(WIP) GPU Programming (5/6) - Triton Impl of Fused Attention
18 May 2024< 목차 >
Efficient Scaled Dot Product Attention (SDPA)
이번에는 지난 post에 이어 memory efficient (and fast) Scaled Dot Product Attention (SDPA) kernel을 짜보려고 한다. 사실 meta의 transformer building block을 최적화하는 이런저런 구현체들이 있는 xformers나 Tri Dao의 Flash attention, 그 밖에 다른 기업들이 release한 구현체들에 있는 efficient SDPA kernel은 다 비슷한 철학을 가지고 있다.
- DRAM/SRAM을 오가며 data read/write을 반복하지 말고 한 kernel에서 다 처리하자
- 흔히들 memory bottleneck 이라고 알고있는 self attention map을 명시적으로 만들지 말고 (not materializing) context vector를 계산하자.
- online (cumulative) sofmtax 를 쓴다.
 Fig. Fused Attention은 self-attention에 필요한 여러 operations를 합친다.
Fig. Fused Attention은 self-attention에 필요한 여러 operations를 합친다.
특히 flash attention에 대해서 많은사람들이 A100 hardware의 hierarchy에 대해 memory access time을 줄여 time complexity만 개선했다고 생각하는 분들이 있는데, cumulative attention을 통한 space complexity가 굉장히 큰 contribution point이다. 이를 쓸 경우 보통 알고있는 self-attention의 memory complexity는 sequence length, \(L\)에 대해 \(O(L^2)\)라는 사실과 달리 \(O(L)\)으로 줄어든다.
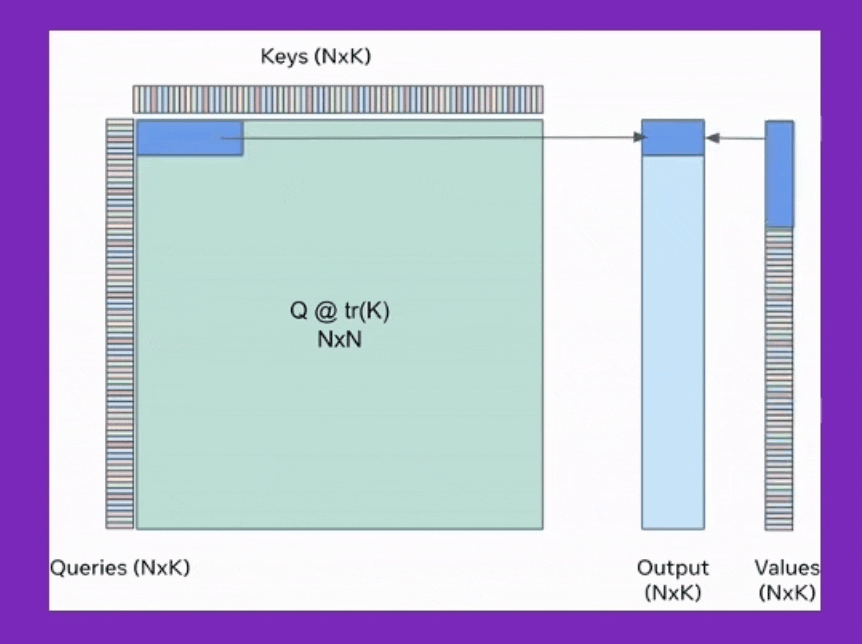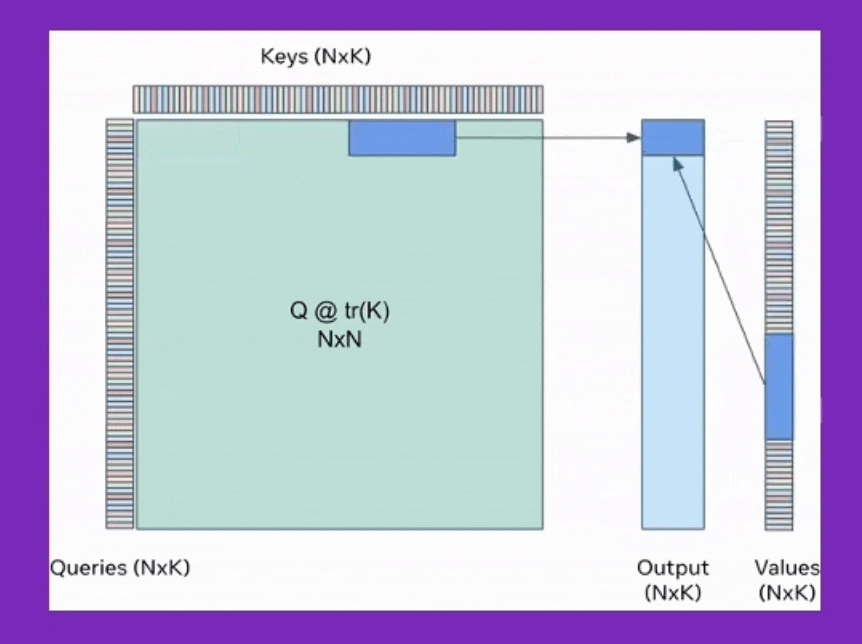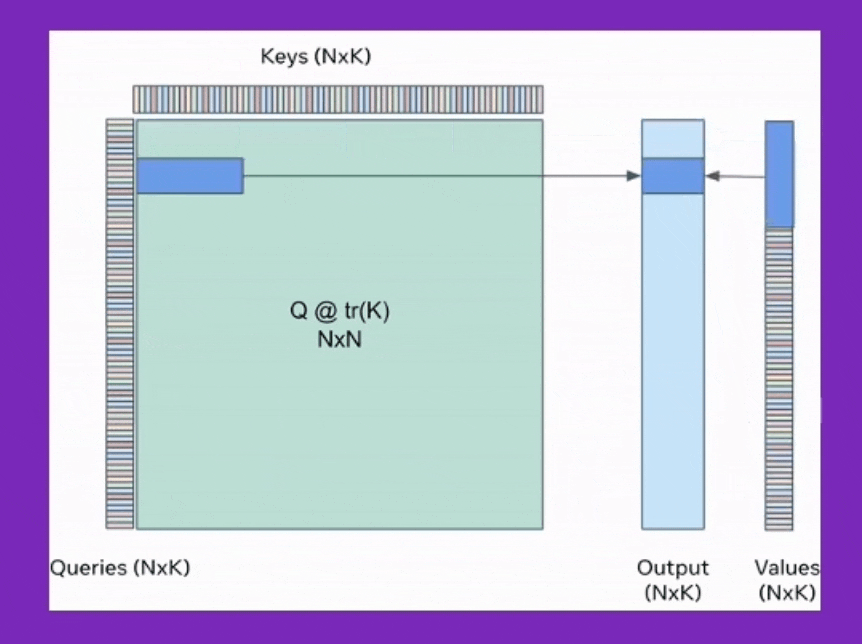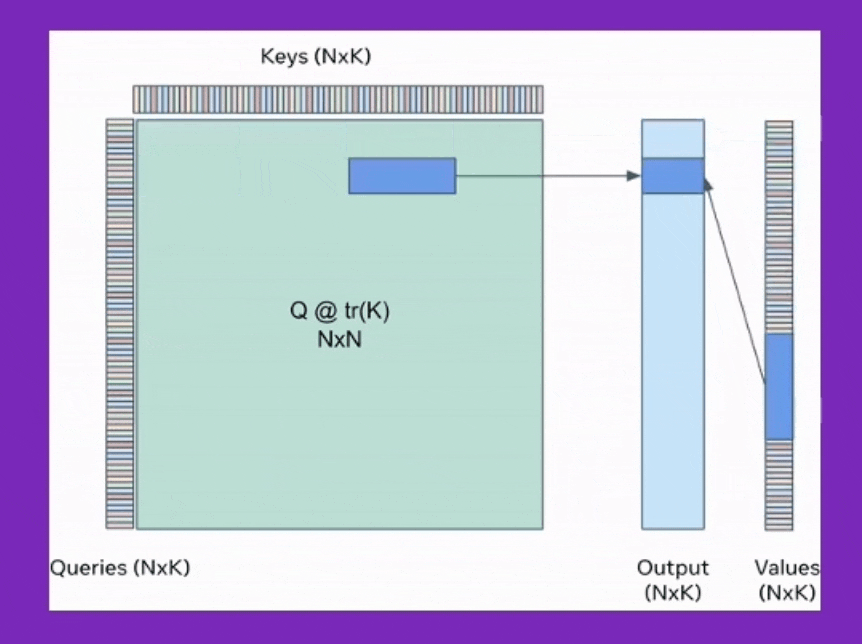 Fig. Cumulative Attention
Fig. Cumulative Attention
사실 flash attention의 원래 구현 repo는 Tri Dao가 만든 것으로 대부분 cpp, CUDA로 이루어져있다. 구현체 자체는 매우 복잡해보이지 않지만 CUDA coding을 해야한다는 것 자체가 스트레스일 수 있다. 그런데 당연하게도 flash attention은 triton 으로 구현할 수 있고, OpenAI에서 triton을 개발한 Phil Tilet이 거의 유사한 성능의 triton based flash attention을 구현하여 Tri Dao의 공식 flash attention repo에도 이것이 반영되어있는 걸 볼 수 있다.

