(ASR) ASR Core Series (0/4) Hidden-Markov-Model (HMM) based ASR Modeling (Road to End-to-End ASR Modeling)
10 Nov 2022< 목차 >
- Overview and Fundamental Equation of Statistical Speech Recognition
- Understanding HMM based ASR Model in High Level
- Bridging to Gaussian Mixture Models (GMMs)
- Back to HMMs
- Compared to E2E Modeles
- References
제가 ASR Core Series post 를 연재하고 싶었던 이유는 2022년 현재까지 나온 Deep Learning 기반의 End-to-End (E2E) 방법론인
- Connectionist Temporal Classification (
CTC) based Model Transducerbased Model- Attention based Encoder-Decoder (
AED or Seq2Seq) Model
에 대한 이해를 높히고 생각을 정리하기 위해서 였습니다.
하지만 공부와 이해를 거듭할수록 CTC 와 Recurrent Neural Network (RNN) 등 E2E 기법의 중요한 모듈들은 모두 Gasussian Mixture Model - Hidden Markov Model (GMM-HMM) 이나 DNN-HMM 등 HMM 과 밀접한 관련이 있다는 사실을 마주할 수 밖에 없었습니다.
그래서 먼저 (작성은 가장 나중에 했지만) 과거에는 어떤식으로 음성 인식 모델을 학습했는지? HMM 기반 모델링 방법론은 현대의 CTC 등과 어떤 연관이 있는지? 에 대해서 알아보도록 하려고 합니다.
Overview and Fundamental Equation of Statistical Speech Recognition
1970 년대부터 40년 동안 ASR 모델링 방법은 아래와 같은 복잡한 수식을 요구했습니다.
 Fig.
Fig.
슬라이드에 나와있는 것 처럼 3가지 모듈을 따로 따로 학습했어야 했는데요,
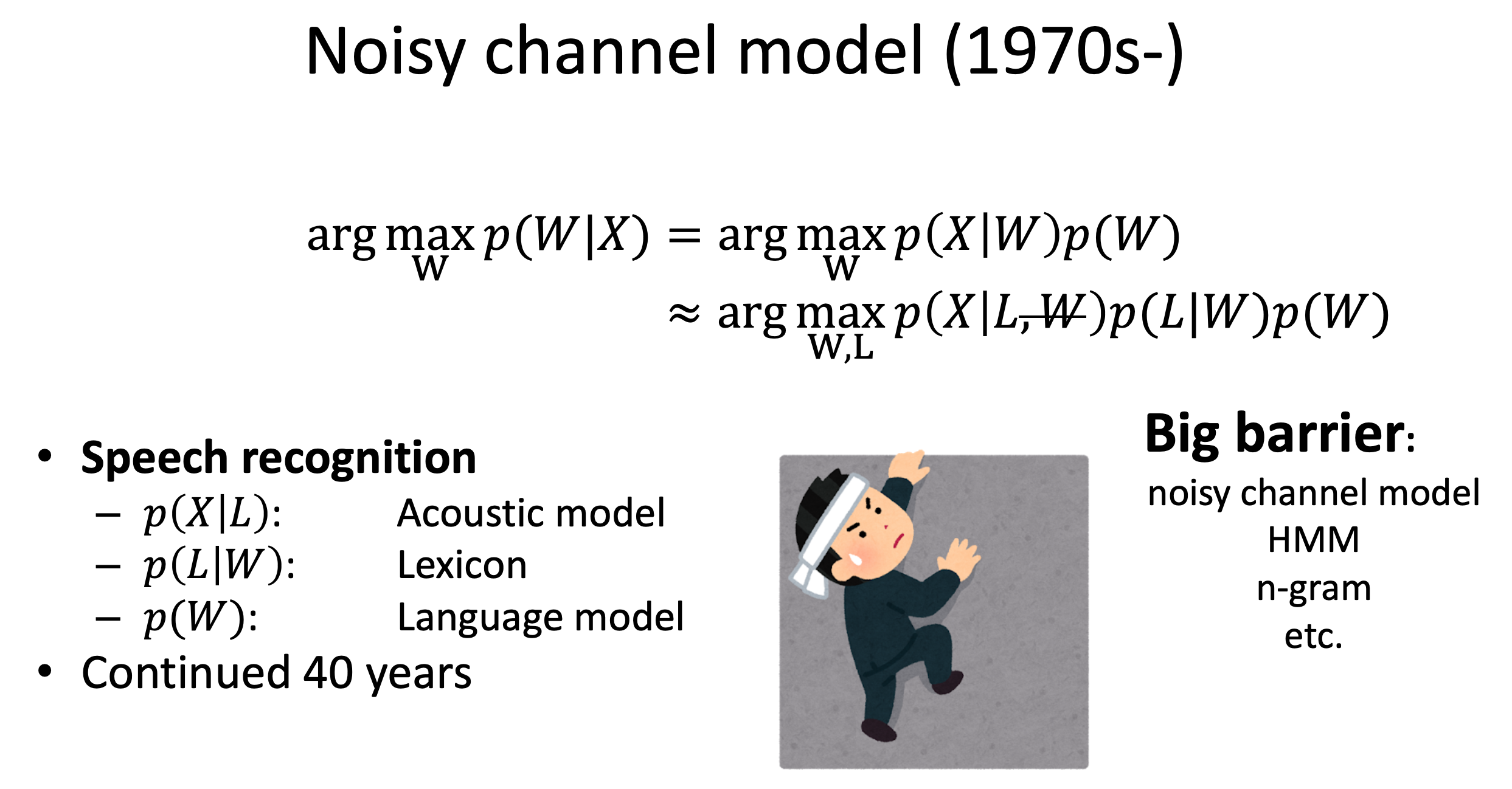 Fig.
Fig.
Acoustic Model (AM), Lexicon, Language Model (LM) 이 세가지 중 AM 을 모델링 하기 위해 GMM-HMM 이 필요한 것입니다.
(최근에는 이런 방법보다는 Neural Network (NN) 하나가 이 세 가지를 Jointly 모델링 하게 되었죠.)
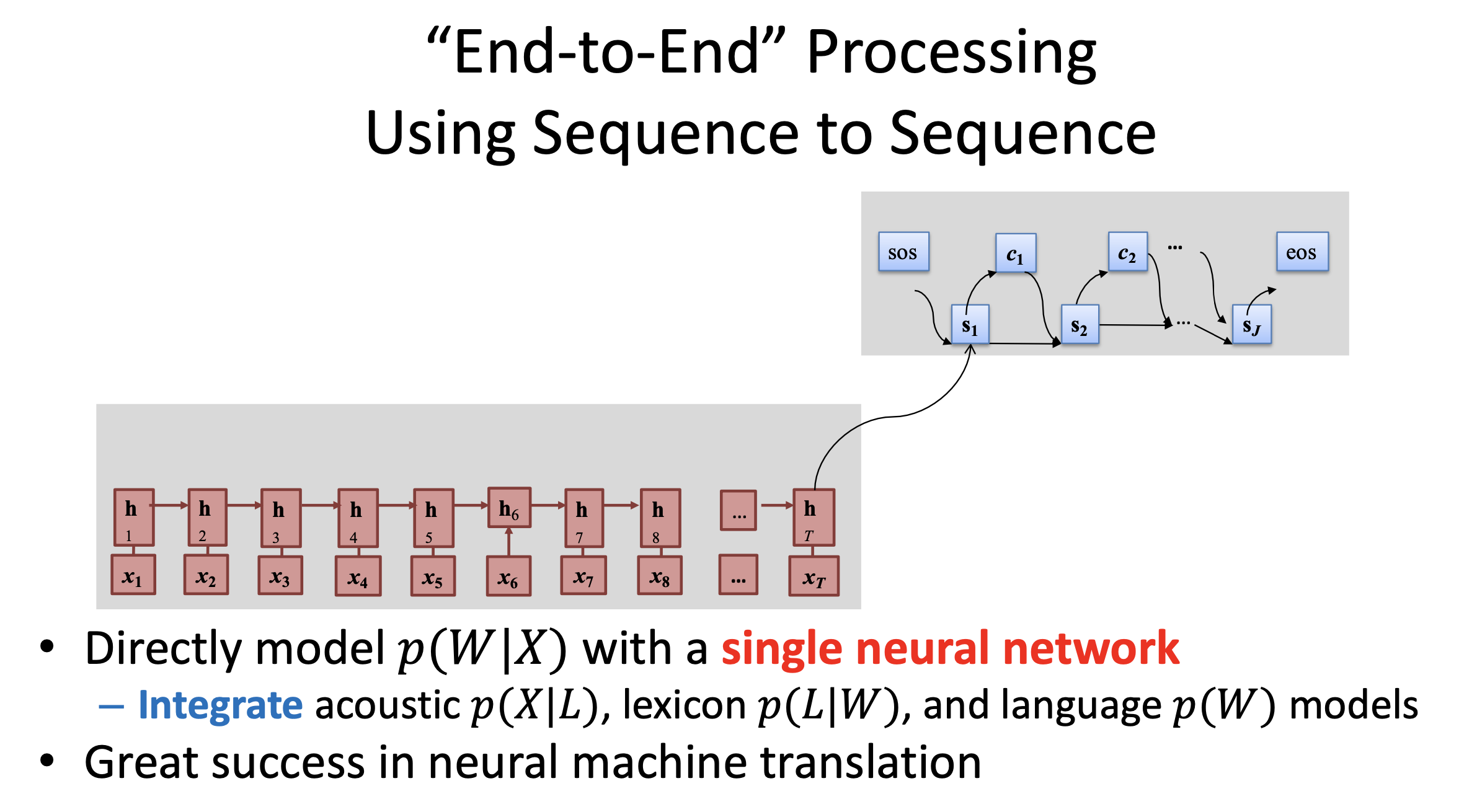 Fig.
Fig.
그렇다면 어떻게 \(p(x \vert L)\), \(p(L \vert W)\), \(p(W))\) 같은 모듈들이 튀어나온 걸까요?
먼저 음성인식의 문제 정의부터 다시 해 봅시다.
우리가 원하는 것은 어떤 음성 X 가 있을 때 이에 해당하는 가장 그럴듯한 문장 (Text), W 를 모델이 뱉어주길 원합니다.
즉 확률 분포 \(p(W \vert X)\) 를 모델링 하고 어떤 음성을 이 분포에 넣어 가장 확률이 높은 W를 뽑으면 되겠죠.
그러면 음성 X 에 대해 어떤 W 가 나올지를 학습해야 겠죠? (확률분포의 파라메터를 조정해야겠죠?)
그런데 여기서 문제가 있는 것이 입력 음성은 예를 들어 길이가 3초이고 Sampling Rate (SR)가 16,000 일 때 48,000 개의 길이를 갖는 반면 이에 해당하는 정답 Hello World 는 Character 단위로 세어도 길이가 11 밖에 안됩니다.
이를 학습하기 위해 머신러닝에서 가장 단순한 방법인 Cross Entropy Objective 를 사용해 frame 마다 정답을 알려주고 이를 최적화 하고 싶겠지만 과연 어디부터 어디까지가 H e l l o 일까? 라는 Alignment 정보가 없기 때문에 불가능합니다.
이런 이유 때문에 우리가 풀고 싶은 문제를 Bayes Rule을 사용해 바꾸게 되는데요,
 Fig.
Fig.
이 과정에서 우리가 최대화 할 수식이 아래처럼 바뀌게 되는 것입니다.
\[\begin{aligned} & \hat{w} = arg max_{w} p(w \vert x) & \\ & \hat{w} = arg max_{w} \color{red}{p(x \vert w)} p(w) & \\ \end{aligned}\]우리가 \(p(w \vert x)\) 에서 \(p(x \vert w)\) 로 바뀌었기 때문에 우리는 일반적인 분류 모델 (Classification Model) 같은 판별 모델 (Discriminative Model)이 아니라 생성 모델 (Generative Model) 을 푸는 것으로 문제가 바뀌게 되었고
여기서 \(p(x \vert w)\) 를 바로 우리가 앞으로 다룰 GMM-HMM 을 사용해서 모델링하게 됩니다.
(\(p(W)\) 는 또 Lexicon 이라는 걸 사용해서 Factorization 할 수 있지만 우리는 지금 AM만 관심있으니 이는 건너 뛰겠습니다.)
Understanding HMM based ASR Model in High Level
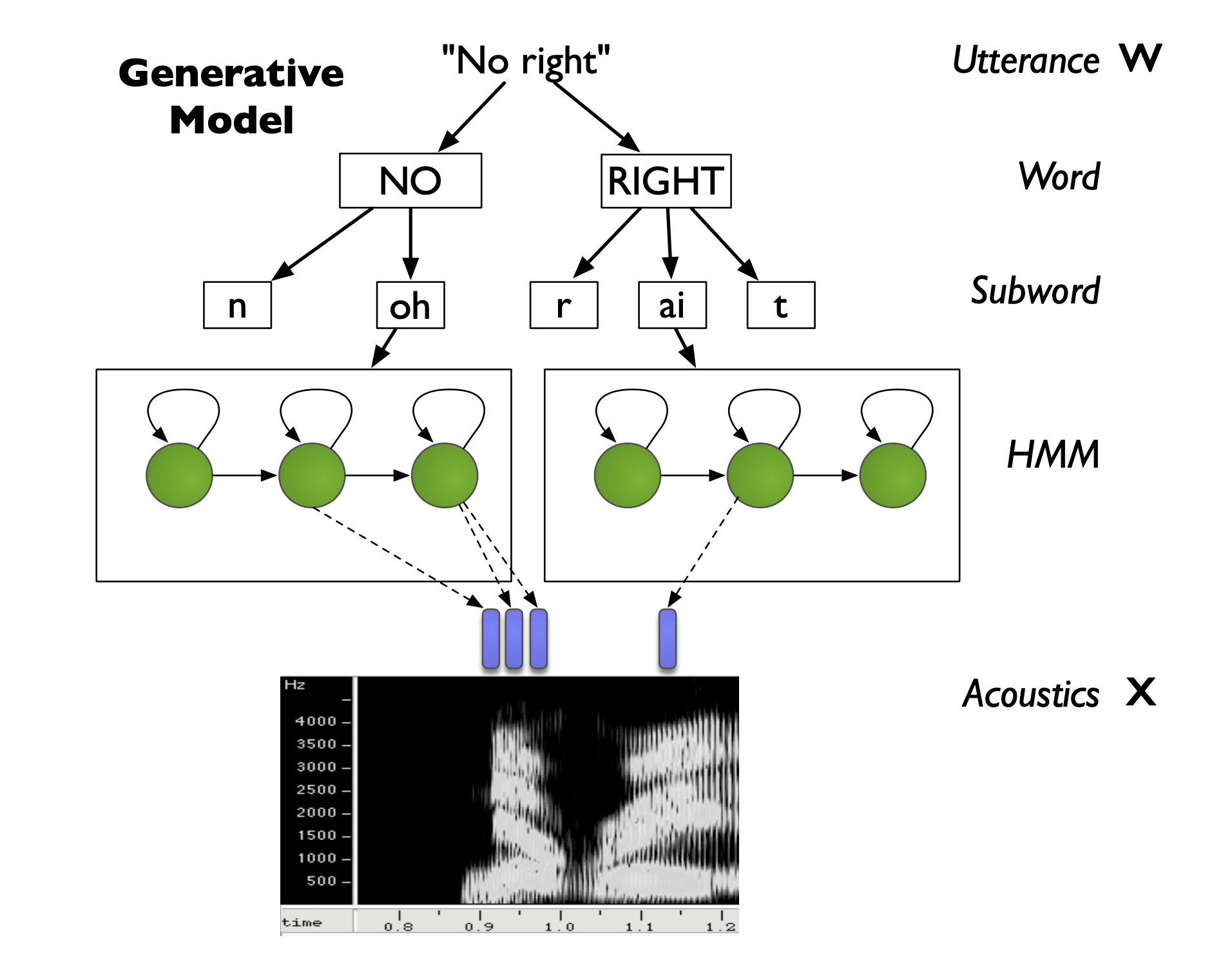 Fig.
Fig.
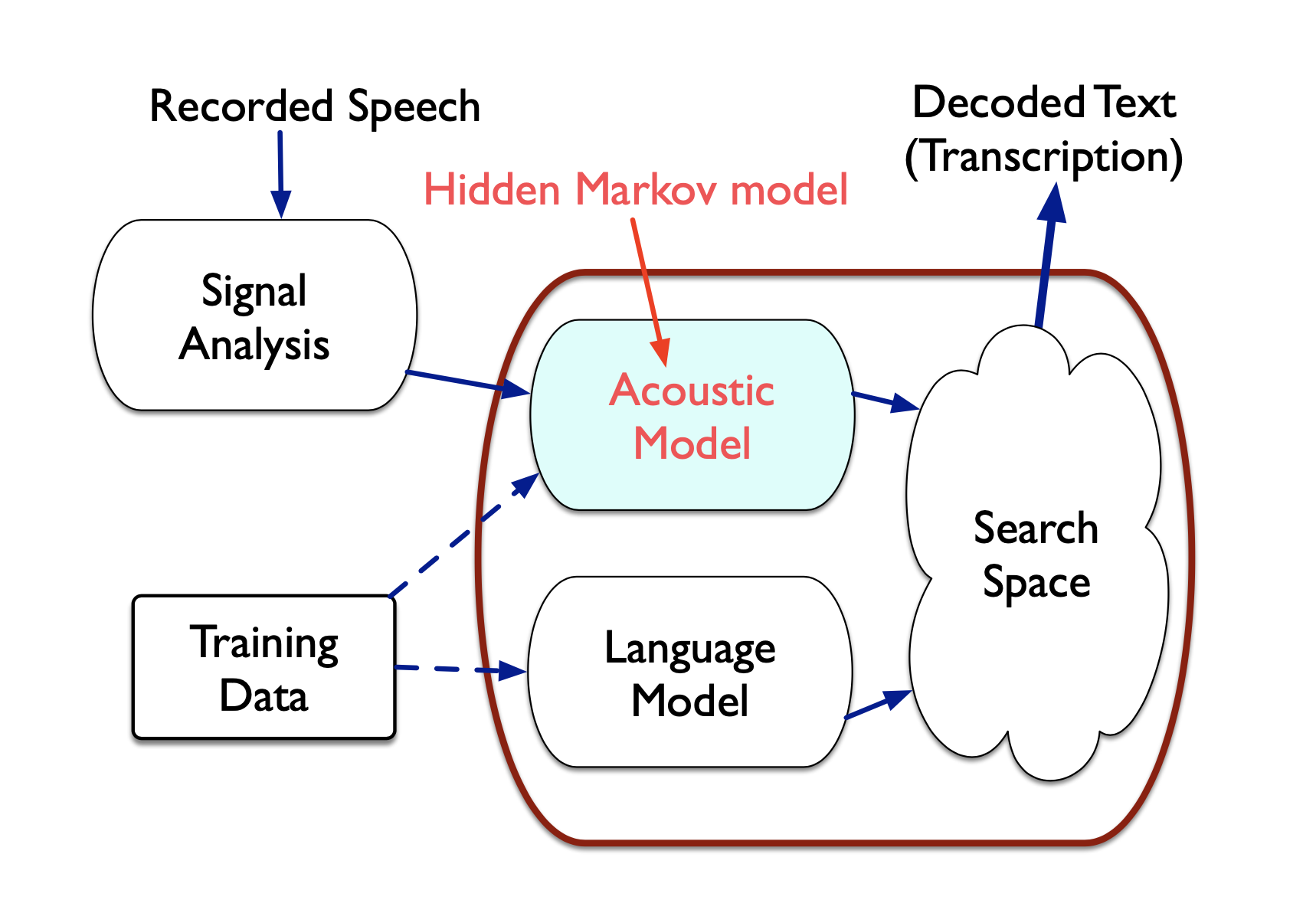 Fig.
Fig.
 Fig.
Fig.
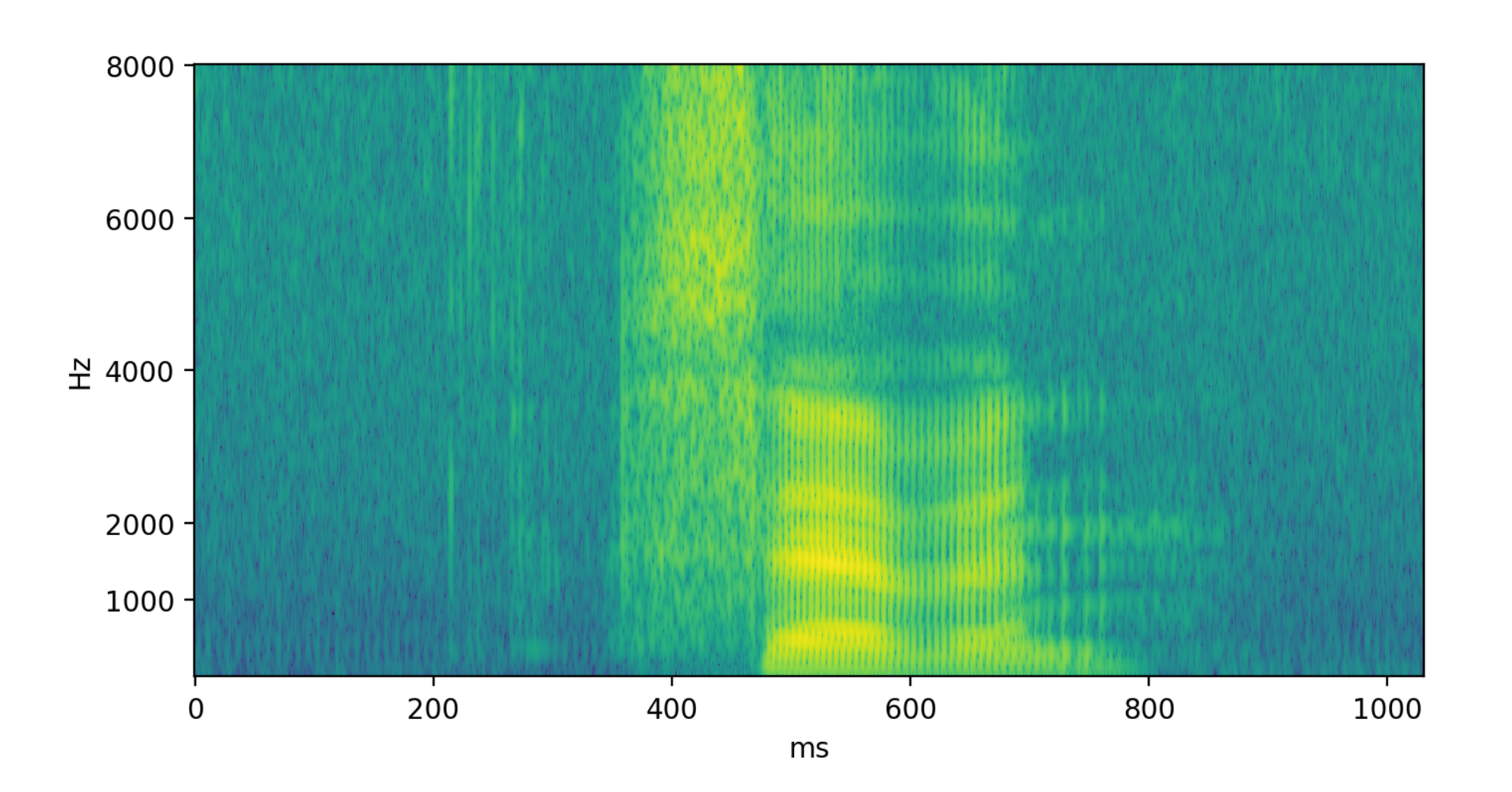 Fig.
Fig.
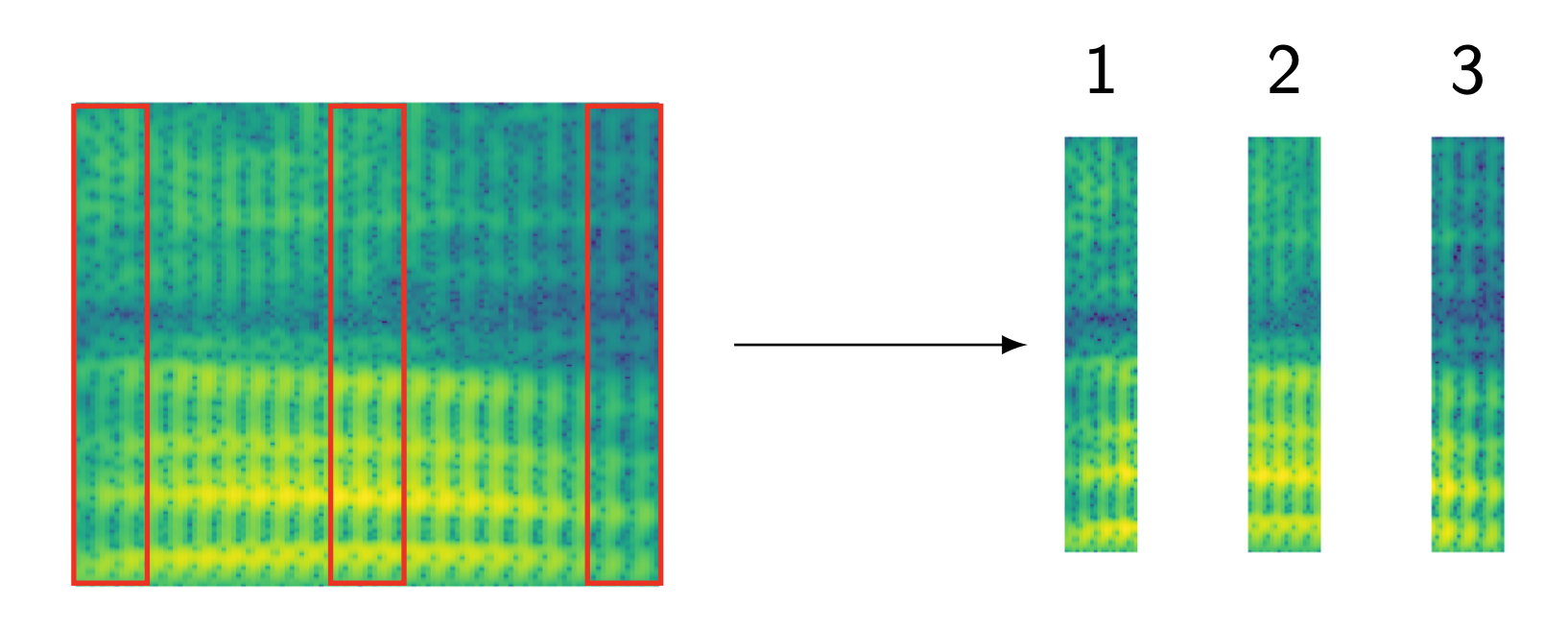 Fig.
Fig.
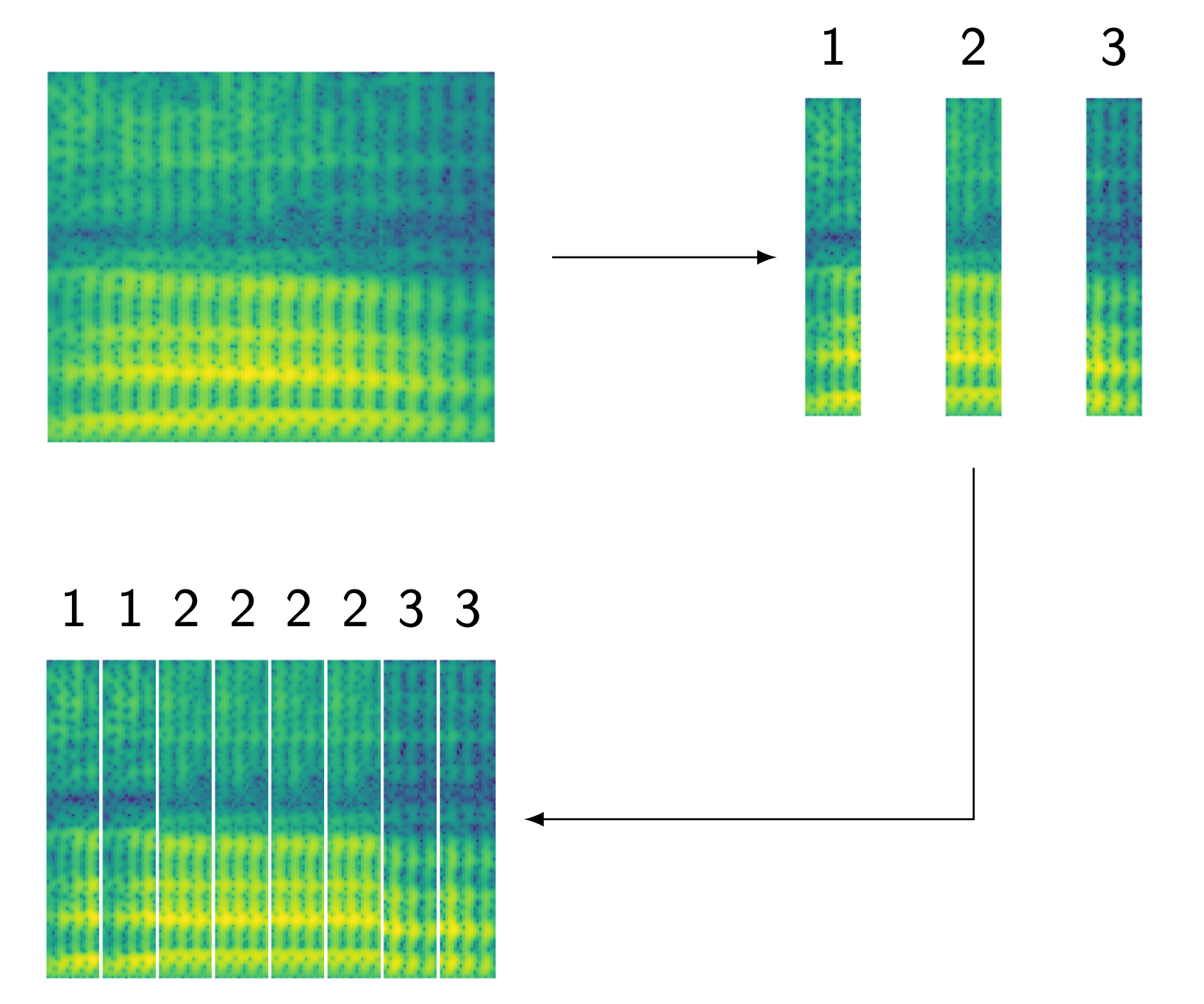 Fig.
Fig.
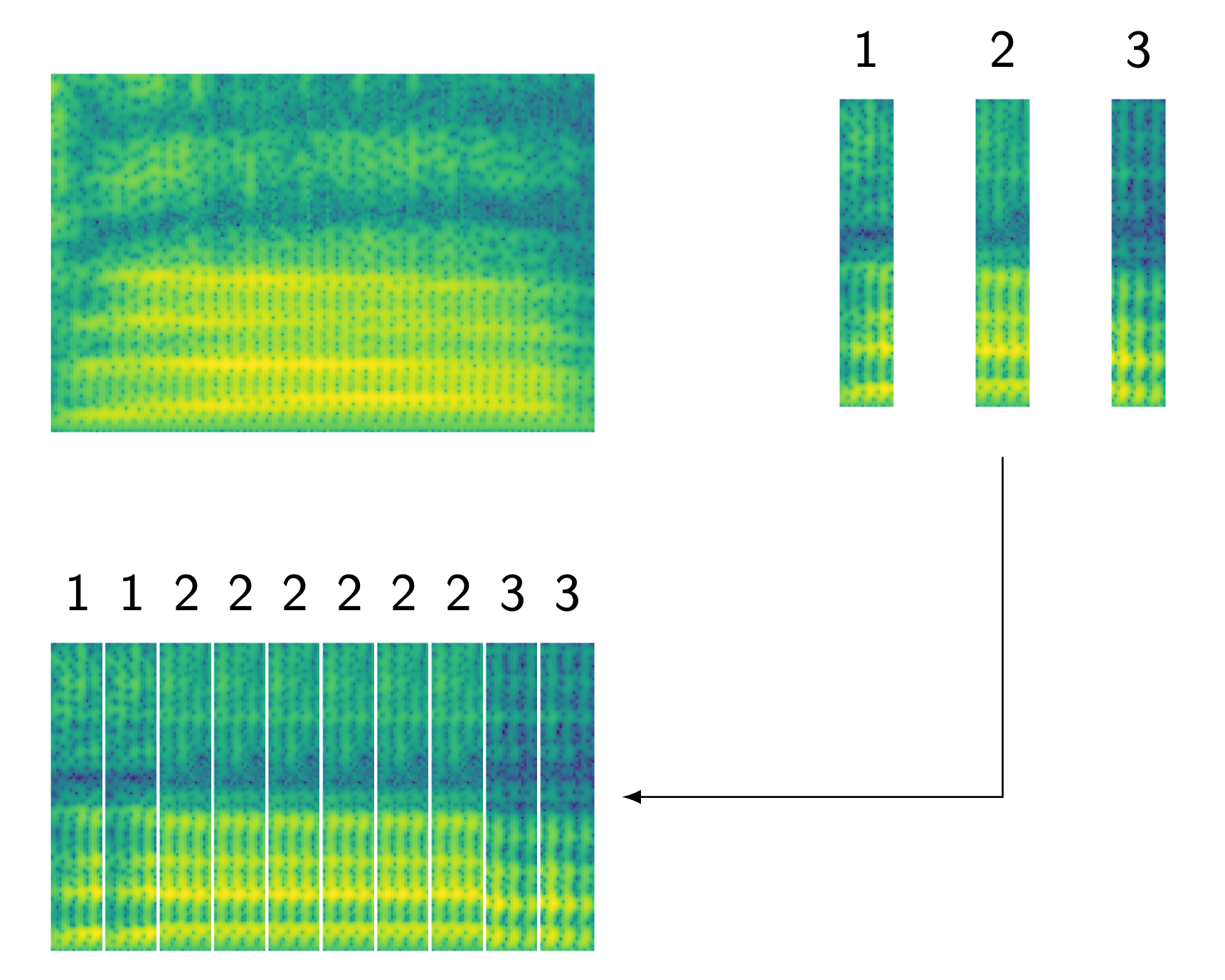 Fig.
