(WIP) Distributed Training for Large Scale Transformer (3/6) - Pipeline Parallelism (PP)
15 Feb 2024< 목차 >
- Motivation
- Overview of Pipeline Parallelism (PP)
- GPipe
- PipeDream
- Interleaved PP
- Zero Bubble PP (ZBPP)
- GraphPipe
- Improved PP from LLaMa-3.1
- References
Motivation
사실 large-scale training을 하면서 distributed training에 대해서는 공부를 할 수 밖에 없었다. 그럼에도 불구하고 “Pipeline Parallelism (PP)까지는 할 일이 없다, 이건 진짜 system engineer의 영역이다”라고 생각했는데, 좀 찾아보니 ML engineer라면 이것도 당연히 알아야 하는 것이라고 결론낼 수 있었다. LLaMa-3.1에서 405B model을 학습하기 위해 Data Parallelism (DP), Tensor Model Parallelism (TP), Pipeline Model Parallelism (PP)를 사용한 3D Parallelism를 사용했으며, 8k이상의 extra long sequence training을 위해서는 Context Parallel (CP)까지 4D parallelism을 했다.
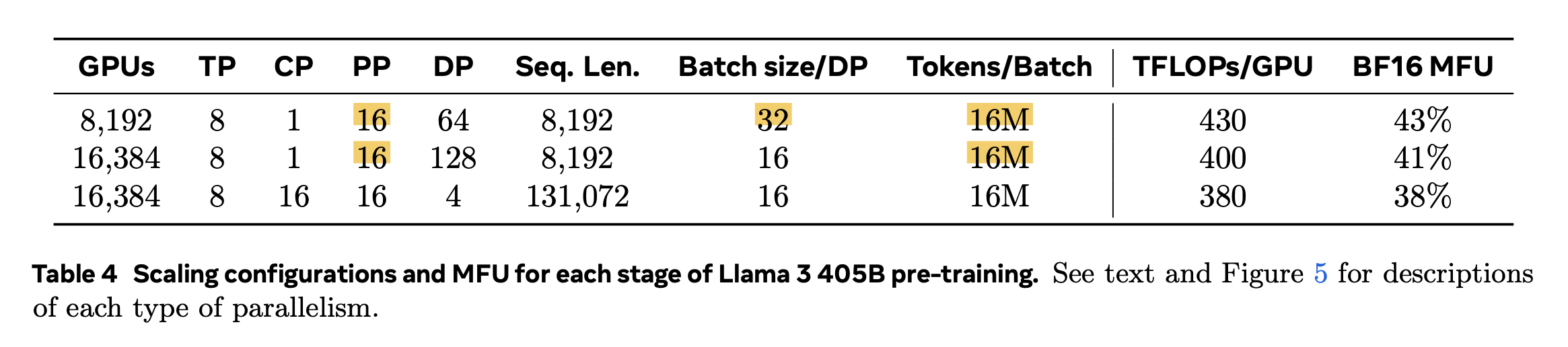 Fig.
Fig.
 Fig.
Fig.
사실 3D, 4D parallelism을 한다는것은 frontier lab들에서는 당연한 (아마도) 것이기 때문에 그렇게 감탄할 거리는 아니지만,
그들이 자랑하는 것은 Improved PP이다.
 Fig.
Fig.
이들은 PP를 쓸 경우 생길 수 있는 여러가지 constraint을 optimization함으로써 activation checkpointing 없이 405B를 fwd+bwd 함으로써 Machine FLOPs Utilization (MFU)를 극대화 할 수 있었다고 하는데, PP를 설명하는데만 2 page 가까이 서술한 것만 봐도 PP가 얼마나 중요한 지 알 수 있겠다.
물론 LLaMa-3.1 수준까지 최적화를 우리가 못 할수도 있다. 그럼에도 불구하고 Megatron-LM같은 framework을 쓸 때 3D parallel에 대한 이해가 없어 distributed training configuration을 잘못 설정하게 되면, 우리는 1달이면 끝나는 실험을 2~3달 걸리는 비효율을 맛볼 수도 있다.
이게 무슨 소리일까?
아래 TP, PP를 포함한 Model Parallelism (MP)에 대해서 생각을 해보자.
