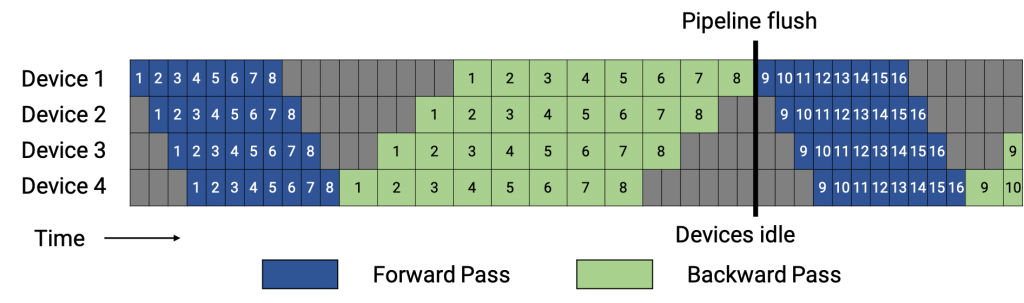 Fig. Simple Pipeline. Pipeline schedule with forward passes (blue) for all microbatches (represented by numbers) followed by backward passes (green). The gray area represents the pipeline bubble time. Source from link
Fig. Simple Pipeline. Pipeline schedule with forward passes (blue) for all microbatches (represented by numbers) followed by backward passes (green). The gray area represents the pipeline bubble time. Source from link
아래처럼 backward pass를 항상 최우선으로 처리하는 방식을 Interleaved Pipeline 혹은 1F1B라고 합니다.
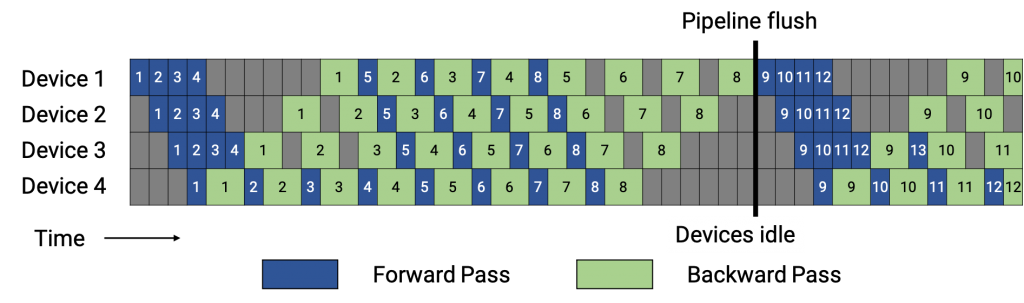 Fig. Interleaved Pipeline. Pipeline schedule with 1F1B schedule (initial warm-up followed by a forward plus a backward pass for some microbatch in steady state). Source from link
Fig. Interleaved Pipeline. Pipeline schedule with 1F1B schedule (initial warm-up followed by a forward plus a backward pass for some microbatch in steady state). Source from link
Tensor (Model) Parallelism (TP)
MP가 MOdel 너무 커서 layer 를 sequential 하게 partitioning 했다면 (inter-layer parallelism) Tensor Parallelism (TP)는 layer 내의 weight matrix tensor를 partitioning한 intra-layer parallelism 방법입니다.
이런 방식의 병렬화는 Mesh-TensorFlow: Deep Learning for Supercomputers와Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism라는 paper들에서 거의 처음 제안되었는데 핵심은 바로 아래 처럼 GEneral Matrix Multiplication (GEMM)을 병렬화 하자는 겁니다.
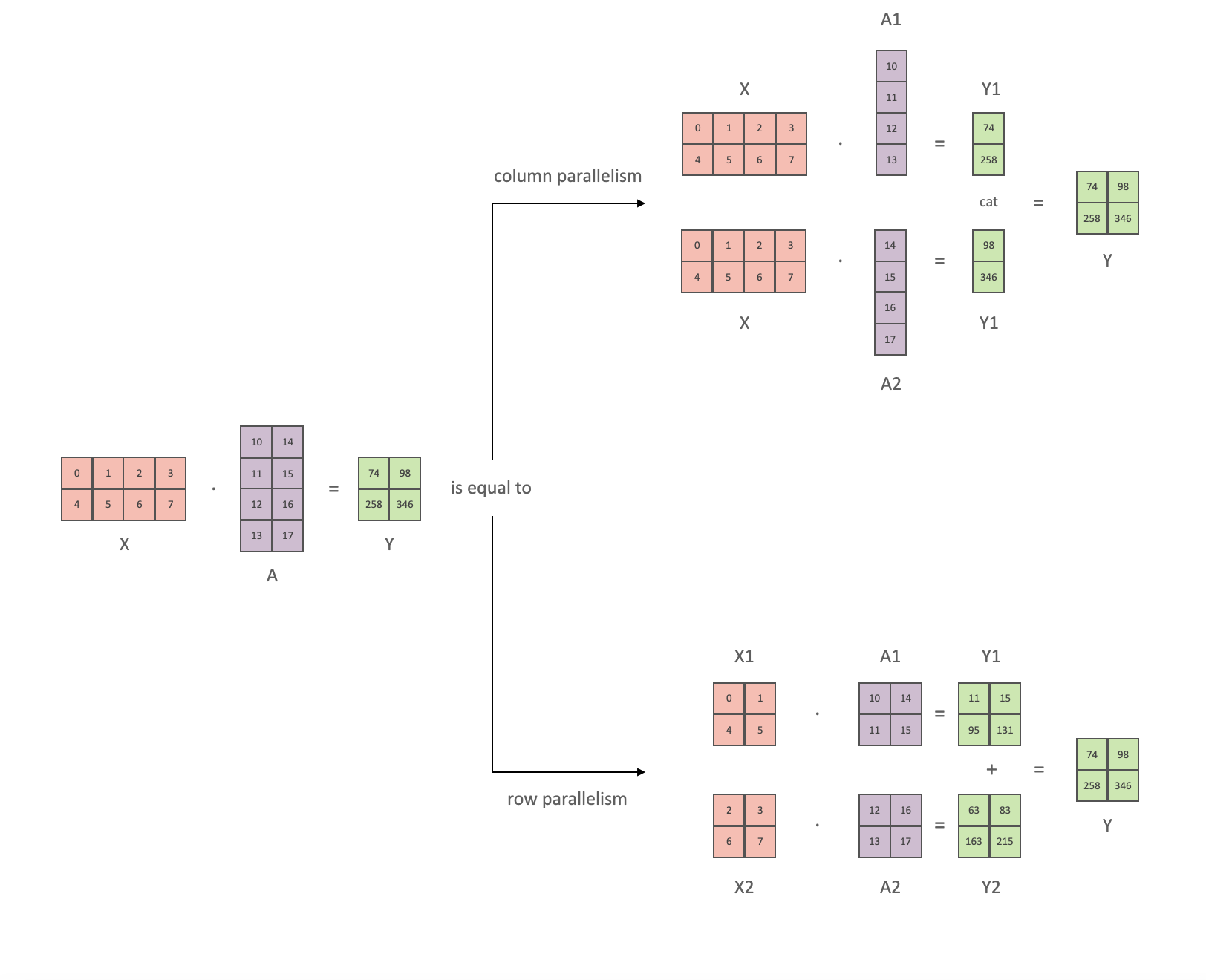 Fig. Y = XA 를 column-wise, row-wise로 나눠서 해도 결국 같다.
Fig. Y = XA 를 column-wise, row-wise로 나눠서 해도 결국 같다.
그런데 하필 Deep Learning에서 모두가 쓰는 Transformer는 matmul과 약간의 non-linear transformation으로 이뤄져 있기 때문에 병렬화 하기가 쉽다는 겁니다.
주의할 점은 병렬화를 할 때 통신을 최소한으로 해야 하기 때문에 module을 잘 쪼개야 한다는 겁니다.
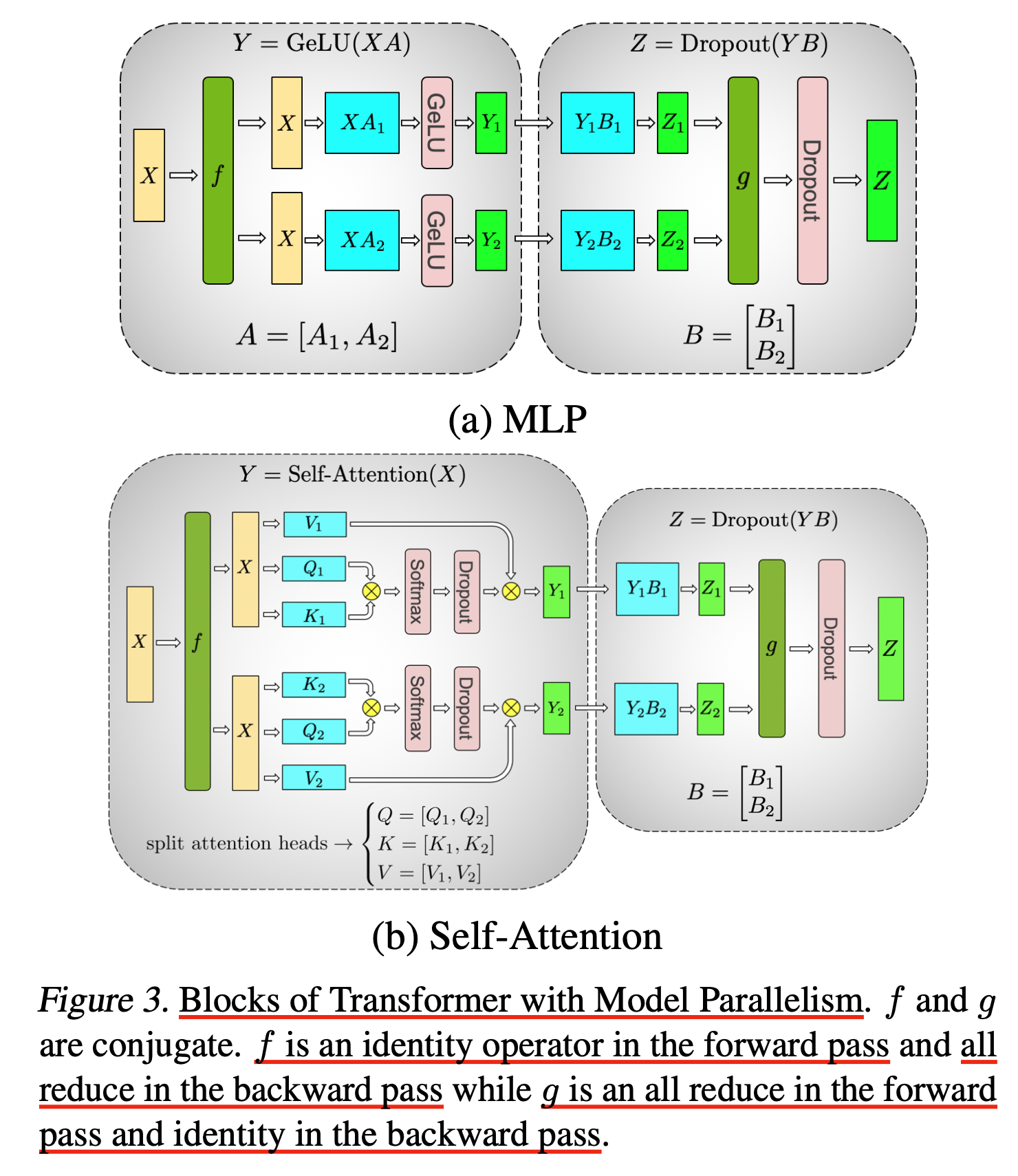 Fig.
Fig.
위의 (a) subfigure를 보면
\[Y=GELU(XA)\]라는 MLP block을 나눌 때
\[X=[X_1, X_2], A= \begin{bmatrix} A_1 \\ A_2 \\ \end{bmatrix}\]가 아니라
\[A=[A_1,A_2]\]로 나눈 것을 볼 수가 있는데, 이는 \(Y=GELU(X_1 A_1 + X_2 A_2) \neq GELU(X_1 A_1) + GELU (X_2 A_2)\) 이기 때문에 중간에 sync를 한번 맞춰야 하기 때문입니다.
Subfigure a, b 에 있는 \(f,g\)는 해당 block의 출력이나 입력을 모든 process와 공유해서 같은 의미 (같은 position)의 값은 더한다는 All Reduce를 의미함으로 figure에서 보이는 MLP, Self-Attention은 forward backward 별로 한번씩의 All Reduce 통신만 발생합니다.
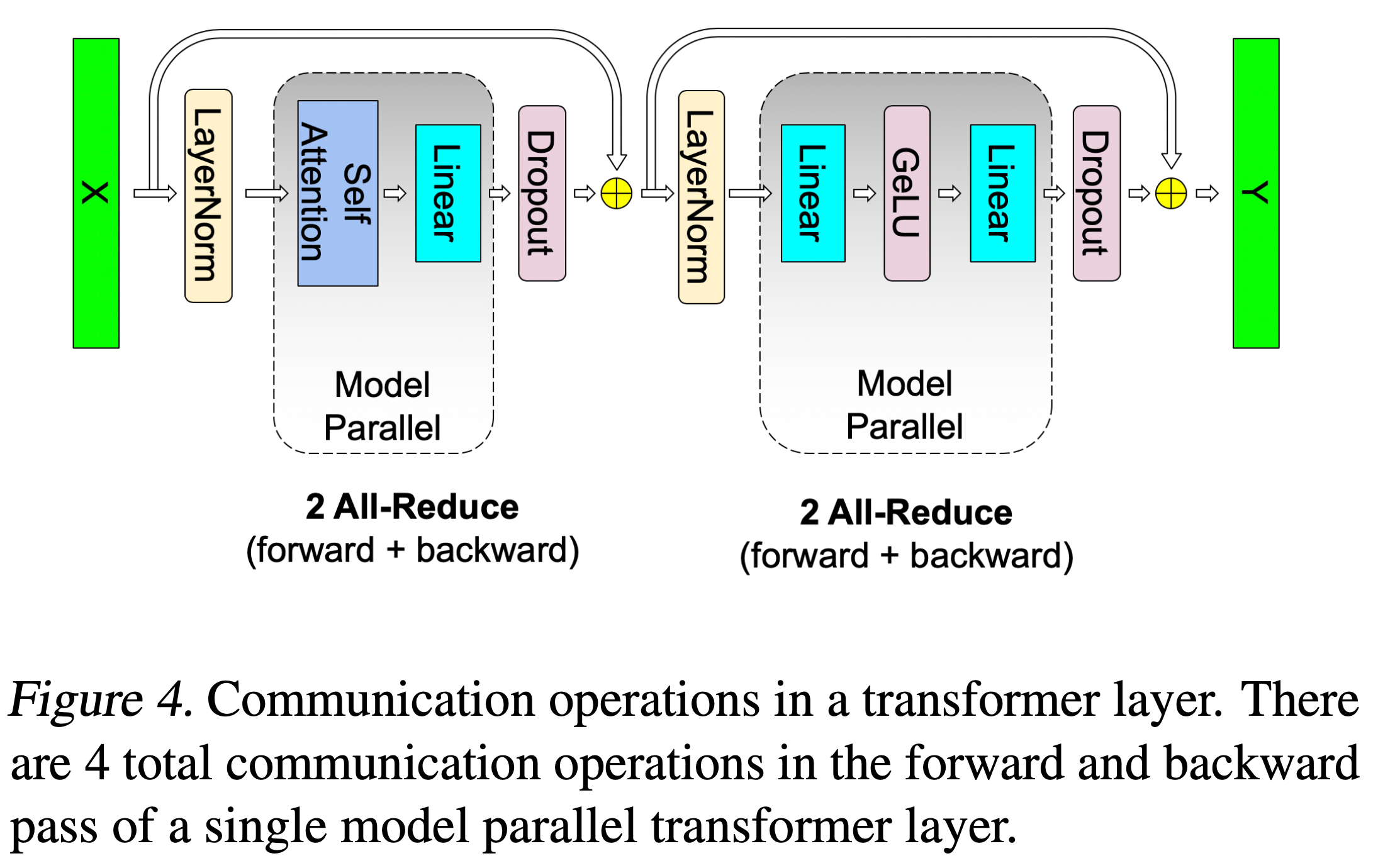 Fig. Transformer Block 하나 당 4번의 통신이 필요.
Fig. Transformer Block 하나 당 4번의 통신이 필요.
즉 DP가 각 batch에서 통신을 딱 한번 (마지막에 gradient 모을 때) 하고 MP는 그보다 조금 더 (layer activation 전달할 때) 필요한 반면 TP는 layer를 forward, backward 할 때 마다 수십회의 통신을 하기 때문에 매우 통신 속도가 빨라야 하며, 최소 한 node 내에서만 통신을 하는것이 권장된다고 합니다. (machine간 통신은 훨~씬 느리기 때문)
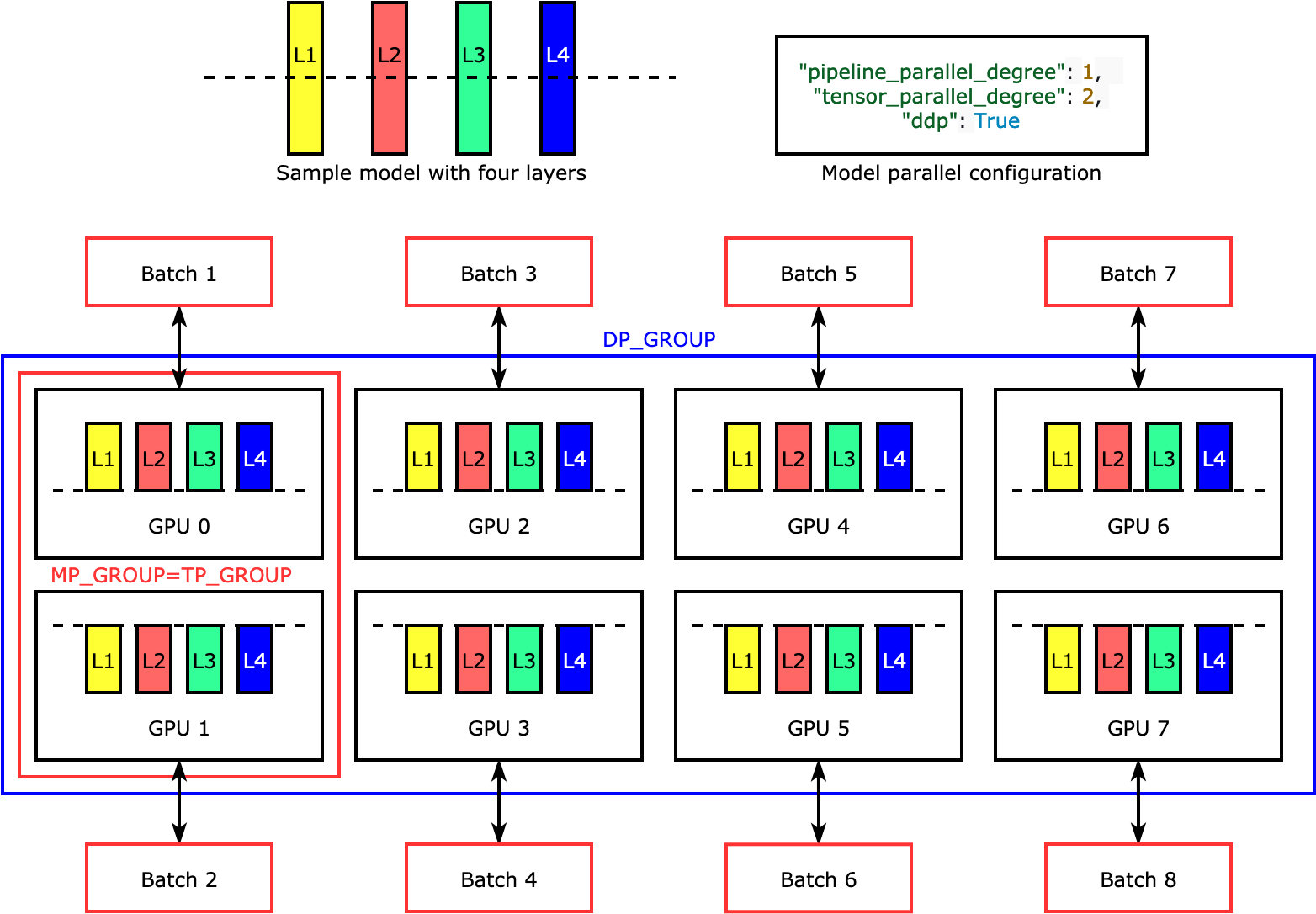 Fig. DP와 MP(MP)를 같이 쓸 수 있는데, 이런 경우 MP나 TP의 degree는 한 node의 GPU를 넘지 않아야 한다. Source from link
Fig. DP와 MP(MP)를 같이 쓸 수 있는데, 이런 경우 MP나 TP의 degree는 한 node의 GPU를 넘지 않아야 한다. Source from link
즉 2 node 4 GPU면 TP degree는 4인 것이 8인 것보다 훨씬 좋다는거죠.
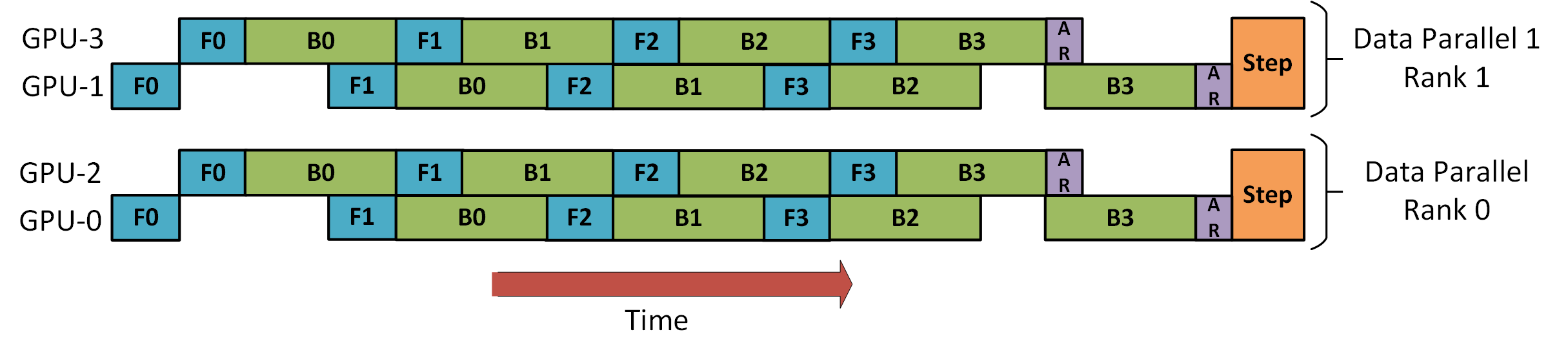 Fig. 얘기한거처럼 DP+복잡한 PP도 가능
Fig. 얘기한거처럼 DP+복잡한 PP도 가능
Distributed Data Parallelism (DDP)
잠시 다시 DP로 돌아가겠습니다.
(앞서 몇 번 Gather, Reduce, All Reduce같은 용어들을 쓰다보니 한 번 설명도 할 겸)
Pytorch 같은 Open-source Framework을 보면 당연히 distributed training 을 위한 module들을 제공하는데요,
nn.DataParallel module class의 문서를 보면 아래와 같은 Warning 문구가 있습니다.
 Fig. DP대신 DDP를 쓰라는 torch docs. Source from link
Fig. DP대신 DDP를 쓰라는 torch docs. Source from link
왜 Distributed DP (DDP)를 권하는 걸까요?
DP가 single node multi gpu 인 상황에서만 쓸 수 있는 반면 DDP는 Dnode가 여러개인 상황에서 distributed training을 가능하게 해줍니다.
하지만 문서에는 single node일 때도 DDP를 쓰는 것을 고려하라고 합니다.
왜 일까요?
문서를 좀 더 찾아보면 DP의 구현상 이슈로 문제점이 몇 가지 있다고 얘기합니다.
 Fig. DP vs DDP 2. Source from link
Fig. DP vs DDP 2. Source from link
물론 장점은 있습니다. 코드 1줄이면 DDP를 쓸 수 있다는 건데
net = torch.nn.DataParallel(model, device_ids=[0, 1, 2])
output = net(input_var) # input_var can be on any device, including CPU
그 외에
- 매 iteration 마다 data, model copy 가 일어남.
- single process (master) 와 multi-thread로 구현되어있는데 python GIL때매 병렬 forward, backward가 느릴 수 있음.
등등의 문제가 발생합니다. 이를 도식화 하면 아래와 같은데요,
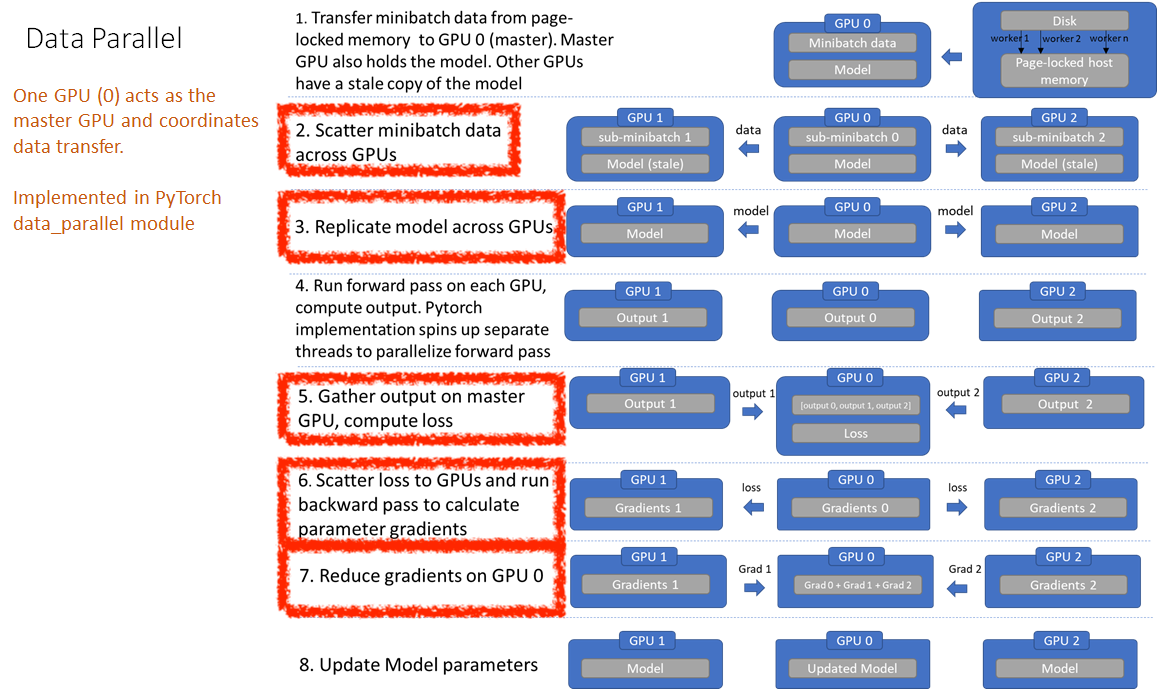 Fig. DP. Source from link
Fig. DP. Source from link
Master GPU 하나에서 data loading, loss계산, model update 등을 모두 모아서 처리하느라 빈번하게 scatter와 gather가 일어나는 걸 볼 수 있습니다. 이럴 경우 master GPU의 memory가 가중되는 문제까지 생겨서 batch size를 크게 못 가져갈 수도 있을 것 같네요. DDP는 이런 비효율을 없앤 것이라 할 수 있는데요, 하나의 process에 multi-thread가 아닌 여러 process를 띄우고 처음부터 각각 dataloader, model 을 띄운 뒤에 gradient 계산할 때만 all reduce를 하는 방식을 택합니다.
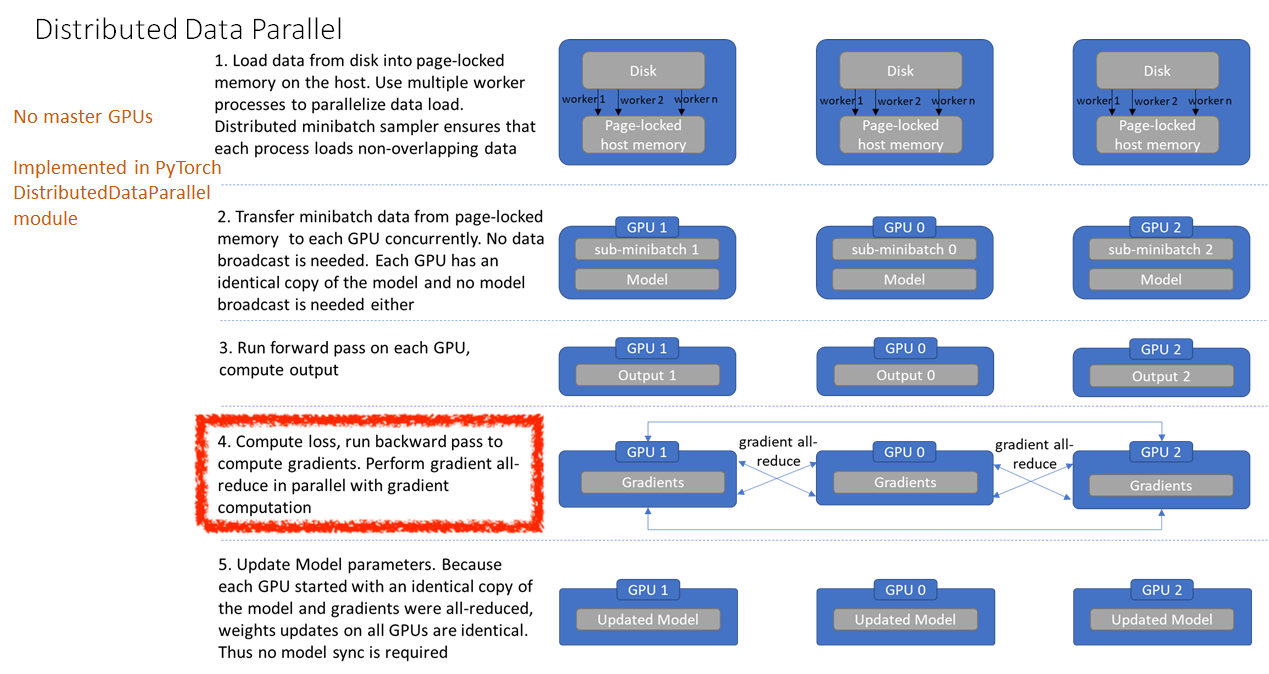 Fig. DDP. Source from link
Fig. DDP. Source from link
그래서 우리는 DDP를 써야 하는것이죠.
Key Communication Utils of pytorch.distributed
Distributed training을 처음 접하신다면 gather, reduce 그리고 broadcast 라는 개념을 모르실 수 있습니다. 각각은 다음의 figure를 보시면 이해가 쉬우실 겁니다. (자주 등장하는 용어이니 알아두시면 좋습니다.)
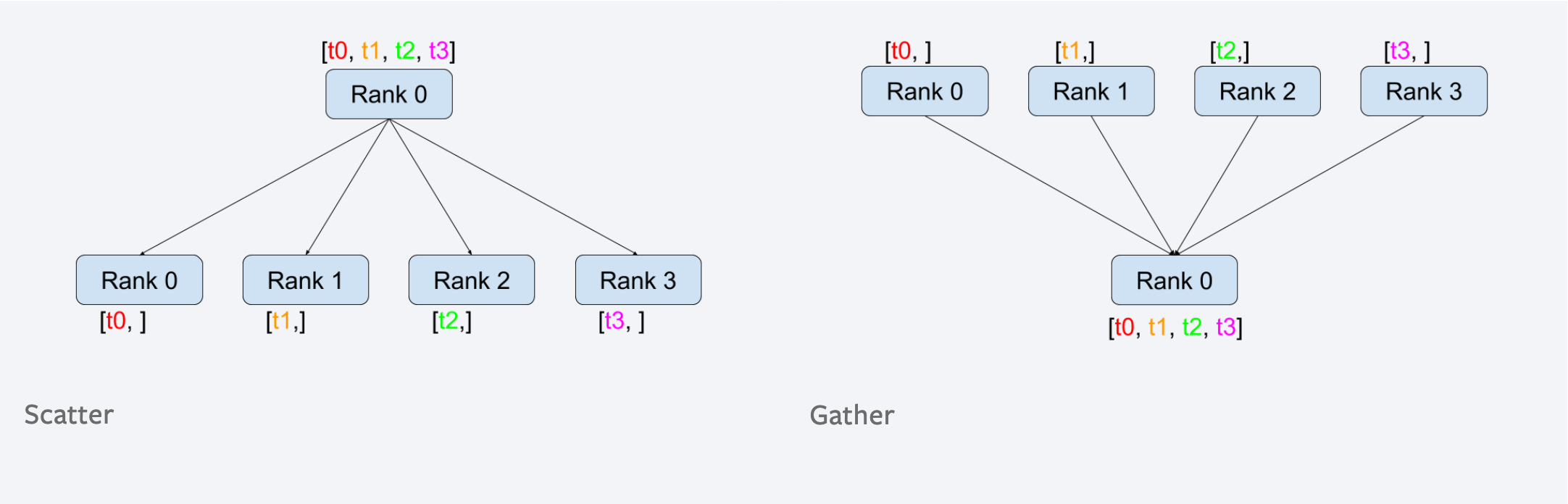 Fig. Scatter는 [B, T]를 [B/N, T]로 나누는 것 where N is #GPU. Gather는 그 반대
Fig. Scatter는 [B, T]를 [B/N, T]로 나누는 것 where N is #GPU. Gather는 그 반대
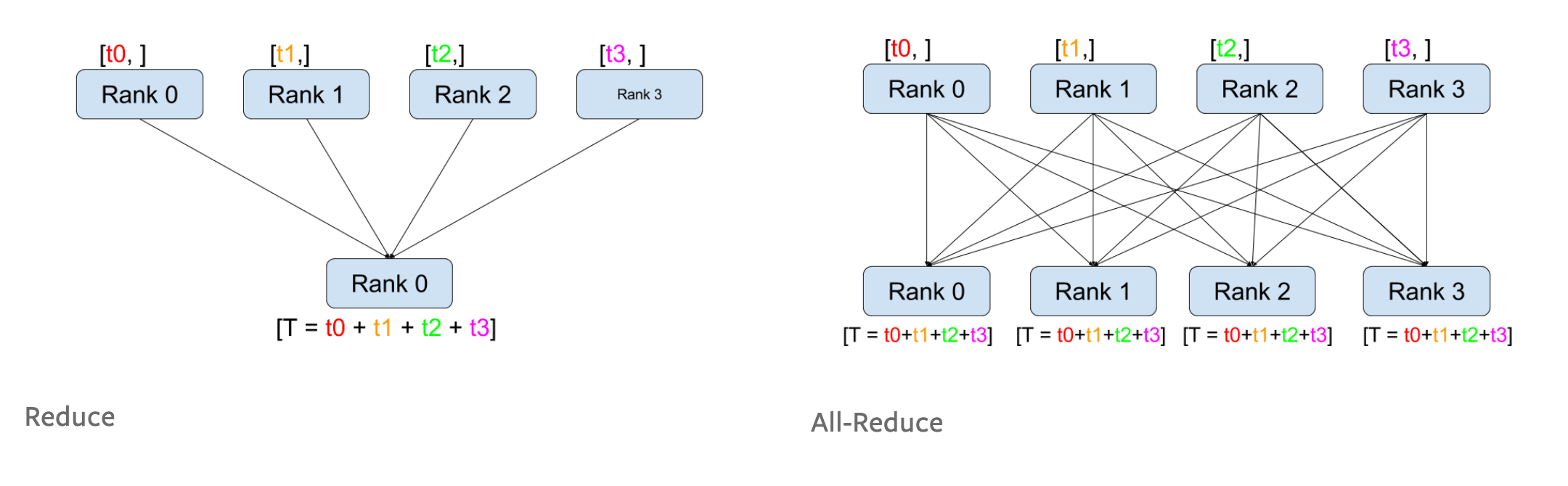 Fig. Reduce는 각 GPU로부터 모든 값을 더해 master process로 가져오는 것. All Reduce는 이를 모든 GPU에 전부 할당하는 것
Fig. Reduce는 각 GPU로부터 모든 값을 더해 master process로 가져오는 것. All Reduce는 이를 모든 GPU에 전부 할당하는 것
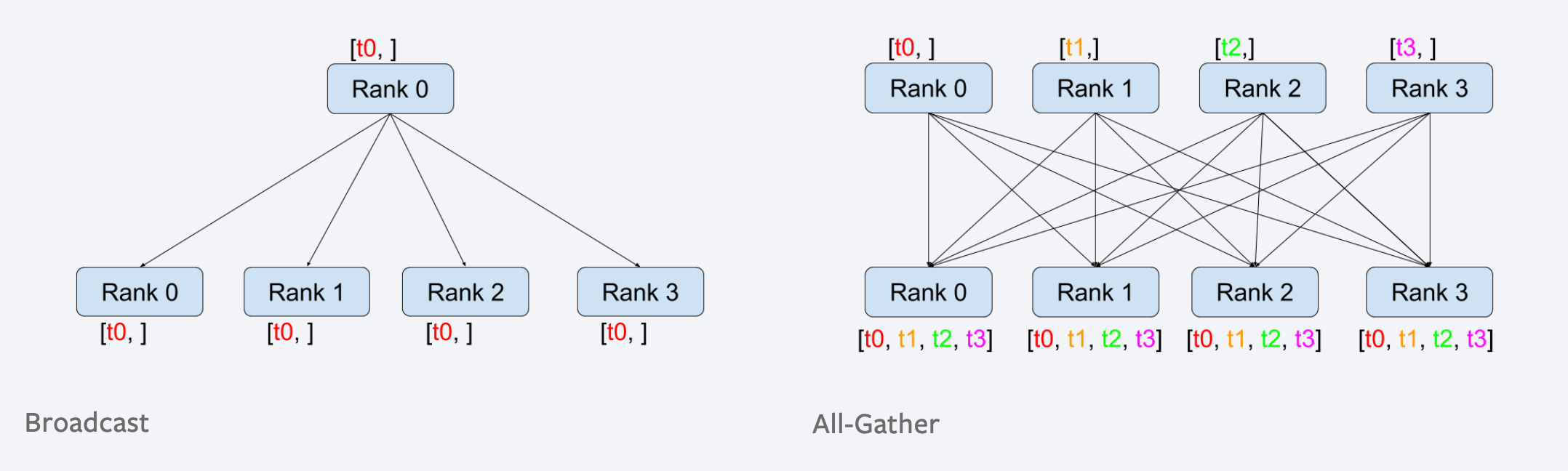 Fig. Broadcast는 Scatter와 대비되는데, [B, T]가 나눠져 각 GPU로 분배되지 않고 그대로 전파 되며 All-Gather는 더한 것이 아니라 모아서 각 GPU에 할당. (All-Reduce와 대비)
Fig. Broadcast는 Scatter와 대비되는데, [B, T]가 나눠져 각 GPU로 분배되지 않고 그대로 전파 되며 All-Gather는 더한 것이 아니라 모아서 각 GPU에 할당. (All-Reduce와 대비)
이를 사용해서 DP를 다시 아래처럼 나타낼 수 있겠습니다.
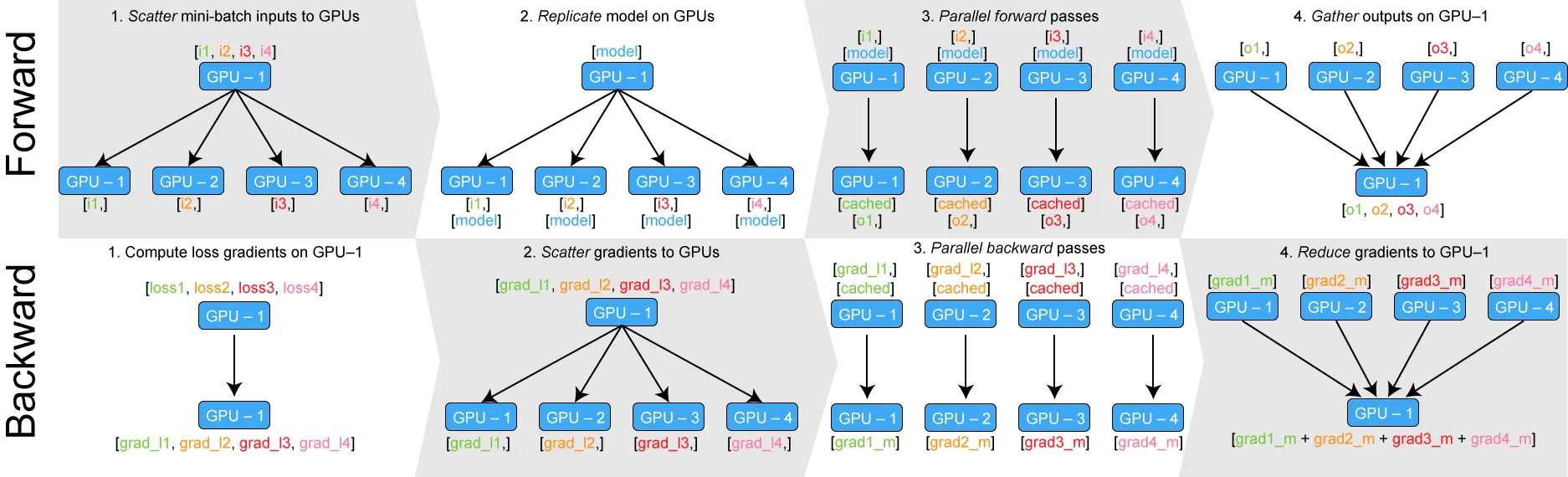 Fig. Forward and Backward passes with torch.nn.DataParallel. Source from link
Fig. Forward and Backward passes with torch.nn.DataParallel. Source from link
한편 DDP는 그럼 각 process에서 loss, gradient 까지 계산하고 이를 다 더한걸 모두에게 배포하는 all reduce를 해야만 하는데요,
어떤식으로 이를 구현해야 할까요?
가장 단순한 방법은 앞서 DP에서처럼 어떤 한 node에서 다 합치고 다시 분배를 하는 것입니다.
하지만 torch DDP 에서는 simple all reduce 대신 Baidu의 Ring All Reduce을 썼다고 알려져 있습니다.
(in Pytorch official docs...)
The model is replicated on all the devices;
each replica calculates gradients and simultaneously synchronizes
with the others using the ring all-reduce algorithm.
이제 all reduce가 왜 효율적인지 까지만 알아보고 넘어 가도록 합시다.
우리가 4개의 Process (P=4)가 각각 model output으로 length=4 (N=4)인 array를 얻었다고 칩시다. 우리가 원하는 것은 같은 위치의 각 element를 모두 더한 결과물을 모두가 가지게 되는 겁니다.
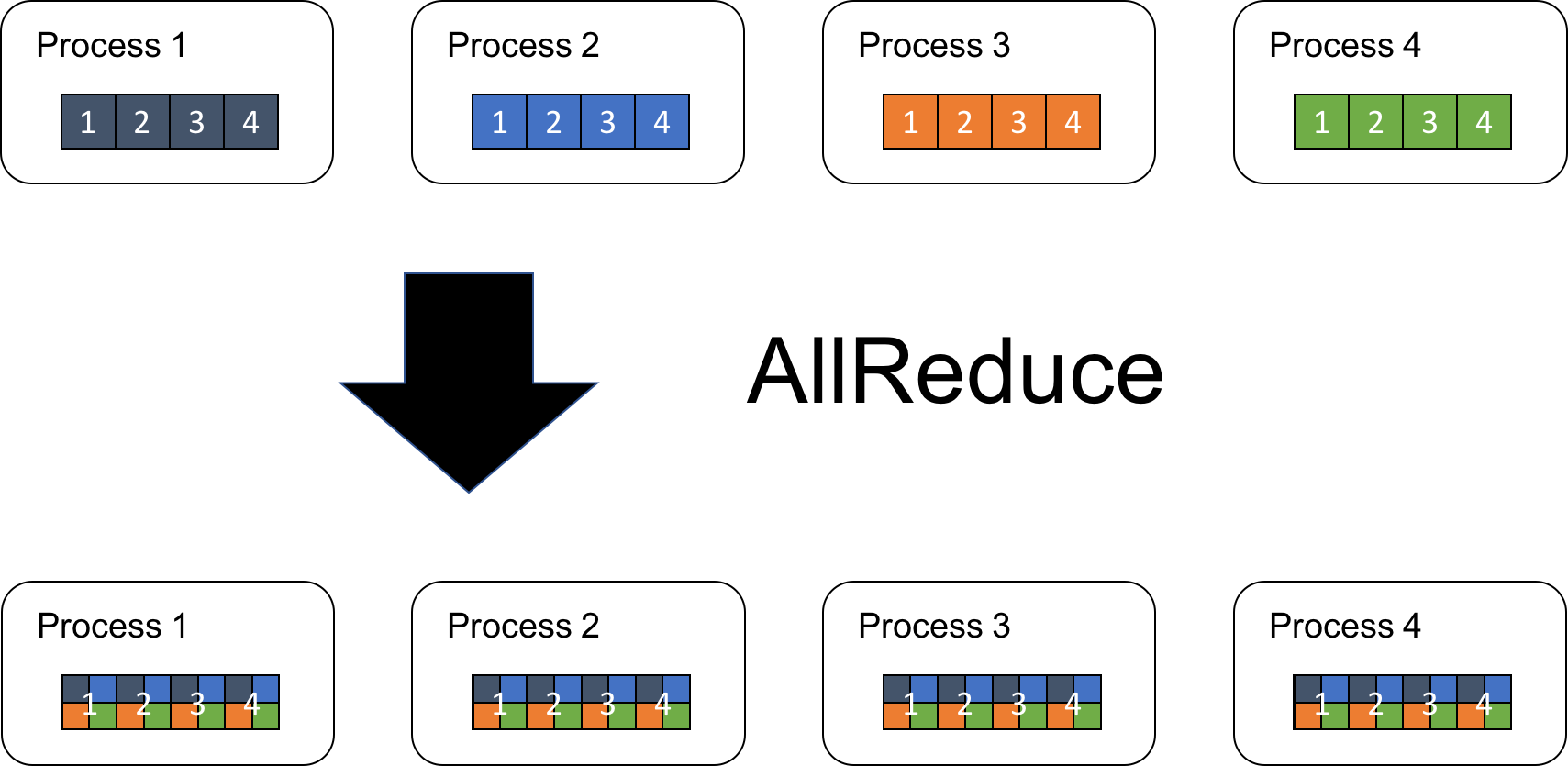 Fig.
Fig.
Ring All Reduce는 아래처럼 N크기의 array를 P개의 subarray로 나눕니다. (지금은 마침 array length N도 4임)
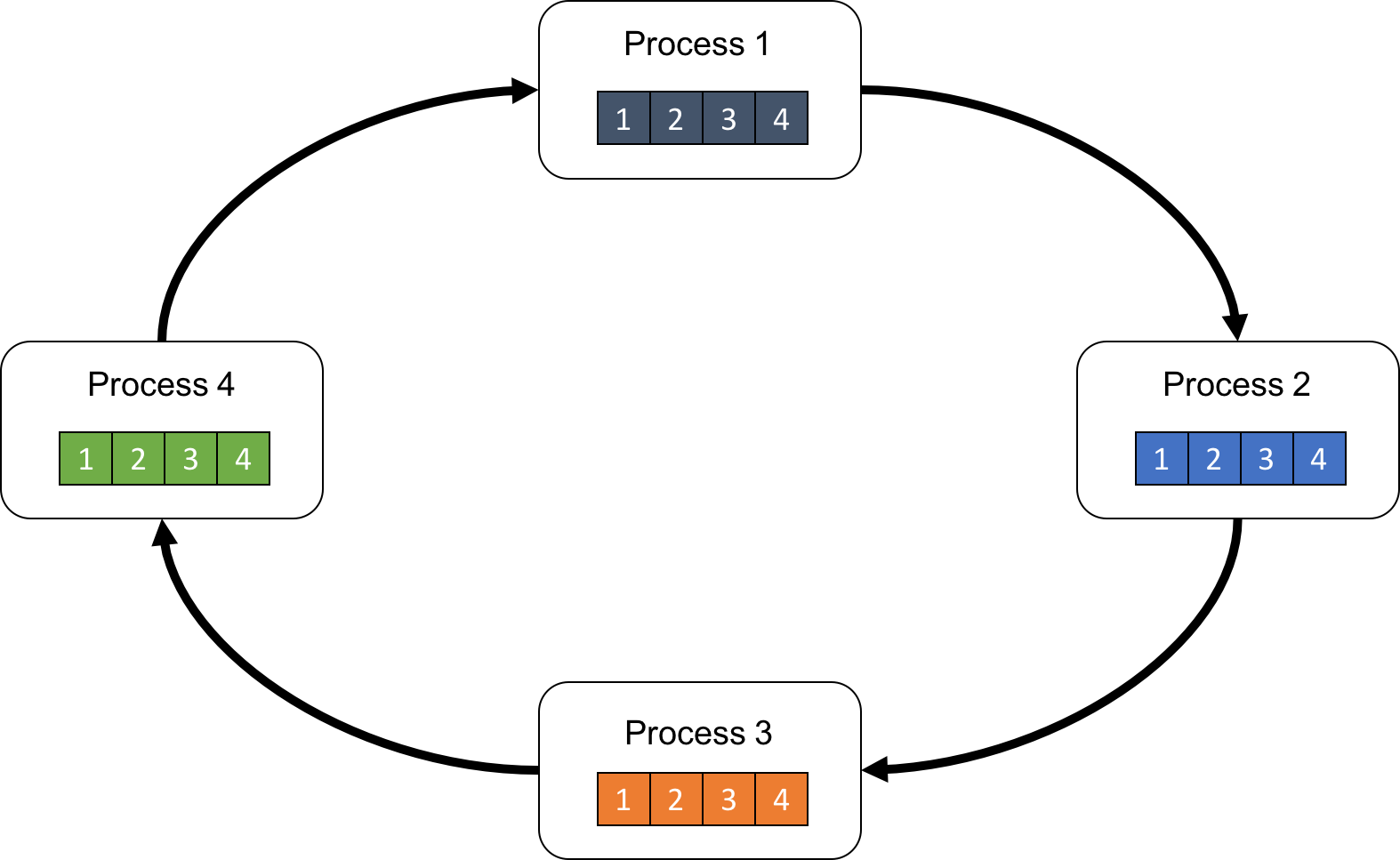 Fig.
Fig.
이를 chunk라고 부르고 우리가 하려는 operation은 sum이기 때문에, 동시에 서로 다른 p개 chunk를 다음 process에 넘기면서 순차적으로 정보를 누적시킵니다.
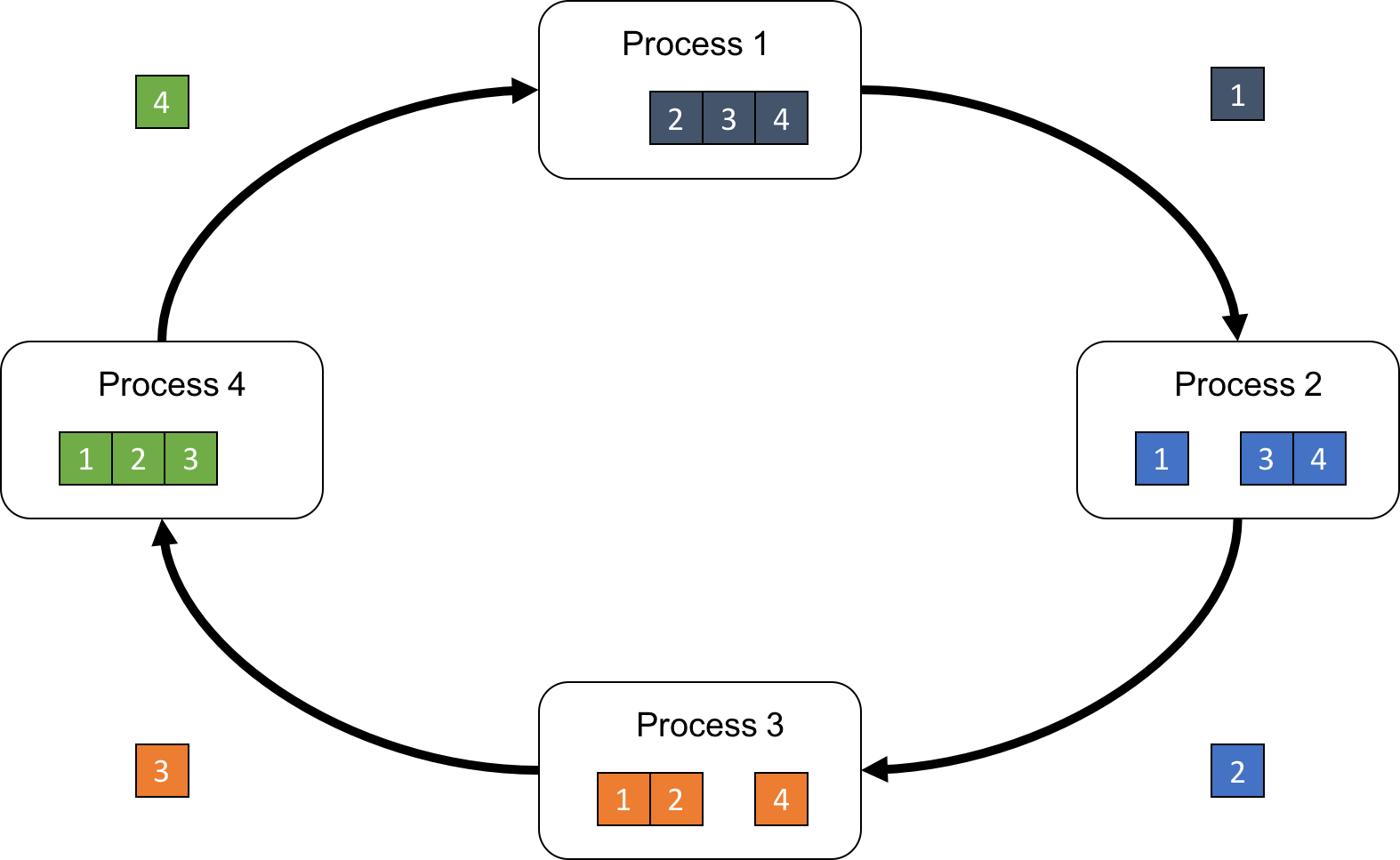 Fig.
Fig.
