Understanding the Role of Self Attention for Speech Encoder
17 Apr 2023< 목차 >
Motivation
이번에 알아볼 논문은 ICLR 2021 에 출판된 논문중에 Understanding the Role of Self Attention for Efficient Speech Recognition 라는 논문 입니다.
Goal은 음성 인식 (Speech Recognition)을 위해 학습된 Transformer 구조의 Self-Attention (SA) 패턴을 분석해서 각 Layer가 어떤 역할 (role)을 하는지를 분석하고 이에 따라 연산 효율성을 증가시키는 겁니다. 결과적으로는 1층부터 24층까지의 Transformer Layer 가 Sequence Length 가 L 일 때 LxL 짜리 SA Score Map 이 있을텐데, 이들이 4개 층 마다 굉장히 유사하게 반복되기 때문에 예를 들어 1층에서 SA 를 계산했으면 불필요한 (Redundant) 계산을 하지않고 이를 반복적으로 재사용 (reuse) 해서 2,3,4 층에 쓰는 식으로 연산 효율을 올리는 겁니다.
특히 SA 는 두 가지 role 을 수행한다는 걸 논문에서는 주장했는데요, 바로 phonetic localization 과 linguistic localization 두 가지이며 Transformer의 저층부에서의 phonetic localization 은 speech vector 들로부터 음운학적으로 유의미한 (phonologically meaningful) feature 들을 추출하고 발화의 음성적 분산 (phonetic variance) 을 줄임으로써 상층부의 linguistic localization 를 수행하도록 한다고 했습니다.
하지만 논문에서 사용된 모델은 Self-Supervised Learning (SSL) 된 Pre-trained Model은 아니고
Supervised Model 이므로 SSL trained Wav2Vec 2.0과는 양상이 다를 가능성이 큽니다.
tmp
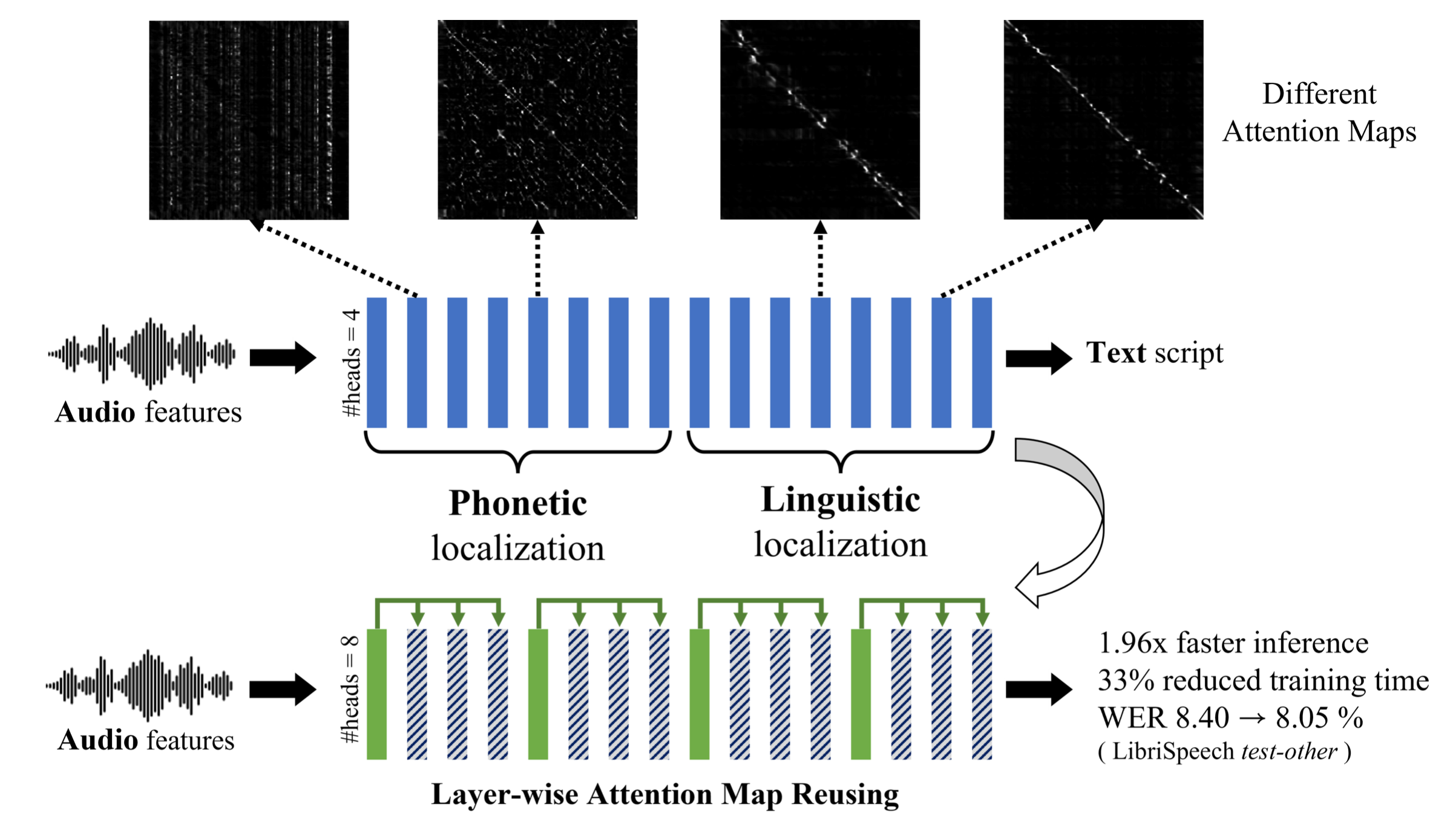 Fig.
