(WIP) Maximal Update (Mu) Parametrization (μP) and Hyperparameter Transfer (μTransfer)
04 Jan 2024< 목차 >
Introduction
OpenAI는 어떻게 GPT-4를 학습시켰을까? Learning algorithm 을 말하는 것이 아니라 Neural Network (NN) initialization과 learning rate, optimizer (adam beta 등)의 hyper parameter tuning 을 어떻게 했느냐는 것이다. Model size가 수백 billion (B)에 달하는 Large Language Model (LLM)에 대해서 hyperparameter를 exhaustive search 하진 않았을 것이다. (당연히 불가능에 가까운 computing resource가 들기 때문)
우리는 그 hint를 GPT-4의 Technical Report에서 찾을 수 있는데,
사실상 이 report paper는 우리는 scaling prediction을 잘 했어요와 우리 model이 이런것도 돼요만 얘기하고 있다.
Scaling law는 OpenAI 연구진들이 2020년에 이미 실험적으로 검증한 바 있으며,
Model Sizes를 \(N\), Compute Budgets를 \(C\), 그리고 Dataset Sizes를 \(D\)라고 할 때, 어떤 Autoregressive Model의 Loss, \(L\)는 다음의 법칙을 따른다는 것이다.
여기서 미지수, \(x\)는 \(N,C,D\) 모두가 될 수 있으며 \(L_{\infty}\)는 irreducible loss로,
이는 reducible loss와 다음과 같은 차이가 있다.
다시 말하면 irreducible loss는 실제 dataset의 distribution의 entropy를 말하며, reducible loss는 model이 예측하는 distribution과 true dataset distribution간의 KL Dirvergence (KLD)이다. 이것은 당연하게도 우리가 사용하는 learning objective인 Cross Entropy (CE) loss가 두 분포간의 KLD를 의미하는 것과 같은 맥락이다.
다시, 결국 OpenAI가 증명하고자 하는 수식인 \(L(x) = L_{\infty} + (\frac{x_0}{x})^{a_x}\)가 의미하는 바는 CE loss를 사용하는 Autoregressive Transformer model은 model size, compute budget이 증가할수록 performance가 증가하는데, 이것이 멱법칙 (power-law)를 따른다는 것을 의미한다.
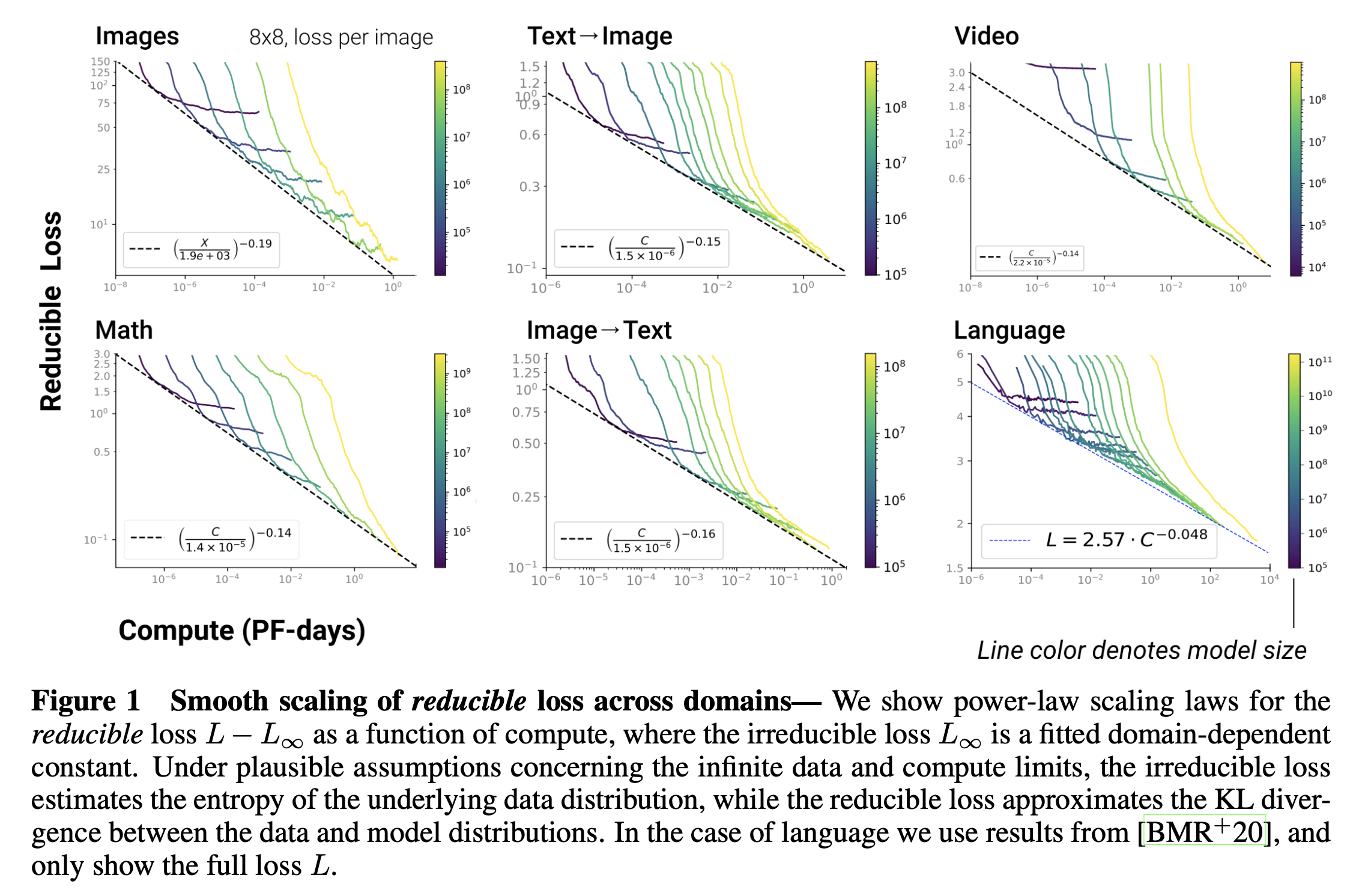 Fig.
Fig.
여기서 GPT-4는 Image-to-Text와 Text-to-Text (Language Modeling; LM)인데, 이들은 다음의 법칙을 따른다.
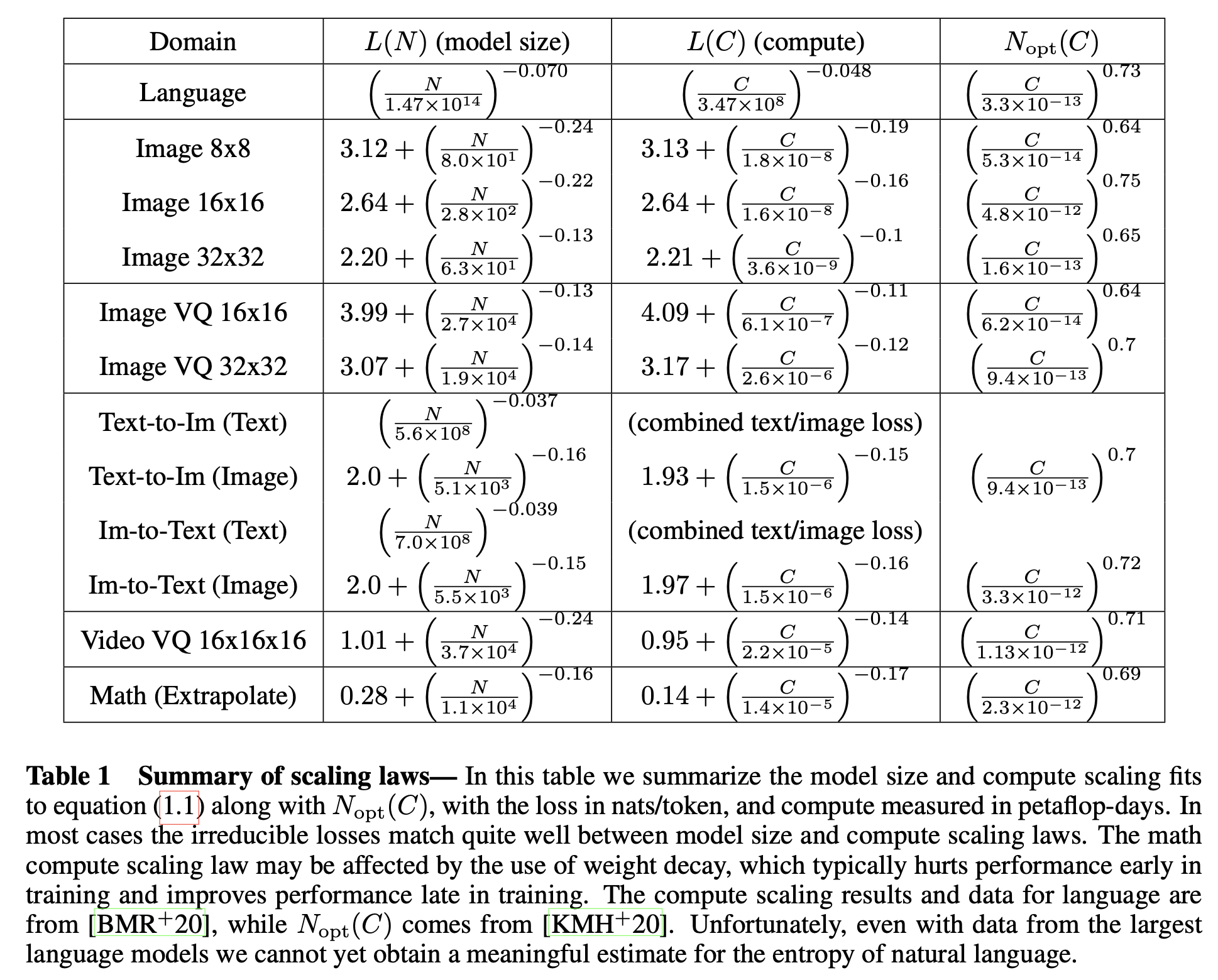 Fig.
