(WIP) Async TP
27 Nov 2024< 목차 >
Async TP
Asyncronous Tensor Parallel (Asnyc TP)는 Breaking the Computation and Communication Abstraction Barrier in Distributed Machine Learning Workloads에서 가장 먼저 제안되었다. 해당 paper에서는 Communication and Computation optimization for neural Networks (CoCoNet)이라는 하나의 system?에 대해서 제안하는데, 여기서 다 알필요는 없고 TP를 비동기적으로 연산-통신하는 것만 보면 된다. 이에 대해 논하기 위해선 먼저 Tensor Parallel (TP)와 기본적인 communication operator들에 대해서 알아야 하는데, blog에서 봤다시피 model이 너무 큰 경우 weight matrix를 각 device별로 쪼개 분산하고, input을 각 쪼개진 partial matrix와 곱한 출력을 all-reduce같은 communication operation을 함으로써 복구하는 것을 말한다. Transformer에 대한 최적화된 TP를 가장 먼저 제안한 paper는 NVIDIA의 Meagtorn-LM인데, 이에 따르면 self_attention과 mlp module을 각각 아래처럼 Column-wise, Row-wise로 쪼개고 transformer block마다 foward시 all-reduce를 한번씩, backward마다 한번씩 해서 총 block당 4번의 통신을 하는 것으로 구현이 되어있다.
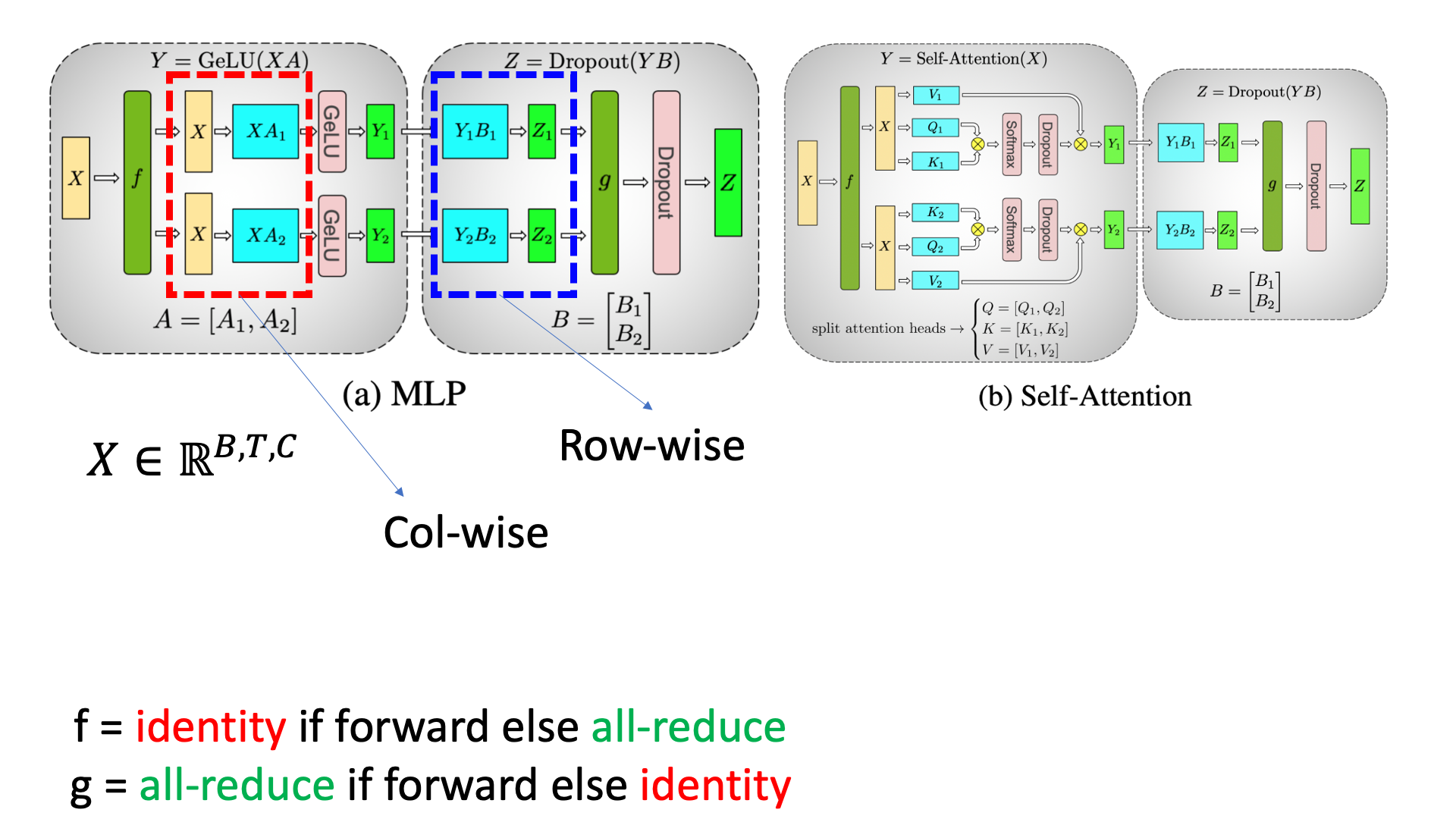 Fig.