Fig.
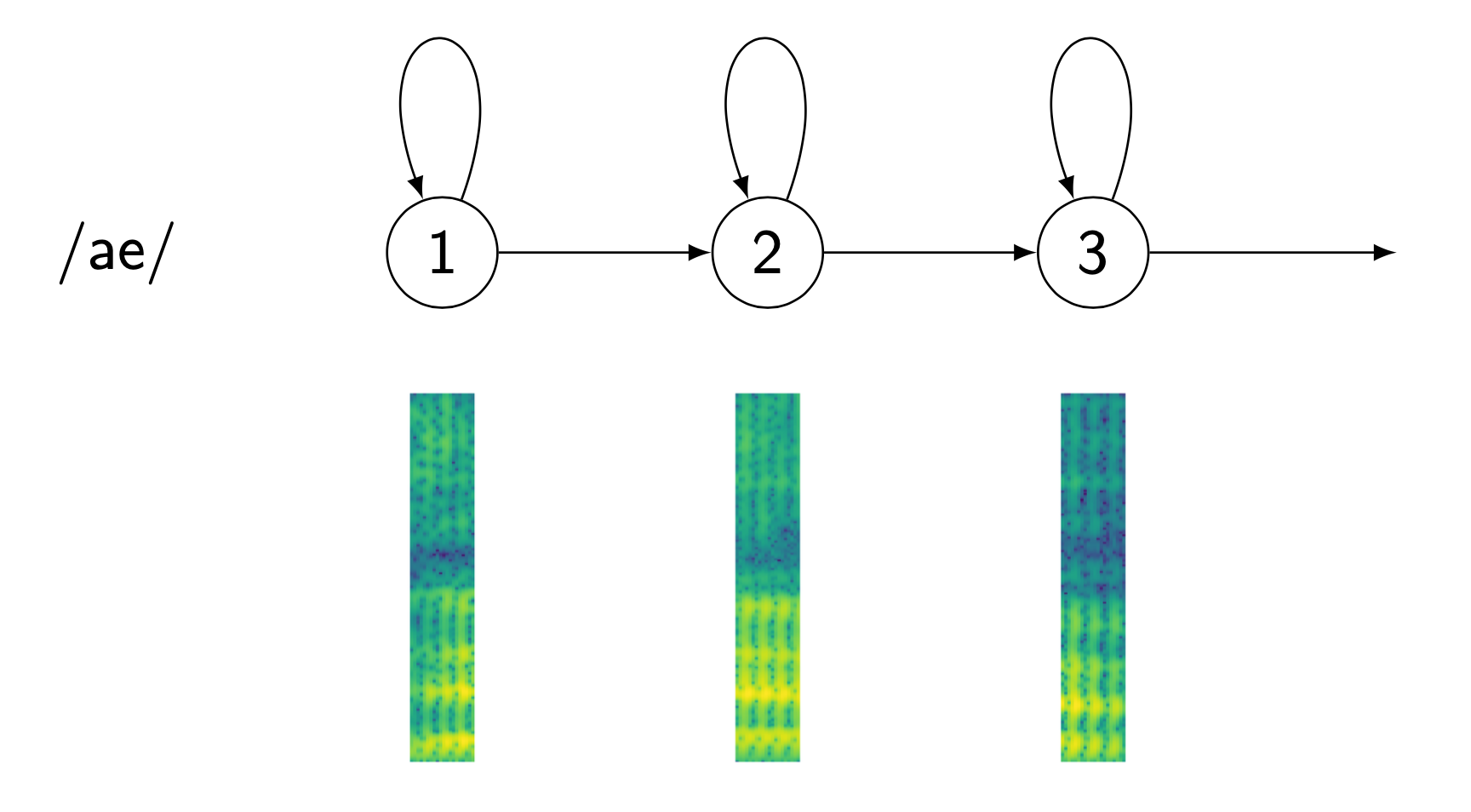 Fig.
Fig.
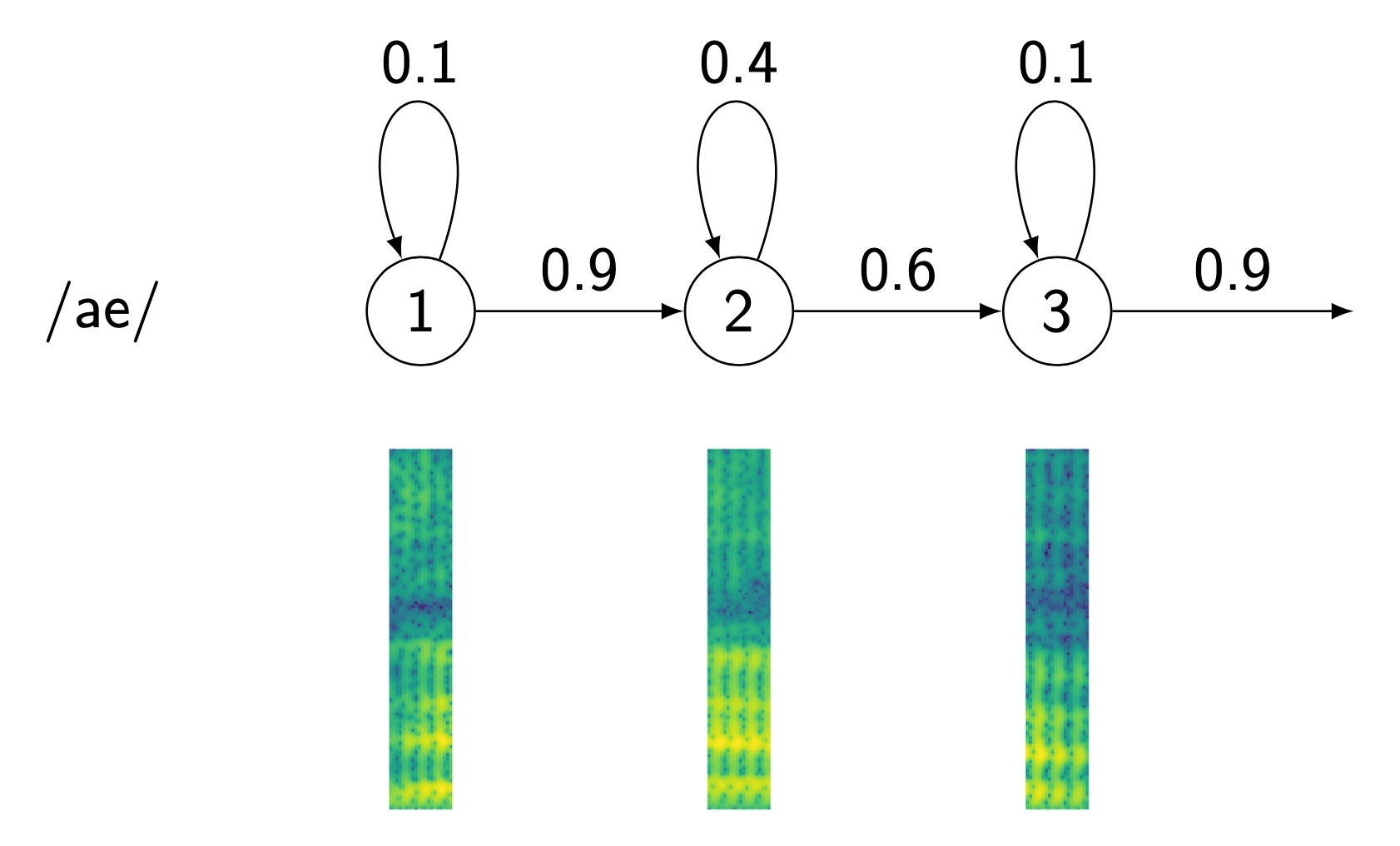 Fig.
Fig.
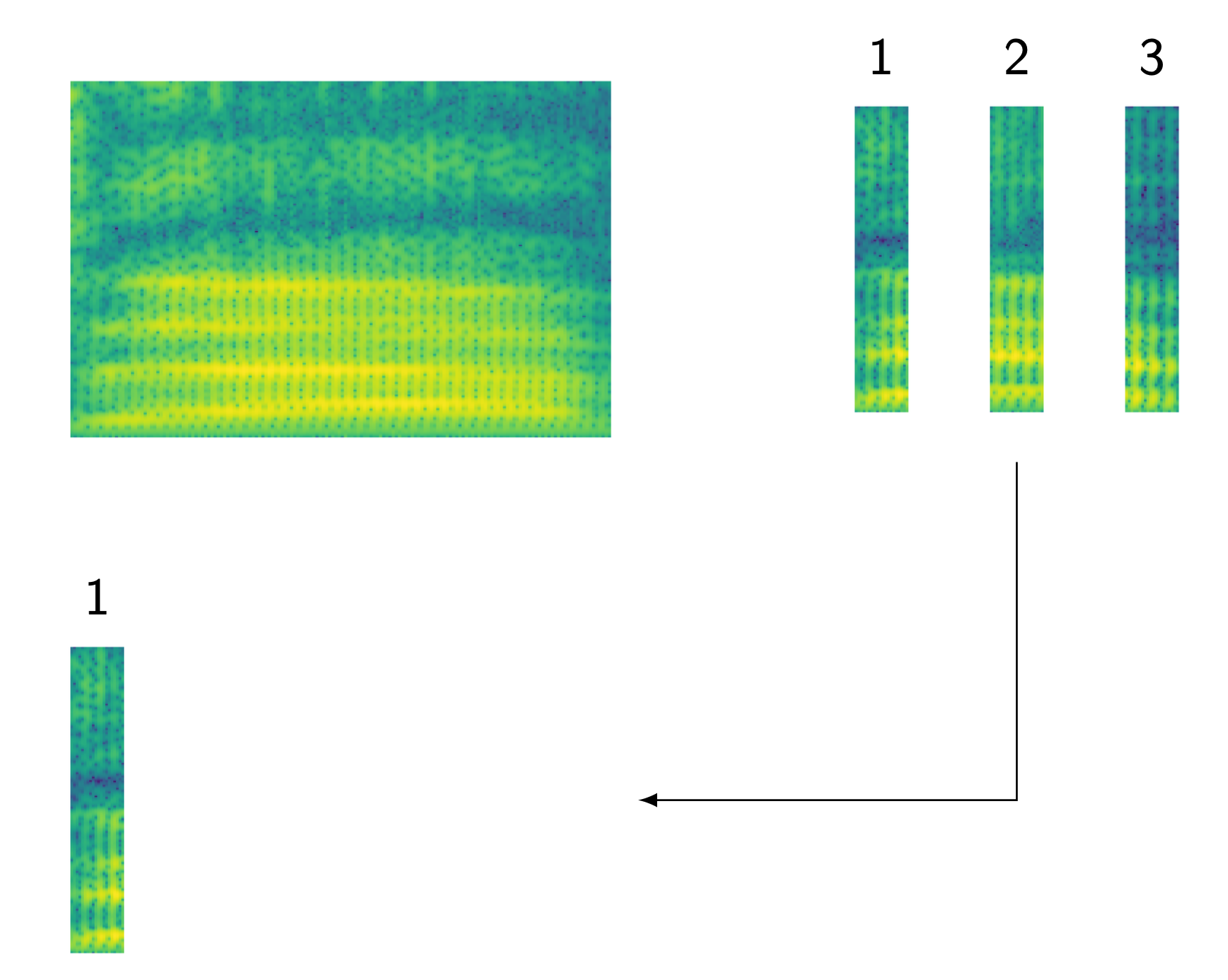 Fig.
Fig.
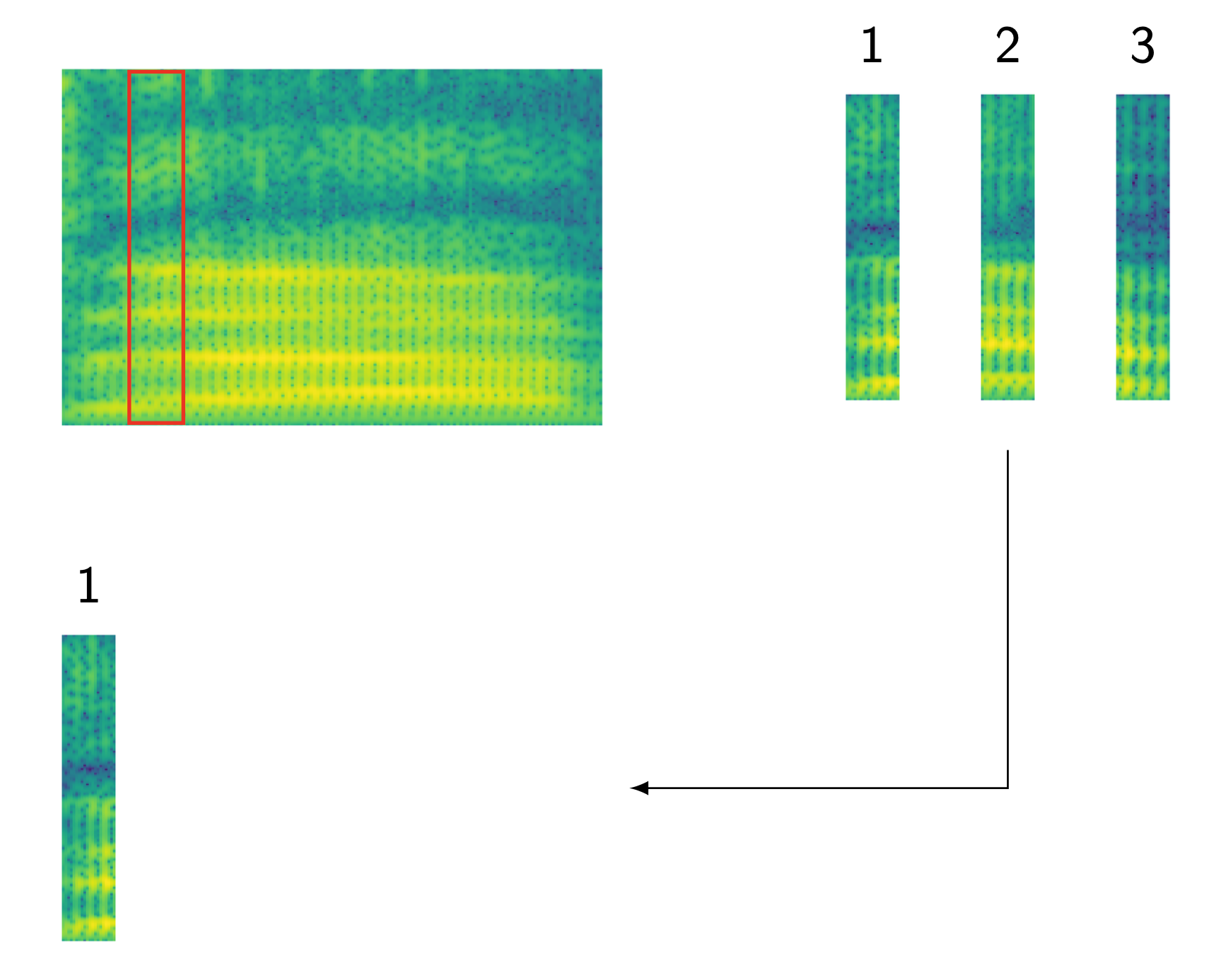 Fig.
Fig.
 Fig.
Fig.
 Fig.
Fig.
 Fig.
Fig.
 Fig.
Fig.
 Fig.
Fig.
 Fig.
Fig.
 Fig.
Fig.
 Fig.
Fig.
Hidden Markov models (HMMs)
HMM topology
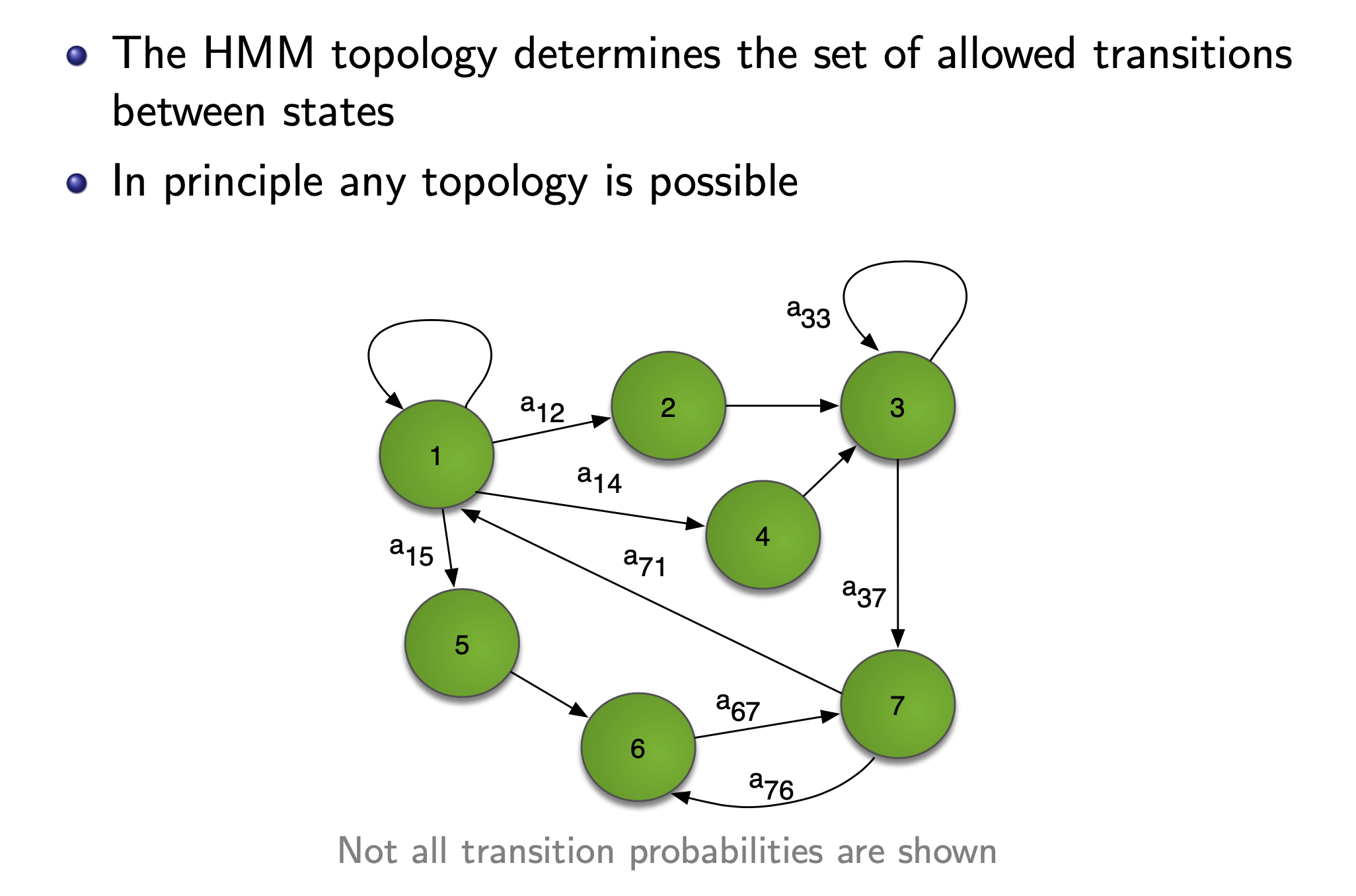 Fig.
Fig.
 Fig.
Fig.
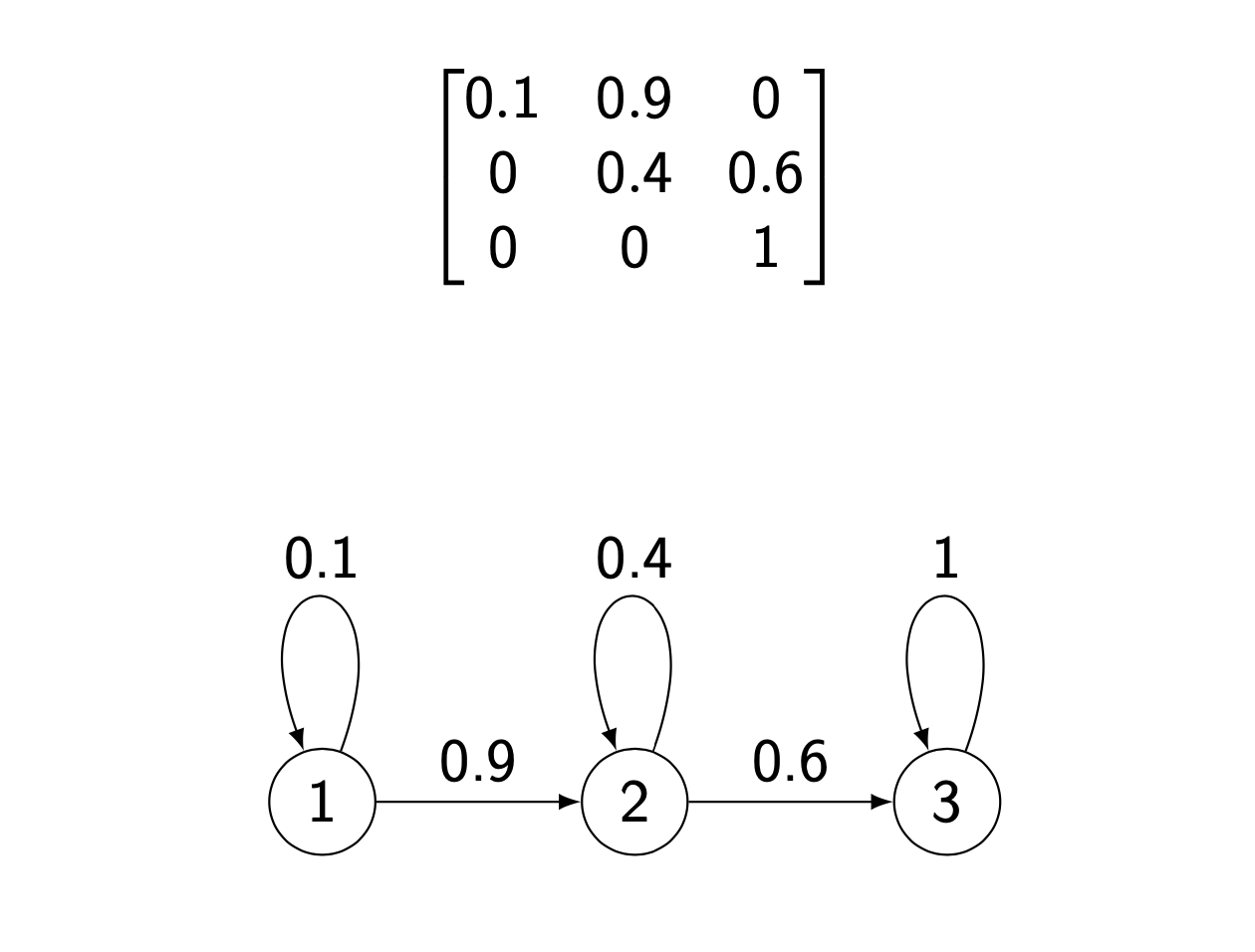 Fig.
Fig.
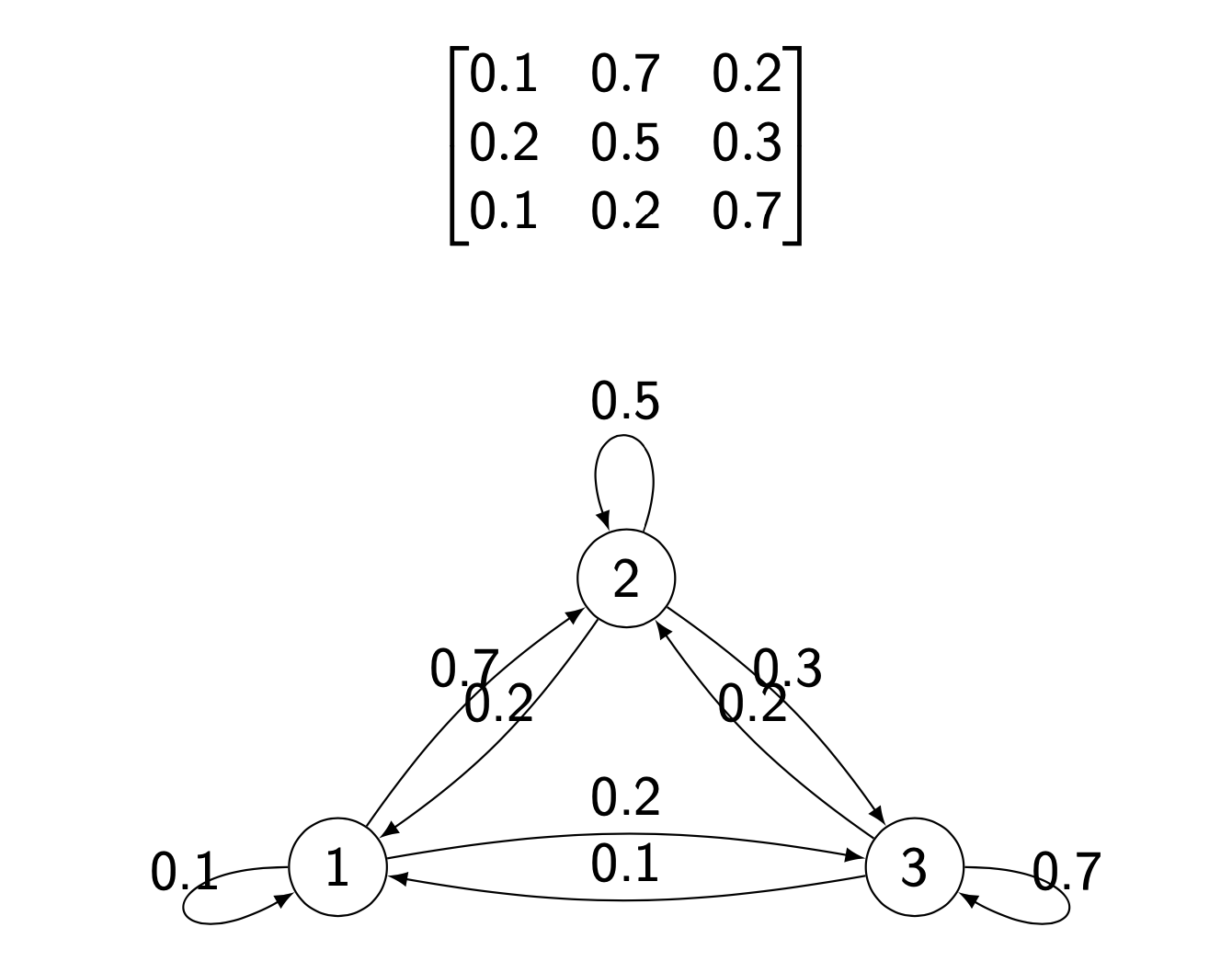 Fig.
Fig.
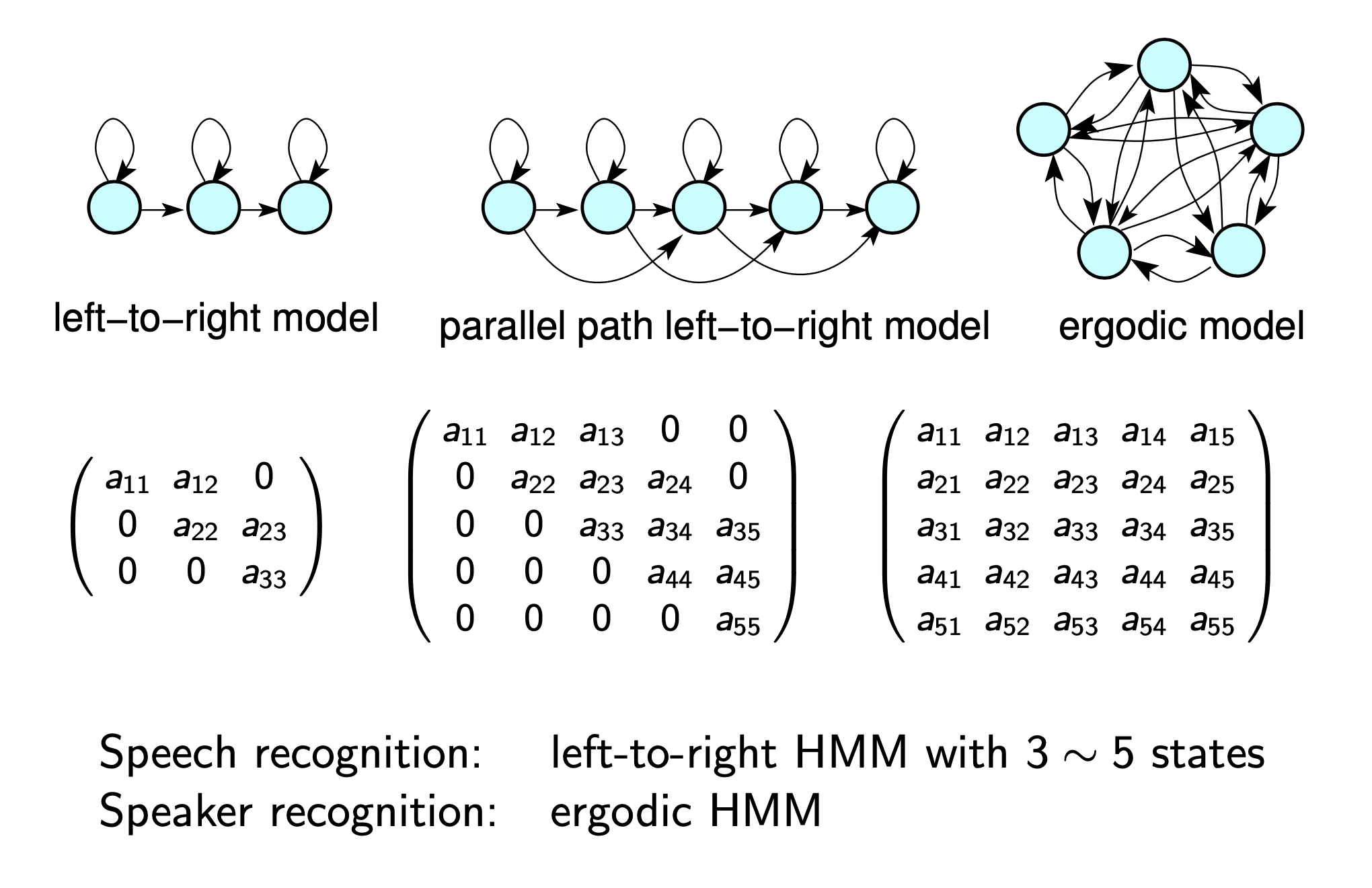 Fig.
Fig.