Fig.
GPT-4의 report에서도 이 scaling law를 정확하게 언급하고 있는데, section 3에서 실제로 이들은 model이 커짐에 따라서 loss predicion을 거의 오차없이 해냈음을 자랑하고 있다.
 Fig.
Fig.
OpenAI는 next token prediction (Perplexity; PPL 같은 것)과 humaneval 지표에서 모두 매우 높은 정확도로 loss (accuracy) predicion을 할 수있었다고 얘기한다.
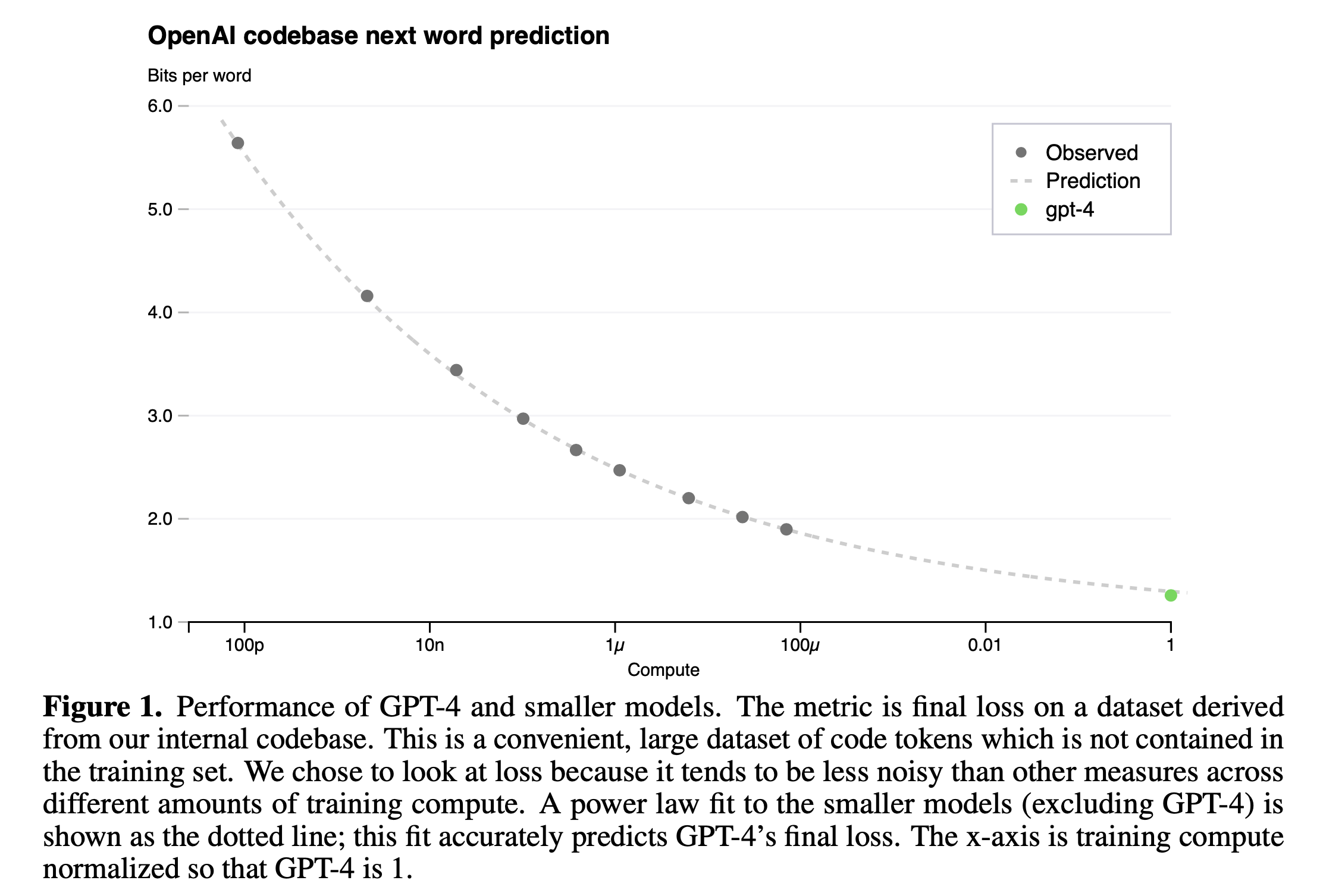 Fig.
Fig.
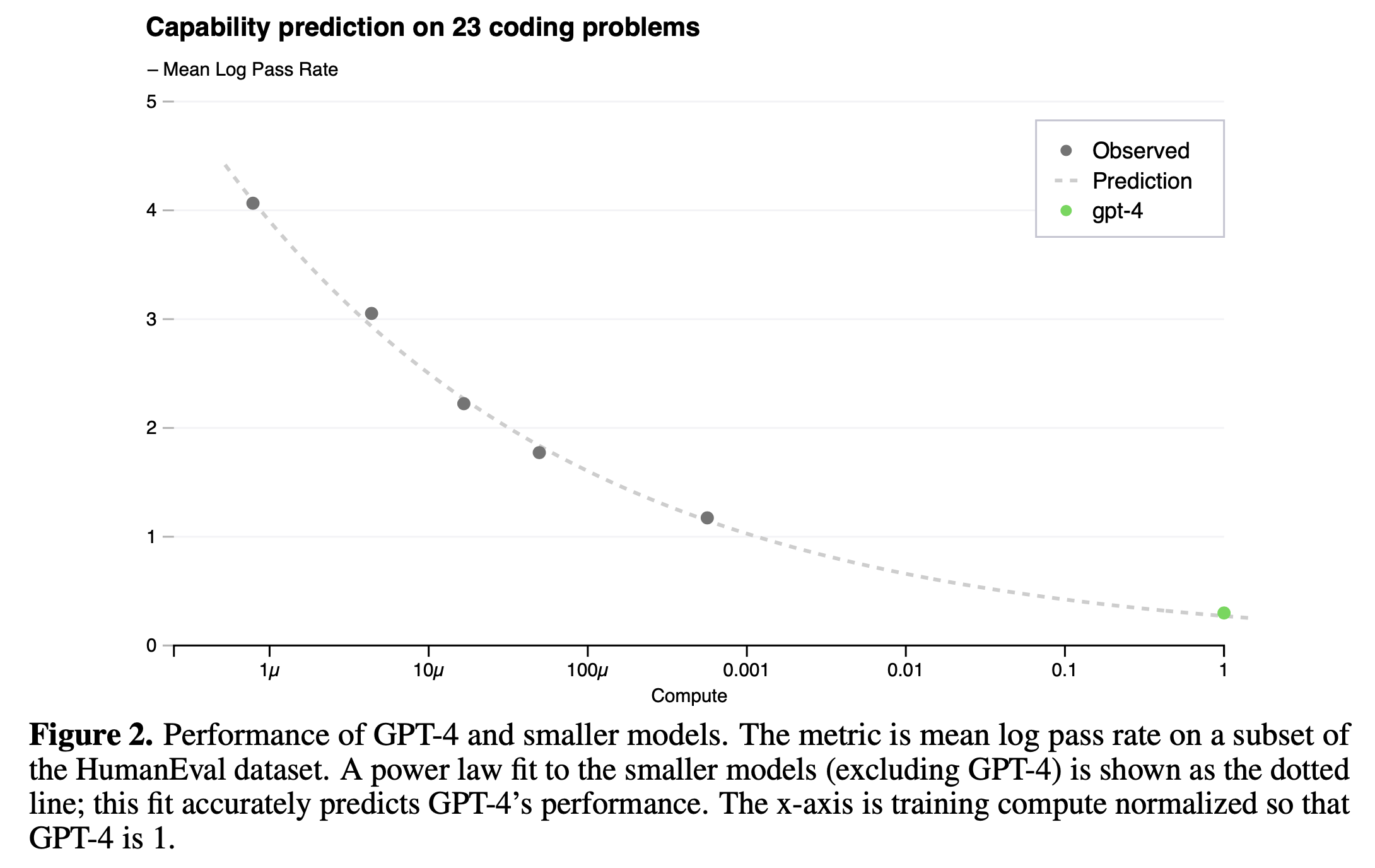 Fig.
