Normalization Series (BN, LN, GN ...)
23 Jul 2022< 목차 >
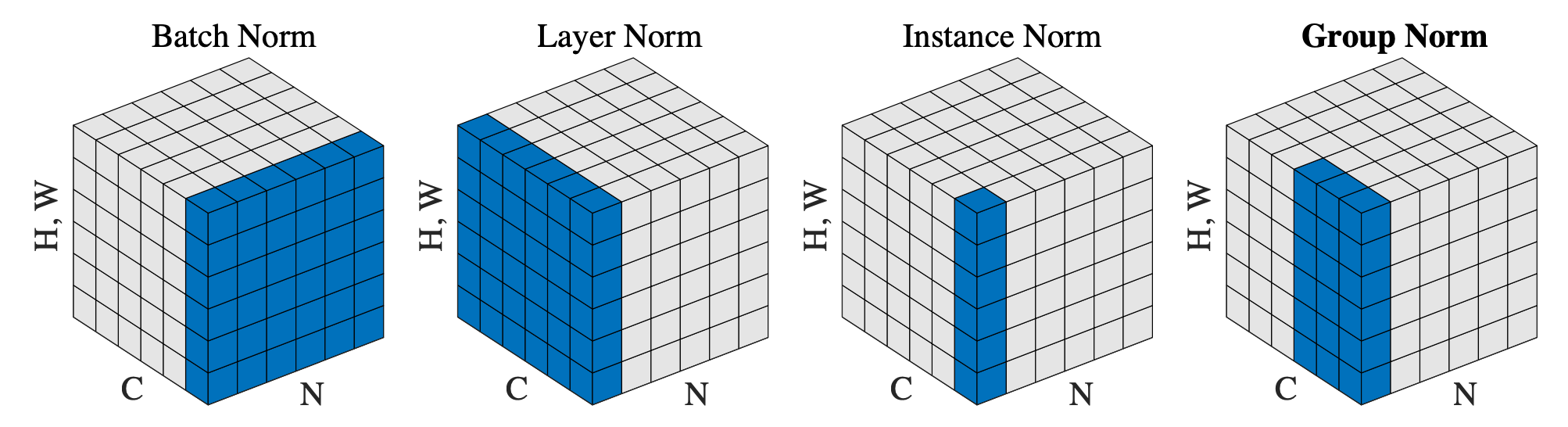 Fig. 현대 딥러닝에 쓰이는 수많은 Normalization Methods
Fig. 현대 딥러닝에 쓰이는 수많은 Normalization Methods
Why Normalization ?
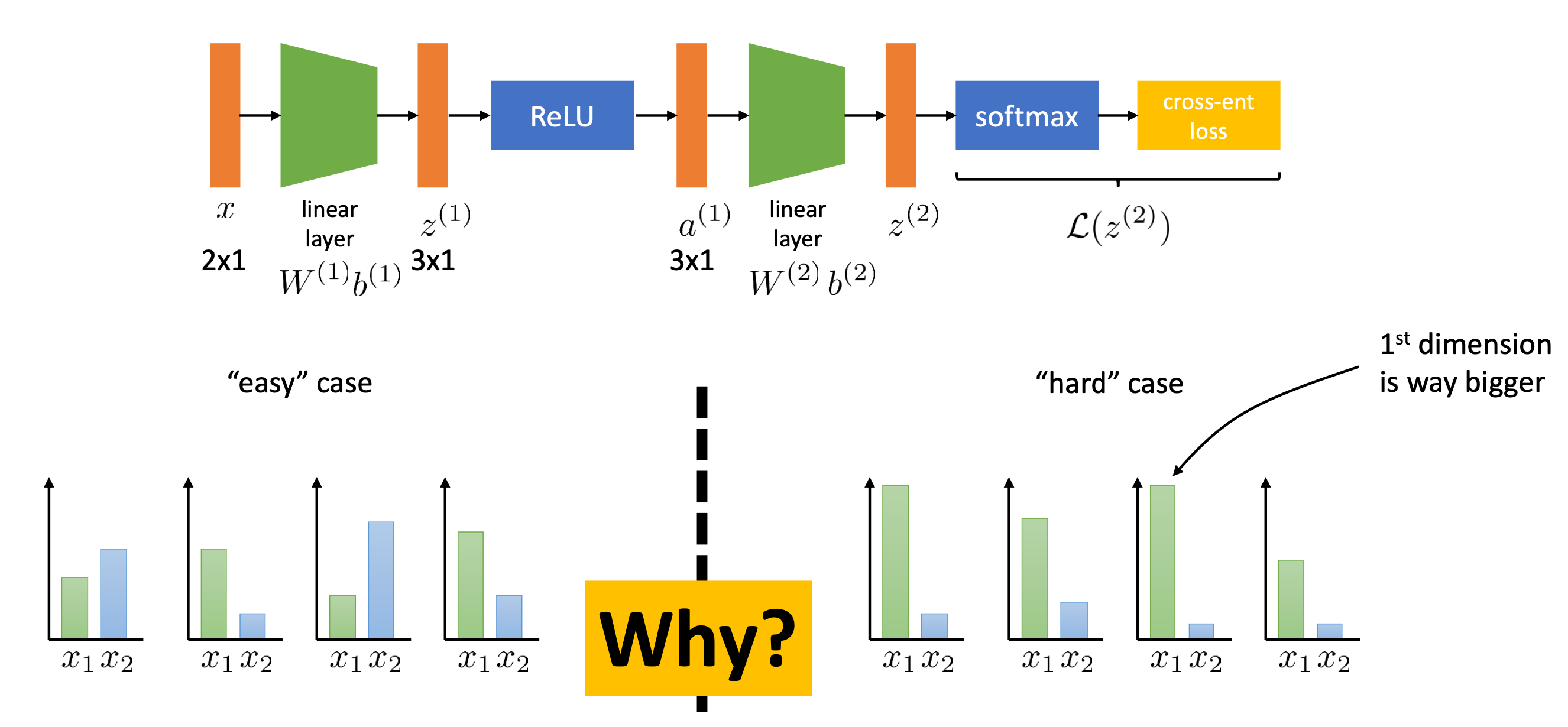 Fig.
Fig.
asd
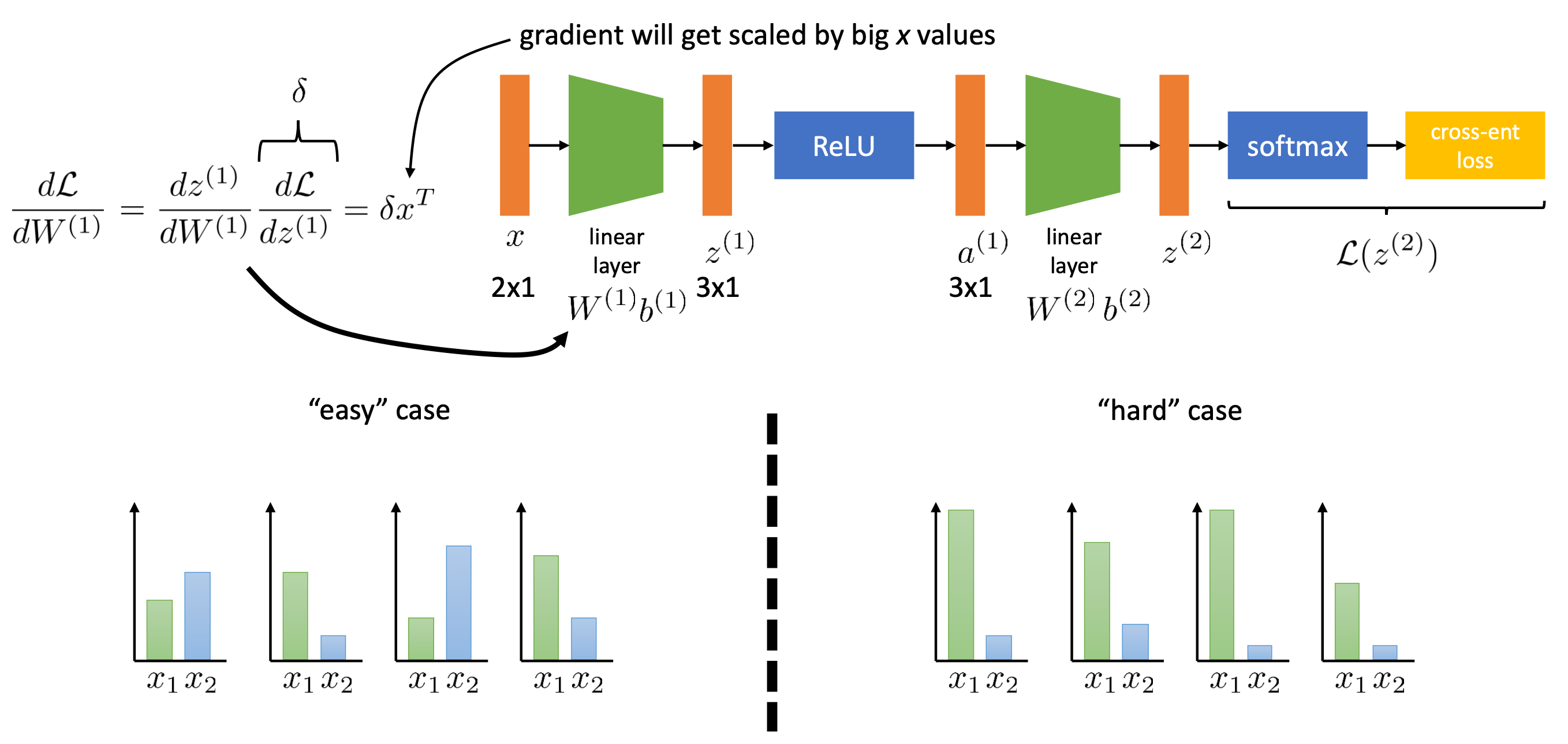 Fig.