Fig.
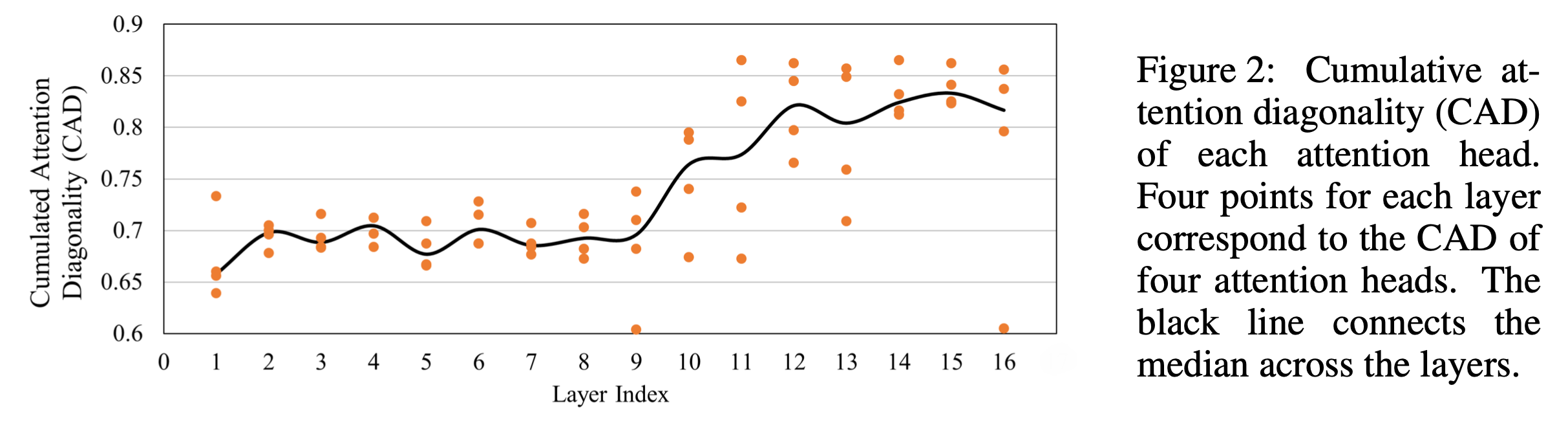 Fig.
Fig.
 Fig.
Fig.
