(WIP) How to (Re-)Warmup Pre-trained Model
27 Nov 2024< 목차 >
- Motivation
- Observations from the paper, 'Continual Pre-Training of Large Language Models: How to (re)warm your model?'
- Observations from the paper, 'Simple and Scalable Strategies to Continually Pre-train Large Language Models'
- Case Study
- References
Motivation
Pre-trained LLM을 continual pre-training 한다거나 downstream fine-tuning 할 경우, 어떻게 learning rate schedule을 해줘야 할까?
아마 이 경우 loss가 갑자기 jump (spike)하는 상황을 목격한 적이 있을 것이다. 왜 그럴까?
먼저 간단하게 유추해볼 수 있는 몇 가지 원인들은 다음과 같다.
- data distribution shift: pre-training에 사용한 dataset과 현재 fine-tuning (혹은 continual pre-training)시 사용하려는 data distribution이 바뀌어서 적응하느라 그렇다.
- optimizer statistics: momentum SGD나 Adam 같은 경우 1st (or 2nd) moment가 Exponential Moving Average (EMA)로 누적되는데, 다시 학습을 재개하는 경우 optimizer states가 초기화 됐기 때문에 처음에 헤맨다.
- struggle to escape local minima: pre-training시 lr decay가 충분히 진행되어 어떤 local minima에 converge할 것이기 때문이다.
대충 위의 이유로 직관적으로 lr warmup은 하는 것이 맞다고 생각하는 사람이 많을텐데, 정말 그런지에 대해서 관련된 paper들을 몇 가지 살펴보도록 하겠다.
Observations from the paper, 'Continual Pre-Training of Large Language Models: How to (re)warm your model?'
먼저 Continual Pre-Training of Large Language Models: How to (re)warm your model?를 살펴보도록 하겠다. 이 논문에서는 두 가지 유명한 LLM pre-training corpus인 The Pile과 SlimPajama를 사용해 실험을 진행했다. Pretrained weight이 어떻게 학습되었는가는 Pythia를 참고하면 되는데, Pythia 410M model이 사용됐으며 이는 the pile 300B로 학습된 것으로 보이며,
 Fig.
Fig.
그 이후 further training을 할 때 warmup을 어떻게 할지 살펴보기 위해 slimpajama 297B를 사용했으며, optimizer로는 adamw 를 사용했다.
 Fig.
Fig.
(미리 얘기하자면 물론 LLM에는 수렴이란 개념이 없지만 300B 가지고 어느정도 model을 어떤 minima에 빠뜨린 것인지? 어떤 optimizer를 썼는지? 등등에 따라 결과가 다를 수 있을 것 같으므로 너무 paper를 맹신하지는 말아야 하지 않을까 싶다)
How long to warm up? (effect of length of the warmup phase)
먼저 저자들이 확인해본 것은 얼마나 warmup phase를 길게 잡아야 The pile에 대해서도 catastrophic forgetting 안하고, loss spike 현상 업이 slimpajama에 대해서도 성능이 가장 좋을까? 였다.
 Fig.
Fig.
결과는 warmup phase를 얼마나 길게잡던지는 upstream, downstream dataset 둘 다에 아무런 영향이 없었다는 것이며, 심지어 constant LR을 쓰는 것도 warmup과 큰 차이가 없다는 것이었다.
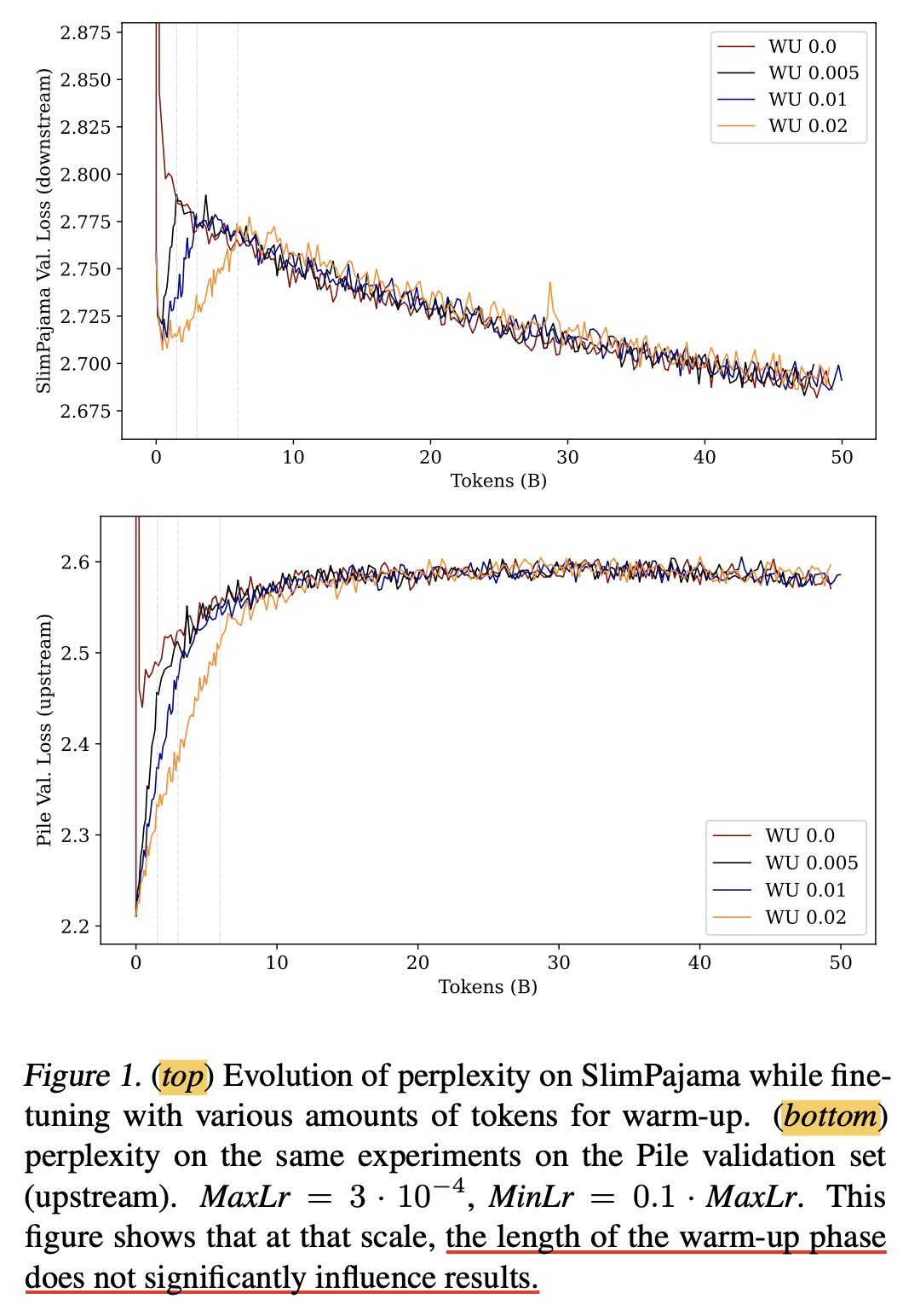 Fig.
Fig.
 Fig.
Fig.