Fig.
asd
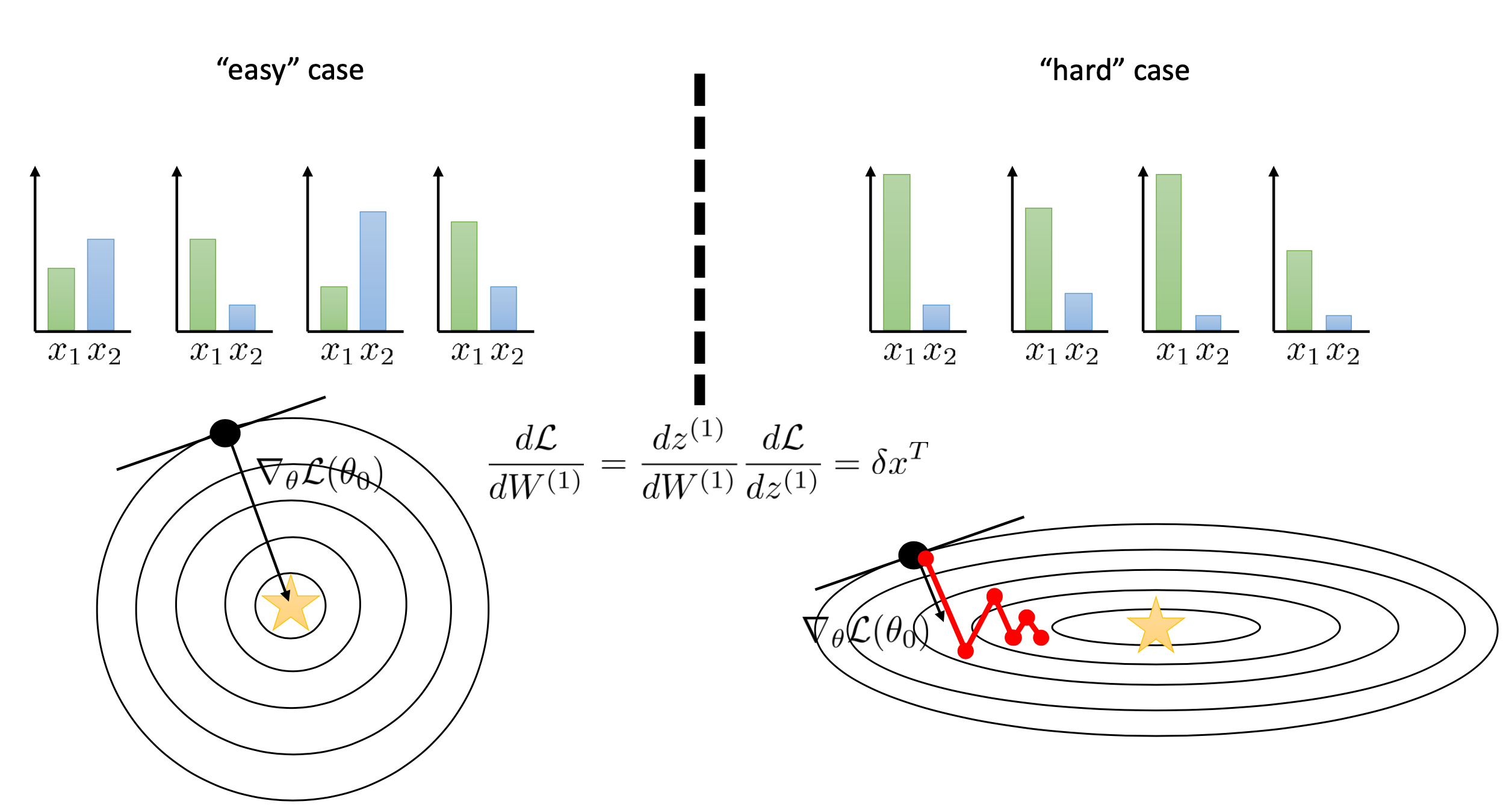 Fig.
Fig.
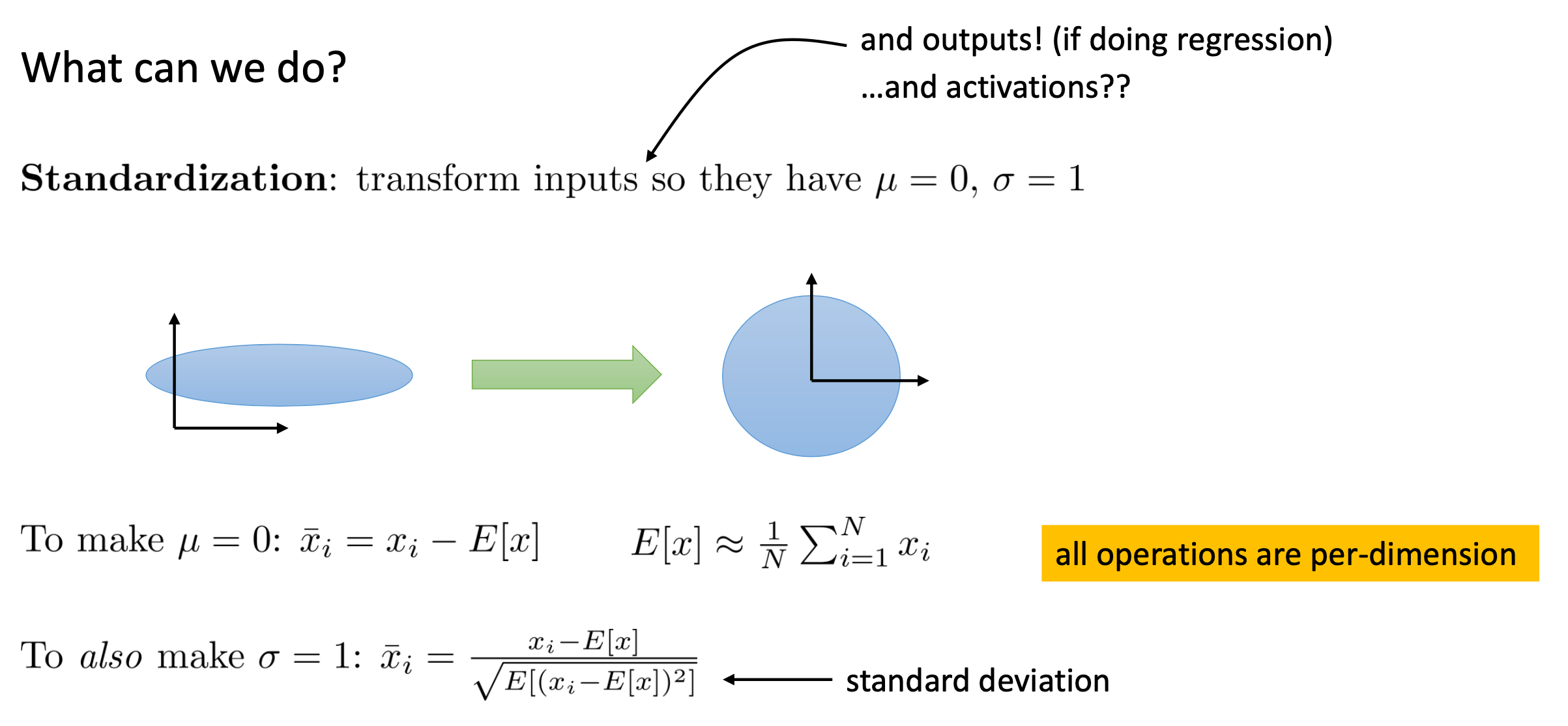 Fig.
Fig.
Batch Normalization (BN)
결국 우리가 원하는건
Fig.
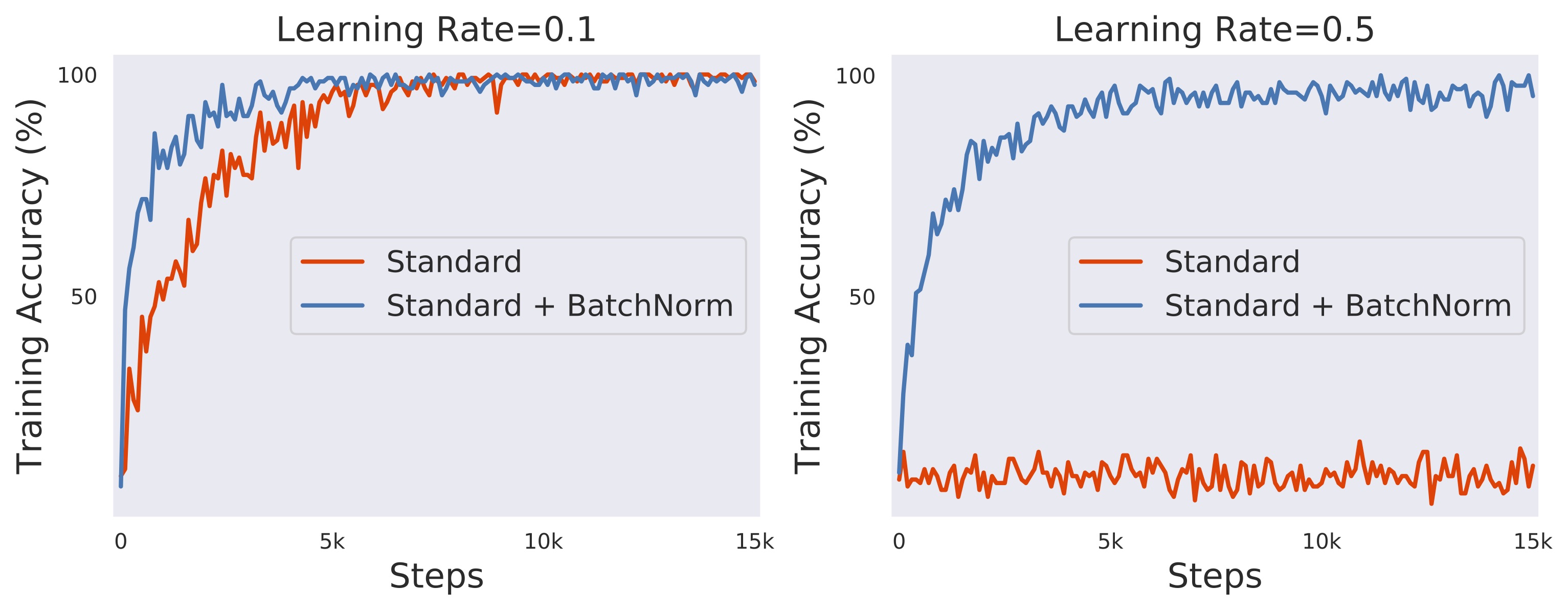 Fig.
Fig.
