Lessons from Google USM and OpenAI Whisper
04 Mar 2023< 목차 >
Motivation
Dataset 의 크기와 Model 크기를 Scale Up 하는것이 성능 향상에 치명적인 요인이라는 것이 여러 논문들에 의해 사실로 받아들여지는 것 같습니다.
음성 인식 (Automatic Speech Recognition, ASR), 음성 번역 (Automatic Speech Translation, AST) 분야에서도 Model의 크기를 엄청나게 키우고 Self-Supervised Learning (SSL) 을 하는 것이 엄청나게 중요해졌는데요, 여태까지의 중요했던 milestone 을 보면
- 2020 Wav2Vec 2.0 : 600,000 hours Monolingual SSL -> ASR or AST Supervised fine-tuning
- 2022, Whisper : 680,000 hours Multilingual Supervised (Multi Task Learning) on AST and ASR
가 있었습니다. 물론 그 사이에 Self-Training, Pseudo-Labeling 같은 방법론이나 Text Speech 정보를 동시에 학습하는 Multimodal Training 도 있었지만 제가 생각하기에 Breakthrough 였던 페이퍼들을 말씀드린 겁니다.
그러던 와중 2023년 3월 2일에 아래와 같은 논문이 나왔습니다.
- 2023, Google USM : 1,200,000 hours Multilingual SSL -> 10,000 ~ 100 hours Multi-Objective Supervised Pre-Training -> Task Specific Supervised Finetuning
기존의 규모와 데이터 크기, 그리고 성능을 아득히 뛰어넘는 논문이 나온건데요, Google, Meta, OpenAI 같은 BigTech 가 아닌 일반 회사나 학계에서 당연히 이런 방식을 쓸 수는 없지만 Whisper 와 USM 에서 실험을 하면서 어떤 시행착오와 인사이트가 있었는지에 대해서 조금 알아보려고 합니다.
USM
