(WIP) Learn from pytorch/lingua (Learning How To 3D Parallelize LLaMa-3 With Pytorch's Native Parallelism Modules and so on)
20 Oct 2024< 목차 >
- Torch Native Parallelism and Lingua Project
- Pytorch Native ZeRO == Fully Sharded Data Parallel (FSDP)
- 3D Parallelism (FSDP + TP + PP)
- Probing
- Profiler
- References
Torch Native Parallelism and Lingua Project
Model scale이 커지면서 Data Parallelism (DP) 만으로 학습이 불가능해지고 Tensor Parallelism (TP), Pipeline Paralellism (PP) 등을 포함한 3d parallelism, 더 나아가 Context Paralellism (CP)까지 해서 4d parallelism을 자유자재로 다룰 수 있어야 하는 시대가 됐다. 하지만 TP, PP같은 Model Parallism (MP)을 사용하기 위한 torch native module은 빨리 개발되지 않았고, 직접 구현하거나 Megatron-LM 같은 opensource를 사용해야만 했다. Megatorn-lm codebase는 많은 기능들을 유기적으로 다루기 위해 추상화를 거듭하고 여러 submodule들을 두기 때문에 수정이 어렵다는 문제가 있고 (not hackable), 따라서 Mixture of Expert (MoE) 같은 model 구조를 바꾸거나 하는 실험에는 구조를 파악하고 코드 수정에 드는 노동이 많이 필요했다. (원래 NVIDIA가 megatron project를 거의 유기했다가 다시 유지하기로 하면서 이제 MoE가 정식적으로 지원되긴 하지만 google등이 MoE를 시도할 적 보다 이미 수년이 늦었다)
하지만 이제 torch에서도 native TP, PP를 지원하기 때문에 더는 어렵게 megatron을 사용할 필요가 없어졌다. 당연히 facebook도 scaling 관련된 기술들을 개발하지 않았던 것은 아니고, 내가 알기로는 FairScale같은게 있었고 내부적으로 사용하는 framework도 있었을 것이다 (안그러면 llama 학습은 불가능 했을테니). 아마 fairscale 에 있던 기술들이 torch native로 적용되는데 시간이 좀 걸린 것 같은데, 이는 flash attention 같은 memory efficient attention이 xformers에서 먼저 개발되고 나중에 편입된것과 같은 맥락이라고 할 수 있다.
torch에 이런 scaling related module들이 편입되면서 pytorch 측에서 이제는 llama를 공개하는, 즉 open weight 을 넘어 codebase를 어느정도 공개하는 opensource를 하기 시작했는데, 아래 세 가지가 주요 repository들이라고 할 수 있다.
torchtune부터 lingua까지 나온 순서대로 리스트를 적었는데,
사실 여기서 아니 셋 다 고만고만 한거 같은데 뭔 차이지? or huggingface trainer 같은거랑 뭐가 다르지?라는 생각을 할 수 있고 실제로 이런 질문들이 lingua를 공개하자 issue에 올라왔다.
물론 여기에 더해서 왜 megatron, deepspeed 말고 torch native parallelism을 써야하지?라고 생각할 수도 있다.
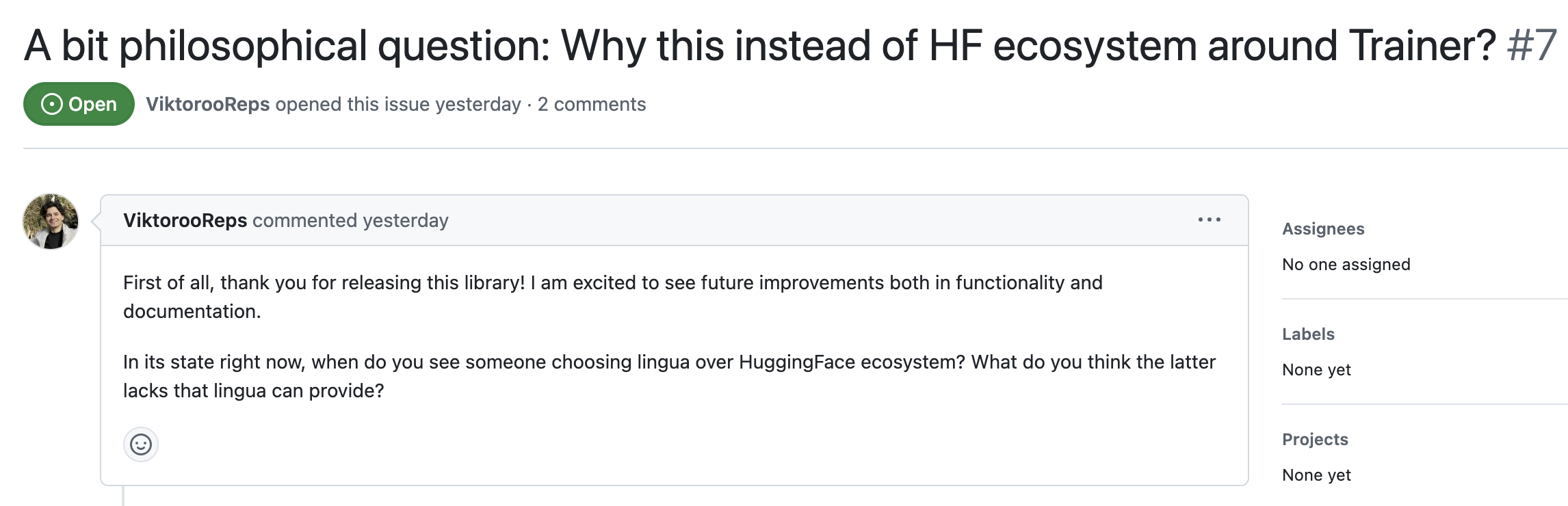 Fig.