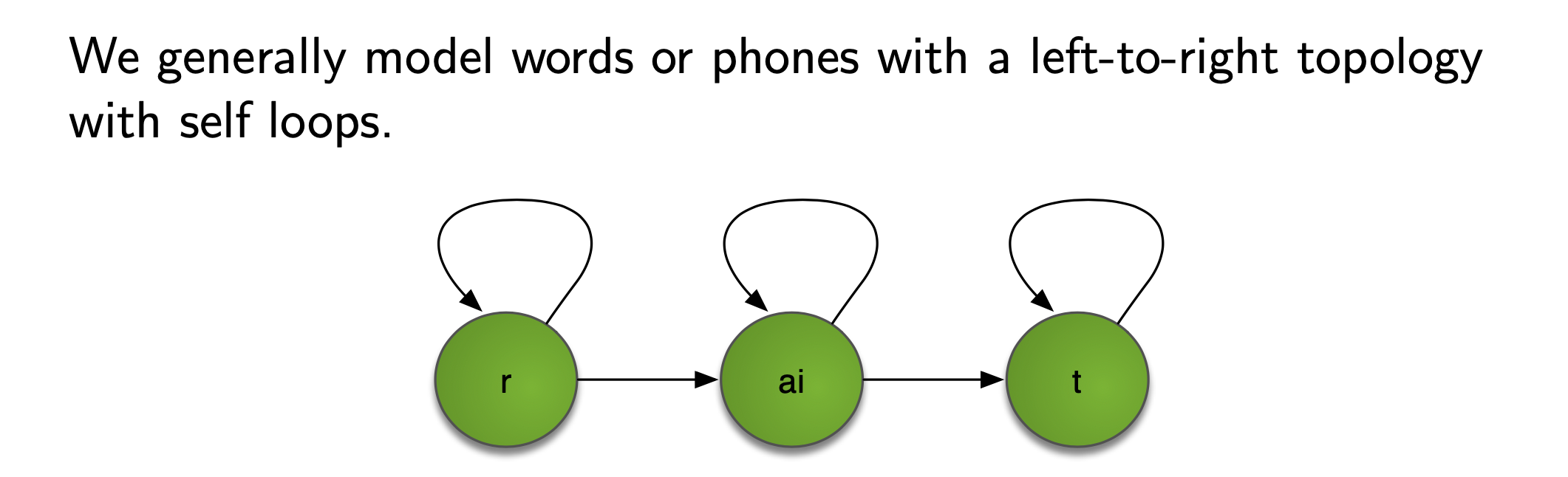 Fig.
Fig.
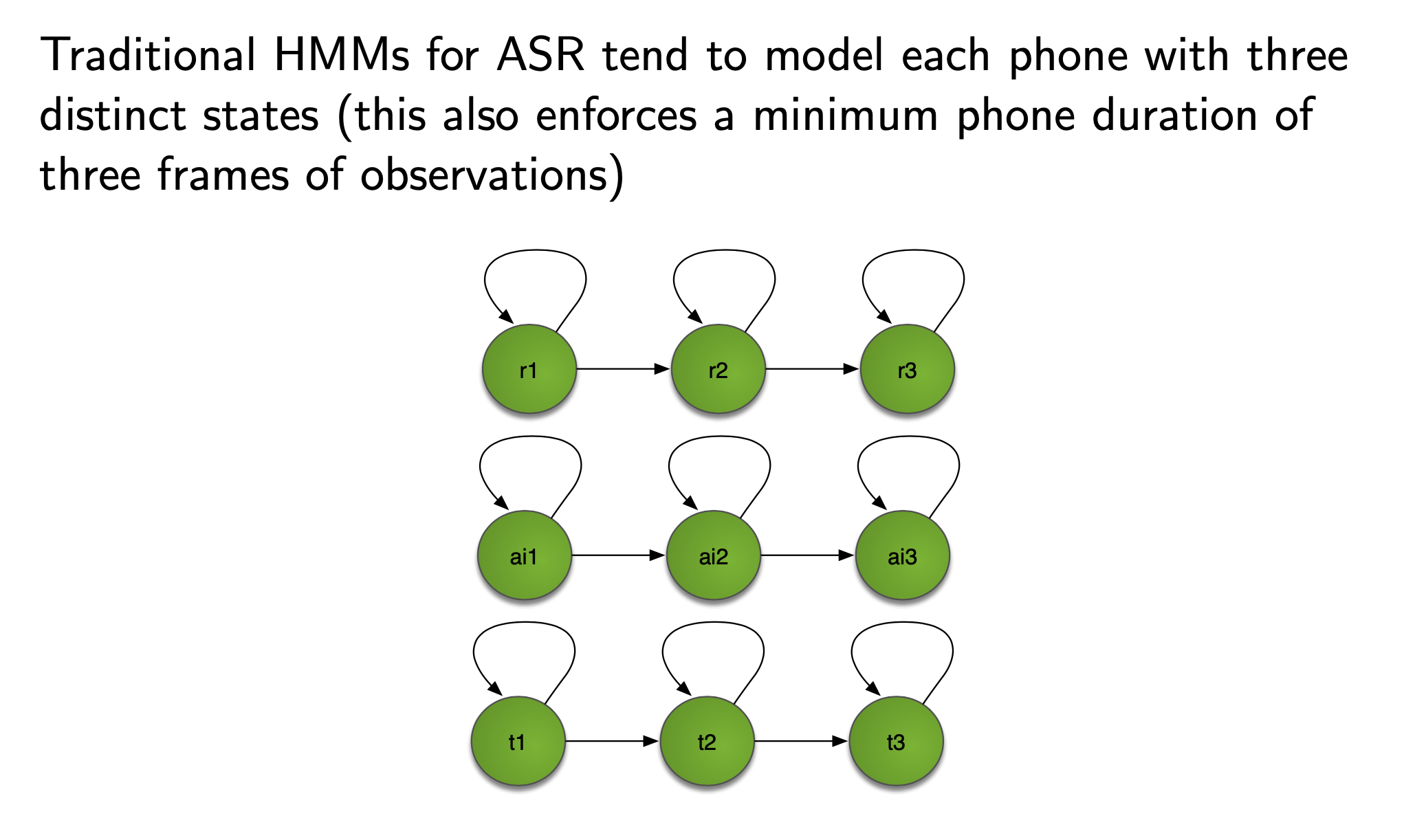 Fig.
Fig.
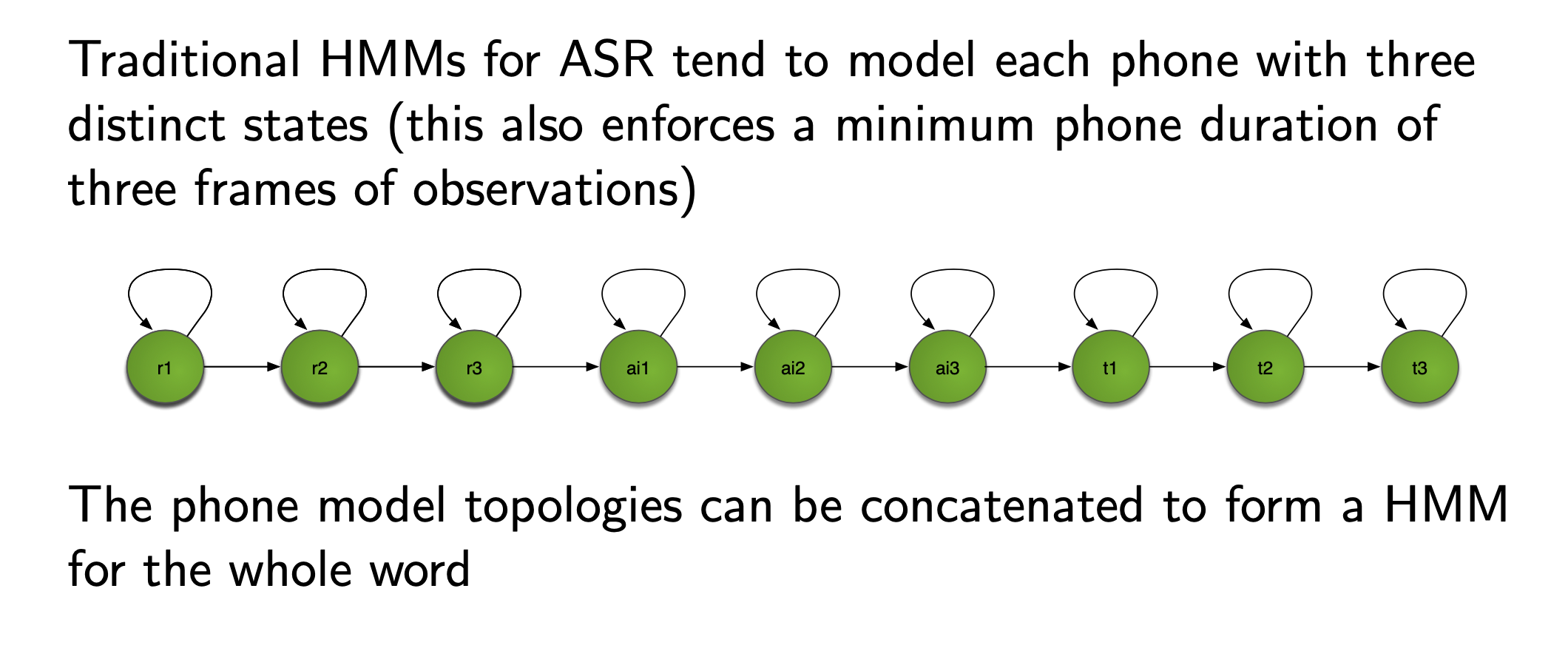 Fig.
Fig.
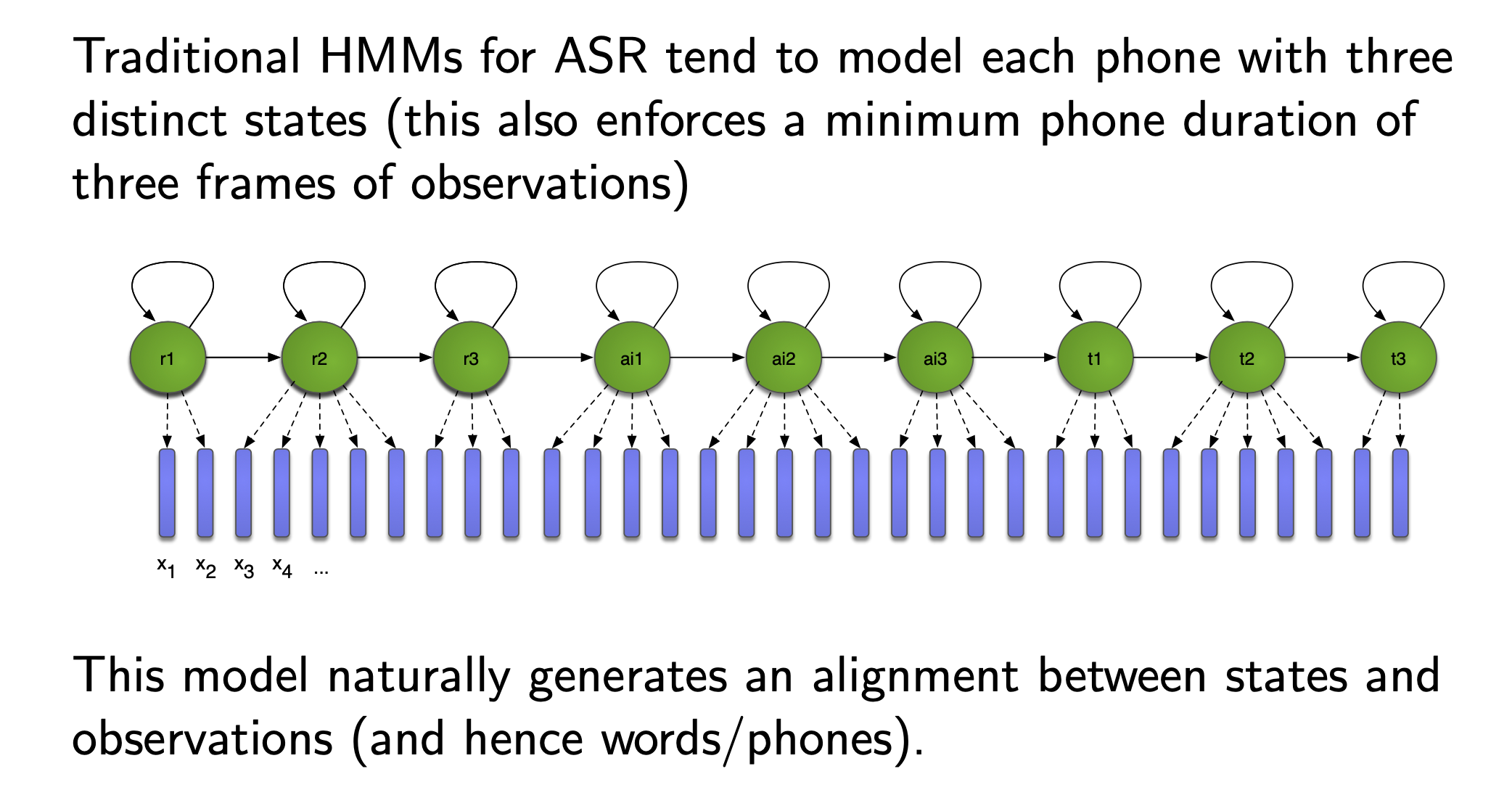 Fig.
Fig.
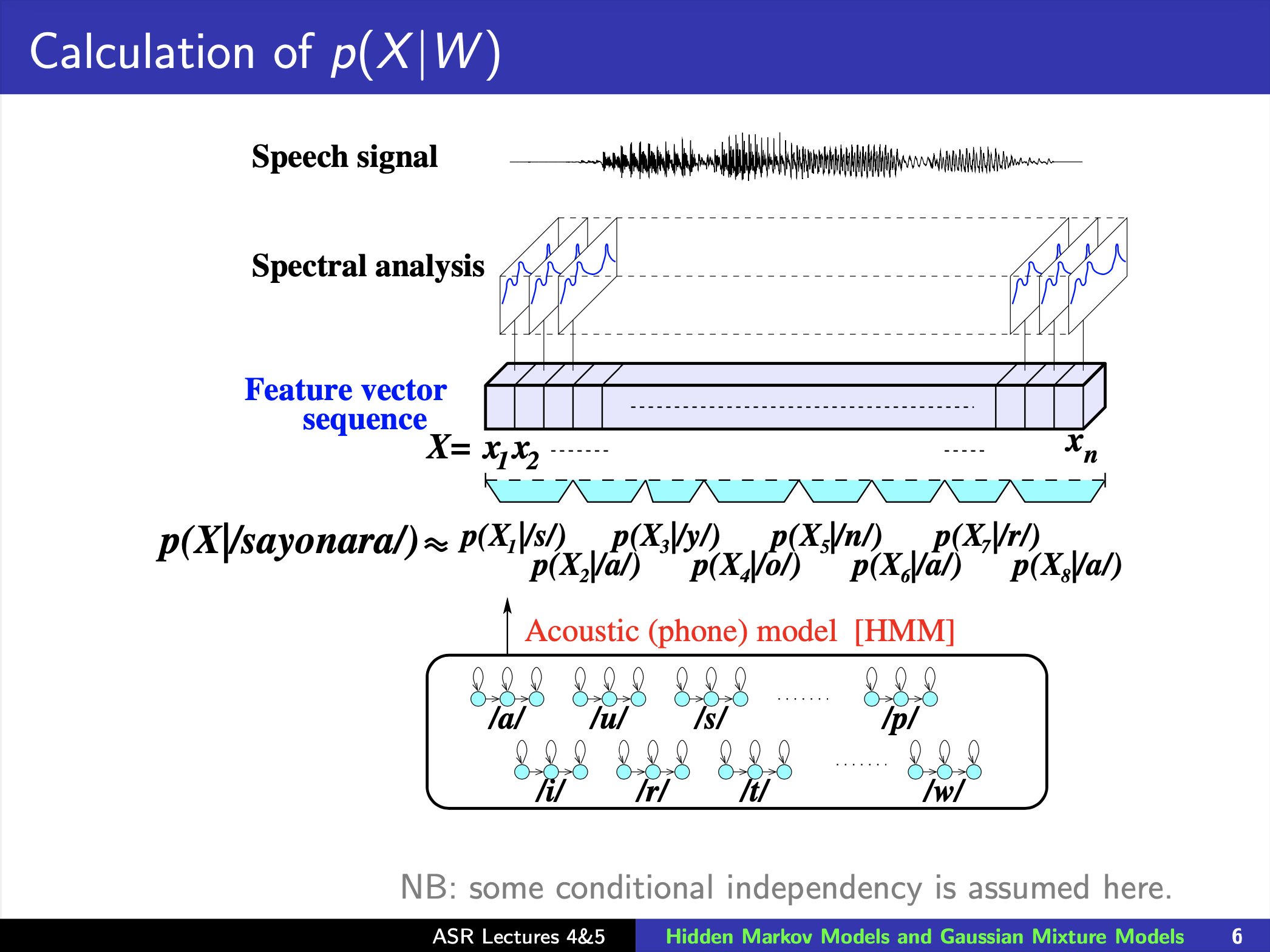 Fig.
Fig.
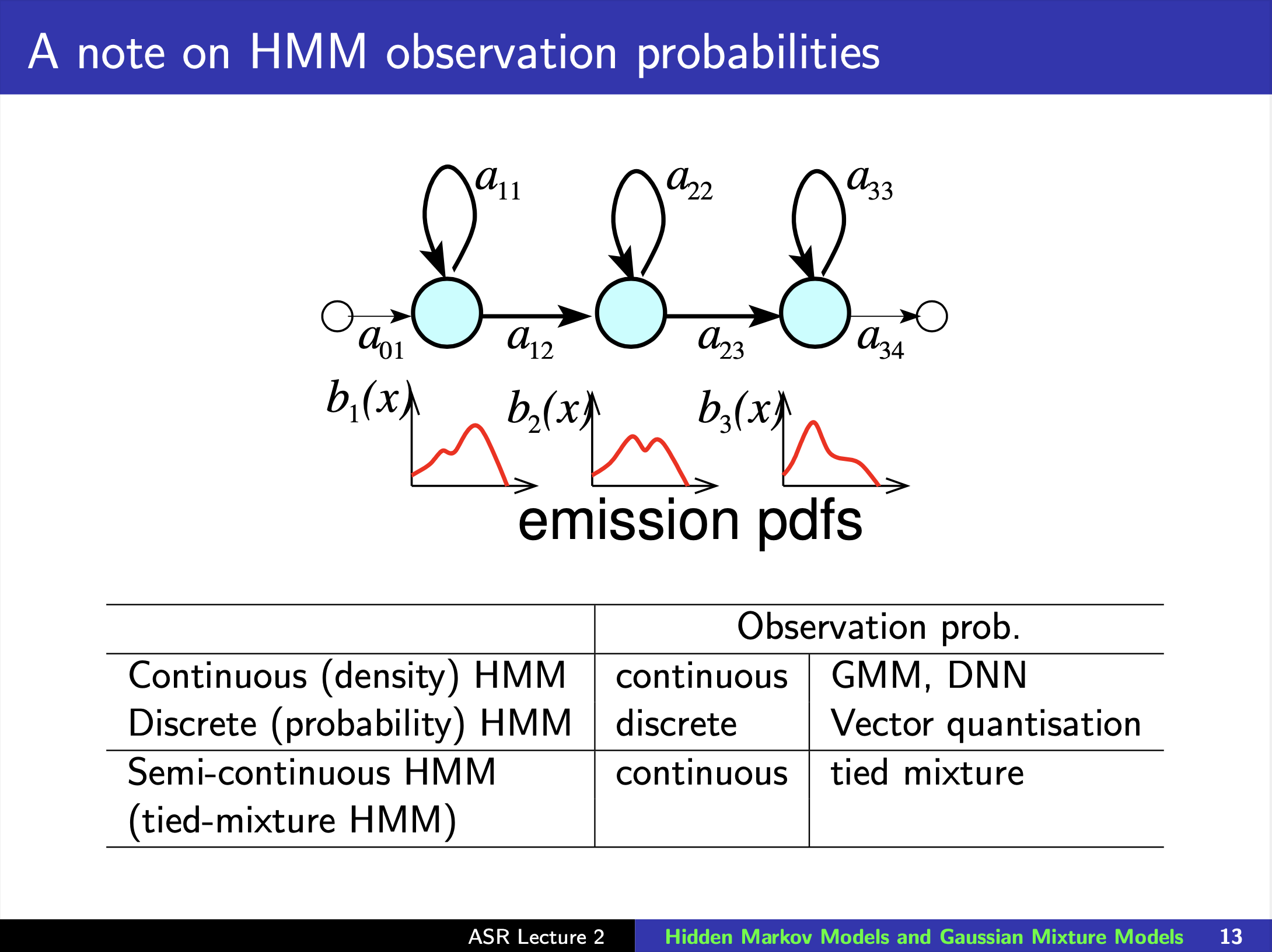 Fig.
Fig.
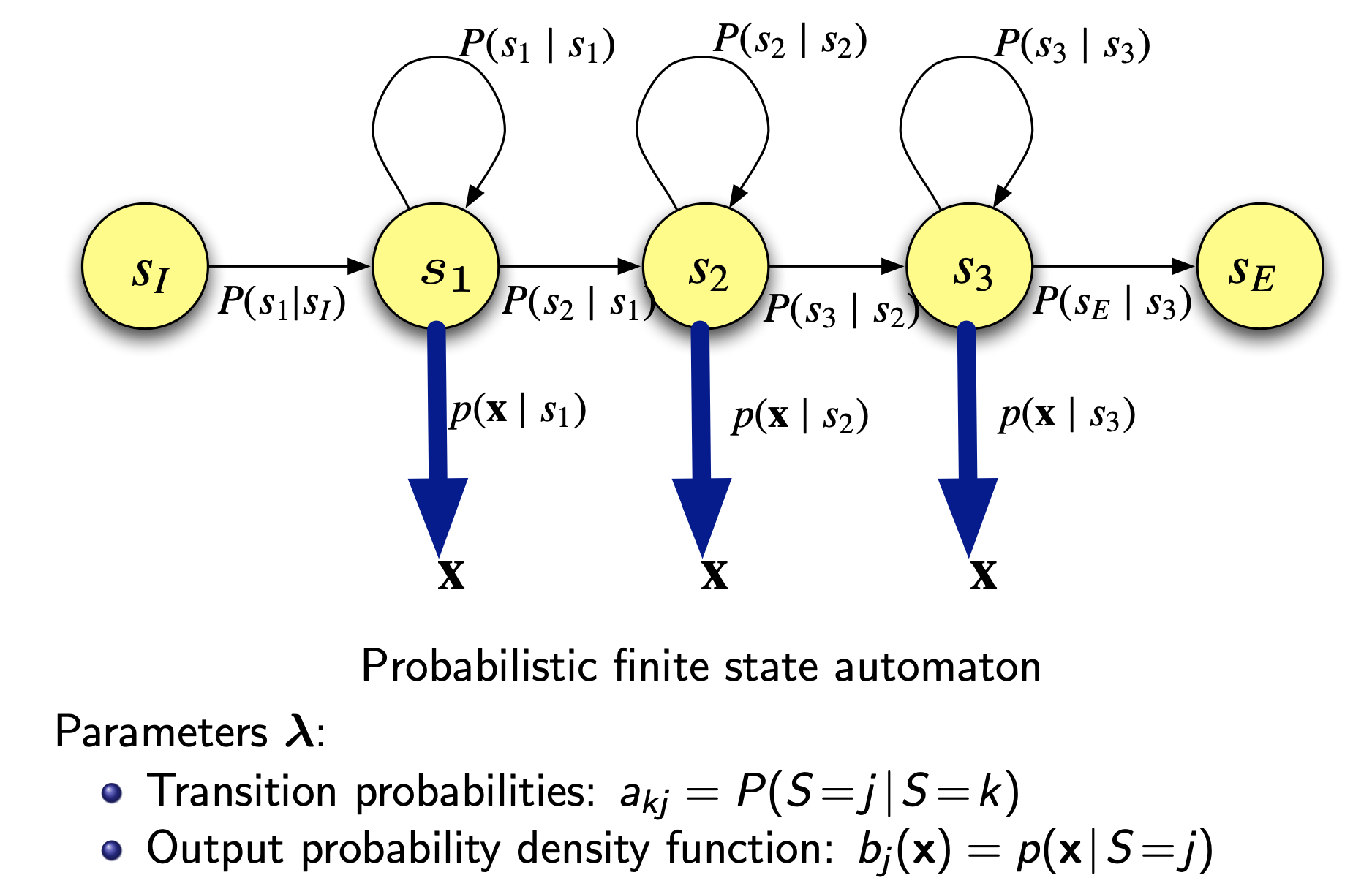 Fig.
Fig.
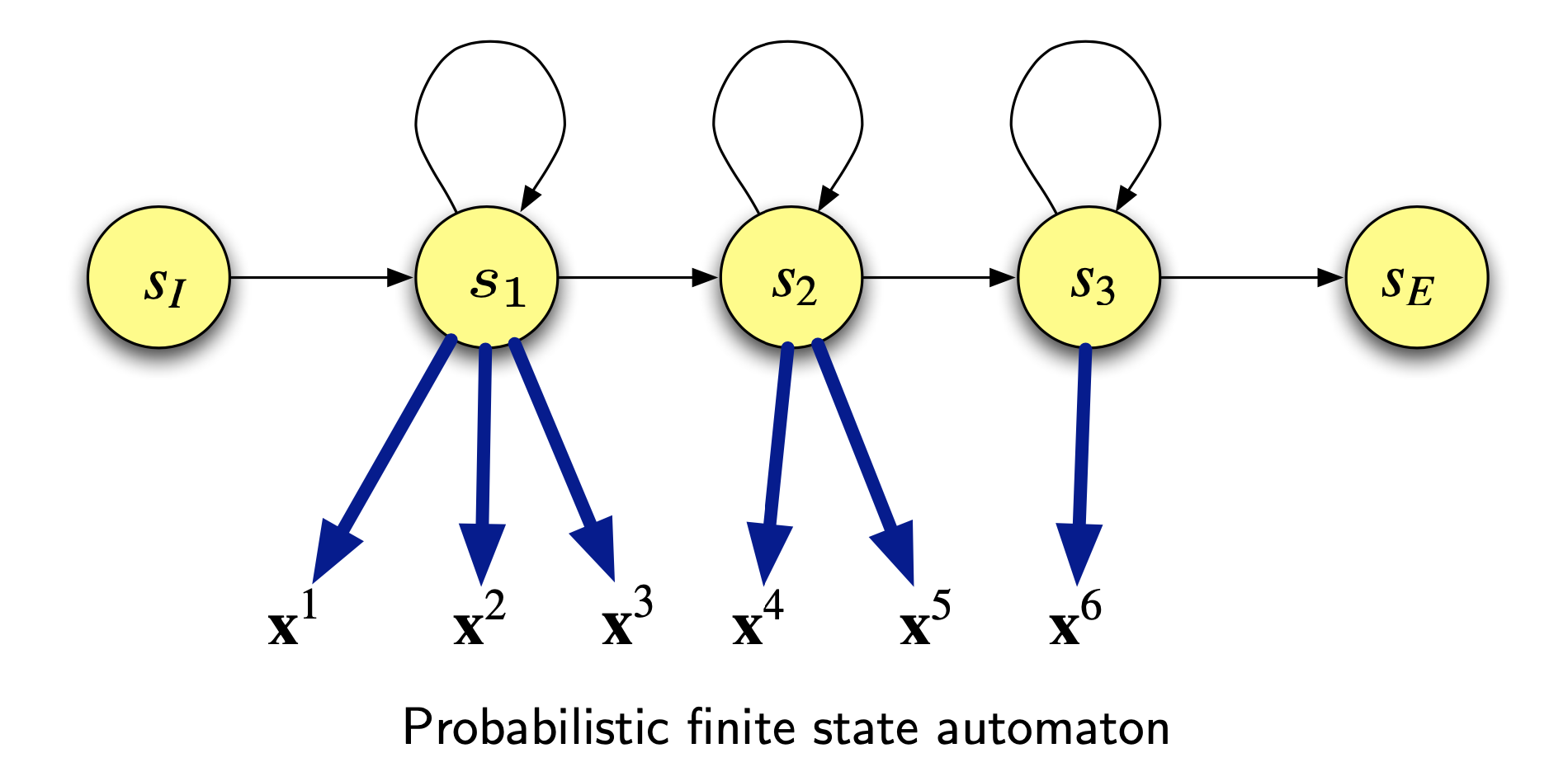 Fig.
Fig.
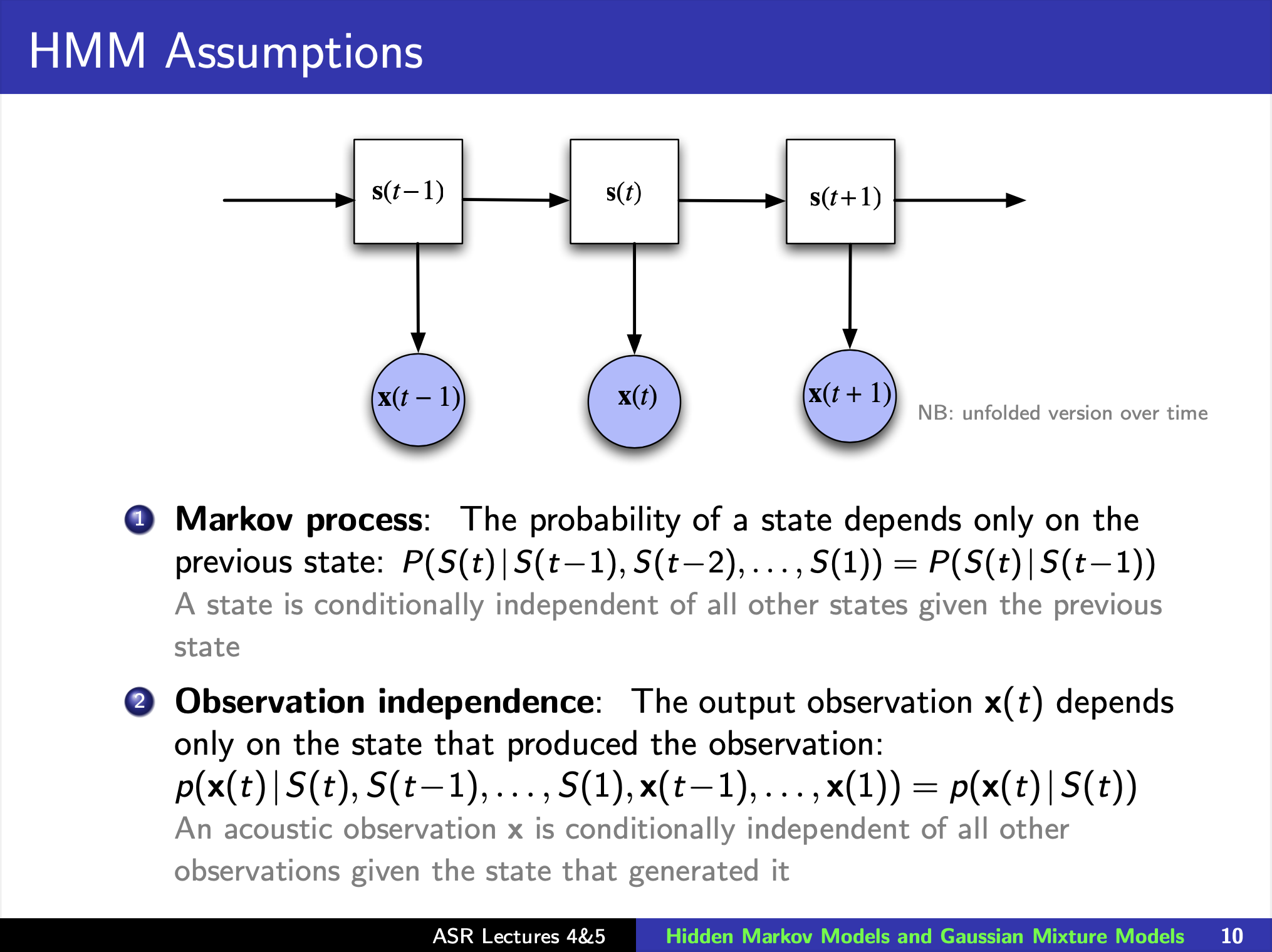 Fig.
Fig.
 Fig.
Fig.