Google의 Universal Speech Model (USM) 은 아래의 과정으로 학습이 되는데요, 총 3가지 stage로 이루어져 있으며
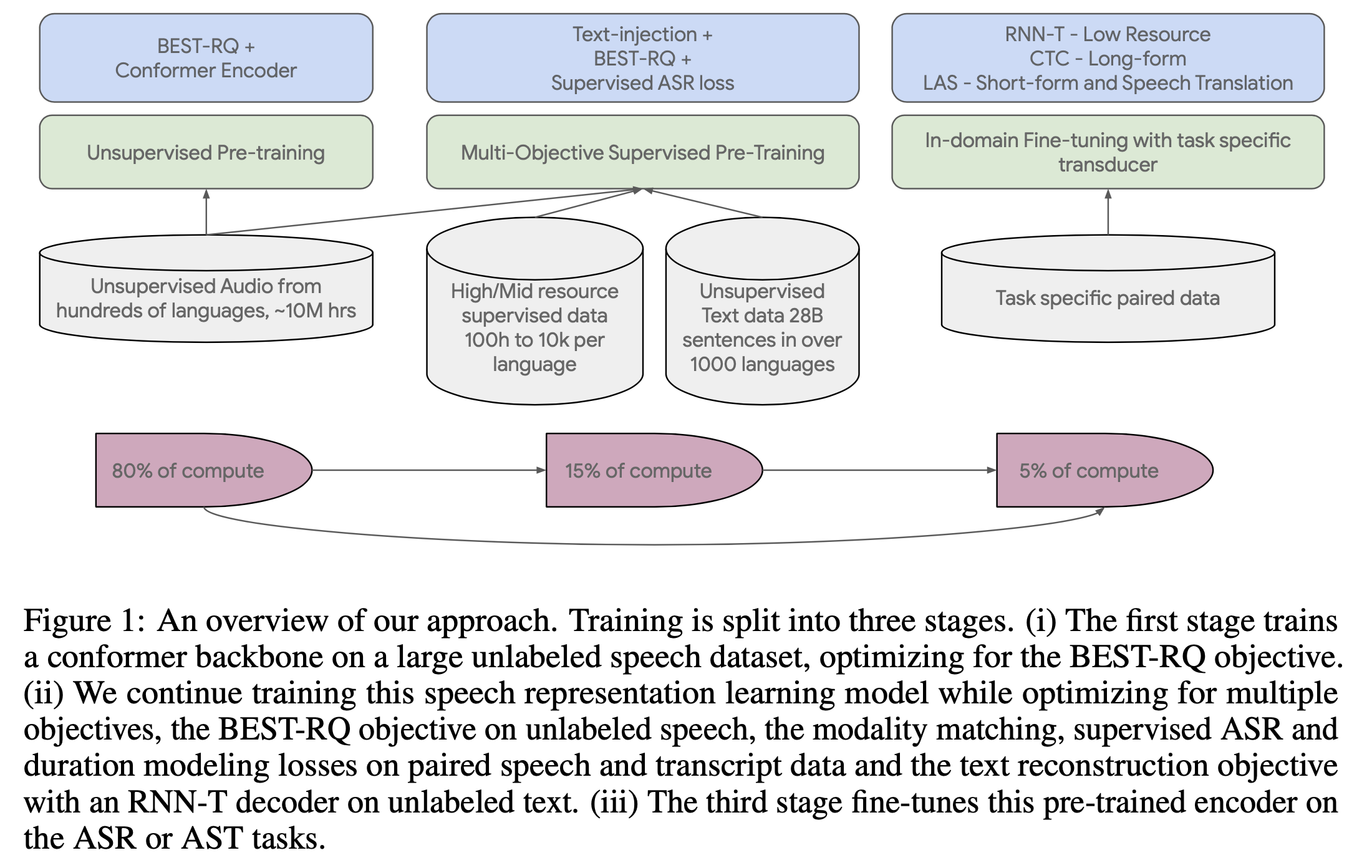
엄청난 양의 unlabeld speech data 로만 먼저 학습한 뒤 (80%), text 와 speech 데이터의 정보를 맞춰주는 (alignment) 작업을 하고 (15%), 이렇게 잘 학습된 Universal Encoder 는 소량의 Computing power, Data 만 가지고 학습해도 (나머지 5%)게 됩니다.
이 때 필요한 데이터가는 아래와 같은데요,
- Unpaired Audio (for 1st stage, 80%)
- YT-NTL-U :
12M(1200만…) 시간의 unlabeld youtube (음성만) 데이터, 300개 이상의 언어가 포함되어 있음. - Pub-U :
429k시간의 unlabeld 음성 데이터로 누구나 이용할 수 있는 public dataset 임. 51개 이상의 언어로 이루어짐.
- YT-NTL-U :
- Unpaired Text (for 2nd stage, 15%)
- Web-NTL : text 만 있는 데이터로
28B (280억)문장이며 1140개 언어를 포함.
- Web-NTL : text 만 있는 데이터로
- Paired ASR Data (for 3rd stage, 5%)
- YT-SUP+ :
90k시간의 label 이 있는 73개국어로 이루어진 데이터 + 추가로 위의 unlabeld youtube 음성 중 en-US (미국식 영어만?)100k시간에 ASR 모델로 pseudo label 을 달아서 총 190k 시간 - Pub-S : 다양한 도메인을 커버하는 en-US public dataset
10k시간에 102개 언어를 커버하는 다국어 public dataset 도10k개 총 20k
- YT-SUP+ :
이 각각의 stage 에서 각각의 데이터를 가지고 모델은 아래와 같은 방식으로 학습되게 됩니다.
- Unsupervised Pre-training (for 1st stage, 80%)
BEST-RQ(BERT-based Speech pre-Training with Random-projection Quantizer) 로 학습.
