(WIP) DDPG, TD3 and SAC
07 Jan 2024< 목차 >
- Overview
- Deep Deterministic Poliy Gradient (DDPG)
- Twin Deplay DDPG (TD3)
- Soft Actor-Critic (SAC)
- Reference
Overview
이번 post의 goal은 SoftQ, DDPG, SAC 그리고 TD3 등의 algorithm에 대해 알아보는 것이다. CS285 lecture 8, Deep RL with Q-Functions post에서 DQN에 대해 다루다가 continuous action space를 가정하는 경우에는 어떤식으로 문제를 풀어야 하는가? 를 얘기하면서 DDPG, SAC에 대한 언급이 있었다.
각 algorithm들의 timeline을 보면 다음과 같은데,
- 1989년, Q-Learning
- 2005년, TD-Gammon (Online Q-Learning)
- 2010년, Double Q-learning
- 2013년, DQN
- 2014년, Deterministic Policy Gradient (DPG)
- 2015년, DDQN
- 2015년 9월, Continuous Control With Deep Reinforcement Learning (DDPG)
- 2018년 1월, Soft Actor-Critic (SAC)
- 2018년 2월, Twin Deplay DDPG (TD3)
OpenAI Spinning Up의 RL intro page를 보면 DDPG, SAC 그리고 TD3는 policy optimization 계열과 Q-Learning 계열의 hybrid 방식이라고 볼 수 있다. TRPO나 PPO 등, Actor-Critic 계열 algorithm들도 value function을 approximate 하므로 hybrid라고 생각할 수 있으나, 그렇게 구분짓지는 않는 것 같다.
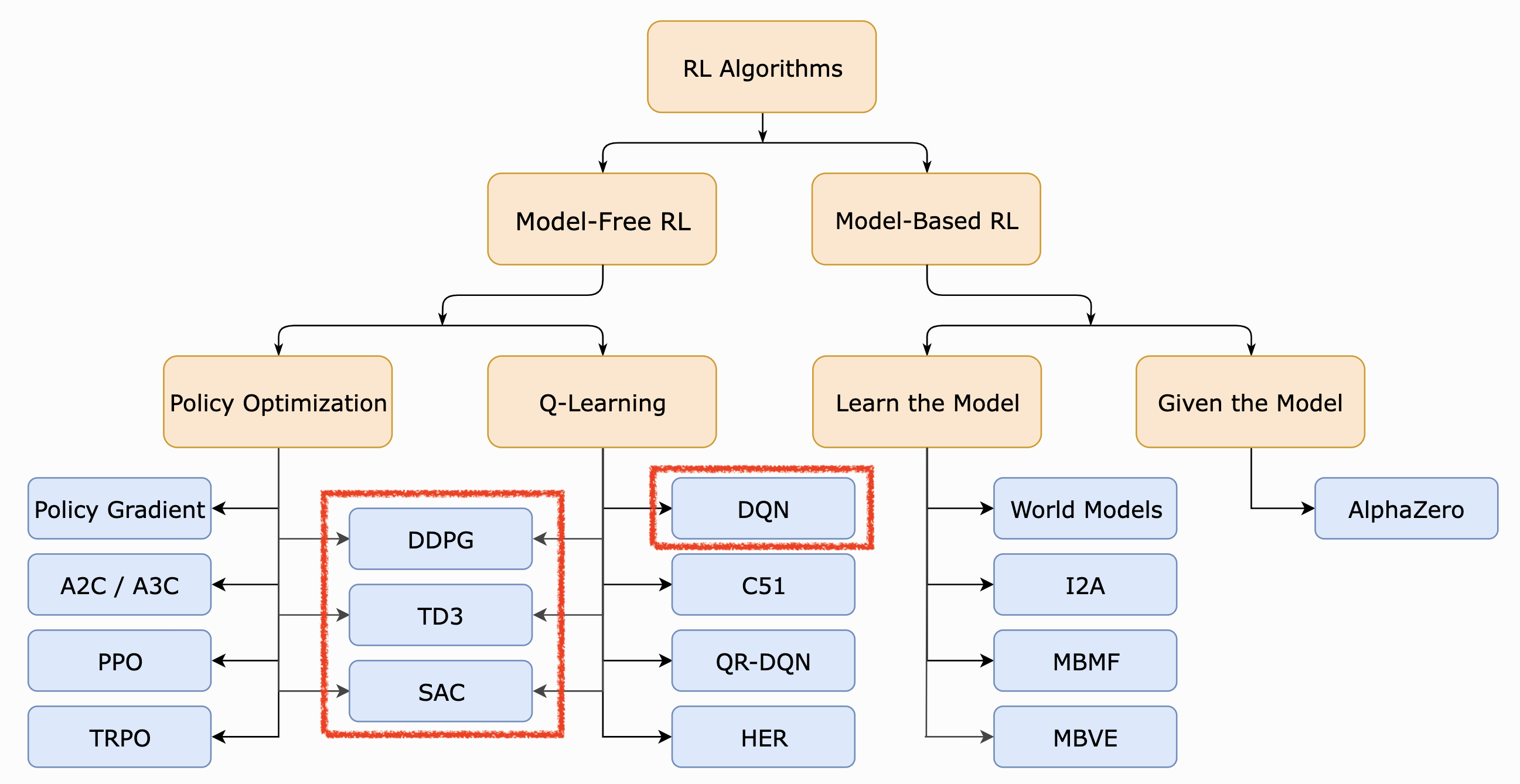 Fig. A non-exhaustive, but useful taxonomy of algorithms in modern RL from OpenAI Spinning Up
Fig. A non-exhaustive, but useful taxonomy of algorithms in modern RL from OpenAI Spinning Up
이번에는 Pieter Abbeel의 lecture slide를 통해 우리가 풀고자 하는 문제가 무엇인지 보자.
 Fig.
Fig.
먼저 TRPO, PPO를 깐다. PPO같은 trust region optimization method는 current policy의 주변부에서 원래의 objective function을 locally approximation한 function에 대해서 계산하여 한 step 안전하게 update 하는 것으로 VPG보다는 더 안전하게 optimal point를 향해 다가가지만 여전히 local한 부근에서만 먹히는 것으로, 다시말하면 old sample들을 활용해서 parameter를 update하는 데 한계가 있다고 한다고 지적한다.