사실 그렇지는 않다. 왜냐면 위 plot은 297B slimpajama를 학습한 것의 앞 50B tokens의 loss curve만 보여줬기 때문이다.
How high to warm up?
그 다음 실험은 warmup시 maximum lr을 얼마나 크게 설정하는지가 upstream, downstream PPL에 어떤 영향을 끼치는가 인데, figure 2, 3에서 constant LR의 문제가 보이기도 한다. 아래 figure에서 관측할 수 있듯 maximum lr이 너무 크면 downstream의 성능이 가장 좋지만 the pile에서 forgetting이 커진다.
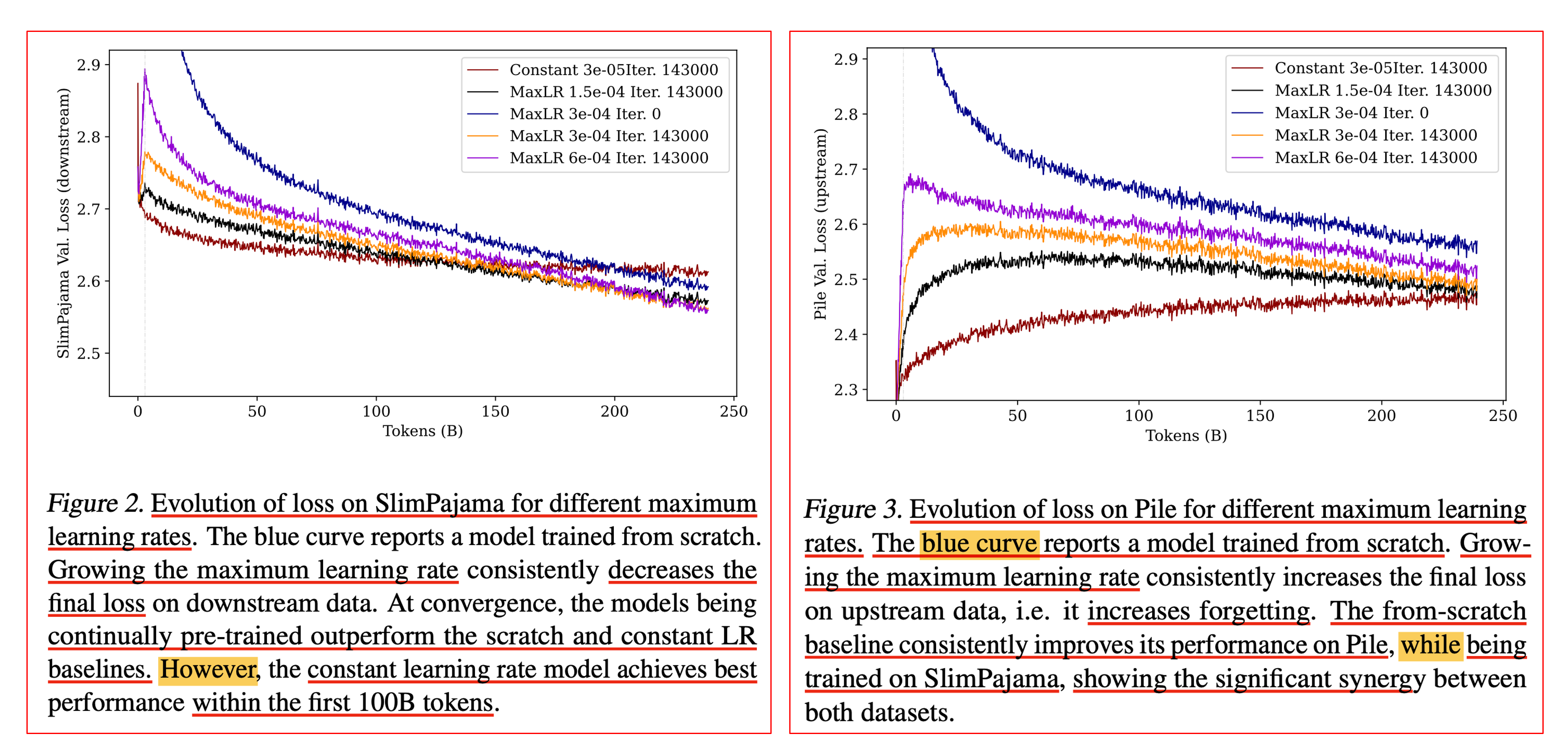 Fig.
Fig.
그리고 constant LR을 보면 처음 100B tokens까지는 warmup을 안하는것보다 좋아보이지만 역전이 일어나는 것을 볼 수 있다. 즉 lr warmup은 어느정도 해주는게 필수이며, 이 때 maximum (peak) lr이 너무 크면 안된다고 할 수 있겠다. (학습량이 얼마안되면 constant LR을 쓰는게 더 경제적일 것이라는 언급도 있다)
 Fig.
Fig.
그리고 이게 왜 여기서 나오는 takeaway인지는 모르겠으나, 당연히 slimpajama 300B정도를 from scratch로 학습하는 것 보다 continual training을 하는 것이 the pile, slimpajama 모두에 긍정적이었다고 한다.
Re-warming on the same data (no data distribution shift)
그 다음은 pretraining시 사용했던 the pile을 further learning에 또 써보는 것이다.
 Fig.
Fig.
이 경우 warmup을 하면 오히려 loss spike가 생기면서 성능이 망가지는 curve를 보여주는데,
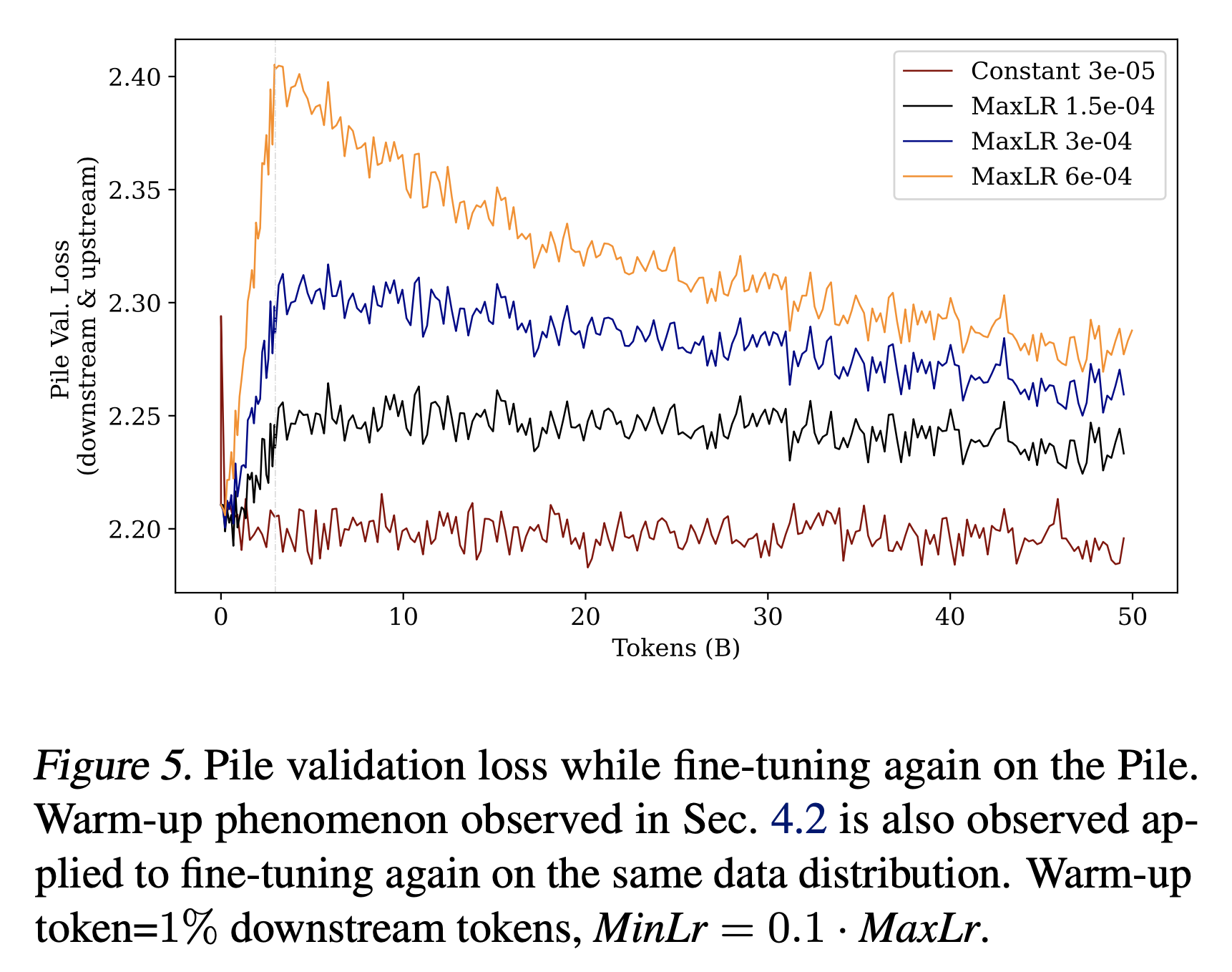 Fig.