Fig.
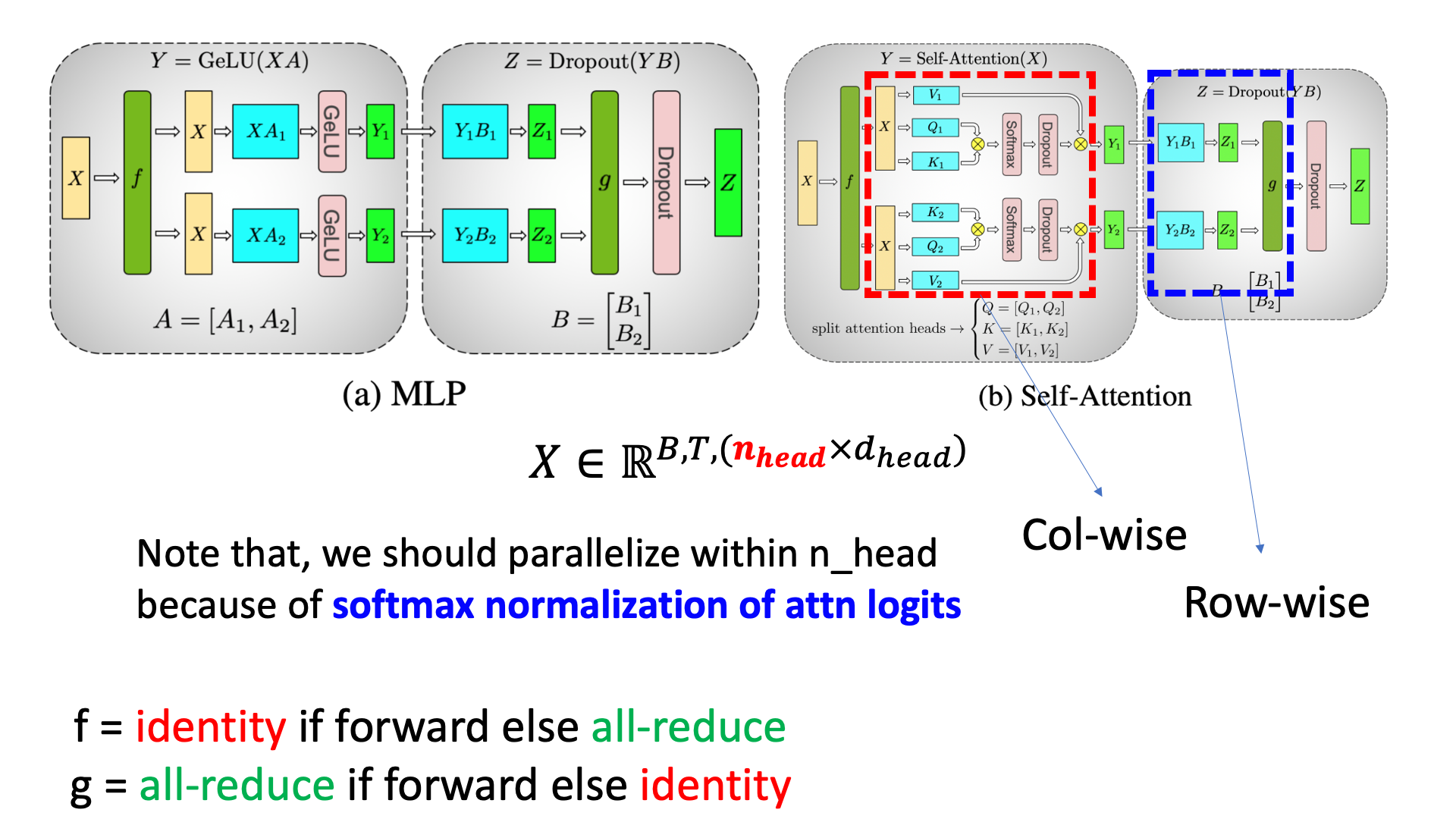 Fig.