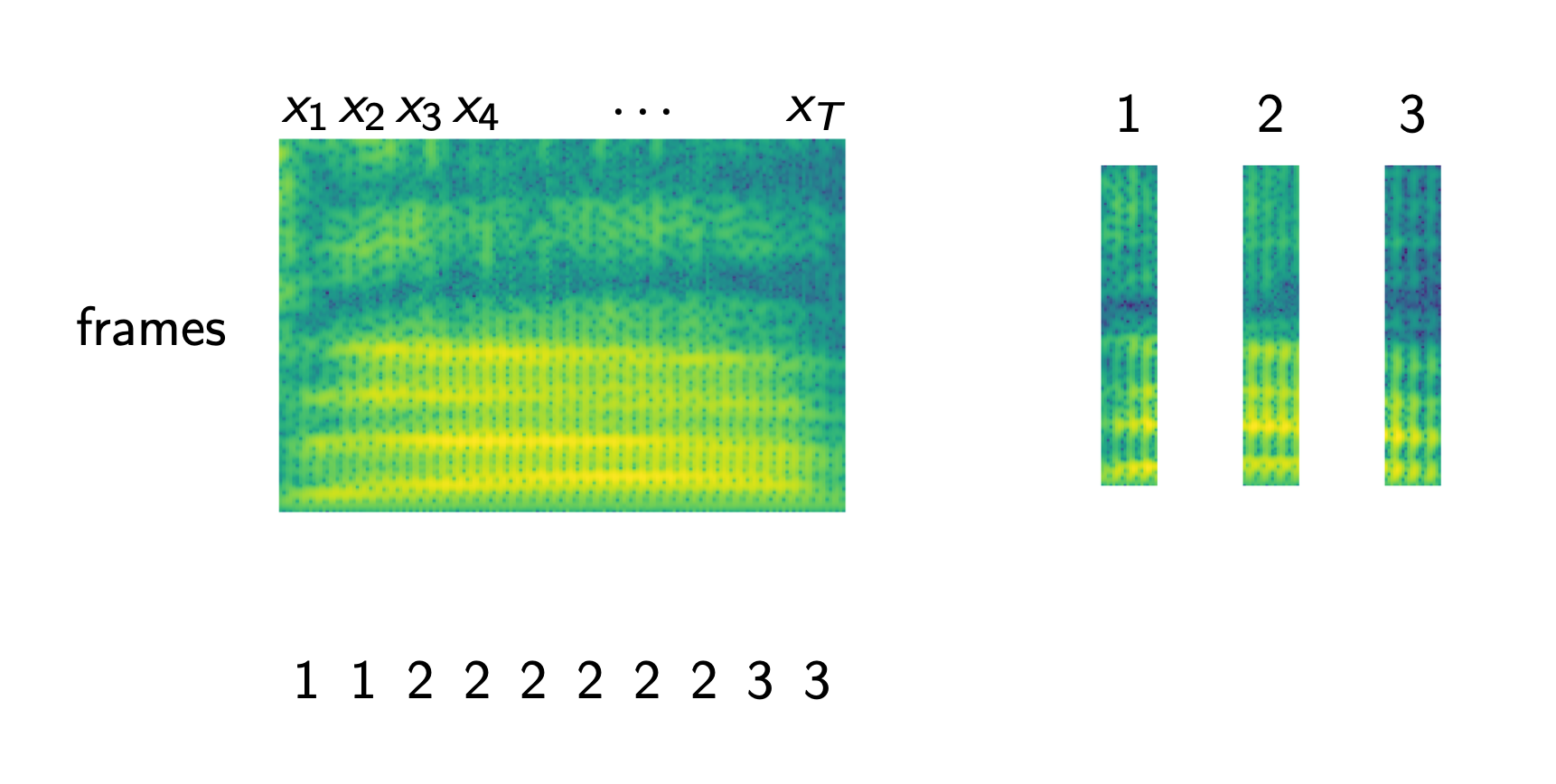 Fig.
Fig.
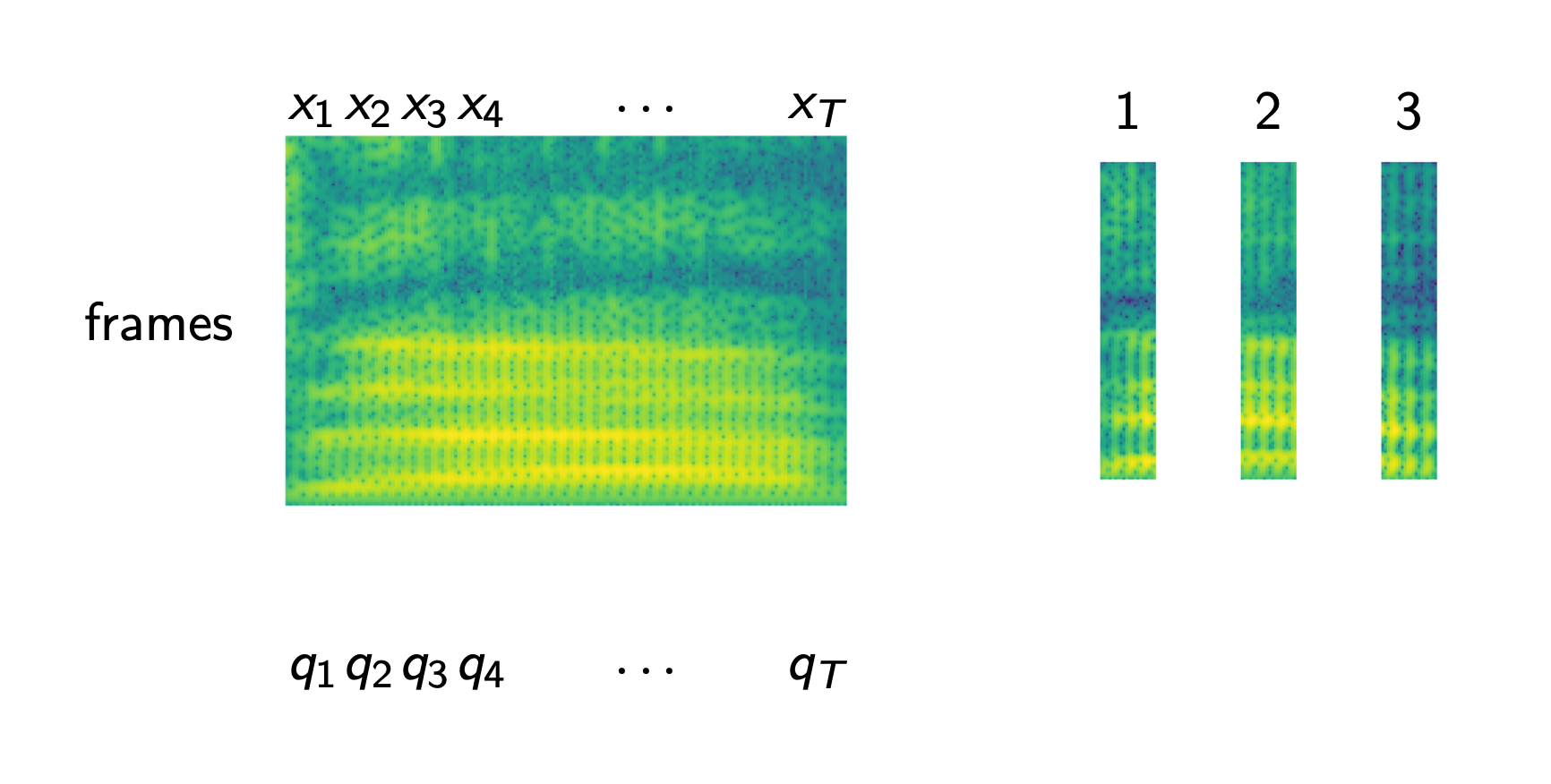 Fig.
Fig.
Bridging to Gaussian Mixture Models (GMMs)
Gaussian Distribution
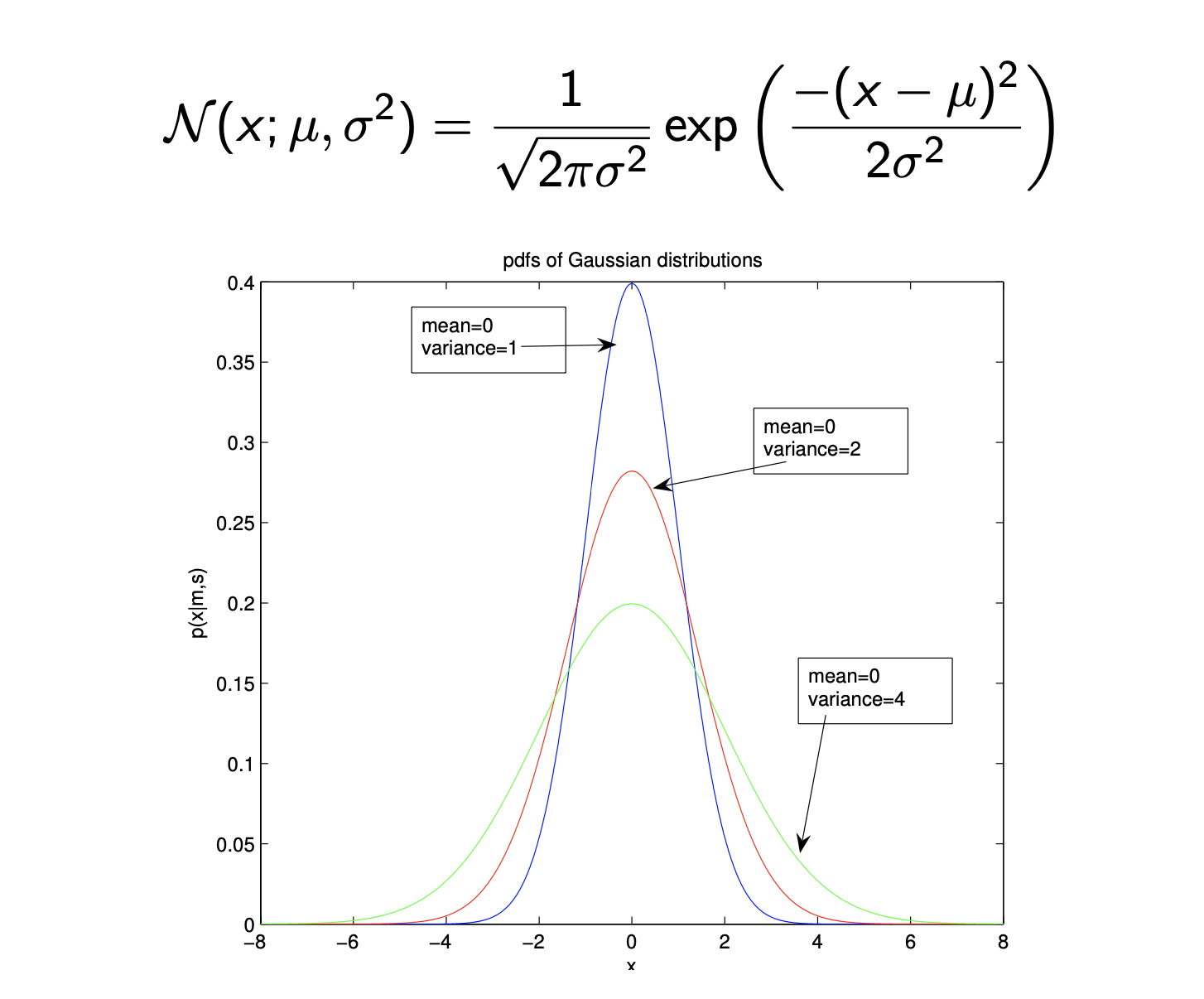 Fig.
Fig.
 Fig.
Fig.
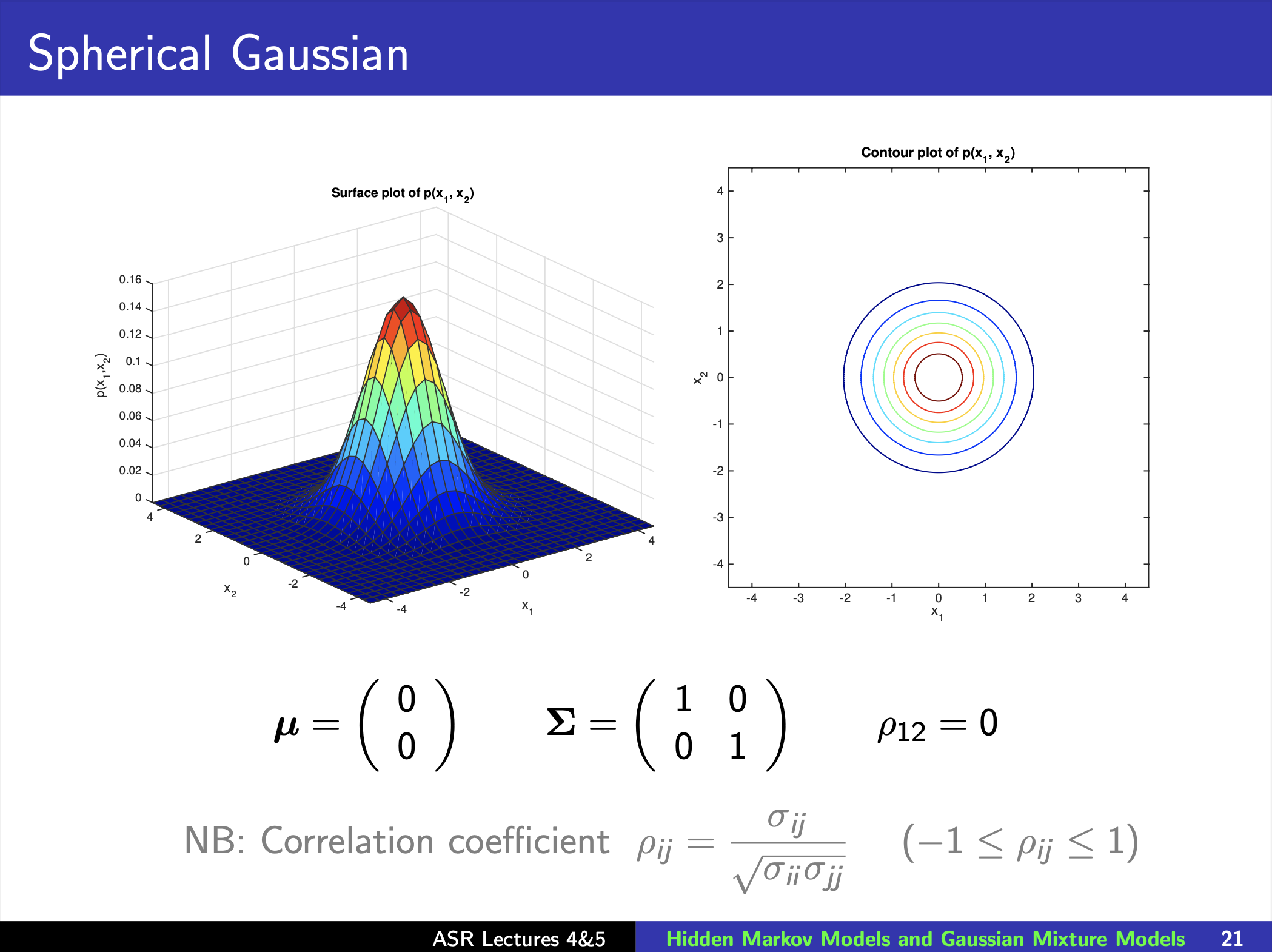 Fig.
Fig.
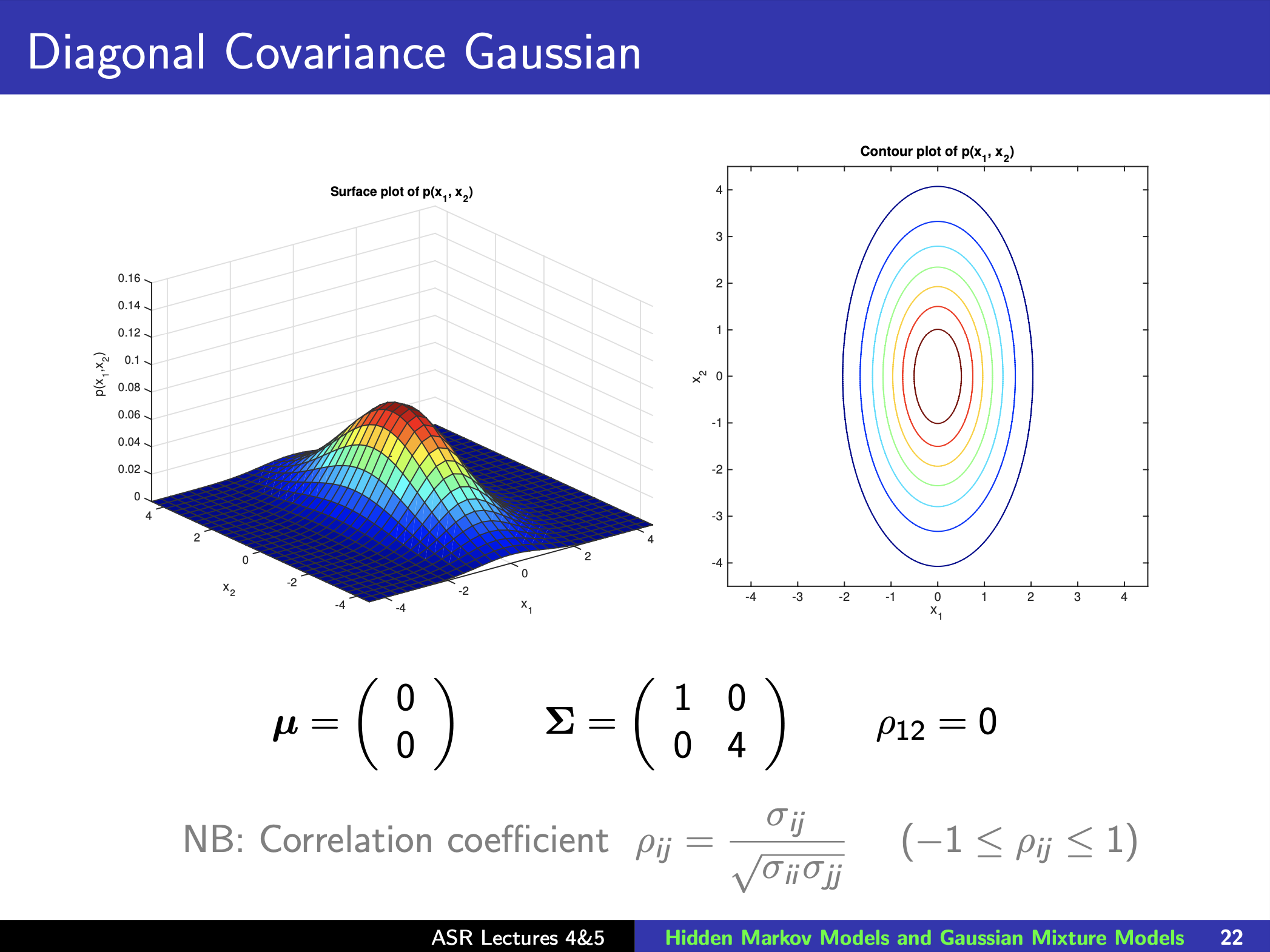 Fig.
Fig.
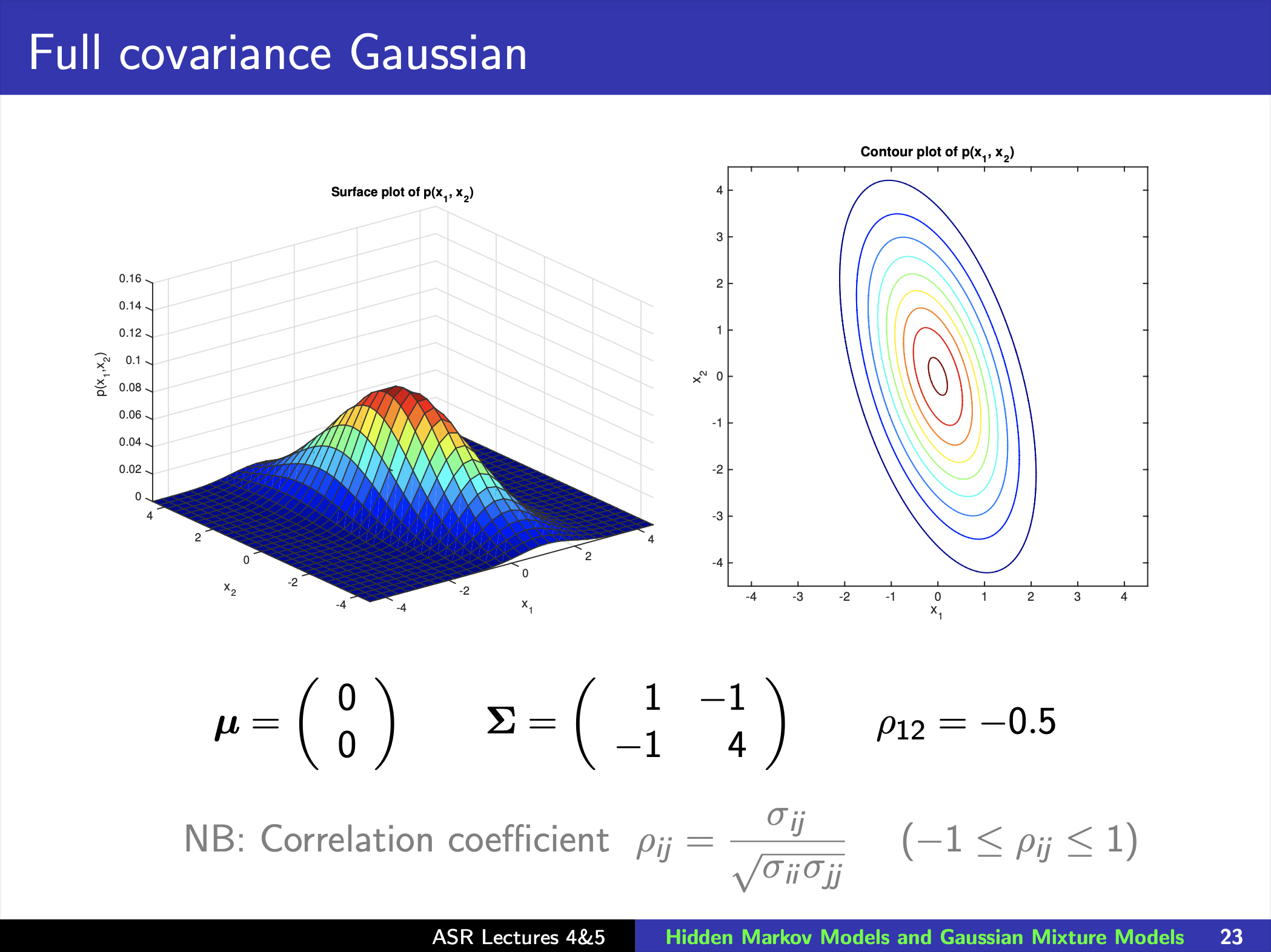 Fig.
Fig.
 Fig.
Fig.
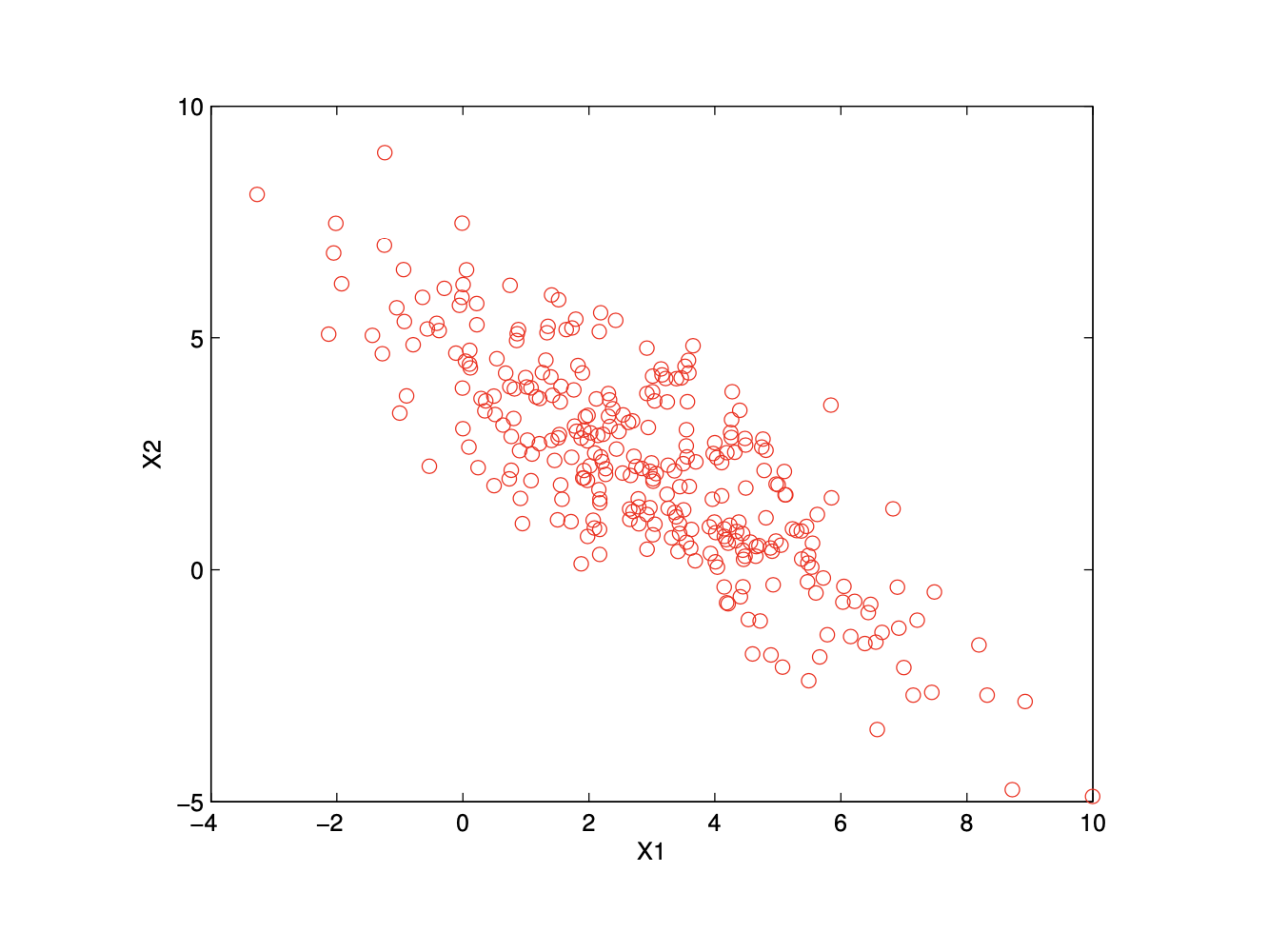 Fig.
Fig.
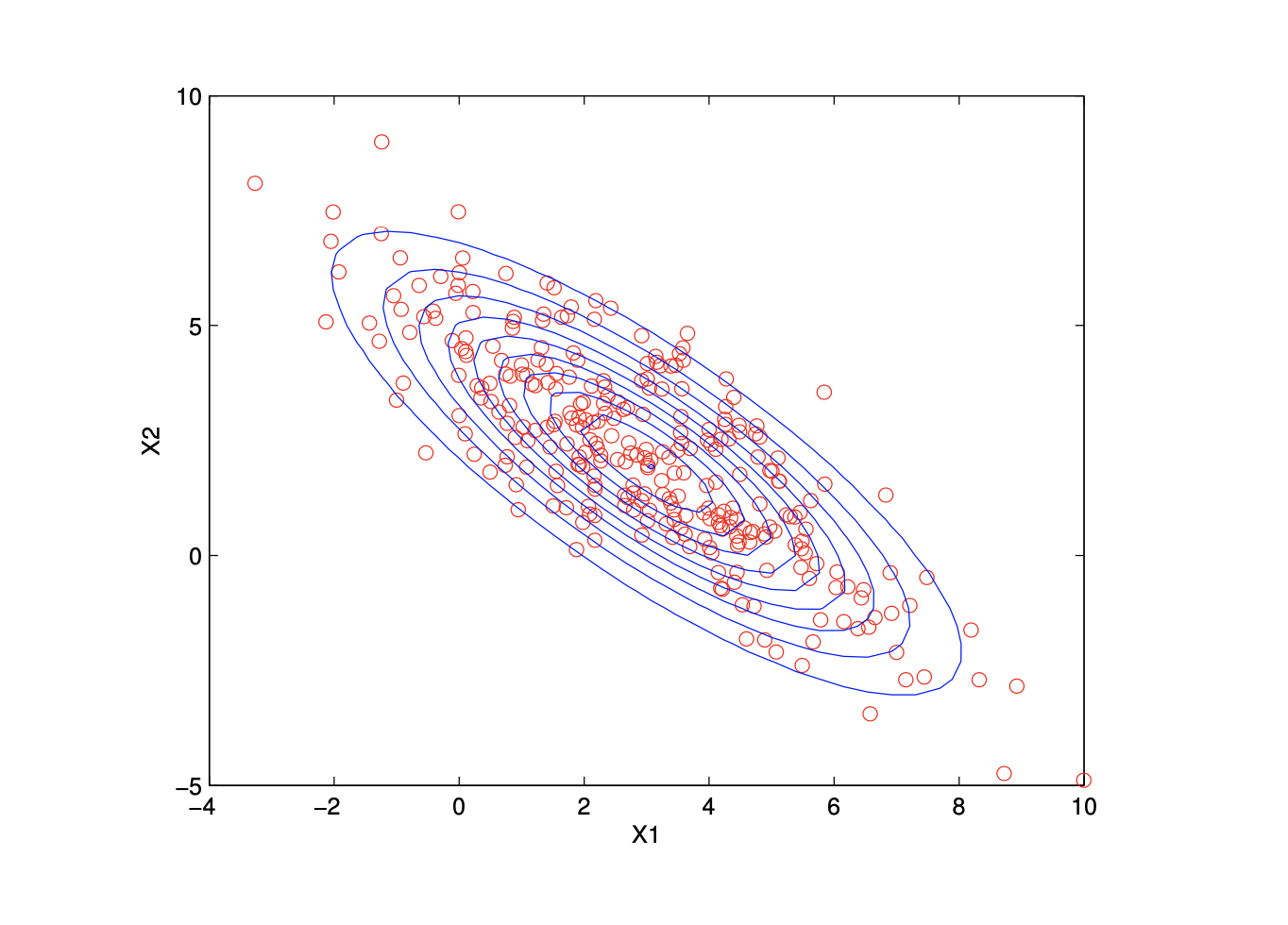 Fig.
Fig.
 Fig.
Fig.
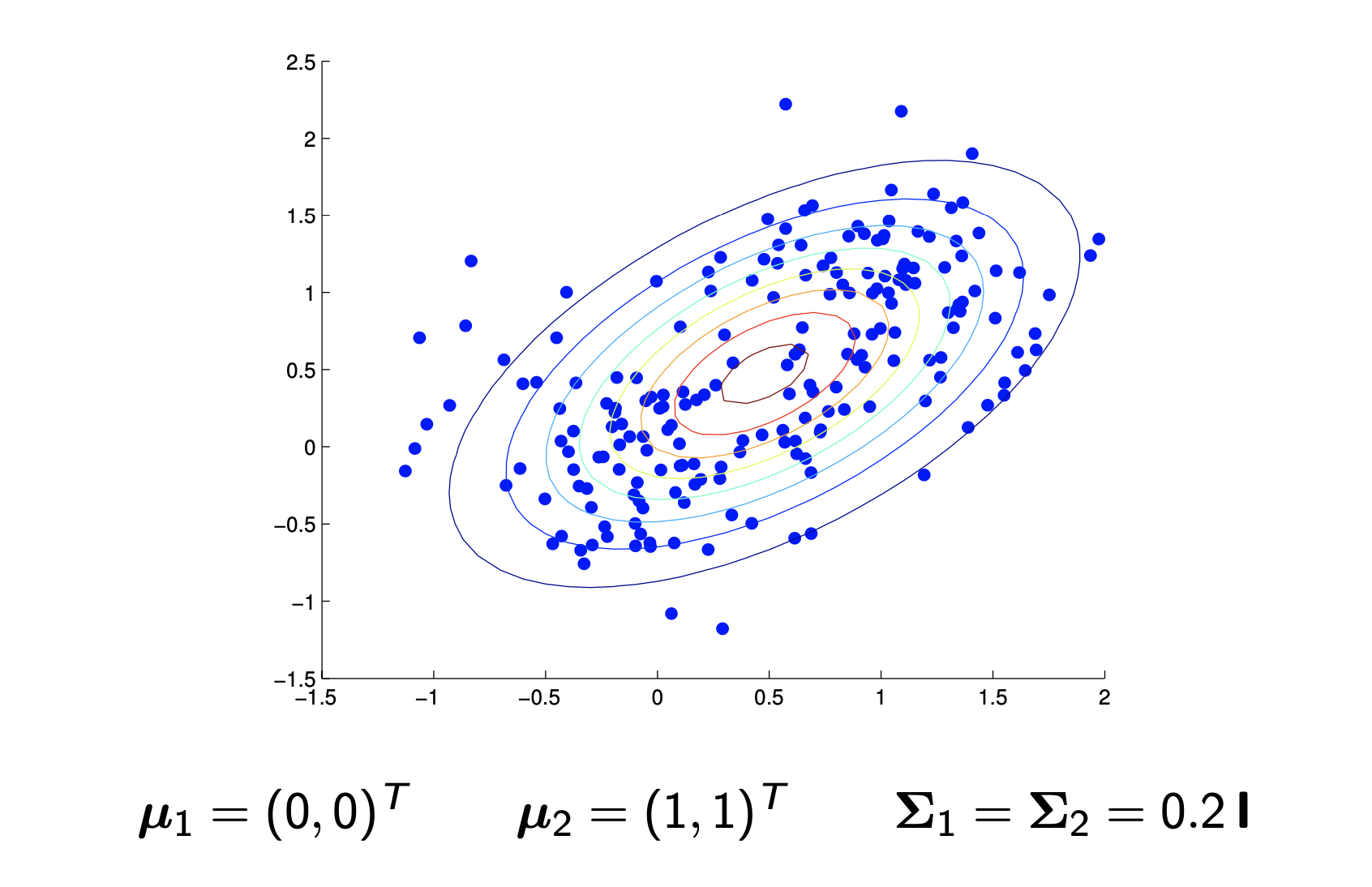 Fig.
