LLM-RLHF Series (6/6) - Implementation Details of PPO and RLHF
18 Dec 2023< 목차 >
- Overview
- Preliminaries
- Training with PPO
- Compared to Transformer Reinforcement Learning X (TRLX)
- Some Details
- Outro
- References
- part 1: Technical Review of LLM and RLHF
- part 2: Model Architecture and Implementation Details
- part 3: Inference (Generation) Details for LLM
- part 3: Evaluation Metrics for LLM
- part 4: Challenges and Future of LLM
- part 5:
Implementation Details of PPO and RLHF
Overview
이번 post에서는 Reinforcement Learning from Human Feedback (RLHF)를 구현한 repository들을 살펴보려고 한다. 유명한 RLHF의 구현체로는 CarperAI의 trlx와 Microsoft Deespeed Team의 DeepSpeed-Chat (dschat)가 있는데, 이 둘을 위주로 살펴보도록 하자. (이 둘은 거의 비슷함)
Supervised Fine-Tuning (SFT)나 Reward Modeling (RM)은 생략할 것이다. 이 둘은 구현이 너무 간단하기 때문이다. (RM을 학습할 때 몇 가지 지켜줘야 하는 것들도 있는데, 가령 같은 prompt내에서의 pairwise data들은 한 batch에 몰아넣어줘야 하지만 이 부분을 구현한 open-source에는 없기도 하고, 이번 post주제는 PPO이기 때문이다.)
사실 very large model에 대해서 제대로 working하는 RLHF trainer를 구성하기 위해서는 rollout을 할 inference engine과 Reward Model (RM), Reference Model (SFT model) 등을 따로 api로 띄워 효율적으로 관리하는 부분을 구현한다거나 memory관리를 위해 이런 model들을 내렷다가 올렸다가 한다거나 logit을 어디 caching해둔다던가 하는 detail들이 많은데, 이 부분은 본 post의 범위를 벗어나기도 하거니와 trlx나 dschat이 이런 것들까지 잘 해주지 않는 것 같아 무시하겠다. 오로지 PPO를 위한 detail과 이를 위해 필요한 것들만 보겠다.
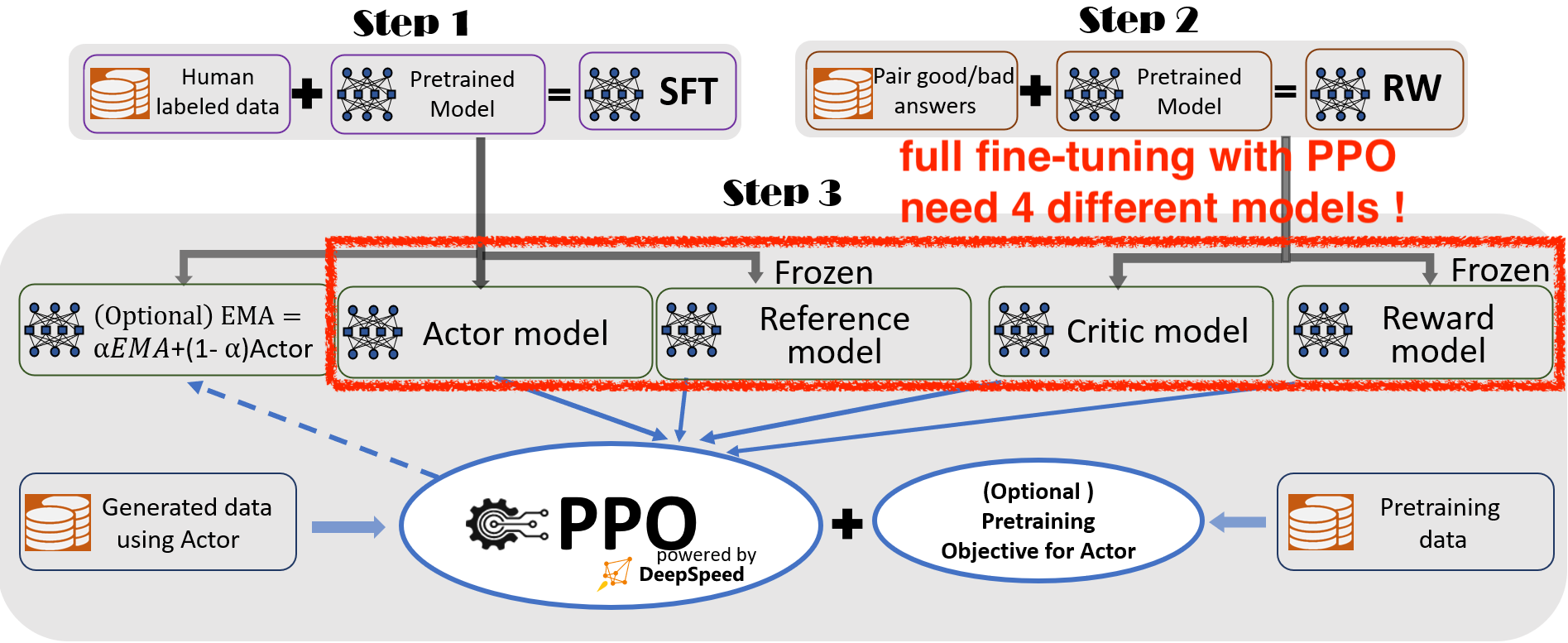 Fig. 일반적으로 RLHF를 위해서는 4개의 Module이 필요하다 (EMA update는 안한다고 칠 때). 학습하는데 필요한 module만 4개이며 여기에 추가적으로 rollout을 하기위해 효율적인 inference를 하려면 Actor model을 inference mode로 control하는 trick이 필요하다.
Fig. 일반적으로 RLHF를 위해서는 4개의 Module이 필요하다 (EMA update는 안한다고 칠 때). 학습하는데 필요한 module만 4개이며 여기에 추가적으로 rollout을 하기위해 효율적인 inference를 하려면 Actor model을 inference mode로 control하는 trick이 필요하다.
나중에 기회가 되면 이 부분까지 알아보겠다. (open-source를 쓰는 user들은 대부분 기껏해야 7B, 13B를 tuning 하는 것이 한계이며 70B를 tuning하는 기관들도 어지간한 scale의 team이 아닌 이상 이런 복잡한 pipelining이 필요하지 않은 SFT나 DPO만 하기 때문이며 충분히 큰 scale의 team들은 자체적으로 engineering을 하지 open-source를 쓰지는 않기 때문에 구현이 없다.)
Preliminaries
Initializing DataLoader
먼저 dataloader 부분이다.
PPO는 더이상 prompt, response pair data, \((x,y)\)가 필요하지 않은 setting이다.
Prompt만 존재하면 rollout을 해서 response를 만들고 environment가 이를 평가해서 "이 trajectory (response)는 몇 점 짜리다" 라고 알려준다.
LLM에는 이 reward를 주는 environment가 안타깝게도 없기 때문에 Reward Model (RM)이 이 역할을 하게된다.
따라서 dataset은 prompt만 있는 형태가 되고 매 optimization step마다 loading된 prompt를 기반으로 LLM으로 response label을 다 달아준 다음에 학습을 한다.
prompt_train_dataloader = DataLoader(
prompt_train_dataset,
collate_fn=data_collator,
sampler=prompt_train_sampler,
batch_size=args.per_device_generation_batch_size)
PPO-ptx에서 pre-training에 썼던 data를 사용해 추가적인 loss를 줌으로써 alignment 를 하는 과정에서 knowledge를 잃어버리는 부분을 상쇄시켰던 게 기억날 것이다.
그래서 pre-training corpus를 추가로 loading해서 학습에 사용할 수 있는 옵션도 넣어준다. (필수는 아님)
if unsupervised_training_enabled:
unsupervised_train_dataloader = DataLoader(
unsupervised_train_dataset,
collate_fn=default_data_collator,
sampler=unsupervised_train_sampler,
batch_size=args.per_device_generation_batch_size)
else:
unsupervised_train_dataloader = [None] * len(
prompt_train_dataloader) # basically a dummy dataloader
Intializing Tokenizer and Model
그 다음은 tokenizer와 model을 만드는 것이다. 원래는 model을 생성하는 부분이 상당히 (내부적으로는) 복잡한데, 간단히 요약하면 아래 세 가지 phase로 나눌 수 있다.
- model init
- layerwise parameter partitioning (ZeRO-3 DP)
- model parameter load
Huggingface model initialization과 ZeRO가 합쳐지면서 더 복잡해졌지만 이 부분은 상당 부분 생략하겠다.
# load_hf_tokenizer will get the correct tokenizer and set padding tokens based on the model family
args.end_of_conversation_token = "<|endoftext|>"
additional_special_tokens = args.end_of_conversation_token if args.add_eot_token else None
tokenizer = load_hf_tokenizer(args.actor_model_name_or_path,
fast_tokenizer=True,
add_special_tokens=additional_special_tokens)
# RLHF engine is responsible for creating models, loading checkpoints, ds-initialize models/optims/lr-schedulers
rlhf_engine = DeepSpeedRLHFEngine(
actor_model_name_or_path=args.actor_model_name_or_path,
critic_model_name_or_path=args.critic_model_name_or_path,
tokenizer=tokenizer,
num_total_iters=num_total_iters,
args=args)
간단한 pseudocode로 말씀드리면 dschat의 rlhf engine은
- Actor (SFT initialized)
- Critic (RM initialized)
- Ref Actor (SFT initialized)
- RM
으로 구성되어있는데, 각 module을 생성할 때는 아래와 같은 과정을 거친다.
- huggingface model 생성
- optimizer 생성
- lr scheduler 생성
- wrapping (model, optimizer, lr_scheduler) with deepspeed (ZeRO-3)
import deepspeed
from deepspeed.runtime.engine import DeepSpeedEngine
class DeepSpeedRLHFEngine():
def __init__(self, actor_model_name_or_path, critic_model_name_or_path,
tokenizer, args, num_total_iters):
self.args = args
self.num_total_iters = num_total_iters
self.tokenizer = tokenizer
self.actor = self._init_actor(
actor_model_name_or_path=actor_model_name_or_path)
self.ref = self._init_ref(
actor_model_name_or_path=actor_model_name_or_path)
self.critic = self._init_critic(
critic_model_name_or_path=critic_model_name_or_path)
self.reward = self._init_reward(
critic_model_name_or_path=critic_model_name_or_path)
def _init_actor(self, actor_model_name_or_path) -> DeepSpeedEngine:
## for example (not working)
actor_model = create_hf_model()
optim = create_optim()
lr_scheduler = create_lr_scheduler()
actor_engine, *_ = deepspeed.initialize(model=actor_model,
optimizer=optim,
lr_scheduler=lr_scheduler,
config=ds_config)
return actor_engine
def _init_ref(self, actor_model_name_or_path) -> DeepSpeedEngine:
return ref_engine
def _init_critic(self, critic_model_name_or_path) -> DeepSpeedEngine:
return critic_engine
def _init_reward(self, critic_model_name_or_path) -> DeepSpeedEngine:
return reward_engine
이제 아래처럼 rlhf engine에서 필요한 module을 call해서 input 을 넣으면 logit값이나 reward score (scalar tensor)를 얻을 수 있는 것이다.
logits = rlhf_engine.actor(inputs)
logits = rlhf_engine.ref(inputs)
values = rlhf_engine.critic(inputs)
score = rlhf_engine.reward(inputs)
기본적으로는 Actor, Critic을 분리하는게 좋다. 왜냐하면 Critic이 하는 일은 어차피 각 token이 최종적인 return을 내는 데 얼만큼의 기여를 했는가? (credit asignement)를 추정하는 것인데, 유사하게 RM이 이미 이를 학습한 것이나 다름이 없기 때문에 SFT model로 init을 하게 되면 Critic이 이를 학습할 동안 Actor는 gradient 를 제대로 추정하지 못해 방황하게 될 것이다. 그 동안에 model이 아예 맛이 가버릴 수도 있다. 하지만 만약에 GPU resource 여건이 안된다면 SFT model에 regression head를 하나 추가로 붙힌 Hydra 구조를 생각해 볼 수 있다. 그리고 trlx에는 이 부분이 구현되어 있다.
