Why Data2Vec 2.0 Works Well?
23 Mar 2023< 목차 >
Motivation and Contribution
Data2vec (d2v) 시리즈는 Meta AI Research (FAIR) 의 논문으로 2022년 ICML 에 1.0 version 이 나왔고 같은해 12월에 2.0 version이 나왔습니다.
d2v (1.0) 의 motivation 은 Speech, Text, Vision 이라는 각기 다른 domain 에서 모두 working 하는 general 한 Self-Supervised Learning (SSL) 을 만들겠다는 것이었는데요, Text 쪽에서는 BERT, GPT 방식으로 학습하는게 일반적이고 음성에서는 이를 조금 변형해 Wav2Vec (w2v) 이라는 방식으로 학습하는 등 서로 다른 방식으로 학습하는 것이 종래에 이런 서로다른 mode 를 합친 multimodal 상황에 잘 맞지 않을 것이라는 이유 때문입니다.
주의할 점은 이 논문 자체에서는 Multimodal 학습을 한 실험결과는 없다는 것입니다.
(마치 그 실험을 했을것 처럼 얘기했으나… 그래서 제대로 읽어보지 않은 분들 중에서는 이 논문에서 그럼 3개 modality 를 드디어 같이 학습한 것이 아니냐고 얘기하는 분들도 많았습니다.)
이 post의 최종 goal 인 d2v 2.0 (d2v2) 를 이해하기 위해서 알아얄 몇가지 key module 들이 있는데 이는 다음과 같습니다.
- BYOL style
Self Supervised Learning (SSL)ApproachExponential Moving Everage (EMA) Teacher(Mean Teacher)
- Masked Auto Encoder (MAE) Style Approach
Data2Vec
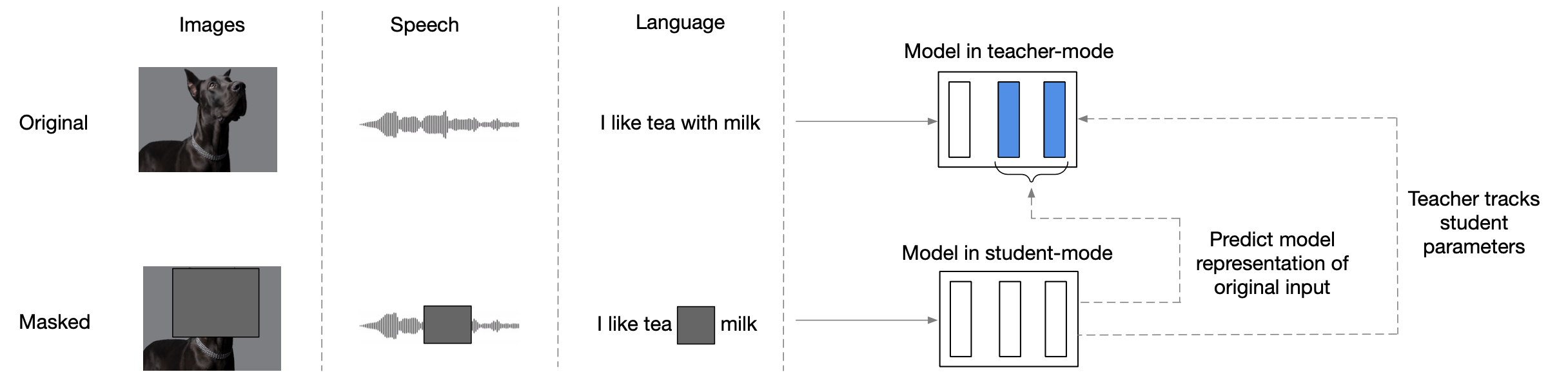 Fig.
Fig.
BYOL Style Self-Supervised Learning (SSL)
 Fig.
Fig.