Fig.
Rethink All-Reduce (AR) as Reduce Scatter (RS) + All Gather (AG)
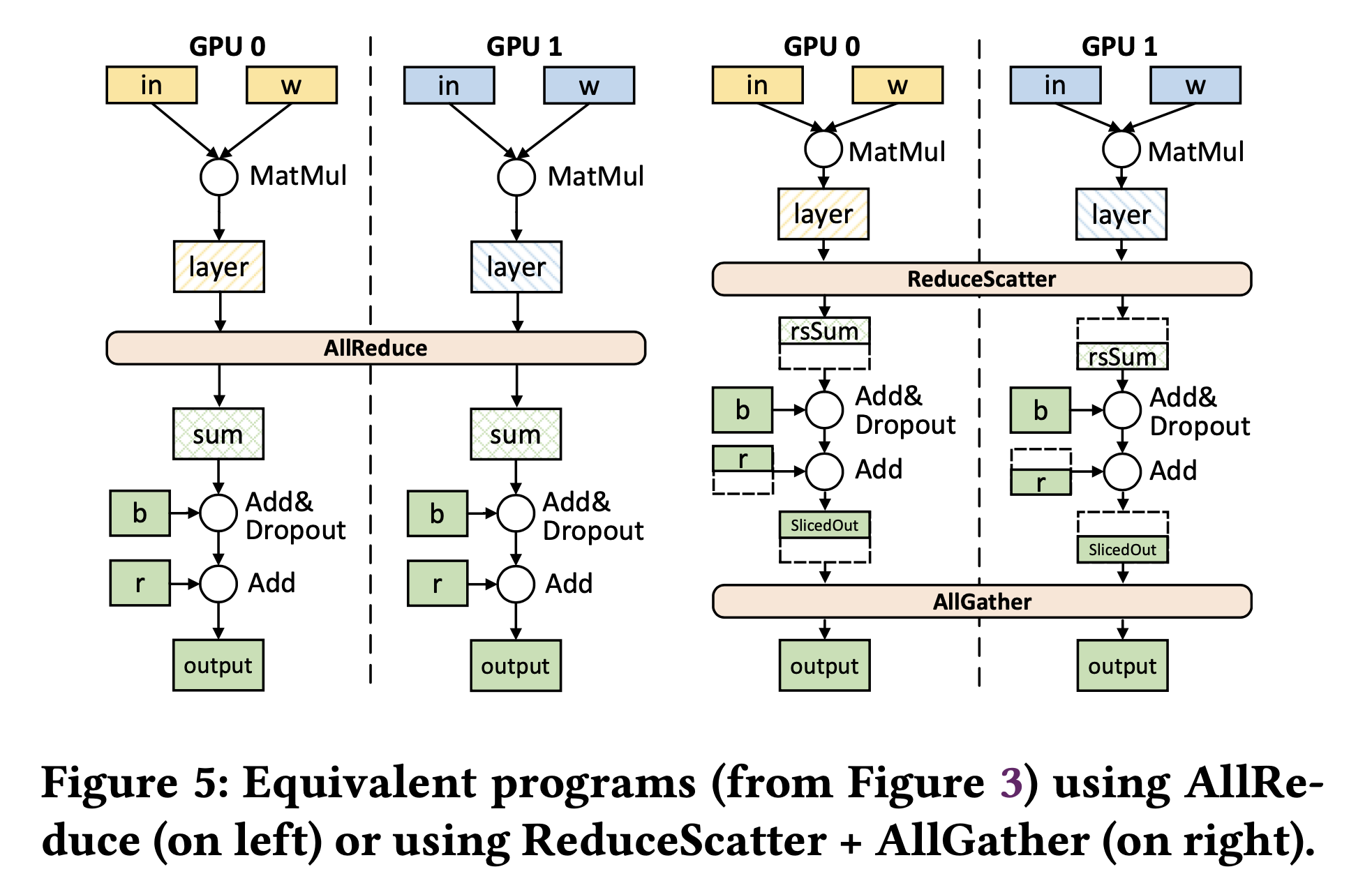
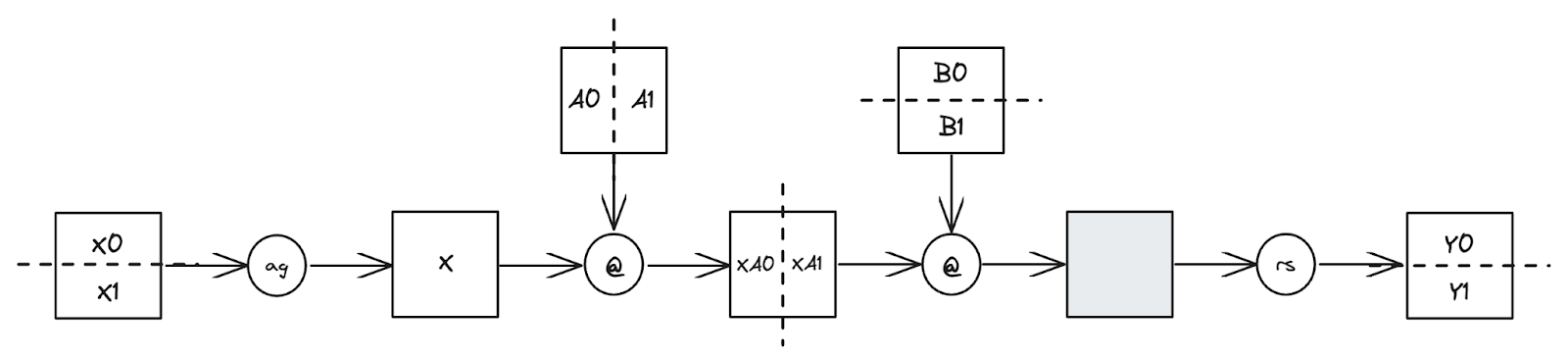 Fig. TP applied to a two-layer FFN sharded across 2 devices