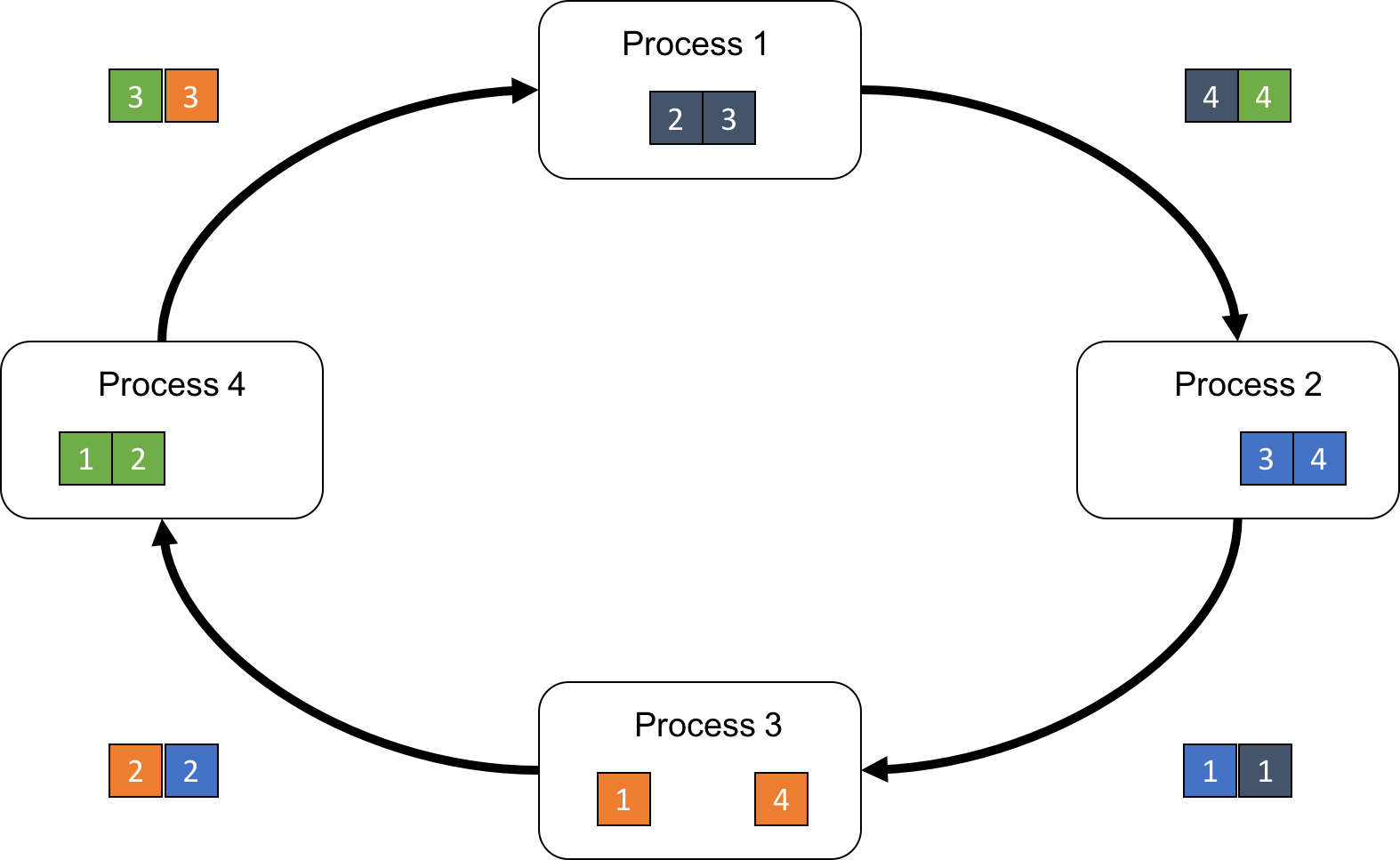 Fig.
Fig.
이를 P-1 번 반복하면 마지막으로 방문한 process는 우리가 원하는 최종 결과물의 서로 다른 part (chunk)를 완성하게 됩니다.
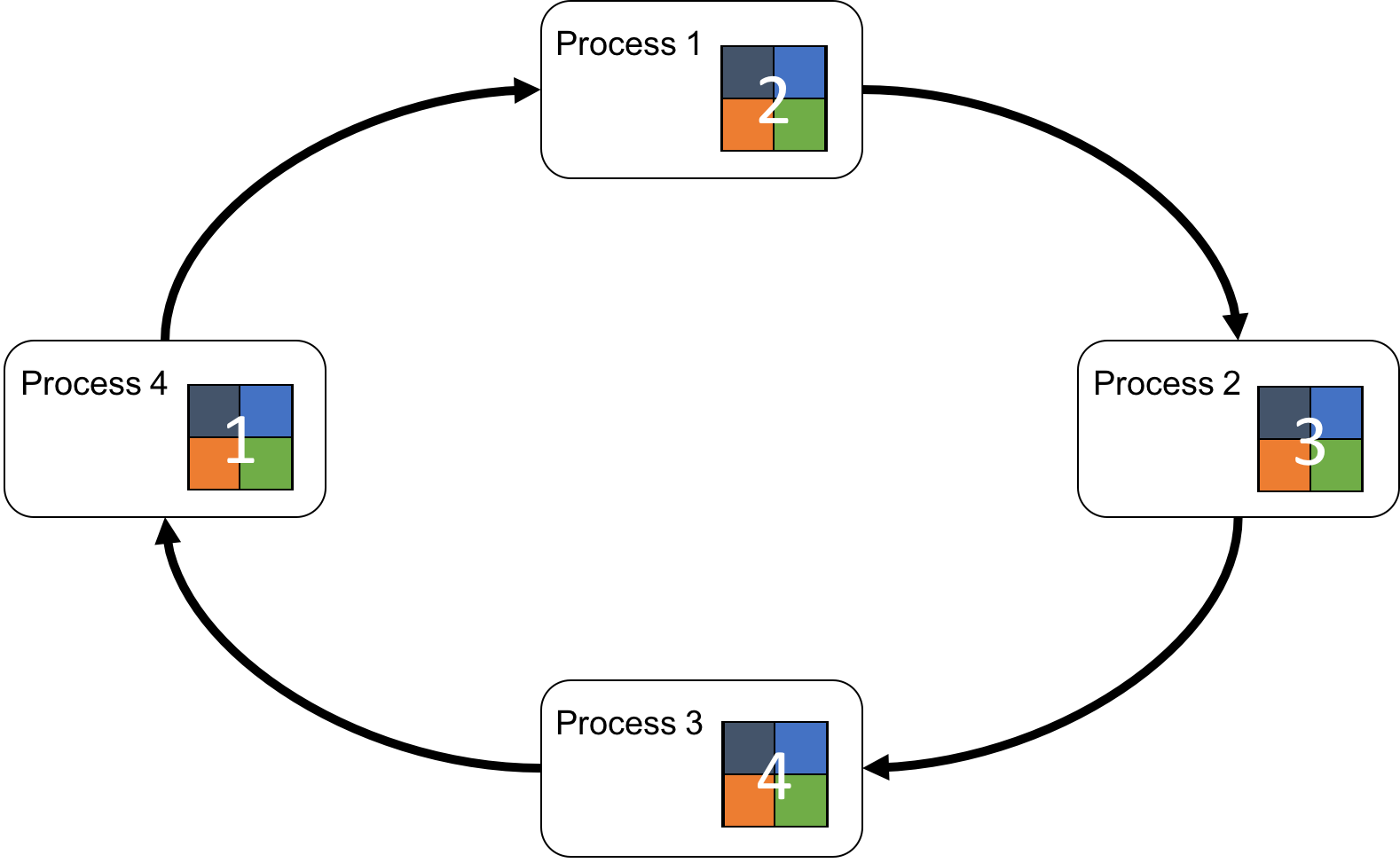 Fig.
Fig.
마지막으로 각 Part를 서로에게 공유해주면 완성입니다.
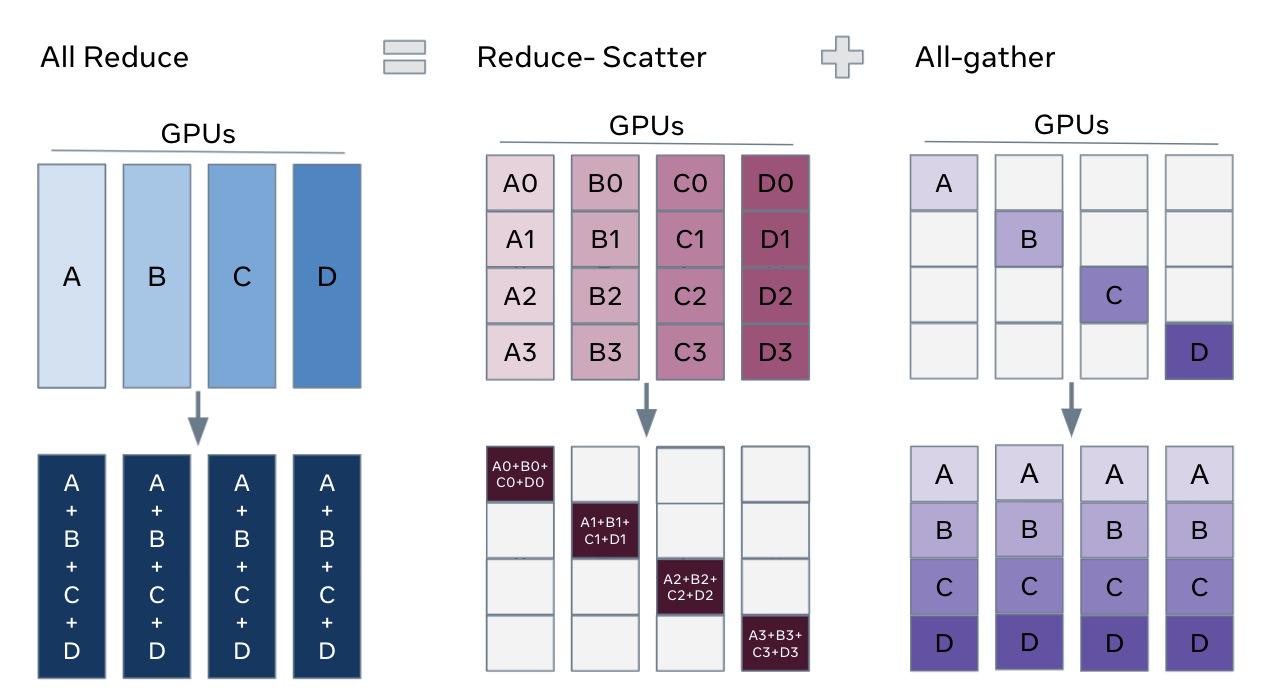 Fig. All Reduce = (Reduce) (Scatter) (All Gather)의 합작이다. Source from link
Fig. All Reduce = (Reduce) (Scatter) (All Gather)의 합작이다. Source from link
앞서 간단하게 master node가 모두 모아서 더하고 다시 분배하는 방식은 (P-1)N 만큼의 data를 master가 받고 sum한 후 다시 이를 (P-1)N 만큼 처리해야 하기에 총 통신량이 P에 비례하나, Ring All Reduce는 각 process가 한번에 드는 통신 비용은 N/P 사이즈의 Chunk를 (P-1) 번 처리하며 마지막에 한번 더 같은 사이즈를 (P-1)번 교환하기에 2N(P-1)/P 가 되므로 실제로는 P에 independent해지면서 process가 늘어날수록 통신량이 선형적으로 증가하는 것을 막고 각 process에 계산과 통신을 균등하게 분배함으로 병목을 제거할 수 있었다고 합니다.
Ranking Mechanism when Using a Combination of PP and TP
앞서 MP와 DP를 섞어서 Pipelining하는 방법이 있었습니다. 다음은 굉장히 복잡하지만 예시인데, 복잡하지만 최대의 효율을 이끌어내기 위해서 이런 조합도 가능하다고 생각하시면 될 것 같습니다.
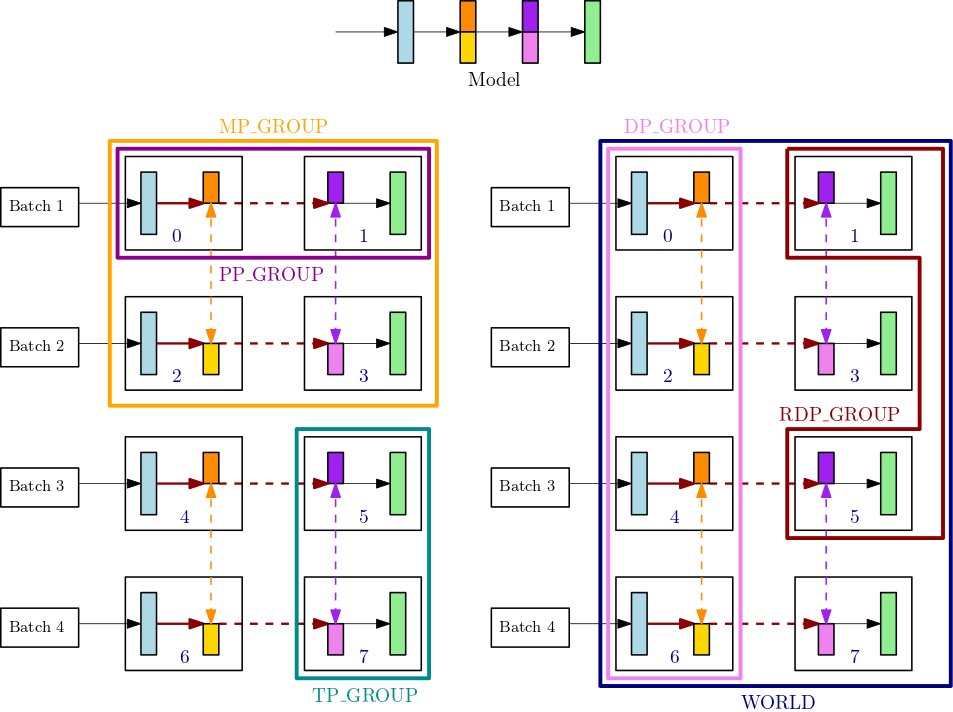 Fig. Source from link
Fig. Source from link
(일반적으로는 여기까지 쓸 일이 없고 복잡해서 넘어가도록 하겠습니다. 관심있는 분들은 link로..)
Summary of Parallelism
지금까지의 Parallelism을 요약한 것입니다.
- (D)DP
- 각 process가 dataloader, model을 갖고 있으며 gradient계산 후 all reduce만 하면 되는 편리함.
- process 별 통신은 적지만
model parameter가 각 procee에 전부 올라가야 하므로 memory efficiency 하지는 않음.
- MP
- model이 너무커서 layer를 각 GPU process에 나눠서 올림.
- 예를 들어 layer0 의 activation을 layer1이 받아야 하므로 기다리는 동안 bubble time 생김
layer간 통신 필요
- PP
- MP의 bubble을 최소화 하기 위해 micro batch 단위로 scheduling을 함.
- classic MP보다
통신 더 필요
- TP
- interlayer (MP의 방식)가 아닌 intralayer 병렬화
통신 많이 필요- 같은 node (machine) 내에서 하길 권함
- MP + PP + TP
- 분할, scheduling을 잘 해야함.
Zero Redundancy Optimizer (ZeRO)
앞서 parallelism 에 대해 기본적으로 알아봤는데 사실 이것만으로는 large model을 학습하기엔 부족합니다. 3B, 7B … 이상의 large model을 distributed training 하려면 Zero Redundancy Optimizer(ZeRO)를 반드시 알아야 합니다.
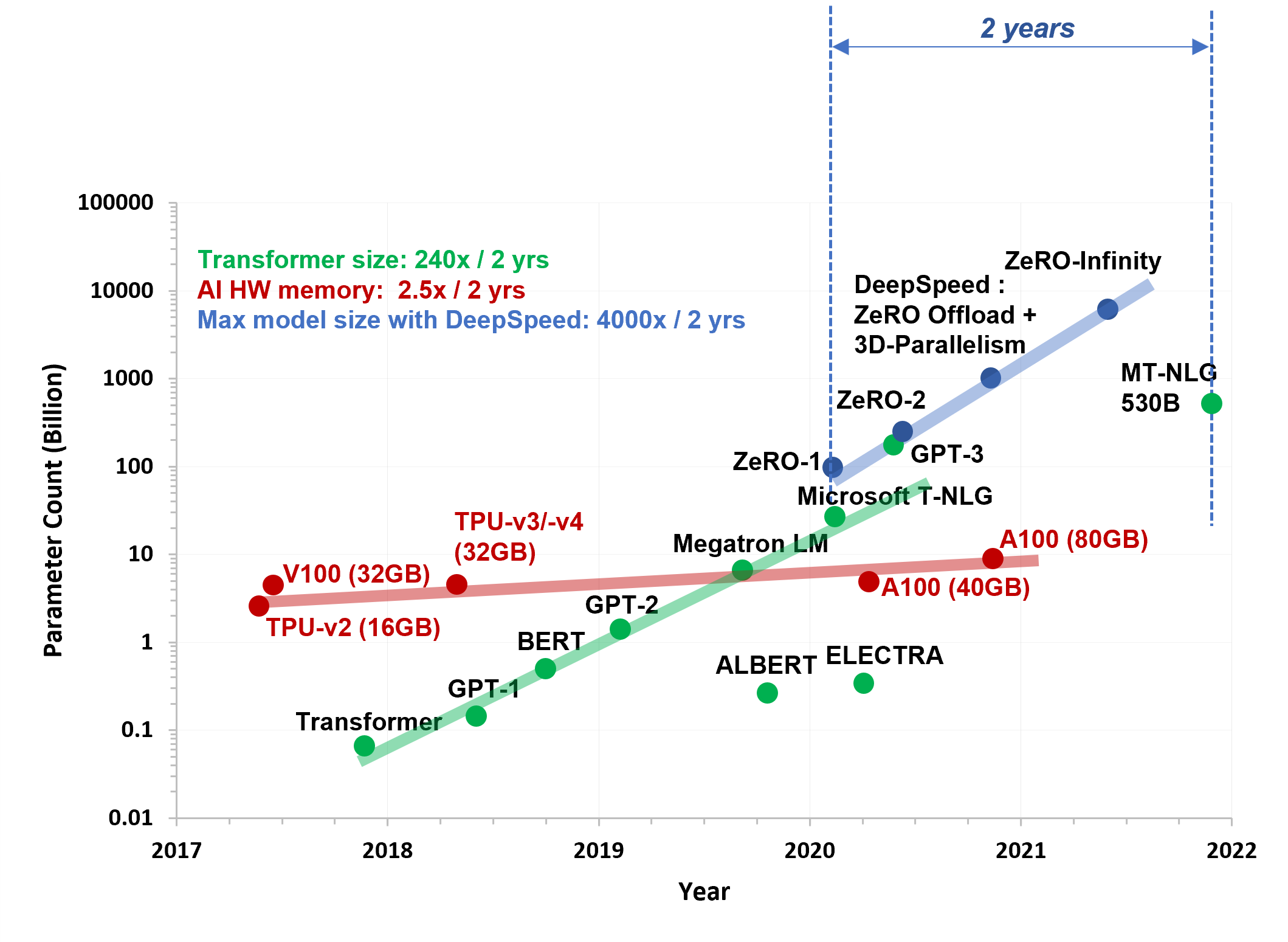 Fig. Hardware (HW)의 발전속도는 Model Size의 발전 속도를 따라가지 못한다. 결국 ZeRO같은 algorithm을 사용해야만 HW의 한계를 이겨내고 학습할 수 있다. Source from here
Fig. Hardware (HW)의 발전속도는 Model Size의 발전 속도를 따라가지 못한다. 결국 ZeRO같은 algorithm을 사용해야만 HW의 한계를 이겨내고 학습할 수 있다. Source from here
ZeRO는 Microsoft에서 개발한 method로 모델의 크기가 수십 billion 을 넘어가는 large model을 상대적으로 적은 GPU를 가지고 학습하기 위해 제안되었습니다.
앞서 TP를 설명하며 언급드렸던 Megatron-LM이 수백 billion에 달하는 model을 학습하는 대표적인 algorithm이었으나 이를 학습하기 위해 천문학적인 GPU가 들어갔다고 알려져 있습니다.
여기에 ZeRO를 추가하거나 ZeRO만으로도 필요한 GPU수를 더 최적화 할 수 있다고 하는데요,
본 post의 highlight인 ZeRO에 대해서 이제 본격적으로 알아보도록 하겠습니다.
Where Did All The Memory Go ?
ZeRO paper를 보시면 다음과 같은 구절이 있습니다.
Let’s take a step back to examine the memory consumption of the current training system.
For example, a 1.5B parameter GPT-2 model requires 3GB of memory
for its weights (or parameters) in 16-bit precision,
yet, it cannot be trained on a single GPU with 32GB memory using Tensorflow or PyTorch.
One may wonder where all the memory goes.
논문에서는 GPT-2를 예시로 드는데요, GPT-2의 model size는 large size가 1.5 billion (B)정도 됩니다.
저자들은 model parameter를 부동 소수점 16자리로만 표현하는 Floating Point 16 (FP16)을 사용해서 학습할 때를 가정합니다.
FP16을 쓰면 weight element 하나당 2 bytes를 model을 다 upload하는 데 3GB 정도의 GPU memory를 쓰게 되는데요,
\[\frac{150,000,000 * 2bytes}{1024^2} \approx 3GB\]32GB (v100)의 GPU 1대로 학습이 불가하다고 합니다.
그 이유는 FP16으로 모델 학습을 하는 것이 실제로는 Mixed Precision Training이라는 algorithm을 쓰는 것이고 이 mixed precision이 엄청난 Redundancy를 가지고 있기 때문이라고 저자들은 주장합니다.
POV: Model States
어느 부분이 redundancy일까요? 우선 Mixed Precision Training method 에 대해 짧게 생각해 봅시다. Deep Neural Network (DNN) model을 Single-Precision (FP32) 대신 Half-Precision (FP16)로 연산을 하면 속도가 수 배로 빨라질 수 있지만, 표현할 수 있는 수의 범위가 더 좁아지게 (narrower) 됨으로써 model accuracy 에 영향을 주게 됩니다. 그래서 fp16이나 custom fp16인 brain float 16 (bf16)등을 사용하여 model을 학습하고자 하는 욕구가 생겼는데, 이는 수를 표현하는 데 있어 정밀도 (precision)가 낮고 표현 가능한 범위가 좁은 문제를 가지고 있기 때문에 그냥 model weight을 전부 fp16, bf16으로 바꿔 학습하면 학습이 잘 되질 않습니다. (bf16은 별 문제가 없을 수 있음)
 Fig. FP32 vs FP16 vs BF16. fp16은 fp32나 bf16과 다르게 표현할 수 있는 실수의 범위가 더 적다. Source from link
Fig. FP32 vs FP16 vs BF16. fp16은 fp32나 bf16과 다르게 표현할 수 있는 실수의 범위가 더 적다. Source from link
그래서 mixed precision training paper에서 내놓은 idea가 바로 FP16과 FP32를 섞어 쓰자는 거였습니다. 이는 크게 3가지 technique으로 구성되어 있습니다.
- (기본) 대부분의 forward/backward 연산은 fp16으로 한다.
- fp32의 weight을 copy한 master copy를 따로 관리하며 매 training step마다 fp16 weight으로 forwarding해서 구한 gradient는 fp32 weight에 더해 update하고 fp16은 이를 copy해서 쓴다. (매 번 copy가 일어남)
- gradient value가 0이될 경우의 수를 줄이기 위해 loss를 scaling해서 gradient를 계산한 뒤, 나중에 다시 unscaling한다.
- 특정 operation들은 fp16이 아닌 fp32로 한다.
(더 관심이 있는 분들은 이 post를 참고하시면 좋을 것 같습니다)
이 중 ZeRO의 motivation은 바로 첫 번째 FP32 copy를 두고 이를 통해 update한다라는 technique 입니다.
이는 backward pass를 통해 계산 된 weight gradients가 그보다 더 작은 값인 learning rate와 곱해지면서 더 값이 작아지고,
결국 상대적으로 큰 수인 weight과 update가 더해질 때 아무런 변화가 생기지 않는 것을 방지합니다.
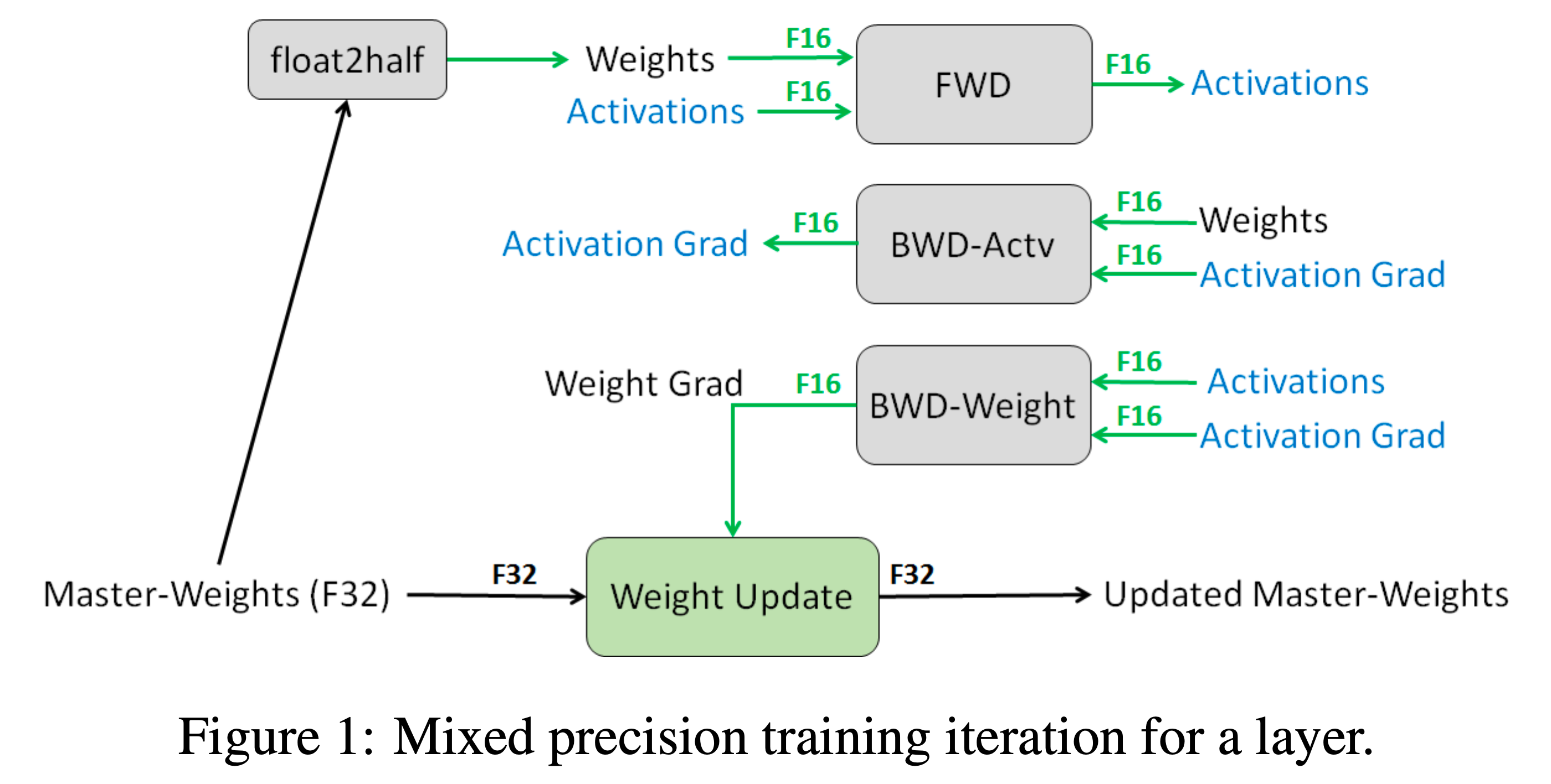 Fig.
Fig.
저자들은 가장 보편적인 Adam optimizer을 쓸 경우 model parameter update를 위해
- Time averaged
momentum Varianceof the gradientsGradientsandWeightsthemselves
이 세가지 optimizer state를 항상 저장하고 있어야 한다고 했는데,
말씀드린 것 처럼 mixed precision을 쓸 경우, model parameter와 각 layer의 activation들은 모두 fp16으로 저장되고 forward pass, backward pass 모두 fp16으로 수행되기 때문에 v100이상의 장비에서 엄청난 throughput (초당 sample 처리량)을 자랑하나 효과적인 parameter update를 위해 결국 backward pass의 마지막에는 optimizer가 model parameter의 fp32 version copy를 가지고 있어야 하며, optimizer state 또한 fp32로 가지고 있어야 하는 문제가 발생합니다.
 Fig. state_dict of Adam. 실제로 torch optimizer는 optimizer state를 관리하는 dictionary를 가지고 있는데, momentum 등은 CUDA tensor형태이다. 즉 model parameter와 같은 크기의 momentum이 또 memory를 잡아먹는 것. Source from link
Fig. state_dict of Adam. 실제로 torch optimizer는 optimizer state를 관리하는 dictionary를 가지고 있는데, momentum 등은 CUDA tensor형태이다. 즉 model parameter와 같은 크기의 momentum이 또 memory를 잡아먹는 것. Source from link
이를 ZeRO에서는 정략적으로 다음과 같이 나타냈습니다.
- the number of model parameter: \(\Psi\)
- for default
- for model param: \(2 * \Psi\) (fp16)
- for gradients: \(2 * \Psi\) (fp16)
- for optimizer
- for fp32 copy of model param: \(4*\Psi\) (fp32)
- momentum: \(4*\Psi\) (fp32)
- variance: \(4*\Psi\) (fp32)
- for default
Optimizer 를 위해 더 필요한 메모리, 즉 memory multiplier 를 \(K\)라 하면 Adam은 언제나 model parameter의 수 \(\Psi\)에 대해
\[2\Psi + 2\Psi + K\Psi = 16\Psi\]나 필요한 겁니다.
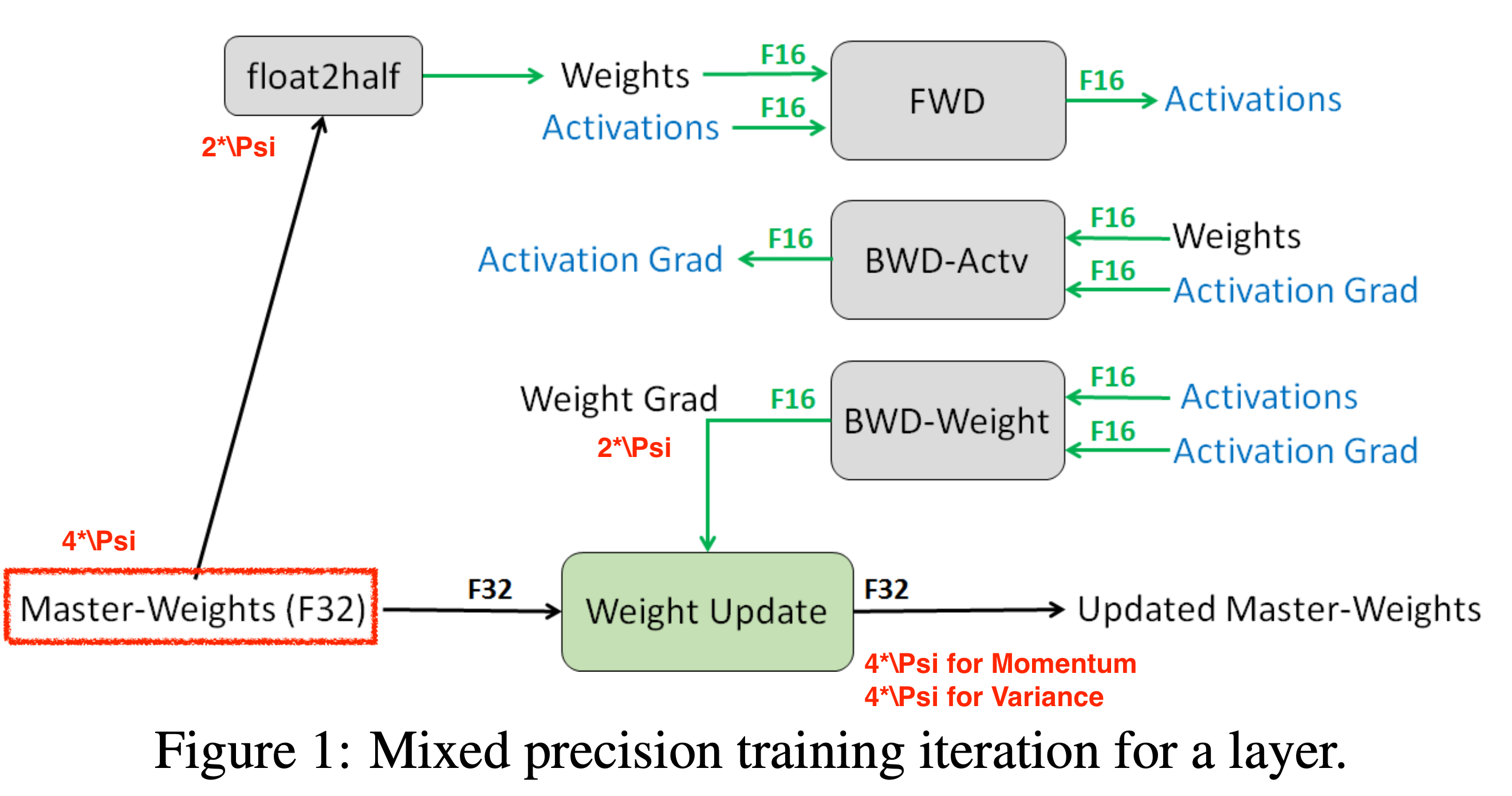 Fig.
Fig.
즉 1.5B GPT-2가 실제로는 학습에 필요한 Memory가 3GB가 아니라 기본적으로 8배나 큰 24GB나 필요했던 것이죠.
 Fig. 2 device로 DP를 한다면 이렇게 heavy한 요소들을 모든 device가 들고 있어야 한다. 파란색은 model parameter, \(2\psi\)를 의미하고 노란색은 gradient, \(2\psi\)를 그리고 나머지는 optimizer state \(K \psi\)를 의미한다.
Fig. 2 device로 DP를 한다면 이렇게 heavy한 요소들을 모든 device가 들고 있어야 한다. 파란색은 model parameter, \(2\psi\)를 의미하고 노란색은 gradient, \(2\psi\)를 그리고 나머지는 optimizer state \(K \psi\)를 의미한다.
그러니까 mixed precision은 사실 학습 속도를 높혀주지만 memory save는 장담이 안되는 것입니다.
 Fig. link에는 efficient training을 위한 tool들이 소개되어 있는데, mixed precision은 memory saving이 된다고는 볼 수는 없다.
Fig. link에는 efficient training을 위한 tool들이 소개되어 있는데, mixed precision은 memory saving이 된다고는 볼 수는 없다.
물론 model parameter와 더불어 layer들의 output activation 값들이 다 fp16일 것이기 때문에 model size가 작을 때는 memory가 save가 돼서 batch를 좀 늘려볼 수 있지만 model size가 커지면 문제가 생길 수 있다는 것입니다.
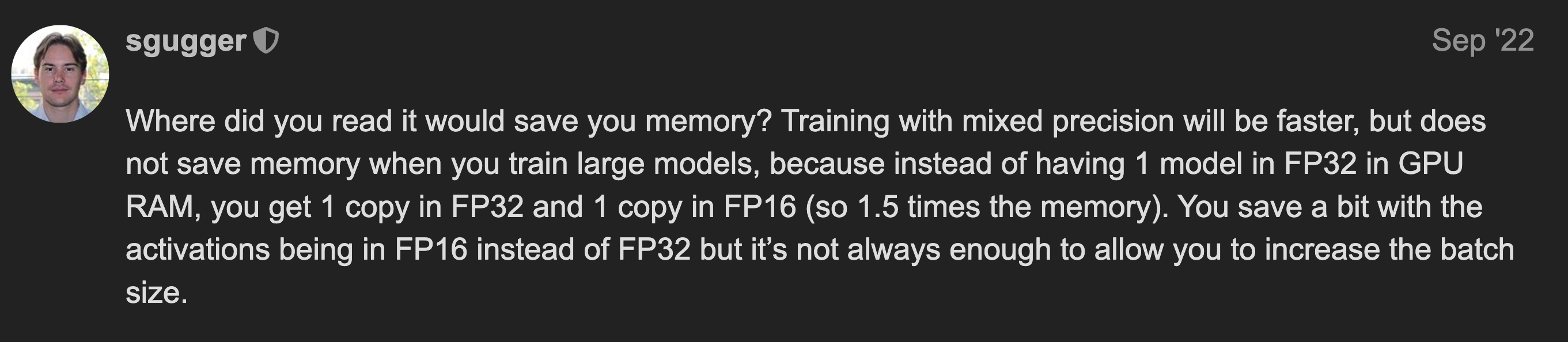 Fig. “누가 memory save 해준대?” 언제나 Huggingface의 Engineer Sgugger는 매운 답변을 달아준다. Source from link
Fig. “누가 memory save 해준대?” 언제나 Huggingface의 Engineer Sgugger는 매운 답변을 달아준다. Source from link
POV: Residual Memory Consumption
앞서 model parameter, optimizer state 관점에서의 redundancy에 대해 알아봤습니다.
이번에는 residual memory관점에서 redundancy를 분석하고 이에 대한 해결책들에 대해 얘기해보려고 합니다.
(이들은 보이지 않는 부분에 대한 최적화로 사소해 보일 수 있으나 결코 사소한 것들이 아닙니다.)
paper에서는 아래 세 가지를 주로 얘기합니다.
- Activations
- Temporary buffers
- Memory Fragmentation
먼저 첫 번째 Activation 입니다. Model이 GPT-2 large로 1.5B크기를 가지고 있고 주어진 sequence input의 batch size가 32, 길이가 1K일 때 필요한 memory량은 얼마일까요? 60GB나 된다고 합니다. Transformer의 경우 activation에 필요한 memory는 다음에 비례합니다.
- (the number of transformer layer) * (hidden dim) * (sequence length) * (batch size)
GPT-2의 경우 12배를 해주면 60GB가 나온다고 합니다. Model size나 batch size가 커지면 부담은 더 커지겠죠?
 Fig. Source from Low-Memory Neural Network Training: A Technical Report
Fig. Source from Low-Memory Neural Network Training: A Technical Report
게다가 activation은 MP를 할 경우 더 문제가 된다고 하는데, MP중 하나인 TP (vertical MP)를 한다고 할 경우 layer output을 각 gpu device로 서로 copy해줘야 다음 layer의 forward computation을 할 수 있기 때문에 문제가 된다고 합니다.
물론 이를 효과적으로 해결해주는 방법이 있으니, 바로 activation (gradient) checkpoint입니다. ZeRO paper에서는 분석한 결과 (아마도 Gpt-2에 대해) activation checkpointing을 쓰면 memory 소비를 8GB까지 줄일 수 있었지만 속도가 33%정도 느려졌다고 합니다 (re-computation overhead 때문에). 8GB까지로 줄어든 이유는 activation checkpointing이 보통 원래 memory cunsumption을 \(x\)라 할 때, \(\sqrt{x}\)까지 줄여주기 때문입니다.
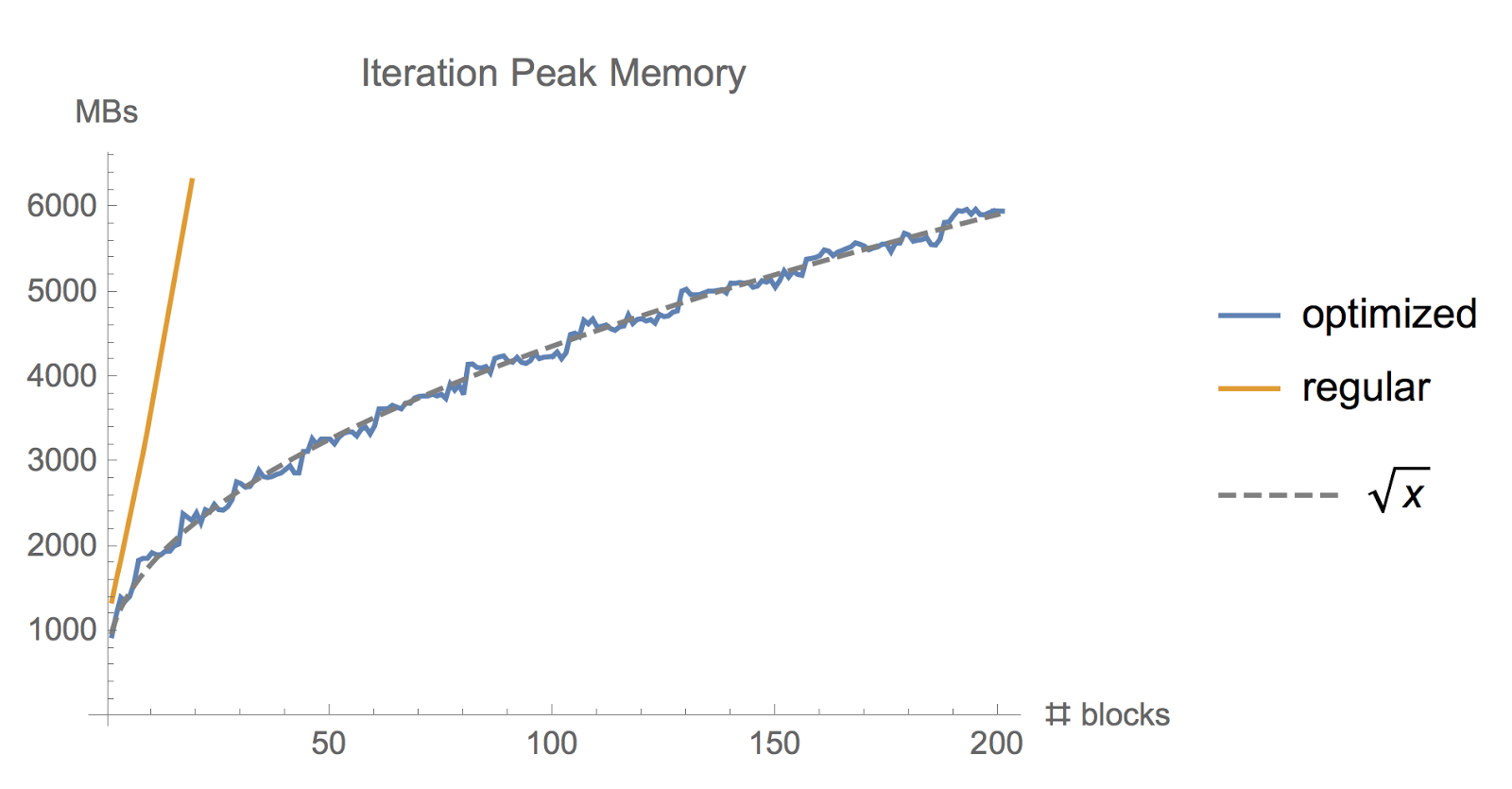 Fig. Memory used while training a ResNet model with large batch size, using the regular tf.gradients function and using memory-optimized gradient implementation
Fig. Memory used while training a ResNet model with large batch size, using the regular tf.gradients function and using memory-optimized gradient implementation
Activation checkpointing에 대해서 간단히만 말씀드리고 넘어가도록 하겠습니다.
Key idea는 layer들의 activation output들을 다 저장하지 않고 일부만 띄엄 띄엄 저장한 다음에 forward가 다 끝나면 loss를 계산하고 backpropagation을 할 때 빈 activation output들을 다시 계산 (re-computation)하자는 겁니다.
즉 Training time을 20% 추가로 쓰는 대신 10배 더 큰 NN 모델을 gpu memory에 넣을 수 있는 기법으로,
parallelism이나 CPU-offloading등과 함께 orthogonal 하게 쓸 수 있어 Large Model을 학습하는 데 있어 중요한 기술 중 하나입니다.
아래의 animation을 보시면 vanilla backpropagation을 할 경우, forward activation을 다 저장해 둔 다음에 끝에가서 loss를 계산하고 차례 차례 memory를 release하는 걸 보실 수 있습니다.
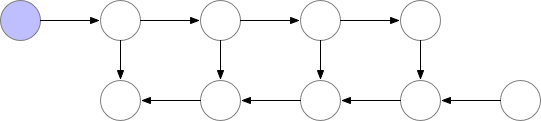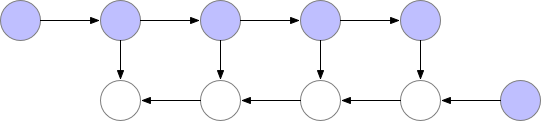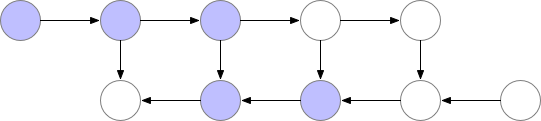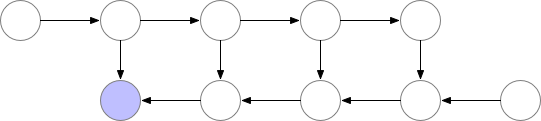 Fig. Vanilla Backprop
Fig. Vanilla Backprop
만약 GPU에 memory를 model 올리는 데 이미 거의 다 썼다면 아래와 같이 정말 비효율적으로 다시 계산하는 방법을 택할 수 도 있을겁니다.
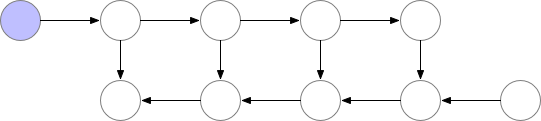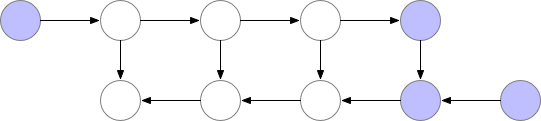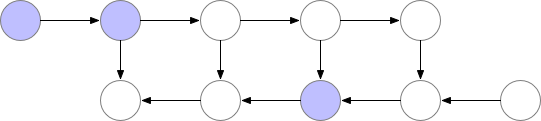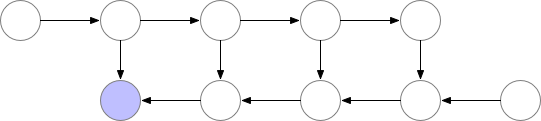 Fig. Memory Poor Backprop
Fig. Memory Poor Backprop
Activation Checkpointing은 이 둘의 절충안으로 checkpoint지점들을 두고 그 지점부터만 현재 node까지 빈 activation을 다시 계산하면서 backward를 하는 겁니다.
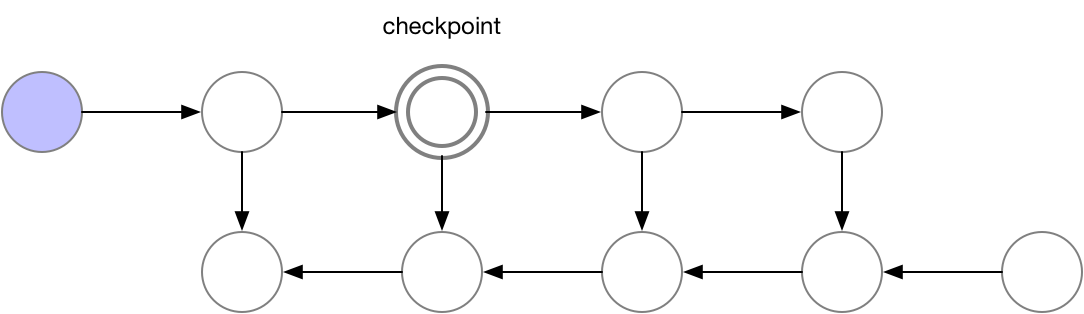 Fig. Checkpoint of Activation Checkpointing method
Fig. Checkpoint of Activation Checkpointing method
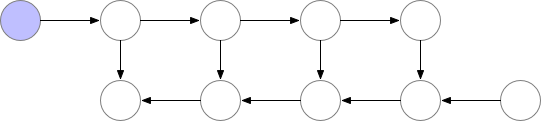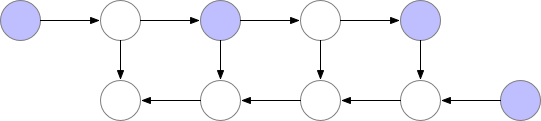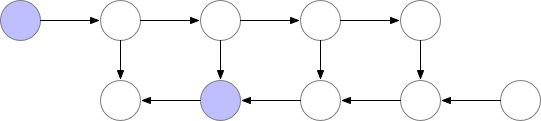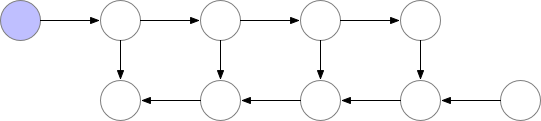 Fig. Checkpointed Backprop
Fig. Checkpointed Backprop
하지만 ZeRO가 지적하는 점은 model size가 커지면 activation checkpointing으로도 감당이 안된다는 겁니다. 100B정도 되는 model size가 되면 32 batch size를 쓸 때 checkpointing을 해도 60GB에 달하는 memory가 필요하기 때문에 학습이 불가능한거죠.
그 다음은 일시적인 버퍼 (Temporary Buffers) 문제 입니다.
이들은 학습시 발생하는 중간 결과 (intermediate results)를 저장하는데 쓰이는 buffer들인데,
가령 (바로 아래에서 배우게 될) ZeRO-DP를 할 경우 각 device별로 흩어져있는 gradient를 한데 모으거나 gradient norm을 계산하는 행위를 효율적으로 하려면 보통 여러 gradient를 하나로 모아서 처리 (통신) 한다고 합니다.
그 이유는 all-reduce같은 연산이 large message size에 대해서 더 효율적 (throughput이 잘나옴) 이기 때문이라고 합니다.
이런 fused buffer의 memory overhead는 model size에 비례하게 되므로 너무 작아질수도 커질수도 있어서 문제가 발생할 수 있습니다.
마지막으로 메모리 조각화 (Memory Fragmentation)는 짧은 시간 동안만 존재하는 (short-lived) tensor들과 긴 시간 존재하는 (long-lived) tensor들이 번갈아 나타나는 (interleaving) 현상 때문에 발생하는데, activation checkpointing 과 gradient를 계산할 때 발생한다고 합니다.
생각해보면 forward시에 어떤 activation들은 checkpoint지점이기 때문에 backward가 계산될 때까지 남고, checkpoint지점이 아닌 activation tensor들은 지워지며 backward에서도 parameter gradient는 마지막에 parameter update를 할 때까지 살아남지만 gradient를 계산하는데 쓰이는 나머지들은 바로 필요없어지죠.
여기서 문제가 발생하는데 예를 들어 activation들이 일부가 지워졌다고 칩시다.
이렇게 지워진 공간들을 다 합치면 충분히 memory가 많이 saving이 될테지만, 이 freed memory의 위치들이 연속적이지 않아서 (contiguous하지 않아서) 나중에 어떤 큰 memory를 할당하려고 하면 OOM이 발생할 수 있는겁니다.
둘째로 contiguous piece가 있다 하더라도 memory allocator가 이를 찾는 데 시간을 많이 써서 비효율이 발생할 수 있게 됩니다.
그래서 우리는 이 Memory Fragmentation을 줄여야 하는겁니다.
ZeRO-DP
그렇다면 어떻게 ZeRO가 memory 관리를 해주길래 V100 GPU한장에서 13B model까지 학습이 가능하다고 광고하는 것일까요? 한 번 알아보도록 합시다.
Overview of ZeRO-3
먼저 model state관점에서의 최적화만 알아봅시다.
ZeRO-DP는 이름에서도 알수 있듯 DP를 하되 Redundancy를 제거한 것입니다.
Paper에서는 이를 3가지 단계로 구분했습니다.
 Fig.
Fig.
ZeRO-1에서 ZeRO-3로 점점 더 많이 쪼갠 것이라고 생각하시면 되는데, 직관적으로 이해가 안가실 것 같아 DeepSpeed team의 영상을 animation화 해서 가져왔습니다. 이하는 ZeRO-3가 어떻게 학습과정에서 쓰이는지를 시각화 한 것입니다. (ZeRO-3를 이해하면 ZeRO-1,2는 그냥 이해할 수 있으므로 ZeRO-3만 볼겁니다)
 Fig. 우리가 학습할 model이 16층 짜리 transformer라고 생각해 보겠습니다.
Fig. 우리가 학습할 model이 16층 짜리 transformer라고 생각해 보겠습니다.
 Fig. 먼저 거대한 dataset이 있습니다.
Fig. 먼저 거대한 dataset이 있습니다.
 Fig. 이를 4개의 GPU device에 나눠서 학습하려고 합니다. Data Prallel (DP)를 하는 것이죠.
Fig. 이를 4개의 GPU device에 나눠서 학습하려고 합니다. Data Prallel (DP)를 하는 것이죠.
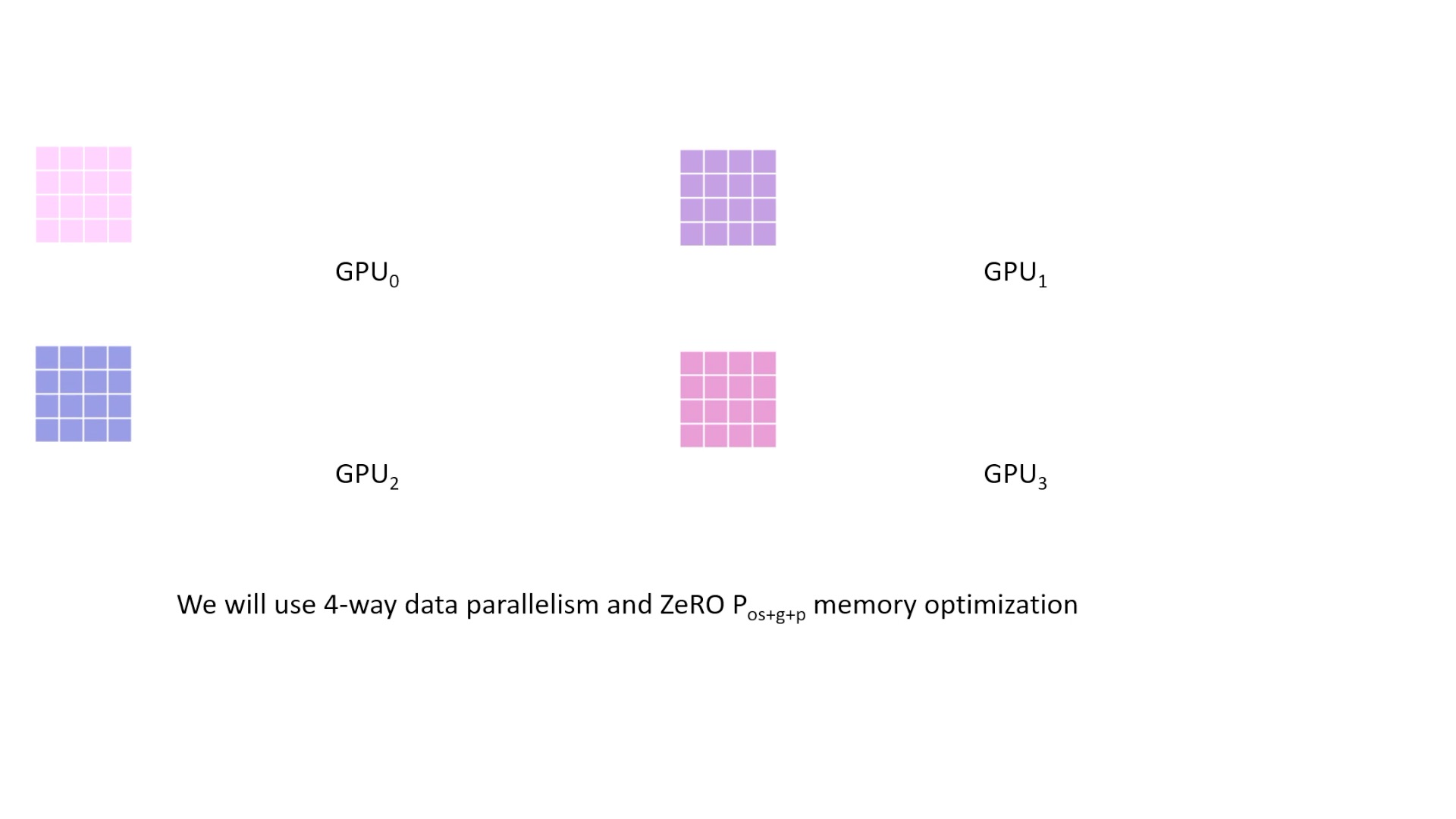 Fig. batch size를 micro batch size 로 4등분 했습니다. 이 animation에서는 모든 memory optimization technique을 다 사용한 Stage-3를 설명드릴 겁니다.
Fig. batch size를 micro batch size 로 4등분 했습니다. 이 animation에서는 모든 memory optimization technique을 다 사용한 Stage-3를 설명드릴 겁니다.