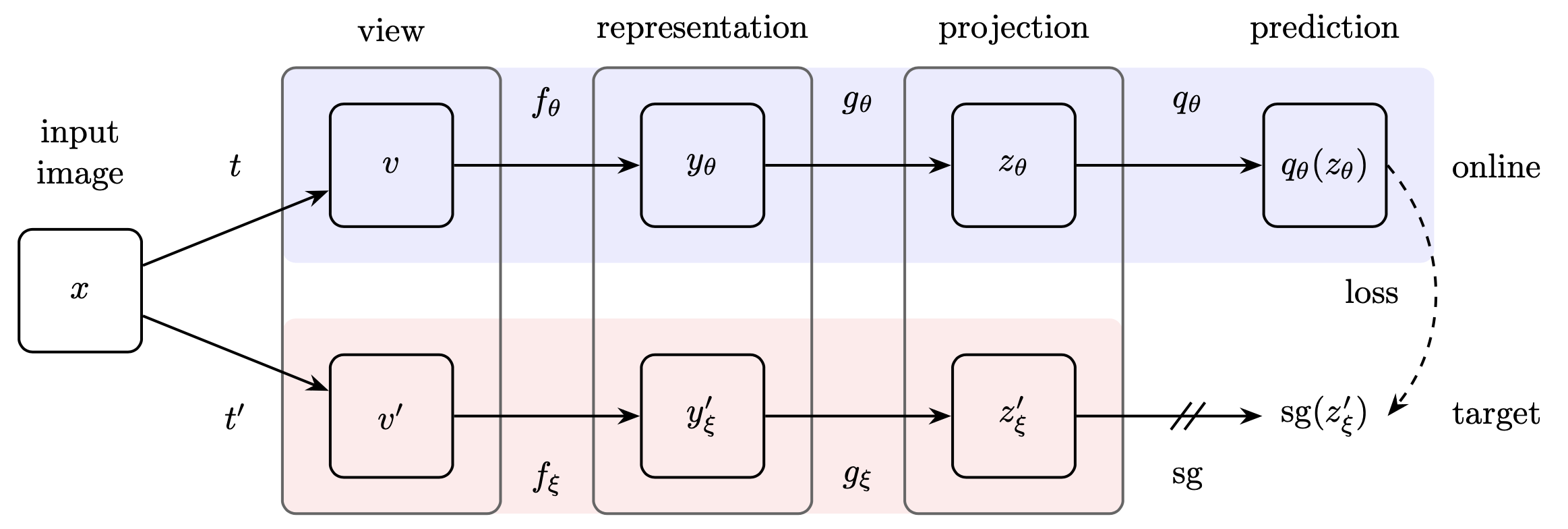 Fig.
Fig.
Masking
Training Targets
Teacher Parameterization
\[\Delta \leftarrow \tau \Delta + (1-\tau) \theta\]Network Architecture
d2v 1.0 버전의 네트워크 아키텍쳐는 아래와 같이 생겼습니다.
- domain specific feature extractor
- speech : 1d-cnn layers (downsampler)
- num.layers : 7
- 512 channels
- strides (5,2,2,2,2,2,2)
- kernel widths (10,3,3,3,3,2,2)
- speech : 1d-cnn layers (downsampler)
- contextualized encdoer
- for all : transformer encoder layers
- positional encoding
- speech : convolutional positional encodig
- num.layers : 5
- speech : convolutional positional encodig
- num.layers : 12 (base), 24 (large)
- hiddem.dim : 768 (base), 1024 (large)
- positional encoding
- for all : transformer encoder layers
num. shared model params: 314,326,016 (num. trained: 314,326,016)
Data2VecAudioModel(
(feature_extractor): ConvFeatureExtractionModel(
(conv_layers): ModuleList(
(0): Sequential(
(0): Conv1d(1, 512, kernel_size=(10,), stride=(5,), bias=False)
(1): Dropout(p=0.0, inplace=False)
(2): Sequential(
(0): TransposeChannel()
(1): Fp32LayerNorm((512,), eps=1e-05, elementwise_affine=True)
(2): TransposeChannel()
)
(3): GELU(approximate='none')
)
(1-4): 4 x Sequential(
(0): Conv1d(512, 512, kernel_size=(3,), stride=(2,), bias=False)
(1): Dropout(p=0.0, inplace=False)
(2): Sequential(
(0): TransposeChannel()
(1): Fp32LayerNorm((512,), eps=1e-05, elementwise_affine=True)
(2): TransposeChannel()
)
(3): GELU(approximate='none')
)
(5-6): 2 x Sequential(
(0): Conv1d(512, 512, kernel_size=(2,), stride=(2,), bias=False)
(1): Dropout(p=0.0, inplace=False)
(2): Sequential(
(0): TransposeChannel()
(1): Fp32LayerNorm((512,), eps=1e-05, elementwise_affine=True)
(2): TransposeChannel()
)
(3): GELU(approximate='none')
)
)
)
(post_extract_proj): Linear(in_features=512, out_features=1024, bias=True)
(dropout_input): Dropout(p=0.0, inplace=False)
(dropout_features): Dropout(p=0.0, inplace=False)
(encoder): TransformerEncoder(
(pos_conv): Sequential(
(0): Sequential(
(0): Conv1d(1024, 1024, kernel_size=(19,), stride=(1,), padding=(9,), groups=16)
(1): SamePad()
(2): TransposeLast()
(3): LayerNorm((1024,), eps=1e-05, elementwise_affine=False)