Fig.
먼저 앞의 두개 질문에 대한 나의 생각은 다음과 같은데, code author도 똑같이 생각하는 모양이다.
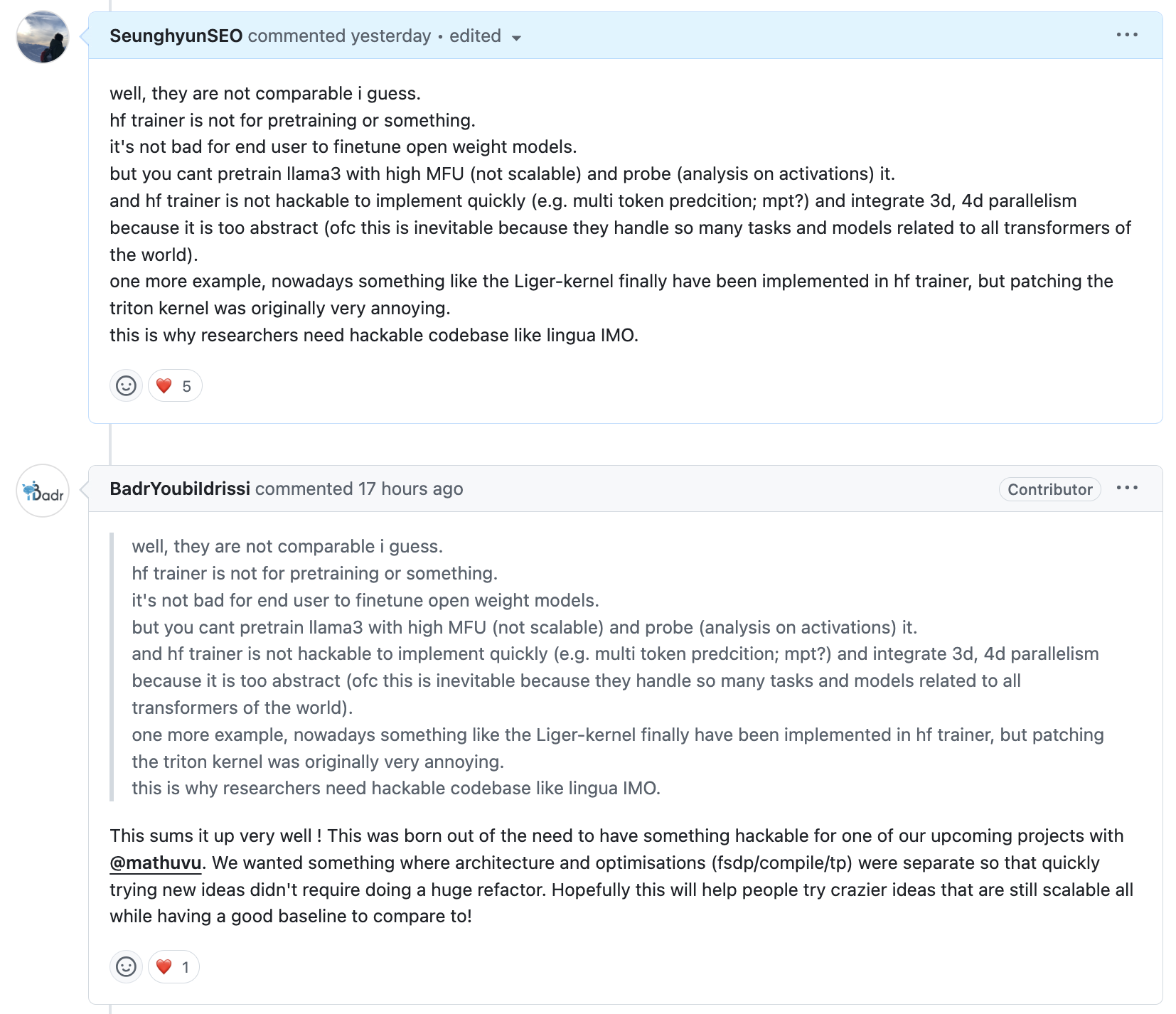 Fig.
Fig.
요약하자면 hf trainer가 너무 wrapping이 많이 되어있어서 전혀 hackable하지 않다는 것이다. 그리고 hf trainer는 3d parallelism 이 나온지가 오래됐는데도 전혀 적용이 되어있지 않기 때문에 대규모 pre-training에 적합하지 않다. (적당히 fine-tuning하는데는 괜찮을지 모르나)
물론 lingua나 torchtitan같은것도 production level llm을 pre-training 하는데 충분하지 않을 수 있는데, 적어도 128~256대 GPU scale에서 높은 Machine FLOPs Utilization (MFU)을 보이면서, model architecture 등을 유연하게 바꾸기 좋은 minimal codebase라고 할 수있다.
torchtitan, lingua 그리고 torchtune의 차이에 대해서는 아래와 같은 author들의 답변이 있었는데, 쉽게 말하면 torchtitan은 torch 에서 계속해서 release 되는 cutting-edge feature들을 선보이는, 즉 engineering?에 좀 집중된 project라고 볼 수 있고, torchtune은 QLoRA같은 low-resource user들을 위한 fine-tuning 에 집중된 project라고 할 수 있으며, lingua는 좀 더 research 향이라고 볼 수 있다.