Fig.
K-means Clustering
 Fig.
Fig.
 Fig.
Fig.
 Fig.
Fig.
 Fig.
Fig.
 Fig.
Fig.
 Fig.
Fig.
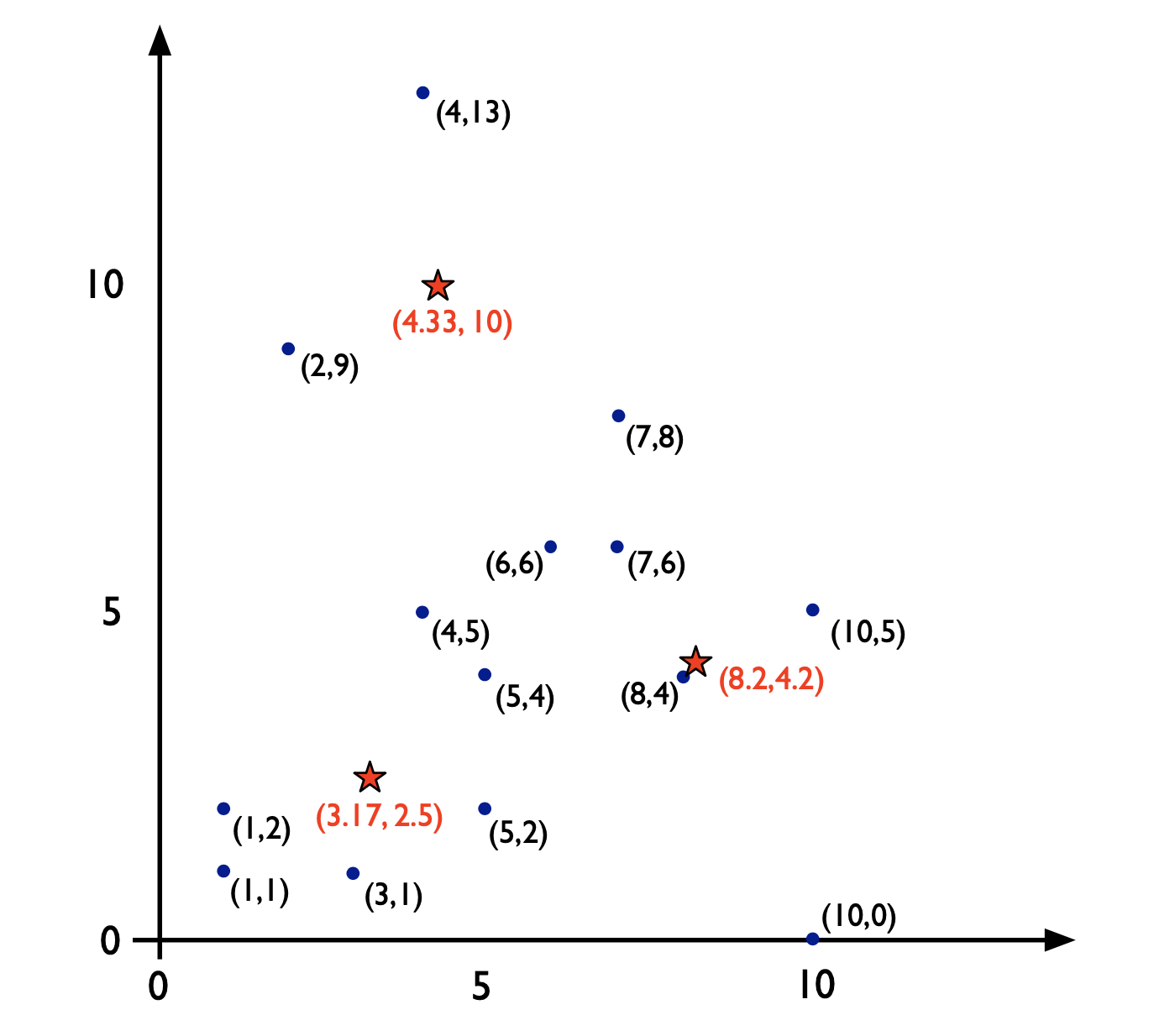 Fig.
Fig.
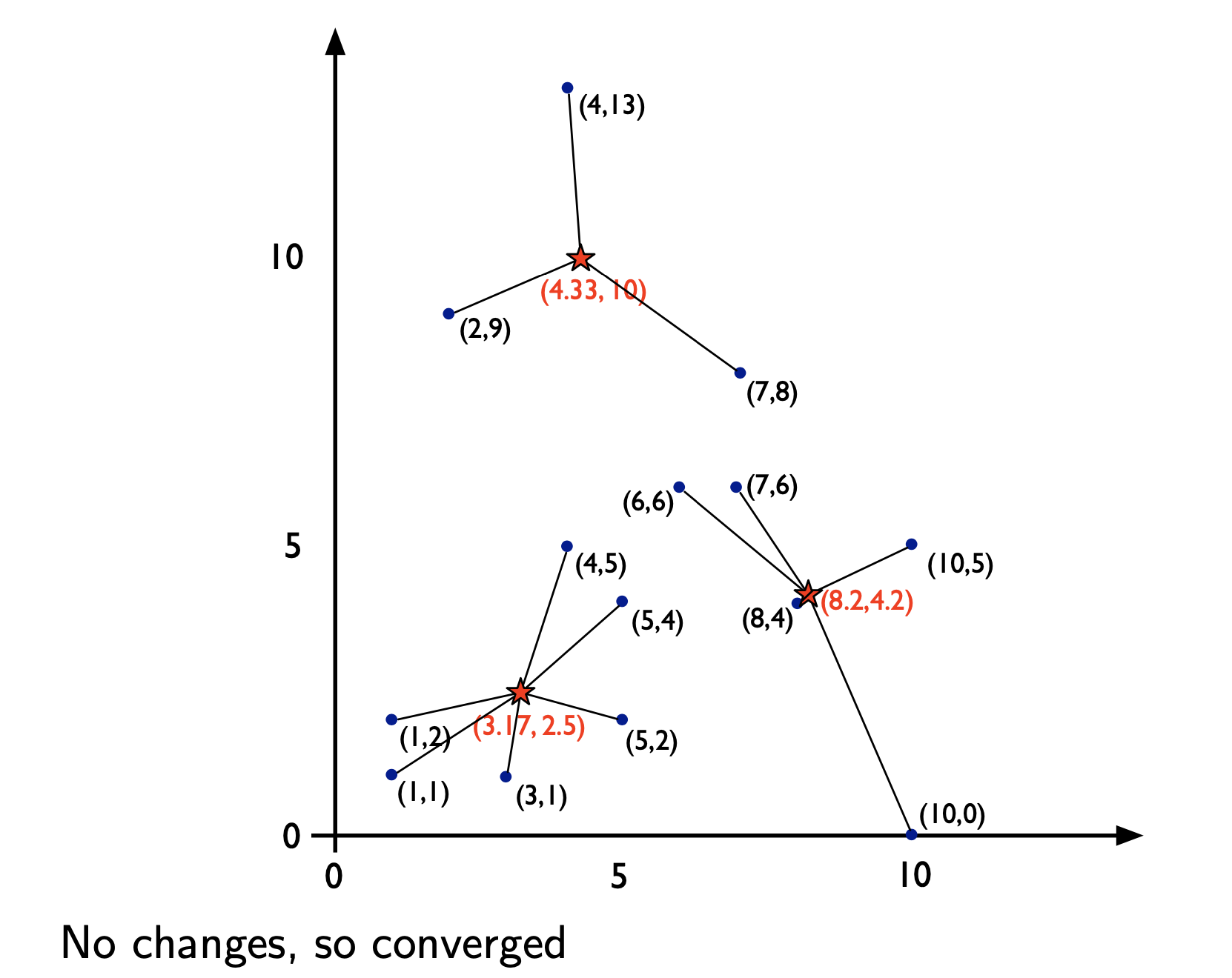 Fig.
Fig.
(Gaissuain) Mixture Model (GMM)
 Fig.
Fig.
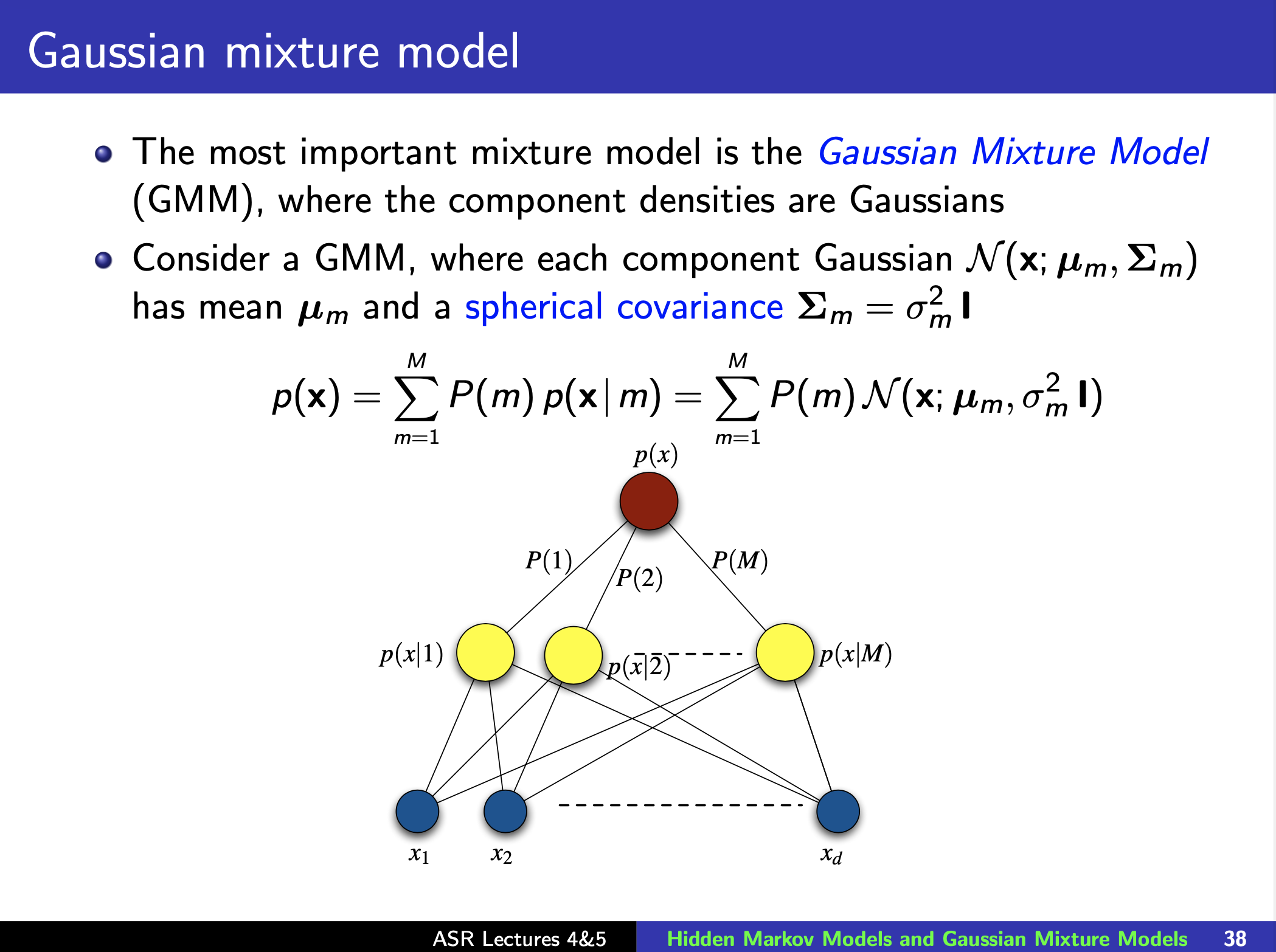 Fig.
Fig.
Expectation and Maximization Algorithm for Training GMM Parameters (EM algorithm)
 Fig.
Fig.
 Fig.
Fig.
 Fig.
Fig.
 Fig.
Fig.
 Fig.
Fig.
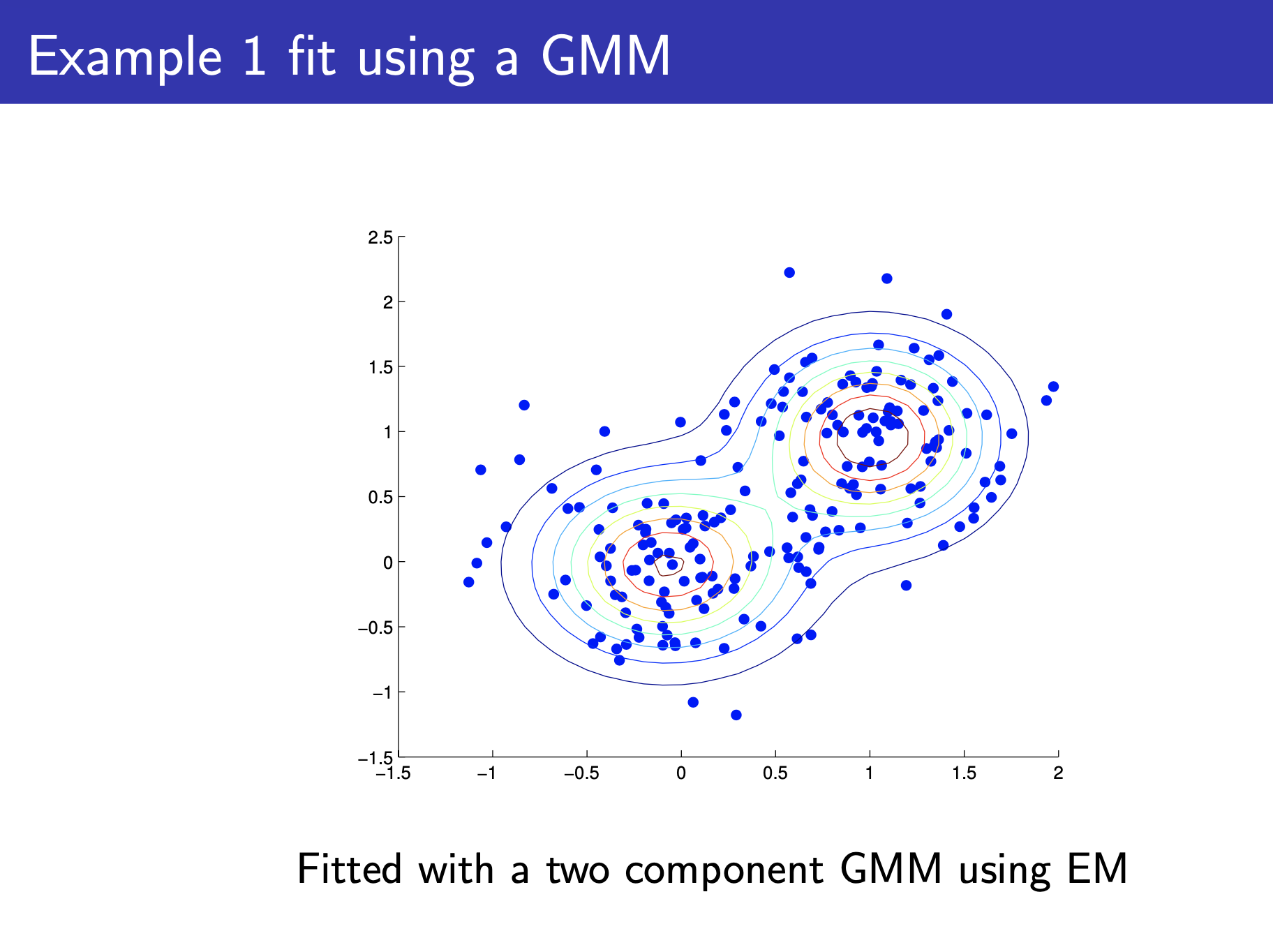 Fig.
Fig.
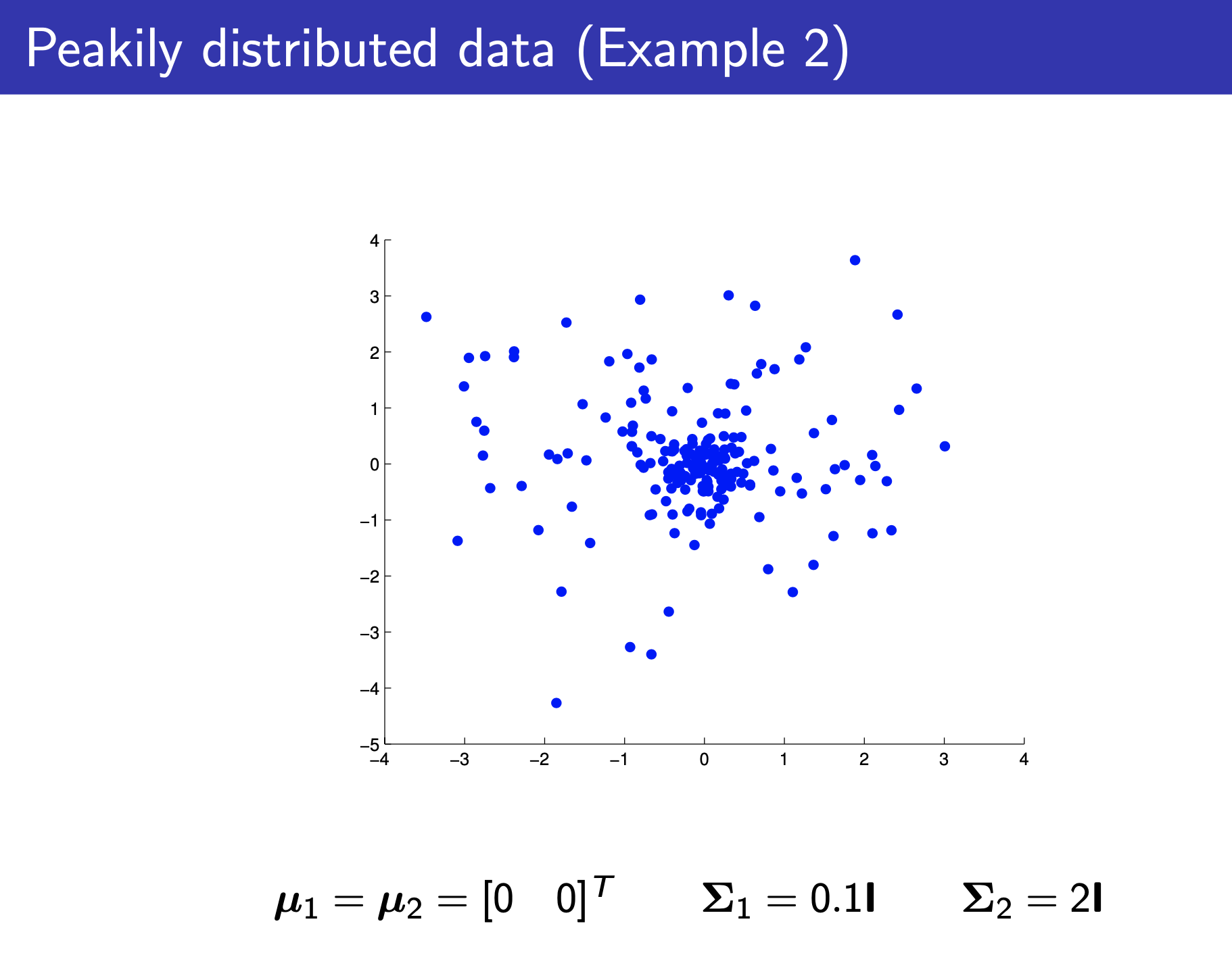 Fig.
Fig.
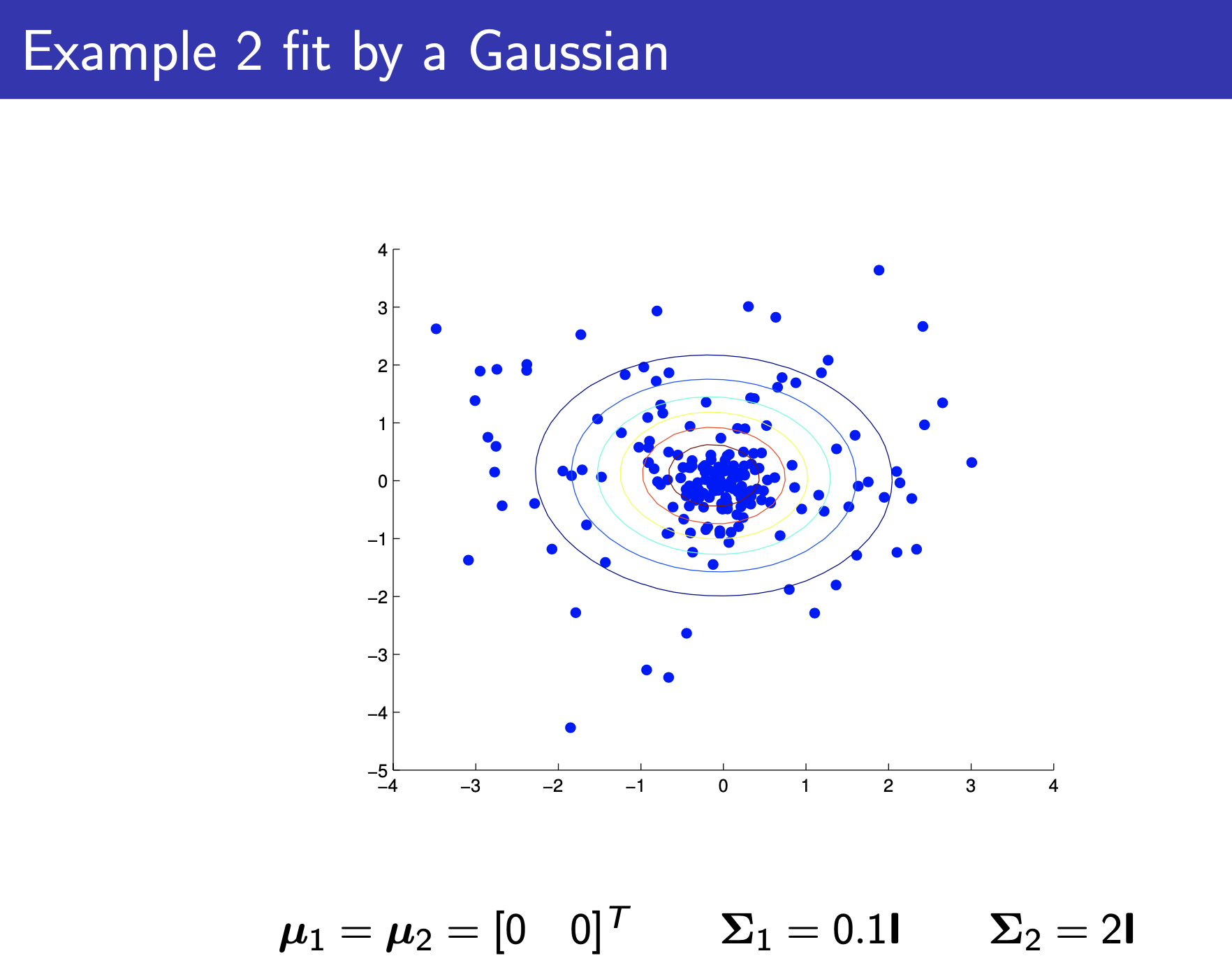 Fig.
Fig.
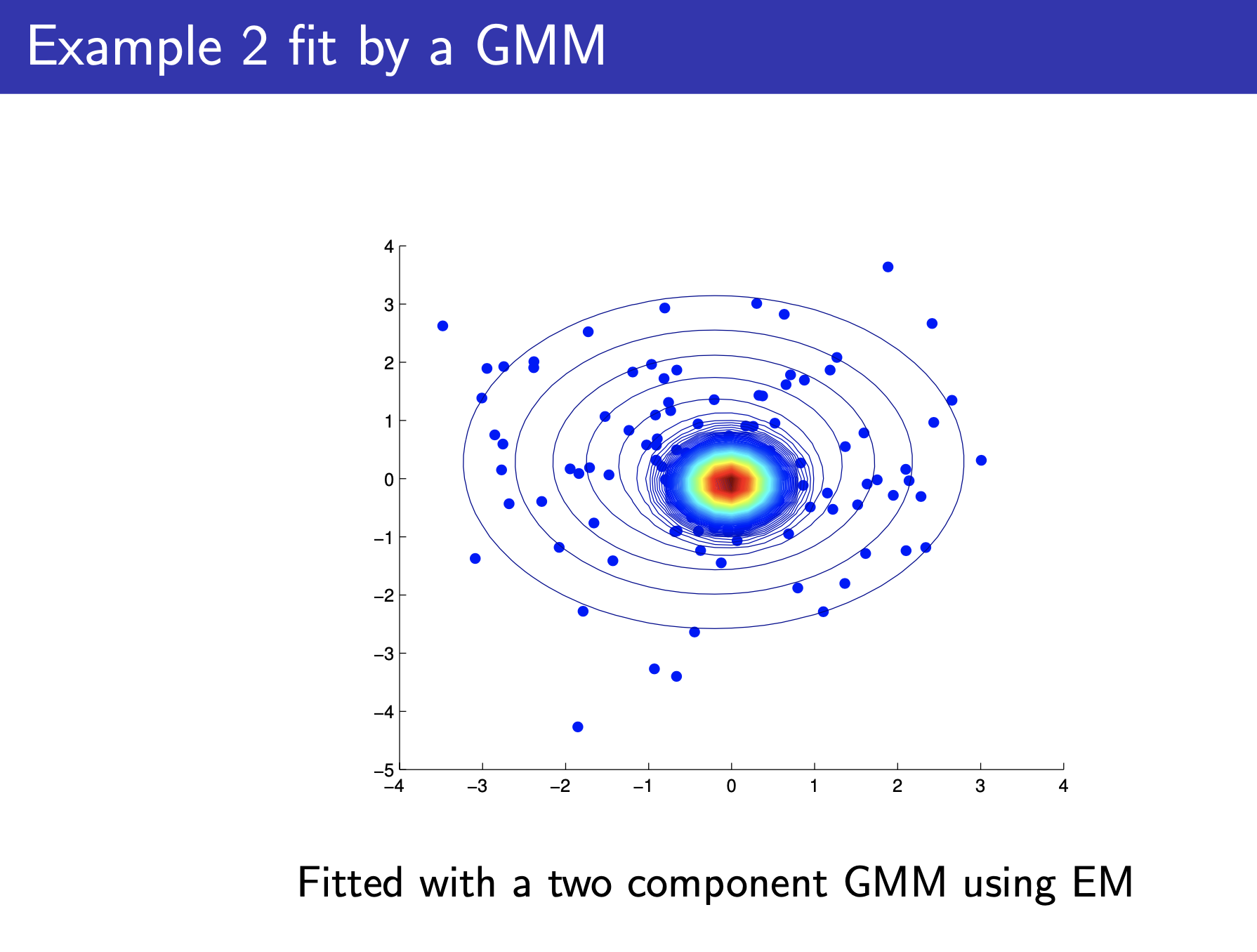 Fig.
Fig.
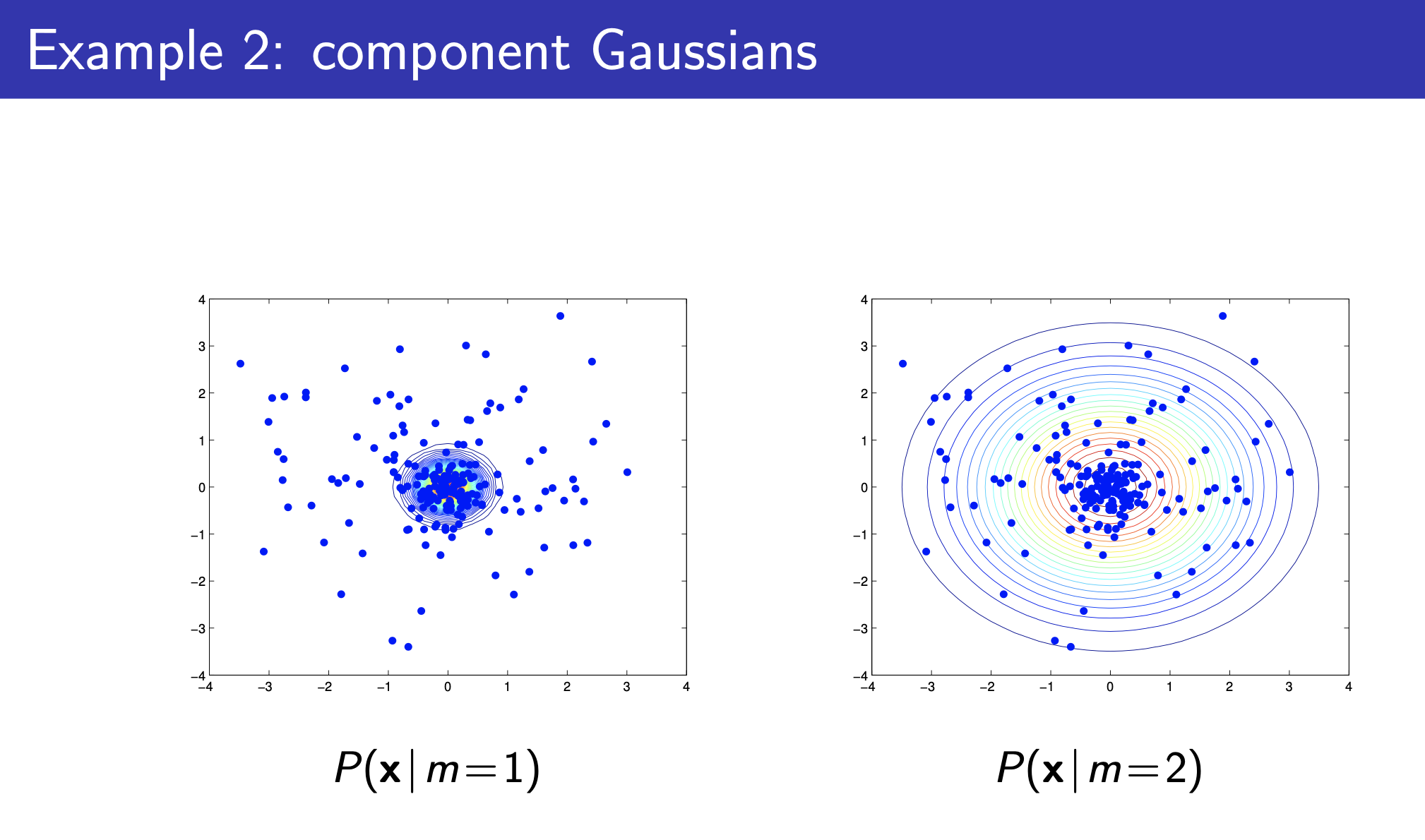 Fig.
Fig.
Back to HMMs
How to Calculate Likelihood?
 Fig.
Fig.
