(ASR) Unsupervised Speech Recognition
14 Jan 2022이번 글에서는 2021년 5월 21일에 공개된 Unsupervised Speech Recognition 라는 논문을 요약해서 리뷰해 보려고 합니다.
본 논문은 Facebook AI Research (FAIR) 에서 출판한 논문이며 (Google 리서쳐 한분이 계신데 FAIR에서 이직했습니다), 이를 다룬 Blog post, High-performance speech recognition with no supervision at all의 제목에서도 알 수 있듯이, Supervised Finetuning 을 “전혀” 안하고도 ASR model 을 학습할 수 있는 방법을 제시한 논문입니다.
< 목차 >
- Problem Definition and Contibution Points
- Illustration of Wav2Vec-U
- Background
- Proposed Method
- Experiments and Results
- Reference
Problem Definition and Contibution Points
본 논문에서 정의하는 Problem과 Contribution Point은 다음과 같습니다.
- 1.MIT CSAIL의 Speech2Vec 등을 시작으로 FAIR는 Wav2Vec, VQ-Wav2Vec,
Wav2Vec 2.0등을 내왔다. 이는 BERT와 유사한 방법론으로 특히 labeled data가 많아야 하지만 구축하는데 비용이 비싼 음성인식 분야에서 획기적인 성과를 거뒀다. - 2.Self-Supervised Learning (SSL) 방법론을 사용한 Wav2Vec 2.0은 1번에서 언급한 것 처럼 unlabeled data를 무지막지하게 사용해서 사전학습을 했기 때문에, 파인튜닝을 할 때에는 심지어 10분정도의 labeld data만 있어도 어느정도 음성인식이 잘 되는 놀라운 결과를 보여줬지만, 이는 여전히 labeld data가 필요하다는 문제가 있다.
- 3.본 논문에서는 unlabeld speech, unlabeld text (두 음성, 텍스트 데이터는 전혀 연관이 없다. 정답 관계가 아니라는 것)를 사용해서
Generative Adversarial Network (GAN)기반의 네트워크를 구성해서Totally Unsupervised ASR네트워크 (학습 방법론)을 제시한다. - 4.Librispeech 데이터셋에서 supervised에 견주는 성능을 보여줬다. (근데 Language Model (LM)은 썼음)
사실 기존 End-to-End ASR들은 960시간(clean데이터 460시간 + noisy데이터 500시간)의 LibriSpeech Benchmark dataset을 전부 지도학습으로 돌려서 성능 싸움을 했었습니다. 그러다가 2017,8년 부터 BERT같은 Unsupervised training 방법론이 자연어처리에서 성공적으로 적용되면서, 음성쪽에서도 이를 모방한 방법론이 등장했고 BERT를 그냥 따라한 Wav2Vec부터 Vector-Quantized (VQ)를 쓴 VQ-Wav2Vec 을 실험적으로 거쳐 드디어 성공적인 Speech Unsupervised Model인 Wav2Vec 2.0이 등장했습니다. 이는 많게는 50000시간의 Speech only data만을 사용해서 Representation을 학습하기 때문에 Speech-Text pair 데이터가 10분, 1시간 100시간만 있어도 엄청난 성능을 보여줬습니다.
Wav2Vec 2.0이 시사하는 바는 아프리카 소수 부족의 언어 같이 Speech-Text pair 데이터가 부족하지만 Speech만 이라도 대량으로 수집하면 Speech-Text pair데이터가 조금만 있어도 어떻게든 음성인식을 할 수는 있다 라는거였는데요, Wav2Vec-U는 이를 뛰어넘어서 비교적 수집이 더 저렴한 Speech only data와 Text only data만 있으면 학습이 된다는 겁니다.
이는 머신러닝/딥러닝 관점에서도 재밌는 Approach임과 동시에 pair 데이터가 없다시피한 언어들에 대해서도 음성 인식을 가능하게 하는 방법으로 인류에 기여하는 (? 너무갔나요…) 중요한 논문이 될 수도 있을 것 같습니다.