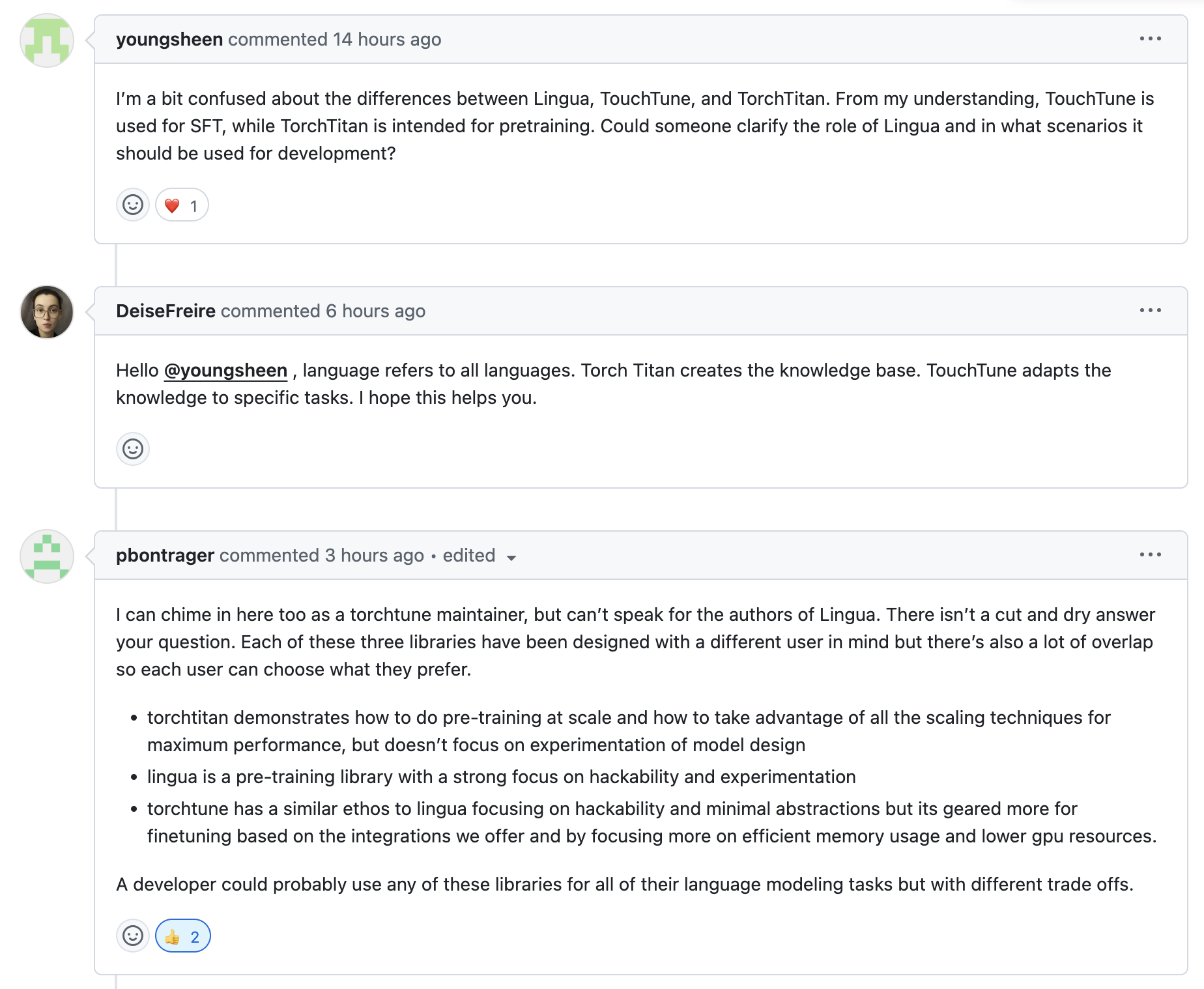 Fig.
Fig.