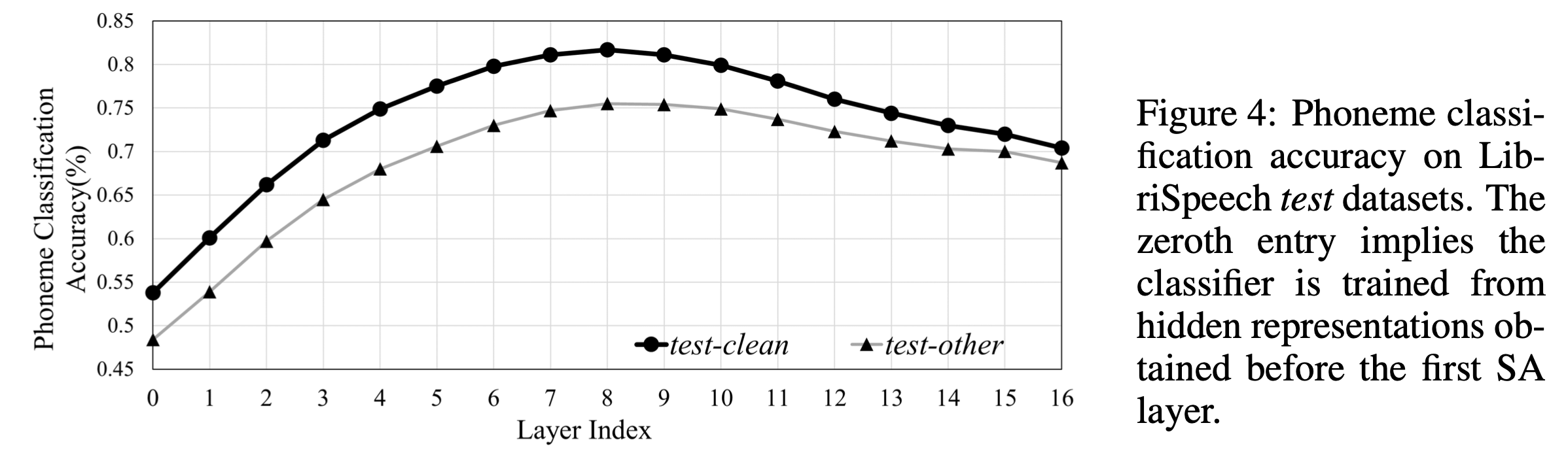 Fig.
Fig.
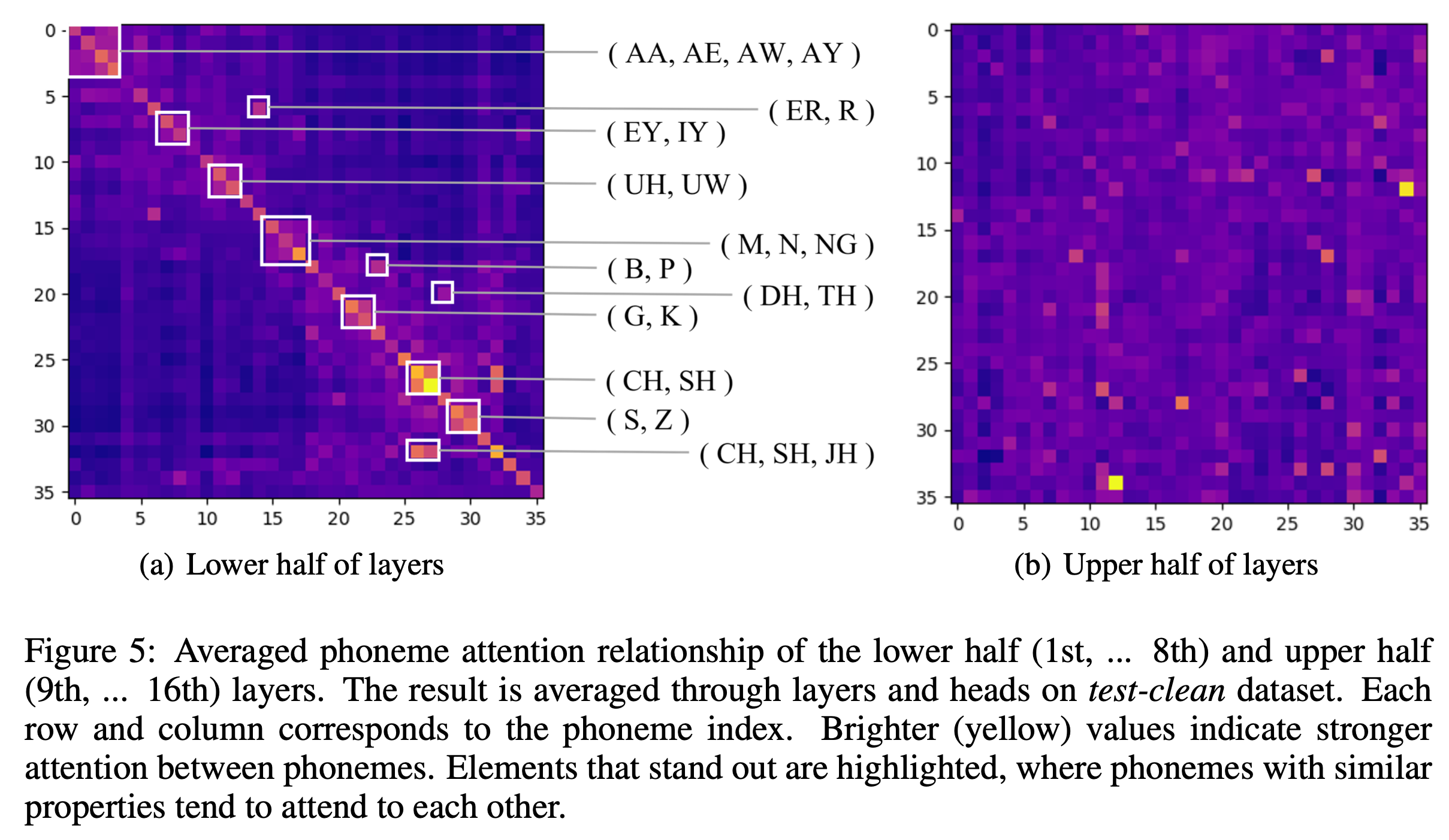 Fig.