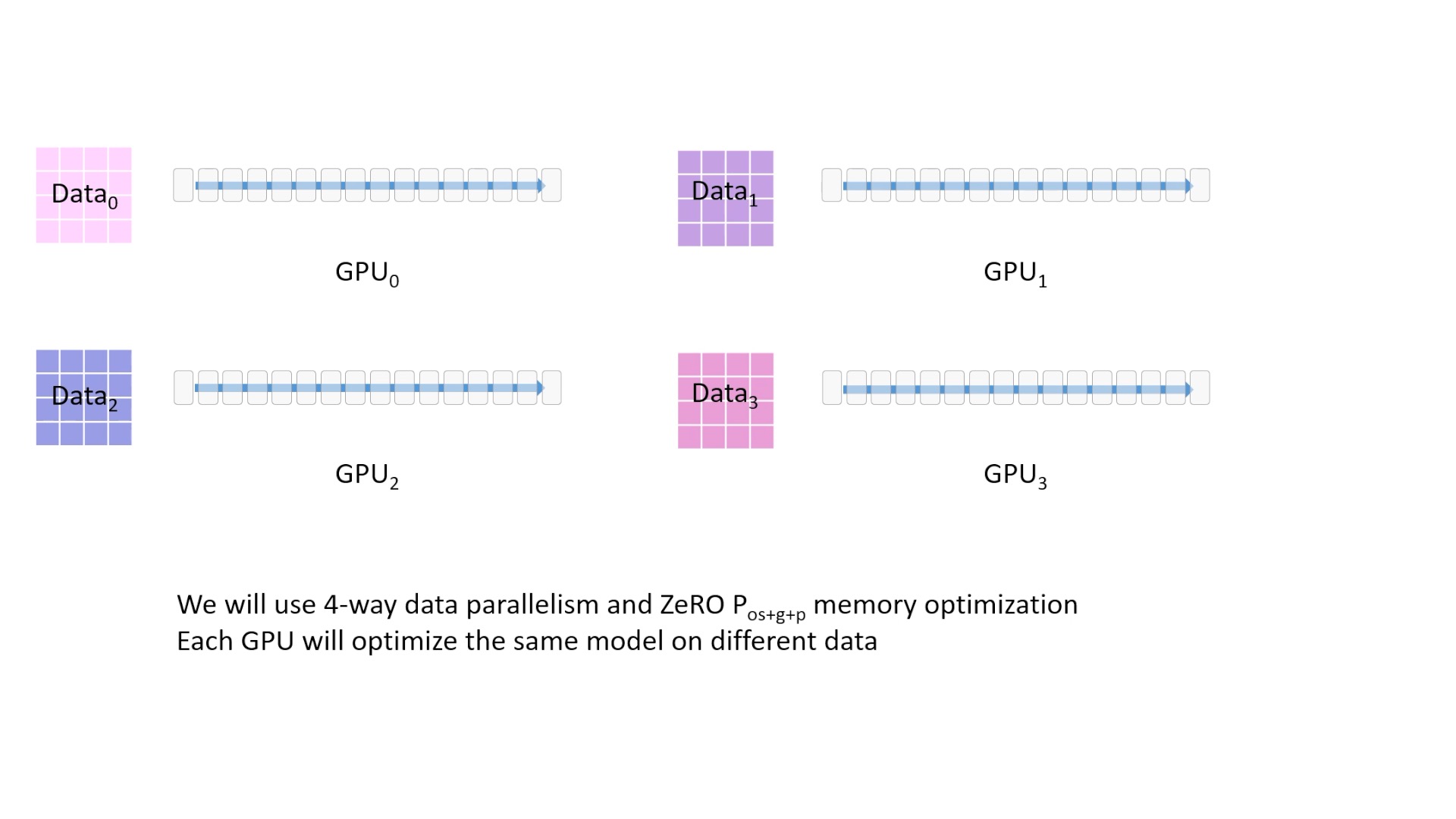 Fig.
Fig.
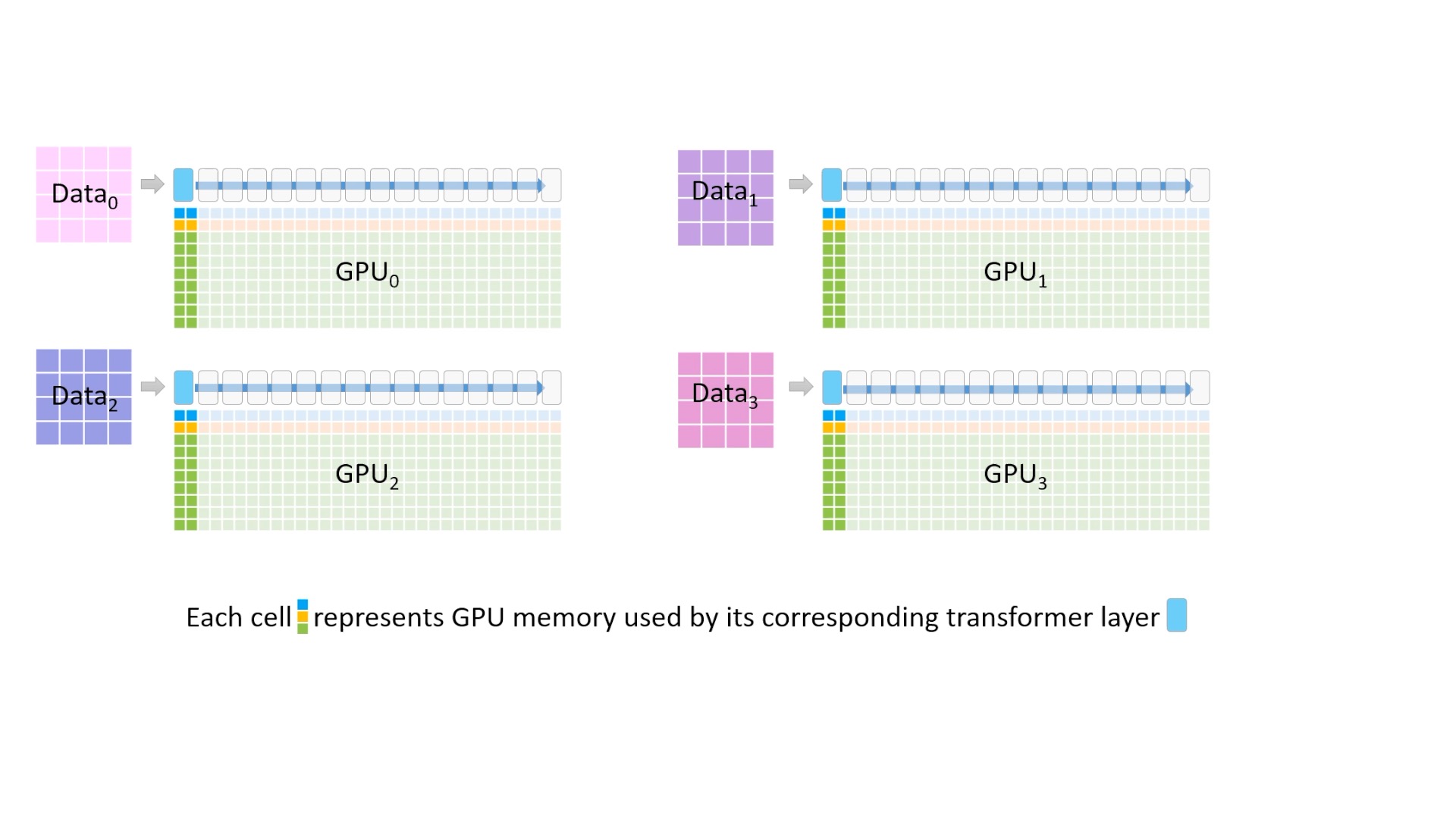 Fig. 파란색 작은 block은 model parameter를, 노란색은 gradient를, 그리고 초록색은 optimizer state를 의미합니다. 그리고 맨 상단에 있는 가장 큰 block은 transformer layer의 진행 과정을 시각화 했습니다.
Fig. 파란색 작은 block은 model parameter를, 노란색은 gradient를, 그리고 초록색은 optimizer state를 의미합니다. 그리고 맨 상단에 있는 가장 큰 block은 transformer layer의 진행 과정을 시각화 했습니다.
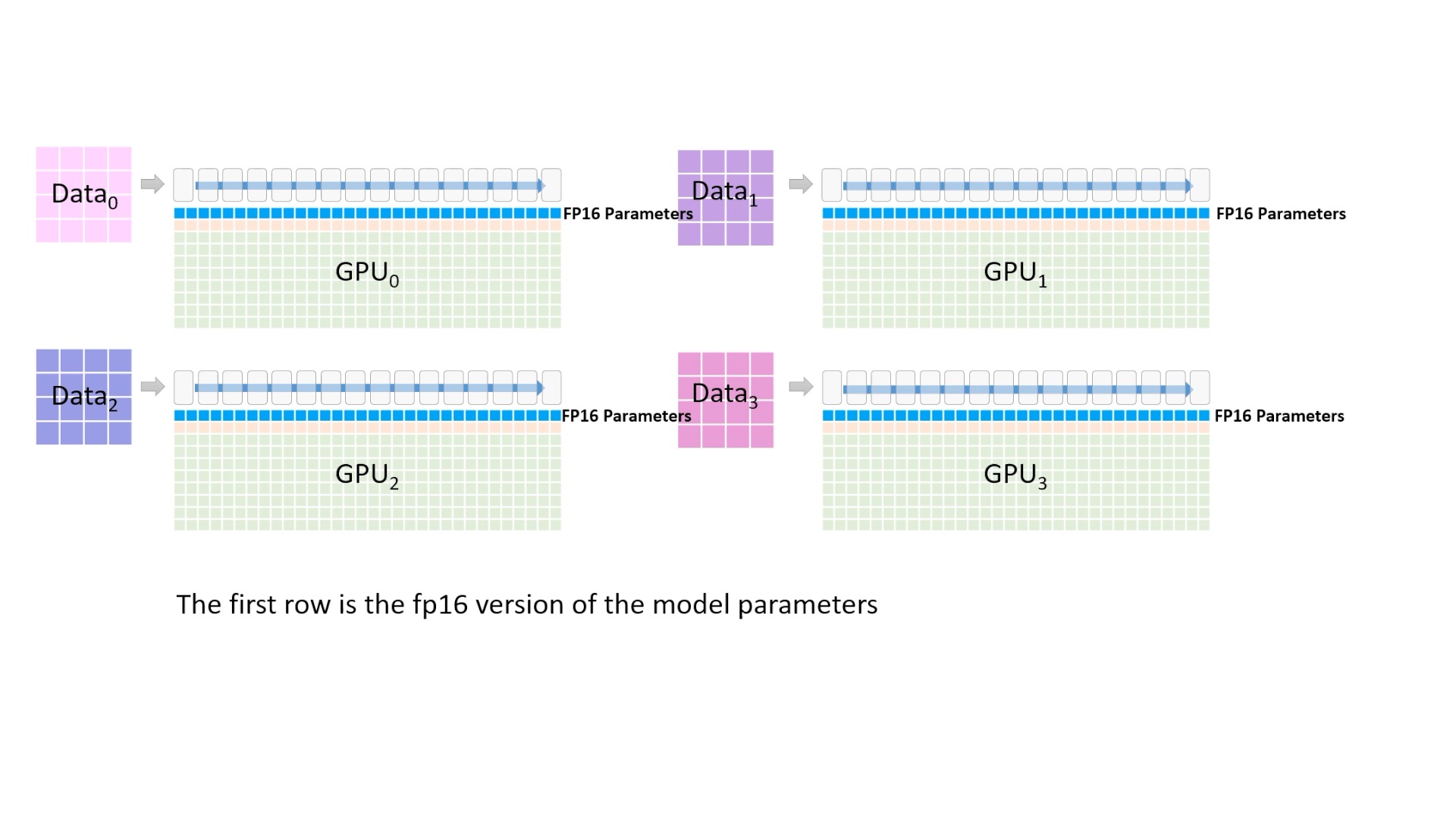 Fig. 파란색 block은 fp16 model parameter
Fig. 파란색 block은 fp16 model parameter
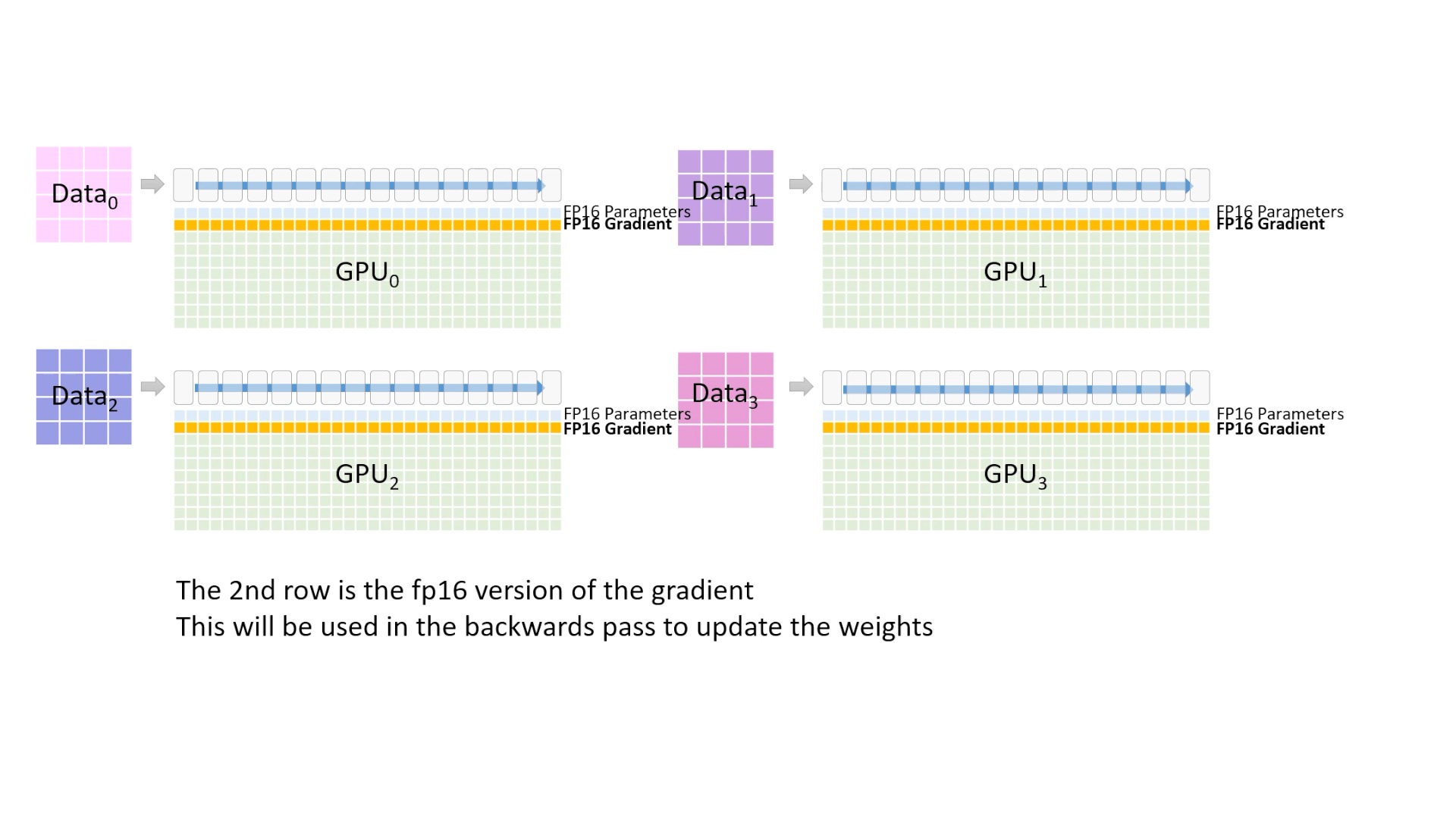 Fig. 노란색 block은 fp16 gradient
Fig. 노란색 block은 fp16 gradient
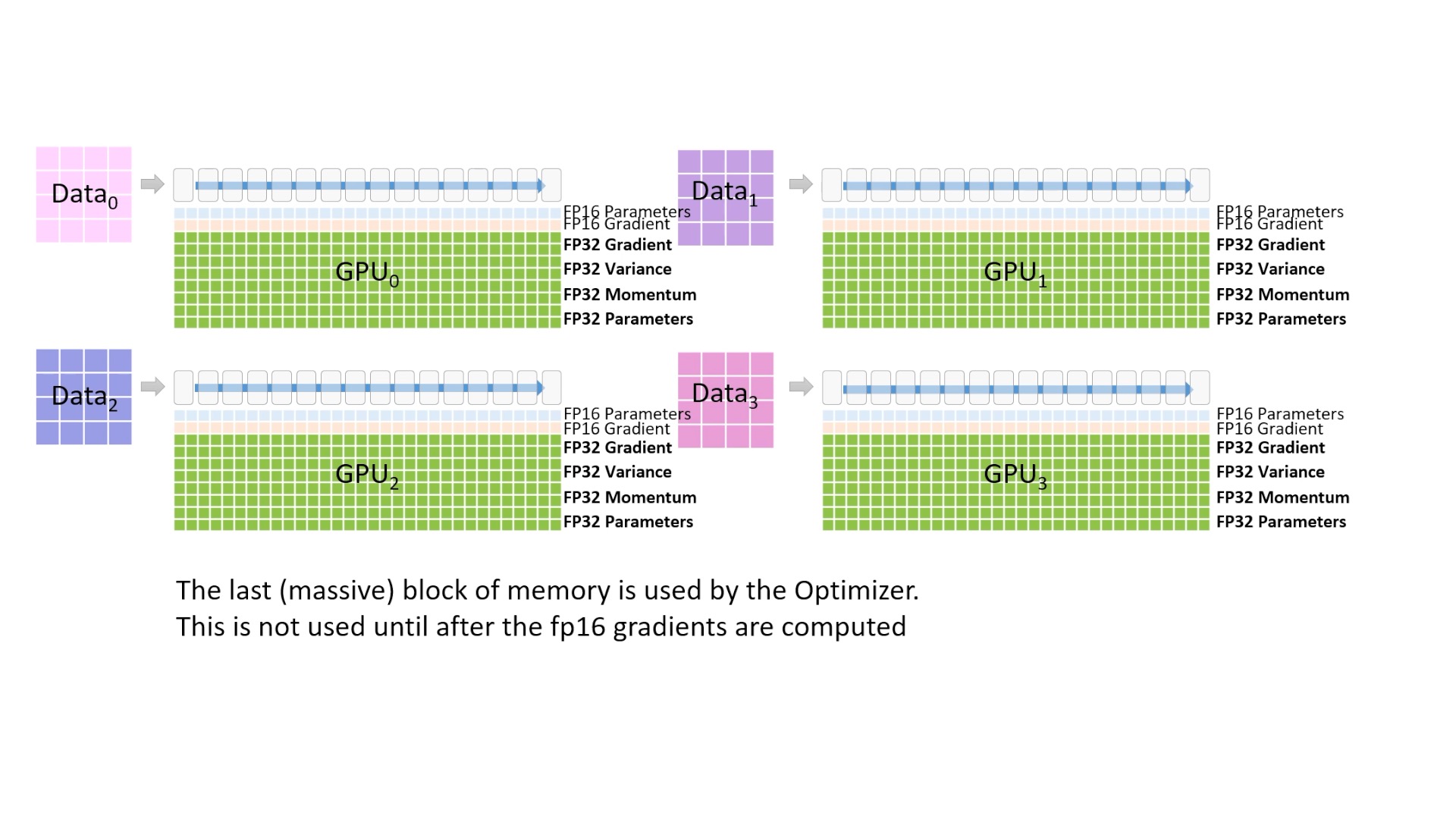 Fig. 초록색 block은 optimizer state를 나타내는데, 이는 fp32 parameter, fp32 variance, fp32 momentum, fp32 gradient를 의미합니다. 이부분이 딱 보기에도 가장 많은 memory를 차지합니다.
Fig. 초록색 block은 optimizer state를 나타내는데, 이는 fp32 parameter, fp32 variance, fp32 momentum, fp32 gradient를 의미합니다. 이부분이 딱 보기에도 가장 많은 memory를 차지합니다.
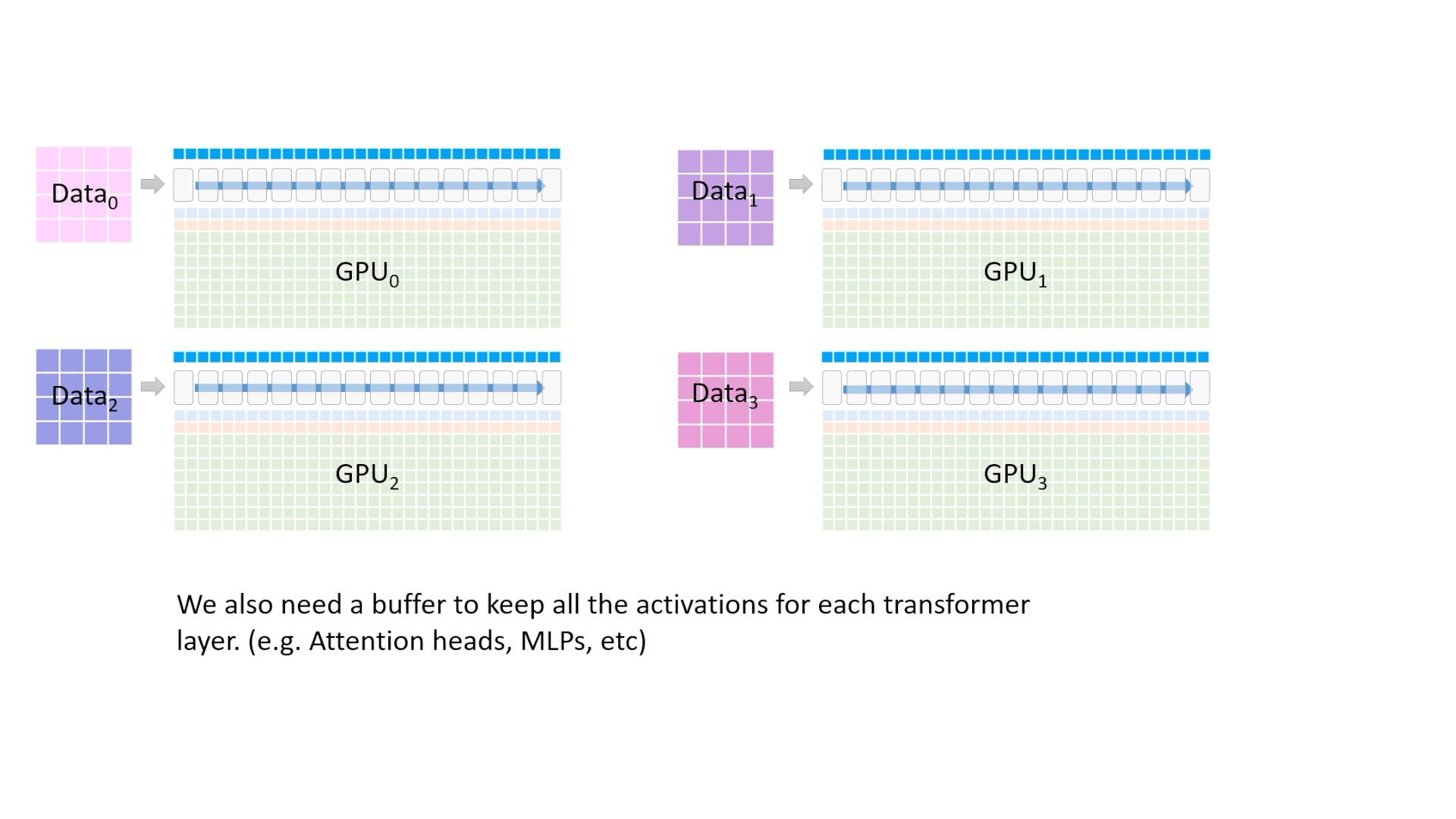 Fig. 추가로, 최상단에 있는 파란색 block은 각 layer들의 activation들을 말합니다. batch size, model size가 커질수록 잡아먹는 용량이 더 커집니다.
Fig. 추가로, 최상단에 있는 파란색 block은 각 layer들의 activation들을 말합니다. batch size, model size가 커질수록 잡아먹는 용량이 더 커집니다.
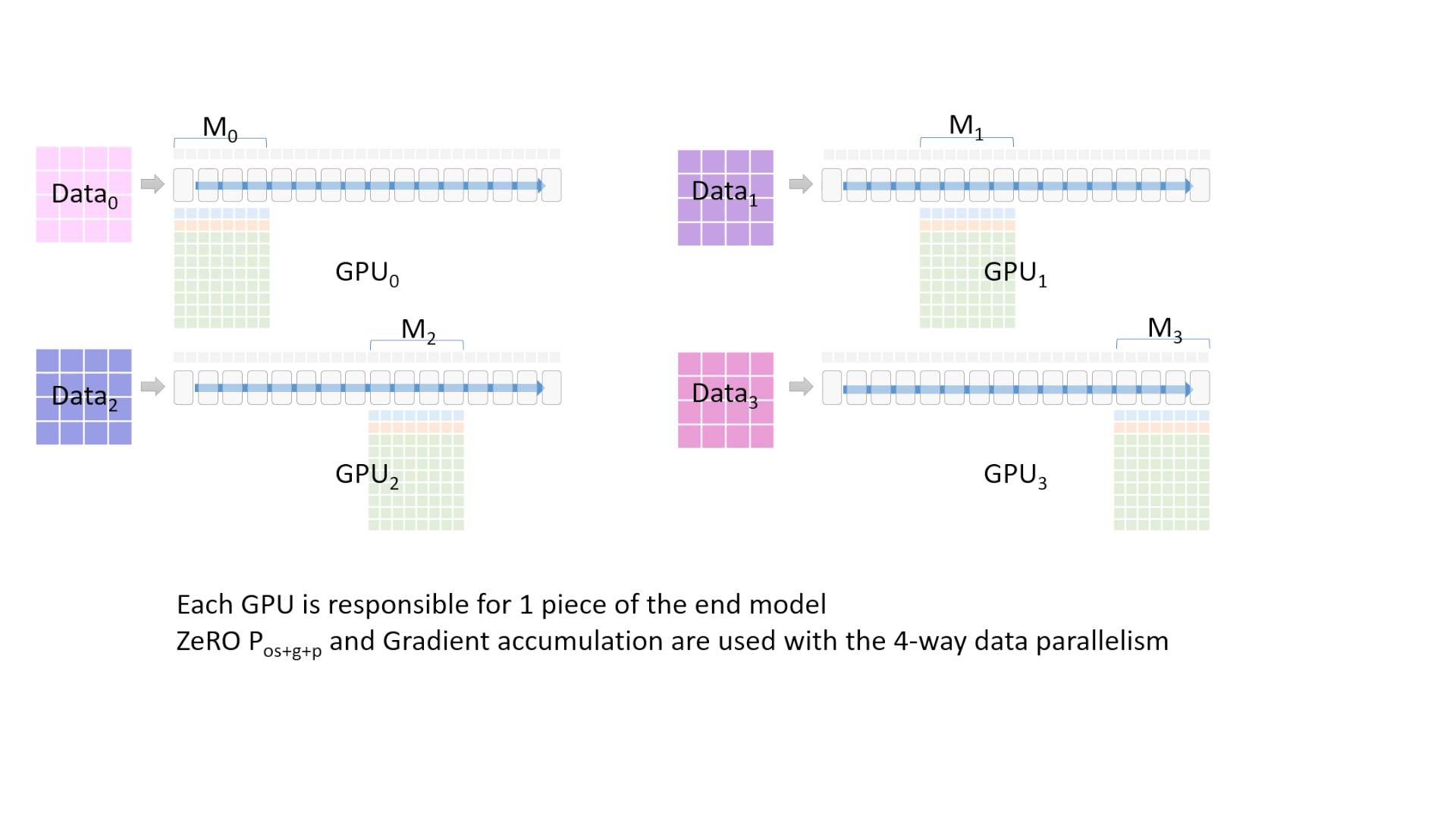 Fig. 이제 모든준비가 끝났습니다. 각 process가 다른 Data를 처리하는 DP이긴 한데, 각 process가 서로 다른 model state들을 나눠서 들고있는 형태가 ZeRO-DP의 기본적인 형태입니다.
Fig. 이제 모든준비가 끝났습니다. 각 process가 다른 Data를 처리하는 DP이긴 한데, 각 process가 서로 다른 model state들을 나눠서 들고있는 형태가 ZeRO-DP의 기본적인 형태입니다.
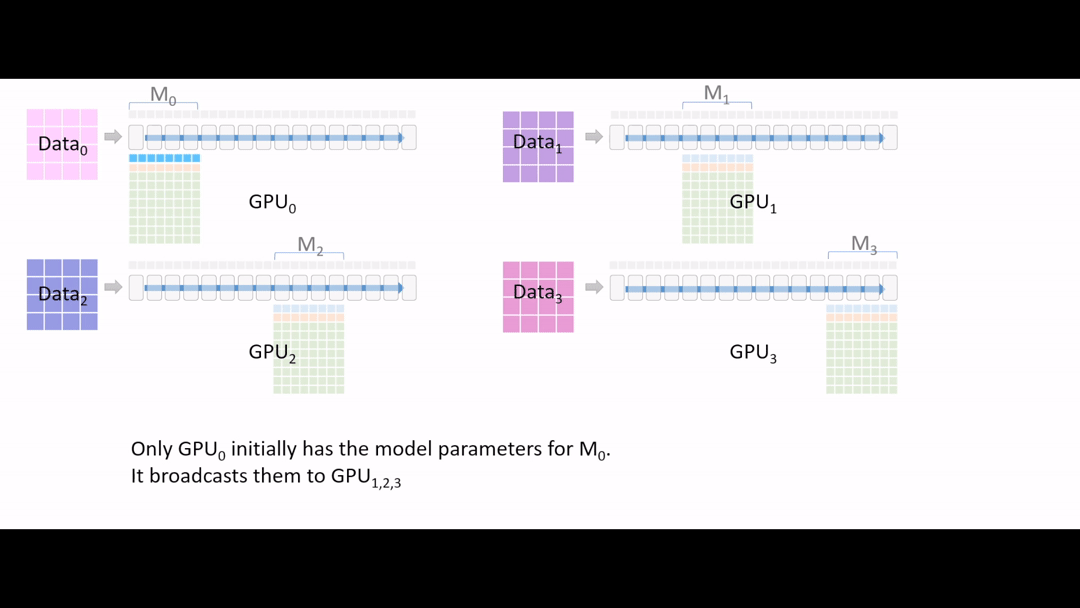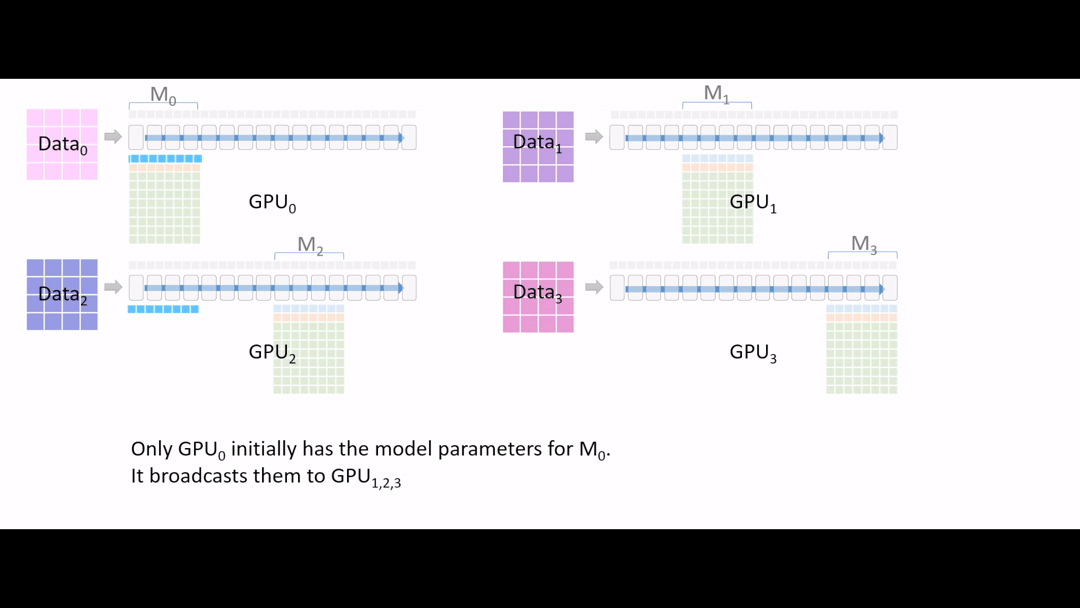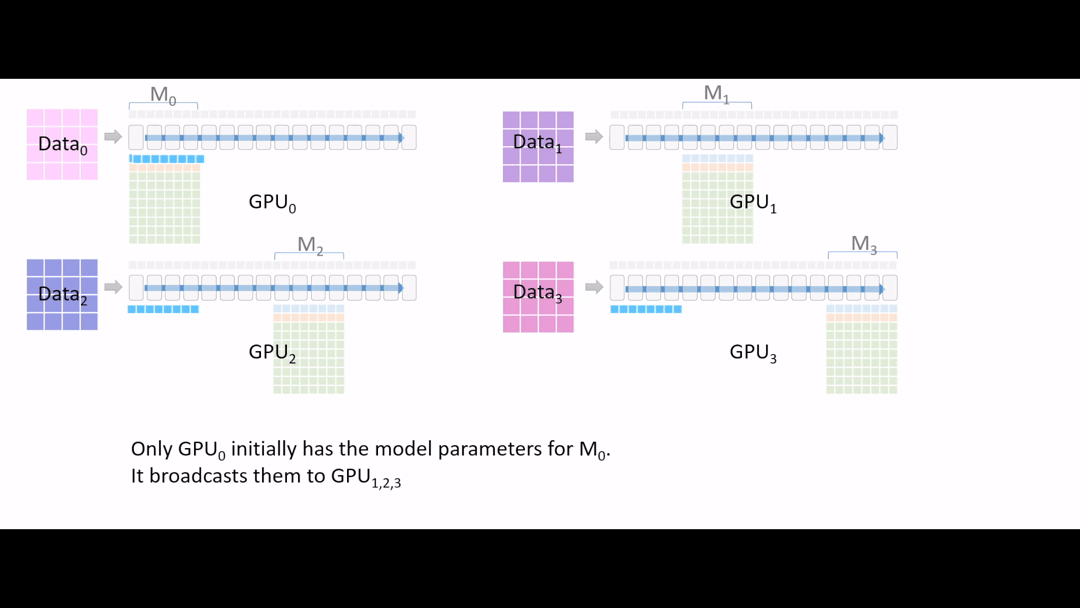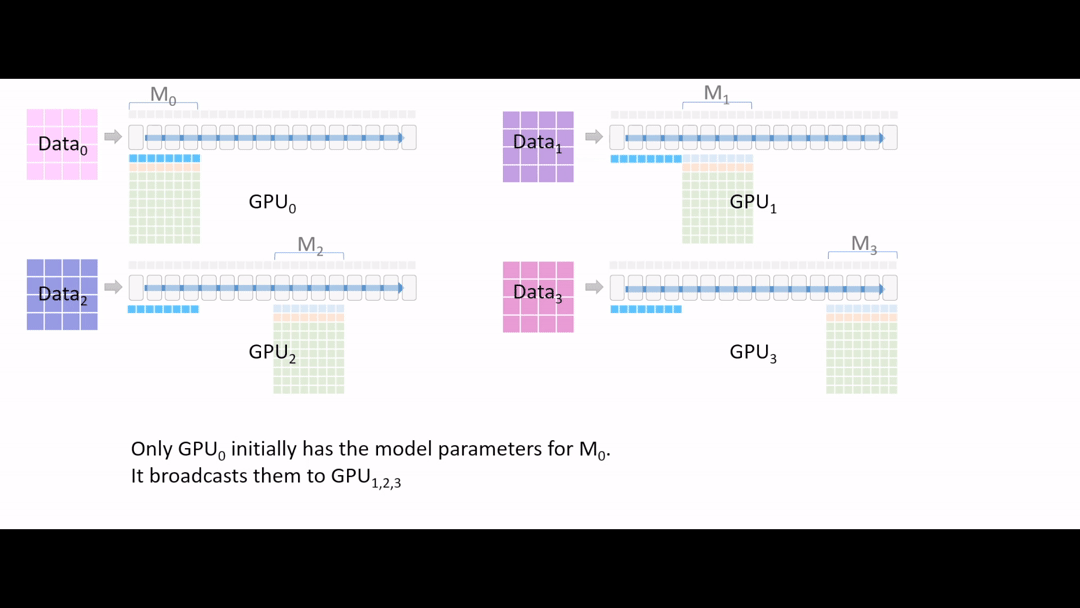 Fig. (GIF) model forward를 해야하는데, GPU1,2,3은 초반부 layer에 대한 model parameter가 없는 상태이기 때문에 GPU0 에서 나머지 device로 나눠 줍니다 (broadcast).
Fig. (GIF) model forward를 해야하는데, GPU1,2,3은 초반부 layer에 대한 model parameter가 없는 상태이기 때문에 GPU0 에서 나머지 device로 나눠 줍니다 (broadcast).
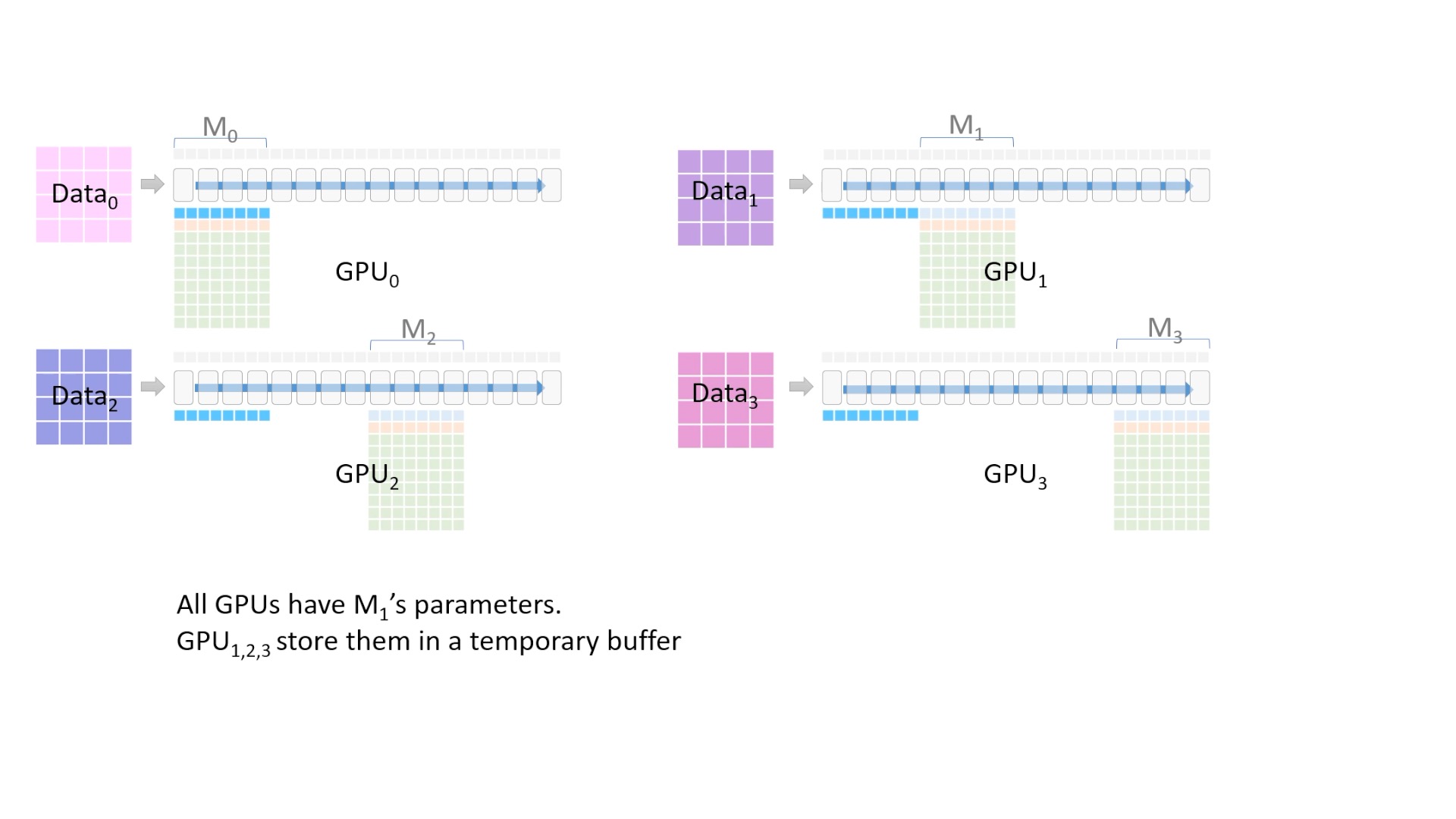 Fig. 이제 모든 device가 첫 4개 Layer의 model parameter를 들고 있습니다.
Fig. 이제 모든 device가 첫 4개 Layer의 model parameter를 들고 있습니다.
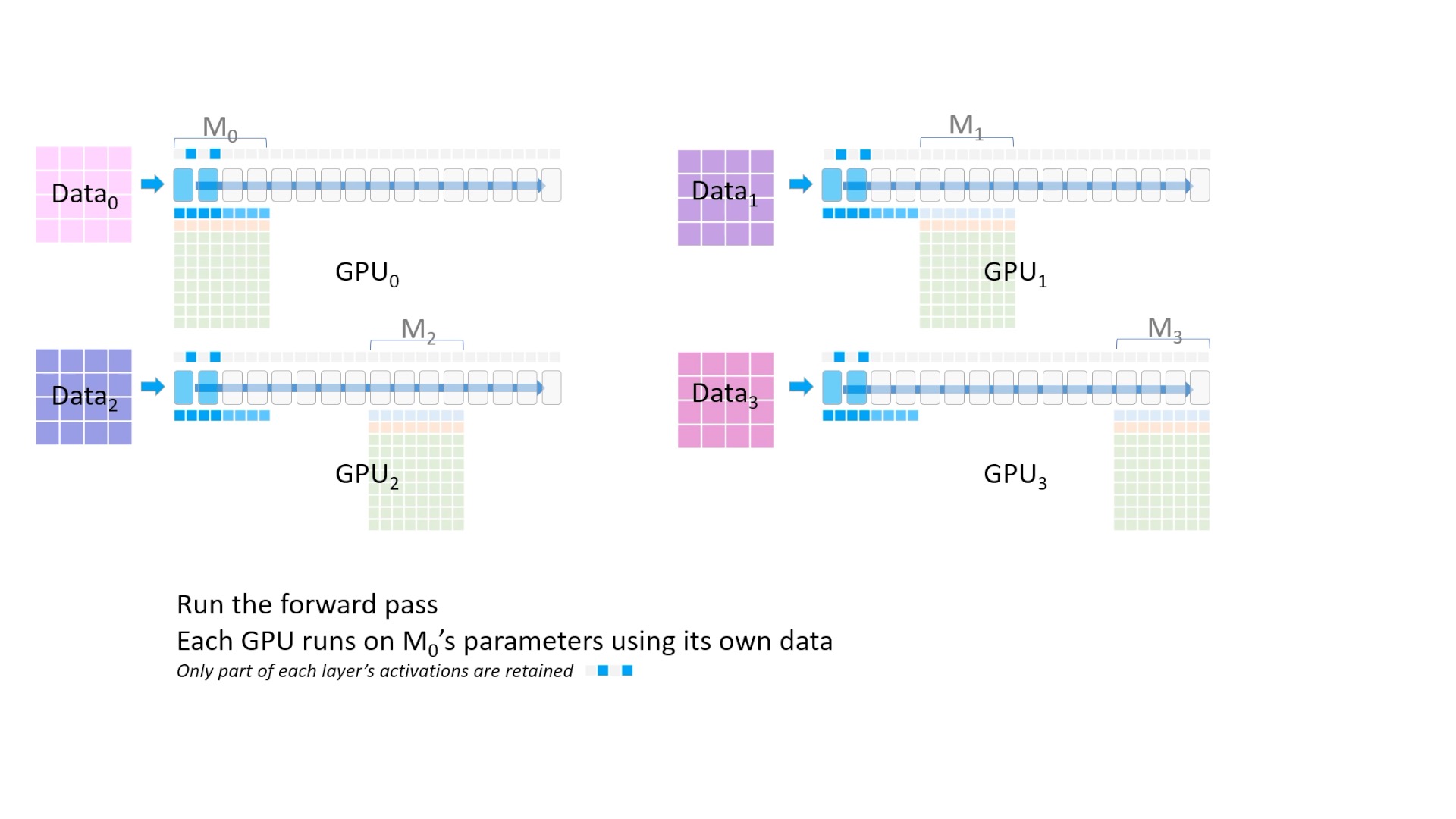 Fig. 이제 forward pass 연산을 합니다. 최상단의 activation을 보시면 띄엄 띄엄 값이 저장되고 있는 걸 알 수 있는데, 이를 activation checkpointing이라고 합니다. (후술)
Fig. 이제 forward pass 연산을 합니다. 최상단의 activation을 보시면 띄엄 띄엄 값이 저장되고 있는 걸 알 수 있는데, 이를 activation checkpointing이라고 합니다. (후술)
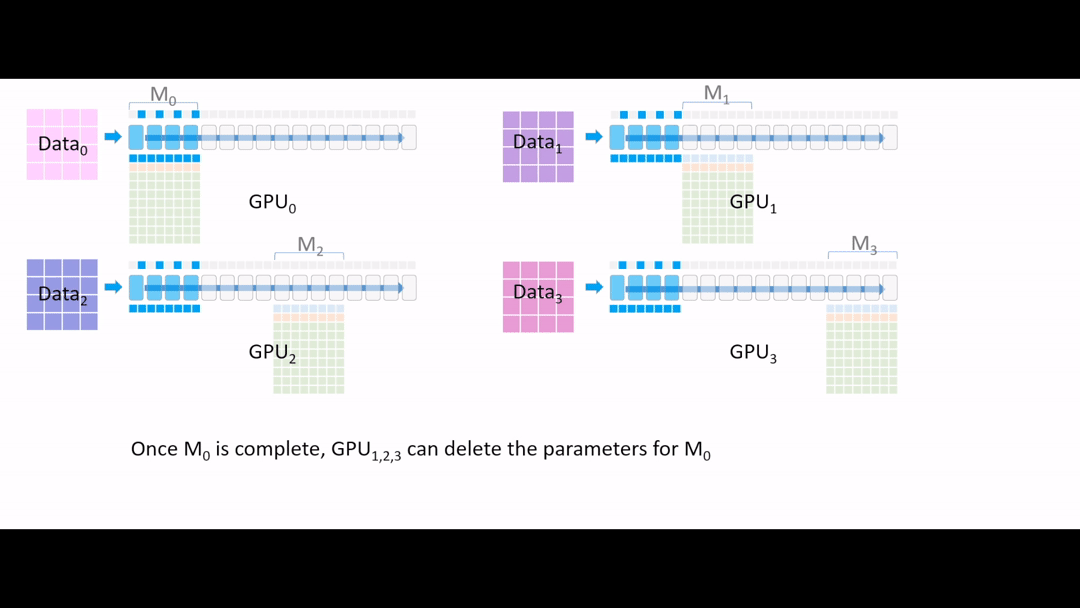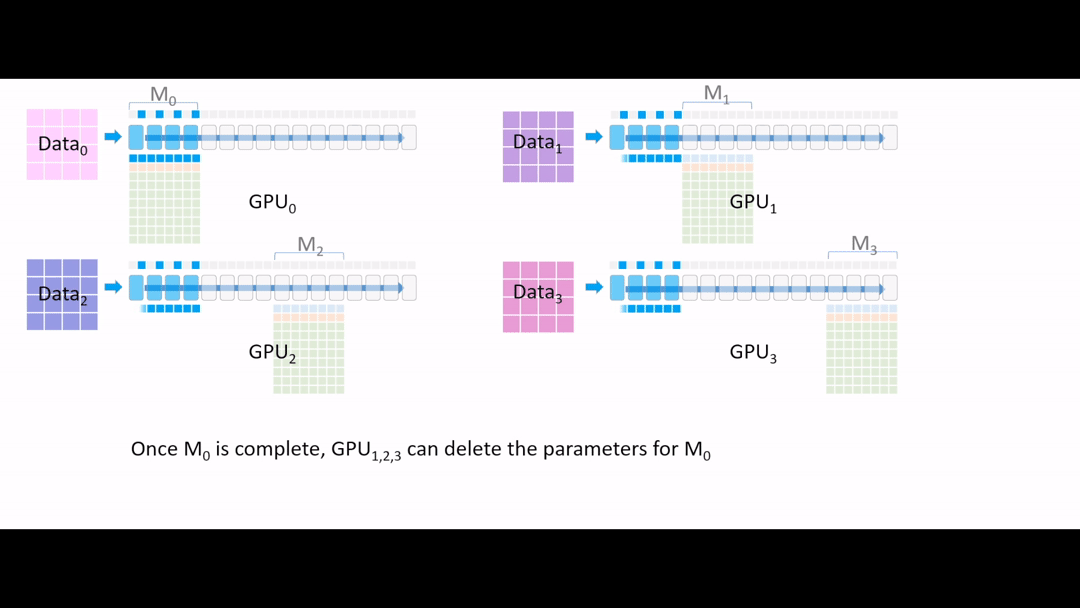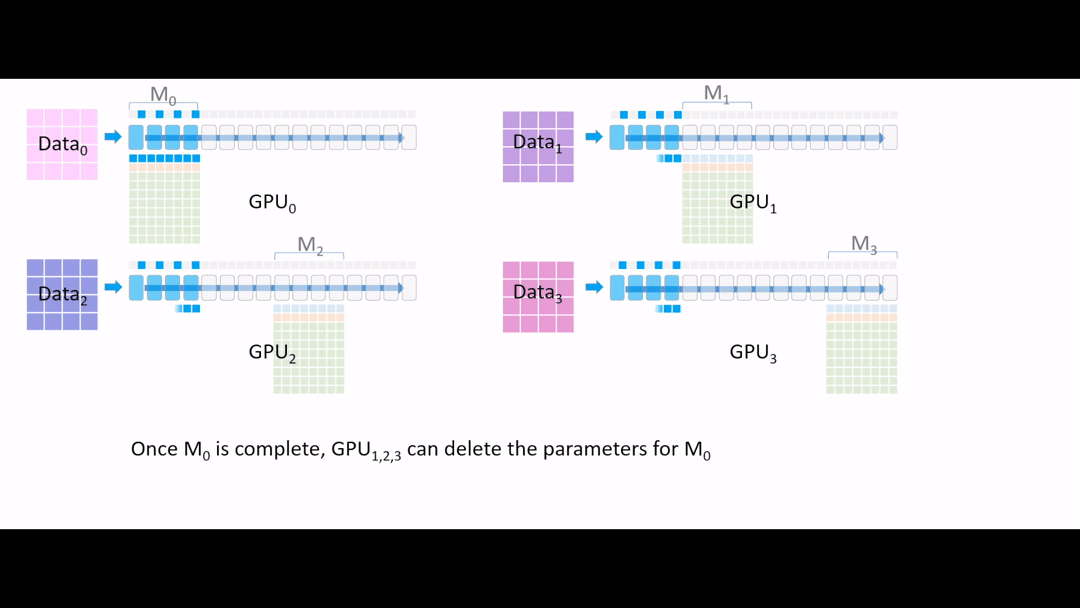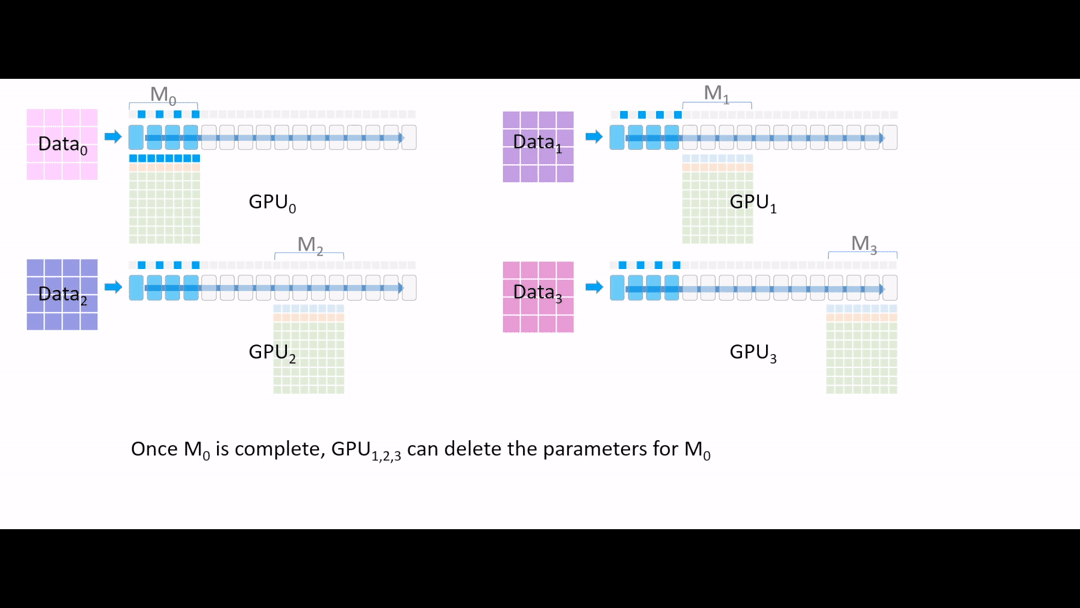 Fig. (GIF) forward pass 과정을 시각화
Fig. (GIF) forward pass 과정을 시각화
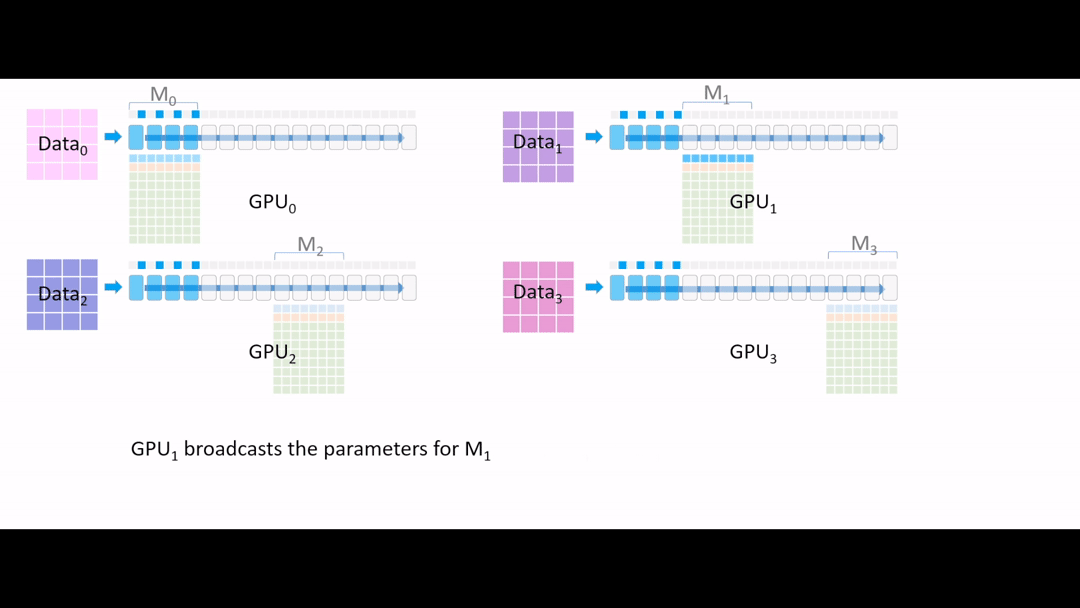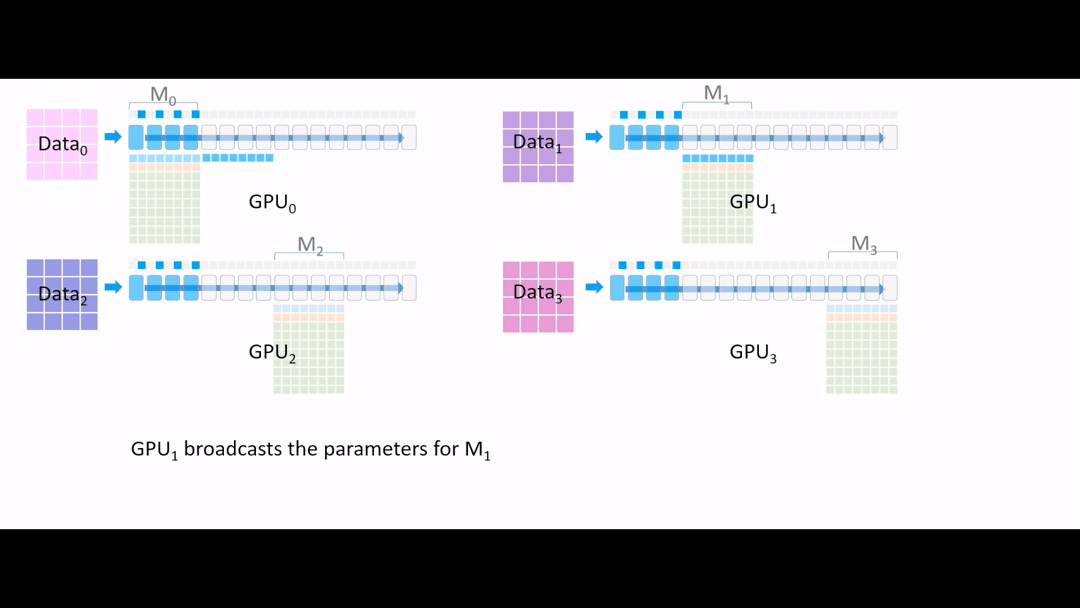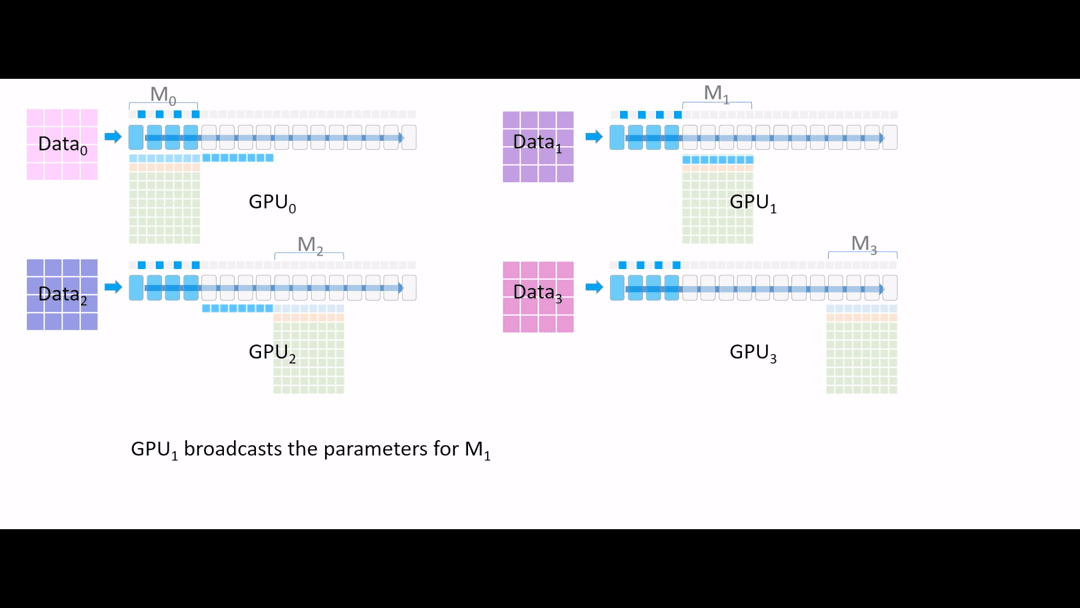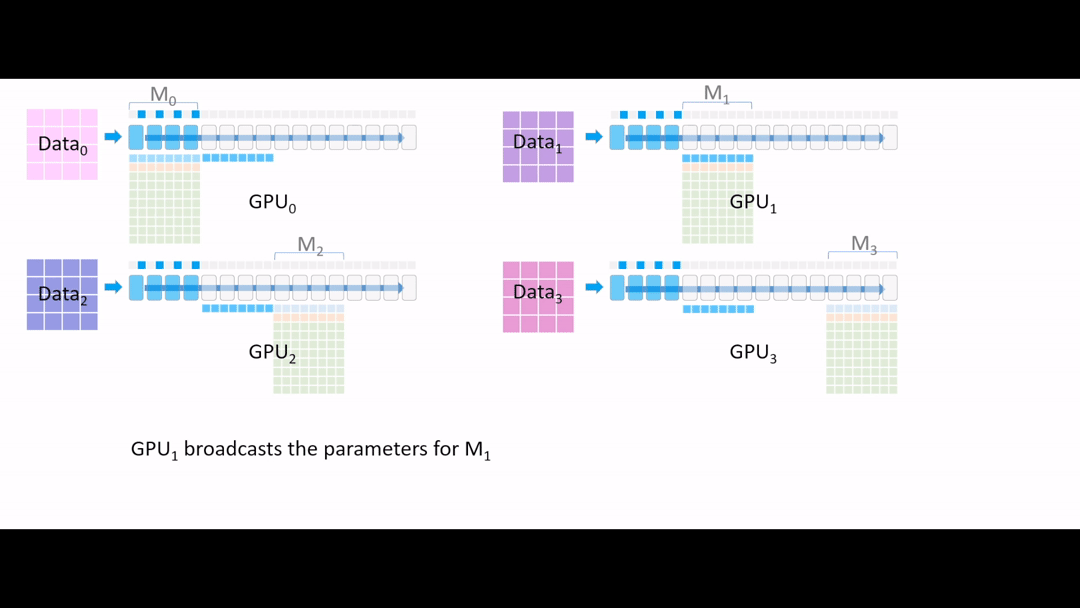 Fig. (GIF) 이제 GPU1,2,3 들은 activation 값들을 얻었으니 필요가 없어진 layer parameter를 다 지웁니다.
