(yet) Learn From o1 (how to make LLM reason and plan?)
13 Oct 2024< 목차 >
tmp
솔직히 말해서 AlphaGo로부터 inference시 parallel computing degree와 time을 늘릴 수록 성능이 좋아진 다는 직관은 모두가 가지고 있었을 것이다. 그러나 수학, 과학 영역에서 LLM의 inference budget을 늘린다고 실제로 추론 성능이 좋아질까?에 대해 betting하라고 하면 감히 할 사람이 몇이나 됐을까?
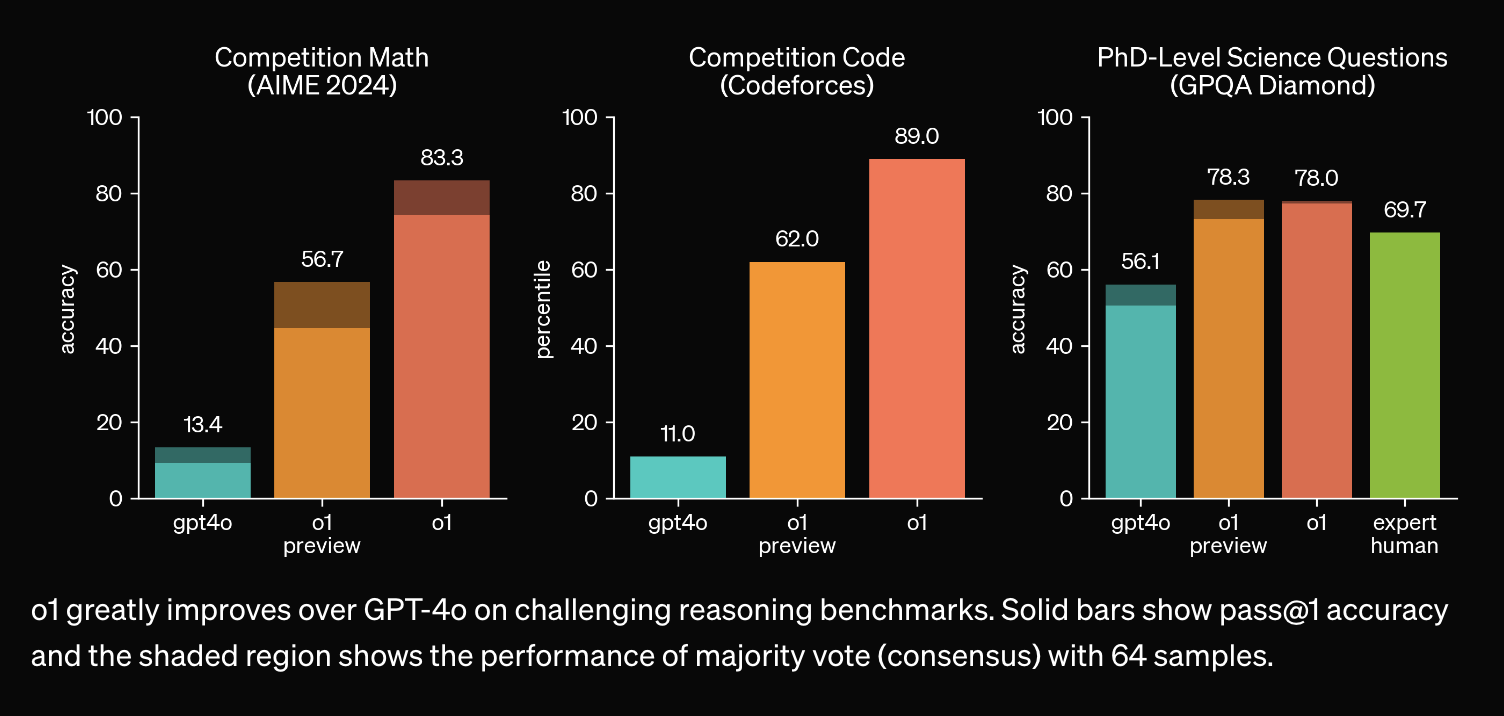
STEM 분야 성능을 높히기 위해, 더 자세하고 논리적인 답변을 듣기 위해 reasoning capability를 높히려는 STaR: Bootstrapping Reasoning With Reasoning같은 노력은 계속 있어왔지만 o1의 planning 능력과 problem solving 능력은 현재까지 math/humaneval/ifeval 등의 benchmark에서 gpt-4에 비비는 qwen 2.5등과 차원이 다르다.