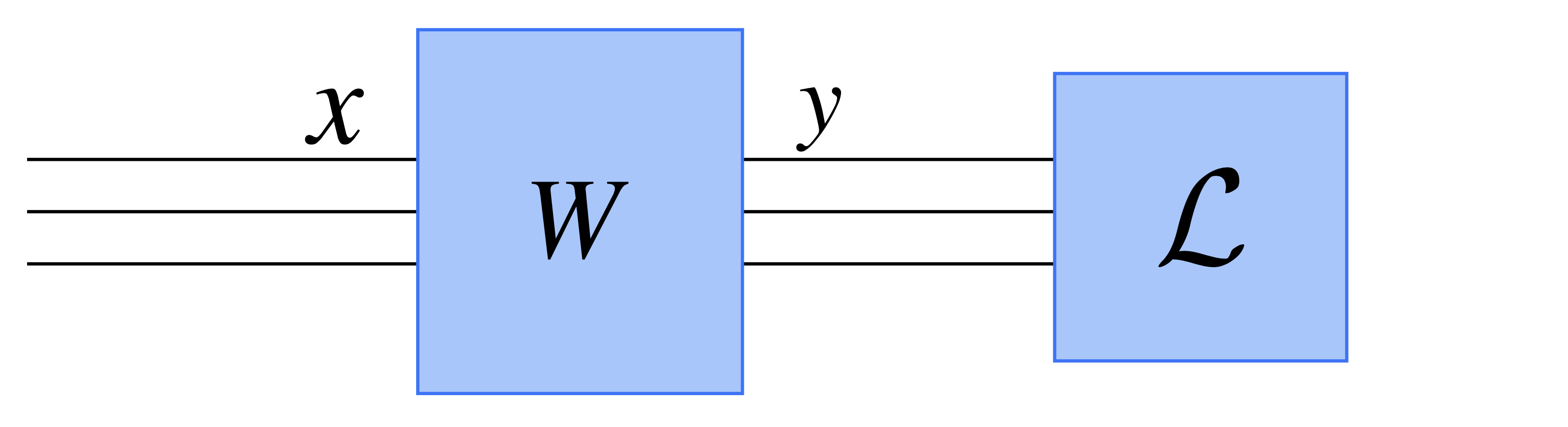 Fig. Vanilla Network
Fig. Vanilla Network
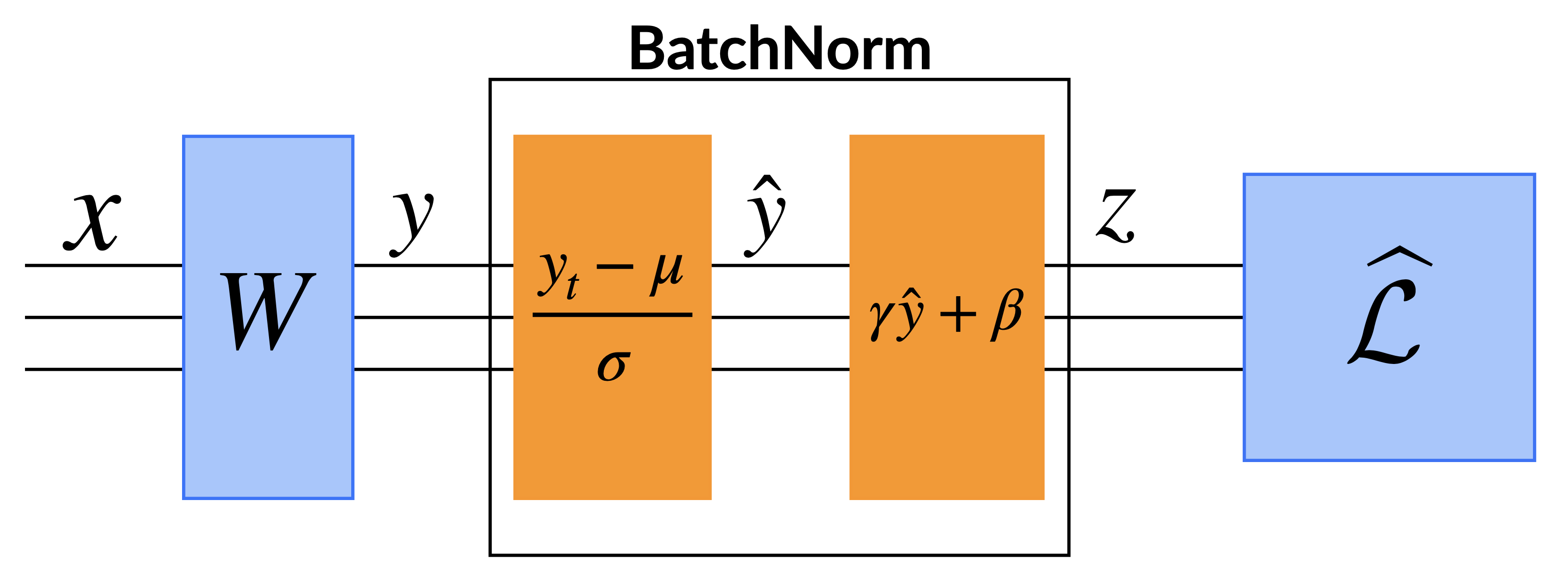 Fig. Vanilla Network + BatchNorm Layer
Fig. Vanilla Network + BatchNorm Layer
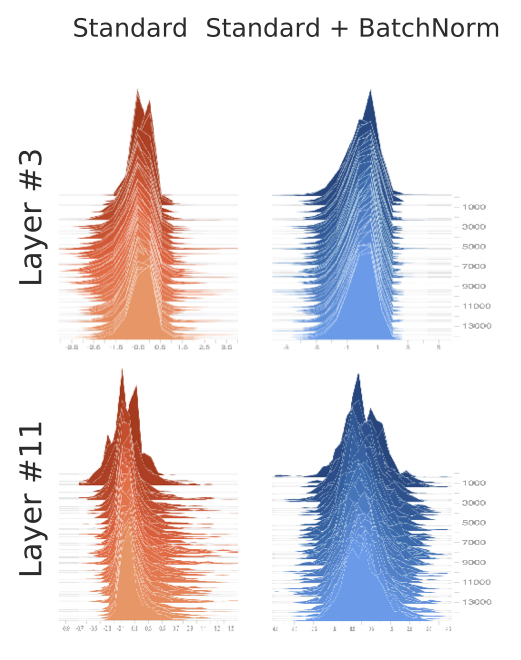 Fig.
Fig.
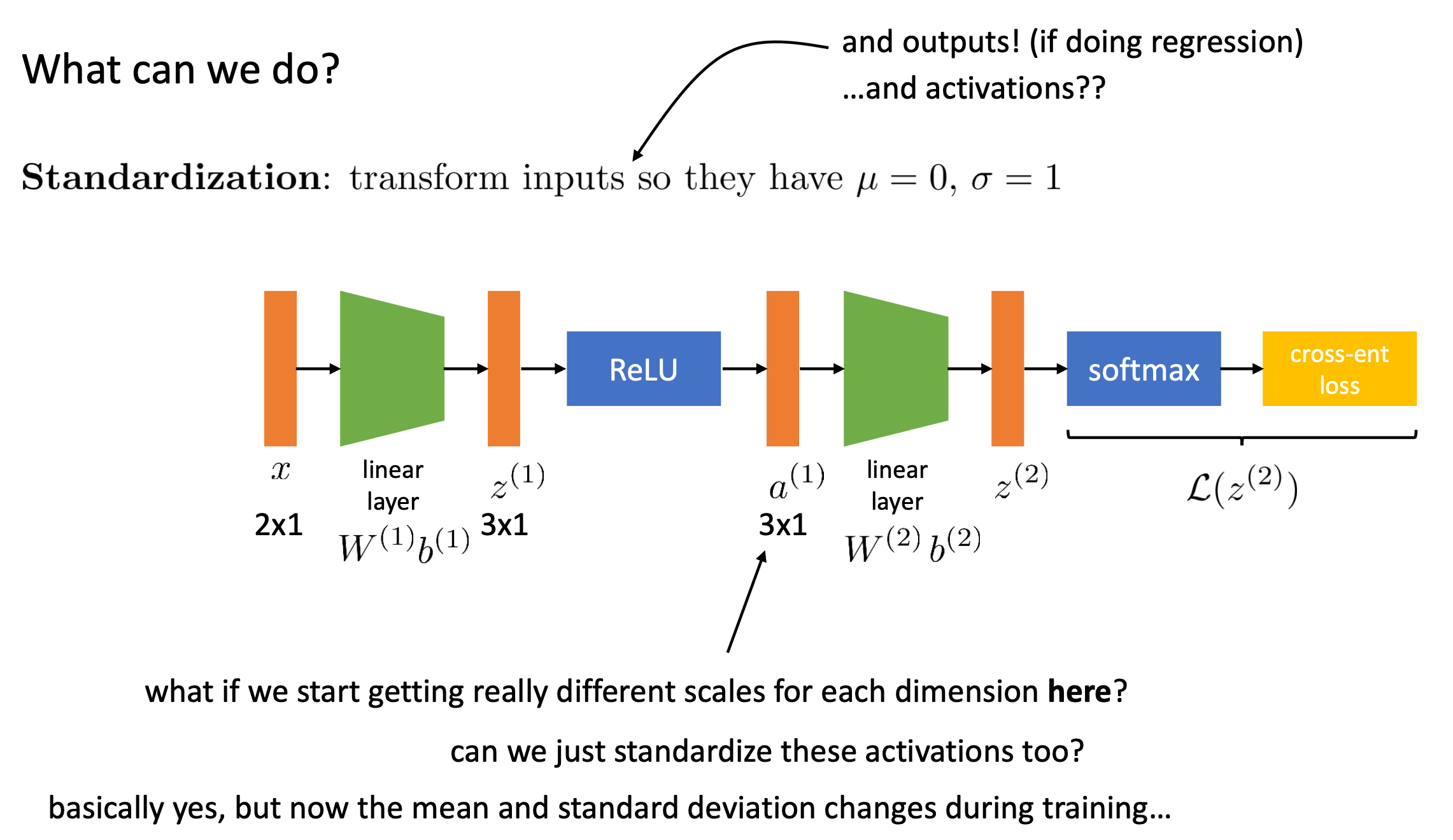 Fig.
Fig.
