(WIP) Theoretical Memory Usage of Large Language Model (LLM)
27 Nov 2024< 목차 >
- Peak Memory for Activation Memory
- Peak Memory for Parameters and Optimizer States (given DP/TP/PP)
- Some Profiling Results
- References
Peak Memory for Activation Memory
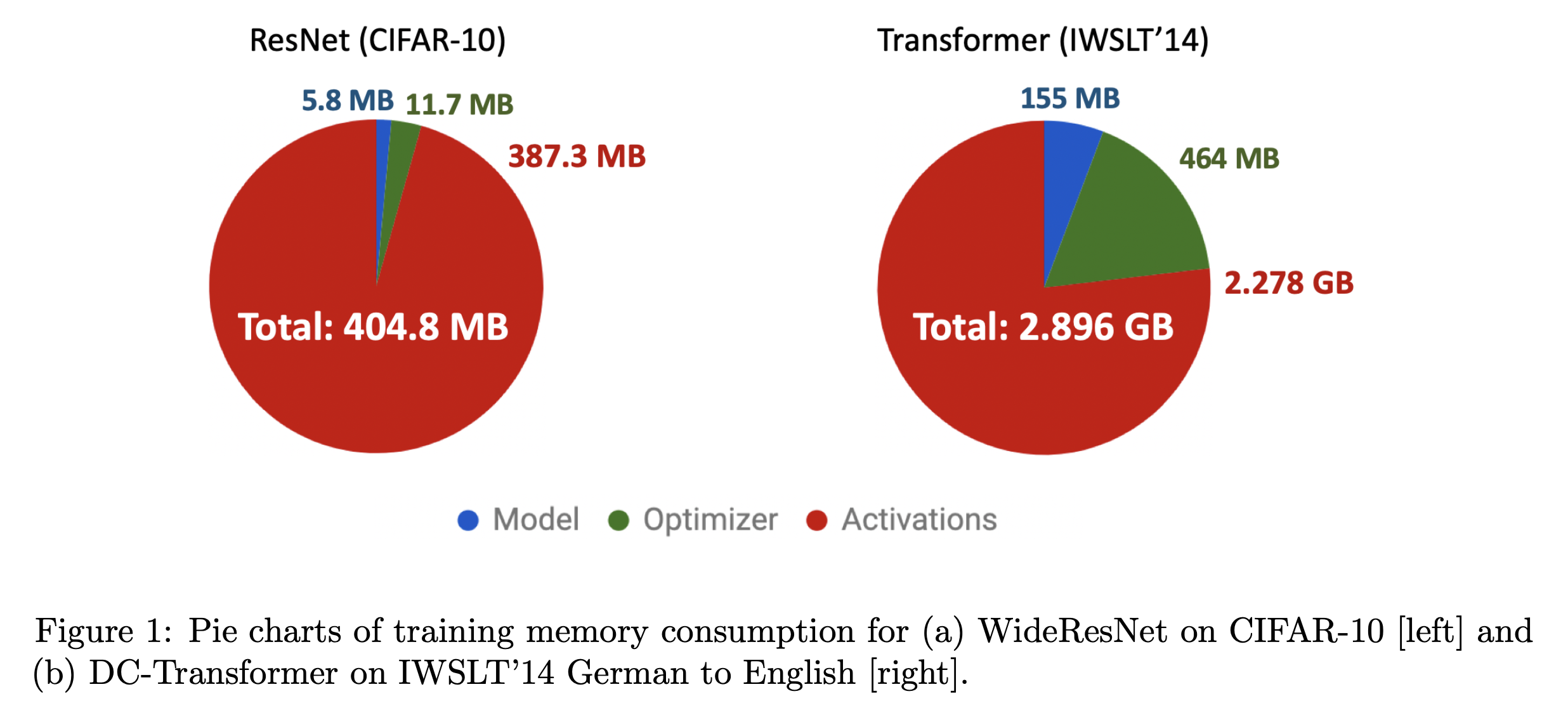 Fig.
Fig.
 Fig.
Fig.