Viterbi Algorithm
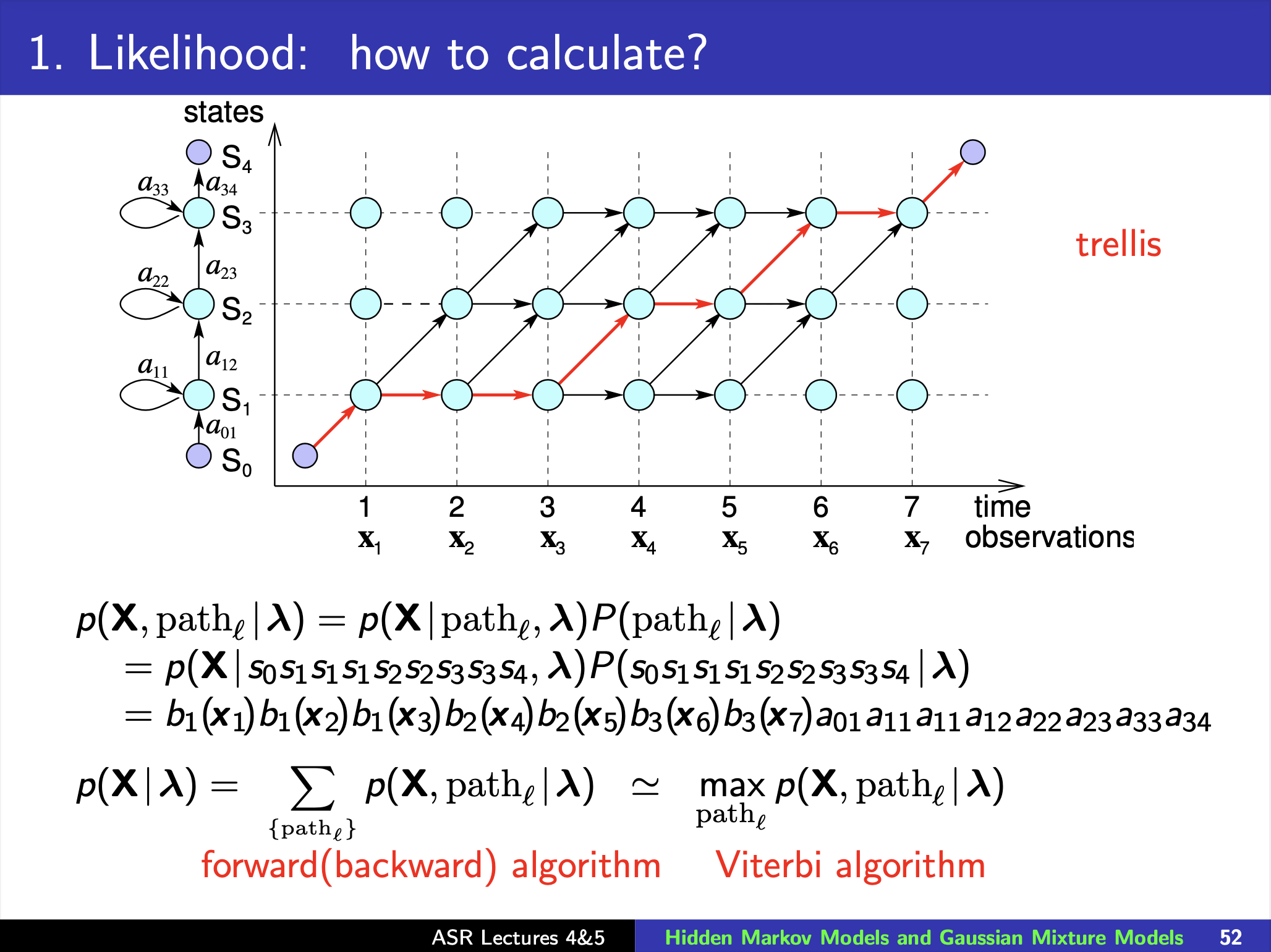 Fig.
Fig.
 Fig.
Fig.
Viterbi Algorithm
HMMs with Gaussian observation probabilities
 Fig.
Fig.
 Fig.
Fig.
 Fig.
Fig.
 Fig.
Fig.
Compared to E2E Modeles
Connection to DNN-HMM
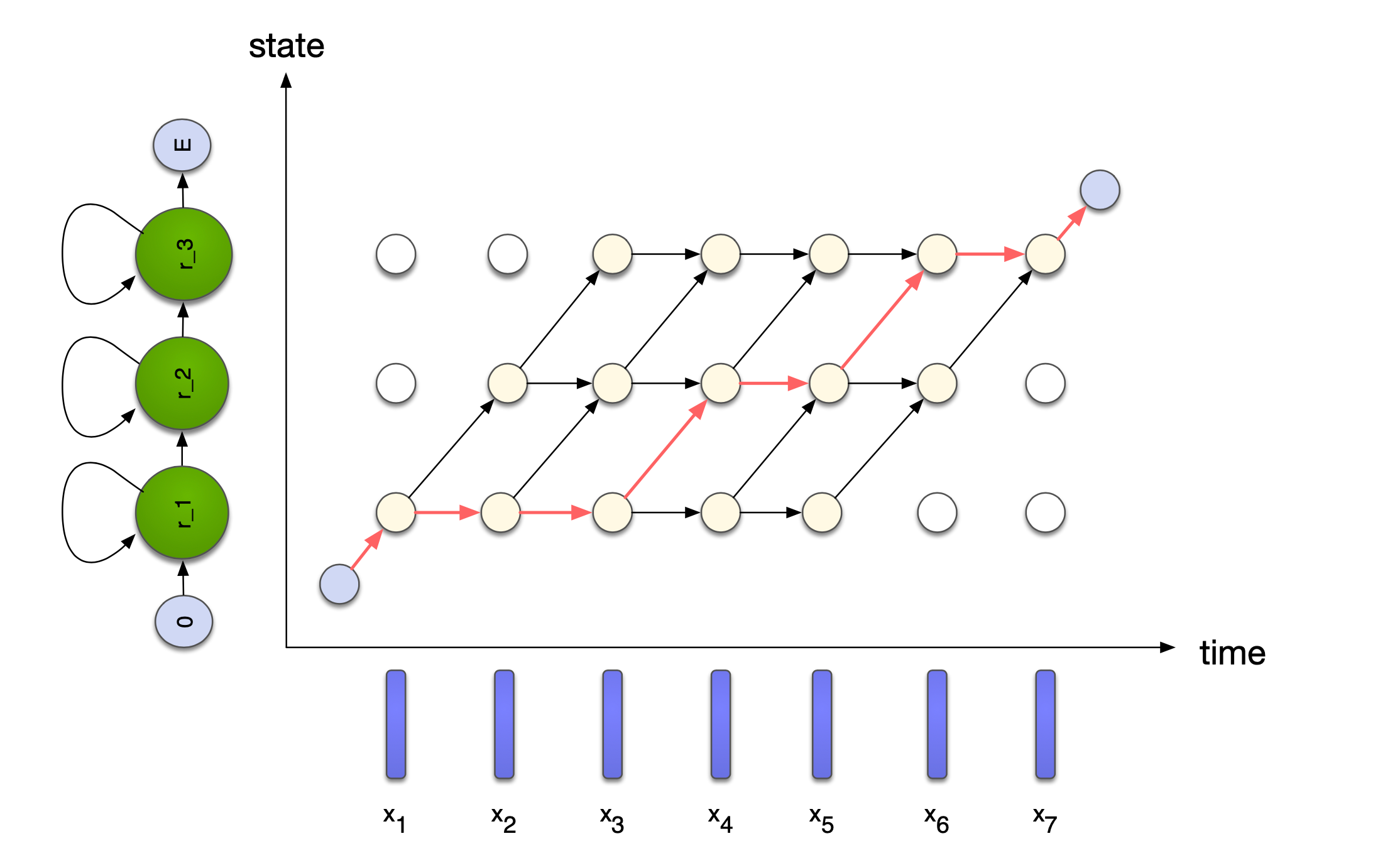 Fig.
Fig.
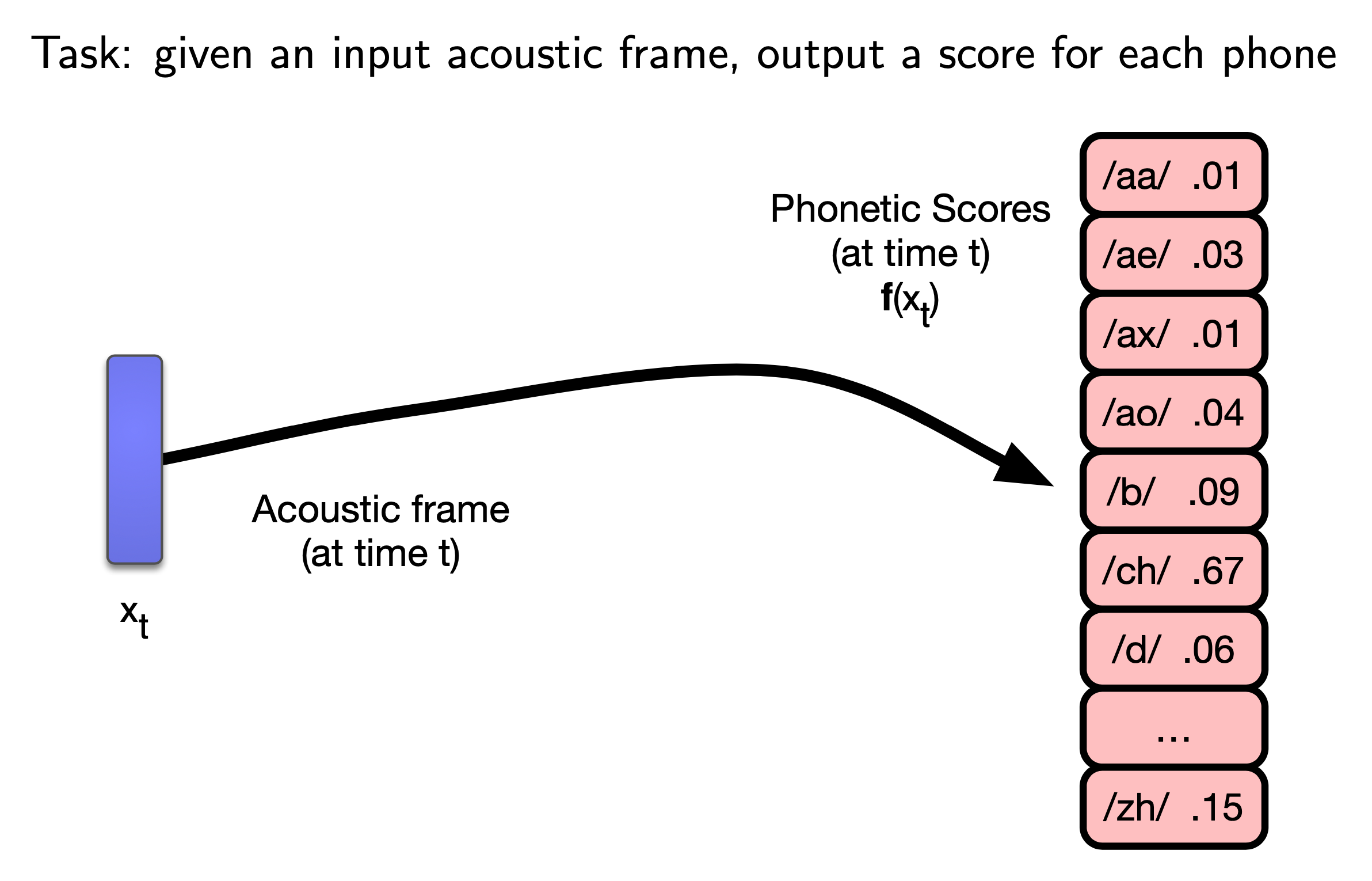 Fig.
Fig.
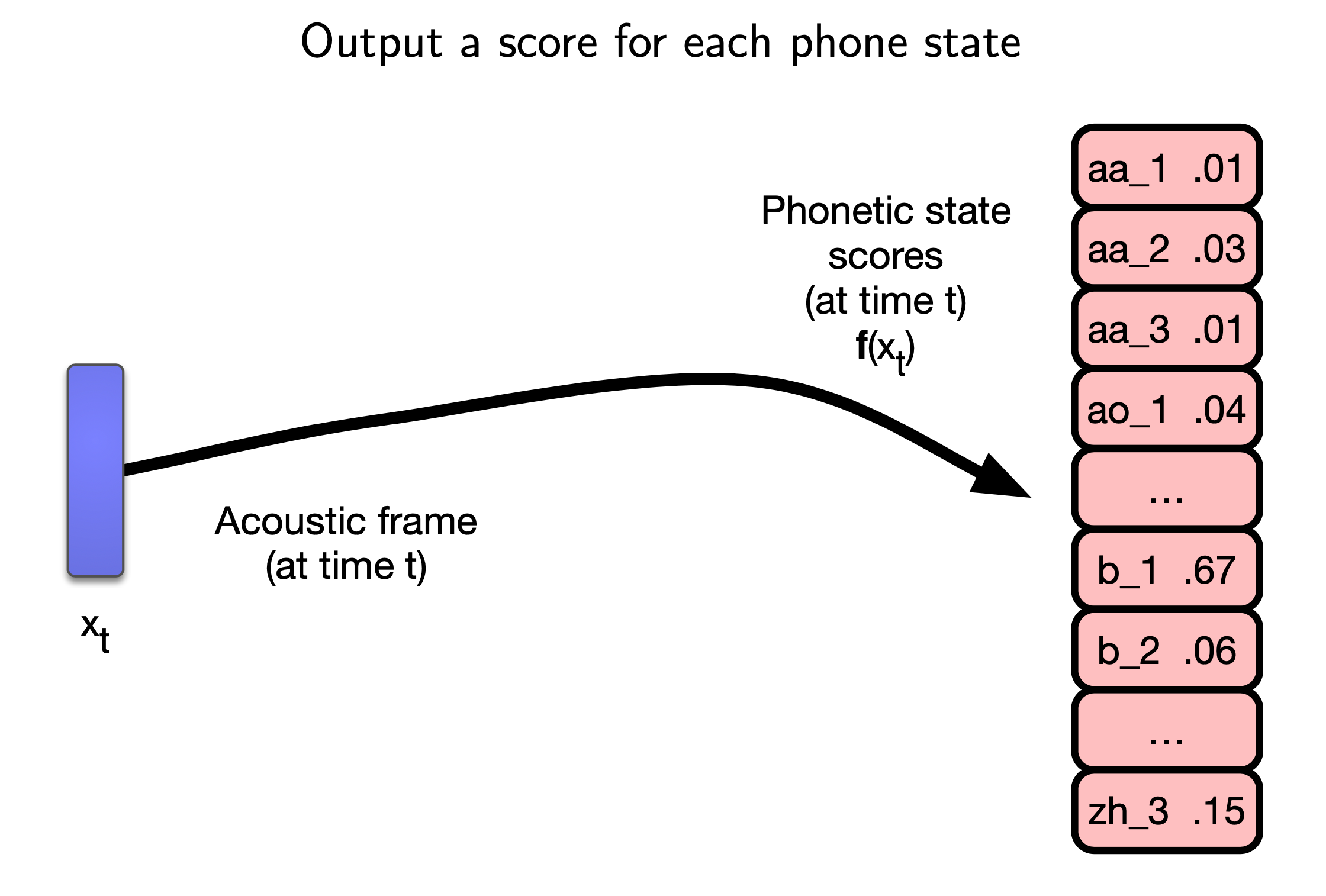 Fig.
Fig.
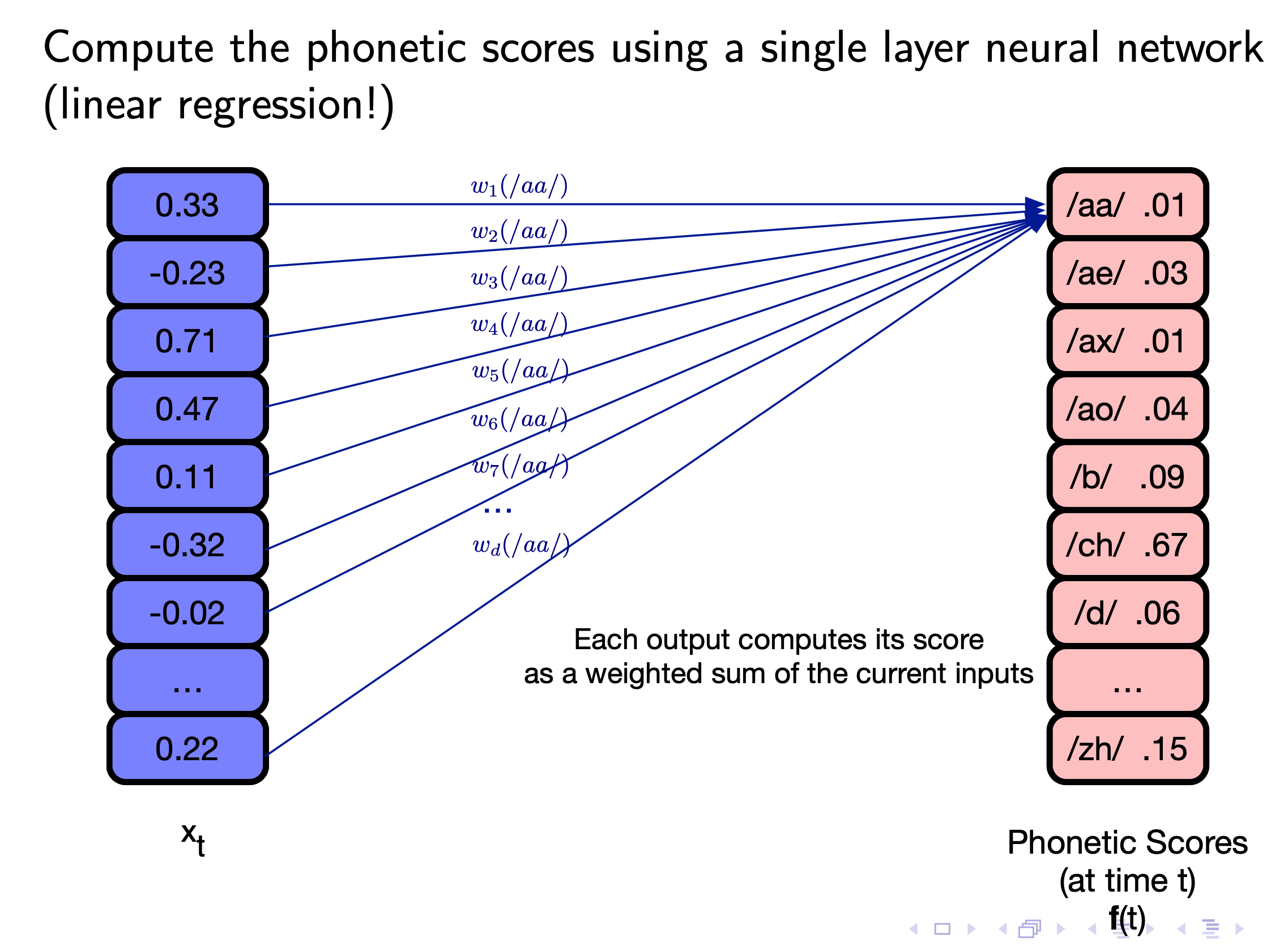 Fig.
Fig.
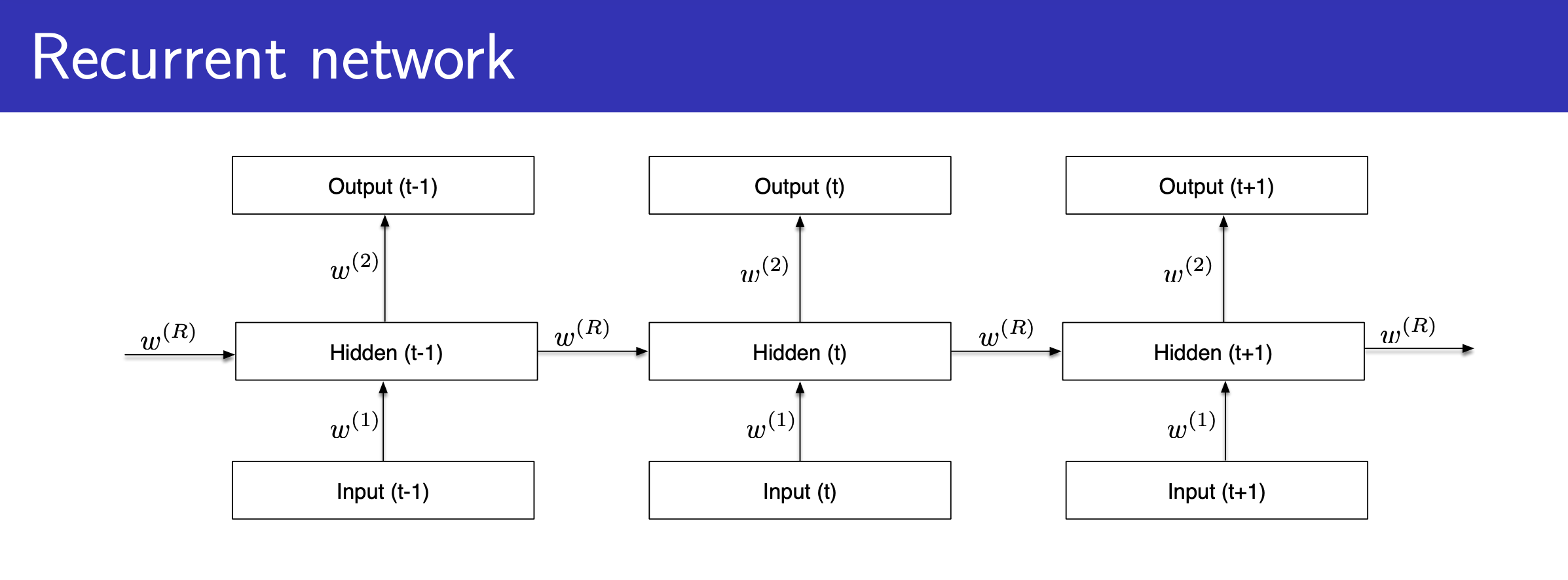 Fig.
Fig.
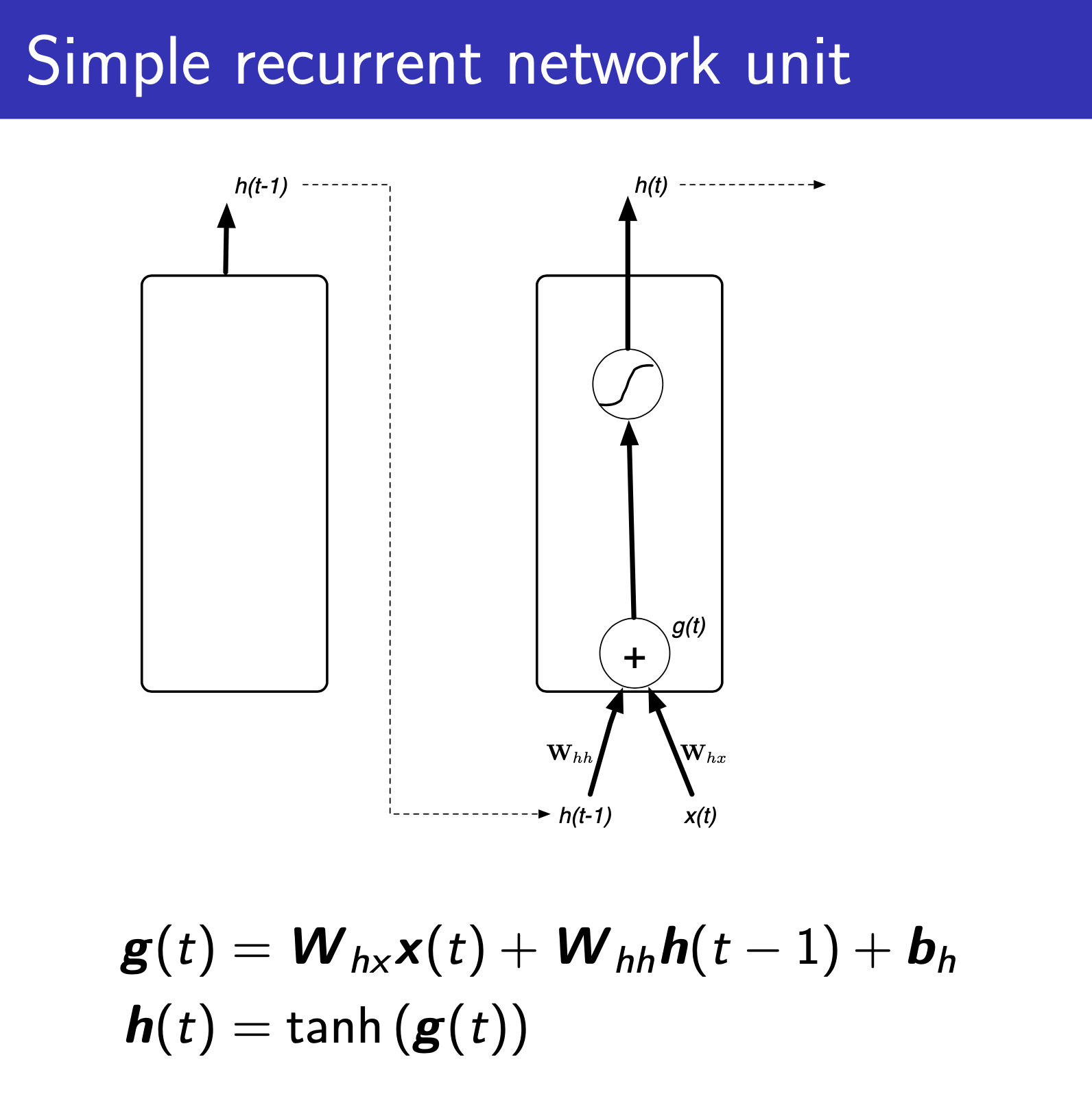 Fig.
Fig.
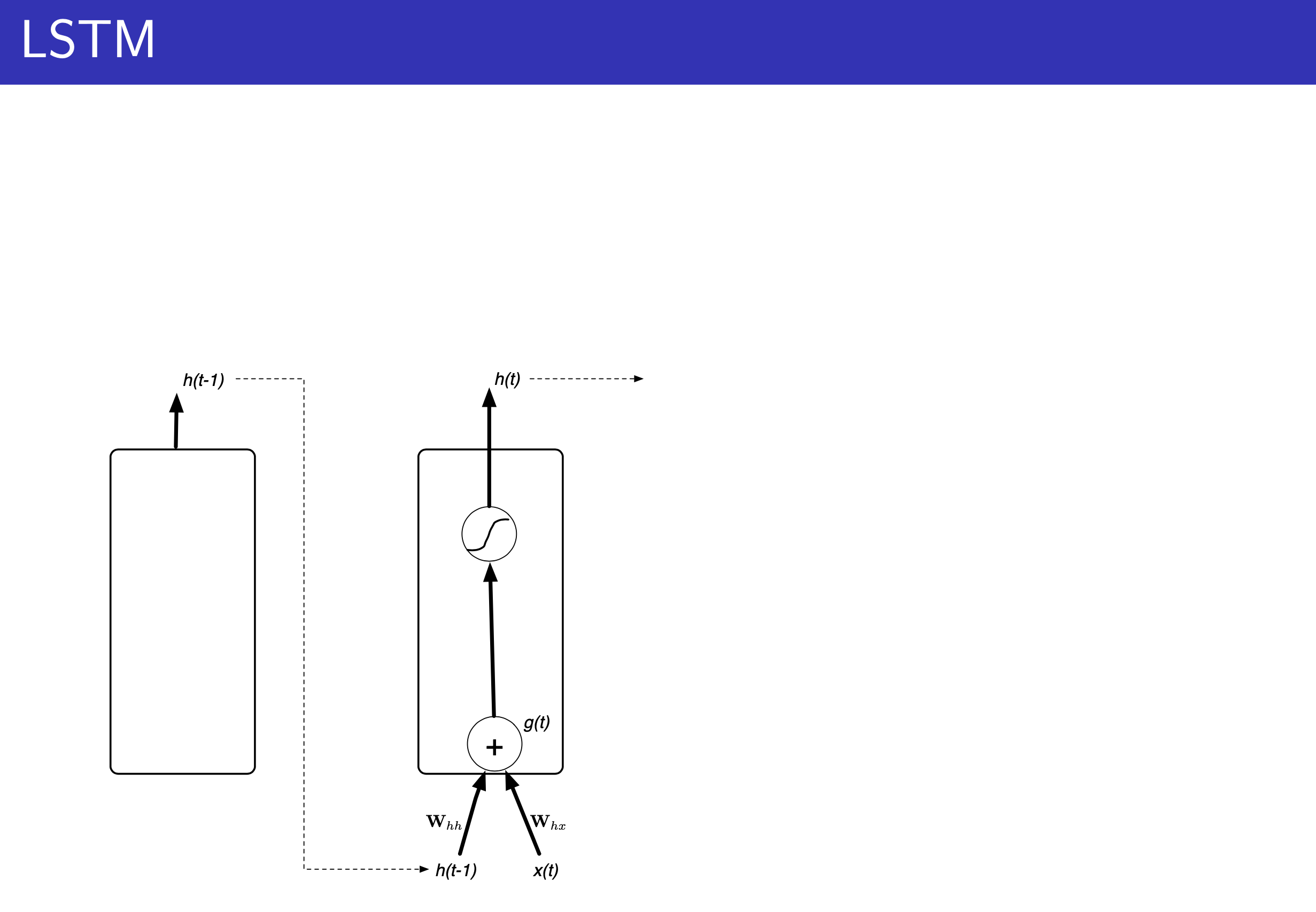 Fig.
Fig.
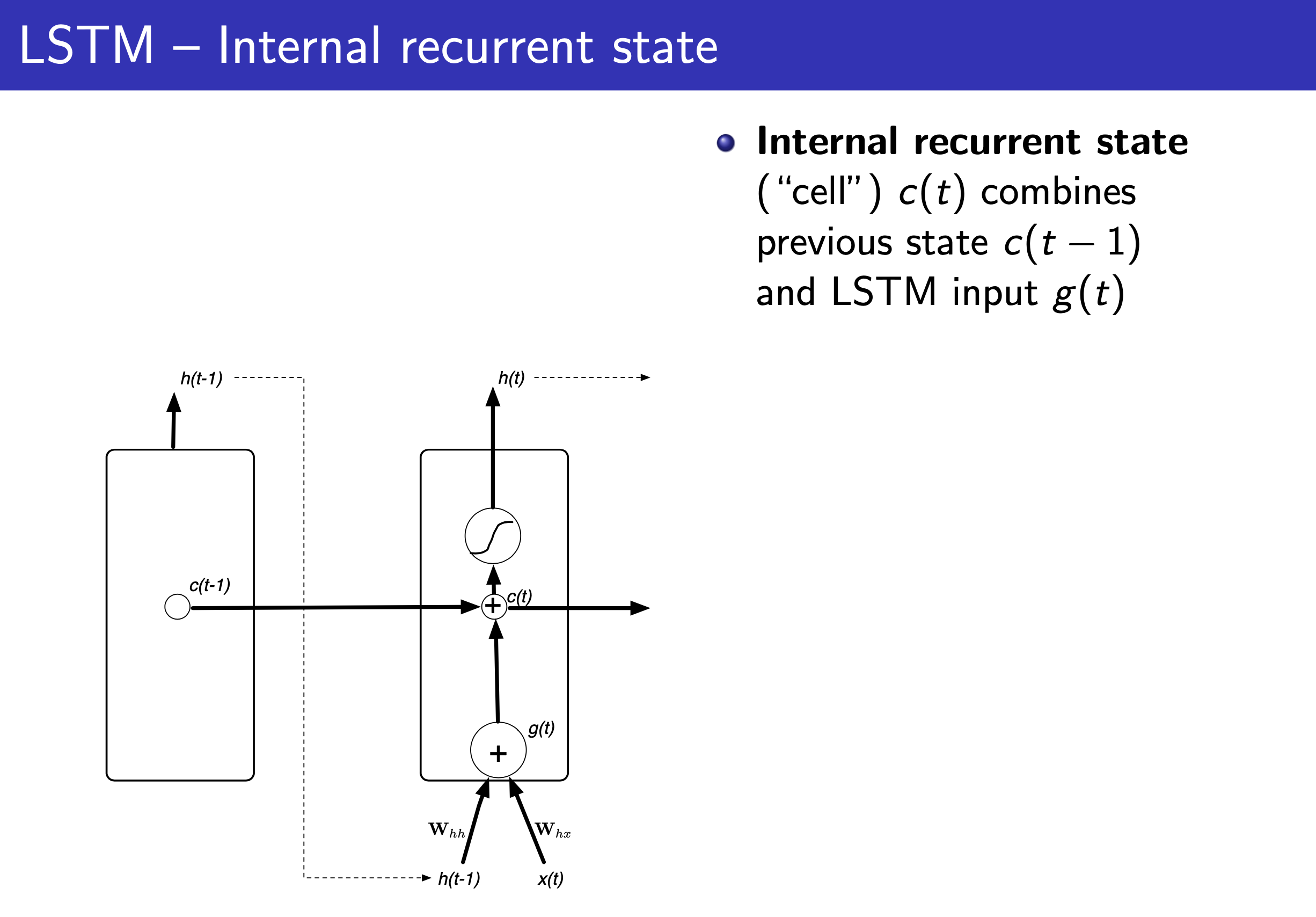 Fig.
Fig.