(4): TransposeLast()
(5): GELU(approximate='none')
)
(1): Sequential(
(0): Conv1d(1024, 1024, kernel_size=(19,), stride=(1,), padding=(9,), groups=16)
(1): SamePad()
(2): TransposeLast()
(3): LayerNorm((1024,), eps=1e-05, elementwise_affine=False)
(4): TransposeLast()
(5): GELU(approximate='none')
)
(2): Sequential(
(0): Conv1d(1024, 1024, kernel_size=(19,), stride=(1,), padding=(9,), groups=16)
(1): SamePad()
(2): TransposeLast()
(3): LayerNorm((1024,), eps=1e-05, elementwise_affine=False)
(4): TransposeLast()
(5): GELU(approximate='none')
)
(3): Sequential(
(0): Conv1d(1024, 1024, kernel_size=(19,), stride=(1,), padding=(9,), groups=16)
(1): SamePad()
(2): TransposeLast()
(3): LayerNorm((1024,), eps=1e-05, elementwise_affine=False)
(4): TransposeLast()
(5): GELU(approximate='none')
)
(4): Sequential(
(0): Conv1d(1024, 1024, kernel_size=(19,), stride=(1,), padding=(9,), groups=16)
(1): SamePad()
(2): TransposeLast()
(3): LayerNorm((1024,), eps=1e-05, elementwise_affine=False)
(4): TransposeLast()
(5): GELU(approximate='none')
)
)
(layers): ModuleList(
(0-23): 24 x TransformerSentenceEncoderLayer(
(self_attn): MultiheadAttention(
(dropout_module): FairseqDropout()
(k_proj): Linear(in_features=1024, out_features=1024, bias=True)
(v_proj): Linear(in_features=1024, out_features=1024, bias=True)
(q_proj): Linear(in_features=1024, out_features=1024, bias=True)
(out_proj): Linear(in_features=1024, out_features=1024, bias=True)
)
(dropout1): Dropout(p=0.1, inplace=False)
(dropout2): Dropout(p=0.0, inplace=False)
(dropout3): Dropout(p=0.1, inplace=False)
(self_attn_layer_norm): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(fc1): Linear(in_features=1024, out_features=4096, bias=True)
(fc2): Linear(in_features=4096, out_features=1024, bias=True)
(final_layer_norm): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
)
)
(layer_norm): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
)
(layer_norm): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
(final_proj): Linear(in_features=1024, out_features=1024, bias=True)
)
teacher and student architectures are exactly same
Representation Collapse
Data2Vec 2.0
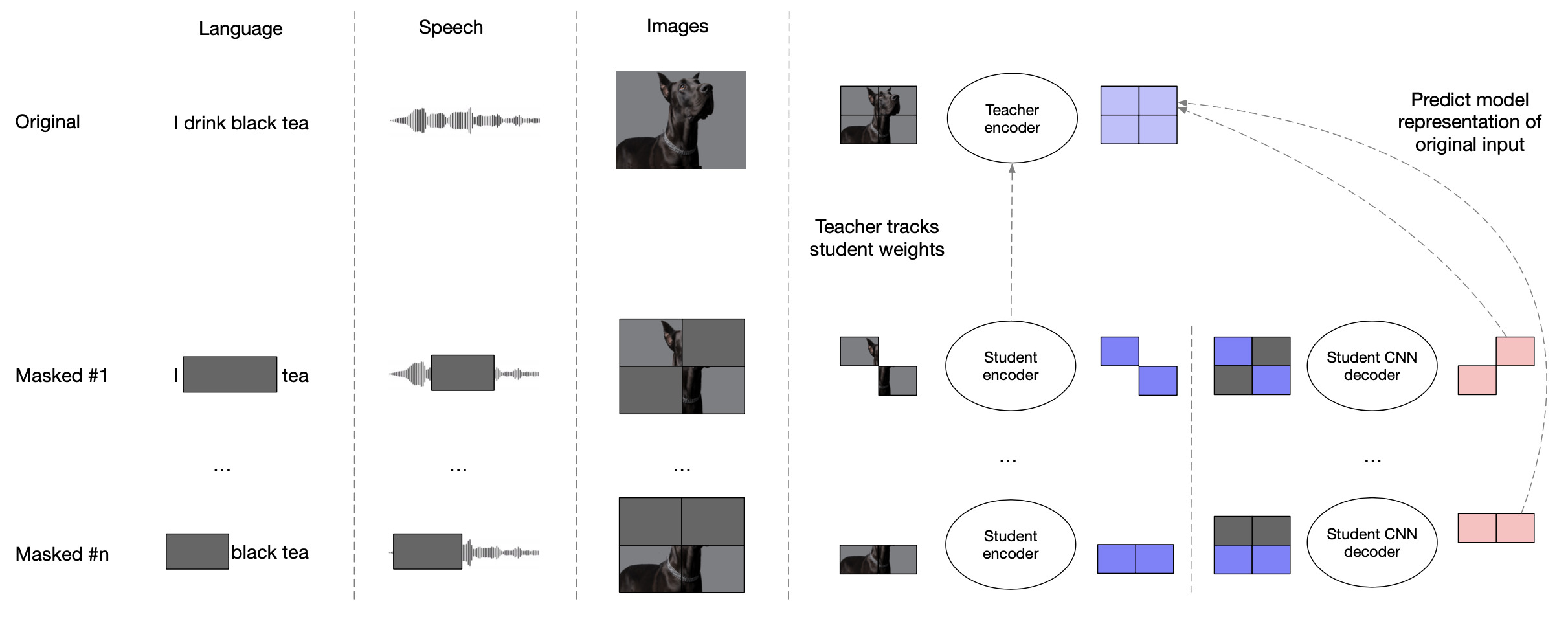 Fig.