Fig. TP applied to a two-layer FFN sharded across 2 devices
 Fig. Async-TP applied to an all-gather followed by a matmul
Fig. Async-TP applied to an all-gather followed by a matmul
Point-to-Point Communication in Pipeline Parallelism

Caveats
Compatibility between Async TP and SP
근데 megatron을 보면 Sentence Parallel (SP)과 Async TP는 같이 쓸 수 없다.
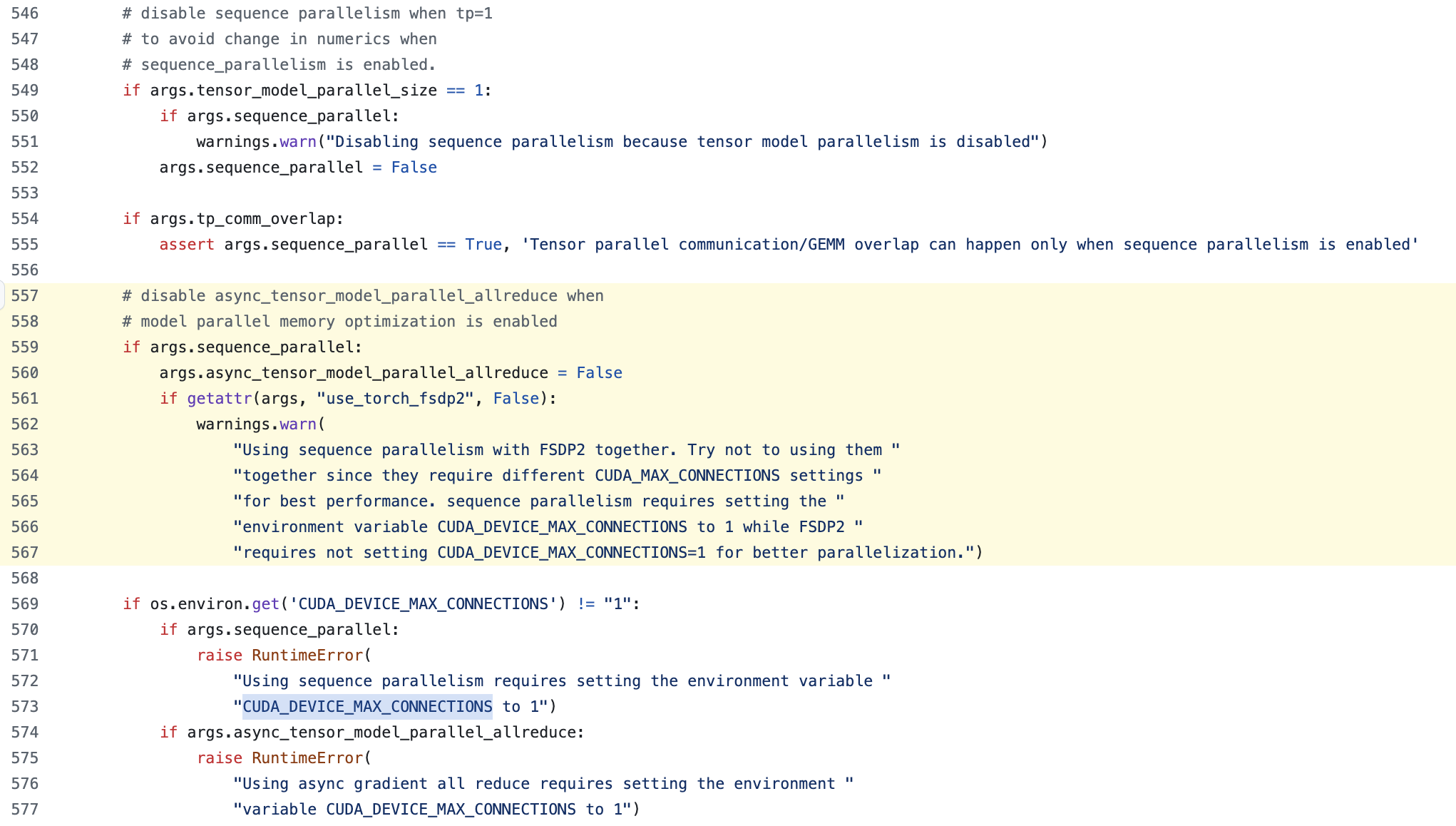 Fig.