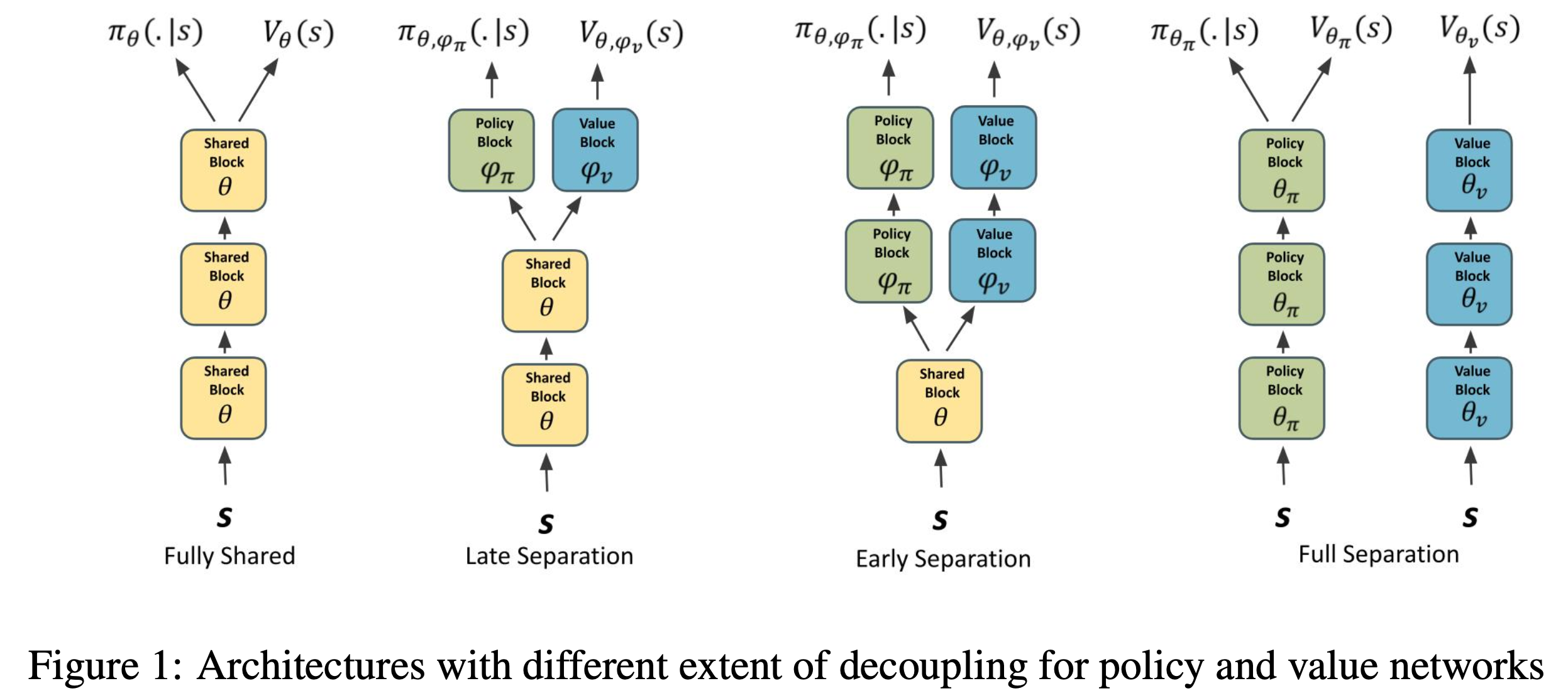 Fig. Hydra model (Shared Network). 아예 head만 분리할 수도 있고 중간부분부터 분기를 만들 수도 있다만 LLM에서 중간 부분부터 이를 나눠도 되는지는 모르겠다. Source from Analyzing the Sensitivity to Policy-Value Decoupling in Deep Reinforcement Learning Generalization
Fig. Hydra model (Shared Network). 아예 head만 분리할 수도 있고 중간부분부터 분기를 만들 수도 있다만 LLM에서 중간 부분부터 이를 나눠도 되는지는 모르겠다. Source from Analyzing the Sensitivity to Policy-Value Decoupling in Deep Reinforcement Learning Generalization
하지만 Shared version과 RM으로 critic을 init하는 version중 어떤게 더 좋은지는 해보기 전 까지는 알 수 없다. [21년 12월에 publish된 WebGPT]에서는 여건상 separated critic, actor를 사용했지만 future direction은 shared network를 쓰는 것이라고 했다.
 Fig. PPO details from WebGPT: Browser-assisted question-answering with human feedback
Fig. PPO details from WebGPT: Browser-assisted question-answering with human feedback
그런데 또 22년 3월에 publish된 InstructGPT에서는 입을 싹 닫고 RM으로 critic을 initialize 했다. 그 뒤로 GPT-3.5나 GPT-4에서는 어떻게 했는지 모르겠으니 실제로 해본느 수 밖에 없다.
 Fig. PPO details from Training language models to follow instructions with human feedback
Fig. PPO details from Training language models to follow instructions with human feedback
Training with PPO
Outermost Loop of Trainer
본격적으로 PPO 구현체에 대해서 살펴보기 전에 Trainer를 먼저 선언해준다.
ppo_trainer = DeepSpeedPPOTrainerUnsupervised if unsupervised_training_enabled else DeepSpeedPPOTrainer
trainer = ppo_trainer(rlhf_engine, args)
그리고 Trainer는 다음과 같은 loop를 돌게 된다. 아래의 code는 dschat의 step3_rlhf_finetuning/main.py를 단순화 한 것이다. (코드의 가독성을 위해 gradient checkpointing이라던가 ema actor 같은 부분과 logging을 하는 부분 등은 제거하였음)
for epoch in range(args.num_train_epochs):
for step, (batch_prompt, batch_unsupervised) in enumerate(
zip(prompt_train_dataloader, unsupervised_train_dataloader)):
batch_prompt = to_device(batch_prompt, device)
## rollout with current policy
out = trainer.generate_experience(batch_prompt['prompt'],
batch_prompt['prompt_att_mask'],
step)
## add to buffer
exp_dataset = exp_mini_dataset.add(out)
## dataset used for pre-trained
if batch_unsupervised is not None:
batch_unsupervised = to_device(batch_unsupervised, device)
unsup_dataset = unsup_mini_dataset.add(batch_unsupervised)
else:
unsup_dataset = unsup_mini_dataset.add(
[[None] * args.per_device_generation_batch_size])
## Measure Advantage (using Critic) and do Policy Optimization
if exp_dataset is not None:
inner_iter = 0
actor_loss_sum, critic_loss_sum, unsup_loss_sum = 0, 0, 0
average_reward = 0
## How many ppo training epochs to run for generated data
for ppo_ep in range(args.ppo_epochs):
for i, (exp_data, unsup_data) in enumerate(
zip(exp_dataset, unsup_dataset)):
## Compute Loss for Actor (Policy Gradient) and Critic (MSE Loss)
## and do backpropagation (in trainer.train_rlhf)
actor_loss, critic_loss = trainer.train_rlhf(exp_data)
actor_loss_sum += actor_loss.item()
critic_loss_sum += critic_loss.item()
average_reward += exp_data["rewards"].mean()
## PPO-ptx (CE Loss)
## and do backpropagation (in trainer.train_rlhf)
if unsupervised_training_enabled:
unsup_loss = trainer.train_unsupervised(
unsup_data, args.unsup_coef)
unsup_loss_sum += unsup_loss.item()
inner_iter += 1
## shuffle after 1 iteration
random.shuffle(exp_dataset)
random.shuffle(unsup_dataset)
average_reward = get_all_reduce_mean(average_reward).item()
이해가 안가실 부분은 없을 것 같고, 중요한 것은 trainer.train_rlhf같은데서 input에 대한 gradient를 구하고 backpropagation을 수행한다는 것이다.
그러니까 이 부분을 제대로 살펴보도록 하자.
Member variables of Trainer
Trainer를 initialization하는 부분이다. 당연히 actor, critic module을 받아 member variable로 정의하고 PPO학습에 필요한 coefficient나 arugment등을 정의한다.
class DeepSpeedPPOTrainer():
def __init__(self, rlhf_engine, args):
self.rlhf_engine = rlhf_engine
self.actor_model = self.rlhf_engine.actor
self.critic_model = self.rlhf_engine.critic
self.ref_model = self.rlhf_engine.ref
self.reward_model = self.rlhf_engine.reward
self.tokenizer = self.rlhf_engine.tokenizer
self.args = args
self.max_answer_seq_len = args.max_answer_seq_len
self.end_of_conversation_token_id = self.tokenizer(
args.end_of_conversation_token)['input_ids'][-1]
self.z3_enabled = args.actor_zero_stage == 3
self.compute_fp32_loss = self.args.compute_fp32_loss
# In case the generated experience is not valid (too short), we use the last valid
# generated experience. Alternatively, we can skip the step (on all workers).
# For now, use the last valid experience which is a simpler solution
self.last_generated_experience = None
# Those value can be changed
self.kl_ctl = 0.1
self.clip_reward_value = 5
self.cliprange = 0.2
self.cliprange_value = 0.2
self.gamma = 1.0
self.lam = 0.95
self.generate_time = 0.0
여기서 아래에 있는 7개 정도의 값들이 바로 PPO를 위해 tuning할 수 있는 값들이다. 먼저 Policy Optimization을 할 때 우리가 얻게 될 gradient는 다음과 같다.
\[\nabla_{\theta} J(\theta) \approx \frac{1}{N} \sum_{i=1}^N \sum_{t=1}^T \nabla_{\theta} \log \pi_{\theta} (a_{i,t} \vert s_{i,t}) \color{green}{A^{\pi} (s_{i,t}, a_{i,t})}\]당연히 여기서 True Advantage값은 얻을 수 없으니 (expectation을 다 계산할 수 없음), 우리는 Monte Carlo (MC) method나 Critic을 사용한 Bootstraped method로 이를 계산해야 한다.
\[\hat{A}_{\color{red}{C}}^{\pi} (s_t,a_t) = r(s_t,a_t) + \gamma \hat{V}_{\phi}^{\pi} (s_{t+1}) - \hat{V}_{\phi}^{\pi} (s_{t})\] \[\hat{A}_{\color{red}{MC}}^{\pi} (s_t,a_t) = \sum_{t=t'}^{\infty} \gamma^{t'-t} r(s_{t'},a_{t'}) - \hat{V}_{\phi}^{\pi} (s_{t})\]하지만 각각은 bias가 있다거나 (bootstrapped method), variance가 너무 크다거나 (MC)하는 문제가 있기 때문에 이들의 절충안인 nstep method를 쓰기도하지만, RL의 권위자 중 하나인 Sergey가 개발한 Generalized Advantage Estimator (GAE)를 쓰는게 요즘은 기본인 것 같다.
\[\begin{aligned} & \hat{A}_{\color{red}{GAE}}^{\pi} (s_t,a_t) = \sum_{n=1}^{\infty} ( \color{green}{\gamma} \color{green}{\lambda} )^{t'-t} \color{blue}{\delta_{t'}} & \\ & \text{where } \color{blue}{\delta_{t'}} = r(s_{t'},a_{t'}) + \gamma \hat{V}_{\phi}^{\pi}(s_{t'+1}) - \hat{V}_{\phi}^{\pi} (s_t) & \\ \end{aligned}\]따라서 아래 인자들은 GAE값을 계산하기 위해 사용되는 값들이다.