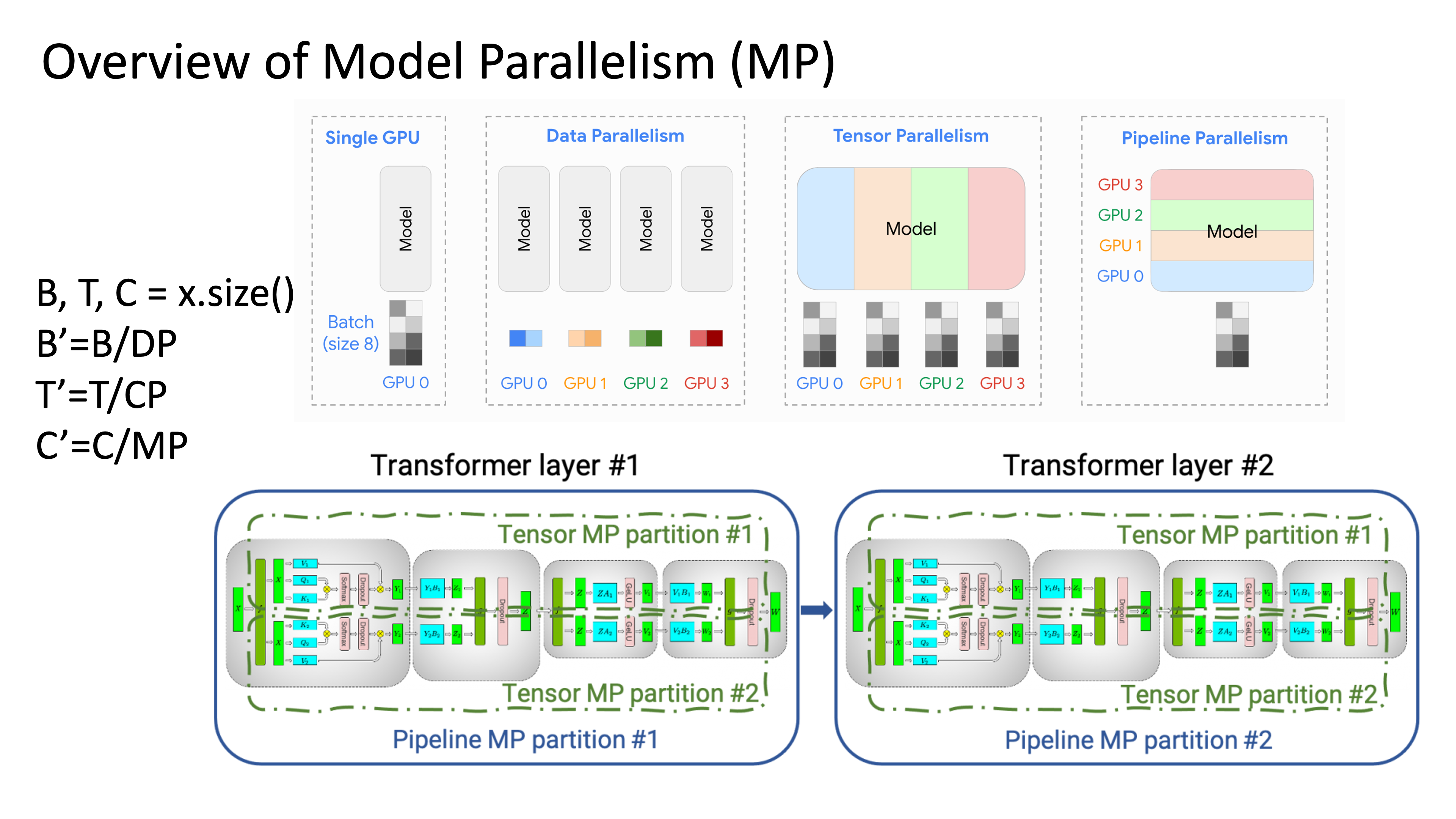 Fig.
Fig.
우리에게 똑같이 model을 16등분 할 수 있는 기회가 주어진다 하더라도 (MP degree=16), model을 가로 세로로 몇 등분 하는지에 따라서 (vertical, horizontal), 즉 TP, PP degree를 각각 몇으로 하냐에 따라서 우리는 놀랍도록 큰 MFU 차이를 경험할 수 있다. MP degree가 6이라면 TP:PP = 4:4로 할 수도 있고, 아니면 8:2, 2:8로도 설정할 수 있는데, Efficient Parallelization Layouts for Large-Scale Distributed Model Training에 따르면 LLaMa-3 30B에 대해서 TP보다 PP에 투자하는게 더 좋다는 걸 알 수 있다. (해보면 실제로도 그렇다)
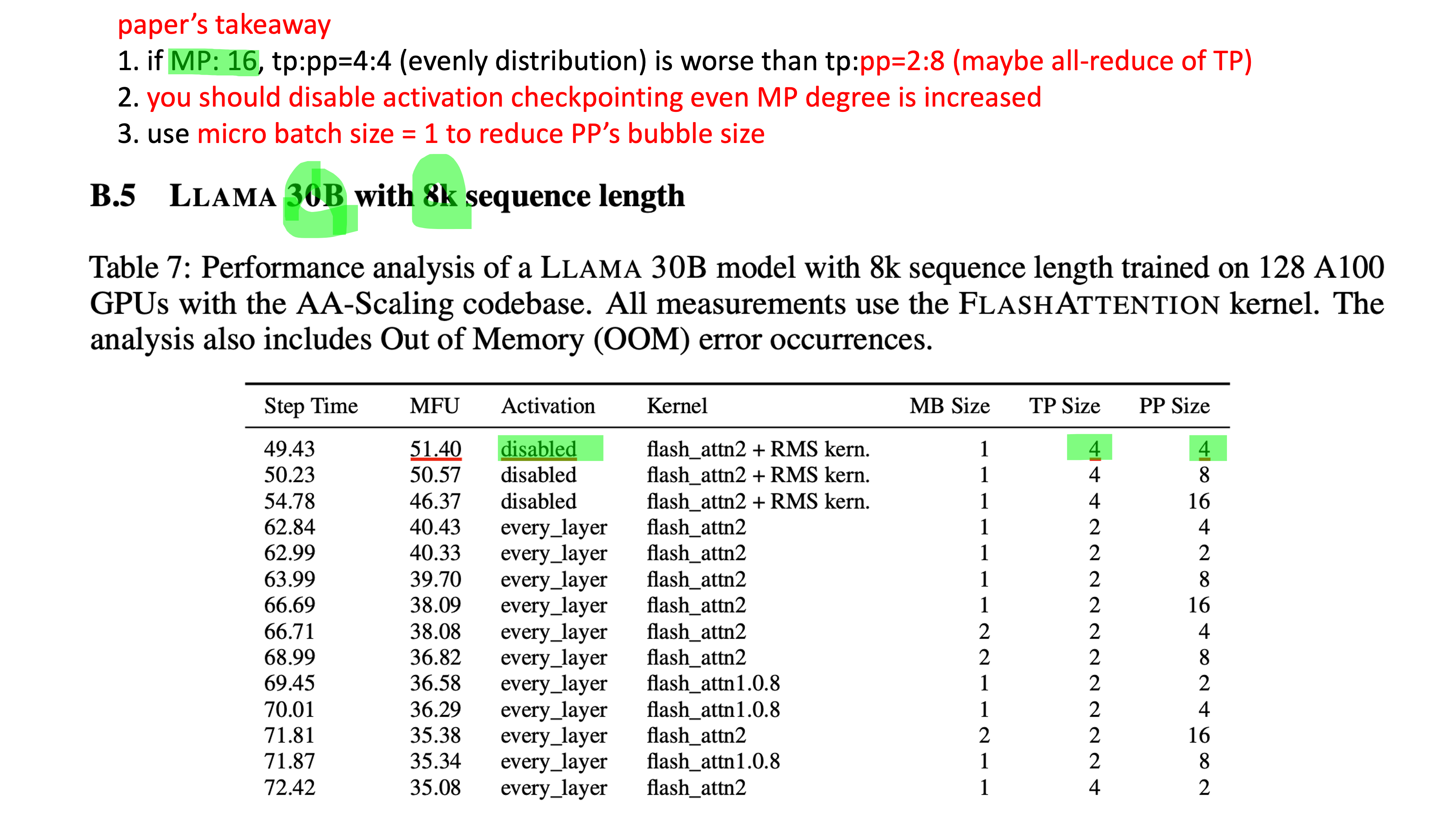 Fig.
Fig.
그리고 paper에 따르면 MP degree를 늘리더라도 (즉 통신이 늘어나더라도), activation checkpointing을 끄는 것이 훨씬 빠르다는 결론에 이른다. 이렇게 MP degree가 몇인지, PP에 더 투자할 것인지에 따라서 throughput (MFU)가 아예 달라질 수도 있는데, 이번 post의 목표는 어떻게 이것이 가능한지에 대해서 이해하는 것이다.
Overview of Pipeline Parallelism (PP)
Low GPU Utilization
하지만 naive PP에는 큰 문제가 있다. 바로 어떤 layer들이 forwarding이 진행되는 동안 그것을 제외한 device들은 놀고 있다는 점과 더불어, communication을 하는 동안에도 gpu kernel operation이 쉰다는 점이다. 이말은 전체 wall clock time중 GPU가 일하는 비율이 적다는 것으로, 즉 utilization이 낮다는 것을 말한다.
GPipe
PipeDream
GPipe의 또 다른 문제는 memory demand가 높아진 다는 것이다. 아래 animation을 보자.