이번 post에서 나는 lingua를 기준으로 torch paralleism을 어떻게 적용하는지에 대해 설명하고, lingua의 billion scale LLM을 분석하기위한 각종 feature들에 대해 설명해보려고 한다. 왜냐면 train부터 eval까지 가장 minimal하기 때문이고,
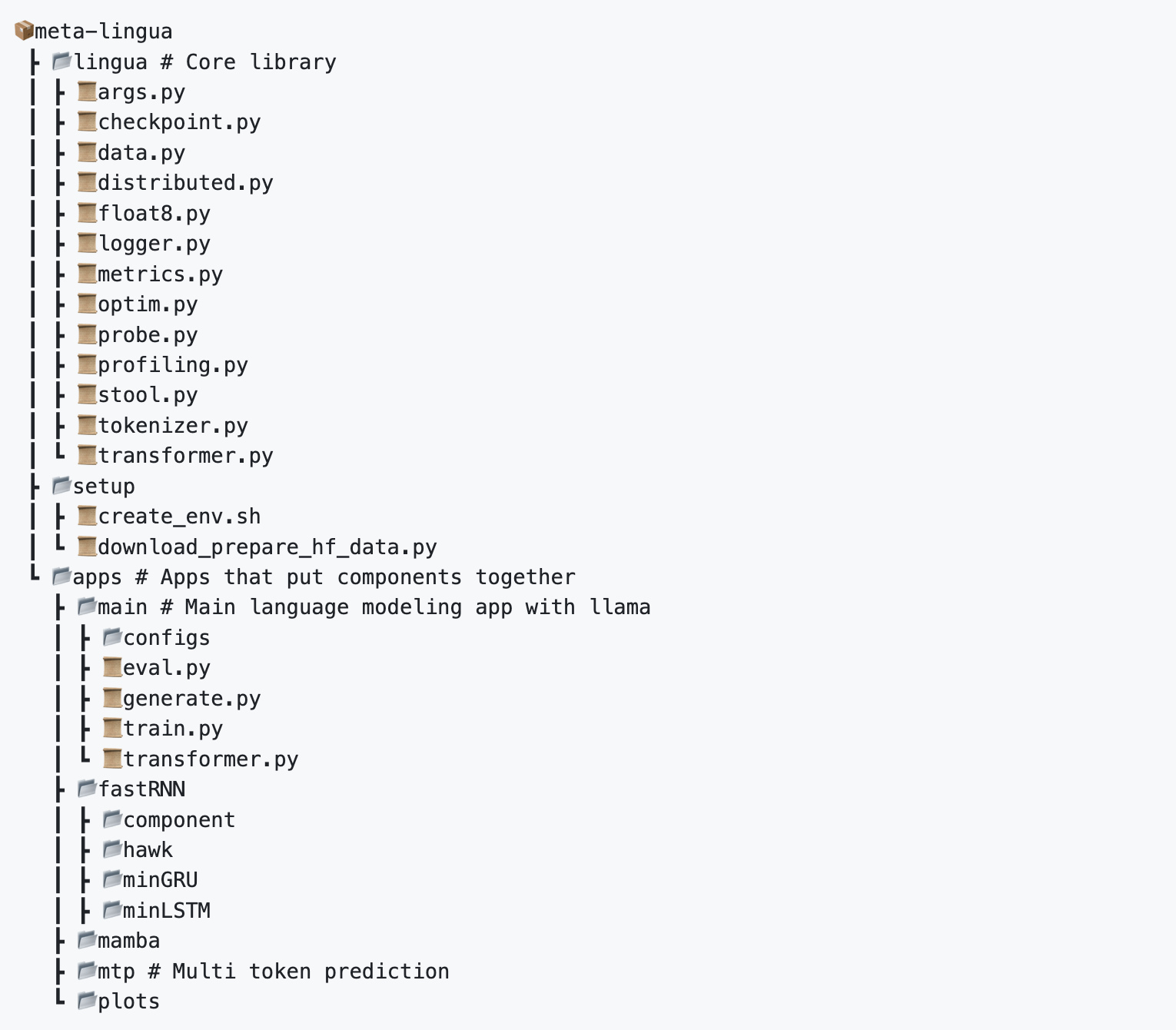 Fig.
