How to Analysis SSL Trained Speech Encoders ? (using CCA and CKA)
10 Mar 2023< 목차 >
- Motivation
- Singular Vector Canonical Correlation Analysis (SVCCA)
- Analysis on SSL-trained Speech Encoder
- +Additional) Centered Kernal Analysis (CKA)
- +Additional) Analysis on Self-Attention
- References
Motivation
Layer-wise Analysis of a Self-supervised Speech Representation Model 라는 논문의 목적은 Self-Supervised Learning (SSL) Pre-training 이 된 Speech Encoder 를 분석하는 것 입니다.
논문의 Focus 는 음성쪽 SSL의 Standard 인 Wav2Vec 2.0 (w2v2) 인데요, 1년 뒤 출판된 Comparative layer-wise analysis of self-supervised speech models 라는 논문에서는 서로다른 SSL Encoder 인 WavLM, HuBERT 등에 대해서도 비교하기도 합니다.
왜 Layer 별로 분석을 할까요? w2v2 는 CNN 7층 으로 이루어진 Feature Extractor, 혹은 DownSampler 를 지나고 나면 여러층의 Transformer Layer 를 지나게 되는데요, Multi Head Attention (MHA) 을 하게 되면서 feature vector (frame) 들 끼리 정보를 mixing 해서 contextualized vector 를 최종적으로 만들게 됩니다.
그리고 이는 각각의 Downstream Task 에 쓰일 수 있는데요, 음성 인식 (Automatic Speech Recognion; ASR), 음성 번역 (Speech Translation; S2T) 이나 Speaker Verification 등 다양한 Speech Processing task 에 쓰일 수 있습니다.
하지만 과연 어떤 Layer 가 어떤 특성을 지니고 있는지 research 가 부족했다는게 논문이 지적한 부분인데요, 즉 전체 24층 중에 ASR에 맞는 feature 는 모든 Layer를 통과하고 난 후의 24층이 아니라 18층의 output일 수도 있고 S2T 같은건 또 다른 층일수도있고 그렇다는 거죠.
이를 위해 Canonical Correlation Analysis (CCA) 라는 Tool 을 쓰는데요, 정확히는 Google 에서 2017 년에 publish 한 SVCCA 를 사용합니다.
이제 SVCCA 라는 것이 무엇인지 간단하게 알아보고 어떤식으로 Speech SSL Encoder 를 분석했고 결과적으로 Model 을 어떻게 더 효율적으로 Downstream task finetuning 에 사용했는지 알아보도록 합시다.
Singular Vector Canonical Correlation Analysis (SVCCA)
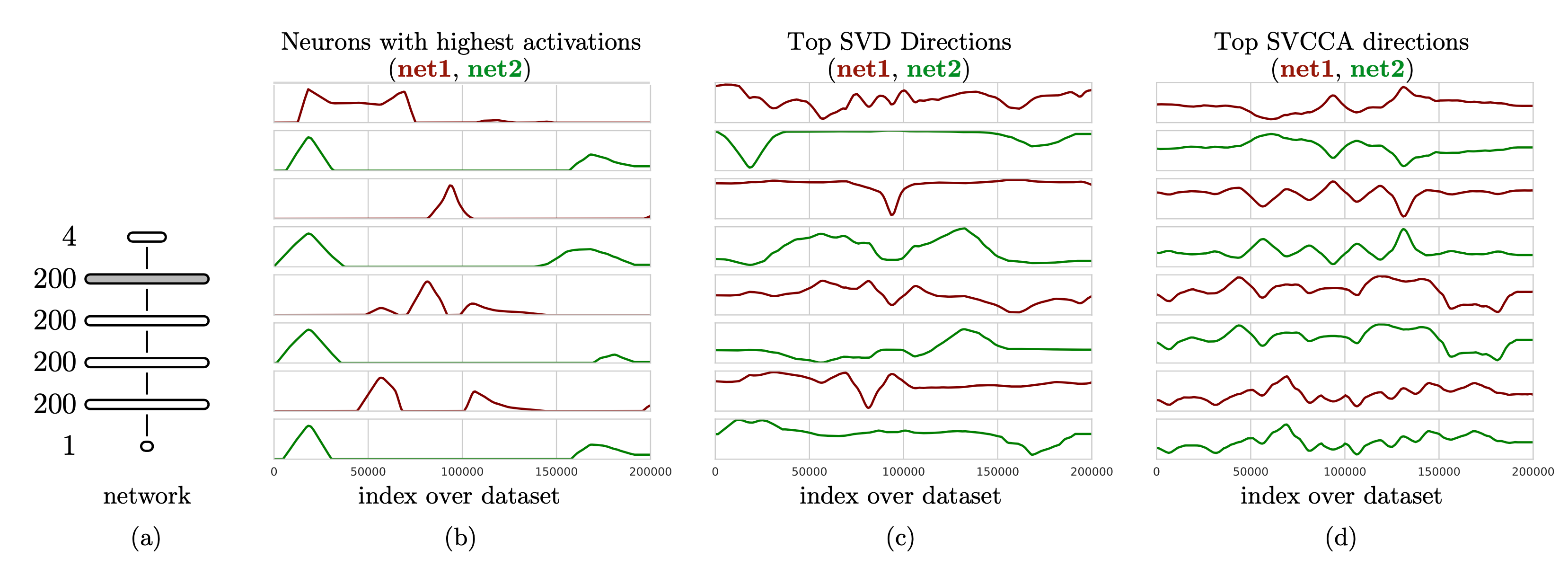
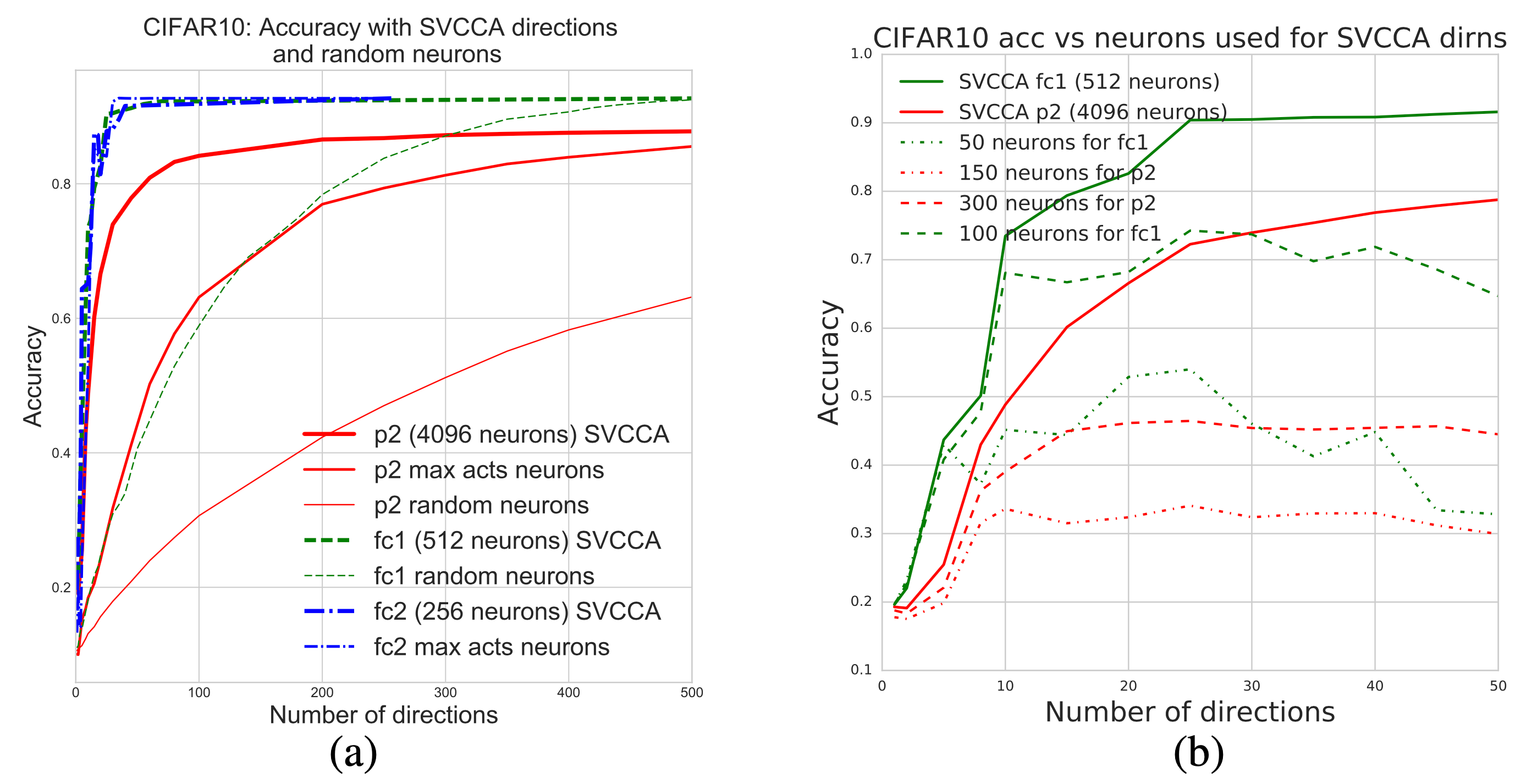
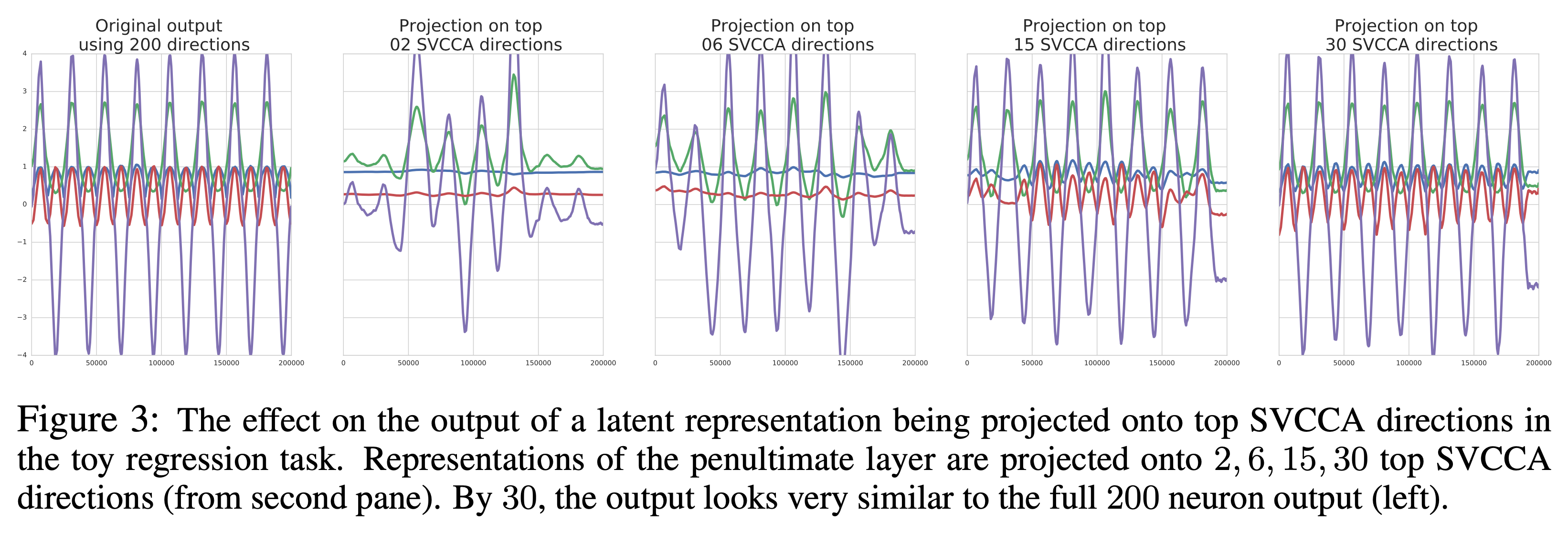
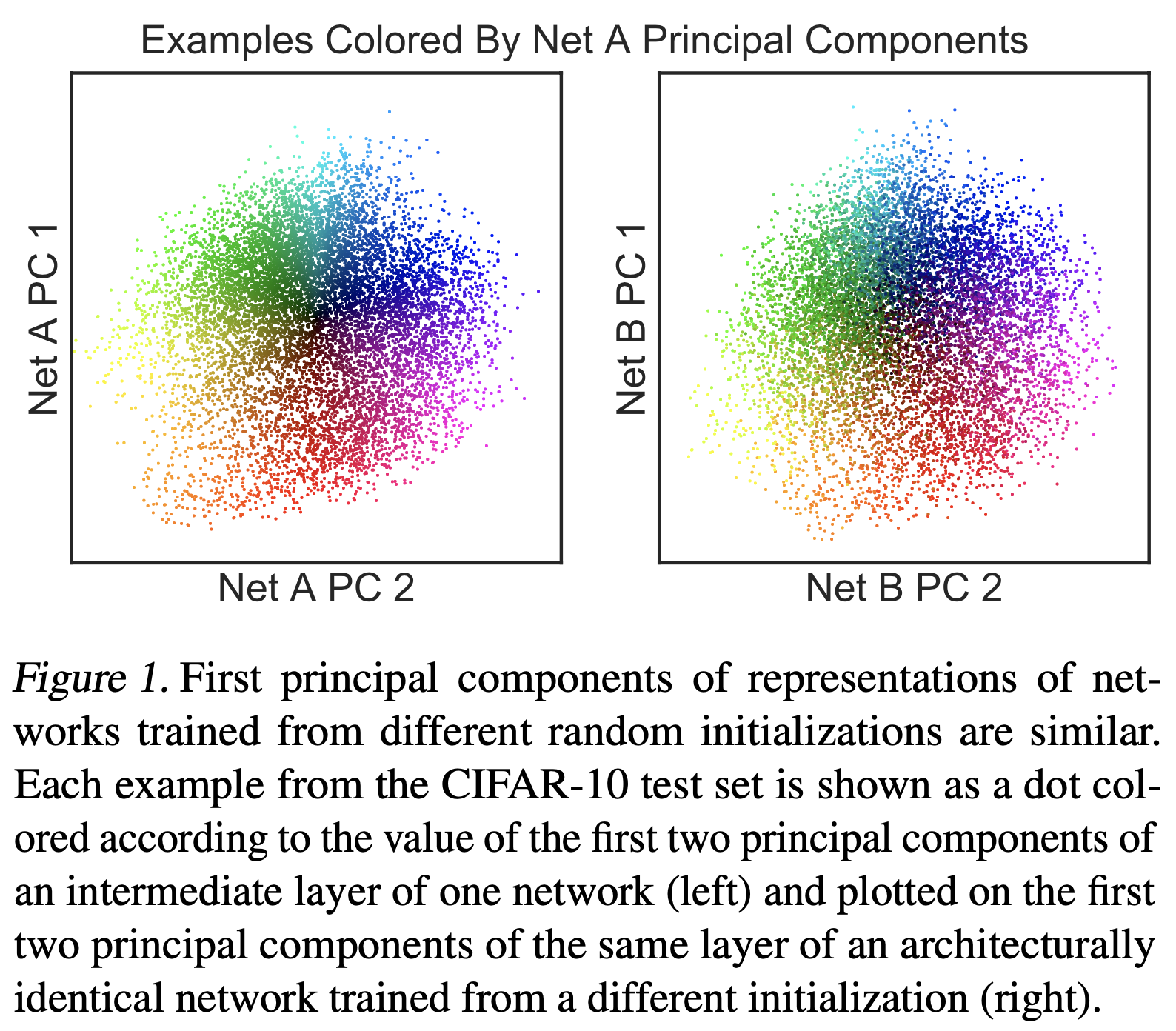
CCA 는 Layer 별 neuron 들의 representation 이 얼마나 유사한지를 비교하게 해주는 알고리즘인데요,
여기에 Singular Vector Decomposition (SVD) 를 더해서 바로 SVCCA가 되는 겁니다.
기본적으로
- 1.같은 구조를 가진 두 개의 네트워크
net1,net2끼리 같은 Layer 의 유사도를 계산 - 2.한 네트워크 내의 서로 Layer 들끼리의 출력값들의 유사도를 계산
하는 것이 가능한데요, 1번같은 경우 모델이 학습되면서 (epoch 10, 20, … 100) 어떤식으로 Layer 의 출력값들이 변하는지를 시간에 따라 분석하는, Learning Dynamics 를 파악할 수 있게 해주고, 2번의 경우 어떤 Layer들이 비슷한 역할을 하는지에 대한 힌트를 제공해주기도 합니다.
어떻게 SVCCA 를 계산할까요? 먼저 우리가 data sample 을 m개 가지고 있다고 합시다.
\[X = \{x_1, \cdots, x_m\}\]그리고 l 번째 layer 의 i 번째 neuron 을 \(z_{i}^l\) 이라고 나타냅니다. 여기서 논문의 notation이 살짝 이상한데 (…), 우리가 network 에 m 개 data를 넣으면 특정 i번째 neuron 에 대응하는 출력값도 마찬가지로 m 개 있겠죠? 이를 다음처럼 정의합니다.
\[z_{i}^{l} = ( z_{i}^{l} (x_1), \cdots, z_{i}^{l} (x_m) )\]여기서 주의할 점은 \(z_{i}^{l}(\cdot)\) 은 어떤 input 하나가 네트워크를 타고 가서 l번째 layer 를 통과했을 때 i 번째 뉴런의 출력값이므로 scalar 값이 되고, 이를 m 개의 데이터에 대해서 하기 때문에 \(z_{i}^{l}\) 는 m차원의 vector가 됩니다.
(왜 똑같은 notation을 사용했는지 이해가 안갑지만…)
논문에서도 이 점을 주의해서 생각하라고 얘기합니다. 일반적으로는 어떤 input 1개의 l번째 layer의 출력을 보통 representation vector 들로 생각하는데 지금은 그렇지 않으니까요.
Note that this is a different vector from the often-considered
vector of the “representation at a layer of a single input.”
Here zli is a single neuron’s response over the entire dataset,
not an entire layer’s response for a single input.