Illustration of Wav2Vec-U
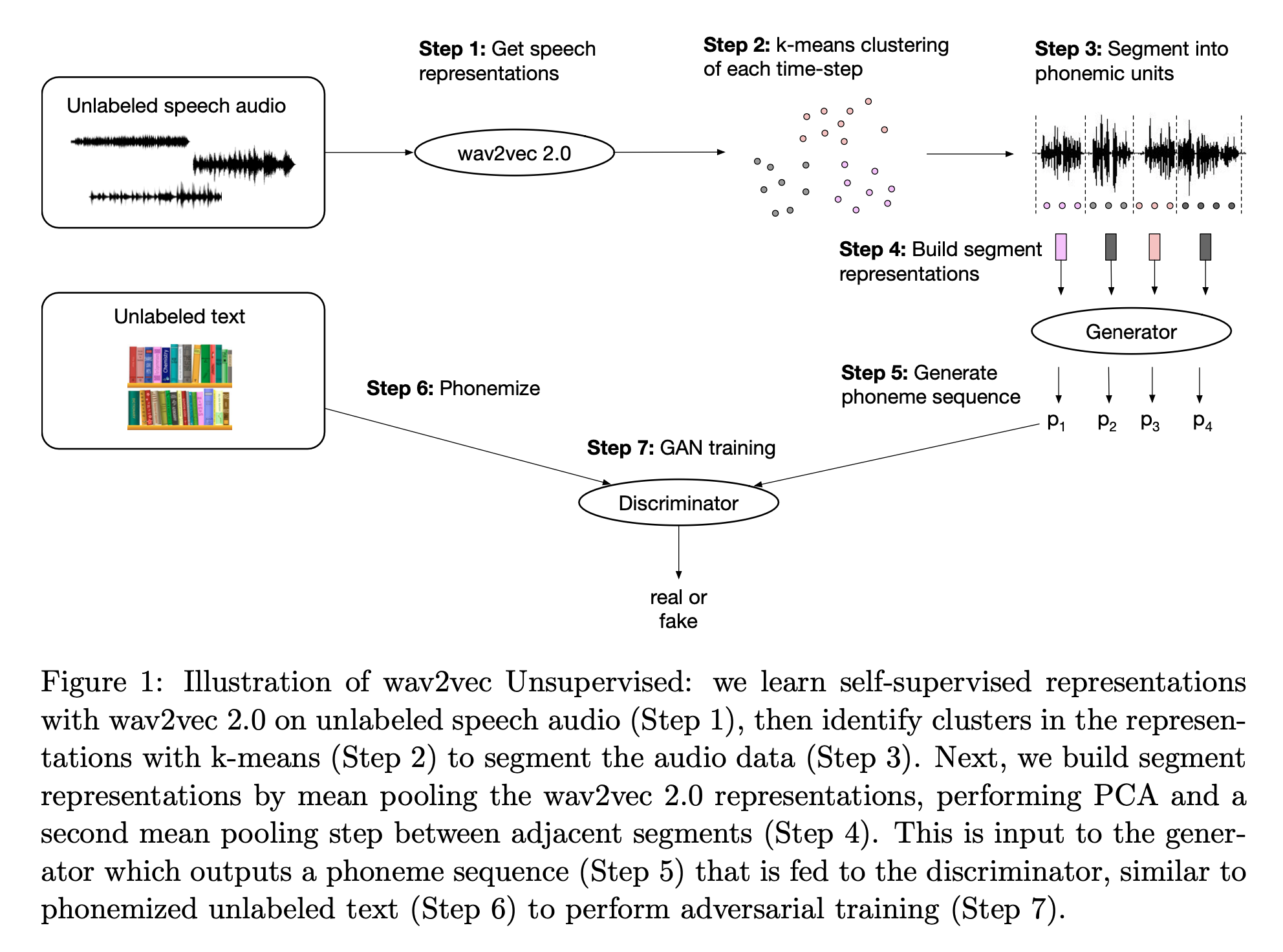 Fig. Overall Architecture of Wav2Vec-U
Fig. Overall Architecture of Wav2Vec-U
Figure와 Caption에도 나와있듯, 절차는 생각보다 간단해보이는데요, 요약하면
- 1.Wav2Vec 2.0을
Unlabeled Speech data에 대해서 사전학습한다. - 2.Wav2Vec 을 통과한 모든 time-step의 representation vector들을
K-means로 뭉친다 (clustering). - 3.