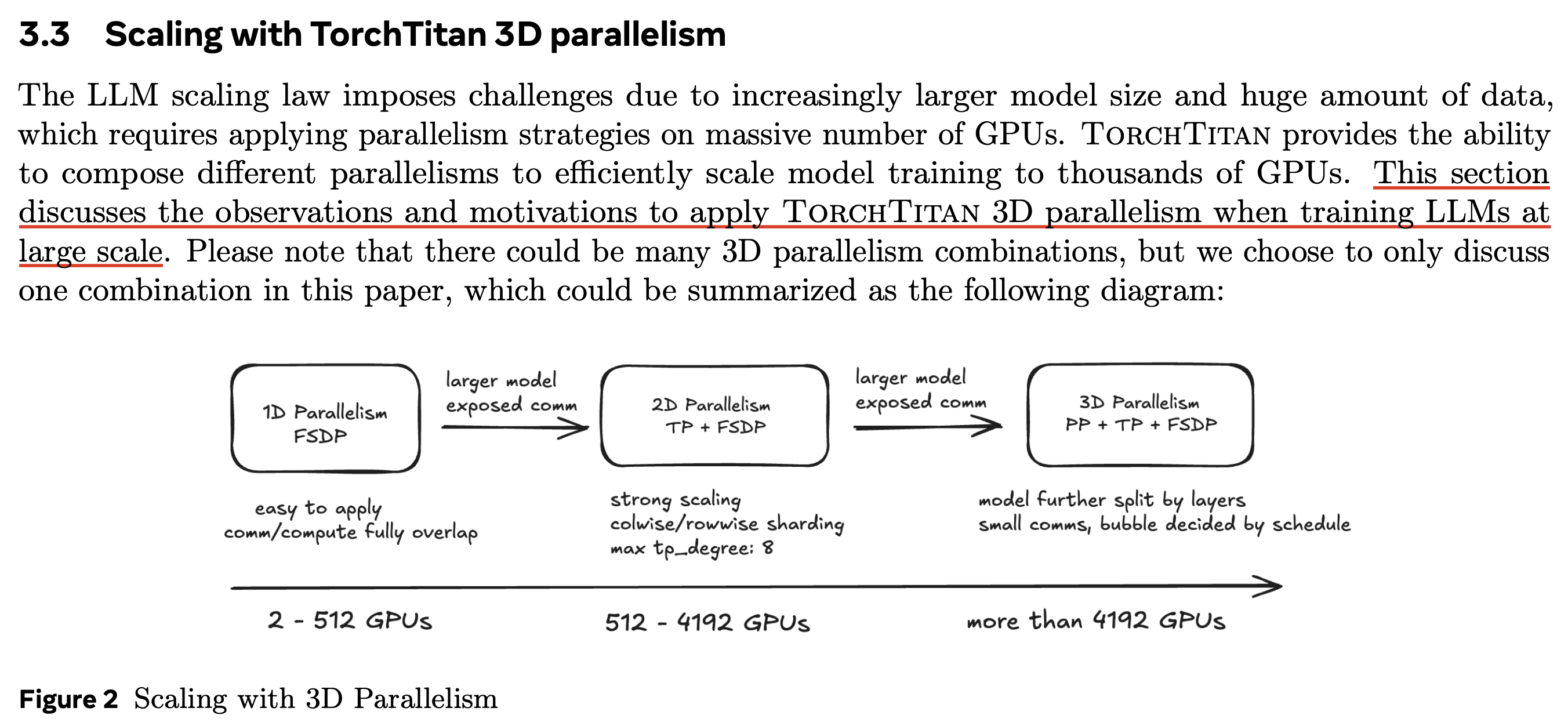 Fig. Source from TorchTitan white paper
Fig. Source from TorchTitan white paper
 Fig. Source from TorchTitan white paper
Fig. Source from TorchTitan white paper
Peak Memory for Parameters and Optimizer States (given DP/TP/PP)
Some Profiling Results
이제 Qwen-72B model을 Supervised Fine-tuning (SFT) 하는 경우에 대해서 memory profiling을 해보자. training setup은 다음과 같다.