MOST(Multi-Objective Supervised pre-Training) (for 2nd stage, 15%)- 각각의 Objective 로 학습.
- Supervised ASR Training (for 3rd stage, 5%)
- CTC, Attention-based (LAS), RNN-T Objective 중 선택해서 학습
이 중에서 만약 ASR 만 할거라면 중간의 Speech-Text Align 을 학습할 필요는 따로 없어서 (해도 되겠지만 굳이?) 2nd stage 는 선택사항이라고 하는데요, 이렇게해서 1st stage 만 해서 얻은 Pre-trained model 은 USM 이라고 하며 2nd stage의 MOST 까지 한 Pre-trained model 은 USM-M 이라고 논문에서 구분짓습니다.
그리고 ASR
제가 논문에서 얻을 수 있었던 흥미로운 몇 가지 인사이트들 중에는
- LAS, CTC, RNN-T 는 어떨 때 쓰는가? 한가지 Objective 가 모든 task에 좋다고 할 수 있을까? -> Task 별로 다름.
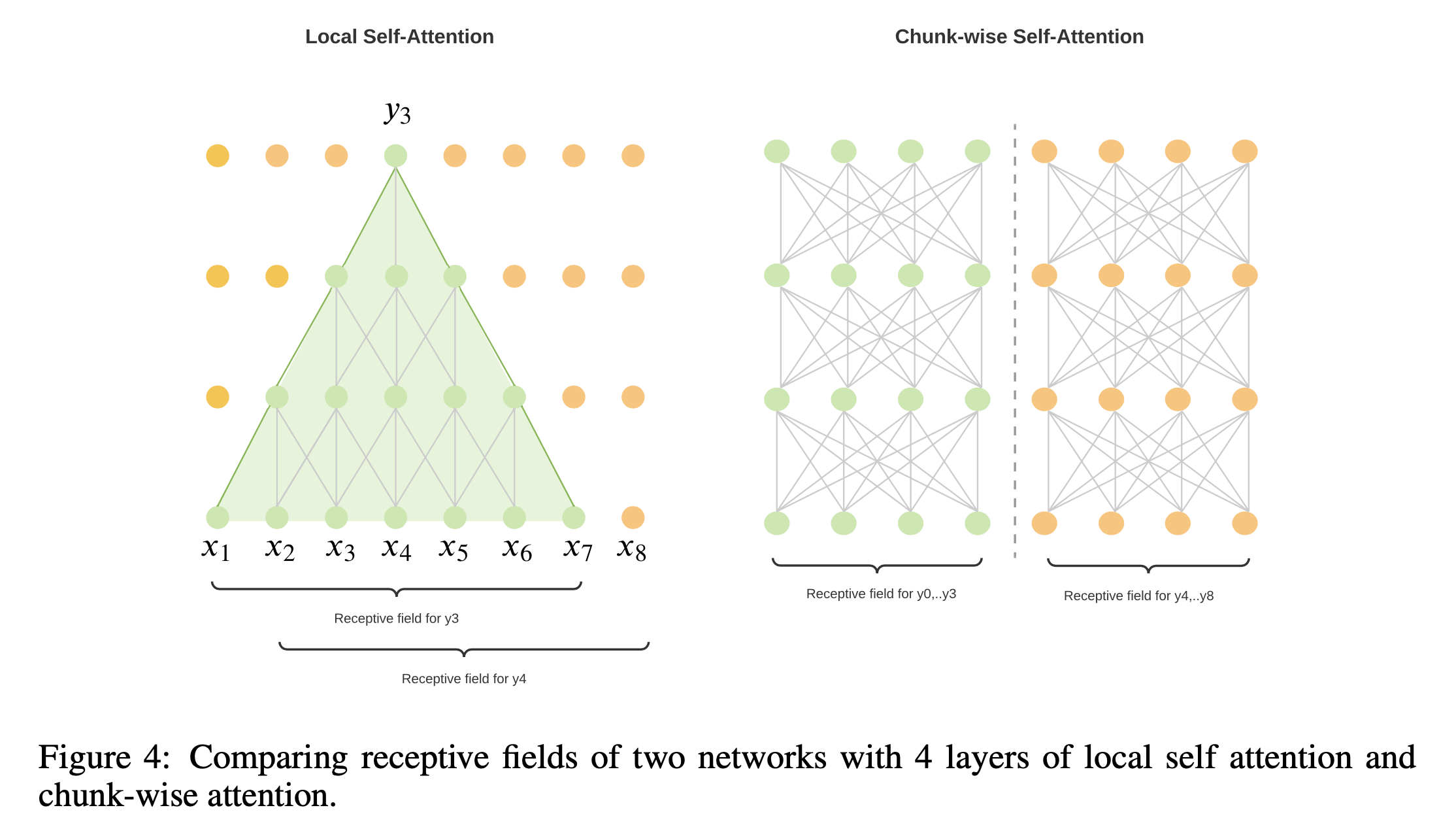
