(WIP) Distributed Training for Large Scale Transformer (4/6) - Sequence Parallelism (SP) and Context Parallelism (CP)
15 Feb 2024< 목차 >
- Introduction and Motivation
- Megatron Sequence Parallelism (Megatron-SP)
- DeepSpeed Ulysses (DS-Ulysses)
- Blockwise Parallel Transformer (BPT) and Ring Attention
- +Updated) A Unified Sequence Parallelism Approach for Long Context Generative AI
- +Updated) Fully Pipelined Distributed Transformer (FPDT)
- References
Introduction and Motivation
Sequence Parallelism (SP)나 Context Parallelism (CP)는 long context input을 효율적으로 처리하기 위해 제안되었다. 이는 training, inference 모두에 기여하는 algorithm이며, 내가 알기론 가장 먼저 megatron-LM의 extended feature로 개발되었고 그 이후로 CP가 등장했다. 앞서 TP에 대해 소개했으니 megatron에 대한 얘기는 생략하고,
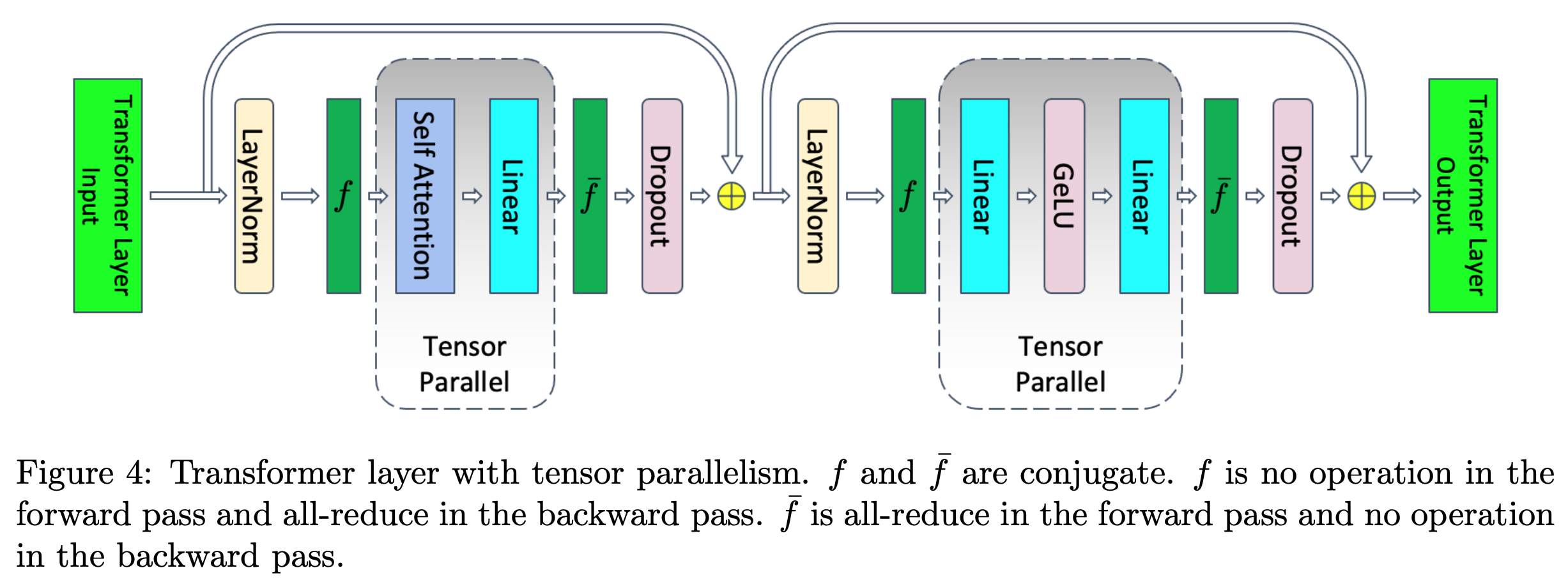 Fig.
Fig.
SP는 transformer block에서 dropout, layernorm같은 특정 layer들에 대해서 예를 들어 GPU device가 2개라면 \([B, T]\)차원의 input을 \([B, T/2]\)으로 나눠 처리하는, 즉 sequence length dimension으로의 분산 처리 기술을 의미한다.
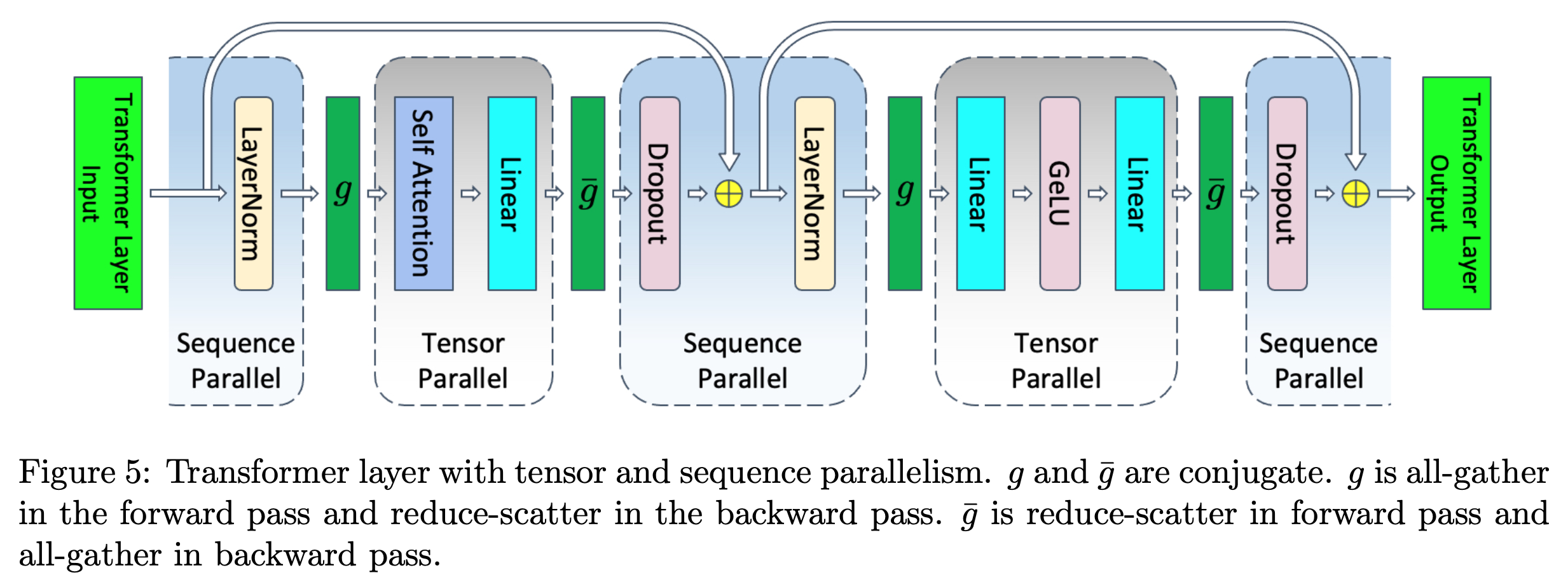 Fig.
Fig.
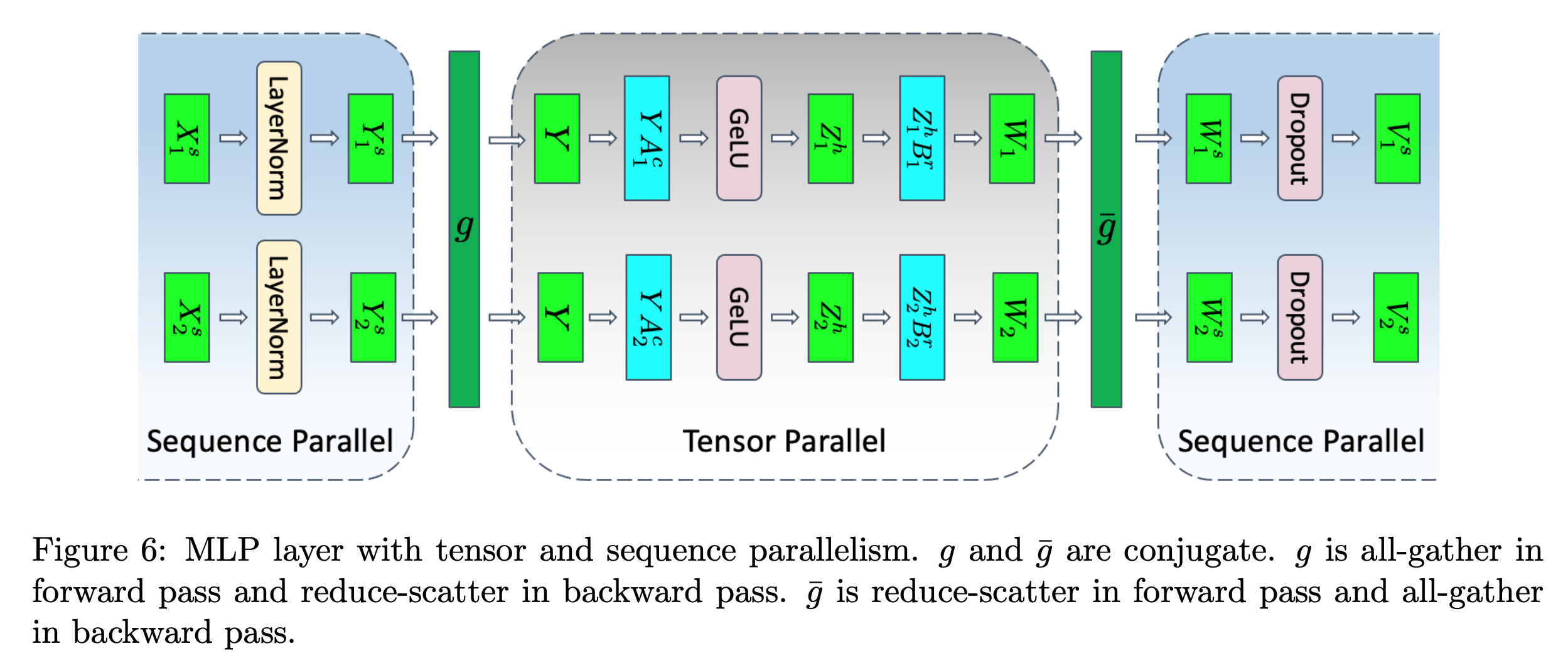 Fig.
Fig.
이는 dropout, layernorm의 activation output에서 발생하는 memory를 save하는 대신 recomputation, communication cost를 지불하는 mechanism을 갖는다.
대부분의 distributed training algorithm들이 그렇듯, 희생한 latency 보다 batch size를 더 넣게되면 초당 토큰 처리량 (throughput; tokens/sec)은 결국 개선된다는 logic에 따라 SP, CP도 이런식으로 system efficiency에 기여했다고 볼 수 있다.
CP는 megatorn-SP를 넘어 모든 layer input을 sequence dimension으로 분산 처리 하는 것을 말하는데,
사실 SP나 CP를 섞어서 부르는 경우가 많아서 큰 의미는 없는 것 같다.
차라리 megatron-SP 같은 경우는 attention은 분산 처리를 하지 않았기 때문에 attention을 device로 나눠서 했는가?를 의마하는 distributed attention로 부르기도 한다.
이는 megatron-lm이 처음 나와 model weight을 vertical, horizontal로 번갈아 자르는 technique을 Tensor Parallelism (TP)라고 정의했지만 넓은 범위에서 이것도 model partition을 하는 것은 변함 없기에 megatron-lm 을 Model Parallelism (MP)라고 불러도 큰 위화감이 없는 것과 같다고 생각할 수 있다.
한 편, TP나 CP가 가능한 이유는 transformer가 highly paralleized architecutre 이기 때문에 가능한 것인데, 즉 다시말해 transformer는 intertoken operation이 거의 없다. 예외에 해당하는 것은 Token간의 정보를 mixing하는 attention softmax 같은 operation들인데 (그래서 MLP mixer라는 title의 paper가 있는 것), 그렇기 때문에 forward, backward시 key and value (KV)를 적절히 all-gather or reduce-scatter 해줘야 한다. 이러한 distributed attention을 구현하기 위해 ring all-reduce처럼 ring 구조를 갖는 것이 Ring Attention이다.