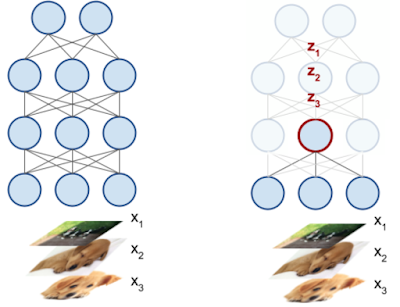 Fig.
Fig.
그리고 최종적으로 l번째 layer에는 이런 m차원의 뉴런이 여러개 있게 되겠죠?
layer can be thought of set of neurons
이런 vector 들의 조합을 통해서 어떤 subspace 를 만들어낼 수 있게 된다고 하는데요 (span), 즉 특정 layer 의 layer representations 은 이 subspace 로 표현되는 겁니다.
이제 SVCCA를 해야 하는데요, 다음의 4 가지 step 을 따르면 됩니다.
- Step 1 : m개의 데이터를 네트워크에 넣어 원하는 layer 들의 출력값들을 뽑는다.
- let \(l_1 = \{ z_{1}^{l_1}, \cdots z_{m_1}^{l_1} \}\) 와 \(l_2 = \{ z_{1}^{l_2}, \cdots z_{m_2}^{l_2} \}\)
- Step 2 : SVD 를 수행해서 가장 중요한 direction 을 구해서 그 축만 남긴다. (subspace -> subsubspace)
