(CS285) RL with Sequence Models & Language Models
13 Nov 2023이 글은 UC Berkeley 의 교수, Sergey Levine 의 심층 강화 학습 (Deep Reinforcement Learning) 강의인 CS285를 듣고 작성한 글 입니다.
- 2023 CS285 Lecture 21
- Youtube Video
- Lecture Slide
전년도 까지만 해도 Lecture 20이 Inverse RL (IRL)을 다루고 Lecture 21의 주제는 Transfer Learning and Multi-Task Learning 였는데, human aligned chatbot인 ChatGPT가 너무나 큰 영향력을 지녔기에 IRL의 extension인 RLHF를 다루지 않을 수 없었던 것 같습니다.
Large Language Model (LLM)과 RLHF에 대한 내용은 제 blog에도 따로 post를 작성했으니 나중에 참고하셔도 좋을 것 같습니다.
< 목차 >
Overview
전반적인 내용은 “Sequence Modeling이 기존 RL과 어떻게 다른가?”, “다르다면 Sequence Modeling의 일종인 Langugage Modeling은 어떻게 풀어야 하며 value-based, policy-based, model-based 등의 algorithm들 중에서 어떤 선택을 해야할까?” 등으로 이루어져 있습니다.
먼저 Sequence Modeling은 Partially Observed Markov Decision Process (POMDP)로 기존의 state를 쓰던 RL setting과는 다른 점이 있다는 얘기부터 시작해서
 Fig. PART 1
Fig. PART 1
대표적인 policy-base method인 Proximal Policy Optimization (PPO)를 사용해서 학습하는 RLHF의 기본적인 setting부터
 Fig. PART 2
Fig. PART 2
Value-based, Offline RL로도 RLHF를 할 수 있는지? 까지 다룹니다.
 Fig. PART 3
Fig. PART 3
아무래도 RL분야의 대세가 Offline RL이며 Sergey 본인이 Offline RL for Natural Language Generation with Implicit Language Q Learning (ILQL)등의 교신저자이기 때문에 아예 part3를 value-based + offline으로 따로 뺀 것 같습니다.
이제 POMDP 얘기부터 간단하게 해보도록 하겠습니다.
POMDP
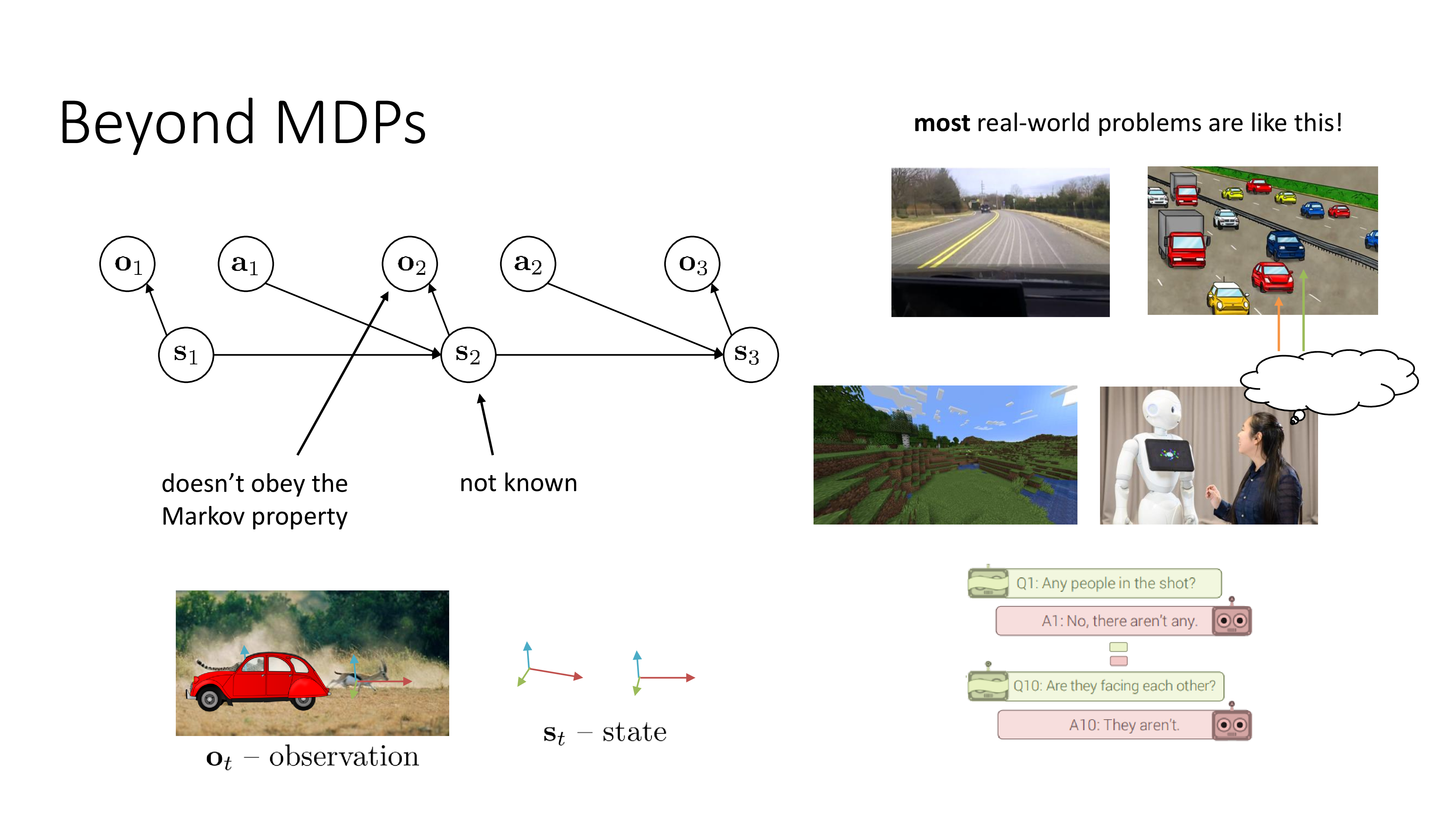 Fig.
Fig.