Fig.
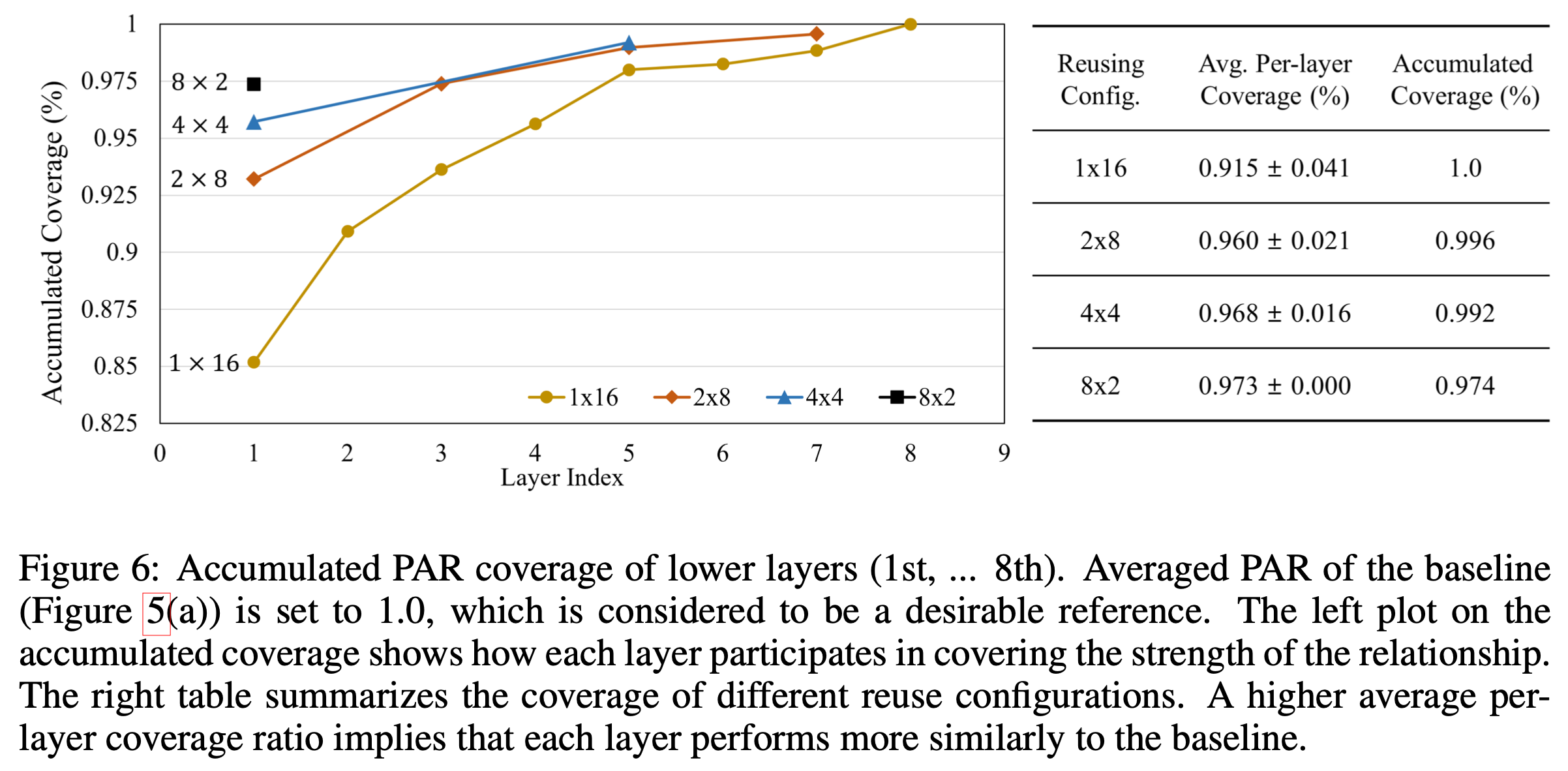 Fig.