- 72B model
- 8k batch tokens
- 4 node A100-80GB
- zero-3
- offload or not
- liger
여기서 liger kernel을 적용한 이유는 Qwen 2.5 series의 vocab size가 150k를 넘기 때문에 fp32 logit을 만들 때 매우 많은 memory가 생기는 것을 피하기 위해서이며 (사실 없으면 8k input에 대해서 못돌린다), 당연히 triton fused kernel을 적용하면 더 빨라지기 때문에 썼다.
Qwen 2.5 72B A100-80GB 4-node ZeRO-3 w/ and w/o offload
먼저 4 node (4x8=32 GPUs)를 사용하고 offload는 사용하지 않은 경우 forward+backward 을 2 step recording한 경우 master process (first node, first GPU)의 GPU memory view와 CPU memory view를 보도록 하자.
 Fig. GPU View of ZeRO-3 w/o offload
Fig. GPU View of ZeRO-3 w/o offload
 Fig. CPU View of ZeRO-3 w offload
Fig. CPU View of ZeRO-3 w offload
당연히 CPU offload를 하지 않았기 때문에 CPU memory view는 0에 수렴하는 걸 확인할 수 있다. GPU memory view를 보면 forward가 시작되기 전 (nn.embedding, nn.linear) GPU memory가 거의 40 GB에 달하는 걸 볼 수 있는데, 이는 model size가 72B일 때 model params, optim states, gradient가 모두 32등분 됐기 때문에 대략 38.6 MB로 이는 말이 되는 수치로 보인다.
\[18 \times 72e9/32/1024/1024 = 38623 \text{ MB}\]그리고 model forward가 시작되면 parameter all-gather를 시작할텐데, vocab size가 매우 큰 qwen의 경우 embedding layer가 가장 클 것이므로 매 layer forwarding시 최대 4738MB가 필요할 것으로 보인다.
\[\begin{aligned} & \text{embedding weight matrix}: \color{red}{151646 \times 8192} & \\ & \text{linear (qkvo and so on) weight matrix}: 8192 \times 8192 & \\ & \text{ffn1,2 (GLU) weight matrix}: 29568 \times 8192 & \\ \end{aligned}\] \[4 \times 151646 \times 8192 /1024/1024 = 4738 \text{ MB}\]아마도 이 밖에 parameter를 들고 있으면서 model forward를 통해 output tensor를 만드는 상황이기 때문에 peak 매 순간 memory는 32등분 된 기본 params + optim states에 더해 가장 큰 layer의 matrix 크기, 그리고 (intermediate) output tensor가 될 것으로 생각된다. 아무튼 figure에서 38 GB정도가 필요한 것으로 보이기 때문에 (지금 모든 상황은 allocated를 말하는 것이고 reserved가 아님), activation은 대충 56448-38623=17825 MB가 필요한 것으로 보인다.
\[\begin{aligned} & \text{total peak memory (allocated)} : 56448 \text{ MB} & \\ & \text{params/optim states/grads} : 38623 \text{ MB} & \\ & \text{activations (including logits)} : 17825 \text{ MB} & \\ \end{aligned}\]이 때 두 번째 profiling step의 peak memory가 조금 더 커 보이는데,
이것은 내가 구현한 dynamic batching이 B*T=valid_tokens가 최대 8192가 되도록 batch를 sorting해서 grouping한 것이기 때문에 실제로 valid tokens이 좀 달라서 그렇다.
이제 offload를 시켜보자.
 Fig. GPU View of ZeRO-3 w/o offload
Fig. GPU View of ZeRO-3 w/o offload
 Fig. CPU View of ZeRO-3 w offload
Fig. CPU View of ZeRO-3 w offload
Offload를 했더니 total peak memory (allocated)가 대략 56448 MB에서 21850 MB로 감소한 것을 확인할 수 있다.
여기서 activation이 되기 전에도 GPU memory가 0이 아닌 것은 아래와 같은 이유 때문일 수 있겠다.
- default cuda context
- training loop을 돌 때 (intermediate) output tensors가 release 잘 되지 않음
- nccl communication을 위한 default buffer
여기서 CPU memory가
2-node
 Fig.
Fig.
 Fig.
Fig.
2-node with offloading optimizer states and gradients only
 Fig.
Fig.
 Fig.
Fig.
tmp
References
- Papers
- Estimator Implementations
- torchtitan
- megatron
- deepspeed