(WIP) Thoughts on o1
13 Oct 2024< 목차 >
- o1
- Recapitulate Planning (MCTS)/ Self-play/ AlphaGo
- Self-Improved LLM
- Process Reward Model (PRM)
- (Self-)Refinement/ (Self-)Correction/ Reflection/ Backtracking
- Inference Scaling Laws
- RL is Dead-end for LLM?
- Reasoning vs Memorization
- o1 is not the only one way
- What's Next Step?
- Continuous/ Latent Space for CoT
- (tmp) some remarkable papers
- +Updated) 24. 12. 20. o3 is here
- References
다른 post들도 그렇지만 이번 post의 주제인 gpt-o1은 알려진 정보가 거의 없기 때문에 특히나 더 내 생각 위주로 적었음을 알린다. reference들을 보면 o1이 이런 기술들을 썼을 것이라고 추측한 blog들이 있으니 그것들을 봐도 좋다.
o1
gpt-o1이 나왔다. 이는 training time에 compute budget을 scaling하는 것이 성능 개선을 보장하는 scaling law에 test-time scaling 이라는 새로운 차원을 증명했다고 할 수 있다. 아마 대부분의 연구자들이 AlphaGo로부터 inference시 parallel computing degree와 time을 늘릴 수록 성능이 좋아질 것이라는 생각은 한번쯤 해봤을 것이다. 그러나 수학, 과학 영역에서 LLM의 inference budget을 늘린다고 실제로 추론 (reasoning) 성능이 좋아질까?에 대해 betting하라고 하면 할 사람이 얼마나 됐을까. (이건 board game에서의 test time scaling과는 다른 차원인 것으로 보인다.)
o1은 기존의 MATH, Humaneval 등 기존의 STEM reasoning task에서 압도적인 성능을 보이며, 미국 수학 경시대회 (AIME), 경쟁적 프로그래밍 대회 (codeforces) 그리고 박사과정 수준의 QA 평가셋 (GPQA)등에서도 압도적인 성능을 보였다.
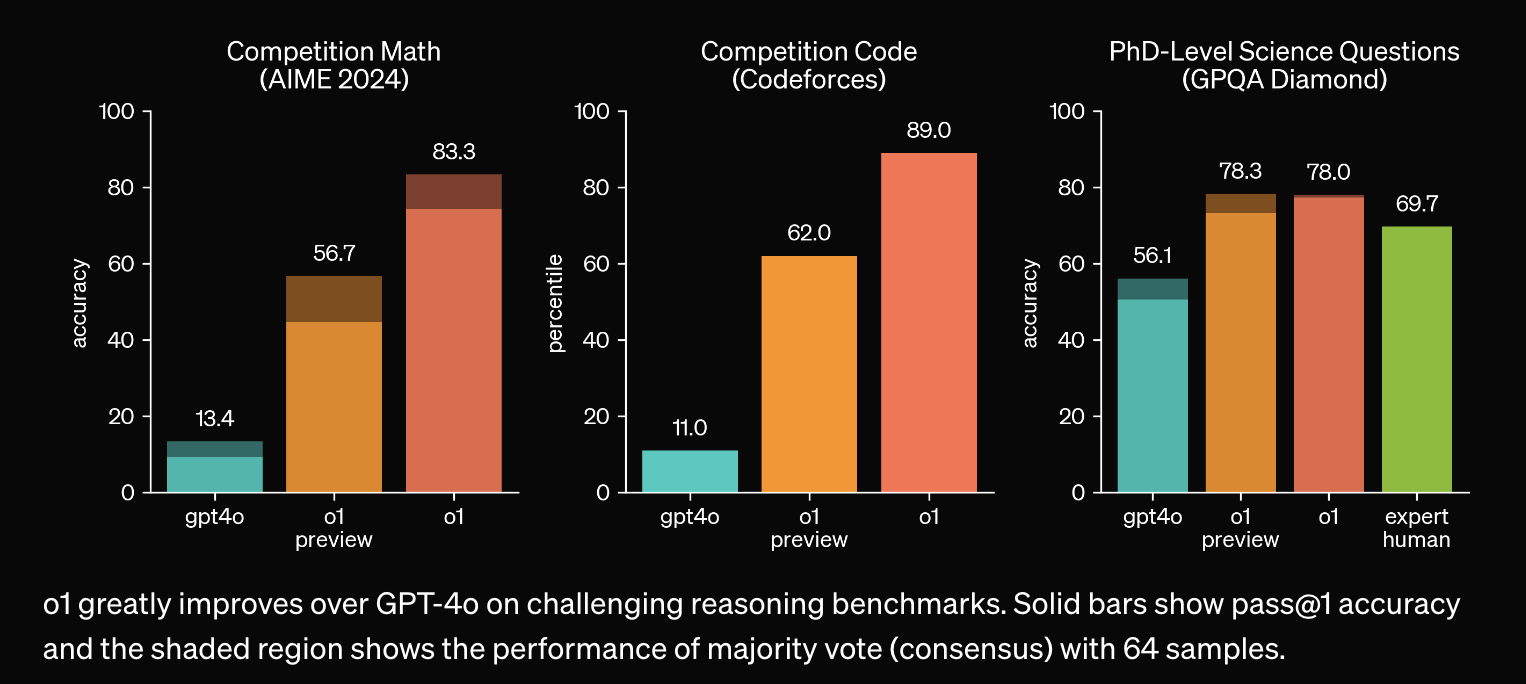 Fig.
Fig.
Test-time scaling
o1은 크게 두 가지 특징이 있는 것으로 보이는데, 먼저 하나는 Test Time Scaling이다. Scaling Scaling Laws with Board Games같은 paper를 보면 아래와 같은 figure를 확인 할 수 있는데,
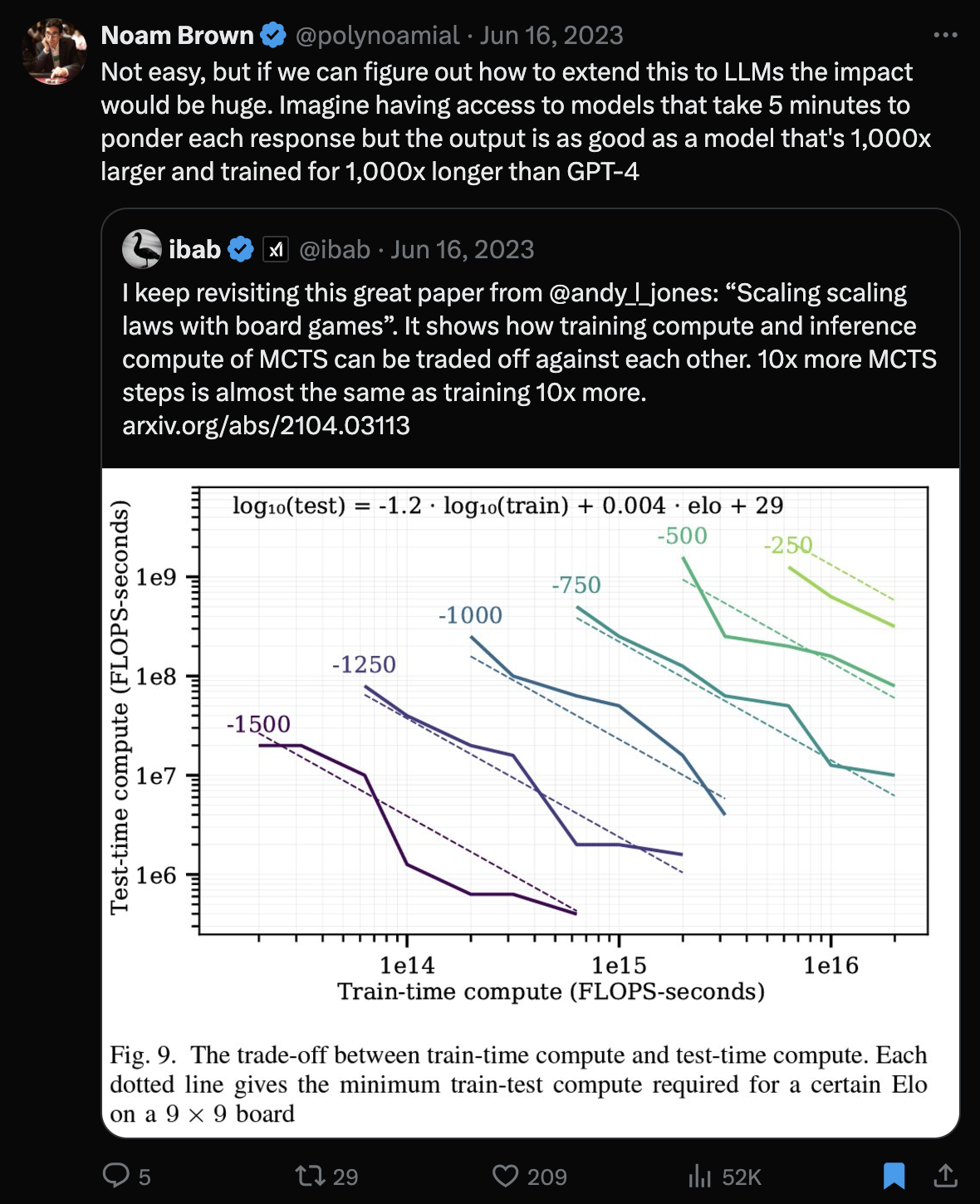 Fig.
Fig.
위 figure에서 x-axis는 ‘training time에 얼마나 compute (즉 시간)을 부었는가?’를 의미하며, y-axis는 ‘test (inference) time에 얼마나 compute를 썼는가?`이다. 여기서 알 수 있는 것은 작은 size의 model을 test time에 얼마나 오랫동안 compute를 쓰느냐에 따라 (예를 들어 tree search같은 것), model size를 수백만배 scaling하는 것만큼의 효과를 누릴 수 있다는 것이다.
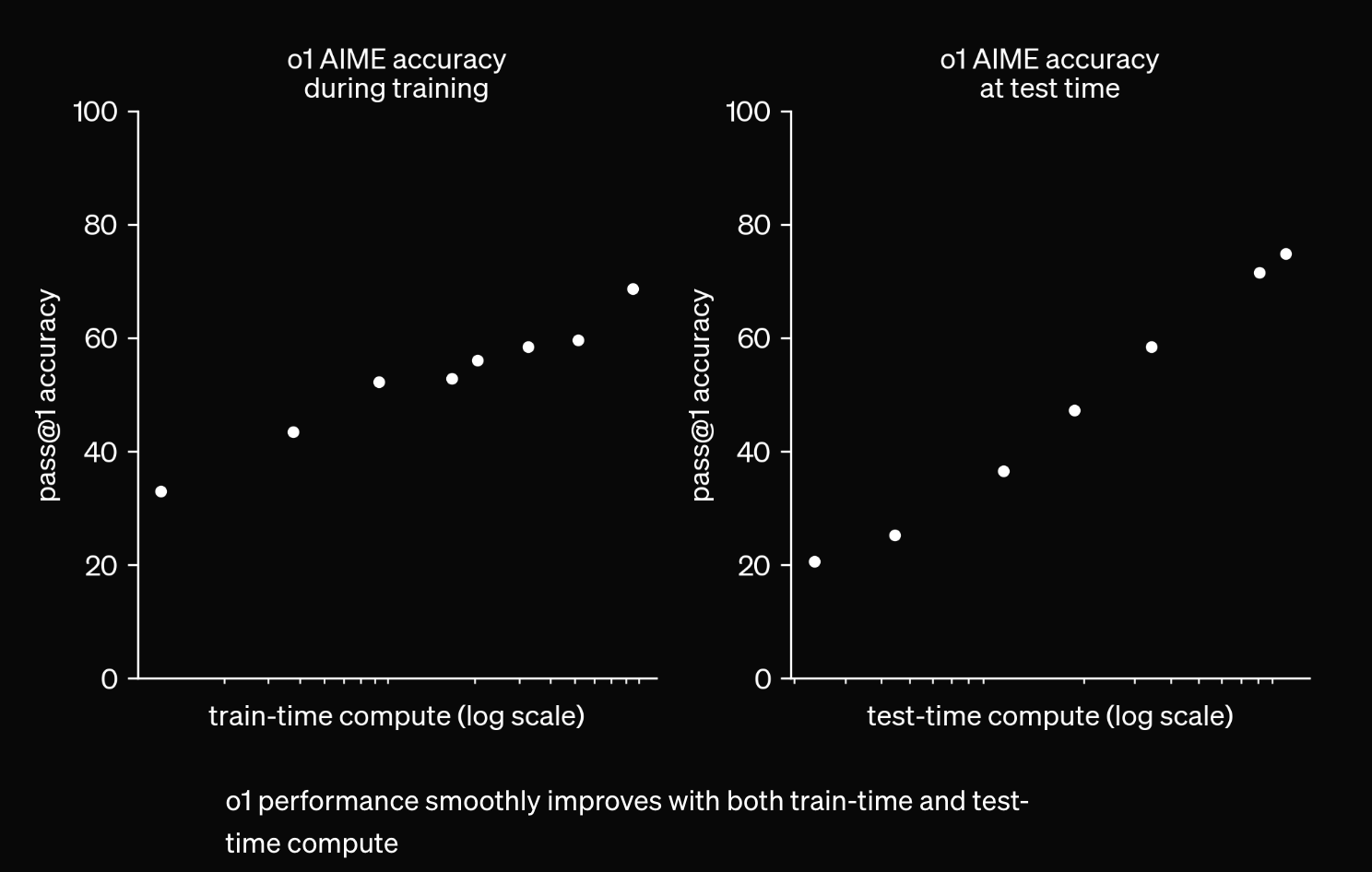 Fig. tweet link
Fig. tweet link
내 생각에 위 plot가 포함하는 중요한 내용 중 하나는 '더 오래 생각할수록 더 잘한다'라는 것인데,
이는 test time의 시간을 임의로 조절할 수 있다는 것을 의미하는 것 같다.
아마 간단한 생각으로는 beam search를 할 때 beam을 늘리거나 Monte Carlo Tree Search (MCTS)시간을 늘리거나 아니면 CoT를 n회 학습하는 것을 condition으로 줘서 가능하게 학습을 했다면 test time을 user가 임의로 늘리 수 있을 것이고 어떤식으로든 이것이 가능해 보이긴 한다.
물론 여기서 beam search를 한다면 reasoning에 특화된 process reward model (PRM)이나 어떤 prover를 사용해서 beam을 평가해야지 Nerual Machine Translation (NMT)에서 하던 것 처럼 할 수는 없을 것이다.
(beam search하니 생각나는 말인데, 보통 greedy decoding은 틀려도 주워담을 수 없는데, beam search는 그게 가능하다는 표현을 하곤 했다. o1이 correction이 가능하다는걸 고려해봤을 때 생각해 봐야 할 것 같다)
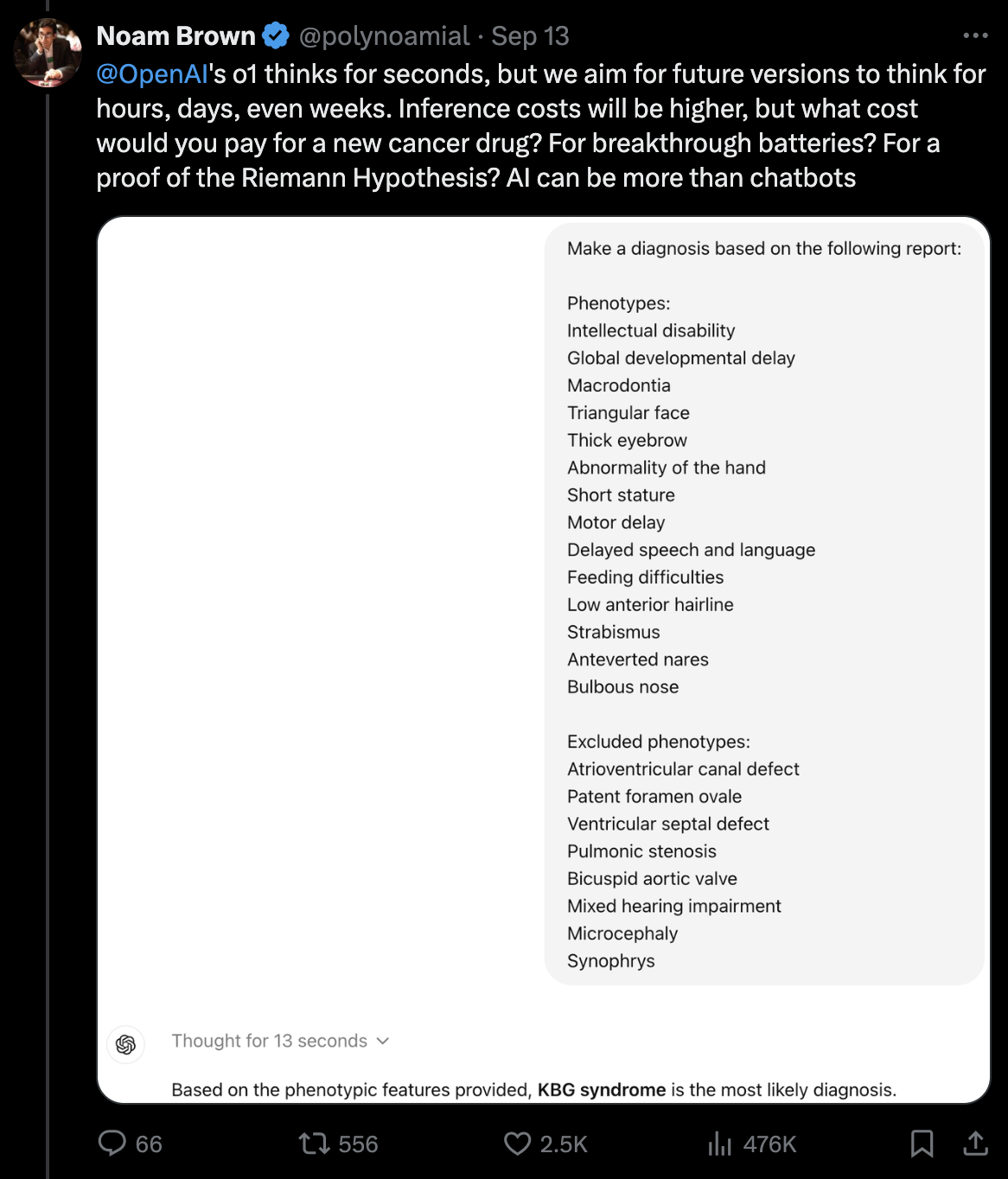 Fig.
Fig.
아무튼 noam brown은 우리가 간단한 문제를 풀 때 이렇게 긴 latency는 필요 없겠지만 예를 들어 밀레니얼 문제를 풀거나 불치병을 위한 신약 개발을 하는데 몇주, 몇달을 쓰는 걸 상상해보라고 한다. 그런데 어떤 inference algorithm을 사용했는지는 모르지만 아마도 무작정 beam이나 tree search time을 늘리는 것으로는 부족할 것이다. 왜냐면 직관적으로 사람도 어떤 task에 대한 지식과 사고하는 방식을 배우지 않는다면 이세돌같은 바둑 기사를 상대할 때 1수당 1년씩 시간을 줘도 이세돌을 이길 확률은 0에 가까울 것이기 때문이다.
 Fig.
Fig.
그래서 어떻게 test time scaling을 논하기 전에 ‘어떻게 reasoning 하는 방법을 배울 것인가?’가 또 하나의 문제라고 할 수 있다.
Learn how to CoT
openai blog를 보면 o1이 "CoT를 생성하는 방식을 배웠다 (learn to hone its CoT)"고 하기 때문에 아마 확실히 학습을 하긴 했을 것이라는 걸 유추해볼 수 있다.
 Fig.
Fig.
생각의 연쇄 (Chain-of-Thoguht; CoT)는 뭘까.
CoT prompting은 model이 어떤 질문에 답변을 할 때 즉답하지 말고 여러 단계로 나눠 생각을 하게 한 뒤 답변하게 하는 방법으로,
think step by step같은 prompt를 넣어주거나 답변하기 직전에 prefix로 넣어주거나,
실제로 단계적으로 생각하는 예시를 몇 개 넣어주는 few-shot prompting을 통해 model이 그렇게 행동하도록 이끄는 것이다.
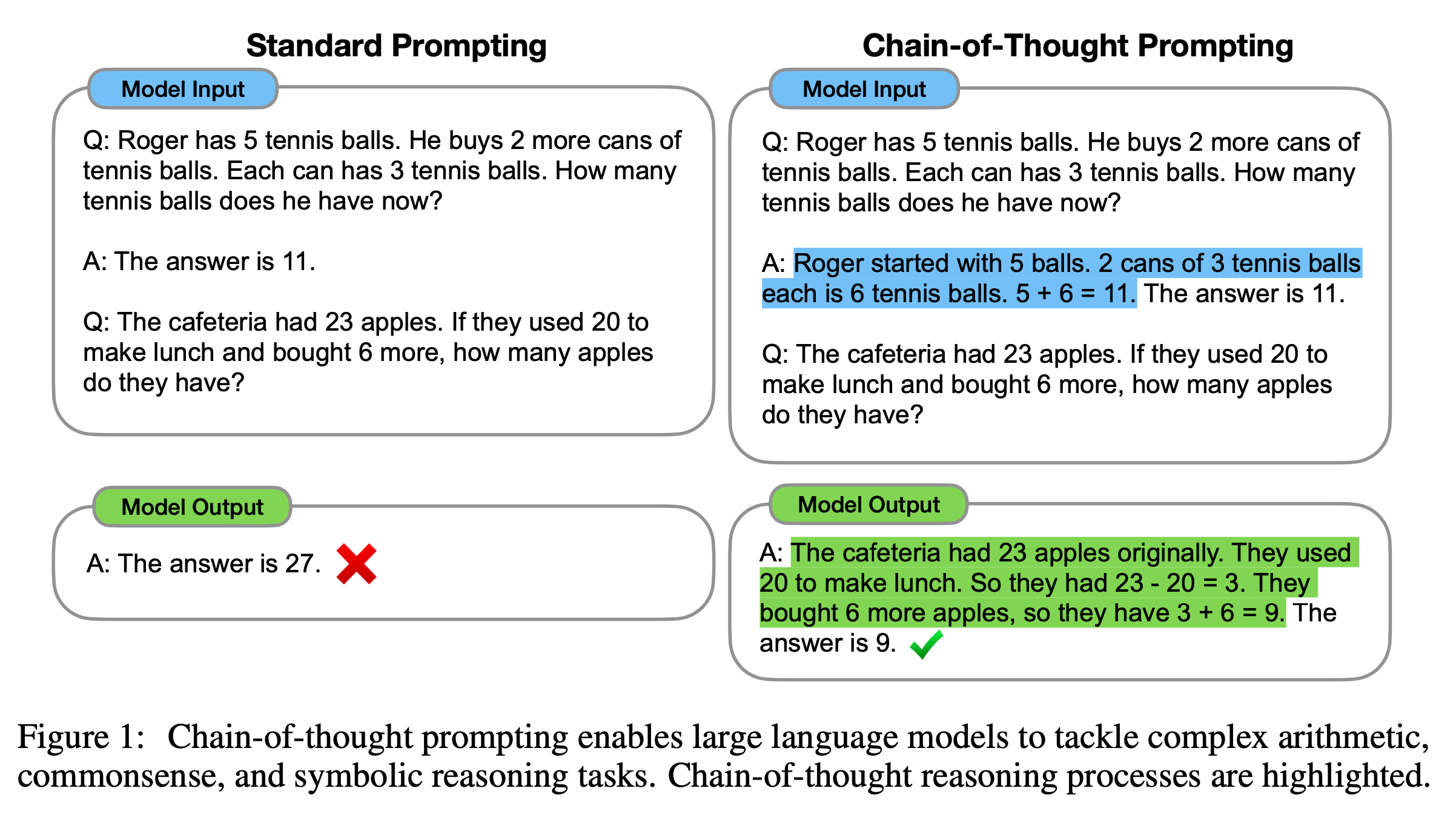 Fig.
