(WIP) (Paper) ODIN, Disentangled Reward Mitigates Hacking in RLHF
14 Feb 2024< 목차 >
Motivation
왜 Odin인가?
TL;DR 하자면 paper가 주장하고자 하는 바는 다음과 같다.
- RLHF를 하면
length biases가 생기기 쉽다. - 이는 RM이 주는 reward signal을 기반으로 PPO할 때 ‘답변이 길기만 하면 점수가 높군?’이라고 model이 오해해서 그렇다.
- LM head를 두개 만들어서 학습하는데, Length 기반으로 ranking하는 head와 Quality만을 기반으로 ranking하는 head을 만들어 ranking을 매기는 기준을 disentangle한다.
- 그리고 Length LM head에 길이를 기준으로 ranking하는 정보가 다 담겼기 때문에 Quality head는 실제로 length에 대한 bias가 없을 것이고 Quality head만으로 PPO를 한다.
Footprint에 따르면 “Odin sacrificed one eye for wisdom, similarly our RM discards the length head for more focus on the actual content.”라고 되어있다. 진짜로 RM학습할 때는 달려있던 2개의 head중 하나를 희생했기 때문에 paper title이 ODIN인 것이다 (… 오우).
Length bias는 LLM에서 흔히 발생하는 일인데, OpenAI의 ChatGPT에 대한 blog post를 보면 ChatGPT가 어떤 size와 형태의 Reward Model (RM)과 어떤 regularization term을 Reinforcement Learning (RL) 하는데 썼는지는 몰라도 여전히 그럴싸해보이는 긴 답변을 더 선호한다고 한다.
 Fig. Sourec from here
Fig. Sourec from here
2023년 10월에 publish된 A Long Way to Go: Investigating Length Correlations in RLHF라는 paper를 보면 RM은 일단 학습이 되고 나면 더 긴 답변에 더 높은 score를 할당하는 경향이 있었다고 한다. 이 RM의 reward signal을 바탕으로 LLM을 강화하면 당연히 더 긴 답변을 생성하게 되는 것이 문제인 것이다.
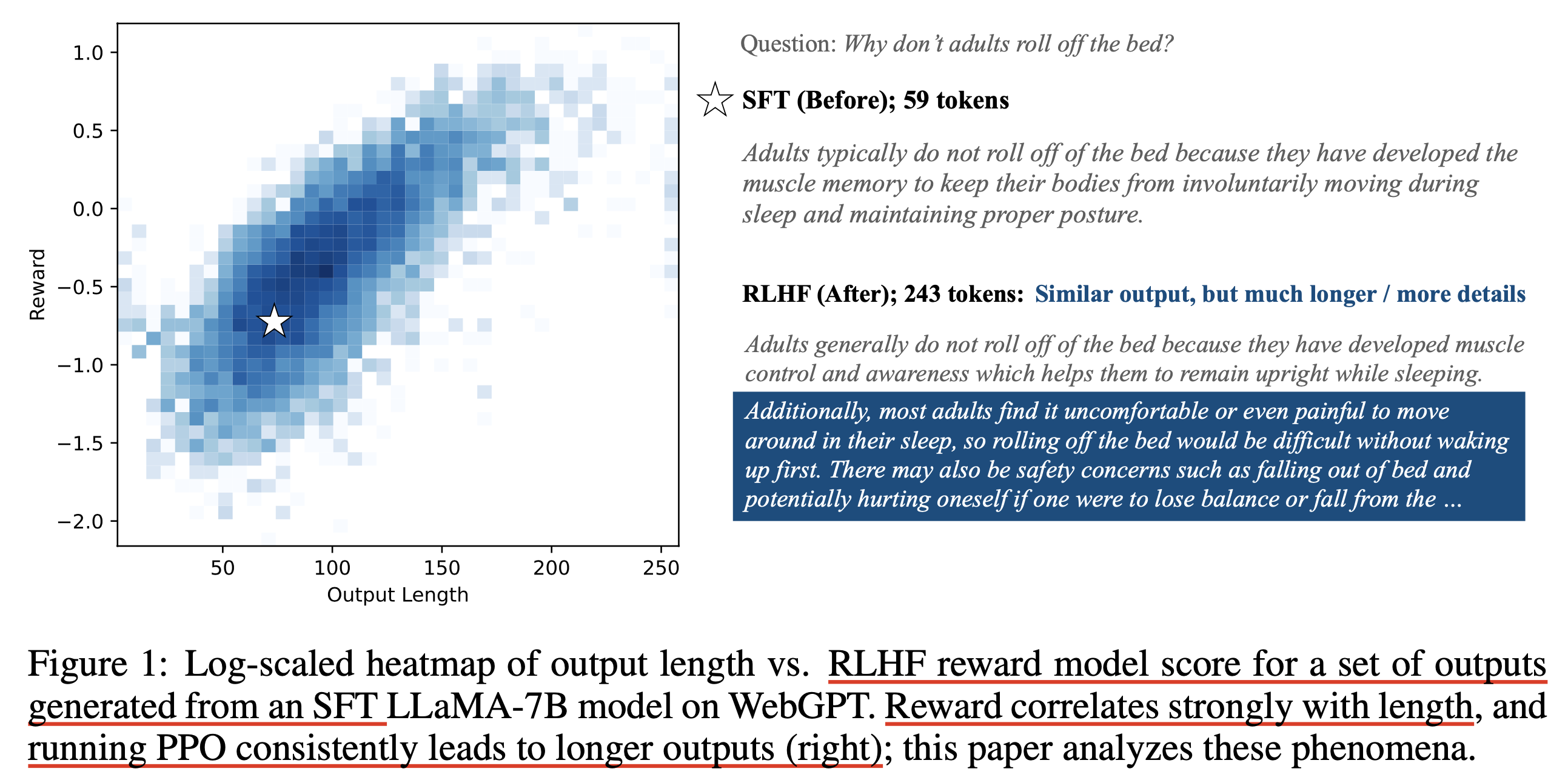 Fig. 학습한 RM으로 일반적인 RL을 할 경우 LLM은 유사한 내용도 더 길게 답변하려는 경향이 있다.