- self.lam = 1.0
- self.gamma = 0.95
그리고 아래의 인자들은 reward 를 계산할 때 SFT로 부터 policy가 너무 멀어지지 않도록 하는
\[R(x,y) = r_{\phi}(x,y) - \beta \log [\pi_{\theta}^{RL} (y \vert x) / \pi_{\theta}^{SFT} (y \vert x)]\]kl penalty term 에 쓰이는 인자이다.
- self.kl_ctl = 0.1
나머지는 PPO의 Clipped Surrogate Loss를 위한 값들이다.
\[\begin{aligned} & L_{ppo-KL-penalty}(\theta) = \hat{\mathbb{E}_t} [ \frac{\pi_{\theta} (a_t \vert s_t)}{\pi_{\theta_{old}} (a_t \vert s_t)} \hat{A_t}] - \color{blue}{ \beta D_{KL} ( \pi_{\theta_{old}} (\cdot \vert s_t), \pi_{\theta} (\cdot \vert s_t) ) } \\ & L_{ppo-clip}(\theta) = \hat{\mathbb{E}_t} [ \min ( \frac{\pi_{\theta} (a_t \vert s_t)}{\pi_{\theta_{old}} (a_t \vert s_t)} \hat{A_t}, \color{red}{ \text{clip} ( \frac{\pi_{\theta} (a_t \vert s_t)}{\pi_{\theta_{old}} (a_t \vert s_t)}, 1-\epsilon, 1+\epsilon ) } \hat{A_t} ) ] \\ \end{aligned}\]- self.clip_reward_value = 5
- self.cliprange = 0.2
- self.cliprange_value = 0.2
물론 KL regualized objective를 써도 되겠으나, PPO paper에서도 밝히길 성능이 clipped version이 더 좋고 효율도 좋기 때문에 (왜냐면 KL divergence를 계산하는 것 자체가 또 cost가 들기 때문) clipped version을 쓰는 것이 좋고 대부분이 clipped version만 쓴다. 여기서 눈에 띄는 점은 state value와 reward value도 clipping을 한다는 것인데, 이에 대해서는 곧 알아보도록 하겠다.
Rollout before PPO
그리고 마지막으로 PPO를 하기 위해 sample generation 하는 부분을 보자. 이 부분은 policy를 직접 environment상에서 돌려 state, action pair, (\((s_0, a_1, r_1, \cdots, s_T,a_T,r_T)\))를 얻는 행위이다.
 Fig.
Fig.
아래 구현체를 보면 주어진 prompt에 대해 reseponse를 먼저 생성한다.
(이는 _generate_sequence() 에 구현되어 있다)
그리고 만들어진 response들에 대해서 다음을 구한다.
- Actor의 각 response token들에 대한 logit
- Reference Actor의 각 response token들에 대한 logit
- RM의 response에 대한 return (어차피 sparse reward이기 때문에 최종 scalar만 나온다)
- Critic의 각 response token들에 대한 state value 값
def generate_experience(self, prompts, mask, step):
## sample generation part
self.eval()
generate_start = time.time()
seq = self._generate_sequence(prompts, mask, step)
generate_end = time.time()
if seq is None:
assert self.last_generated_experience is not None, f'Invalid generated experience at {step=}'
prompts = self.last_generated_experience['prompts']
seq = self.last_generated_experience['seq']
else:
self.last_generated_experience = {'prompts': prompts, 'seq': seq}
self.train()
## get logits from Actor and Ref model, Return from RM and Values from Critic
pad_token_id = self.tokenizer.pad_token_id
attention_mask = seq.not_equal(pad_token_id).long()
with torch.no_grad():
output = self.actor_model(seq, attention_mask=attention_mask)
output_ref = self.ref_model(seq, attention_mask=attention_mask)
reward_score = self.reward_model.forward_value(
seq, attention_mask,
prompt_length=self.prompt_length
)['chosen_end_scores'].detach()
values = self.critic_model.forward_value(
seq,
attention_mask,
return_value_only=True
).detach()[:, :-1]
logits = output.logits
logits_ref = output_ref.logits
if self.compute_fp32_loss:
logits = logits.to(torch.float)
logits_ref = logits_ref.to(torch.float)
self.generate_time = generate_end - generate_start
return {
'prompts': prompts,
'logprobs': gather_log_probs(logits[:, :-1, :], seq[:, 1:]),
'ref_logprobs': gather_log_probs(logits_ref[:, :-1, :], seq[:, 1:]),
'value': values,
'rewards': reward_score,
'input_ids': seq,
"attention_mask": attention_mask
}
Return이나 value score를 return하는 forward_value() function은 여기에 구현되어 있는데, 하는 연산이라곤 각 token별로 linear projection을 하는 것에 지나지 않는다.
그리고 gather_log_probs()은 다음과 같이 구현되어 있는데,
먼저 Categorical distribution으로 logit을 변환해주기 위해 softmax를 취해주고 log를 취한다.
그리고 정답 label에 대한 (우리는 SL이 아니라 RL을 하는 것이므로 실제로는 정답이 아니고 내가 선택한 action에 대해) log probability 만 return하는 것이다.
def gather_log_probs(logits, labels):
log_probs = F.log_softmax(logits, dim=-1)
log_probs_labels = log_probs.gather(dim=-1, index=labels.unsqueeze(-1))
return log_probs_labels.squeeze(-1)
그래서 어떻게 response는 sampling되는가? 그냥 huggingface라면 어떤 model이나 상속받는 function인 generate() function을 call해서 만든다. 주의할 점은 당연히 beam search가 아니라 sampling을 한다는 것이다. (왜인지는 모르겠는데 llama는 sampling을 버그때문에 안하는 것 같다 (…?))
여기서 sample strategy를 어떻게 정하느냐에 따라서 diversity가 정해질텐데, 이것은 RL의 exprolation, exploitation에 해당할 것이기 때문에 이를 잘 정하는것이 좋은 policy를 학습하는 데 도움이 될 것으로 보인다. 그리고 training and inference mismatch도 고려해서 값을 정해야 할 것이다.
def _generate_sequence(self, prompts, mask, step):
max_min_length = self.max_answer_seq_len + prompts.shape[1]
# This has been added due to a probability/nan error that happens after
# meta-llama/Llama-2-7b-hf enabled do_sample:
# https://huggingface.co/meta-llama/Llama-2-7b-hf/commit/6fdf2e60f86ff2481f2241aaee459f85b5b0bbb9
if self.actor_model.module.config.model_type == "llama":
kwargs = dict(do_sample=False)
else:
kwargs = dict()
with torch.no_grad():
seq = self.actor_model.module.generate(
prompts,
attention_mask=mask,
max_length=max_min_length,
pad_token_id=self.tokenizer.pad_token_id,
synced_gpus=self.z3_enabled,
**kwargs
)
여기에 추가로 문장이 아예 생성되지 않는 경우에 대한 처리를 해준다. 그럴 경우는 거의 없겠지만 바로 end of sentence token이 나온다던가? 하는 경우를 대비한 것 같다.
# Filter out seq with no answers (or very short). This happens when users directly use the pre-training ckpt without supervised finetuning
# NOTE: this will causes each GPU has different number of examples
batch_size = seq.shape[0]
prompt_length = prompts.shape[1]
self.prompt_length = prompt_length
ans = seq[:, prompt_length:]
valid_ans_len = (ans != self.tokenizer.pad_token_id).sum(dim=-1)
if self.args.print_answers and (step % self.args.print_answers_interval== 0):
print(
f"--- prompt --> step={step},
rank={torch.distributed.get_rank()},
{self.tokenizer.batch_decode(prompts, skip_special_tokens=True)}"
)
print(
f"--- ans --> step={step},
rank={torch.distributed.get_rank()},
{self.tokenizer.batch_decode(ans, skip_special_tokens=True)}"
)
out_seq = []
for i in range(batch_size):
if valid_ans_len[
i] <= 1: # if the answer is shorter than 1 token, drop it
print(
f'Dropping too short generated answer: {step=}: \n'
f'prompts: {self.tokenizer.batch_decode(prompts, skip_special_tokens=False)}\n'
f'answers: {self.tokenizer.batch_decode(ans, skip_special_tokens=False)}'
)
continue
else:
out_seq.append(seq[i:i + 1])
if not out_seq:
print(
f'All generated results are too short for rank={self.args.local_rank} step={step}\n'
f'-> prompts: {self.tokenizer.batch_decode(prompts, skip_special_tokens=False)}\n'
f'-> answers: {self.tokenizer.batch_decode(ans, skip_special_tokens=False)}'
)
return None
out_seq = torch.cat(out_seq, dim=0) # concat output in the batch dim
return out_seq
이제 최종적으로 prompt에 대한 response (trajectory)를 sampling했고, 각 reponse에 대한 Actor들의 logit 값과 value값, return을 계산했다.
Main Inner Loop of Trainer
이제 어떻게 policy optimization을 하는지 알아보자. 일단 trajectory들은 예를 들어 1024개 정도가 생성이 된 것이다. 그리고 이 1024개에 대해서 loop를 돌면 한 batch에 대한 update가 된 것이다.
def train_rlhf(self, inputs):
# train the rlhf mode here
### process the old outputs
prompts = inputs['prompts']
log_probs = inputs['logprobs']
ref_log_probs = inputs['ref_logprobs']
reward_score = inputs['rewards']
values = inputs['value']
attention_mask = inputs['attention_mask']
seq = inputs['input_ids']
start = prompts.size()[-1] - 1
action_mask = attention_mask[:, 1:]
그리고 이 train_rlhf라는 실제로 loss를 계산하고 paramter update를 하는 것은 생성된 trajectory들에 대해서 여러 번 반복될 수 있다.