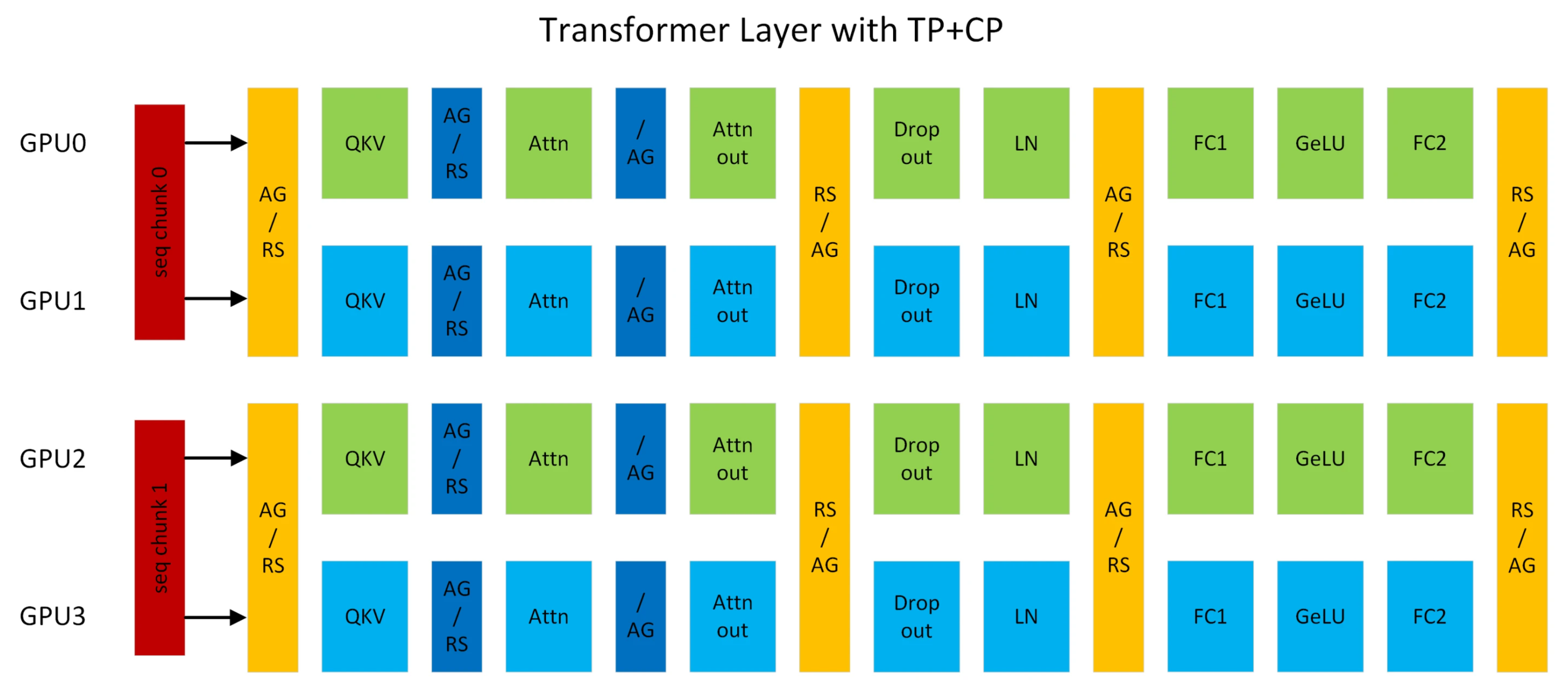 Fig.
Fig.
이번 post의 goal은 SP, CP 그리고 ring attention의 작동원리에 대해 이해하고 이를 자세히 분석하는 것이인데, key papers는 다음과 같다.
- Reducing Activation Recomputation in Large Transformer Models
- DeepSpeed Ulysses: System Optimizations for Enabling Training of Extreme Long Sequence Transformer Models
- Ring Attention with Blockwise Transformers for Near-Infinite Context
Megatron Sequence Parallelism (Megatron-SP)
Megatron-LM의 SP의 paper title은 Reducing Activation Recomputation in Large Transformer Models 이다.
Transformer languagge model의 self attention, Feed Forward Network (FFN)만 colwise, rowwise parallelism으로 자른 TP는 획기적이긴 했으나,
여전히 VRAM memory가 부족했기 때문에 further optimization을 한 것이다.
대부분의 distributed training paper 들이 그렇듯, 해당 paper도 어디가 bottleneck인지 분석하는데,
지금의 경우 전체 각 layer에서 드는 activation memory를 분석하여 이를 해결한다.
Paper의 전반적인 흐름은 아래와 같은데,
- Activations Memory Profiling Per Transformer Layer
- How to Parallize Dropout and LayerNorm layers
- Selective Activation Recomputation
- Model FLOPs Utilization (MFU) and Overheads Analysis
여기서 activation pofiling을 할 때 주의해서 봐야할 점이 있다. (왜냐면 지금 글을 쓰는 시점은 2024년이기 때문에)
- flash attention같은 memory efficient attention의 activation recomputation 등은 고려되지 않은 것 같음
- LLM training 시 dropout을 안쓰는 추세임
그리고 paper의 title에서도 알 수 있듯, 기존 TP나 ZeRO같은 distributed system이 모든 residual block의 output마다 checkpointing을 했던것과 다르게 원하는 층마다 selective checkpointing을 할 수 있도록 한 것도 main contribution 중 하나이다. Selective checkpointing 이라는 내용이 헷갈릴 수도 있는데, 원래 내가 알고있던 맥락은 num. layer가 L일 때 sqrt(L)마다 checkpointing을 하는 것이 MFU와 memory의 tension에서의 sweet spot일 수 있기 때문에 (link), every layer 마다 하는 것이 아니라 선택적으로 한다는 것이었는데, (즉 transformer block 마다 하는 것이므로 안에 있는 qkv projection, qk matmul, softmax, ffn1, 2의 output을 caching 하지 않고 backward에 다시 계산하는 것을 모든 layer마다 하는 것)
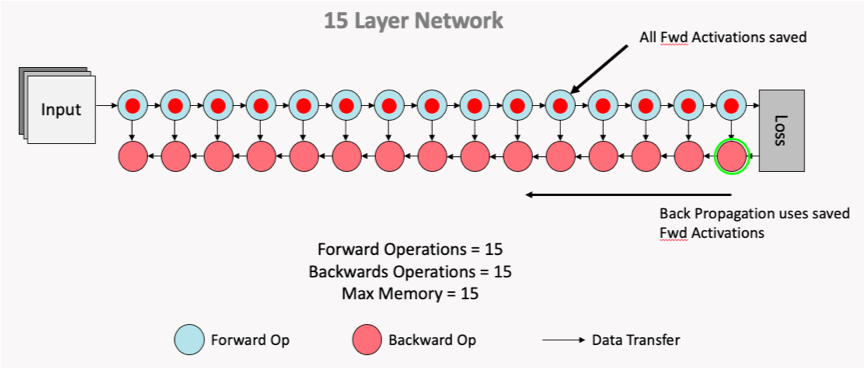 Fig. no checkpointing
Fig. no checkpointing
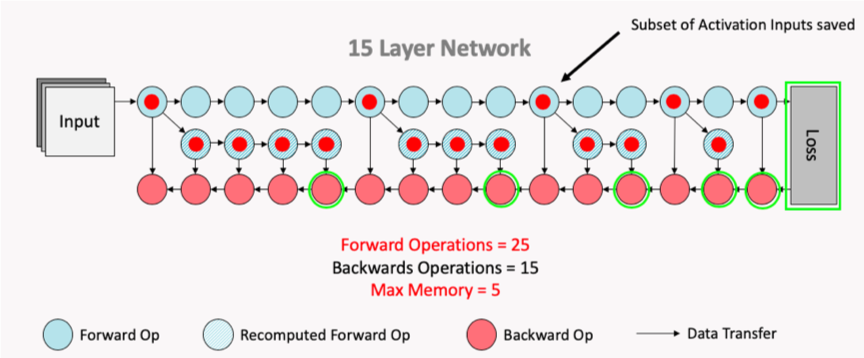 Fig. selective checkpointing
Fig. selective checkpointing
여기서 말하는 것은 transformer residual block안에 있는 operation 중 어떤 것만 선택적으로 할 것인지를 말한다. 즉 다시말해서 SP paper에서의 selective checkpointing은 sequence length, \(L\)에 대해서 \(L^2\)만큼의 space complexity를 요구하는 QK matmul이 가장 문제가 되니 이것만 checkpointing 하겠 다는 것이고 나머지들은 TP를 쓰니까 어느정도 문제가 해결된다는 관점인 것 같은데, 사실 이는 flash attention kernel을 사용할 경우 중복이 되기 때문에 실제로는 쓸모가 없다.
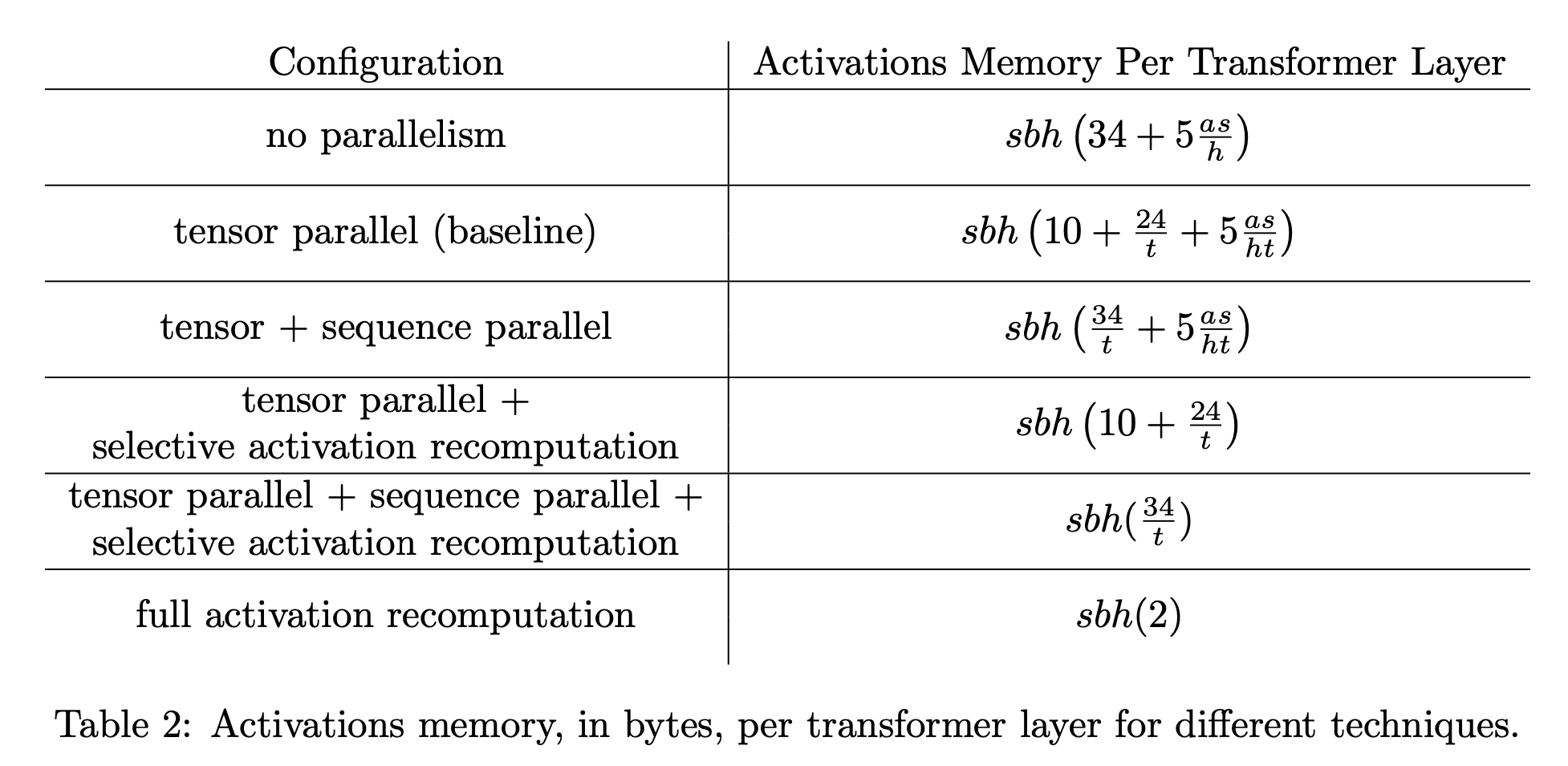 Fig.