Fig.
이에 대한 근거로 저자들은 local minima에서 빠져나오려 하기 때문일 것이라고 추측했으며, slimpajama가 아닌 pile에 대해서도 이러한 현상을 보이는 것을 보니 dataset distribution이 바뀌는 것 뿐만 아니라 optimization dynamics 때문에 이런 일이 발생하는 가능성도 고려해야 한다고 얘기한다.
 Fig.
Fig.
 Fig.
Fig.
좀 더 생각해보자. 만약 우리가 pretraining하다가 모종의 이유로 잠시 cluster를 shutdown했어야 한다고 치자. 당연하게도 adam statistics를 다 가지고있는 경우 실험을 재개하면 정확히 똑같은 loss에서 아무런 spike없이 학습을 재개할 수 있다. 그런데 이런 학습을 재개하는 경우와 지금 다른 것은 다시 lr을 0부터 warmup하는 것과 optimizer states를 초기화 한다는 것 두 가지 일 것이다 (data distribution은 같을테니).
여기서 pretraining에서 fully decayed lr과 비슷할 값인 3e-5를 constant로 쓴 경우 adam statistics가 초기화 됐음에도 불구하고 loss jump도 없었고 성능도 개선이 됐으니 우선 adam statistics가 사라졌기 때매 문제가 될 것인가?에 대해서는 나는 의문이 생겼다.
정리하자면 pile 300B pretraining -> pile 50B further 인 경우 아래와 같이 정리할 수 있는 것이다.
- adam statistics alive / constant LR with small LR: O
- adam statistics removed / constant LR with small LR: O
- adam statistics alive / re-warmup LR:
??? - adam statistics removed / re-warmup LR: X (spike)
여기서 adam statistics가 살아있는데 re-warmup 을 하면 어떻게될까?에 대한 정보는 Scaling Law with Learning Rate Annealing에서 얻을 수 있는데, 아래 figure를 보면 LM학습시 cyclic (periodic) LR Scheduler를 쓰는게 꼭 문제는 아닌 것으로 보인다. 물론 spike가 생기긴 하지만 회복 불가능한 것은 아닌 것으로 보이는데, 종합적으로 re-warmup자체가 아예 문제라기보다는 adam optimizer가 없어진 CPT (contiunal pre-training) 상황이 lr warmup과 결합되어 뭔가를 일으키는 것 같긴한데 그게 정확히 뭔지는 모르겠다.
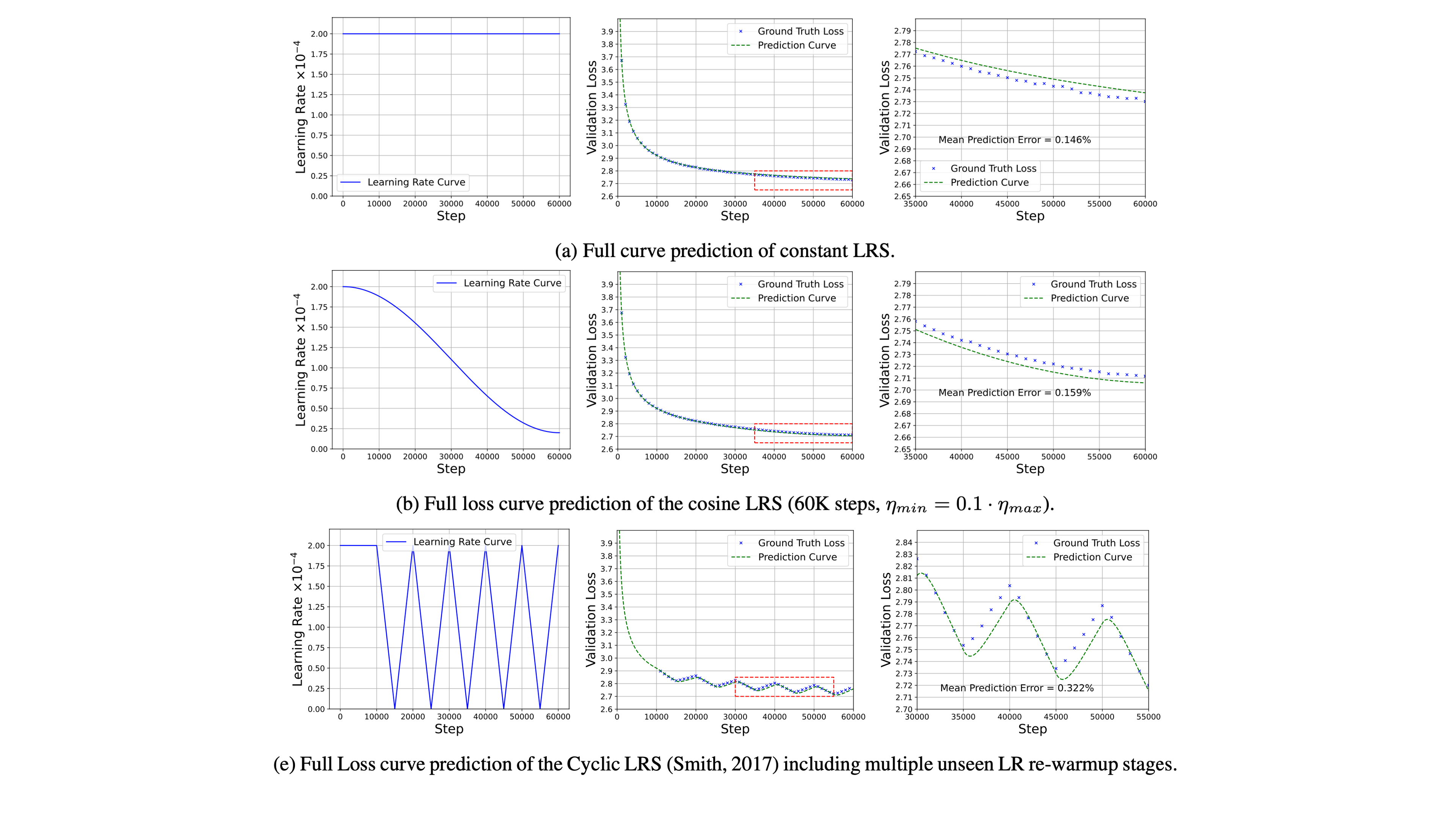 Fig. Source from Scaling Law with Learning Rate Annealing
Fig. Source from Scaling Law with Learning Rate Annealing
해당 논문에 대해 좀 더 얘기해보자면,
저자들은 scaling law prediction을 할 때 learning rate을 고려한 term을 추가하여 더 완벽한 loss prediction을 하고자 했으며,
이에 따라 data distribution shift가 없는 setting에서 CPT를 할 때의 loss prediction을 한 결과 현재 paper (Gupta et al.)에서 주장하는 바와 같이 max lr에 따라 loss spike가 더 커보이지만 길게 학습할 경우 결국 더 좋은 성능을 낼 수 있음을 보였다.