Fig.
더불어 MFU도 잘 나오고 baseline benchmark도 잘 측정돼있어서 앞으로도 실험하기 용이할 것 같기 때문이다.
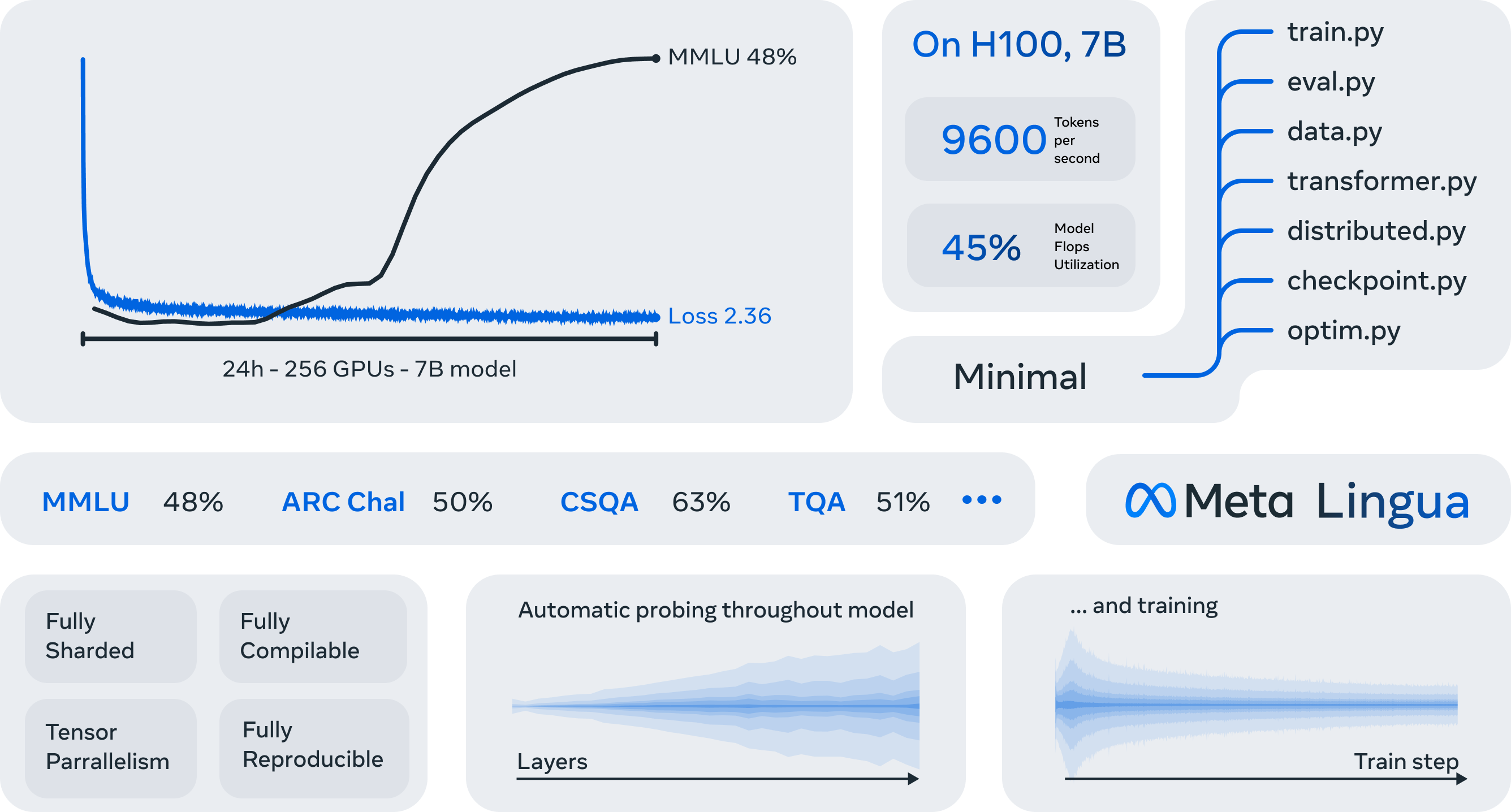 Fig.
Fig.
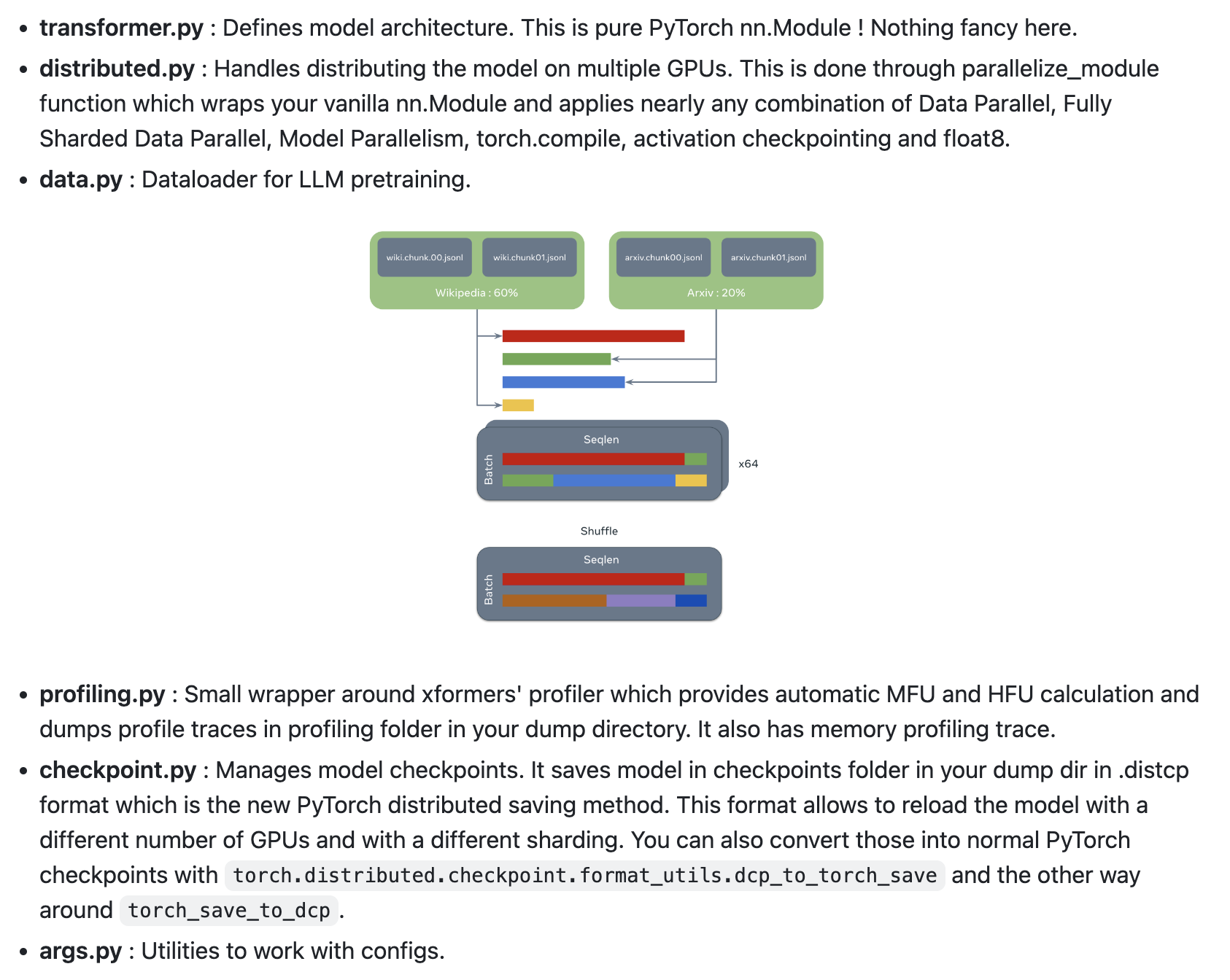 Fig.