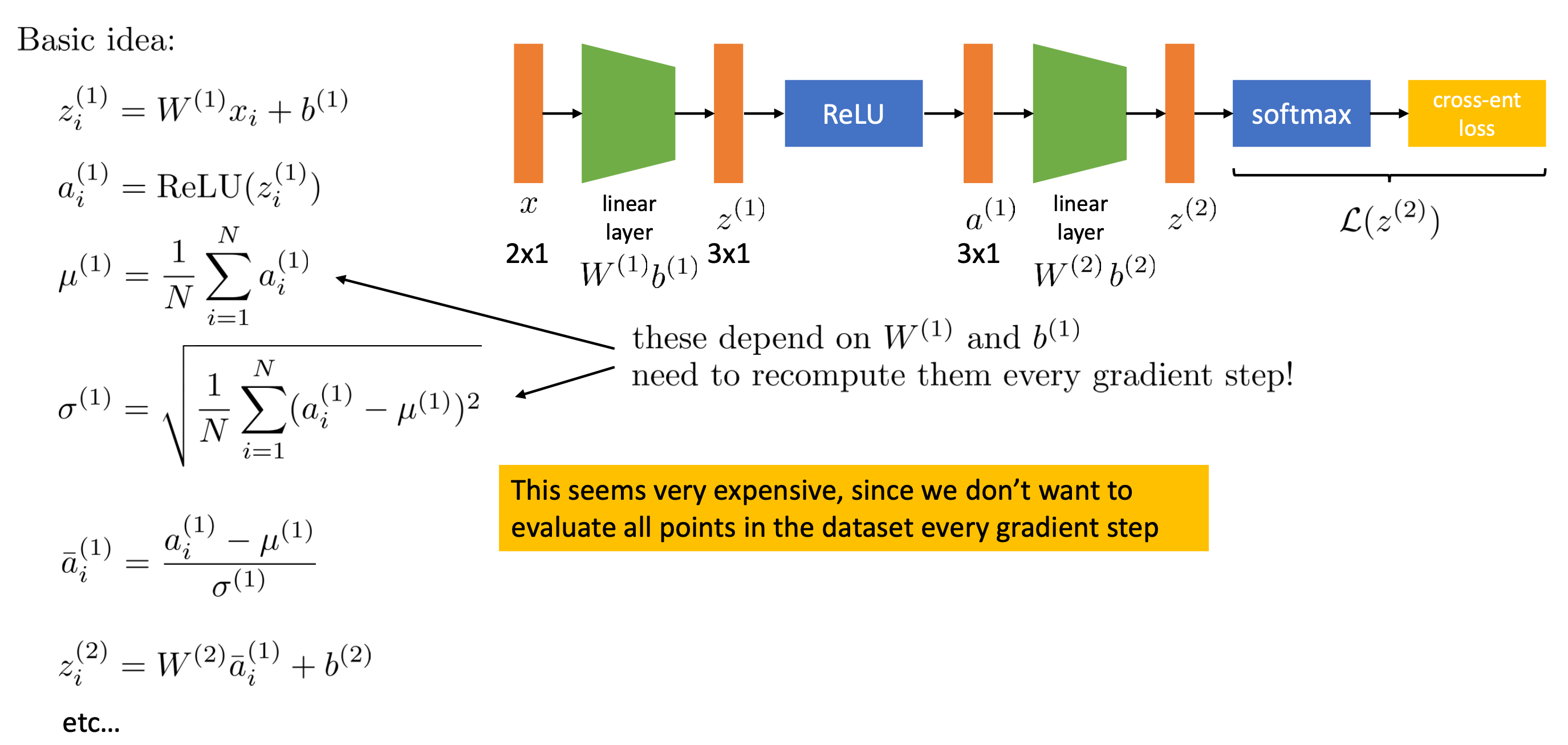 Fig.
Fig.
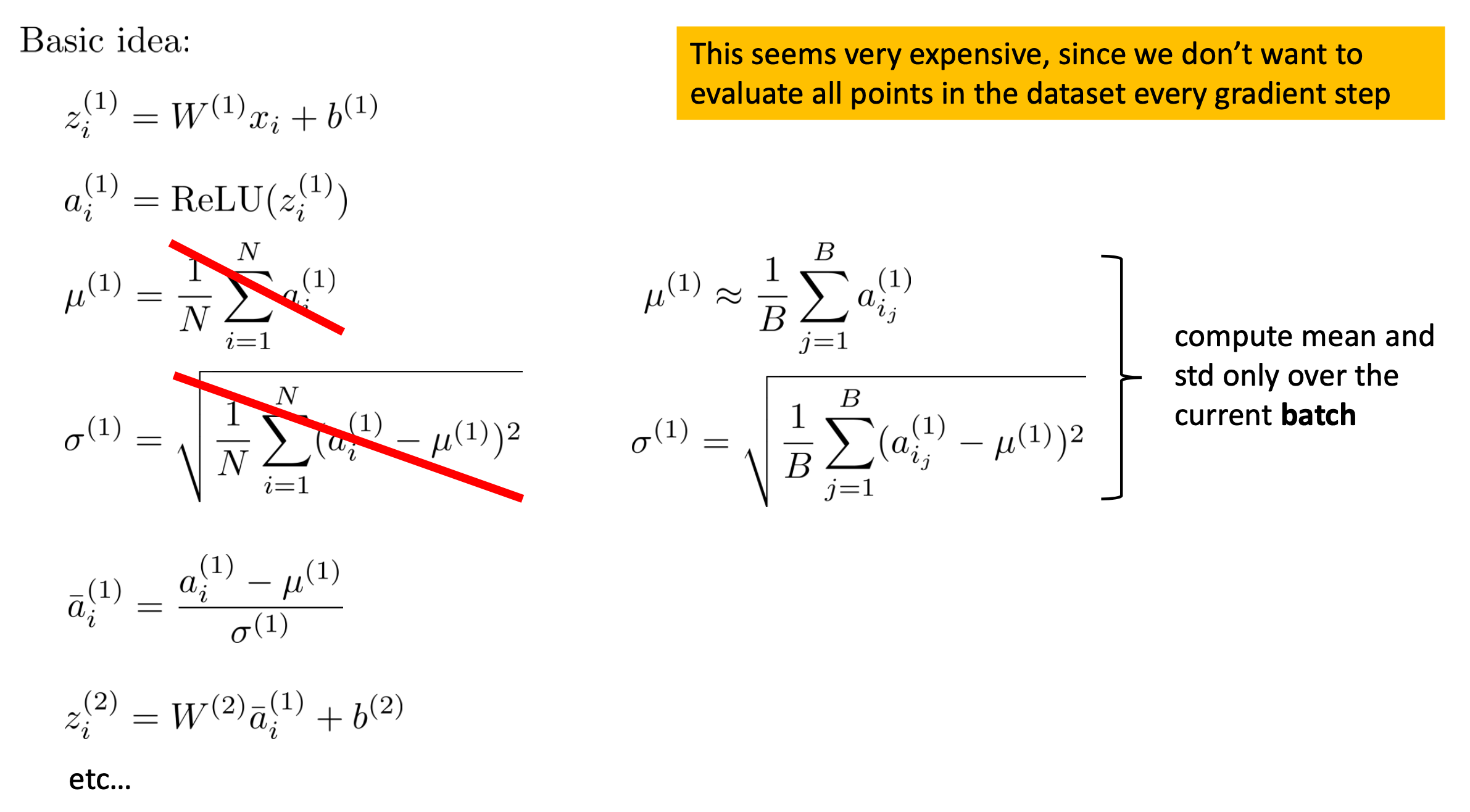 Fig.
Fig.
 Fig.
Fig.
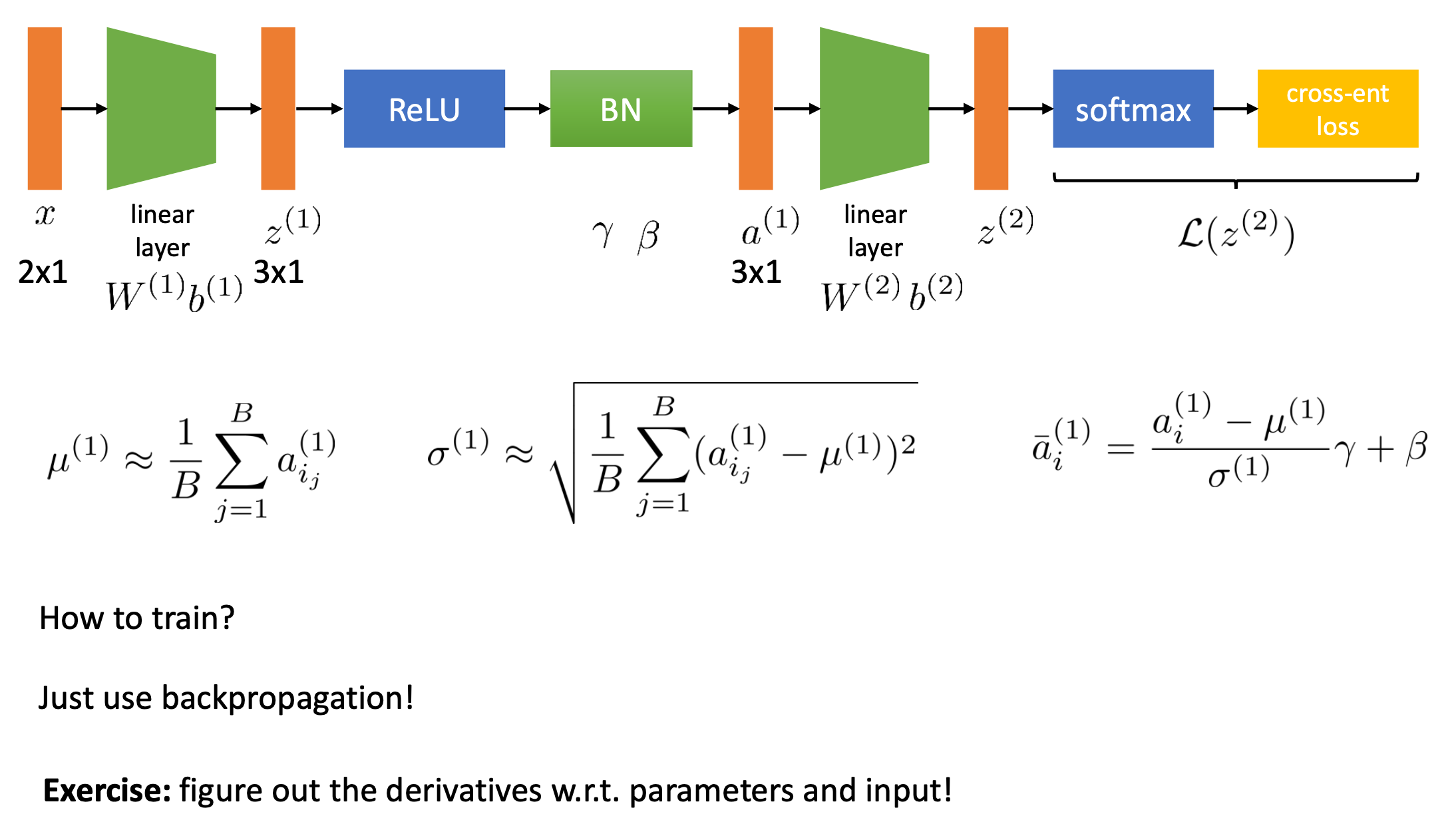 Fig.