Fig. 학습한 RM으로 일반적인 RL을 할 경우 LLM은 유사한 내용도 더 길게 답변하려는 경향이 있다.
아래의 figure를 보면 실제로 Proximal Policy Optimization (PPO)까지 학습이 된 LLM의 경우 긴 답변의 reward가 대폭 상승했음을 볼 수 있다.
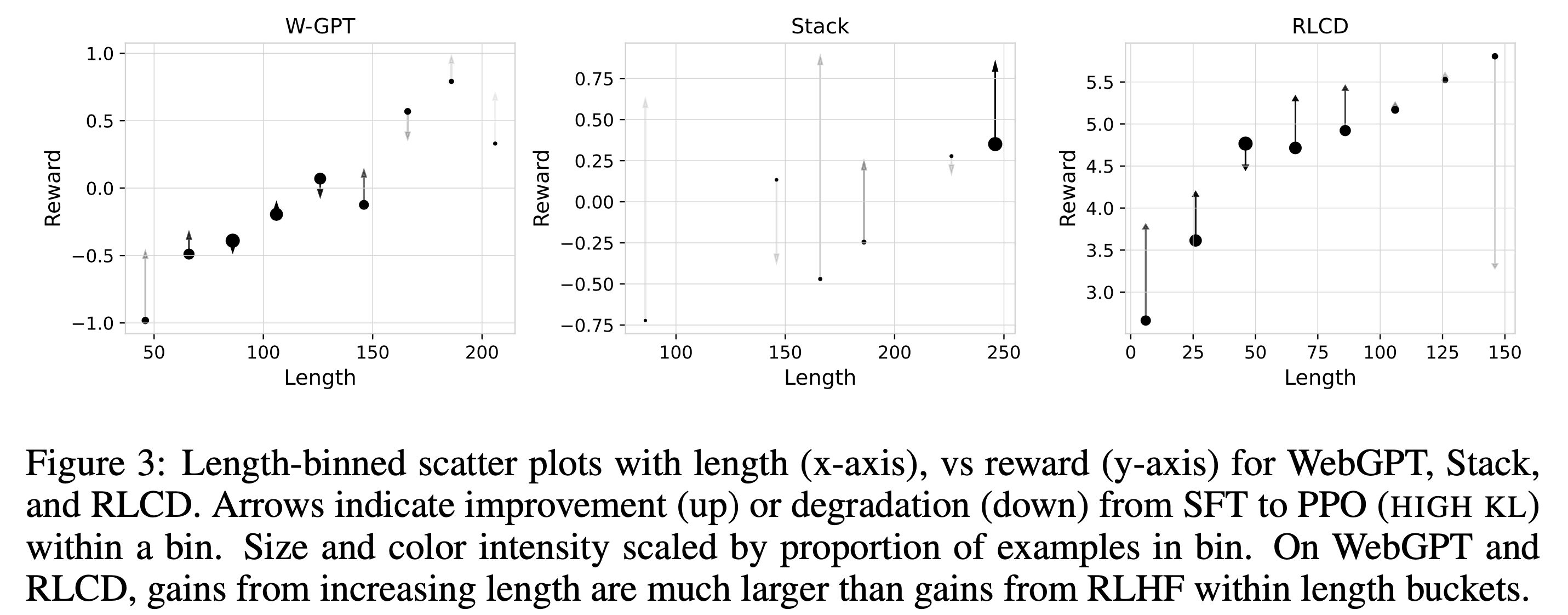 Fig.
Fig.
일반적으로 이를 reward hacking 혹은 reward overoptimization 현상이라고 설명하기도 하는데,
reward hacking은 reward function이 실제로는 ‘좋은 답변에 좋은 점수를 준다’라고 생각하고 긴 답변에 높은 점수를 줬어도 model이 이를 오해해서 ‘음 ~~이런 단어나 추론 능력때문에 이 답변이 좋은게 아니라 긴 답변에 좋은 reward를 주는구나?’라고 생각하기 때문에 일어난다.
(RM의 overfitting은 OOD data에 대해 chosen reject을 잘 못고른다는 얘기라 overoptimization과 구분된다)
그렇다면 어떻게 이런 model의 bias를 막을 수 있을까? (당연히 variance-bias tradeoff의 bias를 말하는게 아니다)
일반적으로 Reinforcement Learning from Human Feedback (RLHF)을 할 때 최대한 보수적으로 policy improvement가 일어나도록 몇 가지 장치를 해주는데, paper에서 언급한 것들은 다음과 같다.