Fig.
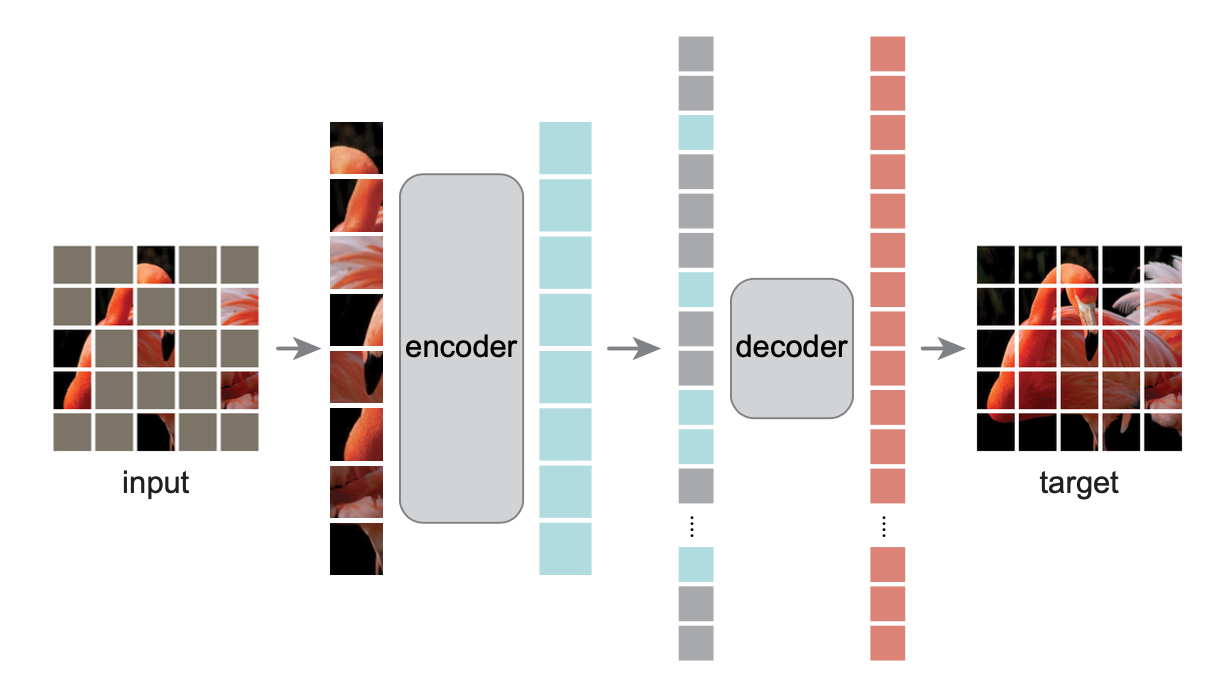 Fig.
Fig.
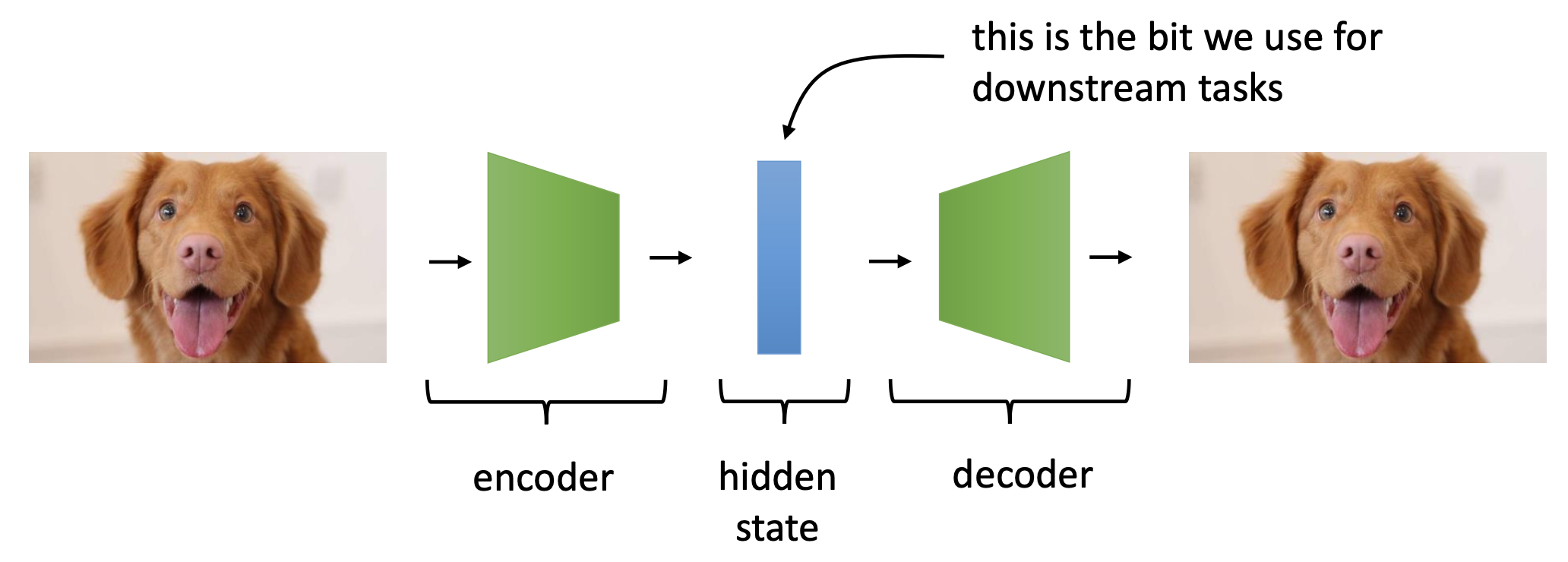 )
Fig.
)
Fig.
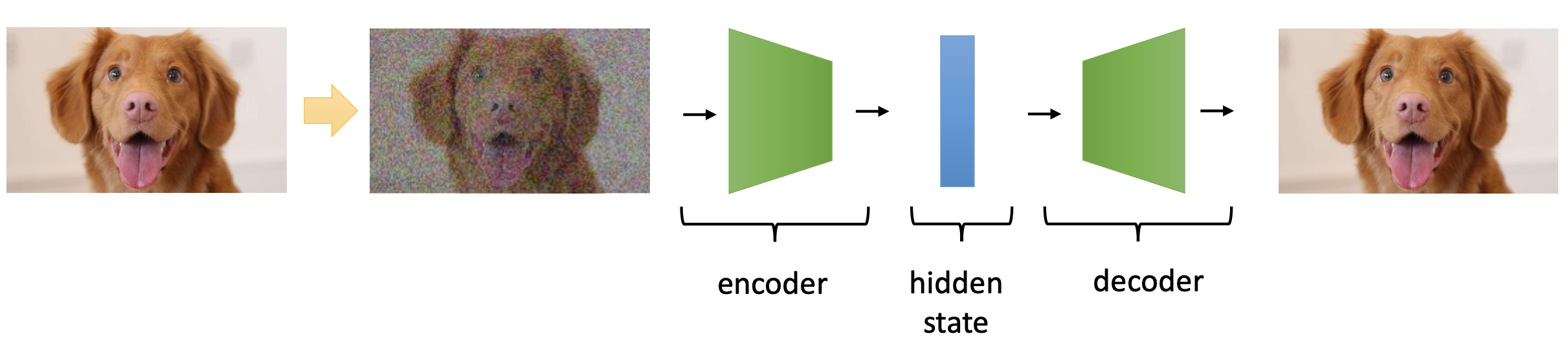 )
Fig.
)
Fig.
 Fig.
Fig.
Target Representations and Learning Objective
Network Architecture (Asymmetric Encoder/Decoder Architecture)
d2v2 의 전체 모델 구조는 아래와 같습니다.
- domain specific local_encoder
- AutoEncoder like modules
- encoder
- feature_extractor
- transformer encoder layers
- positional encoding
- speech : convolutional positional encodig
- num.layers : 5
- speech : convolutional positional encodig
- num.layers : 16 (large)
- hidden.dim : 1024 (large)
add alibi biasfor relative positional encoding
- positional encoding
- transformer encoder layers
- contextualized_encoder
- transformer encoder layers
- num.layers : 8 (large)
- hidden.dim : 1024 (large)
add alibi biasfor relative positional encoding
- transformer encoder layers
- feature_extractor
- decoder
- speech : 1-d conv decoder
- num.layers : 4
- speech : 1-d conv decoder
- encoder
우선 domain 마다 local_encdoer 가 있어서 raw data 에서 feature 를 뽑는 모듈이 하나 있습니다.
저의 경우 speech domain 을 주로 보기 때문에 이 기준으로 설명드리면 1d signal 를 입력으로 사용해 7 개의 서로 다른 kernel, stride size 를 갖는 1d conv layer 가 feature 를 추출합니다.
이 때 speech domain 의 local feature 들 간의 correlation 을 고려한 domain knowledge가 사용되었다고 생각할 수 있고,
vision, nlp 에서도 각 domain 에 맞게 디자인된 모듈이 사용됩니다.