Fig.
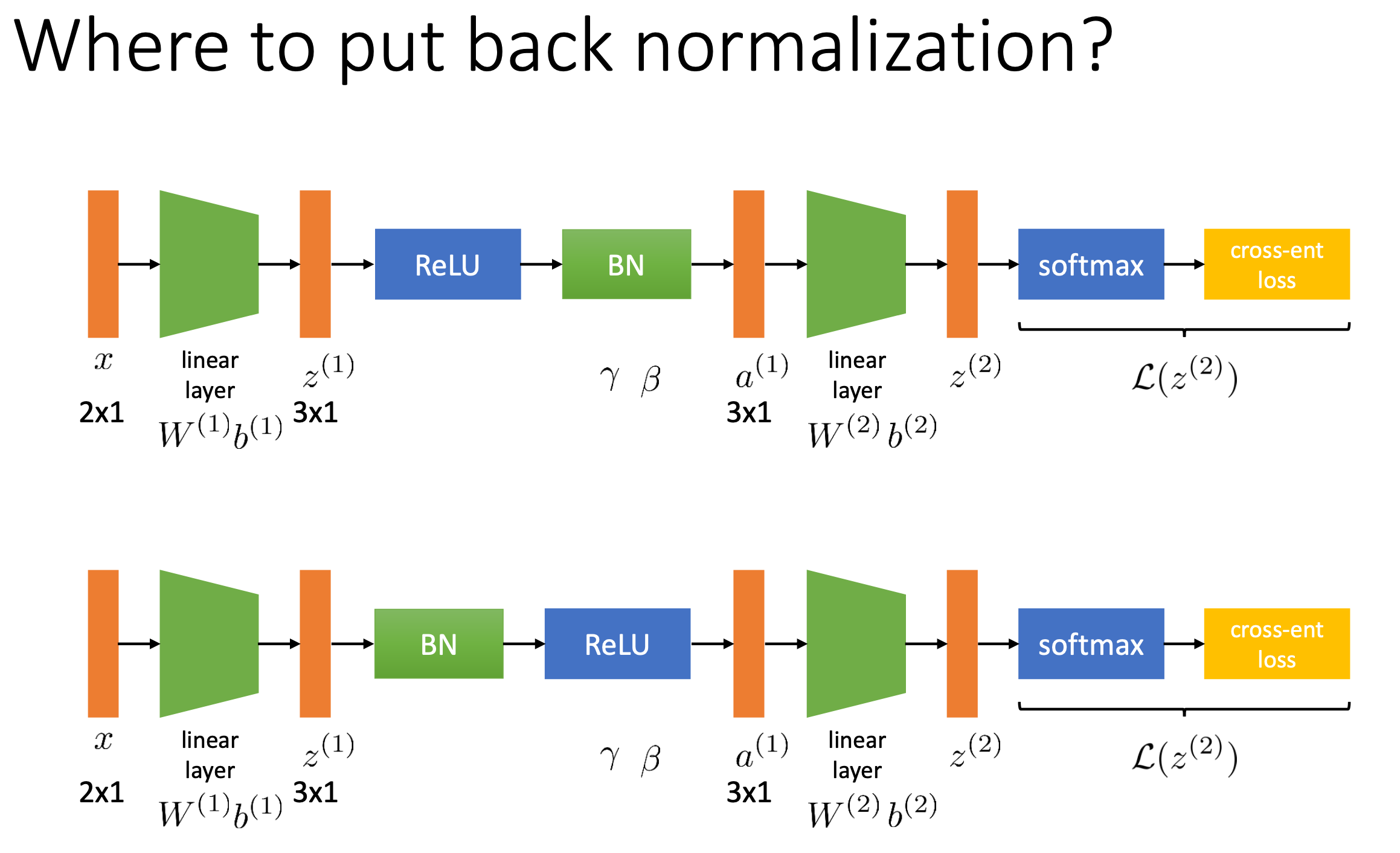 Fig.
Fig.
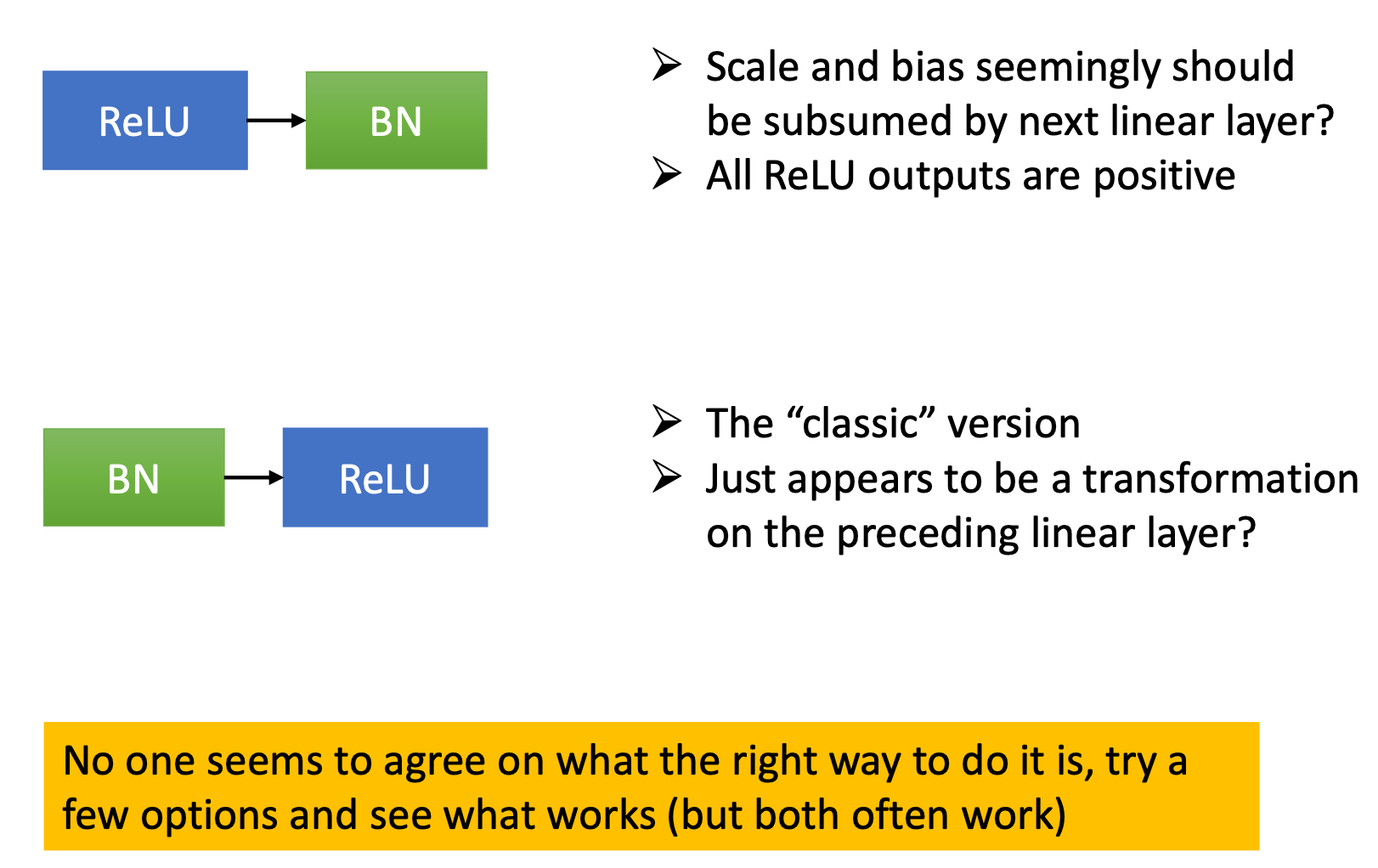 Fig.
Fig.