- KL Regularization
- PPO Clipping
- Sampling from the olf policy
- Reward Clipping
- Length Penalty
Observation
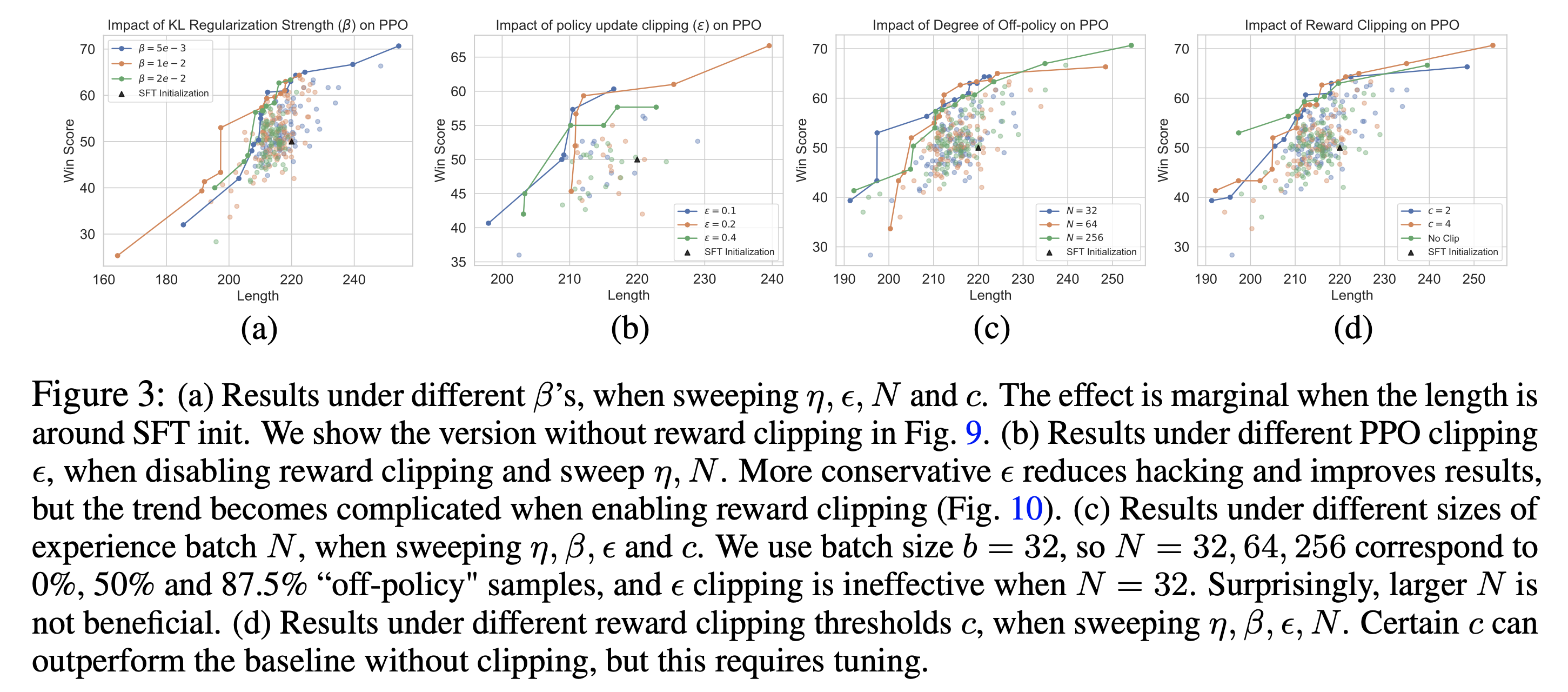 Fig.
Fig.