- let \(l^{'}_{1} \subset l_{1}\), \(l^{'}_{2} \subset l_{2}\)
- Step 3 :CCA 를 수행한다.
- CCA 는 \(l_{1}^{'} = \{ z_{1}^{'l_1}, \cdots, z_{m_1}^{'l_1} \}\), \(l_{2}^{'} = \{ z_{1}^{'l_2}, \cdots, z_{m_2}^{'l_2} \}\)

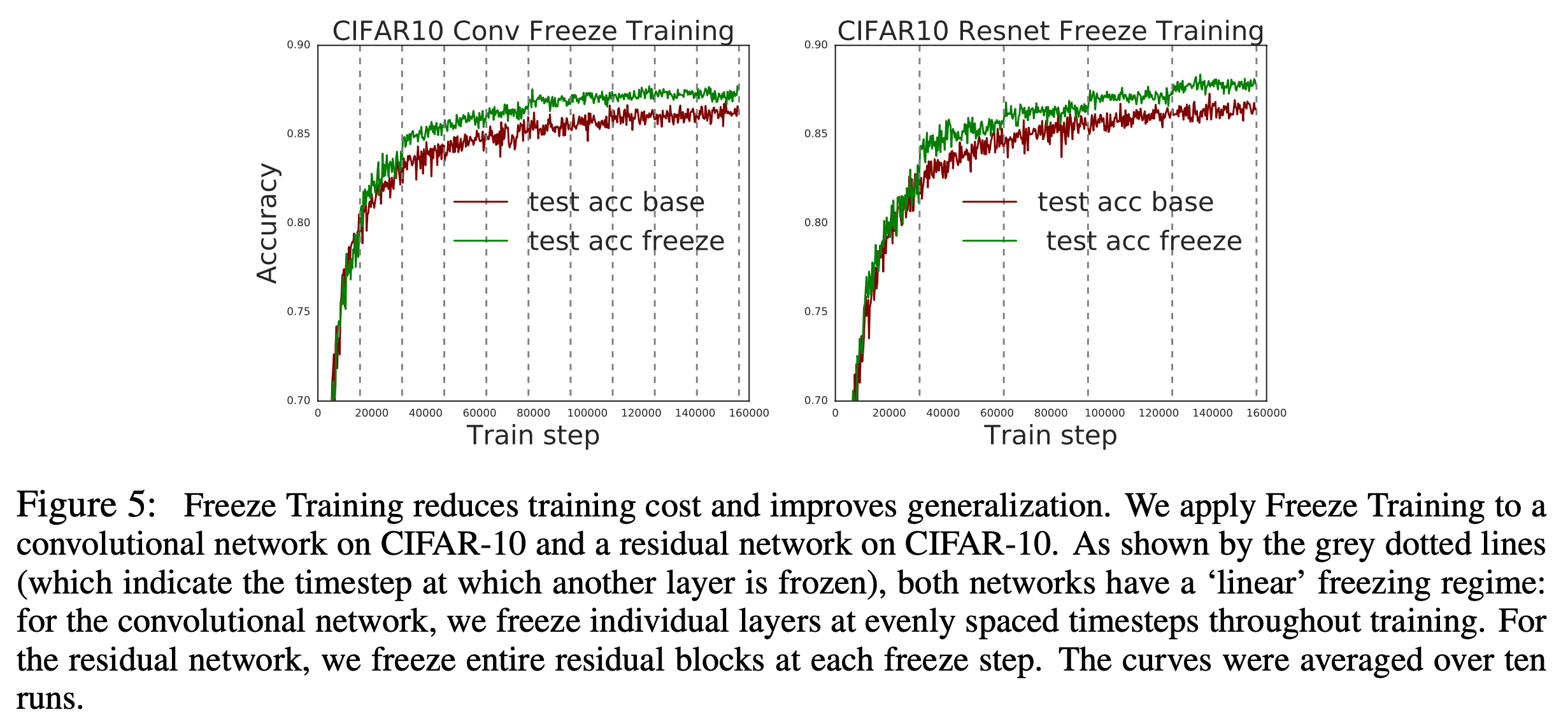
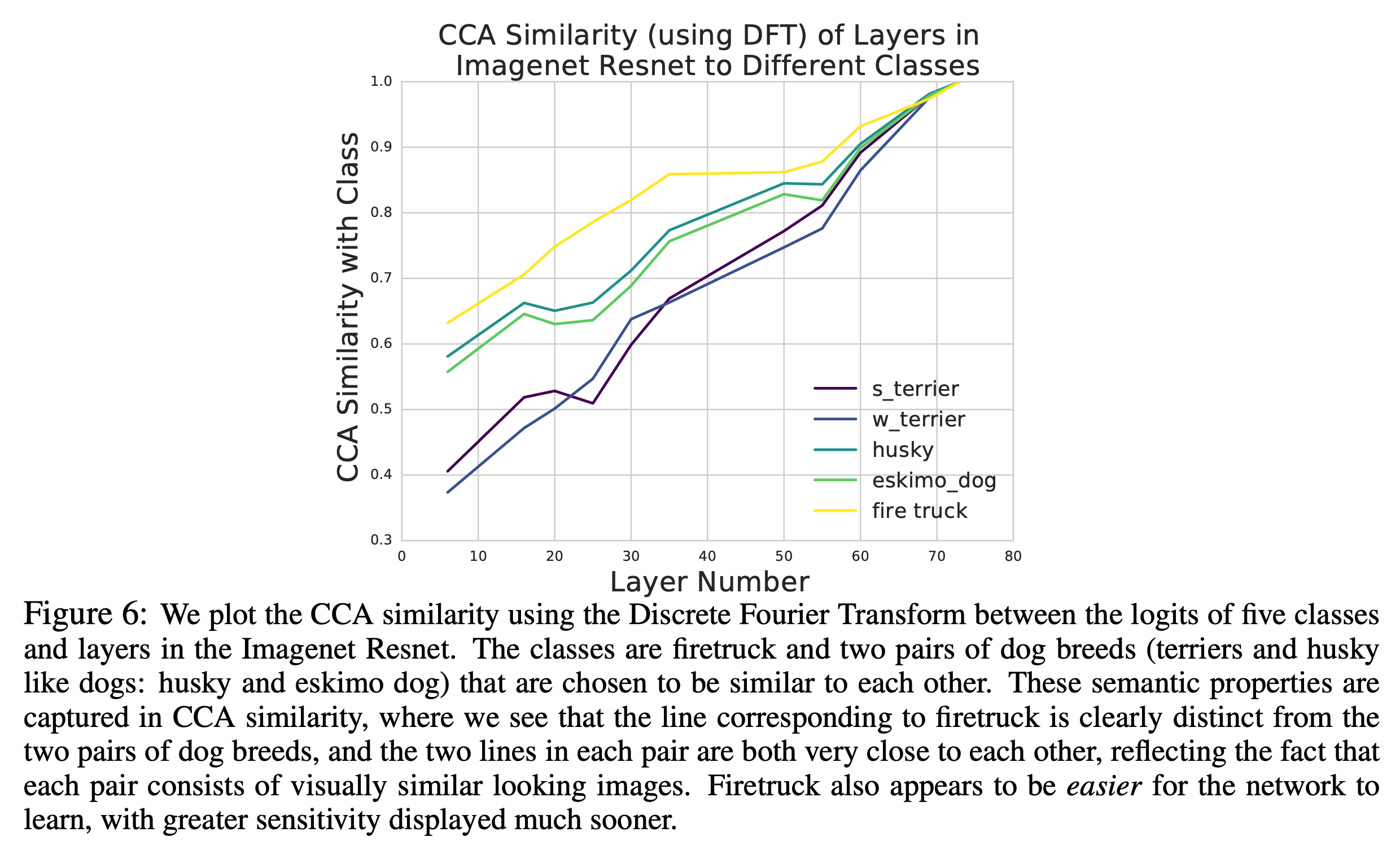
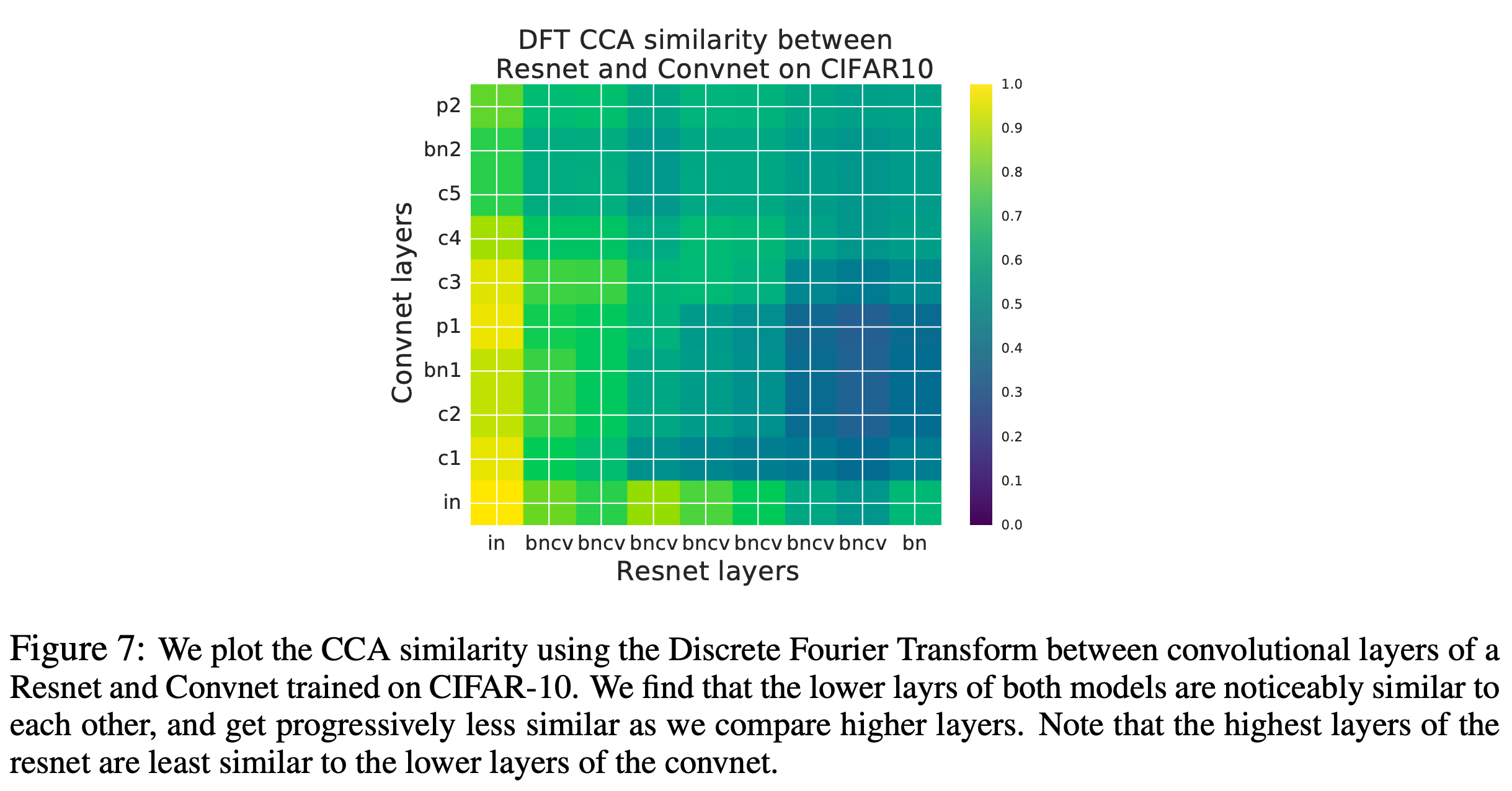
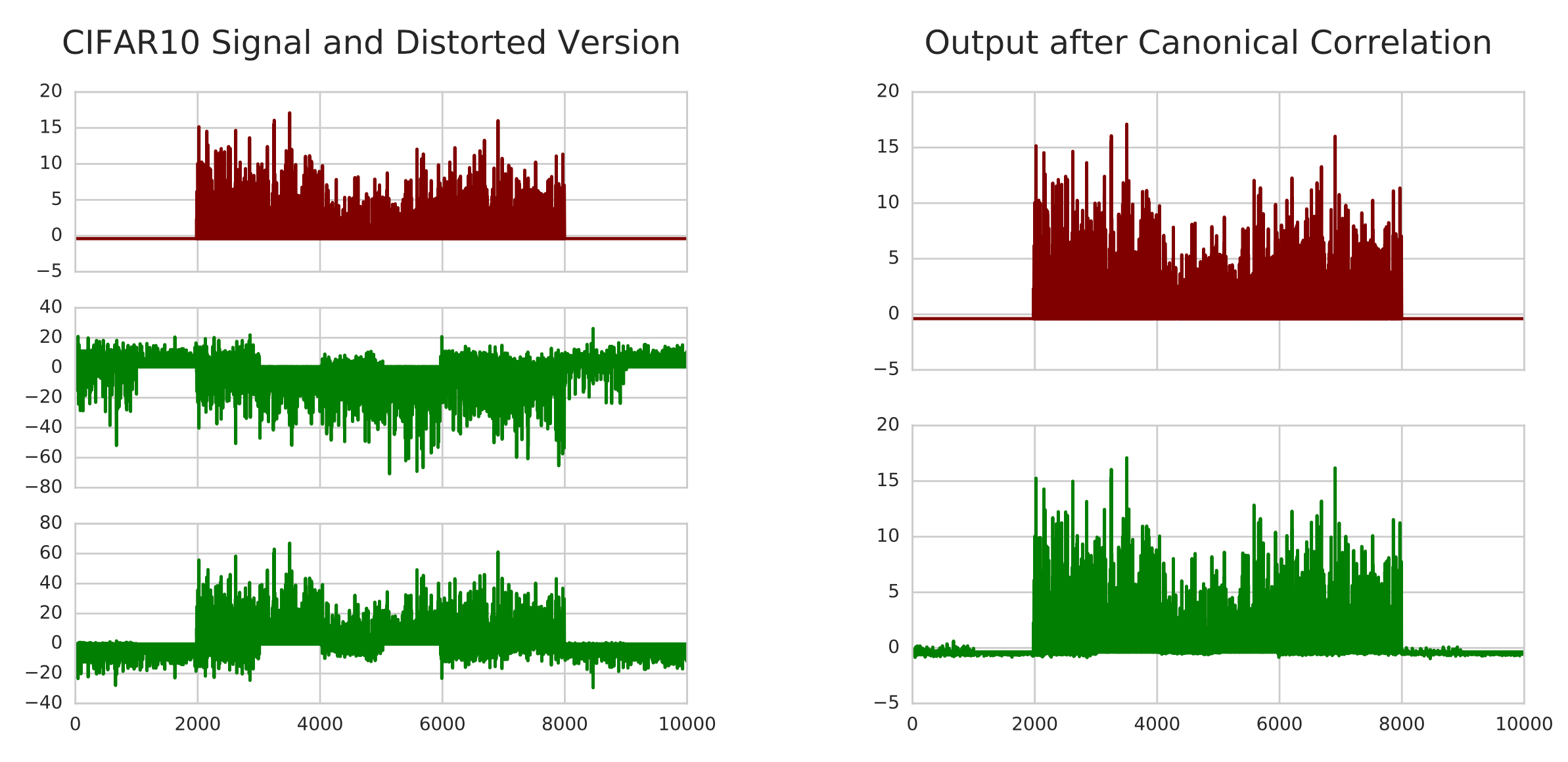
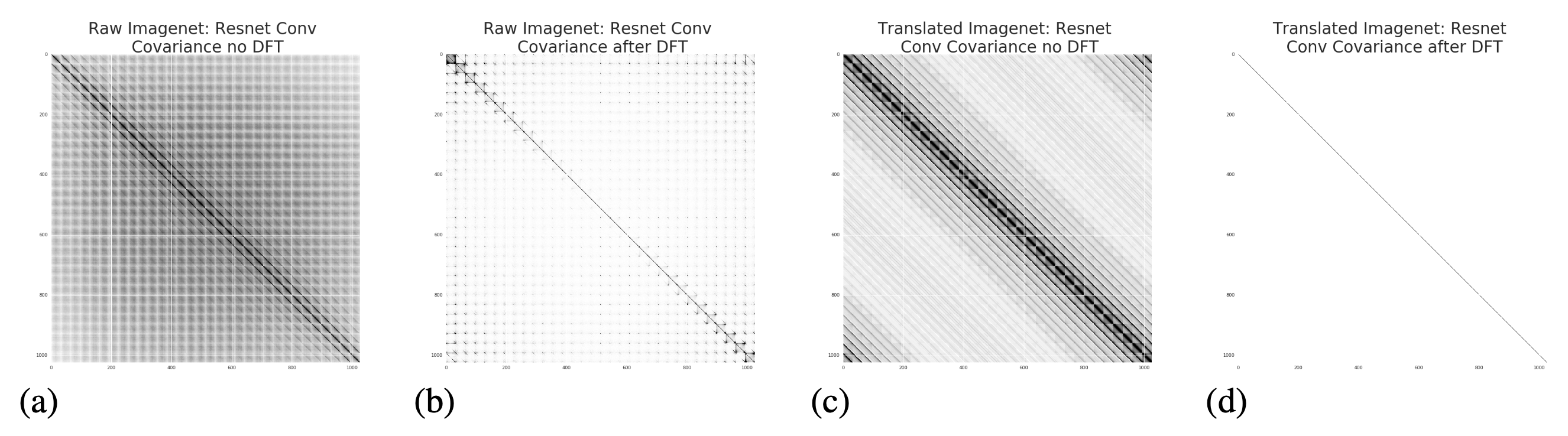
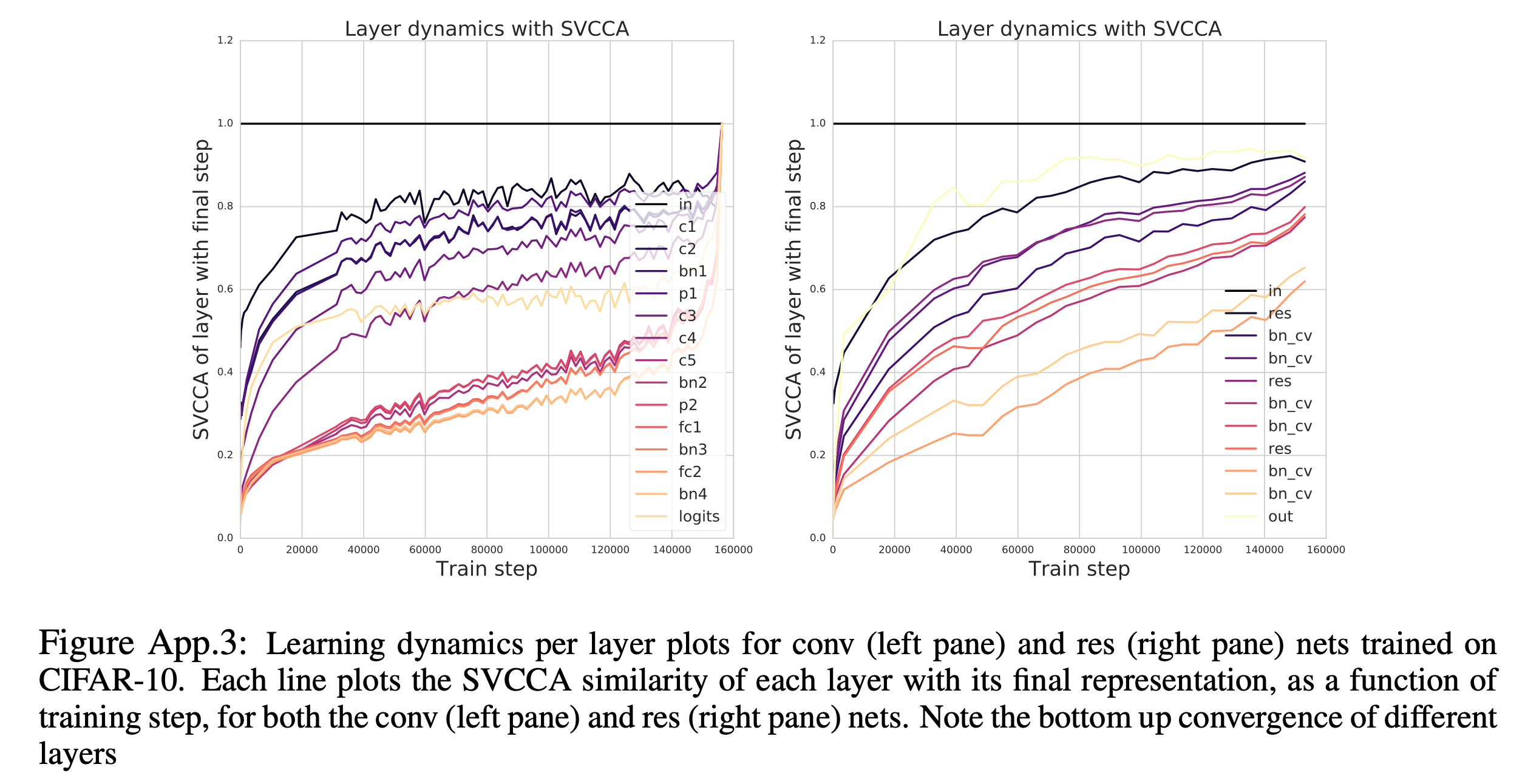
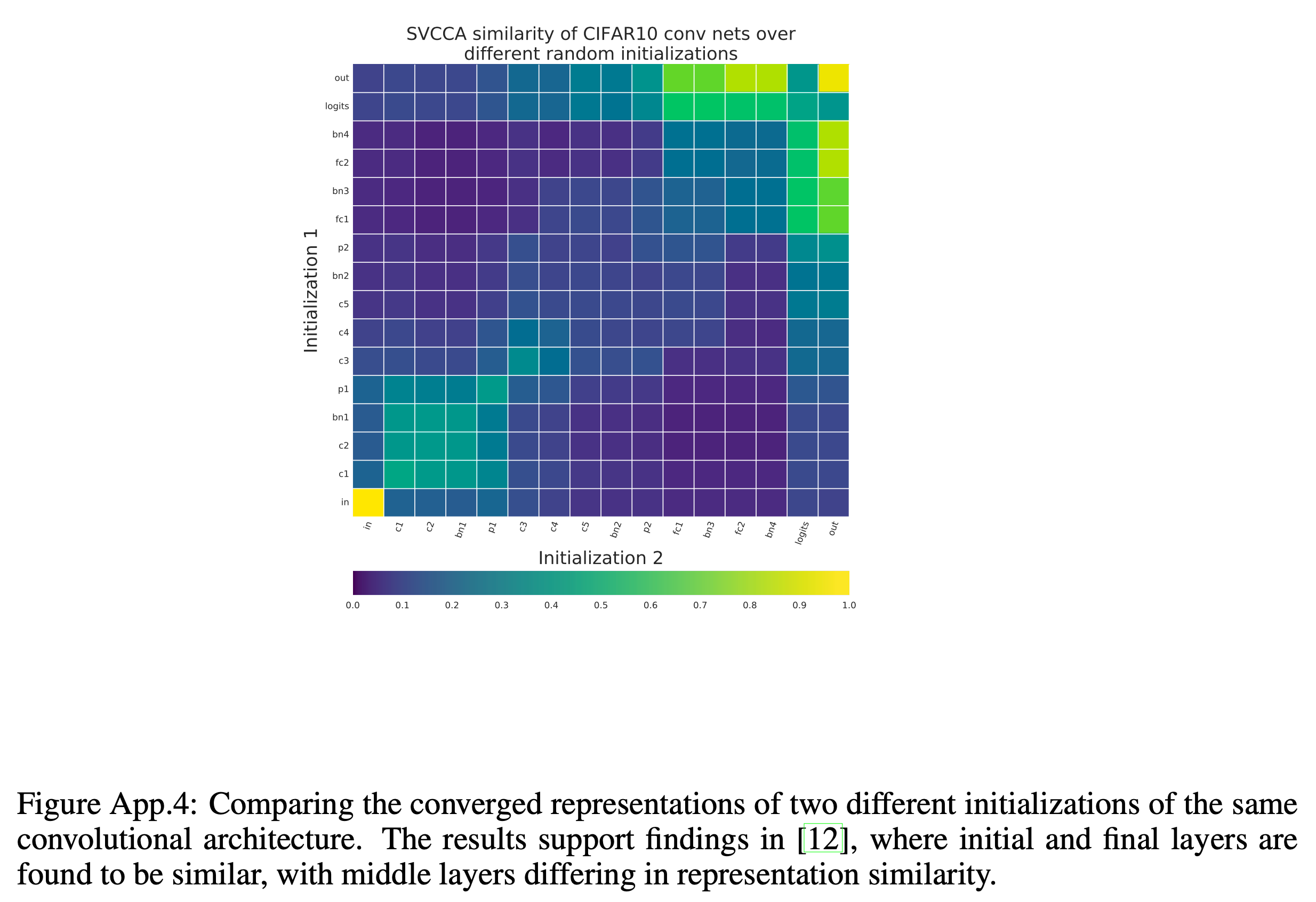
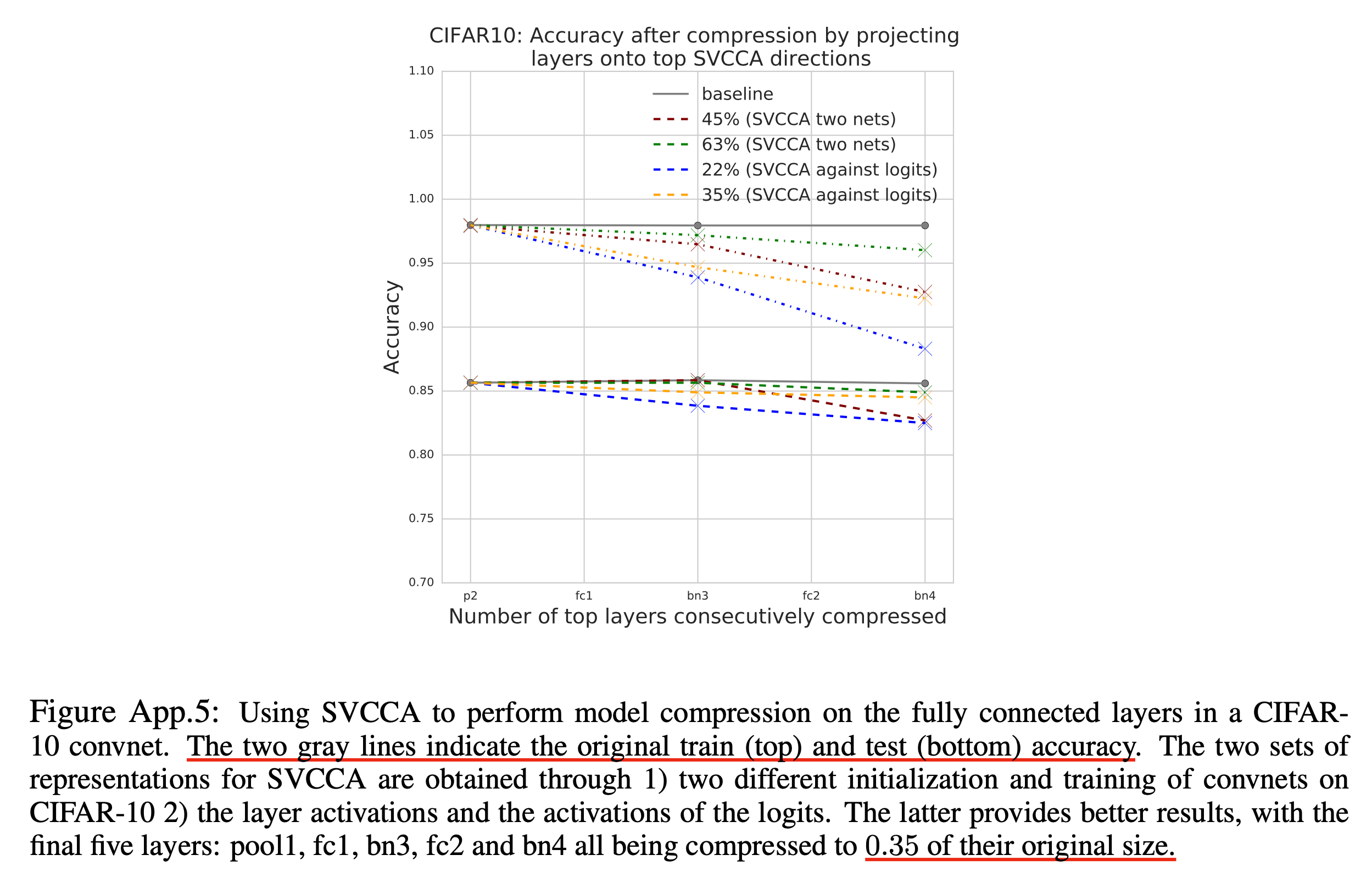
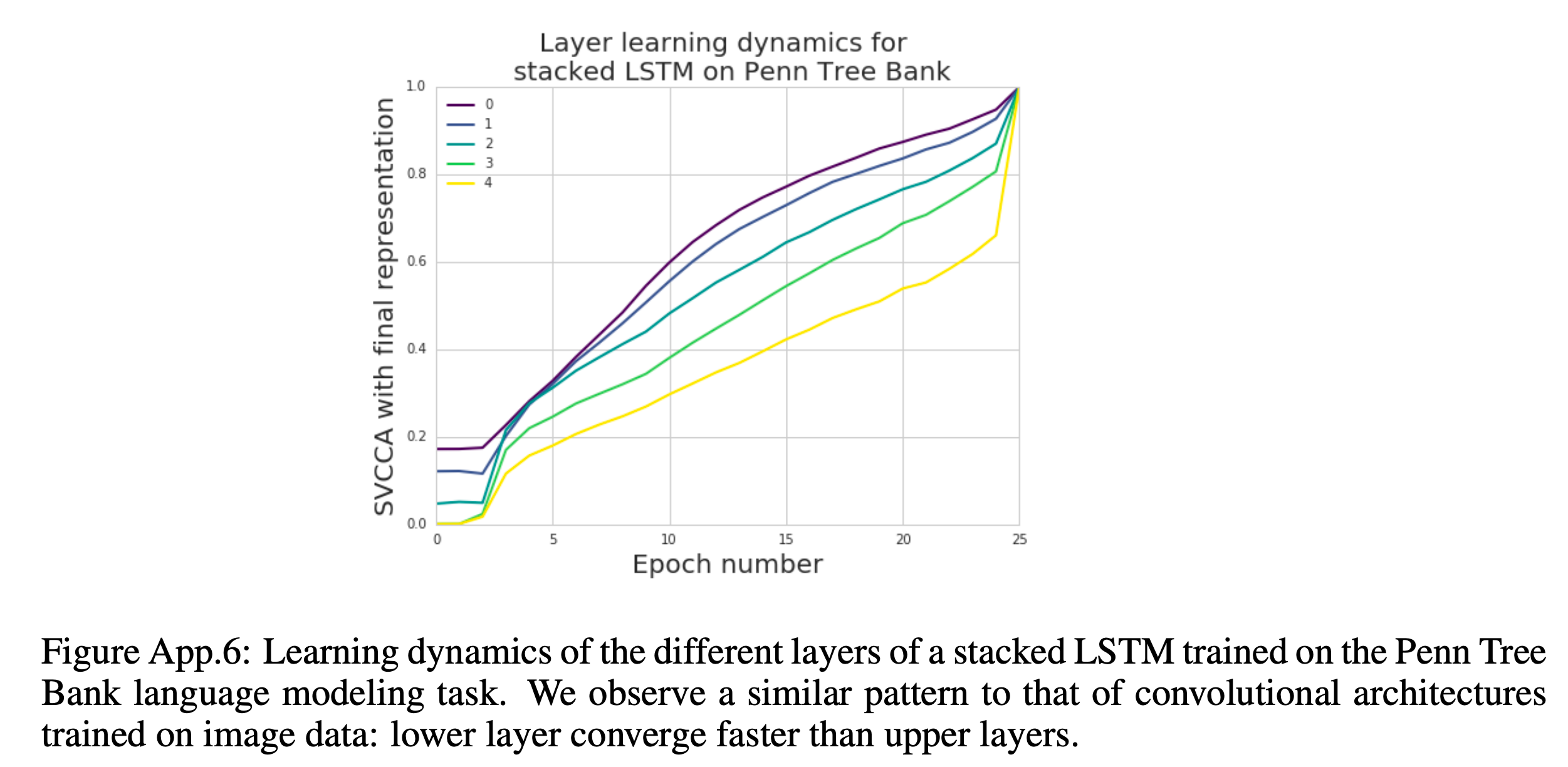