이제 MAE 구조를 따르는 d2v2 이기 때문에 크게 encoder / decoder 두개 구조가 있어야 되는데요, encoder 쪽을 보시면 transformer encoder 24층을 2가지로 구분짓습니다.
먼저 local encoder output 을 받아서 일부분을 masking 한 다음에 transformer block 16개를 통과시키는데요, 이를 feature_extracotr 라고 합니다.
이 떄는 speech domain 의 경우 w2v2 에서 처럼 relative positional encoding 정보를 주입해주는데요, local encoder 에서 처럼 conv layer 를 여러번 통과시키는 것이 이 역할을 하게 됩니다.
그리고 마지막으로 8층 정도 되는 context_encoder가 있어 이를 통과하면 모든 encoder를 통과하게 됩니다.
이 때 모든 transformer block 들에는 또 추가적으로 Alibi bias 를 QK attention map 에 더해주는데요, 이미 relative positional encoding 가 들어간 시점에서 꽤 redundant 한 것으로 보이나 실험 결과 성능에 중요한 영향을 끼쳤다고 합니다. Alibi 는 초기화 된 아래처럼 자기 자신과 가까운 부분에만 추가 점수를 주는, 즉 local feature 를 더 보라는 bias 를 주는데, 이를 학습하지 않고 head 별로 (head 가 large 는 16개 있음) learnable scalar 를 둬서 이를 학습하게 했습니다.
아래는 downstream finetuning 을 했을 때 head 별 alibi scalar 값 입니다.
Parameter containing:
tensor([[[[[ 5.9082e-01]],
[[ 1.2866e-01]],
[[ 3.2153e-01]],
[[ 1.4374e-02]],
[[ 3.9917e-01]],
[[ 5.4346e-01]],
[[ 4.3457e-01]],
[[ 3.7598e-01]],
[[ 2.4402e-01]],
[[ 2.0401e-02]],
[[ 2.9572e-02]],
[[ 1.3199e-02]],
[[ 2.1698e-02]],
[[-2.1100e-05]],
[[ 3.7346e-03]],
[[ 1.3786e-02]]]]], device='cuda:5', dtype=torch.float16,
requires_grad=True)
즉 어떤 head 는 글로벌 하게 보라는 의미죠.
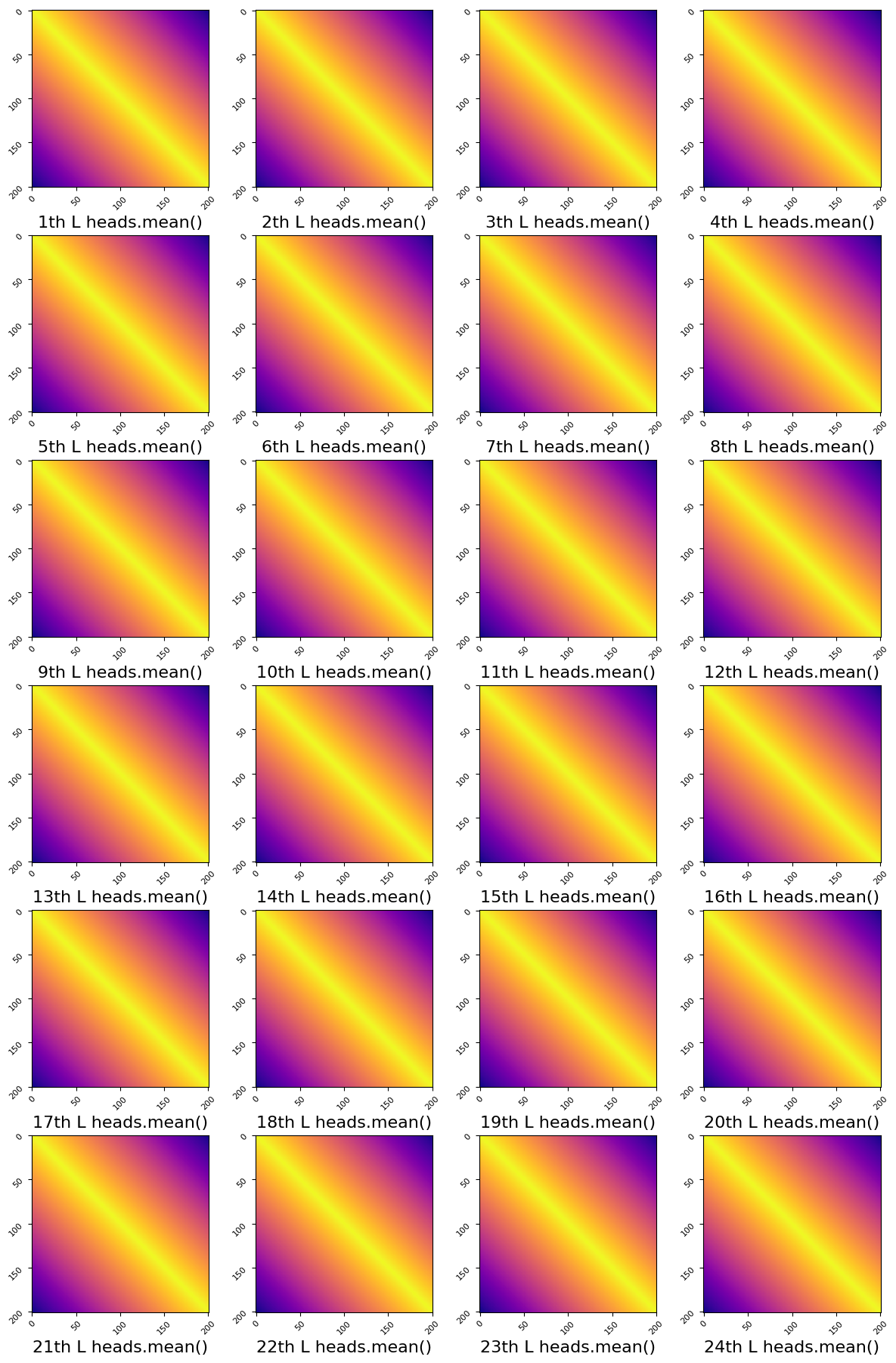 Fig. head 를 Average 했고 visualize 했으므로 아무런 차이가 없어보인다.
Fig. head 를 Average 했고 visualize 했으므로 아무런 차이가 없어보인다.
여기서 아니 transformer encoder 를 굳이 16, 8층으로 나눠서 선언한 이유가 뭐지? 라는 생각이 드실 수 있습니다.
논문에서는 굳이 전체 24층의 encoder 를 2개로 구분지어 서로 다른 역할을 하게 한다는 언급자체는 없는데요,
코드를 살펴본 결과 사실 둘의 차이는 없다고 할 수 있겠습니다.
제 생각에는 d2v 시리즈가 여러 modality 의 입력을 joint 하게 SSL 하기 위해서 이를 나눠둔 것 같습니다.
그러니까 사실상 24층짜리 똑같은 alibi bias 가 들어간 transformer encoder block 인데 나중에 modality fusion 을 하는 부분이 16층 부근이어서 그랬던 것이죠.
이제 마지막으로 이를 다시 reconstruct masking 되기 전의 feature vector 들로 복원해줄 decoder 가 필요한데요, 이는 4개의 conv layer 로 구성되어 있습니다.
num. shared model params: 315,184,144 (num. trained: 315,184,144)
Data2VecMultiModel(
(modality_encoders): ModuleDict(
(AUDIO): AudioEncoder(
(local_encoder): ConvFeatureExtractionModel(
(conv_layers): ModuleList(
(0): Sequential(
(0): Conv1d(1, 512, kernel_size=(10,), stride=(5,), bias=False)
(1): Dropout(p=0.0, inplace=False)
(2): Sequential(
(0): TransposeChannel()
(1): Fp32LayerNorm((512,), eps=1e-05, elementwise_affine=True)
(2): TransposeChannel()
)
(3): GELU(approximate='none')
)
(1-4): 4 x Sequential(
(0): Conv1d(512, 512, kernel_size=(3,), stride=(2,), bias=False)
(1): Dropout(p=0.0, inplace=False)
(2): Sequential(
(0): TransposeChannel()