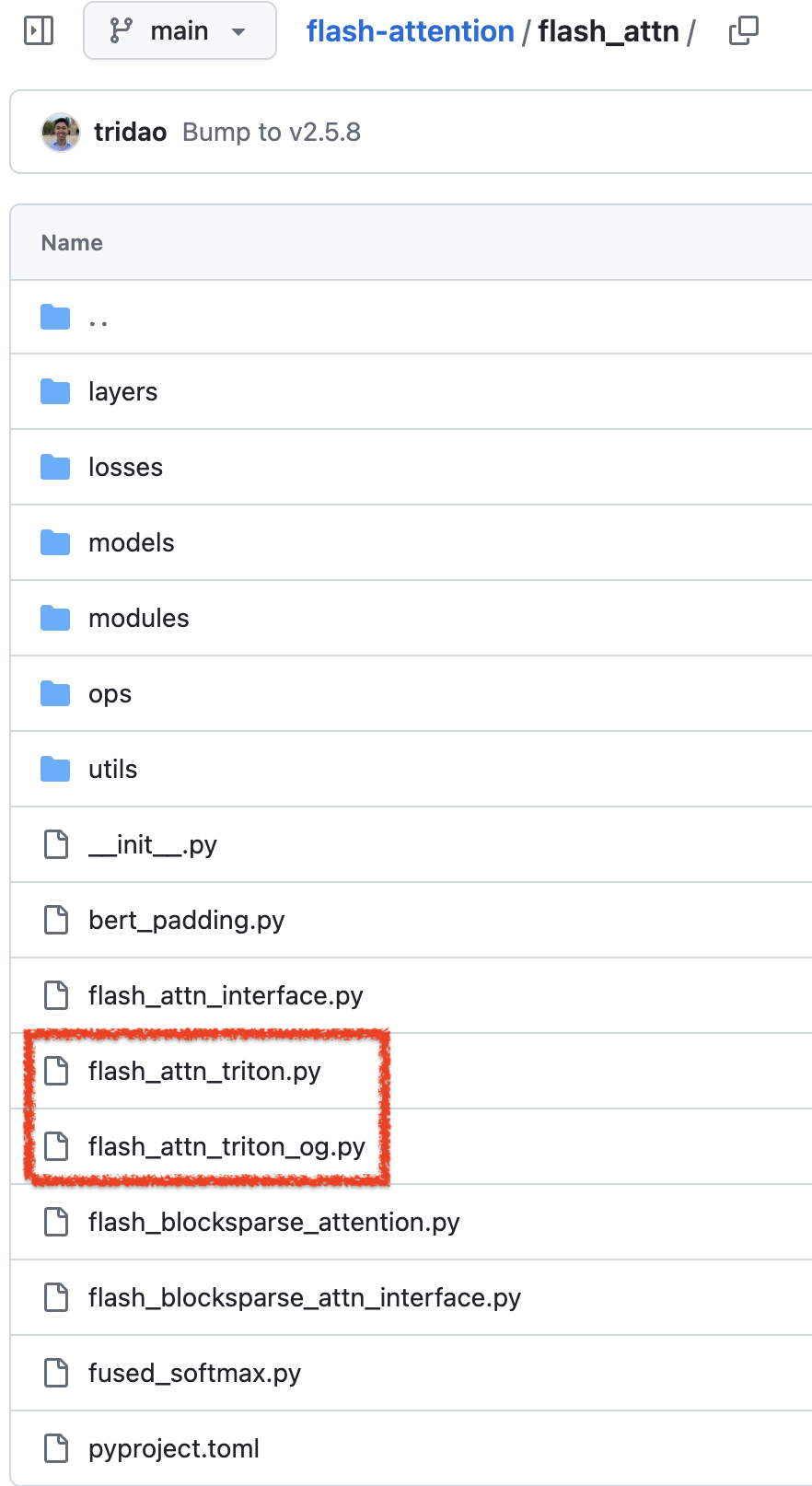
이는 다른 layenorm, MLP, CE loss 에 대해서도 마찬가지이다. 원래는 모두 C기반으로 구현되어 있지만,