왜냐하면 LLM이 trajectory를 만드는데 이걸 한번 쓰고 버리기 아까워서인데 (sample efficiency),
우리가 쓰는 PPO가 locally off-policy가 가능하기 때문에 큰 문제가 없어서 그렇다.
for epoch in range(args.num_train_epochs):
for step, batch_prompt in enumerate(prompt_train_dataloader):
batch_prompt = to_device(batch_prompt, device)
## rollout with current policy and add to buffer
out = trainer.generate_experience()
exp_dataset = exp_mini_dataset.add(out)
## Measure Advantage (using Critic) and do Policy Optimization
if exp_dataset is not None:
## How many ppo training epochs to run for generated data
for ppo_ep in range(args.ppo_epochs):
for i, exp_data in enumerate(exp_dataset):
actor_loss, critic_loss = trainer.train_rlhf(exp_data)
inner_iter += 1
## shuffle after 1 iteration
random.shuffle(exp_dataset)
하지만 training stability 때문에 그런지 default값은 ppo_epochs=1이다.
그리고 1024개 trajectory를 sampling했다고 쳐도 마찬가지로 off-policy가 가능하므로 이를 쪼개서 policy improvement 하는 데 쓸 수 있다.
이는 GPU device의 memory한계 때문에 최대 처리할 수 있는량이 정해져있기 때문이기도 하다.
예를 들어 1024개 중 128개씩 8회 처리할 수도 있는 것이다.
이제 본격적으로 어떻게 PPO로 gradient를 계산하는지 알아보자.
Get Rewards from RM and Compute Advantage
가장 먼저 하는 것은 old_rewards라는 것을 계산하는 것이다.
old_values = values
with torch.no_grad():
old_rewards = self.compute_rewards(
prompts,
log_probs,
ref_log_probs,
reward_score,
action_mask
)
ends = start + action_mask[:, start:].sum(1) + 1
# we need to zero out the reward and value after the end of the conversation
# otherwise the advantage/return will be wrong
for i in range(old_rewards.shape[0]):
old_rewards[i, ends[i]:] = 0
old_values[i, ends[i]:] = 0
먼저 RM으로부터 얻은 return signal에 LLM의 RLHF에서 중요한 regularization term 중 하나인 SFT model과 current policy간의 KLD를 계산해서 reward에 추가로 빼준다.
\[R(x,y) = r_{\phi}(x,y) - \beta \log [\pi_{\theta}^{RL} (y \vert x) / \pi_{\theta}^{SFT} (y \vert x)]\]여기서 RLHF를 처음 접하는 사람들은 헷갈릴 만한 부분이 있는데, reward에 실제로 빼주는 것은 KLD가 아니라 log ratio라는 것이다. 그런데 어차피 이는 나중에 action에 대한 log prob에 곱해지는 term이기 때문에 완전히 KLD를 계산하는 것과 동치이다.
\[\begin{aligned} & KL[q,p] = \sum_{x} q(x) \log \frac{q(x)}{p(x)} & \\ & = \mathbb{E}_{x \sim q} [\log \frac{q(x)}{p(x)}] & \\ & = \mathbb{E}_{x \sim q} [\log q(x) - \log p(x)] & \\ \end{aligned}\]이를 entropy bonus라고 부르는 이들도 있는데,
원래 PPO학습을 할 때에는 actor, critic loss 말고도 exploration을 장려하기 위해서 action distribution의 entropy를 maximize하는 term을 같이 추가해서 학습하는데 그것과 비슷한 기능을 하기 때문이다.
실제로는 alignment tuning을 하면서 Natural Language Understanding (NLU)성능을 까먹는,
이른 바 catastrophic forgetting을 막아주는 기능을 하는데,
SFT distribution으로부터 너무 멀어지지 말라는 것이 PPO를 하면서 너무 reward가 높은 action의 확률만 높히지 말라는 의미이기 때문에 비슷하게 해석할 수 있겠다.
(다시 생각해보니 entorpy 를 maximize하는 것은 어떻게 보면 uniform distribution 과의 kl divergence를 최소화 하는 것과 같은데 (실제로는 label smoothing이나 confidence penalty가 이런 구현임), RLHF PPO는 SFT model과의 divergence를 재서 최소화 하는 것이니 같은 개념이라고 말해도 될 것 같다.)
def compute_rewards(
self, prompts,
log_probs, ref_log_probs,
reward_score,
action_mask
):
kl_divergence_estimate = -self.kl_ctl * (log_probs - ref_log_probs)
rewards = kl_divergence_estimate
start = prompts.shape[1] - 1
ends = start + action_mask[:, start:].sum(1) + 1
reward_clip = torch.clamp(
reward_score,
-self.clip_reward_value,
self.clip_reward_value
)
batch_size = log_probs.shape[0]
for j in range(batch_size):
rewards[j, start:ends[j]][-1] += reward_clip[j]
return rewards
여기서 KLD를 계산한 것은 token별로 계산된 것이라는 점에 주의하고,
마지막 token에는 KLD 값에 추가로 reward_clip이라는 것을 더해준다.
그 이유는 당연하게도 sparse하게 reward가 마지막 step에서만 발생했고,
이를 앞으로 propagate할 것이기 때문이다.
reward_clip 이란 말 그대로 RM이 return해준 signal가 특정 값을 넘어가면 clip해주는 것인데,
너무 높은 reward를 받거나 너무 낮은 reward를 받는 걸 방지한다고 보면 된다.
이는 PPO에서 제안된 것은 아니지만 training stability를 위해 추가된 것으로 보인다.
어쨌든 이렇게 해서 각 trajectory별로 noramlize 된 것 까지는 아니지만 clip이 되고, KL penalized까지 된 return을 얻었다. 이제 각 timestep의 action, \(\pi_{\theta}(a_t \vert s_t)\) 별로의 advantage 값을 계산하자.
advantages, returns = self.get_advantages_and_returns(
old_values,
old_rewards,
start
)
앞서 advantage값은 GAE를 사용해 계산한다고 했다.
\[\begin{aligned} & \hat{A}_{\color{red}{GAE}}^{\pi} (s_t,a_t) = \sum_{n=1}^{\infty} ( \color{green}{\gamma} \color{green}{\lambda} )^{t'-t} \color{blue}{\delta_{t'}} & \\ & \text{where } \color{blue}{\delta_{t'}} = r(s_{t'},a_{t'}) + \gamma \hat{V}_{\phi}^{\pi}(s_{t'+1}) - \hat{V}_{\phi}^{\pi} (s_t) & \\ \end{aligned}\]이를 계산하려면 다음이 필요하다.
- current reward
- current time step’s value
- next time step’s value
그리고 각 timestep별 value 값은 이미 critic model을 forward함으로써 가지고 있다. Advantage에는 discount factor, \(\gamma\)가 곱해지고 추가로 GAE는 각 timtstep별 advantage 값을 누적한다. 그렇기 때문에 편의를 위해 terminal state, \(T\)부터 역산하는것이 보통이다.
def get_advantages_and_returns(self, values, rewards, start):
# Adopted from https://github.com/CarperAI/trlx/blob/main/trlx/models/modeling_ppo.py#L134
lastgaelam = 0
advantages_reversed = []
length = rewards.size()[-1]
for t in reversed(range(start, length)):
nextvalues = values[:, t + 1] if t < length - 1 else 0.0
delta = rewards[:, t] + self.gamma * nextvalues - values[:, t]
lastgaelam = delta + self.gamma * self.lam * lastgaelam
advantages_reversed.append(lastgaelam)
advantages = torch.stack(advantages_reversed[::-1], dim=1)
returns = advantages + values[:, start:]
return advantages.detach(), returns
그리고 여기서 returns이라는 것이 또 계산되는데 이는 critic model의 target이 될 값이다.
구현은 timestep별 advantage값에 (우리가 역순으로 list를 만들었기 때문에 advantages_reversed[::-1]를 통해 time dim에 대해 역으로 뒤집어준다) 해당 timestep별 state value값을 각각 더해준 것인데,
이는 당연하게도 GAE값에 current timestep의 value가 포함되어 있기 때문이다.
그리고 advantage에 대해서는 gradient가 흐르지 말아야 하므로 detach를 했다.
Compute Gradient for Actor and Critic and Update
이제 backprop을 통해 gradient를 계산하고,
optimization step을 1회 해야한다.
우리는 model을 deepspeed로 wrapping했기 때문에 deepspeed training document에 따라서 backward(), step() function을 call하면 되겠다.
먼저 Actor의 gradient를 계산하자.
### process the new outputs
batch = {'input_ids': seq, "attention_mask": attention_mask}
actor_prob = self.actor_model(**batch, use_cache=False).logits
actor_log_prob = gather_log_probs(actor_prob[:, :-1, :], seq[:, 1:])
## Compute Actor Loss
actor_loss = self.actor_loss_fn(
actor_log_prob[:, start:],
log_probs[:, start:],
advantages,
action_mask[:, start:]
)
self.actor_model.backward(actor_loss)
if not self.args.align_overflow:
self.actor_model.step()
실제 loss가 계산되는 부분은 actor_loss_fn() function을 봐야하는데,
여기에 input에 들어가는 인자에 주의할 필요가 있다.
왜냐면 우리는 1024개 sampled trajectory를 128 batch씩 8회 update 할 수가 있기 때문이다.
예를 들어 \(\theta_{100}\)으로부터 sampling을 했다고 치자.
그러면 우리는 \(\theta_{100}\)과 \(\theta_{101}\)의 ratio … \(\theta_{100}, \theta_{107}\)의 ratio까지 parameter가 update될 수록 계산해줘야 한다.
advantages 값은 Actor parameter와 상관없는 값이고,
log_probs는 \(\theta_{100}\)로 구한 log prob이므로 이 또한 다시 계산할 필요가 없다.
우리는 current policy의 log prob인 actor_log_prob만 매 step다시 구해주면 되고,
이제 Clipped PPO loss를 계산하면 된다.
def actor_loss_fn(self, logprobs, old_logprobs, advantages, mask):
## policy gradient loss
log_ratio = (logprobs - old_logprobs) * mask
ratio = torch.exp(log_ratio)
pg_loss1 = -advantages * ratio
pg_loss2 = -advantages * torch.clamp(
ratio,
1.0 - self.cliprange,
1.0 + self.cliprange
)
pg_loss = torch.sum(
torch.max(pg_loss1, pg_loss2) * mask
) / mask.sum()
return pg_loss
PPO를 계산하는 부분은 stable baseline 3와 trlx 등 대부분의 구현체가 유사한데, torch.clamp를 사용해서 구현한다.
여기서 주의할 점이 있는데, 실제로 loss가 clipping되면 더이상 gradient가 흐르지 않는다는 것이다. 즉 gradient clipping과 다르다. 왜냐하면 clipping된 값은 상수로, 더이상 parameter에 대해 미분을 해봐야 0이기 때문이다.