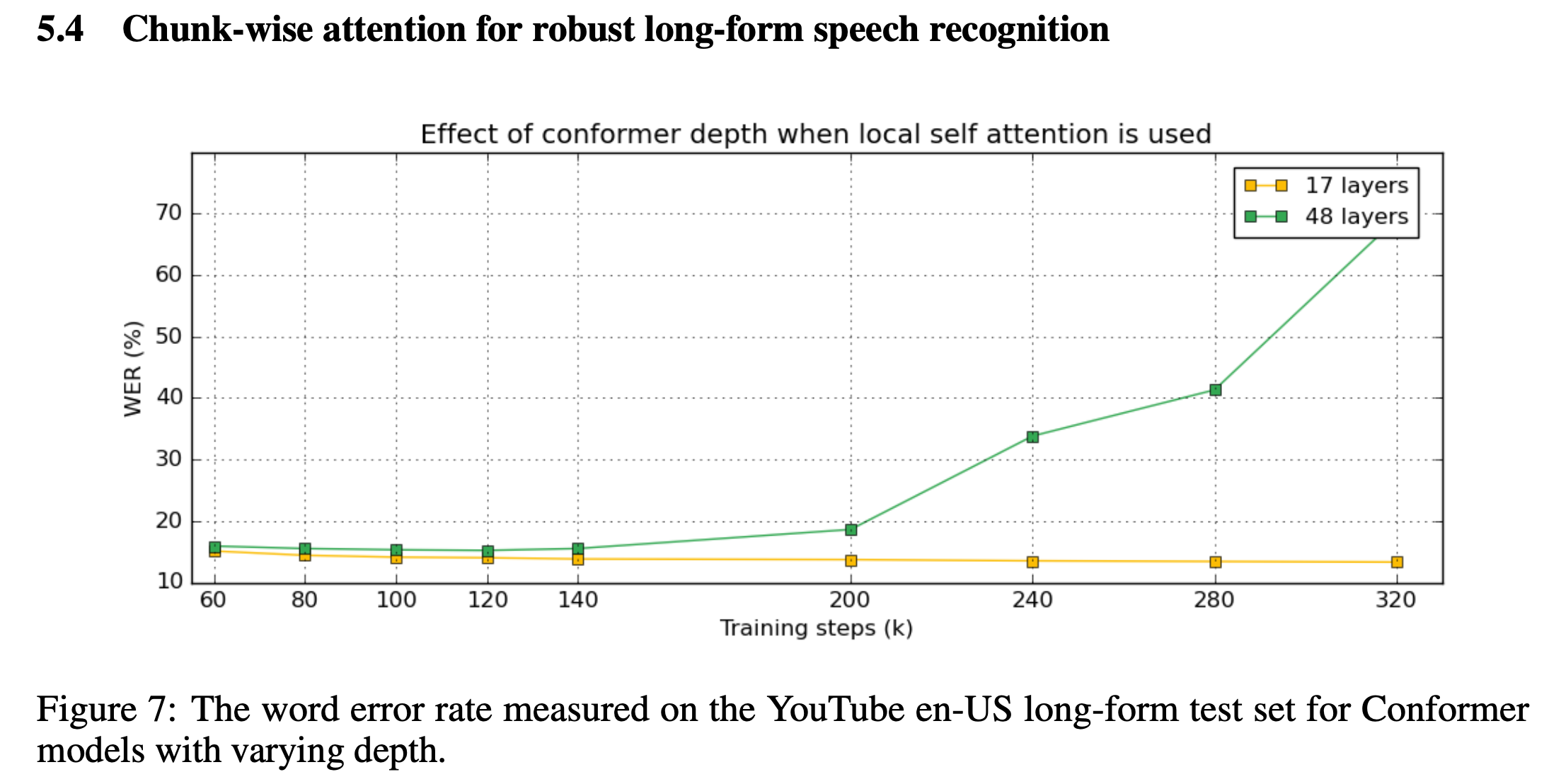
- ASR은 실시간성 (Straeming) 이 중요한데 Supervised Learning 시에 Full context 를 보는 Full Attention 대신에 다른걸 써야된다. -> 널리 알려져 있는 것 처럼 Local Attention, Chunk-wise Attention 이 대안이 될 수 있는데 이에 대해 분석을 많이 함 (결국 Chunk-wise 가 좋음)
- ASR 에서도 Adapter 등을 사용하는 (Parameter Efficient Fine-Tuning;
PEFT) 가 잘 먹힐 여지가 있다. (제가 실험할 때는 Wav2Vec 기반의 Contrastive Objective 로 학습된 SSL Encoder 에는 LoRA, Adapter 를 적용하는 것이 Full-Finetuning 보다 좋지 않았는데 꽤 잘 되는듯) - 하지만 그럼에도 가장 중요한 것은 Domain 별로, Task 별로 Fine-tuning 을 하는게 가장 크리티컬 했다.
등이 있었습니다.
