(WIP) Some Thoughts on Synthetic Datasets and MS Phi Series
11 Dec 2024< 목차 >
Introduction (Thoughts on Synthetic Dataset and Benchmark)
이 분야는 연례행사처럼 12월에 뭔가 큰걸 빵 하고 터뜨리는 문화가 있는 것 같다. NIPS랑 크리스마스가 같이 껴있어서 그런 것 같은데, 그래서 NIPS submission이 있는 4~5월달에도 뭐가 많이 풀리기도 한다. 그리고 KST로 24년 12월 13일에 Microsoft Phi-4가 공개됐다.
Large Language Model (LLM)하면 보통 OpenAI, Anthropic, Google Deepmind (GDM)을 big three로 얘기하고 여기에 meta나 mistral, cohere, NVIDIA 등이 치고 올라오고 중국에서도 alibaba의 qwen이나 deepseek 등이 좋은 model들을 보여주지만, 사실 MS도 무시할 수 없는 기업이다. 시총이 매우 큰 기업인 만큼 GPU infra가 어마어마하고 이전부터 알고리즘적으로도 여러 임팩트 있는 연구들을 많이 보여줬으며, deepspeed team (지금은 openai로 갔다는 소문이 있다)을 꾸려 ml system engineering에도 엄청난 임팩트를 보여줬다. 그리고 무엇보다 openai와 기술적인 교류를 계속 하고 있을 것이기 때문에 MS가 좋은 모델을 만들어 낼 것이란 것은 시간문제로 보였다.
Phi는 MS가 밀고있는 언어모델로, 타사의 LLM들보다 model size가 상대적으로 작지만 high quality textbook data 위주로 pretraining corpus를 구성하여 작지만 강력한 모델을 만드는 것이 목적인 lineup이다. 그런데 이번에 나온 phi-4는 말도 안되는 성능을 보여준다.
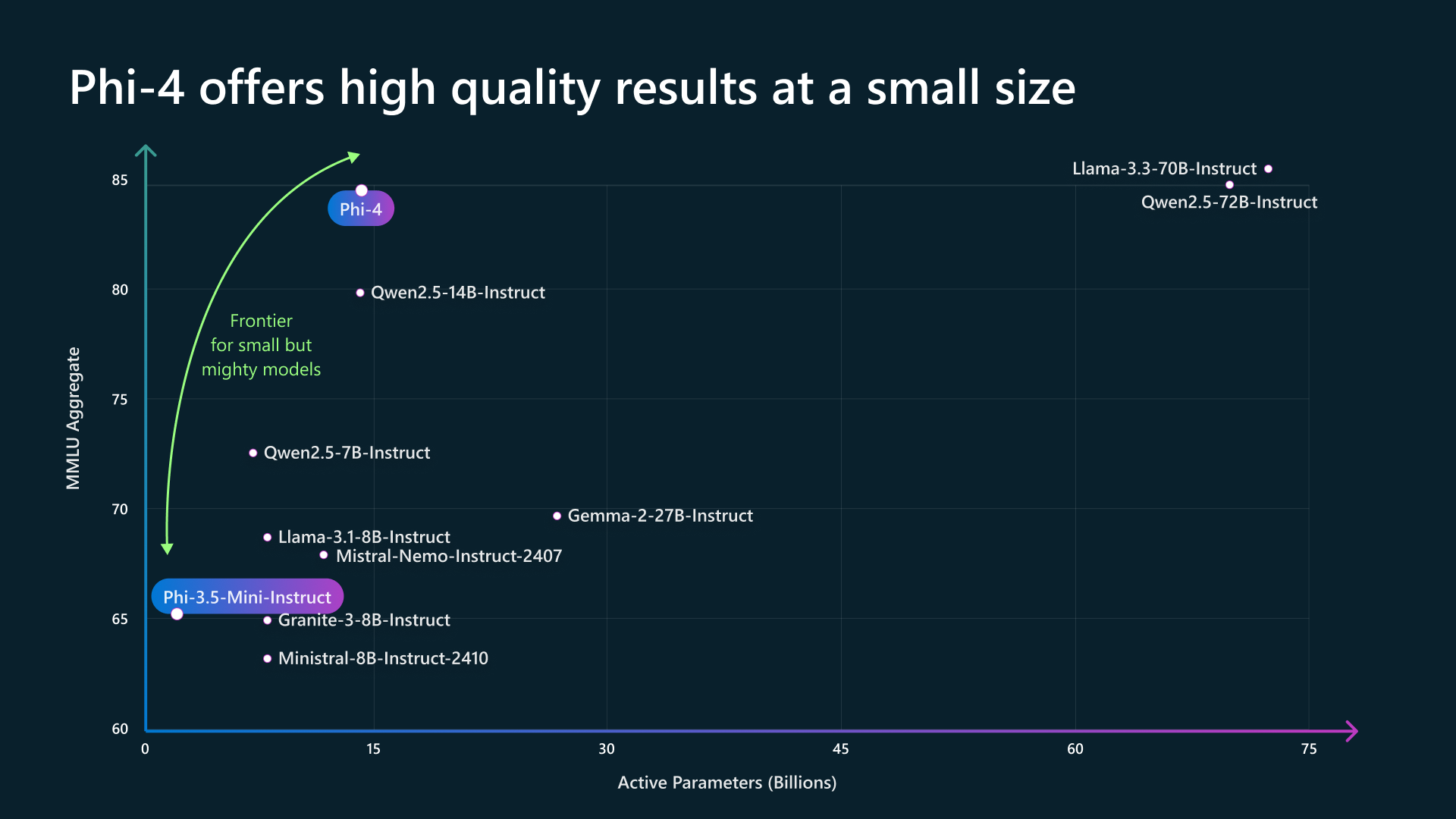 Fig.