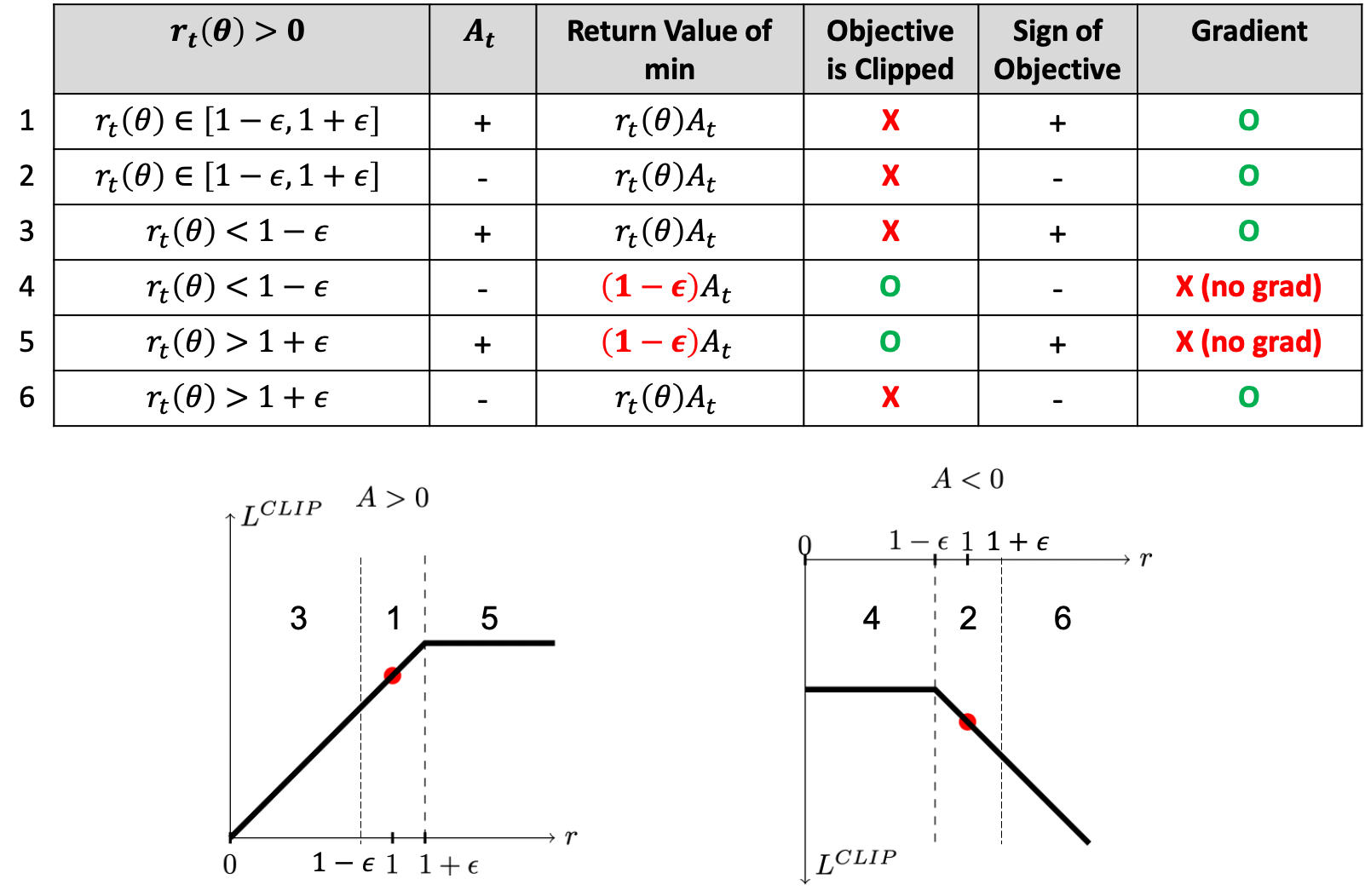 Fig. Clipped objective에는 gradient가 흐르지 않는 구간이 있다. Source from link
Fig. Clipped objective에는 gradient가 흐르지 않는 구간이 있다. Source from link
다만 위의 구현체를 보면 cliprange를 넘어가면 무조건 gradient가 흐르지 않게 되는 것 같다. 이는 위의 table보다 좀 더 pessimistic하게 gradient를 계산하겠다는 것 같다. (좀 더 generous하게 할거면 advantage가 양수인지 음수인지에 대해서 계산을하고, 그에 따라 clamp가 다르게 적용돼야할 것 같은데, 이러면 surrogate loss surface가 이상해지는것인지? 아니면 구현의 편의성 때문인지 모르겠으나 암튼 이렇게 되어있다)
다음은 Critic의 loss를 구할 차례이다. 이는 단순히 regression task로 Mean Squared Error (MSE) Loss를 쓰면 된다. 사실 이는 Actor와 다르게 importance weight을 매 step마다 구해줄 필요가 없지만 (PPO paper에 이런 내용은 없지만), Actor와 비슷한 철학으로 training stability를 위해서 ratio를 구하고 clipping을 해준다.
value = self.critic_model.forward_value(
**batch,
return_value_only=True,
use_cache=False
)[:, :-1]
## Compute Critic Loss
critic_loss = self.critic_loss_fn(
value[:, start:],
old_values[:, start:],
returns,
action_mask[:, start:]
)
self.critic_model.backward(critic_loss)
이것도 직관적으로 생각을 해보자면 critic value가 \(\phi_{100}\)에는 \(s_t\)에 대해서 100이었는데, update가 되다보니 \(95 \sim 105\)를 넘어 \(120\)이렇게 된다면 이는 잘못된 것이므로 regress하지 말라는 것이다. (좀 더 생각해봐야 할듯)
def critic_loss_fn(self, values, old_values, returns, mask):
## value loss
values_clipped = torch.clamp(
values,
old_values - self.cliprange_value,
old_values + self.cliprange_value,
)
if self.compute_fp32_loss:
values = values.float()
values_clipped = values_clipped.float()
vf_loss1 = (values - returns)**2
vf_loss2 = (values_clipped - returns)**2
vf_loss = 0.5 * torch.sum(
torch.max(vf_loss1, vf_loss2) * mask
) / mask.sum()
return vf_loss
이는 openai의 Fine-Tuning Language Models from Human Preferences 구현체에도 포함되어 있는 trick이다.
그리고 최종적으로 overflow인지 check한 뒤에 update를 하면 끝이다.
if self.args.align_overflow:
actor_overflow = self.actor_model.optimizer.check_overflow(
external=True)
critic_overflow = self.critic_model.optimizer.check_overflow(
external=True)
rank = torch.distributed.get_rank()
if actor_overflow and not critic_overflow:
self.critic_model.optimizer.skip_step = True
print_rank_0(
"OVERFLOW: actor overflow, skipping both actor and critic steps",
rank)
elif not actor_overflow and critic_overflow:
self.actor_model.optimizer.skip_step = True
print_rank_0(
"OVERFLOW: critic overflow, skipping both actor and critic steps",
rank)
elif actor_overflow and critic_overflow:
print_rank_0(
"OVERFLOW: actor and critic overflow, skipping both actor and critic steps",
rank)
self.actor_model.step()
self.critic_model.step()
return actor_loss, critic_loss
Compared to Transformer Reinforcement Learning X (TRLX)
DeepSpeedChat code를 보다보면 TRLX에서 참고한 부분이 많은 걸 알 수 있다. 이 둘간에 어떤 detail차이가 있는지 조금만 더 알아보자. (또 TRLX는 cleanRL등을 참고했다)
Computing KL Penalty
먼저 KL penalty를 계산하고 logging하는 부분이다. 이는 policy를 run해서 trajectory들을 sampling하고 logprob, reference logprob, KL penalized rewards, … 등을 계산하는 부분에 있는데, [이 discussion]에 따르면 TRLX가 RM score에 penalty를 주기위해서, policy가 얼마나 달라졋는지 measure하기 위해서… 등등 다양한 곳에서 KLD를 계산한다는 걸 알 수 있다. 그런데 특이한 점이 하나 더 있다면 TRLX에서는 일반적인 KLD 계산 식을 쓰지 않고 PPO의 1st author인 John Schulman의 구현체를 쓴다는 것이다.
자세한 내용은 blog를 참조하면 되는데, 핵심은 아래의 KL term을 실제로 계산하기 위해서는 distribution, \(q(x)\)의 variable에 대해서 full expectation을 구해야 하는데, 이는 불가능에 가깝기 때문에 Monte-Carlo approximation 하겠다는 것이다. (게다가 어떤 distribution들에 대해서는 closed form solution이 존재하지 않는다. gaussian은 존재)
\[\begin{aligned} & KL[q,p] = \sum_{x} q(x) \log \frac{q(x)}{p(x)} & \\ & = \mathbb{E}_{x \sim q} [\log \frac{q(x)}{p(x)}] & \\ & = \mathbb{E}_{x \sim q} [\log q(x) - \log p(x)] & \\ \end{aligned}\]물론 어떤 sampled variable, \(q\)들에 대해서 deepspeedchat은 \(\log q(x) - \log p(x)\)를 하는 가장 간단한 approximation을 썼지만, 이는 unbiased but high variance라고 한다. 결론은 \(\frac{1}{2}(\log p(x) - \log q(x) )^2\)의 sample average를 취하는 것인데, 최종적으로 우리가 사용할 수식은 \(r = \frac{p(x)}{q(x)}\)일 때, \(KL[q,p] = (r-1) - \log r\)이다. 그리고 이는 unbias이며 우리가 아는 훨씬 적은 variance를 갖는다고 한다.
 Fig. Variance of True KL vs Approximate KL. 3번째 approximation이 훨씬 variance가 낮으면서도 unbiased임을 알 수 있다.
Fig. Variance of True KL vs Approximate KL. 3번째 approximation이 훨씬 variance가 낮으면서도 unbiased임을 알 수 있다.