Method
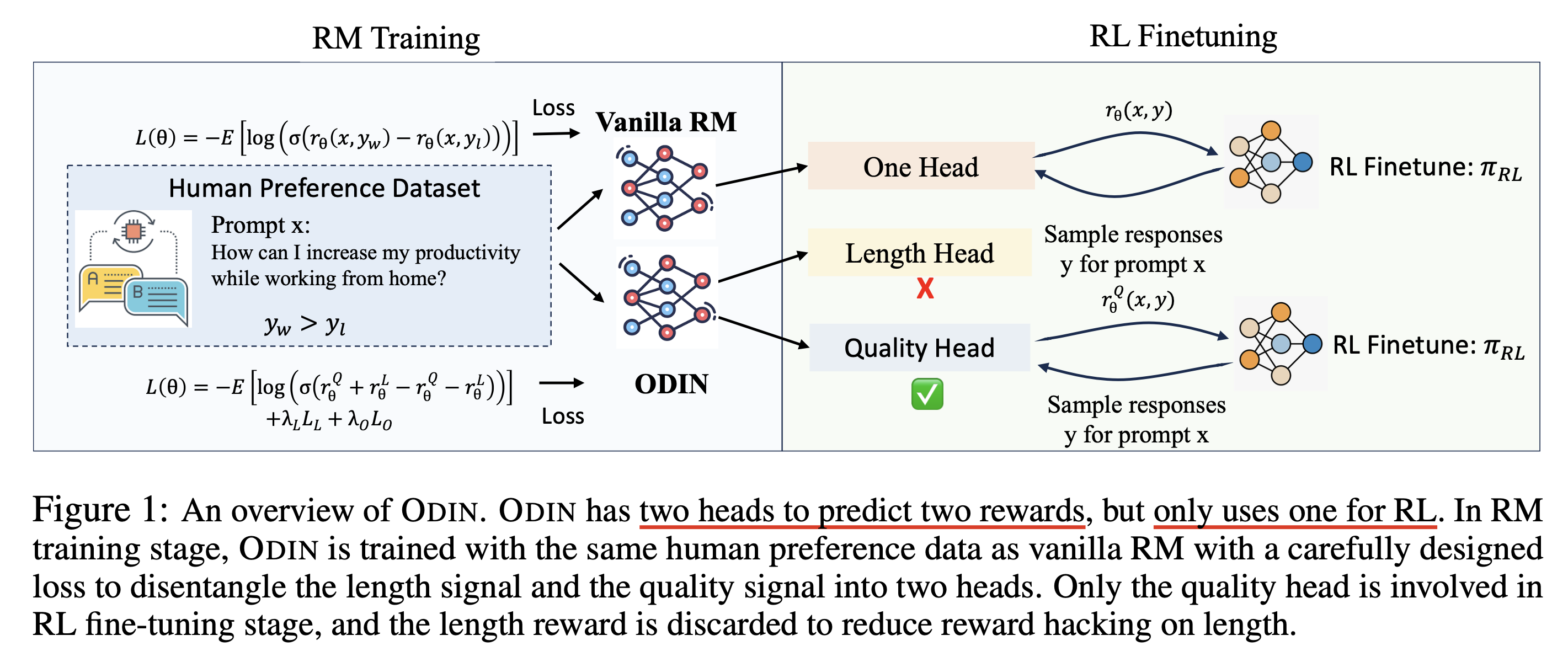 Fig.
Fig.
Learning Objective
\[\mathcal{L}^{R}_{\theta} (x, y_w, y_l) = -\mathbb{E} [ \log ( \sigma( r^{Q}_{\theta} (x,y_w) + r^{L}_{\theta} (x,y_w) - r^{Q}_{\theta} (x,y_l) - r^{L}_{\theta} (x,y_l) ) ) ]\]Experimental Results
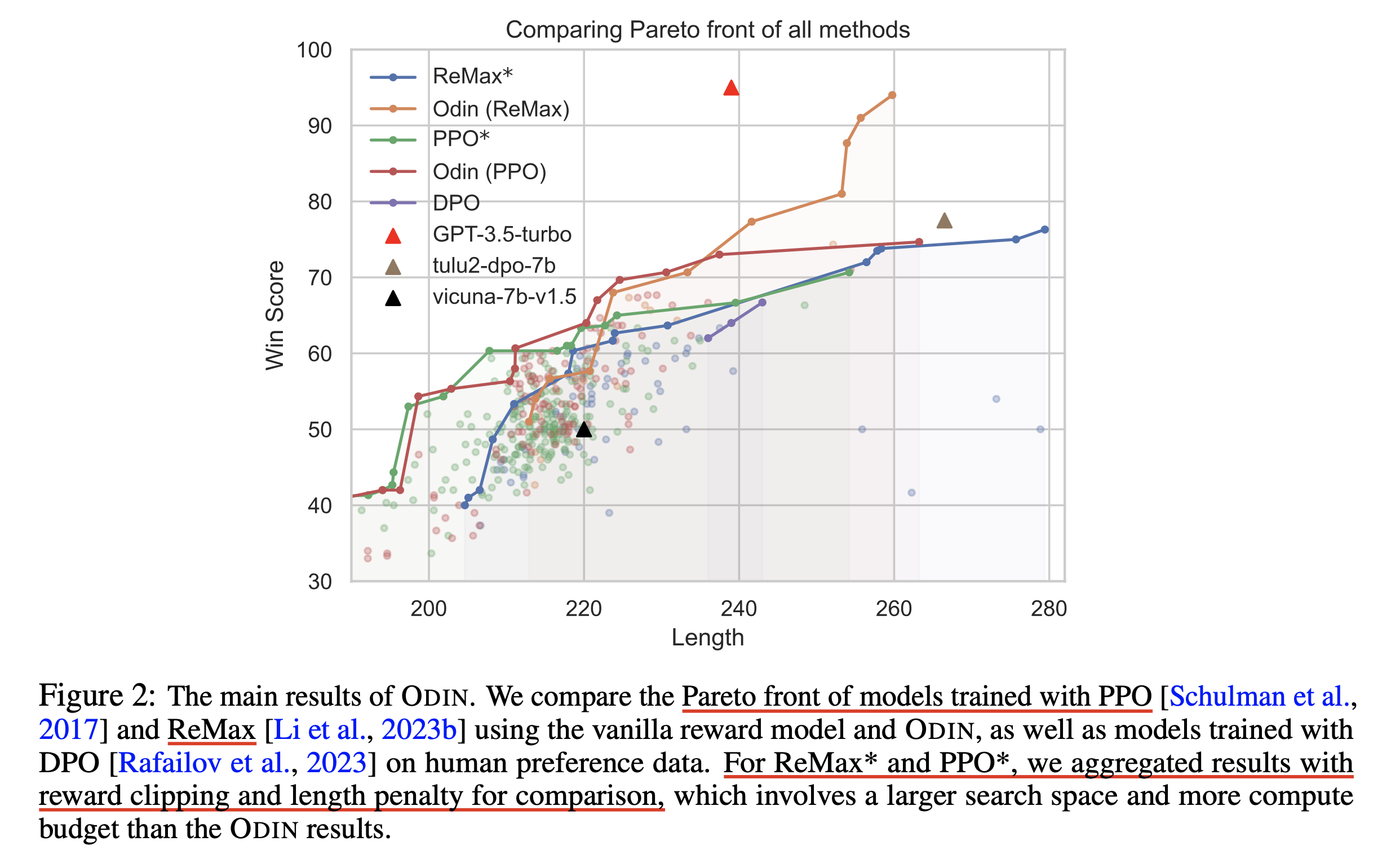 Fig.