Fig.
결과적으로 selective checkpointing의 결과 overhead를 확 줄일 수 있었다고 하는데, backward의 execution time이 줄지 않은 것 등 자세한 analysis는 곧 살펴보도록 하겠다.
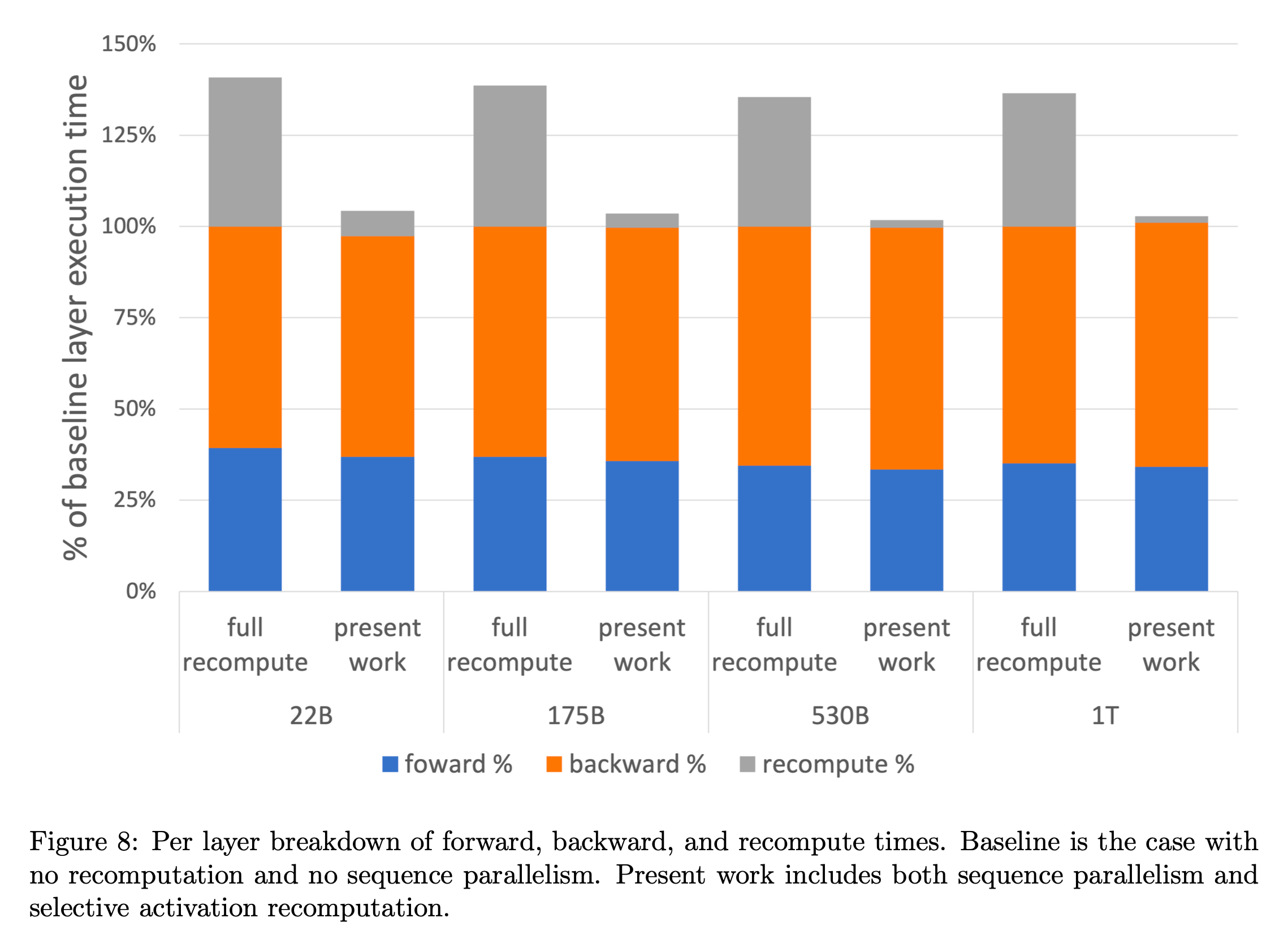 Fig.
Fig.
DeepSpeed Ulysses (DS-Ulysses)
시작하기 앞서 이 distrubted training algorithm의 이름이 DS-Ulysses인 이유는 율리시스 (Ulysses) 라는 매우 긴 소설같은 책 한 권 분량을 처리할 수 있을 정도로 memory requirements를 개선했다는 의미에서 지어진 것으로 보인다.
(In Paper)
...
In this paper, we introduce DeepSpeed-Ulysses (or Ulysses, a very long novel),
a simple, portable, and effective methodology for enabling highly efficient
and scalable LLM training with extremely long sequence lengths.
 Fig.
Fig.
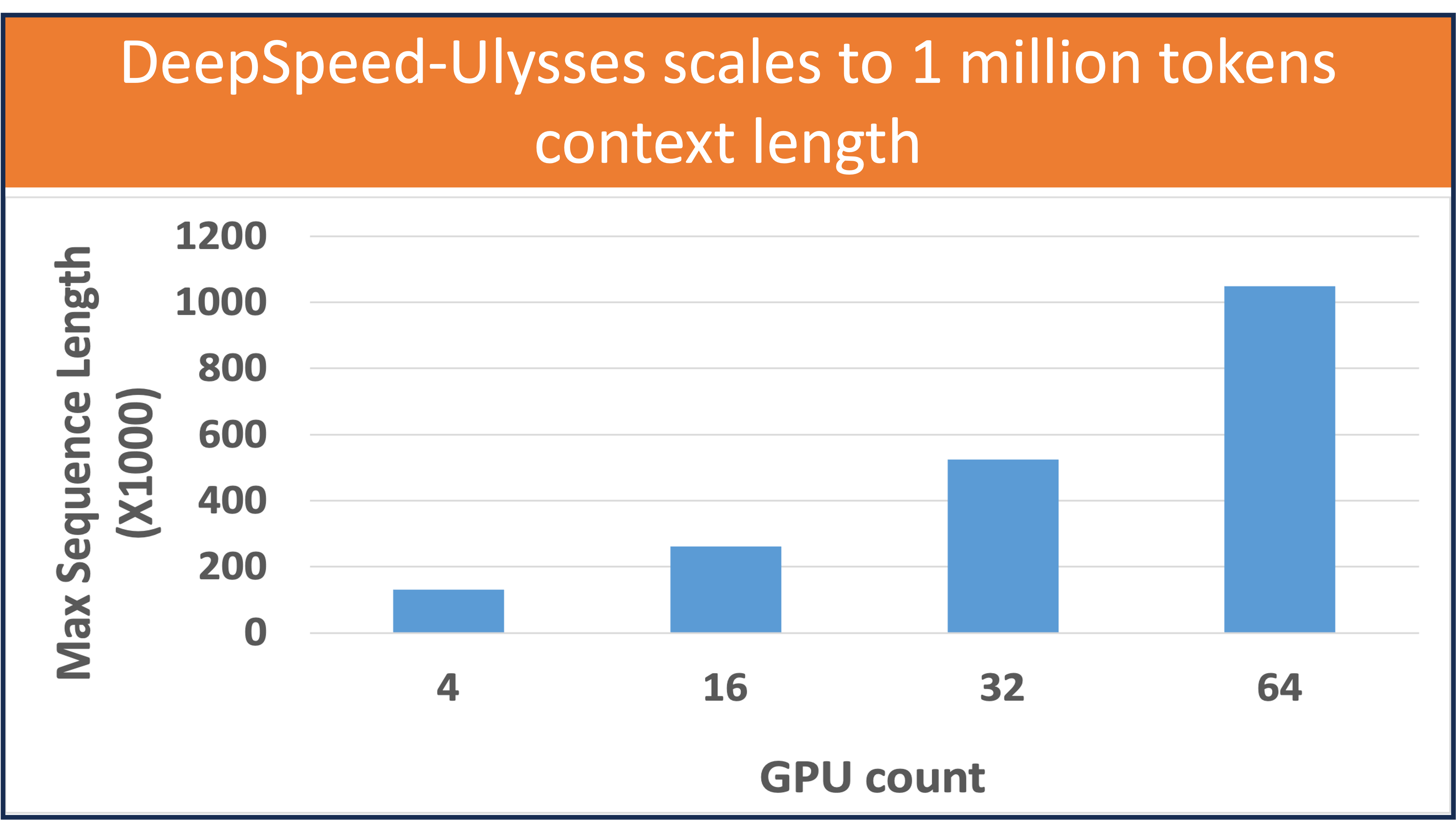 Fig.
Fig.
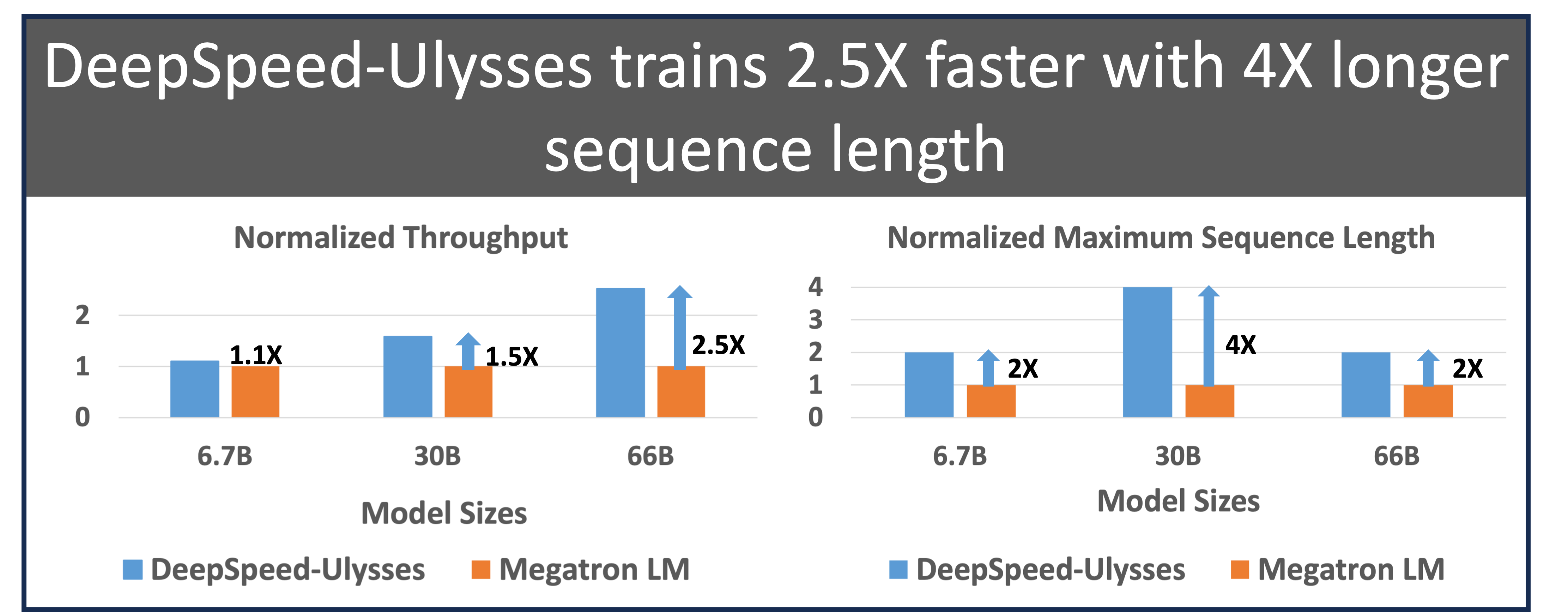 Fig.