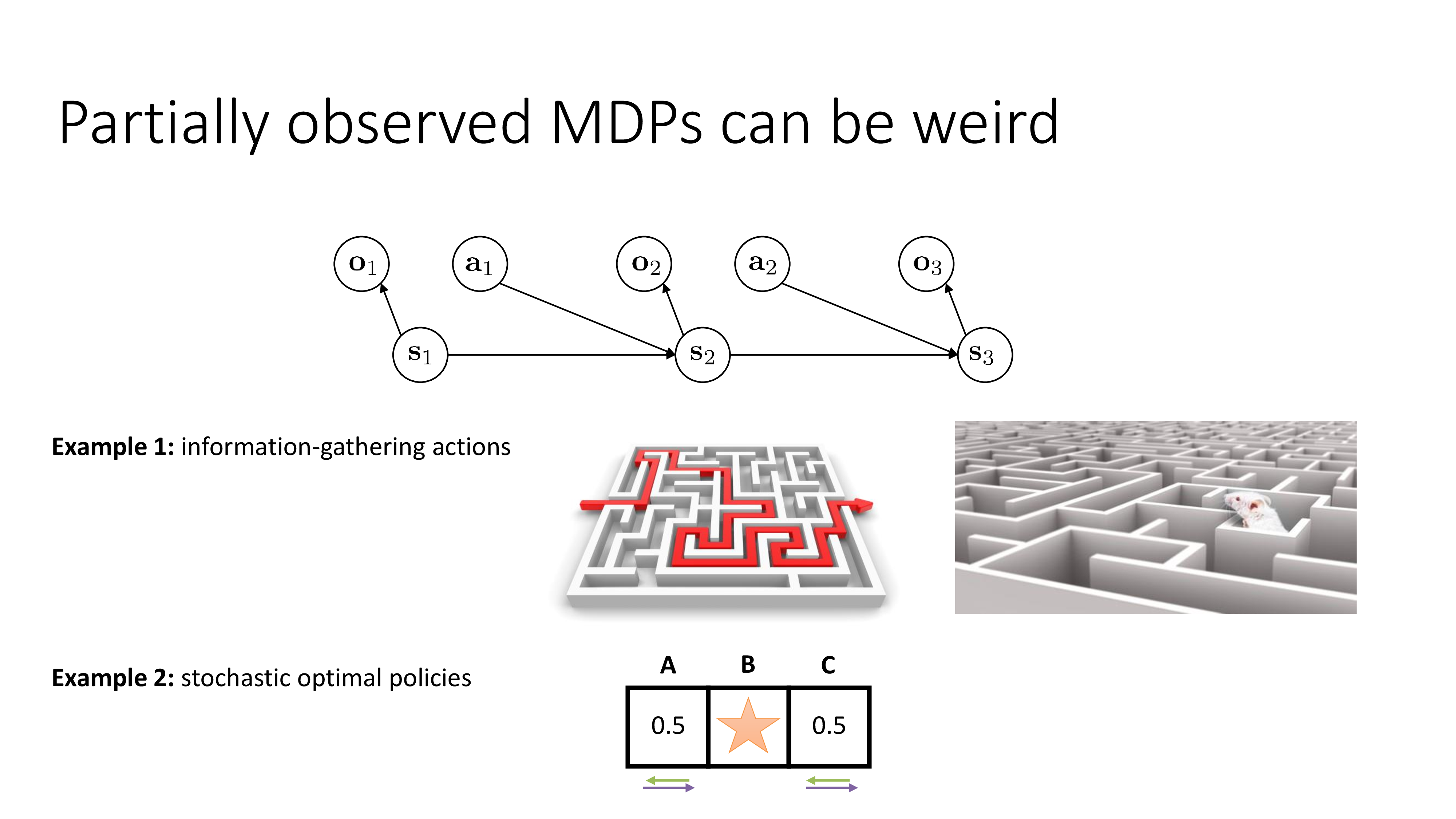 Fig.
Fig.
 Fig.
Fig.
 Fig.
Fig.
 Fig.
Fig.
 Fig.
Fig.
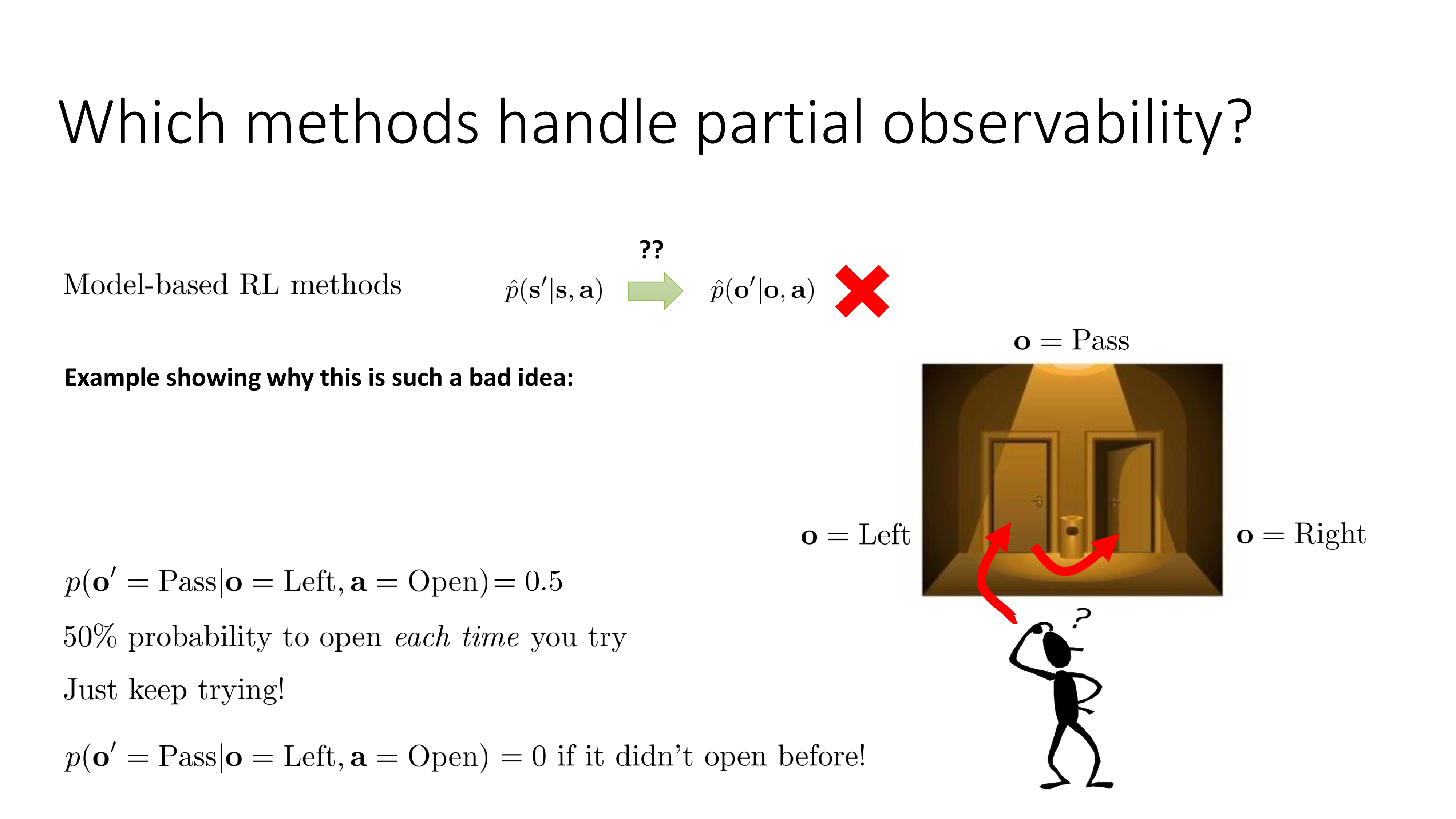 Fig.
Fig.
 Fig.
Fig.