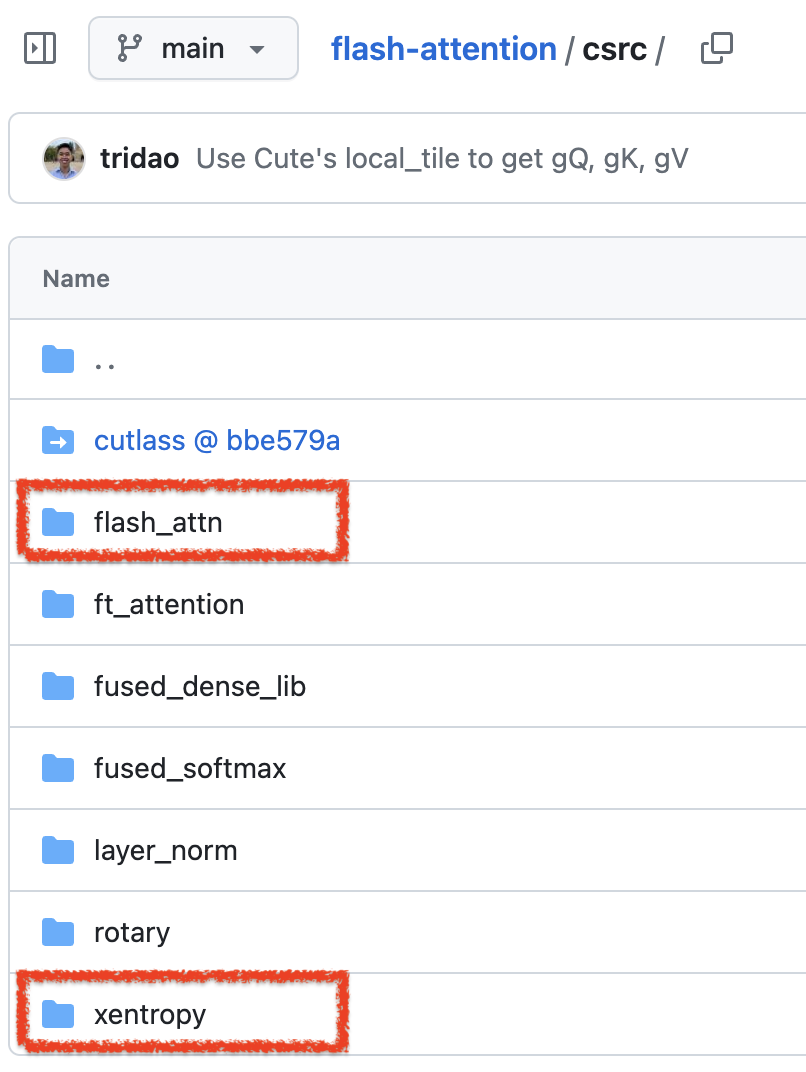
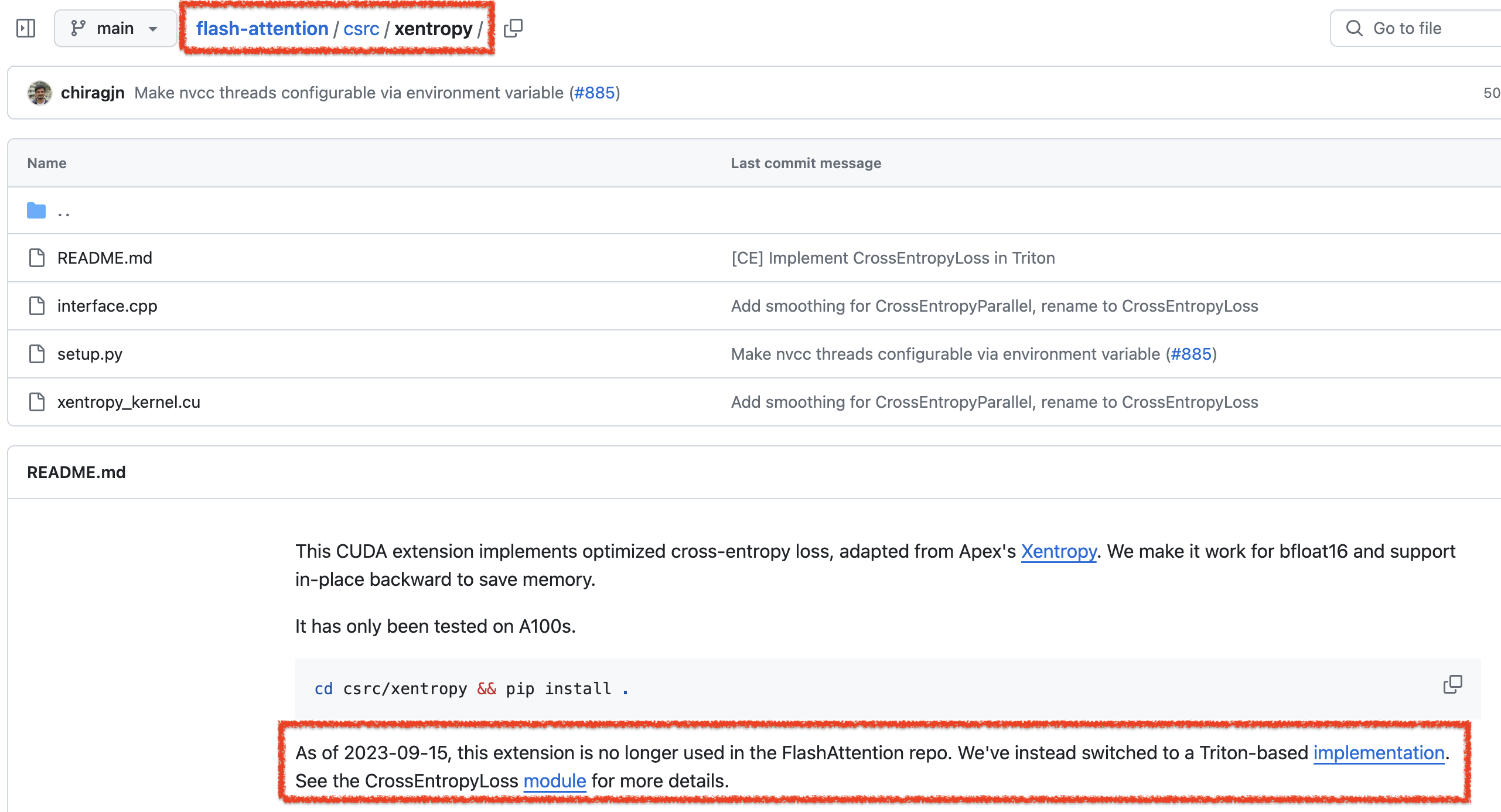
이 또한 옛날옛적에 deprecation 되었고 