mean pooling -> PCA -> 인접 segment들 간의 mean pooling과정을 통해서 segment representation을 만든다. - 4.이렇게 만들어진 segment vector들을 GAN의 Generator에 넣어서 문장을 만든다. (단순히
segment vector -> phoneme의로의 mapping (projection) function인 것) - 5.우리가 다룬 스피치와는 정답관계가 아닌
Unlabeld Text data와 Generator가 만든 문장을 GAN의 Discriminator/Critic에 넣어서 GAN과 같은 Objective로 학습을 한다. (이 때 학습을 잘 하기 위해서 Diversity term이라던지 Penalty term이 추가됨)
절차는 위와 같습니다.
즉, 이렇게 ASR을 Supervision 없이 학습하는게 가능하려면 잘 초기화된 Wav2Vec 2.0이 필요하기 때문에 이를 잘 아는건 중요합니다. 그럼 이제 Wav2Vec 2.0과 기타 논문에서 언급했던 Background들, 방법론들과 실험결과들에 대해서 알아보도록 하겠습니다.
Background
Pre-training : Wav2Vec 2.0
Wav2Vec 2.0의 핵심은 아래와 같습니다.
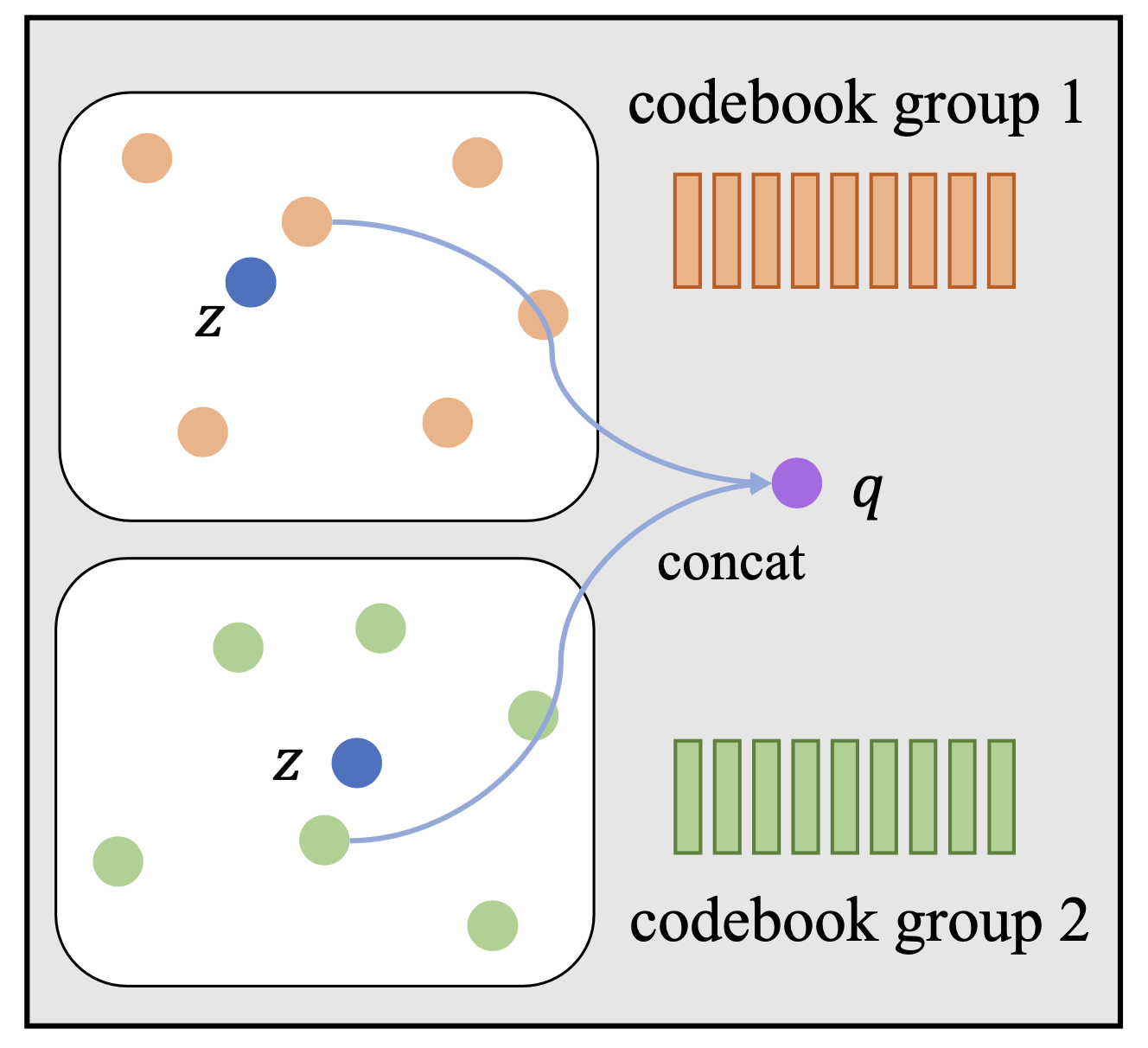 Fig. 이미지 출처 : UniSpeech: Unified Speech Representation Learning with Labeled and Unlabeled Data
Fig. 이미지 출처 : UniSpeech: Unified Speech Representation Learning with Labeled and Unlabeled Data
Wav2Vec 2.0은 직관적으로 성별, 악센트등에 상관없이 전체 음성의 맥락에서, 같은 발음을 나타내는 음성 벡터들은 한데 모아서 표현 (represent) 하겠다는 의미를 가지고 있습니다.
맥락을 배우는 것은 Transformer Encoder가 수행하고, 각각의 음성 벡터들이 speaker 같은 정보에 independent하게 하는 것은 Quantization Module이 담당합니다.
이렇게 Discrete Speech Representation을 배우는 과정은 위의 그림에 잘 나타나 있는데요,
1d-conv 신경망을 통과시켜서 지역적으로 의미있는 벡터들을 표현한 뒤 이렇게 temporal resolution이 줄어든 벡터들을 VQ-VAE에서 처럼 Discrete Codebook을 통해 가까운 표현 벡터로 뭉치게 합니다.