Fig.
충분히 크거나 오래 학습된 LLM은 이런 prompt를 받으면 즉답하지않고 let's think step by step이라는 식으로 답변을 하기 시작하는데,
실제로 prompting을 하기 전과 다르게 좀 더 길고 그럴싸한 답변을 내길 기대한다.
이 경우 CoT 없이는 수학, 프로그래밍 같은 task에서는 예를 들어 60점이던 것이 실제로 65점으로 올라가는 일을 관측할 수도 있다.
왜 잘되는지에 대해서는 사실 나는 그렇게 큰 의심이나 근거는 딱히 없었지만, 내가 이해하고 있는 Chain of Thought (CoT) prompting이나 few-shot prompting 같은 것들은 prompting을 함으로써 token을 sample할 distributon을 특정 conditional probability distribution으로 바꿈으로써 더 likely한 distribution에서 sampling하게 해서 작동하는 것이다. 이 외에 prompting을 하는 것 자체가 model이 내부적으로 gradient descent를 한다고 하는 mesa-optimizer같은 관점 같은게 있는 것 같기도 하다.
하지만 CoT의 창시자인 Jason Wei는 CoT를 개발할 적에는 GDM에 있다가 지금은 openai에 있는 연구자인데, o1은 단순한 CoT를 말하는 것이 아니라고 언급한다.
 Fig.
Fig.
Jason Wei의 tweet을 보면 기존의 CoT는 우리가 바랬던 것과 달리 기존에 학습해서 외운 reasoning path를 다시 재현하는 것과 같았고,
그렇기 때문에 의미없이 음 정답은 5야, 왜그런지 차례차례 생각해보면...같은 답변을 할 때 5에 엄청난 정보량이 몰려 있었다고 한다.
(여기서 당연히 5에 정보량이 모인걸 어떻게 확인했는지? 단순히 엔트로피를 쟀는지? 등에 대해 생각해보고 o1 재현시 metric으로 써보면 좋을 것 같다)
즉 o1은 단순 CoT prompting 이상이라는 것이고 blog에 CoT하는 법을 배웠다고 얘기했으니 뭔가 학습되긴 한 것이다. 사실 o1이 등장하기 이전에도 LLM의 추론 성능을 높히려는 시도들은 많이 있었다. 이들의 주된 방법론들은 대부분 CoT data를 생성해서 Supervised Fine-tuning (SFT) 해서 CoT를 더 잘하게 하는 것이었는데, 잘 알려진 방법들로는 Rejection Sampling Fine-Tuning (RFT)나 Self-Taught Reasoner (STaR)같은 것들이 있다. 이들은 대부분 model에게 CoT few shot example 같은 것과 함께 query를 model input으로 주고 정답이 생성하게 한 뒤, 답변들을 Reward Model (RM)이나 code, math 같은 경우라면 별도의 compiler, verifier등을 통해 맞는지 판단해서 맞는 답변들이 SFT하는 loop를 여러 번 도는 방식이었다.
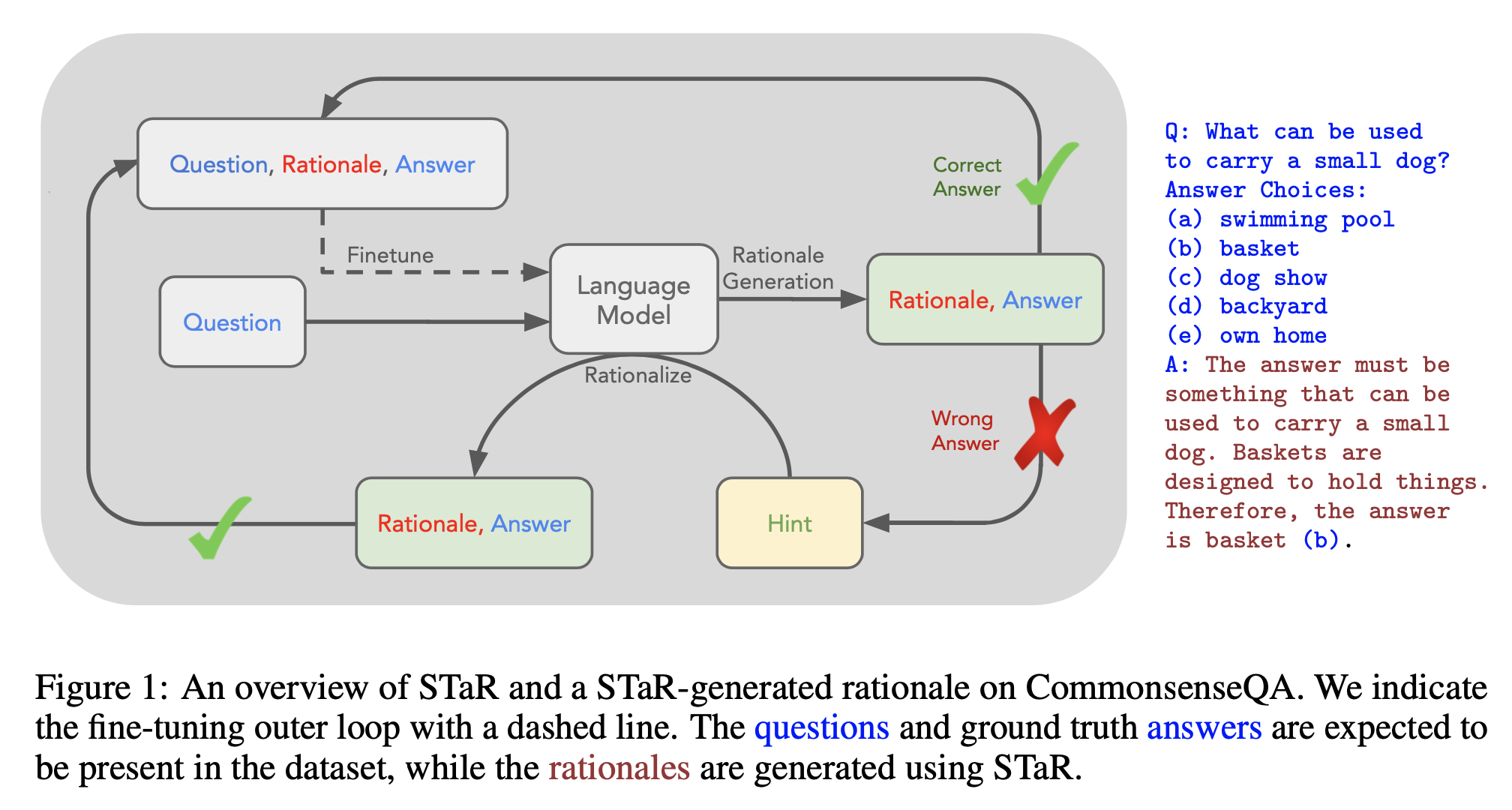 Fig. STaR Training Pipeline
Fig. STaR Training Pipeline
하지만 이런 식으로는 blog에서 말하는 실패했을 때는 아예 다른 방법을 시도하는 법을 배움, 실수를 수정하는 방법을 배움이 가능하지는 않다.
왜냐면 이런 방식들은 그냥 CoT를 여러번 생성하게 한 뒤 그중에서 가장 좋아보이는 애들로 학습했기 때문에 답변할 때 rationale을 생성하는 법만 조금 배운 것 뿐이기 때문이다.
그리고 o1은 기존 model들과 다르게 벽에 가로막혔을 때 아예 다른 시도를 한다고 하기도 하는데 이 부분도 중요한 것 같다.
게다가 CoT를 단순히 SFT하는 경우 또 다른 문제가 있을 수 있는데, 예를 들어 math task에 대해서 STaR pipeline을 돌면 (cot data를 합성하고, parameter를 update하고, updated LLM으로 다시 cot data를 합성하고…를 반복), 근본적으로 reasoning하는 방법을 배우지 못하고, 이것이 coding이나 글쓰기 혹은 다른 open-ended task로 전이되지 못할 가능성이 있다. 즉 generalize가 되지 않는 것이다.
o1이 이런 문제를 해결했는지는 모르겠지만 일단 최근까지 openai에 있었으며 PPO를 개발하는 등 RL의 근본이자 chatgpt post-training을 leading했던 John Schulman에 따르면 o1은 아무래도 math에 대해서만 학습된 것이 유력해 보인다.
 Fig. tweet
Fig. tweet
물론 John의 tweet이 LLM이 verifiable task인 math에 대해서 학습이 더 쉽다는 것이고 완전히 전이가 되지 않는다고 보기에는 어패가 있지만 o1이 다른 글쓰기 등의 task가 gpt-4o에 비해 떨어지는 등 여러 정황상 아직 일반화가 잘 됐다고 보긴 어려울 것 같다.
STaR의 후속 연구인 Quiet-STaR 같은 데에도 이런 언급이 있는데,
 Fig.
Fig.
저자들은 특정 mathmetical QA dataset에 STaR training 하는 것이 아니라 임의의 다양한 도메인을 갖는 large internet text corpus에 대해서 현재까지의 text given, CoT를 병렬적으로 많이 생성한 뒤에 next text prediction에 도움이 되는 CoT들만 남겨 학습하도록 했다.
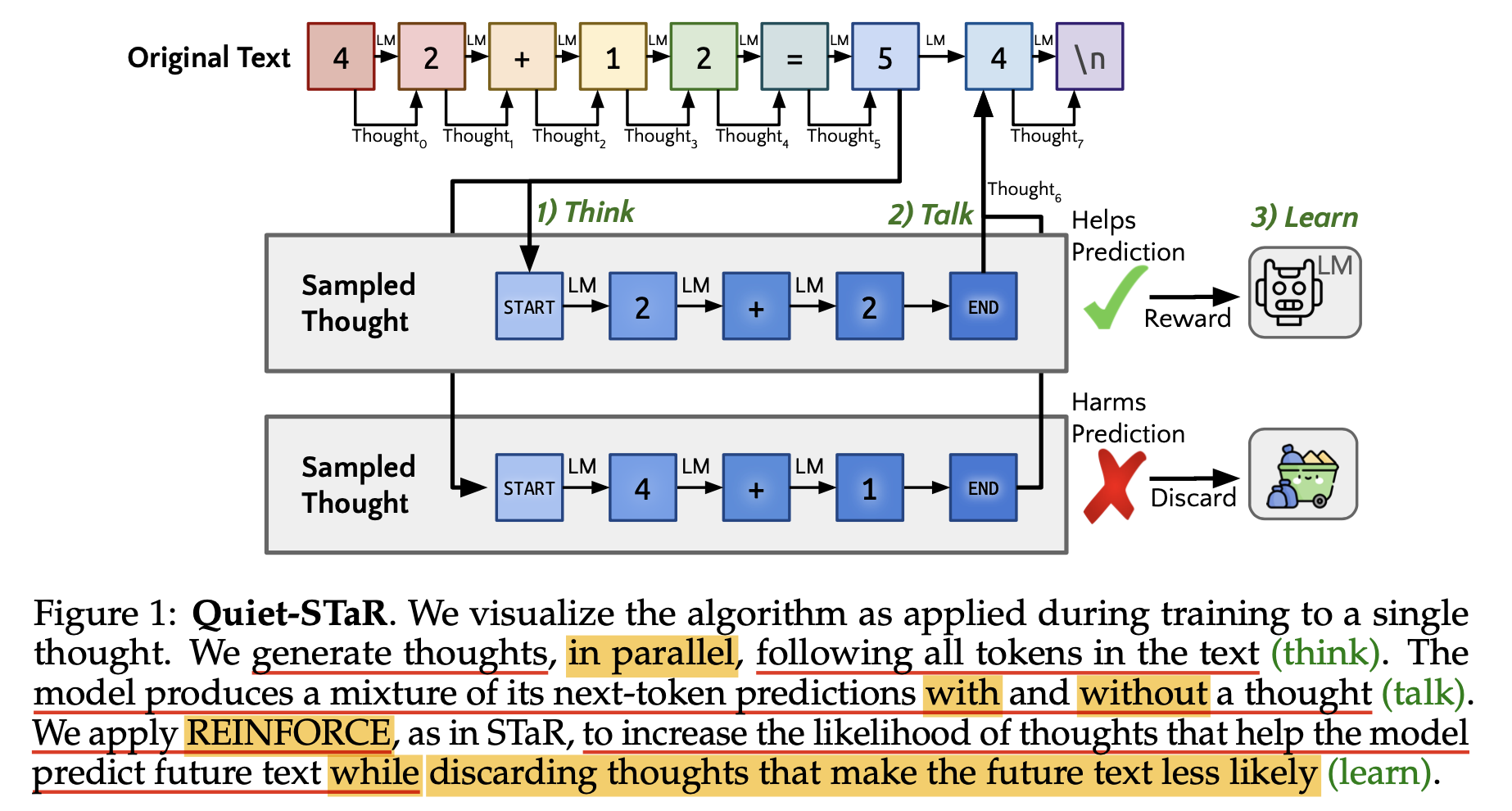 Fig.
Fig.
그 결과 GSM8K와 CommensenseQA라는 서로 다른 main, general domain QA dataset에 대해서 zero-shot으로 아래와 같은 성능을 얻을 수 있었다고 하는데, 이는 후에 자세히 살펴볼 것이다.
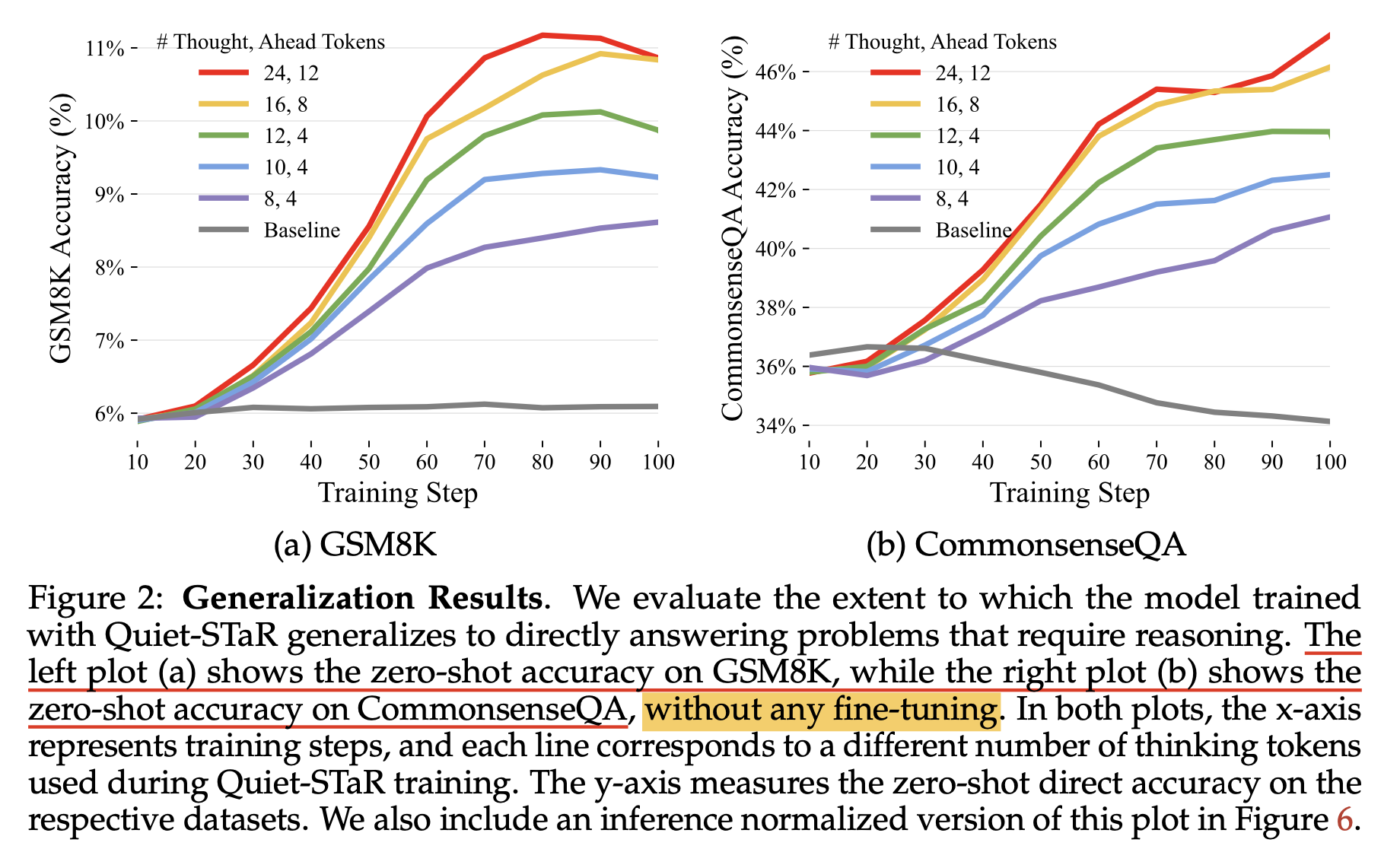 Fig.
Fig.
아무튼 o1을 역 추적하는 시점에서 나는 다음과 같은 특징을 주효하게 체크하면서 알고리즘을 생각해야 할 것이라고 본다.
- Inference Time Scalability
- 임의로 inference time을 늘릴 수 있어야 함
- 늘릴수록 성능이 개선돼야 함
- Learn how to CoT
- CoT 하는 법을 배움
- 실패했을 때 다른 방법을 시도하거나 실수를 수정하는 방법도 배움
- 단순 SFT로 학습하진 않았을 것
- quiet-star 처럼 특정 task-specific CoT를 학습한 것이 아니라 generalization이 가능한 reasoning 자체를 학습했을 것
Hidden CoT, Monologue and Legibility
o1의 또 하나의 특징은 hidden cot or monologue이다.
hidden cot에 대해서는 blog에서 아래와 같이 언급되고 있다.
 Fig.
Fig.
예를 들어 만약 model이 답으로 가는 길에 있어 폭력적인 생각이나 사람이 이해할 수 없는 chain을 생성한다면 (not legibile) 어떻게 해야할까? 사람한테 맞춰야 (정렬해야) 할까? o1은 model performance에 제약을 두지 않기 위해서 cot가 어떤 폭력적인 말을 하던 상관하지 않으며, 다만 user에게 공개하지 않도록 했다. 정확히는 공개하지 않는 것이 아니라 생성된 chain을 user에게 제공할 때는 따로 학습한 summarizer을 이용해 요약된 결과만 보여주며, 이는 사람이 위화감을 느끼지 않도록 정렬됐을 가능성이 높다.
그리고 o1의 결과물을 보면 뭔가 독백 (monologue) 을 하는 듯 보인다.