triton 기반으로 갈아탔다는 것을 볼 수 있다.
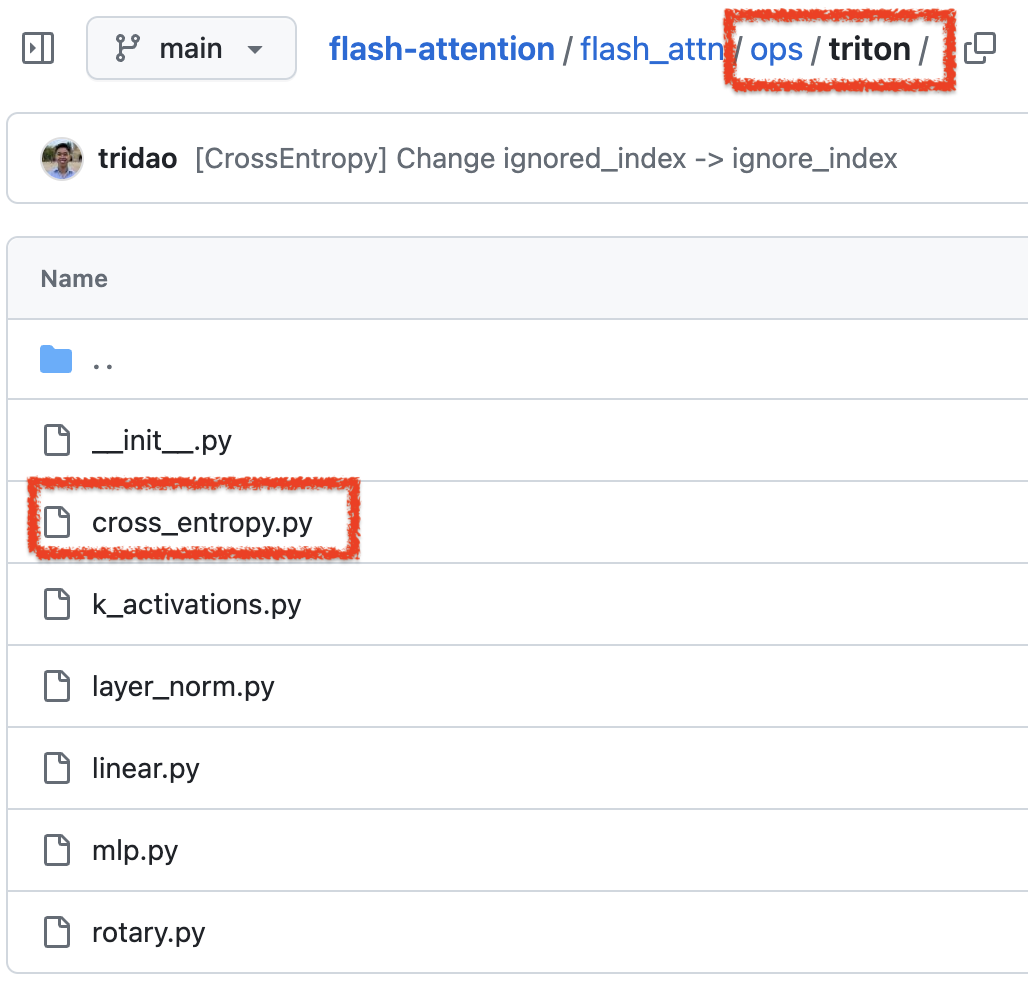
그럼 triton 기반의 flash attention에 대해서 알아보자.