Analysis on SSL-trained Speech Encoder
Study on Wav2Vec 2.0
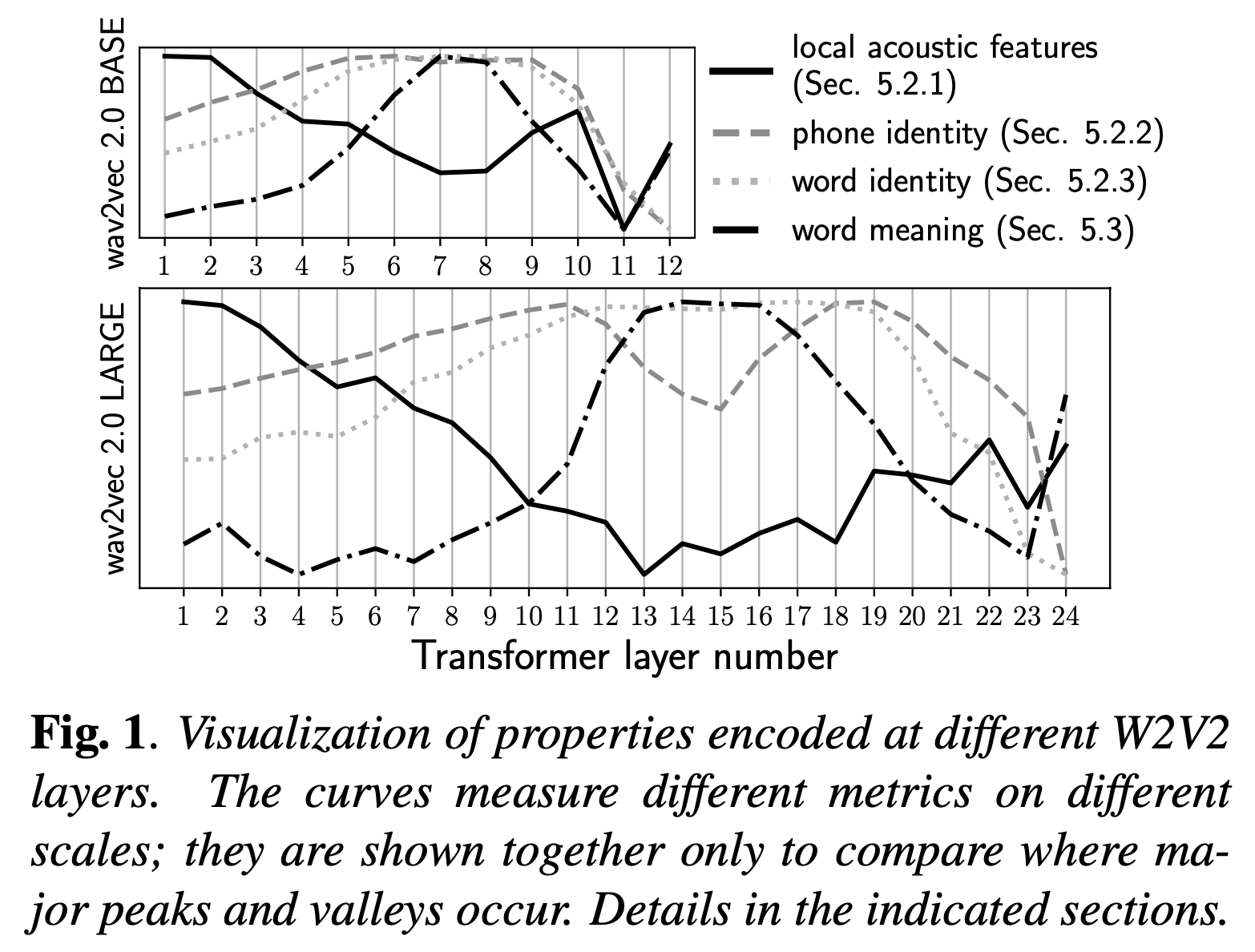
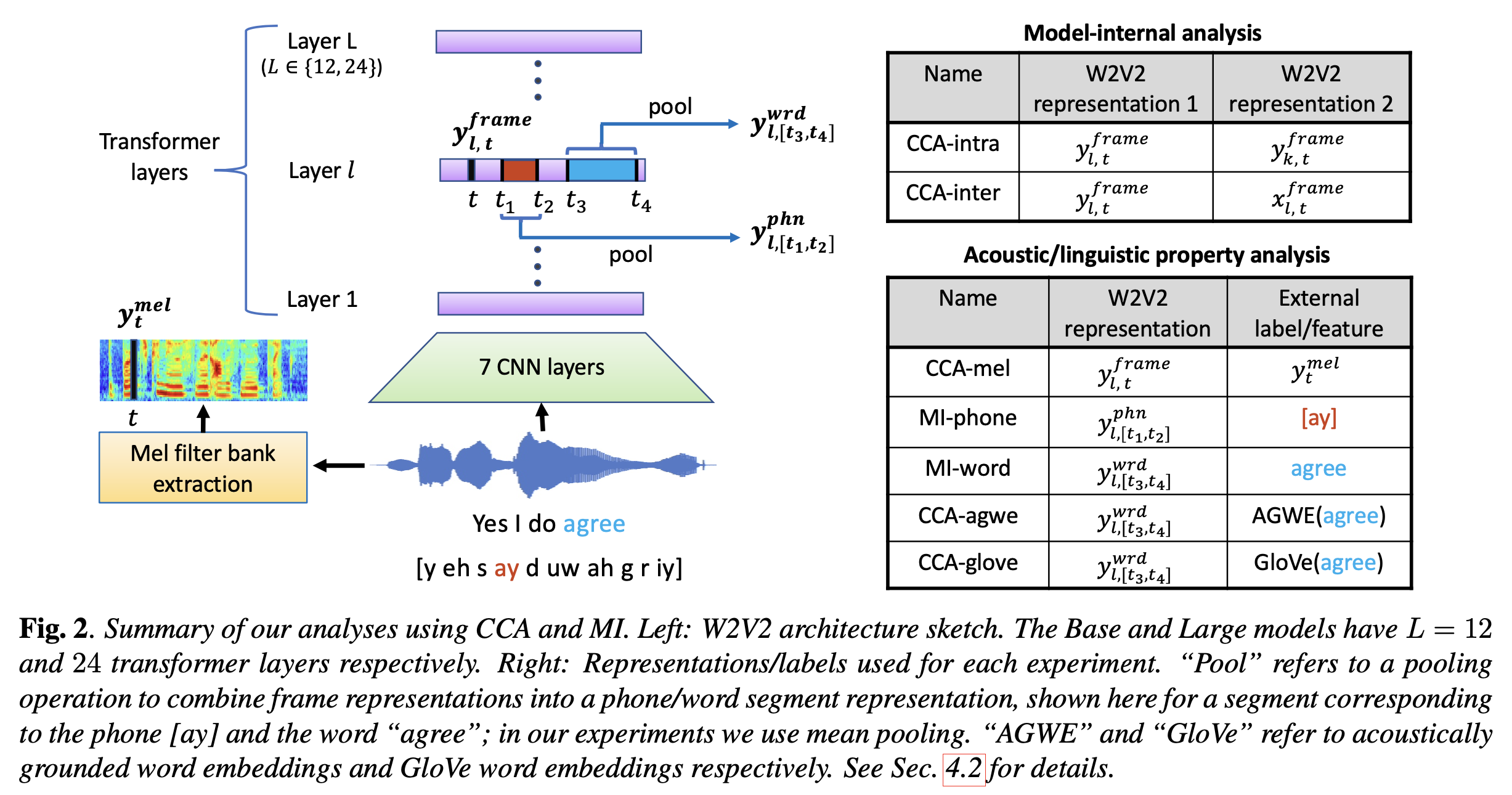
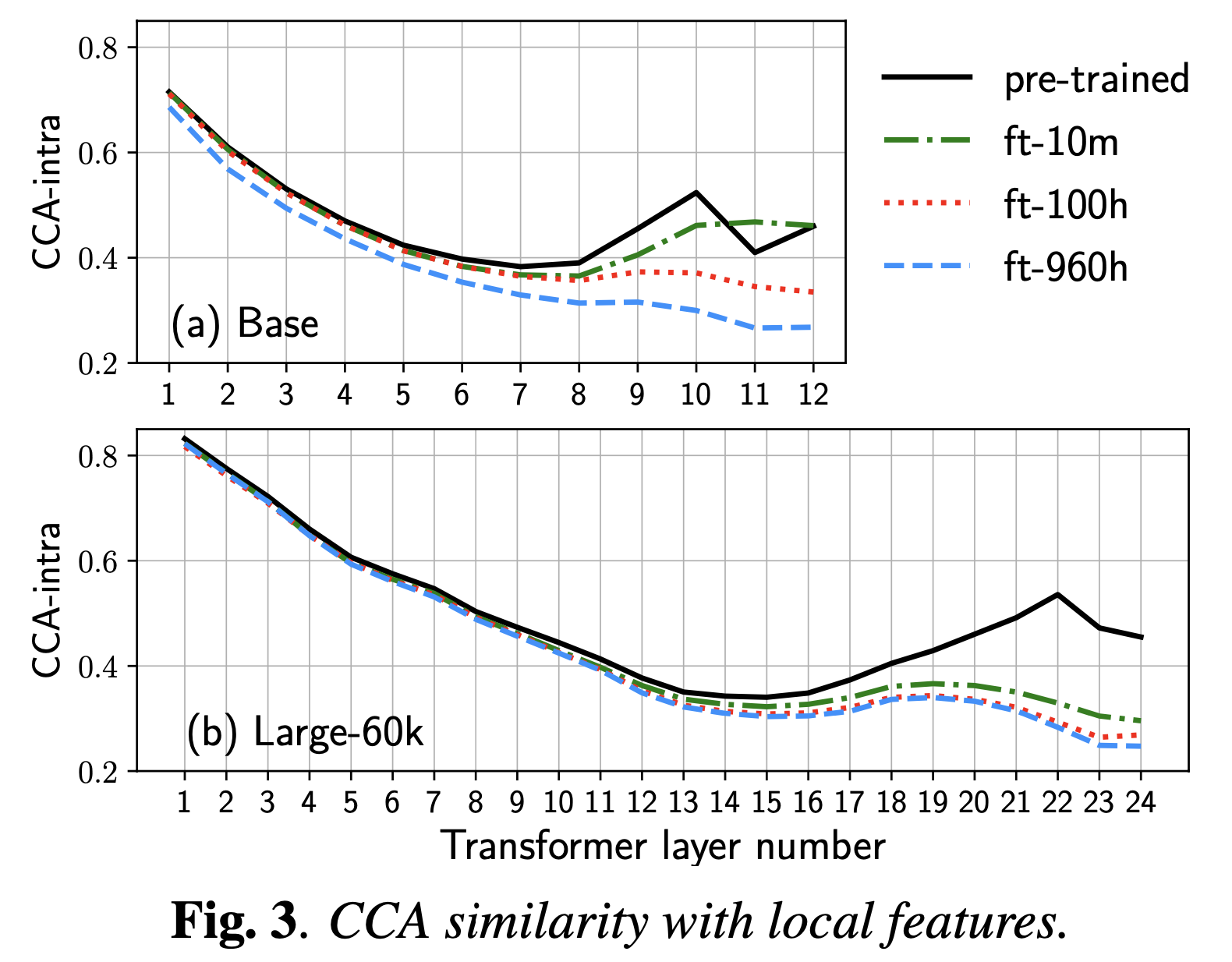
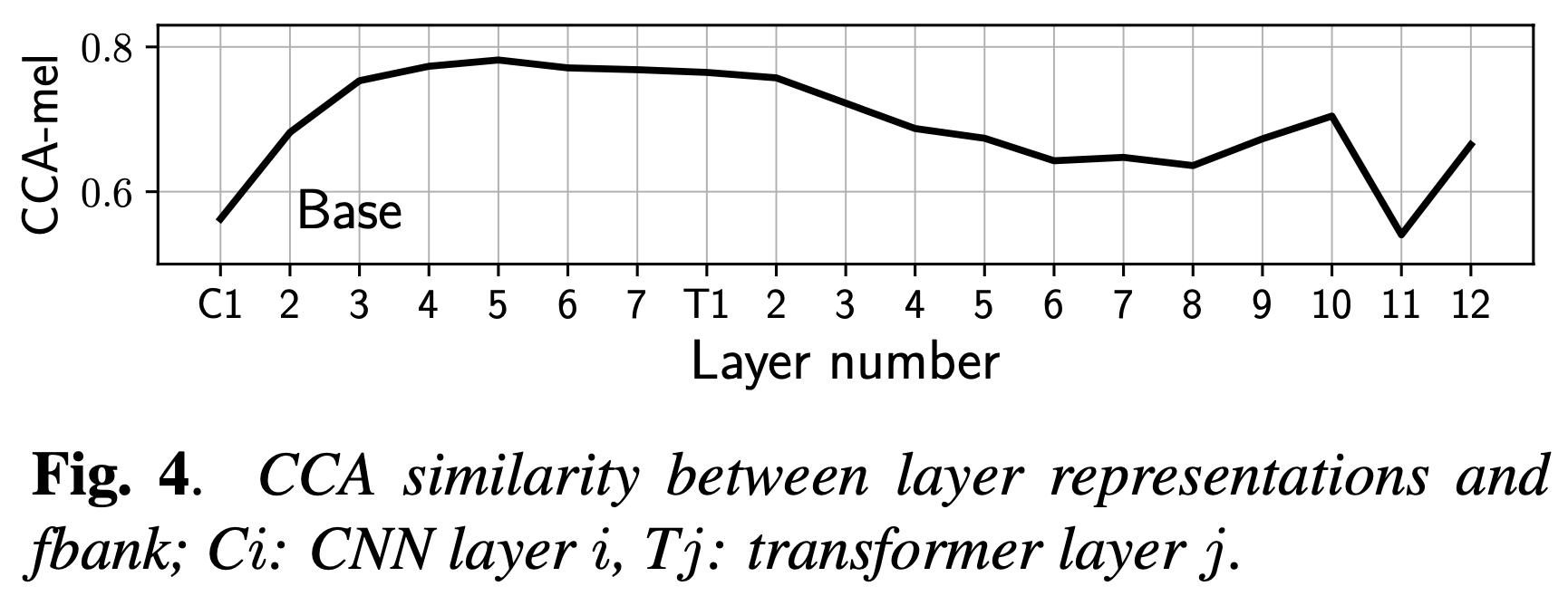
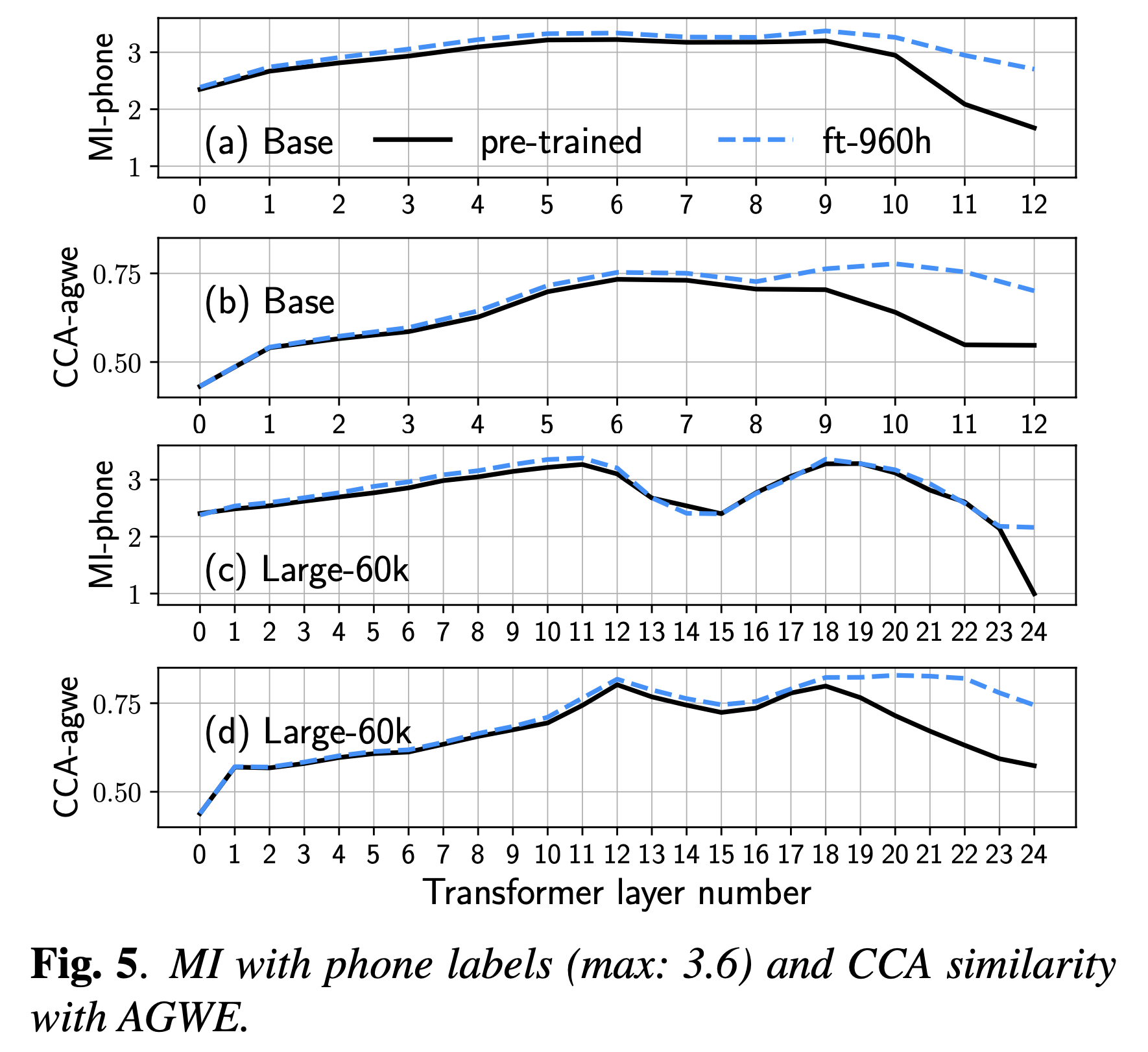
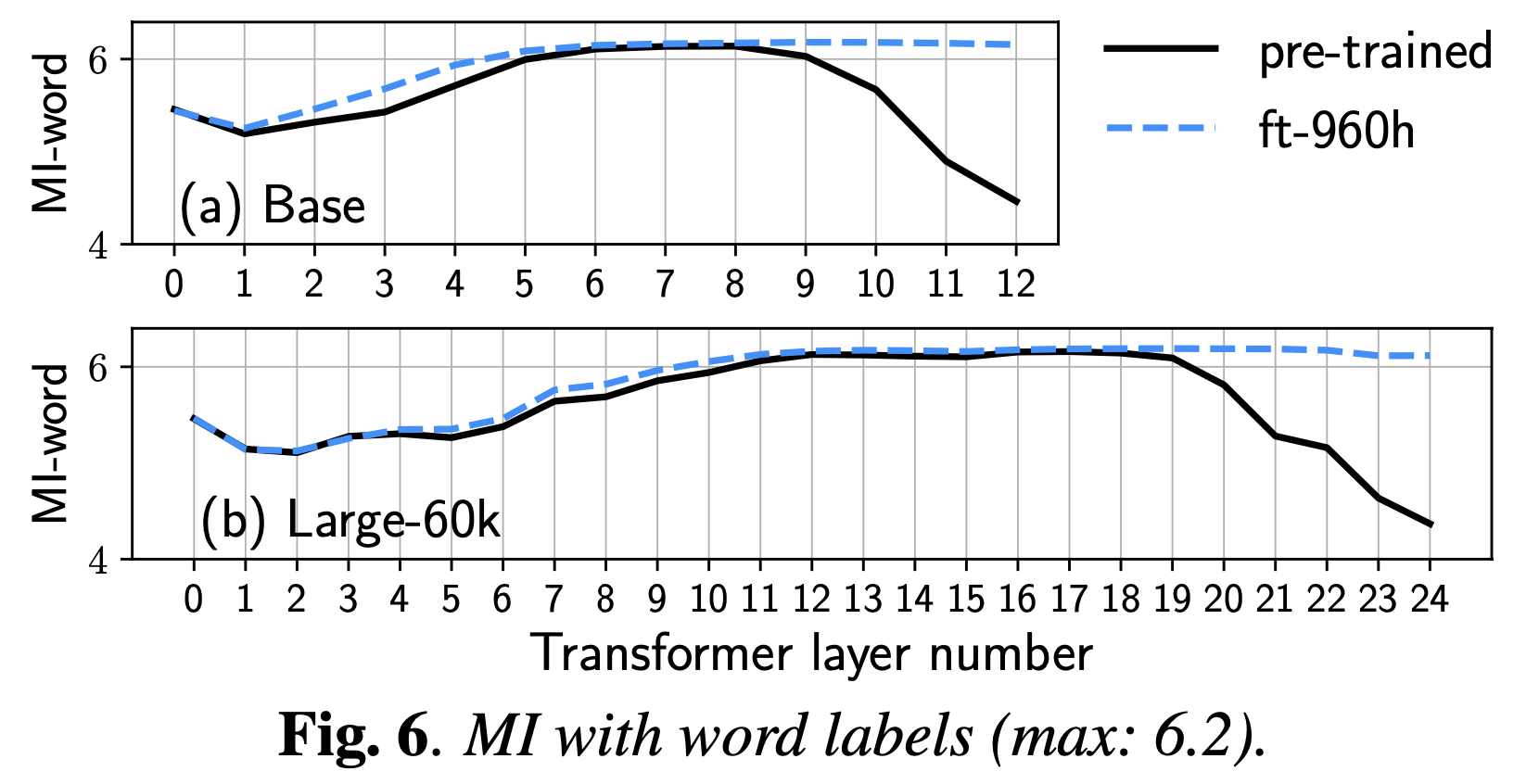
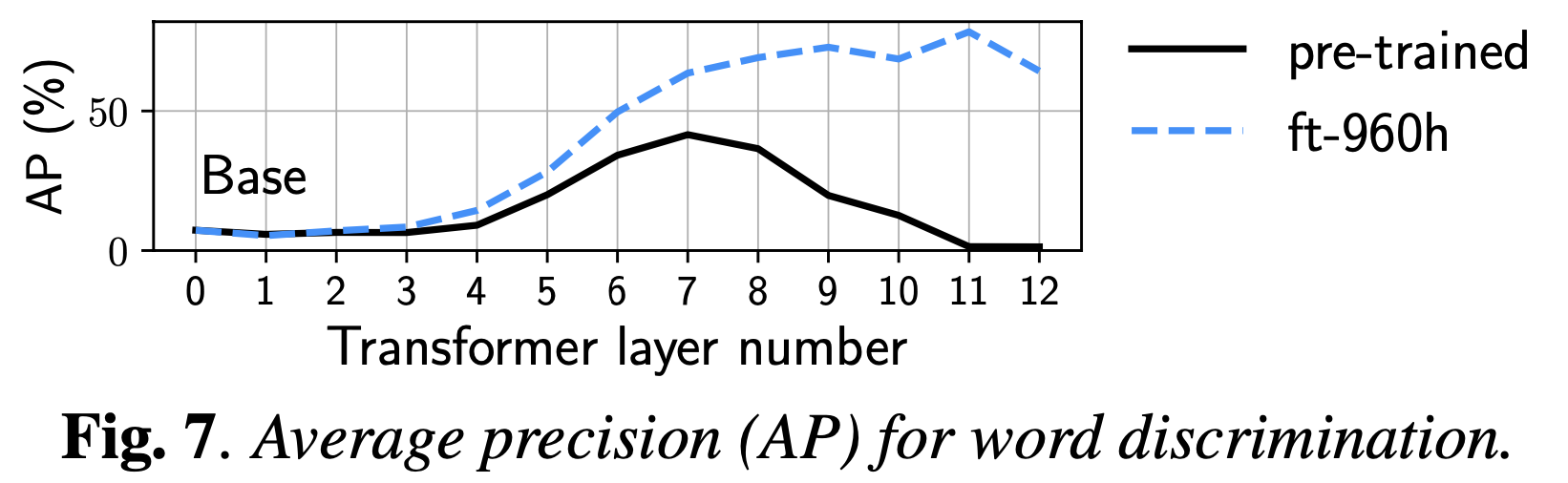
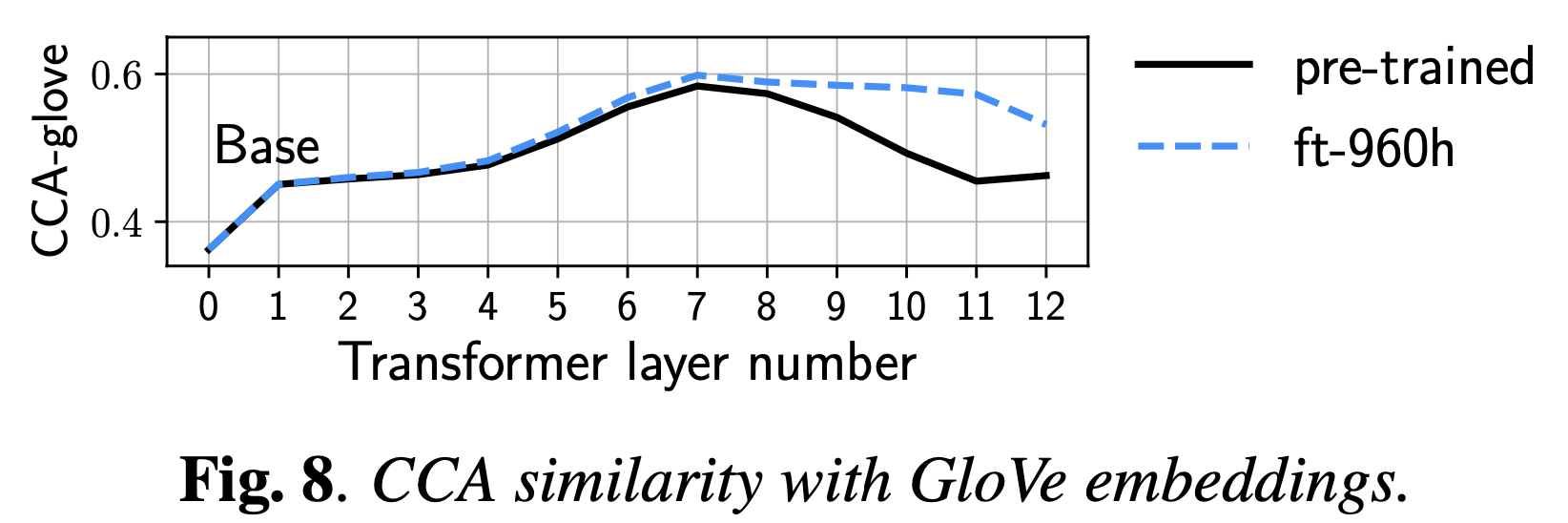
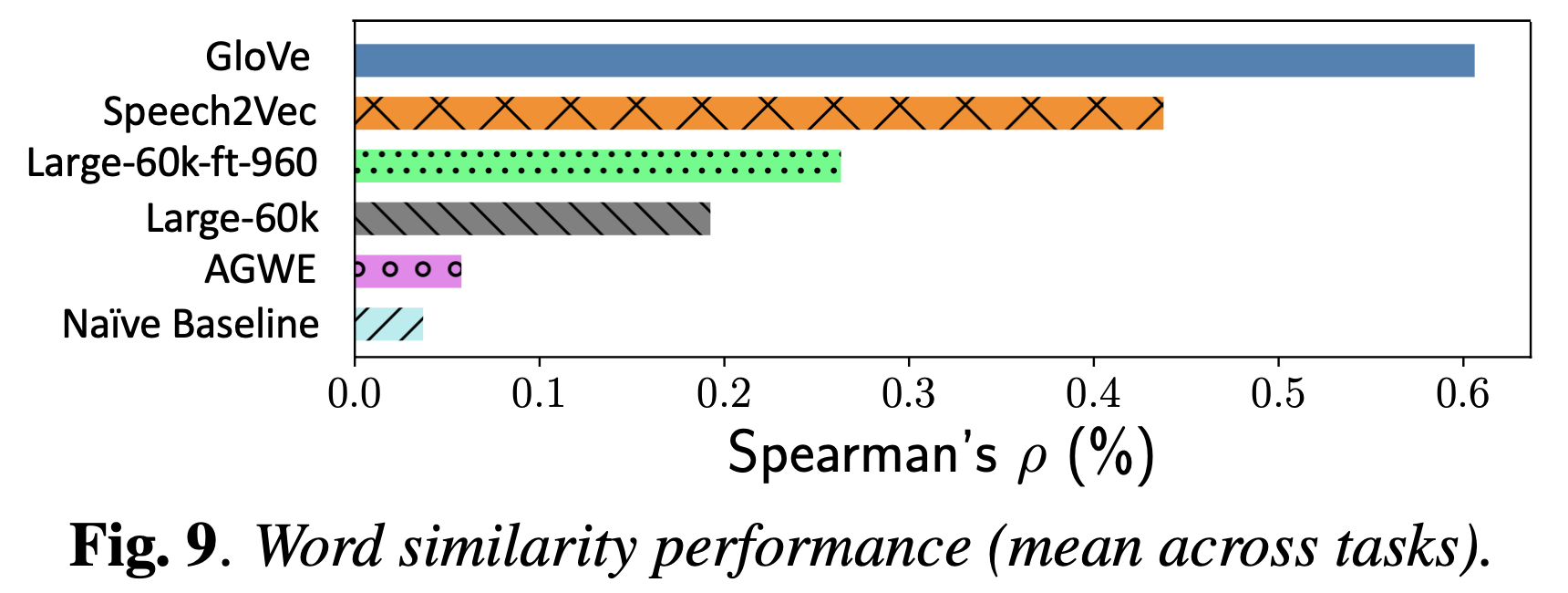
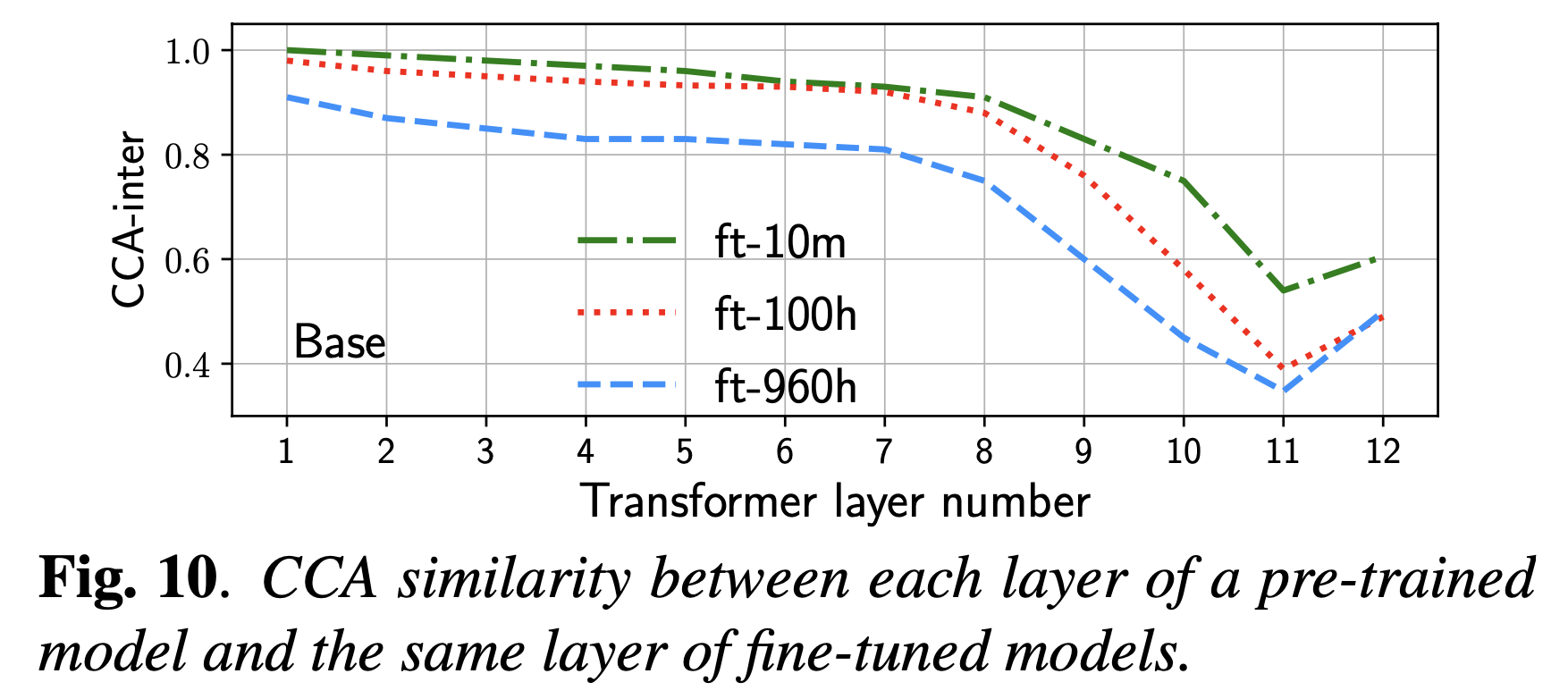
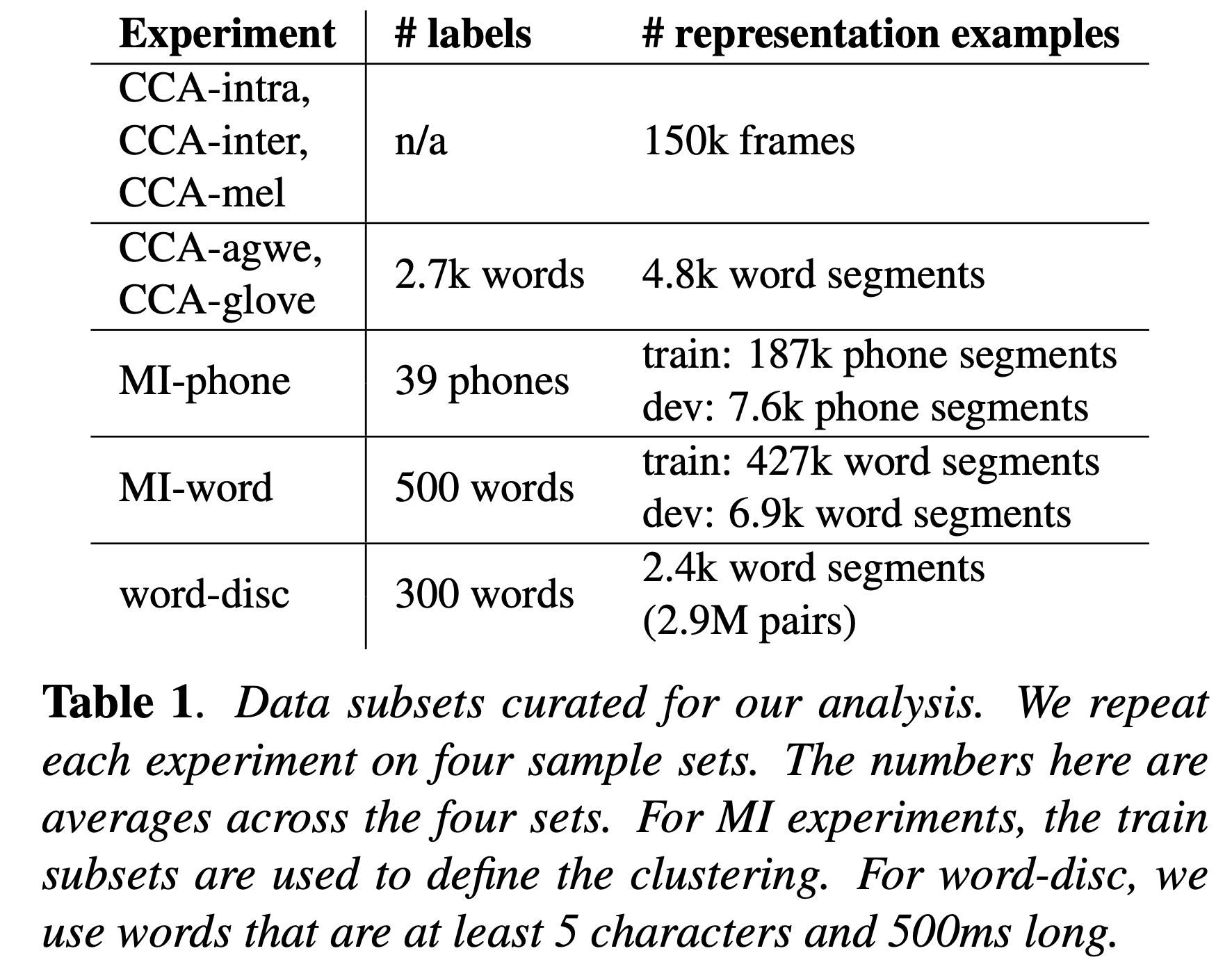
Comparative Study on Various Encoders