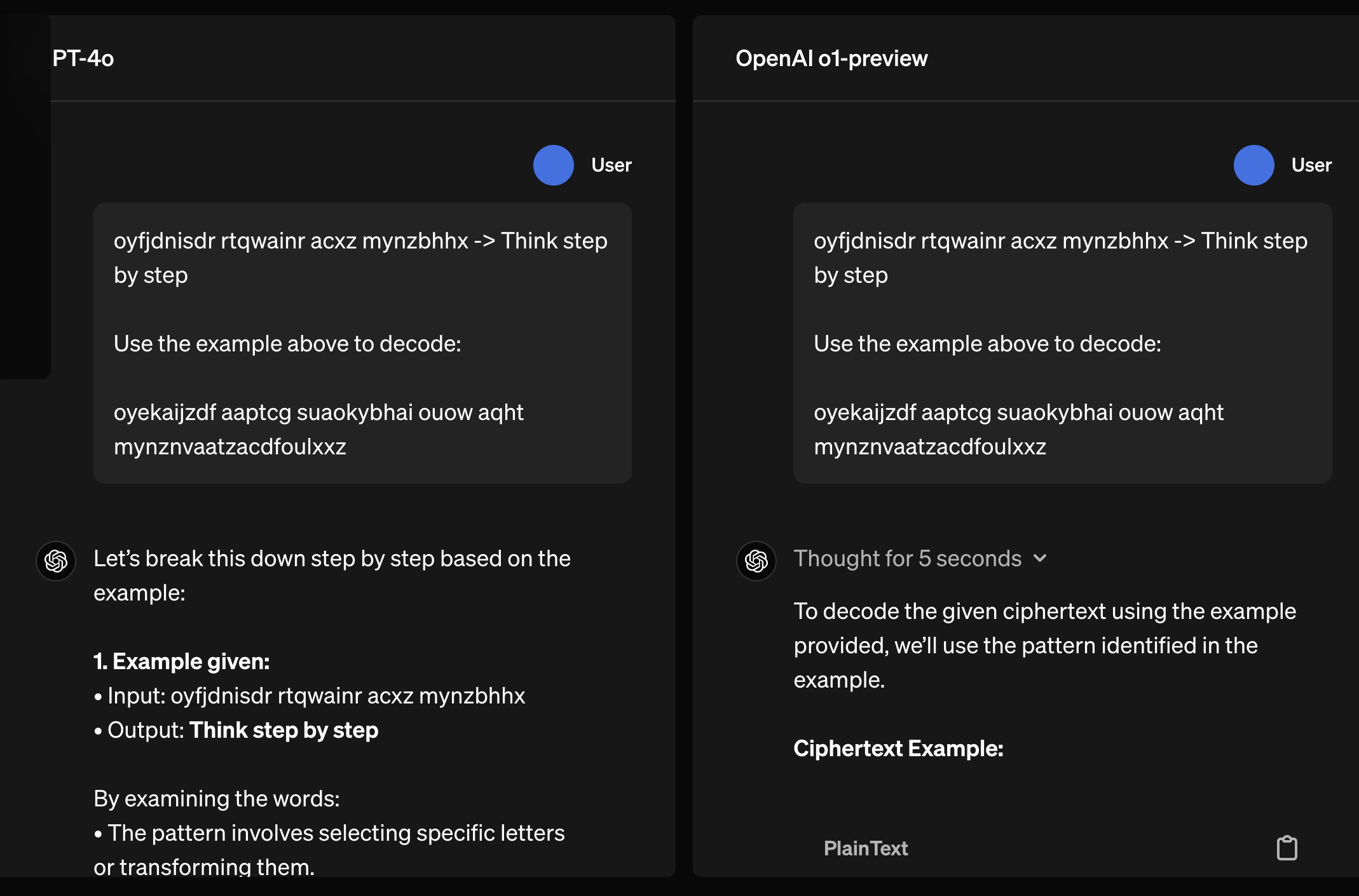 Fig. gpt-4o vs o1. o1 produce hidden cot
Fig. gpt-4o vs o1. o1 produce hidden cot
 Fig. gpt-4o vs o1. o1 produce hidden cot
Fig. gpt-4o vs o1. o1 produce hidden cot
hidden cot가 생성된 결과를 보면 가끔 이해가 안가는 내용들이 있는데, 이것이 summarizer issue인건지 아니면 진짜 그런 chain이 생긴건지는 잘 모르겠다.
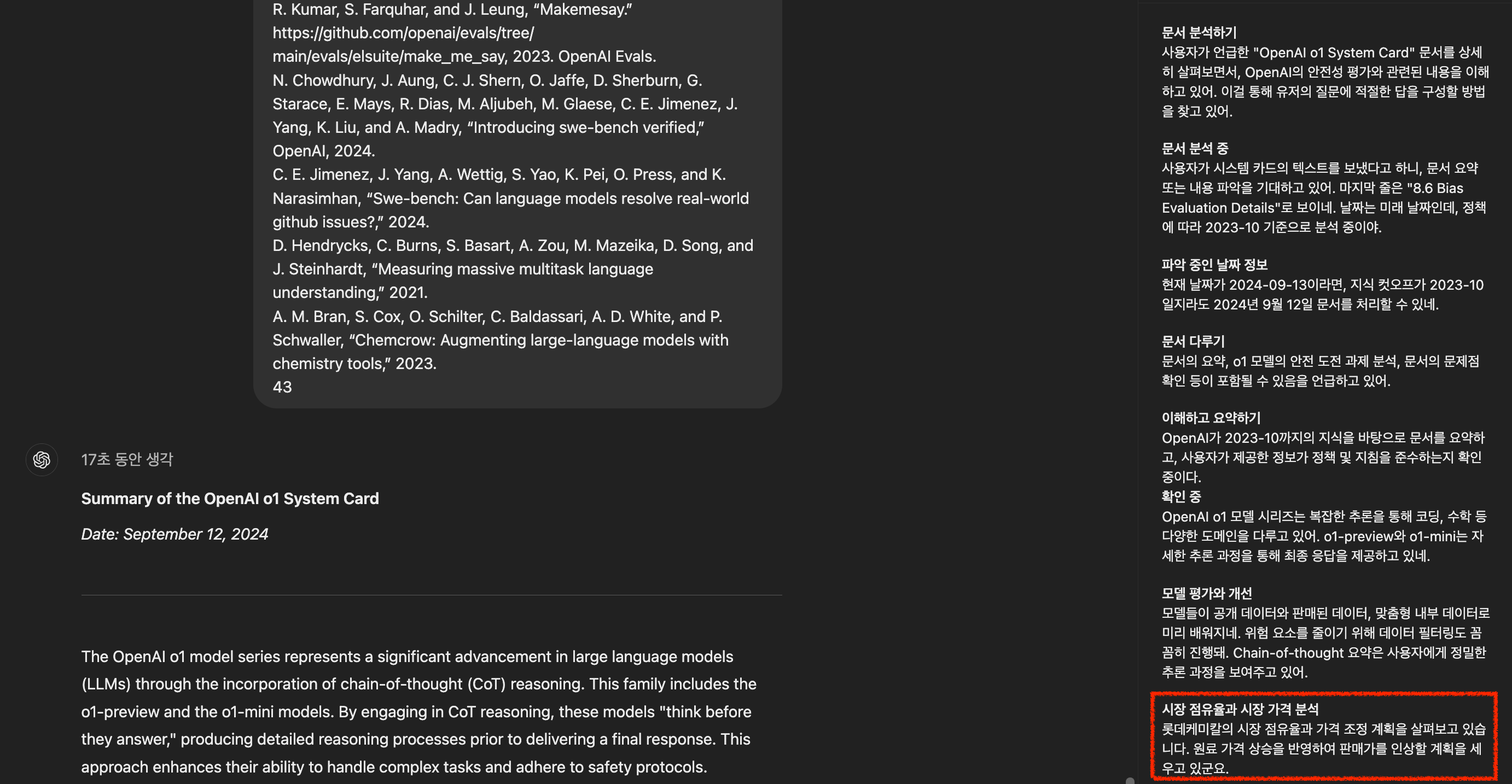 Fig. 갑자기 뜬금없이 롯데 케미칼 얘기가 나온다
Fig. 갑자기 뜬금없이 롯데 케미칼 얘기가 나온다
그리고 o1의 hidden cot summary를 보면 약간
여기서 hidden cot에 대해서 드는 의문이 몇가지가 있는데, 첫 번째는 openai가 legibility에 굉장히 신경을 쓰는 것으로 보였는데 왜 갑자기 이를 접었냐는 것이다. 아래는 Prover-Verifier Games improve legibility of LLM outputs라는 paper의 일부인데, LLM이 super-alignment로 가는 과정에서 만약 사람이 이해할 수 없는 답변을 뱉는다면 의사결정을 하는데 문제가 될 수 있기 때문에 이를 중요하게 보는 것도 중요하다는 내용이다.
 Fig.
Fig.
결과적으로 제안된 방법을 통해 legibility tax를 최소한으로 내면서도 performance도 끌어올릴 수 있었다고 하는데,
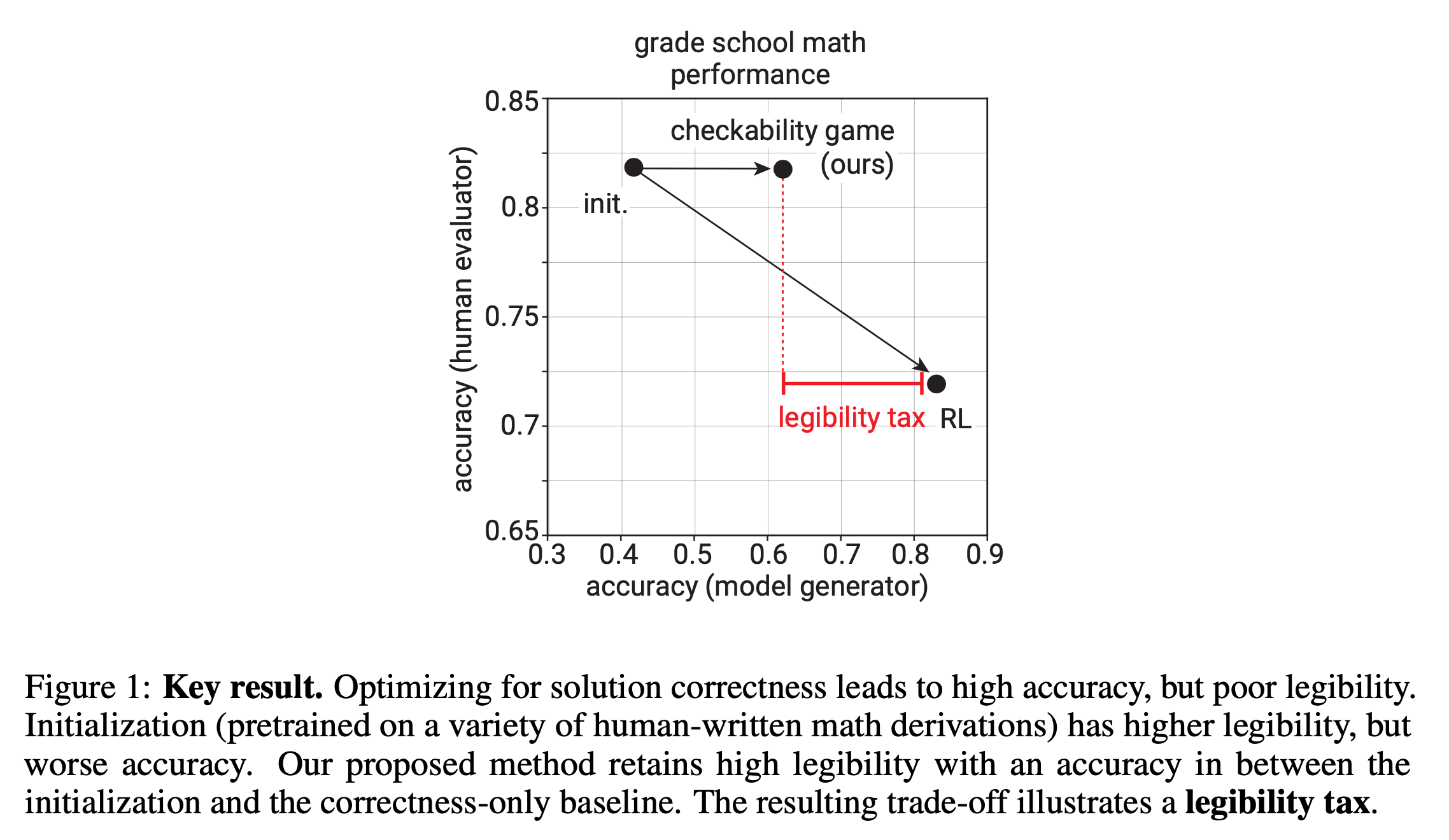 Fig.
Fig.
o1은 이것과는 반대되는 길을 간 것으로 보인다. (super-alignment 팀이 해체되면서 Jan Leike등이 anthropic으로 가게 됐는데, 정렬, 안전성 문제에서 갈등이 생긴 것인가? 하는 생각도 든다)
두 번째로 궁금한 것은 summarizer를 학습했는데 non-aligned chain을 input으로 하는 것은 알겠지만 target은 그럼 뭘로 했냐는 것이다. 만약 hidden cot가 unsafe한 것을 넘어서 사람이 읽을 수가 없다고 치자. 실제로 얼마전까지 openai에 있었던 Andrej Karpathy는 o1이 출시되고 며칠 후 아래와 같은 tweet을 남겼는데, o1 project에 karpathy가 참여했는지는 모르지만 만약 사람이 읽을 수 없는 chain이라면 더더욱 summarizer의 training dataset을 상상하기 어려운 것 같다.
 Fig. tweet
Fig. tweet
이 부분에 대해서 아래와 같이 해석하는 사람도 있는데,
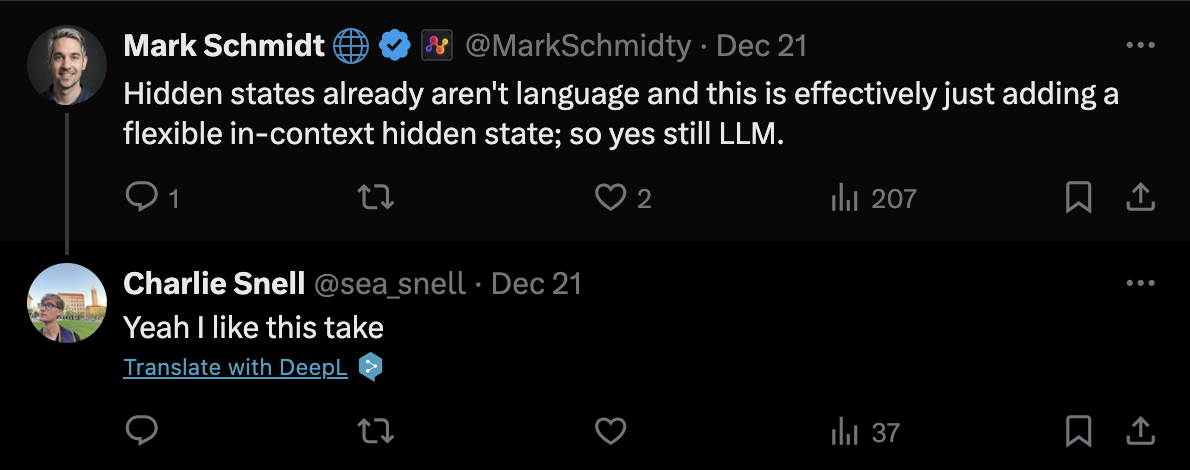 Fig. “hidden states는 원래 언어가 아니고, 이건 단지 더 유연한 context 내 hidden states 추가하는 것일 뿐이라, 여전히 언어 모델이라고 볼 수 있음”. tweet
Fig. “hidden states는 원래 언어가 아니고, 이건 단지 더 유연한 context 내 hidden states 추가하는 것일 뿐이라, 여전히 언어 모델이라고 볼 수 있음”. tweet
이게 hidden cot를 개선함으로써 chain을 강화한다는 걸 의미하는건지? 모르겠다. 마치 diffusion 처럼 말이다.
그에 아니라 여전히 token level에서 chain을 생성하고 있는데 진짜로 점점 사람이 알아갈 수 없는 언어를 뱉게 되는거라면 어떻게 summarizer를 학습했는지 추론하기 어렵지만, 이에에 대해 몇 가지 생각을 해보자면 self-play를 하면서 legible 하지 않은 chain를 given으로 evaluation하는 방식으로 학습이 됐거나, generative verifier (or value network)가 학습돼서 전체 action에 대한 score를 매길 때 evaluation chain을 만드는 식으로 학습됐거나 하는 것들도 가능하지 않을까 싶다. 물론 이러면 너무 process가 복잡해지기 때문에 오캄의 면도날 (Occam’s Razor)에 따라 가능성이 낮아보인다.
이제 o1의 후보가 될 방법론들이 만족해야 할 조건은 아래와 같다고 할 수 있겠다 (물론 내생각).
- Inference Time Scalability
- 임의로 inference time을 늘릴 수 있어야 함
- 늘릴수록 성능이 개선돼야 함
- Learn how to CoT
- CoT 하는 법을 배움
- 실패했을 때 다른 방법을 시도하거나 실수를 수정하는 방법도 배움
- 단순 SFT로 학습하진 않았을 것
- quiet-star 처럼 특정 task-specific CoT를 학습한 것이 아니라 generalization이 가능한 reasoning 자체를 학습했을 것
- hidden CoT
- CoT는 human align 되지 않도록 할 수 있어야 한다.
- 사람이 읽을 수 없음 (?)
- 다만 CoT를 Legible 하게 만들어 사람이 monitoring하기 위해서는 summarizer가 필요하다.
- summarizer를 학습하려면 align된 target text가 존재한다 (?)
- CoT는 human align 되지 않도록 할 수 있어야 한다.
- constraint
- 오캄의 면도날 (Occam’s Razor)에 따라 최대한 단순할 것
RL vs RLHF
o1에 대한 또 하나의 중요한 point는 oai 연구자들이 자꾸 “이번에 RL을 많이 했다고 어필는 것”이다.
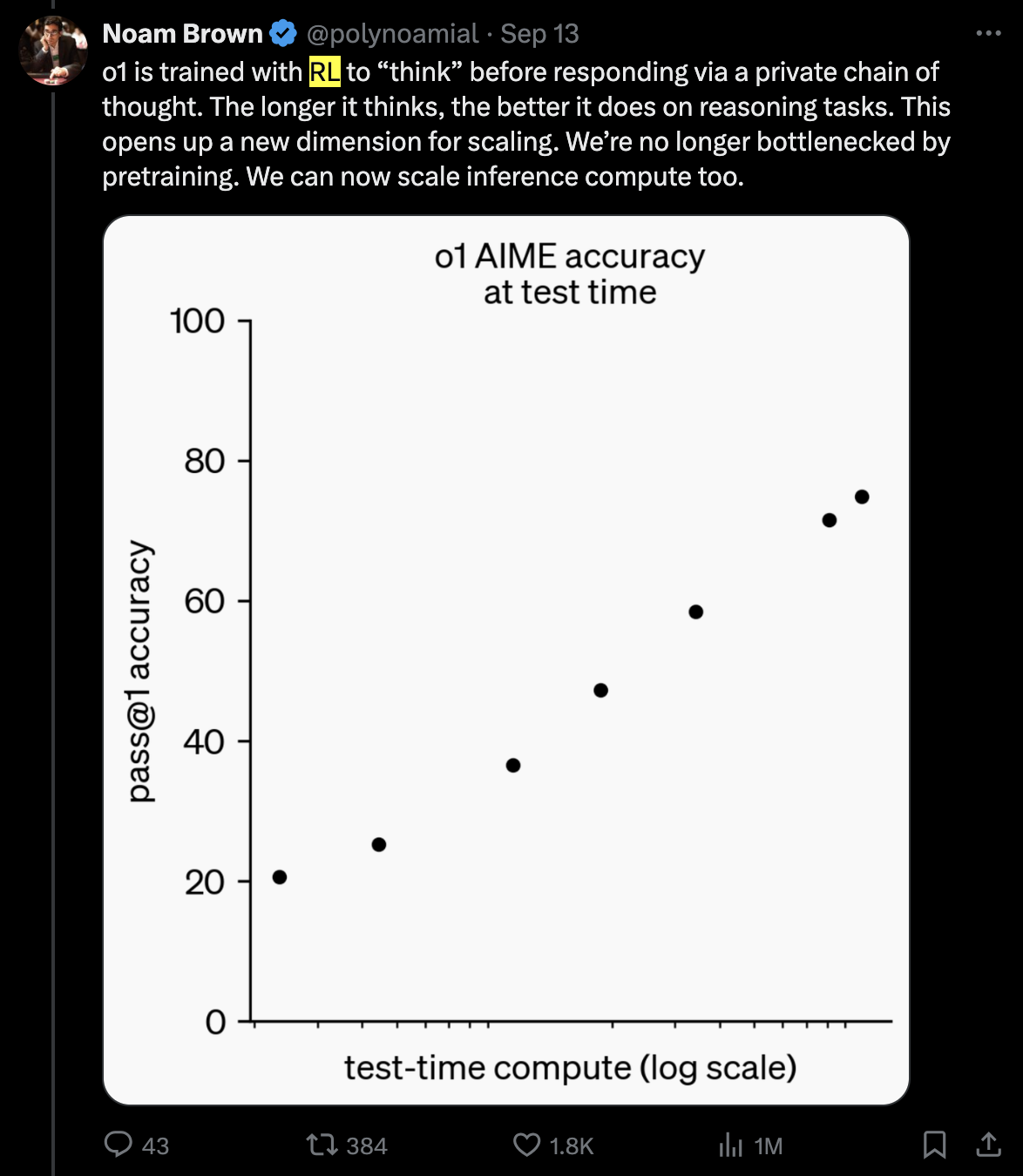 Fig. tweet link
Fig. tweet link
근데 여기서 드는 의문이 있다. 물론 STaR 같이 SFT만 하는 방법론들은 formulation 부터가 expected sum of total reward를 maximize하는 것이 아니기도 하고, 여러모로 RL이라고 보기 어렵긴 한 것 같다.
근데 Reinforcement Learning from Human Feedback (RLHF)에는 RM, PPO training phase가 있지않은가?
현재 LLM powered chatbot을 만들기 위해서는 pre-training 이후 post-training을 해야 하는데,
post-training에 해당하는 RLHF는 Supervised Fine-Tuning (SFT) -> Reward Modeling (RM) -> Proximal Policy Optimization (PPO)를 따른다.
이는 Human-in-the-Loop RL (Preference-based Learning)
라고 하며,
분명 RL의 한 종류로 나는 알고있었다.
요즘은 Direct Preference Optimization (DPO)같은 offline method를 선호하는 그룹이 늘어나고 있지만,
PPO같은 online rl algorithm을 하는 경우에는 주어진 reward function으로부터 발생하는 reward를 따라서 무한히 trajectory를 sampling하고 reward를 받아 좋은 trajectory는 더 likely해지도록 policy를 optimization을 한다.
하지만 Alphago project lead인 David Silver는 아직 LLM에서 superhuman으로 가려면 RL이 부족하다고 얘기한다.
 Fig. tweet link
Fig. tweet link
 Fig. tweet link
Fig. tweet link
이 부분에 대해서는 alphago series의 prototype인 alphago는 먼저 human expert의 바둑 기보를 supervised learning 하고 (chatgpt의 SFT 단계), Actor (go agent; 즉 LLM)를 reinforcement learning (RL)으로 강화하면서 value network도 같이 학습한 뒤, 실제 inference시에는 Monte Carlo Tree Search (MCTS)를 했는데, 그 뒤에 나온 AlphaZero 부터는 SFT같은 것 없이 더 빡세게 RL을 했고 결과적으로 alphago를 능가하게 됐다. 이런 관점에서 보면 RL이 쓰이긴 했지만 부족한 것은 맞는 말일 것이다.