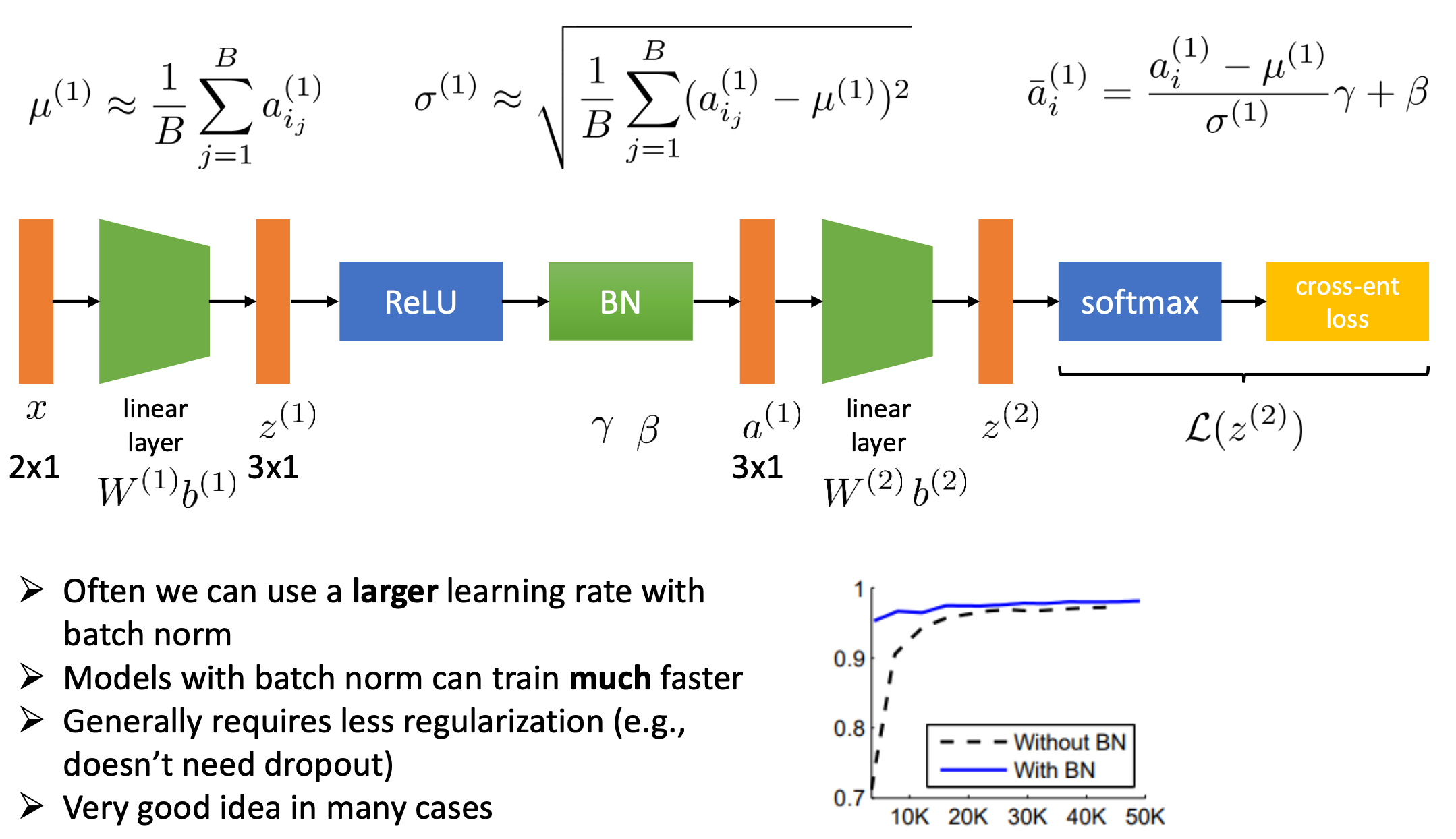 Fig.
Fig.
Internal Covariate Shift (ICS)
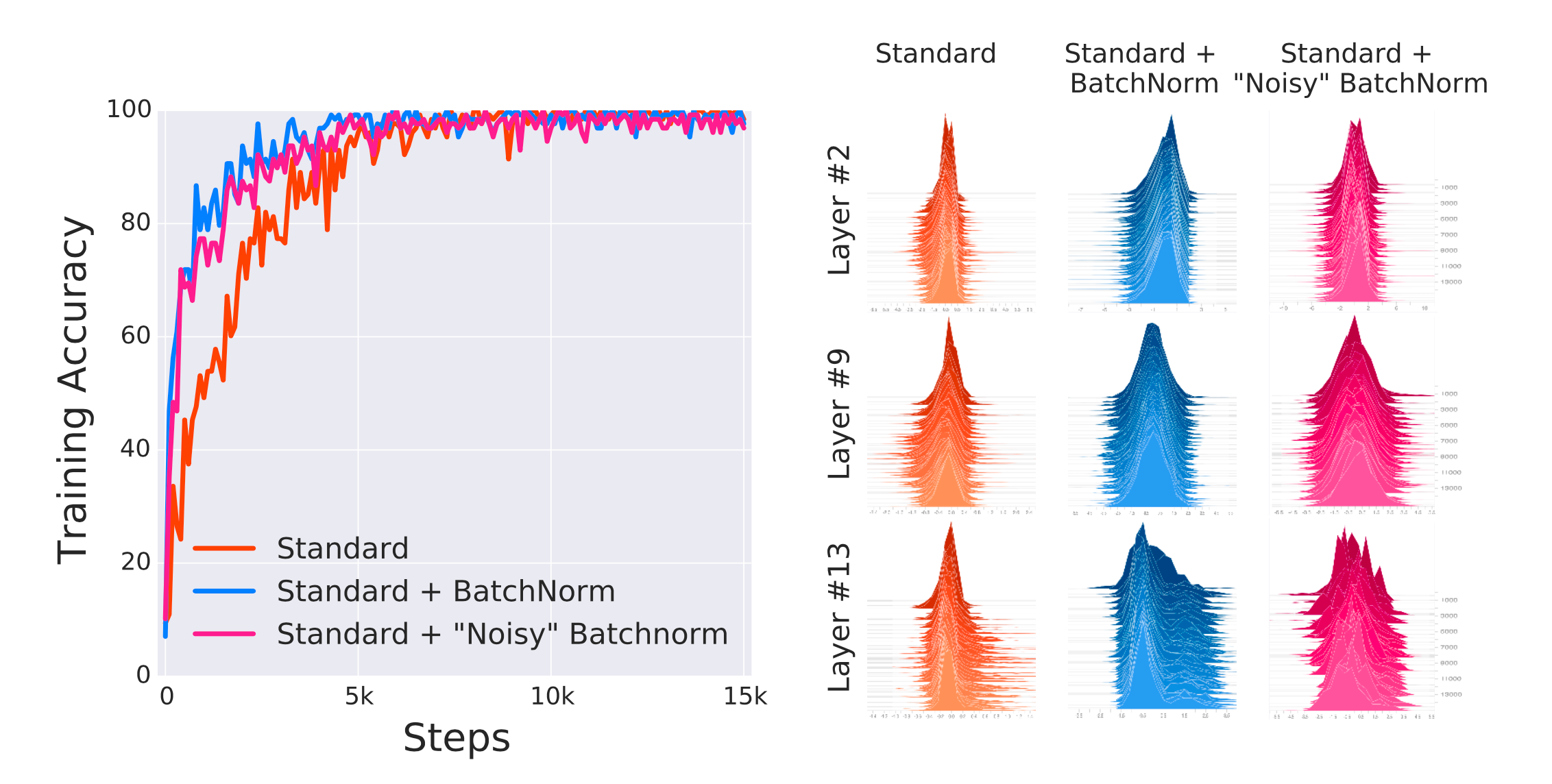 Fig.
Fig.
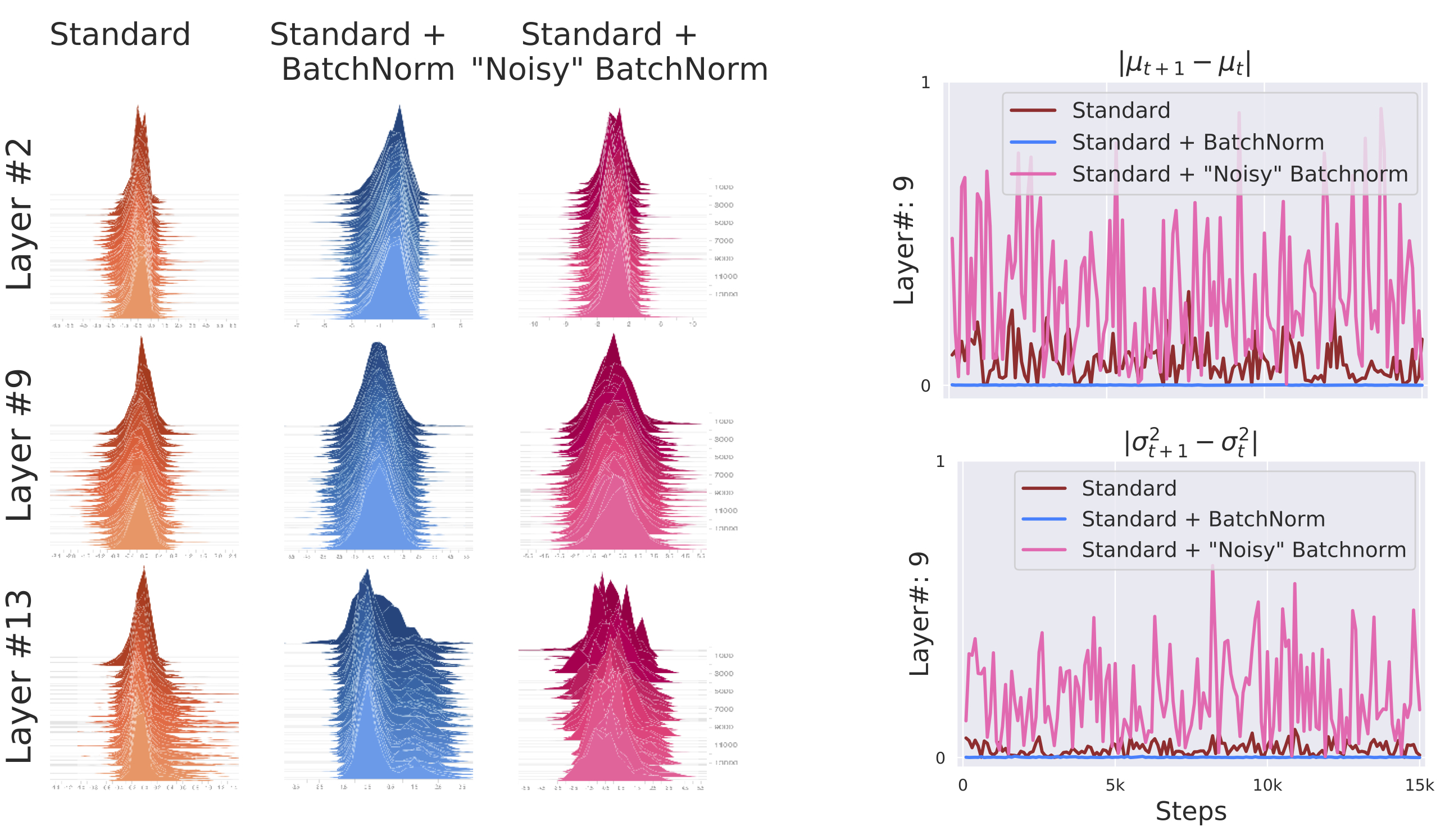 Fig.
Fig.