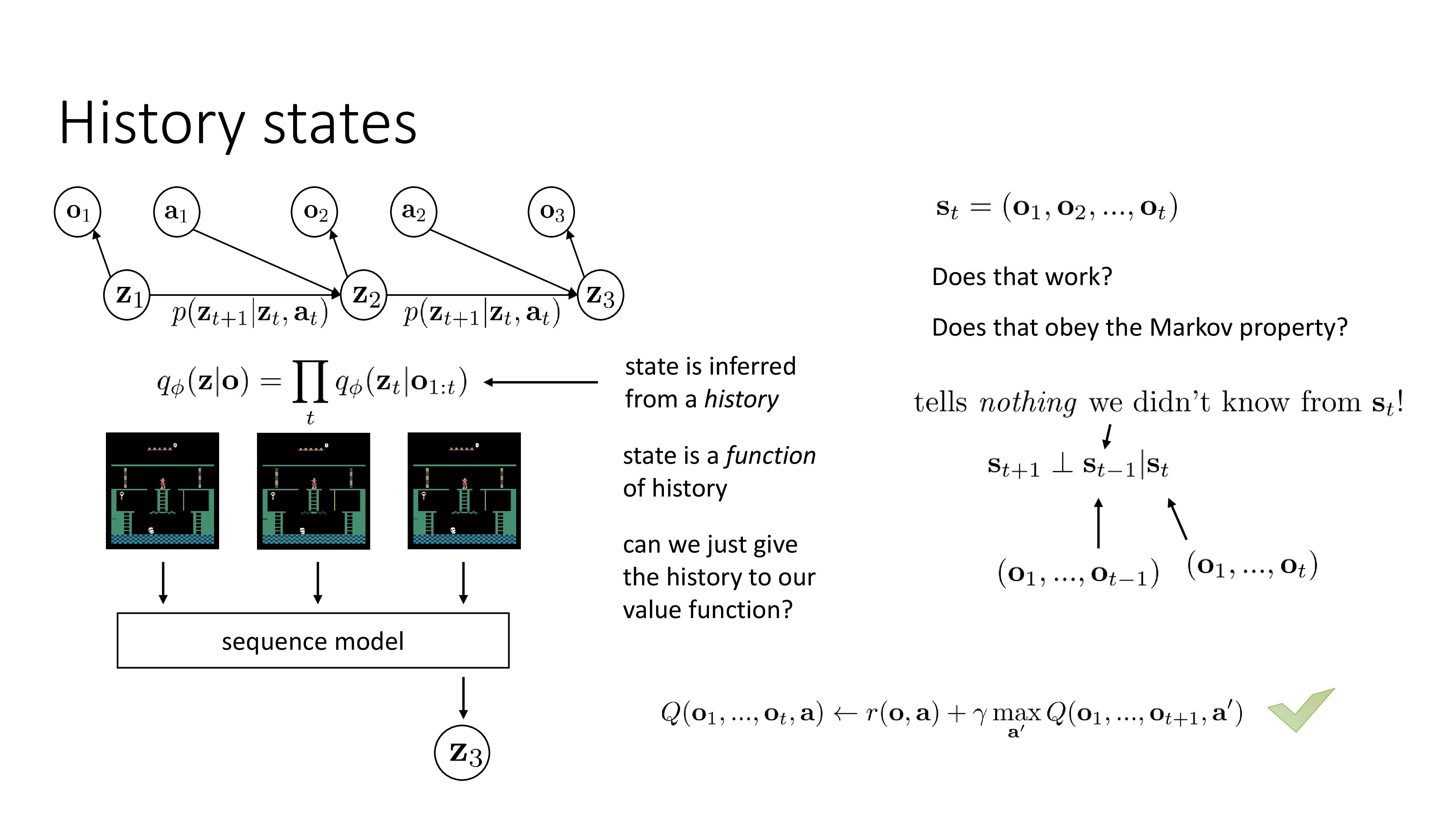 Fig.
Fig.
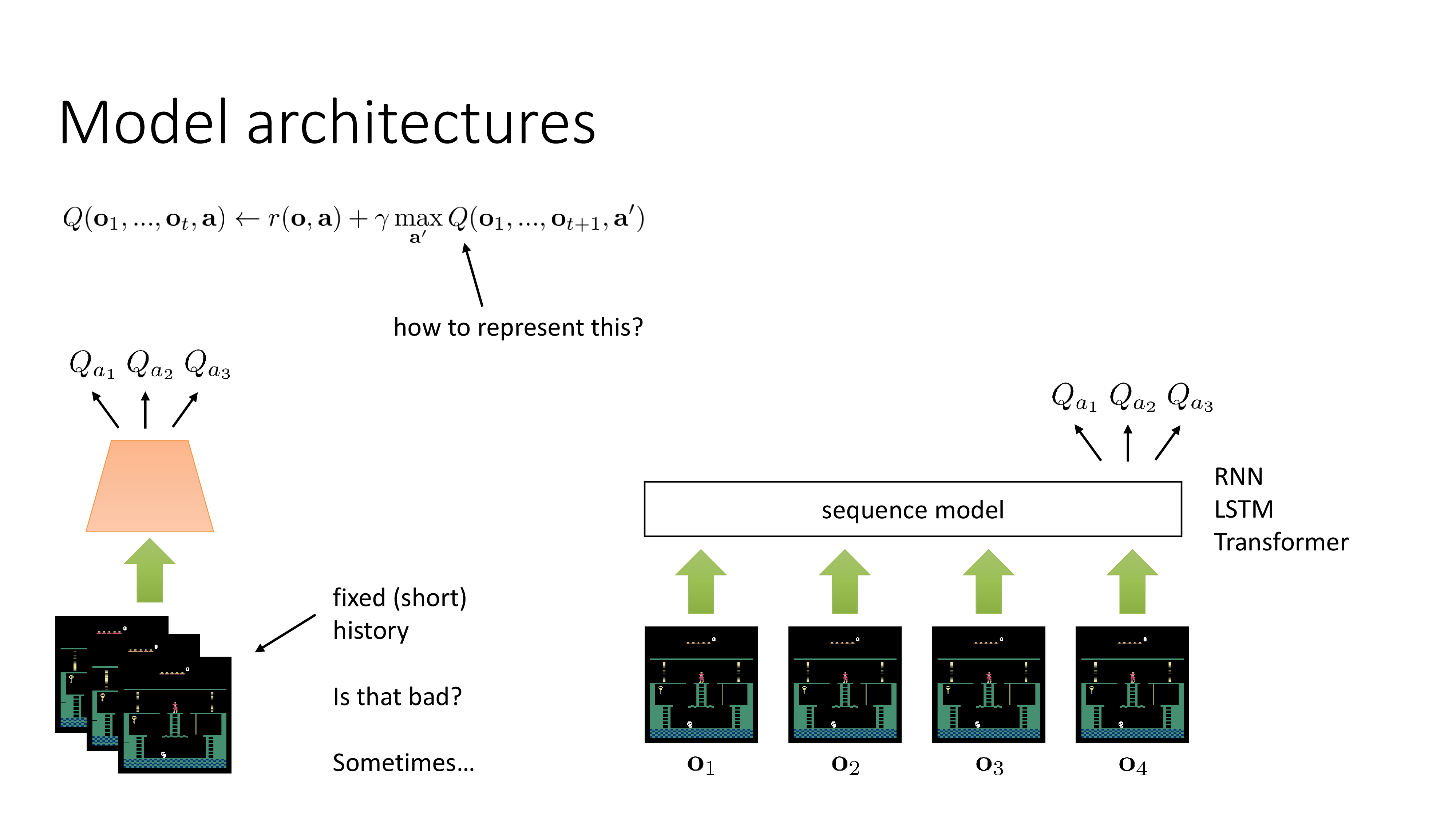 Fig.
Fig.
 Fig.
Fig.