Andrej Karpathy는 RLHF에 대해 아래와 같은 tweet을 남겼는데, 요약하자면 RLHF는 기존의 superhoman ai에 도달한 method들이 완벽에 가까운 (이기면 1 지면 0) reward signal로 부터 학습된 것과 다르게 어떤것이 그럴싸한가 사람이 평가한 것을 모방했기 때문에 겨우 RL축에 낀다는 것이다 (즉 더 발전이 필요함).
 Fig. tweet link
Fig. tweet link
뭐 가장 처음 나온 alphago의 경우에도 human feedback을 학습에 쓰진 않은건 사실이지만, 그데 좀 이건 억까인 것 같은게 java code를 python으로 변환하는 경우에도 여러가지 답이 있을 수 있으며, 뭐가 틀렸다고 확실히 말하기 어려우니까 human preference를 학습하는 것이 아닌가? 생각해보면 원래 RL이 많이 쓰이는 분야중에서도 supermario game이나 chess, Go같이 이기면 1점 지면 0점을 받는 확실한 setup이 아닌 이상 사람이 reward design을 해야 하는건 어느 분야나 마찬가지 일 것 같기 때문에 너무 억까가 아닌가 싶다.
Andrej는 이를 human’s generator-discriminator gap 라고 부르는데, code를 직접 생성하는 것 보다 두개의 생성된 code를 보고 보고 평가하는게 더 쉽다는 걸 의미하며 RLHF는 이런 특성을 이용한 것이라고 말한다.
사실 openai에 최근까지 있던 Andrej가 왜 이런말을 했는지 모르겠지만, 뭐 아무튼 RL이란 역사적으로 결국 사람이 범접할 수 없는 superinteligence를 가능케 하는 key algorithm 이었고, LLM이 그렇게 되기 위해서는 RLHF로는 부족하다라는 말을 하고 싶었던 것 같다.
- Inference Time Scalability
- 임의로 inference time을 늘릴 수 있어야 함
- 늘릴수록 성능이 개선돼야 함
- Learn how to CoT
- CoT 하는 법을 배움
- 실패했을 때 다른 방법을 시도하거나 실수를 수정하는 방법도 배움
- 단순 SFT로 학습하진 않았을 것
- RLHF가 아니라 RL했다고 강조함
- quiet-star 처럼 특정 task-specific CoT를 학습한 것이 아니라 generalization이 가능한 reasoning 자체를 학습했을 것
- hidden CoT
- CoT는 human align 되지 않도록 할 수 있어야 한다.
- 사람이 읽을 수 없음 (?)
- 다만 CoT를 Legible 하게 만들어 사람이 monitoring하기 위해서는 summarizer가 필요하다.
- summarizer를 학습하려면 align된 target text가 존재한다 (?)
- CoT는 human align 되지 않도록 할 수 있어야 한다.
Aha moment of oai researchers
openai researcher들이 o1개발 소감에 대한 얘기를 공개했다. Building OpenAI o1 (Extended Cut)를 보면 이런 저런 내용을 들을 수 있는데, 그 중에는 researcher들이 o1을 개발하는데 trigger가 된 aha moment에 대한 얘기가 있다.
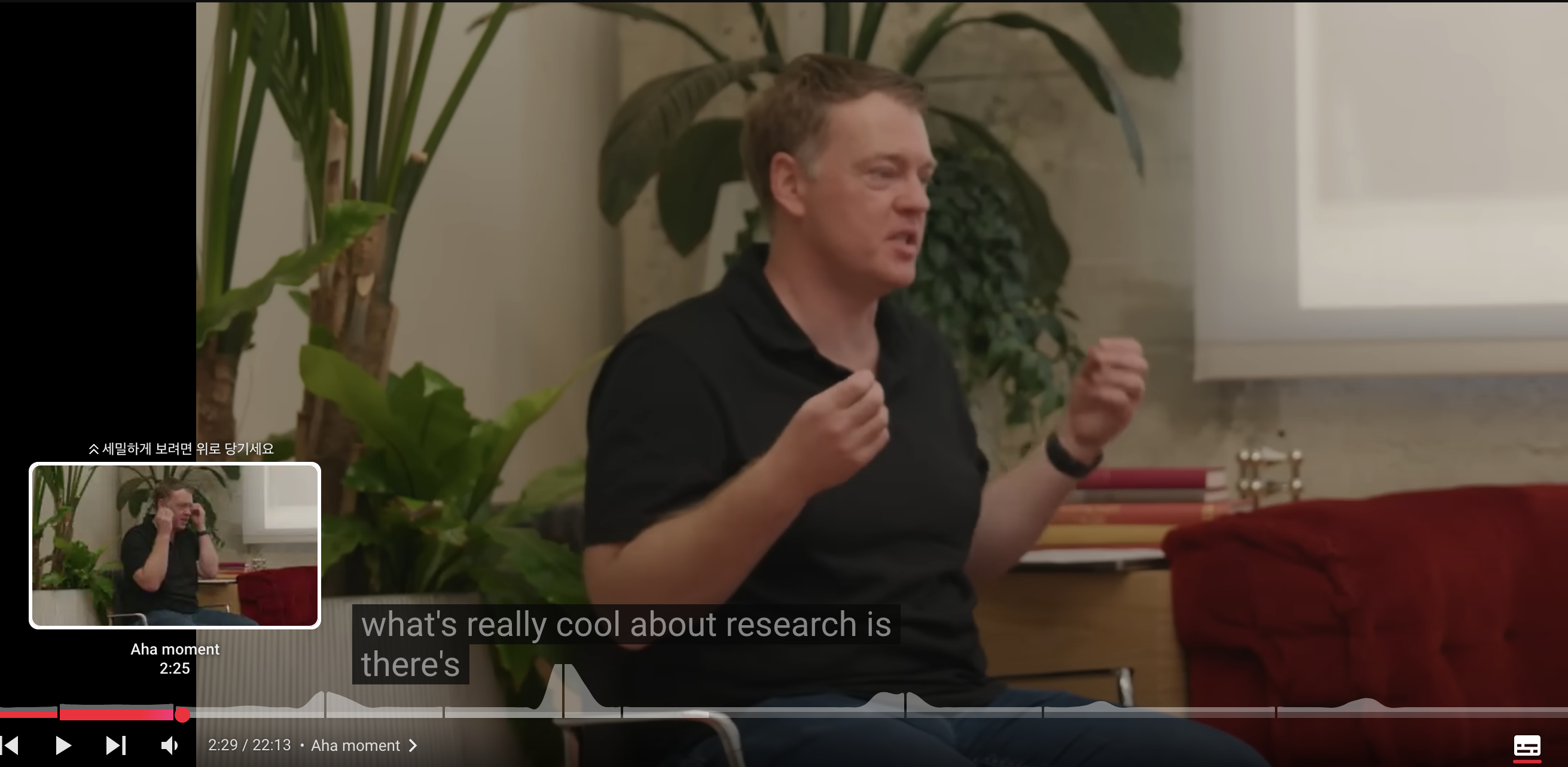
aha moment for me was like when we saw that if you train the model
using RL to generate and hone its own chain of thoughts it can do even
better than having humans right chains of thought for it
and that was in aha moment that you could really scale this
and explore models reasoning that way for a lot of the time
that I've been here we've been trying to make the models better at
solving math problems as an example and we've put a lot of work into this
one thing that I kept like every time I would read these outputs from the models
I'd always be so frustrated the model just would never seem to question
what was wrong or when it was making mistakes or things
like that but one of these early uh o1 models when we trained it
and we actually started talking to it we started asking it these questions
and it was scoring higher on these math tests we were giving it
we could look at how it was reasoning um and you could just see that
it started to question itself and have really interesting reflection
and that was a moment for me where I was like wow like we we've uncovered
something different this is going to be something new and and it was just like
one of these coming together moments that that that was really powerful so
o1's backbone is not gpt-4?
Recapitulate Planning (MCTS)/ Self-play/ AlphaGo
o1같은 reasoner과 관련있는 것들 중 내 생각에 중요한 것은 크게 세 가지다.
- MCTS 같은 Search Algorithm
- 현재 state가 얼마나 좋은지를 판단할 수 있는 Verifier, Value Network, 혹은 Process Reward Model (PRM)
- Self-Play
이 세 가지가 어떤것인지 감을 잡기 위해 AlphaGo를 사용해 설명하려고 한다.
How to make Artificial Go Player?: Monte Carlo Tree Search (MCTS)
Monte Carlo Tree Search (MCTS)는 Alphago같은 two player game의 agent를 만들기 위한 core module이다.
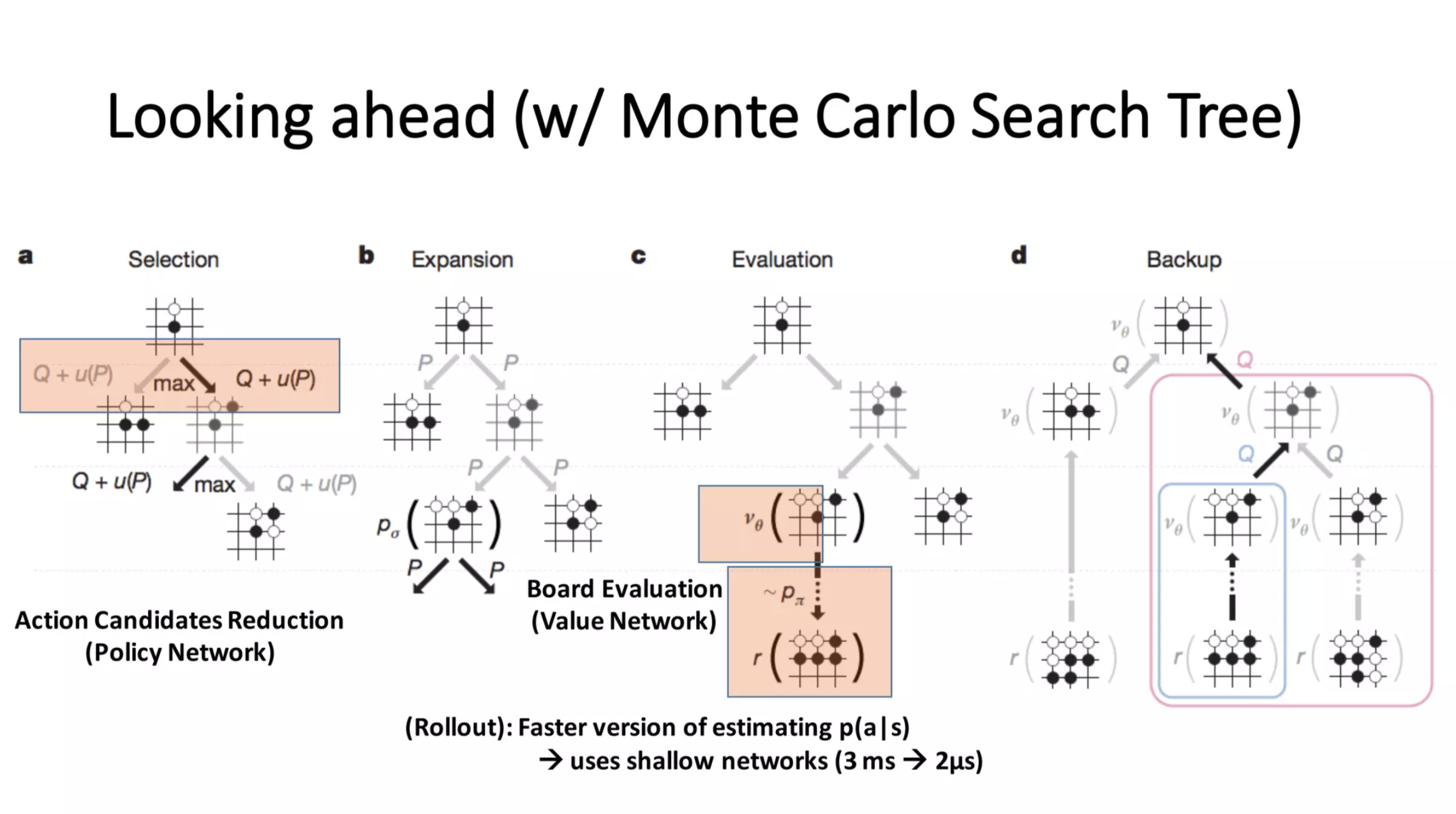 Fig. source
Fig. source
MCTS는 말 그대로 Tree Search를 하는 데 Monte Carlo (MC) method를 쓴다는 걸 의미하는데,
monte carlo method는 위키를 찾아보면 무작위 추출된 난수를 이용하여 원하는 함수의 값을 계산하기 위한 simulation 방법이라고 되어있다.
RL이나 통계학 관련된 것들을 보면 monte carlo 가 붙은 방법들을 찾아 볼 수 있는데,
MC가 붙으면 보통 게임이 끝날 때 까지 수를 둬 봄으로써 가치를 판단하는 것이라고 할 수 있다.
직관적으로 게임이 끝날 때 까지 현재 policy (혹은 random policy)를 사용할 것이므로 그것이 NN이라면 GPU 자원을 많이 필요하거나 시간이 많이 필요할거고,
이 행위를 많이 반복해서 simulation sample 횟수가 늘어나면 신뢰도가 올라갈 것이다 (5번 해서 4번 이기고 1번 졌는데 1000번했더니 623번 이기고 377번 진다던가).
Alphago에 대해 얘기하기 전에 먼저 아래와 같은 간단한 게임인 connect2를 통해 MCTS를 이해해보자.
 Fig. source
Fig. source
connect2는 player 두 명이 4개 place 중 한 곳에 번갈아가면서 coin을 두어 이를 잇는데 성공하면 이기는 게임 (저차원의 tic-tac-toe, bingo라고 할 수 있다) 이다.
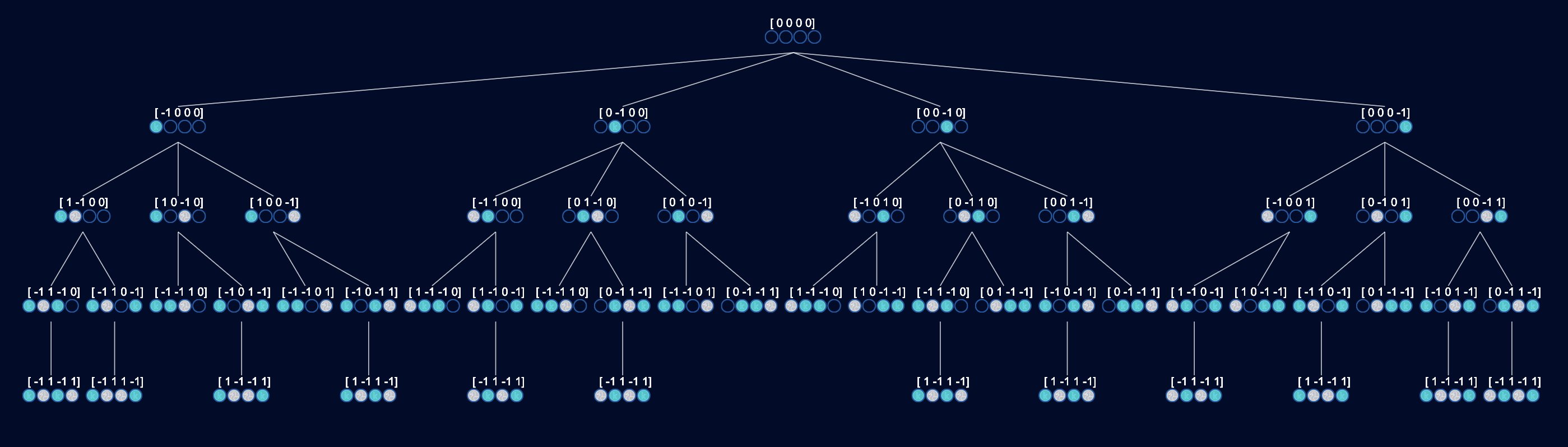 Fig. source
Fig. source
connect2 agent를 만들 때 우리가 생각해 볼 만한 아주 간단한 방법 중 하나는 바로 아래와 같이 모든 경우의수를 다 따지는 tree를 만드는 것이다. tree에는 양쪽 player가 수를 둘 수 있는 모든 상황이 포함되어 있으며, tree의 끝인 leaf node에 다다라서는 누가 이기고 졌는지? 혹은 비겼는지를 알 수 있다.
Fig.
AlphaGO
이제 바둑 (Go)에 대해서 생각해보자. 어떻게 하면 go agent를 만들 수 있을까?
사실 위의 connect2를 한 차원 확장시켜 tic-tac-toe로 확장시키기만 해도 경우의 수는 매우 늘어나게 되며, 흔히 Go에 대해 얘기할 때 매 바둑 판 상태 (state)마다 경우의 수를 다 고려하는 것은 우주의 원자 수보다 많기에 불가능 하다는 얘기를 한다. 그래서 Go는 tree search같은 고전 algorithm으로 풀 수 없으며 뭔가 고차원의 추론 능력 (reasoning) 없이는 정복할 수 없다고 얘기했고, 이런 벽을 깨 부순 것이 바로 DeepMind이다.
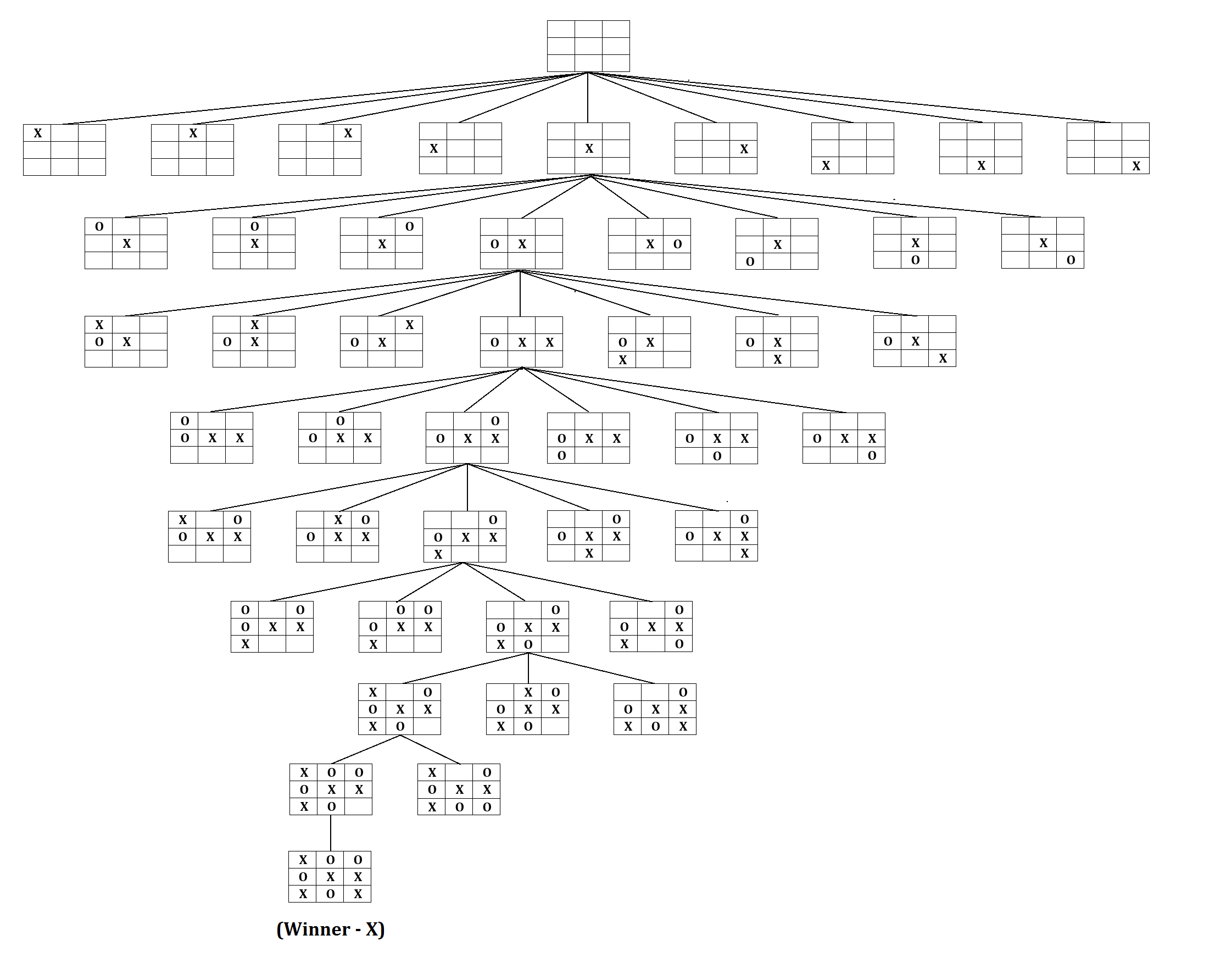 Fig. tic-tac-toe 정도만 돼도 일단 사람이 보기에 공간이 부족해서 모든 tree를 표현할 수 없다. source
Fig. tic-tac-toe 정도만 돼도 일단 사람이 보기에 공간이 부족해서 모든 tree를 표현할 수 없다. source
AlphaGO의 mechanism은 직관적으로 이해하자면 간단하게 설명할 수 있다. (alphago 학습에 사용된 feature, objective나 hyperparameter등의 자세한 설명은 여기서는 하지 않겠다)
- human experts의 바둑 기보를 매우 많이 확보하고 Nerual Network (NN)을 학습한다.
- 단순히 현재 기보를 보고 다음 수가 무엇인지 학습하는 것으로, supervised learning (SL)임.
- LLM으로 치면 next token prediction에 해당 (next action prediction)
- 이 때 바둑판이 19x19 크기라면 input이 19x19x48로 채널이 48개나 되는데, 이는 바둑판의 어떤 특정 상태에 돌이 놓인다던가 하면 우세하다는 human prior를 반영한 feature라고 할 수 있다.
- 어느정도 SL policy가 학습됐으면 (수렴했으면) RL로 이를 강화한다.
- Actor-Critic 방법으로 학습하며 따라서 value network, policy network가 jointly 학습된다.
- value network의 target value는 그 상태에서 둘 수 있는 모든 action에 따라 얻을 수 있는 total reward (이기면 1 지면 0)의 기대값 (expected sum of total reward)를 의미하므로, 현재 바둑판 상태 (state)의 판세, 승률을 의미하는 것과 같다.