(근데 직접 실험을 안해본거 같아서 믿을만 한 지는 모르겠다.)
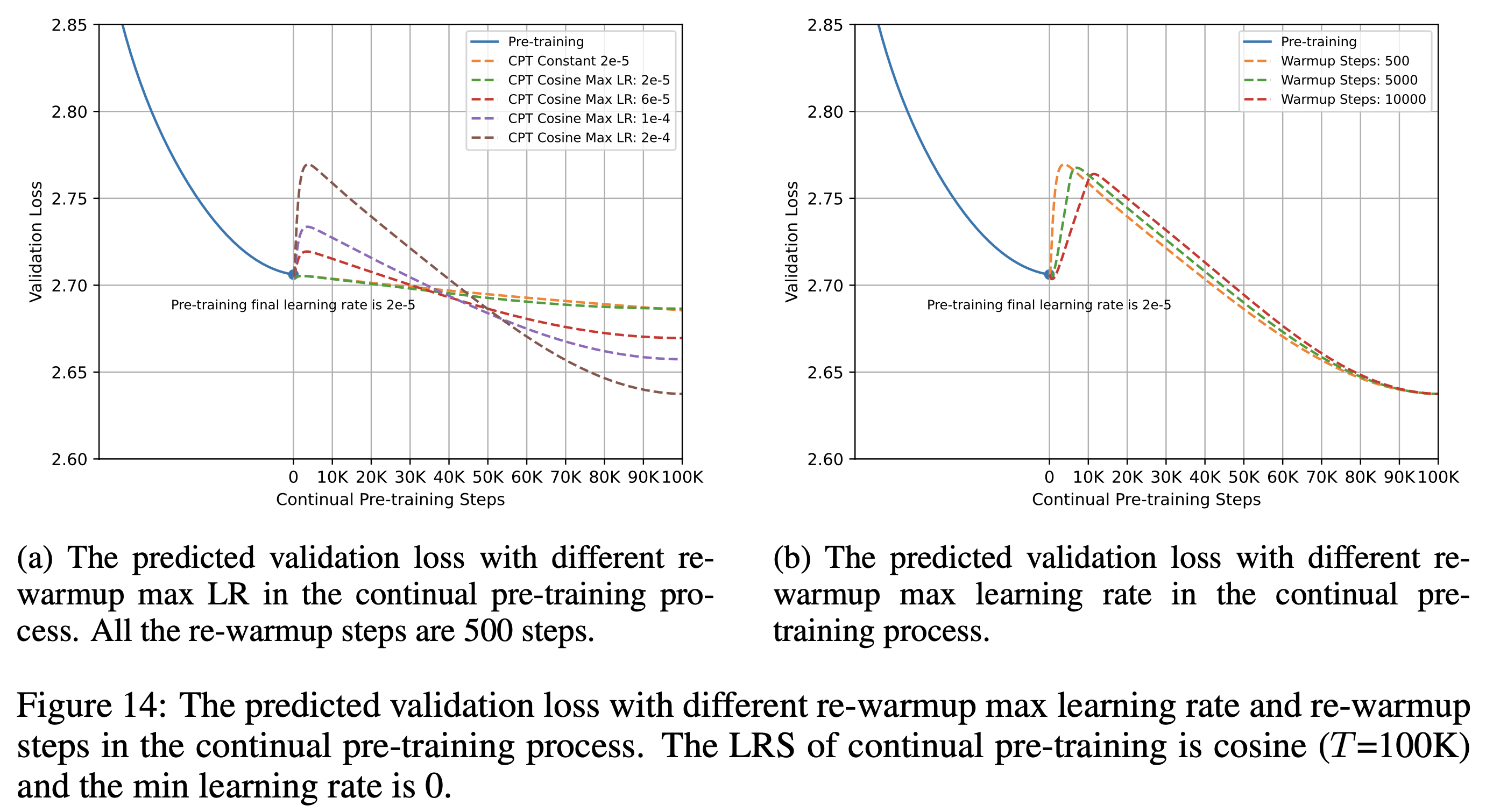 Fig. Source from Scaling Law with Learning Rate Annealing
Fig. Source from Scaling Law with Learning Rate Annealing
위 figure가 사실이라는 가정하에 Gupta et al.의 the pile -> the pile의 실험이 re-warmup이 안좋게 나온 것은 parameter update 횟수가 적기 때문일까? 같은 생각도 해보게 된다. (TBC)
Earlier or latest checkpoints
410M model의 earlier checkpoint (the pile을 수십 billion tokens만 본 경우)가 slimpajama downstream에 대해 더 좋은 성능을 보이지 않으니 그냥 latest checkpoint 쓰세요.