Fig.
GPT-4 논문에는 architecture가 어떻게 생겼는지? 어떤 data sample들을 사용해서 얼만큼 학습했고 learning objective가 어떻게 되는지? 에 대한 얘기는 없지만 이는 Transformer와 RLHF를 썼다는 것 외에 할 말이 없어서 일 수도 있다. 뭐 GPT-4는 Mixture of Expert (MoE)로 학습되었다는 것이 ground truth처럼 여겨지고 있는데, 여타 수많은 실리콘밸리 기업들이 만드는 SOTA opensource model들이 MoE인 것을 보면 소문이 사실인 것으로 보이지만 중요한 것은 그게 아니다. (MoE를 학습하기 위한 기술력 (expert parallel, megablocks 등 각종 computing optimization)이 필요하지만, 비효율적으로라도 어떻게든 학습은 가능하다고 칠 때 문제가 되는 것은 여전히 어떻게 이를 prediction할 것인가? 이라는 의미)
주어진 dataset, model 구조가 있을 때, Scaling Law를 찾아내려면 얼마나 많은 computing resource를 태워야 할까?
어떻게 100~200B에 달하는 model을 hyperparameter search 없이 학습할 것인가?
한 편, GPT-4가 introduction에 인용한 paper들 중에는 Maximal Update Transfer (Mu Transfer)라는 것이 있는데, 이는 Maximal Update Parameterization (Mup)의 확장판으로 요약하자면 작은 model에서 learning rate, layer initialization, 그리고 layer 별 scaling factor등의 hyperparameter를 찾고, 예를 들어 작은 model의 optimal setting을 찾았으면 이를 1000배, 10000배 큰 model로 그대로 확장하여도 (transfer) 그것이 큰 model의 optimal hyperparameter가 된다는 것이다.
Mu Transfer는 Microsoft에서 large neural networks training에 대해 연구하던 수학과 출신 Greg Yang과 마찬가지로 Microsoft에서 같이 연구하며 LoRA를 제안한 Edward Hu가 공동연구를 했다. (Edward가 초기 OpenAI-Microsoft parternership onsite engineering team 멤버 8명 중 한명이며 GPT-4 technical report에도 reference가 달려있기 때문에 아마 GPT-4를 학습하는데 반드시 쓰였을 것으로 보인다)
 Fig. Edward의 video에 따르면 Cerebras와 Deepmind의 LLM에도 사용된 것으로 보인다.
Fig. Edward의 video에 따르면 Cerebras와 Deepmind의 LLM에도 사용된 것으로 보인다.
사실 Mup와 같은 것들은 모두 Greg Yang이 연재하는 Tensor Program (TP)라는 serires로 묵이는데, Mup와 mutransfer는 각각 TP4와 TP5에 해당한다.
 Fig. Greg Yang은 2019년 2월부터 혼자 paper를 내는 또라이다.
Fig. Greg Yang은 2019년 2월부터 혼자 paper를 내는 또라이다.
Greg의 궁극적인 goal은 NN을 scaling up 하는 optimal한 방법과 그러한 모델들에 대한 robust undertanding을 제공함으로써 safety와 alignment를 하는 데 도움이 되는 large scale deep learning을 위한 모든 것의 이론을 정립하는 것이라고 (…) 한다.
그래서 Mup와 Mu transfer는 정확히 무엇인가? Mup는 network parameterization을 의미하는데, network parameterization은 model의 width에 따라서 각 layer의 weight initialization과 그에 맞는 learning rate를 어떻게 할지?를 의미한다.
 Fig.
Fig.
왜 이게 필요할까? 그 이유는 pytorch의 weight initialization이 training dynamics를 고려하지 않았기 때문이라고 한다.
 Fig.
Fig.
아래의 figure처럼 pytorch의 standard parameterization을 따를 시에는 model의 width가 다를 때 (지금은 MLP 얘기하는데 Transformer도 같음) optimal learning rate로 보이는 지점이 다른 것을 알 수 있다 (각 training curve는 다른 width를 의미한다).
반면에 Mup를 적용한 경우 training loss가 0에 수렴하는 toy example이라서 잘 안보이지만 거의 비슷한 learning rate를 사용해도 그것이 곧 optimal learning rate가 되는 것을 볼 수 있다.
이말인 즉 mup를 사용해서 model init을 하면 small scale model에서 hparam tuning을 빡세게 한 뒤,
그대로 model을 수십배 scale up해도 hparam tuning을 할 필요가 없다는 것을 의미한다.
말 그대로 Mup를 사용해서 학습할 model들에 대해서는 hyperparameter가 전이 (transfer)된다는 것이다.
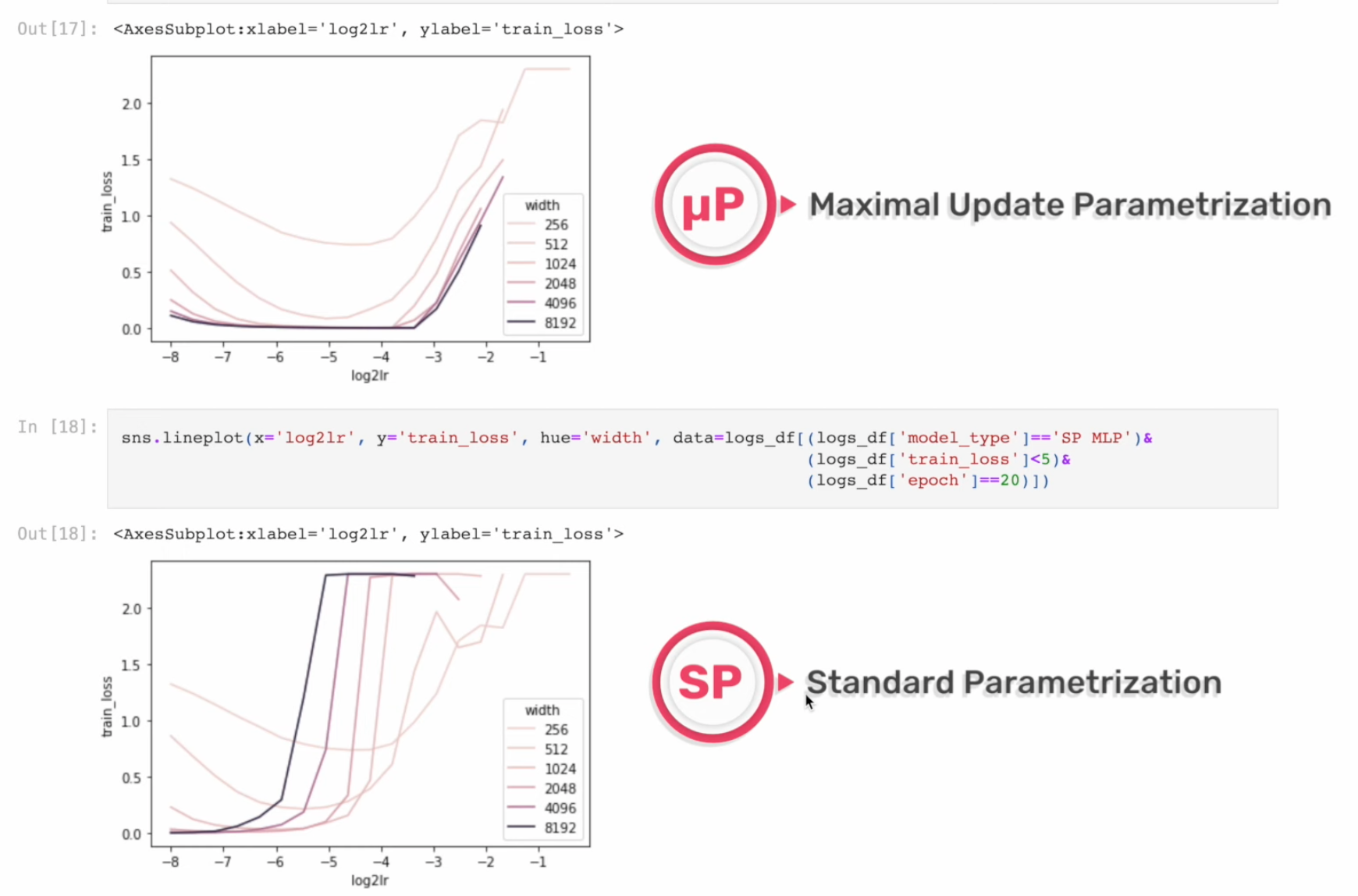 Fig.