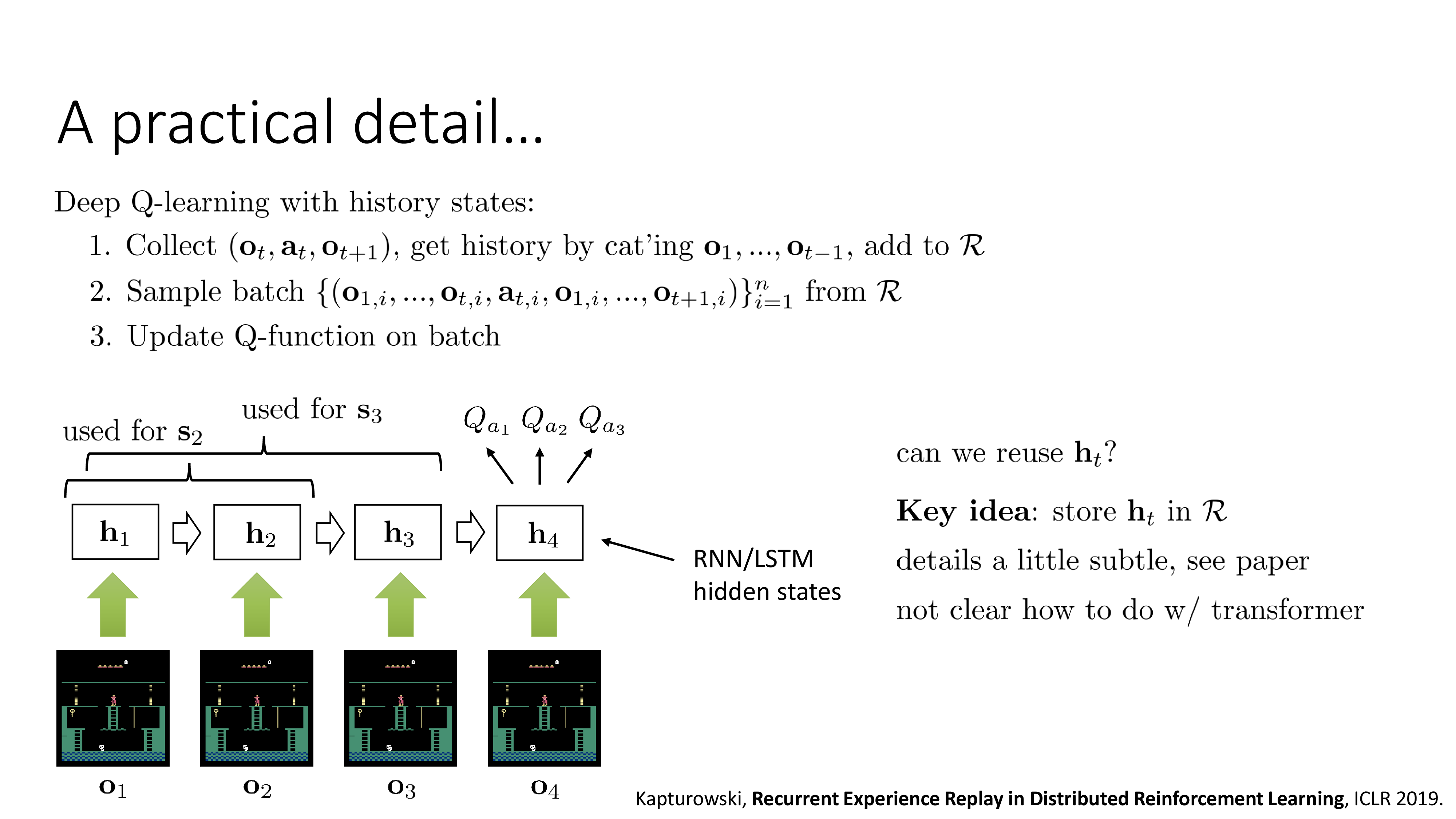 Fig.
Fig.
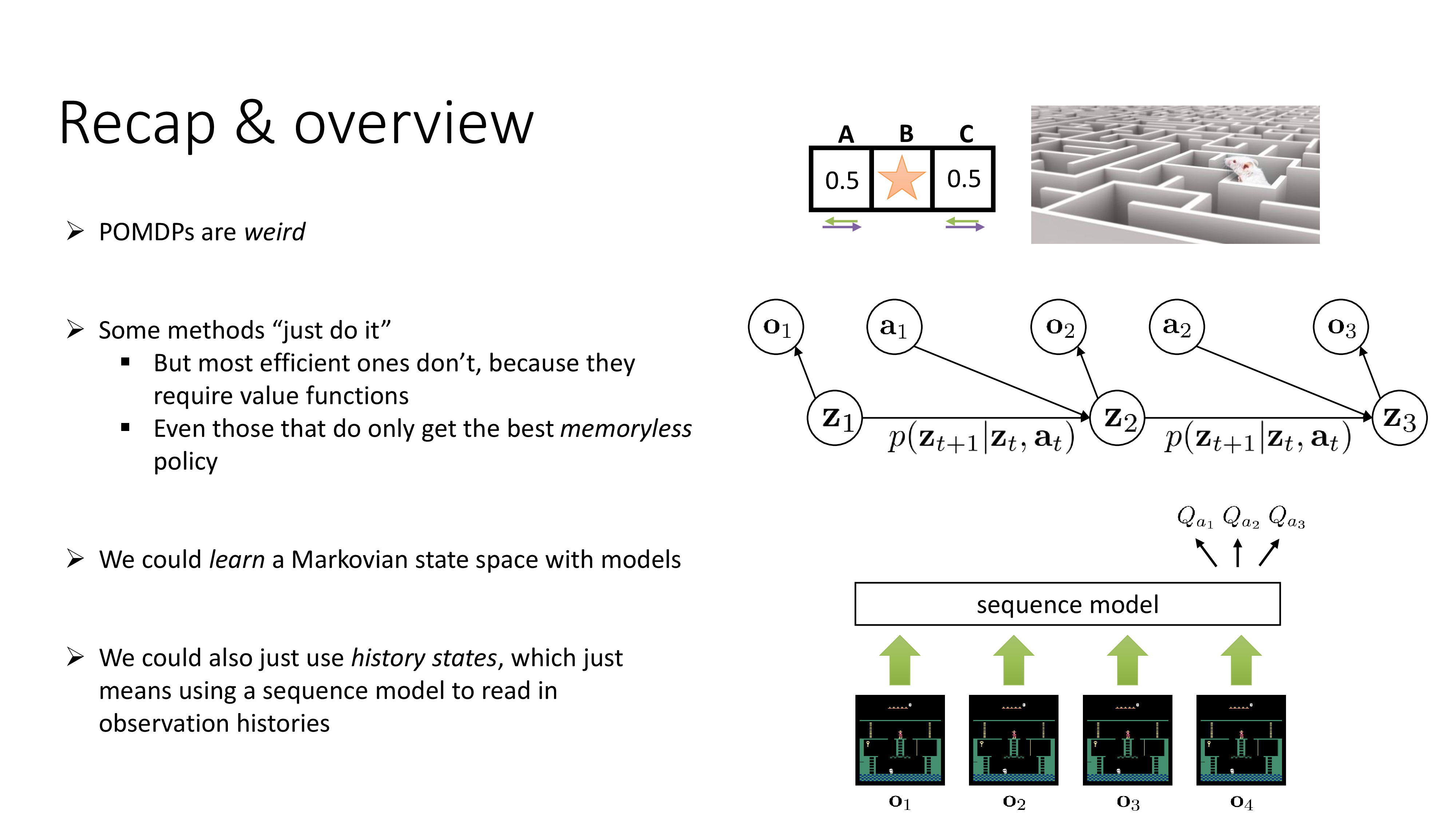 Fig.
Fig.
RL and Language Models
Fig.