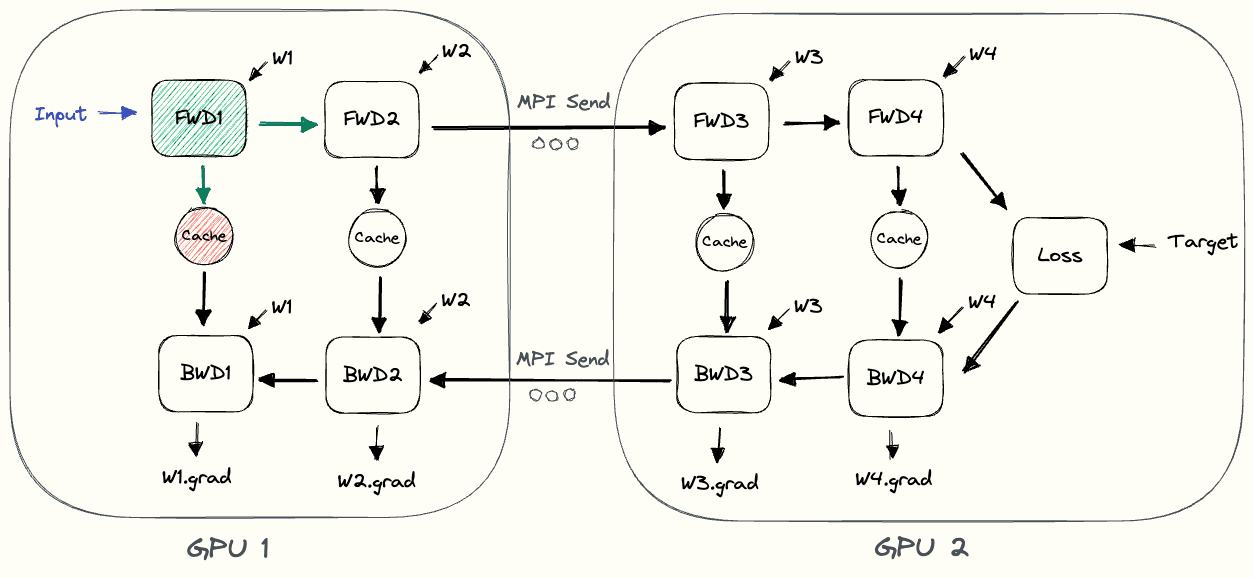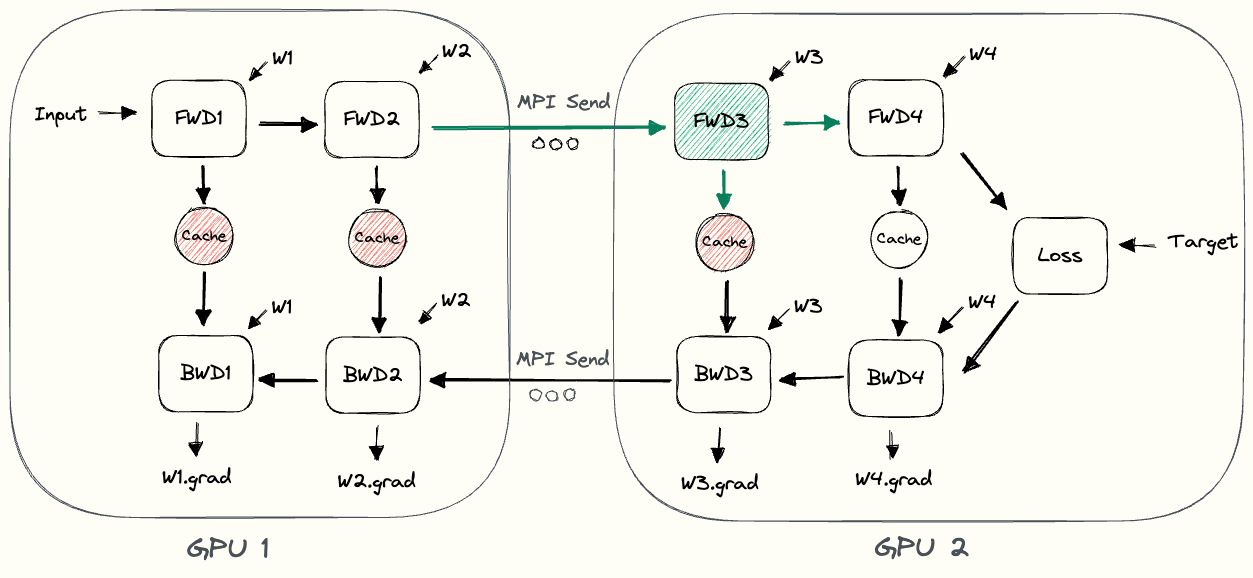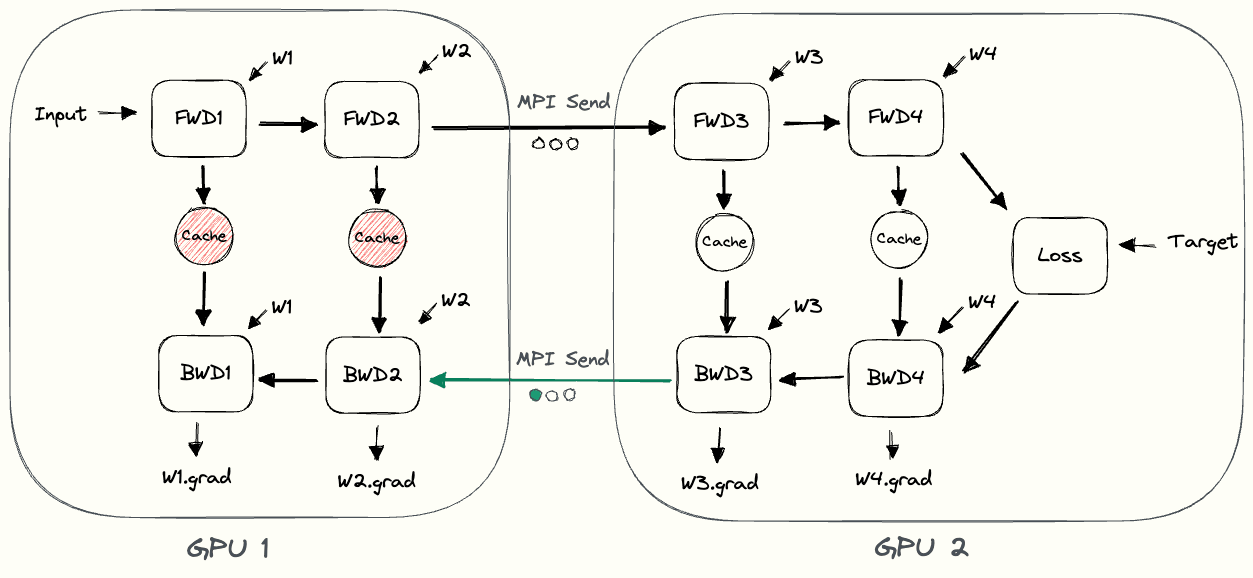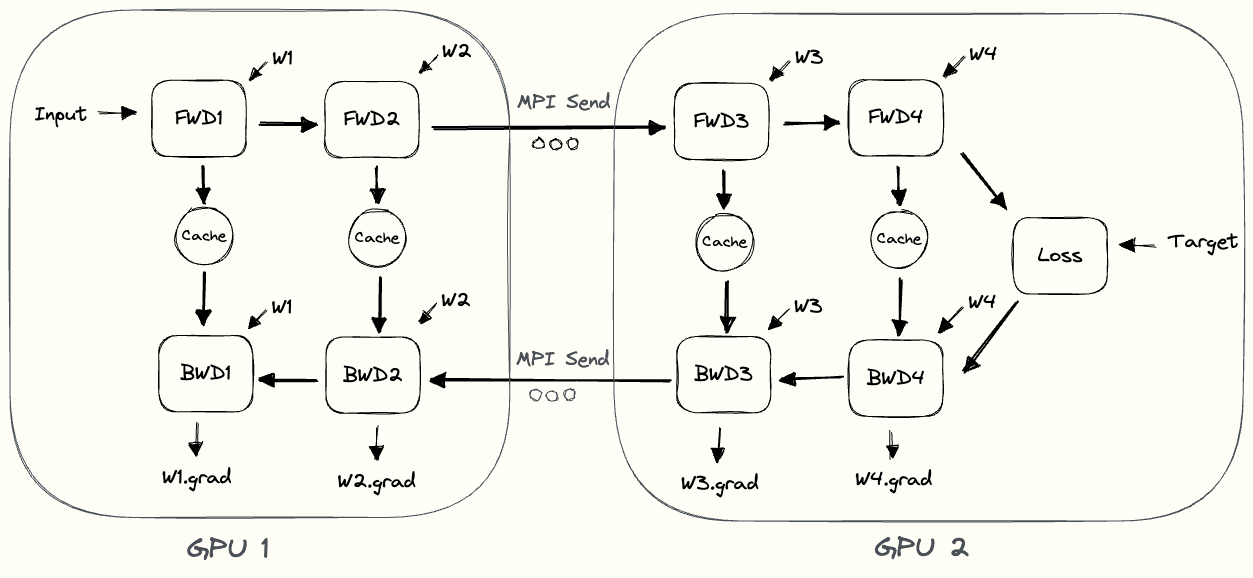 Fig.
Fig.
가장 앞단의 layer들을 담당하는 device 1은 backward가 다 끝날 때 까지 activation을 들고 