Fig.
그런데 놀랍게도 transfer가 되는 hyperparameter는 learning rate뿐만이 아니라고 하며, label smoothing 등의 hyperparameter도 전이가 된다는 것을 실험적으로 보인것이 바로 TP5이다.
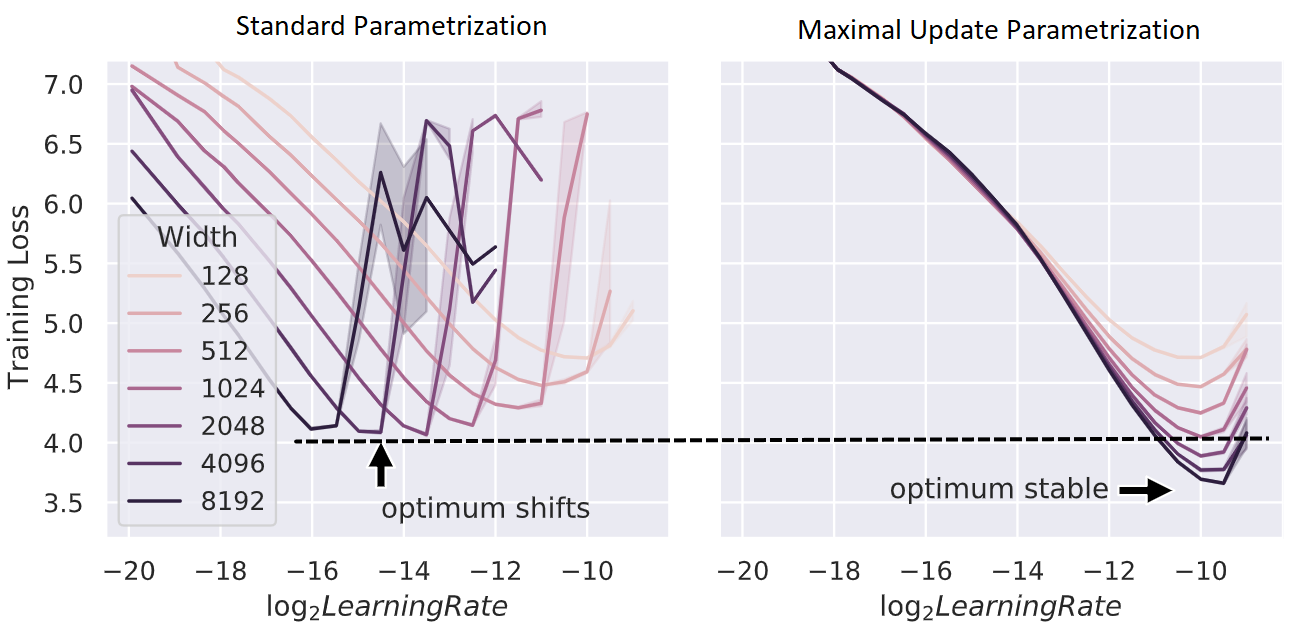 Fig.
Fig.
이를 standard (pytorch) parameterization과 interpolation해본 결과 Mup가 거의 유일한 (unique) optimal parameterization과 learning rate setting을 제공한다고 저자들은 주장한다.