Fig.
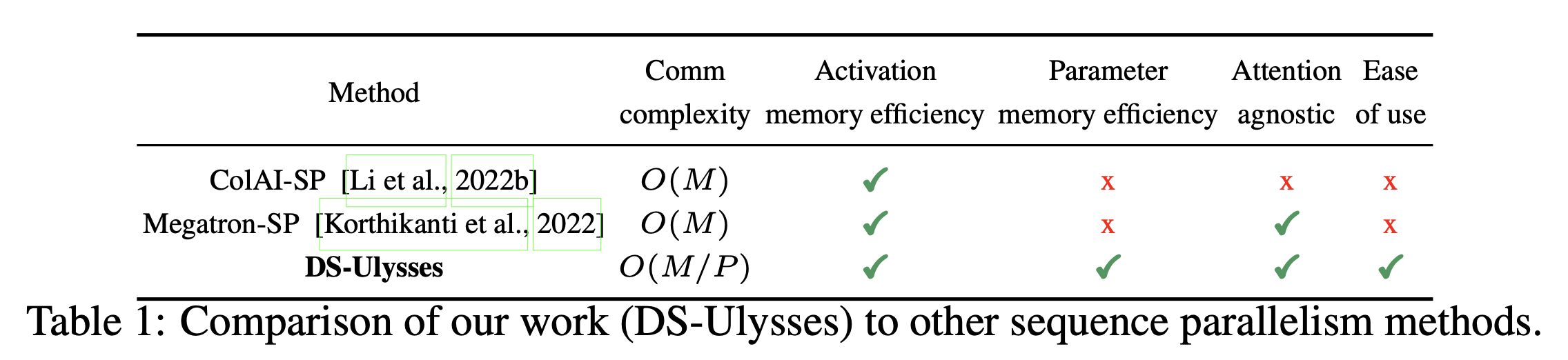 Fig.
Fig.
Implementation
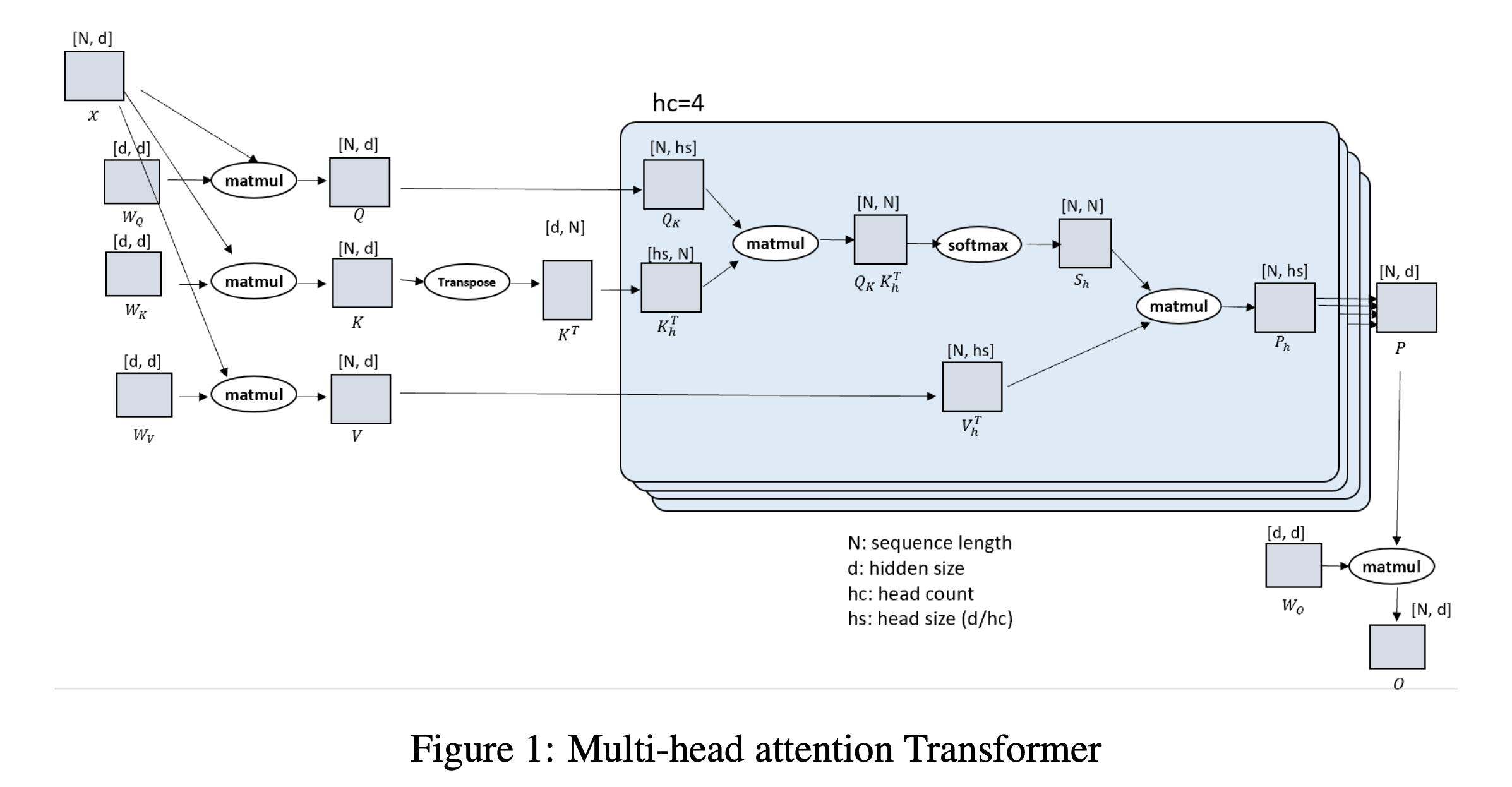 Fig.
Fig.
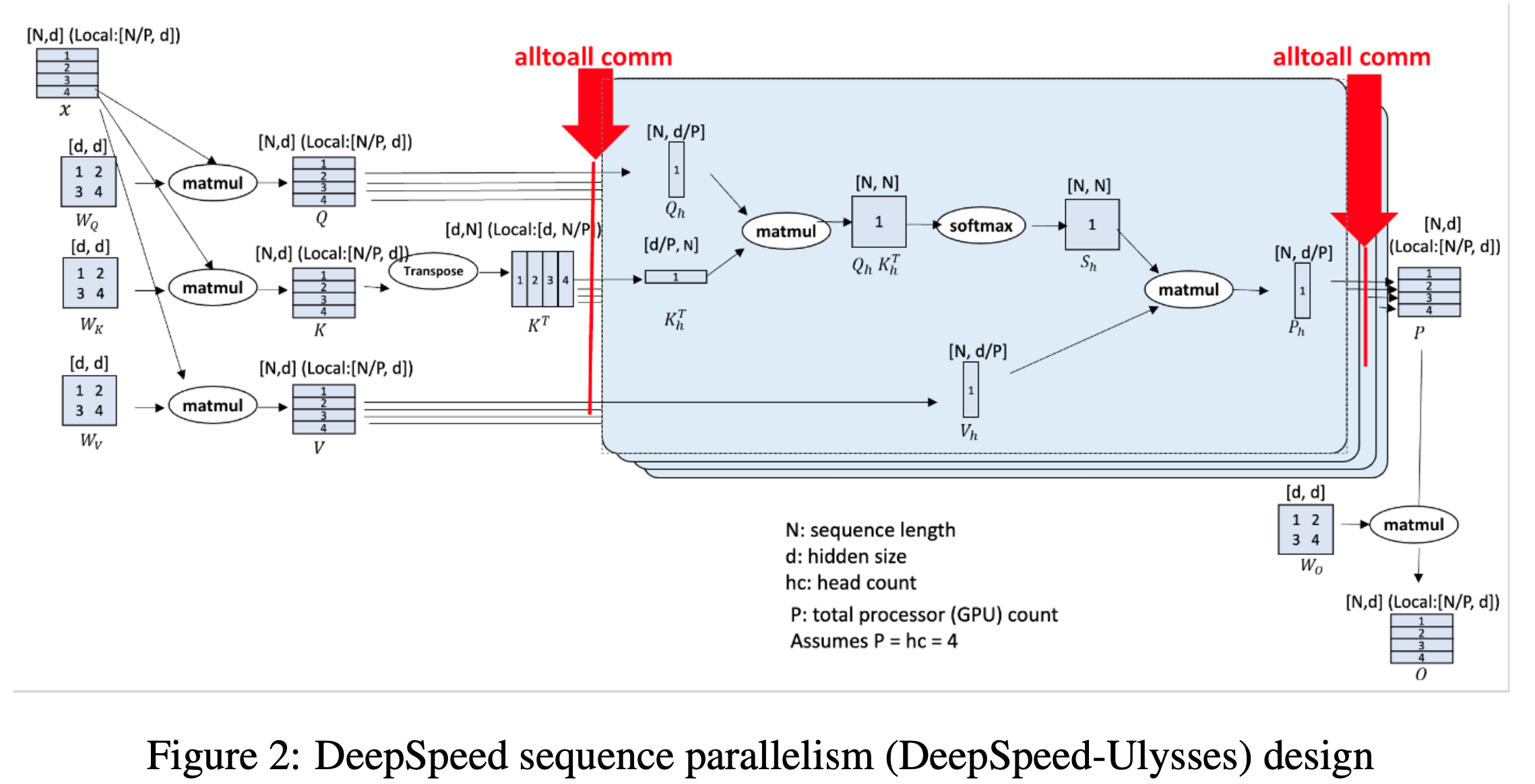 Fig.
Fig.
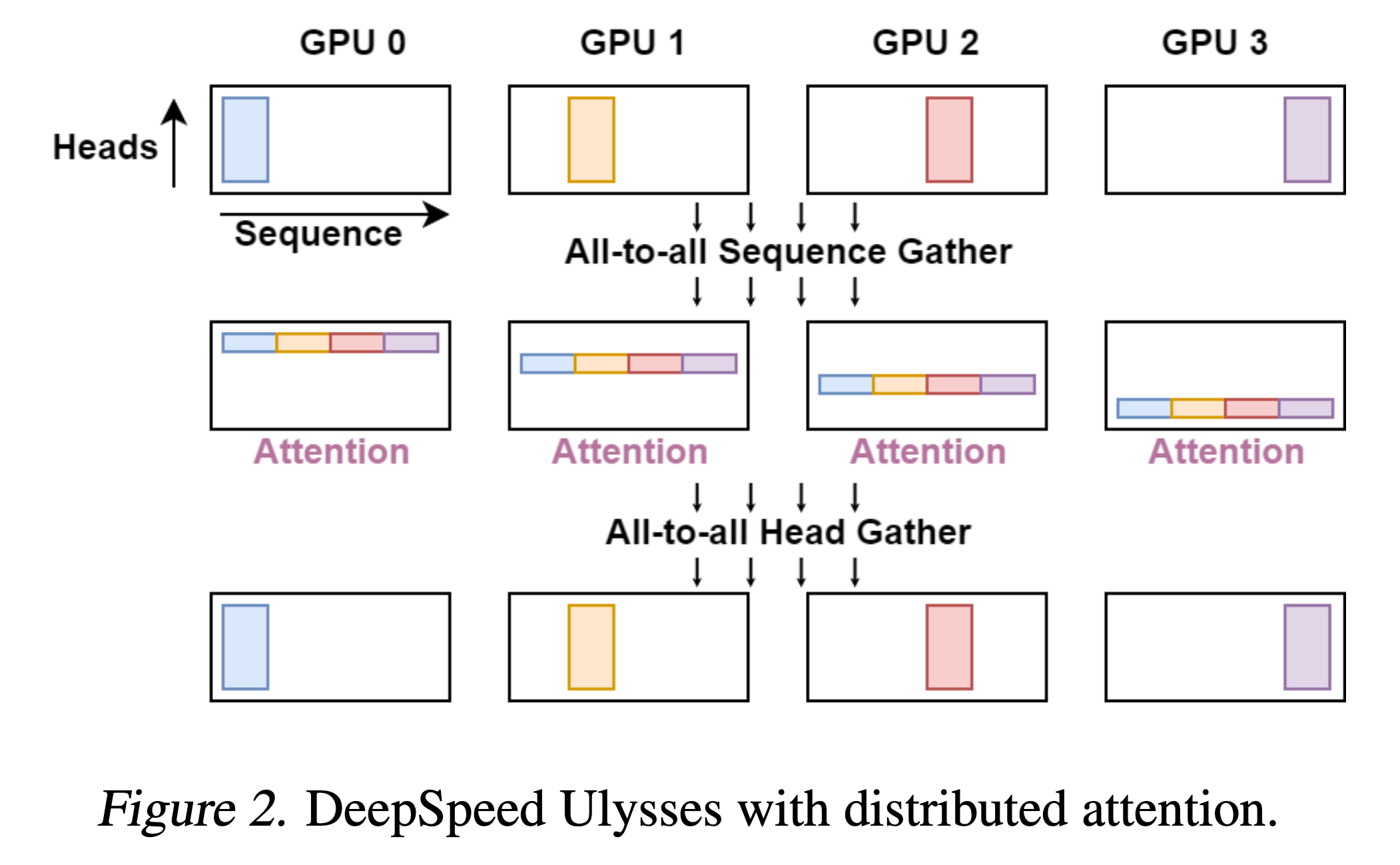 *Fig.