Fig.
사실 이쯤되니 Massive Multitask Language Understanding (MMLU)는 점점 saturation되고 있어서 식상한데, 문제는 아래 paper figure에서 처럼 몇가지 고난이도 benchmark에서 phi-4가 14B model size에도 불구하고 gpt-4o를 이겨버렸다는 것이다.
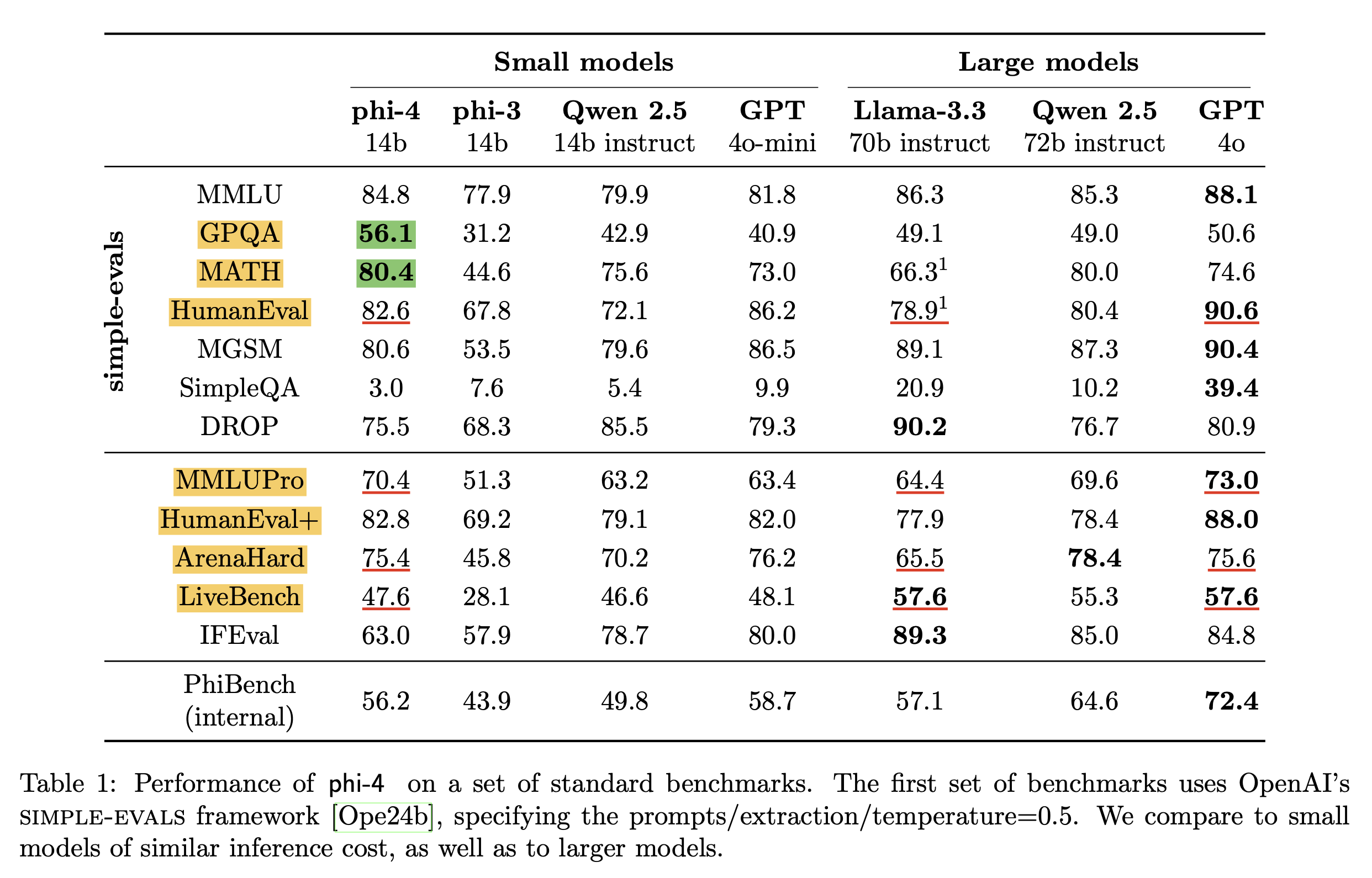 Fig.
Fig.
이 중에서 Graduate-Level Google-Proof Q&A Benchmark (GPQA)나 Arena-Hard, 그리고 LiveCodeBench등은 매우 어려운 benchmark로 알려져 있고 실제로 o1이 등장하기 전까지의 preminum lineup이었던 chatgpt gpt-4도 잘 못했었는데, 여기서 phi-4가 gpt-4o를 앞서기도 한 것이다. (MATH 또한 GSM8K같은 완전 초등생 문제가 아니라 중고등 수학 문제 인데, 요즘은 대부분의 model이 이를 target해서 optimization해서 그런지 점점 saturation되고 있는 상황이지만 여전히 challenging한데 gpt-4o를 이겼다)
 Fig.
Fig.
어떻게 이런 일이 가능할까??
그 배경에는 gpt-4로 합성한 dataset이 있었다.
 Fig.
Fig.
곧 자세히 살펴보겠으나 MS가 주장하는 바는 다음과 같다.