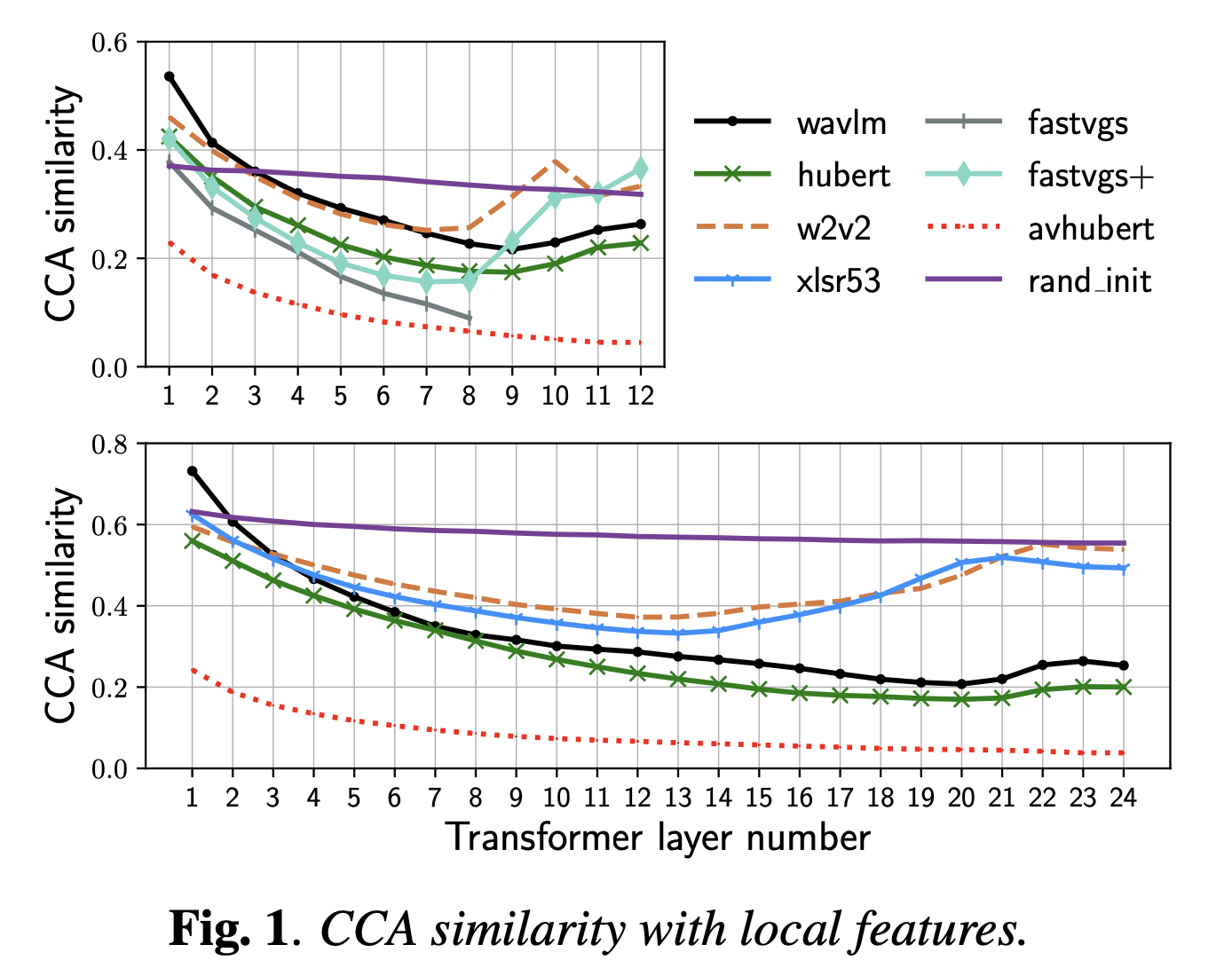
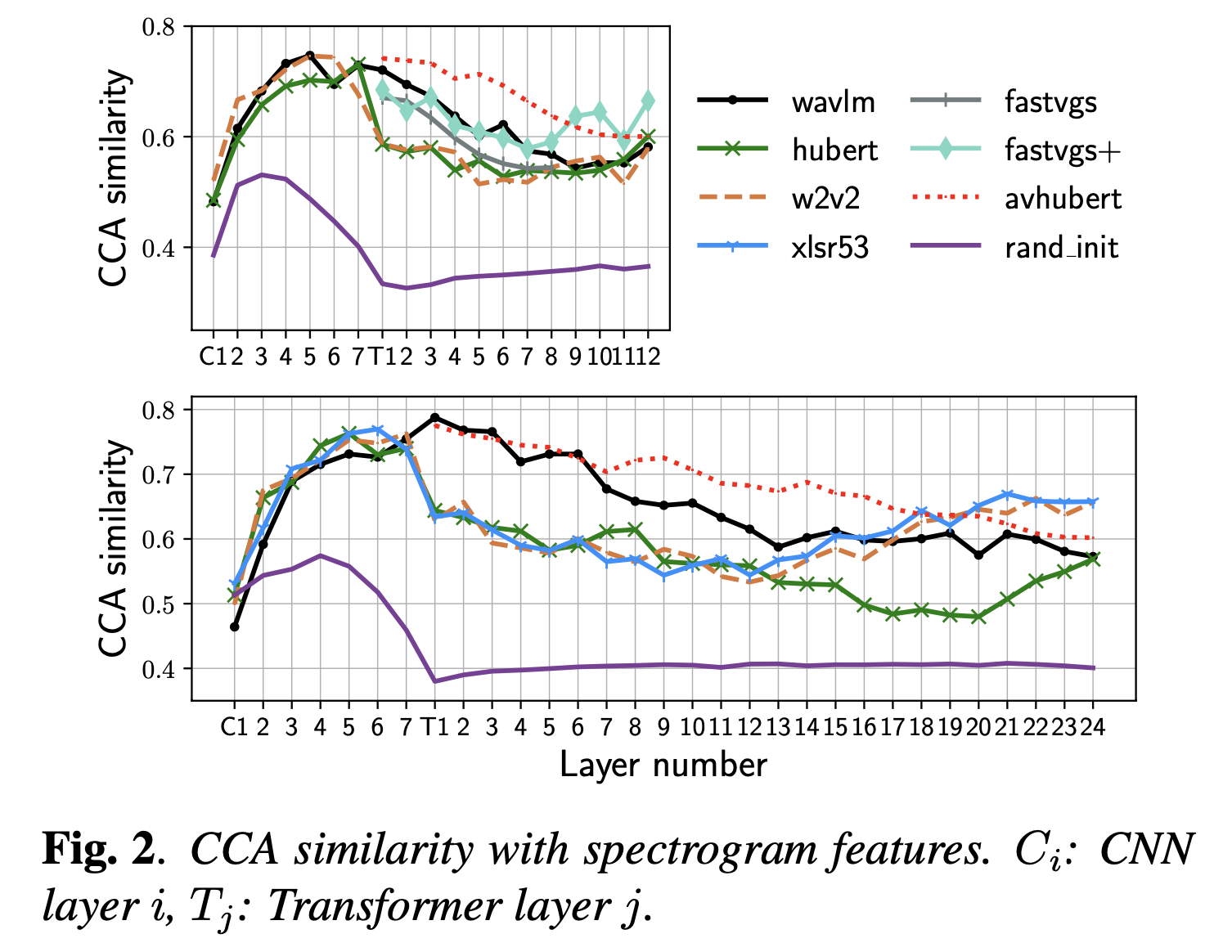
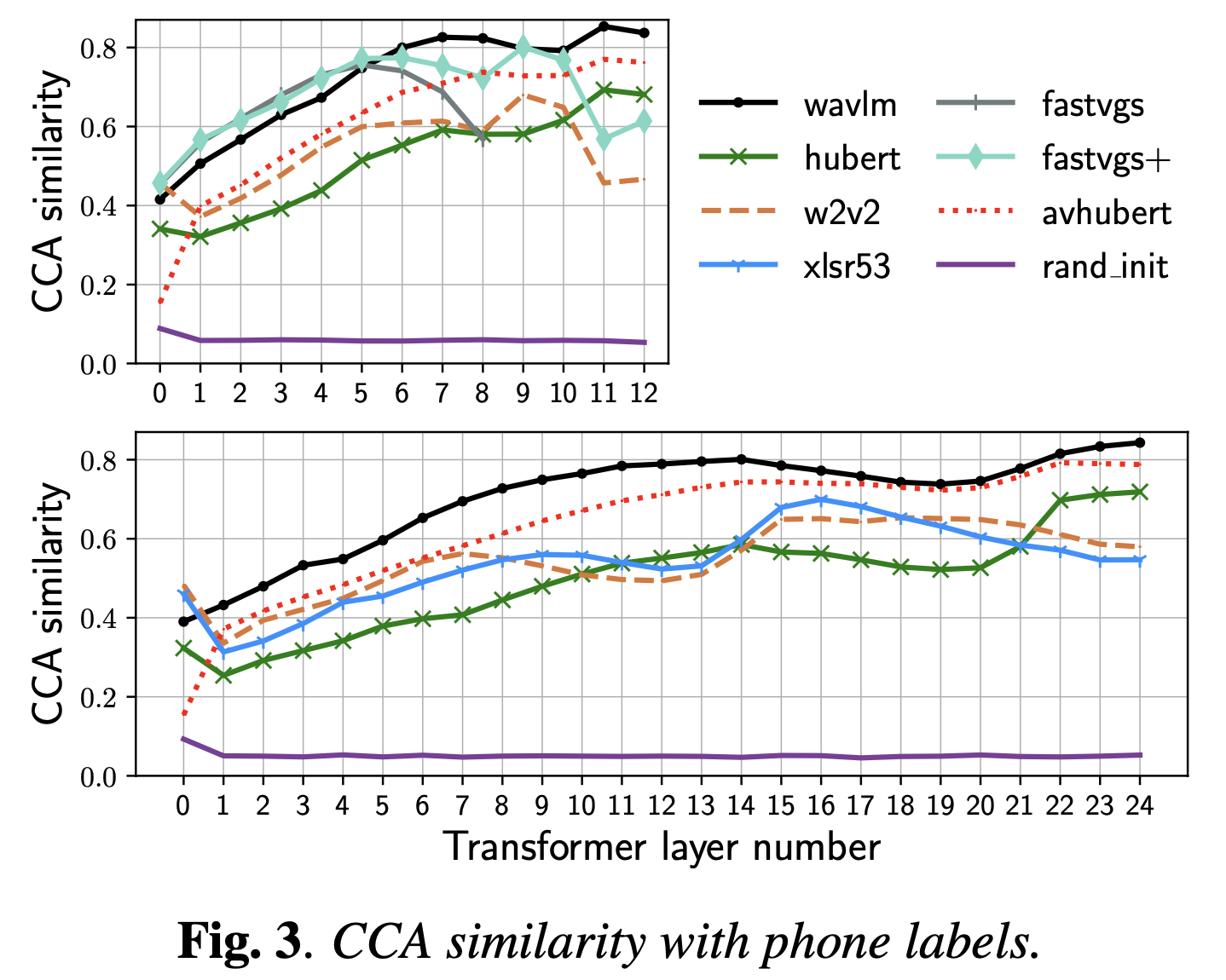
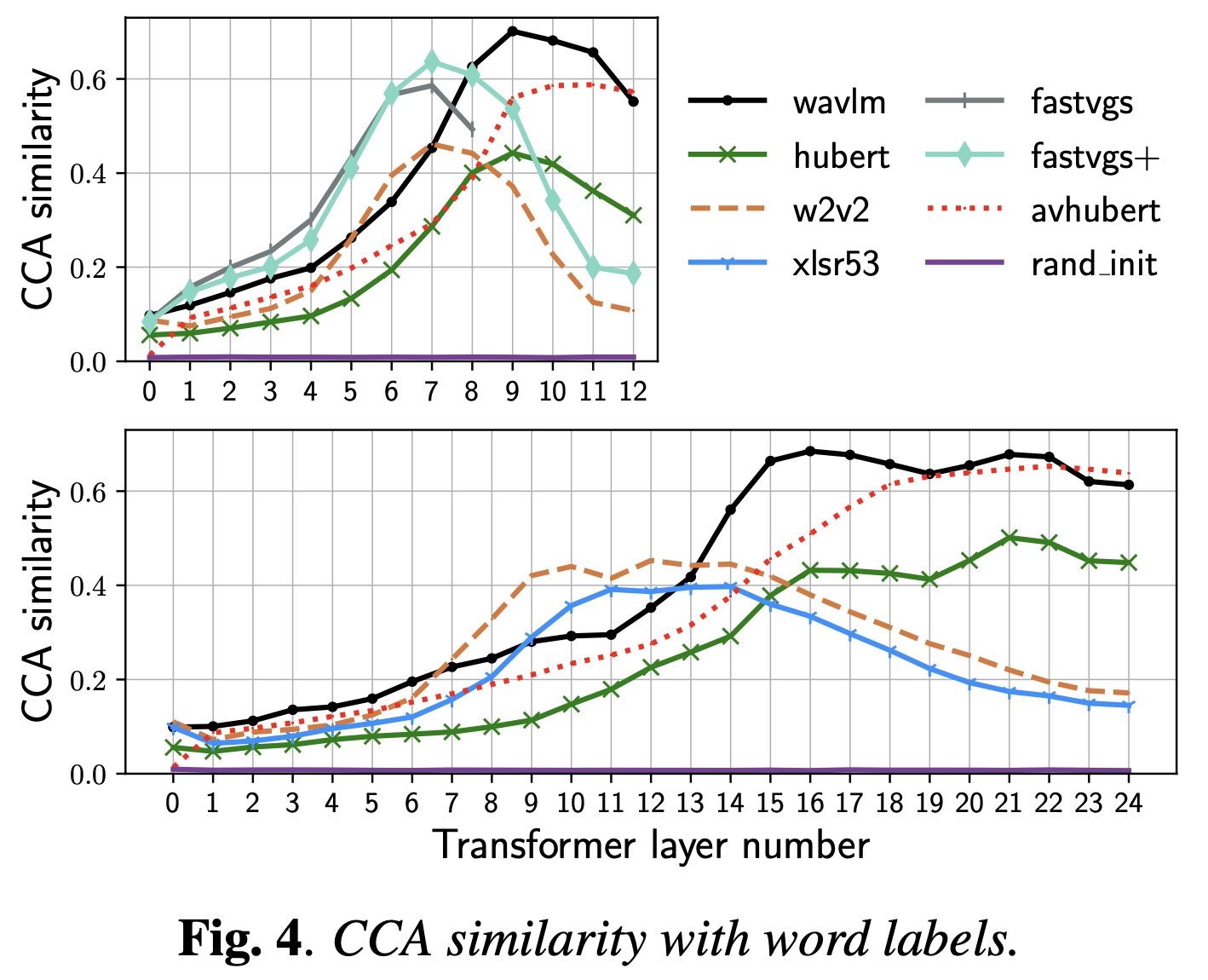
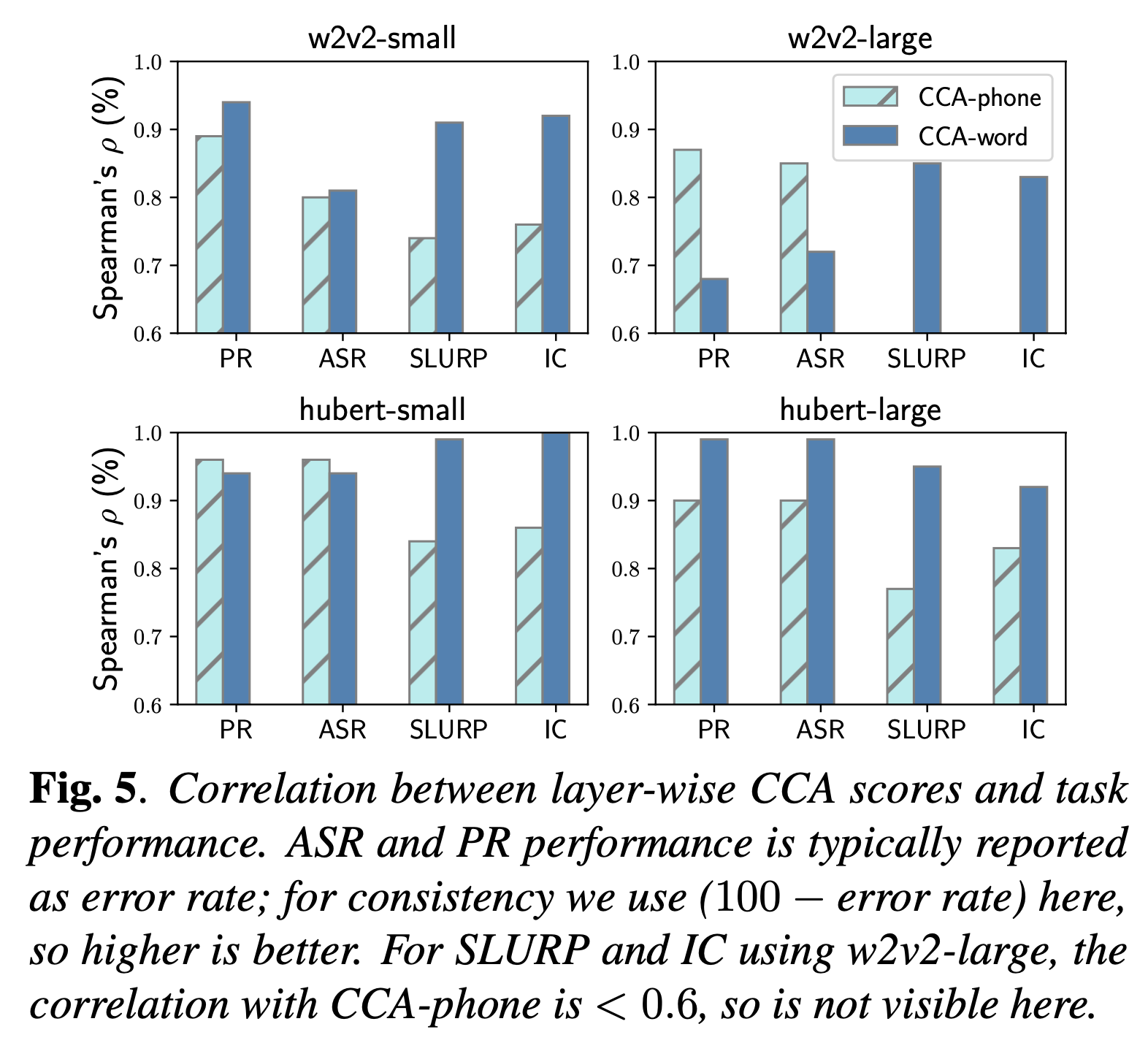
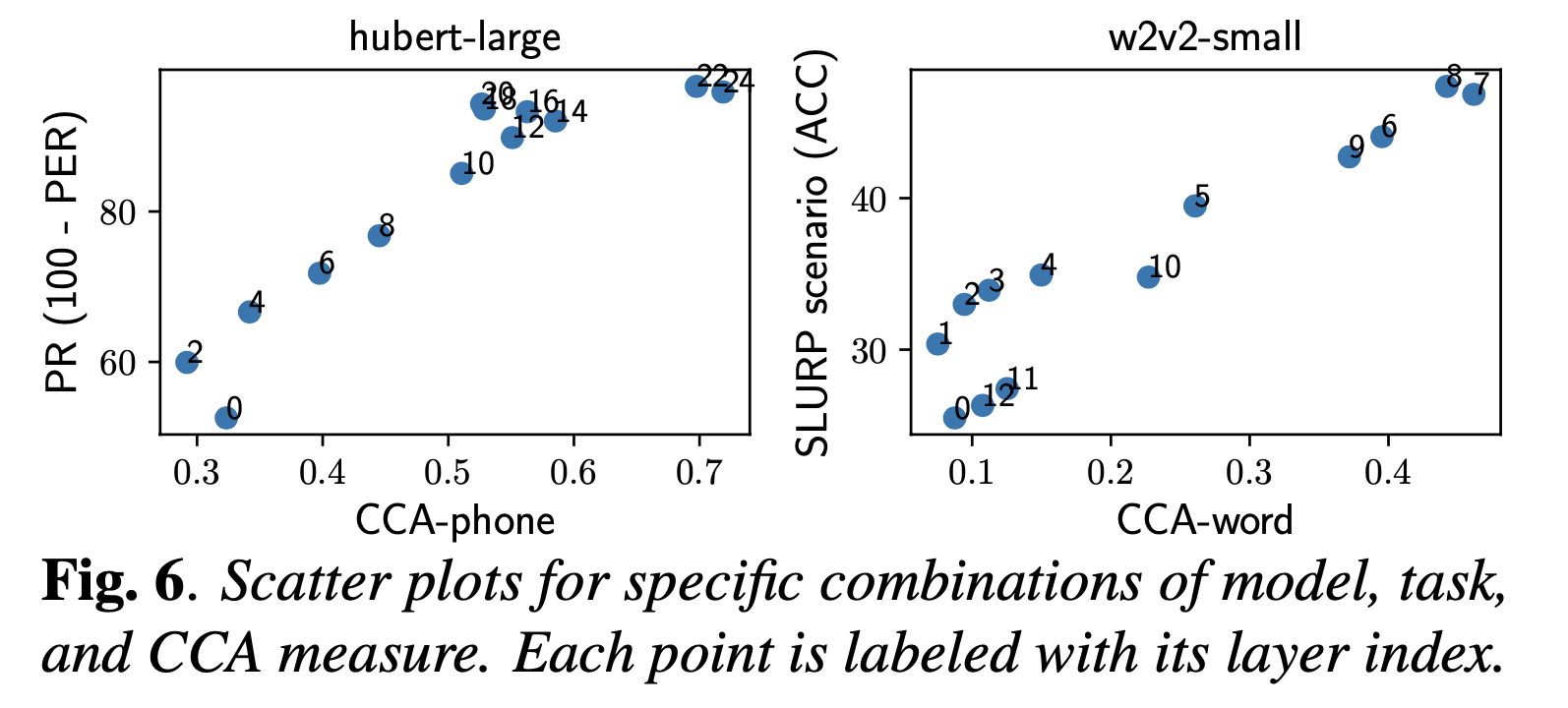
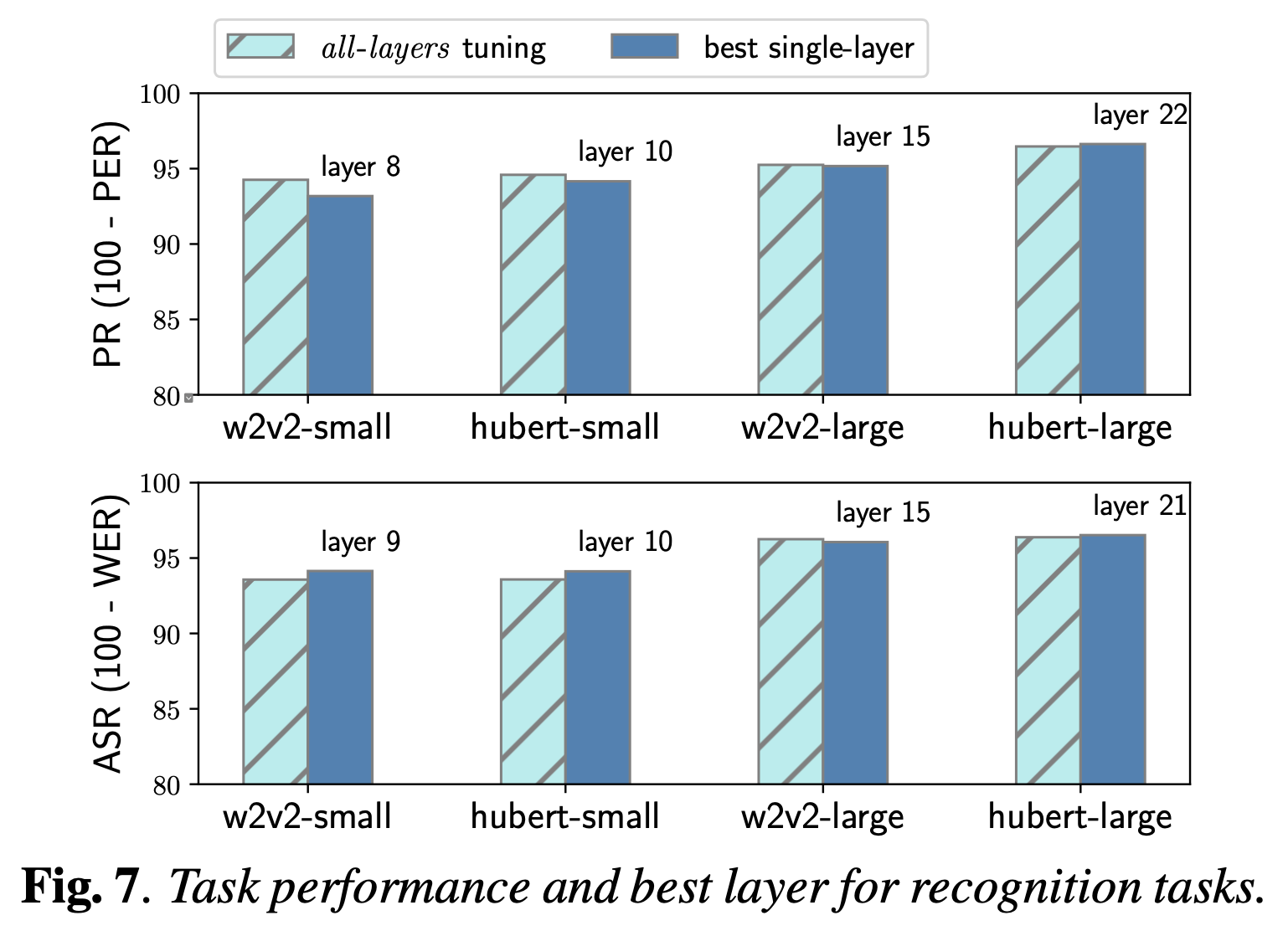
+Additional) Centered Kernal Analysis (CKA)

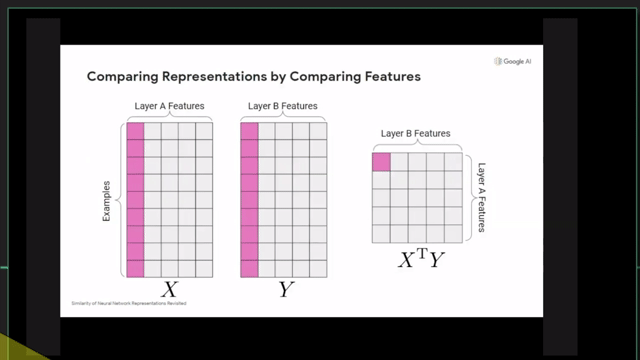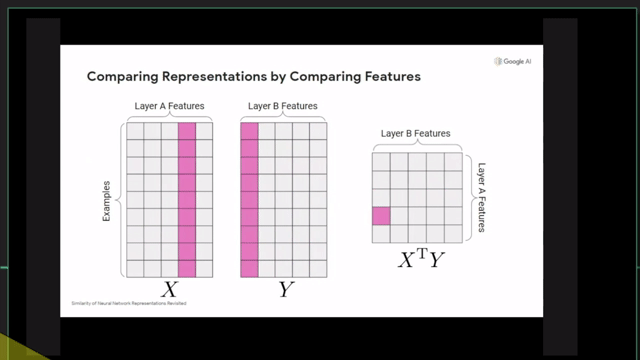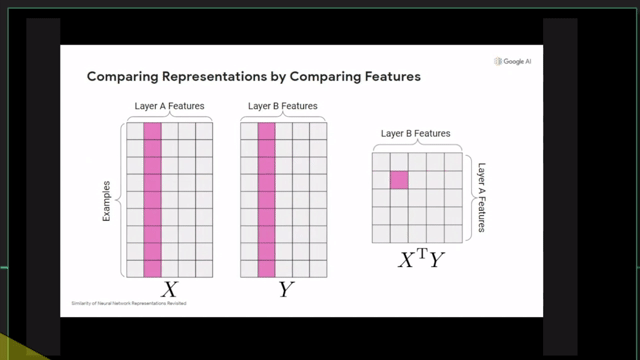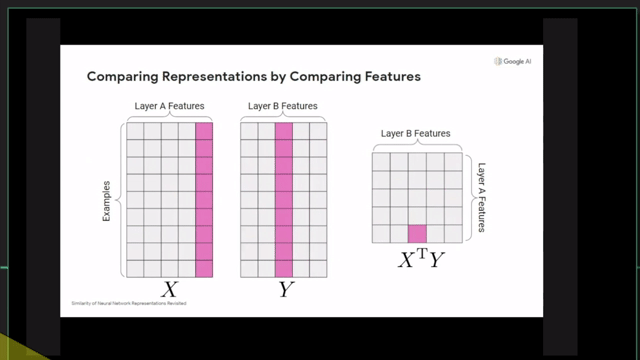