Fig. you should discount model init by 1/device?
DeepSpeed Domino (Batch axis Async TP)
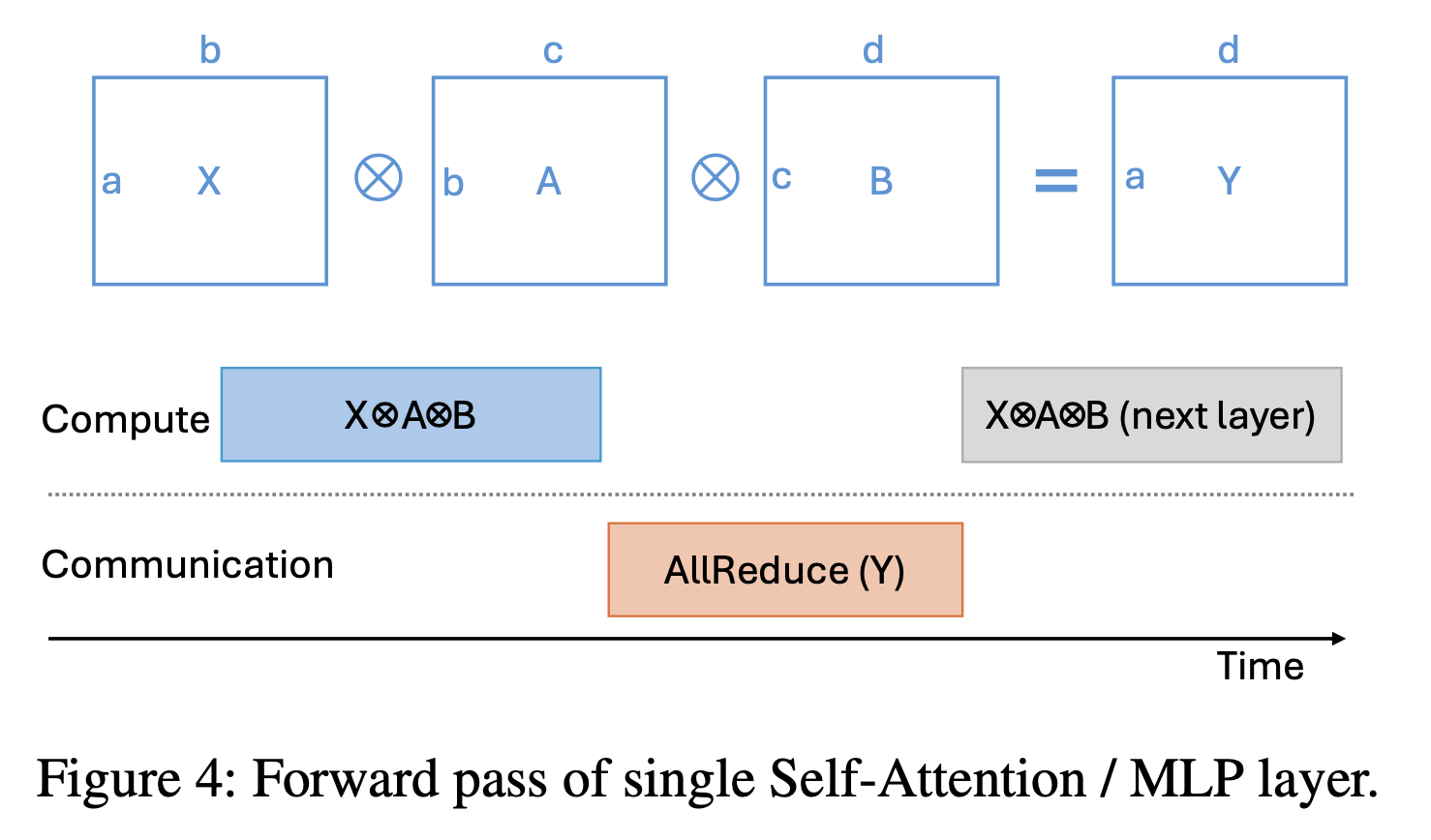 Fig.
Fig.
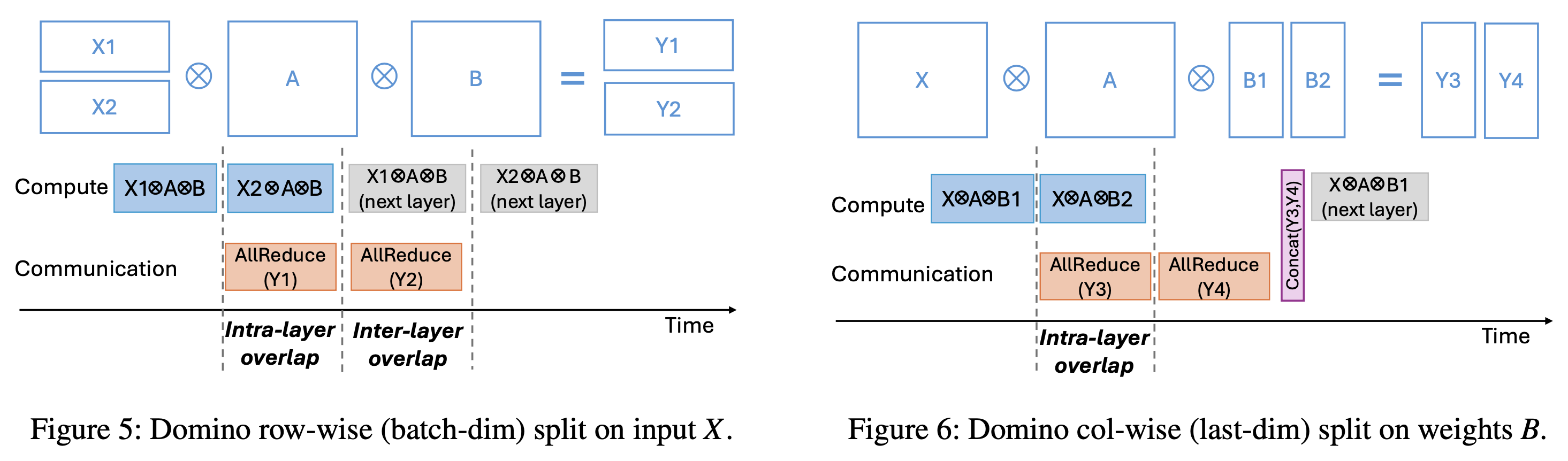 Fig.