- model architecture 보다 dataset을 어떻게 구성하느냐가 더 중요
- 물론 learning algorithm, architecture도 중요하긴 하지만 뭐가 더 중요하냐 따지면
- web corpus filtering을 통해 high-quality 를 가려내는 것이 중요
- web corpus에서 reasoning, refinement등의 어려운 난이도 task를 학습하기 어렵기 때문에 이미 존재하는 document등을 더 어려운 형식으로 바꾸고자 했고, 그것이 gpt-4를 사용해서 document를 Question-Answering (QA)형태로 rewrite 하는 것
- 요즘 많이들 하는 pre-training stage를 1, 2, 3로 나누는 것, 즉 curriculum learning (pre-training -> mid-training)이 중요
- post-training (RLHF)시에 DPO를 썼는데, 여기서도 synthetic pair를 만드는 데 reasoning path를 잘 배우기 위해서 개발한 algorithm을 도입함
이전 phi series paper들에서도 이를 밝혔는지 기억이 안나지만, 이렇게 노골적으로 gpt-4 distill을 했다고 아예 문구를 박아버린 것은 나는 처음 보는 것 같은데, 이런 approach는 사실 다른 연구 그룹들에서 많이 한다고 알려져 있긴 했다. 아래는 Qwen2.5-Math technical report에 나오는 figure인데, 이들이 이전에 gpt-4를 썼는지 알 길은 없지만 일단 이전 세대 qwen model들을 통해 dataset filtering과 math QA dataset을 합성해서 이를 다음 세대인 2.5세대 model을 만드는 pre-training corpus에 주입했다는 내용을 담고 있다.
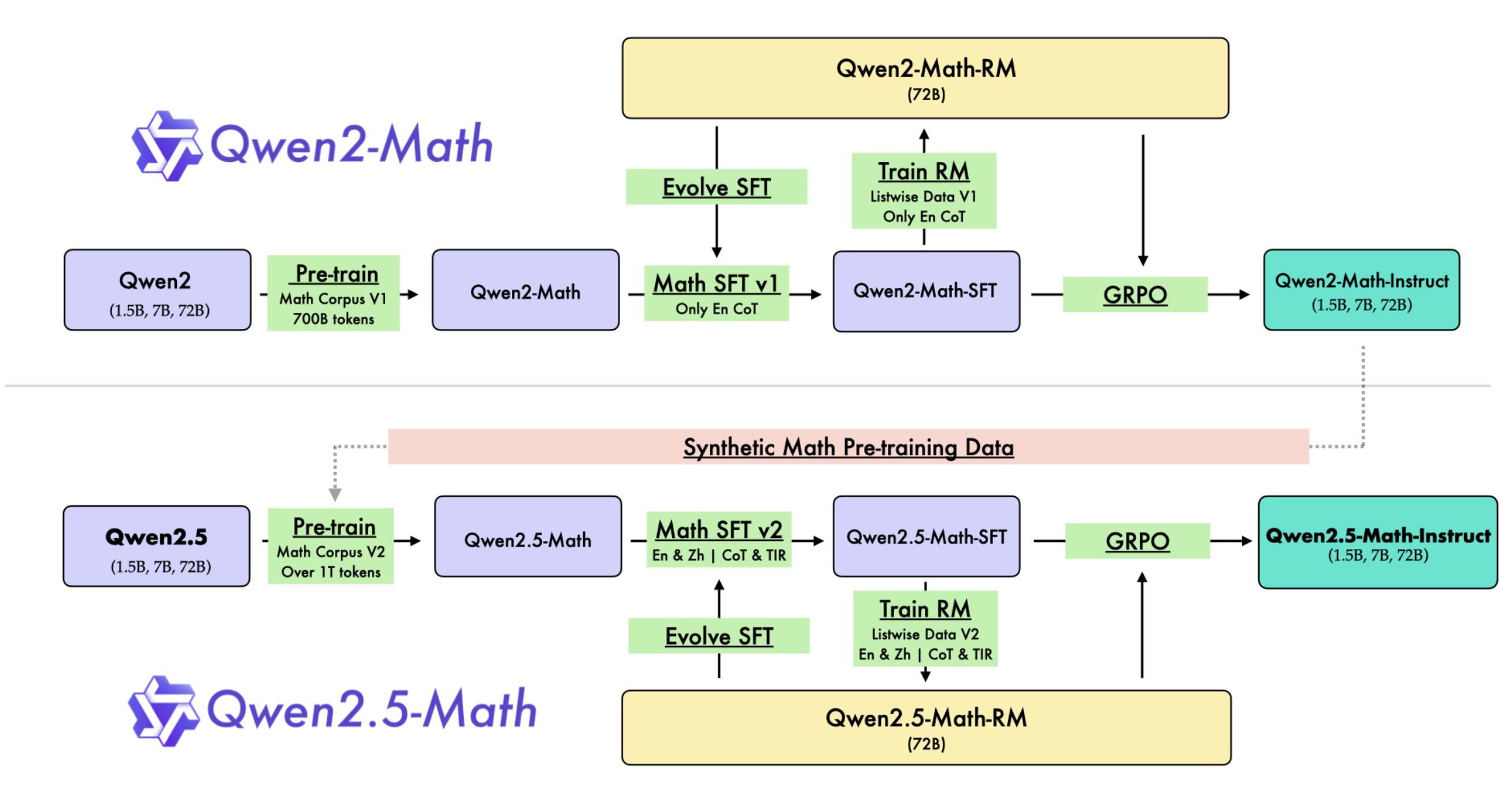 Fig.
Fig.
그 결과 솔직히 1.5B model이 MATH를 70점 찍는 것은 이전에 상상할 수 없는 것이었지만 그걸 해내버렸다.