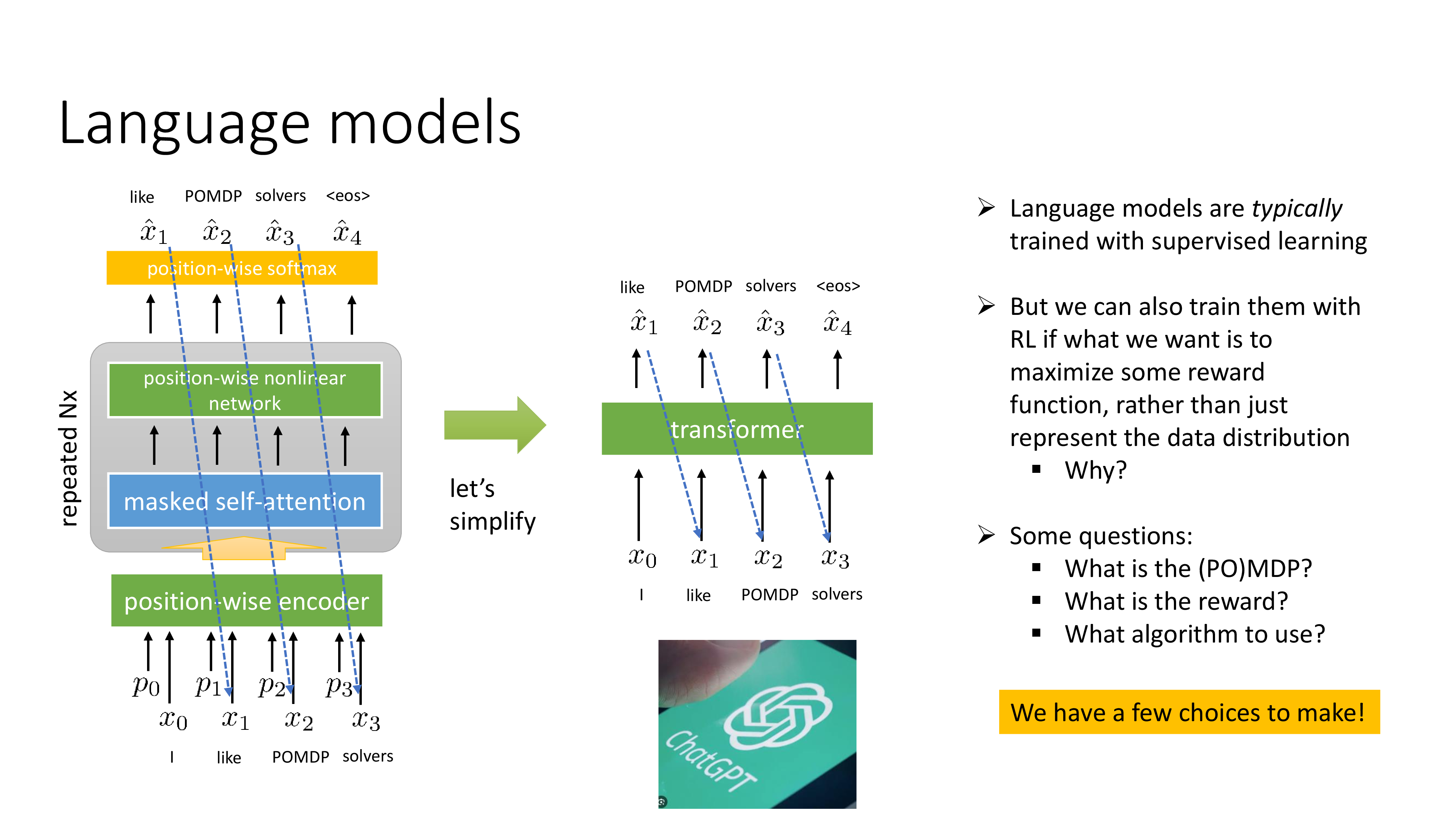 Fig.
Fig.
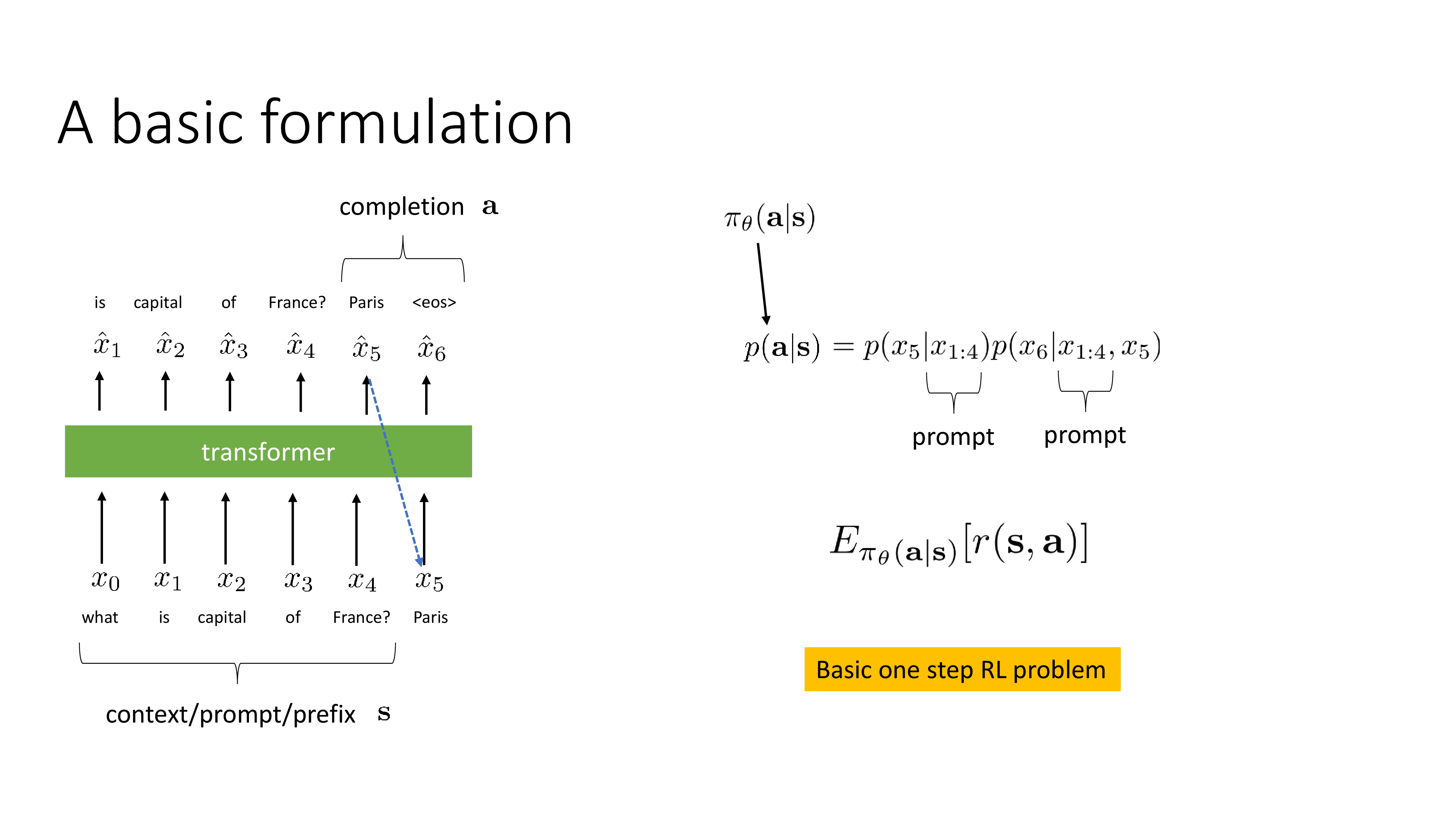 Fig.
Fig.
 Fig.
Fig.
 Fig.
Fig.
