(WIP) Recent Promising GPT Variants (Diff Transformer and nGPT)
24 Oct 2024< 목차 >
24년 10월, Large Language Model (LLM)의 model architecture 중 유망해보이는 논문이 두 개 arxiv에 올라왔다.
- Differential Transformer
- nGPT: Normalized Transformer with Representation Learning on the Hypersphere
나에게 유망하다는 것에 대한 기준은 아래 네 가지 정도이고, 위 논문들은 이들에 부합한다.
- minimal한가? (직관적인가?)
- 적당히 큰 scale에서도 검증이 됐는가?
- 얼마나 convergence speed가 개선됐는가?
- 믿을만한 기관에서 연구했는가?
이 중 minimal한가?에 대해서는 Do Transformer Modifications Transfer Across Implementations and Applications?라는 paper에도 잘 나와있는 것으로, 경험적으로 activation function등 minimal modificication이 성능향상을 가져오는 경우가 다른 domain이나 task등에 전이가 잘 되고 scaling했을때도 먹힌다는 것 같다.
Diff Transformer
Motivation and TLDR
먼저 Differential Transformer에 대해서 보자.
처음 봤을 때는 “transformer building block은 fully differntiable한데 무슨소리지?”라는 생각이 들었지만 이내 differntial이 “미분가능한” 같은 의미가 아님을 알았다.
여기서는 신호의 차이를 의미하는 것인데,