전체적인 학습 과정은 아래의 그림에 더 자세히 나와있는데요,
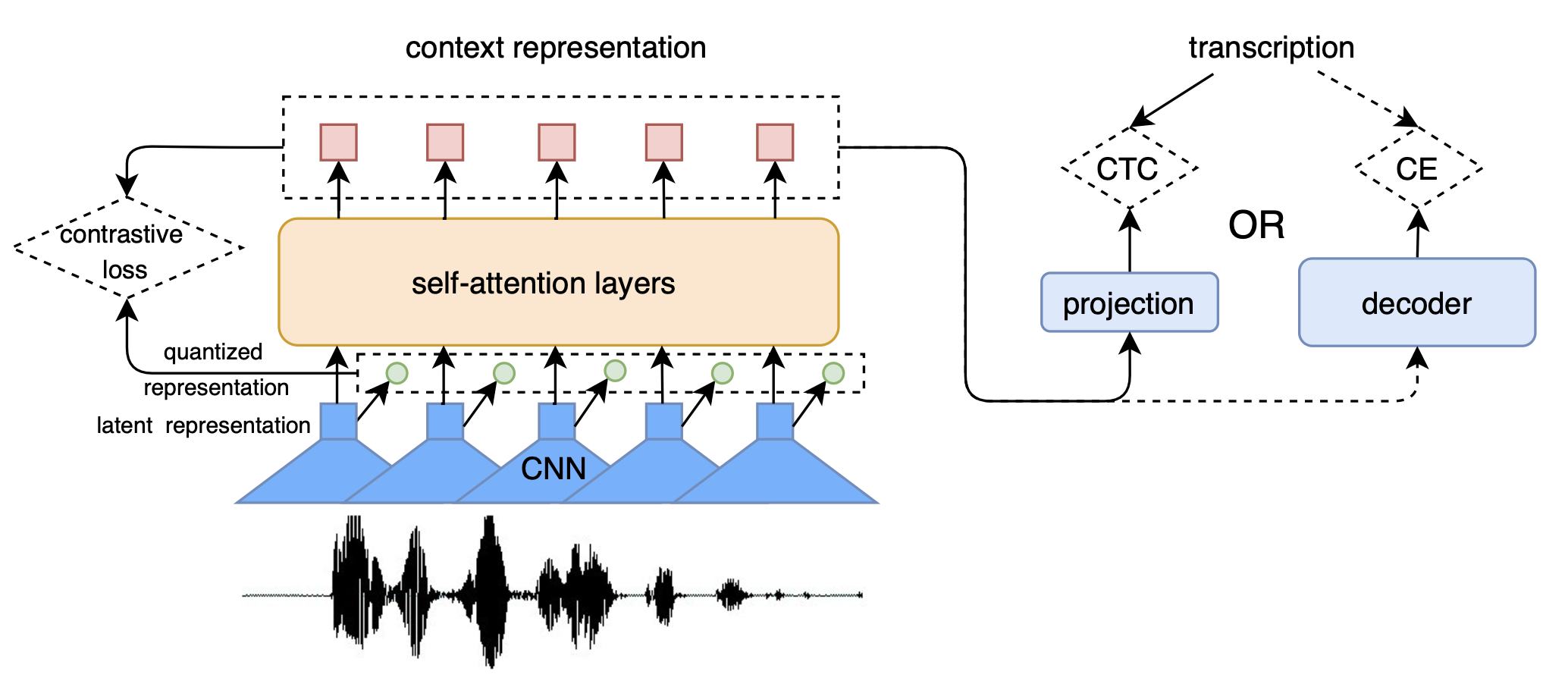 Fig. 이미지 출처 : Applying Wav2vec2.0 to Speech Recognition in Various Low-resource Languages
Fig. 이미지 출처 : Applying Wav2vec2.0 to Speech Recognition in Various Low-resource Languages
1d-conv layer를 통과시킨 벡터들을 BERT 처럼 매 time-step마다 일정 확률로 마스킹하고 이를 트랜스포머에 통과시킨 후 quantization 된 벡터들, 그러니까 앞서 말한 discrete representation vector들과 함께 Contrastive Loss를 통해서 학습합니다.
- Contrastive Loss의 직관적인 이해
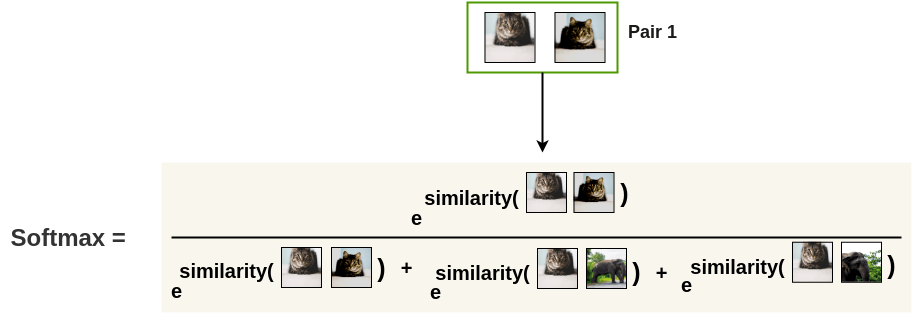 Fig. 이미지를 사용한 예시로, Contrastive Learning의 목적은 비슷한 의미를 가진 벡터 (고양이들)과 아닌 벡터들 (코끼리,개 등)의 사이를 서로 밀고 당기는 것이다.