Key Ideas
Online Softmax
Implementation
Main Class
import pytest
import torch
import triton
import triton.language as tl
class _attention(torch.autograd.Function):
@staticmethod
def forward(ctx, q, k, v, sm_scale):
BLOCK = 128
# shape constraints
Lq, Lk, Lv = q.shape[-1], k.shape[-1], v.shape[-1]
assert Lq == Lk and Lk == Lv
assert Lk in {16, 32, 64, 128}
o = torch.empty_like(q)
grid = (triton.cdiv(q.shape[2], BLOCK), q.shape[0] * q.shape[1])
tmp = torch.empty(
(q.shape[0] * q.shape[1], q.shape[2]), device=q.device, dtype=torch.float32
)
L = torch.empty((q.shape[0] * q.shape[1], q.shape[2]), device=q.device, dtype=torch.float32)
m = torch.empty((q.shape[0] * q.shape[1], q.shape[2]), device=q.device, dtype=torch.float32)
num_warps = 4 if Lk <= 64 else 8
_fwd_kernel[grid](
q,
k,
v,
sm_scale,
tmp,
L,
m,
o,
q.stride(0),
q.stride(1),
q.stride(2),
q.stride(3),
k.stride(0),
k.stride(1),
k.stride(2),
k.stride(3),
v.stride(0),
v.stride(1),
v.stride(2),
v.stride(3),
o.stride(0),
o.stride(1),
o.stride(2),
o.stride(3),
q.shape[0],
q.shape[1],
q.shape[2],
BLOCK_M=BLOCK,
BLOCK_N=BLOCK,
BLOCK_DMODEL=Lk,
num_warps=num_warps,
num_stages=1,
)
ctx.save_for_backward(q, k, v, o, L, m)
ctx.BLOCK = BLOCK
ctx.grid = grid
ctx.sm_scale = sm_scale
ctx.BLOCK_DMODEL = Lk
return o
@staticmethod
def backward(ctx, do):
q, k, v, o, l, m = ctx.saved_tensors
do = do.contiguous()
dq = torch.zeros_like(q, dtype=torch.float32)
dk = torch.empty_like(k)
dv = torch.empty_like(v)
do_scaled = torch.empty_like(do)
delta = torch.empty_like(l)
_bwd_preprocess[(ctx.grid[0] * ctx.grid[1],)](
o,
do,
l,
do_scaled,
delta,
BLOCK_M=ctx.BLOCK,
D_HEAD=ctx.BLOCK_DMODEL,
)
# NOTE: kernel currently buggy for other values of `num_warps`
num_warps = 8
_bwd_kernel[(ctx.grid[1],)](
q,
k,
v,
ctx.sm_scale,
o,
do_scaled,
dq,
dk,
dv,
l,
m,
delta,
q.stride(0),
q.stride(1),
q.stride(2),
q.stride(3),
k.stride(0),
k.stride(1),
k.stride(2),
k.stride(3),
v.stride(0),
v.stride(1),
v.stride(2),
v.stride(3),
q.shape[0],
q.shape[1],
q.shape[2],
ctx.grid[0],
BLOCK_M=ctx.BLOCK,
BLOCK_N=ctx.BLOCK,
BLOCK_DMODEL=ctx.BLOCK_DMODEL,
num_warps=num_warps,
num_stages=1,
)
return dq.to(q.dtype), dk, dv, None
attention = _attention.apply
Forward Pass

@triton.jit
def _fwd_kernel(
Q,
K,
V,
sm_scale,
TMP,
L,
M, # NOTE: TMP is a scratchpad buffer to workaround a compiler bug
Out,
stride_qz,
stride_qh,
stride_qm,
stride_qk,
stride_kz,
stride_kh,
stride_kn,
stride_kk,
stride_vz,
stride_vh,
stride_vk,
stride_vn,
stride_oz,
stride_oh,
stride_om,
stride_on,
Z,
H,
N_CTX,
BLOCK_M: tl.constexpr,
BLOCK_DMODEL: tl.constexpr,
BLOCK_N: tl.constexpr,
):
start_m = tl.program_id(0)
off_hz = tl.program_id(1)
# initialize offsets
offs_m = start_m * BLOCK_M + tl.arange(0, BLOCK_M)
offs_n = tl.arange(0, BLOCK_N)
offs_d = tl.arange(0, BLOCK_DMODEL)