있어야 하는데, 여러 microbatch를 처리하는 pipeline에서 device 1은 대부분의 시점에서 microbatch size만큼의 activation을 다 들고 있어야 한다.
Interleaved PP
Bubble time fraction of GPipe
한번 GPipe의 bubble time, \(t_{pb}\)을 정량화해보자.
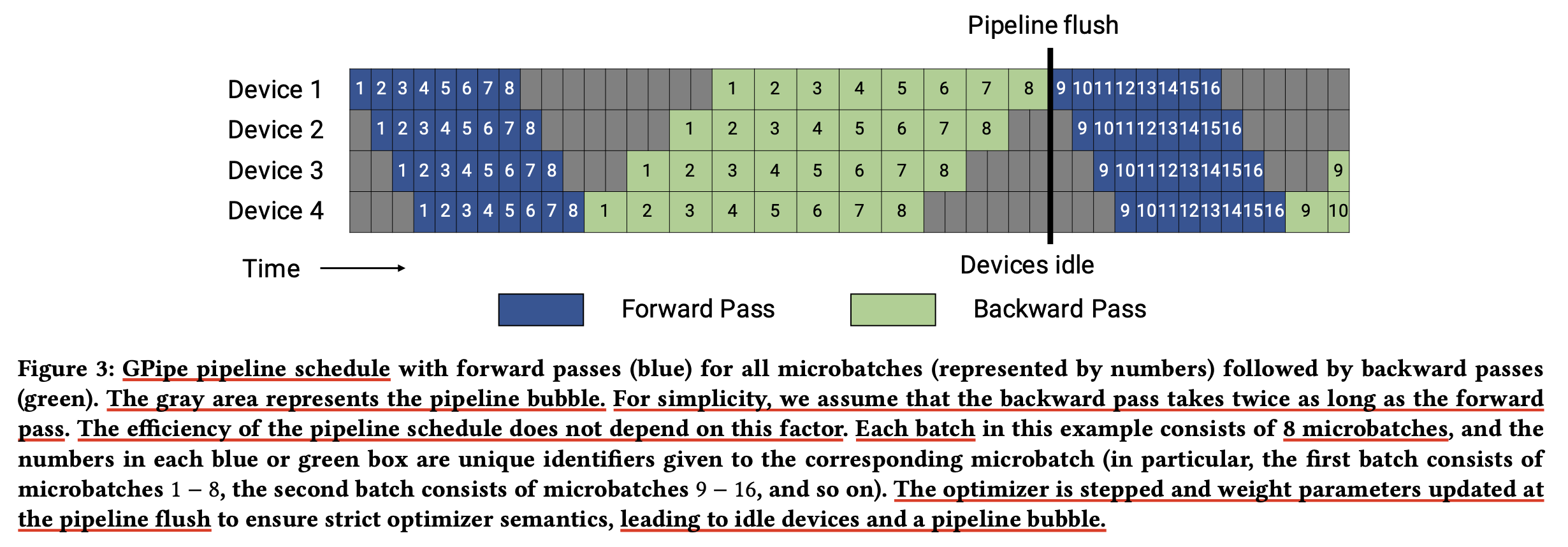 Fig.