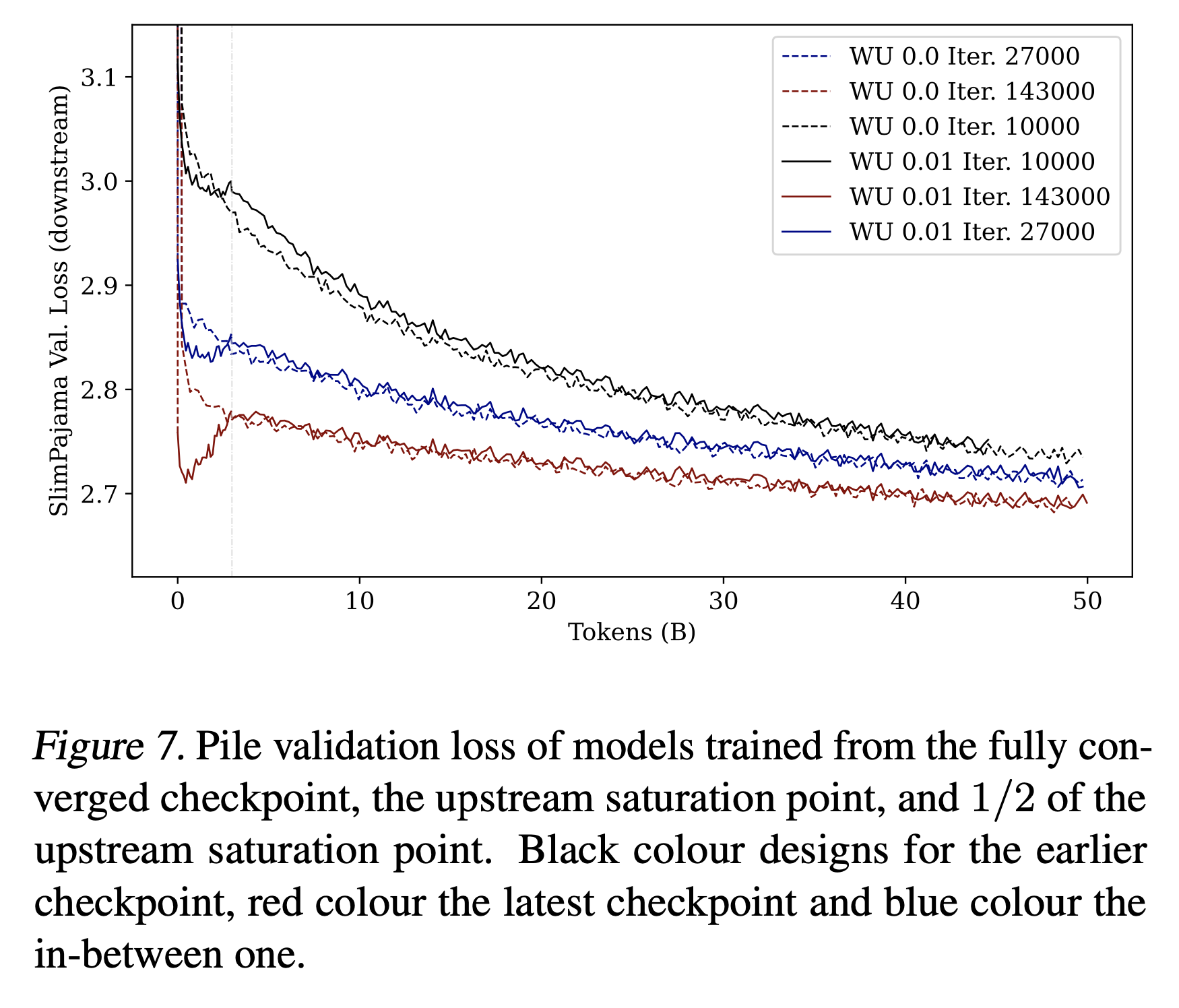 Fig.
Fig.
 Fig.
Fig.
Observations from the paper, 'Simple and Scalable Strategies to Continually Pre-train Large Language Models'
 Fig.
Fig.
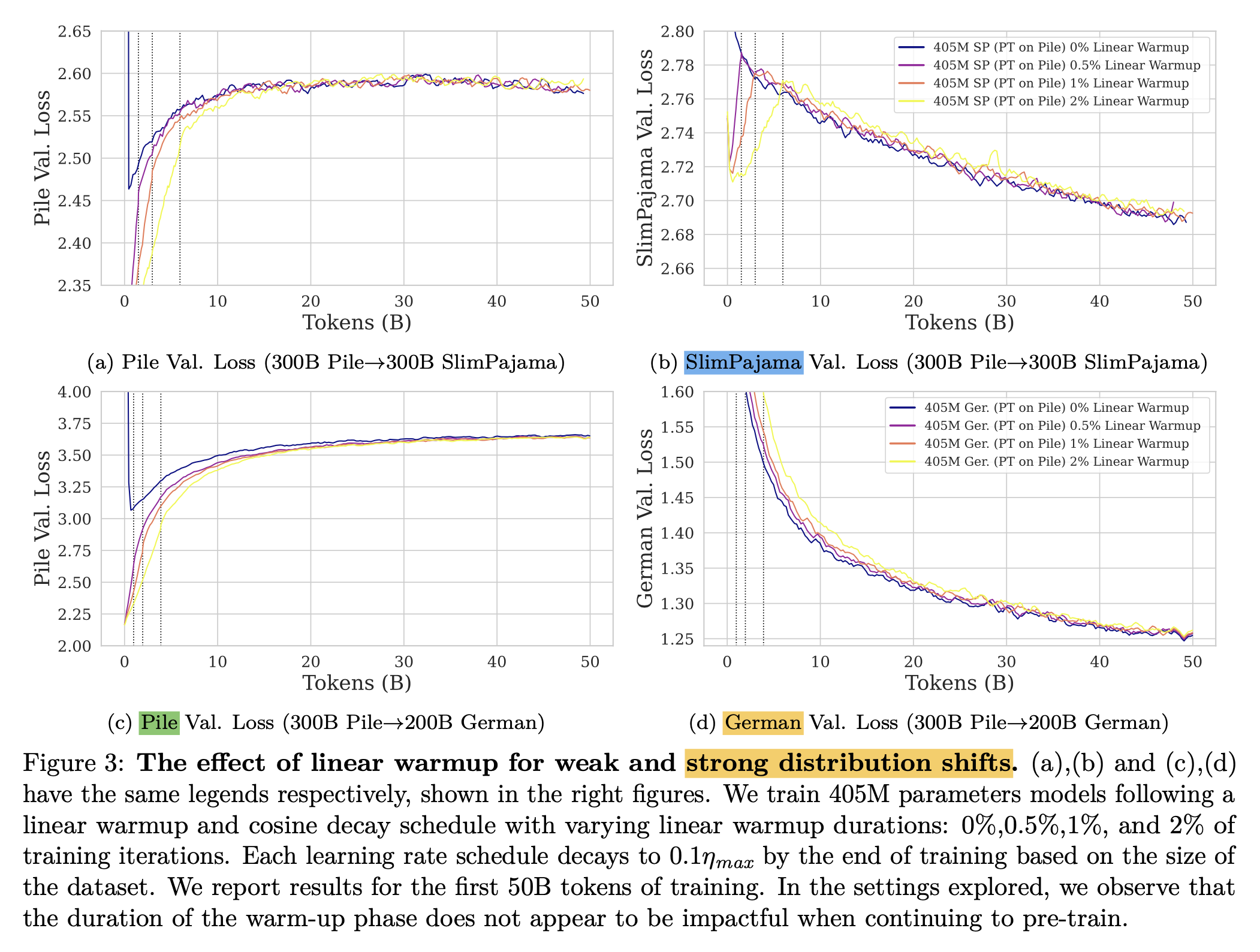 Fig.
Fig.
Infinite LRS
 Fig.
Fig.
 Fig.
Fig.
 Fig.
Fig.
 Fig.
Fig.