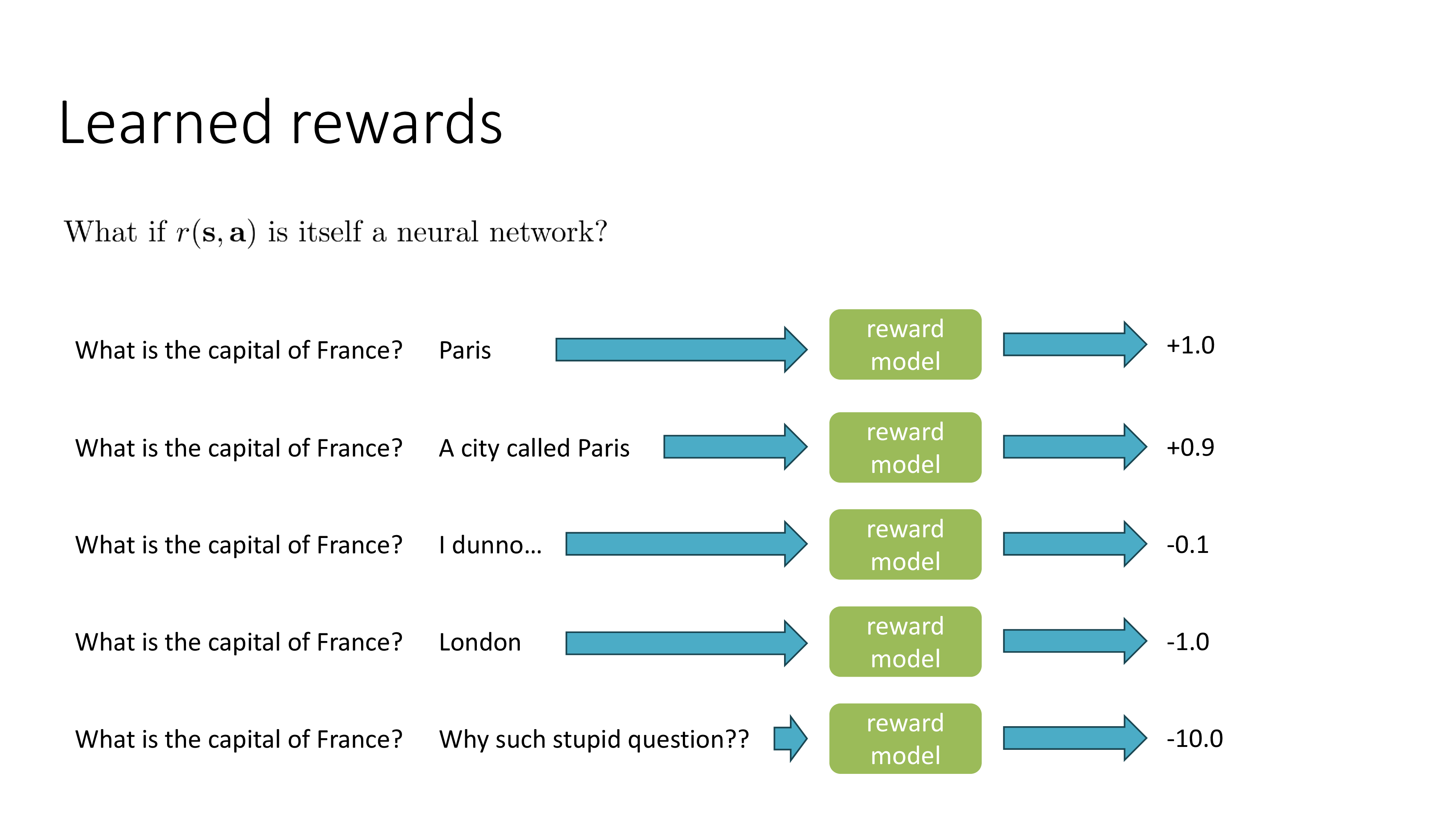 Fig.
Fig.
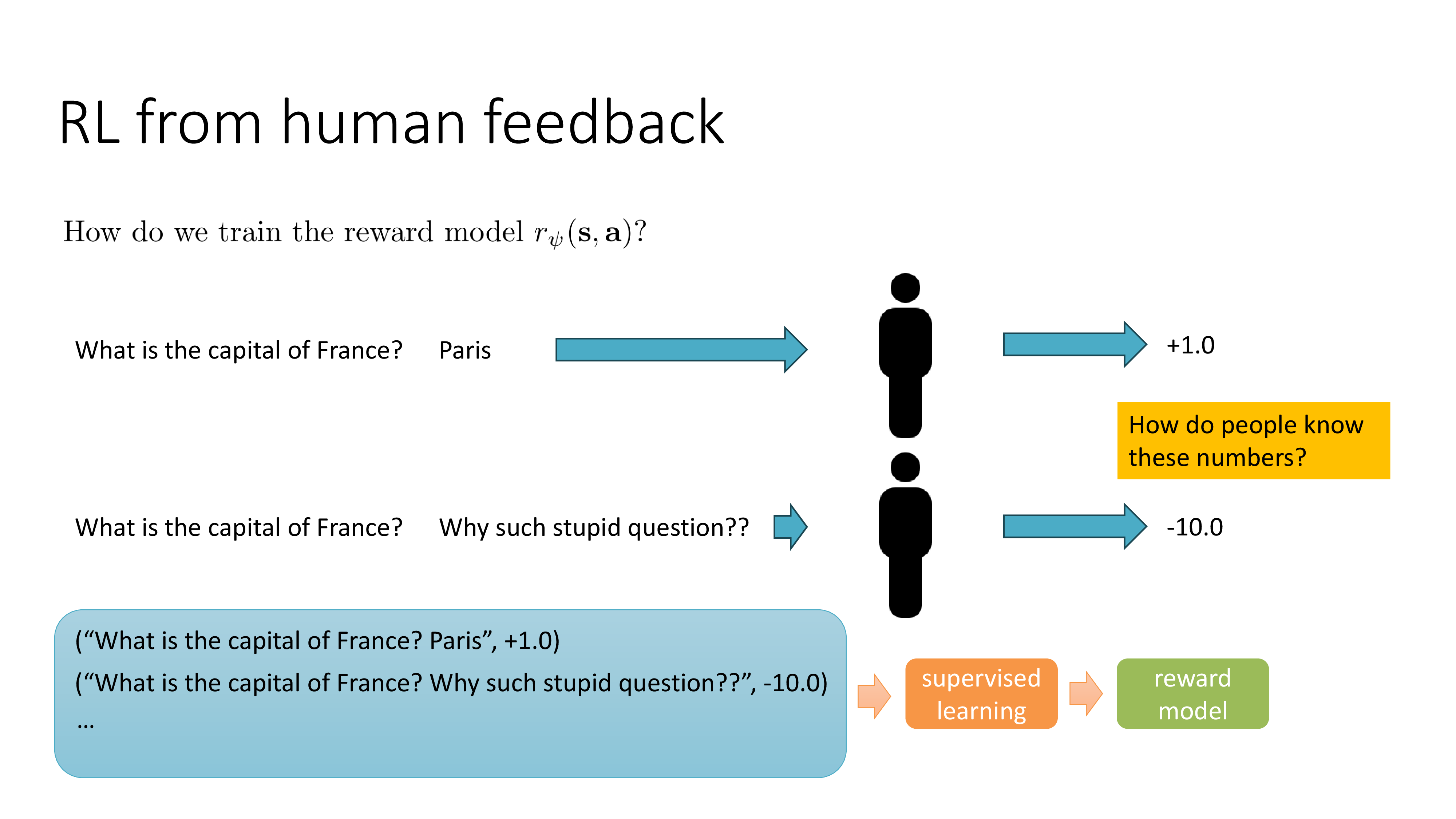 Fig.
Fig.