간단하게 얘기해서 원래 vanilla transformer가 \(Softmax(QK^T, dim=-1)\)처럼 QK attention score map을 만들고 row-wise softmax를 했던 것에 반해서 diff transformer는 \(Softmax(Q_1K_1^T, dim=-1)\), \(Softmax(Q_2K_2^T, dim=-1)\)처럼 두개를 나눠 계산한 뒤,
이 차이를 계산한 score을 사용하는 것이다.
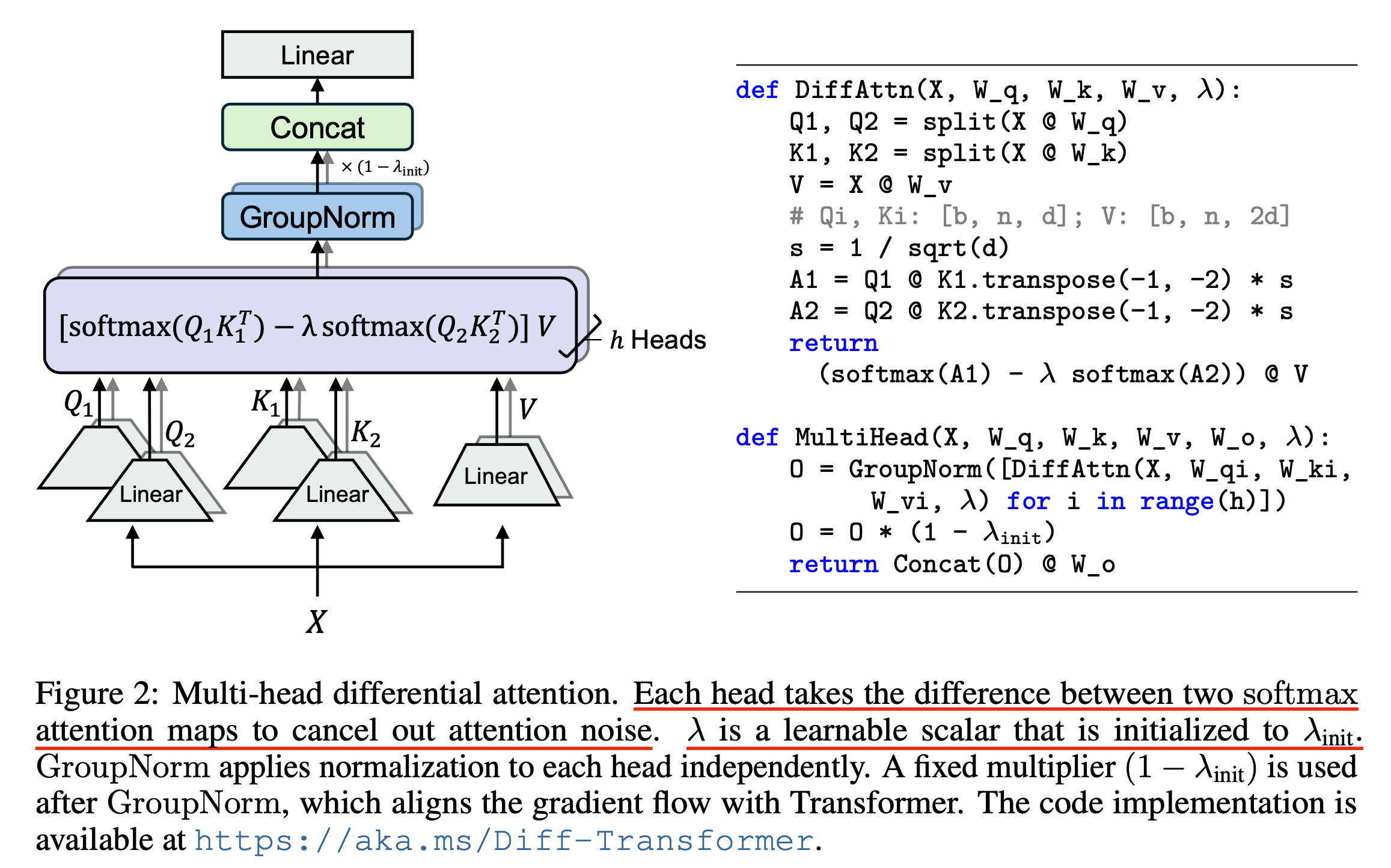 Fig.
Fig.
 Fig.
Fig.
이렇게하면 전자공학, 신호 처리 분야의 noise canceling 처럼 noise가 상쇄된다고 하는데, 저자들은 vanilla transformer가 정답에 너무 적은 attention score를 할당하는 문제가 있어 (즉 noise가 너무 많다는 것) needle in a haystack (NIAH) 등의 long context retrieval task에 문제가 있는데, 이를 큰 폭으로 개선할 수 있다고 설명한다.