그리고 DQN도 까는데, value-based method들이 명시적인 policy가 존재하지 않으며, RL objective를 directly optimize하는 것이 아니기 때문에 비교적 policy based method들 보다 덜 stable하다고 지적한다.
반면 DDPG와 SAC는
Deep Deterministic Poliy Gradient (DDPG)
Twin Deplay DDPG (TD3)
Soft Actor-Critic (SAC)
SAC는 2018년에 publish된 Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor에서 제안되었으며 5, 6장에서 다룬 Actor-Critic method의 off-policy version 라고 한다. SAC가 대표적인 off-policy algorithm 인 것도 중요하지만 continuous action space에 대해서도 많이 쓰이는 algorithm이라고도 한다.
SAC는 DDPG style apporach와 stochastic policy optimization의 중간쯤 되는 algorithm 으로,
이전 algotihm과 비교해 가장 큰 변화는 DDPG의 objective에 entropy를 maximize하는 term을 추가한 것이다.
즉 Entropy-Regularized RL Objective를 optimize한다.
 Fig.
Fig.
한 편, PPO같은 policy optimization method에서도 entropy regularizer를 추가하는 것은 흔한 approach인 것 같다. (Understanding the Impact of Entropy on Policy Optimization같은 paper를 참고하면 좋을 듯)
SAC같은 algorithm을 Maximum Entropy RL method 라고도 부르는 것 같은데, 어렴풋이 exploration을 권장하게 하면서 더 많은 state와 action을 발견한다는 점에서 working할 것이라 생각이 들지만 왜 entropy를 maximizing하는 것이 off-policyness에 도움이 된다는 걸까?
Soft Policy Iteration
먼저 SAC를 이해하기 위해서는 Soft Policy Iteration (SPI)이라는 개념에 대해 알아야 한다.
(TRPO paper에서도 Conservative Policy Iteration (CPI)부터 빌드업을 하는데 비슷한 맥락일 수 있겠다)
 Fig.
Fig.
SPI란 무엇일까?
Pseudo Code for SAC
아래는 SAC algorithm을 구현한 pseudo code이다.
 Fig. Source from here
Fig. Source from here
Reference
- Lectures
- Others
- DDPG vs PPO vs SAC: when to use?
- OpenAI Spinning up
- 강화학습 논문 정리 6편 : The Problem With DDPG 논문 리뷰