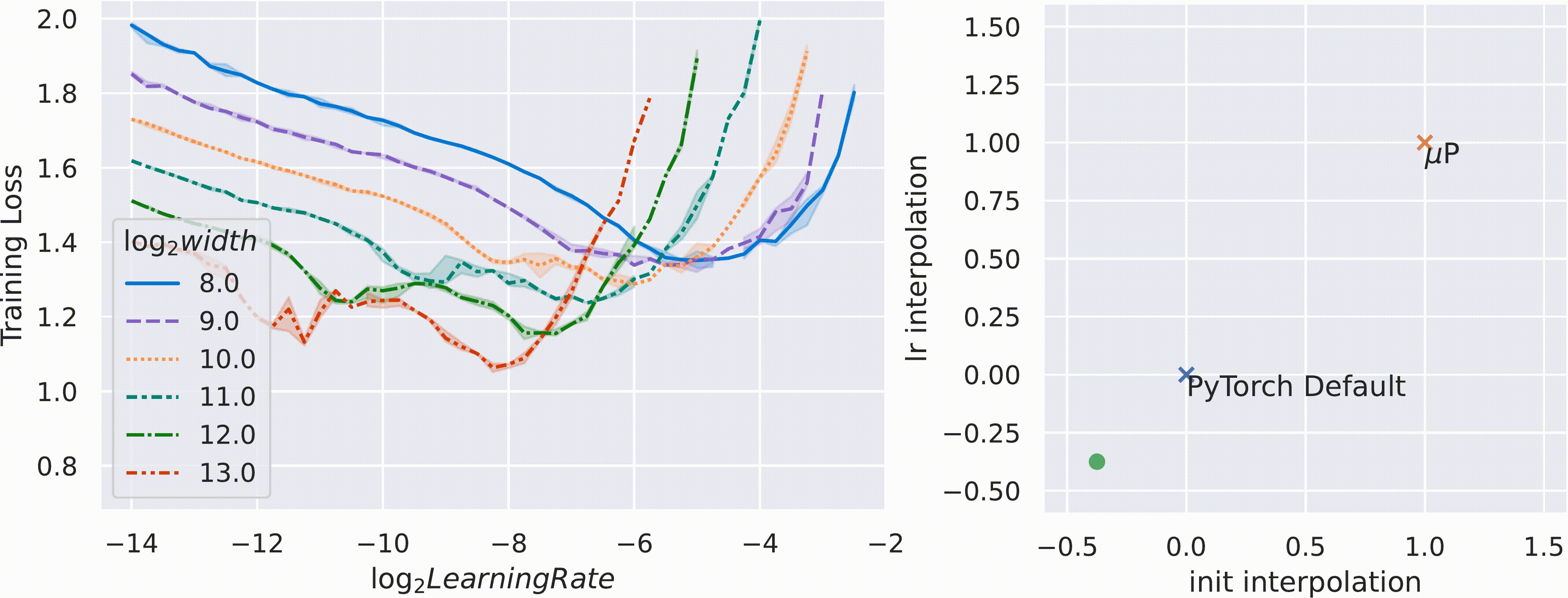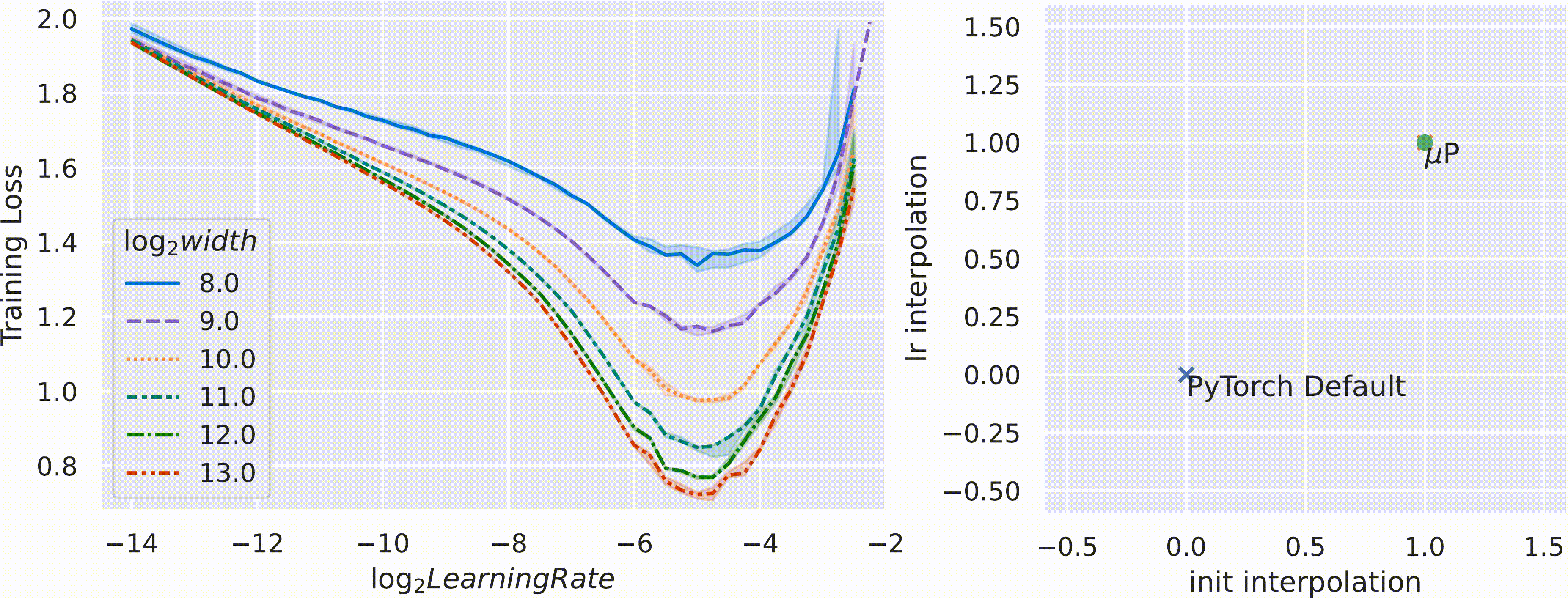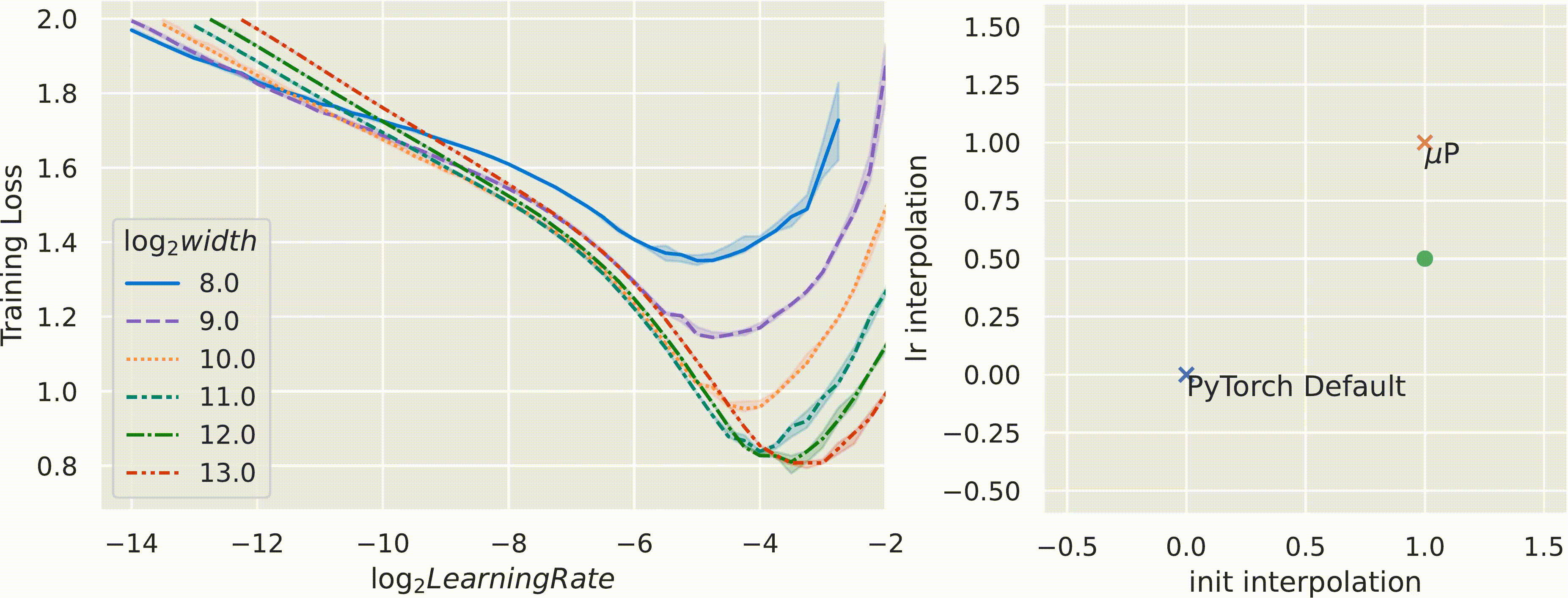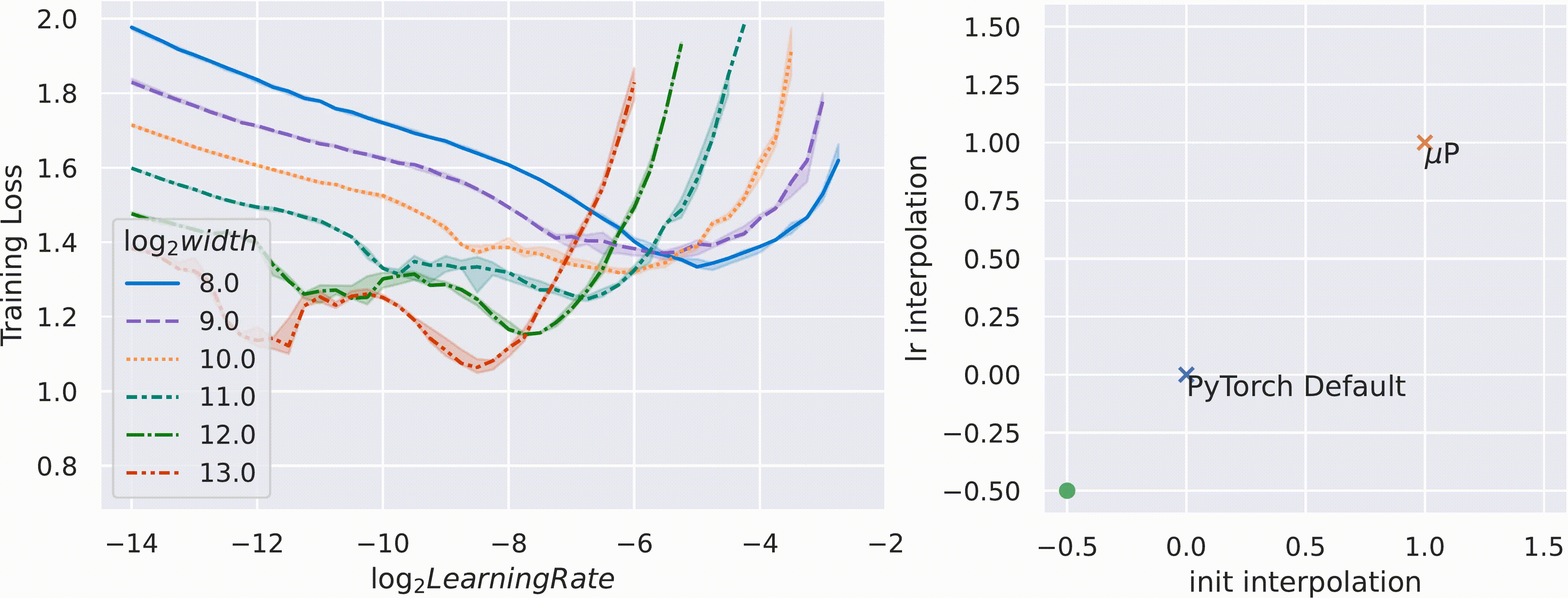 Fig.
Fig.
 Fig. scaled-up model에서 hparam을 찾을 생각을 하는 것이 아니라 어떻게 small scale model의 hparam을 전이할지를 생각하는 것이 훨씬 싸고 심지어 성능도 좋다.