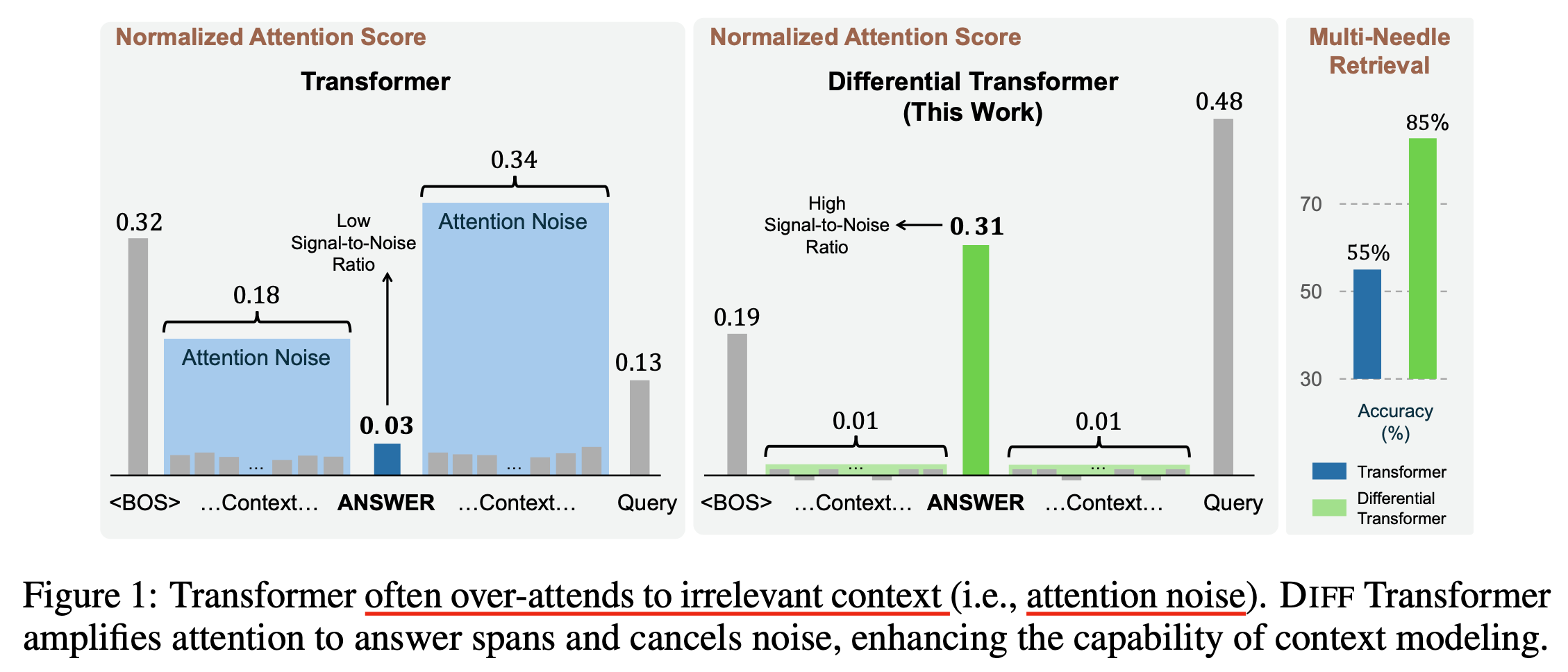 Fig.
Fig.
그런데 그냥 그것뿐만 아니라 아예 loss curve의 수렴 속도가 빨라진다고 주장하는데,
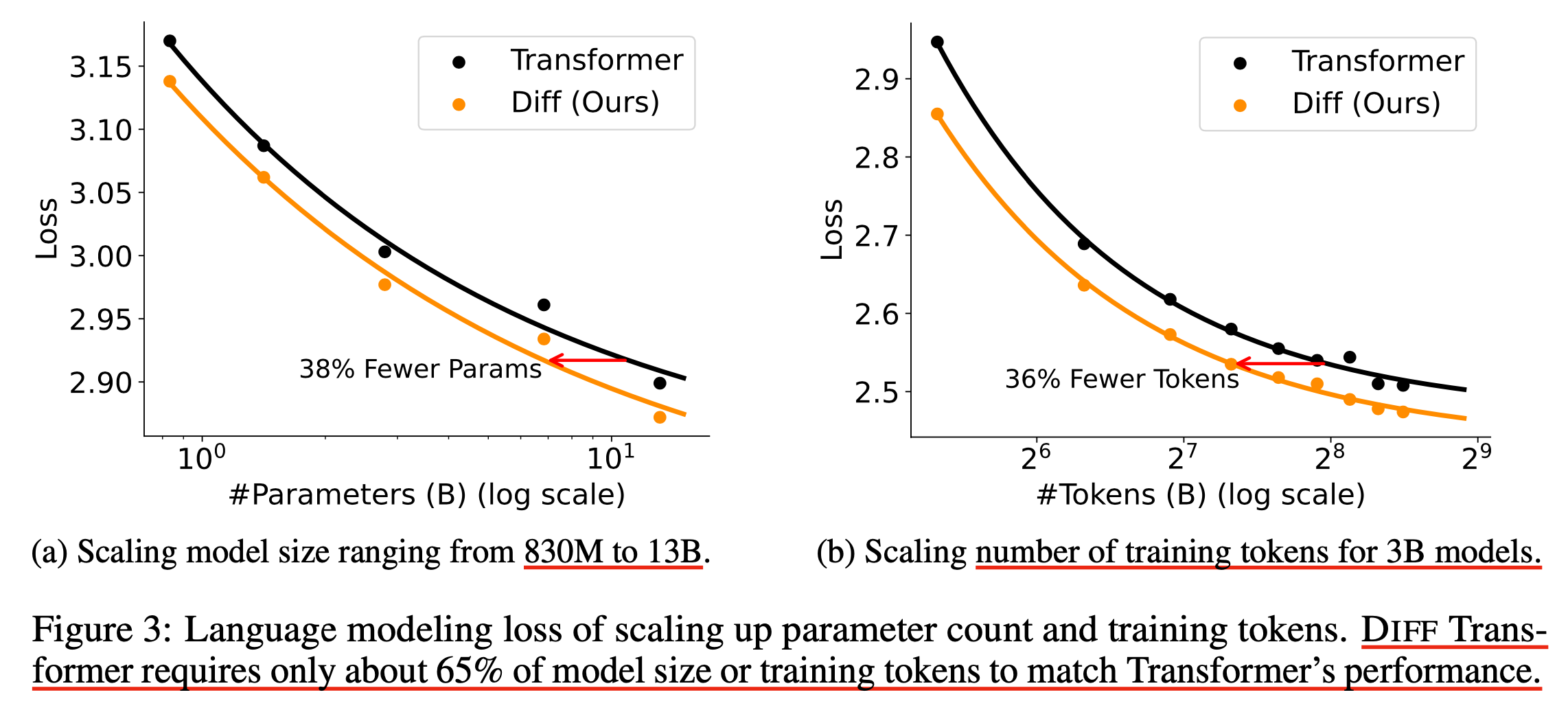 Fig.
Fig.
그 반동으로 throughput (즉 MFU)가 떨어지기 때문에 convergence가 20% 개선된다 하더라도, 연산 효율이 떨어져 10%의 손해를 본다면 train wall clock 기준으로는 10%개선밖에 안되긴 할 것이다.
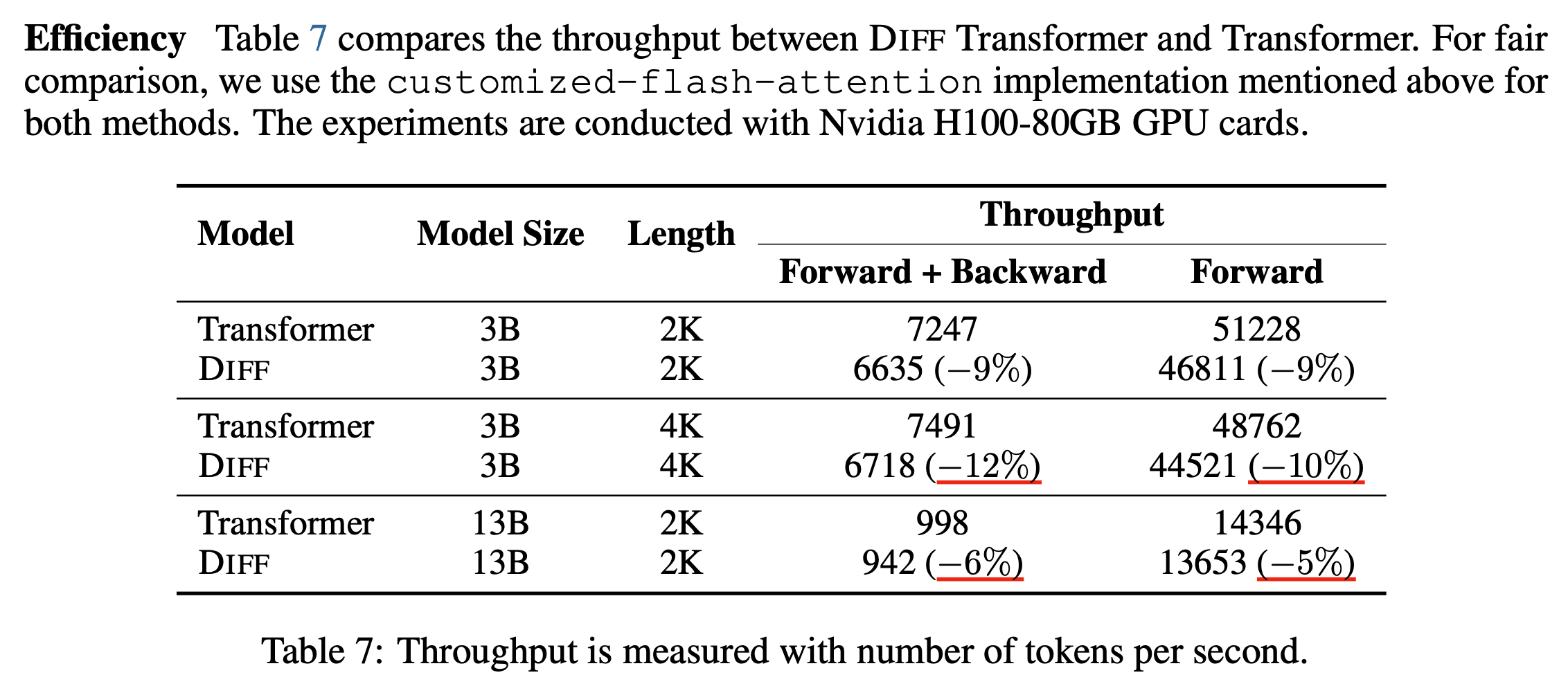 Fig.
Fig.
그리고 저자들은 custom flash attn kernel을 개발했다고 하는데, 왜냐하면 flash attn 은 기본적으로 