*Fig.
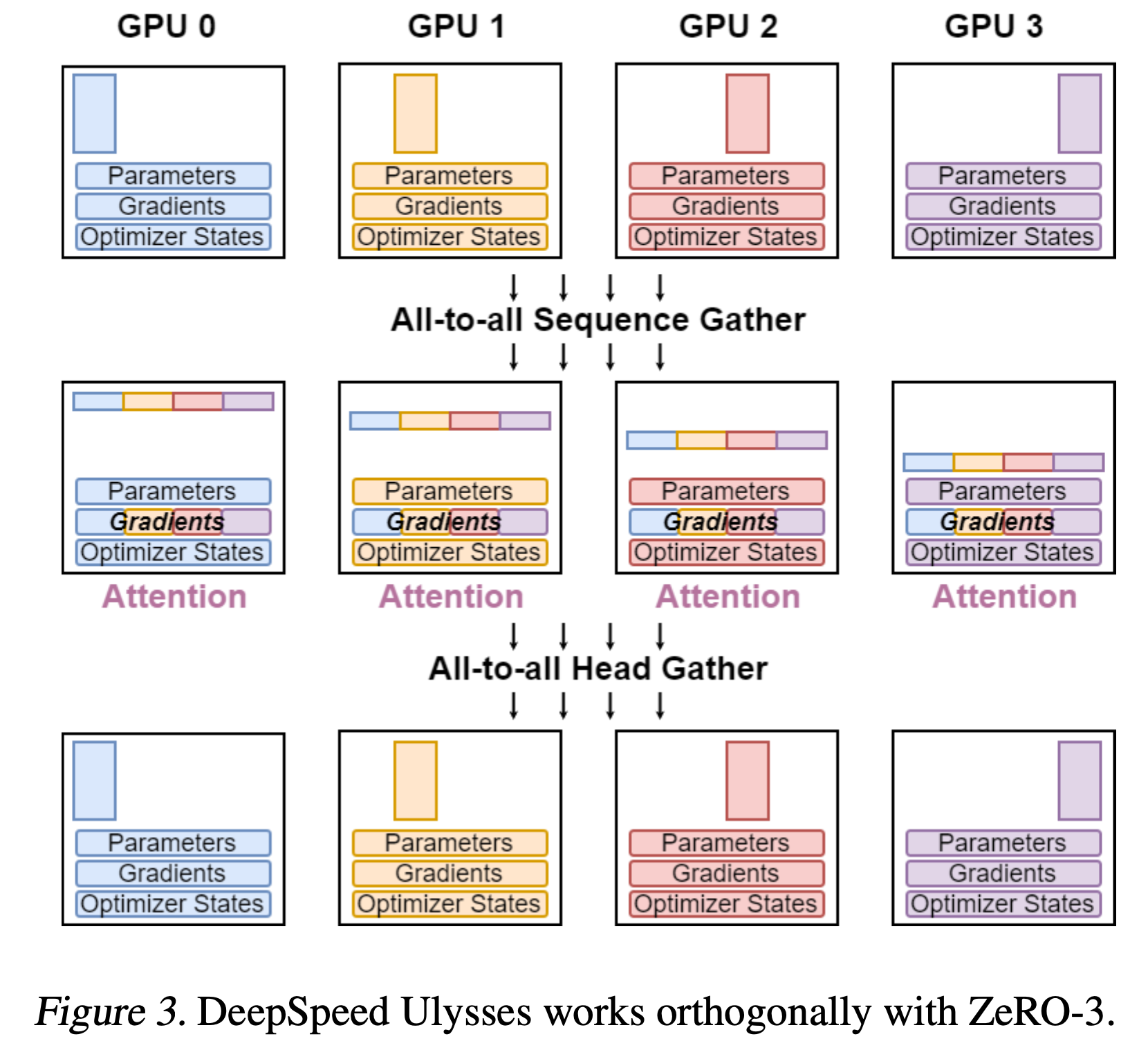 *Fig.
*Fig.
Blockwise Parallel Transformer (BPT) and Ring Attention
Blockwise Parallel Transformer (BPT)나 Ring Attention은 최근 pieter abbeel lab에서 제안된 Large World Model (LWM)를 이루는 핵심 module들이다. 핵심은 flash attention이나 memory efficient attention등에서 제안된 cumulative attention 이다.
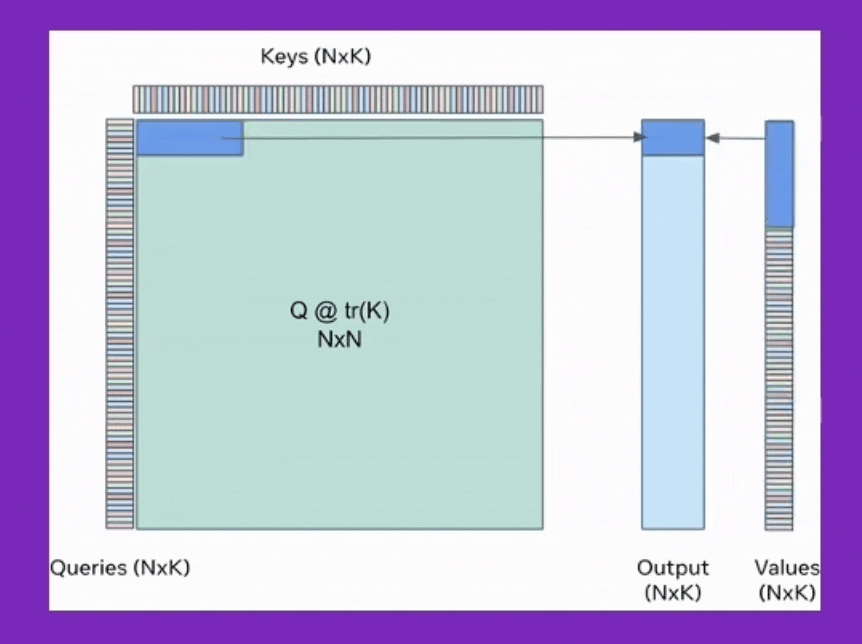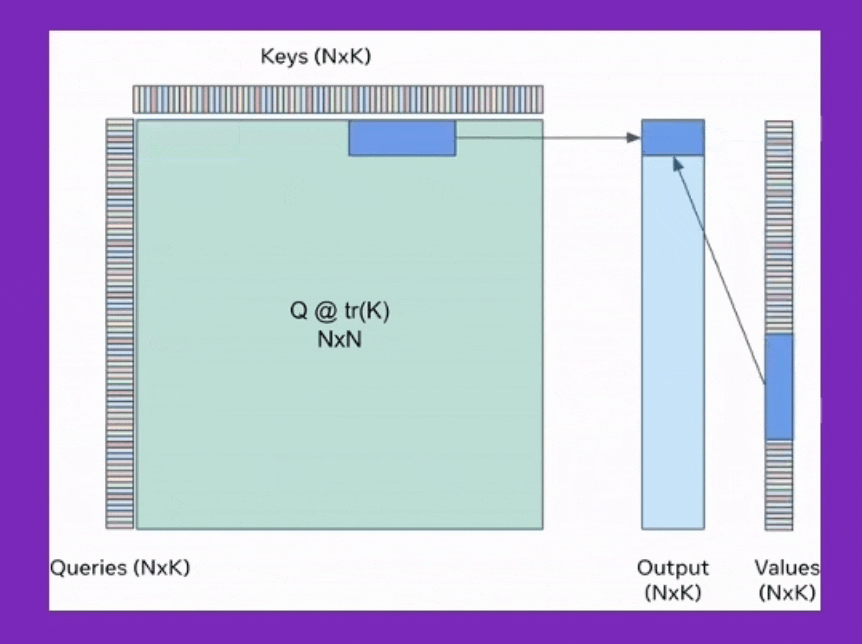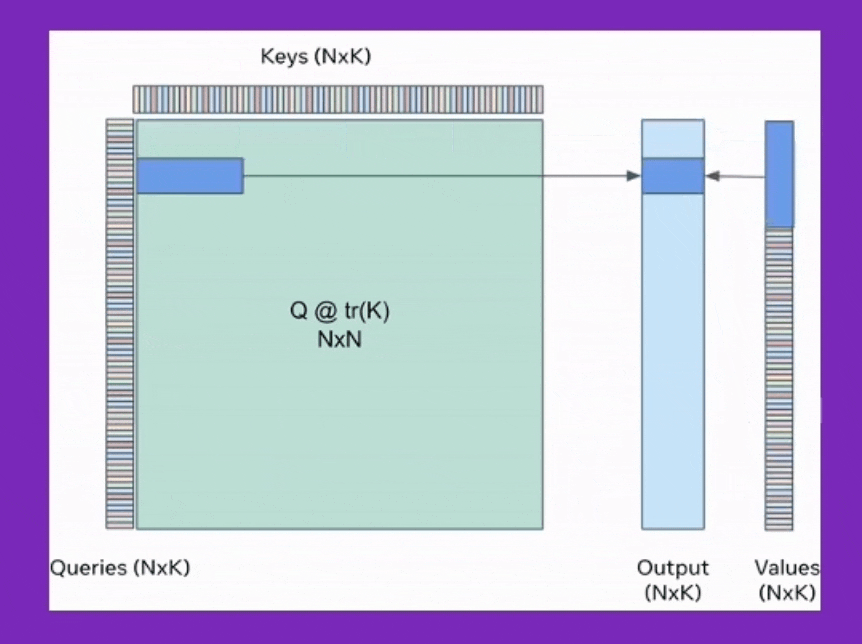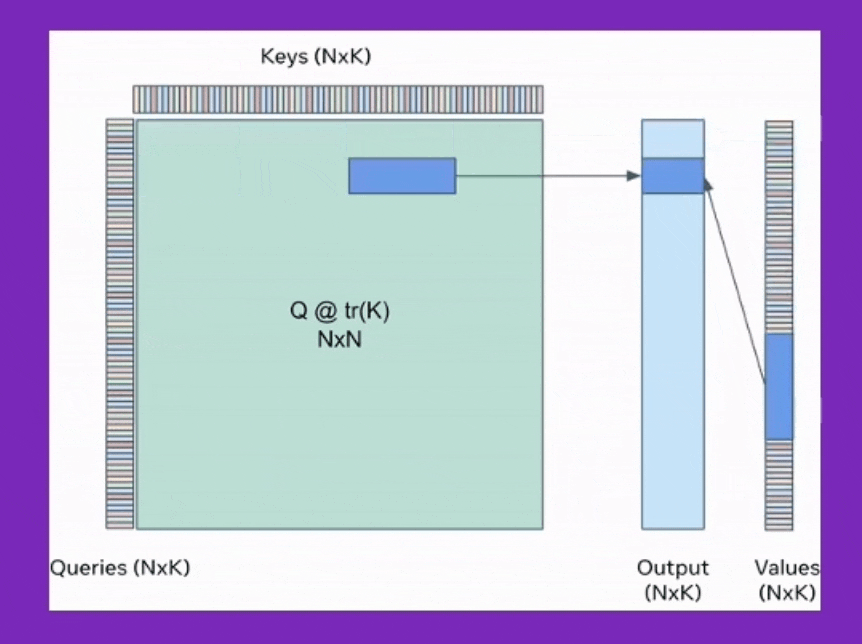
BPT는 이를 확장해서 Feed Forward Neural Network (FFN)에도 적용한 것이며, Ring attention은 이를 device간 communication을 통해 더욱 확장한 것이라고 볼 수 있는데, 어떻게보면 Transformer XL에서 제안된 hidden state를 cache하는 것과도 살짝 연관지어 생각할 수 있을 것 같다.