Fig.
먼저 the number of microbatch를 \(m\)이라고 하고, the number of pipeline stage (number of devices used for pipeline parallelism)를 \(p\)라고 한다. microbatch 하나를 forward, backward하는데 드는 시간을 각각 \(t_f, t_b\)라고 한다. 그러면 우리는 자연스럽게 batch의 시작점 부터 \(p-1\)개의 fowrard와 backward가 존재한다는 걸 알 수 있다. 마지막으로 그리고 ideal time per iteation을 \(t_{id}\)라고 하는데, 이제 \(t_{pb}, t_{id}\)는 다음과 같이 쓸 수 있다.
\[\begin{aligned} & t_{pb} = (p-1) \cdot (t_f + t_b) & \\ & t_{id} = m \cdot (t_f + t_b) & \\ \end{aligned}\]그러므로 the fraction of ideal computation time spent in the pipeline bubble은 다음과 같이 쓸 수 있다.
\[\begin{aligned} & \text{Bubble time fraction (pipeline bubble size)} & \\ & = \frac{t_{pb}}{t_{id}} = \frac{p-1}{m}. & \\ \end{aligned}\]그러므로 pipeline bubble을 줄이기 위해선 \(m >> p\)만큼 충분한 크기의 \(m\)이 필요한데,
Interleaved PP
Interleaved PP의 idea는 이렇다.
먼저 아래와 같이 GPipe의 forward, backward를 섞어서 schedule을 구성하는데,
이는 one forward, one backward를 한다고 해서 1F1B라고 한다.
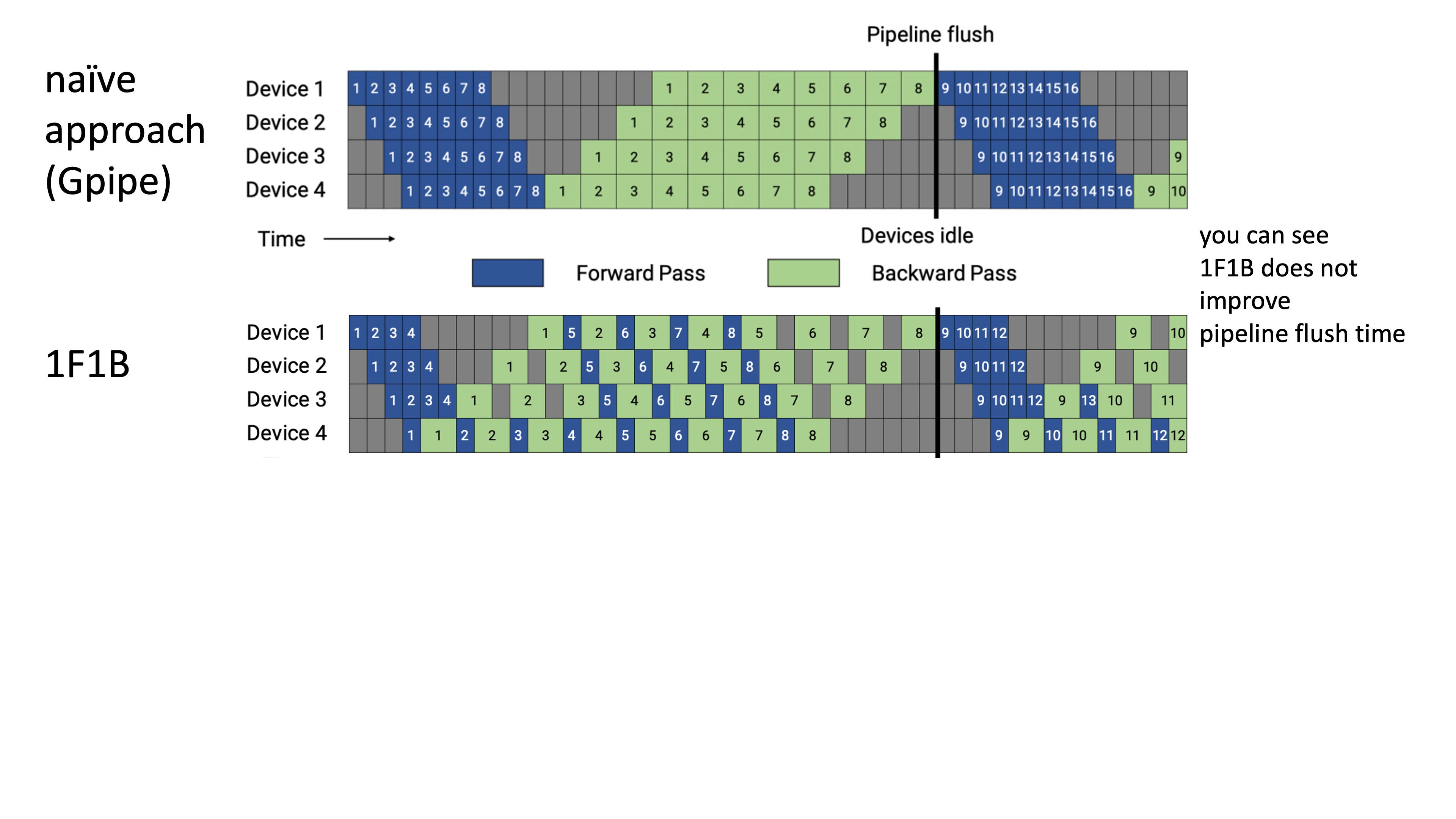 Fig.