Fig.
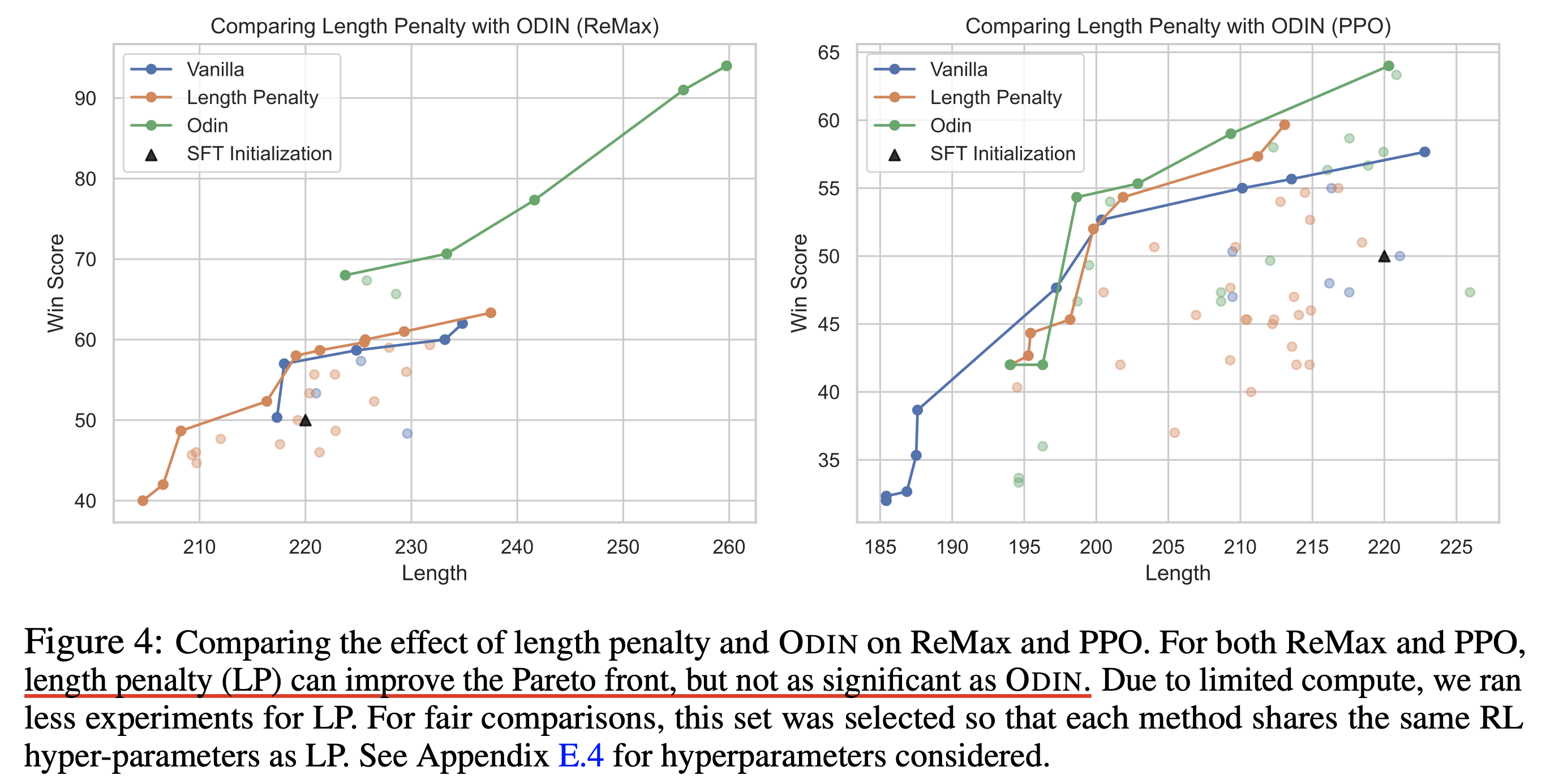 Fig.
Fig.