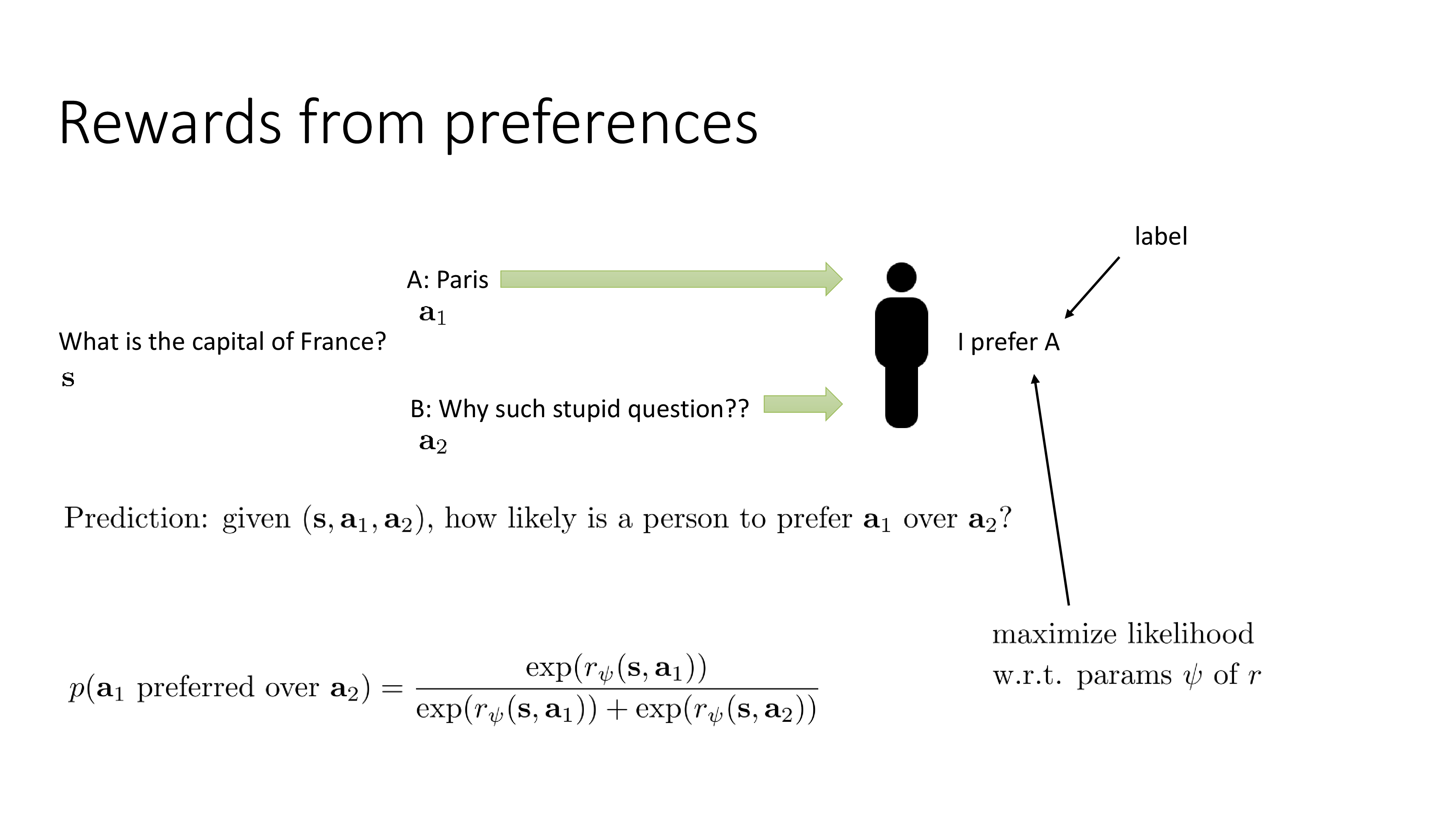 Fig.
Fig.
 Fig.
Fig.
 Fig.
Fig.
 Fig.
Fig.
Multi-step RL and Language Models
Fig.
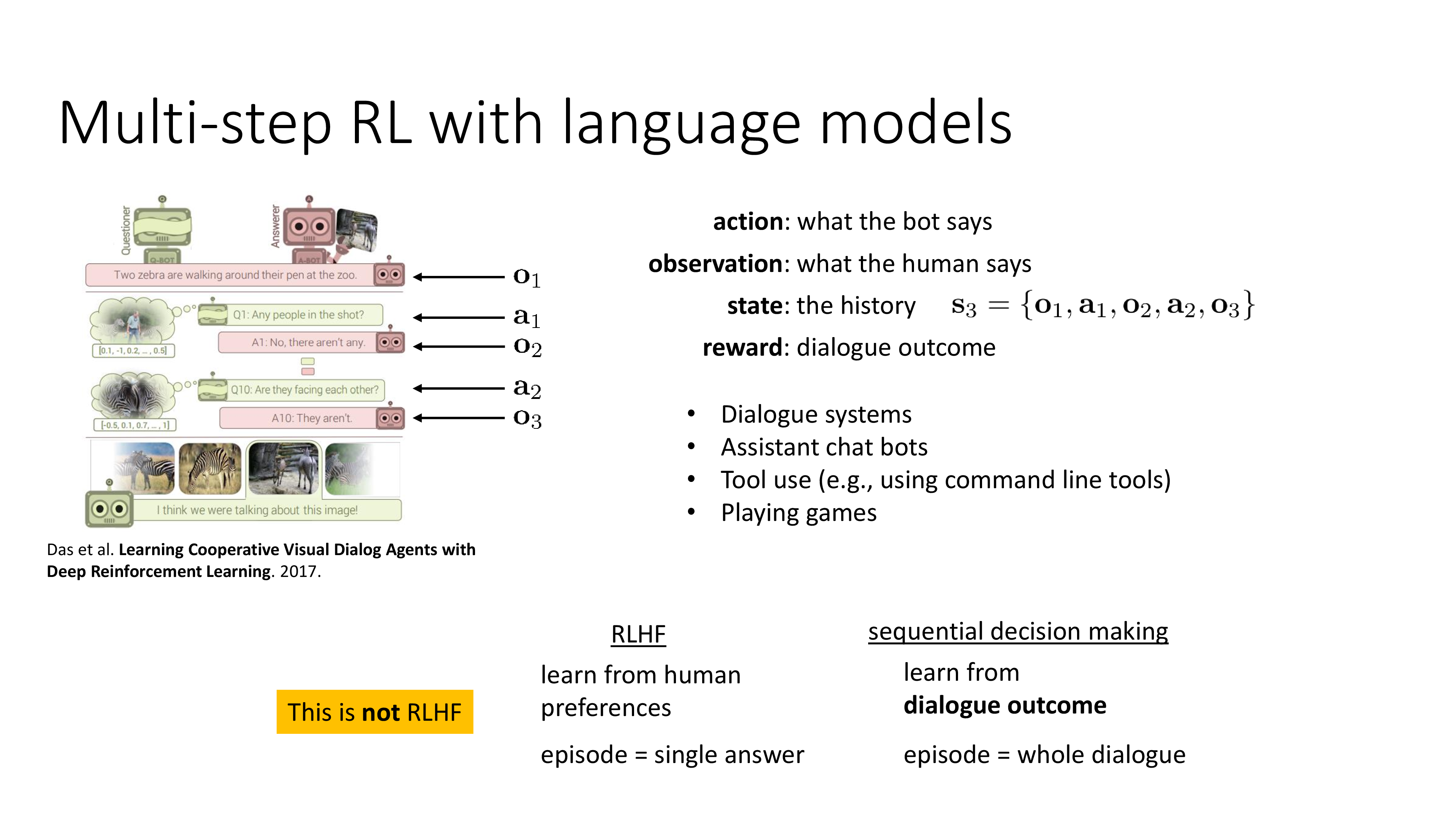 Fig.
Fig.