여기서 중요한점은 Alphago의 핵심이 사실 Reinforcement Learning (RL)로 policy update를 열심히 했다는 것이 아니다. 본체는 사실 MCTS를 했다는 것이다. 다만 MCTS를 그냥 하기에는 search space가 너무 넓기 때문에 tree search의 깊이 (depth), 너비 (breadth)를
요한 것은 1번이다.
AlphaGO-Zero
Alphago paper를 보면 처음에는 놓치기 쉬운 것들이 있는데, 이는 다음과 같다.
- SL policy를 RL로 parameter update를 많이 한 RL policy와 by-product로 Value network가 생겼을텐데, 이 때 강화된 actor는 실제 inference, 즉 MCTS에 사용되지 않는다.
- 왜냐하면 SL policy가 더 좋았기 때문인데, 이는 exploration 을 더 많이 하는게 더 좋아서 그렇다.
- MCTS는 학습에 사용되지 않았다.
Self-Improved LLM
Large Language Models Can Self-Improve
GDM은 일찍이 reasoning capability를 self-improvement하는 pipeline을 만드는 시도를 해왔다. Large Language Models Can Self-Improve라는 work을 보면 CoT와 Self-Consistency에 영감을 받아 self-improvement를 하는 pipeline을 만들어 benchmark 성능을 눈에띄게 개선한 것을 확인할 수 있다. 먼저 self-consistency는 아래와 같이 cot prompting을 해서 나온 n개 다양한 답변들에 대해서 majority vote를 한 결과를 정답으로 출력하는 것이다. 말 그대로 일관성있는 답변이 좋다는 말인데,
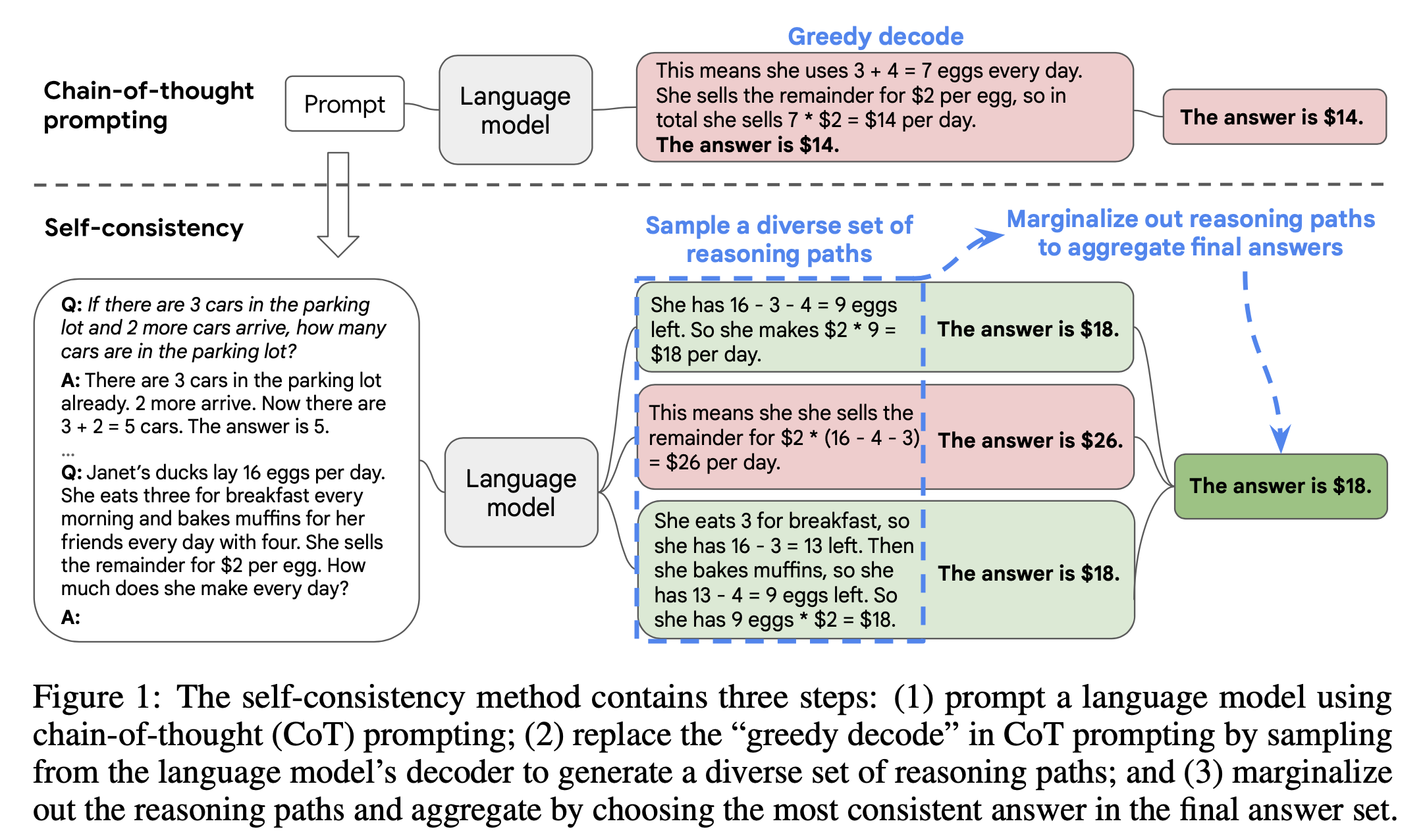
이를 training pipeline에 적용해서 unlabeled query에 대한 답을 sampling하여 LLM을 학습하는 것이 이들이 제안한 방식이다. 학습에 사용할 reasoning path는 이 중에서 confidence가 가장 큰 것을 골랐다고 하는데,
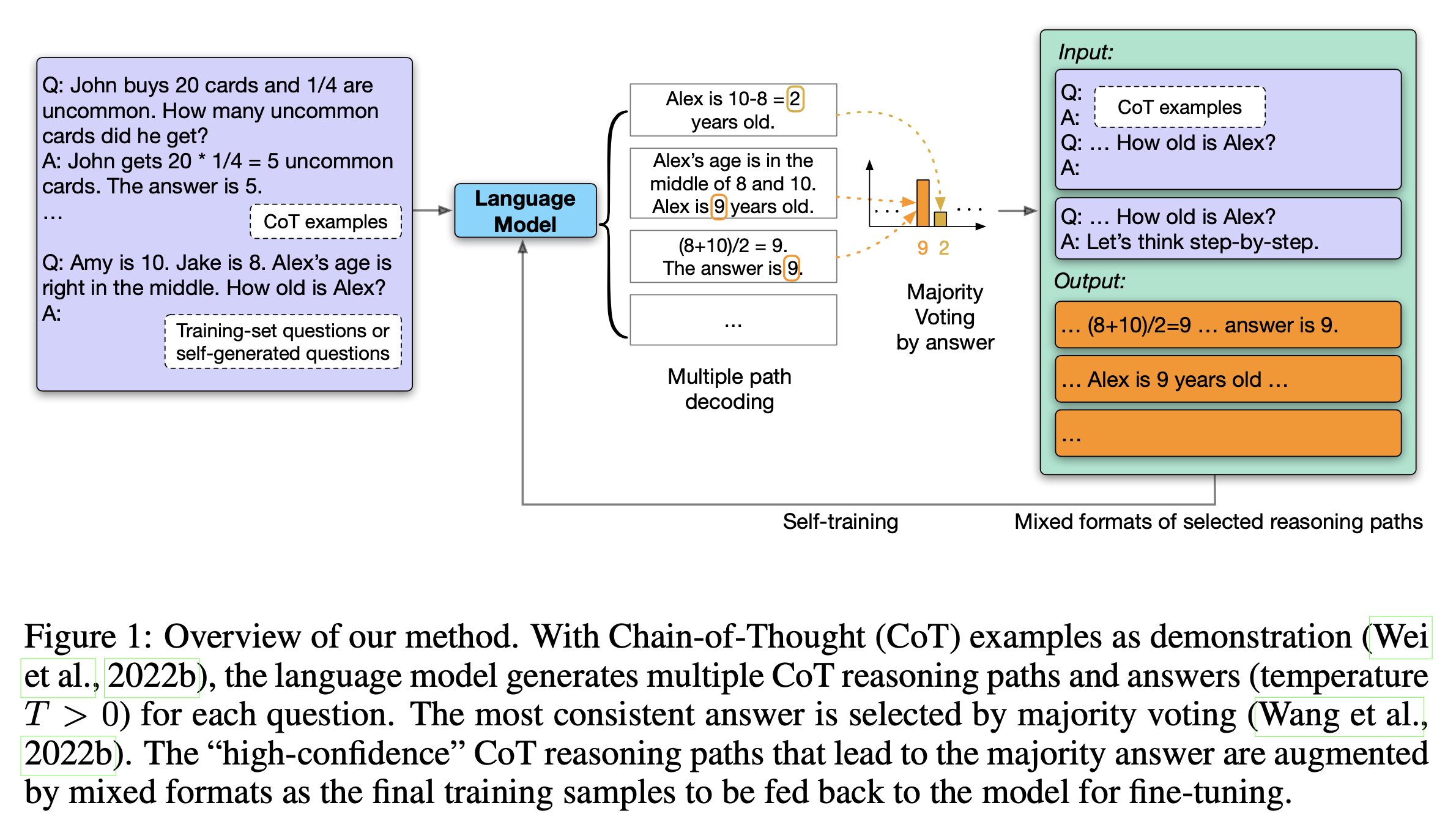
confidence와 gsm8k benchmark의 accuracy는 큰 상관관계를 보였다고 한다.
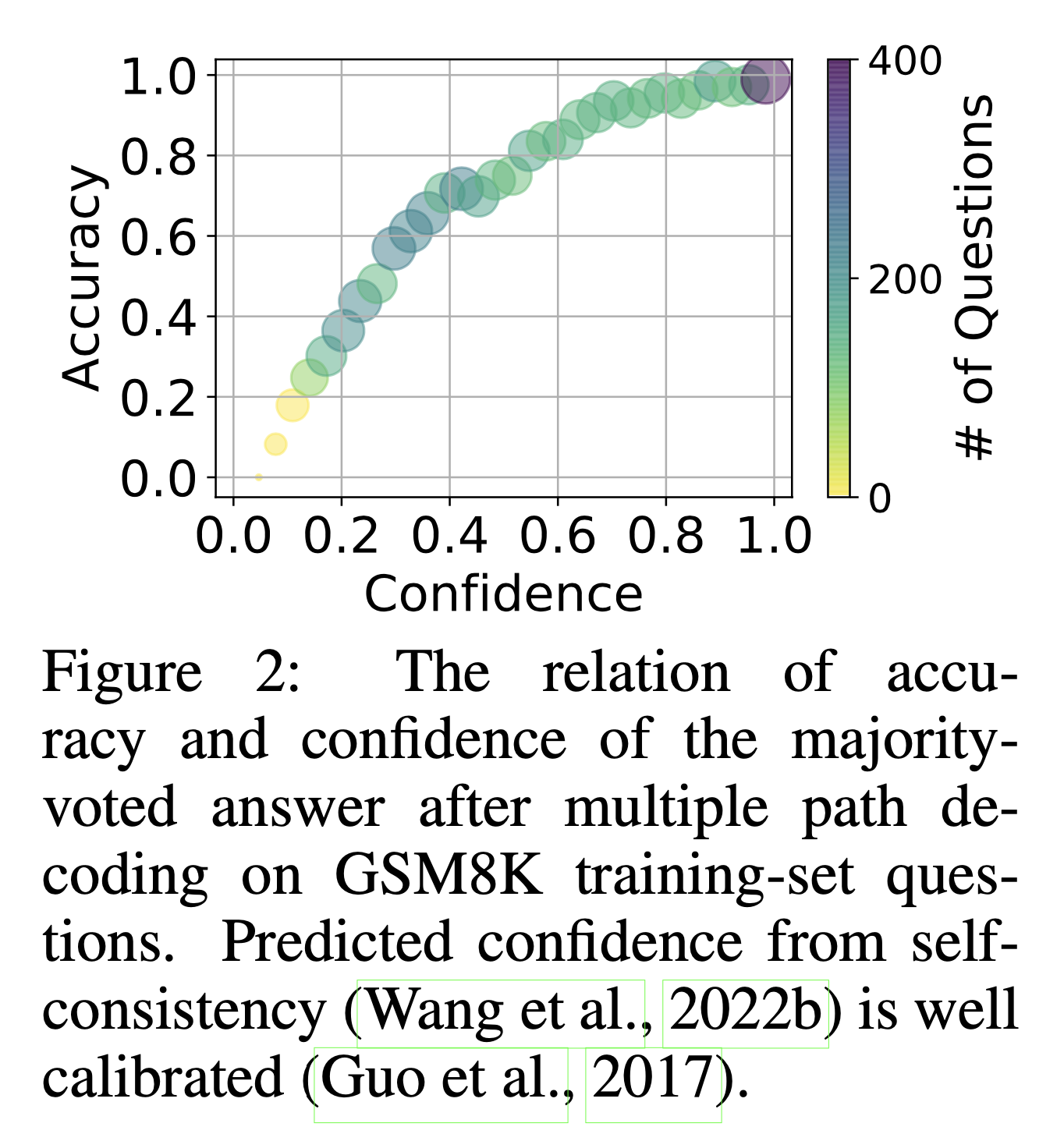
Constitutional AI
Anthropic의 Constitutional AI는 RL from AI Feedback (RLAIF)를 사용해 harmlessness를 개선하는 내용을 담고있다.
 Fig.
Fig.
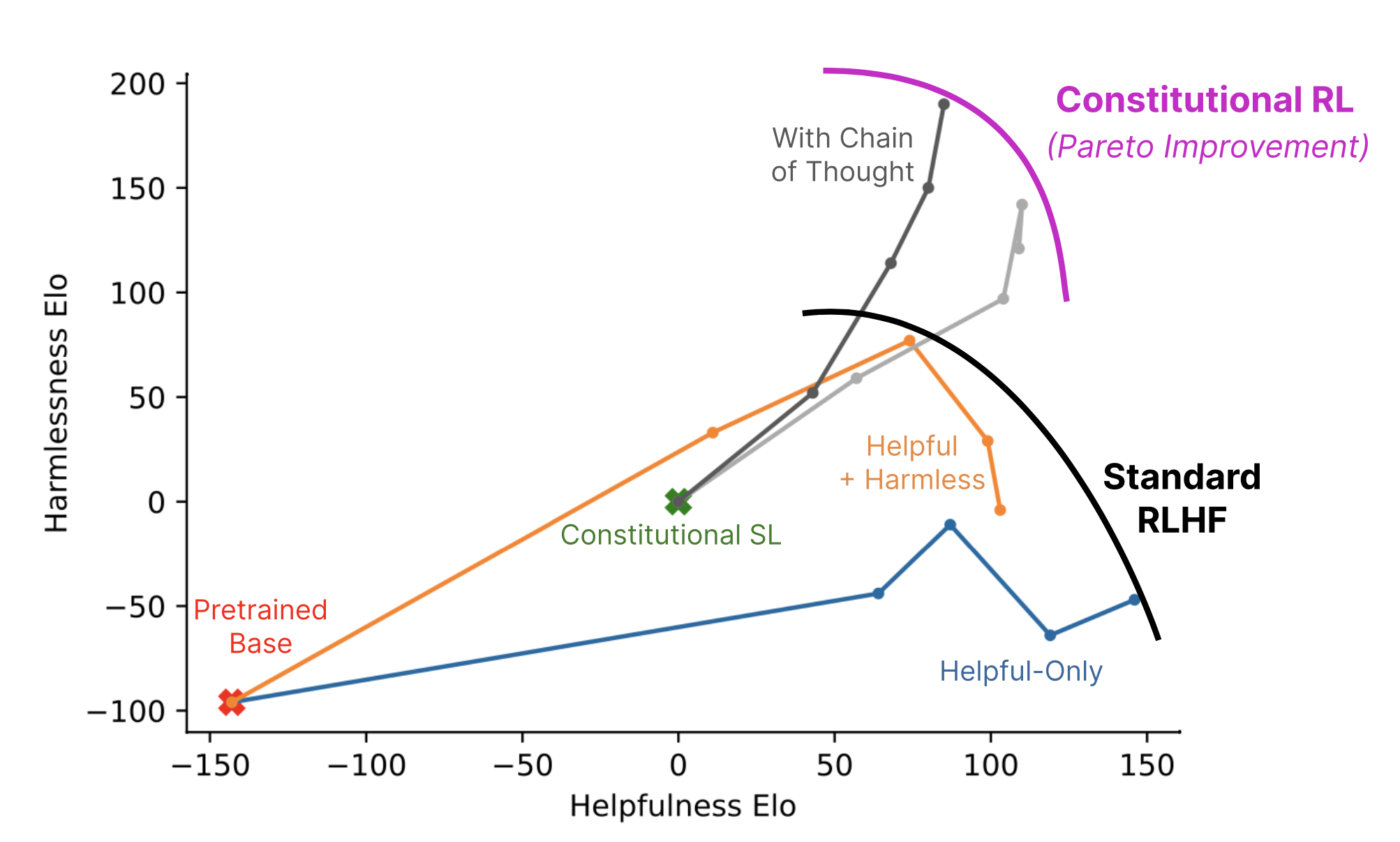 Fig.
Fig.
Process Reward Model (PRM)
so, PRM for what?
Reward modeling에는 크게 두 가지 종류가 있다.
- process reward model (PRM)
- outcome reward model (ORM)
ORM은 예를 들어 바둑을 둘 때 처럼 하나의 trajectory (문장; sequence)를 다 만들고 해당 답변이 몇점인지 labeler가 평가를 하고 이를 학습하는걸 말한다. (평가는 sample별로 이미 offline manner로 사람이 다 해놨다)
그런데 바둑같이 episode가 긴 task들은 150~200수가 지난 후에야 reward가 지면 0, 이기면 +1 생성되는 꼴이기 때문에 너무 reward signal이 sparse해서 학습이 힘들다. 바둑이나 robotics 등 RL을 적용한 대부분의 task에서 이는 심각한 문제고, 따라서 reward signal이 좀 더 빈번하게 발생할 수 있도록 하는 일이 필요하다. Let’s Verify Step by Step에서 제안한 것이 바로 LLM을 Reinforcement Learning from Human Feedback (RLHF)할 때, dense reward, 즉 어떤 수학 문제에 대한 답변을 만들 때 한 줄 마다 reward를 발생 시키도록 했고, PRM은 이런 과정 (process)에 대한 supervision을 하는걸 말한다.
 Fig.
Fig.
oai는 위와같이 data를 만들어 PRM, ORM을 각각 학습했고, 학습된 PRM은 아래와 같이 틀린 답 (오른쪽)에 대해서 각 문장에 대해 맞고 틀림을 분간할 수 있게 되었다고 한다.
 Fig.
Fig.
그리고 성능도 훨씬 좋았다.
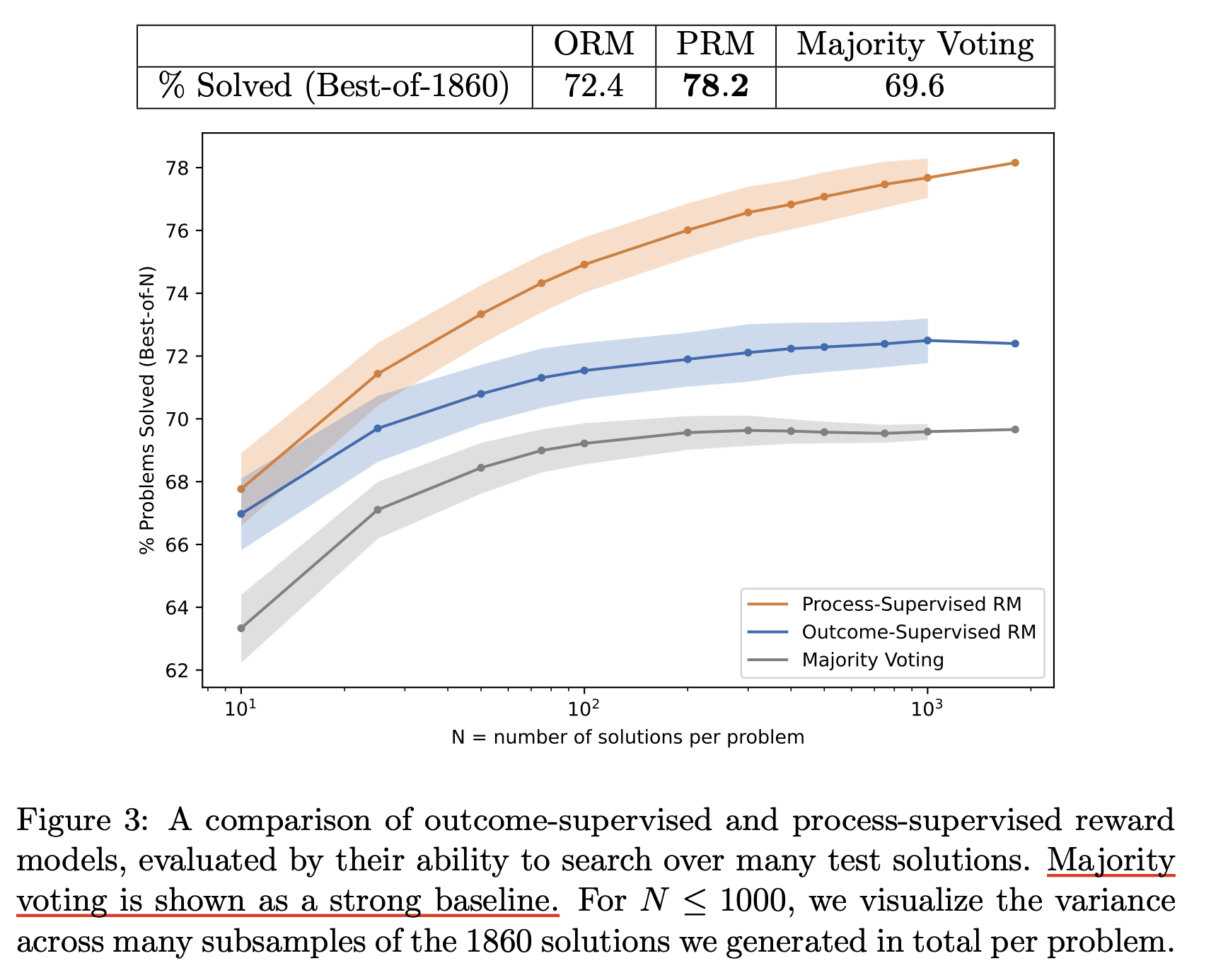 Fig.