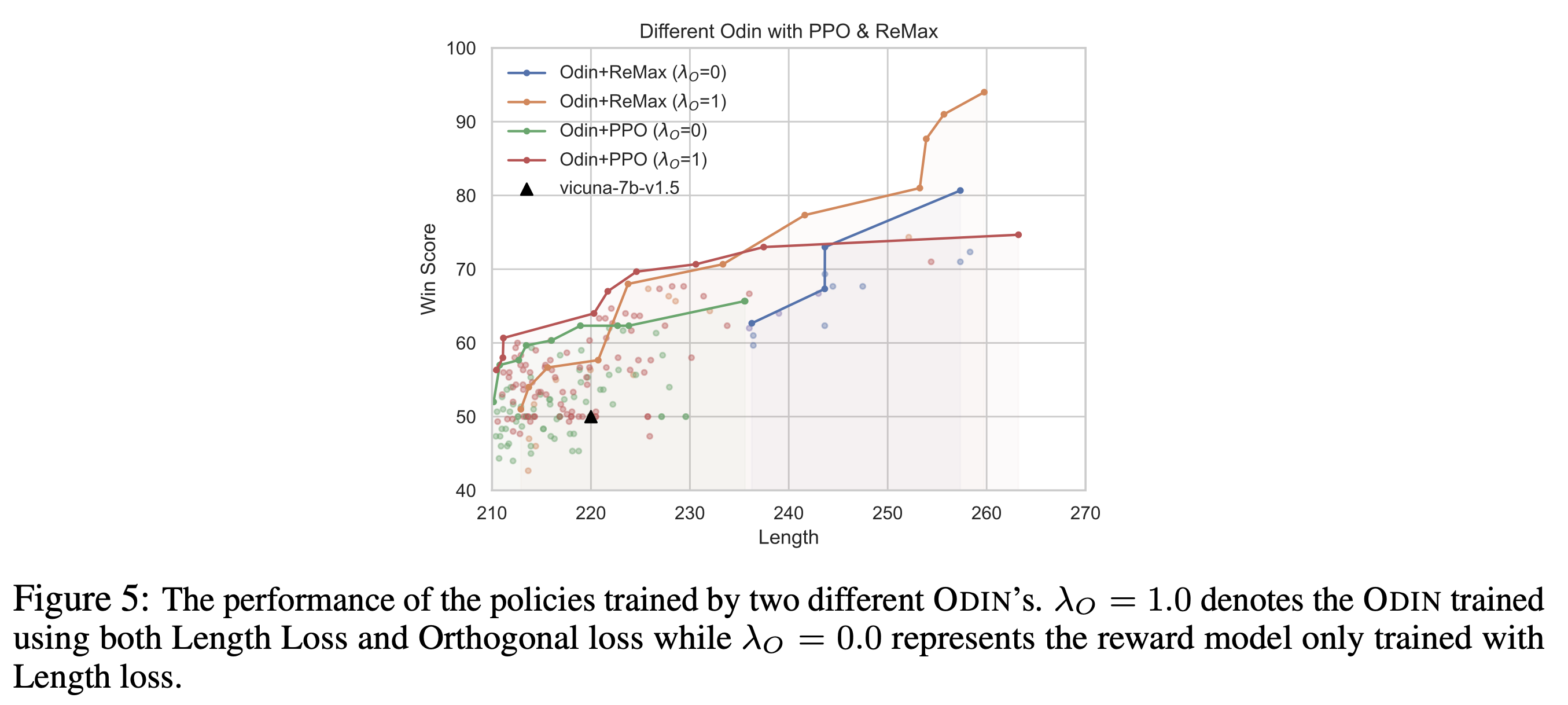 Fig.
Fig.
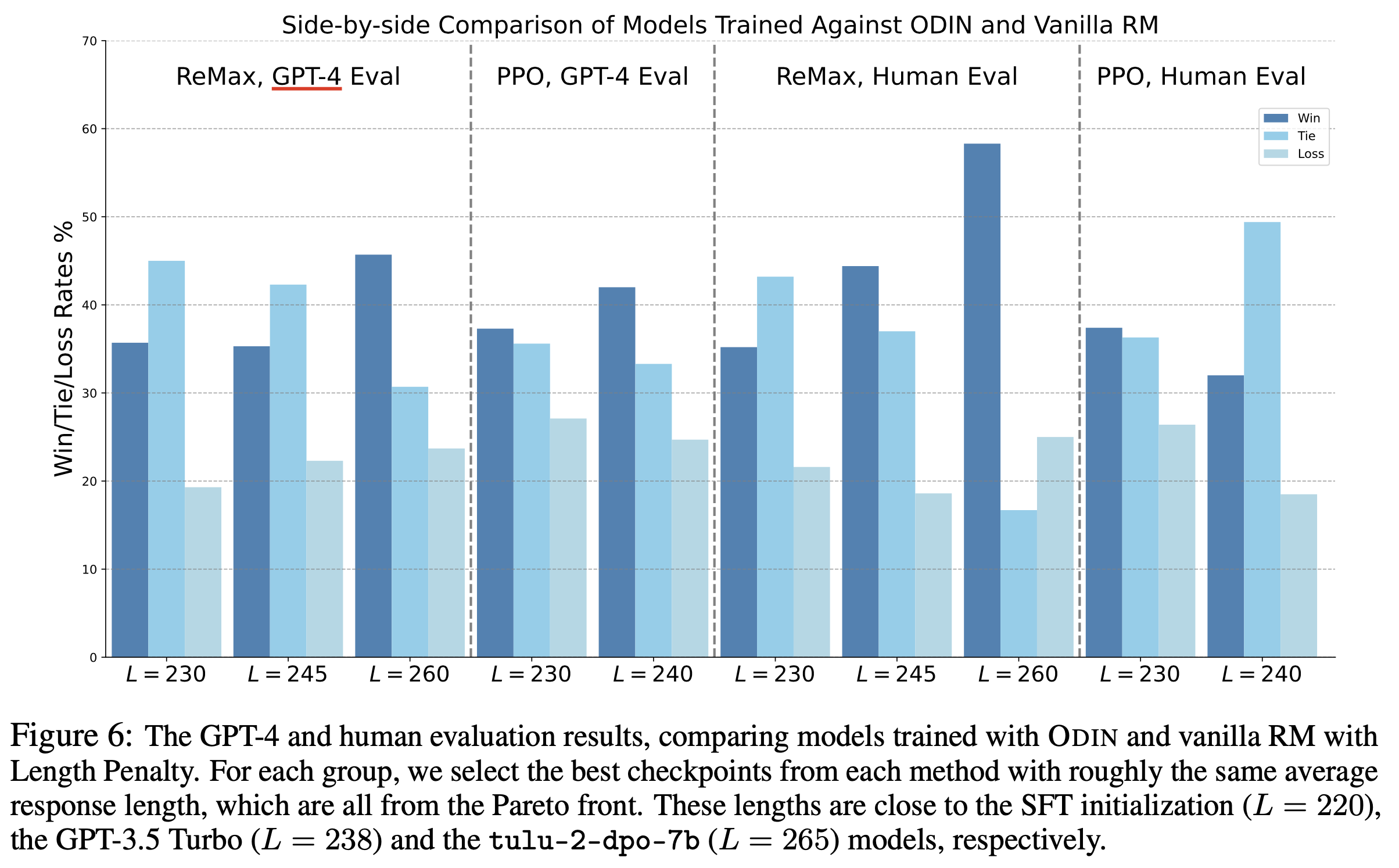 Fig.