QKV tensor들을 받아서 on-chip에서 attention score map을 online softmax manner로 계산하기에 전체 softmax normalized map를 materializing 해서 서로 빼는 행위를 kernel을 짜지 않고서는 할 수 없기 때문이다.
 Fig.
Fig.
연산효율이야 어느정도 acceptable하다면 성능이 좋으니 쓸 수 있을 것이고,
문제는 더 큰 scale에서도 먹히는가?와 성능이 너무 다방면에서 좋은데 scam 아닌가? 이거 왜 되는거지?에 대한 의문에 답을 하는 것이다.
이제 왜 이것이 working하는지에 대해서 생각해보자.
Why does it work?
TBC
Normalized GPT (nGPT)
Motivation and TLDR
Normalized GPT (nGPT)는 NVIDIA team에서 archiving한 paper이다. 저자중에는 AdamW를 개발한 Ilya Loshchilov가 껴있어서 놀랐는데, 6년간 publication 없이 연구하다가 갑자기 들고온게 아래처럼 파격적인 learning curve를 보여 놀라지 않을 수 없었다.
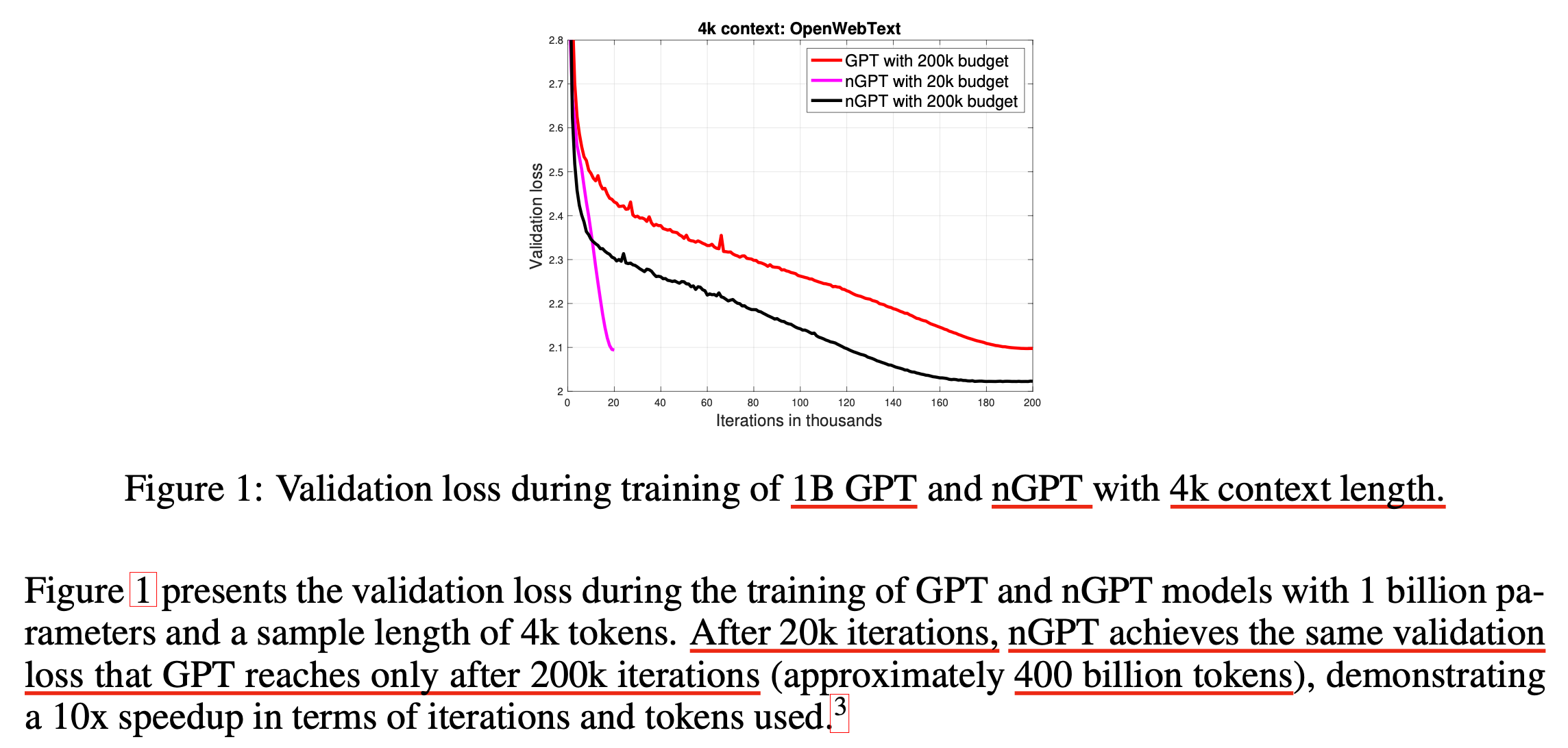 Fig.
Fig.
사실 위 그래프에서 vanilla transformer (GPT라고 부르겠음)의 20k step에 대한 결과가 없어 스캠같아 보이는데, 같은 200k step에 대해서는 red vs black을 봐야 한다. 하지만 이정도도 엄청 큰 차이라고 할 수 있다.
nGPT의 결과는 downstream task (사실 downstream은 아니고 zero-shot, few-shot benchmark)에서도 매우 큰 gap을 보이며, 1k, 4k, 8k 어떤 sequence length로 학습하든 그 차이는 유지된다고 한다.