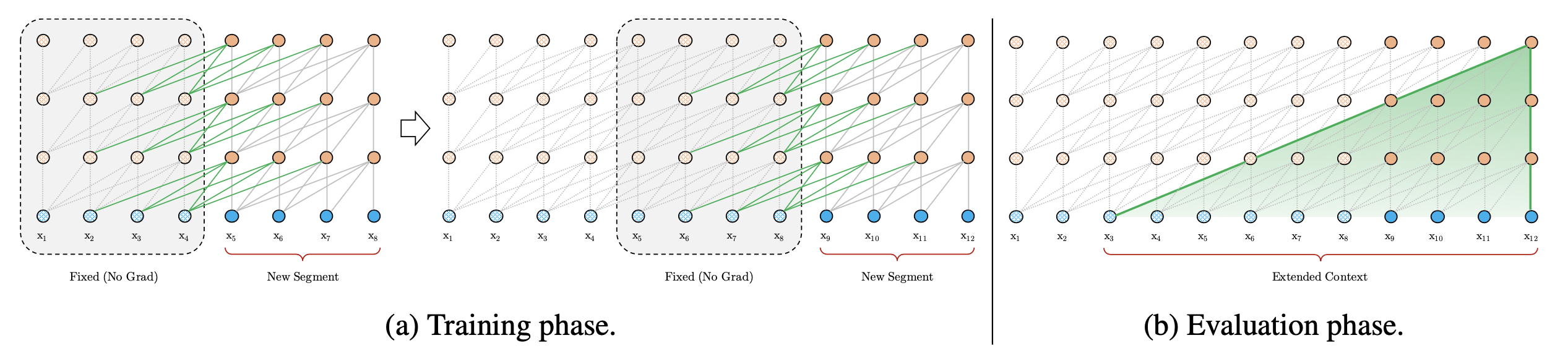 Fig.
Fig.
아무튼 inference시에도 Model Parallel (MP)를 하는데 여러 device가 필요하듯 LWM이나 google의 gemini의 주장대로 1M, 10M의 token 을 처리하기 위해서는 말도안되는 수의 device가 필요할 것으로 생각이 된다. (berkeley의 pieter abbeel lab은 꾸준히 google과 cowork을 했으며 ring attention이 TPU를 사용해 실험한 method이며 바로 gemini 1.5가 나왔으므로 gemini가 ring attention같은 method를 쓴 것은 확실할 것 같다)
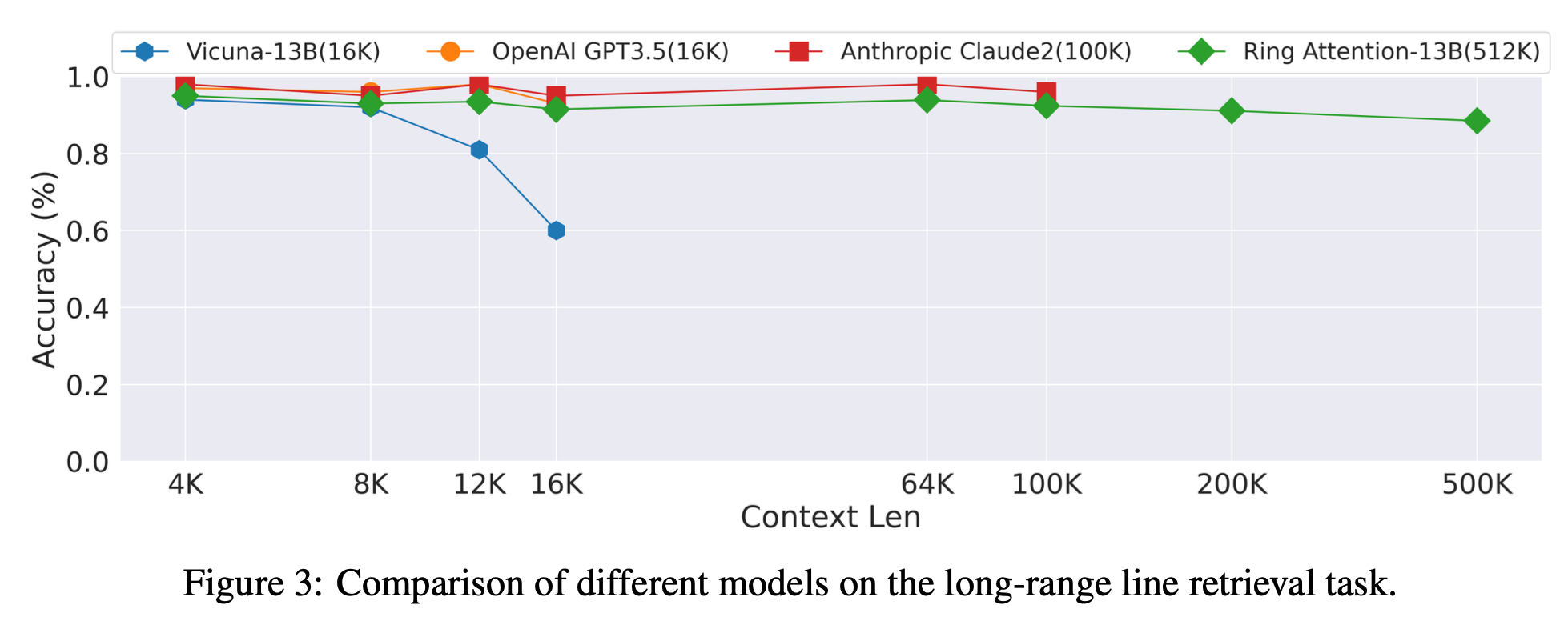 Fig. long context retrieval task에서 SOTA라고 주장하는 ring attention
Fig. long context retrieval task에서 SOTA라고 주장하는 ring attention
Blockwise Parallel Transformer (BPT)
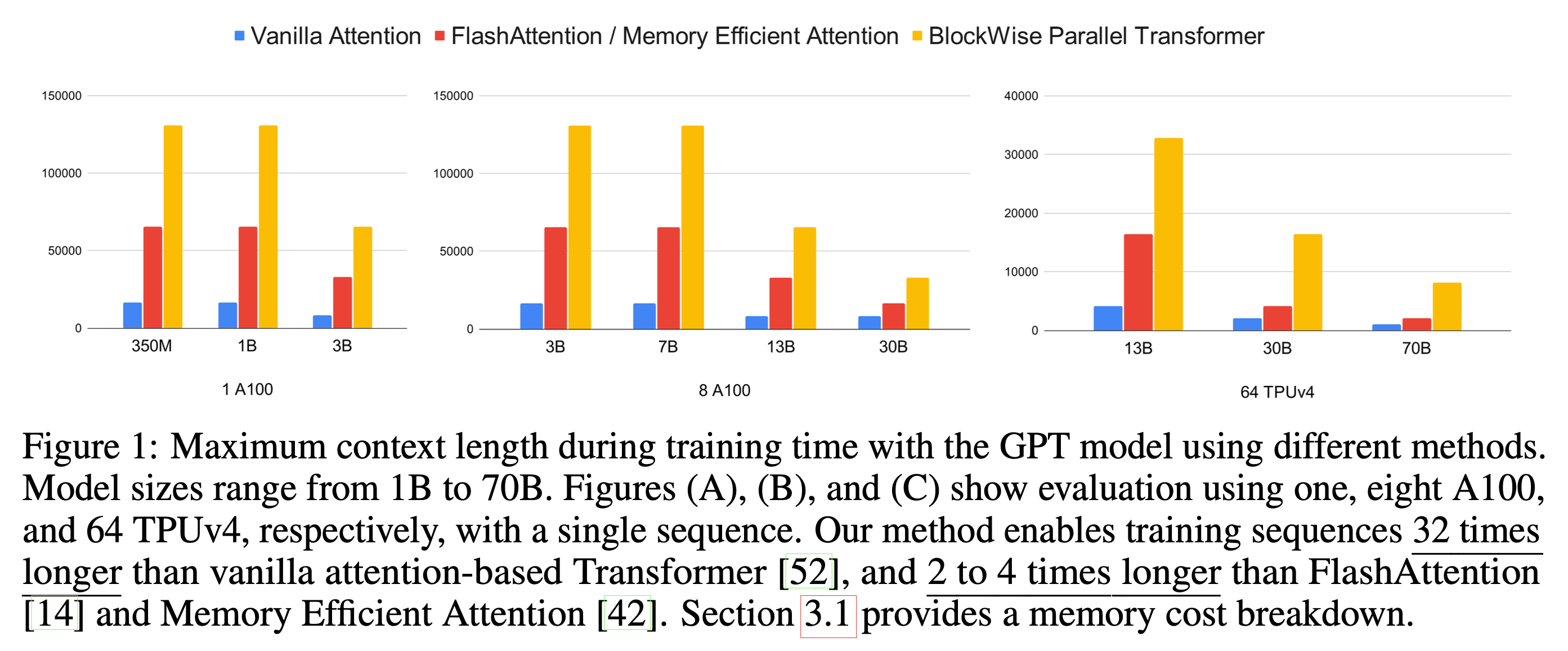 Fig.
Fig.
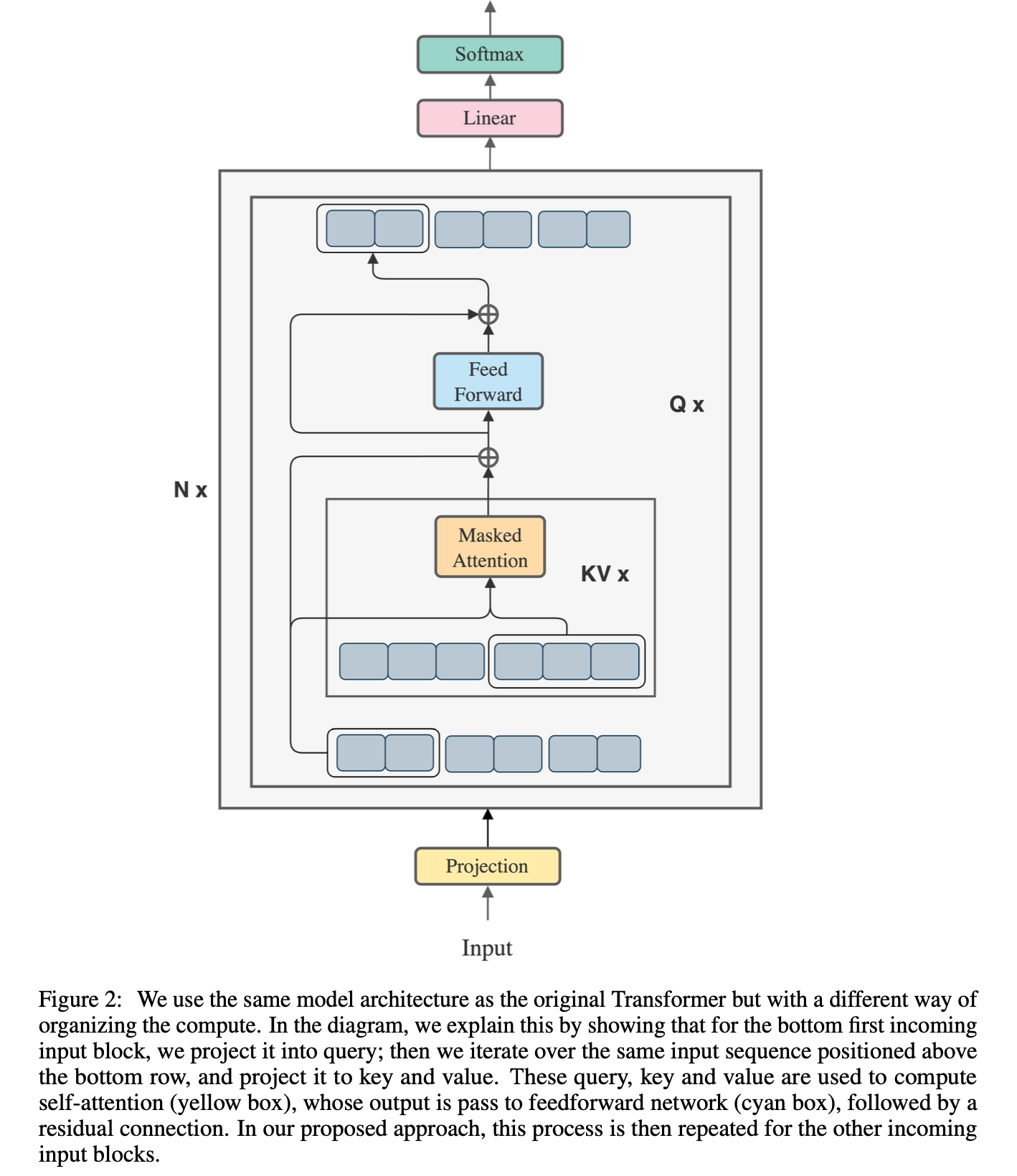 Fig.