Fig. (GIF) 이제 GPU1,2,3 들은 activation 값들을 얻었으니 필요가 없어진 layer parameter를 다 지웁니다.
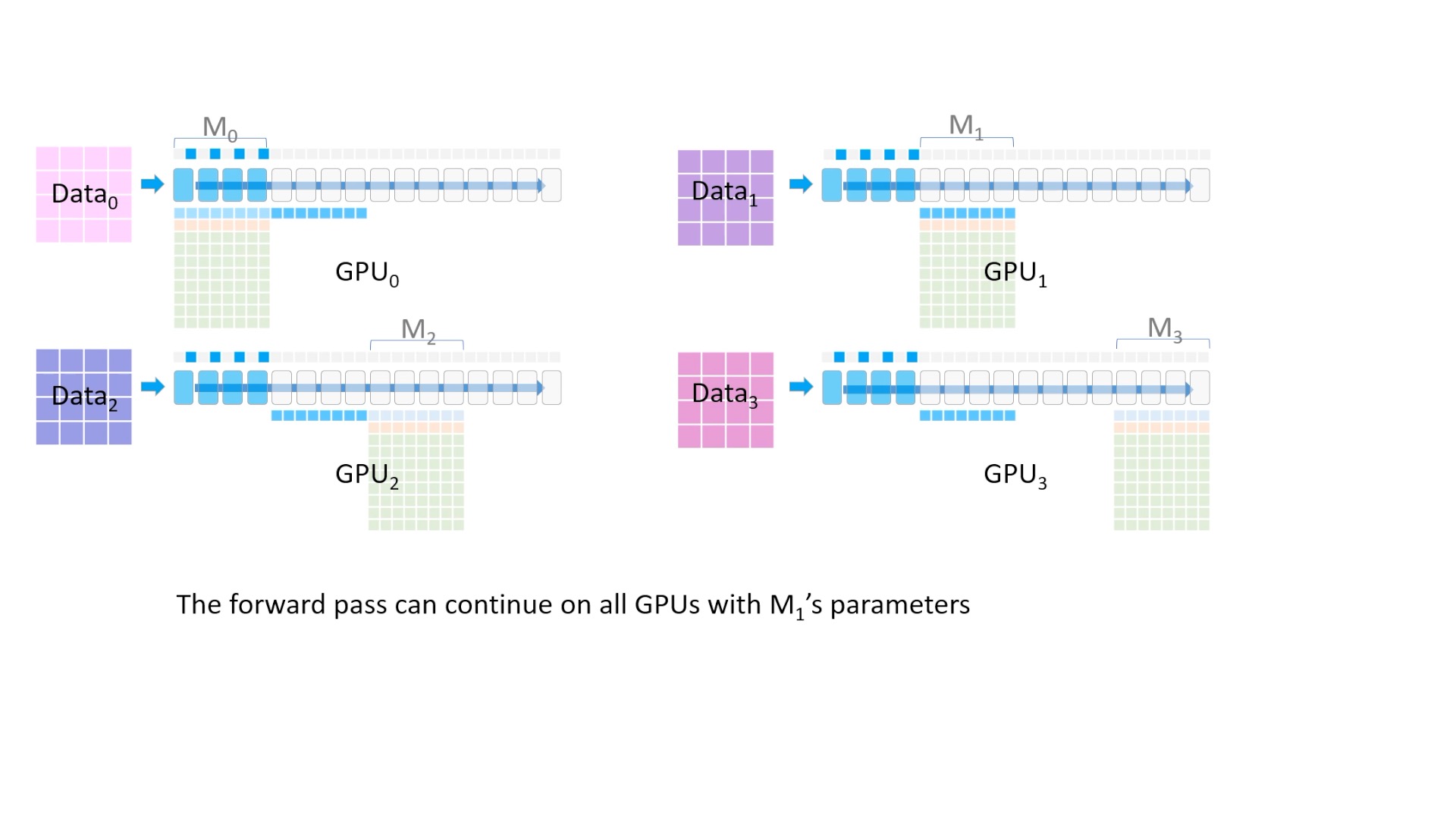 Fig. 그 다음 또 (4~7) 4개 layer를 broadcast를 해줍니다.
Fig. 그 다음 또 (4~7) 4개 layer를 broadcast를 해줍니다.
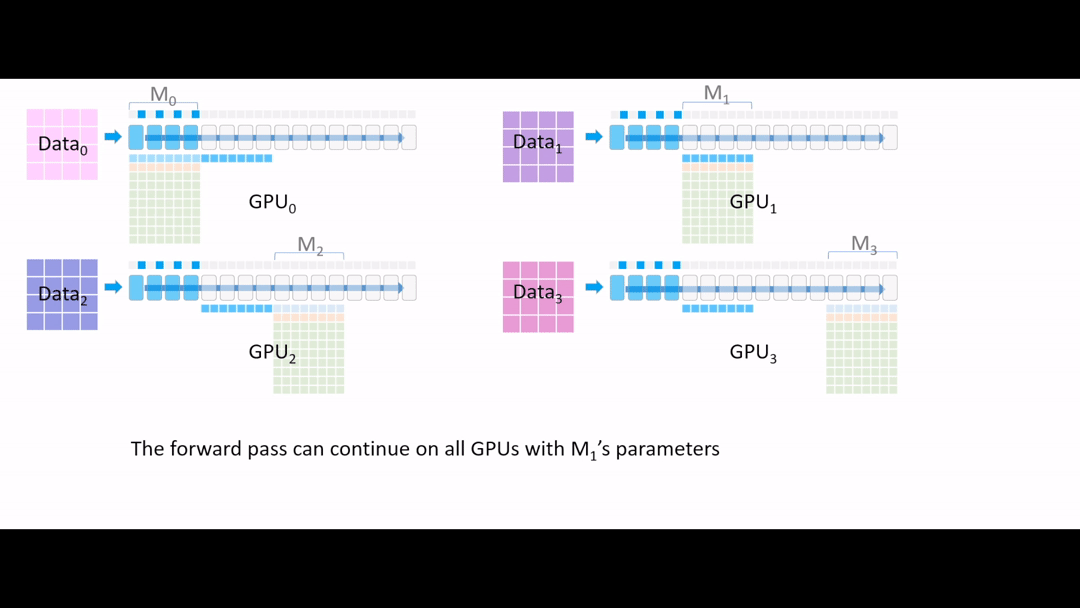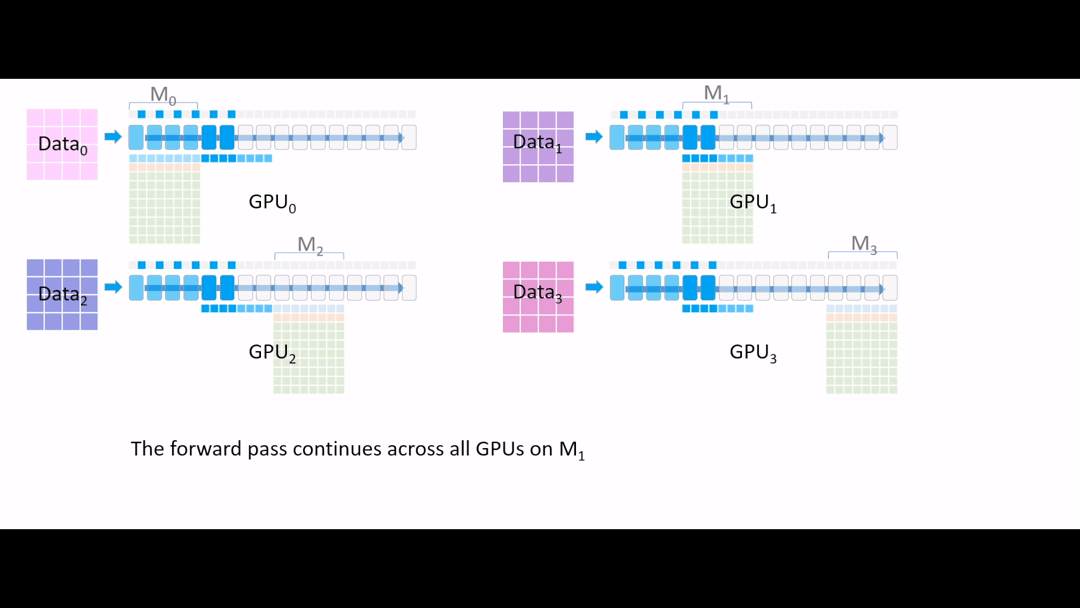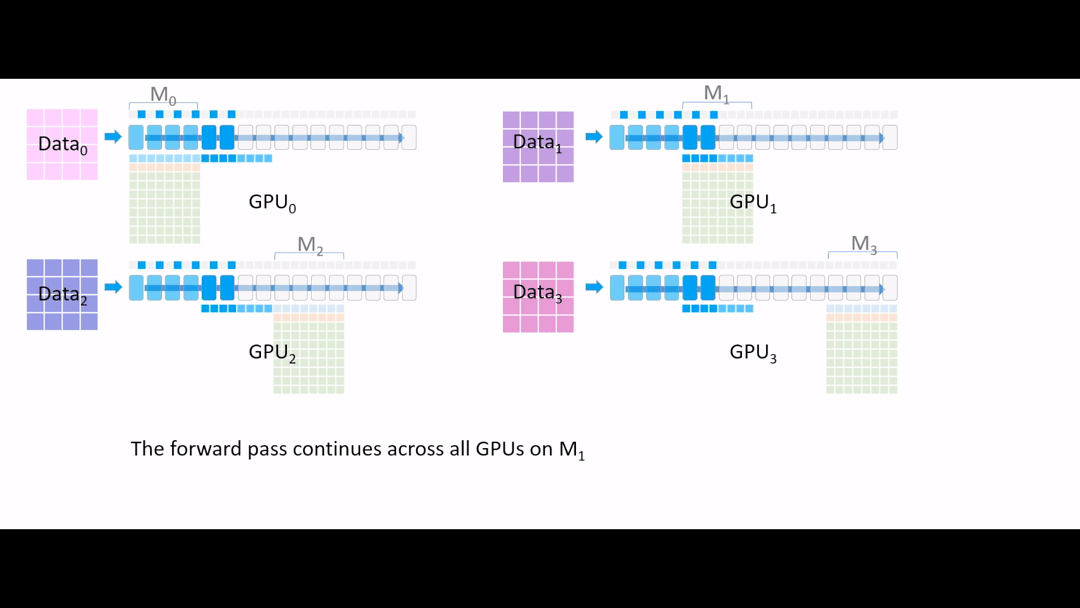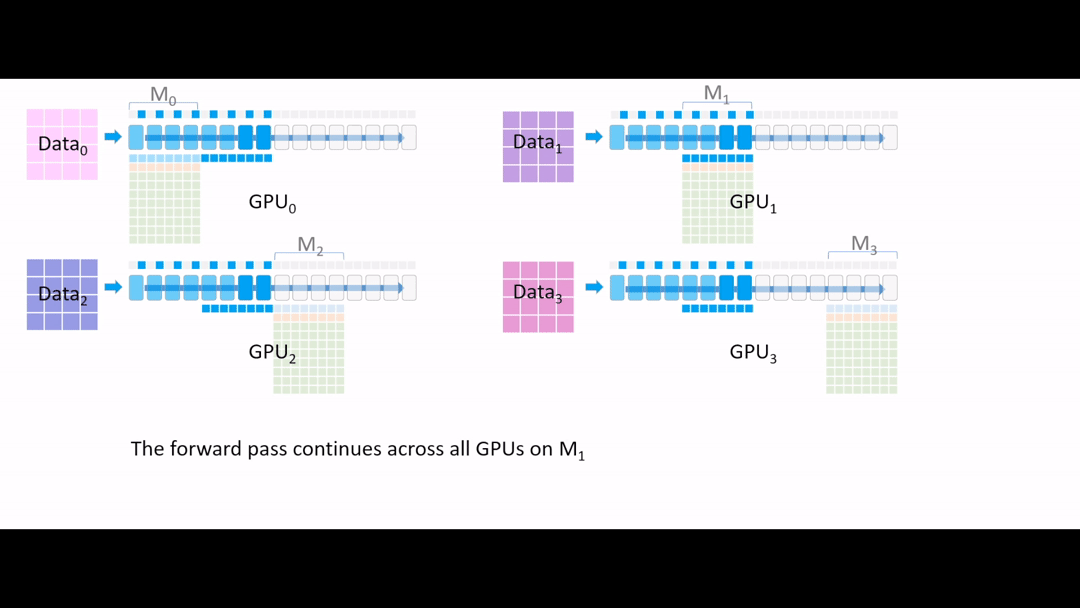 Fig. (GIF) 또 forward를 진행해줍니다. (계속 activation checkpointing)
Fig. (GIF) 또 forward를 진행해줍니다. (계속 activation checkpointing)
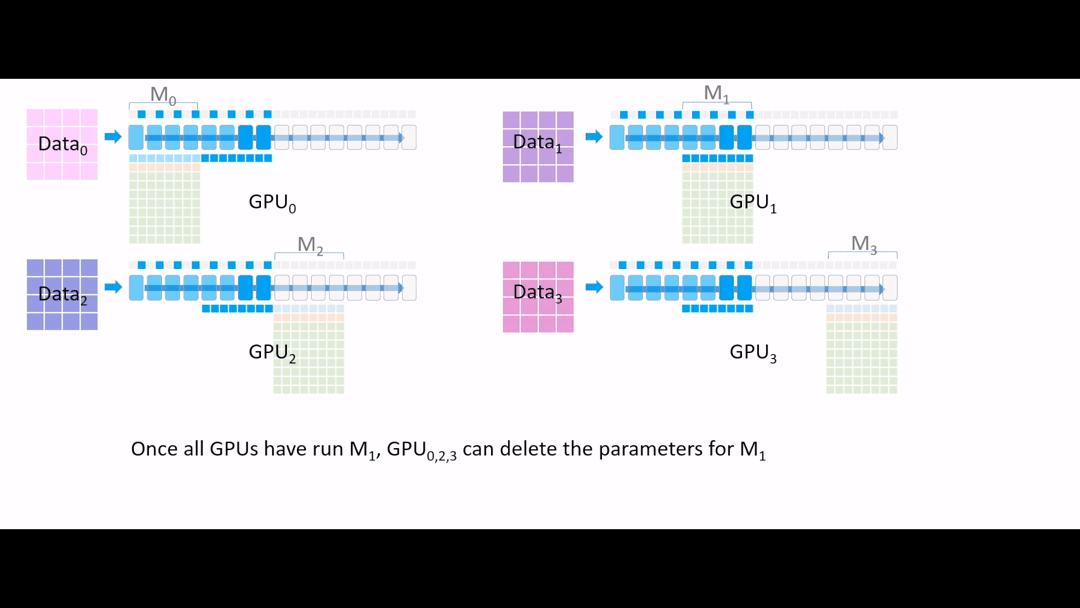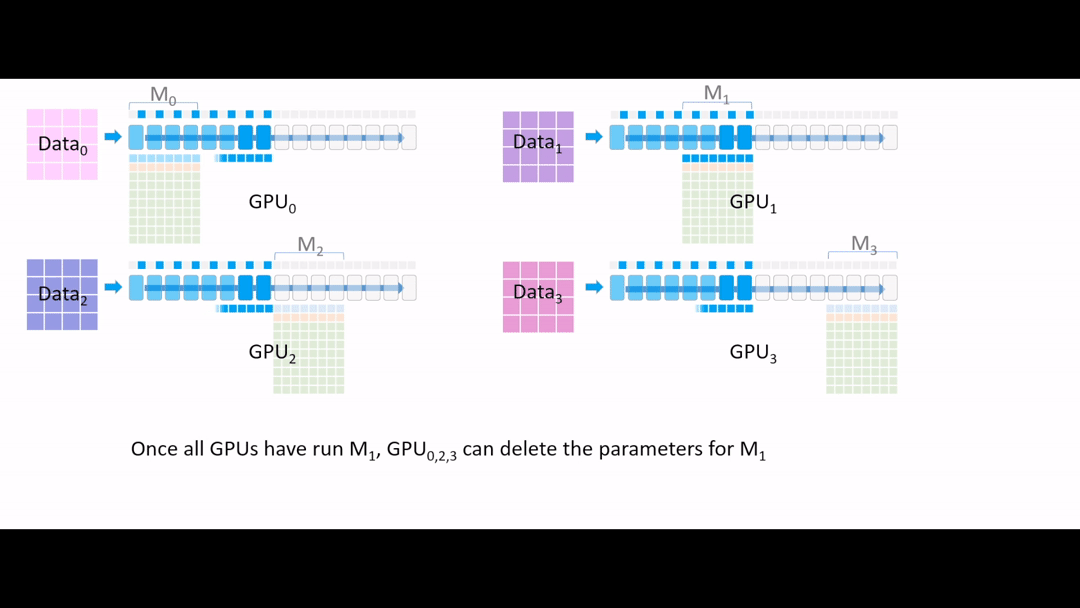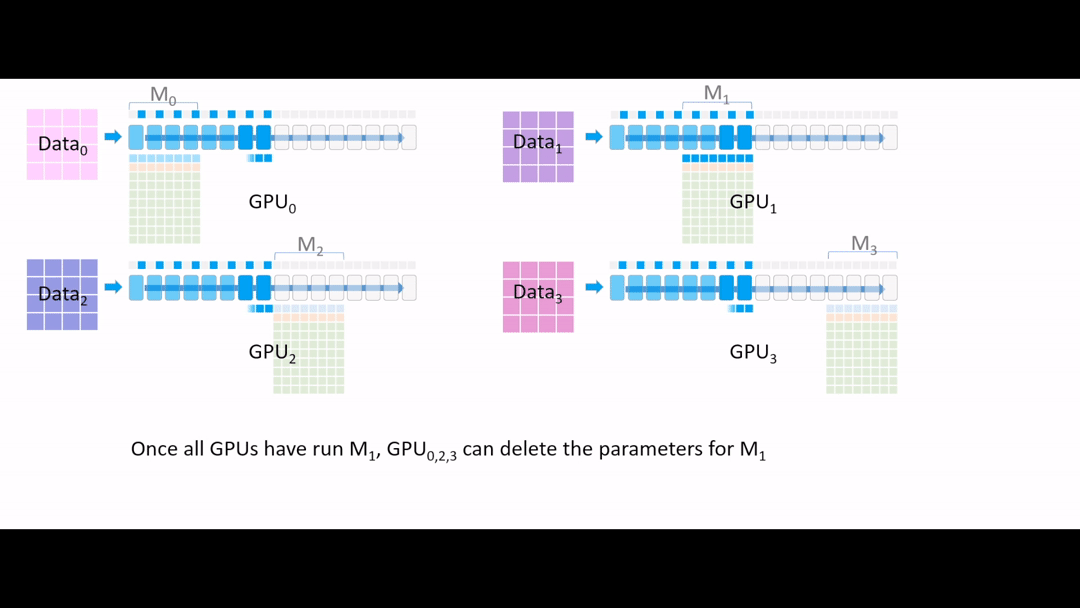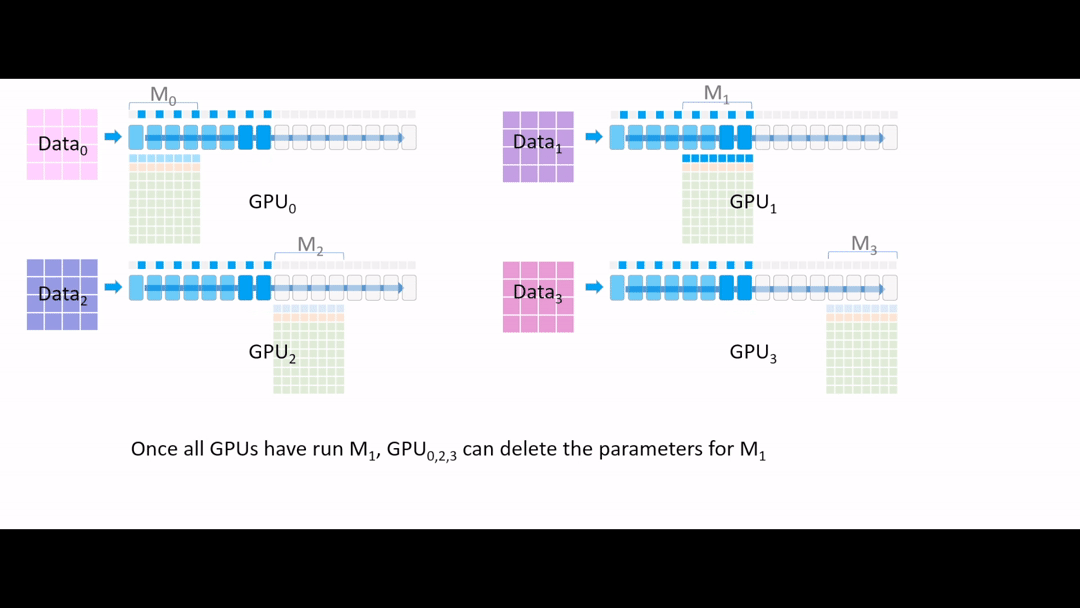 Fig. (GIF) 또 필요없어진 parameter들은 지웁니다.
Fig. (GIF) 또 필요없어진 parameter들은 지웁니다.
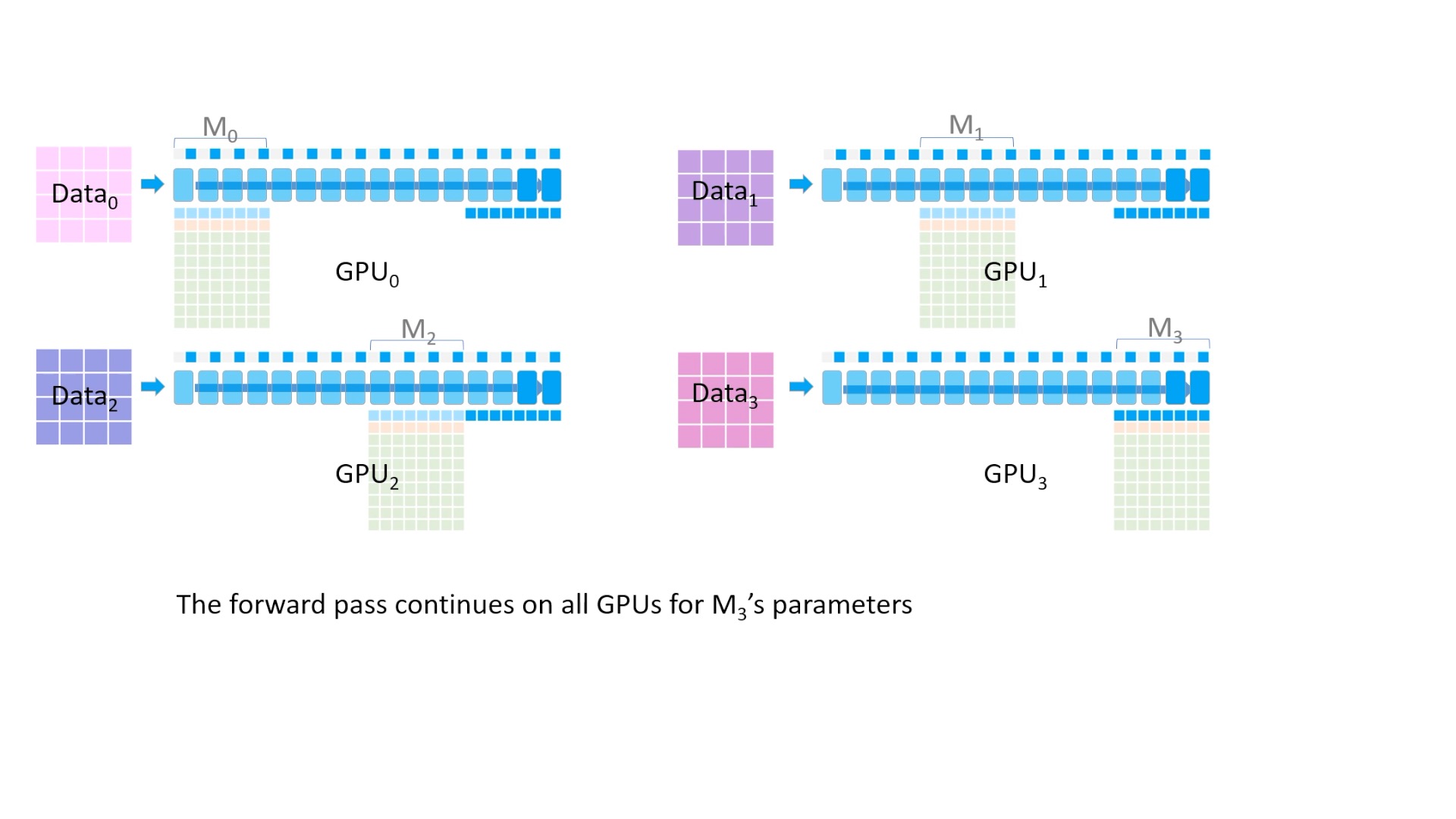 Fig. 이를 반복하면서 마지막까지 전부 forward를 합니다.
Fig. 이를 반복하면서 마지막까지 전부 forward를 합니다.
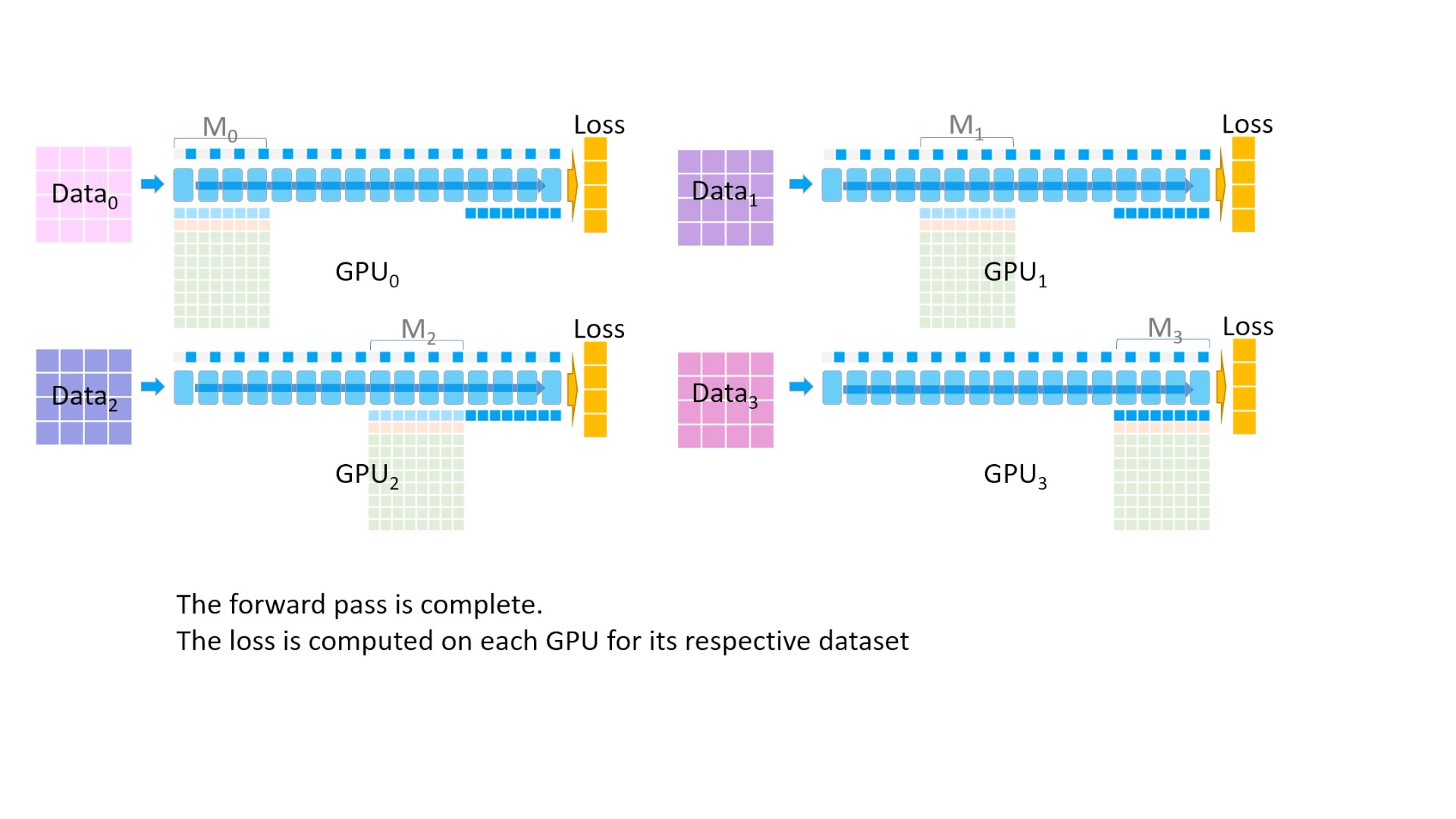 Fig. 최종적으로 모든 process에서 각각 Loss를 구합니다.
Fig. 최종적으로 모든 process에서 각각 Loss를 구합니다.
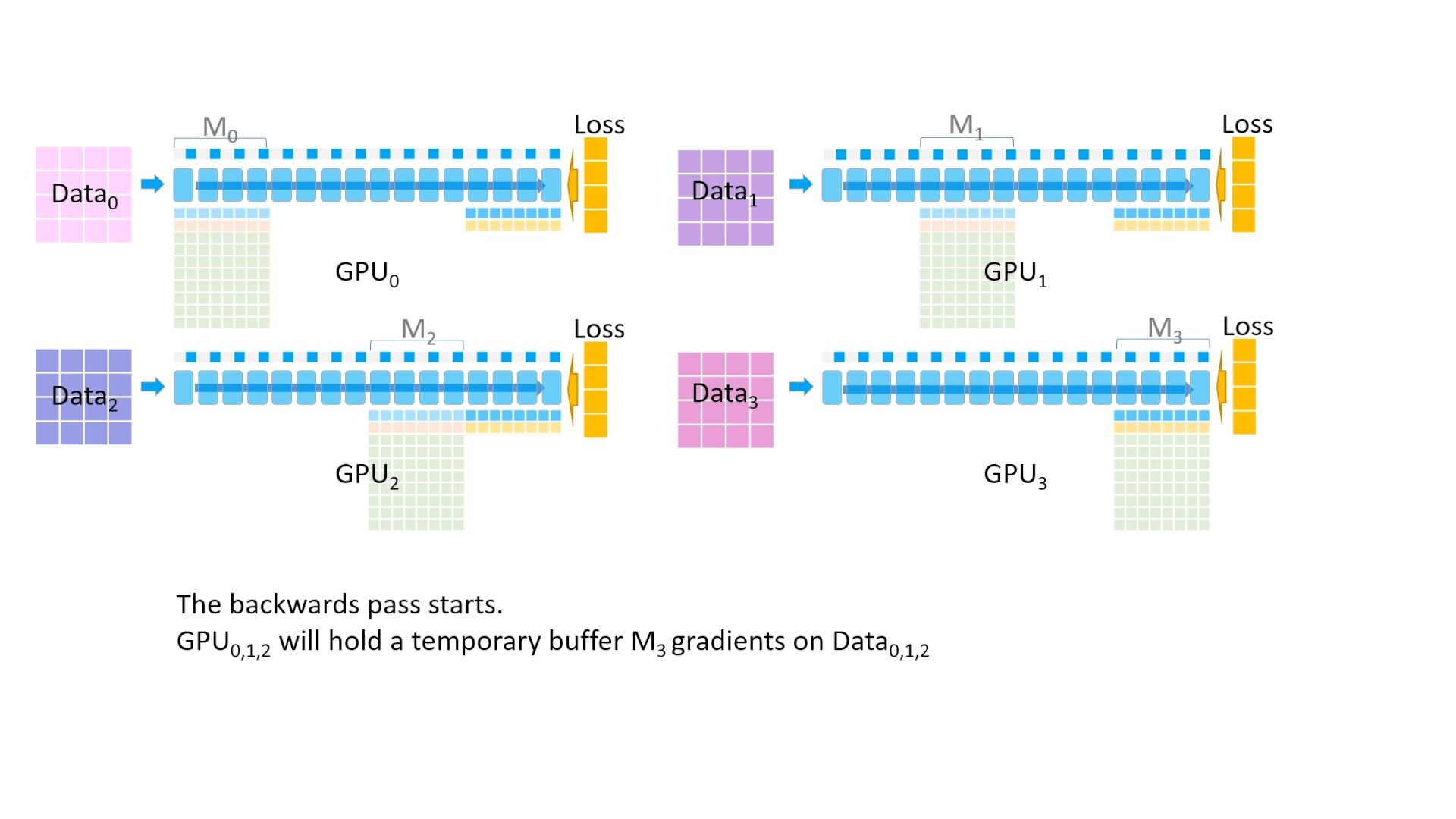 Fig. 이제 parameter를 update하기 위해서 각 activation, parameter를 활용해 gradient를 구해야 합니다. 마지막 layer의 경우 forward를 위해서 broadcast한 parameter를 지우지 않고 그대로 가지고 있는걸 볼 수 있는데, 이는 어차피 gradient를 구하기 위해서 다시 broadcast를 해야 하기 때문입니다.
Fig. 이제 parameter를 update하기 위해서 각 activation, parameter를 활용해 gradient를 구해야 합니다. 마지막 layer의 경우 forward를 위해서 broadcast한 parameter를 지우지 않고 그대로 가지고 있는걸 볼 수 있는데, 이는 어차피 gradient를 구하기 위해서 다시 broadcast를 해야 하기 때문입니다.
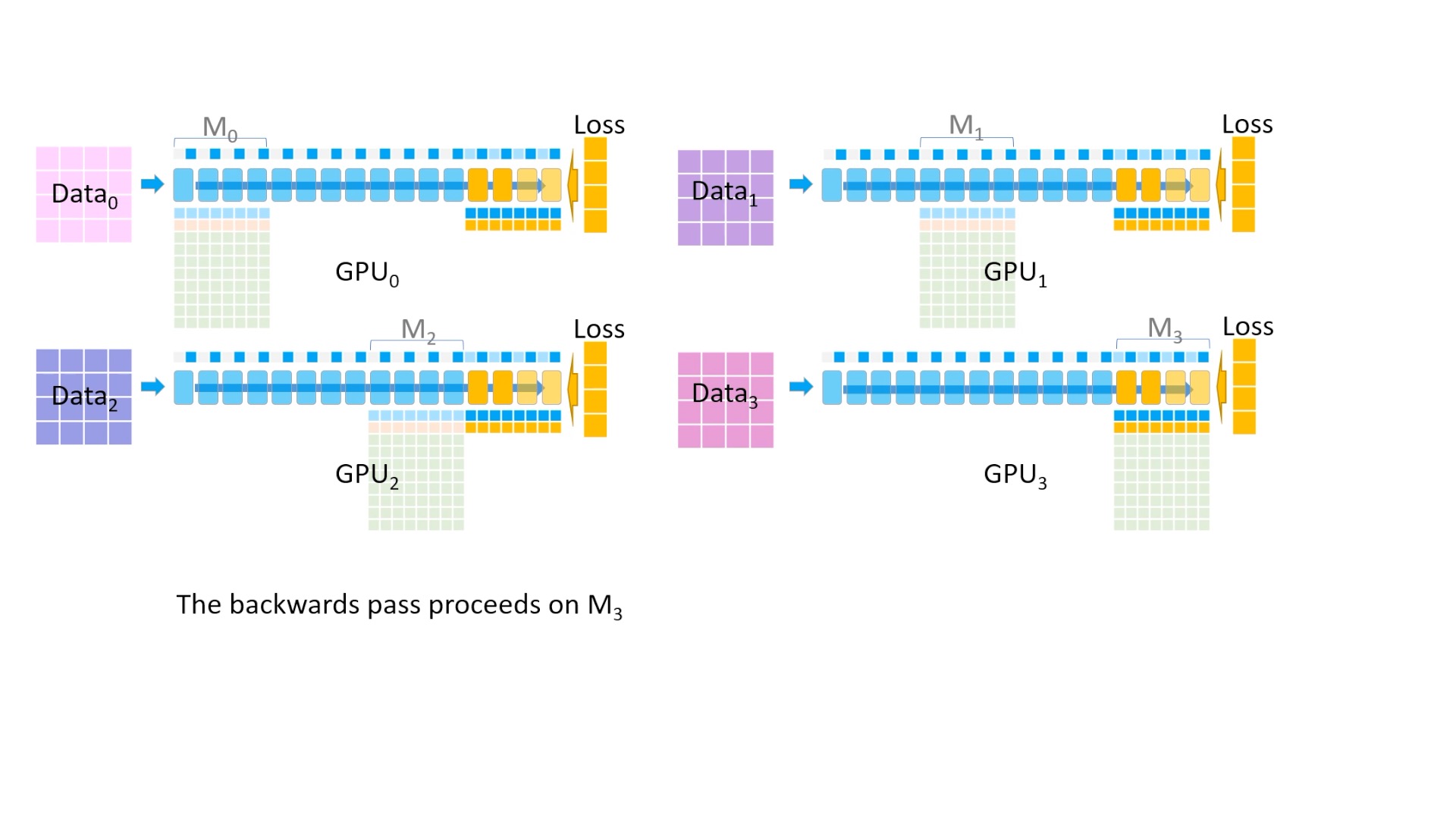 Fig. backward를 해서 fp16 gradient를 구합니다.
Fig. backward를 해서 fp16 gradient를 구합니다.
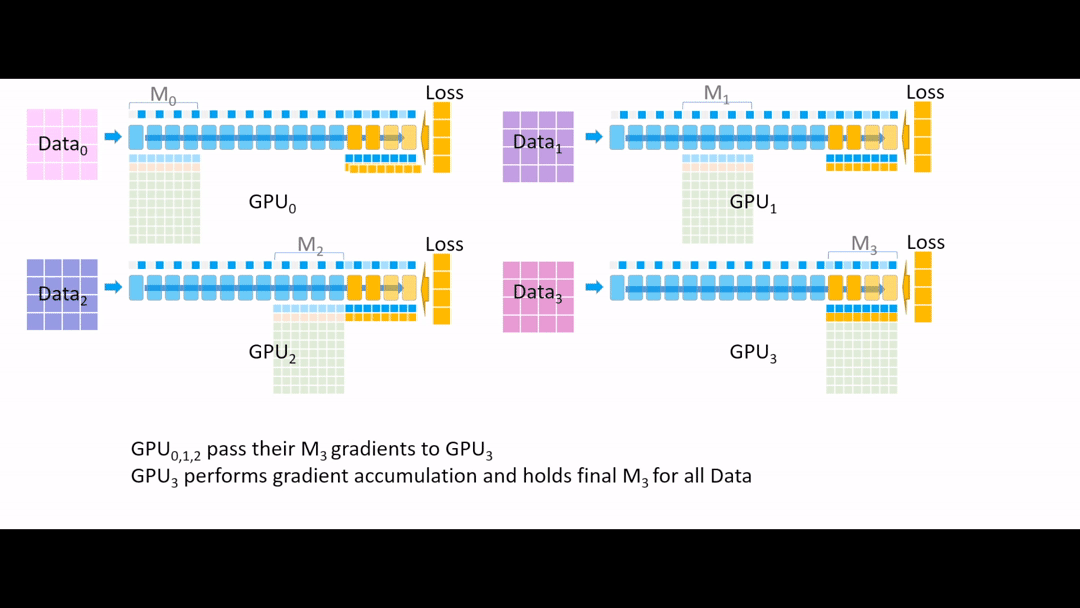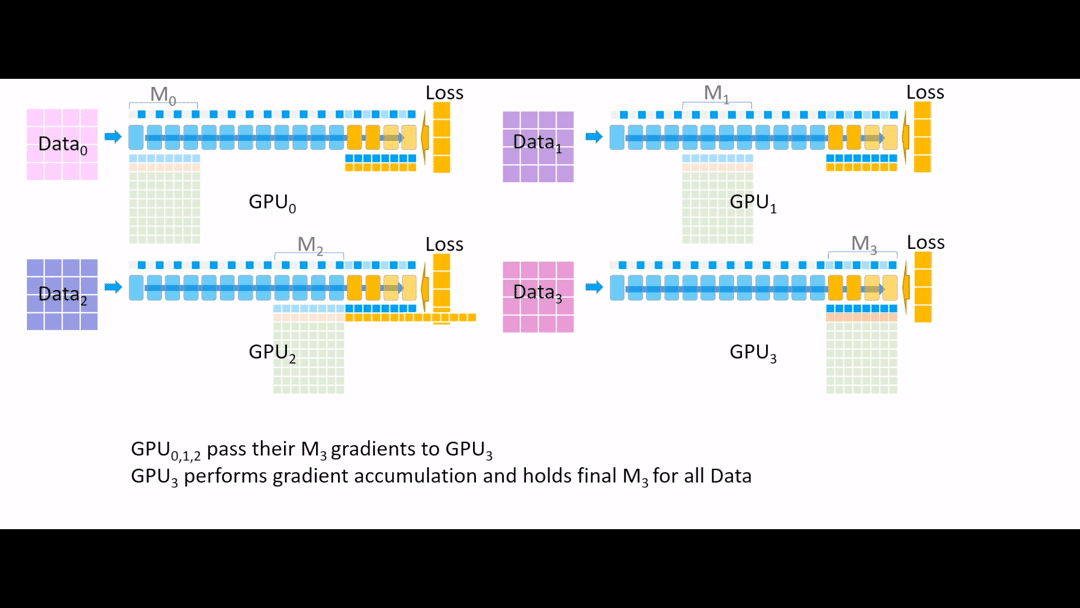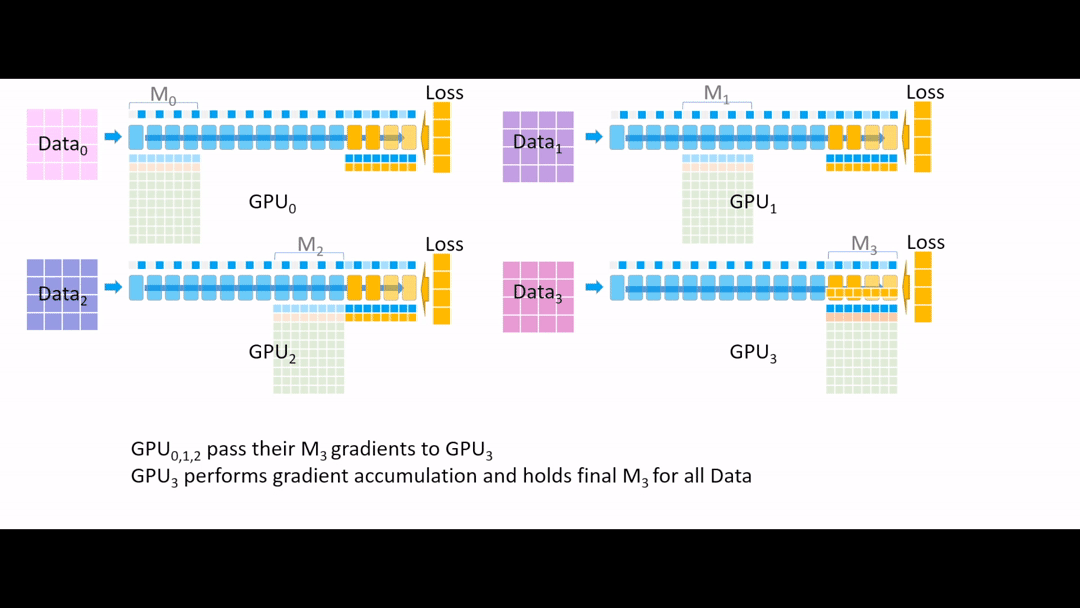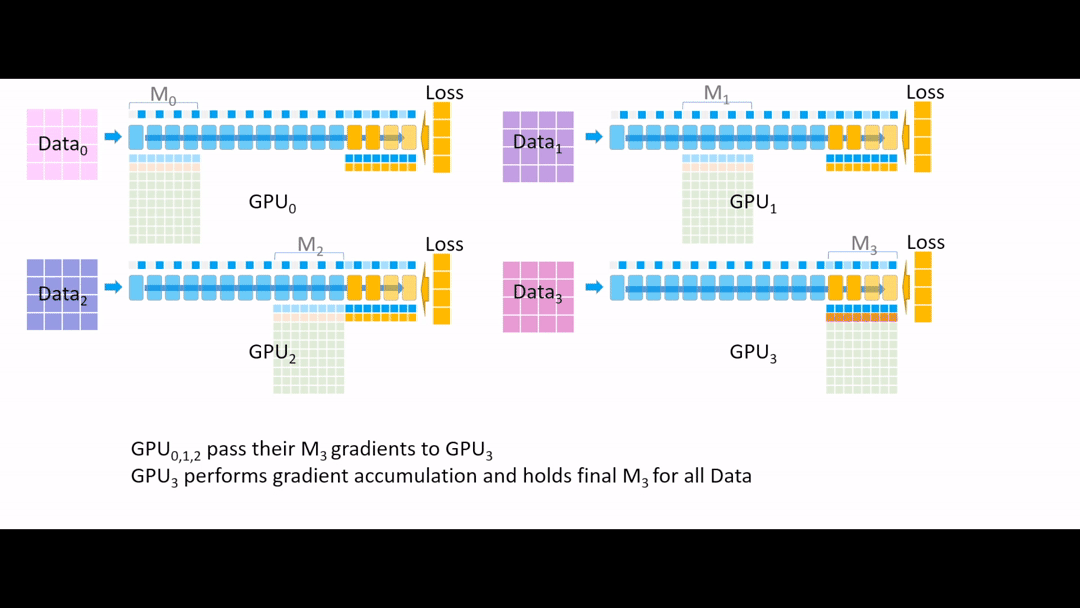 Fig. (GIF) 그 다음 all reduce를 통해 모든 gradient를 한 곳으로 모으는데, 마지막 4개 layer는 GPU3이 관리하므로 GPU3으로 모아준 뒤, 나머지 Device들에서는 gradient, parameter들을 모두 지웁니다.
Fig. (GIF) 그 다음 all reduce를 통해 모든 gradient를 한 곳으로 모으는데, 마지막 4개 layer는 GPU3이 관리하므로 GPU3으로 모아준 뒤, 나머지 Device들에서는 gradient, parameter들을 모두 지웁니다.
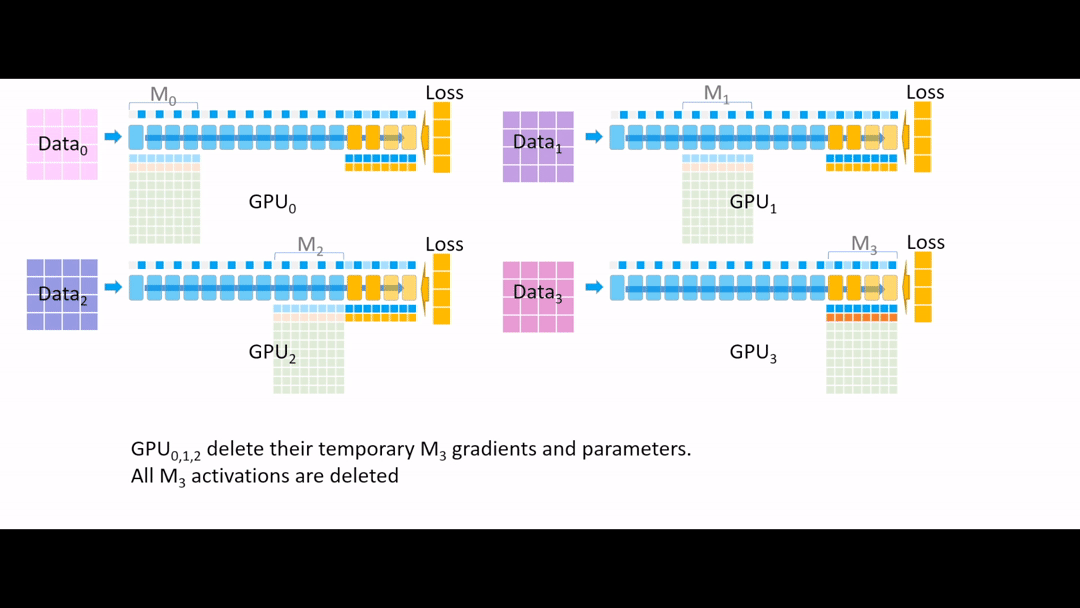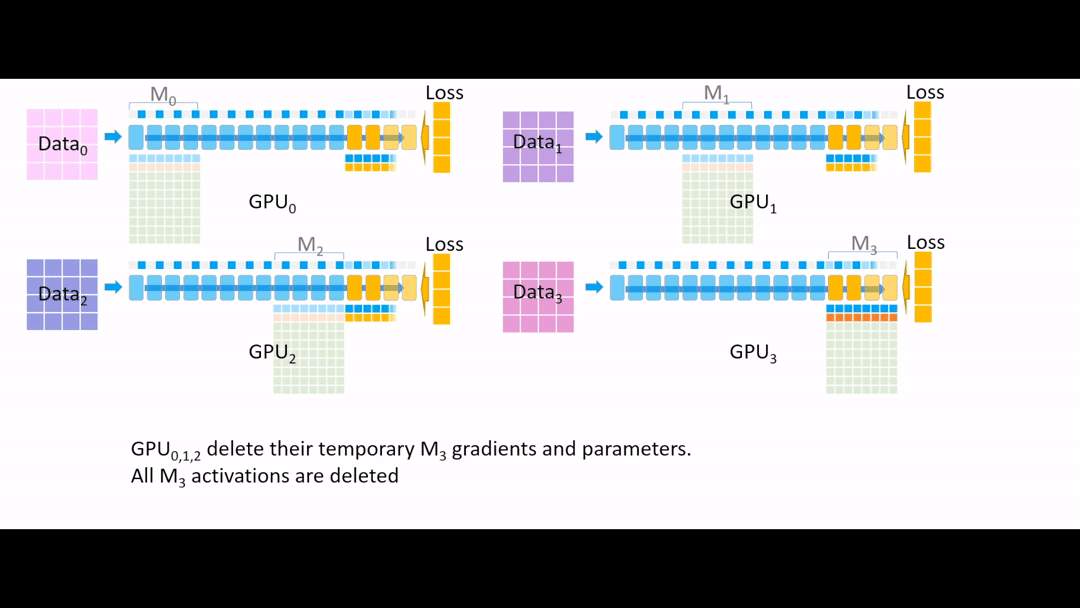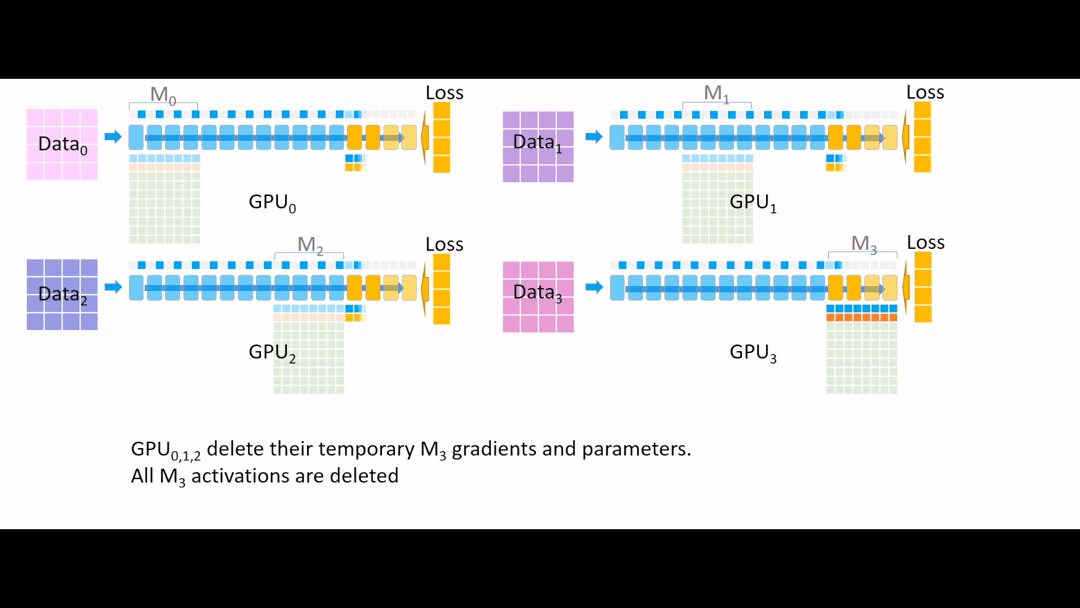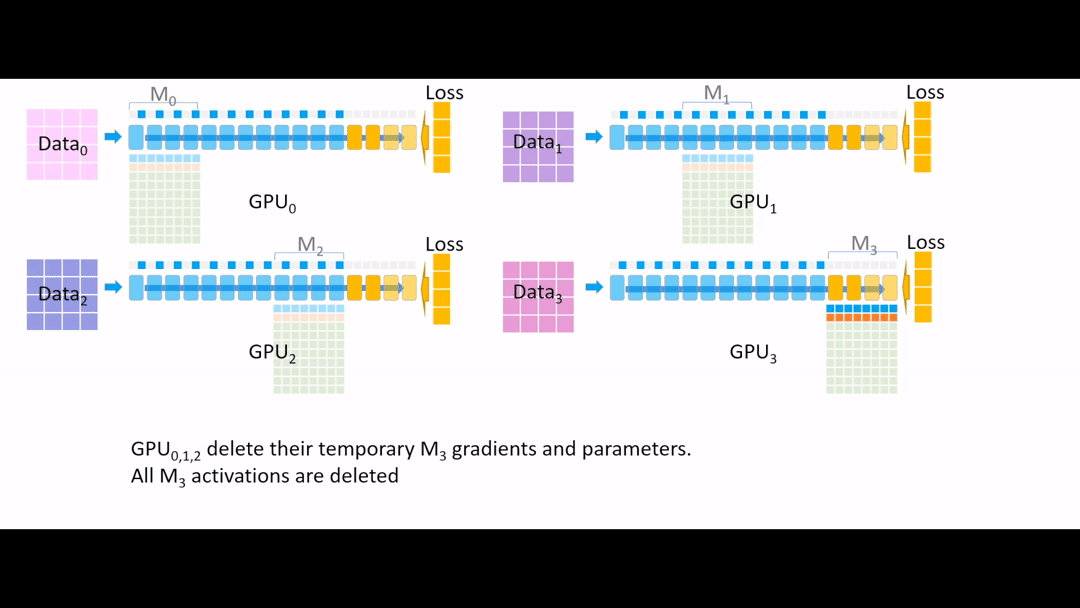 Fig. (GIF) (나머지 Device들에서는 gradient, parameter들을 모두 지움)
Fig. (GIF) (나머지 Device들에서는 gradient, parameter들을 모두 지움)
 Fig. 그 다음 layer들도 backward, all reduce, 지우기 반복.