Layer Normalization (LN)
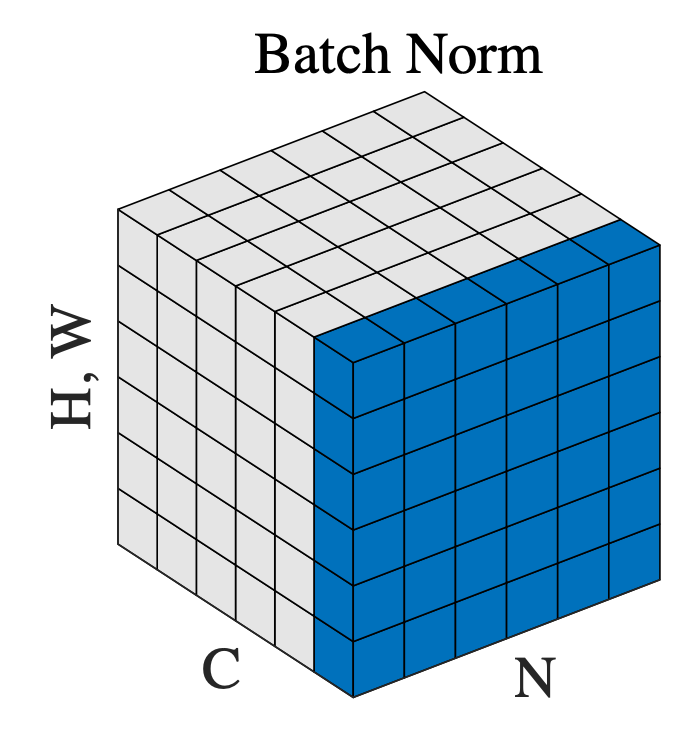 Fig. Batch Normalization
Fig. Batch Normalization
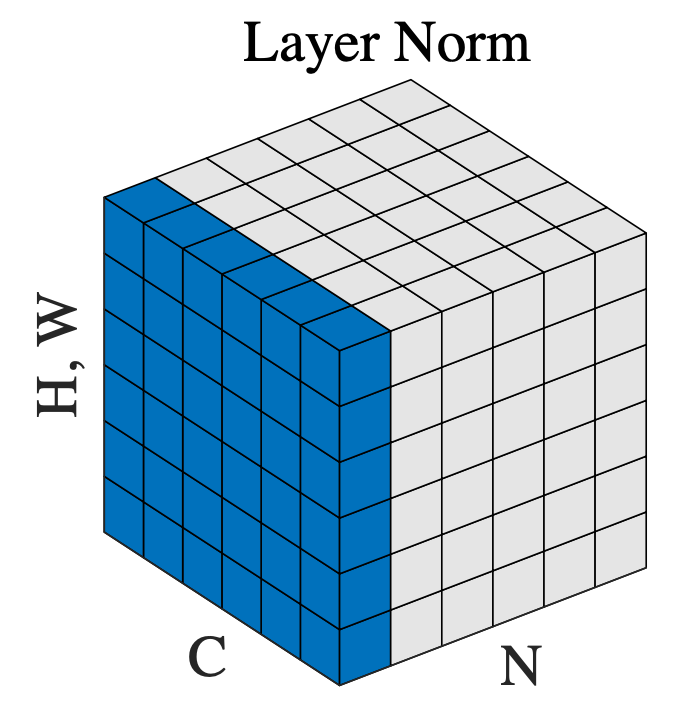 Fig. Layer Normalization
Fig. Layer Normalization
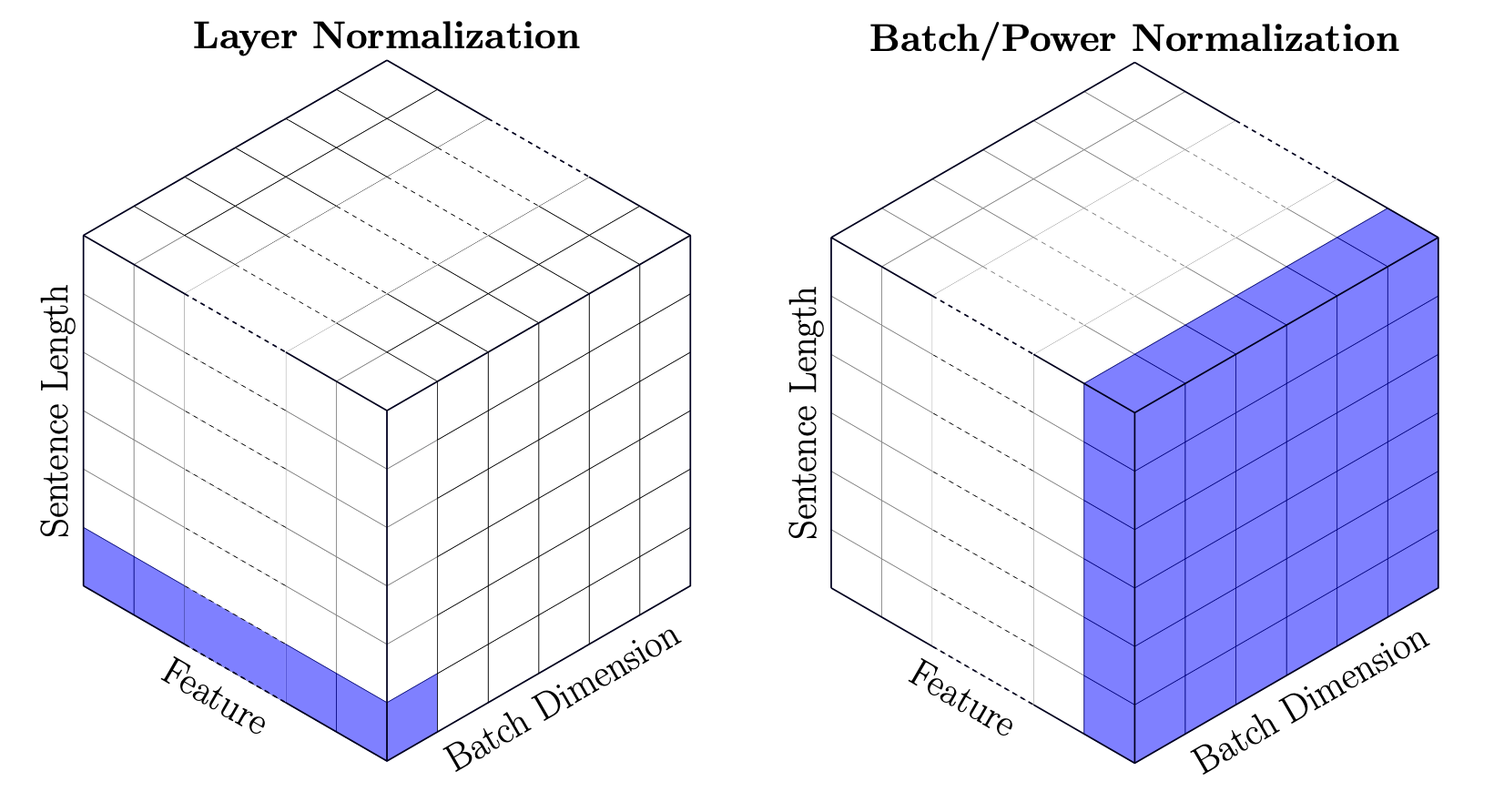 Fig. BN vs LN in 3D Sentence Tensor
Fig. BN vs LN in 3D Sentence Tensor
PreNorm vs PostNorm
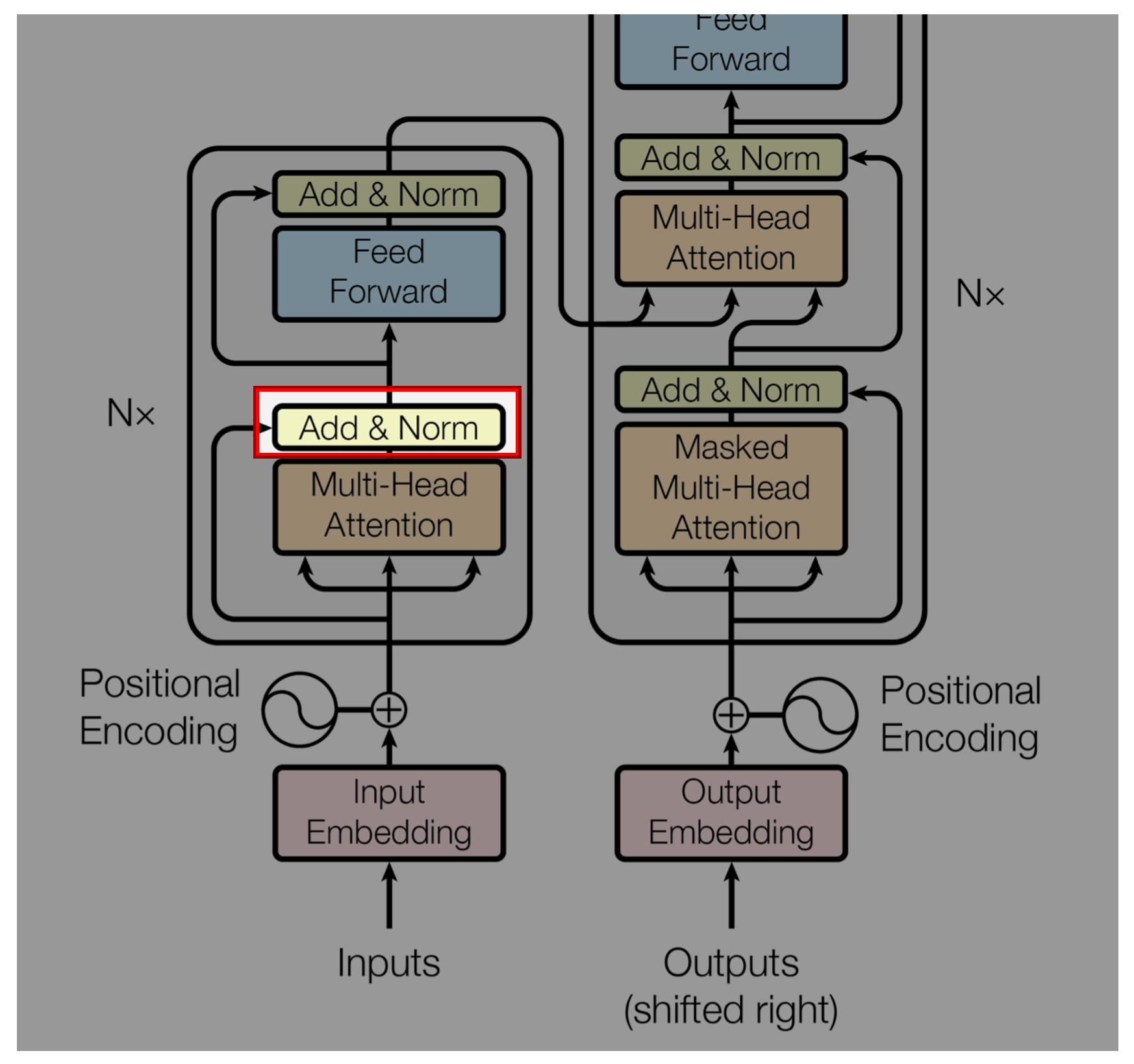 Fig.