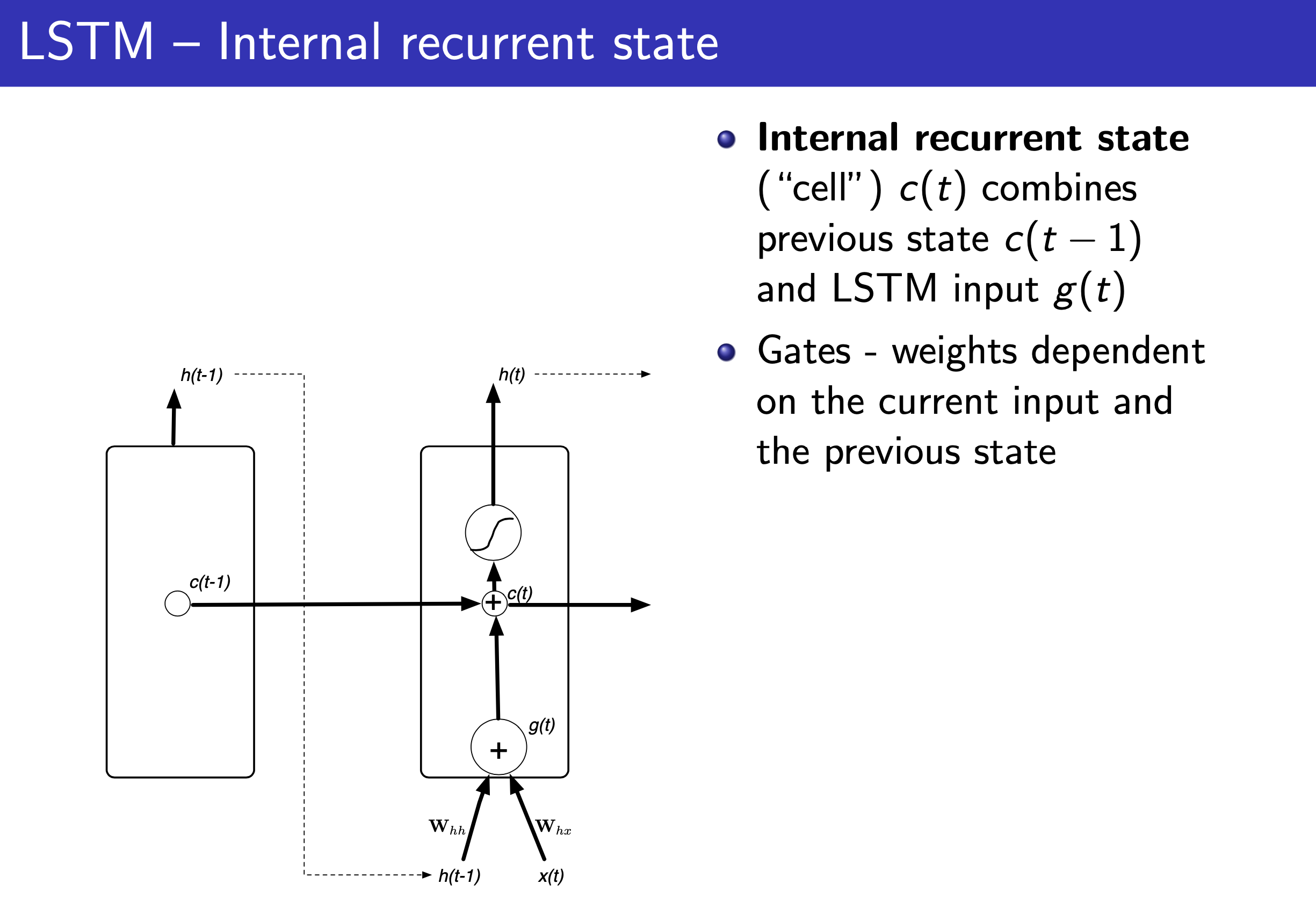 Fig.
Fig.
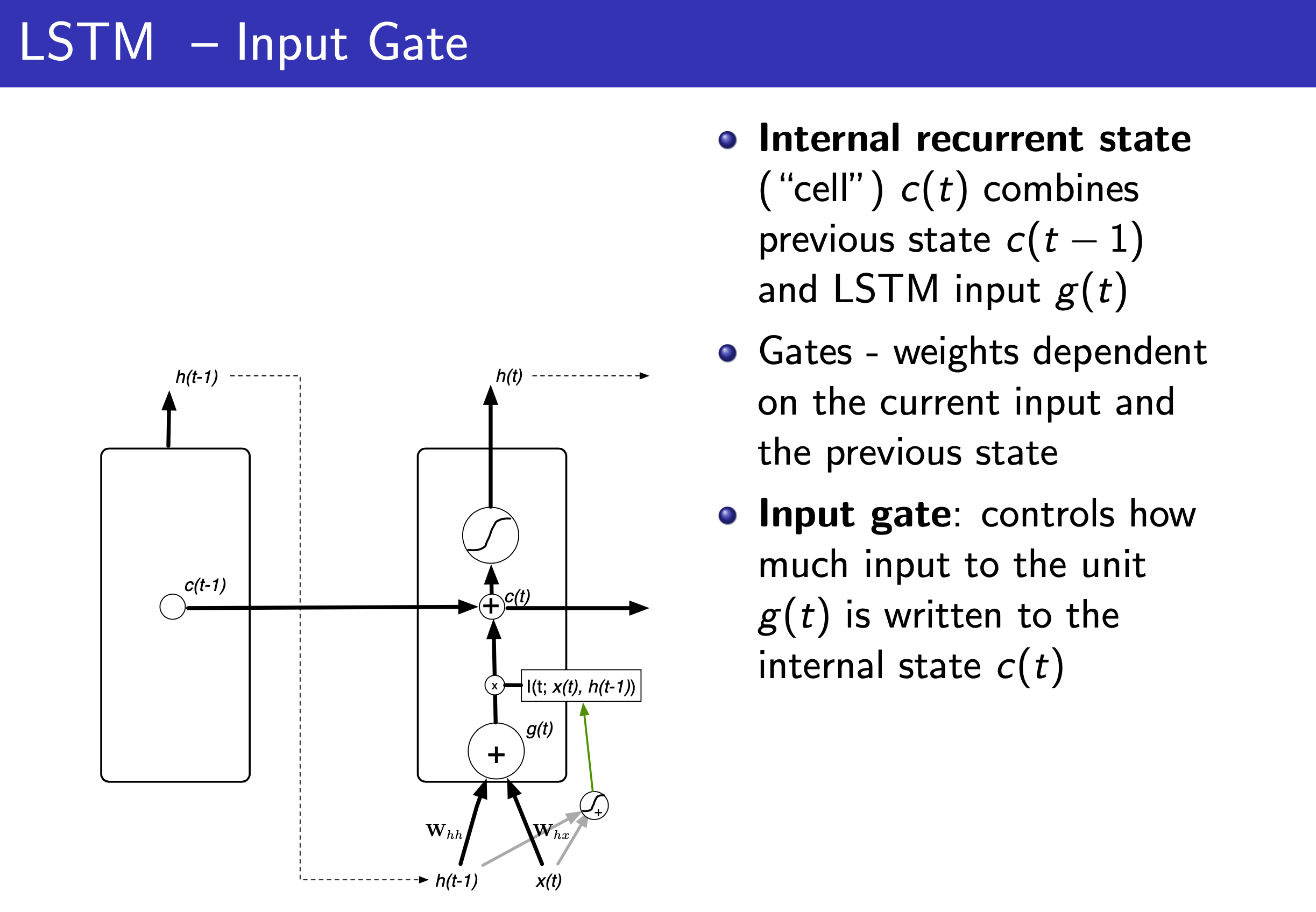 Fig.
Fig.
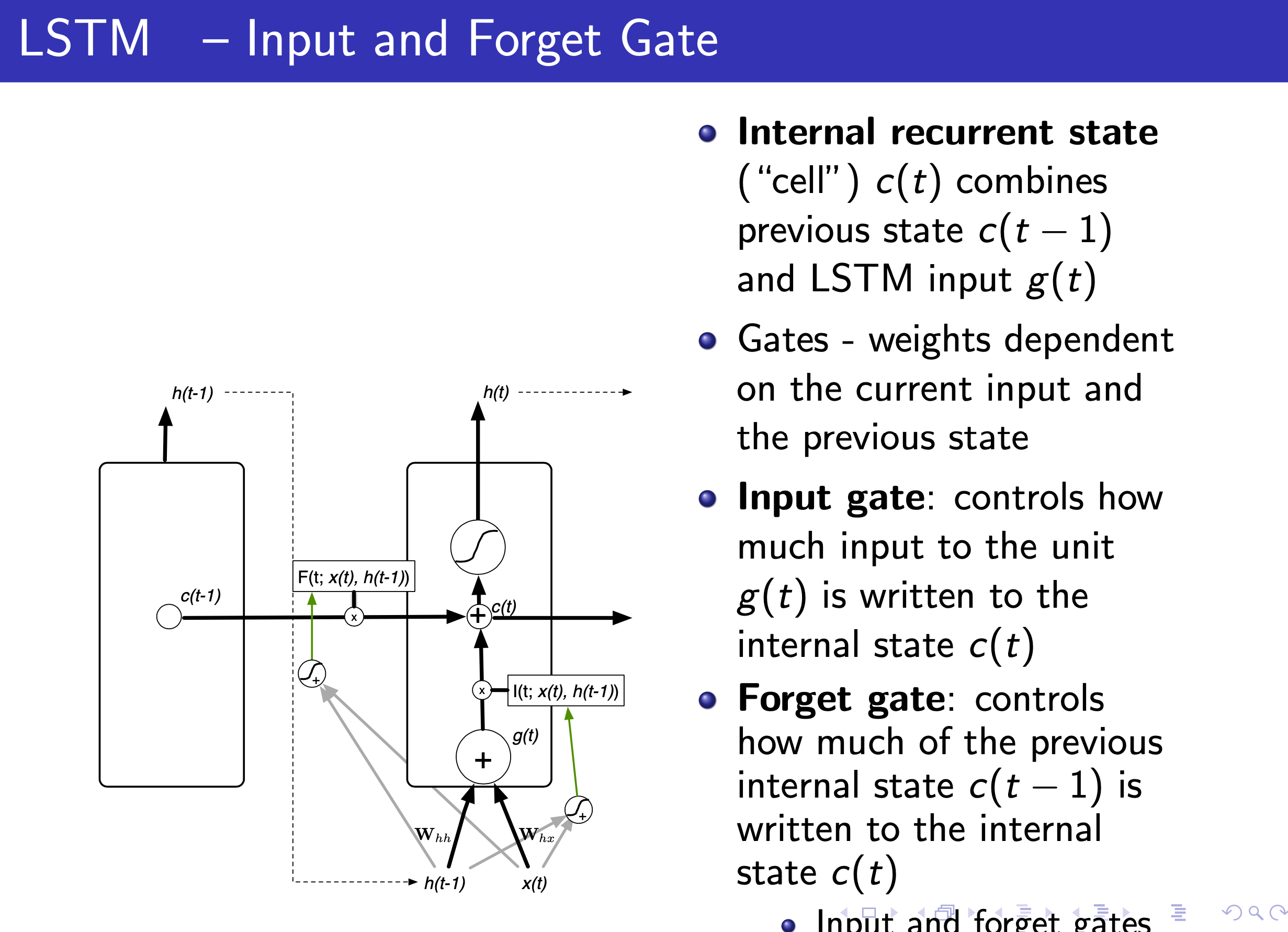 Fig.
Fig.
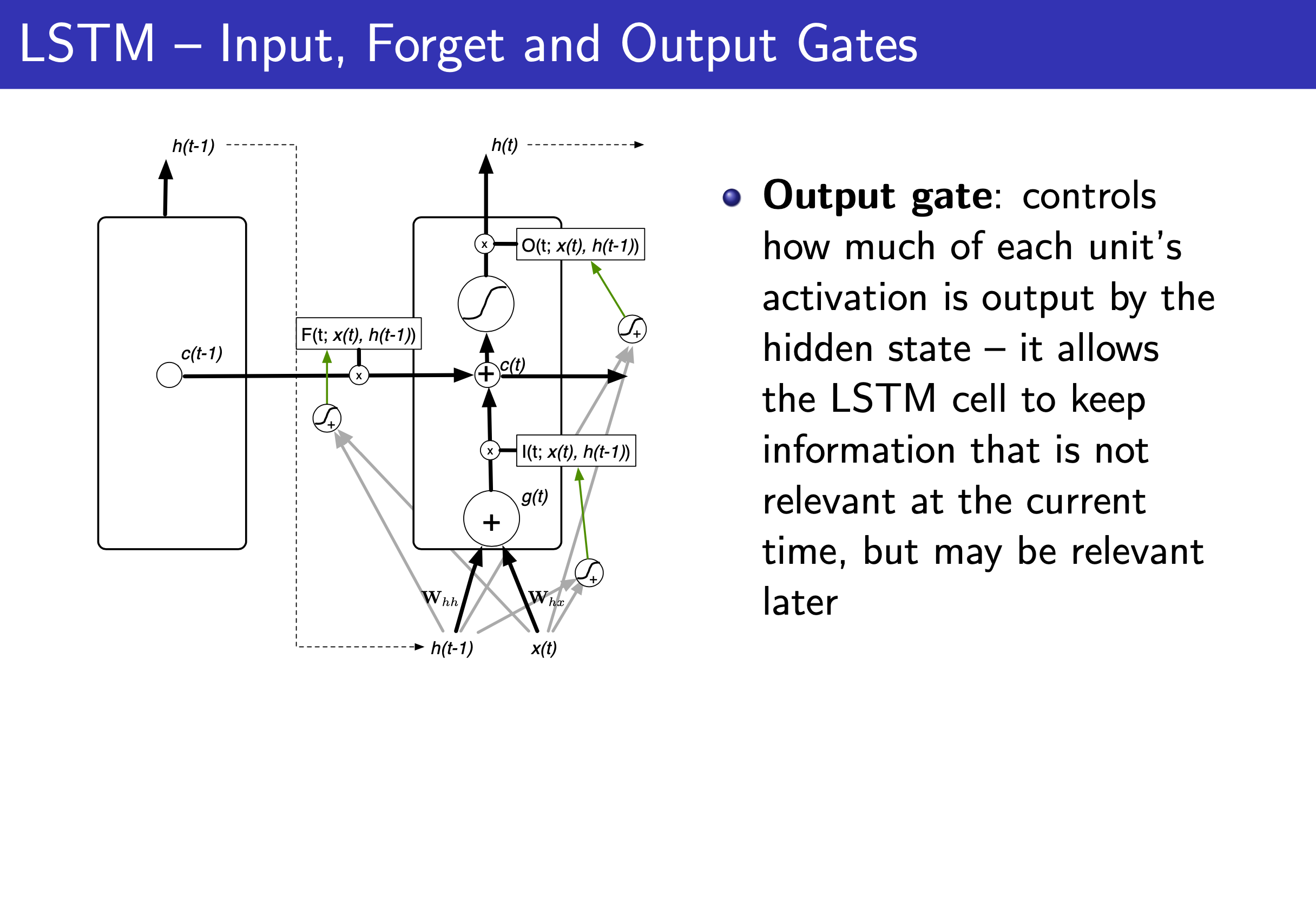 Fig.
Fig.
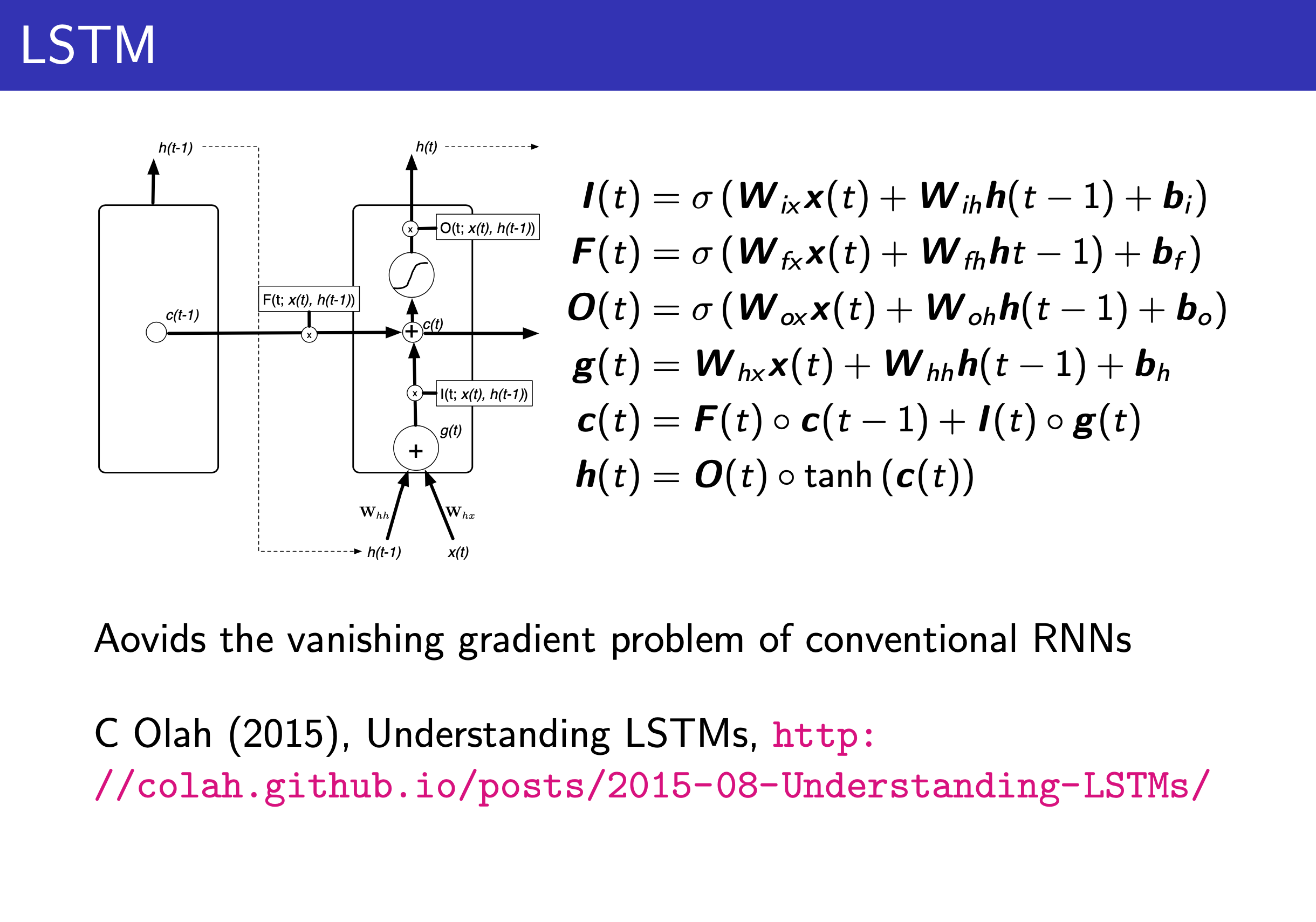 Fig.
Fig.
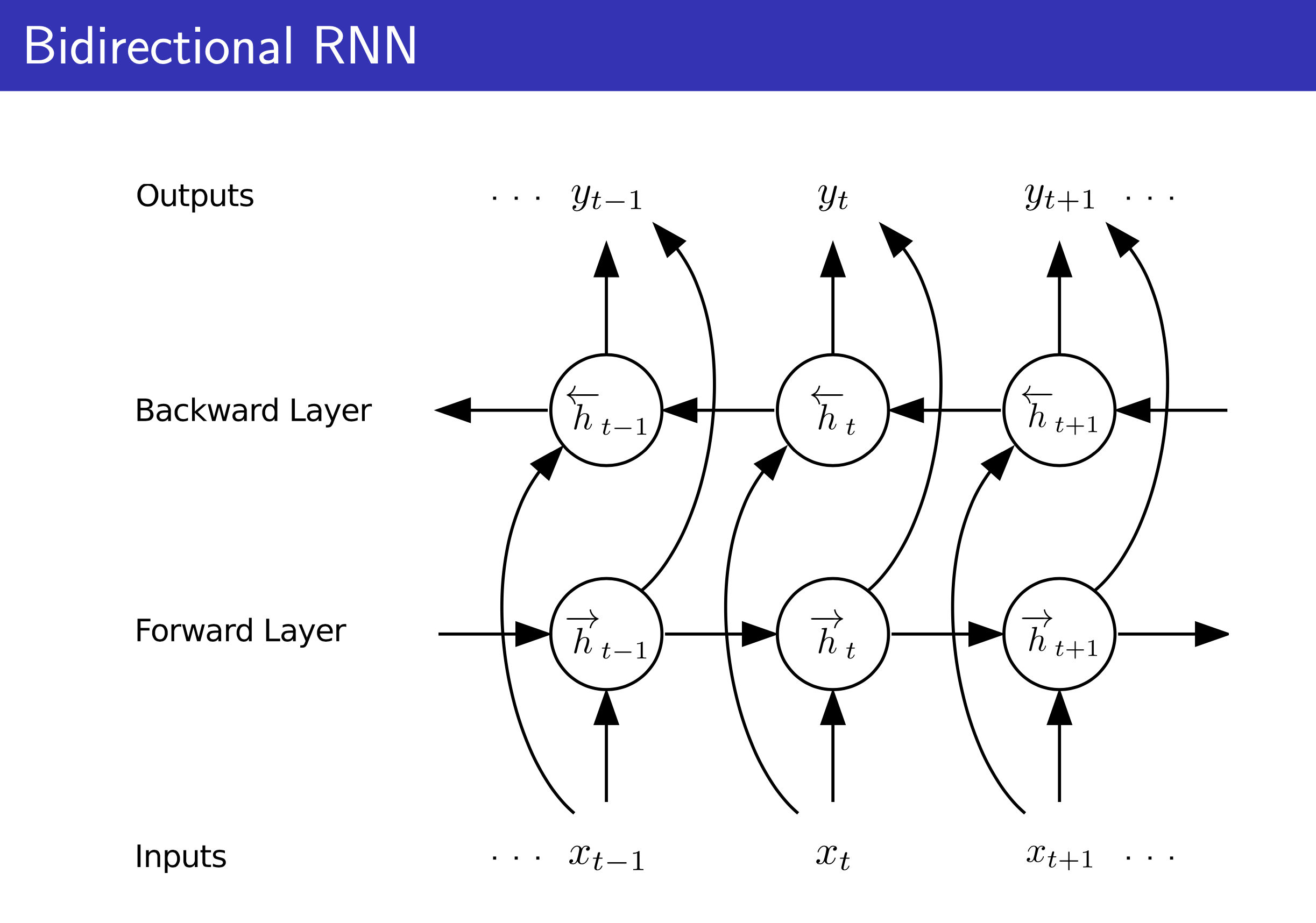 Fig.
Fig.
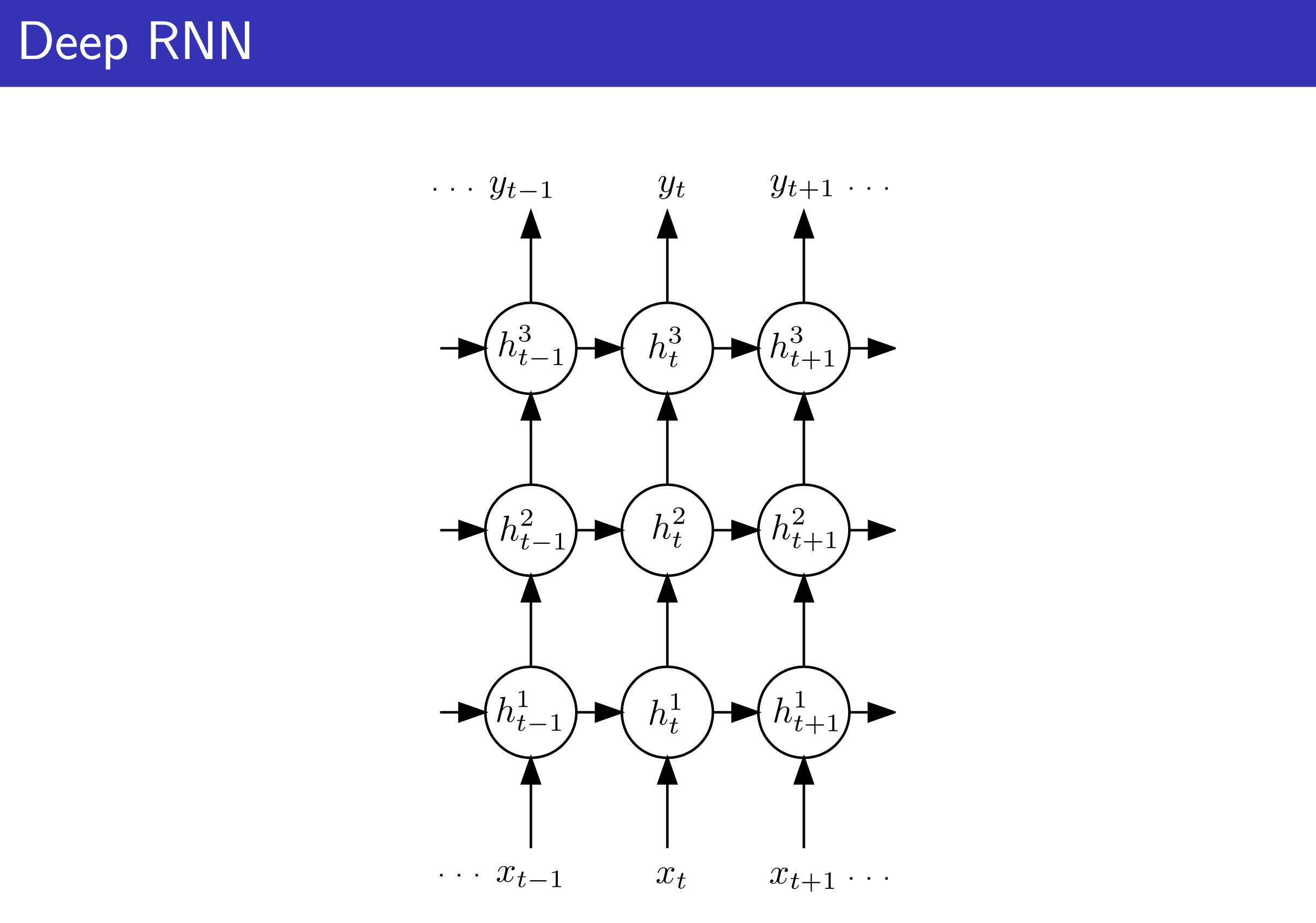 Fig.
Fig.
 Fig.
Fig.
 Fig.
Fig.
 Fig.
Fig.
vs Connectionist Temporal Classification (CTC) Objective
마지막으로 CTC 와의 Connection 입니다.
CTC 는 2006년에 제안됐지만 본격적으로 뉴럴넷과 결합되어 사용된 건 2014년 즈음 부터였습니다.
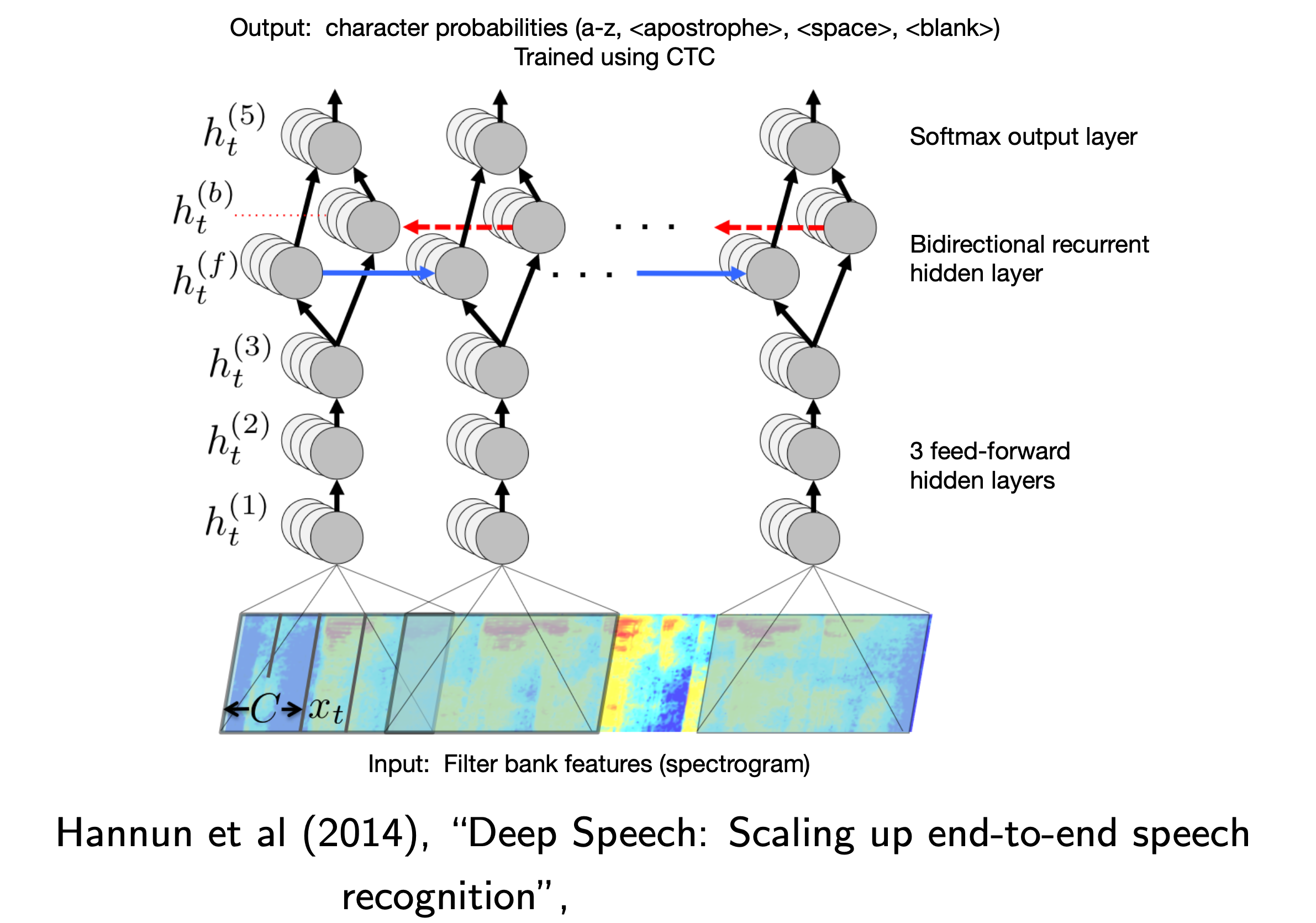 Fig. 2014 년 Deep Speech 에서 제안된 CTC 를 사용한 End-to-End Model. Source from Deep Speech: Scaling up end-to-end speech recognition
Fig. 2014 년 Deep Speech 에서 제안된 CTC 를 사용한 End-to-End Model. Source from Deep Speech: Scaling up end-to-end speech recognition
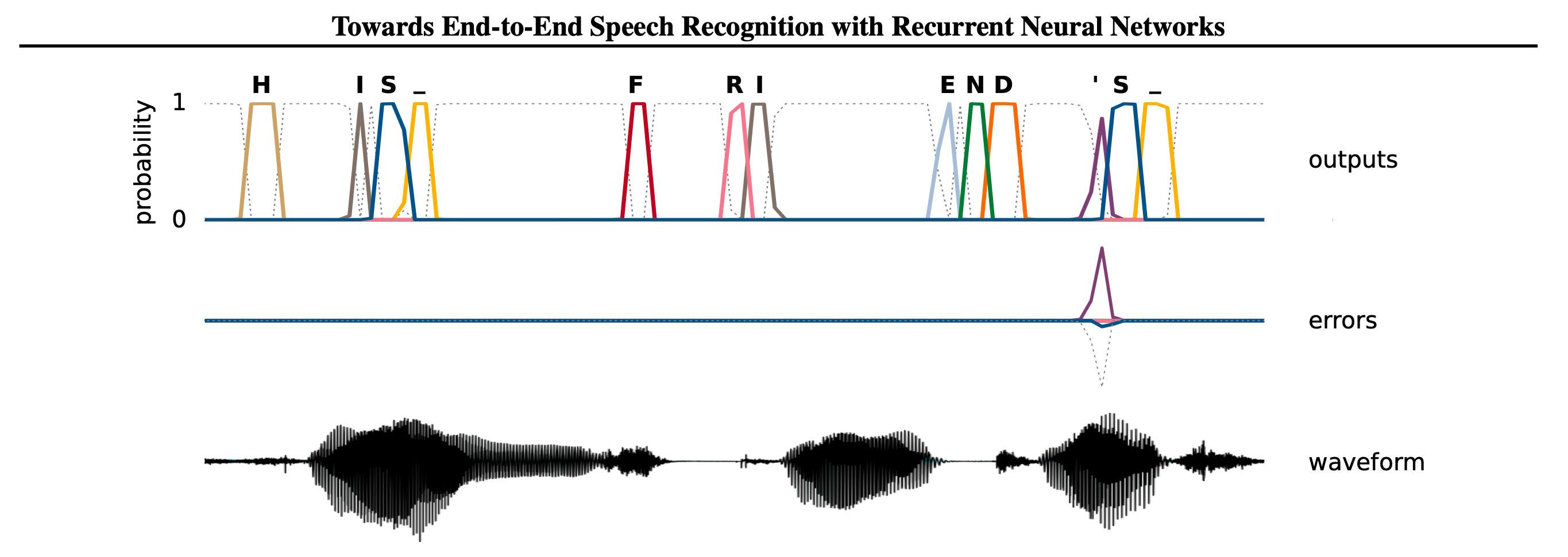 Fig. 2014 년 Graves의 논문에서 제안된 CTC 를 사용한 End-to-End Model 의 출력 결과물. Source from Towards End-To-End Speech Recognition with Recurrent Neural Networks
Fig. 2014 년 Graves의 논문에서 제안된 CTC 를 사용한 End-to-End Model 의 출력 결과물. Source from Towards End-To-End Speech Recognition with Recurrent Neural Networks
Alex Graves 가 제안한 CTC 논문을 보면 HMM과 비교하는 내용이 많이 있는걸 알 수 있는데요, 그도 그럴것이 이는 Topology 만 봐도 HMM 과 상당히 유사하기 때문입니다.