Fig. 이미지를 사용한 예시로, Contrastive Learning의 목적은 비슷한 의미를 가진 벡터 (고양이들)과 아닌 벡터들 (코끼리,개 등)의 사이를 서로 밀고 당기는 것이다.
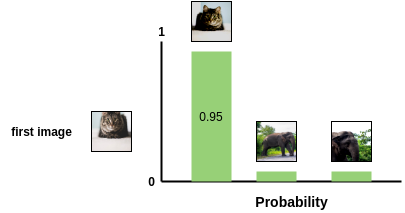 Fig. 비슷한 벡터의 softmax probability를 높히면 자동으로 안비슷한 벡터들은 줄어든다 (=멀어진다). 여기서 어떤걸 가까워지게 또는 멀어지게 해야 하는지는 Self-Supervised Learning답게 알아서 정한다. Wav2Vec의 경우 현재 time-step에서의 양자화된 벡터와, 트랜스포머가 통과된 벡터를 가깝게 하고 나머지 샘플들은 다 멀 만든다.
Fig. 비슷한 벡터의 softmax probability를 높히면 자동으로 안비슷한 벡터들은 줄어든다 (=멀어진다). 여기서 어떤걸 가까워지게 또는 멀어지게 해야 하는지는 Self-Supervised Learning답게 알아서 정한다. Wav2Vec의 경우 현재 time-step에서의 양자화된 벡터와, 트랜스포머가 통과된 벡터를 가깝게 하고 나머지 샘플들은 다 멀 만든다.
전체 Objective를 수식으로 쓰자면 아래와 같습니다.
\[\begin{aligned} & L = L_m + \alpha L_d & \\ & Lm = - log \frac{exp(sim(c_t,q_t) / \kappa)}{ \sum_{\tilde{q} \sim Q_t } exp(sim(c_t,\tilde{q}) / \kappa ) } & \\ & L_d = \frac{1}{GV} \sum_{g=1}^G -H(\tilde{p_g}) = \frac{1}{GV} \sum_{g=1}^G \sum_{v=1}^V \tilde{p}_{g,v} log \tilde{p}_{g,v} & \\ \end{aligned}\]수식은 Contrastive Loss \(L_m\)와 Regularization term인 \(L_d\)의 합으로 이루어져 있는데요, (\(\alpha\)는 하이퍼 파라메터)
수식이 의미하는 바는 Codebook이 최대한 다양한 entry (code)를 사용하면서, Contrastive Learning을 통해 관련 없는 음성은 멀어지게 하고, 관련있는 음성들은 (마스킹해서 트랜스포머 통과시킨 벡터와, 트랜스포머 통과전 벡터를 양자화 한 것) 유사한 벡터를 배우도록 하는 것입니다.
여기서 Diversity Loss 나 코드북을 두개 써서 곱하는 전략 등을 이용해 더욱 성능을 끌어올렸다고 하는데, 둘 다 근거가 없는 말은 아니나 일각에서는 Diversity loss는 효과가 없는 것 같다는 등의 의견이 있긴 합니다.
fine-tuning : End-to-End Supervised Learning
어쨌든 이렇게 학습된 Wav2Vec 2.0 네트워크는 Quantization Module의 아웃풋 벡터가 아닌 Context Vector \(c_t\)를 사용해서 이 뒤에 얕은 층의 Shallow Decoder를 붙히고 CTC loss를 사용해서 Supervised Fine-tuning을 하는데요, 본 논문의 핵심은 이를 제거해버리겠다는 겁니다.
Proposed Method
Objective
앞서 밝혔듯 본 논문에서는 Generative Adversarial Networks (GANs)의 Objective에 Penalty term들을 추가해서 Objective를 구성합니다.