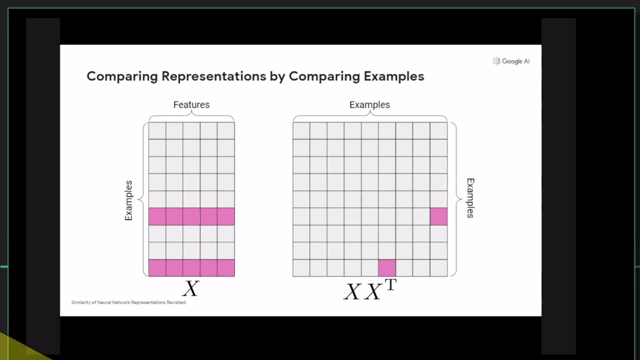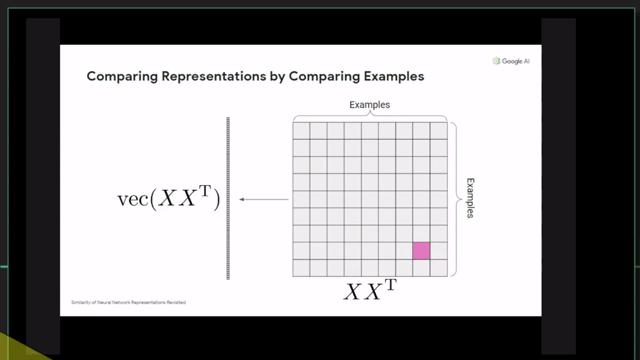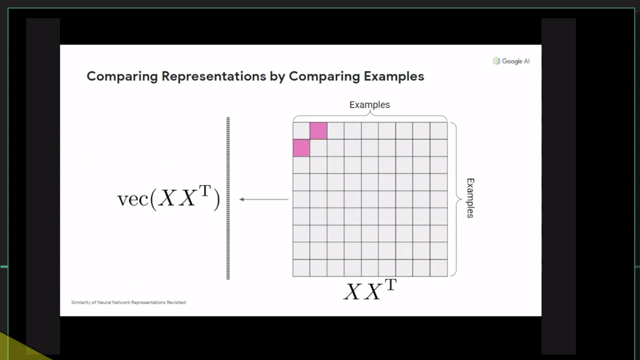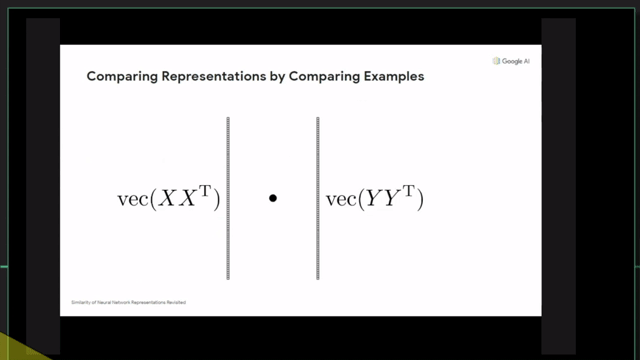
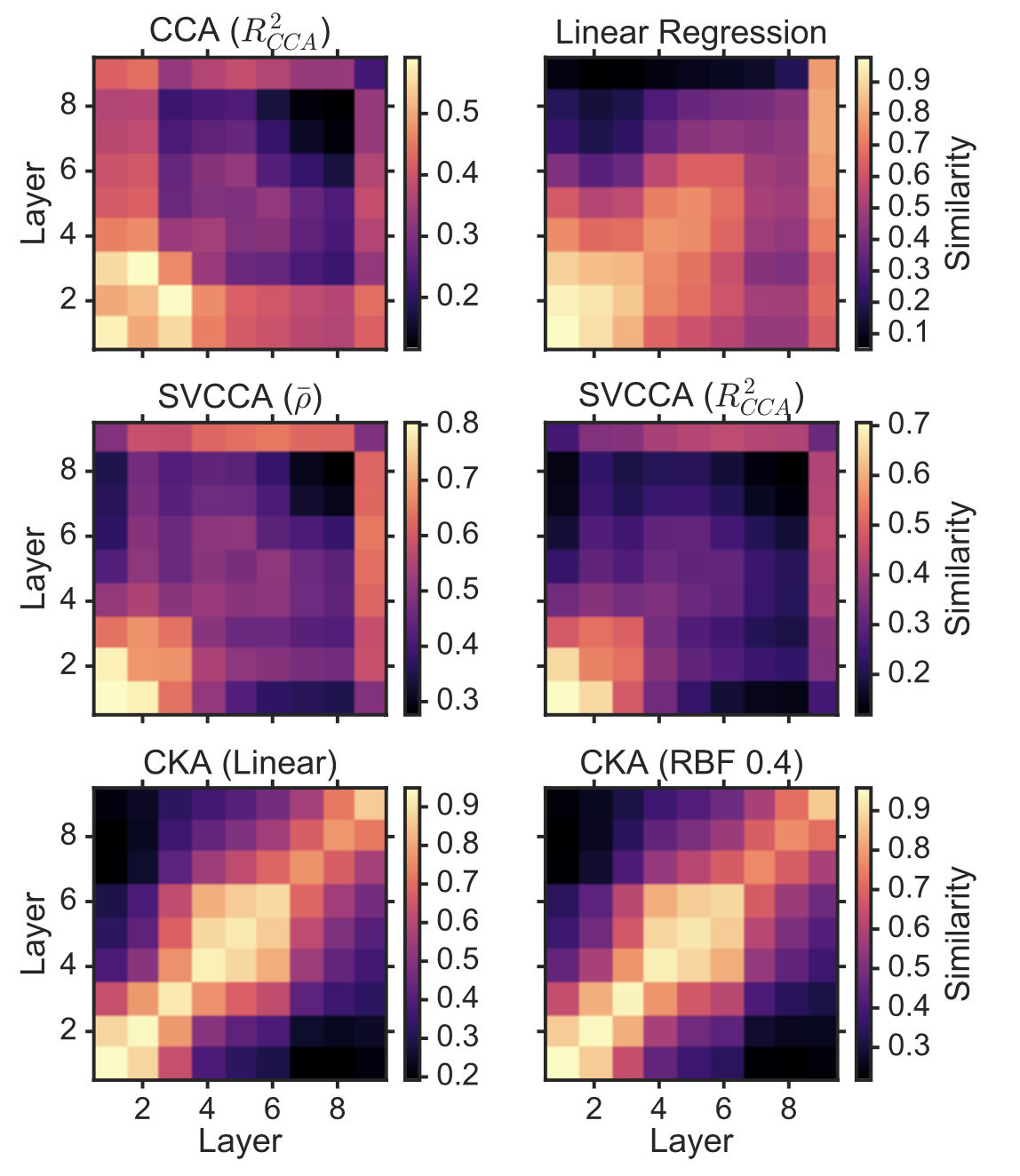
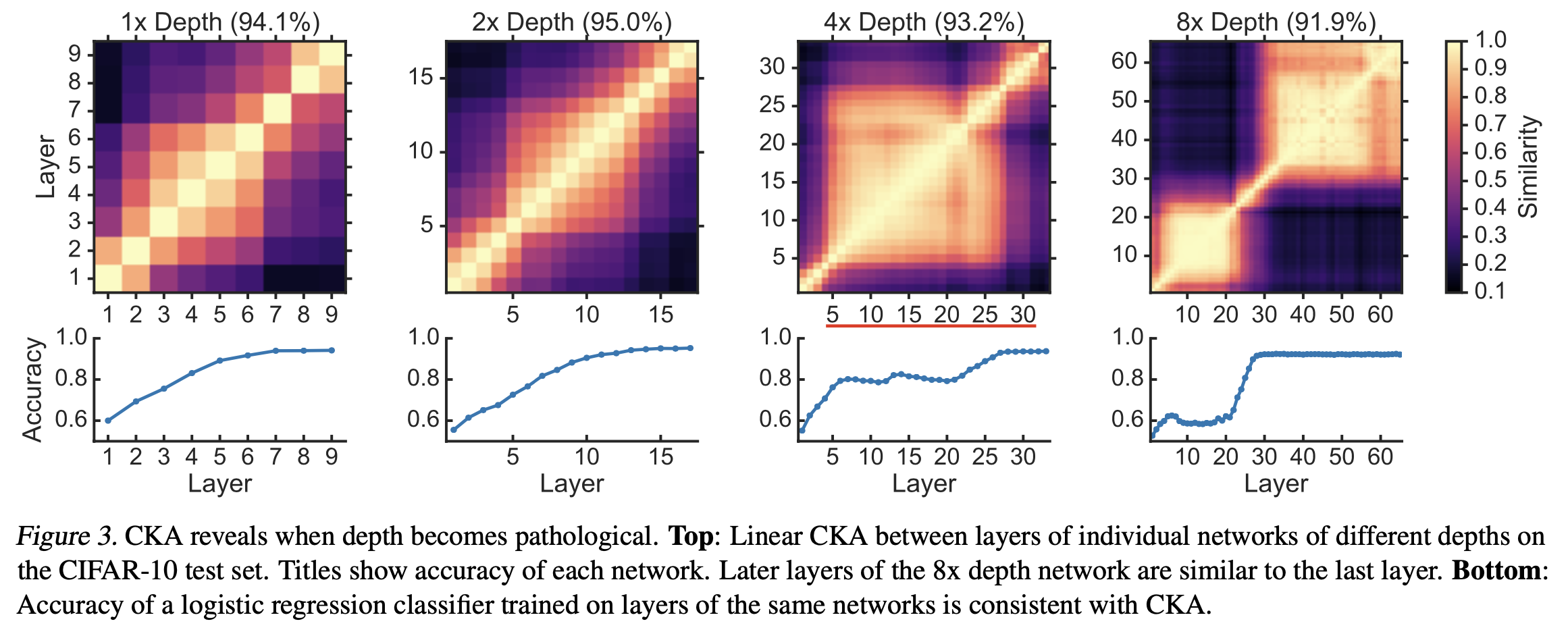

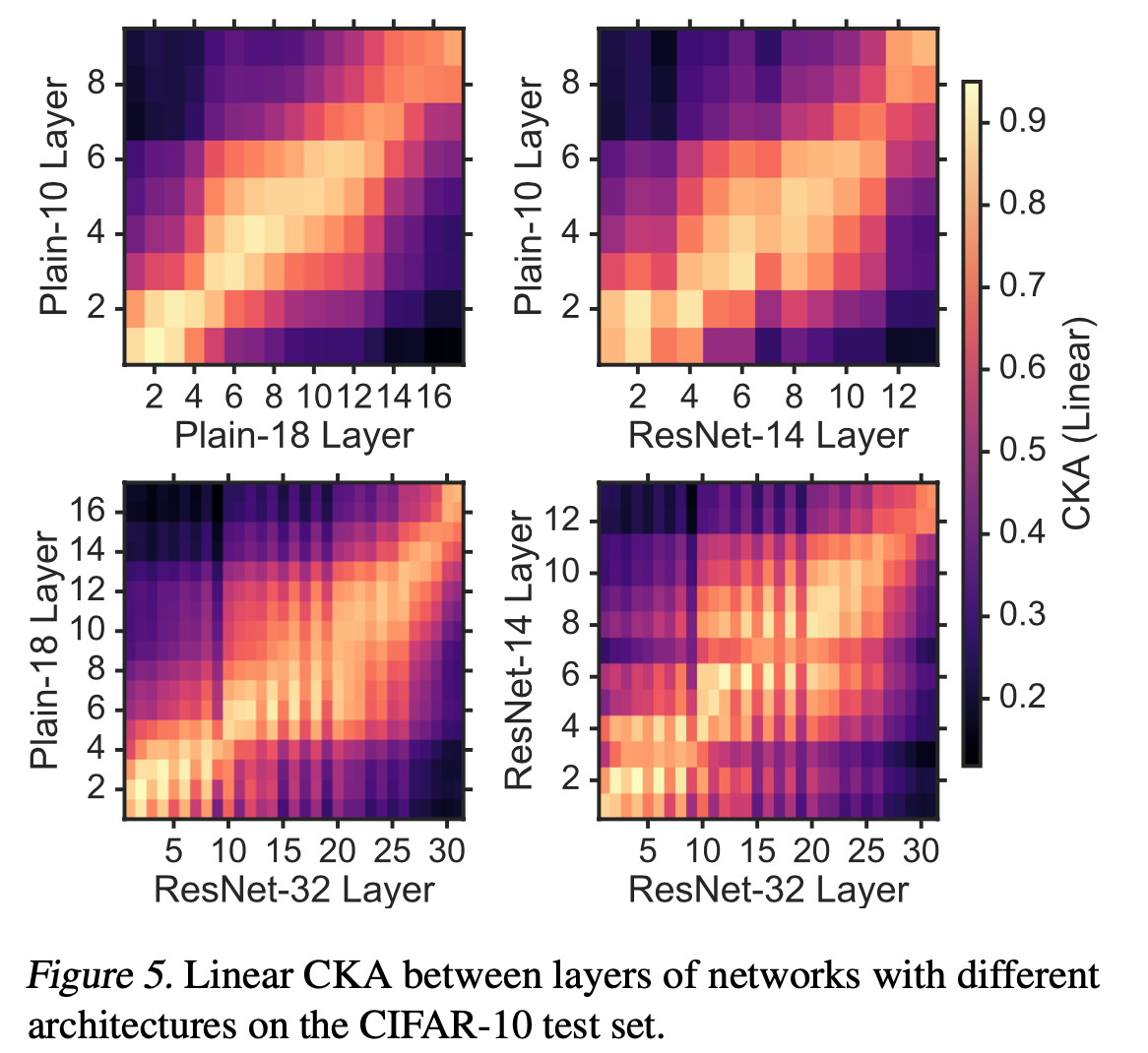
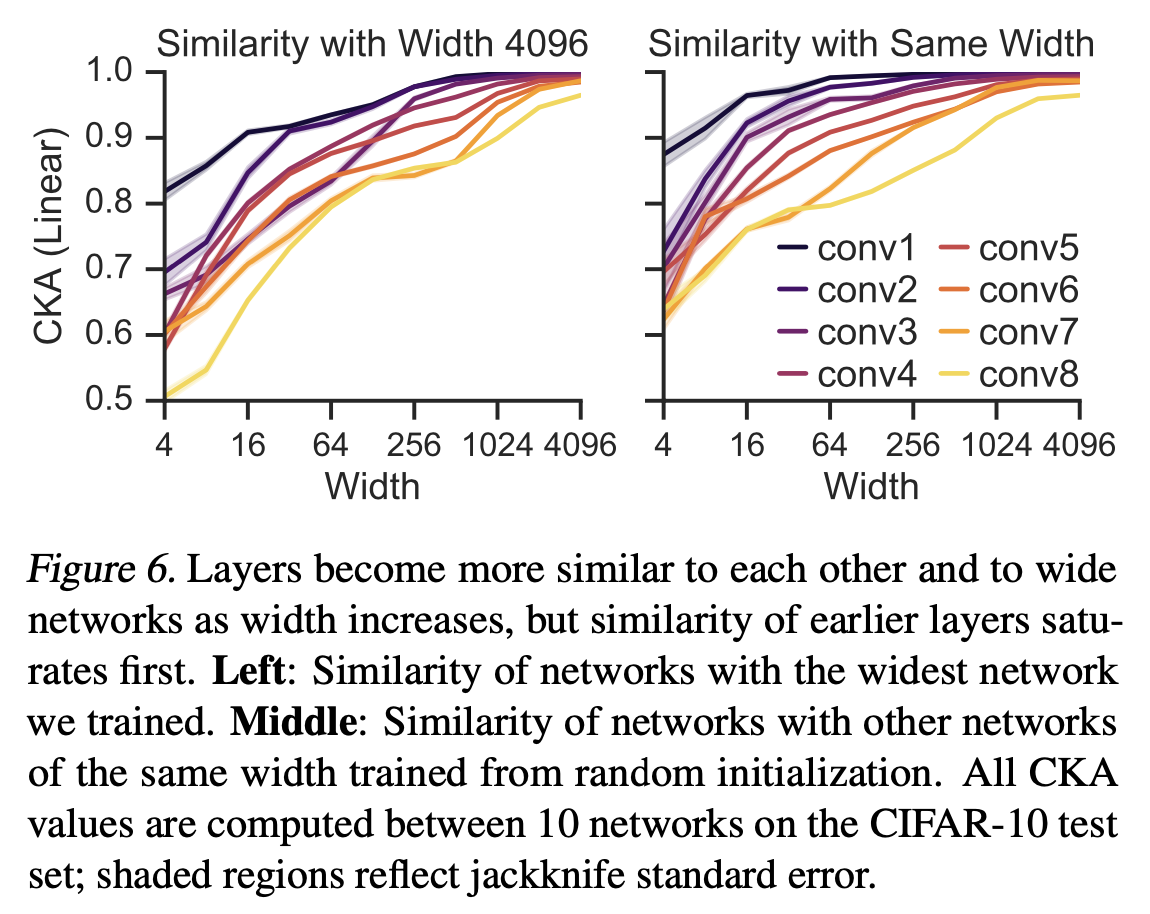
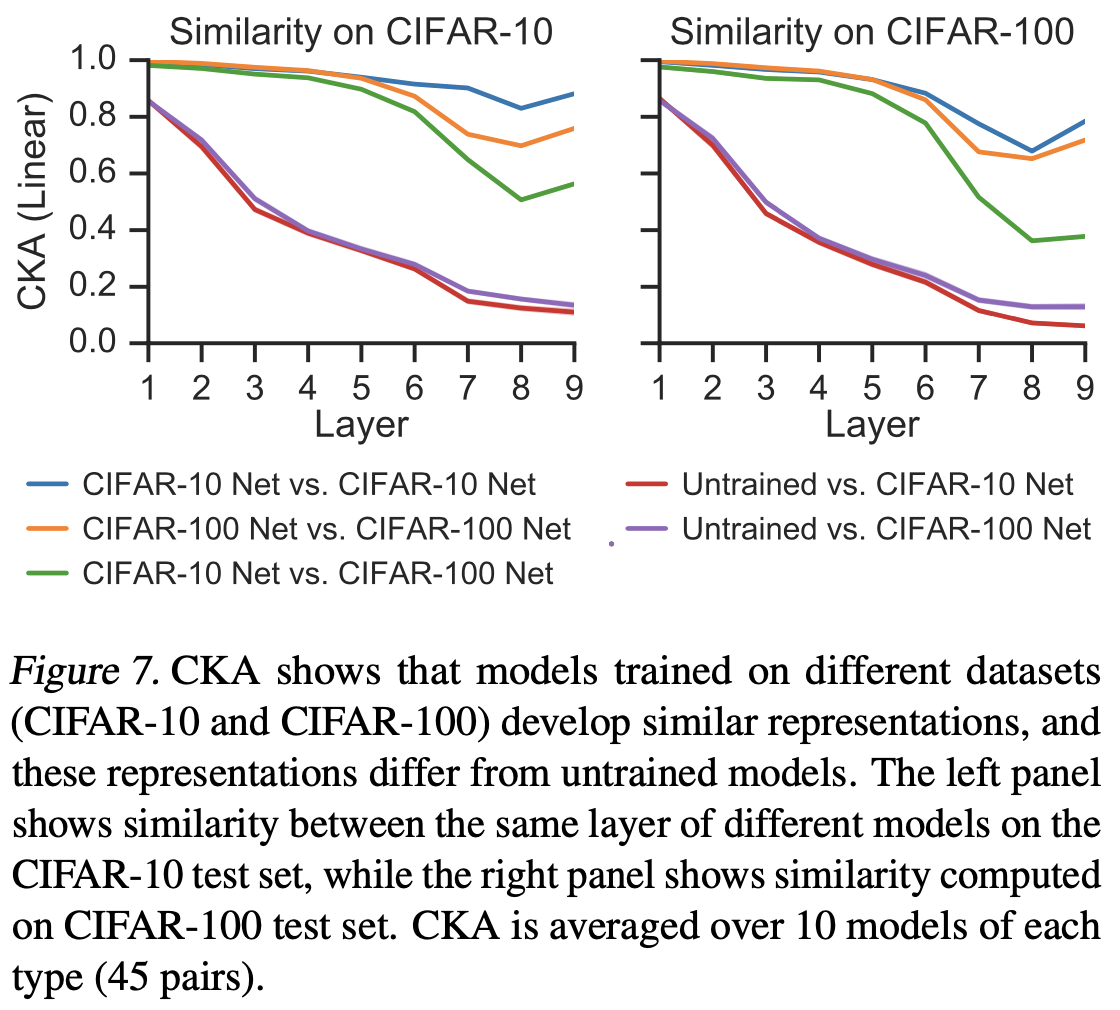
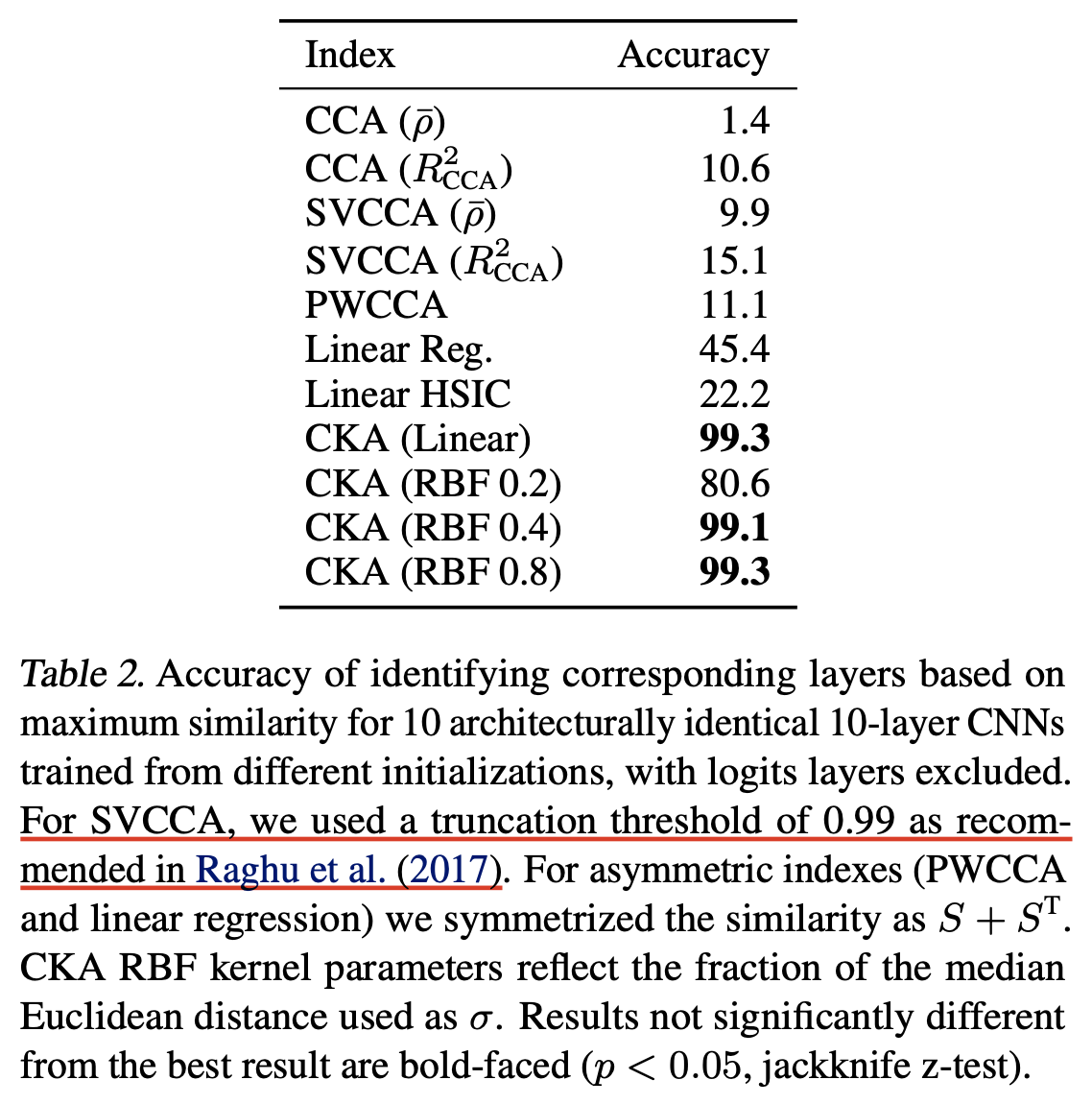
+Additional) Analysis on Self-Attention
ICLR 2021 에 출판된 논문중에 Understanding the Role of Self Attention for Efficient Speech Recognition 라는 논문이 있습니다.