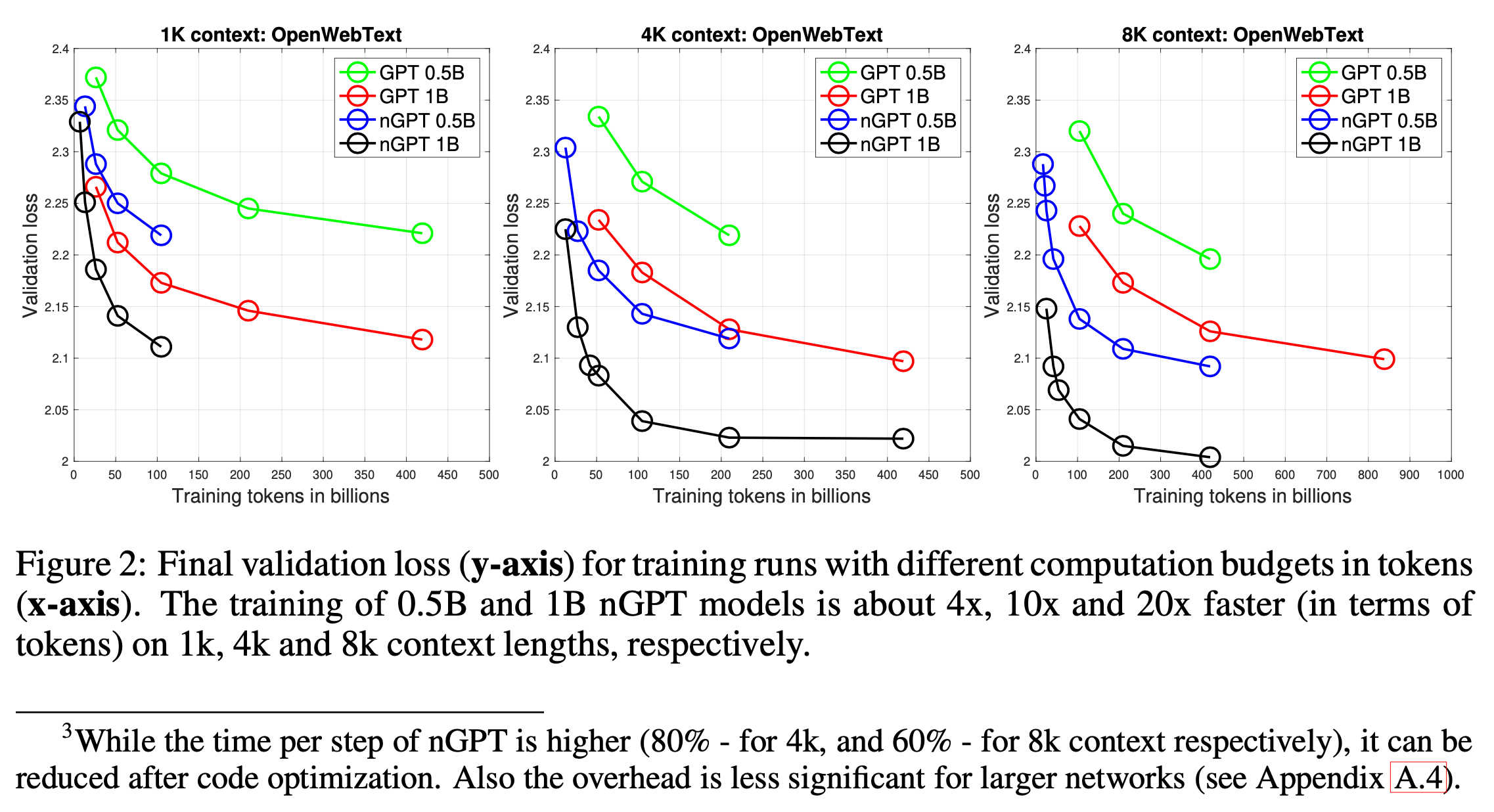 Fig.
Fig.
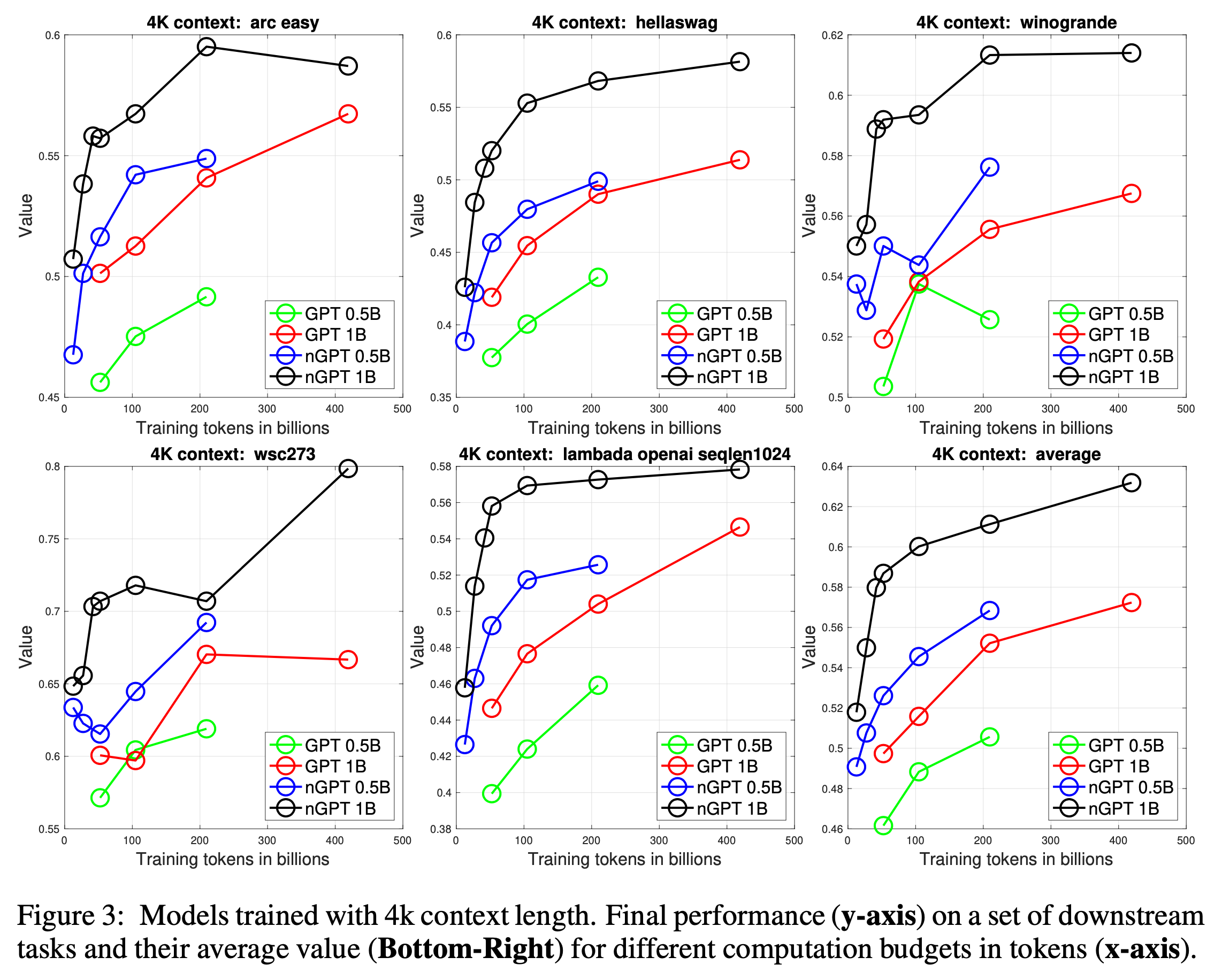 Fig.
Fig.
이정도로 convergence를 잘 한다면 wall clock time을 수배 앞당길 수 있다는 것인데, 이부분에 대해서는 같은 loss에 도달하기 위한 sample 수, 즉 sample efficiency가 좋은건 사실이지만 residual block마다 layer norm module이 2개씩 들어가던 기존 GPT와 다르게 nGPT는 6개씩 필요하기 때문에 fused LN+linear layer 를 도입하는 등의 최적화를 해줘야 computational overhead를 줄일 수 있을테니 주의해야 할 것이다.
그래서 어떻게 이게 가능하냐?
논문의 핵심은 다음과 같은데,

여기서 uni-norm hypersphere에서 optimization을 하겠다는 것이 핵심이다.
그렇게 되면 network 내부의 모든 module에서의 input embedidng vector들과 weight matrix의 dot product가 (실제 matrix-vector matmul은 dot product여러개로 이루어져 있으니) cosine similarity가 되어 \([-1, 1]\)긔 값으로 bound되게 된다고 하며,
weight decay를 불필요하게 만든다고 한다.
사실 nGPT의 결과를 볼 때 이 부분이 핵심인 것으로 보이는데, nGPT는 warmup step과 weight decay를 불필요하게 만들어 convergence point를 앞당겼음을 주장한다고 생각할 수 있다.

References
- Papers
- Implementation