Fig. scaled-up model에서 hparam을 찾을 생각을 하는 것이 아니라 어떻게 small scale model의 hparam을 전이할지를 생각하는 것이 훨씬 싸고 심지어 성능도 좋다.
 Fig. 예를 들어 한 module (layer)에 대해서는 width가 2배 늘어나면 lr을 1/2배 해야겠다. 같은 공식이 TP4에서 유도된다.
Fig. 예를 들어 한 module (layer)에 대해서는 width가 2배 늘어나면 lr을 1/2배 해야겠다. 같은 공식이 TP4에서 유도된다.
그러니까 우리가 200B model을 학습하려고 할 때, 논문의 주장이 사실이라면 유일하게 200B의 optimal hyperparameter를 천문학적인 돈을 들이지 않고 찾을 수 있는 방법인 것이므로, Large Model을 학습하는 모든 그룹은 이를 모르면 막대한 손해를 감수해야 하는 것이다. (하지만 실제로 그런지는 알 수 없을 것 같다)
그래서 어떻게 Mup를 하면 되는가? Modele의 input, output 그리고 hidden weights와 bias는 각각 다음의 rule을 따라 variance를 설정해서 init을 해주면 되는데, 이 때 input weights라고 하는 것은 model의 가장 front-end에서 input을 받는 부분이고 output weights은 loss를 계산하기 직전의 weight을 의미하며 나머지는 hidden weights이다.
 Fig.
Fig.
여기서 fan_in은 layer의 input size를 의미하며,
fan_out은 layer의 output size이다.
그리고 어떤 optimizer를 쓰느냐 (SGD or Adam류)에 따라서 각 layer별로 learning rate를 다르게 설정해주면 된다.
그런데 왜 Mup가 되는걸까?
이것이 Maximul Update (MU) parameterization라고 불리우는 이유는 뭘까?
이는 TP4의 paper title이 Feature Learning in Infinite-Width Neural Networks인 것과 관련이 있는데,
말 그대로 training 과정에서 모든 parameter들이 최대한 도움이 되는방향으로 update (maximul update) 되기 위한 parameterization을 제공하는 것이다.
저자진들은 NN을 학습할 때 (특히 큰 model) gradient가 각 layer별로 vanishing 혹은 exploding되면서 특정 layer들은 training time 동안 의미있는 feature learning을 하지 못하는 경우가 있을텐데,
이를 고려해서 수학적으로 solution을 도출해낸 것이 바로 Mup인 것이다.
Mup에는 수학적인 요소가 많아 이해하기가 매우 어려우나 천천히 이해해보도록 하자.
Scaling Law Prediction
본격적으로 들어가기 전에 한번 더 강조하고 싶은 부분이 있다. 사실 우리는 parameterization을 잘하는 것으로 그치고 싶은것이 아니다. 내가 생각하기에 우리가 진정으로 해야하는 것은 Scaling Law를 정확하게 예측하고, 작은 model로 예측한 더 큰 model의 loss를 단 한번의 hyperparameter tuning 없이 달성하는 것이다.
Fig.
앞서 설명한 것처럼 NanoLM에서도 GPT-4가 loss를 정확히 예측했다고 자랑하긴 하나 그것은 unpublished method이다. 원래대로라면 작은 model들로 scaling law를 찾았다 하더라도 큰 model이 그 loss를 찍기 위해서는 researcher들이 hparam tuning을 해야한다.
 Fig.
Fig.
이런 내용은 NanoLM라는 paper 등에서 찾아볼 수 있는데, NanoLM은 Mup와 scaling law를 결합했을 때 Mup zero-shot transfer를 할 경우 loss가 power function에 fitting 된다는 것을 실험적으로 보였다. 아마 GPT-4가 이렇게 했으리라고 강력히 의심이 되는 바 이지만 알려진 바는 없다. 실제로 원래 scaling law는 model size별로 hparam을 다시 찾아야 했으며, mup를 쓰지 않더라도 model size별 batch size와 learning rate (lr)의 관계식 또한 찾아볼 수도 있고, lr에 민감하지 않은 구조체를 쓴다거나 할 수도 있다. 예를 들어 최근에 나온 cmd r+같은 model은 Transformer의 저자진들이 창업한 Cohere라는데서 만들었는데, q, k projection 전에 각각 서로 다른 normalization layer를 쓴다.
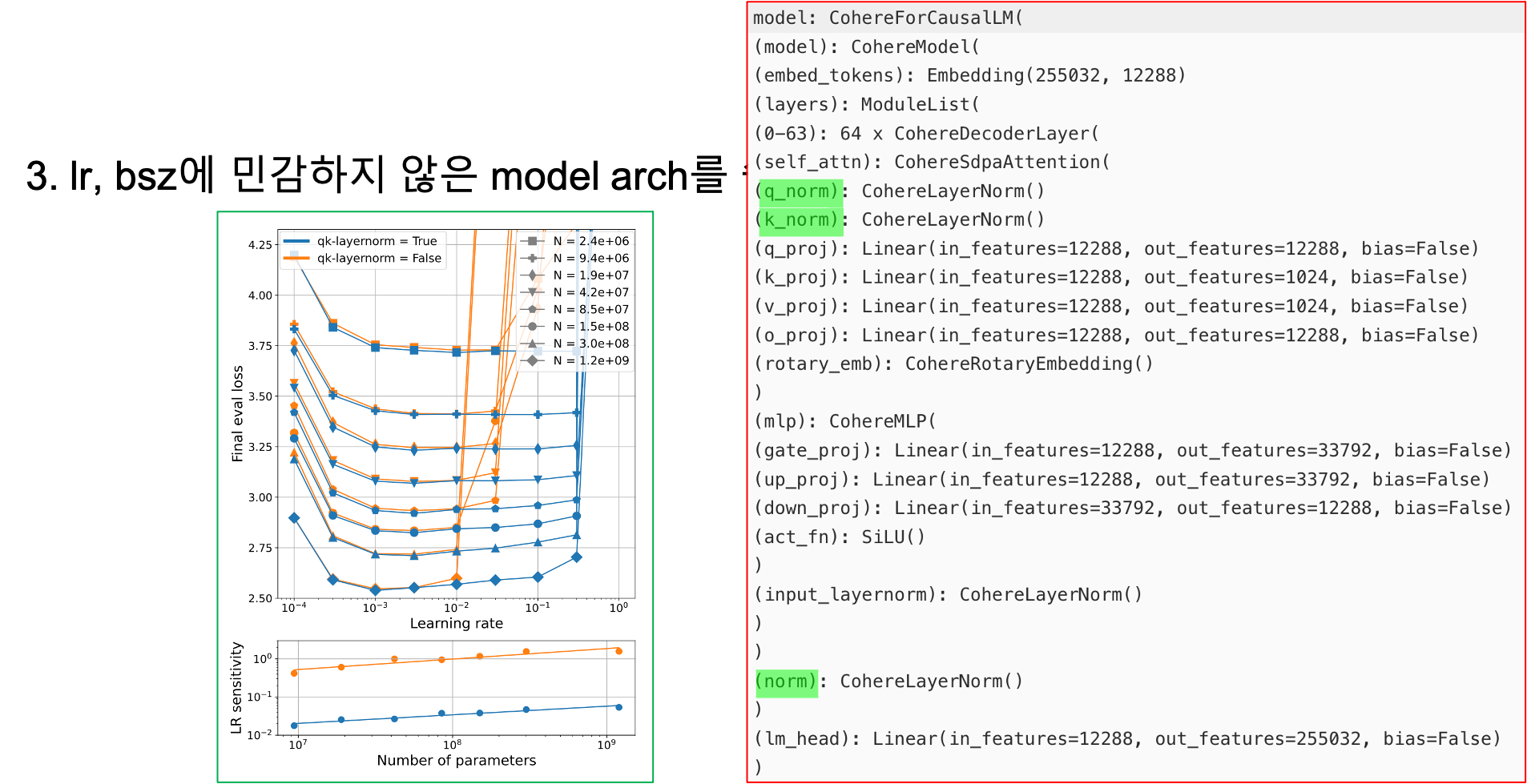 Fig.
Fig.
아마 이 구조체는 lr에 민감하지 않은 것으로 보이는데, 이는 Small-scale proxies for large-scale Transformer training instabilities라는 paper에서 다루고 있는 내용이다. Model size가 커짐에 따라 lr이 크게 다르지 않다면 우리는 lr 변경없이 scaling law prediction을 한 뒤 target size의 model도 같은 lr을 쓸 수도 있을 것 같다.