Fig.
About HF trainer and Megatron-LM
torch가 native TP를 stable로 지원하고 PP는 nightly로 지원할때, Megatron-LM이 가지는 장점은 아예 없을까?
그건 아니다.
Pytorch Native ZeRO == Fully Sharded Data Parallel (FSDP)
왜 Pytorch는 Fully Sharded Data Parallel (FSDP)를 만들었을까. 사실 이는 Microsoft의 Zero Redundancy Optimization (ZeRO)와 거의 같은 기술이다. Google도 ZeRO-like한 무언갈 쓰고 있고 아마 OpenAI도 철학은 비슷할 것이다. 다만 얼마나 이 기술을 최적화 했느냐?는 차이가 있을 수 있겠다.
FSDP를 써야 하는 이유는 아무래도 deepspeed도 계속 개발되고 있기는 하지만 pytorch backend에 직접 결합돼서 극한까지 최적화를 할 수 있는 torch와 달리 deepspeed는 minimum code modification이 철학이기 때문이다. deepspeed도 torch의 module들을 최대한 활용해서 hook, cuda context, async option등을 열심히 썼지만 장기적으로 FSDP가 최적화가 더 잘될것이라고 생각이 당연히 들겠으나 사실 두 framework에 대한 뚜렷한 비교나 뭐가 더 좋다는 근거는 없다. 그럼에도 이번 post에서는 주제가 torch natvie parallelism에 대한 것이기 때문에 FSDP에 대해 먼저 알아볼 것이다.
FSDP2 == enabling Hybrid FSDP (HSDP)
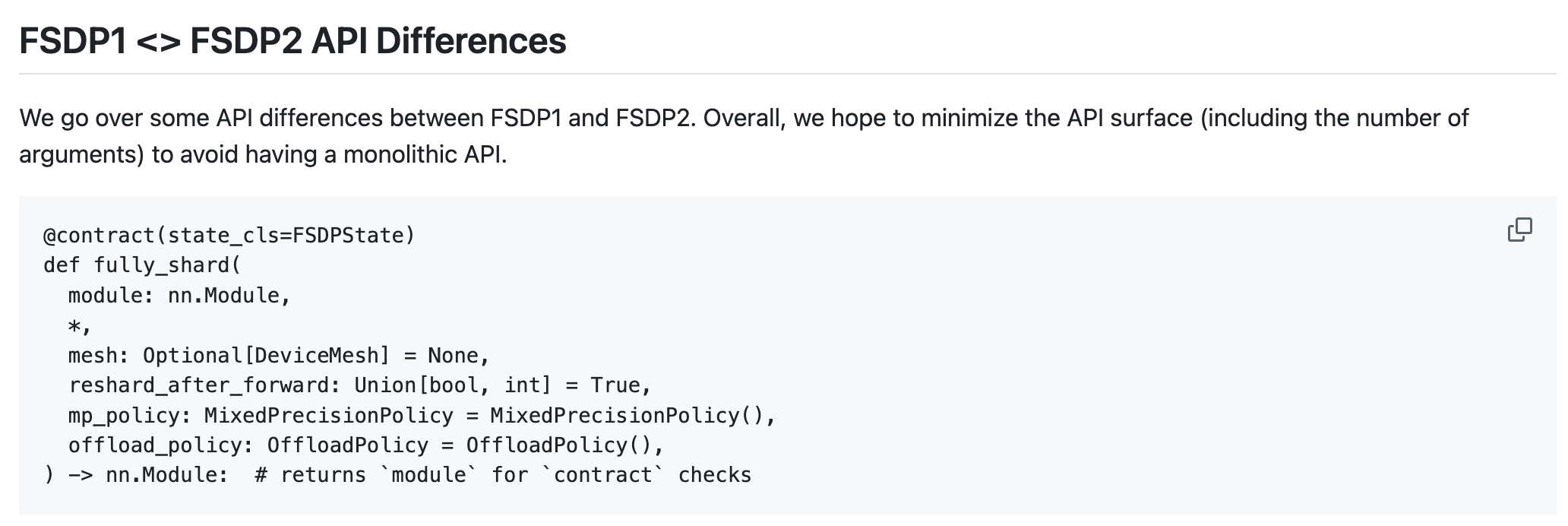 Fig.