Fig.
 Fig.
Fig.
Ring Attention
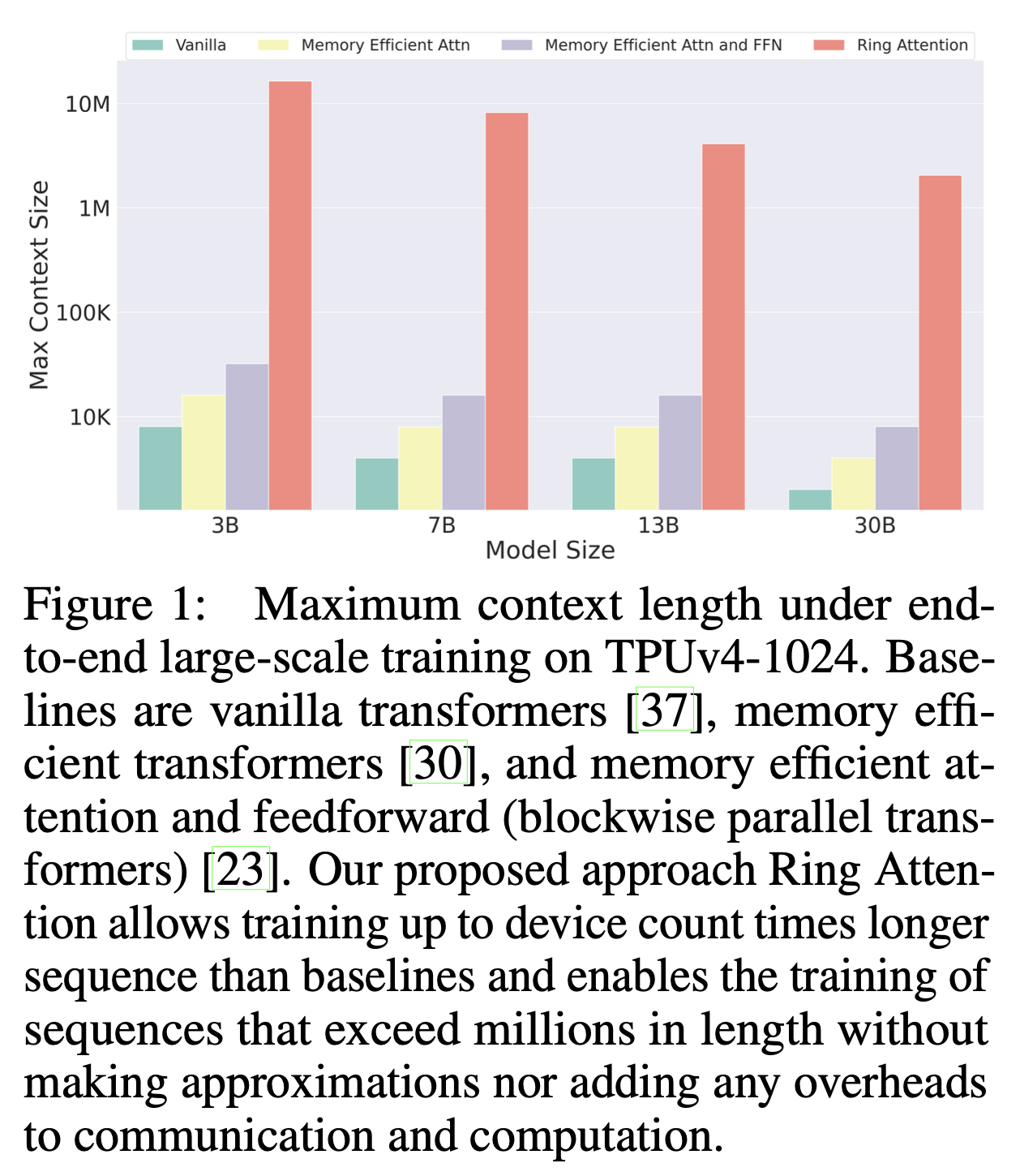 Fig.
Fig.
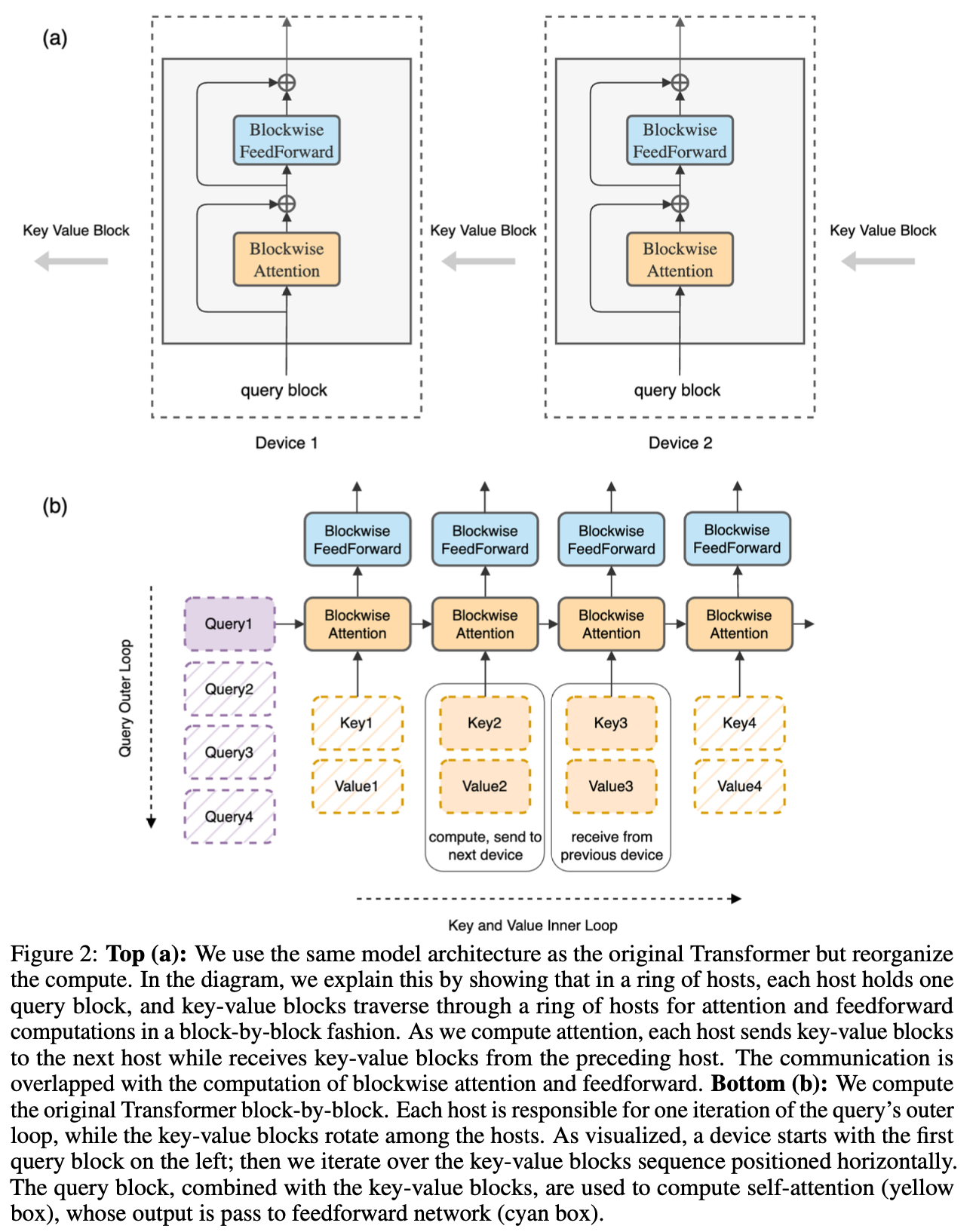 Fig.
Fig.
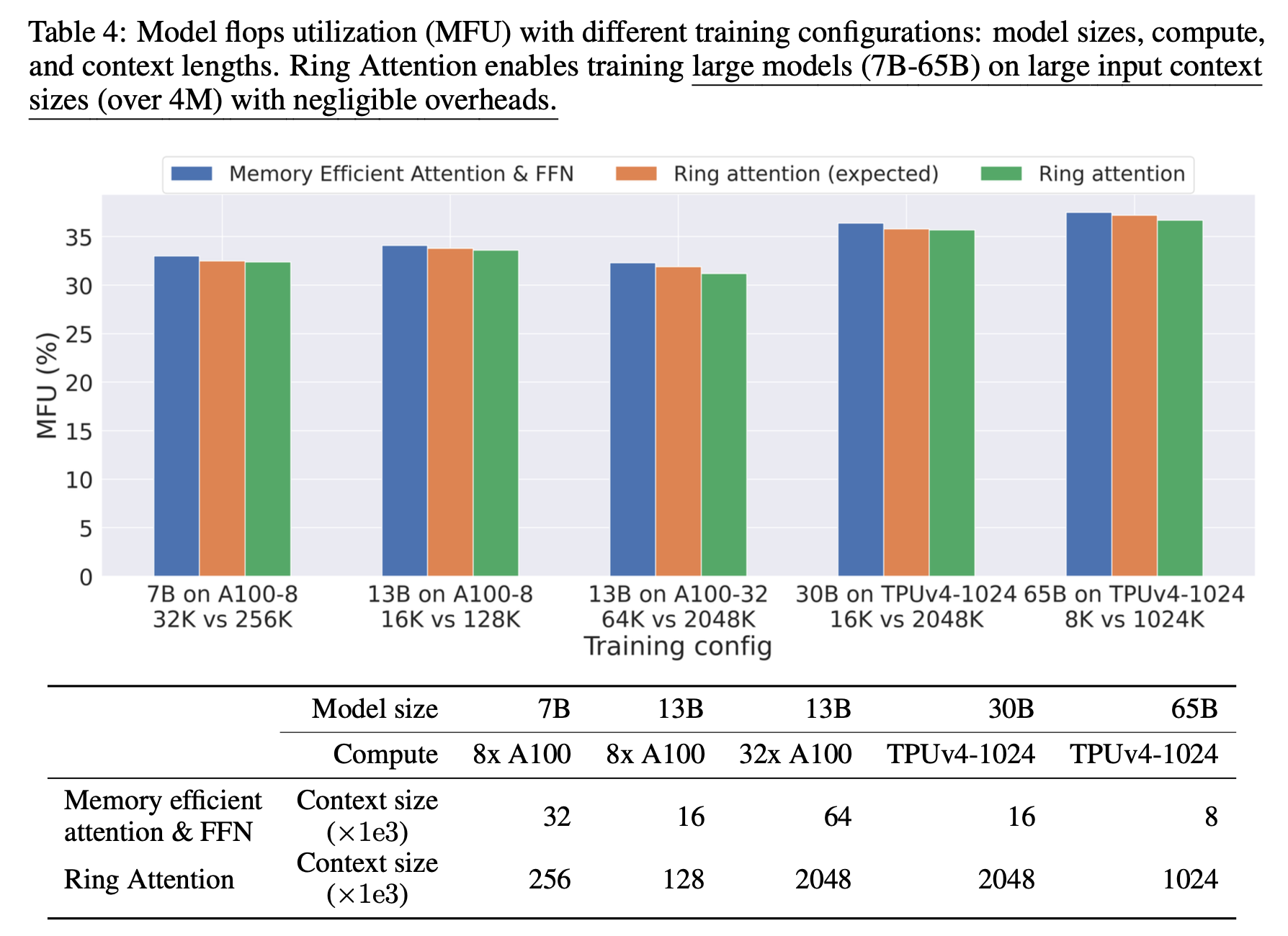 Fig.