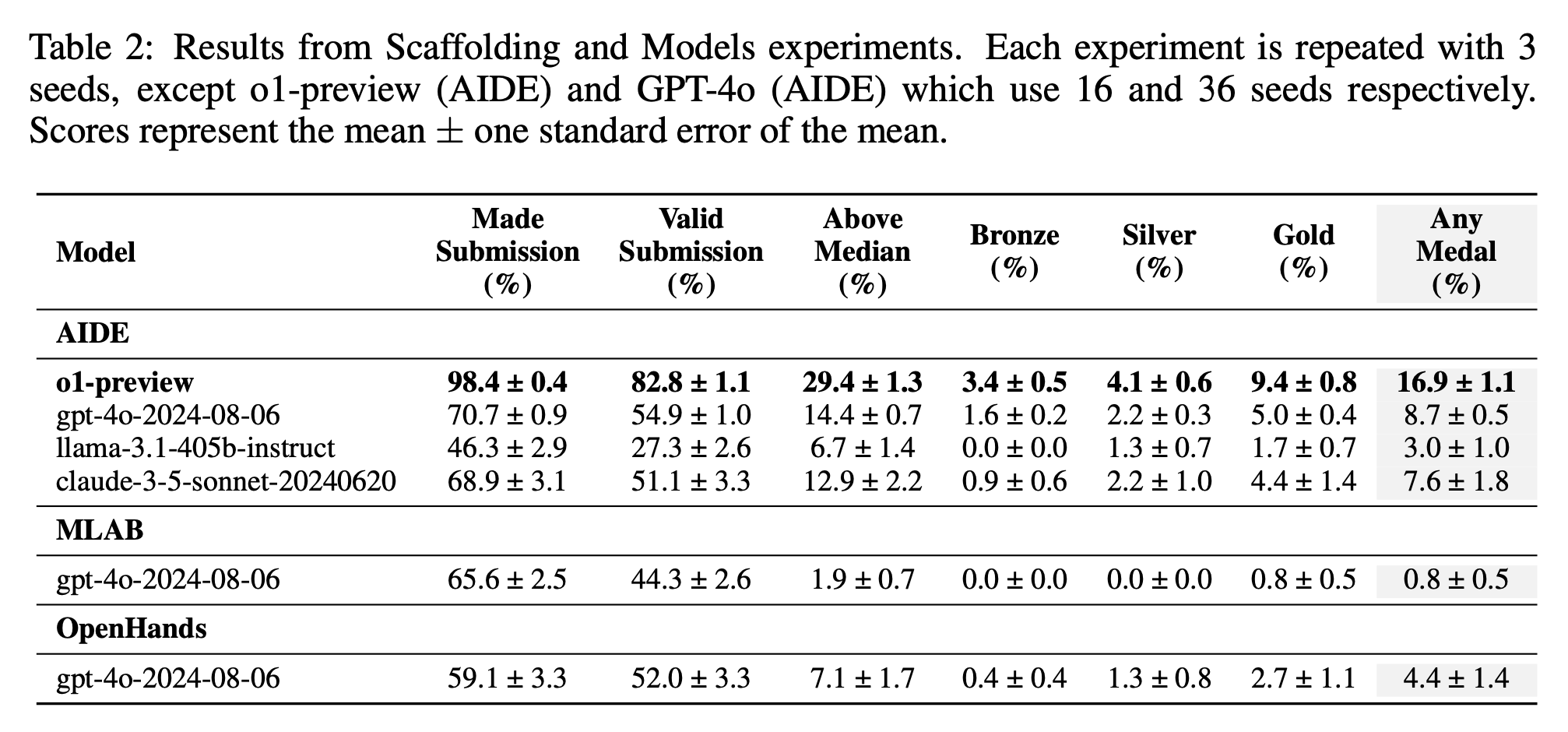
o1은 최근 공개된 MLE-bench라는 kaggle에서 Machine Learning Engineer (MLE)들이 csv file로 된 data sheet를 받아 제출하여 medal을 얼마나 땃는지를 측정하는 benchmark에서도 압도적인 성능을 보인다.
아마 OpenAI, Anthropic, GDM, x.ai 등은 서로 이직이 잦기 때문에 알음알음 알고있는 것 같고, GDM도 원래도 연구를 열심히 하고 있었던 것으로 보이나 새로 설립한 xai 에서는 아예 reasoning 쪽을 전문으로 보는 ai engineer를 뽑으려고 하는 것 같다.
Yuhuai (Tony) Wu는 google에서 STaR, AlphaStar, AlphaGeometry등을 연구한 x.ai의 cofunder인데, 이 position에 대해 원하는 ideal capa는 cot, planning하는 방법을 LLM에 주입하는 것은 물론이거니와 large scale RL environment를 build하고 다룰 줄 아는 것이다. (engineering is all you need)

References
- Learning to Reason with LLMs
- MIT EI seminar, Hyung Won Chung from OpenAI. “Don’t teach. Incentivize.” from Hyung Won Chung
- Parables on the Power of Planning in AI: From Poker to Diplomacy: Noam Brown (OpenAI)
- Learning to Cooperate and Compete via Self Play from Noam Brown
- Self-Play by Noam Brown
- Combining Deep Reinforcement Learning and Search for Imperfect-Information Games from Noam Brown
- Improving mathematical reasoning with process supervision
- MLE-bench from OpenAI
- Rewarding Progress: Scaling Automated Process Verifiers for LLM Reasoning
- Training Language Models to Self-Correct via Reinforcement Learning
- VinePPO: Unlocking RL Potential For LLM Reasoning Through Refined Credit Assignment
- Thinking LLMs: General Instruction Following with Thought Generation