Fig.
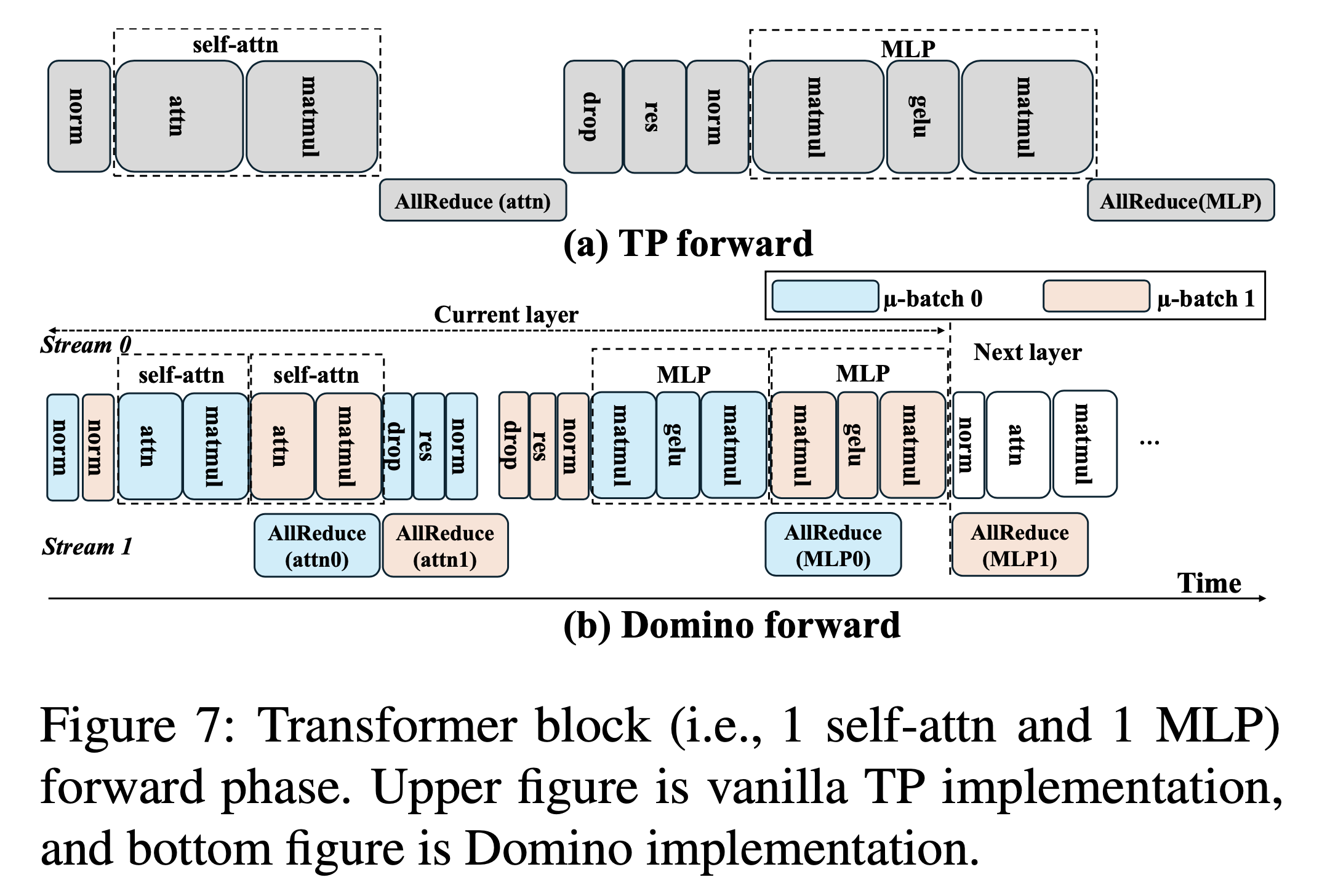 Fig.
Fig.