Fig.
 Fig.
Fig.
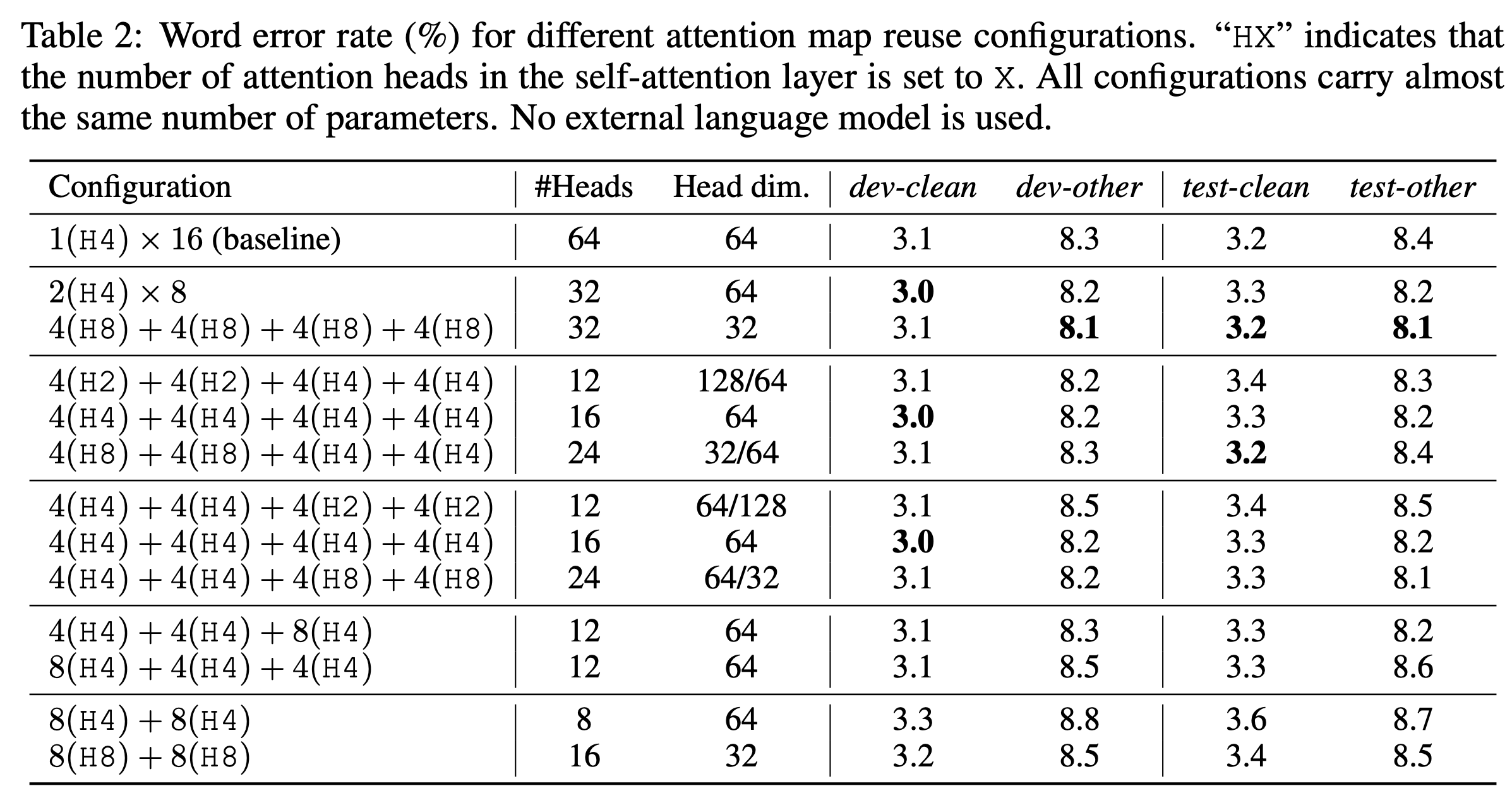 Fig.