Fig.
하지만 PRM이 만능은 아닌 것으로 보인다. 아래 tweet을 작성한 Jan Leike는 이전에 openai에서 super alignment team을 이끌던 사람이고, 현재는 anthrophic에 있다.
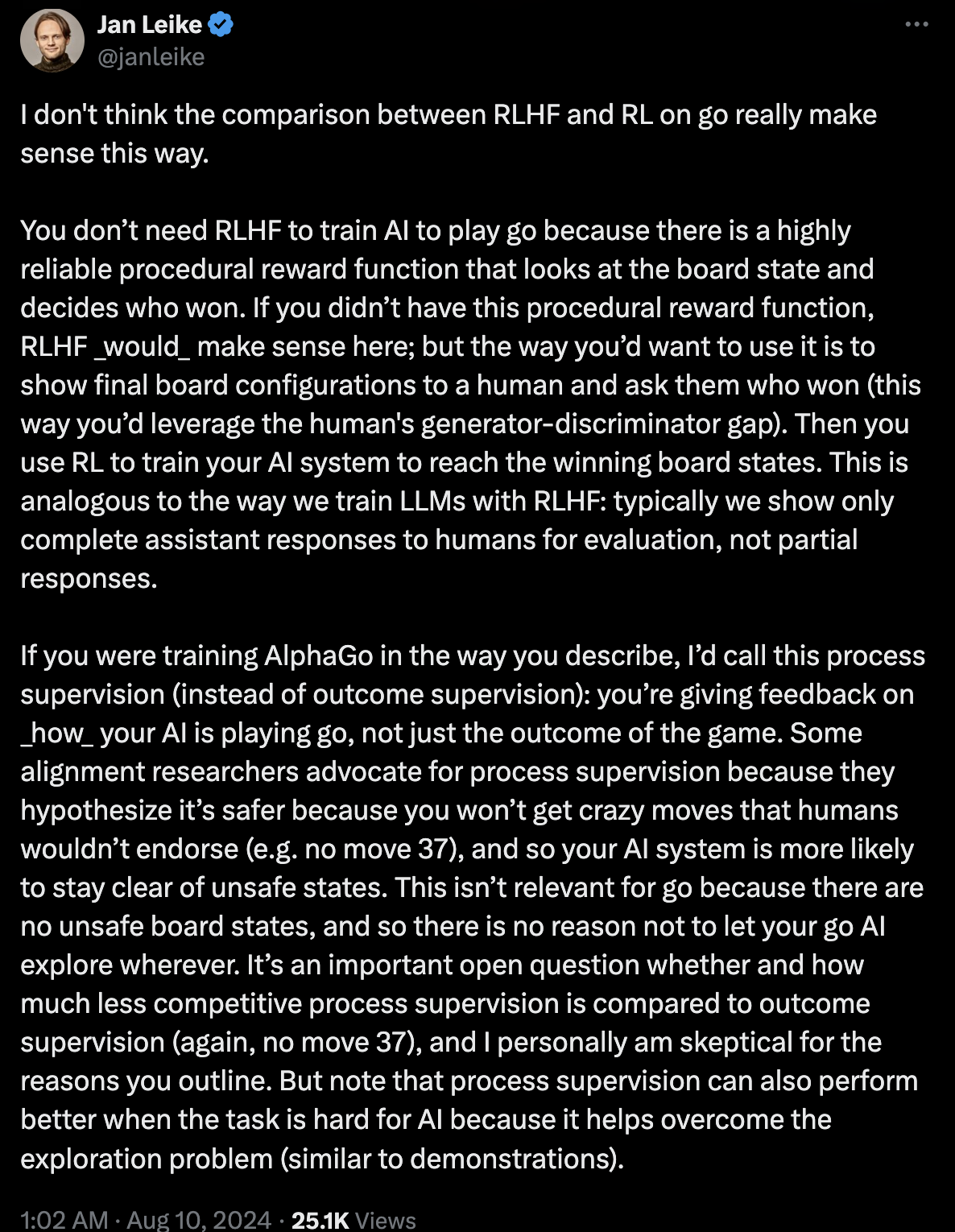 Fig. tweet link
Fig. tweet link
이사람이 하는 말은 PRM을 할경우 alphago의 move 37 (superhuman action)같은 건 나올 수 없을지도 모른다는 것이다.
그의 말에 따르면 PRM이 더 safe할 수는 있다고 한다.
예를 들어 우리가 어떤 agent에게 돈을 많이 벌면 엄청나게 많은 reward를 준다고 해보자.
그러면 마약을 팔아서 돈을벌 수도 있겠지만 사람이 생각하지 못하는 창의적인 방법을 쓰도록 policy를 학습할 수도 있을 것이다.
하지만 사람이 guide를 중간중간 준다면, “일단 스마트스토어로 seed머니를 만든다 -> 주식투자를 해서 돈을 굴린다 -> 부동산에 투자한다”같은 사람이 생각할법한 policy를 학습할 수도 있다.
물론 PRM도 중간 process에 대한 보상이 확실하면 이 문제는 업을 수 있을 것이다. 예를 들어 super mario 게임을 10탄 깨야하는데, 10탄 깰 때까지 reward를 기다리면 너무 오래걸리니 1탄마다 reward를 줄 건데, 그 1탄 마다의 ground truth reward는 무조건 clear했을 때 일 것이다. 이는 반박의 여지가 없다. 하지만 이런게 아닐 경우 alphago move 37같은게 없을 수 있다는 것이다.
그리고 tweet에도 나와있지만 PRM이 move 37같은걸 학습하는데 악영향을 줄 수 있지만 AI가 RL학습 초기에 exploration을 할게 너무 많아서 아예 학습이 진행되지 않는 문제를 완화할 수 있기 때문에 마냥 나쁜것은 또 아니므로 어떤 점이 좋고 나쁜지에 대해서는 한 번 생각을 해 봐야할 문제인 것 같다.
Math Shepherd

Omega PRM
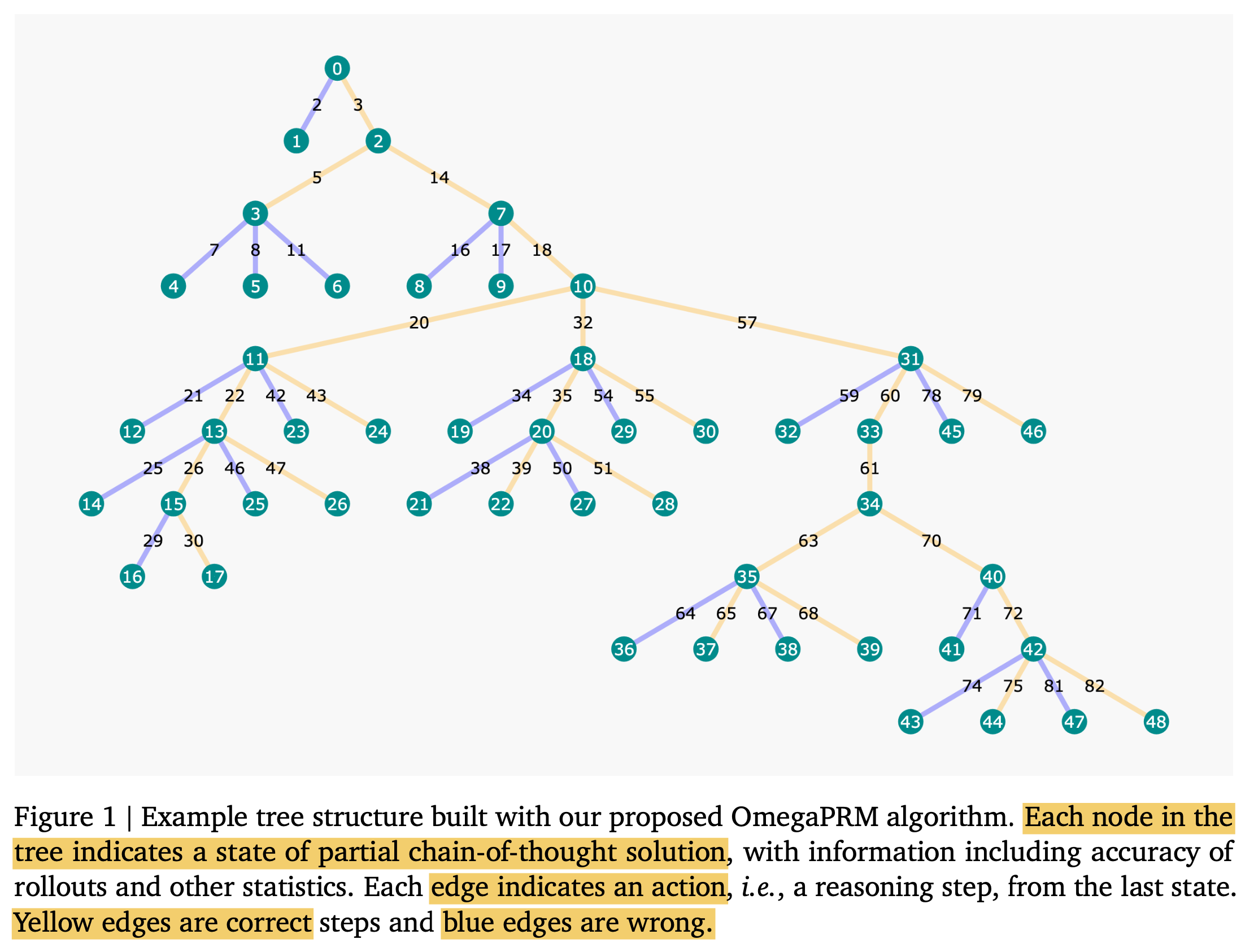
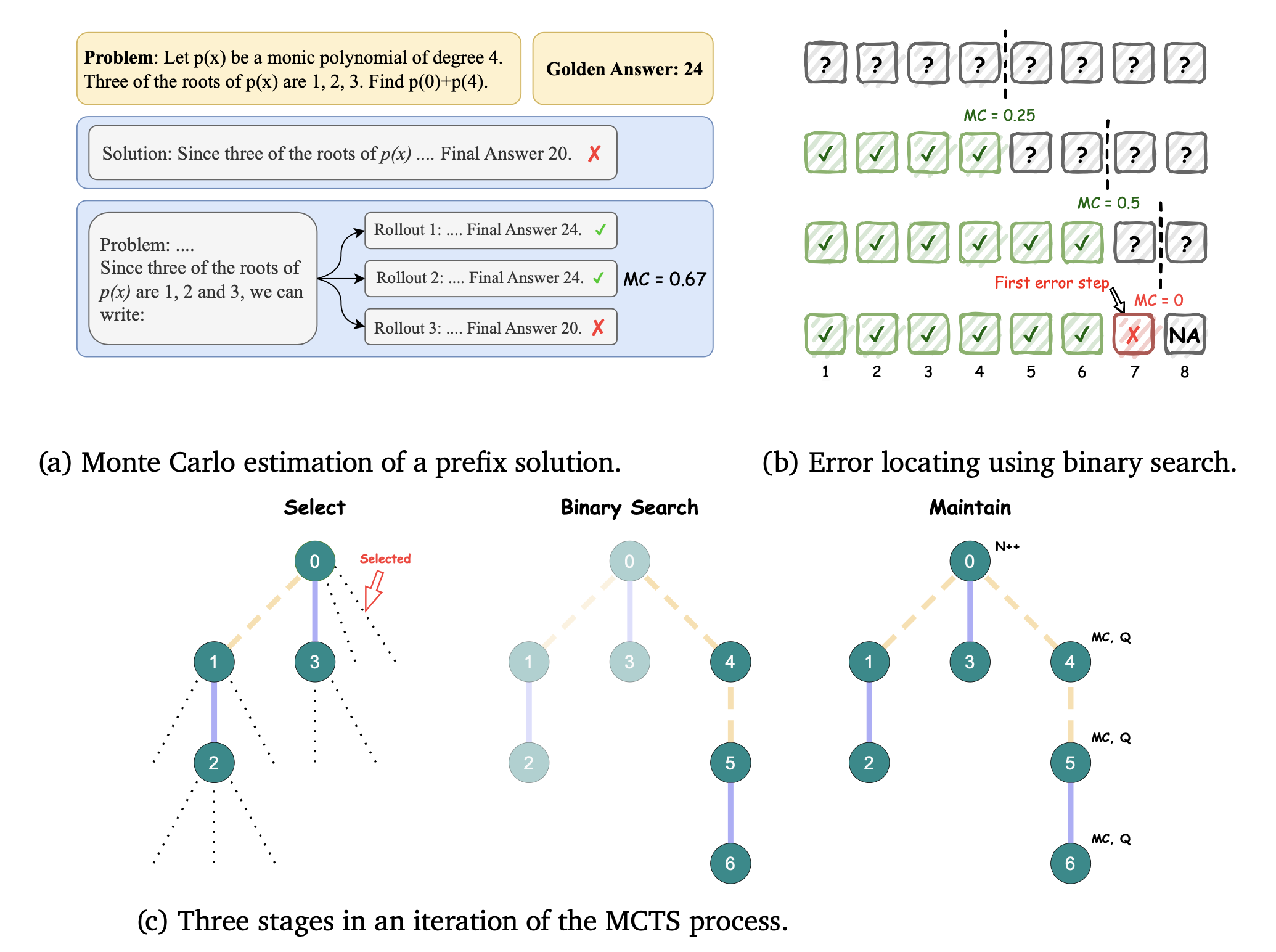
LaTRO

Rewarding Progress
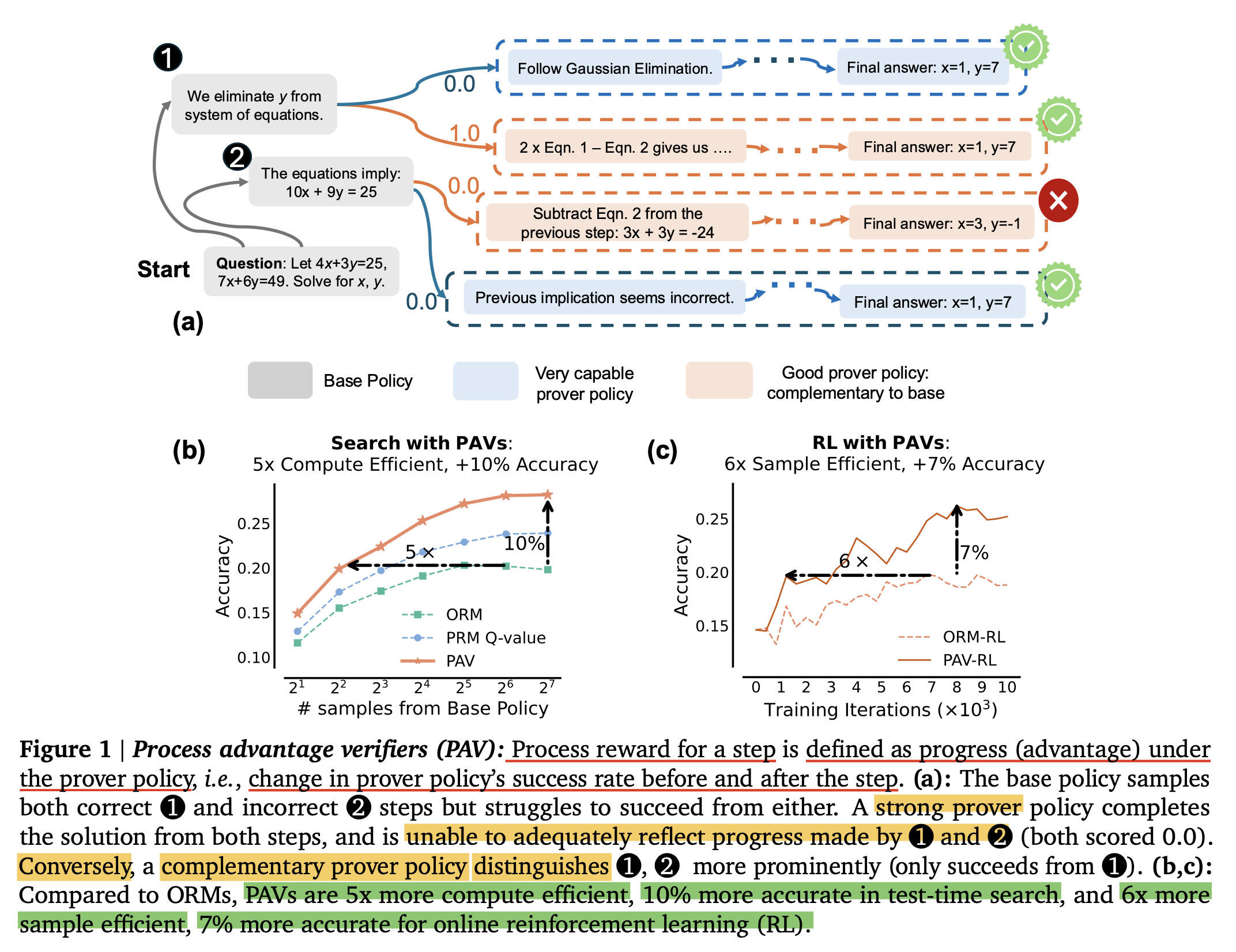
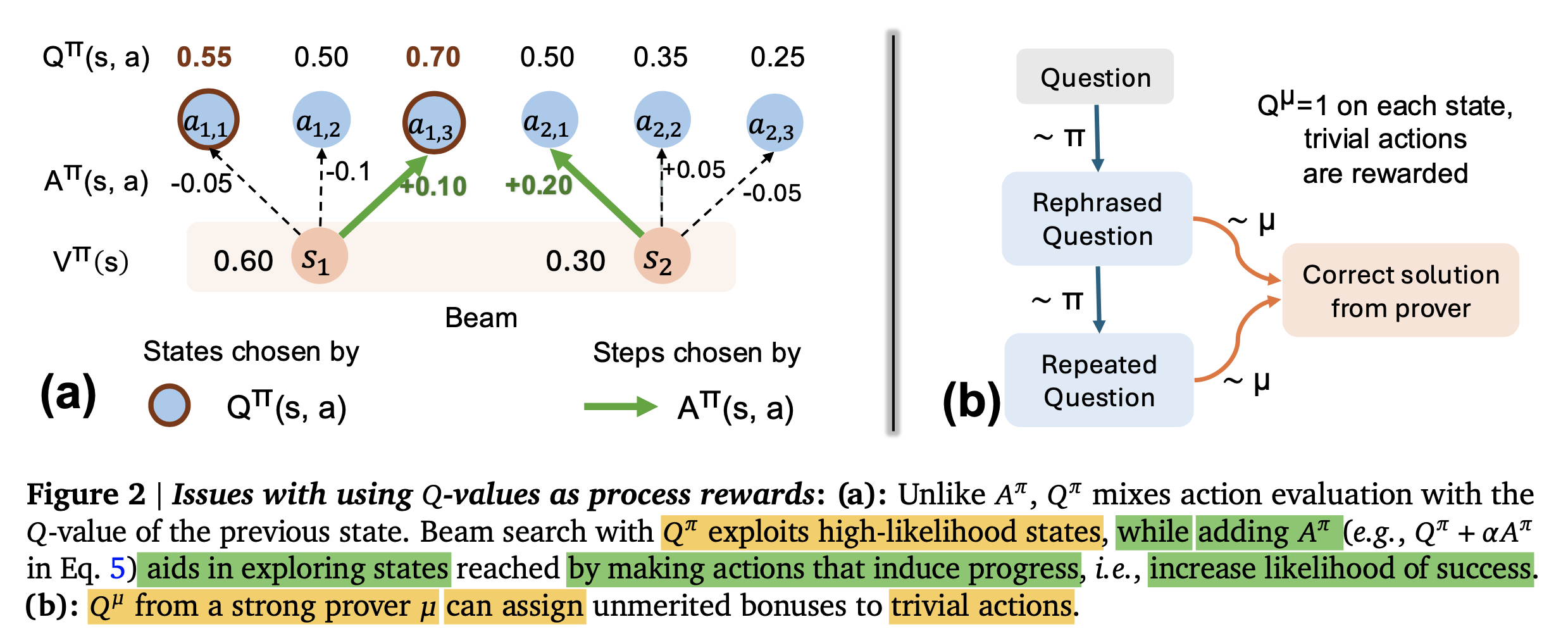
(Self-)Refinement/ (Self-)Correction/ Reflection/ Backtracking
Self-Refine: Iterative Refinement with Self-Feedback
Self-Refine: Iterative Refinement with Self-Feedback
Accessing GPT-4 level Mathematical Olympiad Solutions via Monte Carlo Tree Self-refine with LLaMa-3 8B
Inference Scaling Laws
Overview
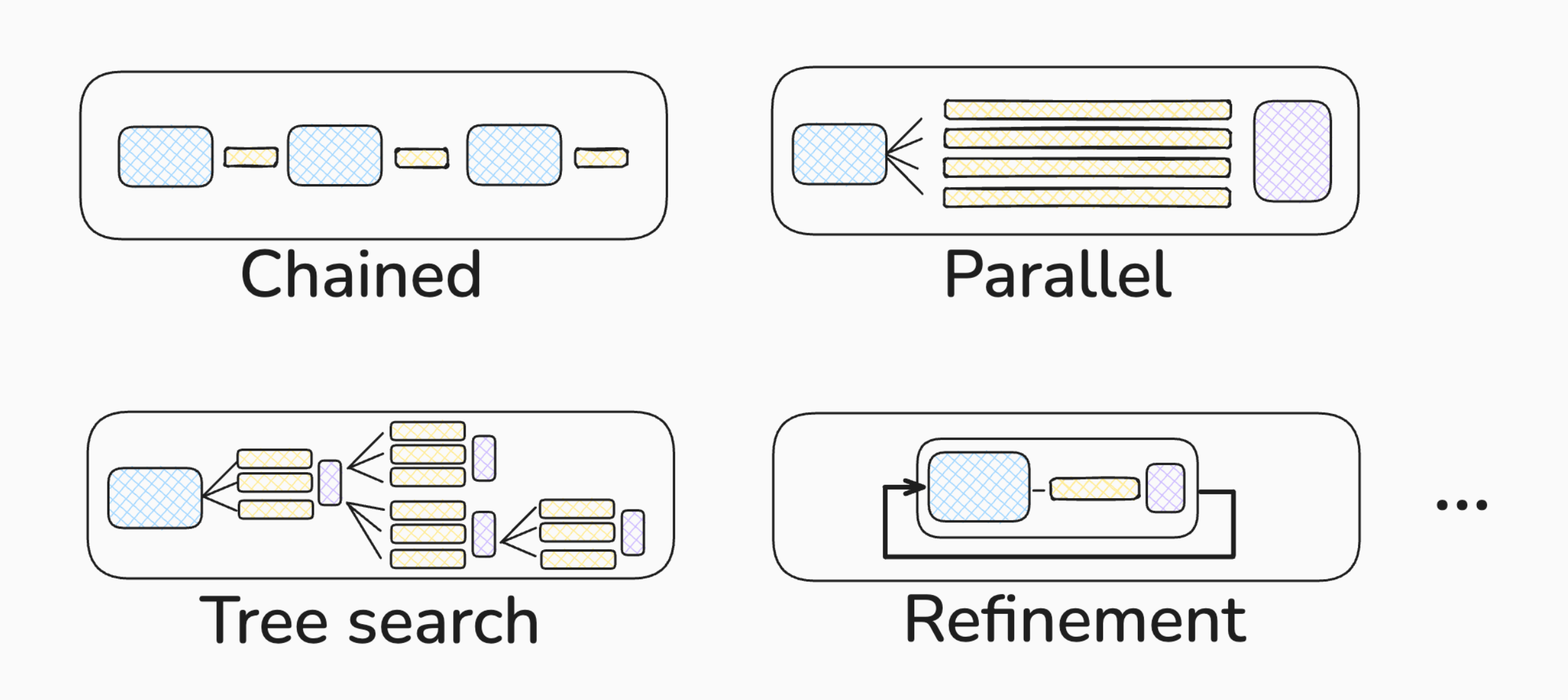 Fig. NIPS 2024 Beyond Decoding
Fig. NIPS 2024 Beyond Decoding
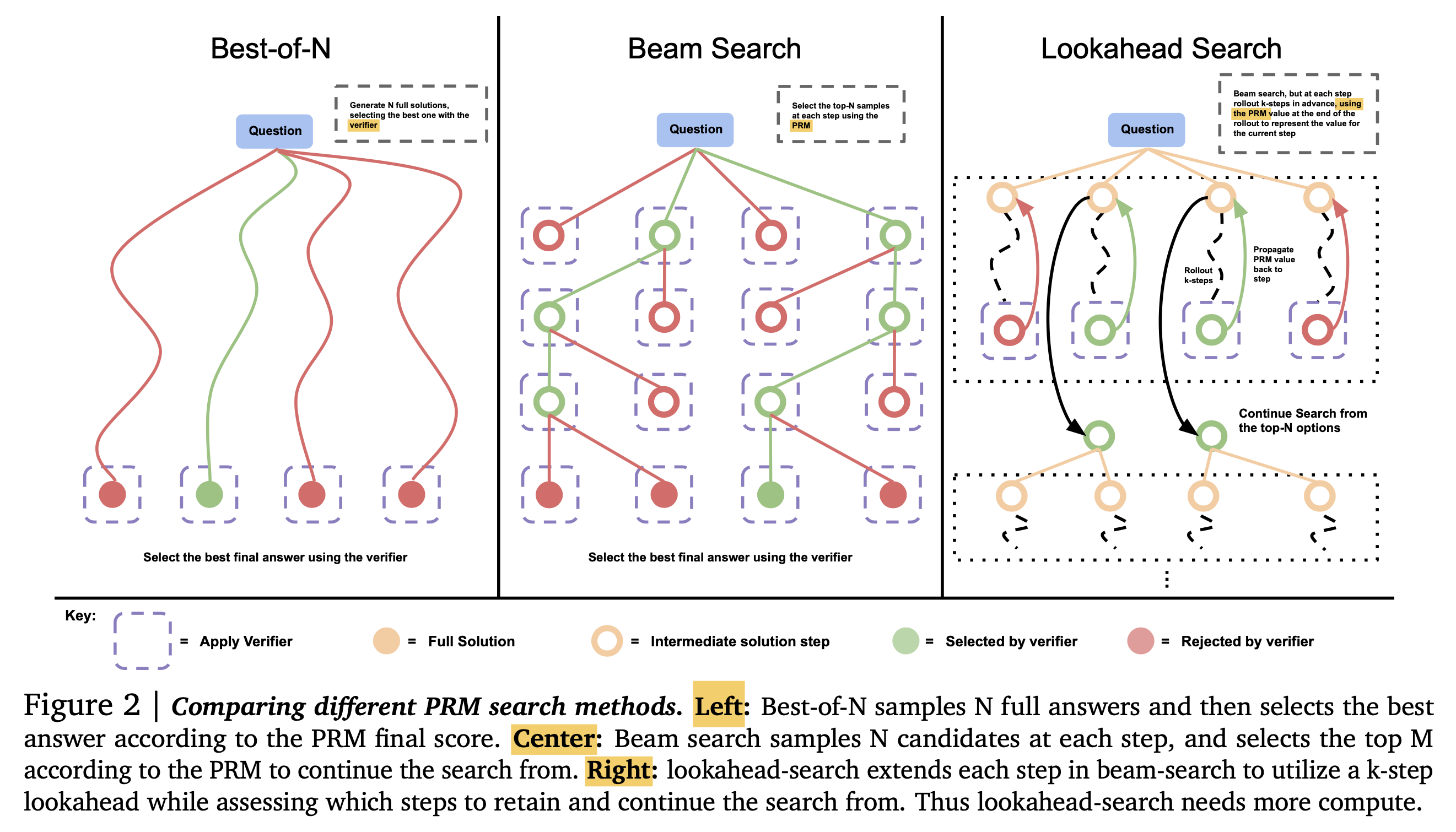 Fig. Source from Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters
Fig. Source from Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters
Inference Scaling 'F'Laws
Inference Scaling ‘F’Laws: The Limits of LLM Resampling with Imperfect Verifiers라는 paper가 공개됐다. 요약하자면 inference time scaling law가 만병통치약 (silver bullet)은 아니라는 것이다. 앞서 얘기한 것 처럼 추론하는 법을 모르고 기초 STEM지식이 없는 base model을 가지고 test time에 시간을 더 줘 봤자기 때문이다. 또 하나 여기서 얘기하는건 verifer가 나쁘면 탐색량을 늘려봐야 False Positive (verifier를 통과했지만 incorrect solution인 것)의 비율을 늘리는 꼴이 된다는 것이다. 즉 공짜 점심은 없는 것이다.