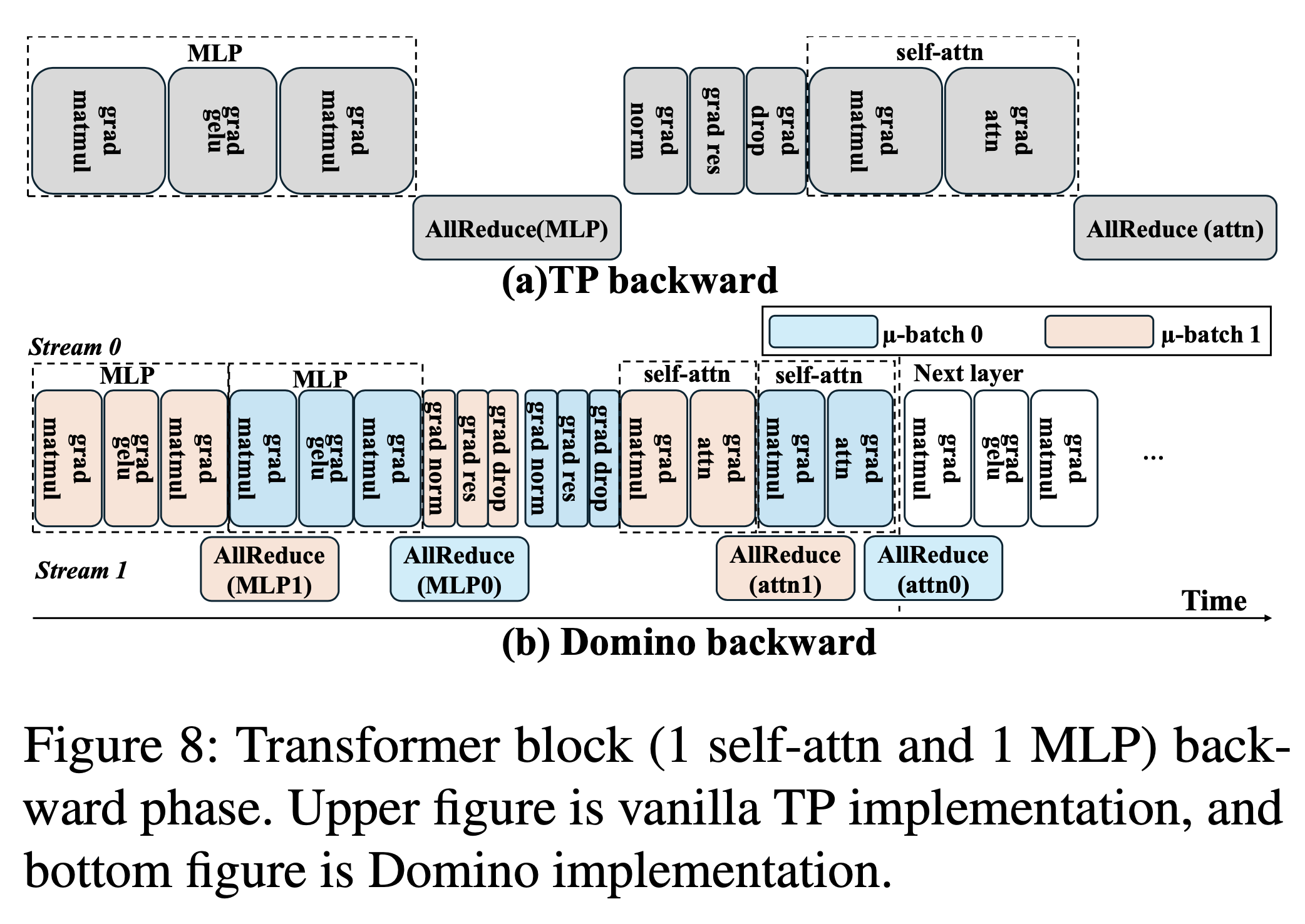 Fig.
Fig.
References
- (Distributed w/ TorchTitan) Introducing Async Tensor Parallelism in PyTorch
- Papers
- Breaking the Computation and Communication Abstraction Barrier in Distributed Machine Learning Workloads
- Scaling Vision Transformers to 22 Billion Parameters
- FLUX: Fast Software-based Communication Overlap On GPUs Through Kernel Fusion
-
Overlap Communication with Dependent Computation via Decomposition in Large Deep Learning Models
- Domino: Eliminating Communication in LLM Training via Generic Tensor Slicing and Overlapping
- UvA DL Notebooks