Fig.
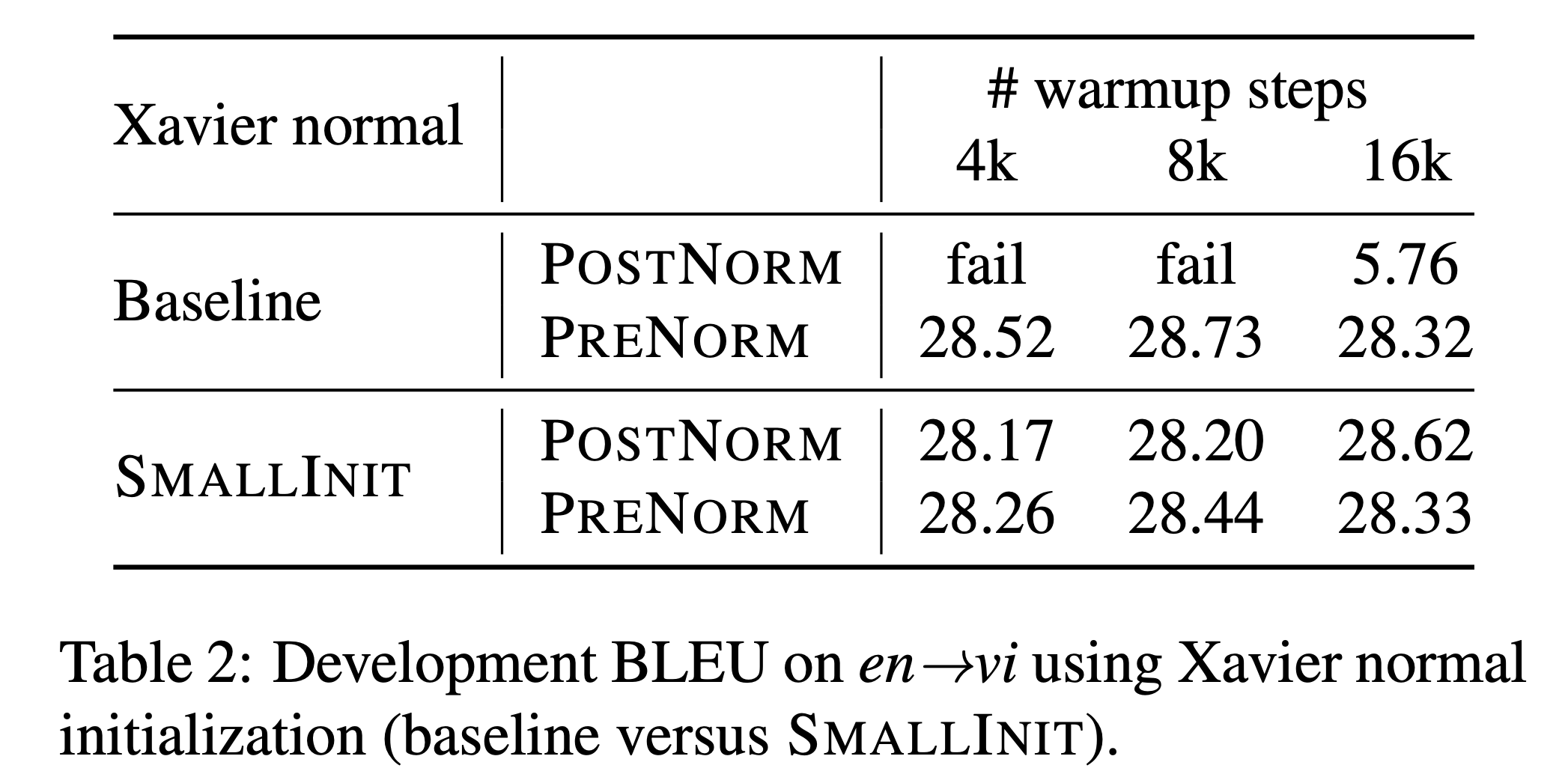 Fig.
Fig.
Instance Normalization (IN)
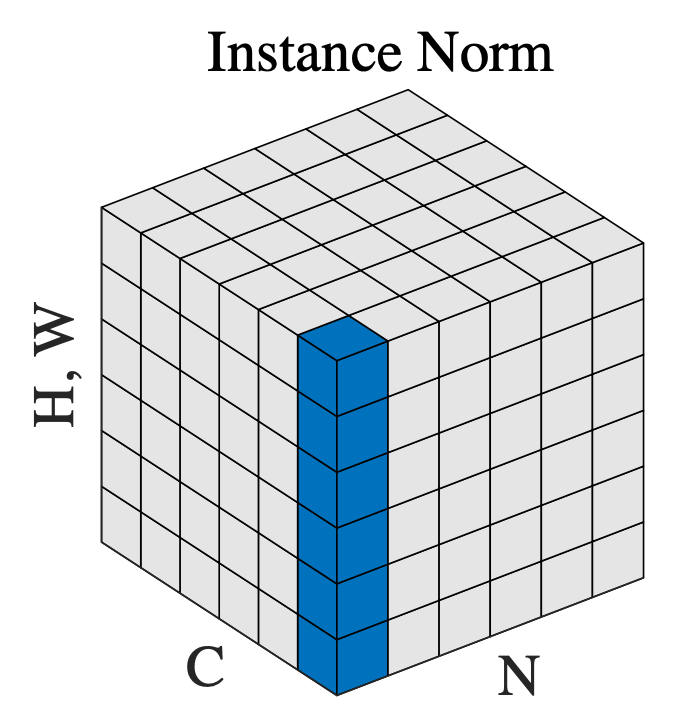 Fig. Instance Normalization
Fig. Instance Normalization
Group Normalization (GN)
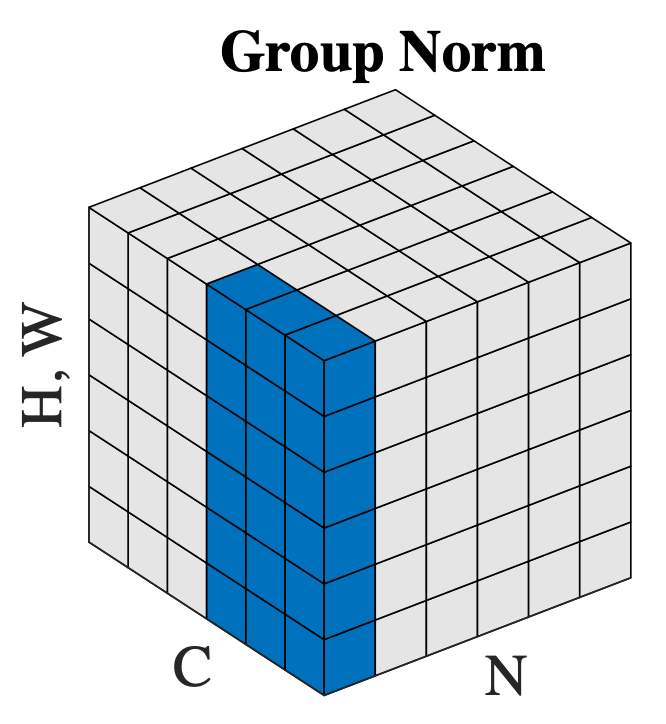 Fig. Group Normalization
Fig. Group Normalization
Pytorch Implementation
import torch
import torch.nn as nn
import torch.nn.functional as F
torch.manual_seed(1234)
## 1d BN
# With Learnable Parameters
m = nn.BatchNorm1d(100)
# Without Learnable Parameters
m = nn.BatchNorm1d(100, affine=False)
input = torch.randn(20, 100)
output = m(input)
## 2d BN
# With Learnable Parameters
m = nn.BatchNorm2d(100)
# Without Learnable Parameters
m = nn.BatchNorm2d(100, affine=False)
input = torch.randn(20, 100, 35, 45)
output = m(input)
## 3d BN
# With Learnable Parameters
m = nn.BatchNorm3d(100)
# Without Learnable Parameters
m = nn.BatchNorm3d(100, affine=False)
input = torch.randn(20, 100, 35, 45, 10)
output = m(input)
import torch
import torch.nn as nn
import torch.nn.functional as F
torch.manual_seed(1234)
# NLP Example
batch, sentence_length, embedding_dim = 20, 5, 10
embedding = torch.randn(batch, sentence_length, embedding_dim)
layer_norm = nn.LayerNorm(embedding_dim)
# Activate module
a = layer_norm(embedding)
# Image Example
N, C, H, W = 20, 5, 10, 10
input = torch.randn(N, C, H, W)
# Normalize over the last three dimensions (i.e. the channel and spatial dimensions)
# as shown in the image below
layer_norm = nn.LayerNorm([C, H, W])
output = layer_norm(input)
import torch
import torch.nn as nn
import torch.nn.functional as F
torch.manual_seed(1234)
input = torch.randn(20, 6, 10, 10)
# Separate 6 channels into 3 groups
m = nn.GroupNorm(3, 6)
# Separate 6 channels into 6 groups (equivalent with InstanceNorm)
m = nn.GroupNorm(6, 6)
# Put all 6 channels into a single group (equivalent with LayerNorm)
m = nn.GroupNorm(1, 6)
# Activating the module
output = m(input)
References
- Papers
- Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
- How Does Batch Normalization Help Optimization?
- Understanding the Disharmony between Dropout and Batch Normalization by Variance Shift
- Understanding Batch Normalization
- Layer Normalization
- Instance Normalization: The Missing Ingredient for Fast Stylization
- Group Normalization
- PowerNorm: Rethinking Batch Normalization in Transformers
- Transformers without Tears: Improving the Normalization of Self-Attention
- Others