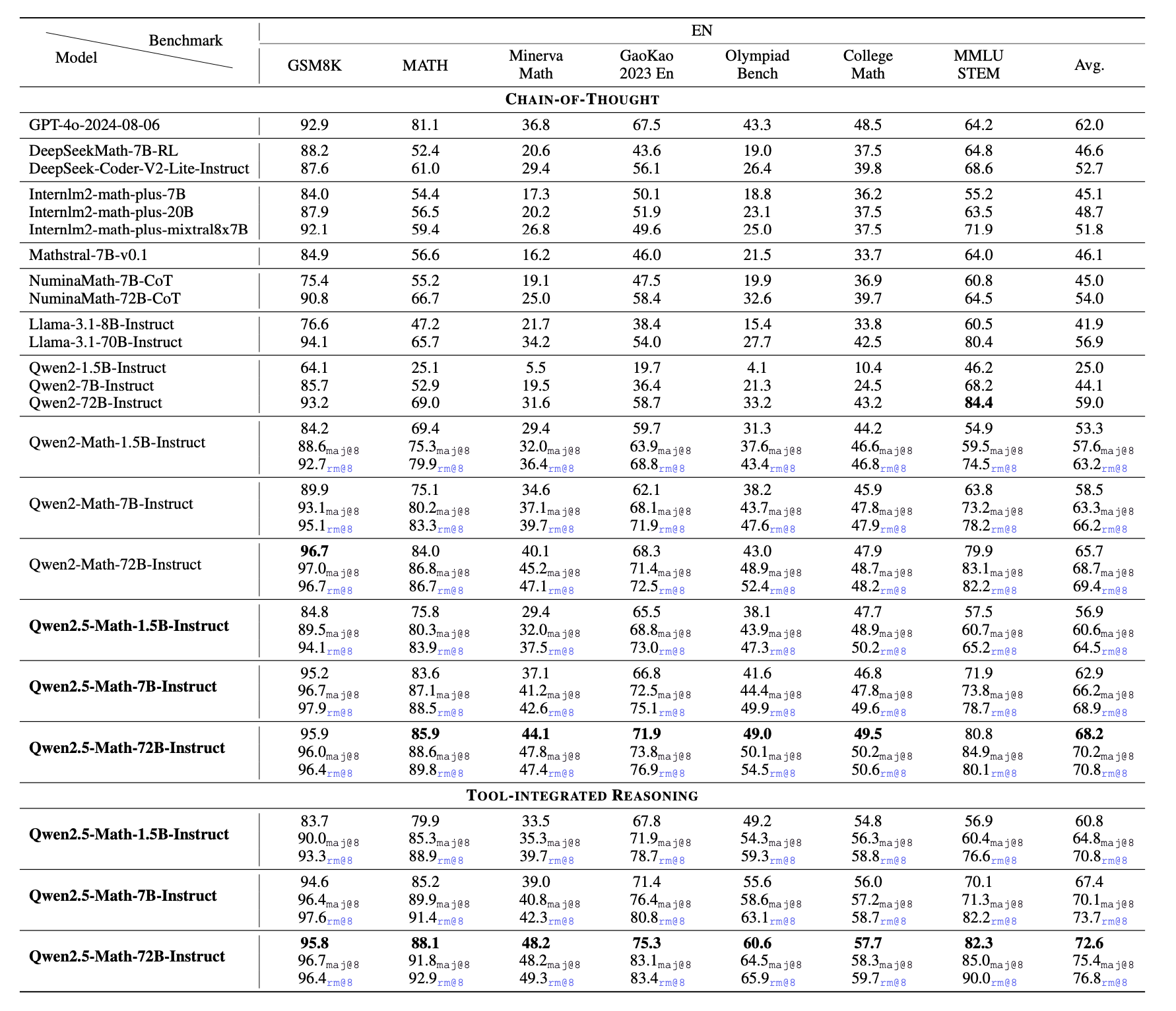 Fig.
Fig.
원래도 Qwen은 model에 사용된 computing budget에 비해 MMLU 점수가 너무 높아서 (phi 처럼) instruction data를 pre-training corpus에 넣거나 합성 데이터를 넣어서 QA task에 너무 overfitting한 것이 아니냐? 하는 의심이 있었는데, 이제 아무도 숨기지 않는 것 같다. 보통 그냥 naive web corpus를 사용한다면 corpus의 quality filtering에 따라 차이가 있을 순 있겠으나 \(3 \times 10^{22}\)FLOPs 정도 부어야 MMLU는 서서히 발현되는 emergent ability에 해당하는 task인데, Qwen은 0.5B model을 아무리 길게 학습했더라도 50점이 나왔는데 이는 매우 높은 점수였고 phi 또한 마찬가지로 twitter 등지에서 의심을 받기도 했다.