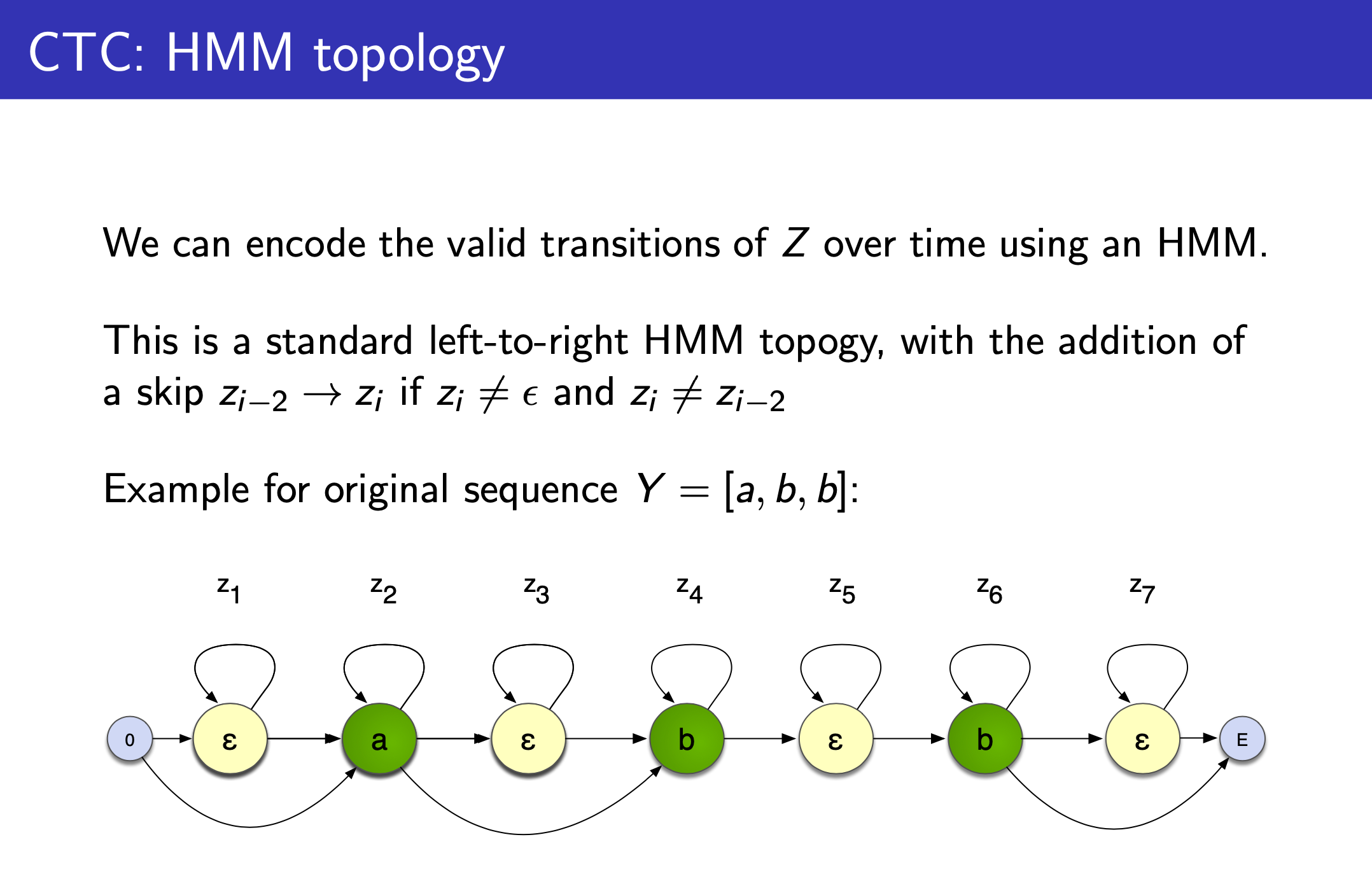 Fig.
Fig.
슬라이드의 설명을 보면 음성 인식에 쓰인 HMM 처럼 left-to-right 이지만 두 가지가 다릅니다.
- 1.Vocabulary 에
blank, \(\epsilon\) 가 state 에 추가되었다. - 2.만약 state가 \(\epsilon\) 이 아니거나 직전 state 가 현재 state 와 같지 않다면 skip 할 수 있는 경우가 허용된다.
위의 예시는 [a b b] 의 경우를 나타낸 겁니다.
CTC 도 HMM 과 마찬가지로 Input (speech) 과 Output (text) 의 길이가 다를 경우, 즉 Alignment 가 없을 경우 사용하는데요,
 Fig.
Fig.
 Fig.
Fig.
 Fig.
Fig.
 Fig.
Fig.
 Fig.
Fig.
 Fig.
Fig.
Fig.
 Fig.
Fig.
 Fig.
Fig.
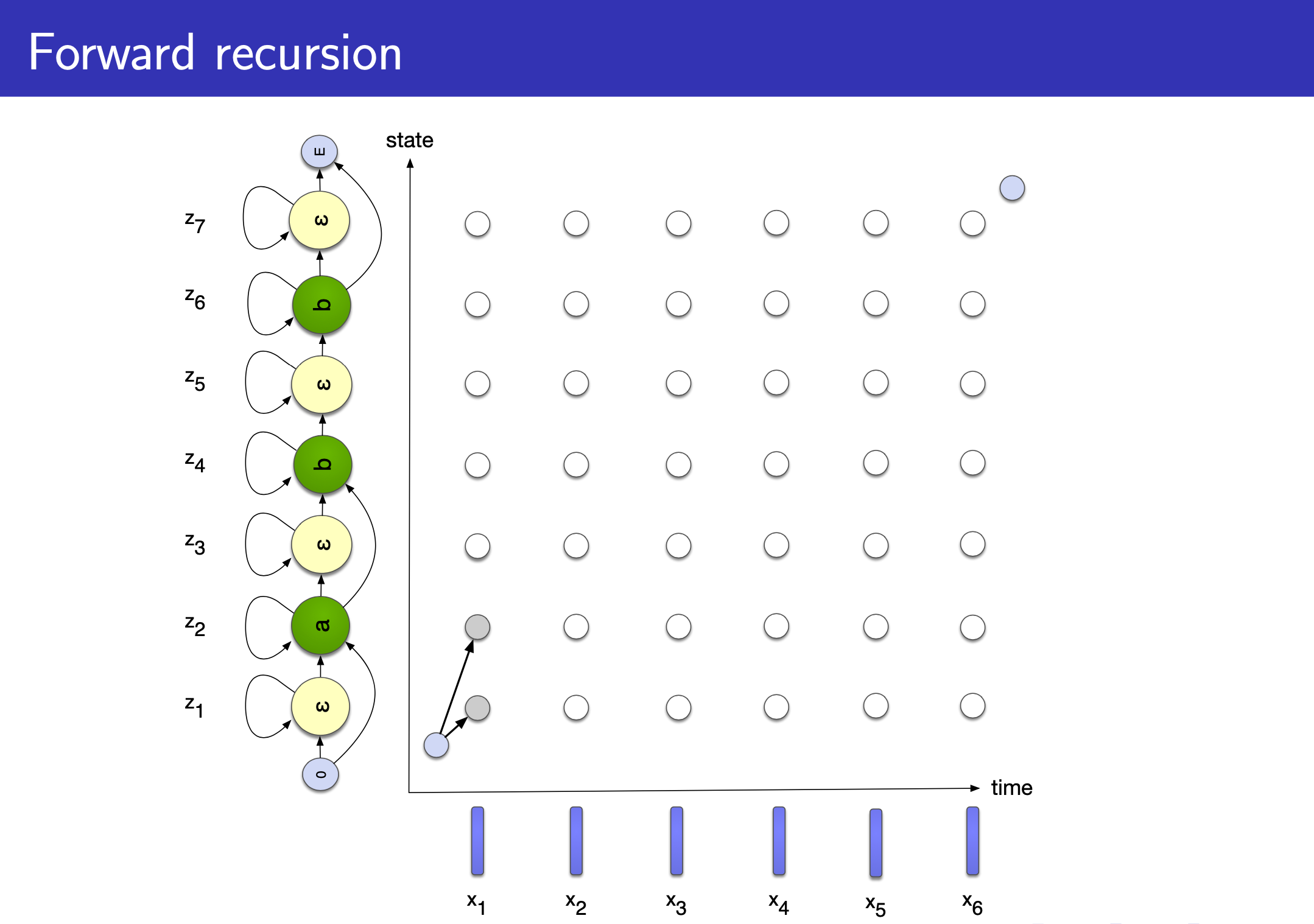 Fig.
Fig.
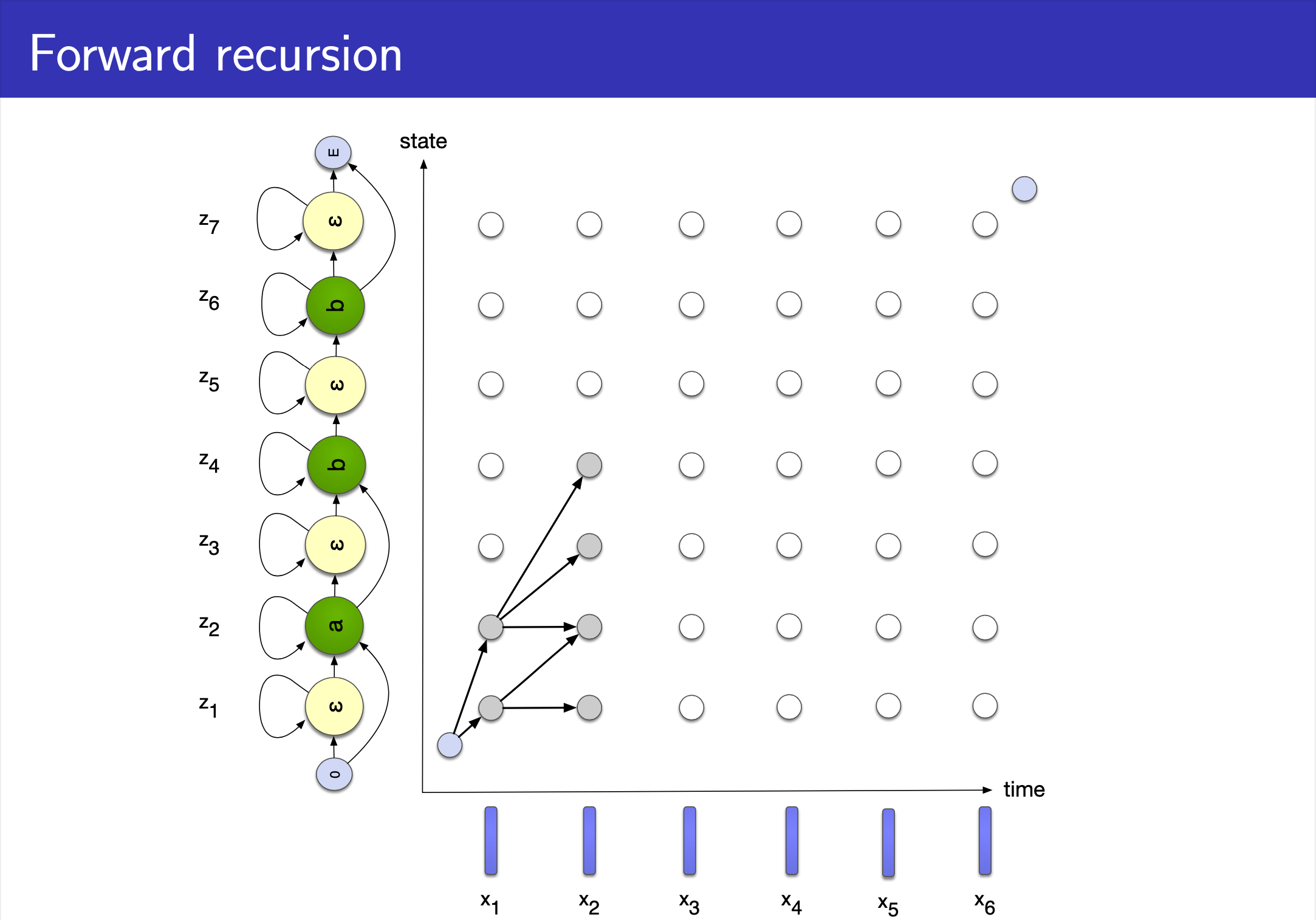 Fig.
Fig.
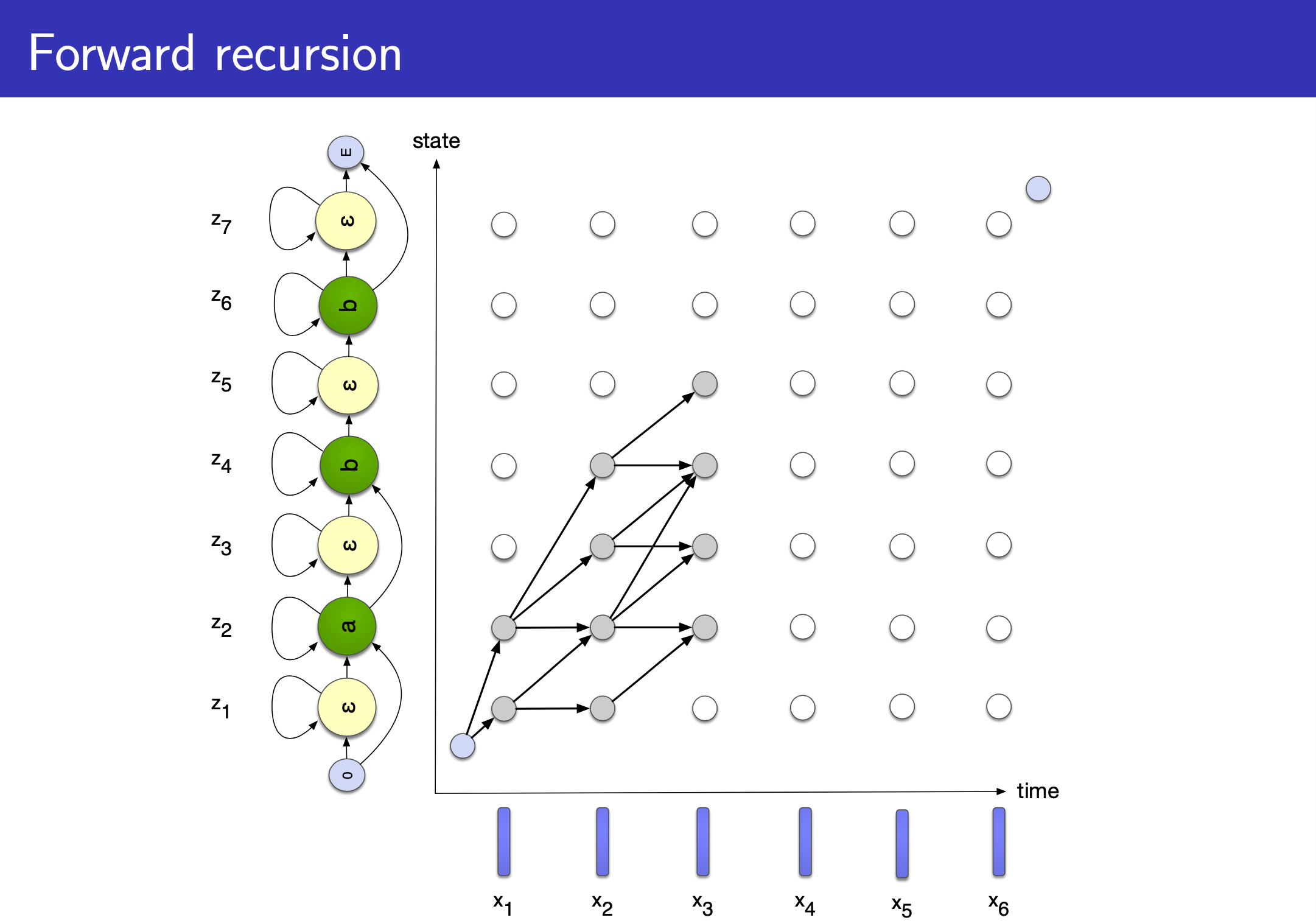 Fig.
Fig.
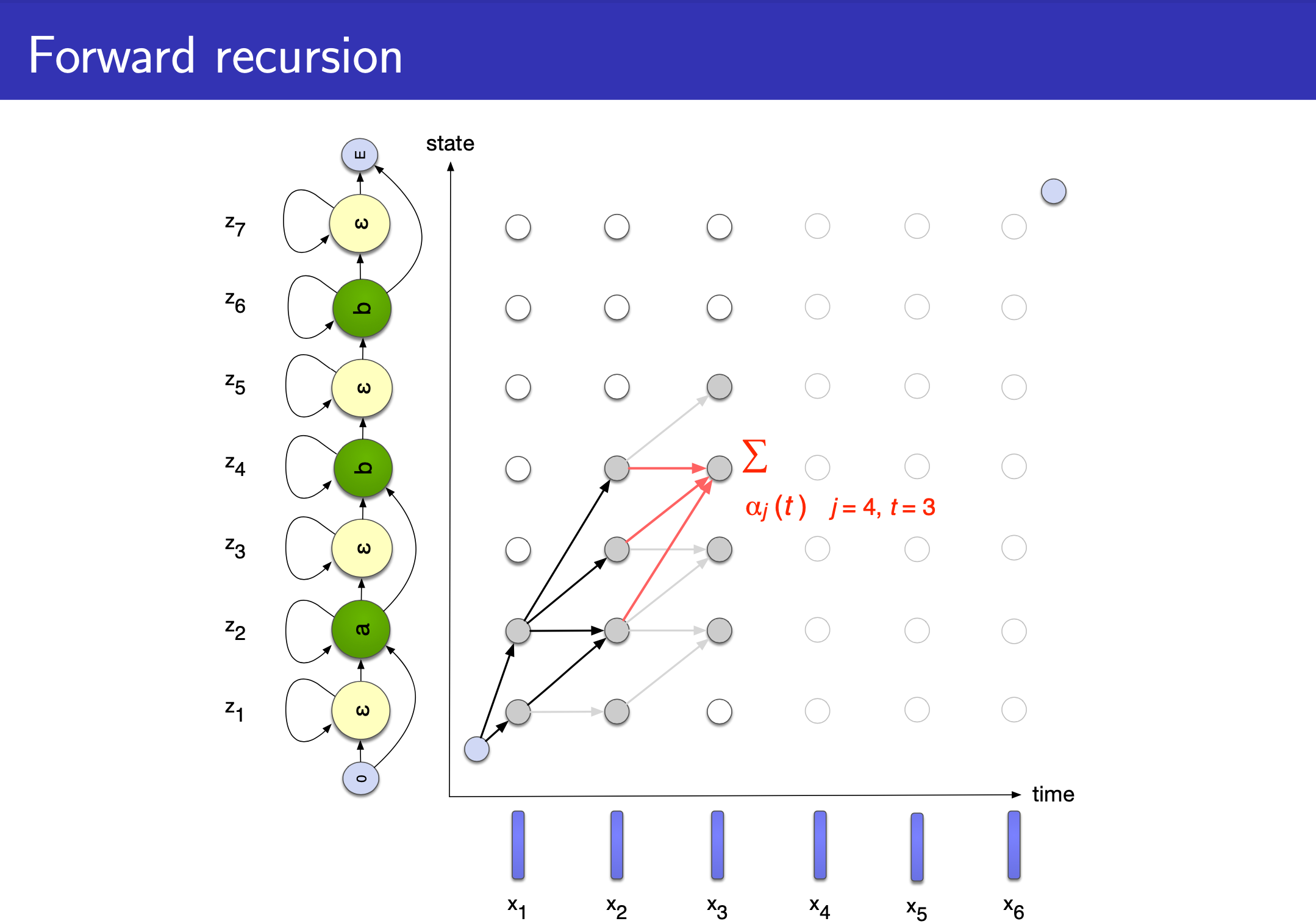 Fig.
Fig.
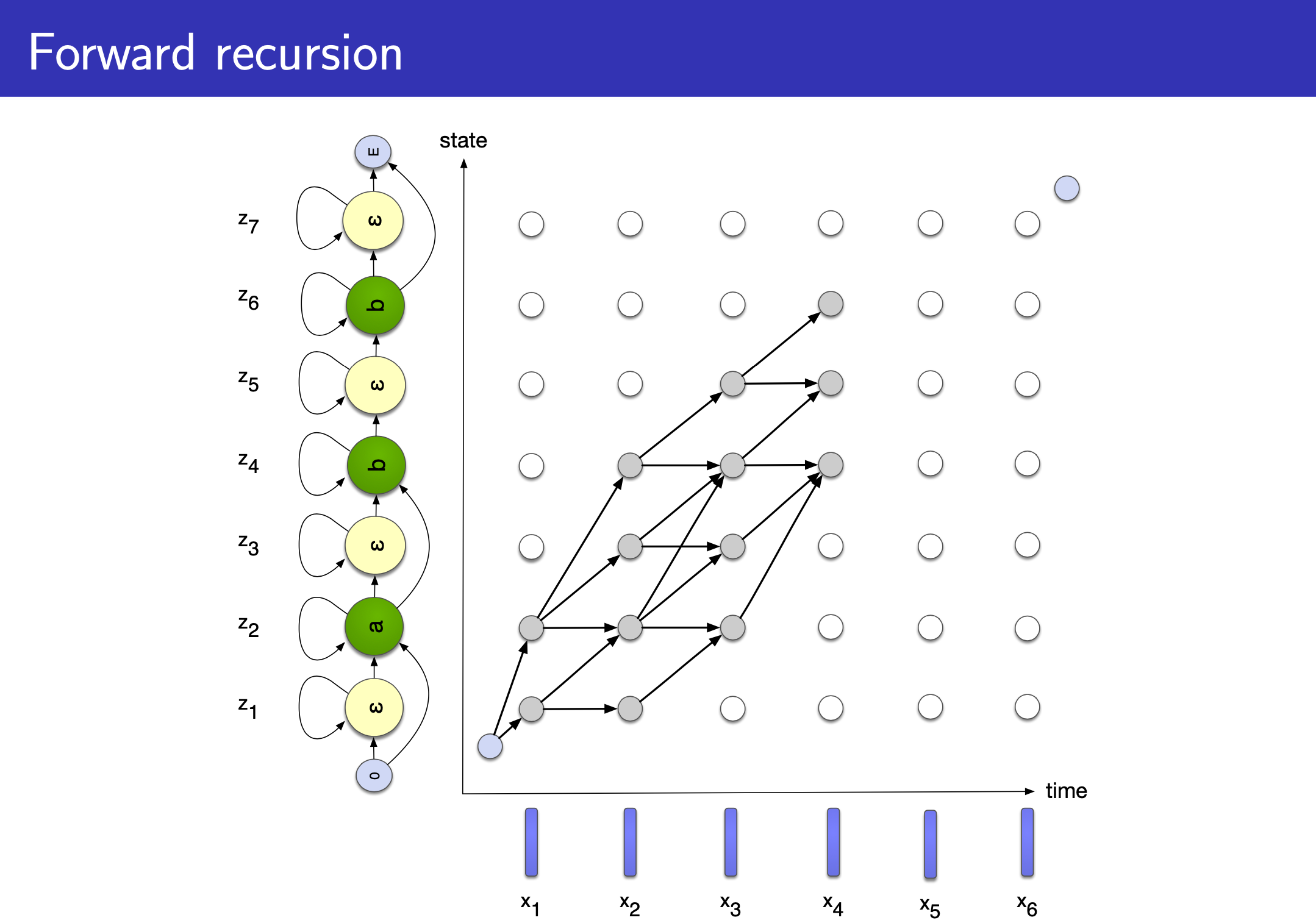 Fig.
Fig.
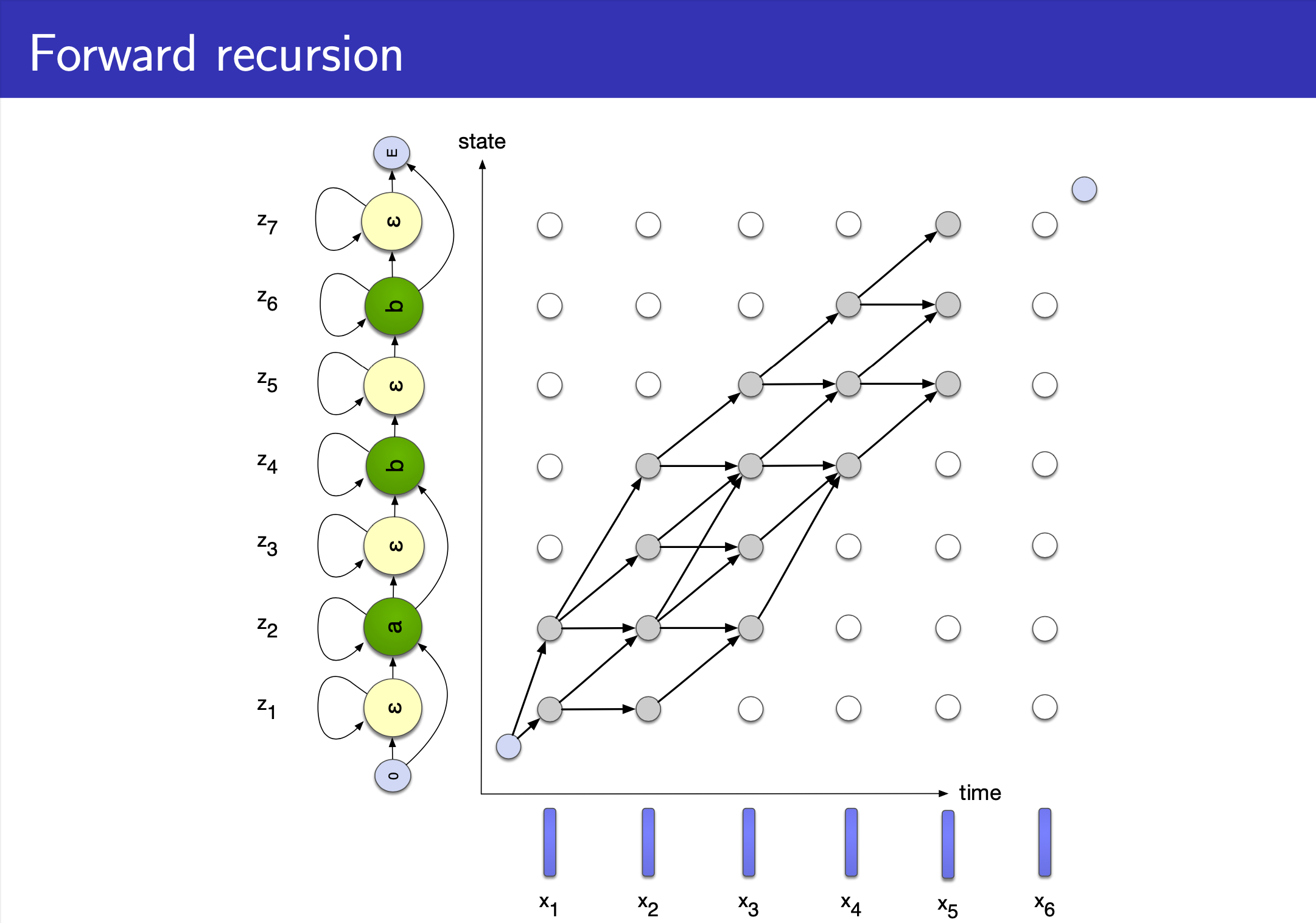 Fig.
Fig.
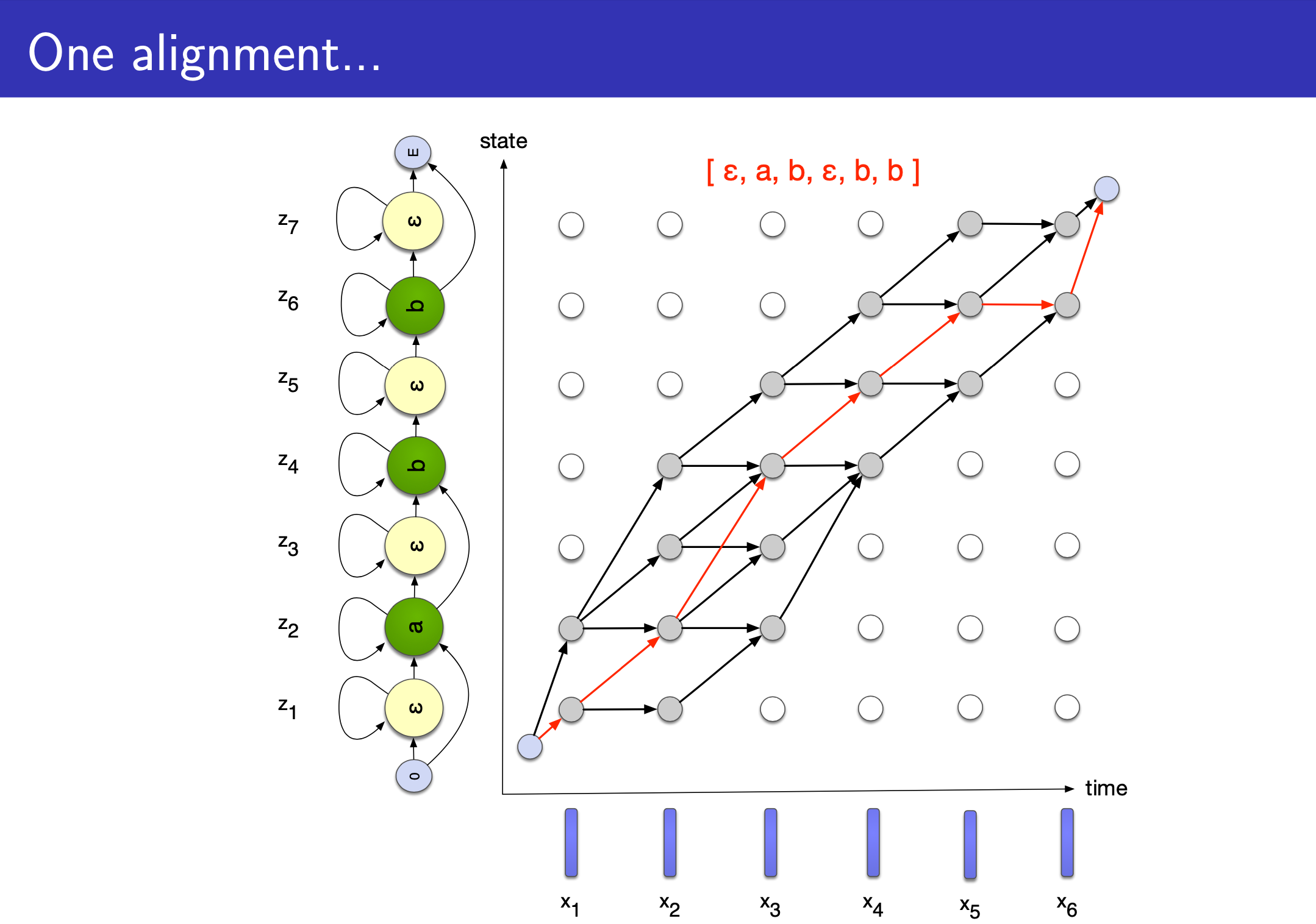 Fig.
Fig.
vs Recurrent Neural Networks (RNNs)
References
- Speech Recognition — GMM, HMM from Jonathan Hui
- tmp1
- tmp2
- The intriguing blank label in CTC
- HMM acoustic modeling from Maël Fabien
- Lecture from University of Edinburgh (Lecture Website)
- (19-20) Lecture 3, Hidden Markov Models and Gaussian Mixture Models from Hiroshi Shimodaira and Steve Renals
- (21-22) Lecture 1, Automatic Speech Recognition: Introduction
- (21-22) Lecture 2, Speech Signal Analysis 1
- (21-22) Lecture 3, Speech Signal Analysis 2
- (21-22) Lecture 4, Hidden Markov Models
- (21-22) Lecture 5, Training Hidden Markov Models
- (21-22) Lecture 6, Gaussian Mixture Models
- (21-22) Lecture 10, Neural Network Acoustic Models 1: Introduction
- (21-22) Lecture 11, Neural Networks for Acoustic Modelling 2: Hybrid HMM/DNN systems
- Paper