비교에 사용된 코드는 아래와 같다.
import torch.distributions as dis
p = dis.Normal(loc=0, scale=1)
q = dis.Normal(loc=0.1, scale=1)
x = q.sample(sample_shape=(10_000_000,))
truekl = dis.kl_divergence(p, q)
print("true", truekl)
logr = p.log_prob(x) - q.log_prob(x)
k1 = -logr
k2 = logr ** 2 / 2
k3 = (logr.exp() - 1) - logr
for i, k in enumerate(k1, k2, k3):
print(f'{i}th approximation: {(k.mean() - truekl) / truekl}, {k.std() / truekl}')
이제 TRLX 구현체를 봐보도록 하자.
def make_experience(self, num_rollouts: int = 1024, iter_count: int = 0): # noqa:
while len(ppo_rl_elements) < num_rollouts:
# ...
logprobs = logprobs_of_labels(logits[:, :-1, :], all_tokens[:, 1:])
ref_logprobs = logprobs_of_labels(ref_logits[:, :-1, :], all_tokens[:, 1:])
log_ratio = (logprobs - ref_logprobs) * attention_mask[:, :-1]
kl = (log_ratio.exp() - 1) - log_ratio
mean_kl_per_token = kl.mean()
mean_kl = kl.sum(1).mean()
logprobs = logprobs.cpu()
ref_logprobs = ref_logprobs.cpu()
prompt_tensors = prompt_tensors.cpu()
sample_outputs = sample_outputs.cpu()
values = values.cpu()[:, :-1]
# Get the logprobs and values, for tokens that are not padding,
# from the end of the prompt up to the <eos> token, while also including the latter
# (these are taken from the student model and not the reference model)
ends = start + attention_mask[:, start:].sum(1) + 1
all_values = [values[ix, start : ends[ix]] for ix in range(n_samples)]
all_logprobs = [logprobs[ix, start : ends[ix]] for ix in range(n_samples)]
kl_penalty = self.kl_ctl.value * -log_ratio.cpu()
kl_penalty = [xs[start : ends[ix]] for ix, xs in enumerate(kl_penalty)]
rollout_count = 0
for sample_idx in range(n_samples):
rewards = kl_penalty[sample_idx]
# Then add in rewards
if scores.shape[1] == 1:
# NOTE: Final reward given at EOS token following HHH practice
rewards[-1] += scores[sample_idx][0].cpu()
else:
score = scores[sample_idx]
score_right_padding = torch.sum(scores_mask[sample_idx])
score = score[:score_right_padding].cpu()
p_score = torch.zeros_like(rewards)
p_score[: score.shape[0]] += score
rewards += p_score
ppo_rl_elements.append(
PPORLElement(
query_tensor=prompt_tensors[sample_idx],
response_tensor=sample_outputs[sample_idx],
logprobs=all_logprobs[sample_idx],
values=all_values[sample_idx],
rewards=rewards,
)
)
rollout_count += 1
if torch.distributed.is_initialized():
torch.distributed.all_reduce(mean_kl, torch.distributed.ReduceOp.AVG)
stats["time/rollout_time"] = clock.tick()
stats["policy/sqrt_kl"] = torch.sqrt(mean_kl).item()
stats["policy/kl_per_token"] = torch.sqrt(mean_kl_per_token).item()
accumulated_stats.append(stats)
tbar.set_description(f"[rollout {len(ppo_rl_elements)} / {num_rollouts}]")
tbar.update(min(rollout_count, num_rollouts))
tbar.close()
stats = {k: sum([xs[k] for xs in accumulated_stats]) / len(accumulated_stats) for k in stats}
stats["kl_ctl_value"] = self.kl_ctl.value
self.mean_kl = stats["policy/sqrt_kl"] ** 2
self.accelerator.log(stats, step=iter_count)
# Push samples and rewards to trainer's rollout storage
self.push_to_store(ppo_rl_elements)
먼저 initial policy (SFT policy)와의 log prob간의 ratio를 구한다. 그리고 deepspeedchat에서는 아래와 같이 kld를 계산을 하는데,
kl_divergence_estimate = -self.kl_ctl * (log_probs - ref_log_probs)
rewards = kl_divergence_estimate
TRLX는 아래와 같은 방식 (john schulman의 구현체)으로 kld를 계산한다.
log_ratio = (logprobs - ref_logprobs) * attention_mask[:, :-1]
kl = (log_ratio.exp() - 1) - log_ratio
mean_kl_per_token = kl.mean()
mean_kl = kl.sum(1).mean()
그리고 마찬가지로 \(\beta\)를 곱한뒤에 RM score와 더하게 된다.
여기서 mean_kl이나 mean_kl_per_token값은 policy가 SFT로부터 얼마나 멀어졌는지를 계속 tracking하기 위한 용도로 사용되는 것 같은데,
일반적으로 kld가 너무 많이 달라졌으면 policy가 망가졌다고 판단하고 early stopping을 하게 된다.
그 이유는 reward overoptimization에 의해서 policy가 update될 수록 평균 reward 값은 계속 올라가지만 이것은 policy가 제작자의 의도를 이해하지 못하고 reward가 높아지기만 하면 문장의 길이를 늘린다던지? 하는 방식으로 policy를 update하는 등의 reward hacking 가능성이 높기 때문에 그런 것이다.
그래서 rollout 된 sample들의 average length와 함께 tracking하는 것이 일반적이다.
Actor, Critic Loss를 구할때에도 한번 더 approximate KL을 계산하는데, report용도로 쓰는 것 같다.
Adaptive KL Controller
다음은 Adaptive KL Controller에 관한 것이다.
deepspeedchat에는 없고 TRLX에만 있는 것인데,
앞서 KL penalty를 구할 때 self.kl_ctl 이라는 class에서 \(\beta\)를 가져와 log ration와 곱해줬다.
log_ratio = (logprobs - ref_logprobs) * attention_mask[:, :-1]
kl_penalty = self.kl_ctl.value * -log_ratio.cpu()
kl_penalty = [xs[start : ends[ix]] for ix, xs in enumerate(kl_penalty)]
이는 fixed version을 쓰면 고정된 값이지만, 2019년에 publish된 Fine-Tuning Language Models from Human Preferences에 따르면 random seed별로 KL값이 많이 달라질 수 있기 때문에 adaptive하게 이를 조절해주는 controller를 도입했다고 했고 이 구현체가 있는 것이다. (오래된 논문이라 지금도 쓰이는지는 모르겠다)
 Fig. formulation for Adaptive KL Controller
Fig. formulation for Adaptive KL Controller
class AdaptiveKLController:
def __init__(self, init_kl_coef: float, target: float, horizon: int):
self.value = init_kl_coef
self.target = target
self.horizon = horizon
def update(self, current: float, n_steps: int):
proportional_error = np.clip(current / self.target - 1, -0.2, 0.2) # ϵₜ
mult = 1 + proportional_error * n_steps / self.horizon
self.value *= mult # βₜ₊₁
class FixedKLController:
def __init__(self, kl_coef):
self.value = kl_coef
def update(self, current: float, n_steps: int):
pass
직관적으로 만약 SFT와 현재 newest policy의 성능? 변화율, KL target값을 5정도로 꾸준히 유지하고 싶다면 (5이상으로 변하게 하고싶지는 않다면), 목적에 맞게 이를 조절 해 주는 것 이라고 생각할 수 있겠다.
Whitening Advantage Value
그 다음은 get_advantages_and_returns() 부분이다.
def get_advantages_and_returns(
self,
values: TensorType["batch_size", "response_size"],
rewards: TensorType["batch_size", "response_size"],
response_length: int,
use_whitening: Optional[bool] = True,
) -> Tuple[torch.Tensor, torch.Tensor]:
lastgaelam = 0
advantages_reversed = []
for t in reversed(range(response_length)):
nextvalues = values[:, t + 1] if t < response_length - 1 else 0.0
delta = rewards[:, t] + self.gamma * nextvalues - values[:, t]
lastgaelam = delta + self.gamma * self.lam * lastgaelam
advantages_reversed.append(lastgaelam)
advantages = torch.stack(advantages_reversed[::-1], dim=1)
returns = advantages + values
if use_whitening:
advantages = whiten(advantages)
return advantages.detach(), returns
TRLX는 deepspeedchat과 다르게 A값을 normalize하는 부분이 있다. Mean, standrad deviation를 측정해서 normalize해주는 것이다.
def whiten(xs: torch.Tensor, shift_mean=True, distributed=True, group=None) -> torch.Tensor:
"""Whitens values"""
if distributed and dist.is_initialized():
mean, var, _ = get_global_statistics(xs, group=group)
else:
var, mean = torch.var_mean(xs)
whitened = (xs - mean) * torch.rsqrt(var + 1e-8)
if not shift_mean:
whitened += mean
return whitened
Some Details
Some Hparam Details of PPO from Papers
몇가지 PPO로 RLHF한 paper들의 detail들에 대해서 살펴보자. 먼저 22년 3월에 publish된 InstructGPT이다.
 Fig.
Fig.
얘네는 RM score에 KL penalty를 넣을 때 coefficient 를 \(0.02\)로 준다. 그리고 총 256k 의 episode 로 학습을 했다. 즉 256번 rollout을 했다는 것 같다. 그리고 이 episode들은 31개의 unique prompt를 갖는다고 한다. 즉 supervised learning (SL) 으로 치면 8~9번의 epoch을 돈 셈이다 (물론 RL은 SL이 아니기 때문에 label은 내가 sample한 response이다.)
그리고 각 iteration의 batch size는 512이고 minibatch는 64라고 쓰여있는데,
말 그대로 unique prompt 512개에 대해서 답변을 각각 1개씩 뽑아서 dataset을 만들었으면 이를 8개로 split 한 다음 학습하는 것이다.
이것이 가능한 이유는 여러번 설명한 것 처럼 PPO가 importance sampling을 하기 때문에 \(\pi_{100}\)이 뽑은 trajectory에도 확률 보정을 해주면 \(\pi_{106}\)을 update하는 데 쓸 수 있기 때문이다.
그리고 이 rollout에 대해서는 1번만 순회하고 버린다 (앞서 이걸 몇 번 순회할지 정할 수 있다고 했다).
나머지는 LR warmpup을 10 iteration동안 했다는 것과 그 이후로는 lr decay를 하지 않고 constant로 유지했다는 것이다. 아무래도 TRPO, PPO계열이 lr과 gradient scale을 정해주는 method라 그런 것 같다. (그럼에도 Adam optimizer를 쓰긴 했는데, 이 점에 대해서는 더 생각해보면 좋을 것 같다.)
그리고 PPO에 대한 detail로는 clip range를 0.2 썼다는 게 있는데, 이는 대부분의 RLHF paper에서 거의 국룰로 쓰이는 값이다. 또한 GAE 값을 계산할 때 discount factor를 1로 뒀다는 점이 있는데, 아무래도 long horizon에 sparse reward problem이라서 그런지 discount하면 reward propagation이 어려워질 것 같아 그런 것 같다.
마지막으로 PPO에 대한 detail은 아니지만 175B크기의 GPT-3를 actor로 쓰면서 RM과 critic은 6B짜리를 썼는데, 실험결과 175B RM과 별 차이가 안나서 이렇게 했다고 한다.
하지만 이는 몇 달 뒤 나온 Scaling Laws for Reward Model Overoptimization라는 paper에서 RM이 크면 클수록 overoptimization (뭐 overfitting이라고도 할 수 있다)이 덜 일어난다고 본인들이 밝히면서 현재는 더 큰 model size를 쓸 것으로 추측이 된다.
(OpenAI의 가장 마지막 기술적인 detail이 적혀있는 paper가 이 두개인데, 이후로 이미 2년이나 지났기 때문에 모든 실험 결과와 detail은 지금 상황에 적용되지 않을 수 있으니 항상 주의하자)
그리고 Exponential Moving Average (EMA)로 parameter update를 했다고 하는데,
이 때 \(0.992\)의 decay rate을 썼다고 한다.
(앞서 EMA에 대해서는 생략했기 때문에 좀 이따 다시 알아보겠다)
그 다음은 23년 7월에 publish된 LLaMa 2의 detail에 대해서 알아보자.