Fig.
 Fig.
Fig.
+Updated) A Unified Sequence Parallelism Approach for Long Context Generative AI
 Fig.
Fig.
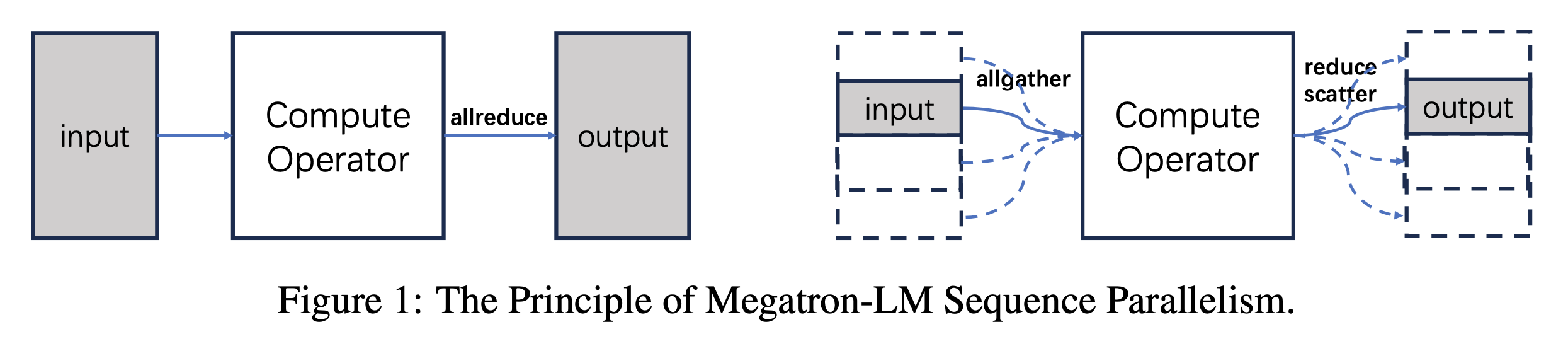 Fig.
Fig.
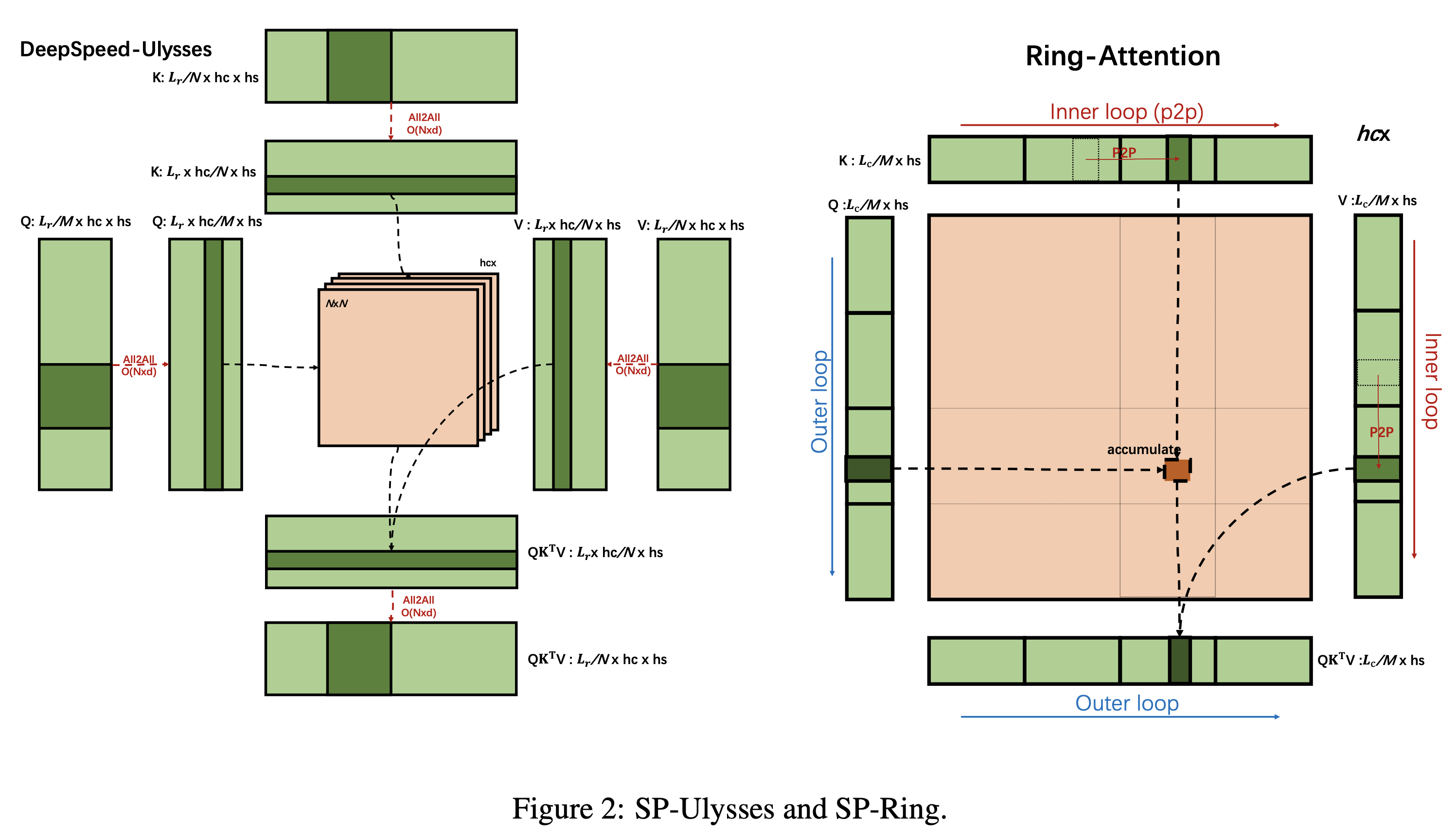 Fig.
Fig.
+Updated) Fully Pipelined Distributed Transformer (FPDT)
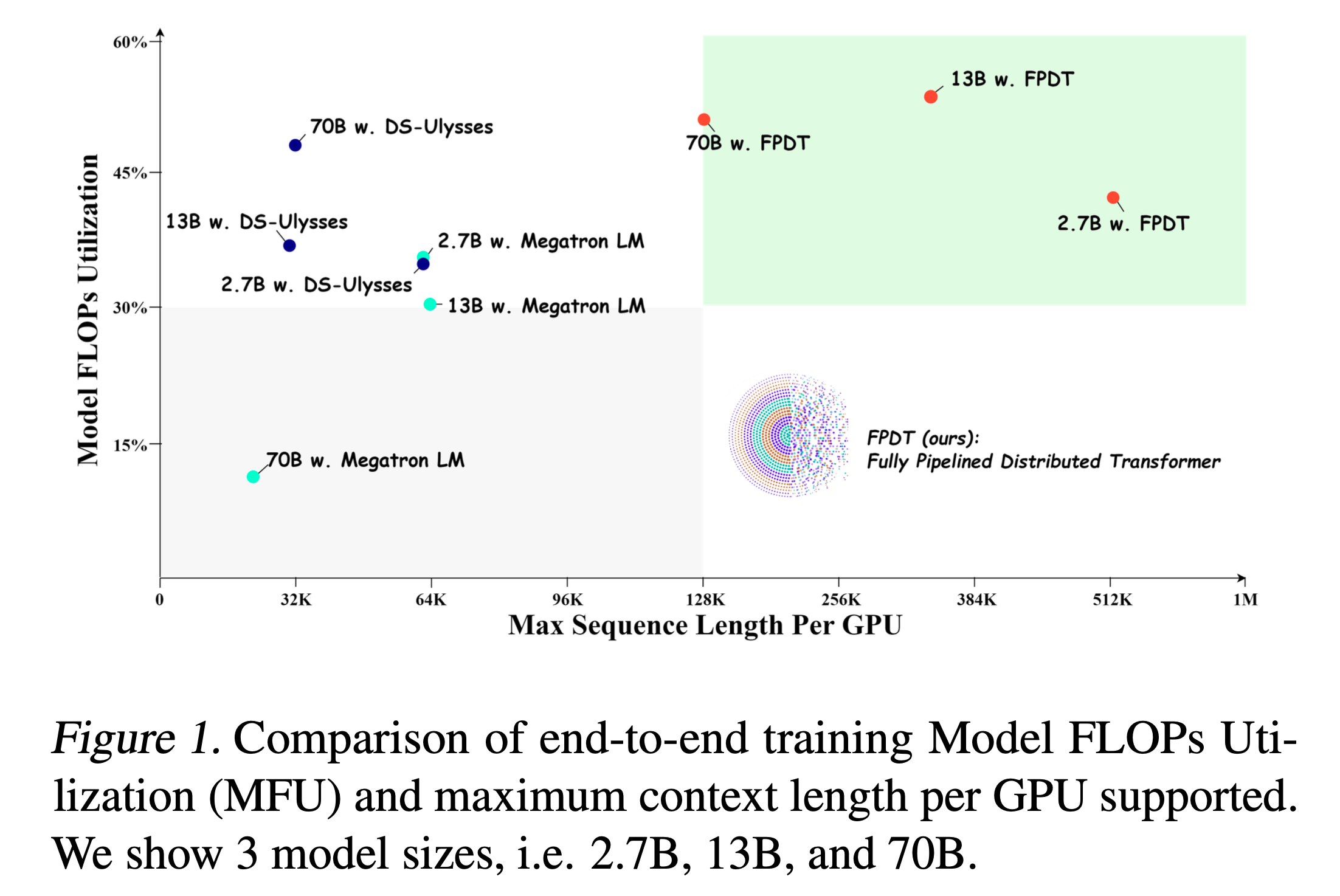 Fig. Megatron-SP와 DS-Ulysses가 있지만 여전히 long sequence에 대해서 MFU가 잘 나오지 않는다.
Fig. Megatron-SP와 DS-Ulysses가 있지만 여전히 long sequence에 대해서 MFU가 잘 나오지 않는다.
References
- Papers
- Reducing Activation Recomputation in Large Transformer Models
- Efficient Large-Scale Language Model Training on GPU Clusters Using Megatron-LM
- Sequence Parallelism: Long Sequence Training from System Perspective
- DeepSpeed Ulysses: System Optimizations for Enabling Training of Extreme Long Sequence Transformer Models
- Blockwise Parallel Transformer for Large Context Models
- Ring Attention with Blockwise Transformers for Near-Infinite Context
- World Model on Million-Length Video and Language with RingAttention
- Leave No Context Behind: Efficient Infinite Context Transformers with Infini-attention
- LoongServe: Efficiently Serving Long-context Large Language Models with Elastic Sequence Parallelism
- A Unified Sequence Parallelism Approach for Long Context Generative AI
- Training Ultra Long Context Language Model with Fully Pipelined Distributed Transformer
- Blogs, Videos and Others
- Ring Attention Explained from Kilian Haefeli
- CUDA MODE Lecture 13: Ring Attention
- Context parallelism overview from NVIDIA
- Context Parallelism from Husein Zolkepli (HF Blog)
- Tensor Parallelism and Sequence Parallelism: Detailed Analysis from Insu Jang
- Doubling all2all Performance with NVIDIA Collective Communication Library 2.12
- slide from Leandro von Werra
- Visualizing 6D Mesh Parallelism
- Code