Key-Findings of USM
- SoTA results for downstream multilingual speech tasks
- BEST-RQ is a scalable speech representation learner
- MOST (BEST-RQ + text-injection) is a scalable speech and text representation learner
- Representations from MOST (BEST-RQ + text-injection) can quickly adapt to new domains
- Chunk-wise attention for robust long-form speech recognition
Pre-training: BEST-RQ and Multi-Softmax
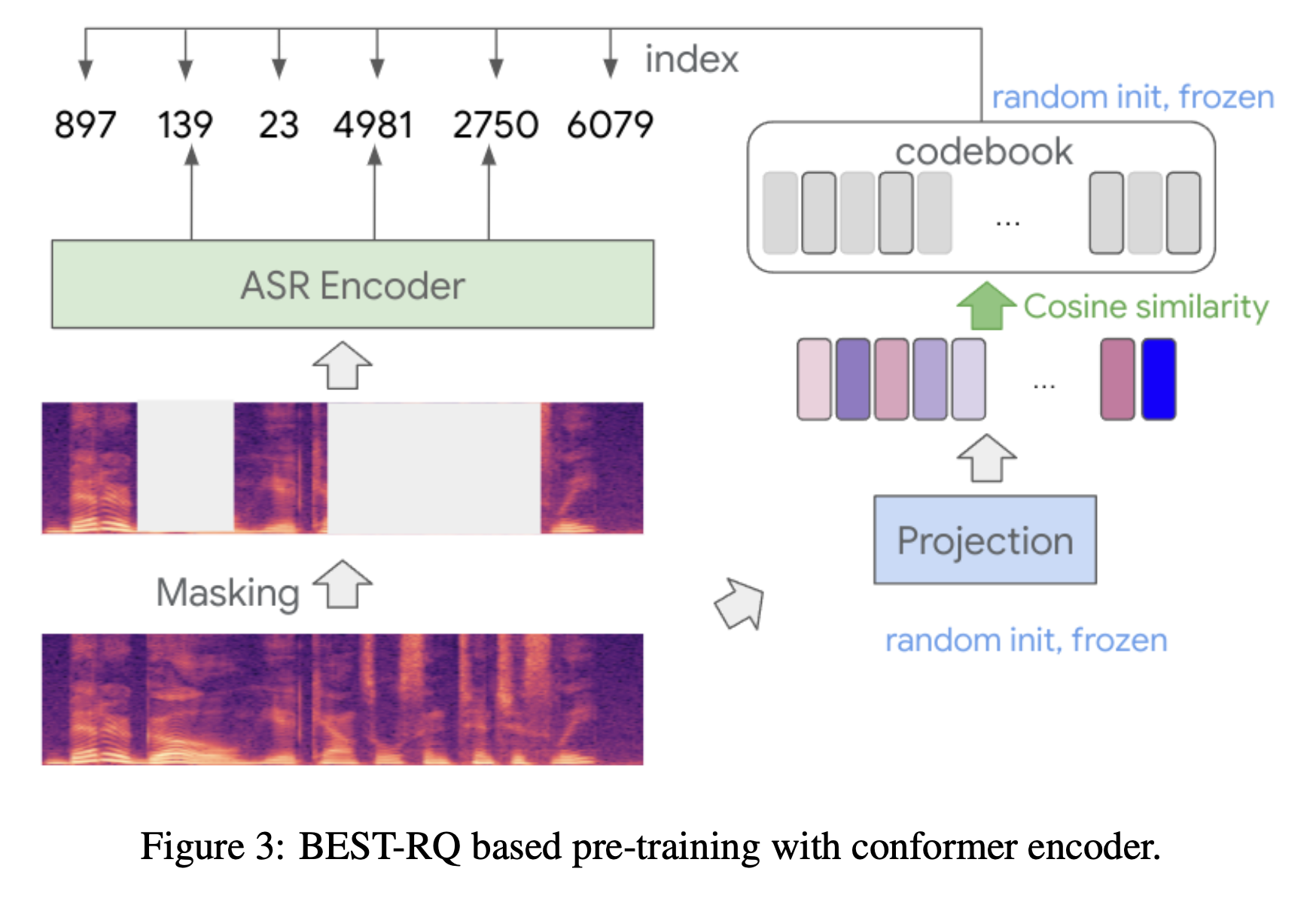
BEST-RQ (BERT-based Speech pre-Training with Random-projection Quantizer) 는 Self-supervised learning with random-projection quantizer for speech recognition 라는 논문에서 제안된 방법론 입니다.
Source Sequence 만 가지고 Pre-training 을 하는 방법은 NLP 의 BERT 같은 Masked Language Modeling (MLM) 이 있을 수 있겠지만 같은 의미를 가지는 frame 들이 반복되어 나타나고 discrete 이 아닌 continuous vector 로 이루어진 음성의 경우 단순 MLM 을 적용하기는 어려웠습니다.
그래서 CPC, SimCLR 등에 영감을 받은 Wav2Vec 2.0 에서 결국 Vector Quantizer, Masking 그리고 Contrastive Loss 같은 방법들을 동원해 결국 유의미한 Speech Representation 을 만드는 데 성공했는데요, 그 뒤로 Quantization 을 하기 위해 Codebook 을 학습하는 대신 K-means 를 Intiial Quantizer 를 학습하기 위해 쓰는 HuBERT 와 Wav2Vec 과 BERT MLM 을 결합한 W2V-BERT 가 등장했었습니다.