Fig.
 Fig.
Fig.
Self-Attention Pattern in Self-Supervised Learning (SSL) Encoder
아래의 Self Attention Map 은 Self-Supervised Learning 방식으로 학습된 Wav2Vec 2.0 의 각 층별로의 여러 head 에서의 Score Map 을 Average 한겁니다.
 Fig.
Fig.
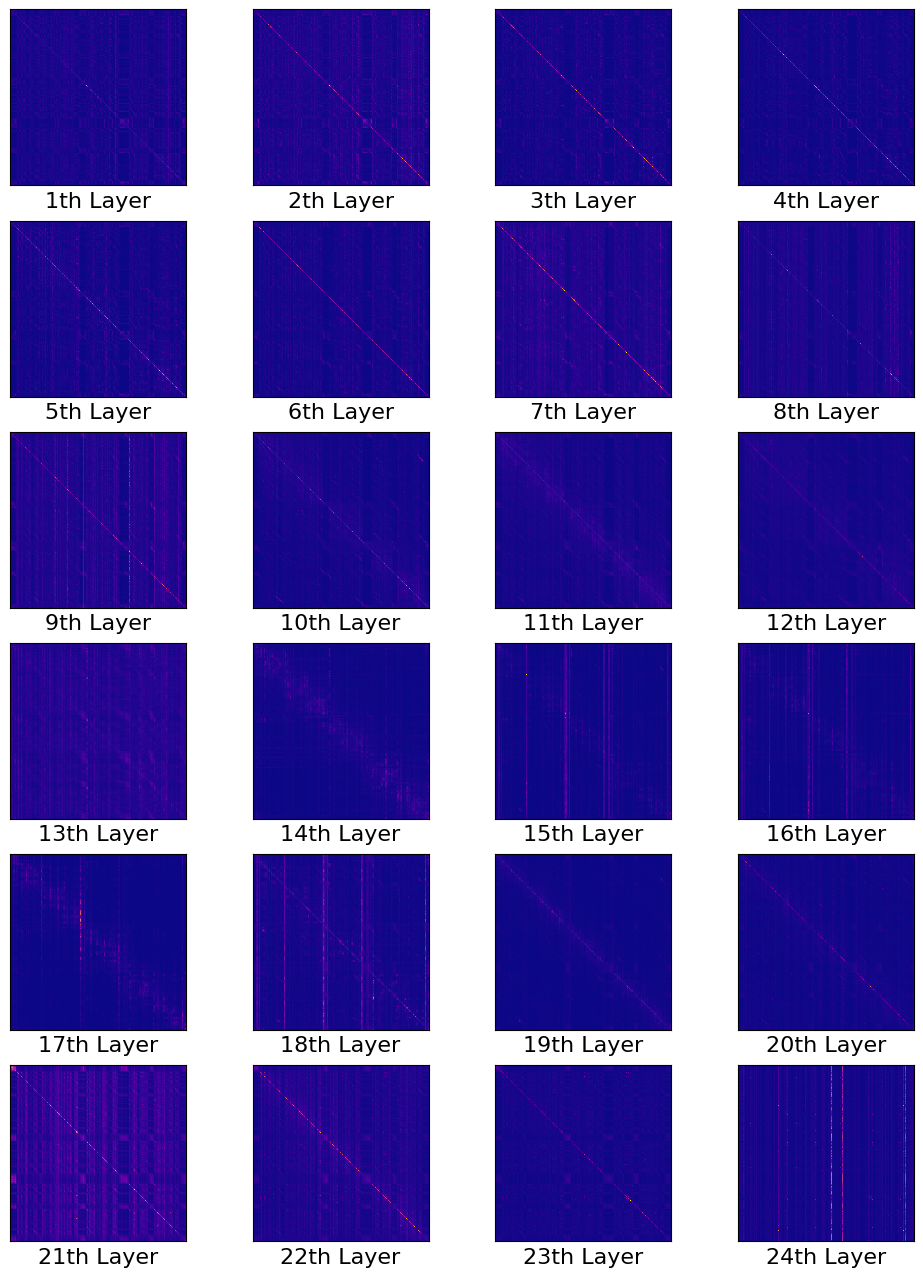 Fig.
Fig.