하지만 그것이 아니라면 실제 target size model의 hparam을 또 찾는걸 피해야 하는데, 그런 점에 있어 mup가 강력한 tool이 된다고 할 수 있다. NanoLM에서는 GPT뿐 아니라 Llama, BERT 구조체에서도 Mup + scaling law가 통한다는 것을 보였는데, 실제로 Mup는 GPT 구조에만 해당하는 방법론이지 Llama처럼 Grouped Query Attention (GQA)를 쓴다거나 Rotary Positional Embedding (RoPE)을 쓴다거나 하는 경우에는 이것이 먹히는지에 대한 단서는 없는 것으로 알고있다. 그 밖에도 embedding을 tie하는 경우 똑같은 matrix에 대해 gradient가 loss 기준 맨 앞단과 맨 뒷단에 동시에 흐르게 되는데, 이런 내용은 Tensor Program 4에 있지만 만약 우리 기관이 실험하고싶은 model architecture가 특별한 경우에 대해 loss prediction을 하고 실제 그 loss를 얻기 위해서는 mup를 잘 결합해야 한다고 생각한다.
 Fig.
Fig.
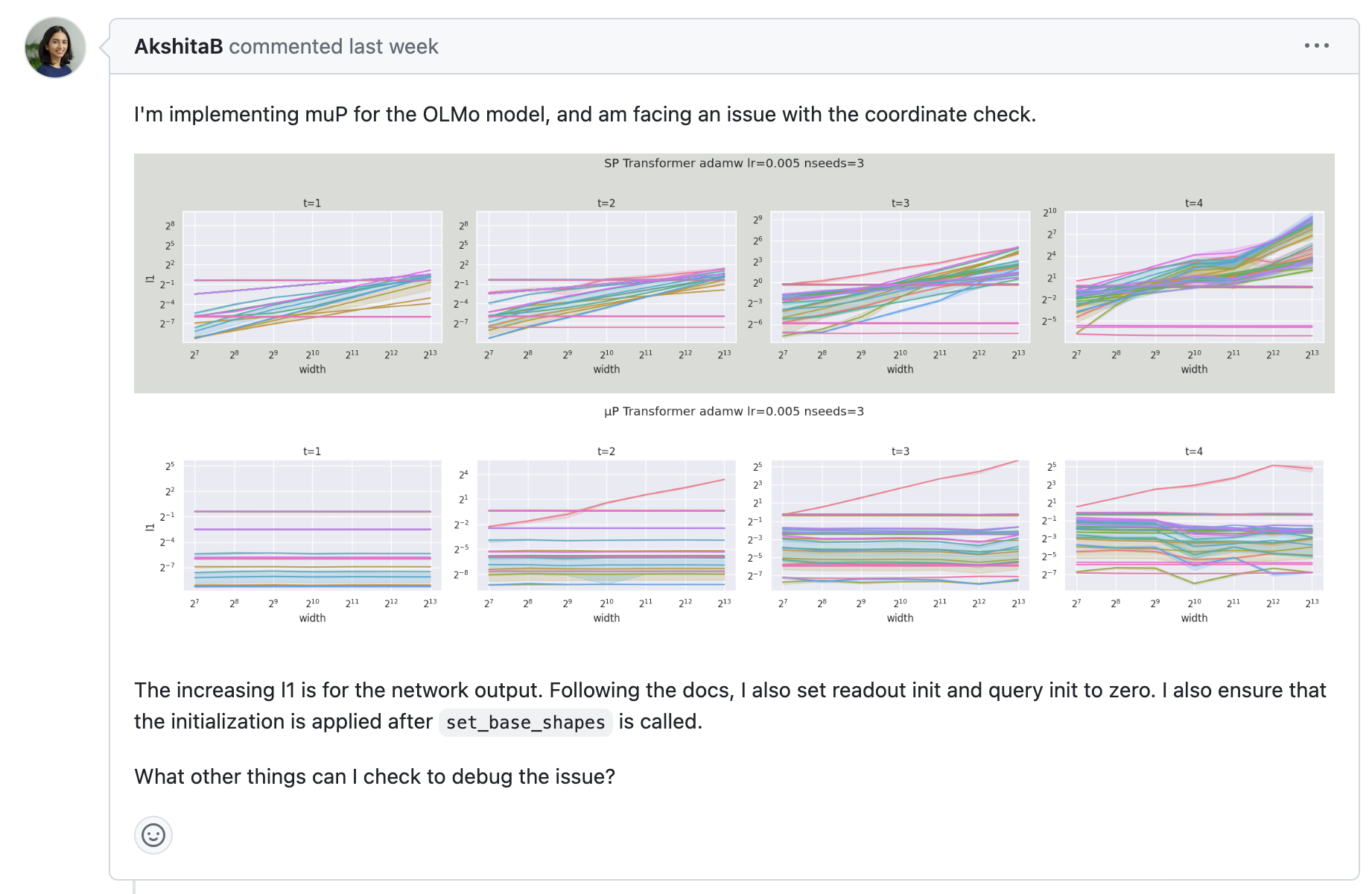 Fig. AI2에서도 OLMo에 mup를 적용하려는 듯 하다.
Fig. AI2에서도 OLMo에 mup를 적용하려는 듯 하다.
Scaling law prediction이 mup와 잘 결합된다면 매 model size별로 hparam을 다시 찾지 않으면서도 power function을 그릴 수 있고, 그렇다면 model architecture뿐 아니라 pretraining을 위한 dataset의 subset별 mixture ratio를 바꿔가면서 어떤 case가 predicted loss가 제일 낮은지를 확인해서 그 조합으로 가면 된다.
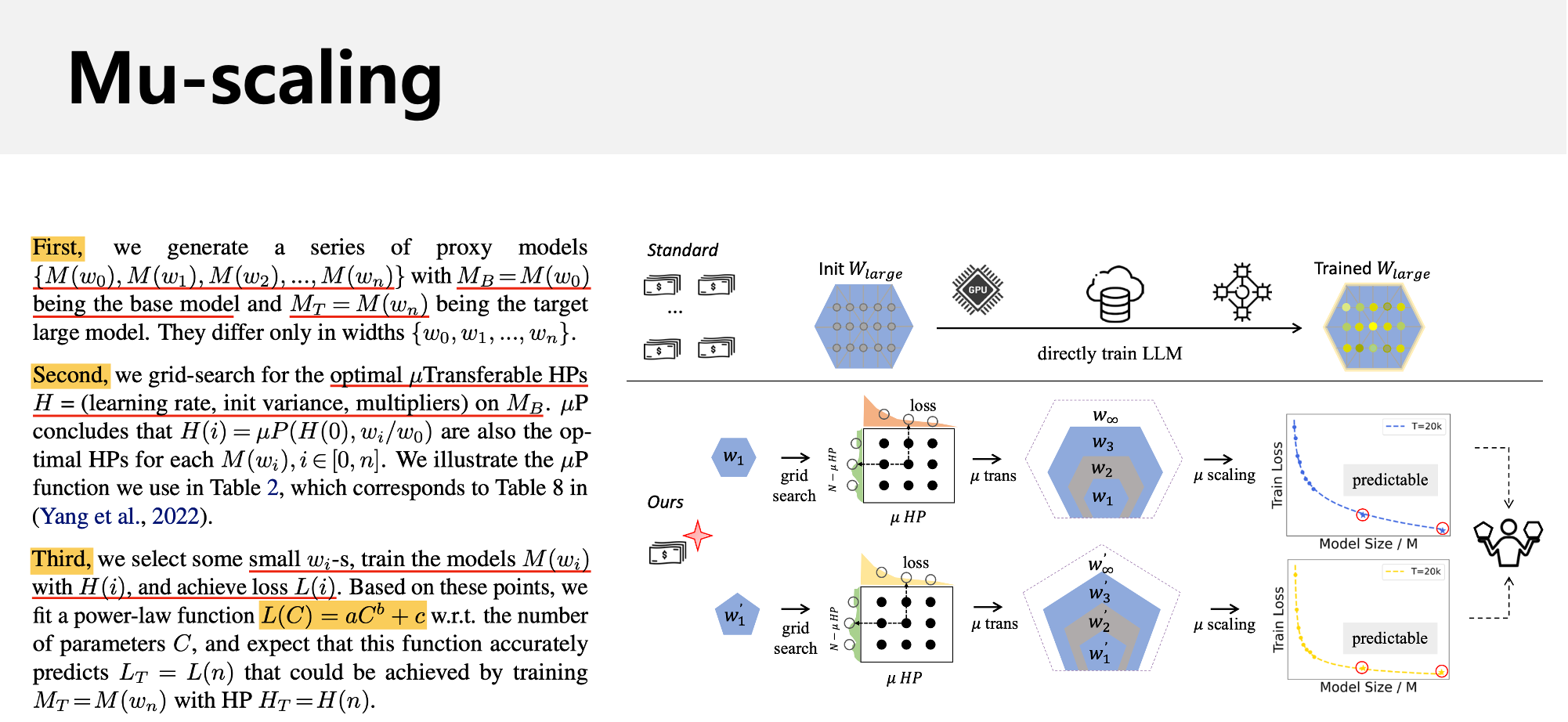 Fig. 3가지 step을 통해 mu-scaling을 해보고 제일 좋은 model architecture를 결정한다.