Local vs Chunk-wise Attention for Long-form ASR
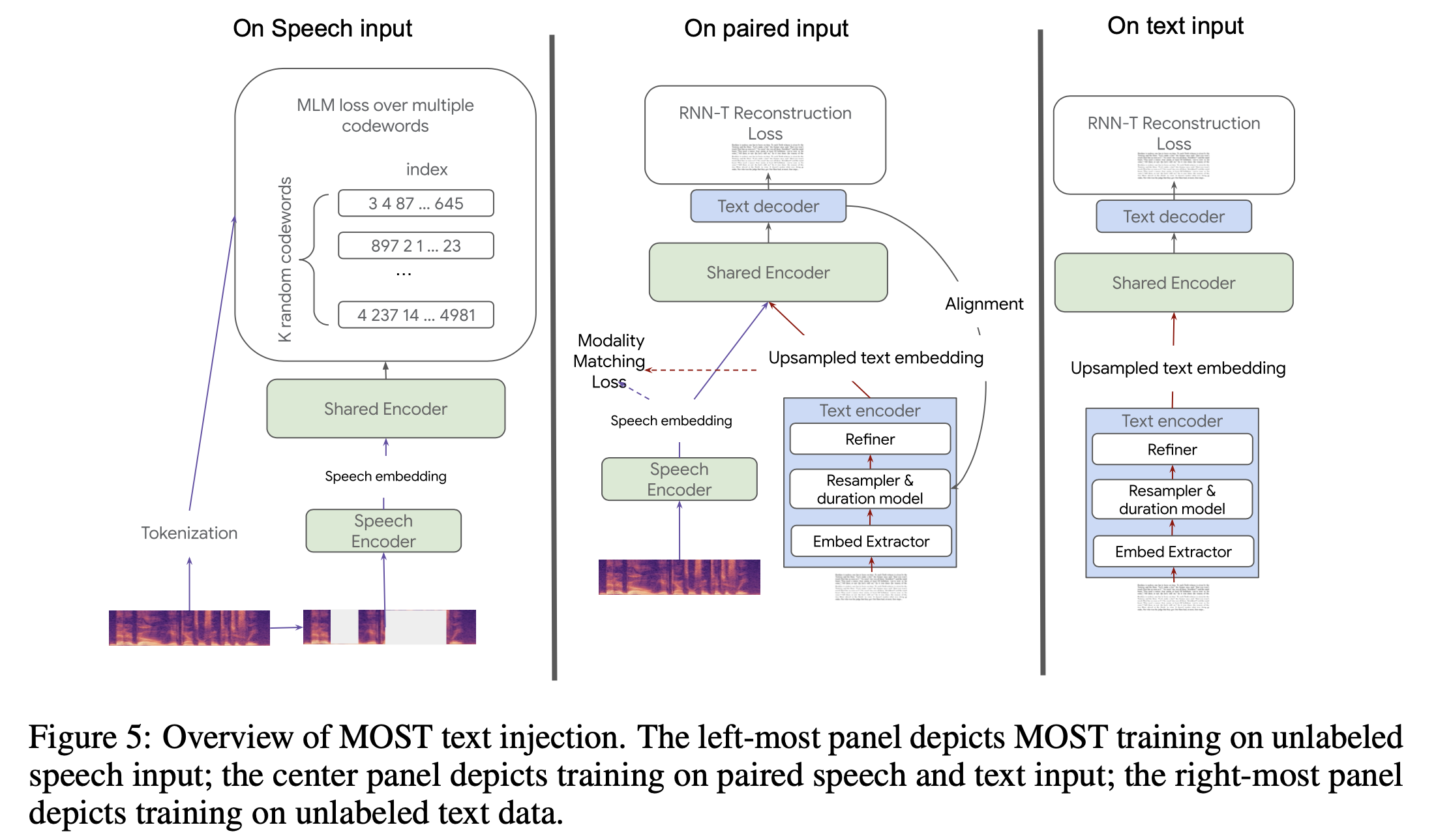
Multi-Objective Supervised Pre-training: BEST-RQ + text-injection