Goal은 Wav2Vec 2.0 구조의 Self-Attention (SA) 패턴을 분석해서 각 Layer가 어떤 역할 (role)을 하는지를 분석하고 이에 따라 연산 효율성을 증가시키는 겁니다. 결과적으로는 1층부터 24층까지의 Transformer Layer 가 Sequence Length 가 L 일 때 LxL 짜리 SA Score Map 이 있을텐데, 이들이 4개 층 마다 굉장히 유사하게 반복되기 때문에 예를 들어 1층에서 SA 를 계산했으면 불필요한 (Redundant) 계산을 하지않고 이를 반복적으로 재사용 (reuse) 해서 2,3,4 층에 쓰는 식으로 연산 효율을 올리는 겁니다.
특히 SA 는 두 가지 role 을 수행한다는 걸 논문에서는 주장했는데요, 바로 phonetic localization 과 linguistic localization 두 가지이며 Transformer의 저층부에서의 phonetic localization 은 speech vector 들로부터 음운학적으로 유의미한 (phonologically meaningful) feature 들을 추출하고 발화의 음성적 분산 (phonetic variance) 을 줄임으로써 상층부의 linguistic localization 를 수행하도록 한다고 했습니다.
하지만 논문에서 사용된 모델은 Self-Supervised Learning (SSL) 된 Pre-trained Model은 아니고
Supervised Model 이므로 SSL trained Wav2Vec 2.0과는 양상이 조금 다를 수 있습니다.
References
- SVCCA: Singular Vector Canonical Correlation Analysis for Deep Learning Dynamics and Interpretability
-
Insights on representational similarity in neural networks with canonical correlation
- Layer-wise Analysis of a Self-supervised Speech Representation Model
-
Comparative layer-wise analysis of self-supervised speech models
- Similarity of Neural Network Representations Revisited