(1): Fp32LayerNorm((512,), eps=1e-05, elementwise_affine=True)
(2): TransposeChannel()
)
(3): GELU(approximate='none')
)
(5-6): 2 x Sequential(
(0): Conv1d(512, 512, kernel_size=(2,), stride=(2,), bias=False)
(1): Dropout(p=0.0, inplace=False)
(2): Sequential(
(0): TransposeChannel()
(1): Fp32LayerNorm((512,), eps=1e-05, elementwise_affine=True)
(2): TransposeChannel()
)
(3): GELU(approximate='none')
)
)
)
(project_features): Sequential(
(0): TransposeLast()
(1): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
(2): Linear(in_features=512, out_features=1024, bias=True)
)
(relative_positional_encoder): Sequential(
(0): TransposeLast()
(1): Sequential(
(0): Conv1d(1024, 1024, kernel_size=(19,), stride=(1,), padding=(9,), groups=16)
(1): SamePad()
(2): TransposeLast()
(3): LayerNorm((1024,), eps=1e-05, elementwise_affine=False)
(4): TransposeLast()
(5): GELU(approximate='none')
)
(2): Sequential(
(0): Conv1d(1024, 1024, kernel_size=(19,), stride=(1,), padding=(9,), groups=16)
(1): SamePad()
(2): TransposeLast()
(3): LayerNorm((1024,), eps=1e-05, elementwise_affine=False)
(4): TransposeLast()
(5): GELU(approximate='none')
)
(3): Sequential(
(0): Conv1d(1024, 1024, kernel_size=(19,), stride=(1,), padding=(9,), groups=16)
(1): SamePad()
(2): TransposeLast()
(3): LayerNorm((1024,), eps=1e-05, elementwise_affine=False)
(4): TransposeLast()
(5): GELU(approximate='none')
)
(4): Sequential(
(0): Conv1d(1024, 1024, kernel_size=(19,), stride=(1,), padding=(9,), groups=16)
(1): SamePad()
(2): TransposeLast()
(3): LayerNorm((1024,), eps=1e-05, elementwise_affine=False)
(4): TransposeLast()
(5): GELU(approximate='none')
)
(5): Sequential(
(0): Conv1d(1024, 1024, kernel_size=(19,), stride=(1,), padding=(9,), groups=16)
(1): SamePad()
(2): TransposeLast()
(3): LayerNorm((1024,), eps=1e-05, elementwise_affine=False)
(4): TransposeLast()
(5): GELU(approximate='none')
)
(6): TransposeLast()
)
(context_encoder): BlockEncoder(
(blocks): ModuleList(
(0-7): 8 x AltBlock(
(norm1): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(attn): AltAttention(
(qkv): Linear(in_features=1024, out_features=3072, bias=True)
(attn_drop): Dropout(p=0.1, inplace=False)
(proj): Linear(in_features=1024, out_features=1024, bias=True)
(proj_drop): Dropout(p=0.1, inplace=False)
)
(drop_path): Identity()
(norm2): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=1024, out_features=4096, bias=True)
(act): GELU(approximate='none')
(drop1): Dropout(p=0.0, inplace=False)
(norm): Identity()
(fc2): Linear(in_features=4096, out_features=1024, bias=True)