여기서는 programming task를 중점적으로 보는데, 저자들은 아래 세 가지를 주효하게 확인했다.
- humaneval이나 mbpp같은 python programming task에서 model이 한번 추론해서 도달 할 수 있는 accuracy인 single-sample accuracy와 false positive rate간에 상관관계가 매우 큼 (즉 weaker model이면 비율이 높음)
- weaker model이 repeated sampling을 하는 것은 더 나쁜 generalizability를 야기함
- false positive solutions은 맞았음에도 불구하고 low-quality임
- 현실적으로 무한히 샘플하는건 benefit 대비 cost-benefit ratio를 늘리는 꼴이기 때문에 finite number가 존재할 수 있음
- 즉 어느 시점부터는 사람이 그 model로부터 solution을 얻어 직접 고쳐야 하는 노동비가 더 많이 들 수 도 있음
Think test-time scaling as model scaling
Test-time scaling에 대해 나의 한 동료는 이런 추론을 했다. 가령 우리가 model size가 72층 transformer라고 해보자.
RL is Dead-end for LLM?
사실 LLM에서 RL이 그렇게 크게 도움이 되지 않을거 같다는 말이 있었다.
이전에 Game같이 보상이 확실한 task는 모르겠지만 LLM reasoning같은 데에서는 RL이 막다른 길 (dead end)에 접어들었다라고 했던 google deepmind의 LLM lead가 있었는데,
언제 트윗을 내렸는지 모르겠지만 (o1이나오고 내린건진) tweet은 현재 내려서 존재하지 않는다.
 Fig.
Fig.
하지만 여전히 이런 관점은 존재한다. Aidan McLau라는 deep learning influencer의 essay에 이런저런 내용이 있는데 (다 받아들이란 얘기는 아니다). 나도 일부는 공감이 되는 부분이 있다.
- Updated)
Reasoning vs Memorization
누군가는 LLM이 하는 일은 단순히 memorization이라고 한다. reasoning 으로 보이는 것들도 결국에 memorization이 된다. 그렇다면 LLM이 reasoning을 한다는 것도 실제로는 memorization인 걸까? CoT를 고안한 Jason wei도 CoT도 pre-training시 본 chain을 retrieve하는 것에 가깝다고 했다. What Do Learning Dynamics Reveal About Generalization in LLM Reasoning?같은 paper를 보면 하지만 memorization이 되는 과정에서도 난이도?나 여러요소에따라 memorization을 하기 전의 pre-memorization을 측정할 수 있고 이것이 실제 test accuracy와 관련되어 있다고 주장한다.
o1 is not the only one way
reasoner를 학습하는 방법은 o1이 유일한 것이 아닐 수 있다고 noam brown은 얘기한다.
 Fig. tweet link
Fig. tweet link
What's Next Step?
openai가 agi로 가기 위한 길은 뭘까. 사실 이들은 얼마 전에 MLE-bench라는 걸 냈다. kaggle식의 task description과 dataset이 주어지면 실제로 model을 학습하고 testbed에서 평가를 거듭하면 model을 개선해나가며 금메달을 얼마나 땄는지를 보는 건데, prototype임에도 불구하고 o1은 MLE-bench에서 꽤 좋은 성능을 보였다.
agi로 가는길에 사람들이 재귀 개선 얘기를 많이 하는데, task가 주어지면 data를 알아서 수집하고 deep neural network에 대한 optimization를 수행하면서 model을 계속 update한다면 길이 보이지 않을까 해서 openai가 이런 benchmark를 만든게 아닌가 싶다.
Continuous/ Latent Space for CoT
- (Coconut) Training Large Language Models to Reason in a Continuous Latent Space
- Compressed Chain of Thought: Efficient Reasoning Through Dense Representations
(tmp) some remarkable papers
Toward Self-Improvement of LLMs via Imagination, Searching, and Criticizing
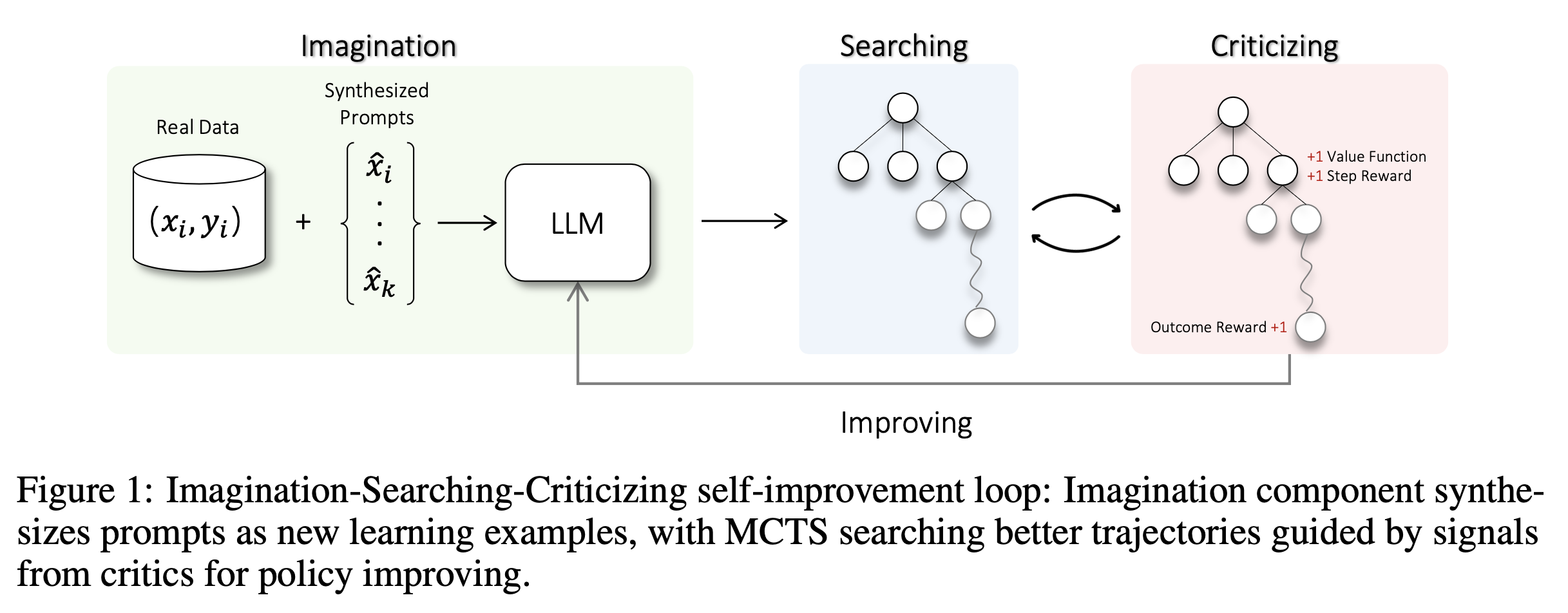 Fig.
Fig.
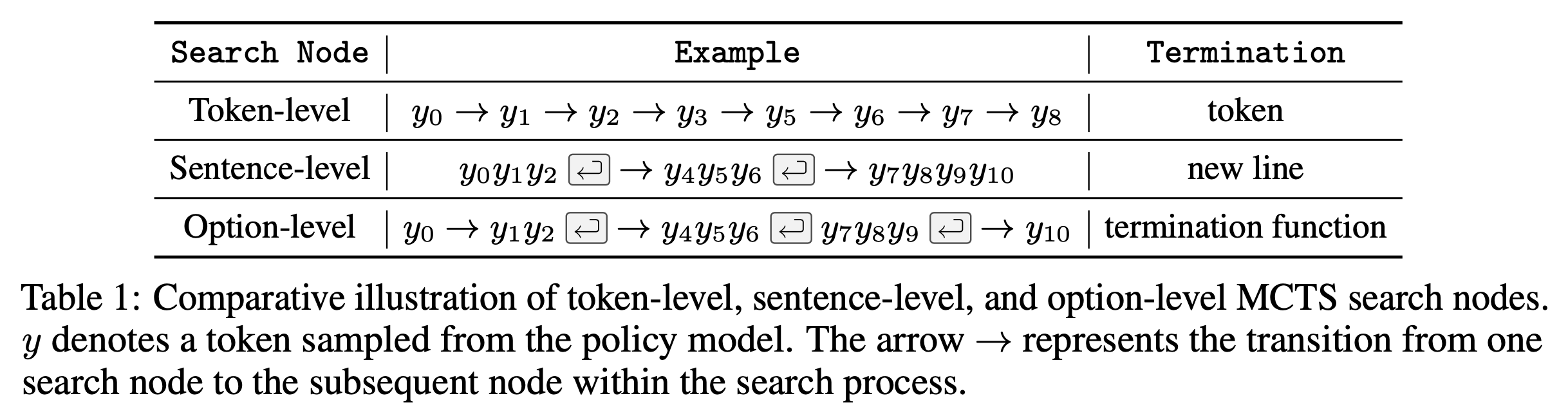 Fig.
Fig.
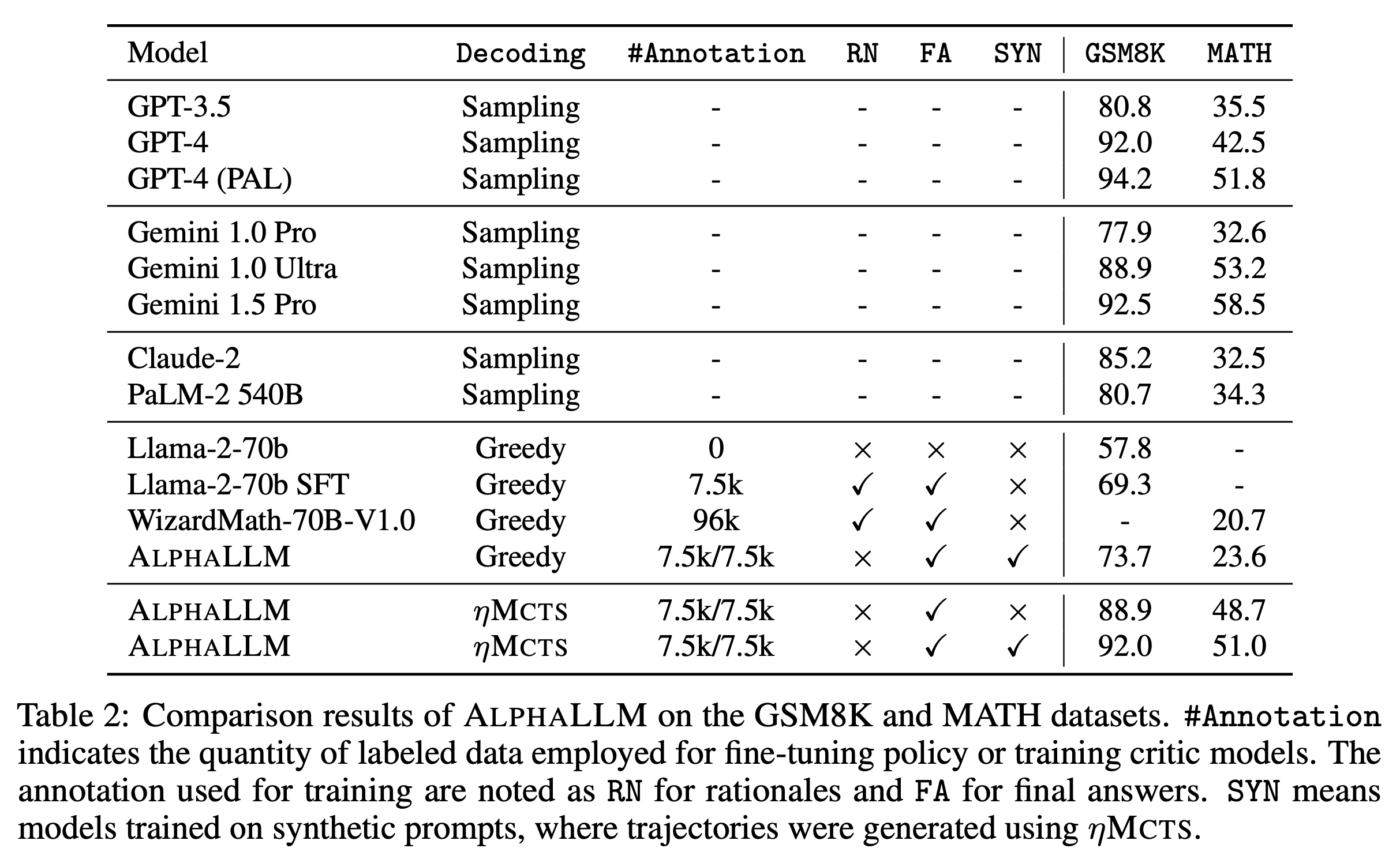 Fig.
Fig.
CPL: Critical Plan Step Learning Boosts LLM Generalization in Reasoning Tasks
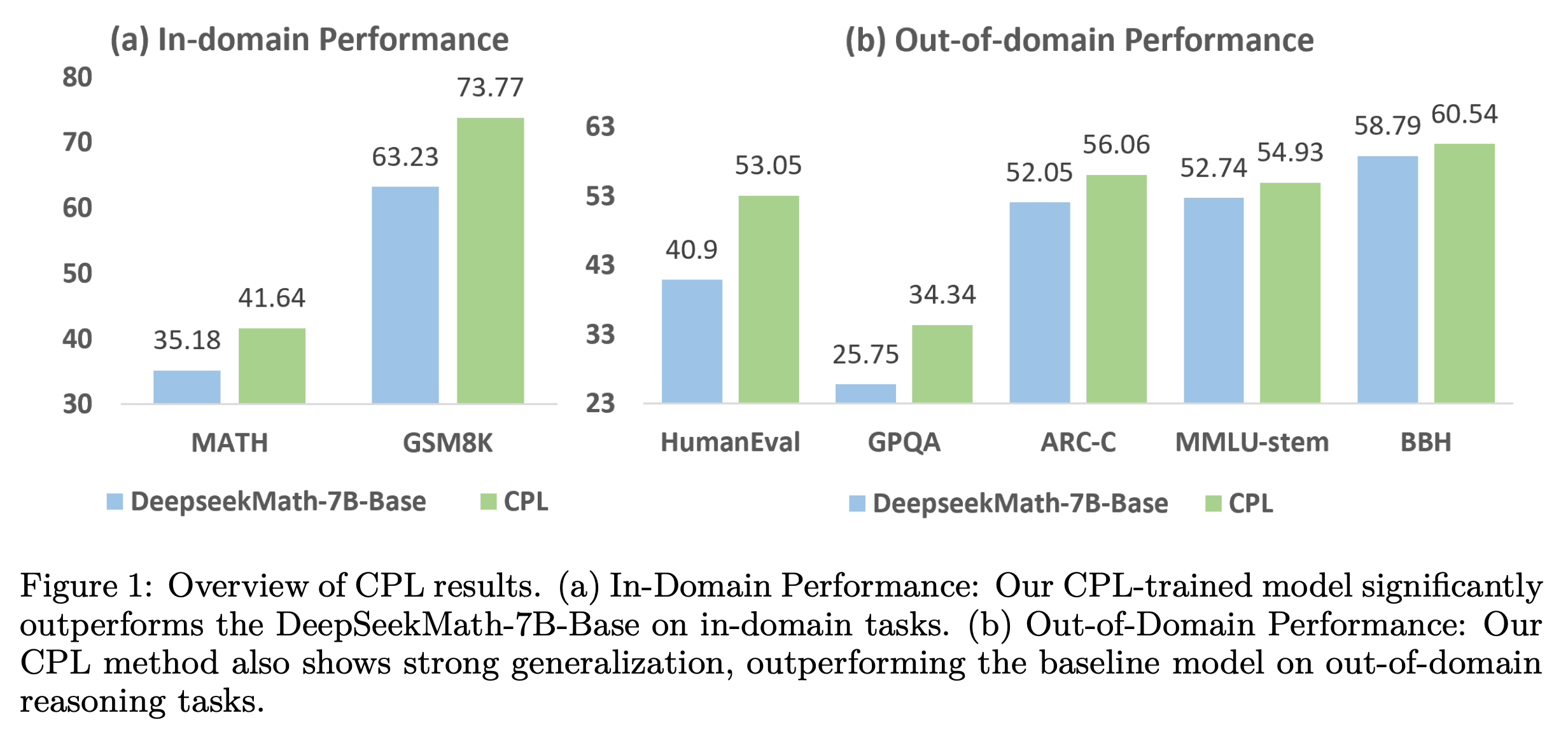 Fig.