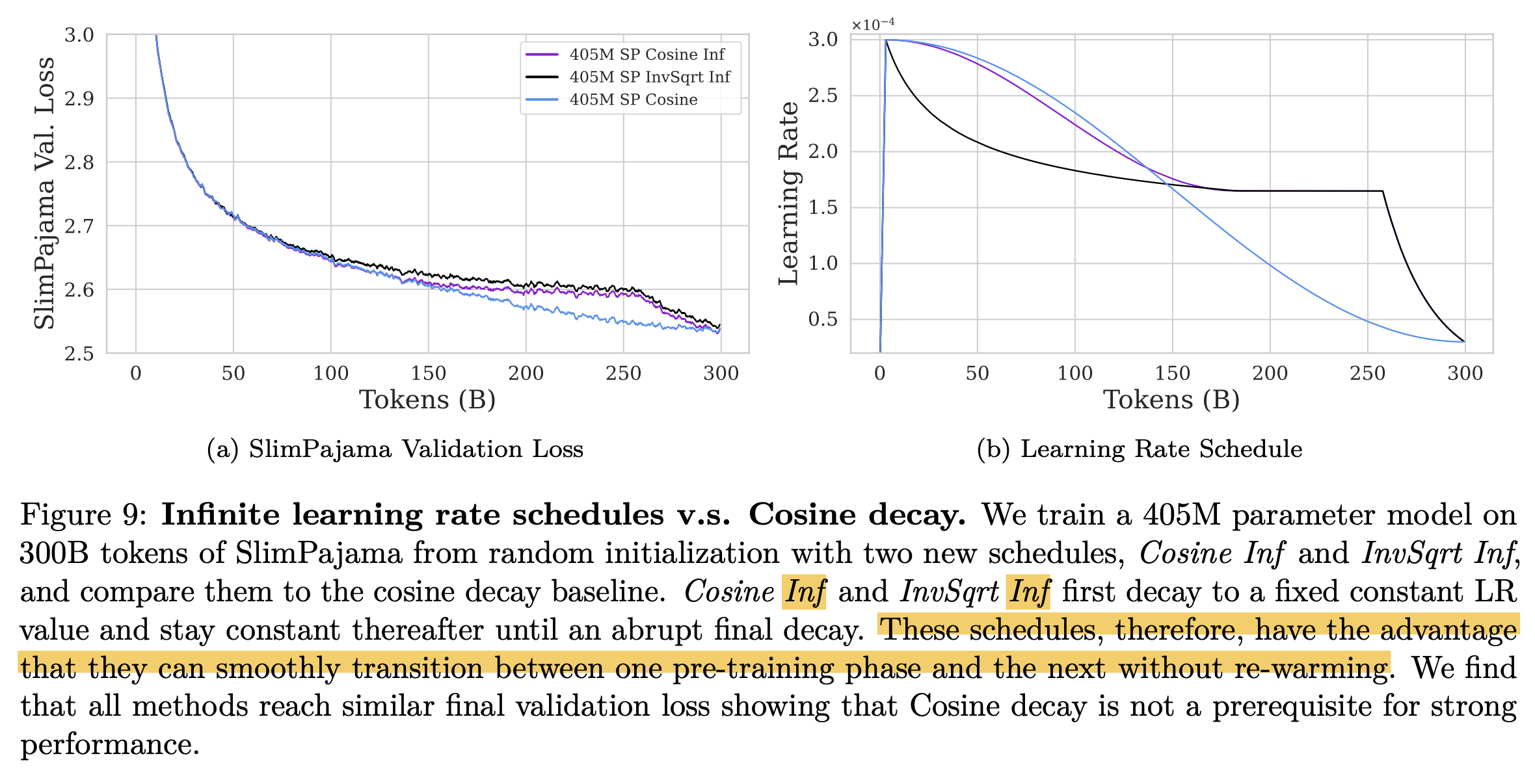 Fig.
Fig.
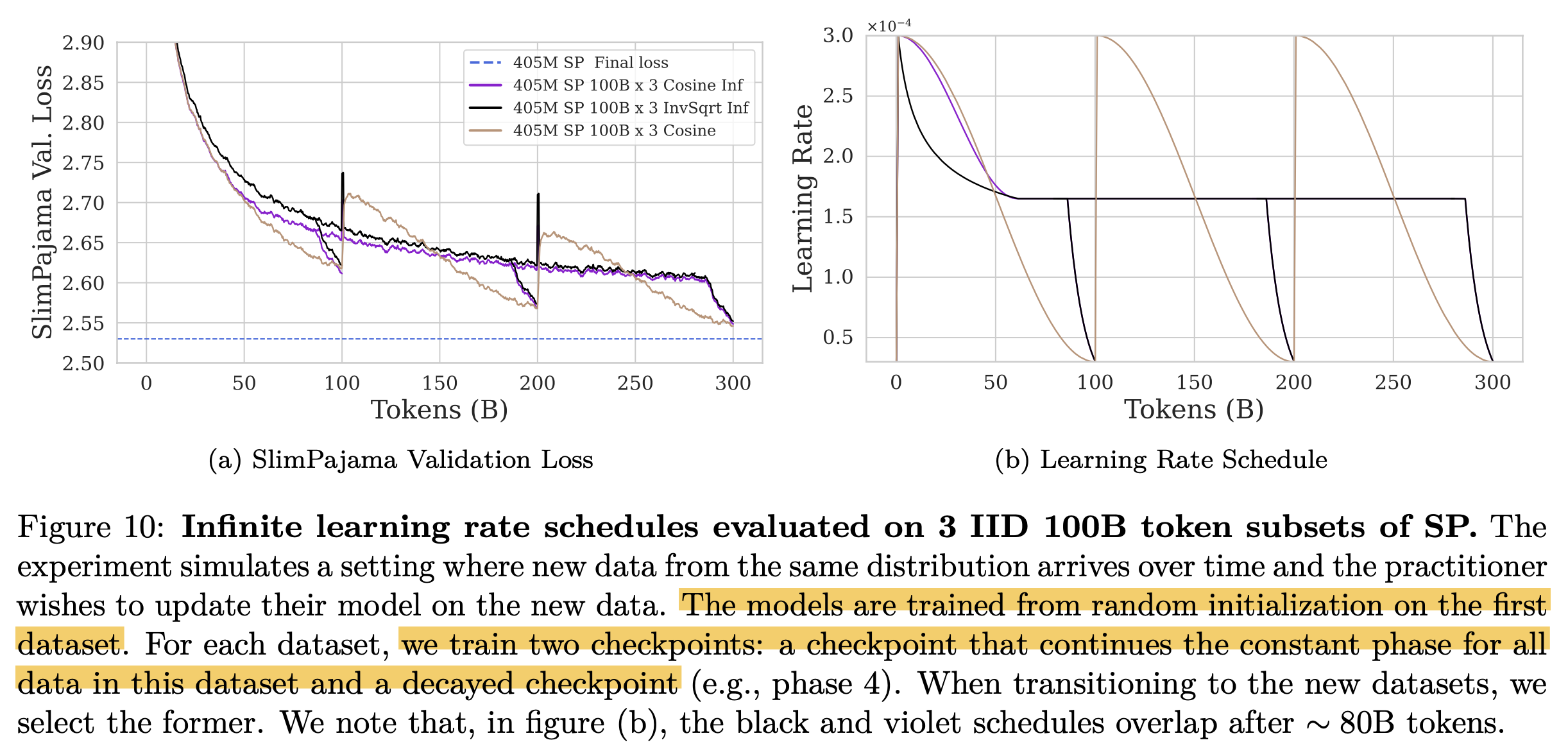 Fig.