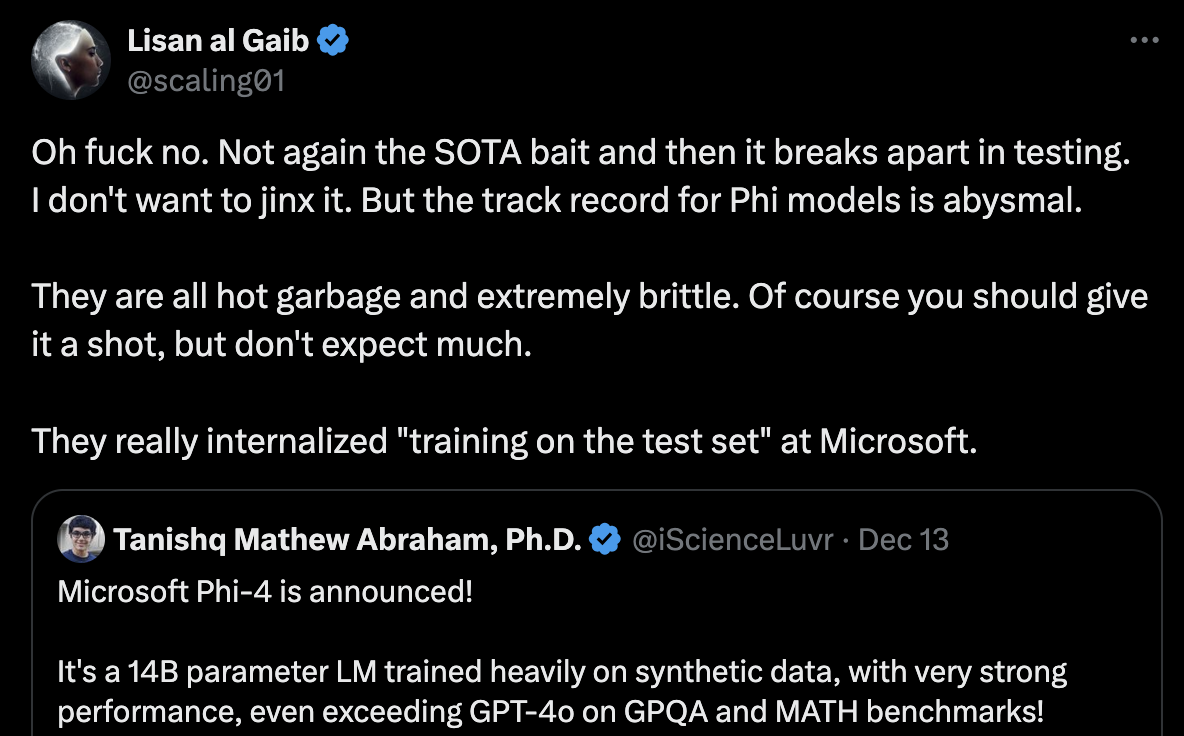 Fig.
Fig.
그 밖에 Hunyuan-Large도 MMLU가 괴랄하게 높은데, 이 model의 배경에도 합성 데이터가 있다.
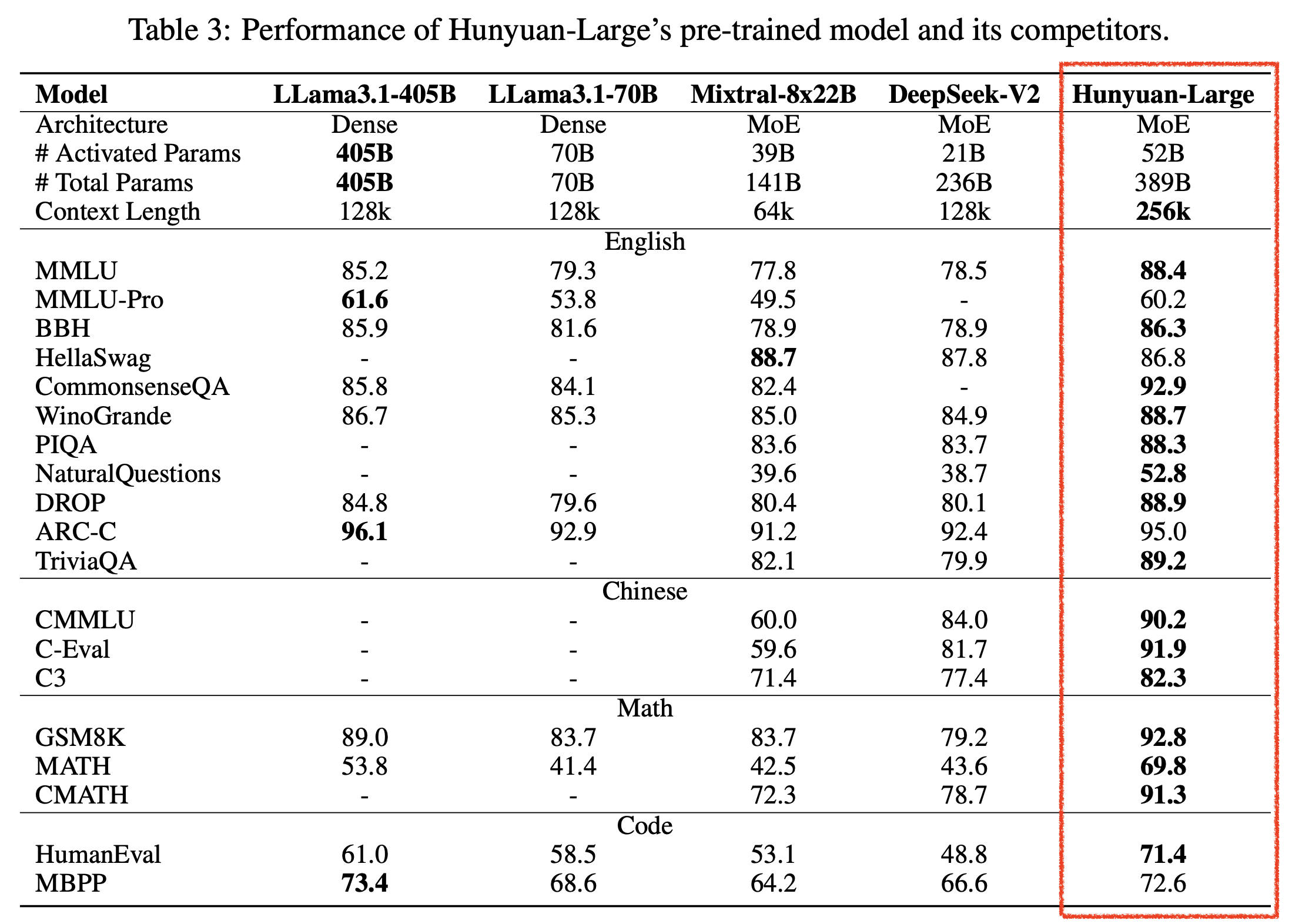 Fig.