off_q = off_hz * stride_qh + offs_m[:, None] * stride_qm + offs_d[None, :] * stride_qk
off_k = off_hz * stride_qh + offs_n[:, None] * stride_kn + offs_d[None, :] * stride_kk
off_v = off_hz * stride_qh + offs_n[:, None] * stride_qm + offs_d[None, :] * stride_qk
# Initialize pointers to Q, K, V
q_ptrs = Q + off_q
k_ptrs = K + off_k
v_ptrs = V + off_v
# initialize pointer to m and l
t_ptrs = TMP + off_hz * N_CTX + offs_m
m_i = tl.zeros([BLOCK_M], dtype=tl.float32) - float("inf")
l_i = tl.zeros([BLOCK_M], dtype=tl.float32)
acc = tl.zeros([BLOCK_M, BLOCK_DMODEL], dtype=tl.float32)
# load q: it will stay in SRAM throughout
q = tl.load(q_ptrs)
# loop over k, v and update accumulator
for start_n in range(0, (start_m + 1) * BLOCK_M, BLOCK_N):
start_n = tl.multiple_of(start_n, BLOCK_N)
# -- compute qk ----
k = tl.load(k_ptrs + start_n * stride_kn)
qk = tl.zeros([BLOCK_M, BLOCK_N], dtype=tl.float32)
qk += tl.dot(q, k, trans_b=True)
qk *= sm_scale
qk += tl.where(offs_m[:, None] >= (start_n + offs_n[None, :]), 0, float("-inf"))
# -- compute m_ij, p, l_ij
m_ij = tl.max(qk, 1)
p = tl.exp(qk - m_ij[:, None])
l_ij = tl.sum(p, 1)
# -- update m_i and l_i
m_i_new = tl.maximum(m_i, m_ij)
alpha = tl.exp(m_i - m_i_new)
beta = tl.exp(m_ij - m_i_new)
l_i_new = alpha * l_i + beta * l_ij
# -- update output accumulator --
# scale p
p_scale = beta / l_i_new
p = p * p_scale[:, None]
# scale acc
acc_scale = l_i / l_i_new * alpha
tl.store(t_ptrs, acc_scale)
acc_scale = tl.load(t_ptrs) # BUG: have to store and immediately load
acc = acc * acc_scale[:, None]
# update acc
v = tl.load(v_ptrs + start_n * stride_vk)
p = p.to(v.dtype)
acc += tl.dot(p, v)
# update m_i and l_i
l_i = l_i_new
m_i = m_i_new
# rematerialize offsets to save registers
start_m = tl.program_id(0)
offs_m = start_m * BLOCK_M + tl.arange(0, BLOCK_M)
# write back l and m
l_ptrs = L + off_hz * N_CTX + offs_m
m_ptrs = M + off_hz * N_CTX + offs_m
tl.store(l_ptrs, l_i)
tl.store(m_ptrs, m_i)
# initialize pointers to output
offs_n = tl.arange(0, BLOCK_DMODEL)
off_o = off_hz * stride_oh + offs_m[:, None] * stride_om + offs_n[None, :] * stride_on
out_ptrs = Out + off_o
tl.store(out_ptrs, acc)
Backward Pass

@triton.jit
def _bwd_preprocess(
Out,
DO,
L,
NewDO,
Delta,
BLOCK_M: tl.constexpr,
D_HEAD: tl.constexpr,
):
off_m = tl.program_id(0) * BLOCK_M + tl.arange(0, BLOCK_M)
off_n = tl.arange(0, D_HEAD)
# load
o = tl.load(Out + off_m[:, None] * D_HEAD + off_n[None, :]).to(tl.float32)
do = tl.load(DO + off_m[:, None] * D_HEAD + off_n[None, :]).to(tl.float32)
denom = tl.load(L + off_m).to(tl.float32)
# compute
do = do / denom[:, None]
delta = tl.sum(o * do, axis=1)
# write-back
tl.store(NewDO + off_m[:, None] * D_HEAD + off_n[None, :], do)
tl.store(Delta + off_m, delta)
@triton.jit
def _bwd_kernel(
Q,
K,
V,
sm_scale,
Out,
DO,
DQ,
DK,
DV,
L,
M,
D,
stride_qz,
stride_qh,
stride_qm,
stride_qk,
stride_kz,