Fig.
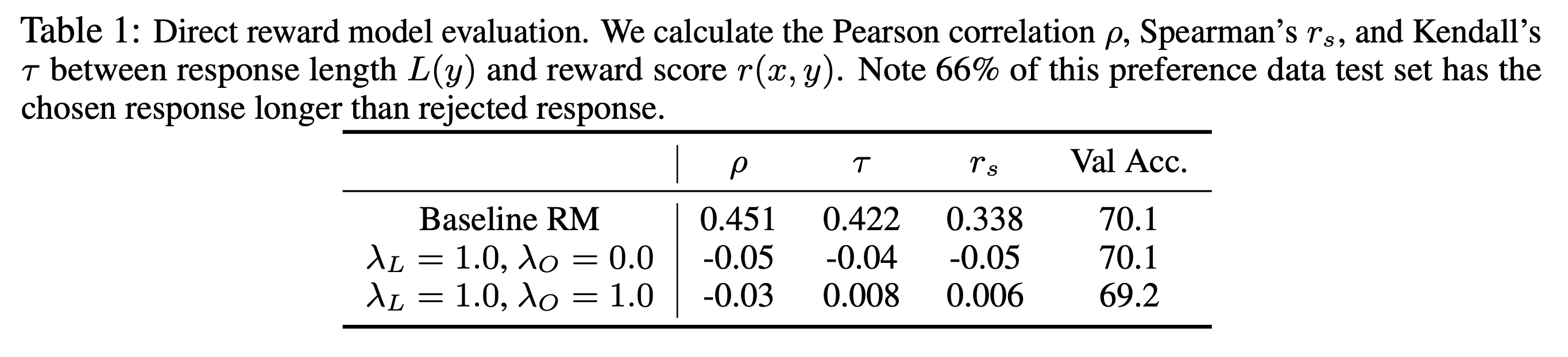 Fig.
Fig.
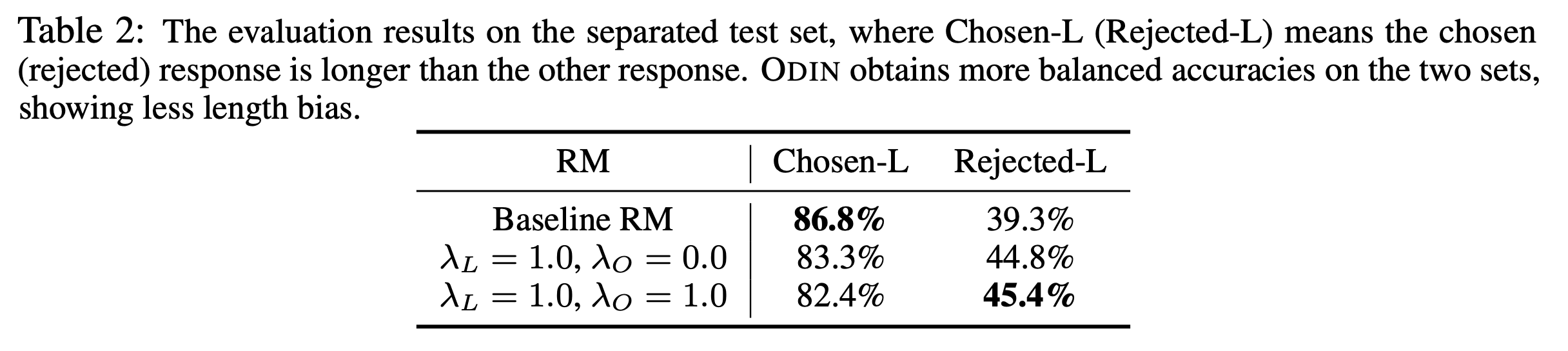 Fig.