Fig.
 Fig.
Fig.
 Fig.
Fig.
 Fig.
Fig.
 Fig.
Fig.
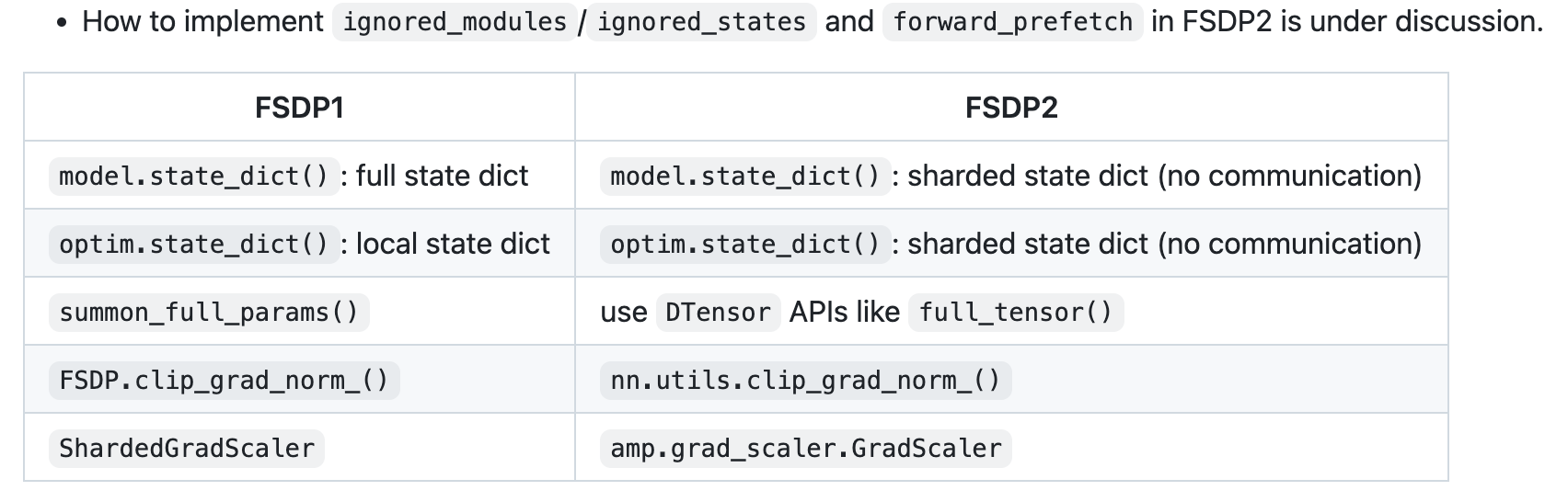 Fig.
Fig.
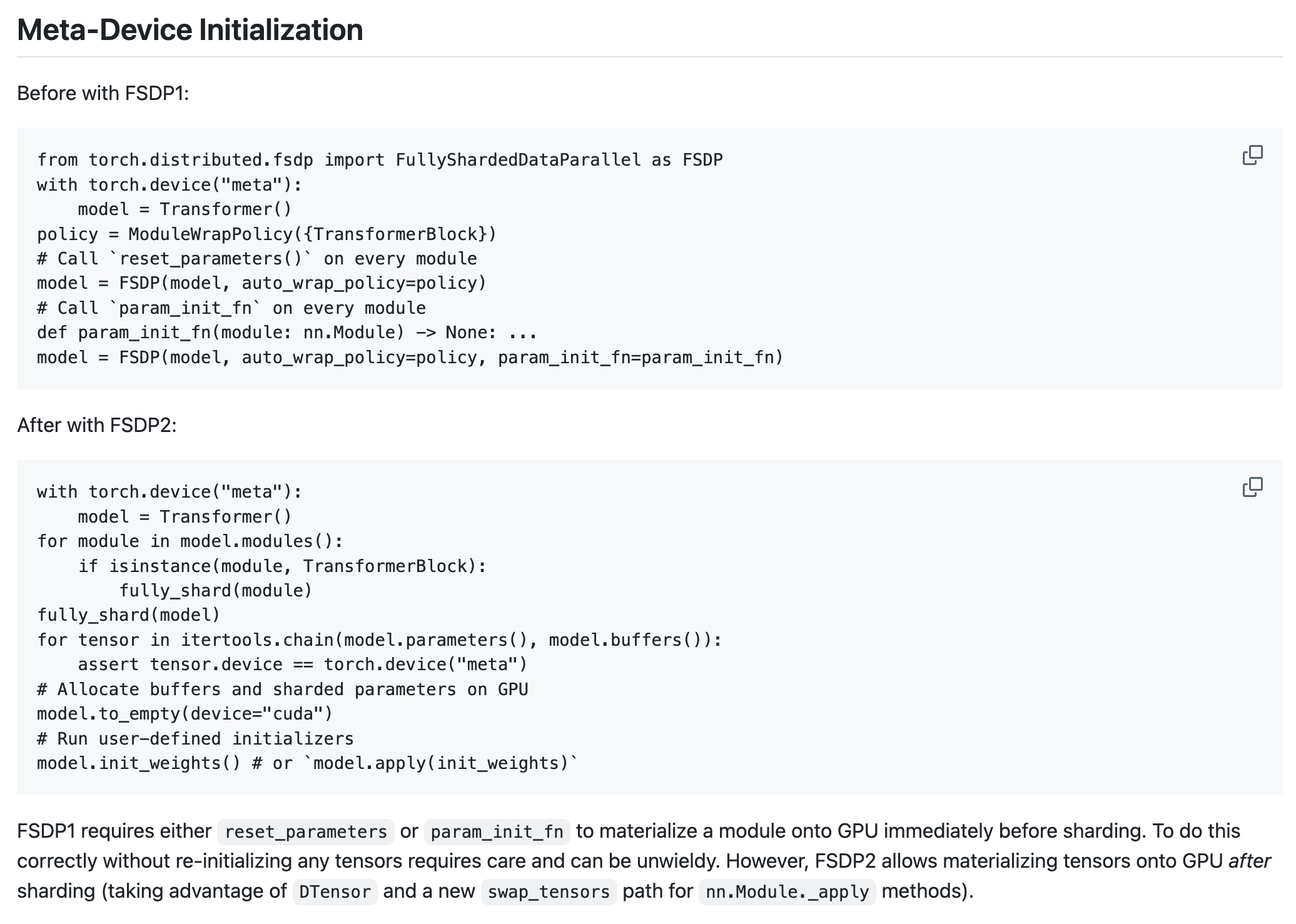 Fig.