(drop2): Dropout(p=0.0, inplace=False)
)
(post_mlp_dropout): Dropout(p=0.1, inplace=False)
)
)
(norm): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=True)
)
(decoder): Decoder1d(
(blocks): Sequential(
(0): Sequential(
(0): Conv1d(1024, 768, kernel_size=(7,), stride=(1,), padding=(3,), groups=16)
(1): SamePad()
(2): TransposeLast()
(3): LayerNorm((768,), eps=1e-05, elementwise_affine=False)
(4): TransposeLast()
(5): GELU(approximate='none')
)
(1): Sequential(
(0): Conv1d(768, 768, kernel_size=(7,), stride=(1,), padding=(3,), groups=16)
(1): SamePad()
(2): TransposeLast()
(3): LayerNorm((768,), eps=1e-05, elementwise_affine=False)
(4): TransposeLast()
(5): GELU(approximate='none')
)
(2): Sequential(
(0): Conv1d(768, 768, kernel_size=(7,), stride=(1,), padding=(3,), groups=16)
(1): SamePad()
(2): TransposeLast()
(3): LayerNorm((768,), eps=1e-05, elementwise_affine=False)
(4): TransposeLast()
(5): GELU(approximate='none')
)
(3): Sequential(
(0): Conv1d(768, 768, kernel_size=(7,), stride=(1,), padding=(3,), groups=16)
(1): SamePad()
(2): TransposeLast()
(3): LayerNorm((768,), eps=1e-05, elementwise_affine=False)
(4): TransposeLast()
(5): GELU(approximate='none')
)
)
(proj): Linear(in_features=768, out_features=1024, bias=True)
)
)
)
(dropout_input): Dropout(p=0.0, inplace=False)
(blocks): ModuleList(
(0-15): 16 x AltBlock(
(norm1): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(attn): AltAttention(
(qkv): Linear(in_features=1024, out_features=3072, bias=True)
(attn_drop): Dropout(p=0.1, inplace=False)
(proj): Linear(in_features=1024, out_features=1024, bias=True)
(proj_drop): Dropout(p=0.1, inplace=False)
)
(drop_path): Identity()
(norm2): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=1024, out_features=4096, bias=True)
(act): GELU(approximate='none')
(drop1): Dropout(p=0.0, inplace=False)
(norm): Identity()
(fc2): Linear(in_features=4096, out_features=1024, bias=True)
(drop2): Dropout(p=0.0, inplace=False)
)
(post_mlp_dropout): Dropout(p=0.1, inplace=False)
)
)
)
Implementation
References
- Papers
- Data2vec: A general framework for self-supervised learning in speech, vision and language
- Efficient Self-supervised Learning with Contextualized Target Representations for Vision, Speech and Language
- Bootstrap Your Own Latent A New Approach to Self-Supervised Learning
- BYOL works even without batch statistics
- A Cookbook of Self-Supervised Learning
- Masked Autoencoders Are Scalable Vision Learners
- Others
- Implementation