Fig. 그 다음 layer들도 backward, all reduce, 지우기 반복.
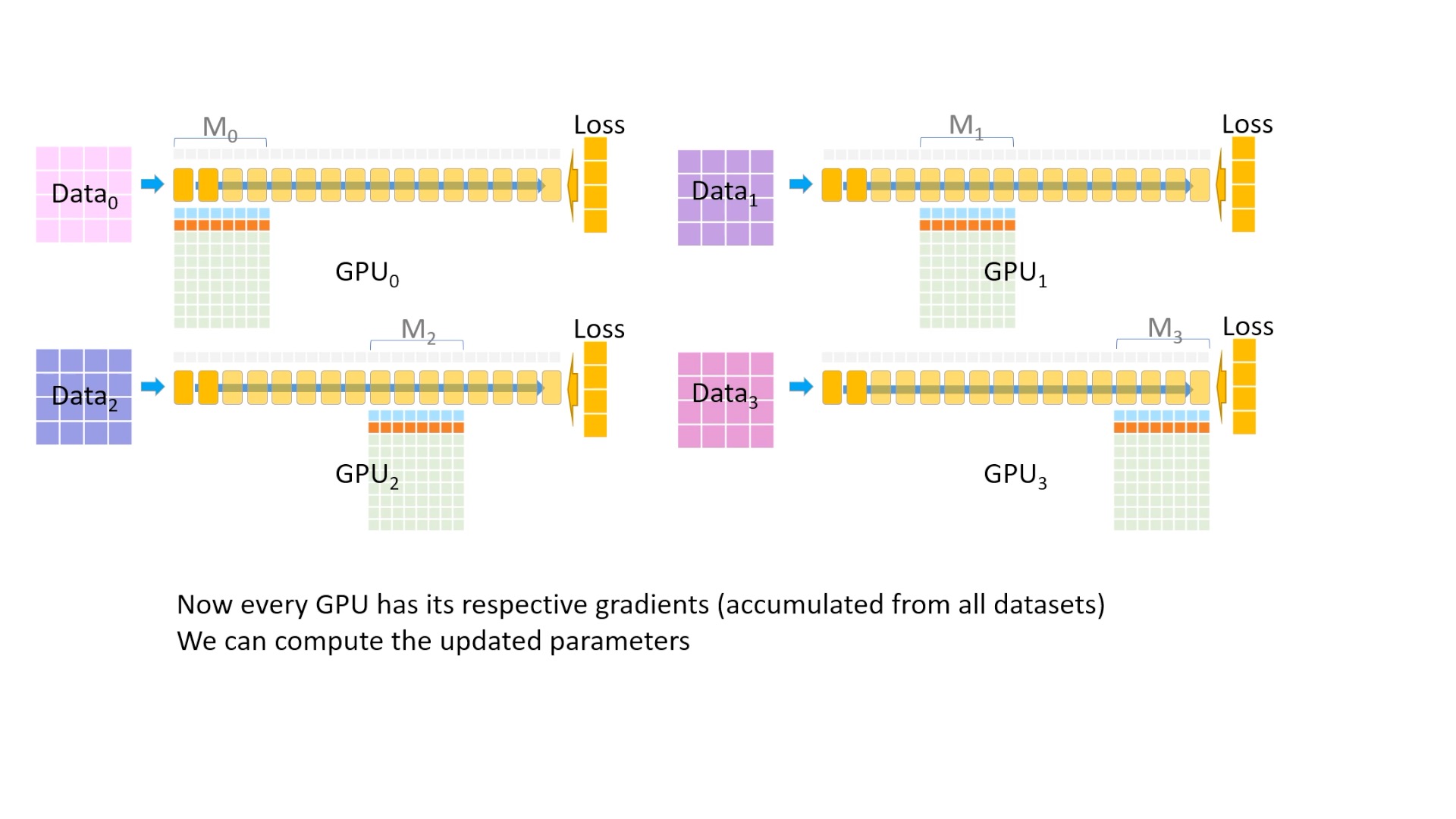 Fig. 이렇게 모든 device가 자신이 관리하는 layer들의 fp16 gradient를 가지게 되었습니다.
Fig. 이렇게 모든 device가 자신이 관리하는 layer들의 fp16 gradient를 가지게 되었습니다.
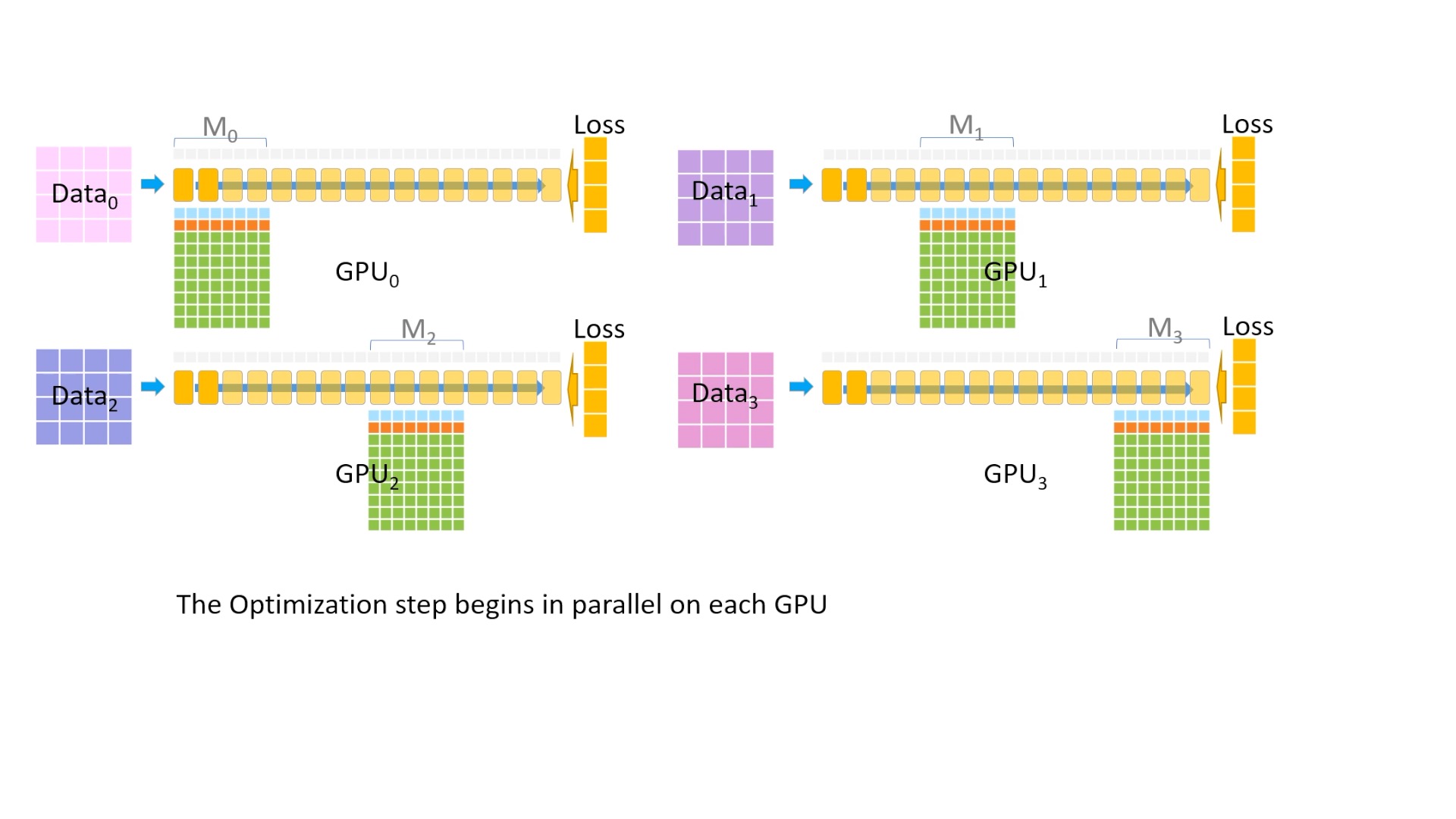 Fig. 이제 갖고있는 fp16 gradient들로 parameter를 각각 update 해야합니다. 각 device에서 optimizer state를 병럴적으로 돌립니다.
Fig. 이제 갖고있는 fp16 gradient들로 parameter를 각각 update 해야합니다. 각 device에서 optimizer state를 병럴적으로 돌립니다.
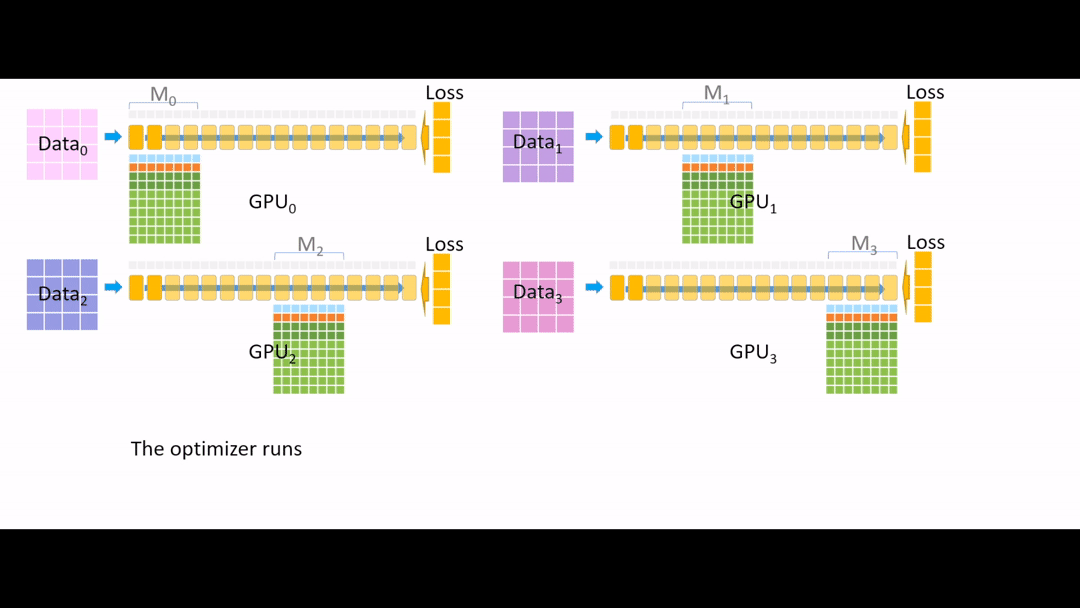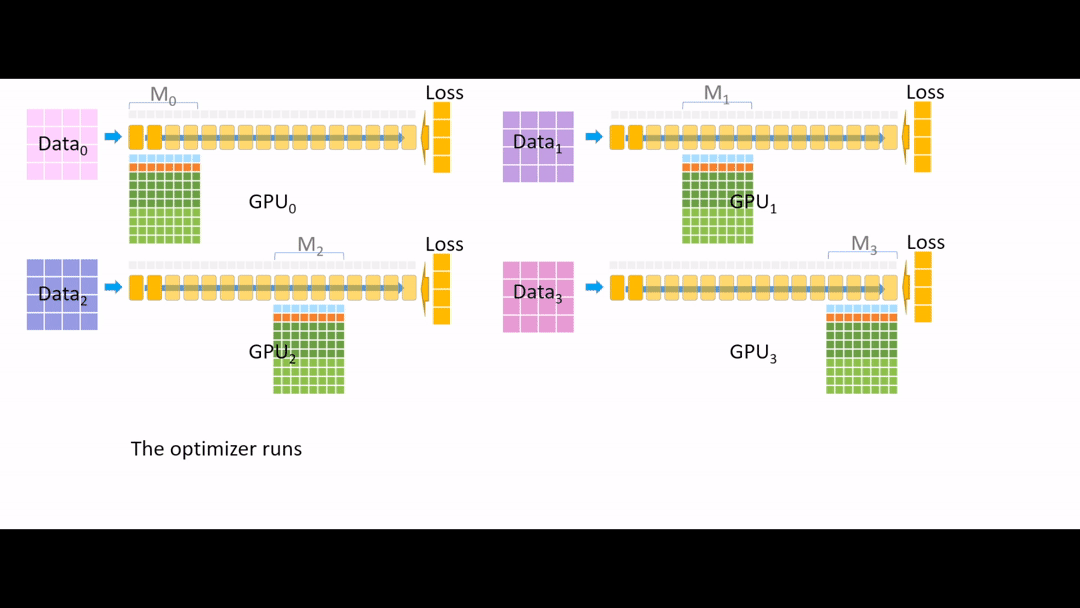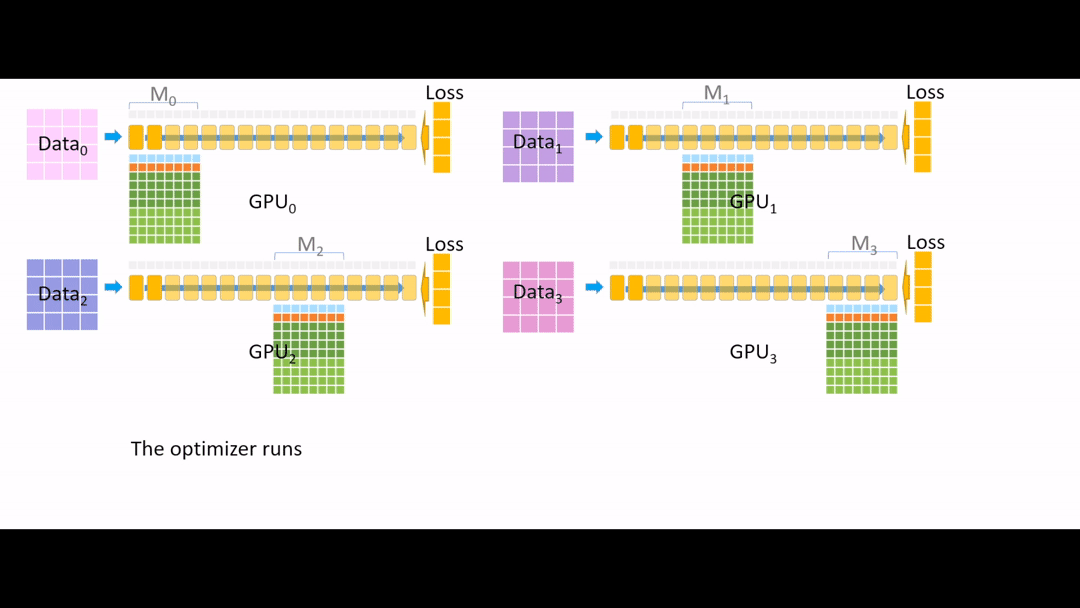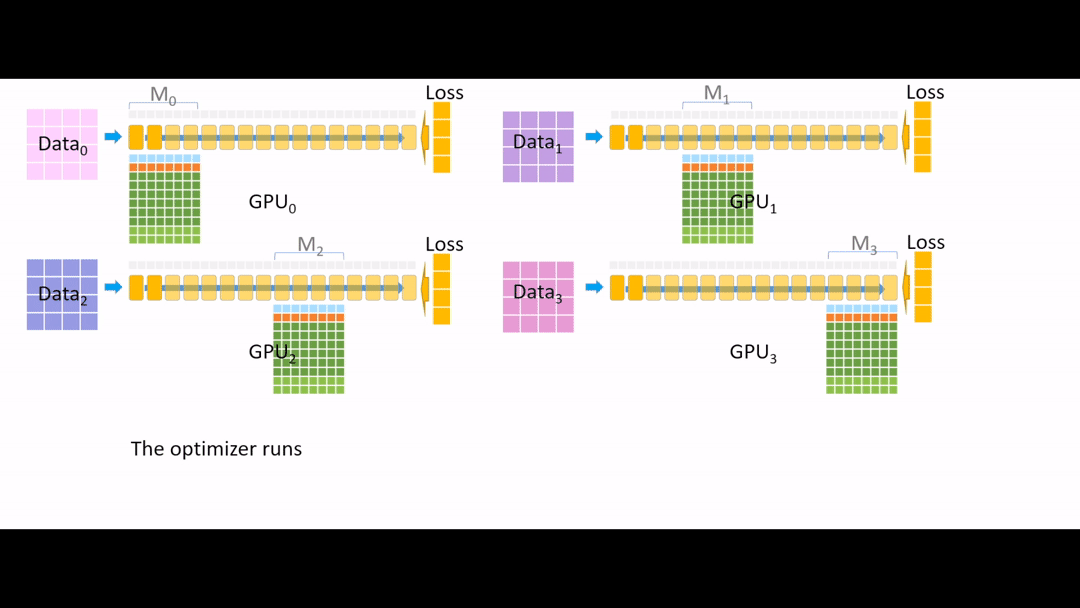 Fig. (GIF) optimizer run 중
Fig. (GIF) optimizer run 중
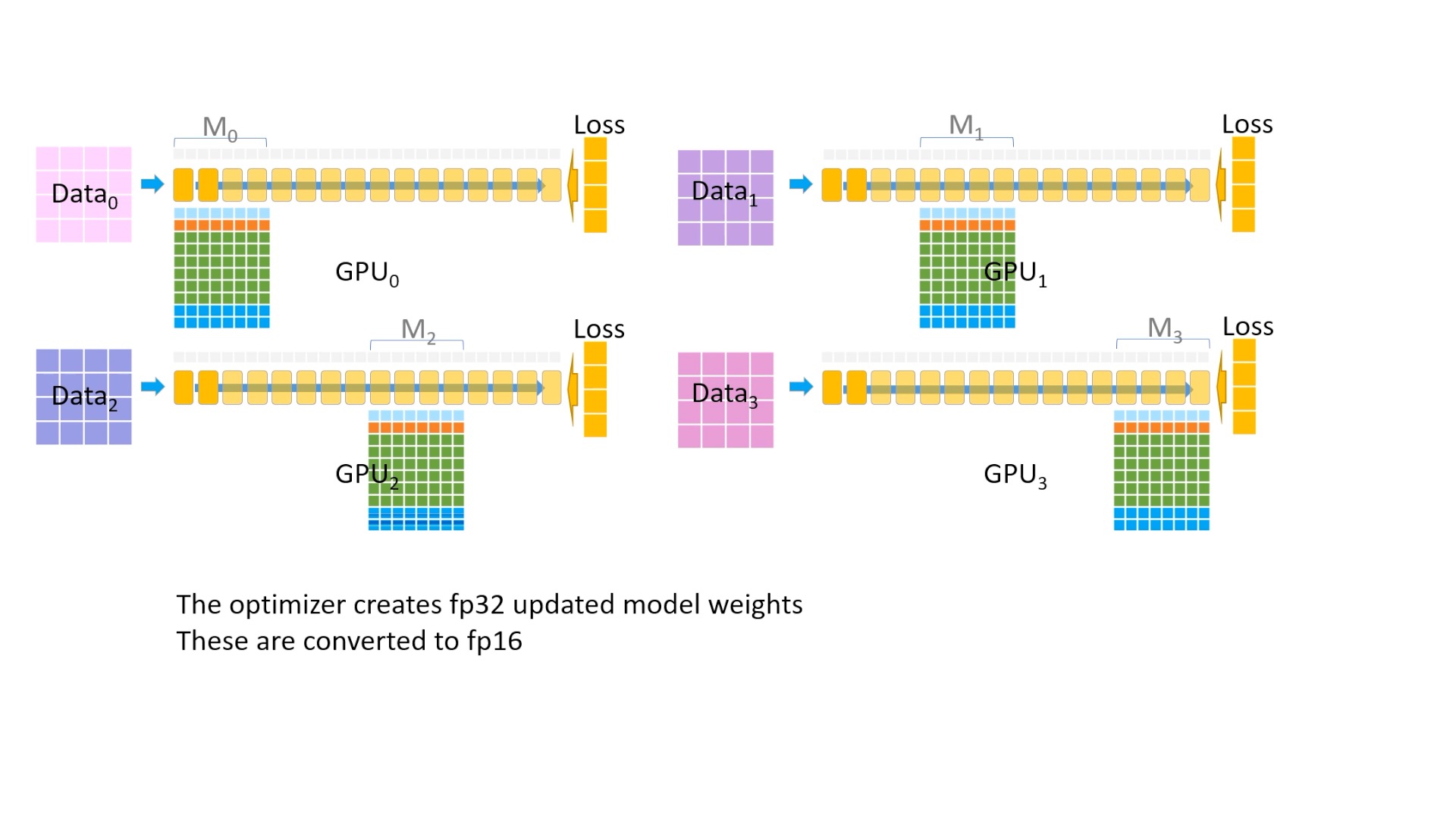 Fig. mixed precision을 하는 중이므로 fp32 model parameter가 momentum, variance, graident를 사용해서 update 됩니다.
Fig. mixed precision을 하는 중이므로 fp32 model parameter가 momentum, variance, graident를 사용해서 update 됩니다.
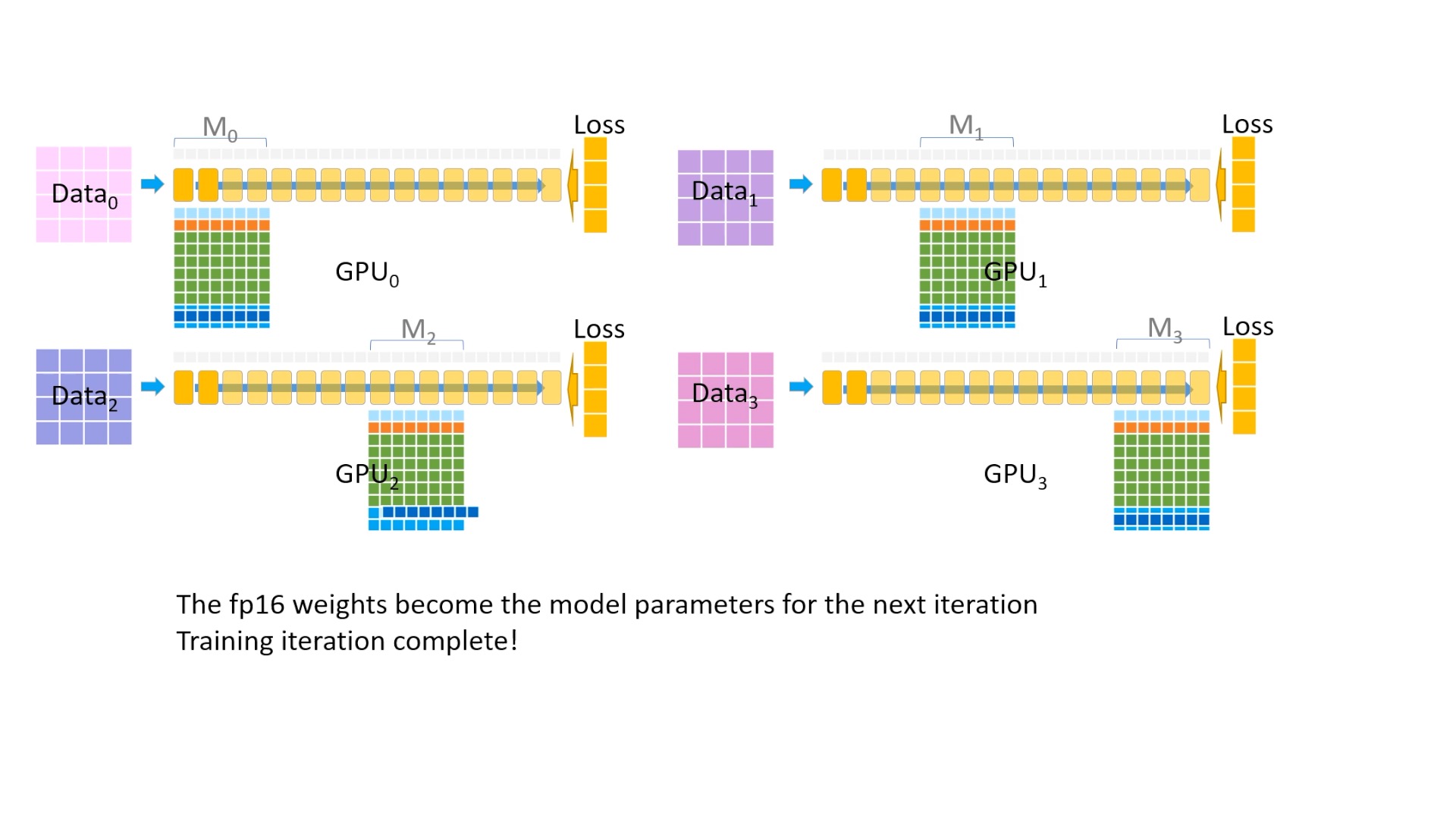 Fig. 이제 이를 다시 fp16 으로 변환해주고
Fig. 이제 이를 다시 fp16 으로 변환해주고
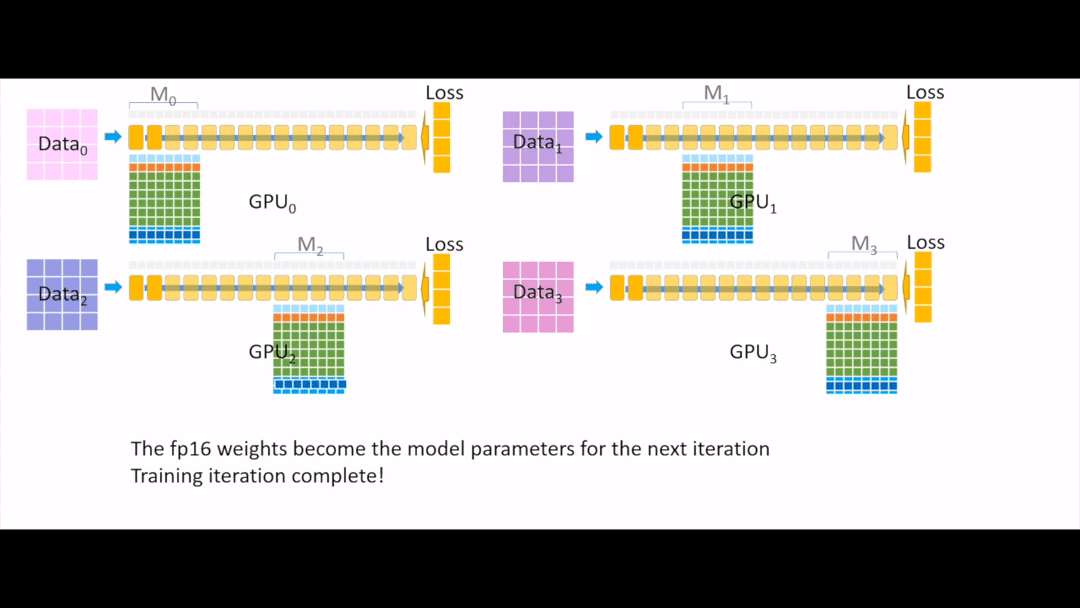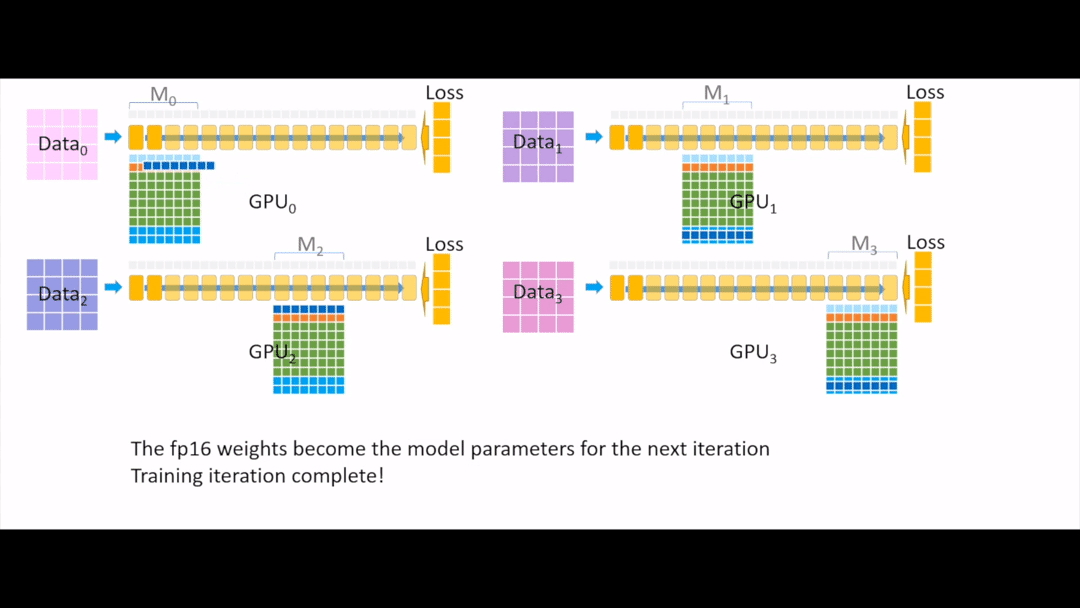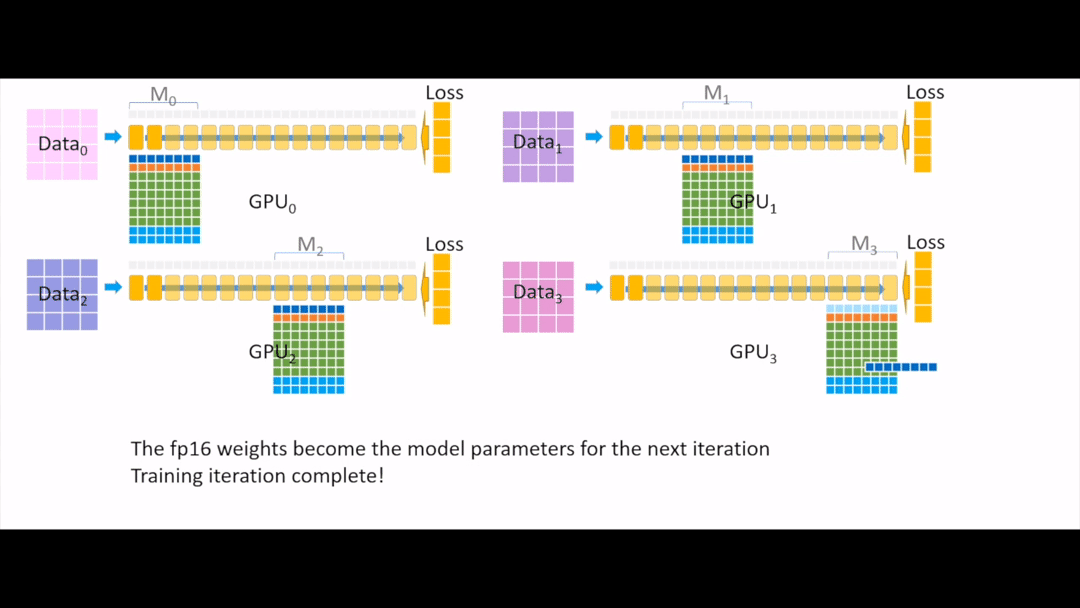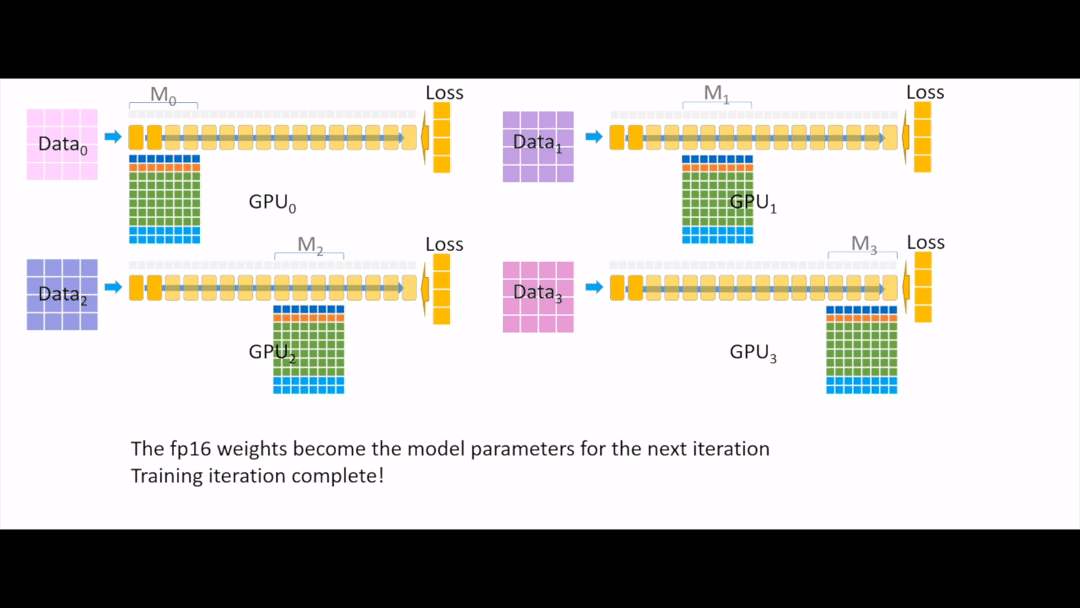 Fig. 각 device들에게 broadcasting을 해주면 한 iteration이 끝이 납니다.
Fig. 각 device들에게 broadcasting을 해주면 한 iteration이 끝이 납니다.
아마 느끼셨겠지만 device 수가 늘어날수록 ZeRO-3의 경우 기하급수적으로 이득을 볼 수 있게 됩니다.
Quantative Analysis of ZeRO-DP
이제 정량적인 수치에 대해서 각 stage를 적용했을 때 얼마나 save 할 수 있는지를 알아보도록 하겠습니다.
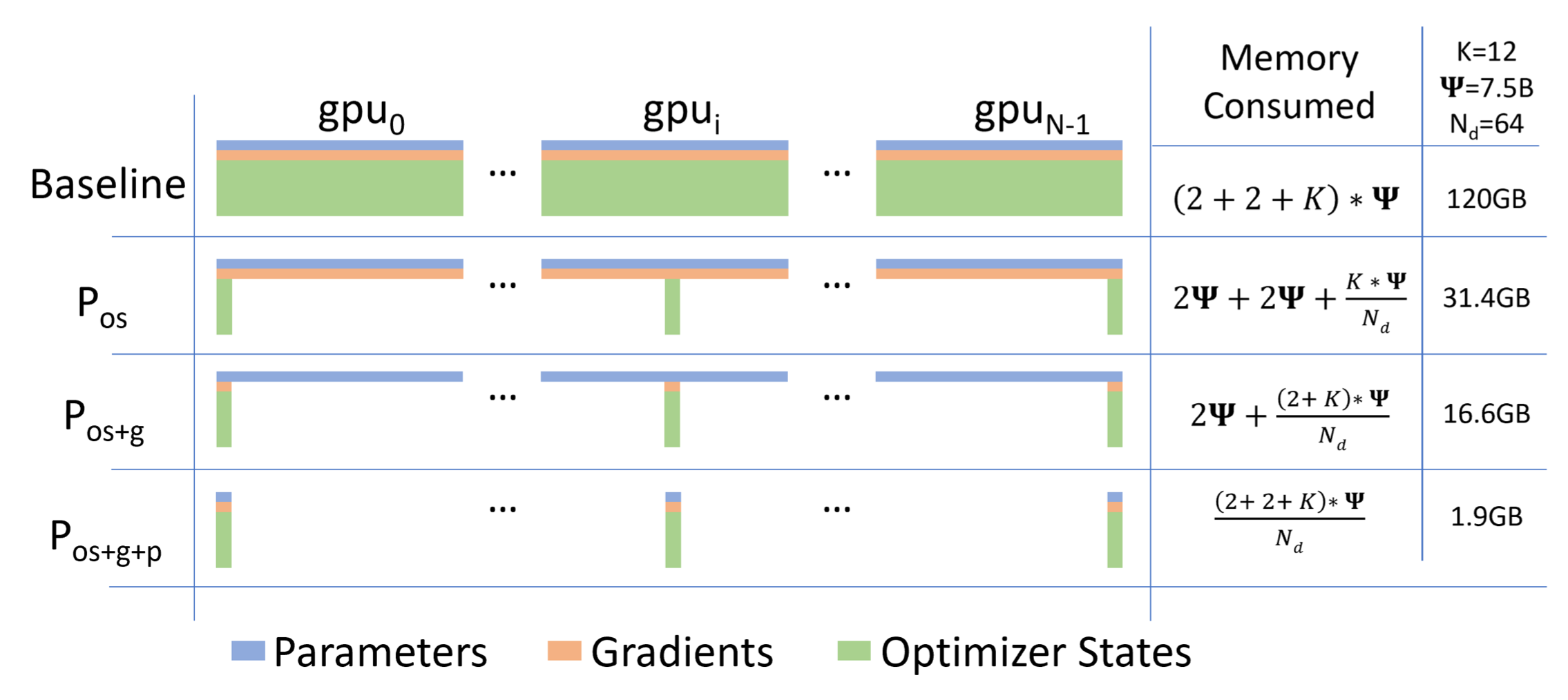 Fig.
Fig.
앞서 말씀드린 것 처럼 model size가 \(\psi\)이고 fp16 mixed precision을 썼으며 adam optimizer를 쓸 때를 가정해서
vanilla DDP를 하면 \((2(\text{fp16 param})+2(\text{gradient})+K(\text{optimizer states}))\cdot \psi\)
가 듭니다.
Model size가 현존하는 open source LLM중 가장 큰 llama2에서 가장 큰 model인 70B 이라고 가정하고 얘기해 보겠습니다.
정말 말이 안되죠? 현존하는 GPU중 가장 좋은 A100-80GB 의 hardware도 이를 감당할 수는 없습니다. 반면 70B model을 각 stage를 사용했을 때 총 필요한 gpu memory는 다음과 같습니다.
- stage 1 (\(P_{os}\)): optimizer state (fp32 param, momentum 등)만 각 device에 나눠서 올리는 것
- 총 Memory = \(2\psi + 2\psi + \frac{K}{N_d}\psi = \color{red}{293.125 \text{ GB}}, \text{ where } K=12 \text{ and } N_d=64\)
- time: DP와 동일한 communication cost, memory: 4배 save
- stage 2 (\(P_{os}+P_{g}\)): stage 1에 추가로 gradient 까지 sharding
- 총 Memory = \(2\psi + \frac{(2+K)}{N_d}\psi = \color{red}{155.3125 \text{ GB}}, \text{ where } K=12 \text{ and } N_d=64\)
- time: DP와 동일한 communication cost, memory: 8배 save
- stage 3 (\(P_{os}+P_{g}+P_{p}\)): stage 2에 추가로 model parameter 까지 sharding
- 총 Memory = \(\frac{(2+2+K)}{N_d}\psi = \color{red}{17.5 \text{ GB}}, \text{ where } K=12 \text{ and } N_d=64\)
- time: parameter를 통신해야 하므로 DDP보다 50%증가, memory: 64배 save
수식에서 보시면 아시겠지만, 각 stage들은 device의 갯수가 늘어날수록 stage 1은 \(4\psi\)로 수렴하고, stage 2는 \(3\psi\), stage 3는 \(\psi\)까지 개선이 될 수 있습니다. (제가 계산에 사용한 코드는 아래와 같습니다)
bytes = {
"fp32": 4,
"fp16": 2,
"bf16": 2,
}
def get_memory(model_size, dp_degree, precision="fp16", K=12, stage=3):
assert precision in ["fp32", "fp16", "bf16"]
assert stage in [1, 2, 3]
if stage == 1:
return (bytes[precision] + bytes[precision] + (K)/dp_degree) * model_size
elif stage == 2:
return (bytes[precision] + (bytes[precision] + K)/dp_degree) * model_size
elif stage == 3:
return ((bytes[precision] + bytes[precision] + K)/dp_degree) * model_size
ZeRO-R
ZeRO-DP에 대해서 알아봤으니 이번에는 ZeRO-R에 대해서 알아봅시다.
ZeRO-R의 R은 앞서 설명드린 것 처럼 Residual State Memory를 의미합니다.
- Activations
- Temporary buffers
- Memory Fragmentation
Paper에서 언급하는 Residual State Memory를 해결하기 위한 전략은 크게 세 가지가 있습니다.
- Partitioned Activation Checkpointing: \(P_a\)
- CPU offloading: \(P_{a+cpu}\)
- Constant Size Buffers: \(C_B\)
- Memory Defragmentation: \(M_D\)
먼저 activation 을 checkpointing하는 것은 기본입니다.
그런데 이 checkpointing 이 된걸 device별로 나누기 까지 하는거죠 (Activation Partitioning).
그래도 부족하면 CPU에 Offloading까지 했다가 필요할 때 (Backward 계산 시) 꺼내 쓰는겁니다.
CPU Offloading은 예를 들어 model parameter, optimizer state, activation 등을 CPU로 내렸다가 필요할 때 꺼내서 사용하는 기술로,
ZeRO가 나오기 전에도 이미 사용되던 방법이지만, model state를 CPU에 offloading 하는것은 학습 시간의 최대 50%를 offloading에 쓴다거나 하는 비효율이 발생하기 때문에 ZeRO-R 에서는 activation 만 offloading하는 방법을 택했다고 합니다.
이렇게 CPU offloading을 막 해도 된는 (?) 이유는 matmul연산이 매우 크기 때문에 그동안 data movement를 함으로써 bandwidth가 낮더라도 movement cost를 숨기는 것이 가능하기 때문이라고 합니다.
이를 \(P_{a+cpu}\)라고 합니다.
그 다음은 all-reduce 같은 연산을 할 시 Constant size Buffer를 쓰는 겁니다.
기본적으로 large all-reduce operation이 small인 것 보다 훨씬 높은 bandwidth를 갖는다고 합니다.
그래서 NVIDIA Apex나 Megatron 같은 library들은 all-reduce를 하기 전에 parameter 들을 모두 하나의 buffer에 넣어서 쓴다고 되어있는데, 이러면 parameter size에 비례해서 3B 일때 12GB가 필요하는 등 (32-bit)의 문제가 생겨 너무 작지도 않지만 너무 커지지도 않게 하는 고정된 buffer를 쓰는 전략을 취한다는 겁니다.
마지막으로 Memory Defragmentation는 forward시 activation을 지우는 행위 등에 따라 남는 memory들이 조각화 되지 않도록 잘 관리해주는 것으로, 미리 연속적인 (contiguous) memory chunk들을 할당해 두고 checkpointed activation이나 gradient 등을 미리 할당된 memory로 옮김으로써 문제를 해결합니다.
Analysis
Cheatsheet for Per-device Memory Consumption
이하는 ZeRO Stage에 따라 얼마나 큰 model을 device에 올릴 수 있는지를 나타낸 것입니다. 이 수치는 V100-32GB 장비를 가정하고 만든 Table이기 때문에 32GB를 기준으로 합니다. 주의해야 할 점은 꼭 device에 optimizer, gradient, parameter가 다 올라간다고 해서 학습이 가능한 것은 아닙니다. 이 외에도 Activation 같은 것들이 있기 때문에 실제로는 더 많은 GPU가 필요한데, 일단 이런건 무시하는 겁니다.
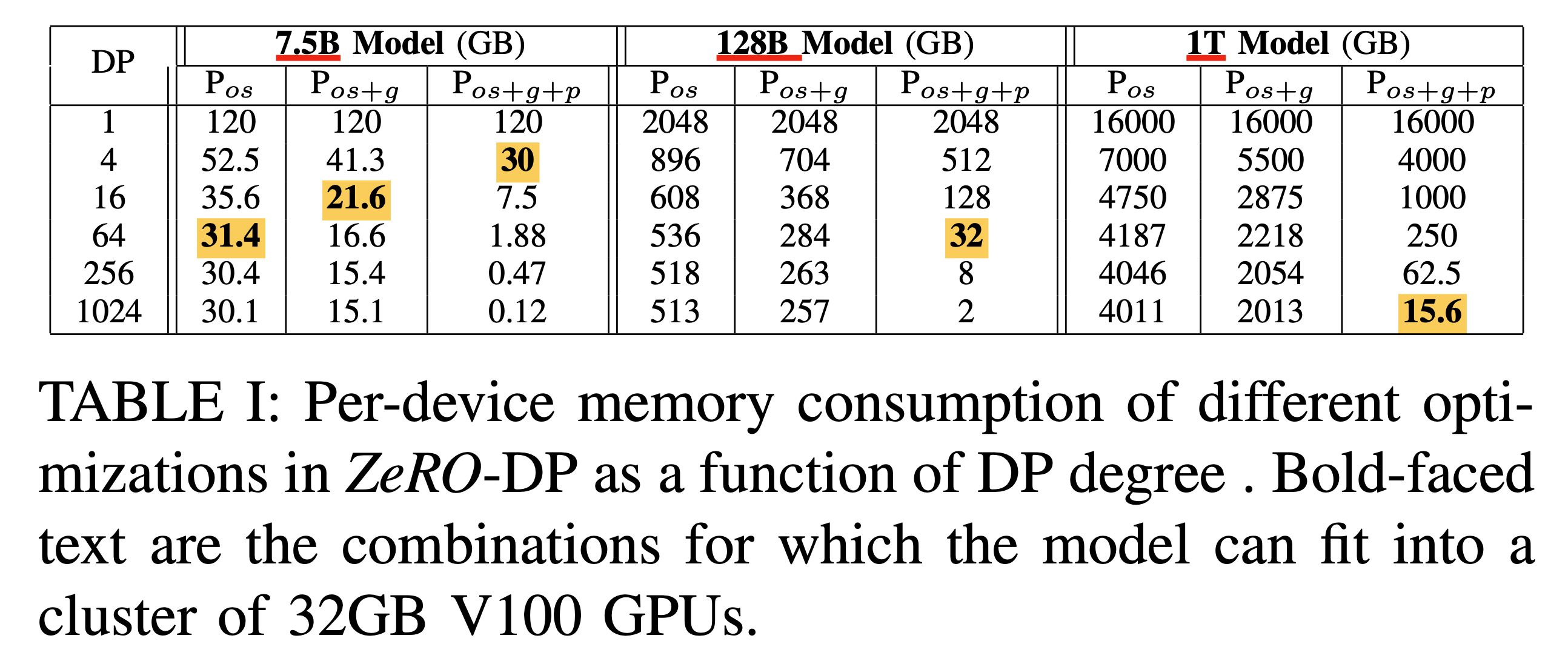 Fig. 128B model을 OOM없이 V100에 올리기 위해선 64장이 필요하다.
Fig. 128B model을 OOM없이 V100에 올리기 위해선 64장이 필요하다.
그 다음은 다양한 ZeRO Configuration에 따른 최대 model size와 할당되는 cached memory 크기, 그리고 Throughput per GPU 입니다.
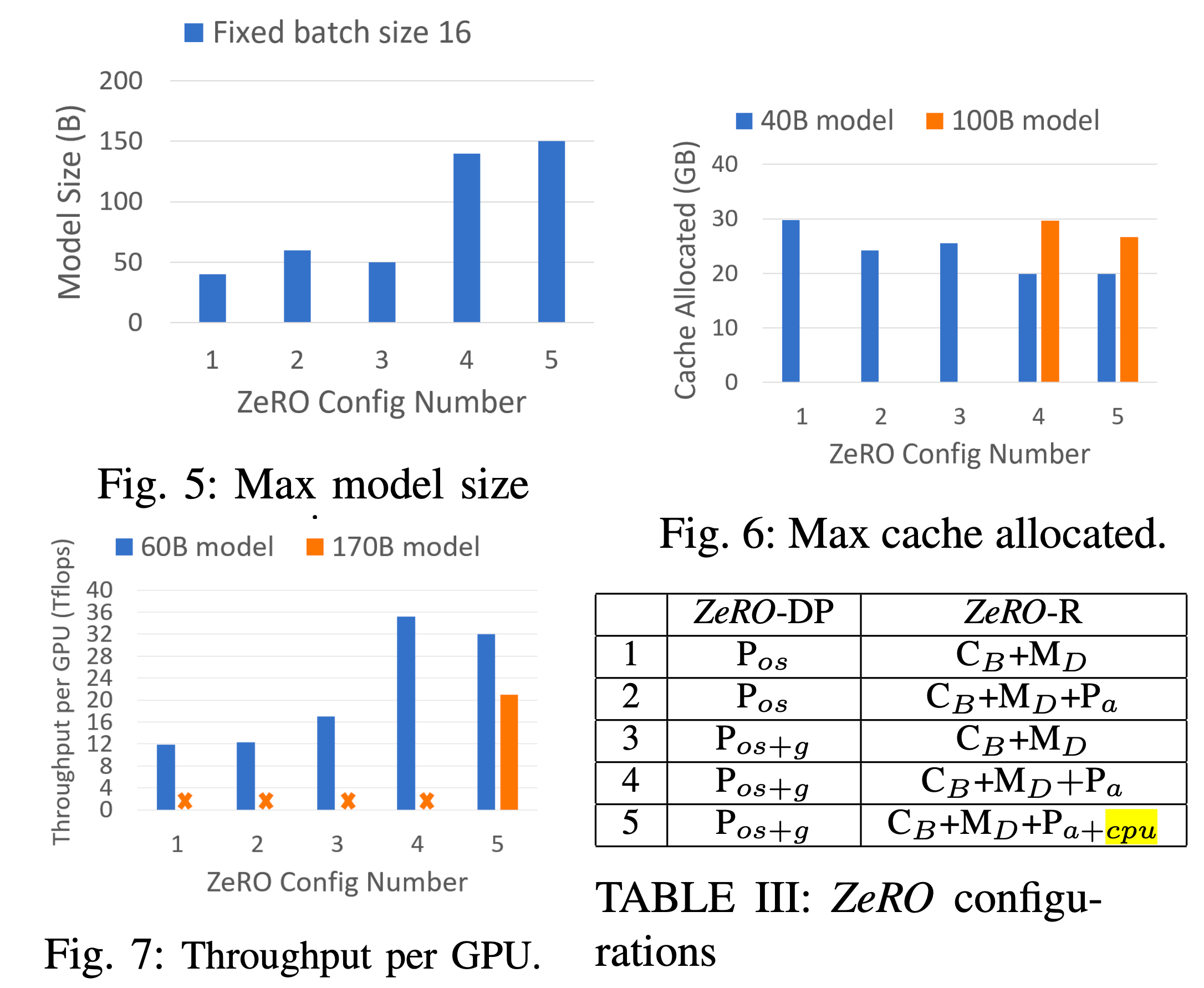 Fig.
Fig.
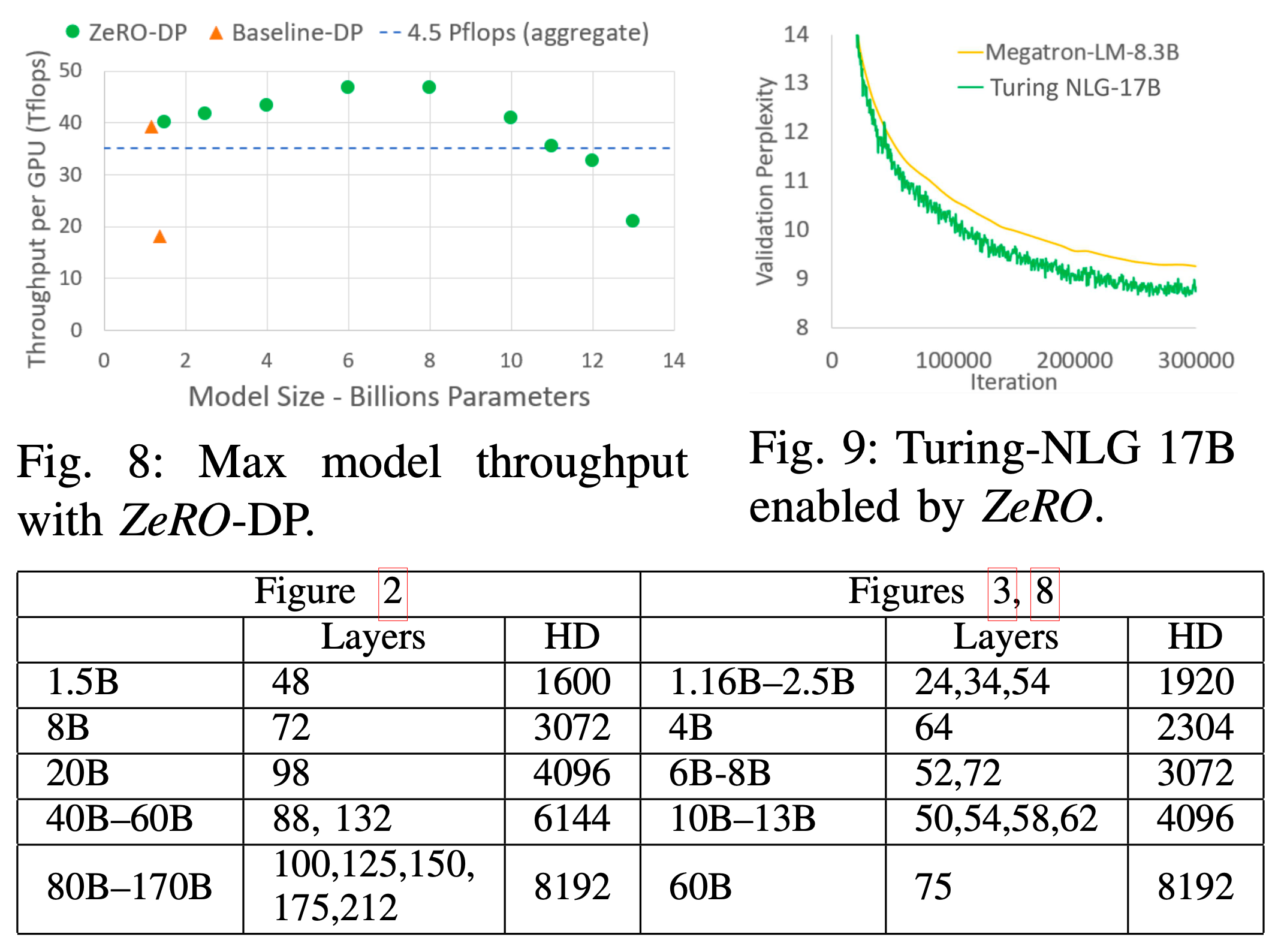 Fig.