Fig.
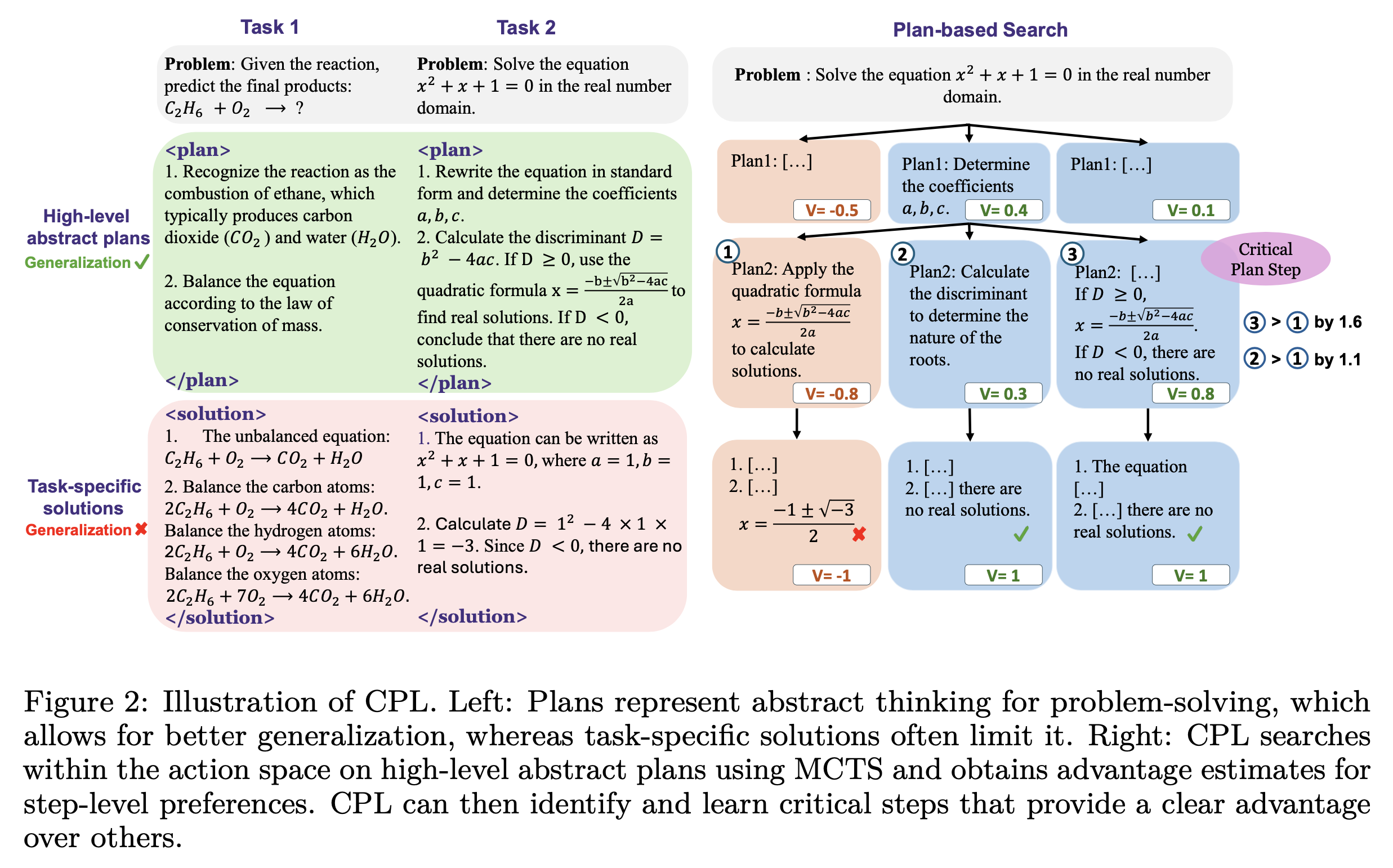 Fig.
Fig.
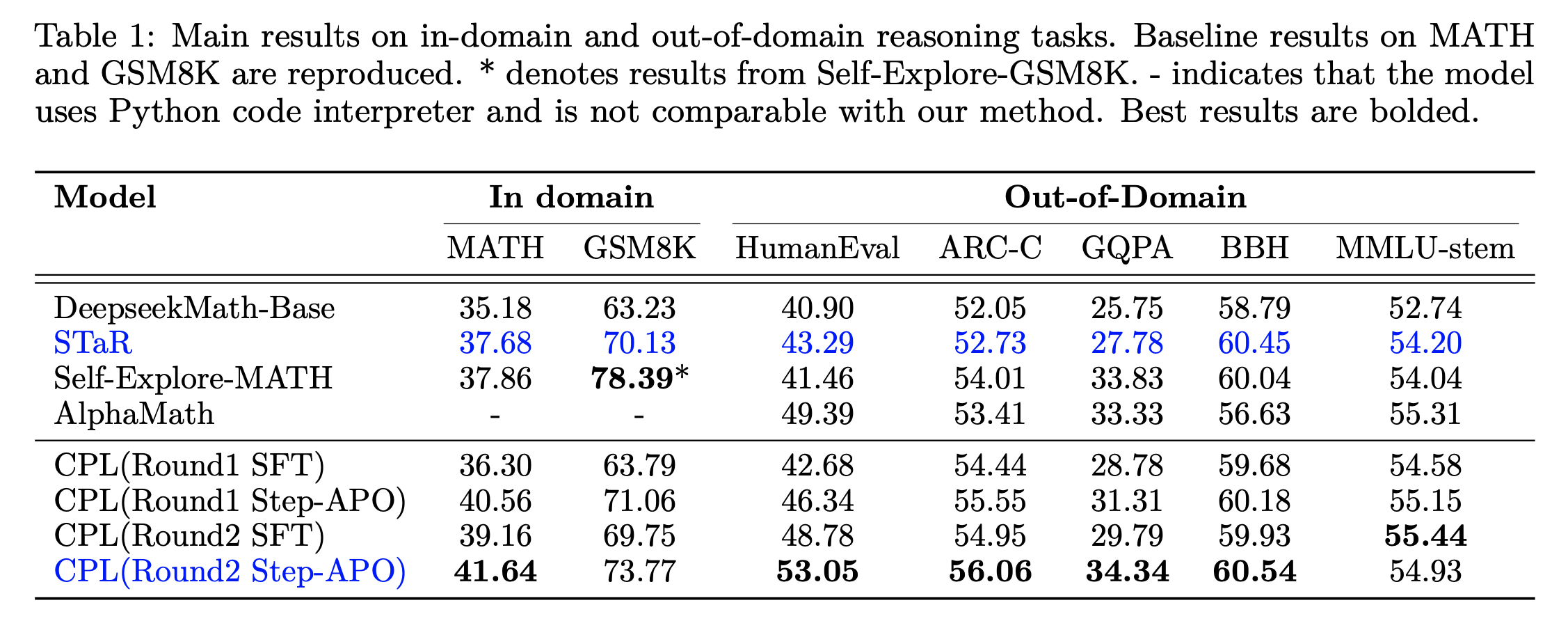 Fig.
Fig.
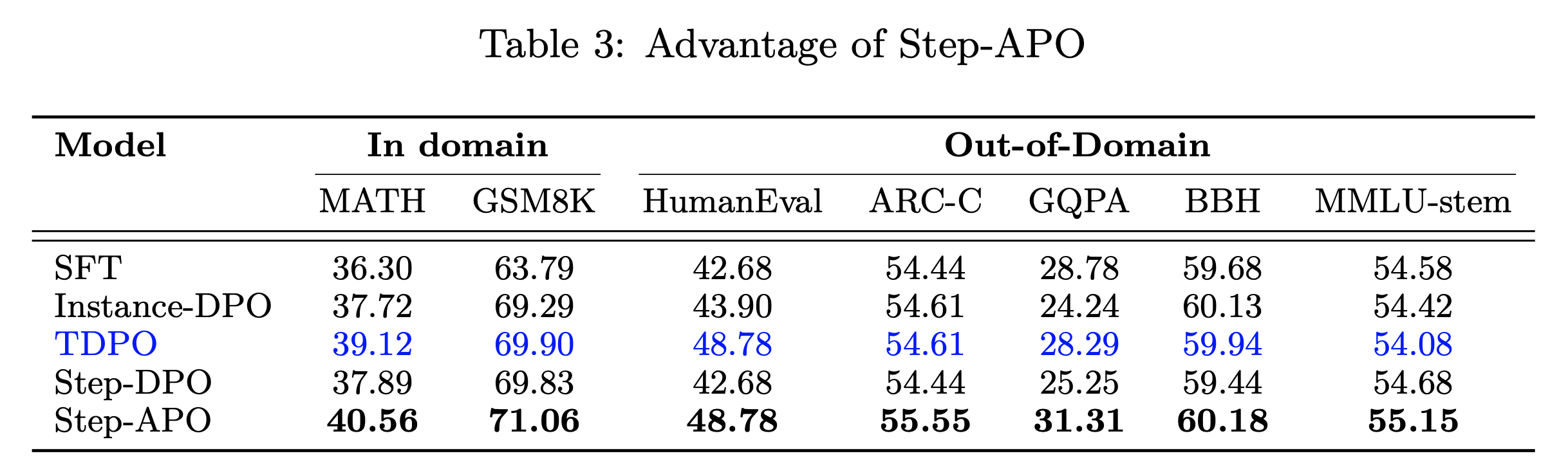 Fig.
Fig.
O1 Replication Journey Series from Generative AI Research Lab (GAIR)
TBC
Generative Flow Network (GFlowNet)
“LLM이 답변을 생성하기 전에 latent variable을 여러 개 생성해서 hierarchical VAE나 diffusion처럼 점진적으로 고퀄리티 답변을 만들면 안될까”라는 생각을 한 적이 있다. Chain of Thought (CoT) reasoning를 latent variable로 생성하게 하고 서비스를 할 때에는 이를 숨기는 것이다. 이런 keyword로 paper들을 찾는 중 Amortizing intractable inference in large language models라는 걸 발견했다.
 Fig. GFlowNet으로 LLM의 CoT를 latent variable modeling 할 수 있다고 한다.
Fig. GFlowNet으로 LLM의 CoT를 latent variable modeling 할 수 있다고 한다.
GFlowNet이란 걸 처음 들었을 때 뭔가 Transformer architecture처럼 새로운 Neural Network (NN) 구조를 떠올리기 쉽지만, 이는 maximum likelihood training이나 reward maximizing policy optimization 같은 Learning Algorithm를 의미한다. (즉 다른 말로 GFlowNet learning objective를 쓴다고 말할 수 있으며, GFlowNet은 RL의 한 종류이다)
사실 나는 latent variable로 CoT하는 것에 대해 생각했기 때문에 GFlowNet에 대해 처음 알게 되었지만,
edward hu가 워낙 유명하고 똑똑한 연구자이며 (LoRA, muP 등의 저자),
PhD 기간 동안 거의 gflownet 위주의 연구만 했고,
최근 gpt-o1이 공개되고 하필 해당 paper의 1저자인 edward가 아래와 같은 tweet을 남겼기에 연관이 있다고 생각했다.
(사실 작년에 이 paper를 처음 접했는데, GFlowNet을 적당히 이해하고 fine-tuning해볼까 싶다가도 use case가 diversity가 중요한 drug discovery같은 것이길래 논문도 어렵고 해서 더 파지는 못했다…)
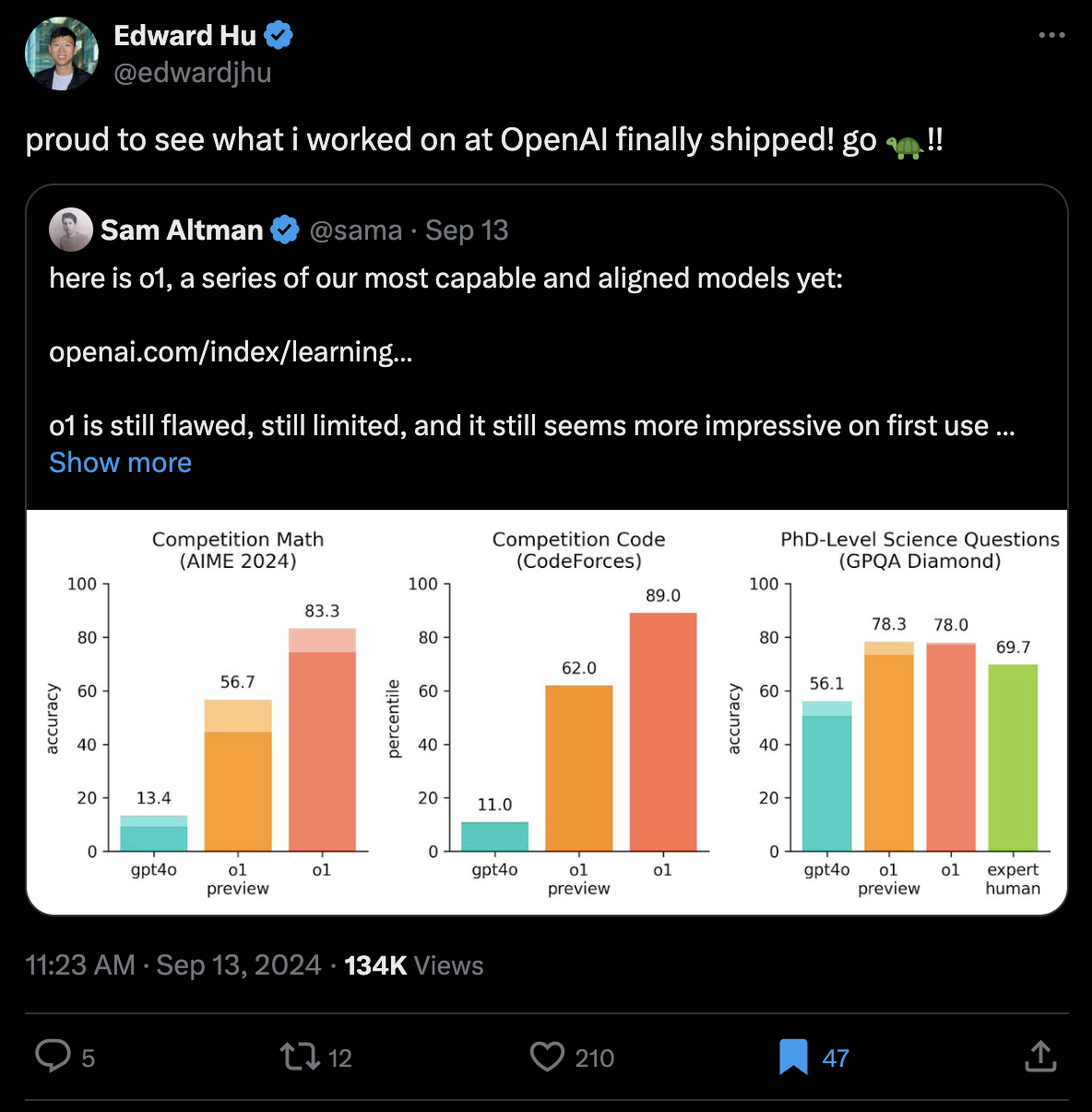 Fig.
Fig.
전반적인 GFlowNet의 내용은 아래와 같이 요약할 수 있을 것 같다.
- maximum likelihood training이나 reward maximizing policy optimization 같이 가장 likely한 답변을 내도록 학습되는 방식과 다르게 GFlowNet은 diversity seeking으로 학습된다.
- distribution matching 이라고 하는데, 사실상 MLE도 true data distribution과의 KL divergence인데 무슨 차이가 있는지 보자.
- application으로 CoT reasoning을 latent variable modeling할 수 있다.
- GFlowNet fine-tuning을 한 결과 higher likelihood인 답변을 내면서도 temperature가 매우 높거나, diverse beam search를 하는 것 보다 더 diversity가 높았다고 한다.
- task가 좀 한정적이다.
+Updated) 24. 12. 20. o3 is here
매년 xmas, NIPS 대목에 frontier lab들은 자신들의 최신 기술이나 product를 공개하곤 한다. openai chatgpt가 2022년 12월에 발표된 것도 그렇고. openai는 2024년에는 shimpas라고 해서 주말을 제외하고 12일간 새로운 feature나 model들을 공개하기로 했다. 첫 날이 o1 preview를 넘은 o1 pro 공개에 대한 발표였다면, 마지막날은 gpt-4.5나 gpt-5가 나올 것이라는 예상과 다르게 o3가 나왔다. (o2가 아닌 이유는 상표권 문제라고 함)
성능이야 당연히 압도적이다.
Deliberative Alignment
day 12의 live를 보다보면 sam altman이 o1 like model을 사용해서 safer prompt-answer에 대한 판단을 내리게 해서 정렬하는 방법인 Deliberative alignment를 현재 진행하고 평가중이라는 언급을 한다 (paper 참고).
References
- o1 focused things
- Learning to Reason with LLMs
- Tweet from Noam Brown
- Parables on the Power of Planning in AI: From Poker to Diplomacy: Noam Brown
- Learning to Cooperate and Compete via Self Play from Noam Brown
- Self-Play by Noam Brown
-
Combining Deep Reinforcement Learning and Search for Imperfect-Information Games from Noam Brown
- Reverse-o1: Reverse Engineering of OpenAI o1(Part 1) from Zhangjunlin
-
Reverse-o1: Reverse Engineering of OpenAI o1(Part 2) from Zhangjunlin
- Reverse engineering OpenAI’s o1 from Nathan Lambert
-
MIT EI seminar, Hyung Won Chung from OpenAI. “Don’t teach. Incentivize.” from Hyung Won Chung
- LLM Reasoning: Key Ideas and Limitations from Denny Zhou
- Resources for Planning, MCTS and AlphaGo
- Alpha Zero and Monte Carlo Tree Search from Josh Varty
- Alphago
- (AlphaGo) Mastering the game of Go with deep neural networks and tree search
- (AlphaGo Zero) Mastering the game of Go without human knowledge
- lecture slide from Katerina Fragkiadaki
- How alphago works from Seungwhan Moon
- alphago/alphago-zero from keita watanabe
- 알파고 논문리뷰 3편 from Seungeun Rho
- 알파고 제로(Zero) 논문 리뷰 from Seungeun Rho
- From AlphaGo to MuZero - Mastering Atari, Go, Chess and Shogi by Planning with a Learned Model
- Using MuZero’s Tree Search To Find Optimal Tic-Tac-Toe Strategy in a Spreadsheet
- Papers
- Neurips 2024 Tutorial: Beyond Decoding: Meta-Generation Algorithms for Large Language Models
- Test-Time (Inference) Scaling Law
- Scaling Scaling Laws with Board Games
- Inference Scaling Laws: An Empirical Analysis of Compute-Optimal Inference for Problem-Solving with Language Models
- Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters
- Inference Scaling ‘F’Laws: The Limits of LLM Resampling with Imperfect Verifiers
- tmp
- Generative Language Modeling for Automated Theorem Proving
- Formal Mathematics Statement Curriculum Learning
- Prover-Verifier Games improve legibility of LLM outputs
- STaR: Bootstrapping Reasoning With Reasoning
- ReAct: Synergizing Reasoning and Acting in Language Models
- Solving olympiad geometry without human demonstrations
- Scaling Relationship on Learning Mathematical Reasoning with Large Language Models
- Language Models are Hidden Reasoners: Unlocking Latent Reasoning Capabilities via Self-Rewarding
- Training Chain-of-Thought via Latent-Variable Inference
- VinePPO: Unlocking RL Potential For LLM Reasoning Through Refined Credit Assignment
- Thinking LLMs: General Instruction Following with Thought Generation
- Quiet-STaR: Language Models Can Teach Themselves to Think Before Speaking
- Toward Self-Improvement of LLMs via Imagination, Searching, and Criticizing
- CPL: Critical Plan Step Learning Boosts LLM Generalization in Reasoning Tasks
- RL on Incorrect Synthetic Data Scales the Efficiency of LLM Math Reasoning by Eight-Fold
- Self-Improvement in Language Models: The Sharpening Mechanism
- PPO, DPO and credit assignment problem
- Self-Improved LLM
- Process Reward Model (PRM)
- Self-Correction
- Training Language Models to Self-Correct via Reinforcement Learning
- When Can LLMs Actually Correct Their Own Mistakes? A Critical Survey of Self-Correction of LLMs
- Self-Refine: Iterative Refinement with Self-Feedback
- Accessing GPT-4 level Mathematical Olympiad Solutions via Monte Carlo Tree Self-refine with LLaMa-3 8B
- Continuous/Latent CoT
- o1 replication
- O1 Replication Journey: A Strategic Progress Report – Part 1
- O1 Replication Journey – Part 2: Surpassing O1-preview through Simple Distillation, Big Progress or Bitter Lesson?
- o1-Coder: an o1 Replication for Coding
- Scaling of Search and Learning: A Roadmap to Reproduce o1 from Reinforcement Learning Perspective
- GFlowNet
- Flow Network based Generative Models for Non-Iterative Diverse Candidate Generation
- GFlowNet Foundations
- Amortizing intractable inference in large language models
- Amortizing intractable inference in diffusion models for vision, language, and control
- GFlowNet-EM for learning compositional latent variable models
- Flow of Reasoning:Training LLMs for Divergent Problem Solving with Minimal Examples
- GDPO: Learning to Directly Align Language Models with Diversity Using GFlowNets
- GFlowNet Fine-tuning for Diverse Correct Solutions in Mathematical Reasoning Tasks
- Others