Fig. 3가지 step을 통해 mu-scaling을 해보고 제일 좋은 model architecture를 결정한다.
앞서 얘기한 것 처럼 NanoLM에서는 가장 작은 model로 hparam search를 주욱 하고, 이것을 zero shot transfer해서 좀 더 큰 proxy model들에 대해 loss를 찍어본 뒤, 최종적으로 scaling law를 구한 뒤 실제 target size model을 학습했을 때 이 loss를 얻을 수 있음을 여러 model에 대해 보였는데,
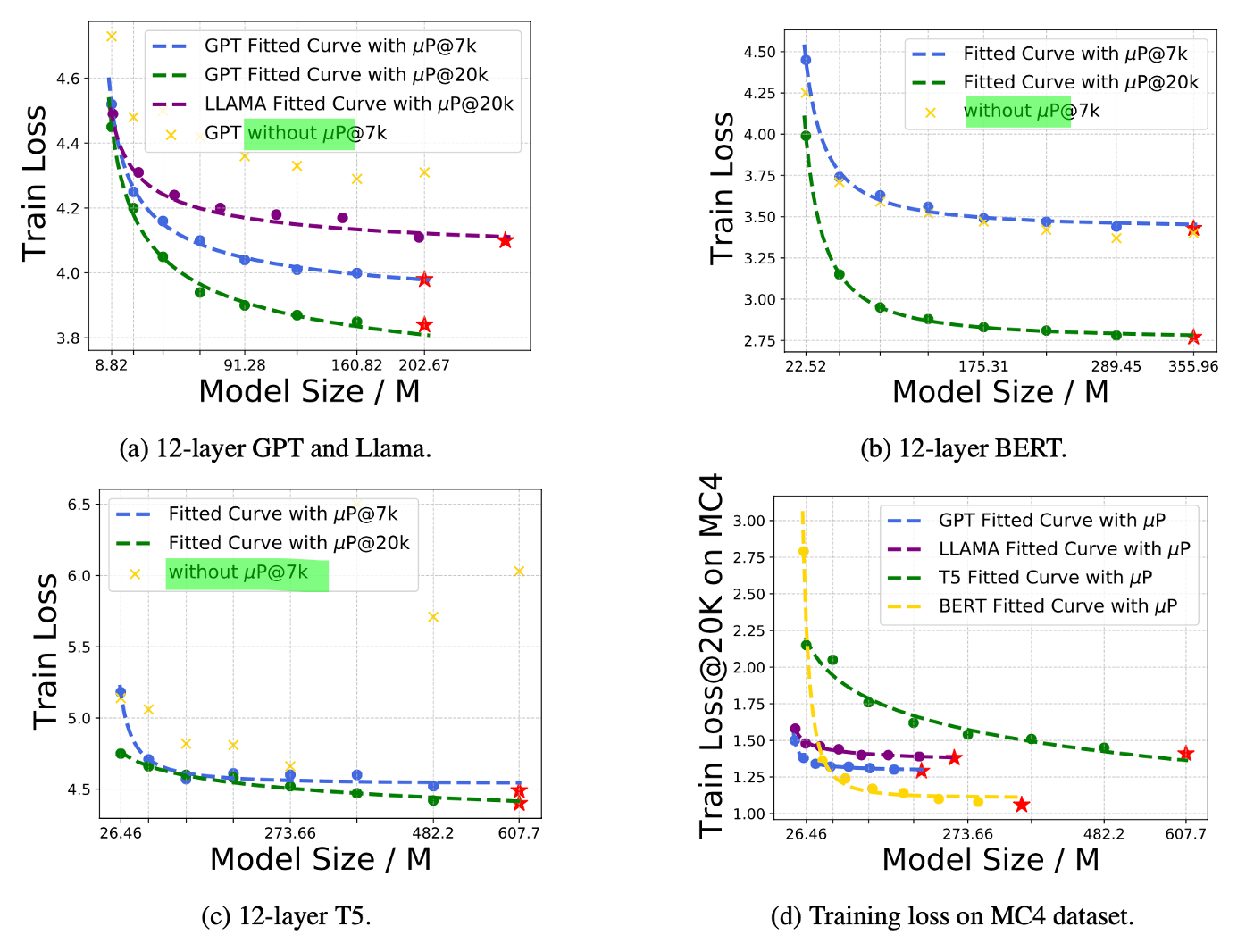 Fig.
Fig.
이 paper는 reject 됐지만 (…), 전달하고자 하는 바는 명확하며 공감이 갔다.
결국 중요한 것은 loss prediction을 굉장히 효율적으로 잘 하고 싶고 mup는 그것을 위한 수단이라는 것이다.
Feature Learning
NN training에서 Feature Learning이란 무엇일까?
Neural Tangent Kernel (NTK)
Neural Tangent Kernel (NTK)란 무엇일까
고전 ML부터 제안되었던 algorithm들을 보면 크게 다음과 같은 발전과정을 거쳤다고 할 수 있다.
- 1.선형 모델 (Linear model)을 통한 regression 혹은 classification 문제 해결
- 2.비선형 함수 (Non-linear function)을 도입하여 feature를 뽑은 뒤 linear model을 적용해 해결
- 3.2번이 너무 cost가 많이 들기 때문에 Kernel Trick을 사용 (Gaussian Process 등)
- 4.Neural Network (NN) 사용
- 5.Deep NN으로 발전
- 6.Transformer and Scaling Law -> LLM
우리가 어떤
tmp
TBC
References
- Papers
- Tensor Program Related Materials
- Tensor Programs IV: Feature Learning in Infinite-Width Neural Networks
- Tensor Programs V: Tuning Large Neural Networks via Zero-Shot Hyperparameter Transfer
- A Spectral Condition for Feature Learning
- NanoLM: An Affordable LLM Study Benchmark via Accurate Loss Prediction Across Scales
- Steering Deep Feature Learning with Backward Aligned Feature Updates
- Neural Tangent Kernel: Convergence and Generalization in Neural Networks
- Neural Tangent Kernel Analysis of Deep Narrow Neural Networks
- Cerebras-GPT: Open Compute-Optimal Language Models Trained on the Cerebras Wafer-Scale Cluster
- DeepSeek LLM: Scaling Open-Source Language Models with Longtermism
- Small-scale proxies for large-scale Transformer training instabilities
- Training Compute-Optimal Large Language Models
- Tensor Program Related Materials
- Blogs
- On infinitely wide neural networks that exhibit feature learning
- µTransfer: A technique for hyperparameter tuning of enormous neural networks
- Some Math behind Neural Tangent Kernel from Lilian Weng
- Understanding the Neural Tangent Kernel Rajat’s Blog
- MiniCPM: Unveiling the Potential of End-side Large Language Models
- Video
- μTransfer: Tuning GPT-3 hyperparameters on one GPU, Explained by the creator
- Large N Limits: Random Matrices & Neural Networks from Greg Yang
- Feature Learning in Infinite-Width Neural Networks from Greg Yang
- Neural Tangent Kernel Analysis of Deep Narrow Neural Networks
- Illustration of NTK from Author (Arthur Jacot)
- Recent Developments in Over-parametrized Neural Networks, Part I
- 수리과학부 류경석 교수 - Training Dynamics and Complexity of Infinitely Wide WGAN and Minimax
- SNU 류경석 - Neural Tangent Kernel Analysis of Deep Narrow Neural Networks
- Lecture 7 - Deep Learning Foundations, Neural Tangent Kernels
- Deep Learning Foundations by Soheil Feizi : Large Language Models
- Codes