Fig.
Case Study
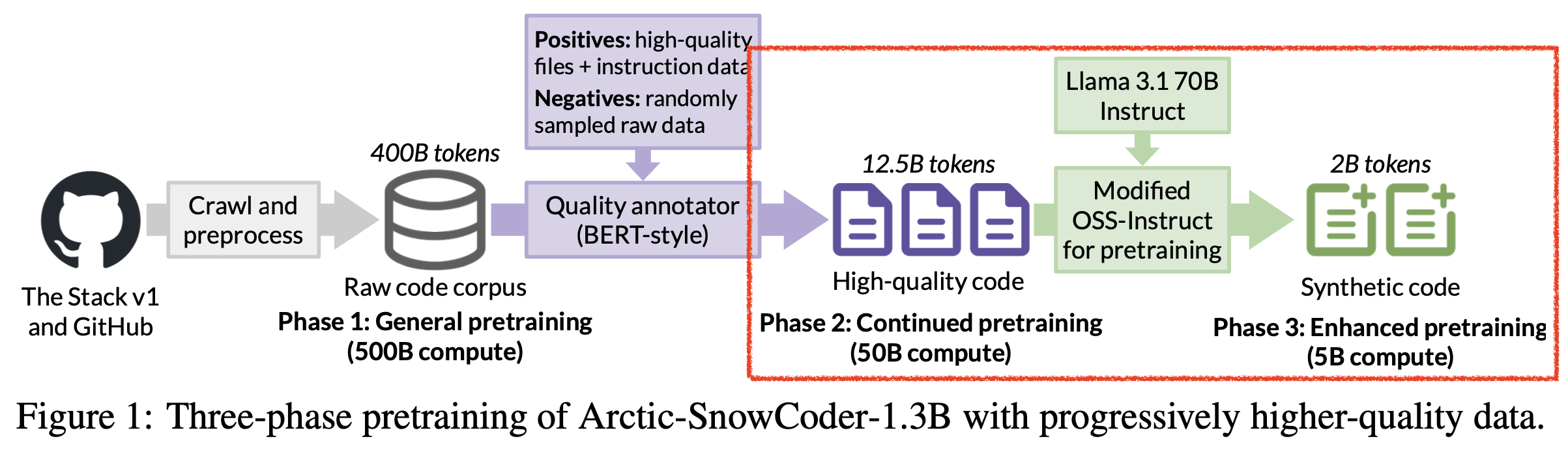 Fig.
Fig.
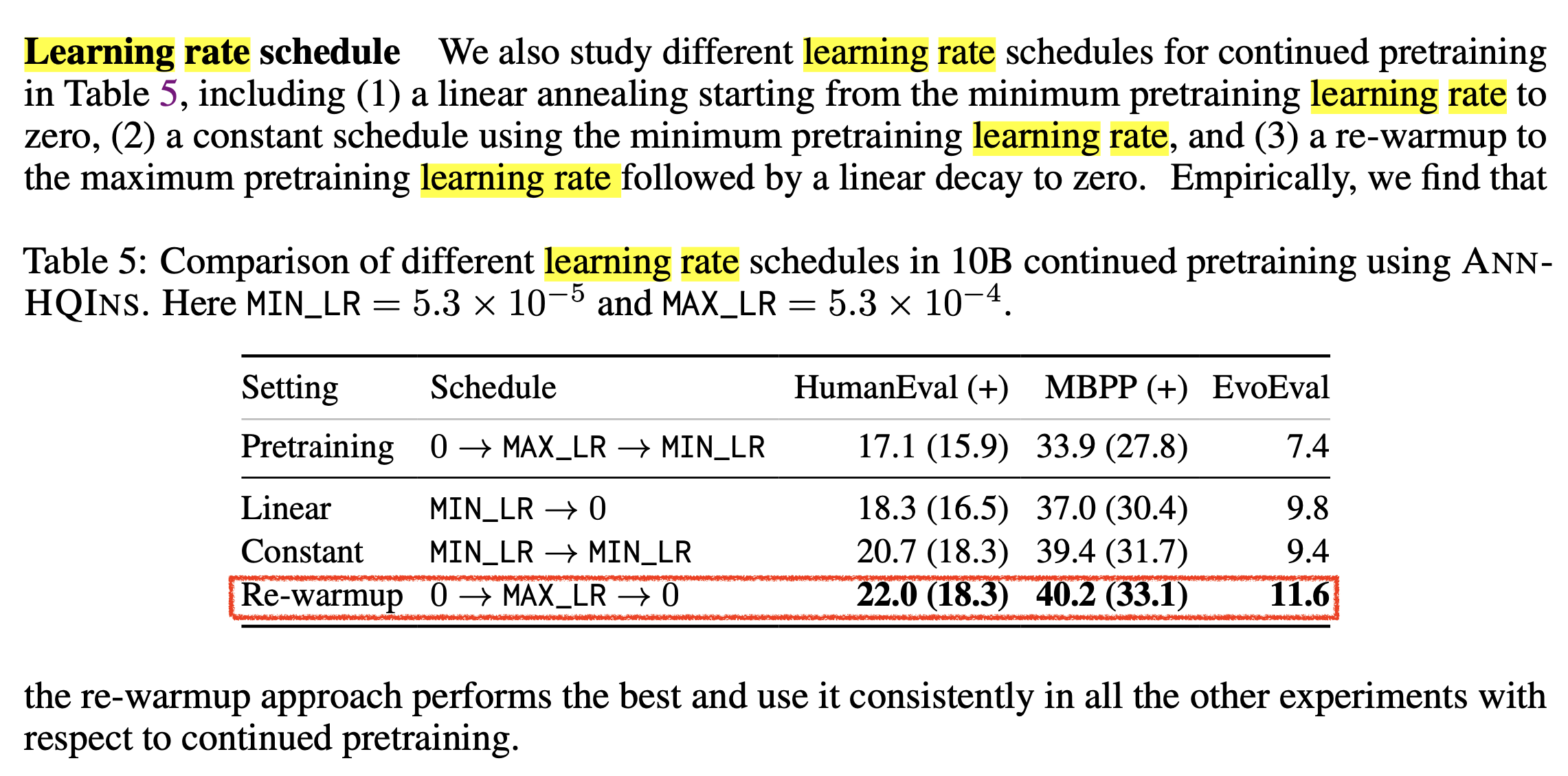 Fig.
Fig.