Fig.
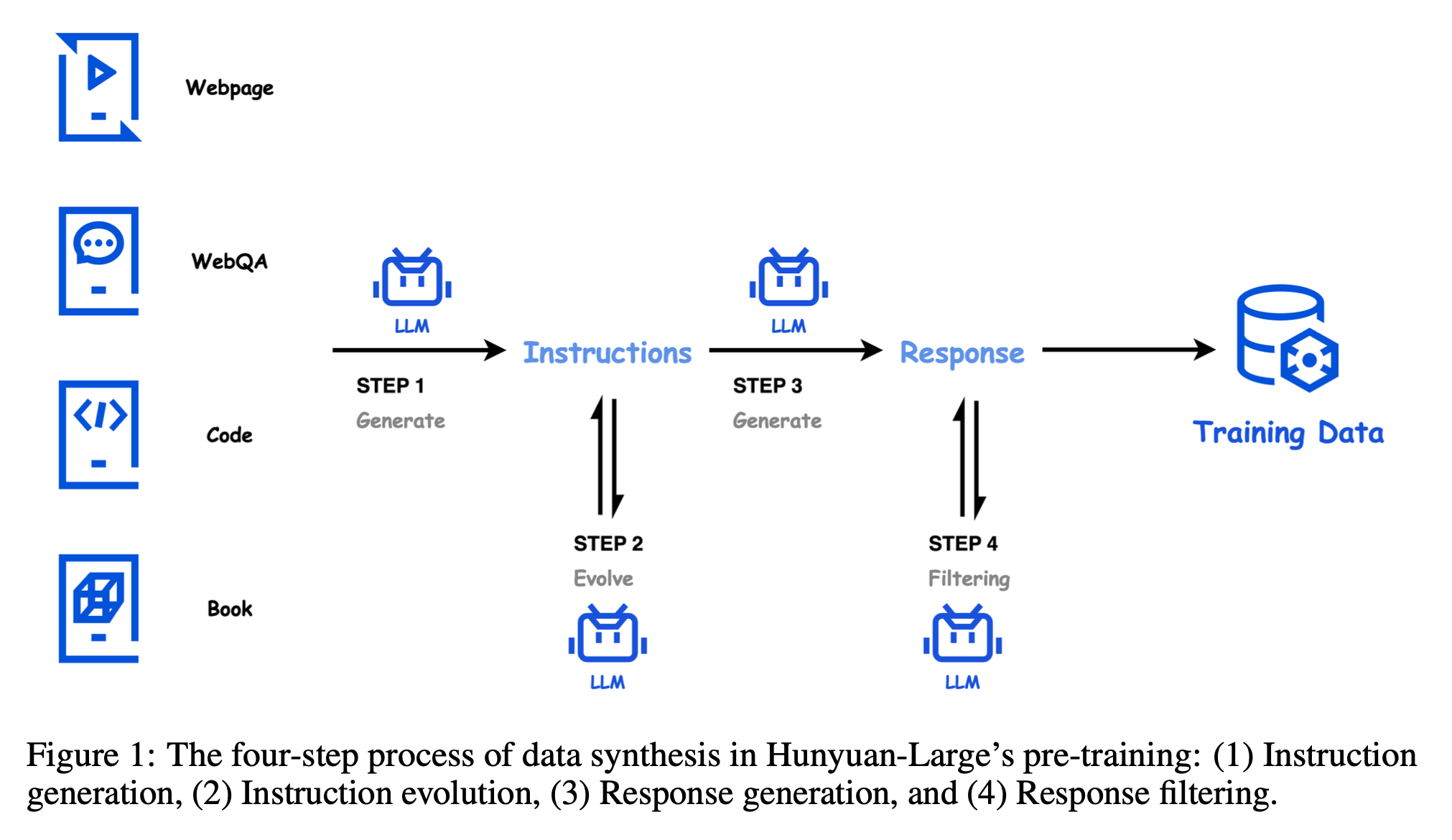 Fig.
Fig.
통상 Mixture of Expert (MoE) model이 total parameter가 dense model과 같을 경우, 제대로 학습 했다면 dense model에 상대가 안되는 것이 정상인데 지금의 경우 405B llama model을 고작 389B total param을 갖는 MoE model이 압살하니 합성 데이터의 힘이 작용했다고 밖에 설명할 수 없을 것 같다는게 내 생각이다.
그렇다면 합성 데이터는 나쁜걸까?
바로 오늘 12월 14일, OpenAI의 Co-founder 였으며 scaling law의 열렬한 신봉자인 Ilya Sutskever가 NIPS에서 talk을 했는데, Ilya는 internet web dataset은 AI에게 화석 연료와 같고 (화석 연료는 언젠가 고갈될 운명), 우리는 곧 web dataset을 다 쓸 것이므로 다른 방법을 강구해야 한다고 얘기했고 그 중에 synthetic dataset이 있었다.