Fig.
Throughputs
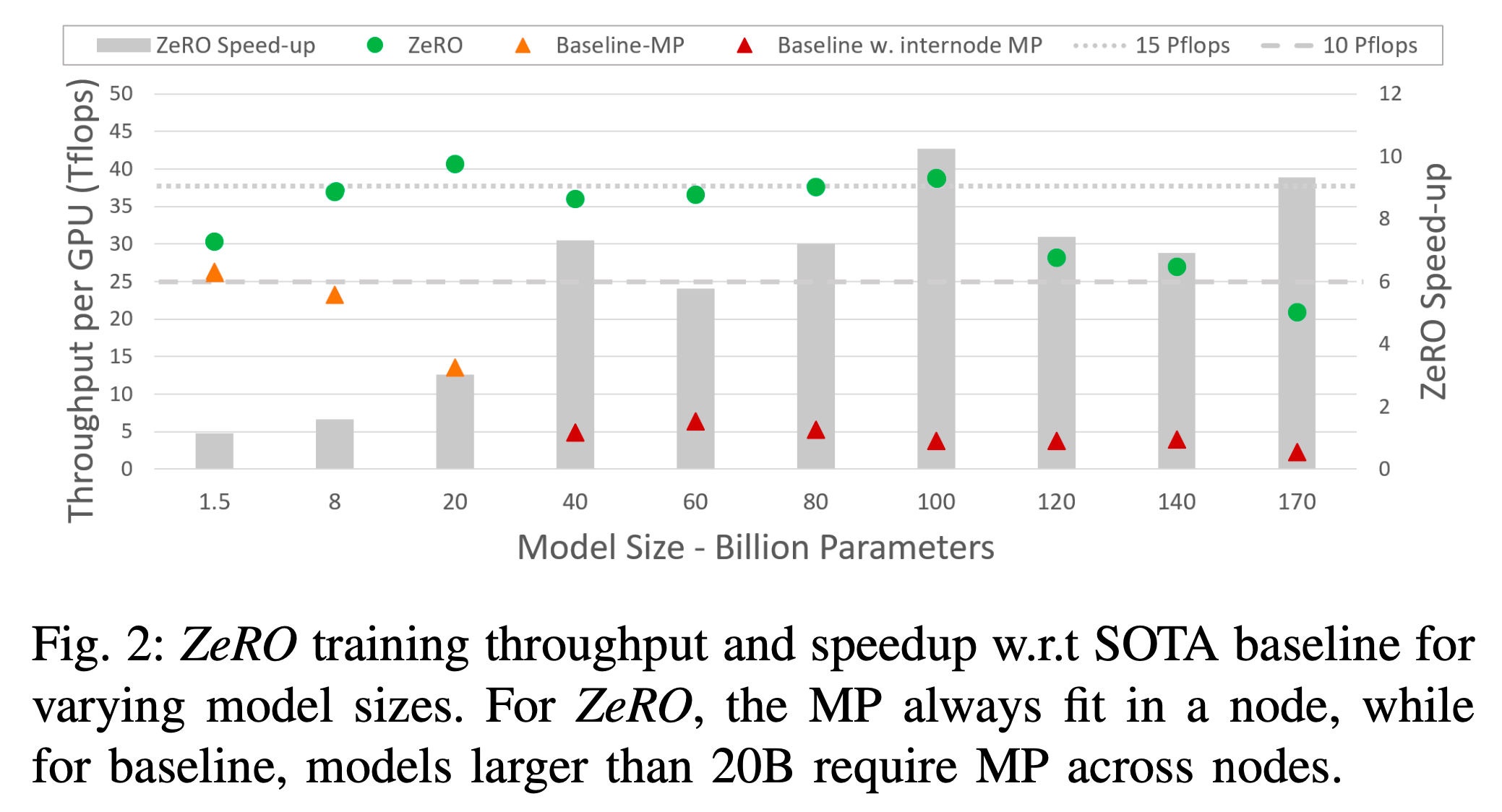 Fig.
Fig.
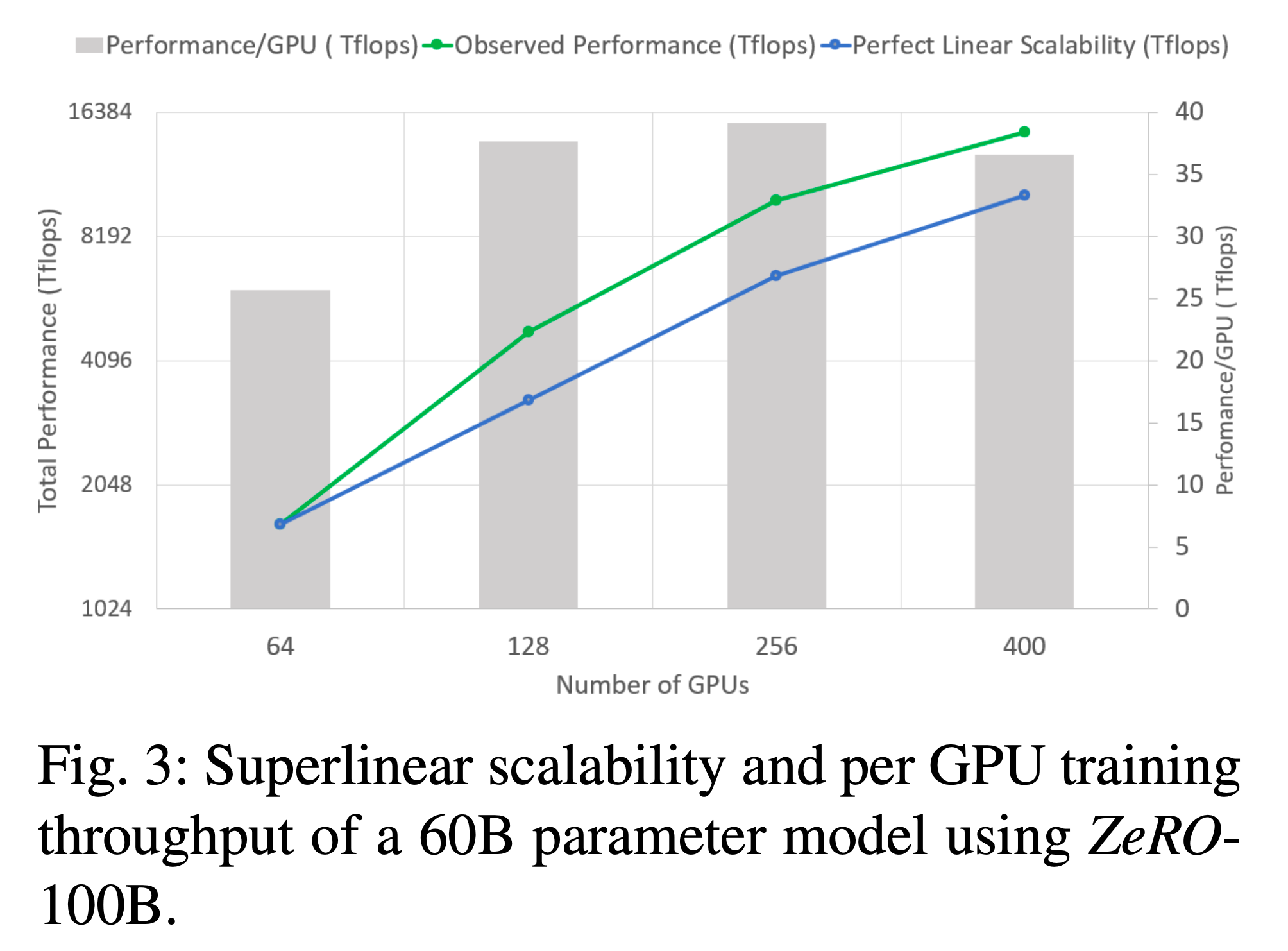 Fig.
Fig.
Communication Analysis of ZeRO-DP
Comparison with MP
앞서 MP는 모델이 너무 큰 나머지 한 device에 올릴 수 없기에 여러 device에 나눠담는 방식이라고 설명드렸습니다.
Communication Analysis of ZeRO-R
Summry of ZeRO and Advanced ZeROs
지금까지의 progress를 요약드리겠습니다.
- (D)DP: Batch size를 키우기 위해 data를 여러 gpu device에 분산해서 처리하고 gradient를 합쳐서 update 했음
- weakness: device마다 똑같은 size의 model과 optimizer state등이 GPU memory 를 잡아먹어서 효율이 좋지 못했다.
- (2020) ZeRO-DP: DP를 하는 데 gradient나 optimizer state등을 각 device에 sharding (partitioning) 해서 관리하도록 한다. 심한 경우 model aprameter까지 MP를 하듯 각 device에 sharding 한다.
- weakness: (stage-3 시) forward, backward 할 때 통신 문제가 발생한다. (stage 1,2 대비 1.5배 정도 느려지지만 더 많은 batch를 쓸 수 있다.)
이제 여기에 advanced ZeRO를 추가로 소개시켜드리려고 합니다. DeepSpeed Team은 지속적으로 ZeRO를 발전시켜서 커뮤니티에 기여를 했는데 2023년 현재까지 3번 정도 더 개선이 있었습니다.
- (2021) ZeRO-Offload
- (2021) ZeRO-Infinity
- (2023) ZeRO++
아래는 같은 setting에서 각 algorithm을 썼을 때 최대로 올릴 수 있는 model의 크기를 보여주는데요,
이 중 ZeRO-infinity는 말 그대로 무한대에 가까운 model을 올릴 수 있는 셈 인거죠.
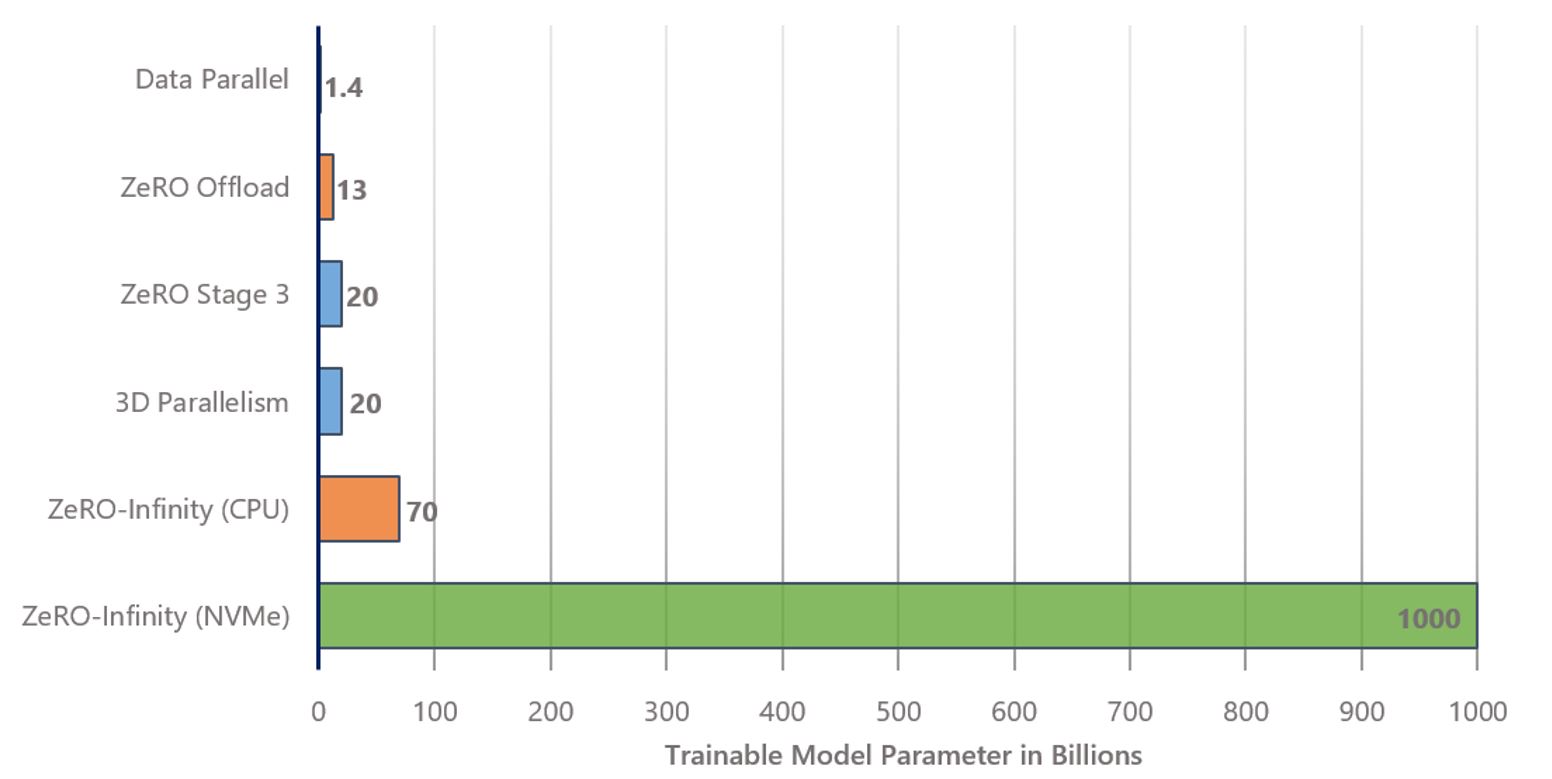 Fig. Comparing the largest model sizes that can be trained on a single NVIDIA DGX-2 node using various parallel DL training technologies. The NVIDIA DGX-2 node consists of 16 V100-32GB GPUs along with 1.5 TB of CPU memory and 20 TB of usable NVMe storage. The blue, orange, and green colors are used to represent technologies that use GPU memory only, GPU with CPU memory, and GPU with both CPU and NVMe memory, respectively. ZeRO-Infinity can in fact run with over a trillion parameters even on a single GPU compared to state of the art, which is 13 billion parameters with ZeRO Offload. Source from link
Fig. Comparing the largest model sizes that can be trained on a single NVIDIA DGX-2 node using various parallel DL training technologies. The NVIDIA DGX-2 node consists of 16 V100-32GB GPUs along with 1.5 TB of CPU memory and 20 TB of usable NVMe storage. The blue, orange, and green colors are used to represent technologies that use GPU memory only, GPU with CPU memory, and GPU with both CPU and NVMe memory, respectively. ZeRO-Infinity can in fact run with over a trillion parameters even on a single GPU compared to state of the art, which is 13 billion parameters with ZeRO Offload. Source from link
이 세 가지의 key idea를 요약하자면 다음과 같습니다.
- ZeRO-Offload: parameter, optimizer, gradient 들 중 원하는 부분을
CPU로 offloading해서 필요할 때만 꺼내 씀. - ZeRO-Infinity: parameter, optimizer, gradient 들 중 원하는 부분을 특정 disk
(NVMe or SSD)로 offloading하고 필요할 때만 꺼내 씀.- NVMe를 써야만 빠르게 쓸 수 있음
- ZeRO++: CPU offloading이나 ZeRO를 쓸 때 여러 tensor들을 통신하게 될텐데, 이를 quantization 해서 더 빠르게 함.
앞서 ZeRO는 아래와 같았습니다.
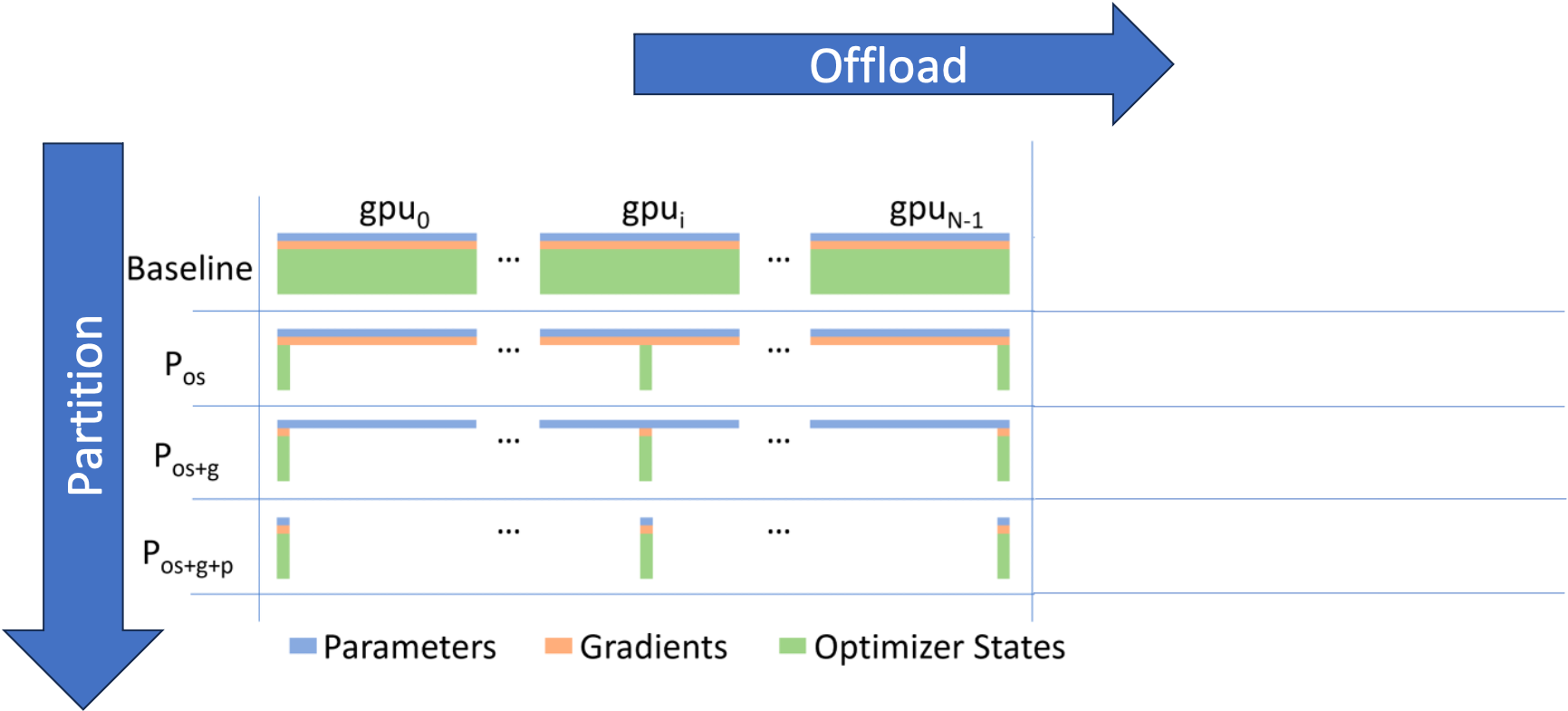 Fig. ZeRO-DP Stage-1,2,3
Fig. ZeRO-DP Stage-1,2,3
ZeRO-Offload는 간단히 말해서 optimizer state를 CPU로 옮긴 것으로 생각할 수 있습니다. 그리고 CPU Adam을 통해서 parameter를 update합니다.
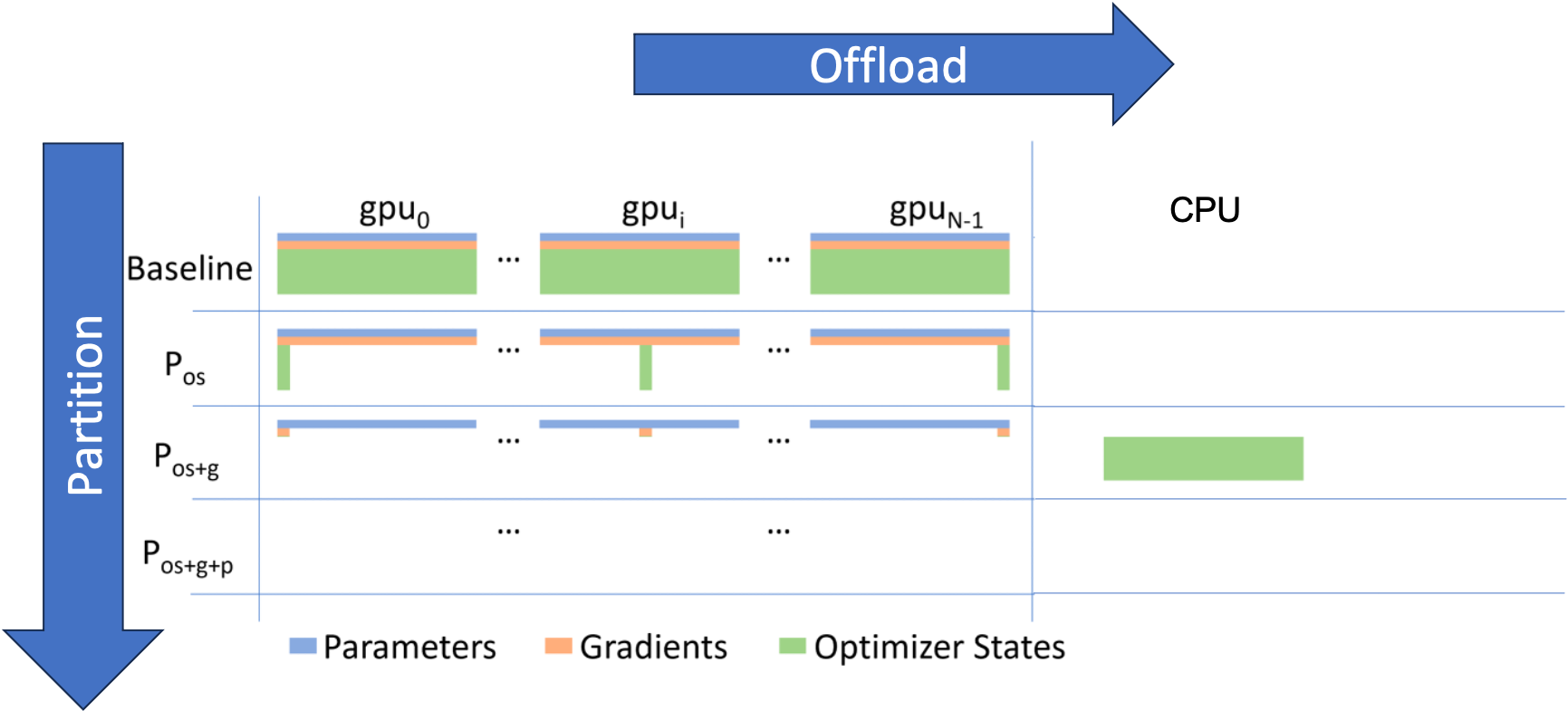 Fig. ZeRO-Offload
Fig. ZeRO-Offload
ZeRO-Infinity는 아예 GPU memory에는 아무것도 올리지 않고 NVMe disk에서 관리를 하면서 forward연산 등은 GPU로 올려서 계산하고 다시 지우고를 반복하는데,
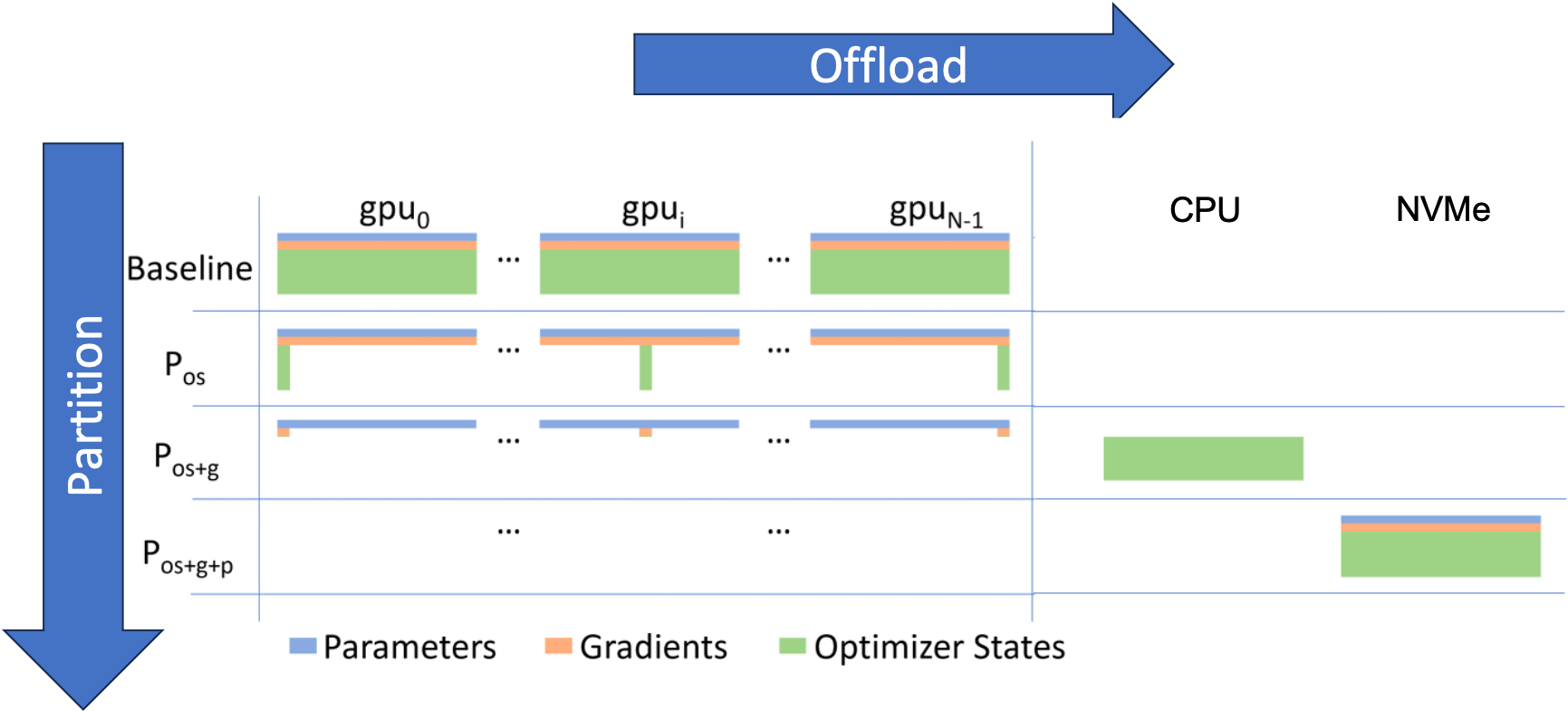 Fig. ZeRO-Infinity
Fig. ZeRO-Infinity
여기서 Nvidia DGX의 GPU, CPU와 NVMe의 capacity 차이를 보시면 NVMe disk의 용량이 훨씬 크기 때문에 ZeRO-Infinity가 일반적인 Offloading보다 훨씬 더 큰 단위의 model을 (B 단위를 넘어 Trillion (T)단위) 학습할 수 있게 된 것이죠.
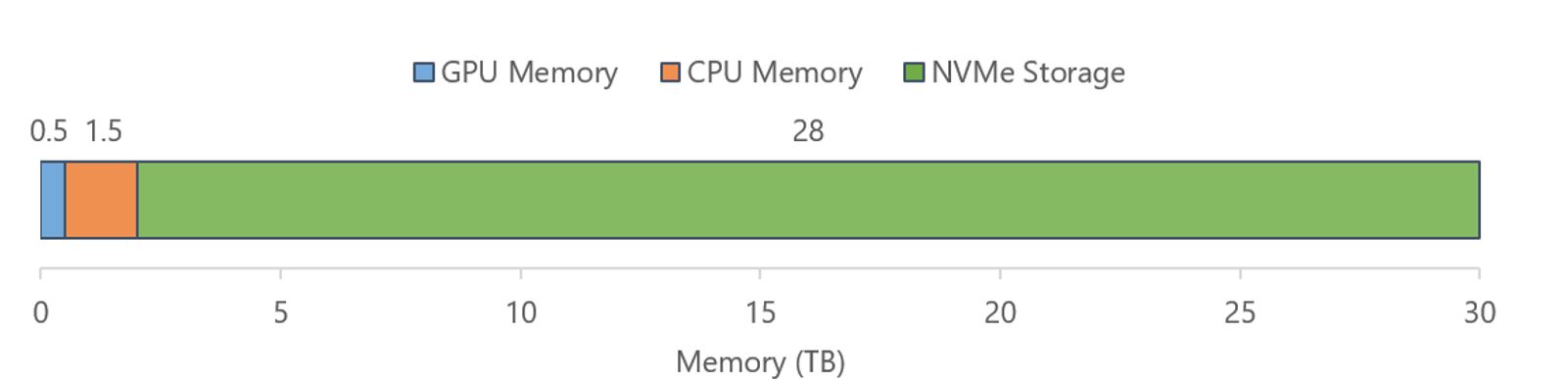 Fig. DGX의 memory
Fig. DGX의 memory
ZeRO-Offload
ZeRO-Offload는 앞서 설명드린 offloading의 확장판입니다. GPU는 한 대당 수십 GB가 한계이지만 CPU는 수백 GB이기 때문에 그 한계치를 더 늘릴 수 있습니다.
 Fig.
Fig.
ZeRO-Offload는 Paper에서 ZeRO-2 위에서 구현된 것으로 보입니다. 따라서 아래의 세 가지를 주로 비교합니다.
- Megatron (TP)
- ZeRO-2
- ZeRO-2 Offload
먼저 Single GPU에서의 ZeRO Offload를 통해 어떻게 algorithm이 돌아가는지 살펴봅시다.
Single GPU Schedule
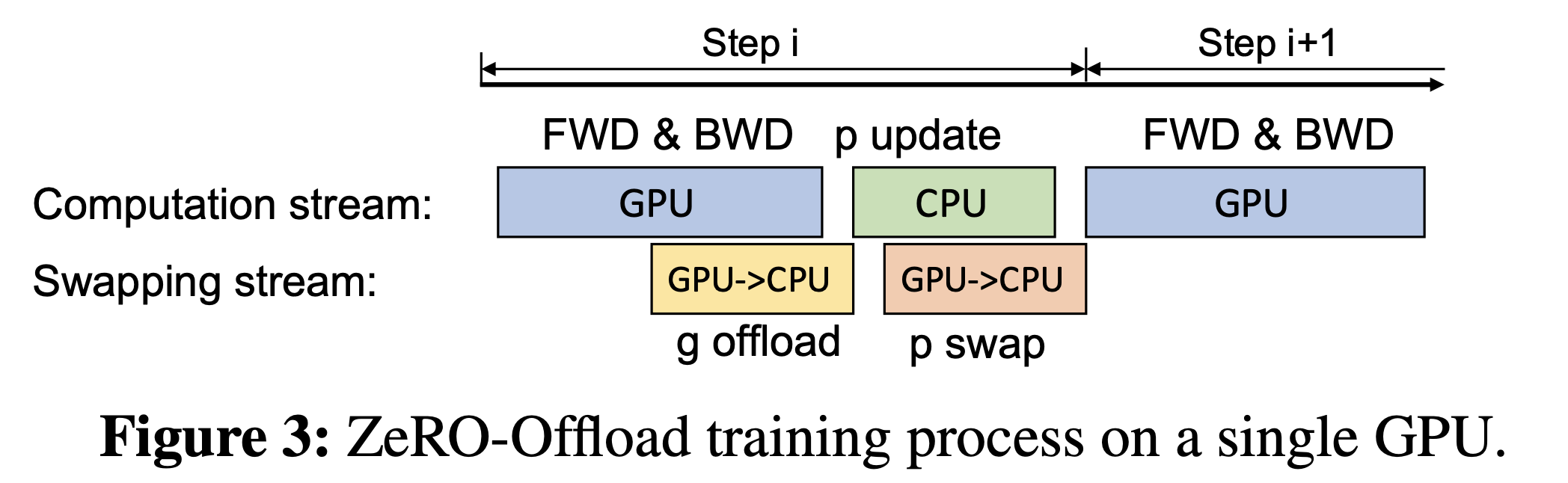 Fig.
Fig.
일단 ZeRO-2니까 gradient와 optimizer state는 device별로 partitioning 된다고 보는 것이고, model parameter는 각 device별로 중복되게 올라가는 setting입니다. 두 가지 stream이 있고 이를 왔다갔다 하면서 결국 gradient를 계산하고 parameter를 update하는 게 목적입니다. 전체적인 과정은 다음과 같습니다.
- (Blue) Forward computation으로 activation을 뽑습니다. (당연히 checkpoint 하면서)
- (Yellow) Backward를 하면서 gradient가 발생할텐데 발생하는 족족 CPU로 보냅니다.
- (Green) Gradient를 다 받았으면 Optimizer를 통해 parameter를 update하는 연산을 하고 (이 때 CPU에서 momentum, variance와 함께 fp32 param update를 합니다)
- (Orange) update되는대로 GPU로 updated param을 보냅니다. (아마 위 figure에서 오타가 난거같습니다. 연산이 끝났으면 GPU로 보내야지 왜 …)
- (Blue) … 반복
Diagram으로도 표시가 되어있어 눈치채셨겠지만, swap을 할 때 CPU <-> CPU communication이 일어나므로 communication time을 최대한 가려 overhead를 없애기 위해서 backward를 하면서 부지런하게 swap을 진행합니다. 그리고 특이한 점은 CPU에서 parameter update를 한다는 것입니다 (gradient descent). (마찬가지로 communication cost를 줄이기 위해서 update 되는 족족 GPU로 부지런하게 swap해서 덮어씌우는겠죠?)
 Fig.
Fig.
따라서 optimization이 거의 끝날 시점에는 backward에서 했던 것 처럼 미리 GPU로 옮기고 있었기 때문에 따로 CPU <-> GPU 로 옮기는 communication cost가 많이들지 않습니다.
이를 반복하면 Single GPU에서 1step gradient descent를 한 것이 됩니다.
DL Training as a Data-Flow Graph
Forward, backward computation을 하고 mixed precision update 까지 하는 과정을 Data-Flow Graph로 표시하면 다음과 같습니다.
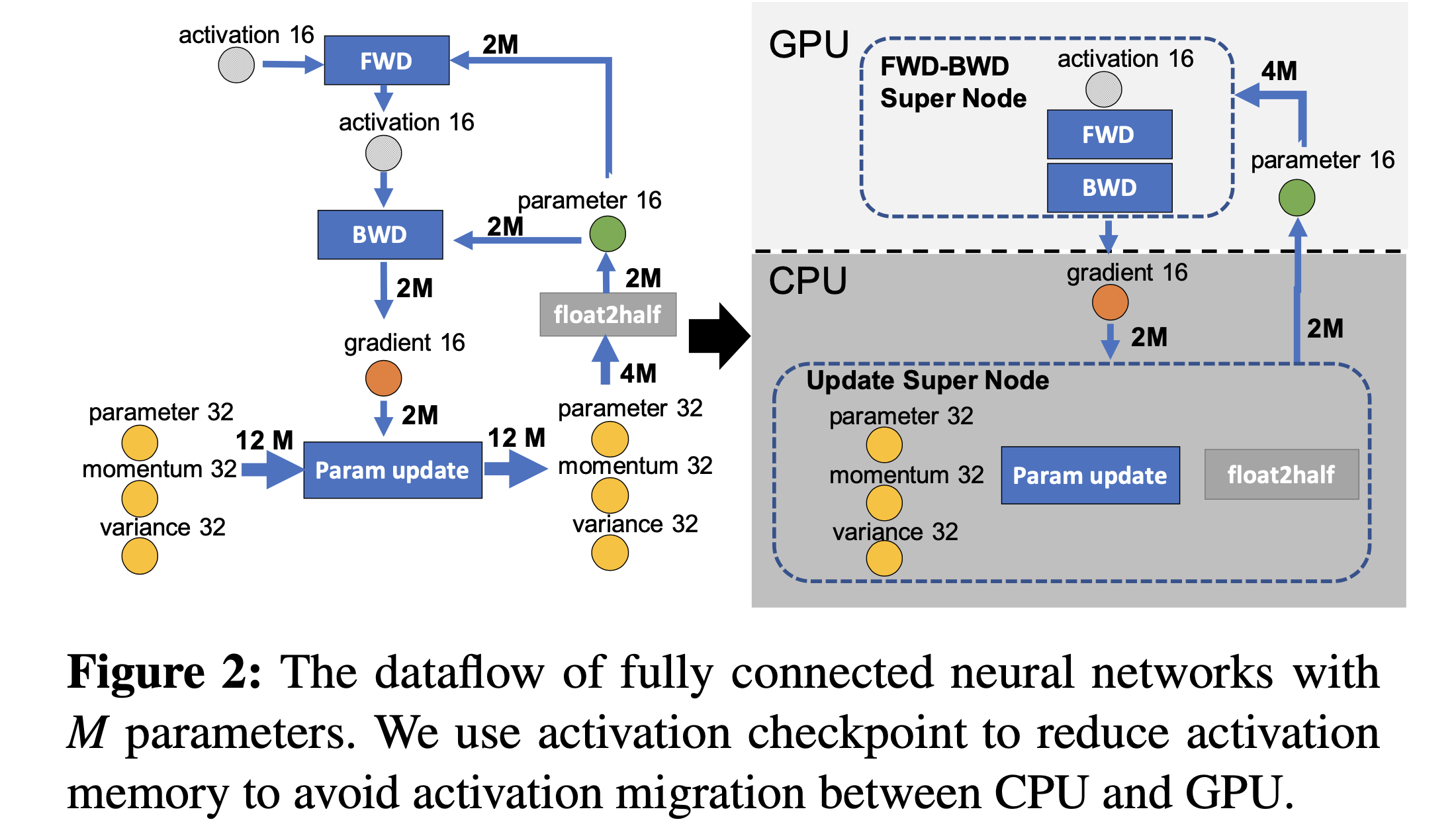 Fig.
Fig.
각 edge들은 communication volume을 나타내는데, 보시면 model param size가 \(M\)일때 \(2M, 4M, \cdots\)씩 communication cost가 든다는 걸 알 수 있습니다. 오른쪽의 ZeRO-Offload를 보면 아래 Update를 하는 부분을 모두 CPU에서 처리함으로써 fp16 gradient를 받고, update한 fp16 parameter를 보내는 딱 두 번의 행위만 communication이 일어나게 함으로써 total communication volume을 \(4M\)으로 줄였다는걸 보실 수 있습니다.
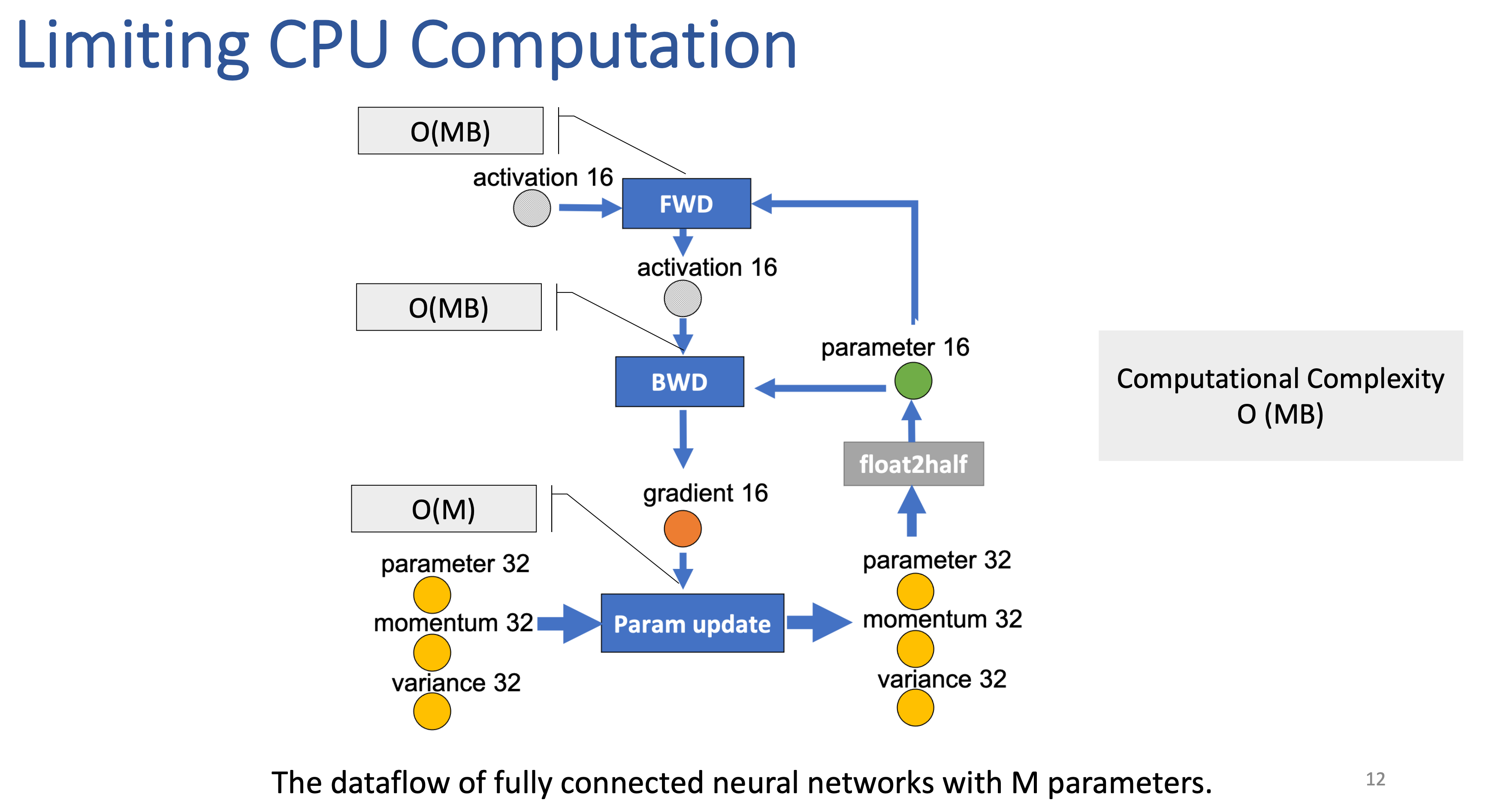 Fig.
Fig.
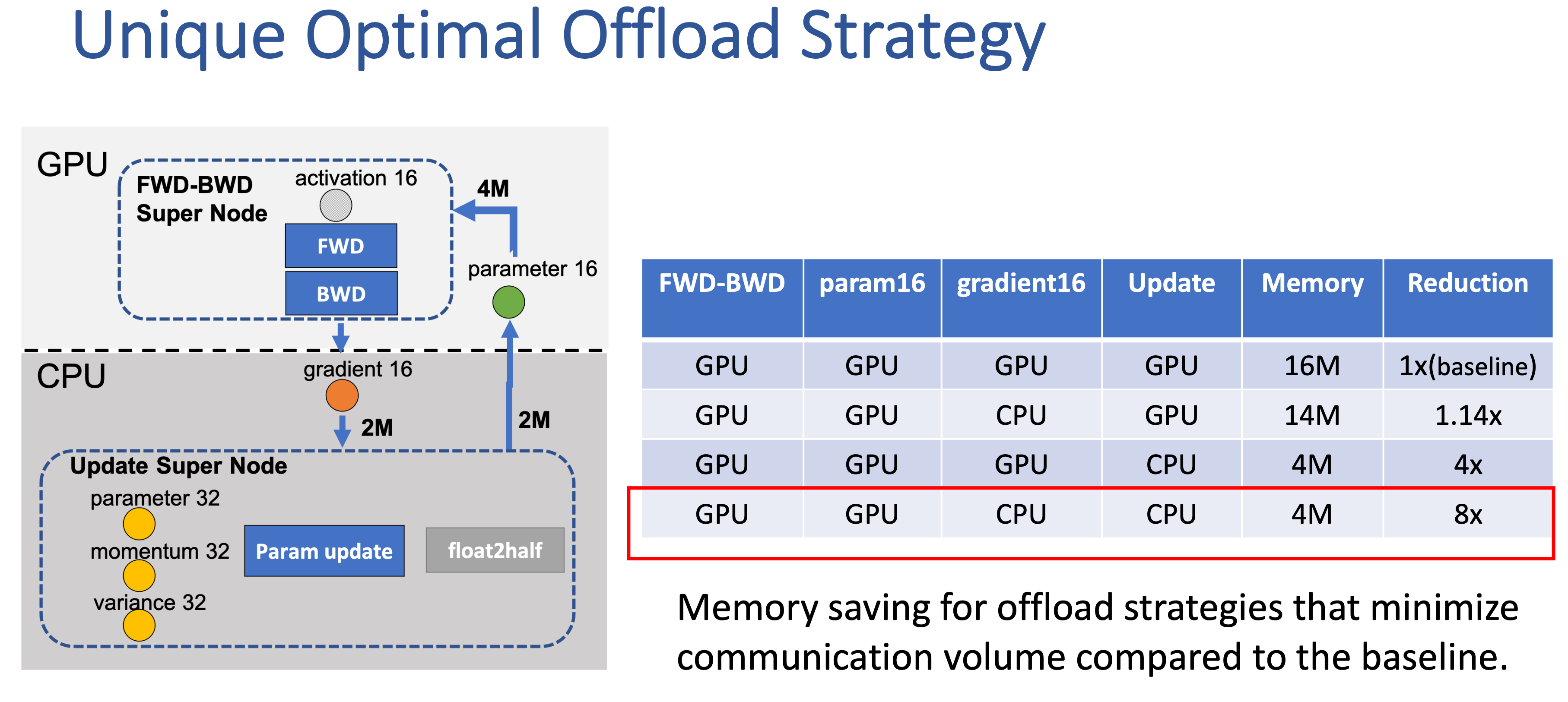 Fig.
Fig.
Scaling to Multi-GPUs
이제 이를 여러 개의 GPU 를 쓰는 상황으로 확장해 봅시다.
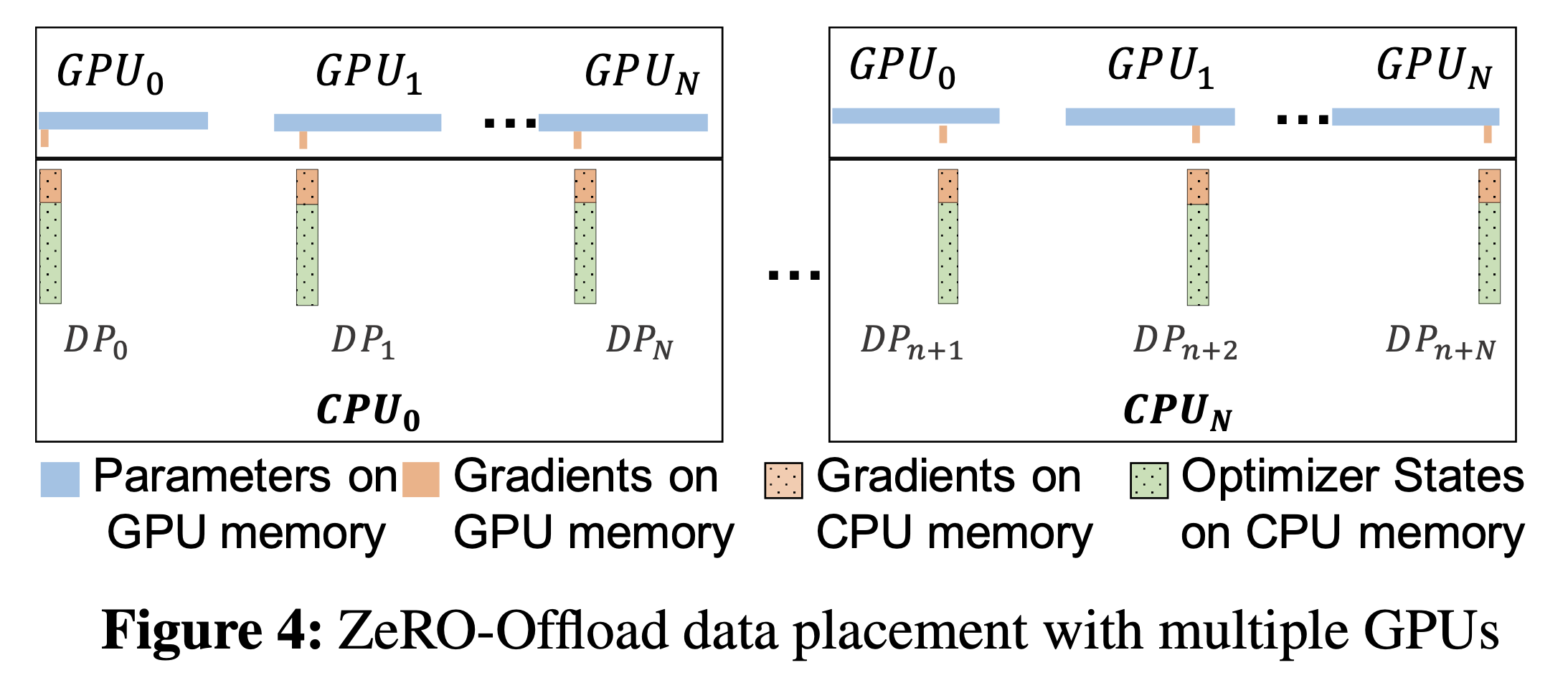 Fig.
Fig.
Delayed Parameter Update (DPU)
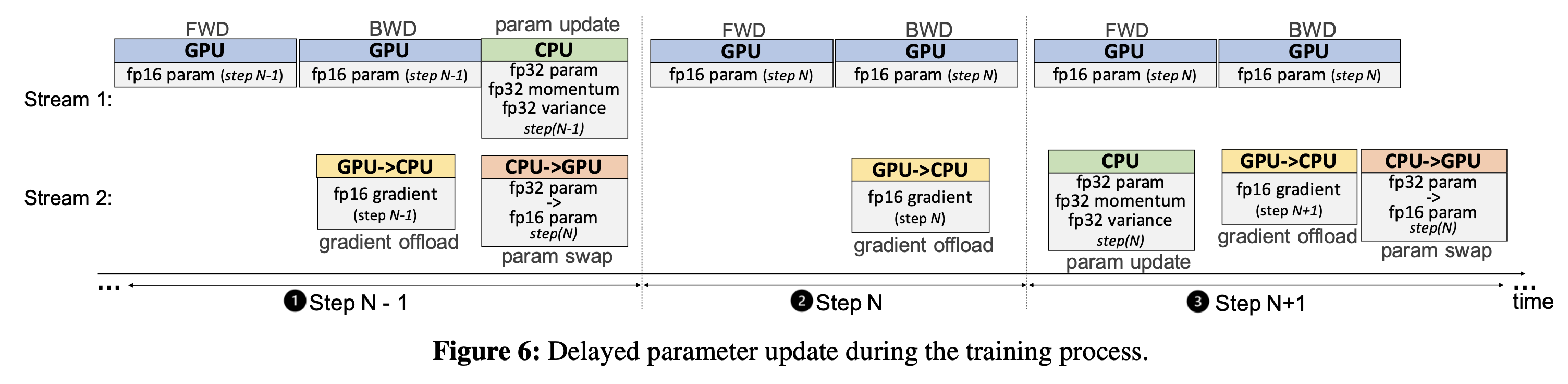 Fig.
Fig.
 Fig.
Fig.
Results
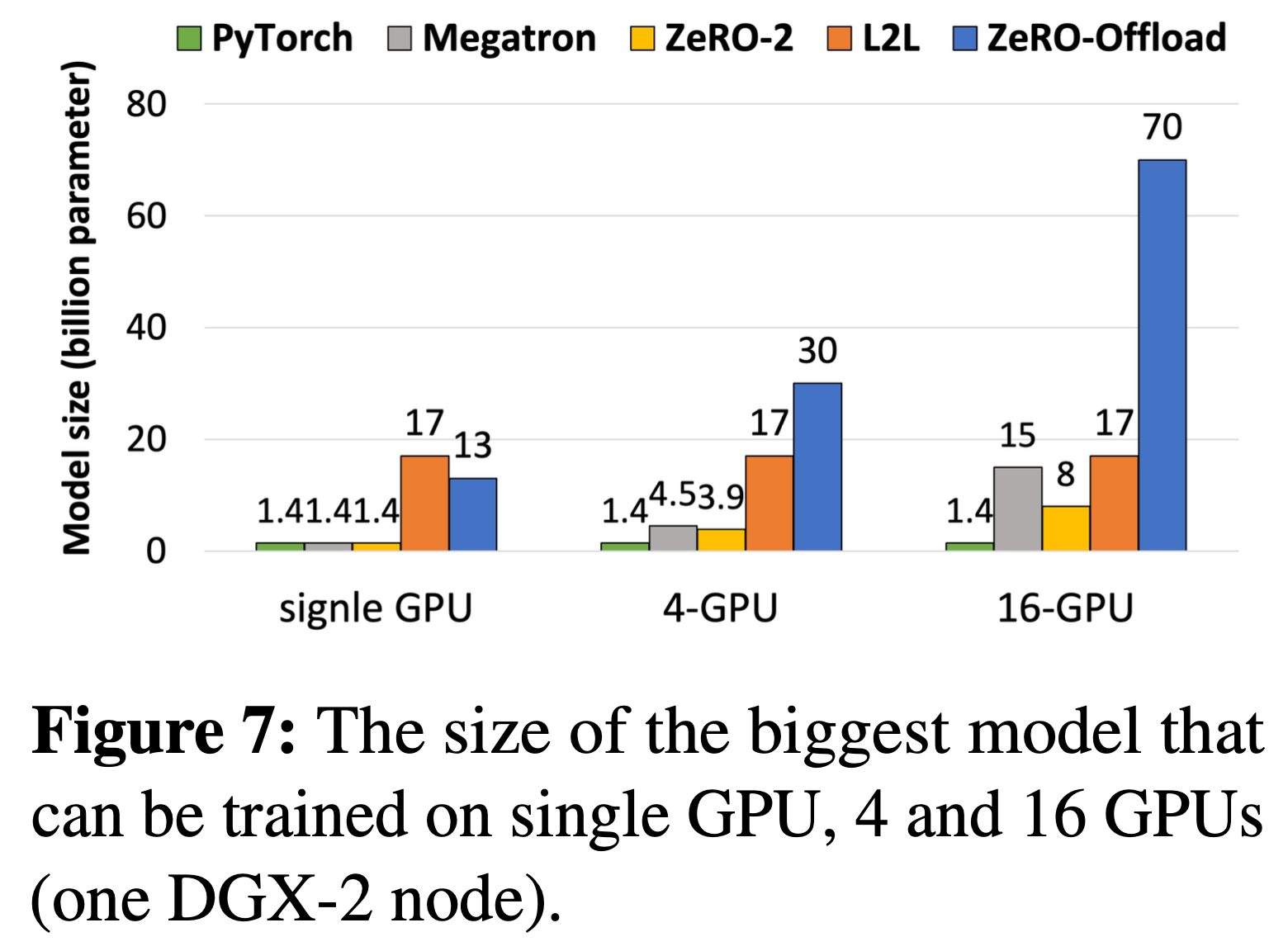 Fig.
Fig.