stride_kh,
stride_kn,
stride_kk,
stride_vz,
stride_vh,
stride_vk,
stride_vn,
Z,
H,
N_CTX,
num_block,
BLOCK_M: tl.constexpr,
BLOCK_DMODEL: tl.constexpr,
BLOCK_N: tl.constexpr,
):
off_hz = tl.program_id(0)
off_z = off_hz // H
off_h = off_hz % H
# offset pointers for batch/head
Q += off_z * stride_qz + off_h * stride_qh
K += off_z * stride_qz + off_h * stride_qh
V += off_z * stride_qz + off_h * stride_qh
DO += off_z * stride_qz + off_h * stride_qh
DQ += off_z * stride_qz + off_h * stride_qh
DK += off_z * stride_qz + off_h * stride_qh
DV += off_z * stride_qz + off_h * stride_qh
for start_n in range(0, num_block):
lo = start_n * BLOCK_M
# initialize row/col offsets
offs_qm = lo + tl.arange(0, BLOCK_M)
offs_n = start_n * BLOCK_M + tl.arange(0, BLOCK_M)
offs_m = tl.arange(0, BLOCK_N)
offs_k = tl.arange(0, BLOCK_DMODEL)
# initialize pointers to value-like data
q_ptrs = Q + (offs_qm[:, None] * stride_qm + offs_k[None, :] * stride_qk)
k_ptrs = K + (offs_n[:, None] * stride_kn + offs_k[None, :] * stride_kk)
v_ptrs = V + (offs_n[:, None] * stride_qm + offs_k[None, :] * stride_qk)
do_ptrs = DO + (offs_qm[:, None] * stride_qm + offs_k[None, :] * stride_qk)
dq_ptrs = DQ + (offs_qm[:, None] * stride_qm + offs_k[None, :] * stride_qk)
# pointer to row-wise quantities in value-like data
D_ptrs = D + off_hz * N_CTX
m_ptrs = M + off_hz * N_CTX
# initialize dv amd dk
dv = tl.zeros([BLOCK_M, BLOCK_DMODEL], dtype=tl.float32)
dk = tl.zeros([BLOCK_M, BLOCK_DMODEL], dtype=tl.float32)
# k and v stay in SRAM throughout
k = tl.load(k_ptrs)
v = tl.load(v_ptrs)
# loop over rows
for start_m in range(lo, num_block * BLOCK_M, BLOCK_M):
offs_m_curr = start_m + offs_m
# load q, k, v, do on-chip
q = tl.load(q_ptrs)
# recompute p = softmax(qk, dim=-1).T
# NOTE: `do` is pre-divided by `l`; no normalization here
qk = tl.dot(q, k, trans_b=True)
qk = tl.where(offs_m_curr[:, None] >= (offs_n[None, :]), qk, float("-inf"))
m = tl.load(m_ptrs + offs_m_curr)
p = tl.exp(qk * sm_scale - m[:, None])
# compute dv
do = tl.load(do_ptrs)
dv += tl.dot(p.to(do.dtype), do, trans_a=True)
# compute dp = dot(v, do)
Di = tl.load(D_ptrs + offs_m_curr)
dp = tl.zeros([BLOCK_M, BLOCK_N], dtype=tl.float32) - Di[:, None]
dp += tl.dot(do, v, trans_b=True)
# compute ds = p * (dp - delta[:, None])
ds = p * dp * sm_scale
# compute dk = dot(ds.T, q)
dk += tl.dot(ds.to(q.dtype), q, trans_a=True)
# # compute dq
dq = tl.load(dq_ptrs, eviction_policy="evict_last")
dq += tl.dot(ds.to(k.dtype), k)
tl.store(dq_ptrs, dq, eviction_policy="evict_last")
# # increment pointers
dq_ptrs += BLOCK_M * stride_qm
q_ptrs += BLOCK_M * stride_qm
do_ptrs += BLOCK_M * stride_qm
# write-back
dv_ptrs = DV + (offs_n[:, None] * stride_qm + offs_k[None, :] * stride_qk)
dk_ptrs = DK + (offs_n[:, None] * stride_kn + offs_k[None, :] * stride_kk)
tl.store(dv_ptrs, dv)
tl.store(dk_ptrs, dk)