Fig.
3D Parallelism (FSDP + TP + PP)
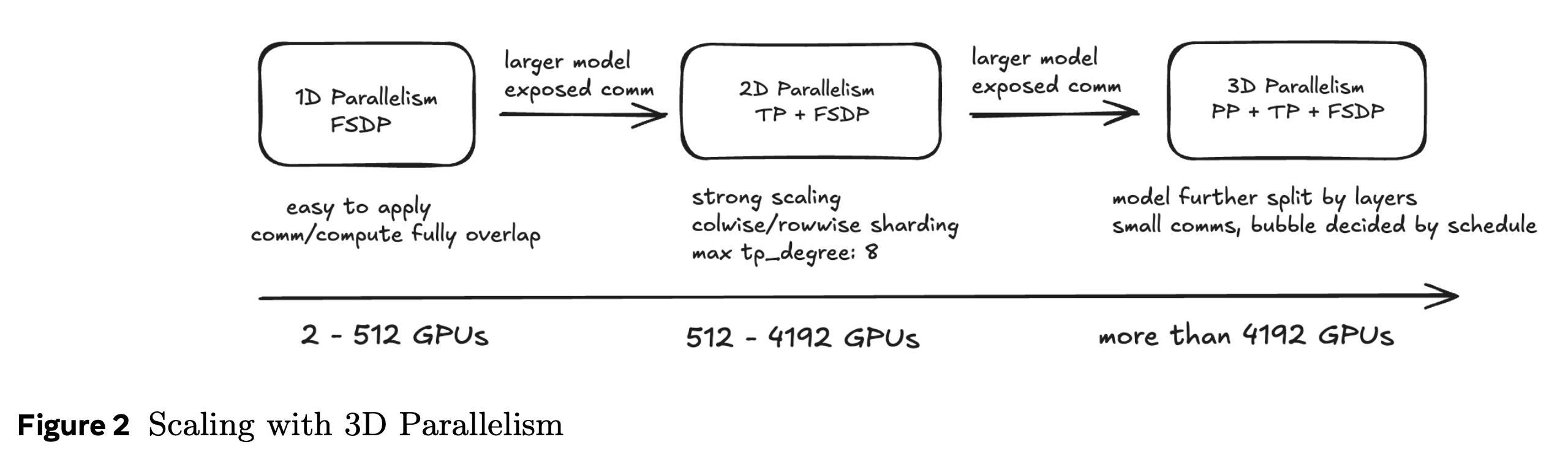 Fig.
Fig.
What Is Device Mesh?
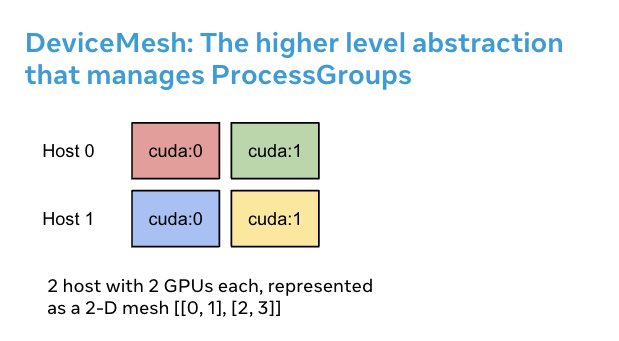 Fig.
Fig.
 Fig.
Fig.
Probing
Profiler
References
- Core Codebases
- torch FSDP resources
- (White Paper) PyTorch FSDP: Experiences on Scaling Fully Sharded Data Parallel
- (Blog) Fully Sharded Data Parallel: faster AI training with fewer GPUs
- (Docs) https://pytorch.org/docs/stable/fsdp.html
- (Docs) torchtitan/docs/fsdp.md
- (IBM Blog) Maximizing training throughput using PyTorch FSDP
- (torch Blog) Maximizing Training Throughput Using PyTorch FSDP and Torch.compile
- tweet
- tmp
- Videos