 Fig. Source from Ilya Sutskever’s Talk from NIPS 2024
Fig. Source from Ilya Sutskever’s Talk from NIPS 2024
Bayesian Deep Learning으로 유명했던 Yarin Gal은 최근 AI models collapse when trained on recursively generated data라는 paper를 낸 적 있는데, 이에 따르면 model generated dataset을 계속 recursivly training할 경우 mode collapse가 발생할 수 있다고 우려했는데, mode collapse는 예를 들어 우리가 생성하려는 data distribution이 gaussian distribution처럼 생겼다고 할 때, 봉우리가 여러가지 였던 것이 하나로 통합/수축 되는 것을 말한다. 결국 가장 그럴듯한 봉우리 (mode)는 하나 밖에 안남게 되었으므로 그 뒤로는 생성될 데이터가 단편적이게 되는 것을 말한다.
한편 phi-4는 명시적으로 gpt-4o를 distillation 하는 것이 메인 전략이라고 밝혔다. 먼저 큰 모델을 만들고 Distillation을 해야한다는 의견은 여러 frontier lab researcher들에 의해 언급되는 것으로 보아 실제로 chatgpt model들이나 gemini에 적용된 것으로 보이는데,
 Fig. tweet
Fig. tweet
 Fig. tweet
Fig. tweet
Lucas bayer는 2024년 11월까지 GDM에 있다가 얼마전 openai로 이적했고, Shane은 먼저 GDM에 있다가 22~23년 까지 openai에 있다가 GDM으로 이적한 인물들이다.
 Fig. GDM에서 오래토록 distributed training, shampoo optimizer를 연구한 rohan은 그러나 동의하지 않는다고 했는데, 어떤 다른 방법이 있는지에 대해서는 따로 언급하지 않았다.
Fig. GDM에서 오래토록 distributed training, shampoo optimizer를 연구한 rohan은 그러나 동의하지 않는다고 했는데, 어떤 다른 방법이 있는지에 대해서는 따로 언급하지 않았다.
gpt-4o가 과연 distillation한 것인지에 대해서는 알려진 정보가 거의 없지만, gemini flash의 경우 parameter size가 알려지지 않은 매우 큰 MoE model인 gemini ultra 1.5를 distill했다는 것은 technical report에서 밝혀졌으며, openai와 gdm은 서로 이적이 잦기 때문에 비슷한 방식으로 접근했을 가능성이 높아 보인다. 또한 아래 epoch AI에서 공개한 report에 따르면 비용과 여러가질르 통해 추정했을 때 gpt-4o는 원래 1.8T 크기의 MoE model인 gpt-4를 distillation하여 200B수준으로 줄인 것 같다는 분석을 내놨다.
 Fig. Source from Epoch AI
Fig. Source from Epoch AI
아무튼 우리가 합성 데이터를 쓴다는 것은 어떻게 보면 gpt-4o나 gemini ultra같은 frontier model이 raw web corpus 등을 input으로 받아 soft label (logit)을 만들게 하고 작은 model이 이를 학습하는 것인데,
 Fig.
Fig.
Summary and My thoughts
합성 데이터에 대한 여러가지 내 생각을 정리 하자면 아래와 같다.
- 찬성
- 곧 internet web에 있는 dataset는 고갈될 것
- video data 등 text mode를 제외하고 다른 modality는 아직 무수히 많이 존재한다는 말도 있음
- chatgpt가 상용화되고 LLM이 폭발적으로 늘어나면서 이미 여러 site에는 ai generated data가 너무 많이 생기고 있음
- 이미 frotier lab들은 큰 model을 만들고 작은 model로 distillation하는데 이게 합성데이터랑 뭔차이지?
- Reinforcement Learning (RL)을 생각해보자. 원래도 RL은 trajectory를 여러 개 만들어 exploration and exploitation, trial and error를 통해 좋은 trajectory는 생성될 확률을 높히고, 아닌 trajectory는 생성 확률을 낮추는 방식으로 작동하는데, 이것이 LLM에 적용되면 합성 데이터를 만들어 supervised learning 하는 것과 크게 다르지 않음
- 곧 internet web에 있는 dataset는 고갈될 것
- 반대
- mode collapse 생길 수 있음
- QA에만 지나치게 over-fitting 될 수 있음
합성 데이터가 점점 더 주류로 인정받는 상황에서 많은 생각이 든다. 내가 현재 열심히 논문 찾아가며 공부하고 실험, 연구하는 training dynamics, scale up 관련된 것들이 결국 gpt-4가 민주화되고 gpt-5까지 나오네 마네 하는 이 상황에서 점점 더 받아먹기만 하면 되는건지? 아니면 받아먹더라도 큰 모델로, 그리고 더 잘 받아먹어야 하니 (optimization) 계속 이를 트래킹 해야 하는건지?
사실 한국의 많은 연구기관들은 xai처럼 10만대 20만대 H100 cluster를 구축할 여럭도 없고 meta처럼 405B학습에 h100을 3만개 태울 수도 없다 (gpt-4는 루머에 의하면 a100 2.5만대). 이런 상황에서는 gpt-4,5를 distill 하기만 해도 된다면 다행이라고 할 수 있겠으나…
확실한건 합성 데이터를 만들더라도 심혈을 기울여서 만들지 않으면 수학 조금 더 잘하고, 벤치마크 조금 더 잘하는데 그치는 모델이 될 수도 있기 때문에 RL로 task specific한 reasoning chain을 배우는게 아니라 실제로 reasoning을 하는 방법 자체를 learning해서 (learning to learn, meta learning) general task에도 전이되도록 데이터를 합성하는 방식을 계속 고안해야 할 것이다.