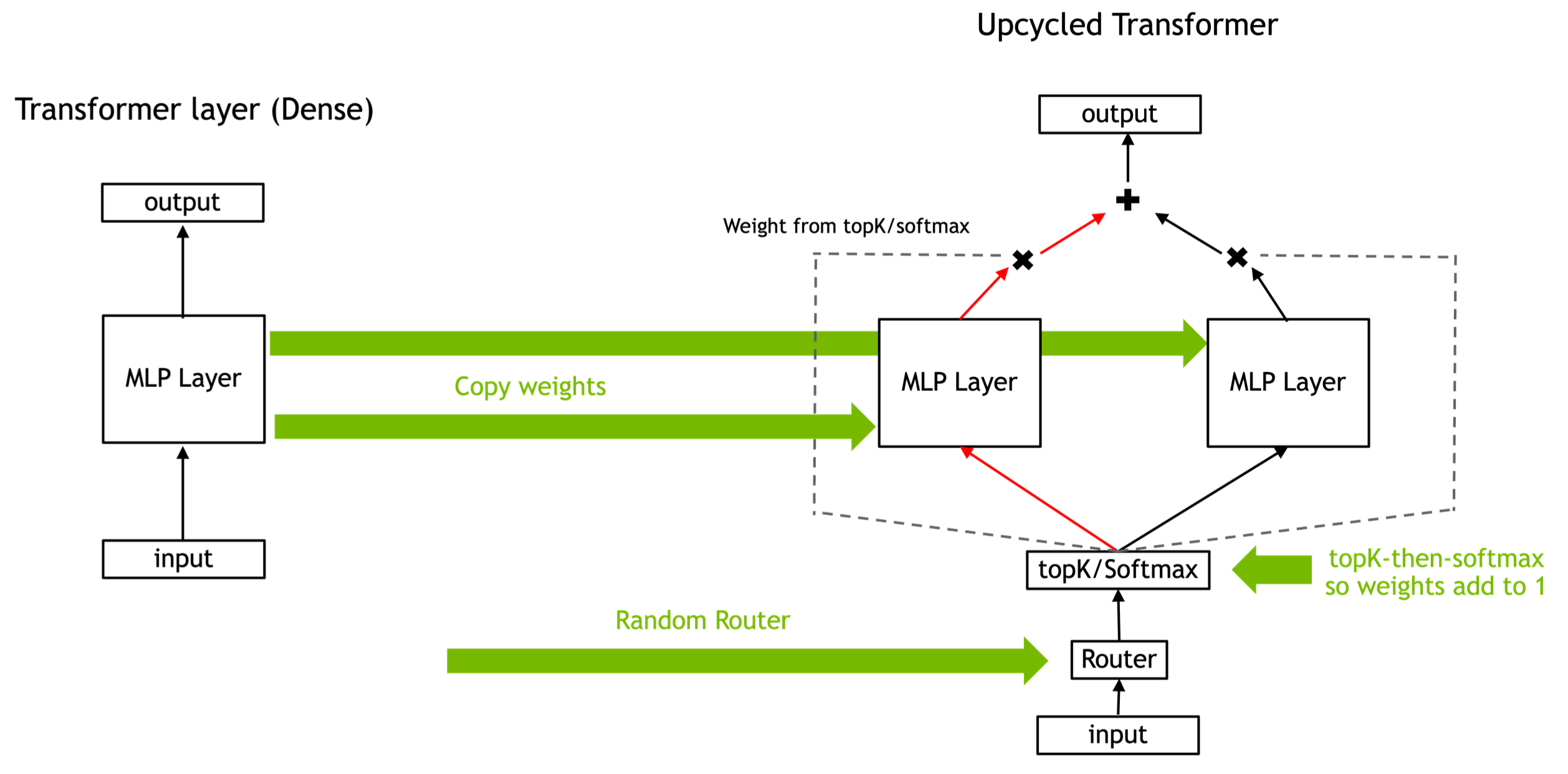 Fig.
Fig.
 Fig.
Fig.
 Fig.
Fig.
 Fig.
Fig.
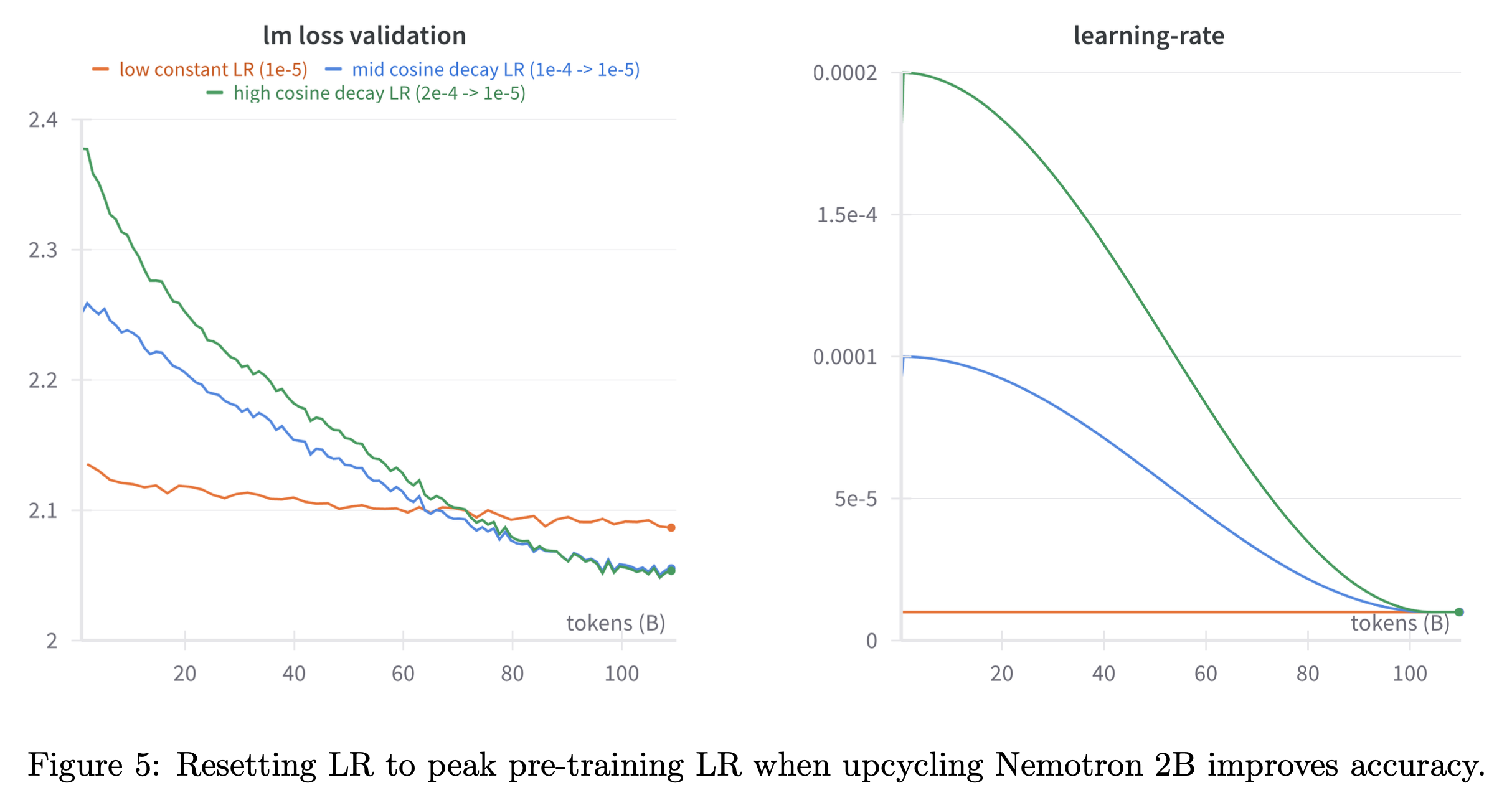 Fig.
Fig.