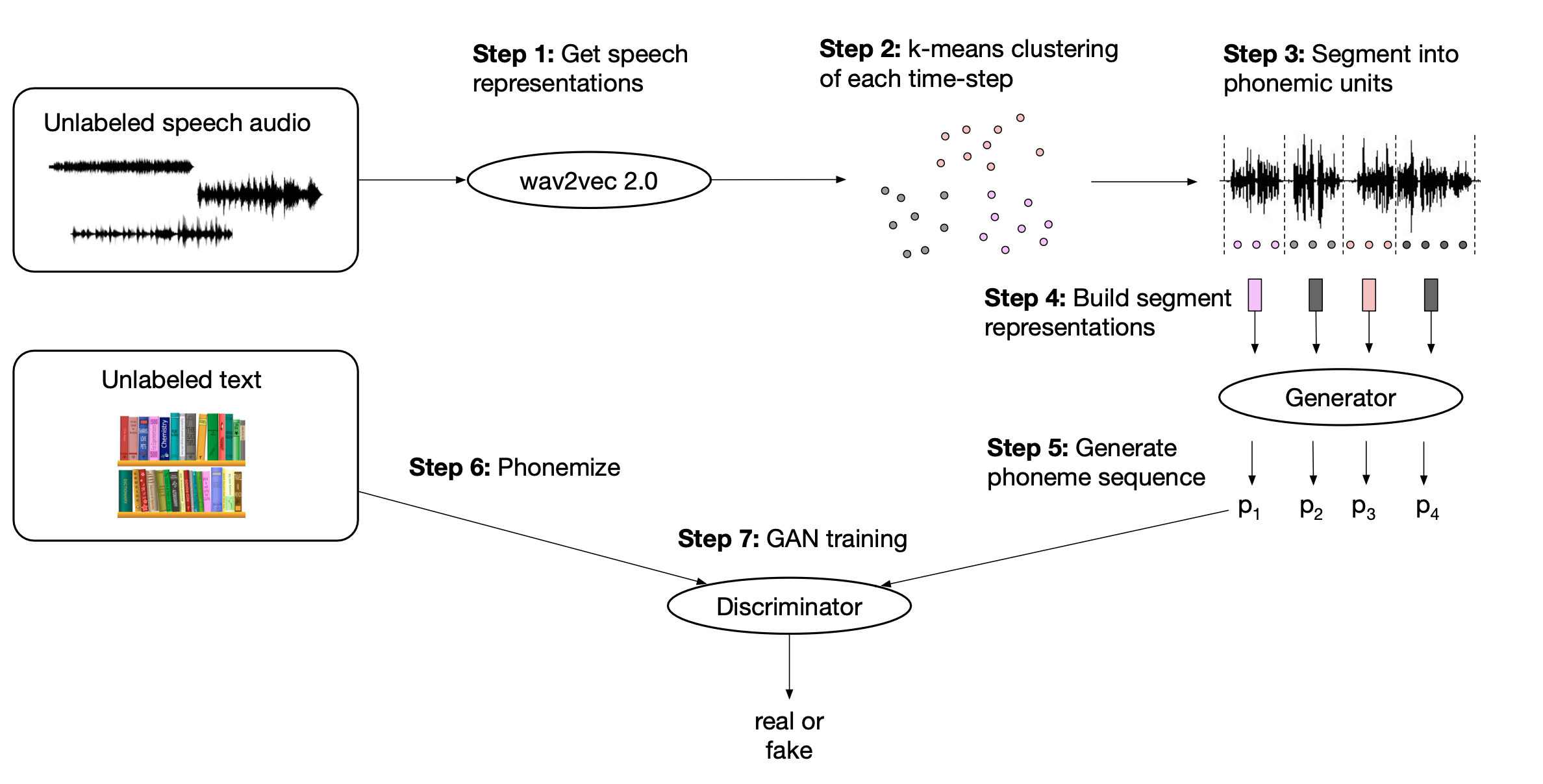 Fig. Overall Architecture of Wav2Vec-U
Fig. Overall Architecture of Wav2Vec-U
Segmenting the Audio Signal
Pre-processing the Text Data
What features from Wav2Vec?
 Fig. asd
Fig. asd
 Fig. asd
Fig. asd