그동안 나는 합성 데이터 사용에 반대하는 입장이었는데 이는 단순히 mmlu같은 multiple choice question answering (MCQA)에만 초점을 맞춰 합성한 것에 대한 반발이 주된 것이었다. 하지만 여러 방면에서 다시 생각해보니 데이터를 합성하는 것도 파볼만한 가치가 있다고 생각이됐고, phi-4가 특히나 합성 데이터 비중이 높으며 내용을 자세히 기술했기 때문에 이에 대한 post를 써보기로 결정했다.
Phi-4
Pre-training Details (Batch Size and Training Time)
 Fig.
Fig.
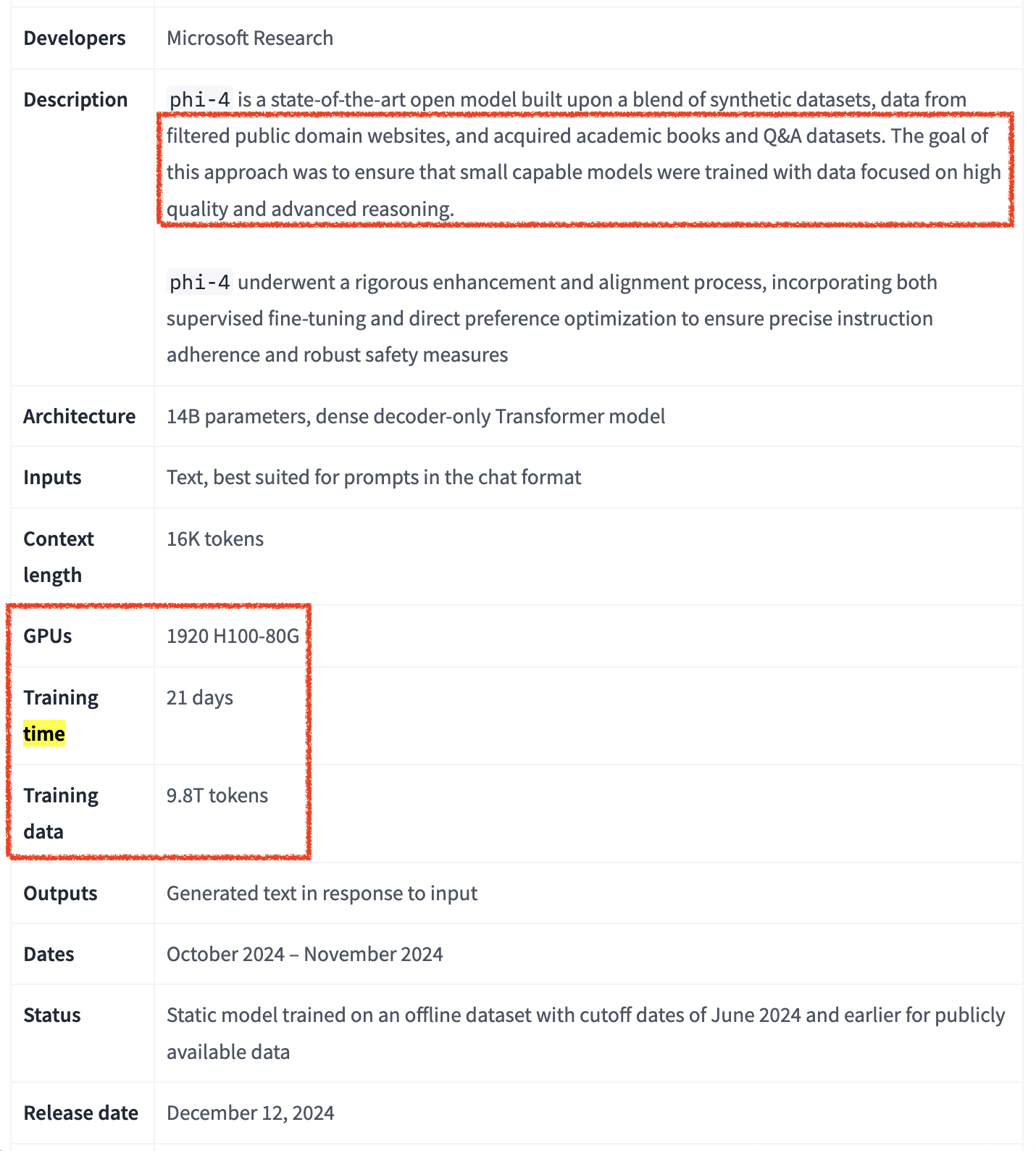 Fig.
Fig.
Mid-training Details
Post-training Details (DPO and Pivotal Token Search (PTS))
그 다음은 post-training detail이다. 요즘 나오는 대부분의 open weight LLM model들 처럼 RLHF처럼 SFT를 하고 DPO를 했는데, 사실 Supervised Fine-Tuning (SFT)는 이렇다 할 게 없다. 단지 high-quality data 8B tokens 을 썼고 dataset은 수학,코딩,추론 등 도메인도 다양하며 multilingual 이었다고 하는데, 이것도 합성을 했다는건지 public 위주로 썼다는건지는 잘 모르겠다. 만약 instruction dataset instance가 하나당 8k tokens라고 치면, 대충 1M개 dataset을 쓴 것으로 보이는데, 요즘 나오는 중국 모델들은 수백만 order를 쓰는 것들도 있는 것으로 봐서 그렇게 비중이 큰 것 같지 않다.
중요한건 Direct Preference Optimization (DPO) phase인데, 저자들은 두 가지를 주효하게 했다.
DPO stage 1학습을 위한 preference pair 합성을 위해Pivotal Token Search (PTS)를 제안- 약 250k개
DPO stage 2로judge-guided DPO를 제안- 약 850k개