Fig.
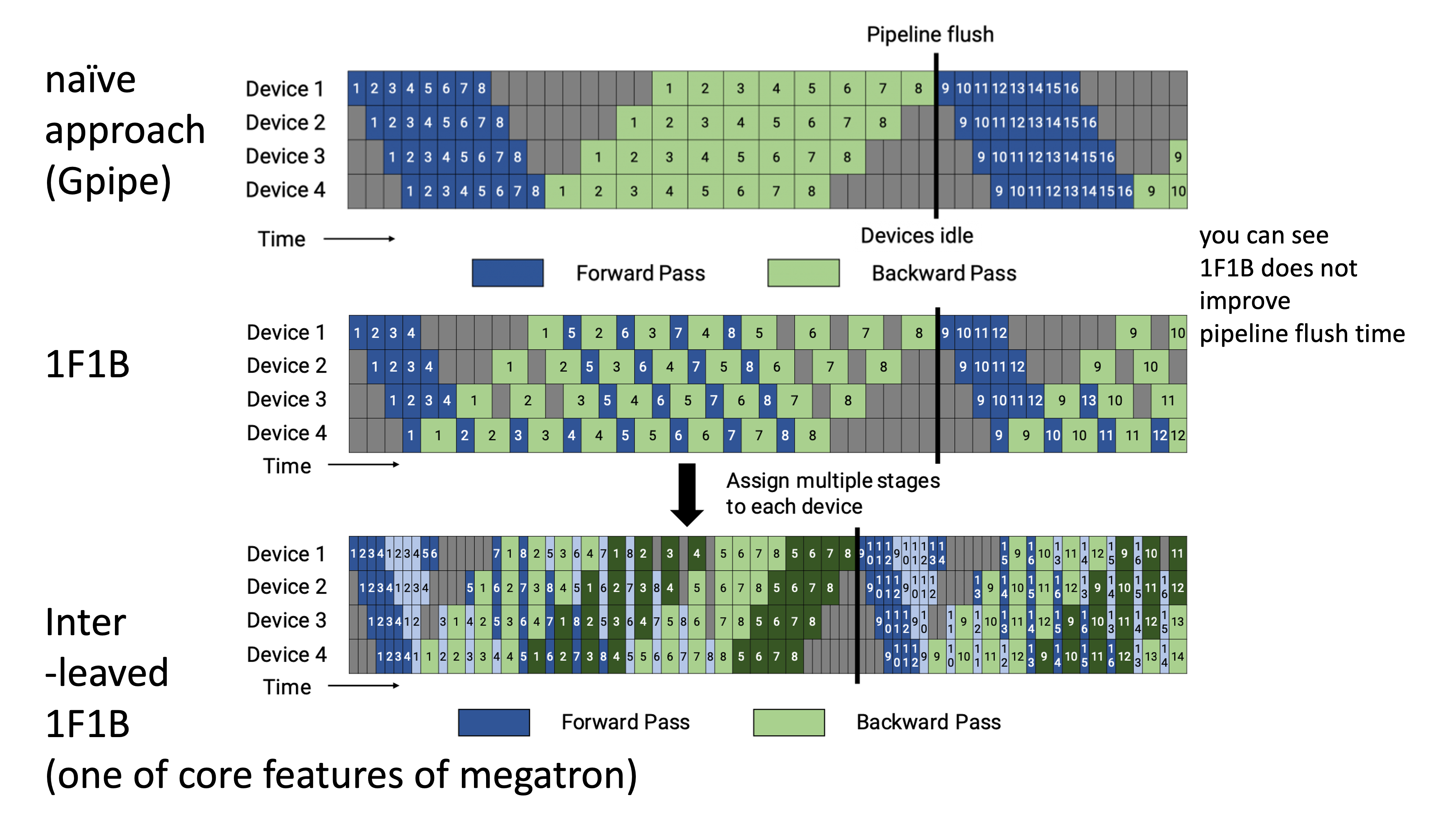 Fig.