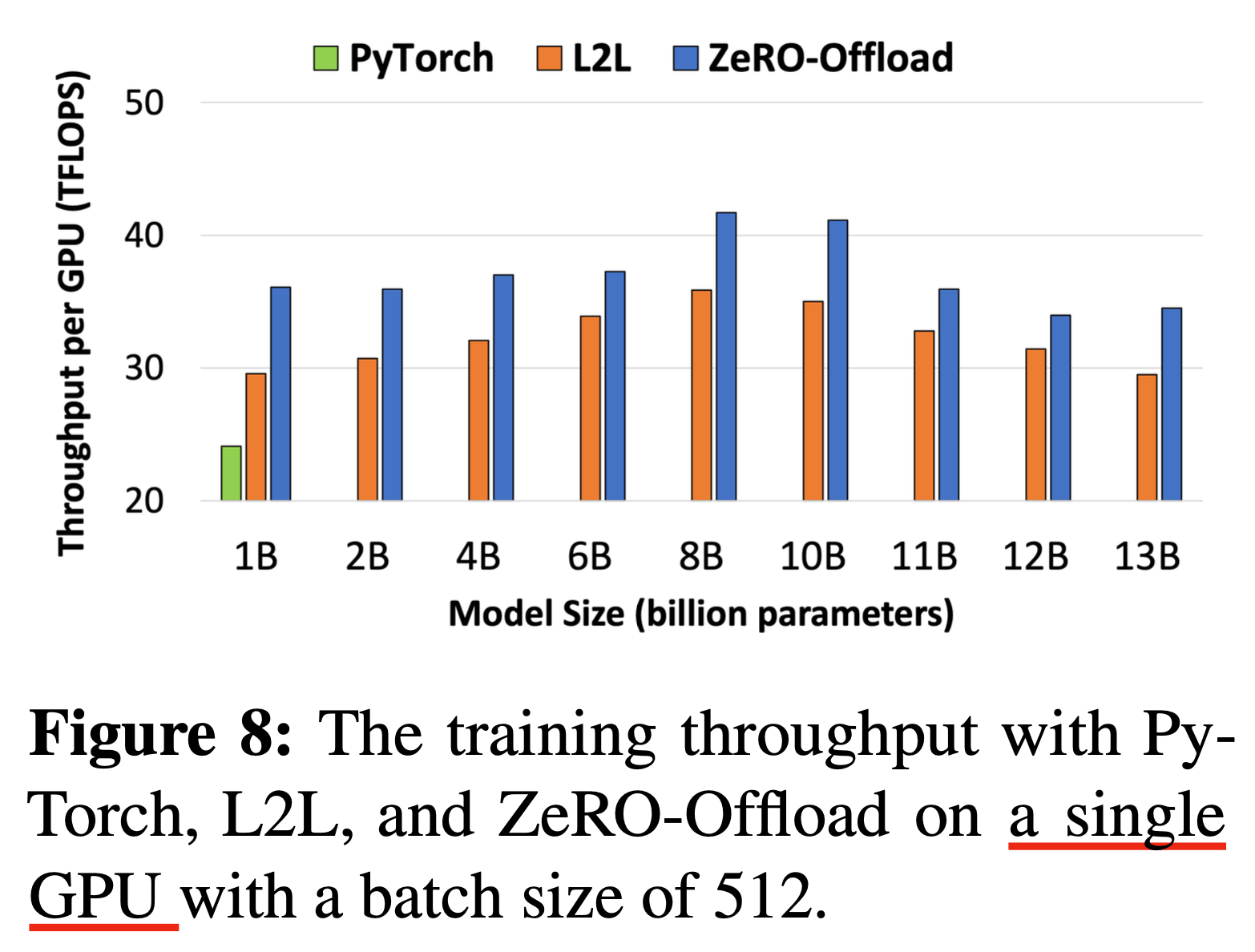 Fig.
Fig.
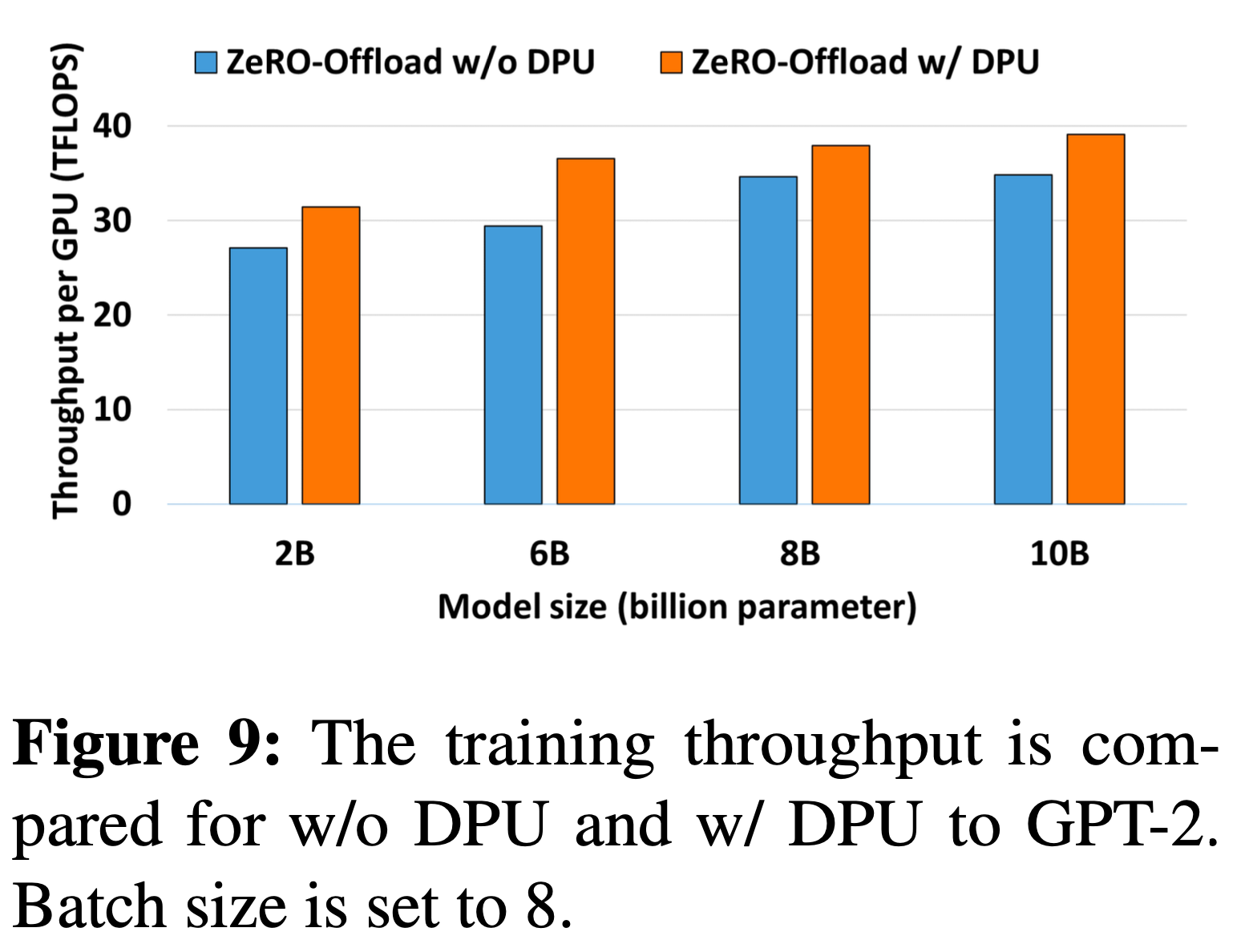 Fig.
Fig.
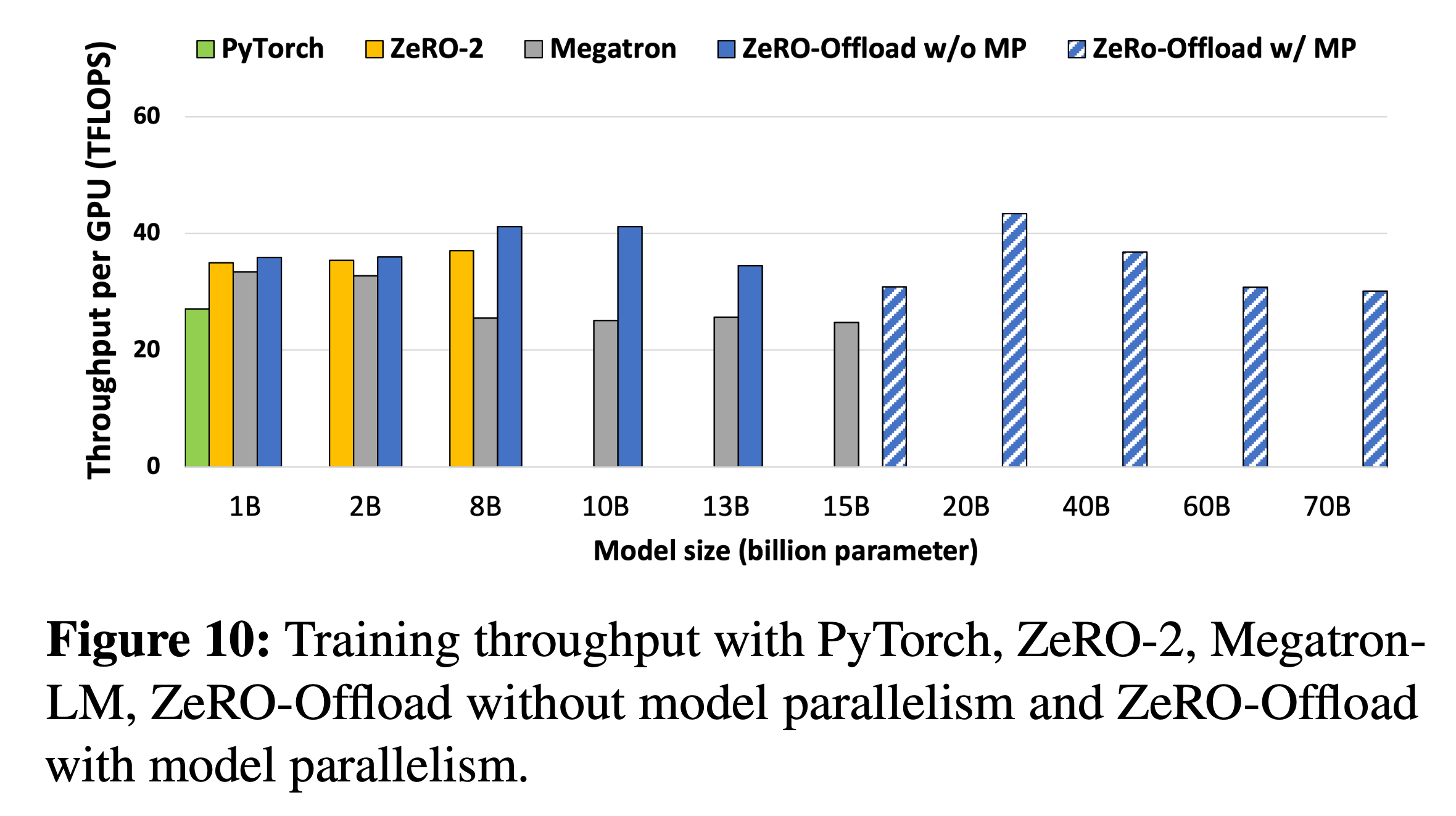 Fig.
Fig.
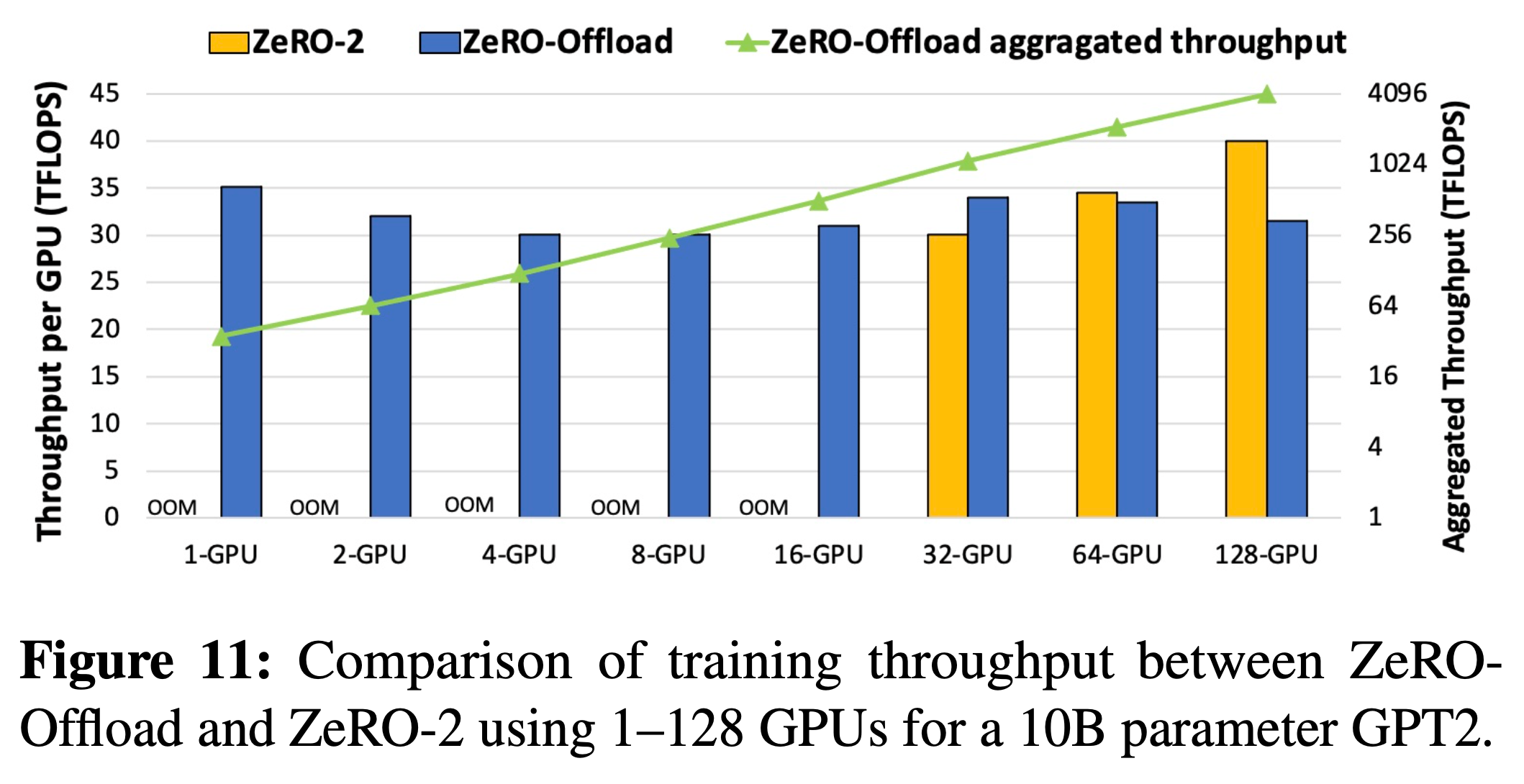 Fig.
Fig.
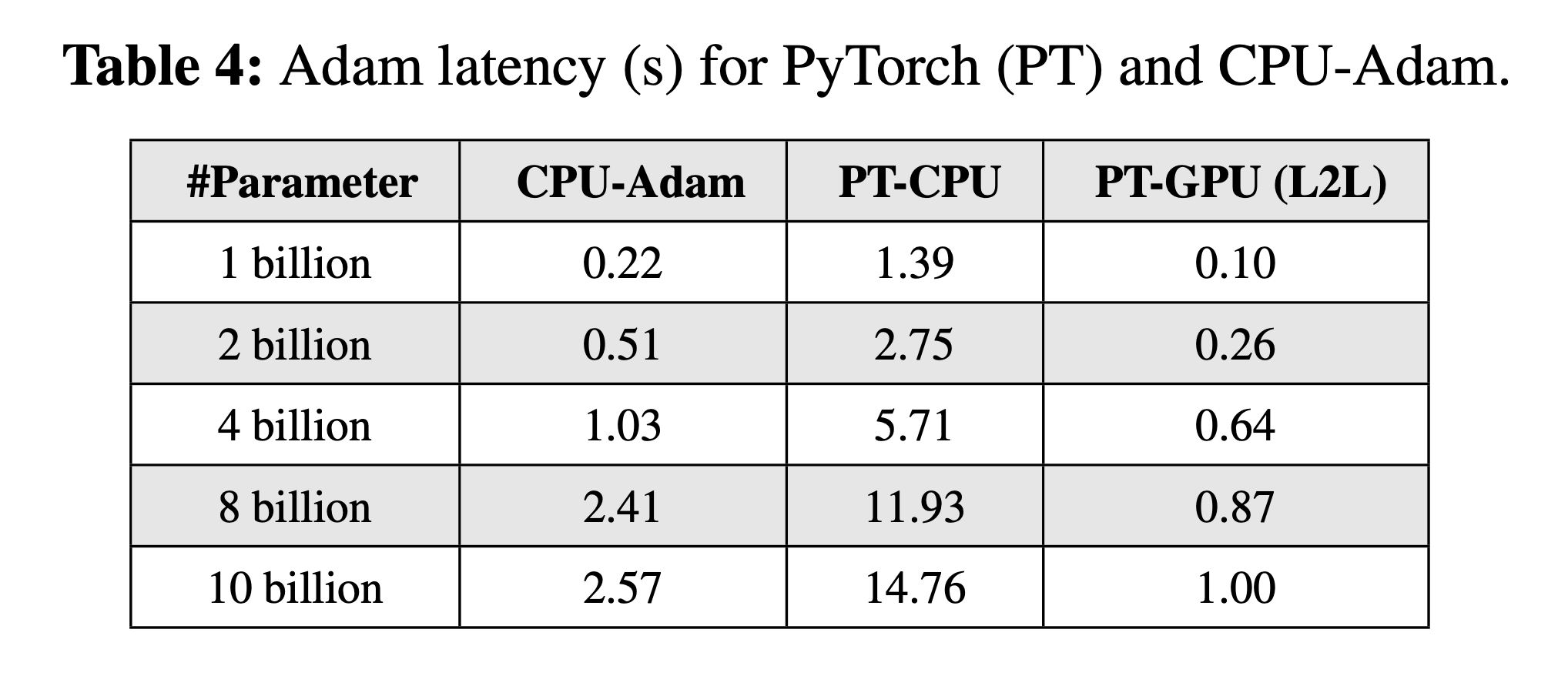 Fig.
Fig.
Offload with ZeRO-3
ZeRO-Offload paper는 ZeRO-2위에서 구동한 실험들만 기재했지만 실제로 CPU offloading은 ZeRO-3 와도 양립합니다.
"zero_optimization": {
"stage": 3,
"offload_param": {
"device": "cpu",
"pin_memory": true
},
"offload_optimizer": {
"device": "cpu",
"pin_memory": true
},
"stage3_gather_16bit_weights_on_model_save": true,
"memory_efficient_linear": true
},
"optimizer": {
"type": "Adam",
"params": {
"lr": "auto",
"betas": "auto",
"eps": "auto",
"weight_decay": "auto"
}
},
Fig. ZeRO-3 CPU Offloading을 위한 configuration 예시
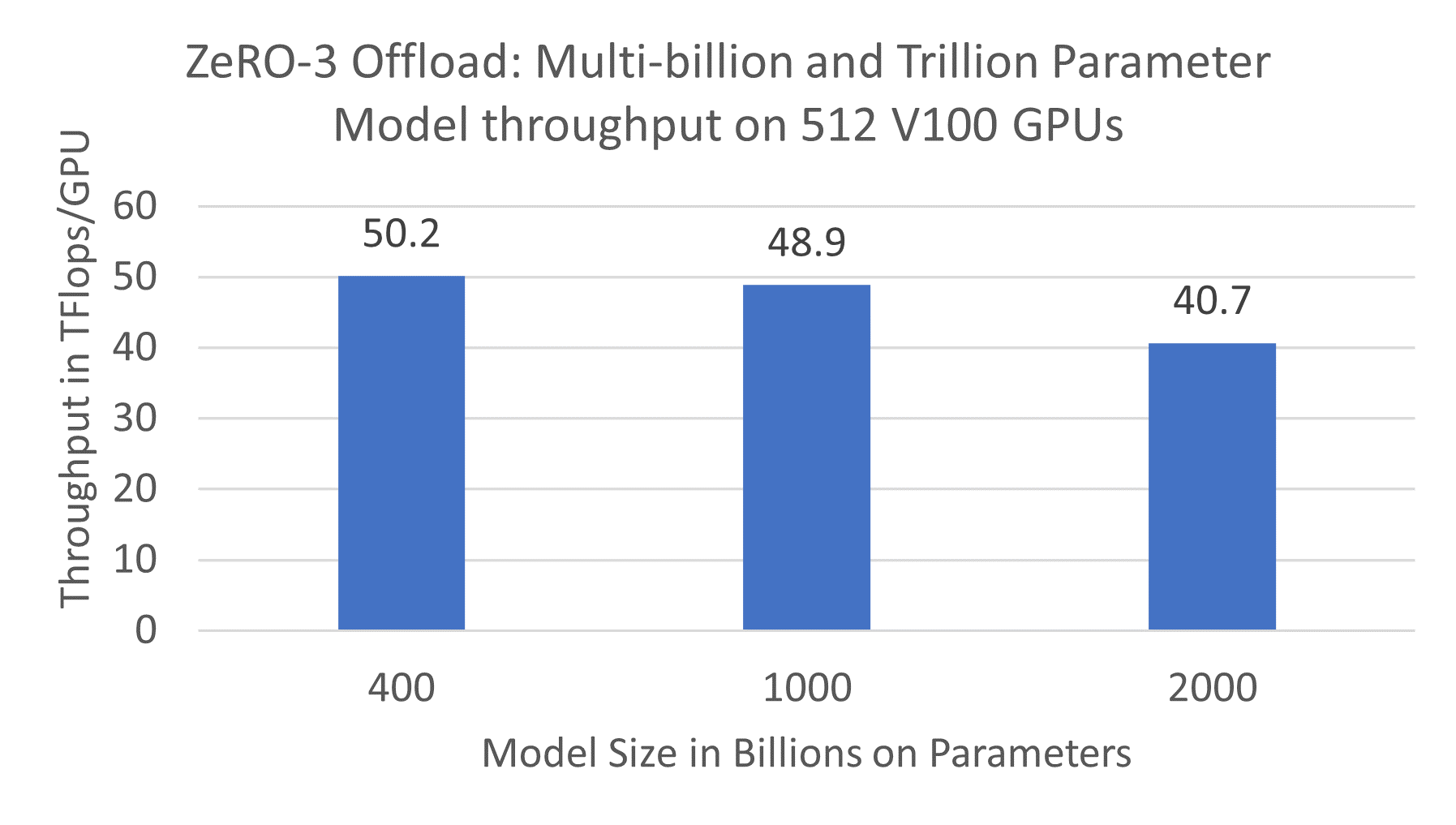 Fig.
Fig.
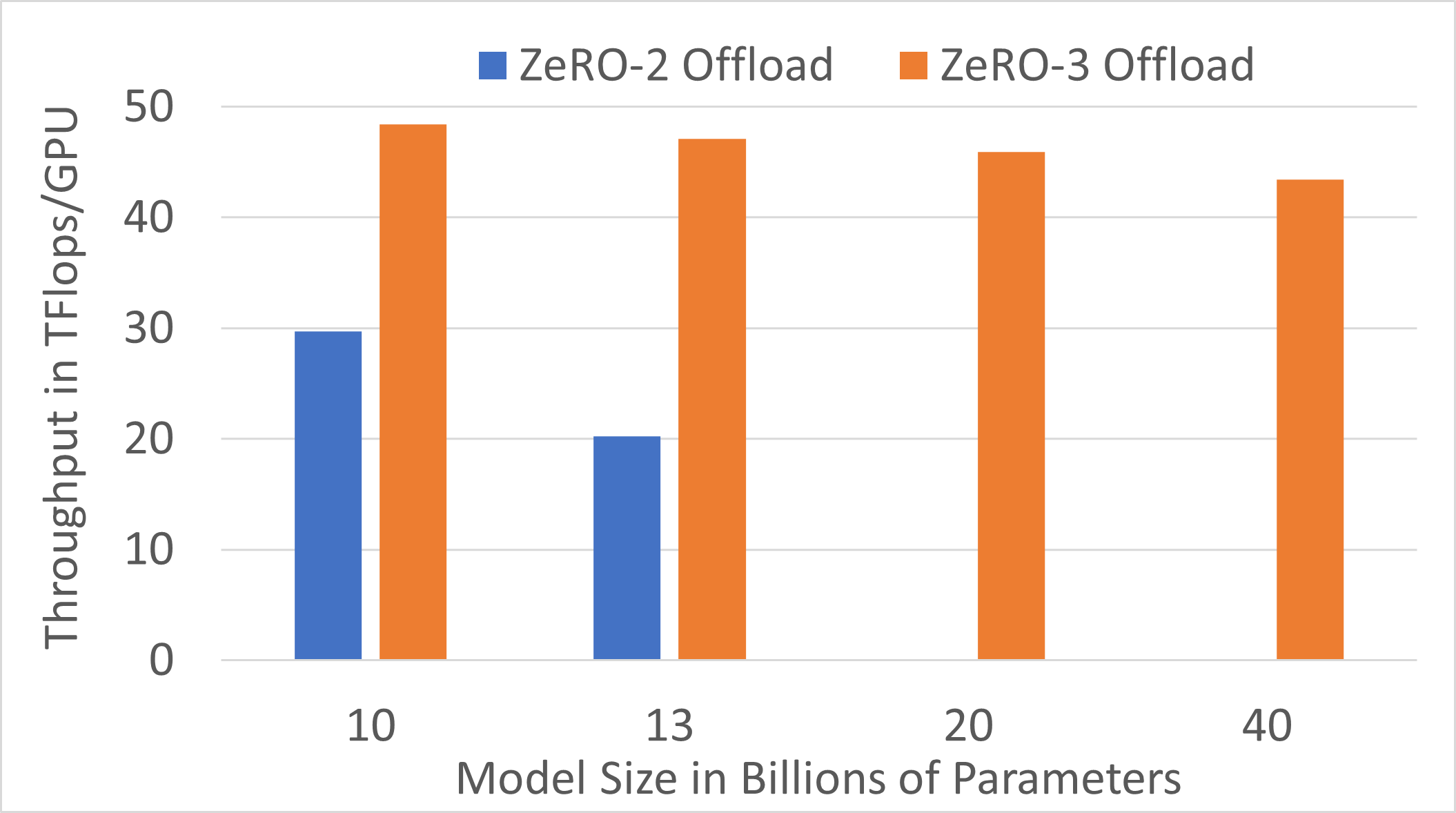 Fig.
Fig.
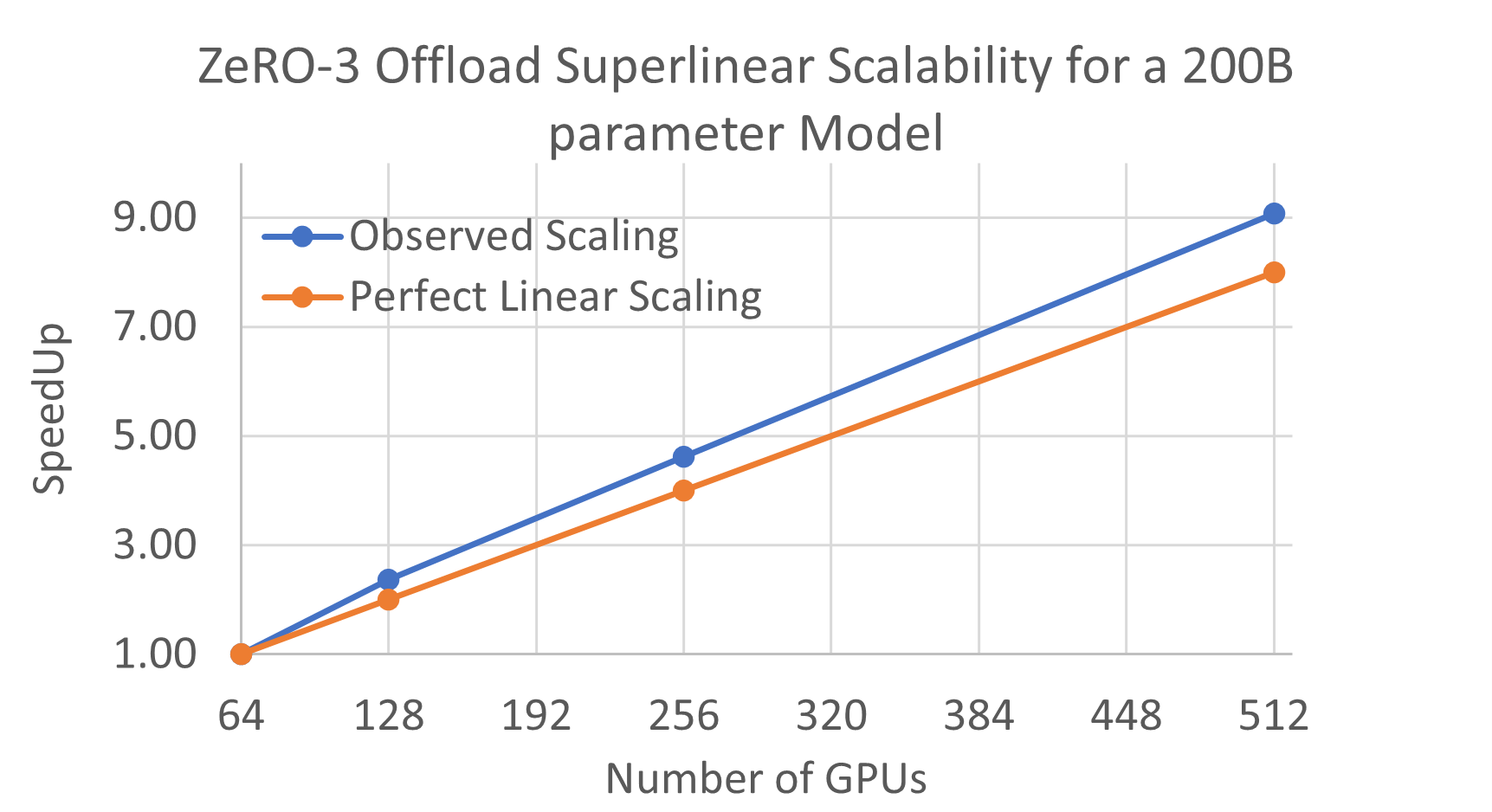 Fig.
Fig.
ZeRO-Infinity
ZeRO-Infinity 를 하면 ZeRO-3 보다 50배 이상 큰 model을 학습할 수 있게 됩니다. 앞서 말씀드린 것 처럼 핵심은 CPU보다도 훨씬 큰 용량의 NVMe disc에 상당수의 tensor를 offloading하는겁니다.
먼저 ZeRO-DP 때와 마찬가지로 animation을 보시겠습니다.
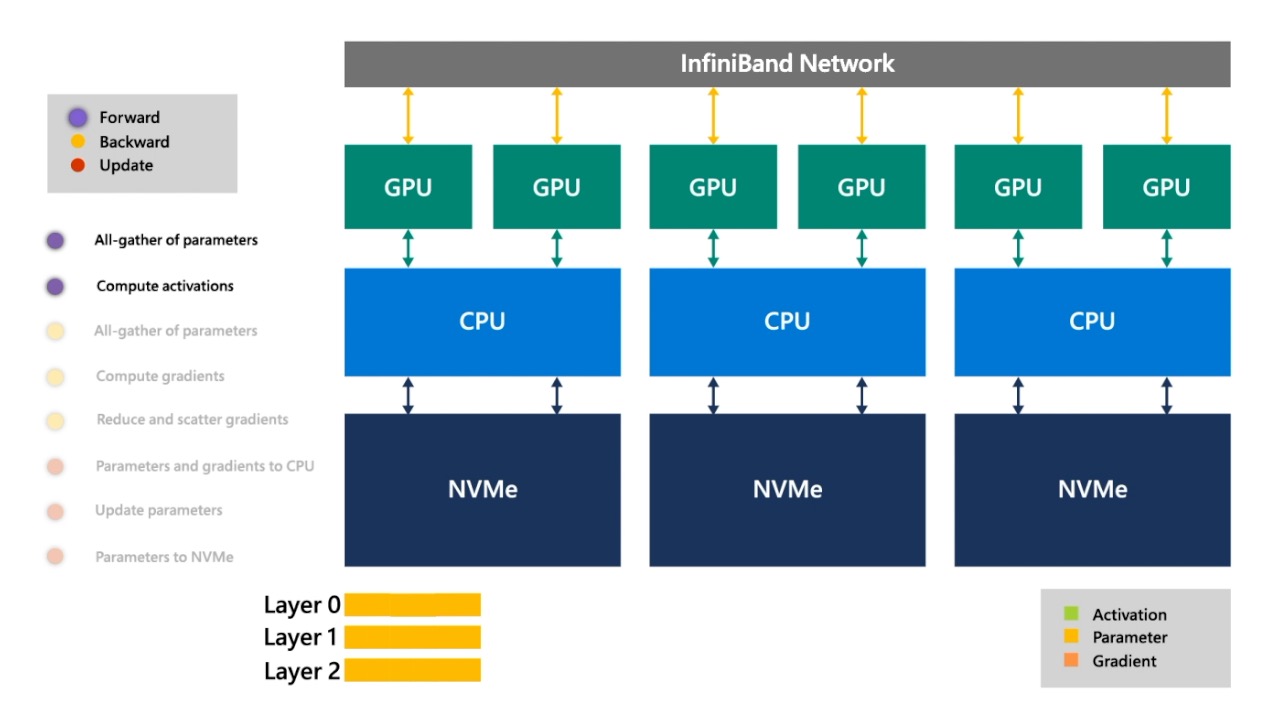 Fig. 어떤 NN의 network가 3개의 layer로 이루어져 있습니다.
Fig. 어떤 NN의 network가 3개의 layer로 이루어져 있습니다.
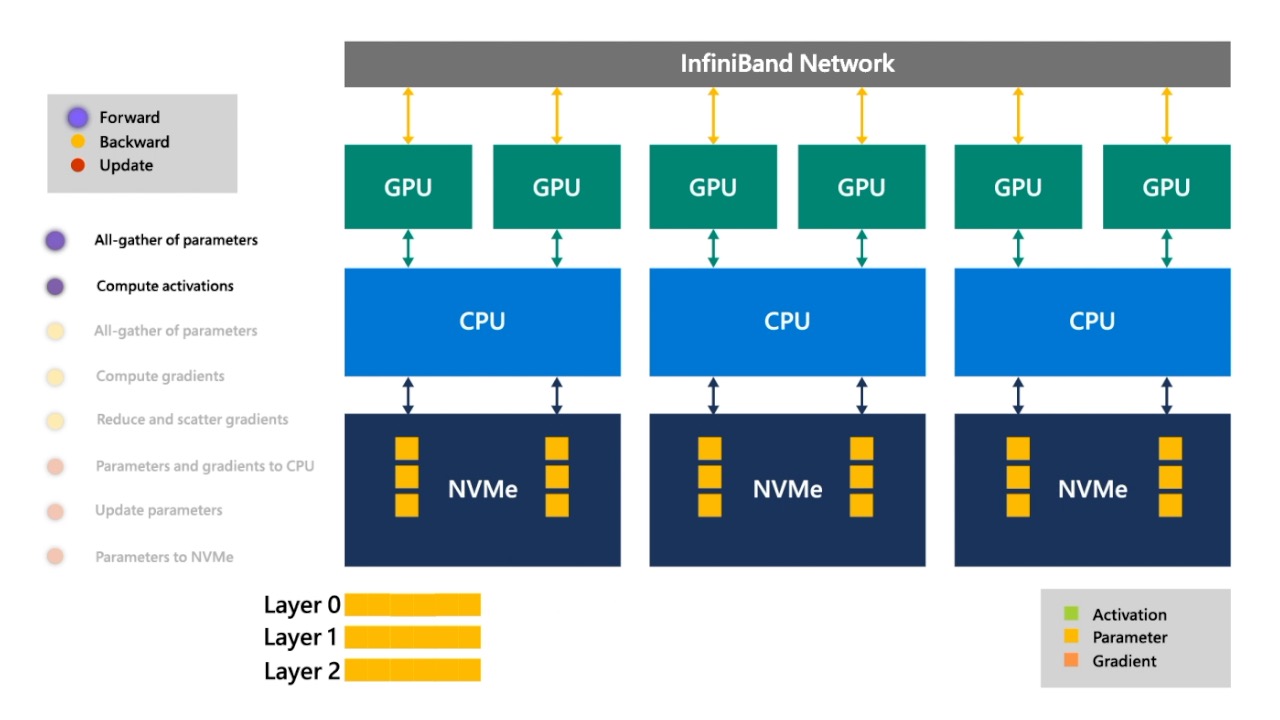 Fig. layer들을 분해해서 각 NVMe disk에 loading합니다.
Fig. layer들을 분해해서 각 NVMe disk에 loading합니다.
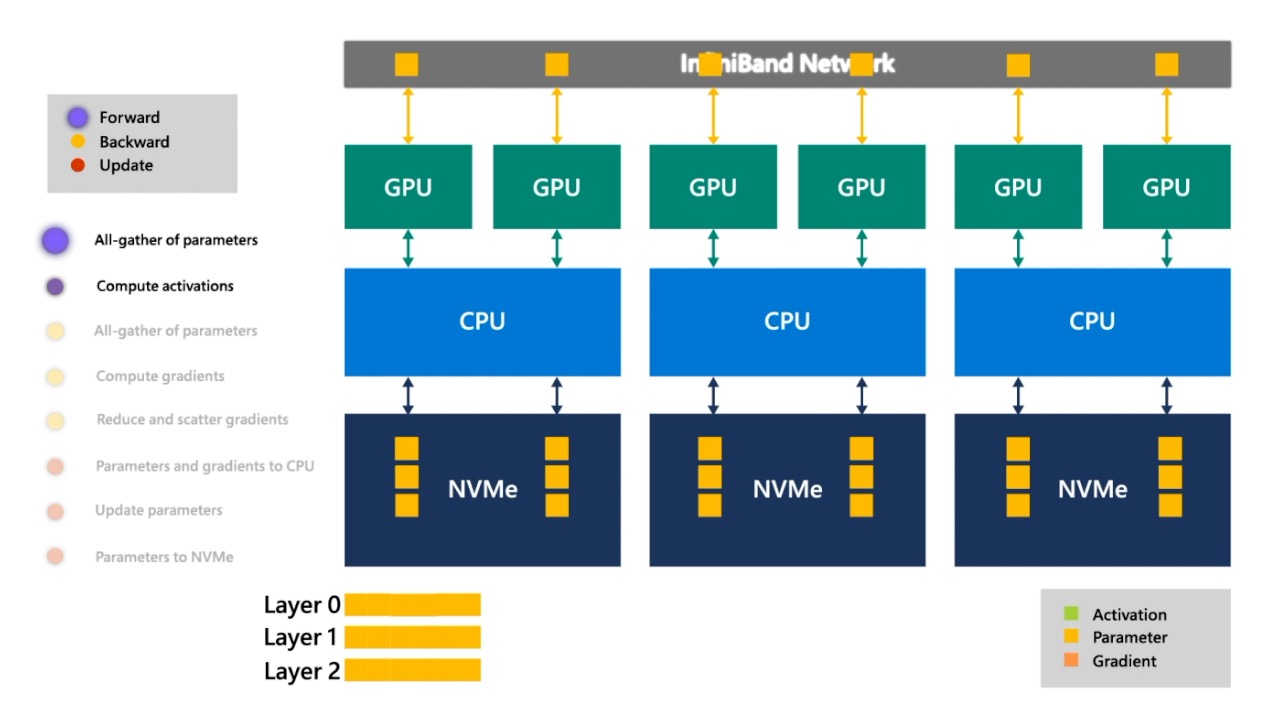 Fig. 맨 먼저 input을 layer 0에 통과시켜 activation을 얻어야 하므로 layer 0의 parameter를 모아서 layer 0을 완성합니다.
Fig. 맨 먼저 input을 layer 0에 통과시켜 activation을 얻어야 하므로 layer 0의 parameter를 모아서 layer 0을 완성합니다.
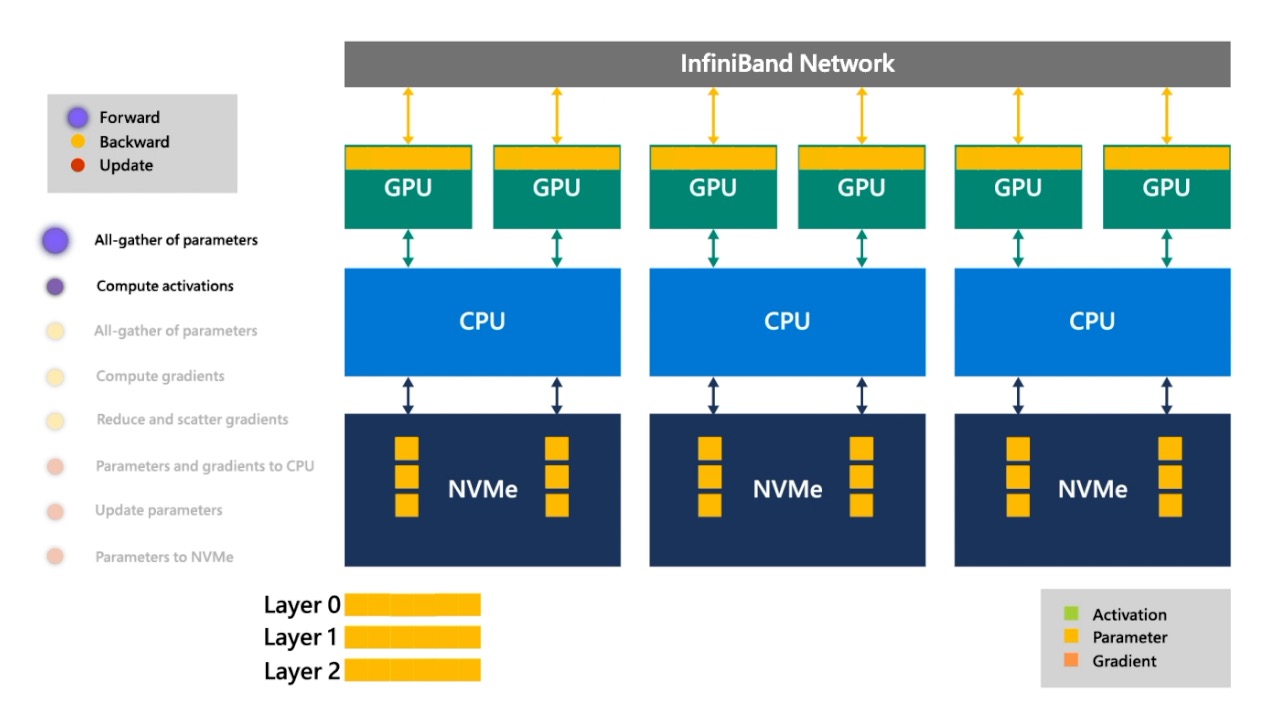 Fig. 이제 각 GPU device에서 각 process마다 서로 다른 data를 layer 0을 통과시켜 activation을 얻습니다.
Fig. 이제 각 GPU device에서 각 process마다 서로 다른 data를 layer 0을 통과시켜 activation을 얻습니다.
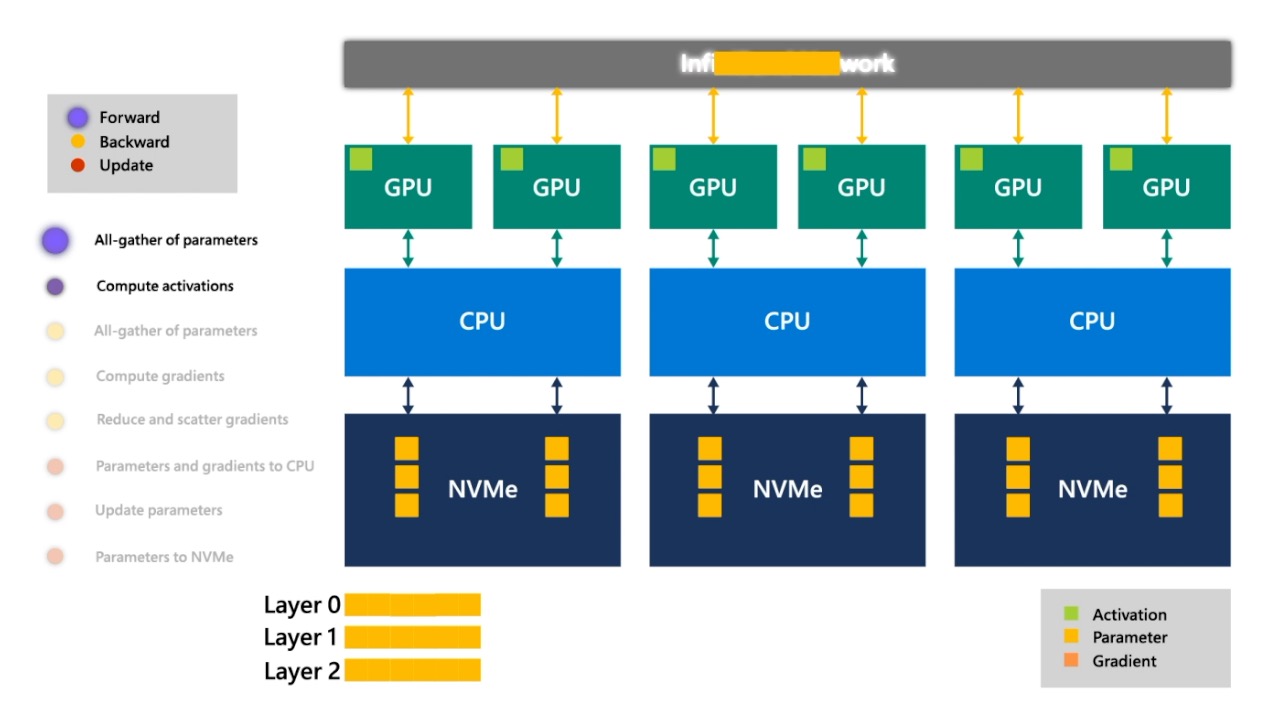 Fig. 얻은 layer 0의 activation은 GPU에 저장해두고 또 layer 1을 조립합니다.
Fig. 얻은 layer 0의 activation은 GPU에 저장해두고 또 layer 1을 조립합니다.
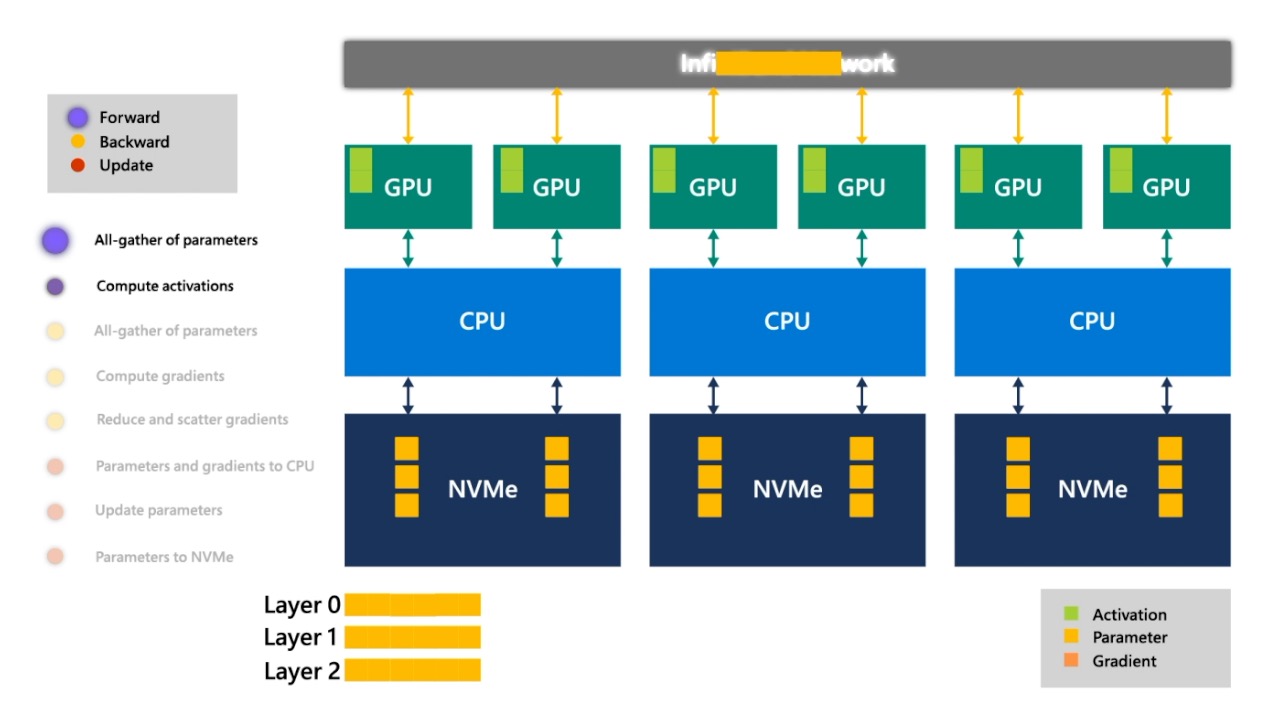 Fig. layer 1의 activation들을 또 각각 저장합니다.
Fig. layer 1의 activation들을 또 각각 저장합니다.
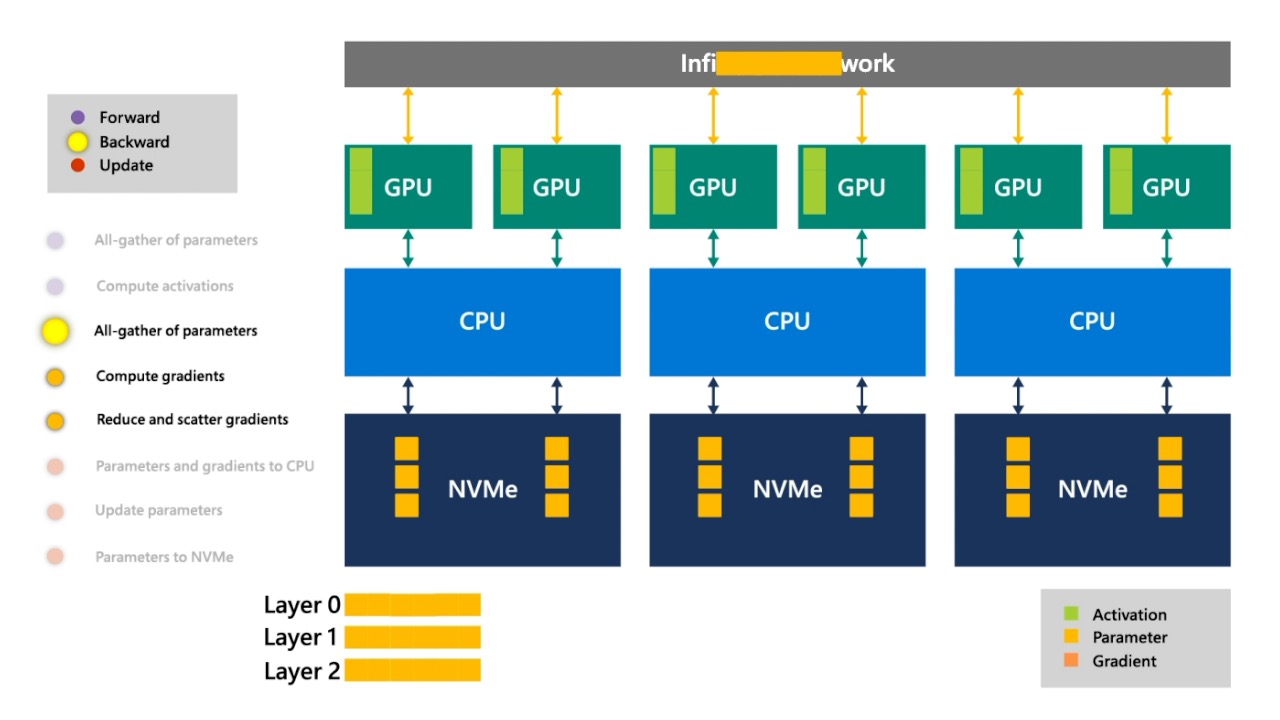 Fig. 이를 layer 끝까지 반복합니다.
Fig. 이를 layer 끝까지 반복합니다.
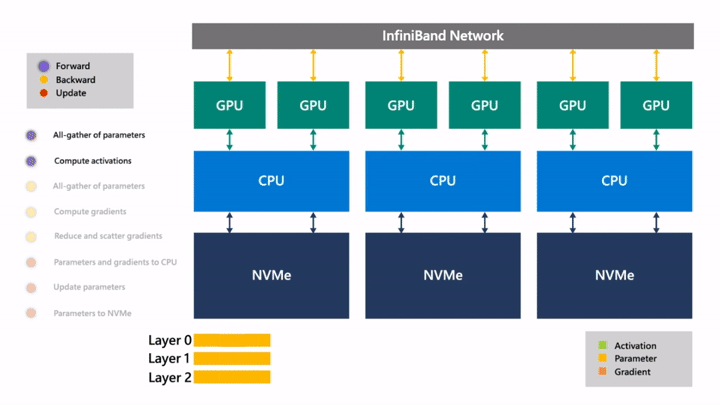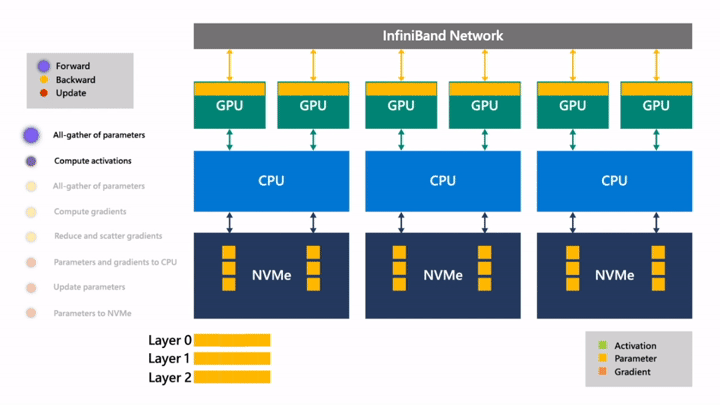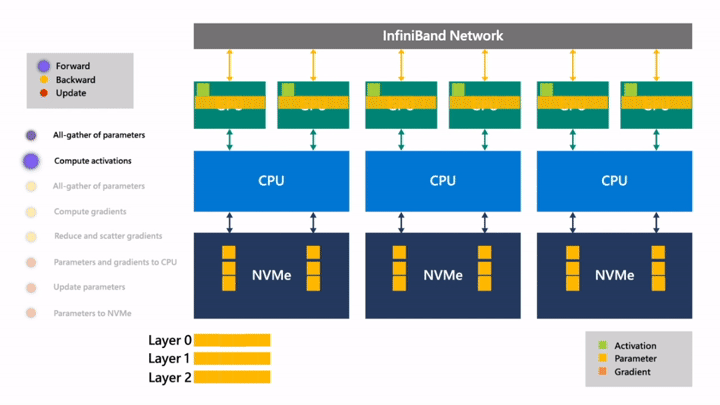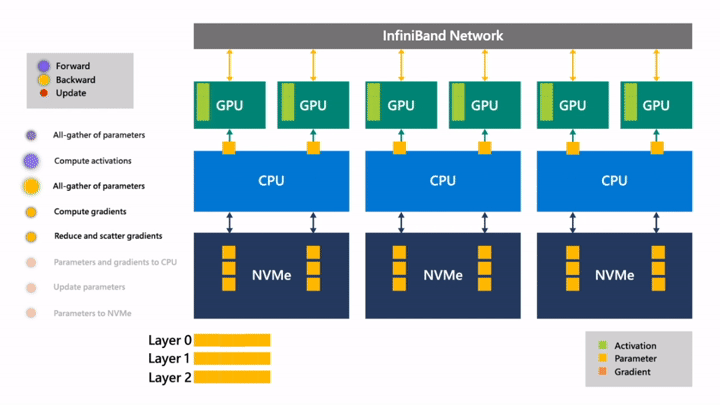 Fig. (GIF) (위의 과정을 연속적으로 나타냄)
Fig. (GIF) (위의 과정을 연속적으로 나타냄)
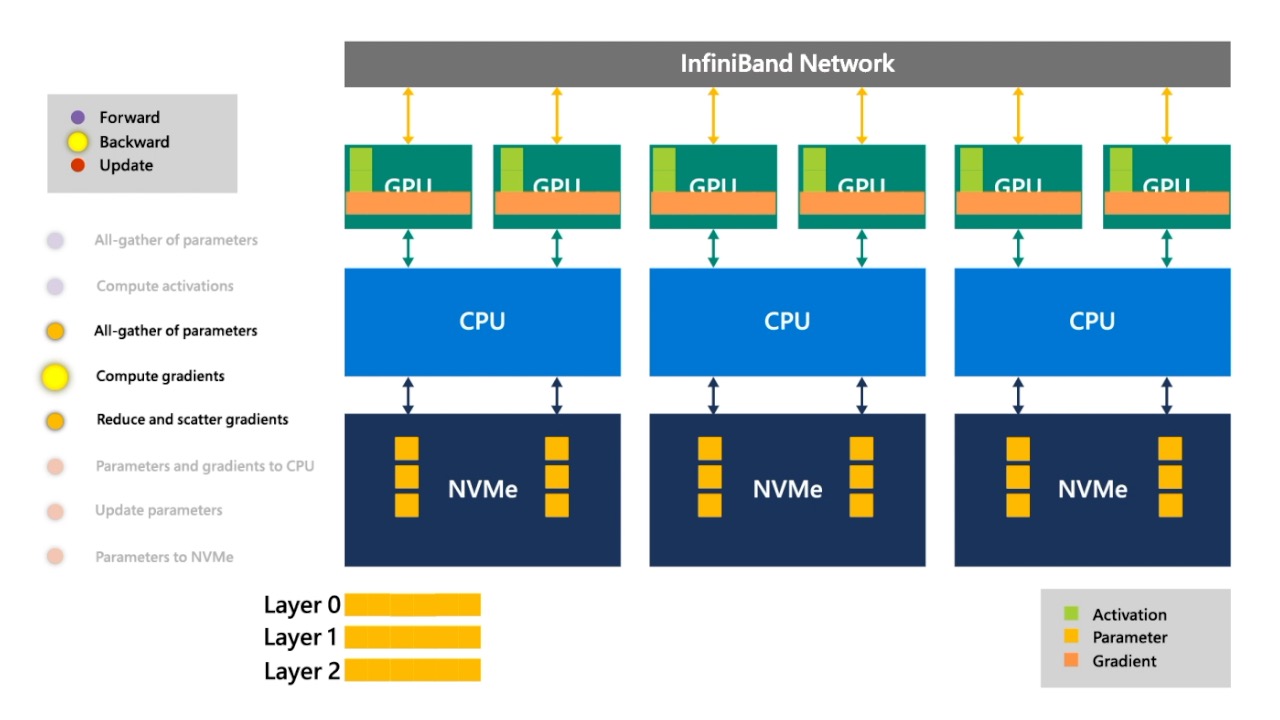 Fig. 이제 fp16 gradient를 계산해야 합니다.