 Fig.
Fig.
먼저 AdamW optimizer를 썼고 \(\beta_1,\beta_2, \epsilon\)까지 명시를 해뒀다. 그리고 gradient clipping 은 1.0으로 주고 weight decay는 0.1로 줬다. 여기까지는 모든 gradient based optimization method를 쓰는 algorithm이라면 적용될 수 있는 값들이니 넘어가고, PPO에 대해서는 clip range를 InstructGPT와 마찬가지로 0.2 주었으며, batch size도 마찬가지로 512에 mini batch도 64를 주었다 (OpenAI를 참고해서 실험하고 결과 비교해본 듯, 혹은 알리기 실어서 그냥 InstructGPT 복붙했거나).
그리고 조금 주목할 부분은 RM score에 더해지는 KL penalty의 coeffcient를 비교적 작은 model size인 7B, 13B model에서는 \(\beta=0.01\)을 썼고 더 큰 model들에 대해서는 \(\beta=0.005\)를 썼다는 것이다. 직관적으로 model size가 더 작을 경우에 gradient가 더 잘 흐르면서 (?) policy가 변할 가능성이 크기 때문에 reward signal을 억제해 주는 것이 아닌가 싶다. 그렇다면 반대로 actor의 lr을 줄여주는 것도 가능하지 않을까? 하는 생각도 든다. 왜냐하면 parameter를 update하는 수식이 아래와 같은데 (대충 단순화 했음),
\[\begin{aligned} & \theta_{t+1} = \theta_{t} + lr \cdot \nabla_{\theta_t} L(\theta_t) \\ & = \theta_{t} + \color{red}{lr} \cdot \sum \nabla_{\theta_t} r(\theta_t) \color{red}{ \hat{A}_t } \\ \end{aligned}\]여기서 A값을 건드리는 것과 lr을 건드리는 것은 비슷한 효과를 낼 것이기 때문이다.
InstructGPT가 175B actor를 위해서 5e-6의 lr을 썼던것과 비교해서 model size가 많이 다름에도 일관되게 1e-6을 썼다는 점을 생가갷보면, lr을 건드리지 않기 위해서 kl penalty를 건드린 것이 아닌가 하는 의심이 든다.
물론 이 모든 것들이 정답은 아니다.
설령 내가 가지고 있는 model이 이들의 규모와 비슷하다고 해도 deep learning은 dataset, model 구조, objective에 따라서 loss surface가 달라지기 때문에 그들의 optimal parameter가 나의 setting으로 transfer된다는 보장은 없다.
(참고만 하되 이 수치를 믿고 실험하지는 말자)
마지막으로 LLM paper중 (dataset을 제외하고) training detail이 꽤 상세하게 report되어 있는, 23년 9월에 publish된 Qwen 72B techinal report의 내용을 살펴보자.
 Fig.
Fig.
먼저 눈에 띄는 점은 가장 첫 문단의 내용중 첫 iteration 50 step동안은 actor는 freezing하고 critic만 update했다는 것이다.
이는 유사하게 중국 연구진들이 publish한 paper, Secrets of RLHF in Large Language Models Part I: PPO에도 나와있는 내용으로,
actor가 받는 reward signal이 실제로 critic이 주는 value를 쓰는데 아무리 critic을 RM으로 initialize하더라도 이 task에 model이 적응을 해야 하고,
적응을 하기 전까지는 별로 도움이 안되는 값을 actor가 받아 학습하기 때문에 training stability를 위해서 이렇게 한 것 같다.
다음으로 KL divergence coefficient를 \(0.04\)로 줬는데, 이는 Instruct GPT의 2배에 해당하는 값이다. 그리고 이들은 actor에 대해서 1e-6, critic에 대해서 5e-6을 줬는데, 이는 실제로 다른 RL task에서 PPO를 할 때 critic에 더 높은 lr을 할당하는 trick을 쓴 것이다. 이것도 마찬가지로 training stability를 위해서 그런 것 같다.
한 편, InstructGPT와 LLaMa2의 lr과 kl penalty를 통해 Qwen의 hparam이 합리적인지 추론해보자. 순수 actor에 대해서 (모두 hydra 안씀) model size, GPU device 수, lr 그리고 kl penalty는 다음과 같았다. (추가로 opensource recipe, deepspeedchat의 recipe같은게 있는데, 이런건 optimal performance를 얻는 hparam가 아닌 것으로 보이니 white paper들을 참고해야 하는데 hparam을 기재한 paper가 별로 없다.)
- InstructGPT
- 175B / ??? / 5e-6 (A-C) / 0.04
- LLaMa 2
- 7B, 13B / ??? / 1e-6 (A-C) / 0.01
- 34B, 70B / ??? / 1e-6 (A-C) / 0.005
- Qwen
- 72B / ??? / 1e-6 (A), 5e-6 (C) / 0.04
- ChineseLLaMa (PPO)
- 7B / 1-node (8-GPUs) / 5e-7 (A), 1.65e-6 (C) / 0.05 ~ 0.2 (ablation)
아무래도 model size가 작을수록 kl penalty를 크게주거나 lr을 줄여줘야 하는 것으로 보이는데, 완전 align이 되지는 않아 보이지만 같은 kl penalty를 쓴 InstructGPT에 대해 model size가 더 작은 Qwen이 적은 lr을 쓰긴 했다.
그 다음 detail은 value clipping을 했다는 것인데, 이는 PPO를 쓸 때 흔한 trick이라고 이미 소개한 바 있다. 그리고 actor가 rollout할 때 sampling parameter인데, InstructGPT는 temperatur를 1로 썼다는 언급만 있고 LLaMa 2에서는 이에 대한 언급이 없으며 Qwen에서는 0.9의 값으로 top-p sampling을 했음을 알 수 있다.
Training without Dropout
SFT를 학습할 때에는 residual dropout만 쓰고 PPO와 RM을 할 때에는 dropout을 쓰지 않는다는 내용이 paper와 openai의 구현체에 있다. 사실 empricial result를 따른 것인지? 아니면 dropout을 쓰면 무슨 문제를일으키는지?에 대한 근거를 찾을 수 없어 이해가 되지 않지만 참고해야할 듯 하다. (maybe this twit can help?)
 Fig.
Fig.
 Fig.
Fig.
혹은 이정도 생각을 할 수 있는데, RM에 대해서는 보통 overfitting이 심하기때문에 1 epoch만 학습하므로 dropout을 끈다는 것이다. PPO에 대해서는 이 paper가 도움이 될 것 같다.
EMA Update
그리고 추가로 training stability를 위한 (?) Exponential Moving Average (EMA)를 활용한 policy update에 대해 알아보려고 한다.
원래는 생략하려고 했는데 deepspeedchat에도 구현이 되어있으며 InstructGPT를 survey하다보니 언급이 있어 추가한다.
여기를 보면 deepspeedchat을 학습할 때 model의 optimization step마다 EMA update를 할 것인지?를 결정할 수 있음을 알 수 있다.
아마 RL이 워낙 불안정하게 학습이 되고 OpenAI RLHF의 core contributer인 John Schulman이 강력한 RL background를 가지고 있기 때문에 쓴 것으로 보인다.
이를 썼을때와 안 썼을때의 비교 실험은 없지만 일단 알아보자.
원래 RL에는 Polyak Averaging이라고 불리는 method가 있다.
이는 아래처럼 old policy가 아니라 moving average를 써서 update하는 걸 말한다.
그런데 여기서 문제가 있는데, InstructGPT에서 어떤 방식으로 EMA update했는지에 대한 언급은 없고 deepspeedchat 구현체는 polyak averaging가 아니다.
일단 어떻게 구현을 했는지 보자. 우선 training loop를 돌기 전에 다음을 선언한다.
step_average_reward = 0.
ema_reward_score = ExponentialMovingAverage() ## here
for epoch in range(args.num_train_epochs):
for step, (batch_prompt, batch_unsupervised) in enumerate(
zip(prompt_train_dataloader, unsupervised_train_dataloader)):
그리고 ExponentialMovingAverage() class는 다음과 같다.
class ExponentialMovingAverage:
def __init__(self, alpha=0.9):
self.alpha = alpha
self.ema = None
def update(self, num):
prev_ema = num if self.ema is None else self.ema
self.ema = self.alpha * prev_ema + (1.0 - self.alpha) * num
return self.ema
def get(self):
return self.ema if self.ema is not None else 0.
앞서 설명한 polyak averaging 수식과 같은데, 엄밀하게 이것은 parameter update를 해주는 것은 아니다. 이는 RM score로 부터 얻은 reward를 moving average하는 것으로 report를 위한 용도인 것 같다.
실제로 parameter update를 위한 moving_average를 써서 update를 하는데, 이는 아래에서 처럼 actor, critic loss를 다 구하고 각 module의 backpropagation 및 parameter update를 다 한뒤에 averaging을 한다.
ema_reward_score = ExponentialMovingAverage() ## here
## for PPO training epochs (e.g. 235k episodes)
for epoch in range(args.num_train_epochs):
## for unique prompts (e.g. 512 batch)
for step, (batch_prompt, batch_unsupervised) in enumerate(
zip(prompt_train_dataloader, unsupervised_train_dataloader)):
## generate trajectory samples (e.g. 512)
exp_dataset = exp_mini_dataset.add(out)
if exp_dataset is not None:
inner_iter = 0
average_reward = 0
## how many times do you want to reuse sampled trajectories? (e.g. 1 epoch)
for ppo_ep in range(args.ppo_epochs):
## policy improvement loop (e.g. 64 of 512 batch a)
for i, (exp_data, unsup_data) in enumerate(
zip(exp_dataset, unsup_dataset)):
actor_loss, critic_loss = actor(exp_data), critic(exp_data)
unsup_loss = actor(unsup_data) ## ppo-ptx
average_reward += exp_data["rewards"].mean()
inner_iter += 1
## EMA
if args.enable_ema:
moving_average(
actor,
actor_ema,
zero_stage=args.actor_zero_stage
)
## update EMA reward score
average_reward = get_all_reduce_mean(average_reward).item()
step_average_reward += average_reward / args.gradient_accumulation_steps_actor
if (step + 1) % args.gradient_accumulation_steps_actor == 0:
ema_reward_score.update(step_average_reward)
step_average_reward = 0.
print_rank_0(
f"Average reward score: {average_reward/inner_iter} | EMA reward score: {ema_reward_score.get()}",
args.global_rank)
실제로 moviing_average()에서는 어떤 일이 일어날까?
if args.enable_ema:
moving_average(
rlhf_engine.actor,
rlhf_engine.actor_ema,
zero_stage=args.actor_zero_stage
)
아래 함수를 보면 먼저 actor와 ema actor를 받는다. 이 둘은 맨 처음에는 같은 SFT model로 initialize된다. 그리고 actor는 PPO step을 통해 1 iteration update 된 셈이다.