Fig.
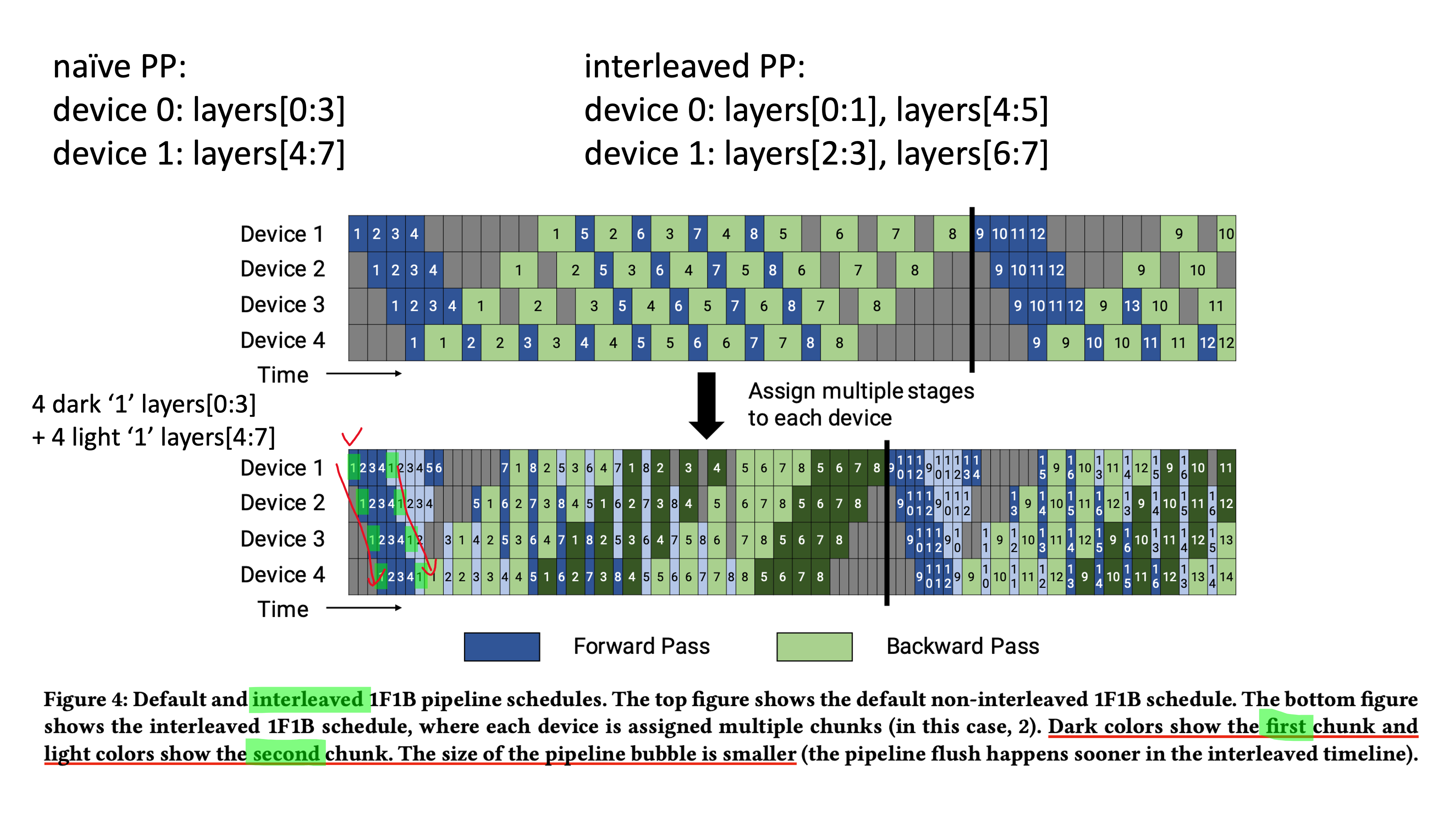 Fig.
Fig.
Communication Optimizations
Evaluations
Zero Bubble PP (ZBPP)
GraphPipe
 Fig.
Fig.
 Fig.
Fig.
Improved PP from LLaMa-3.1
Fig.
 Fig.
Fig.
 Fig.
Fig.
References
- Papers
- GPipe: Efficient Training of Giant Neural Networks using Pipeline Parallelism
- PipeDream: Fast and Efficient Pipeline Parallel DNN Training
- Memory-Efficient Pipeline-Parallel DNN Training
- Efficient Large-Scale Language Model Training on GPU Clusters Using Megatron-LM
- Reducing Activation Recomputation in Large Transformer Models
- Efficient Parallelization Layouts for Large-Scale Distributed Model Training
- On Optimizing the Communication of Model Parallelism
- Breadth-First Pipeline Parallelism
- LLaMa-3
- Others