Fig. 이제 fp16 gradient를 계산해야 합니다.
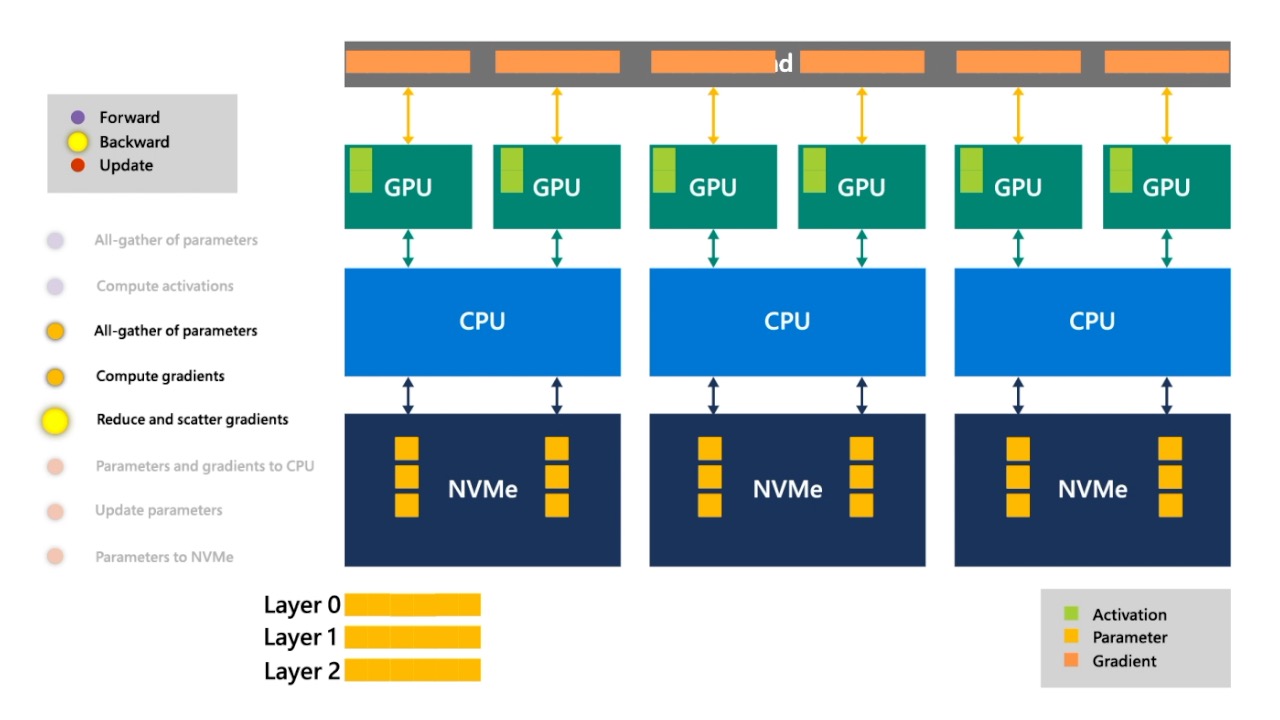 Fig. 먼저 loss를 구한 뒤 마지막 layer와 activation을 이용해 backward를 통해 gradient를 계산합니다.
Fig. 먼저 loss를 구한 뒤 마지막 layer와 activation을 이용해 backward를 통해 gradient를 계산합니다.
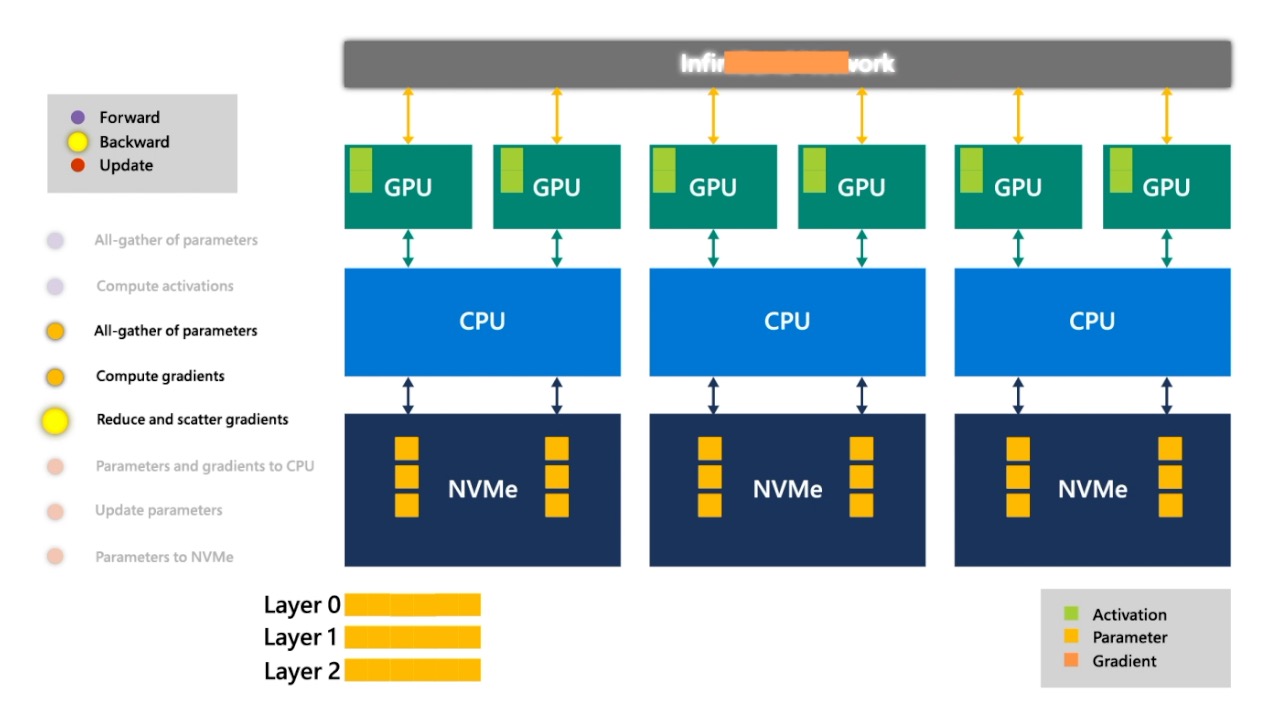 Fig. 계산한 gradient를 all reduce해서 다 합칩니다.
Fig. 계산한 gradient를 all reduce해서 다 합칩니다.
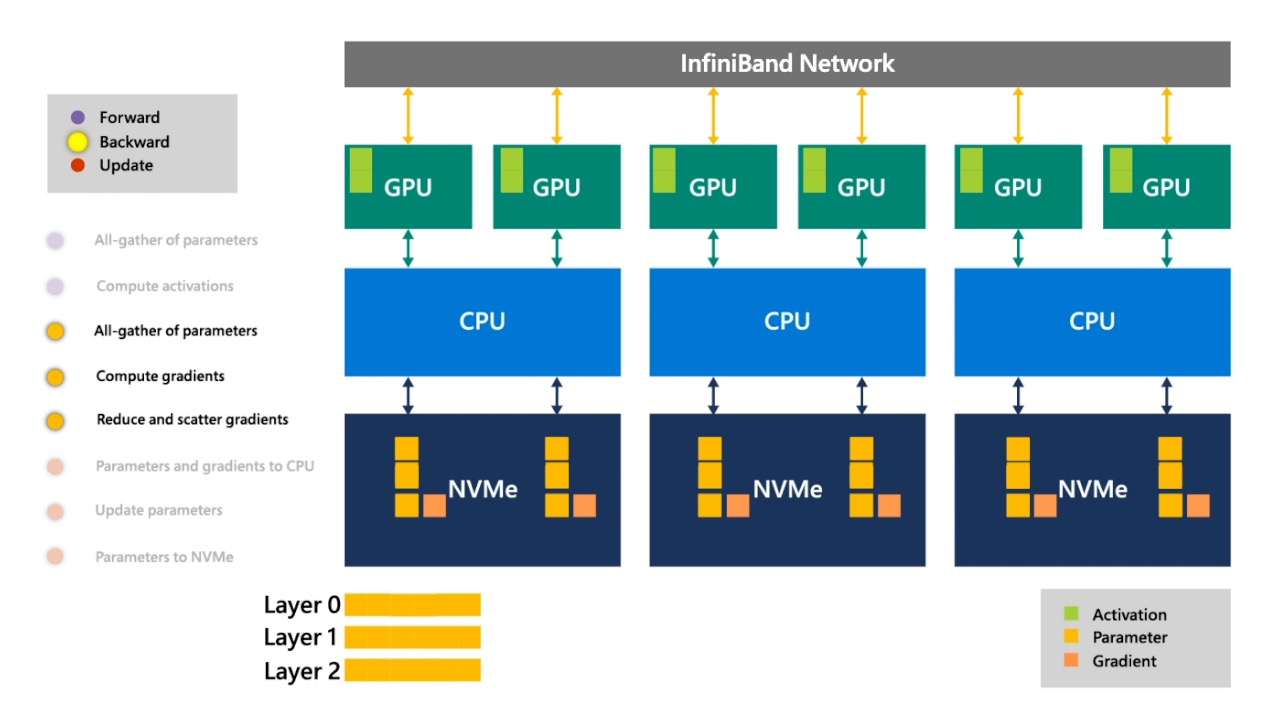 Fig. 그런다음 gradient를 NVMe로 보냅니다.
Fig. 그런다음 gradient를 NVMe로 보냅니다.
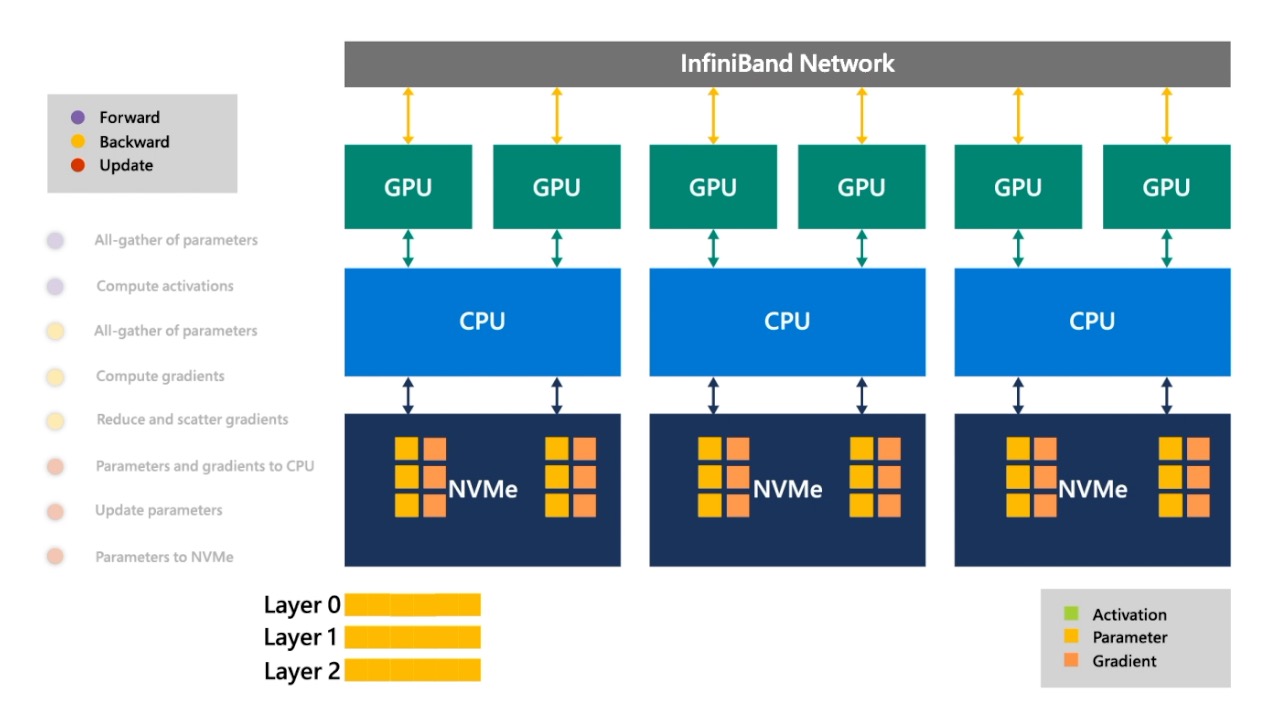 Fig. 이를 layer 0까지 반복하여 모든 layer의 각 parameter별 fp16 gradient가 계산 합니다.
Fig. 이를 layer 0까지 반복하여 모든 layer의 각 parameter별 fp16 gradient가 계산 합니다.
 Fig. (GIF) (위의 과정을 연속적으로 나타냄)
Fig. (GIF) (위의 과정을 연속적으로 나타냄)
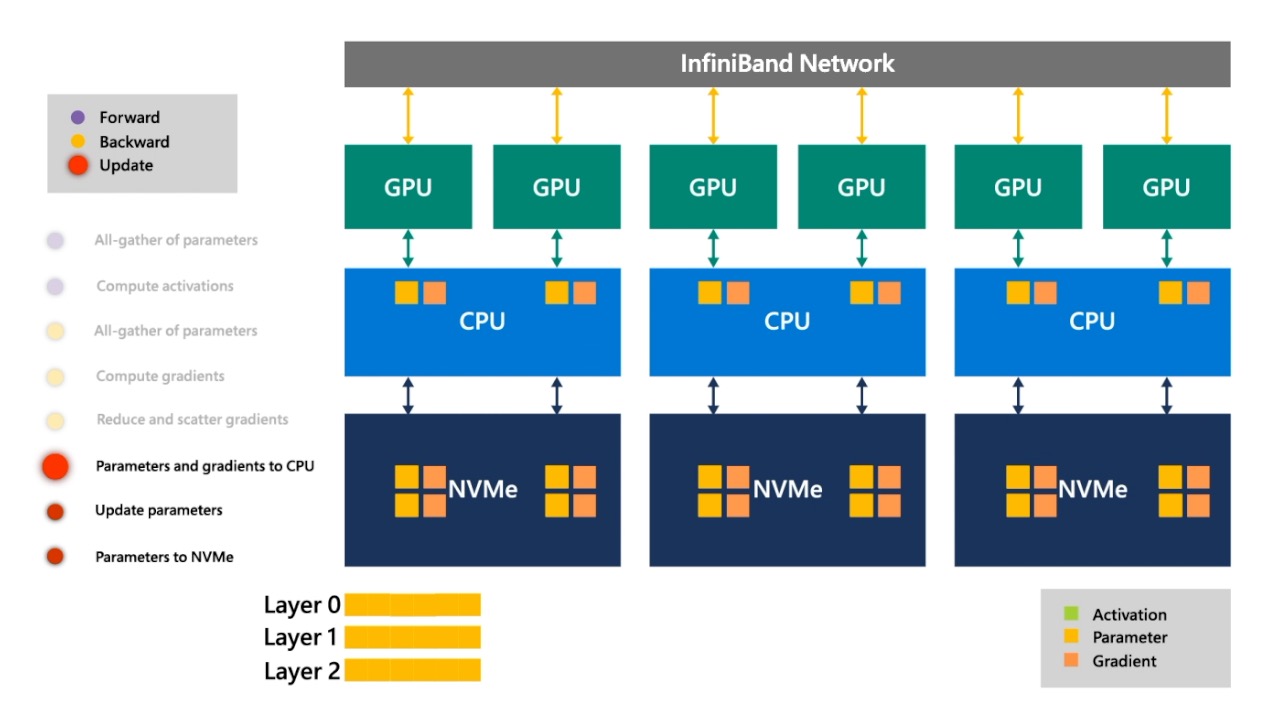 Fig. 이제 마지막으로 update를 해야 합니다. ZeRO-Offload때와 마찬가지로 CPU Adam을 쓸 것이므로 CPU로 올려서 parameter를 update 합니다. (optimizer state는 모두 CPU에 있는듯)
Fig. 이제 마지막으로 update를 해야 합니다. ZeRO-Offload때와 마찬가지로 CPU Adam을 쓸 것이므로 CPU로 올려서 parameter를 update 합니다. (optimizer state는 모두 CPU에 있는듯)
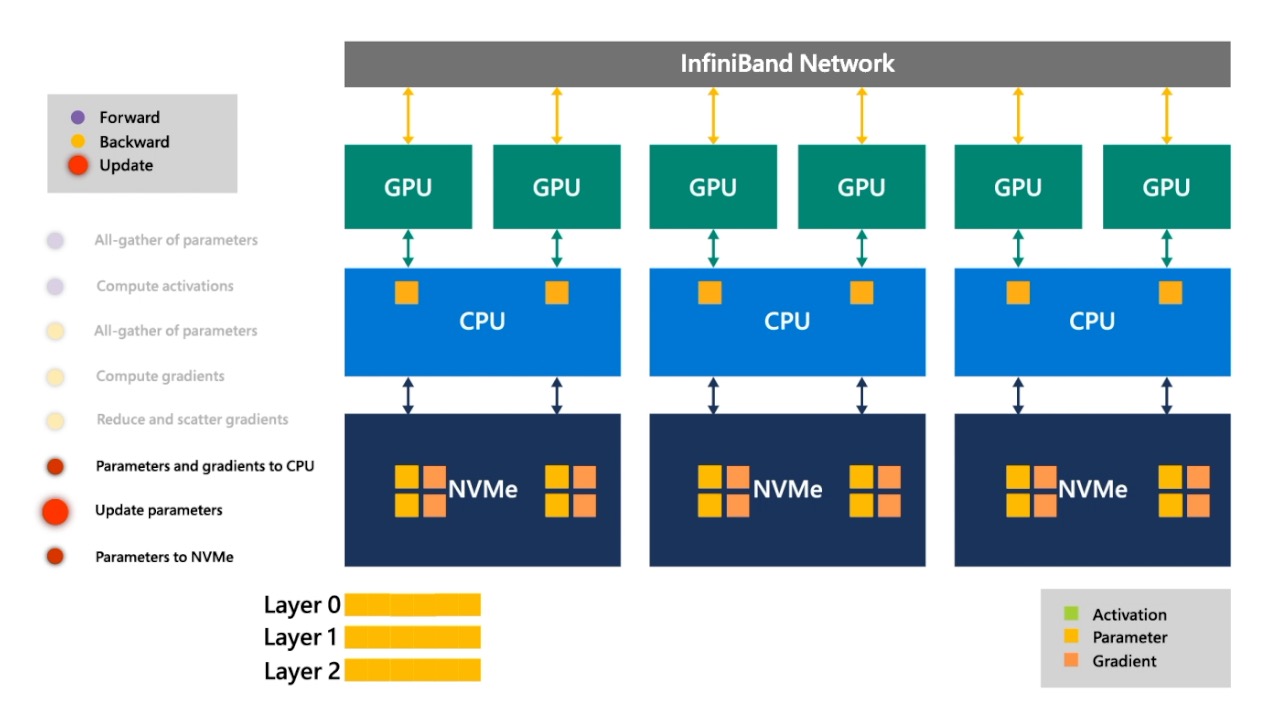 Fig. update된 layer 0의 parameter들
Fig. update된 layer 0의 parameter들
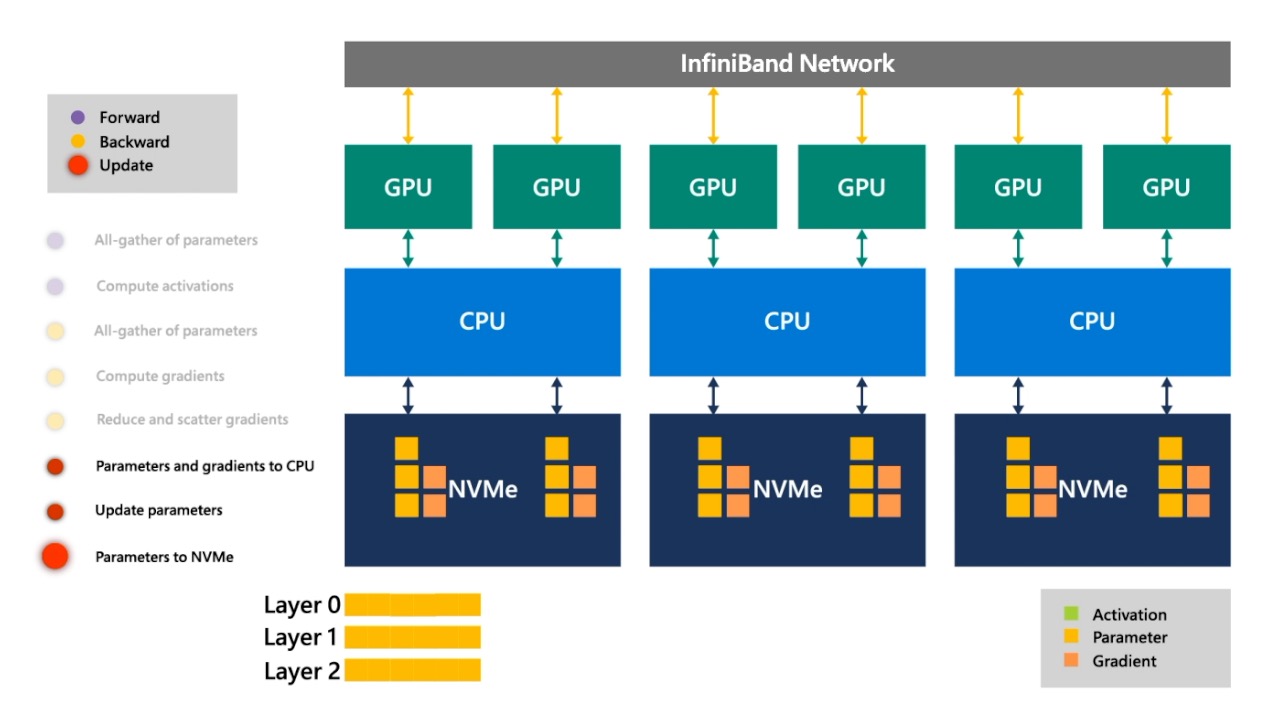 Fig. 교체해줍니다.
Fig. 교체해줍니다.
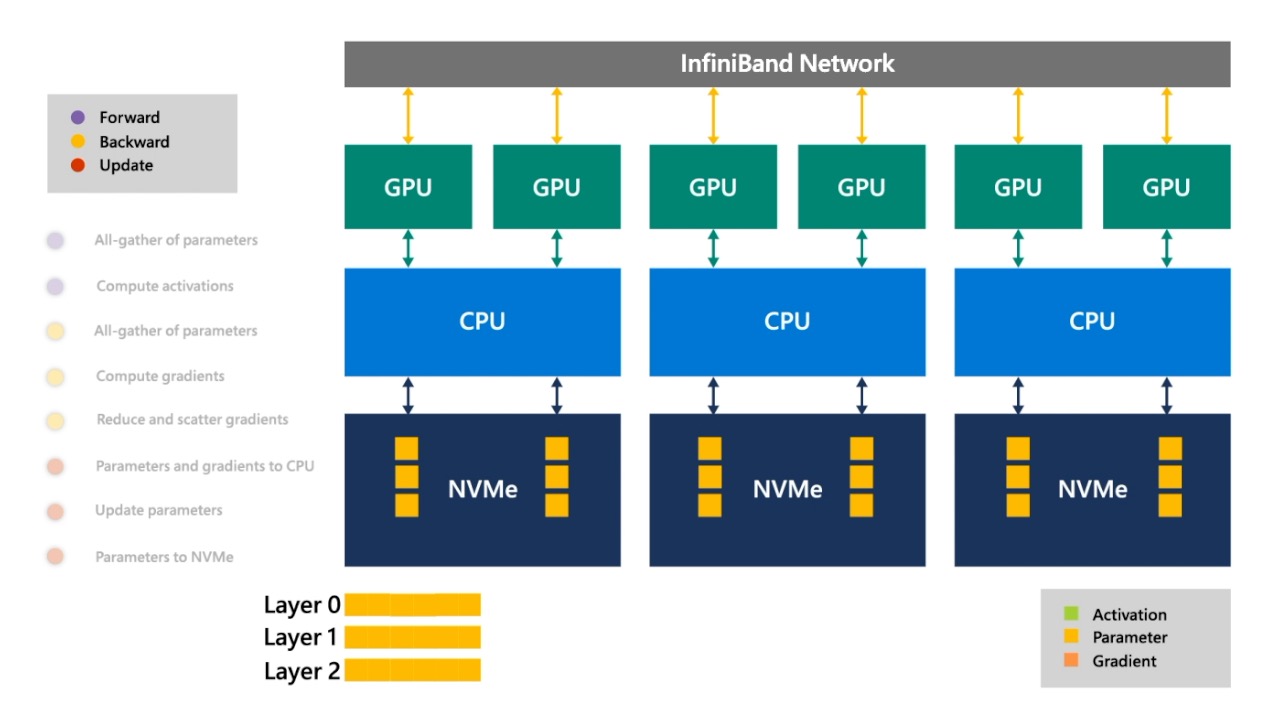 Fig. 이를 모든 layer에 대해 반복해주면 1step이 끝납니다.
Fig. 이를 모든 layer에 대해 반복해주면 1step이 끝납니다.
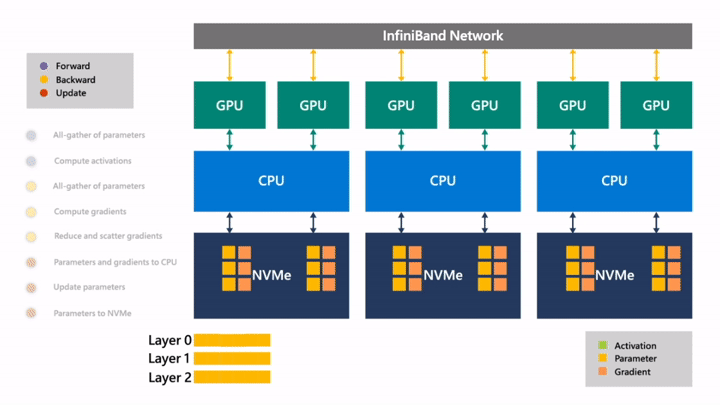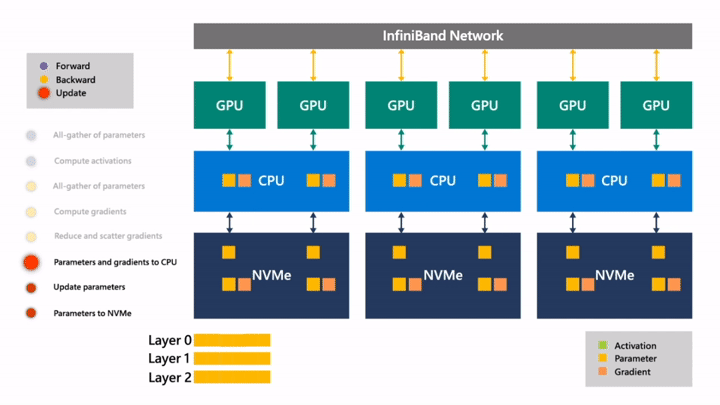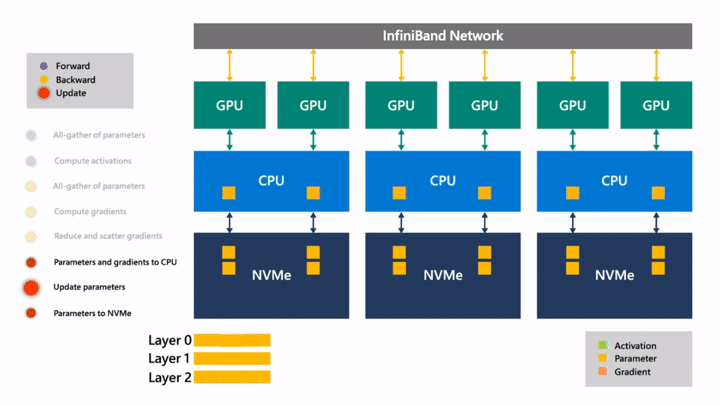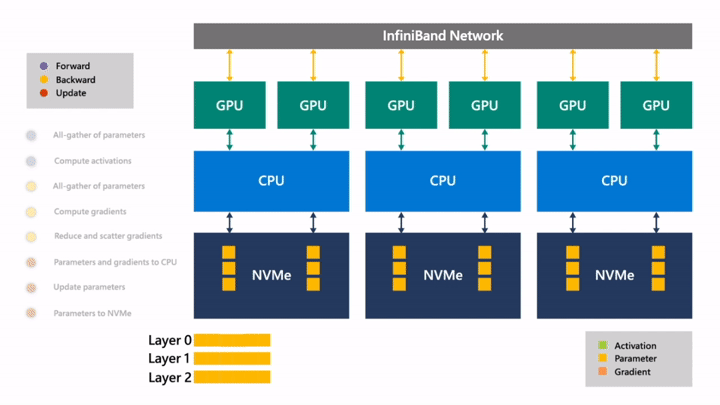 Fig. (GIF) (위의 과정을 연속적으로 나타냄)
Fig. (GIF) (위의 과정을 연속적으로 나타냄)
Analysis
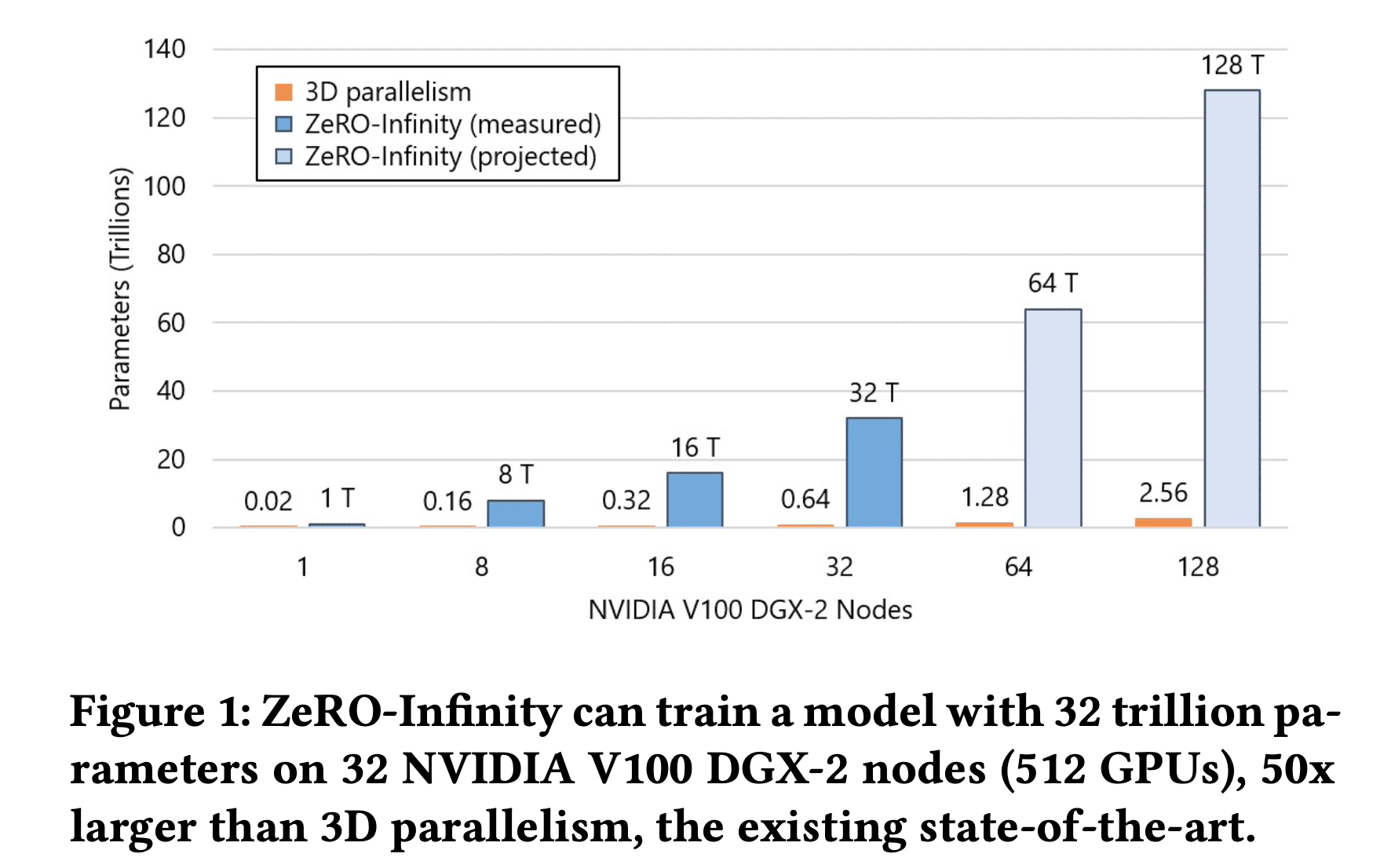 Fig.
Fig.
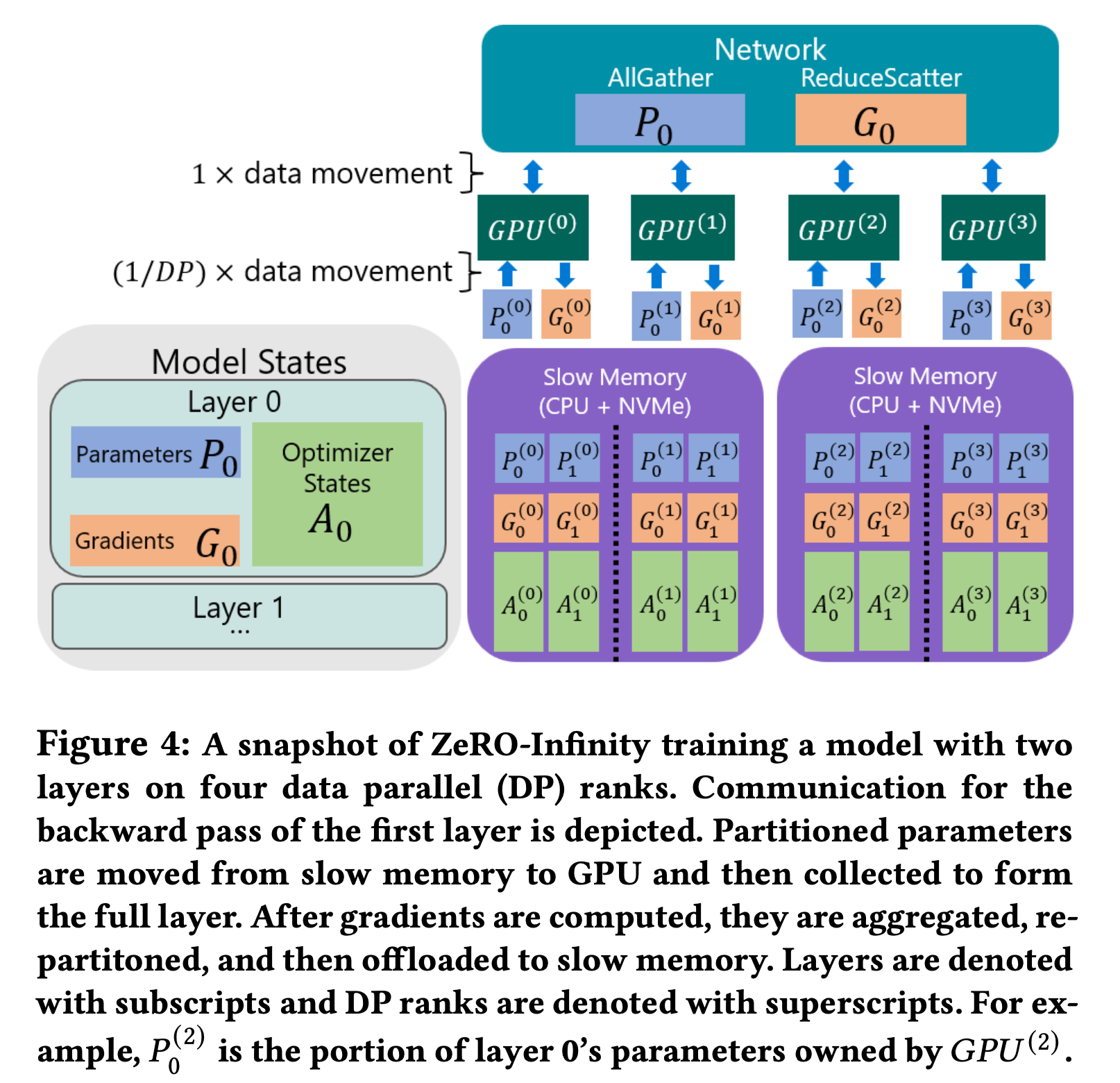 Fig.
Fig.
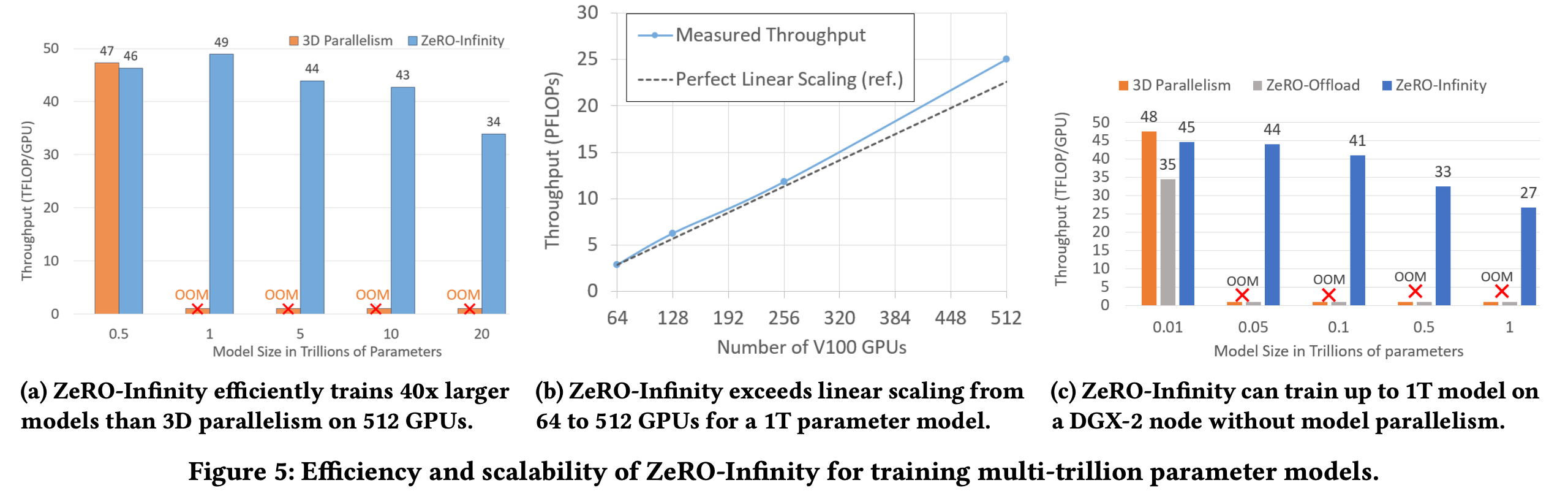 Fig.
Fig.
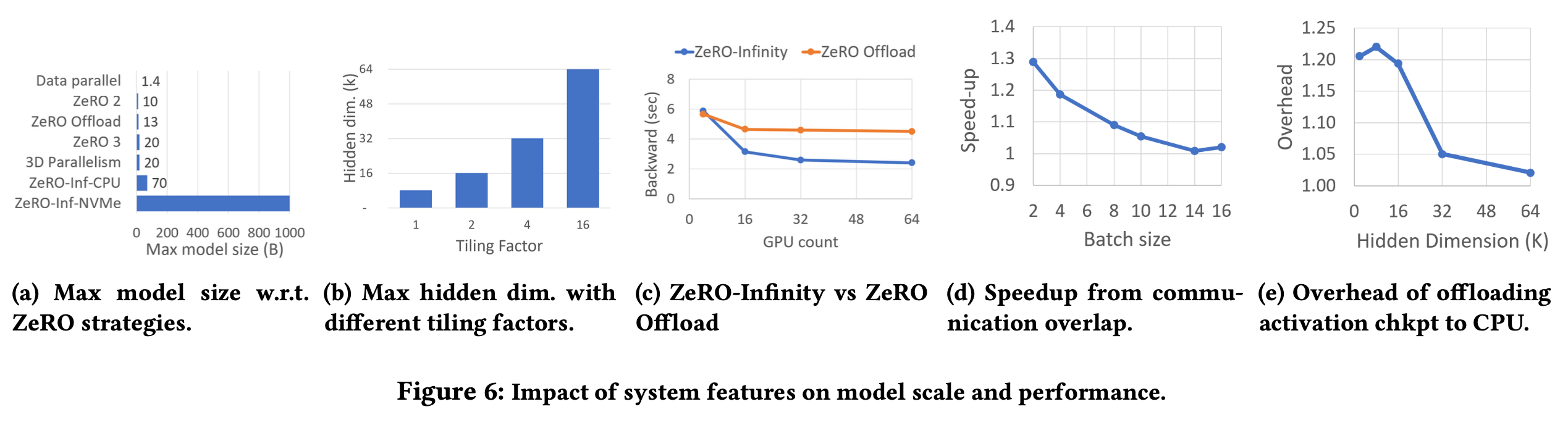 Fig.
Fig.
 Fig.
Fig.
 Fig.
Fig.
 Fig.
Fig.
ZeRO++
ZeRO++ (Zero pp)는 양자화 (quantization)을 통해서 communication cost를 더욱 줄이는 거라고 말씀드렸습니다.
Other Techniques for Large Scale Modeling
Gradient Checkpoint (Activation Checkpoint)
Activation checkpointing 은 앞서 ZeRO-R에 대해 얘기하면서 설명드린 바 있습니다.
Gradient Accumulation
Gradient Accumulation는 간단하게 말해 여러개의 GPU를 쓰는 분산 환경에서 model forward, backward를 통해서 계산한 gradient를 바로 model parameter에 반영해 업데이트 하지 않고 몇 step 누적시킨 후 계산하는 기법입니다.
이렇게 하는 이유는 예를 들어 아래의 figure 처럼 4개의 GPU를 쓸 때 gradient를 각 GPU에서 계산하고 나면 결국 model parameter를 업데이트 하기 위해서 rank 0의 machine에게 gradient를 전달해줘야 (통신) 하는데 이 때 모든 GPU들은 마지막 연산이 끝날 때 까지 기다리게 되는 문제가 생깁니다. 그래서 이런 비효율적인 idle time이 생기는 것을 최소화 하기 위해 누적해서 계산하자는 것이고
 Fig.
Fig.
이렇게 함으로써 통신 횟수도 줄어들기 때문에 분산화경에서 더 효율적으로 학습을 할 수 있게 해주는 겁니다.
추가적으로 일반적인 deep learning argorithm들이 large batch에서 좋은 성능을 내는 경우가 많아 batch size를 키우고 싶지만 그렇지 못할때에도 유용하게 쓰일 수 있습니다.
Library/Frameworks for Distributed Training
DeepSpeed
DeepSpeed는 Microsoft에서 개발한 library로 모델의 크기가 수 billion 을 넘어가는 large scale model을 학습하기 위한 tool 입니다.
Pytorch Fully Sharded Data Parallel (FSDP)
- Tutorials > Getting Started with Fully Sharded Data Parallel(FSDP)
- Shard Optimizer States with ZeroRedundancyOptimizer
Fairscale
Torch의 FSDP는 사실 같은 Meta의 분산 학습 library인 Fairscale에서 나온겁니다. 마치 memory efficient, flash attention의 구현체가 xformers에 먼저 도입되었다가 최신버전 Pytorch에 편입되듯 Fairscale도 먼저 개발되는 dev버전인 것이죠. Fairseq 같은 Sequence-to-Sequence modeling을 위한 Meta의 library에도 일찌감치 FSDP와 Activation Checkpointing같은 것들이 도입되었는데요, 궁금하신 분들은 Document의 예제를 따라 해보셔도 좋을 것 같습니다. (특이하게 자사의 기술만 쓴 것이 아니라 CPU Adam optimizer같은 것은 deepspeed구현체를 사용했습니다)
Accelerate
Accelerate 앞서 말한 deepspeed와 FSDP같은 library들을 user들이 code 몇 줄 추가하는것으로 쉽게 사용할 수 있도록 해주는 wrapper라고 볼 수 있습니다.
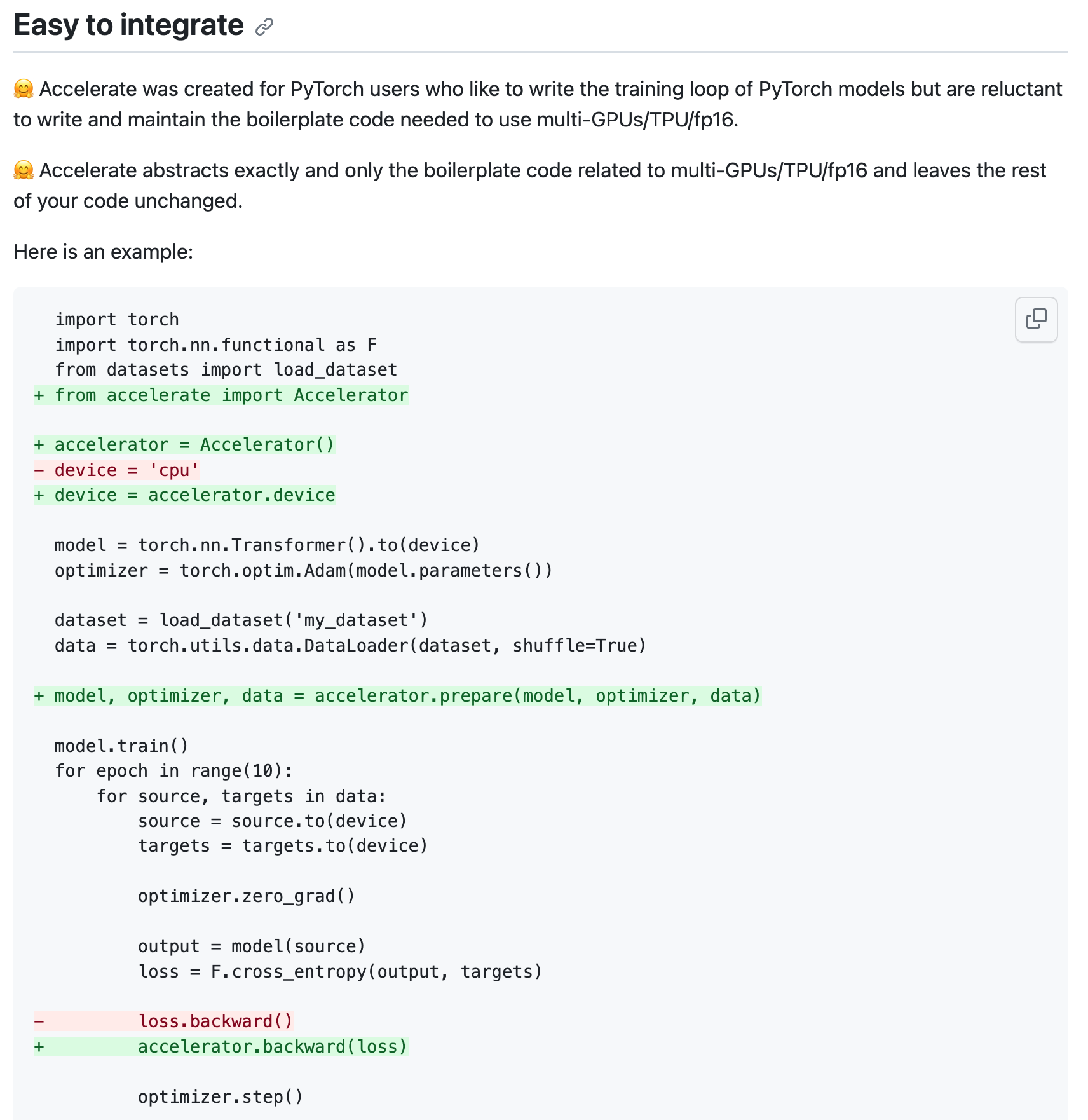 Fig. Accelerate을 쓰는 방법은 매우 쉽다.
Fig. Accelerate을 쓰는 방법은 매우 쉽다.
 Fig. 231007 latest version docs에 PP, TP는 지원 안한다고 한다.
Fig. 231007 latest version docs에 PP, TP는 지원 안한다고 한다.
Accelerate의 내부 code는 굉장히 복잡하게 되어있지만, 하는일은 deepspeed를 사용할 경우 맨 처음 model init을 할 때 ZeRO.Init을 하도록 하는 context manager 역할을 한다거나, model init이 끝난 후 학습이 시작되기 전 deepspeed.initialize를 통해 model을 ZeRO에 맞게 준비시킨다거나 하는 것 등이고, 실제로 forward시 all-gather, backward시 all-reduce등을 하는 건 전부 deepspeed나 FSDP가 합니다.
한편 Accelerate은 deepspeed가 Megatron + ZeRO나 PP를 지원해주는 것과 달리, PP같은걸 지원해주지 않는 것 같습니다. 그러므로 deepspeed를 더 raw level에서 쓰고싶다면 deepspeed를 쓰는게 더 나을 것 같습니다 (deepspeed도 사실 별로 어렵진 않음).
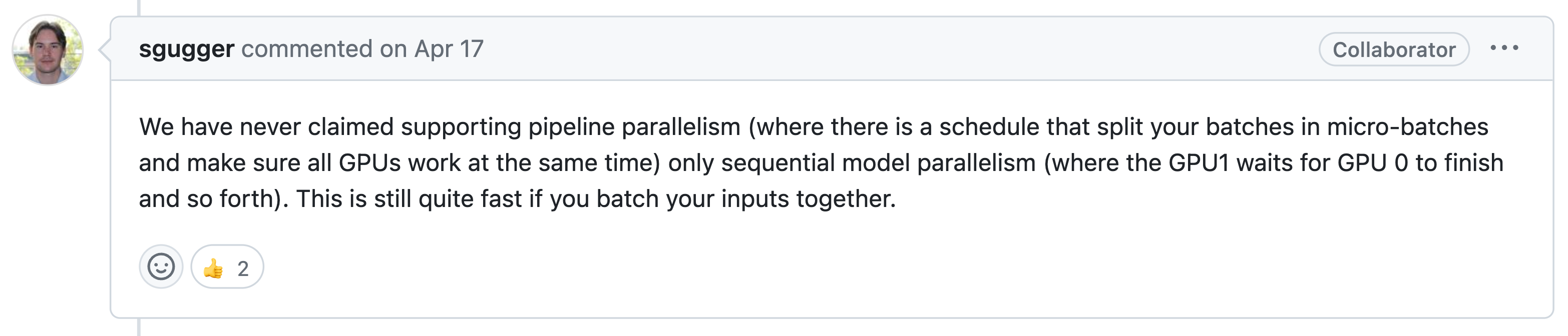 Fig. “누가 PP 지원해준대?” Source from link
Fig. “누가 PP 지원해준대?” Source from link
Key Elements of a GPU
끝으로 GPU (Graphic Processing Units)의 중요 용어들에 대해서 간단하게 정리해봤습니다. 이미 알고계신 분들은 skip하셔도 좋습니다.
- GPU (Graphic Processing Units)
- Core 수:
- Evaluation Metrics
- FLOPs (FLoating Point Operations per Second): 초등 부동 소수점 연산을 얼마나 할 수 있는가?
- Memory (용량):
- Bandwidth (대역폭):
- GPU Cluster: 여러 GPU가 장착된 server들을 bandwidth (대역폭)이 일반 회선의 10~200배인 고속 network로 엮은 분산 처리 시스템
- Infiniband: asd
- DGX: Nvidia DGX는 Deep Learning application을 가속화하기 위해 GPGPU를 사용하는 데 특화된 Nvidia 생산 server 및 workstation 제품군
- NVMe (Non-Volatile Memory Express, 비휘발성 기억장치 익스프레스):
Backends
NVIDIA Collective Communications Library (NCCL)
NVIDIA Collective Communications Library (NCCL)는
References
- Microsoft DeepSpeed Team
- Full Paper List from Deepspeed Team
- ZeRO: Memory Optimizations Toward Training Trillion Parameter Models
- ZeRO-Offload: Democratizing Billion-Scale Model Training
- ZeRO++: Extremely Efficient Collective Communication for Giant Model Training
- ZeRO-Infinity: Breaking the GPU Memory Wall for Extreme Scale Deep Learning
- DeepSpeed-Chat: Easy, Fast and Affordable RLHF Training of ChatGPT-like Models at All Scales
- Blog Posts
- ZeRO & DeepSpeed: New system optimizations enable training models with over 100 billion parameters
- ZeRO-2 & DeepSpeed: Shattering barriers of deep learning speed & scale
- DeepSpeed: Extreme-scale model training for everyone
- ZeRO-Infinity and DeepSpeed: Unlocking unprecedented model scale for deep learning training
- DeepSpeed ZeRO++: A leap in speed for LLM and chat model training with 4X less communication
- Github
- Docs
- ZeRO-Offload slides from USENIX
- ds config json
- Full Paper List from Deepspeed Team
- Meta
- Huggingface
- Others
- parallelism
- gradient checkpointing