- actor : \(\theta_{t}\)
- actor_ema: \(\theta_{t+1}\)
EMA update를 하기 위해서는 model에 deepspeed ZeRO를 썼기 때문에 각 device별로 partition되어 있는 것들을 한 군데로 모아야 한다 (gather). ZeRO에 대한 post가 아니므로 이는 생략할 것이고, 우리가 주의해야 할 부분은 torch.lerp연산을 하는 부분이다.
import deepspeed
from deepspeed.runtime.zero.partition_parameters import ZeroParamStatus
def moving_average(model, model_ema, beta=0.992, device=None, zero_stage=0):
zero_stage_3 = (zero_stage == 3)
with torch.no_grad():
for param, param_ema in zip(model.parameters(), model_ema.parameters()):
# TODO: use prefiltering for efficiency
params_to_fetch = _z3_params_to_fetch([param, param_ema]) if zero_stage_3 else []
should_gather_param = len(params_to_fetch) > 0
with deepspeed.zero.GatheredParameters(
params_to_fetch,
enabled=should_gather_param
):
data = param.data
if device is not None:
data = data.to(device)
param_ema.data.copy_(
torch.lerp(data, param_ema.data, beta)
)
def _z3_params_to_fetch(param_list):
return [
p for p in param_list
if hasattr(p, 'ds_id') and p.ds_status == ZeroParamStatus.NOT_AVAILABLE
]
torch.lrep는 linear interpolation연산을 하겠다는 의미이며,
다음의 수식을 따라 두 tensor를 interpolate한다.
lerp 예시를 보면 단박에 이를 이해할 수 있는데,
>>> start = torch.arange(1., 5.)
>>> end = torch.empty(4).fill_(10)
>>> start
tensor([ 1., 2., 3., 4.])
>>> end
tensor([ 10., 10., 10., 10.])
>>> torch.lerp(start, end, 0.5)
tensor([ 5.5000, 6.0000, 6.5000, 7.0000])
우리의 상황에 대입해보면 \(t=1\)시점의 update를 위해 아래처럼 ema 가 update됨을 알 수 있다.
\[\bar{\theta_{1}} = \theta_{1} + 0.992 \cdot (\theta_{1} - \theta_{0})\]그 다음 timestep에 대해서는 다음과 같을 것이다.
\[\bar{\theta_{2}} = \theta_{2} + 0.992 \cdot (\theta_{2} - \bar{\theta_{1}})\]근데 이게 actor가 아니라 EMA actor에 copy가 되고 있으며 actor의 parameter, \(\theta_1\)에 대해서는 \((1-0.992)\)만큼이 곱해져야 할 것 같은데 이것이 생략되어 있다 (??). 원래 polyak averaging이라 함은 Deep Q-Learning (DQN)등에 많이 쓰이는 trick으로 아래와 같은 update rule에 따라 실제로 optimization step마다의 update rule을 의미하는 것으로 알려져 있다.
# update target network
if global_step % args.target_network_frequency == 0:
for target_network_param, q_network_param in zip(target_network.parameters(), q_network.parameters()):
target_network_param.data.copy_(
args.tau * q_network_param.data + (1.0 - args.tau) * target_network_param.data
)
추가로 Q-Learning 기반의 LM인 ILQL algorithm의 trlx 구현체에도 이 구현이 있는데, 결론은 PPO에선 이것이 쓰이는게 아닌 것 같다. Deepspeedchat의 README에 따르면 ema optiion을 enable하면 ema checkpoint를 따로 얻을 수 있다는 것에 그치는 것 같다. 즉 actor가 parameter update를 할 때 이걸 쓰는게 아니다. 그냥 ema actor는 따로 EMA rule로 update가 되고있고 (정확히 EMA도 아닌걸로 보이는데), 나중에 inference해보면 ema actor checkpoint의 성능이 나쁘지 않다는 것 같다.
We observe ema checkpoint can generally bring better model generation quality
as stated in InstructGPT.
이런식으로 EMA를 하는 것에 대해서는 reference를 찾지 못했는데, 나중에 따로 다뤄보도록 하겠다. (diffusion 쪽에서도 training 하면서 저장된 다양한 ema checkpoint를 사용해서 성능을 높히는 approach가 있는 것 같은데 관련이 있어 보인다. paper)
Important Metrics to Monitor
정말 마지막으로 PPO 학습을 할 때 monitor하면 좋을 metric들에 대해 얘기하고 마치려고 한다.
- Clipped logprob ratio
- Adaptive kl penalty coefficient and logprob ratio between SFT and RL policy
- Reward / Return Mean
먼저 PPO clip range를 넘어가는 logprob의 비율 (ratio)이다.
PPO는 단순 gradient decsent가 아니다.
Optimization step마다 policy improvement 가 최대한 일어나야 하기 때문에 보수적으로 update를 한다.
Old, new policy의 log ratio를 재서 clip range를 넘어가면 gradient가 0이되어 update에 기여하지 못한다.
RLHF paper들을 통해 clip range 가 보통 0.2 임을 알았으므로 우리는 이 값을 넘는 log ratio가 얼마나 존재하는지 tracking할 필요가 있다.
만약 이 range를 넘어가는 element가 너무 많으면 제대로 improvement가 일어나지 않을 것이고 너무 많은 sample이 버려지고 있을 수 있고 policy가 망가질 수도 있다.
그 다음은 SFT parameter와 current policy의 logprob ratio이다.
이는 RLHF를 하면서 RM에 빼지는 값을 얘기한다.
얼마나 init weight으로부터 현재 policy가 바뀌었는지를 말하는데 (KLD between SFT and RL policy) 앞서 언급했던 것 처럼 PPO의 entropy bonus와도 같은 역할을 한다.
RLHF를 할 때는 pretrained LM이 갖고 있던 knowledge를 alignment learning (PPO)하느라 얼마나 잊어버리는가? 를 alignment tax라고 얘기하는데, 이 값이 곧 tax를 얼마나 내는지 알 수 있으며 너무 많이 tax를 지불하지 않는 선에서 early stopping하는데 도움을 주는 값이므로 반드시 tracking해야 한다.
(다른 RL task에서도 측정한다고 하는 것 같다)
마지막으로 rollout을 하면서 얻는 trajectory들의 reward나 return 을 sum하거나 mean한 것을 tracking해야 한다.
보통 RL을하면 actor나 critic의 loss를 잘 보지 않는다.
왜냐하면 critic의 경우 regression을 하는 것이므로 당연히 학습이 될수록 값이 0을 수렴하는게 맞지만,
actor의 경우 이것은 SL이 아니라 RL을 하는 것이므로 언제나 정답 label에 대한 NLL (Negative Log Likelihood)을 재는것이 아니게 된다.
RL에서는 actor loss가 logprob에 advantage, A를 곱한 것이고 A값의 range는 모든 실수이므로 음수가 나올 수 있다.
따라서 actor loss는 실제로 음수가 찍힐수도 있기 때문에 이것을 보는 것 보다 실제로 actor가 얼마나 좋아졌는지는 reward의 평균을 봐야만 한다.
하지만 reward가 계속 높아진다고 해서 LLM task가 꼭 성공적으로 수행되고 있다고 보기엔 어려울 수 있다.
바둑이나 game을 play하는 agent를 학습하는 경우 reward가 무조건 높으면 학습이 잘되고있는게 맞다. 왜냐하면 이기면 무조건 1점을 받는다고 쳤을 때 512개 trajectory가 모두 512점을 받으면 좋은 policy를 갖고 있는게 맞다. 하지만 LLM은 다르다, 우리는 reward signal을 잘 정의된 simulator로부터 받는 것이 아니라 직접 학습한 RM으로 부터 받는다. 그리고 이는 정확한 reward가 아니라 대리의 (proxy) reward를 주는것과 다름 없다.
즉 이 수치가 높다고 다 좋은건 아니며, RL에서는 reward hacking이라고 하여 점수를 높게 받는 행위를 actor가 파고드는 문제가 생길 수 있다. 이를 앞서 설명한 Scaling Laws for Reward Model Overoptimization라는 paper에서 설명하고 있는데, 이는 LLM에만 국한된 문제는 아니라고 한다. 아마 reward design을 잘못하거나 Inverse RL (IRL)을 하는 경우 발생가능성이 꽤 있는 문제 같다. 아무튼 이런 상황에 직면하면 reward는 한없이 높아지지만 실제 actor가 뱉는 답변은 좋지 않은 답변일 수 있다. 가령 길게 답변하기만 하면 reward를 많이 받는다고 해보자, 그러면 actor는 답변의 길이를 늘리기만해도 reward를 많이 받을것이고 실제로 우리가 얻은 trained policy는 장황한 답변만을 할 것이다. 3줄 요약해달라고 해도 말이다.
이는 잘 알려진 reward hacking의 예시로 ChatGPT를 소개하는 OpenAI의 blog나 다른 paper에서도 report되고 있는 내용이다.
The model is often excessively verbose and overuses certain phrases,
such as restating that it’s a language model trained by OpenAI.
These issues arise from biases in the training data
(trainers prefer longer answers that look more comprehensive)
and well-known over-optimization issues
아무튼 reward가 올라가는게 무조건 좋은건 아니므로 주의할 필요가 있겠으나, reward가 올라가지 않는다는건 무조건 문제가 있으므로 monitoring할 필요가 있다.
Outro
PPO implementation은 구현이 상당히 까다롭다고 한다. 논문대로 구현하는걸 말하는 것이 아니라 practical하게 작동하게 하기위해서 그렇다는 것이다. 애초에 PPO자체가 Vanilla Policy Gradient (VPG)의 training stability를 개선하기 위해서 이론적으로 제안된 것인데, 실제 구현체는 군데군데 stability를 위한 trick들이 존재하는 것 같다.
가령 critic loss를 구할 때 PPO style의 clipping을 하는데, 이것은 검증된 것은 아니라고 한다. 물론 openai의 구현체에도 이것이 포함되어 있지만 몇년이 지났기 때문에 더이상 value clipping이 도움이 된다는 것은 정설이 아닐 수도 있다. 최근 ICLR workshop에 PPO Implementation에 대한 detail을 다룬 blog post가 accept된 적이 있다고 하는데, 그만큼 real world application 수준의 policy를 학습하기 위해서는 엄청난 detail이 필요함을 보여주는 예시라 생각되는데, 이 post에서도 value clipping에 대한 지적이 있다.
 Fig.
Fig.
더군다나 LLM을 위한 RLHF를 하는 사람들은 RL background가 아니기 때문에 더더욱 detail에 신경을 써야 할 것 같다. 다음에 기회가 되면 더 많은 trick에 대해서 다뤄보도록 하겠다.
References
- Papers
- RLHF Code Implementation
- The N Implementation Details of RLHF with PPO
- The 37 Implementation Details of Proximal Policy Optimization
- Fine-Tuning Language Models from Human Preferences
- openai/summarize-from-feedback
- openai/lm-human-preferences
- DeepSpeed/blogs/deepspeed-chat/README.md
- CarperAI/trlx
- DeepSpeedExamples/applications/DeepSpeed-Chat/README.md
- karpathy/nanoGPT
- facebookresearch/llama
- OpenLMLab/MOSS-RLHF