Fig.
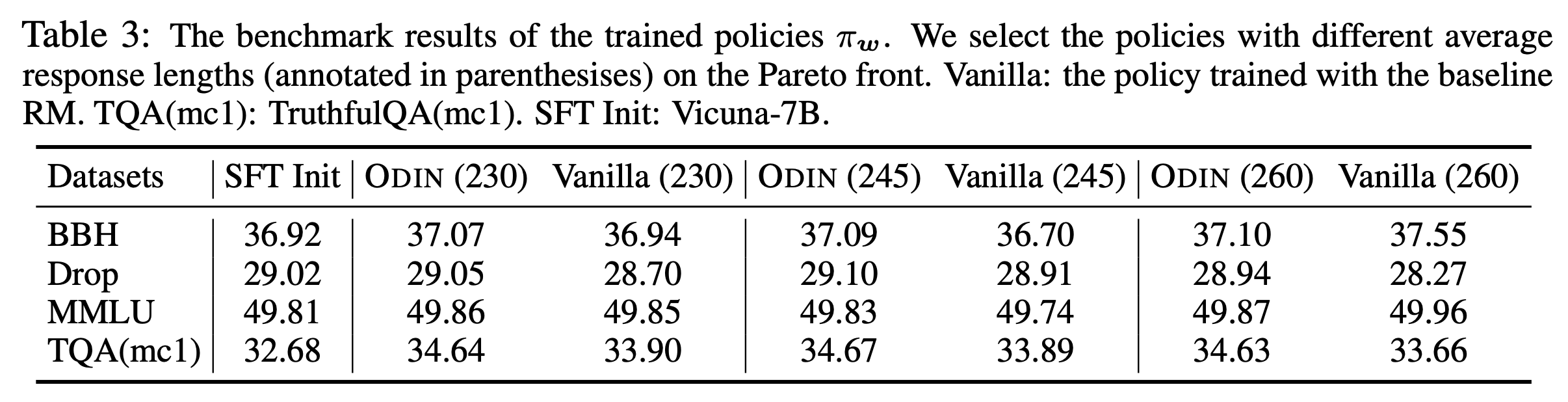 Fig.
Fig.
 Fig.
Fig.
 Fig.
Fig.
Implementation
구현을 위해서 먼저 custom RM class를 정의해준다.
import argparse
from typing import Optional, List, Dict
import torch
from torch import nn
import torch.nn.functional as F
from transformers import AutoModelForCausalLM, AutoTokenizer, AutoConfig
CLASS_TYPE = {
'auto': {
'config': AutoConfig,
'model': AutoModelForCausalLM,
'tokenizer': AutoTokenizer,
}
}
DATA_TYPE = {
'fp32': torch.float32,
'fp16': torch.float16,
'bf16': torch.bfloat16,
}
class Odin(nn.Module):
def __init__(self, model_type, torch_dtype):
super().__init__()
assert model_type in CLASS_TYPE
assert torch_dtype in DATA_TYPE
class_set = CLASS_TYPE[model_type]
torch_dtype = DATA_TYPE[torch_dtype]
config = config_class.from_pretrained(model_path)
model_args = {
'pretrained_model_name_or_path': model_path,
'config': config,
'torch_dtype': torch_dtype,
}
self.model = model_class.from_pretrained(**model_args)
self.config = model.config
n_embedding = self.config.word_embed_proj_dim if hasattr(self.config, "word_embed_proj_dim") else self.config.n_embd
self.q_head = nn.Linear(self.config.n_embd, 1, bias=False, dtype=dtype)
self.l_head = nn.Linear(self.config.n_embd, 1, bias=False, dtype=dtype)
def forward(
self,
input_ids: torch.LongTensor = None,
attention_mask: Optional[torch.Tensor] = None,
labels: Optional[torch.LongTensor] = None,
past_key_values: Optional[List[torch.FloatTensor]] = None,
token_type_ids: Optional[List[torch.Tensor]] = None,
position_ids: Optional[List[torch.Tensor]] = None,
head_mask: Optional[torch.Tensor] = None,
inputs_embeds: Optional[torch.FloatTensor] = None,
):
Pearson, Kendall’s, Spearman’s correltation을 계산하는 수식은 다음과 같은데,
 Fig.
Fig.
paper에서는 주로 pearson correlation을 쓰기 때문에 이 부분을 구현해주면 된다.
def get_corr(
outputs,
lengths
):
outputs_mean = outputs.mean()
lengths_mean = lengths.mean()
nom = torch.sum(torch.dot(outputs_mean, lengths_mean))
denom = torch.sqrt(torch.sum(outputs_mean**2) * torch.sum(lengths_mean**2))
return nom/denom
def length_loss(
q_head_outputs,
l_head_outputs,
lengths,
):
return (
torch.abs(get_corr(q_head_outputs, lengths))
- get_corr(l_head_outputs, lengths)
)