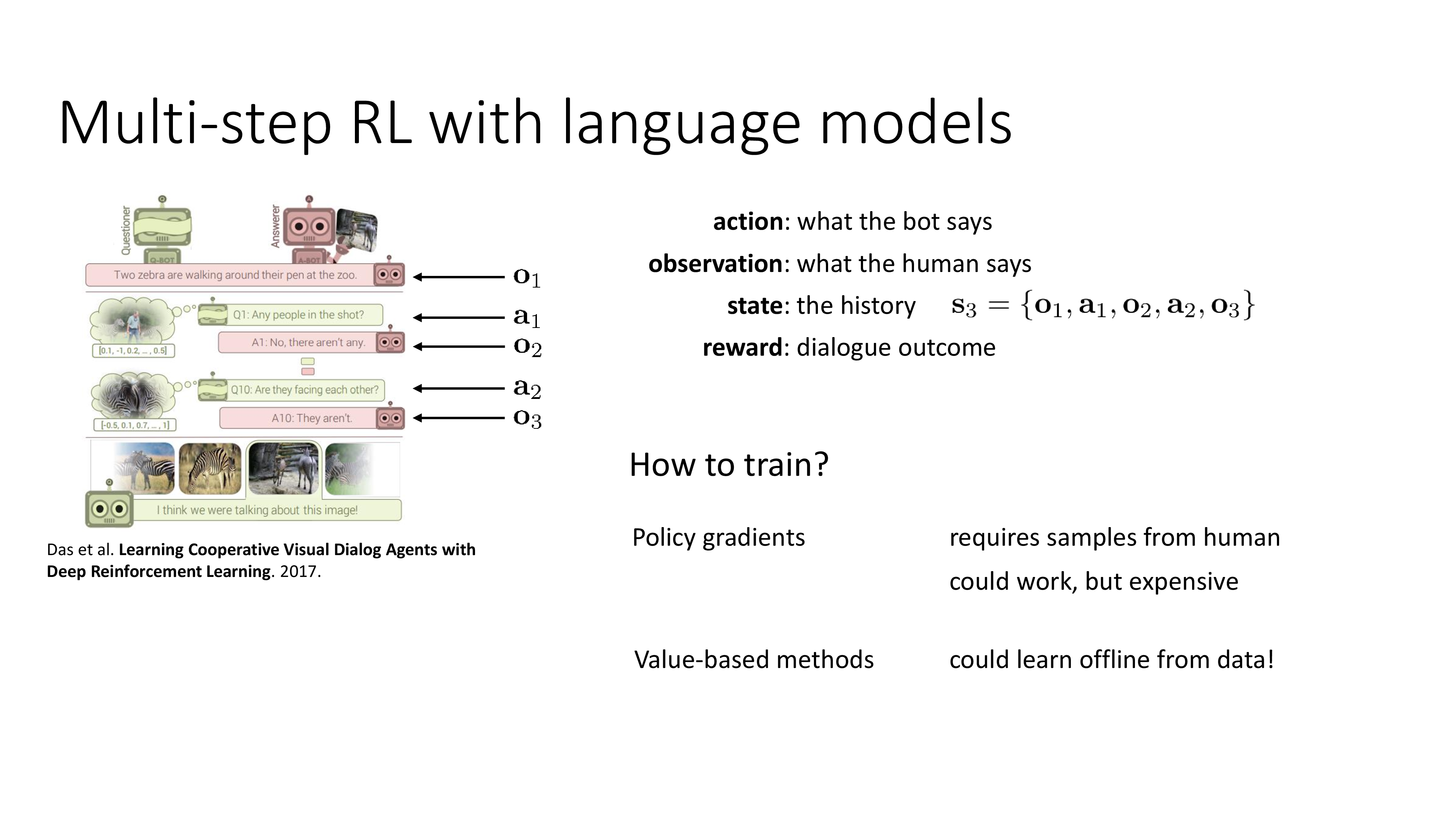 Fig.
Fig.
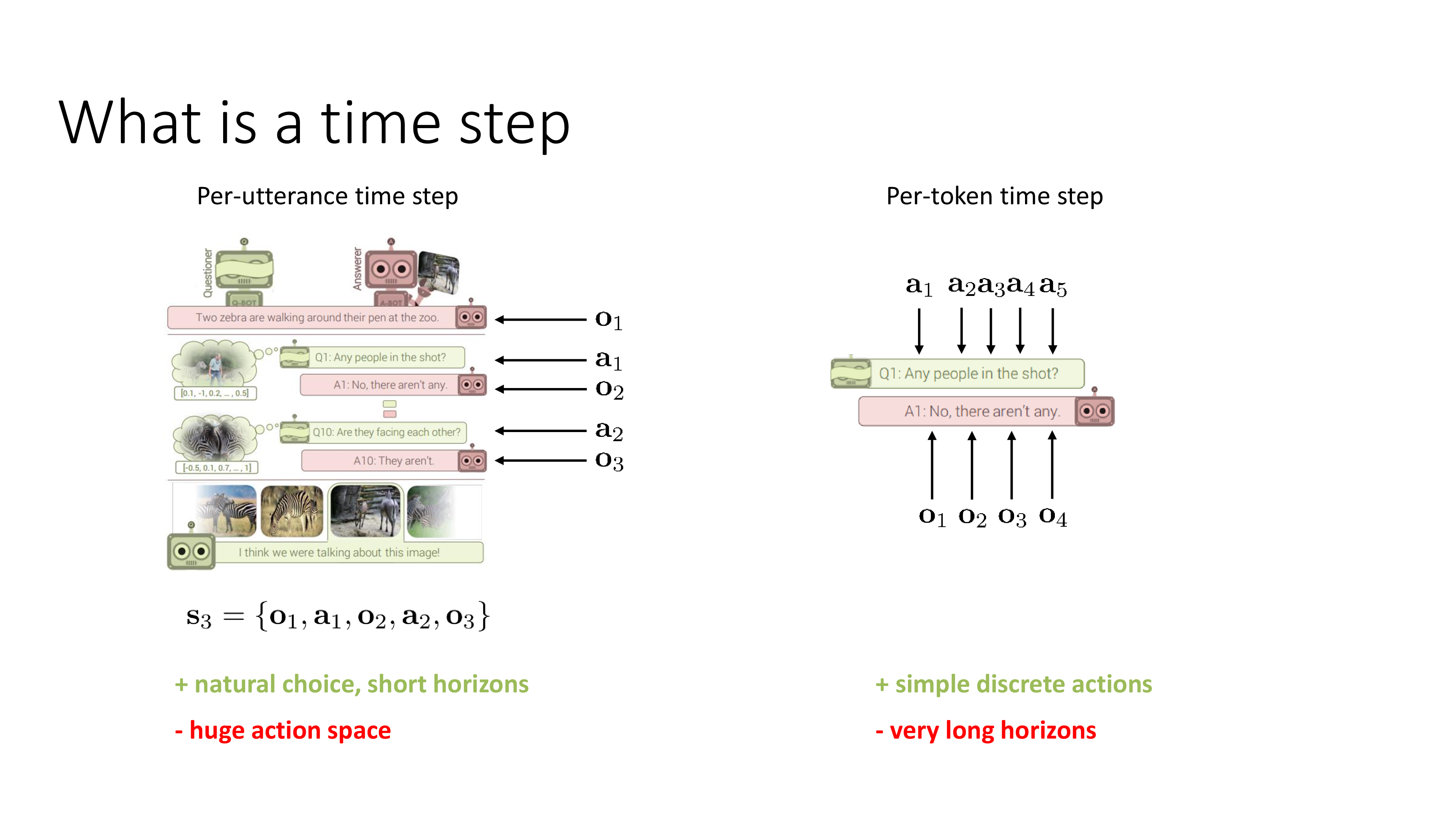 Fig.
Fig.
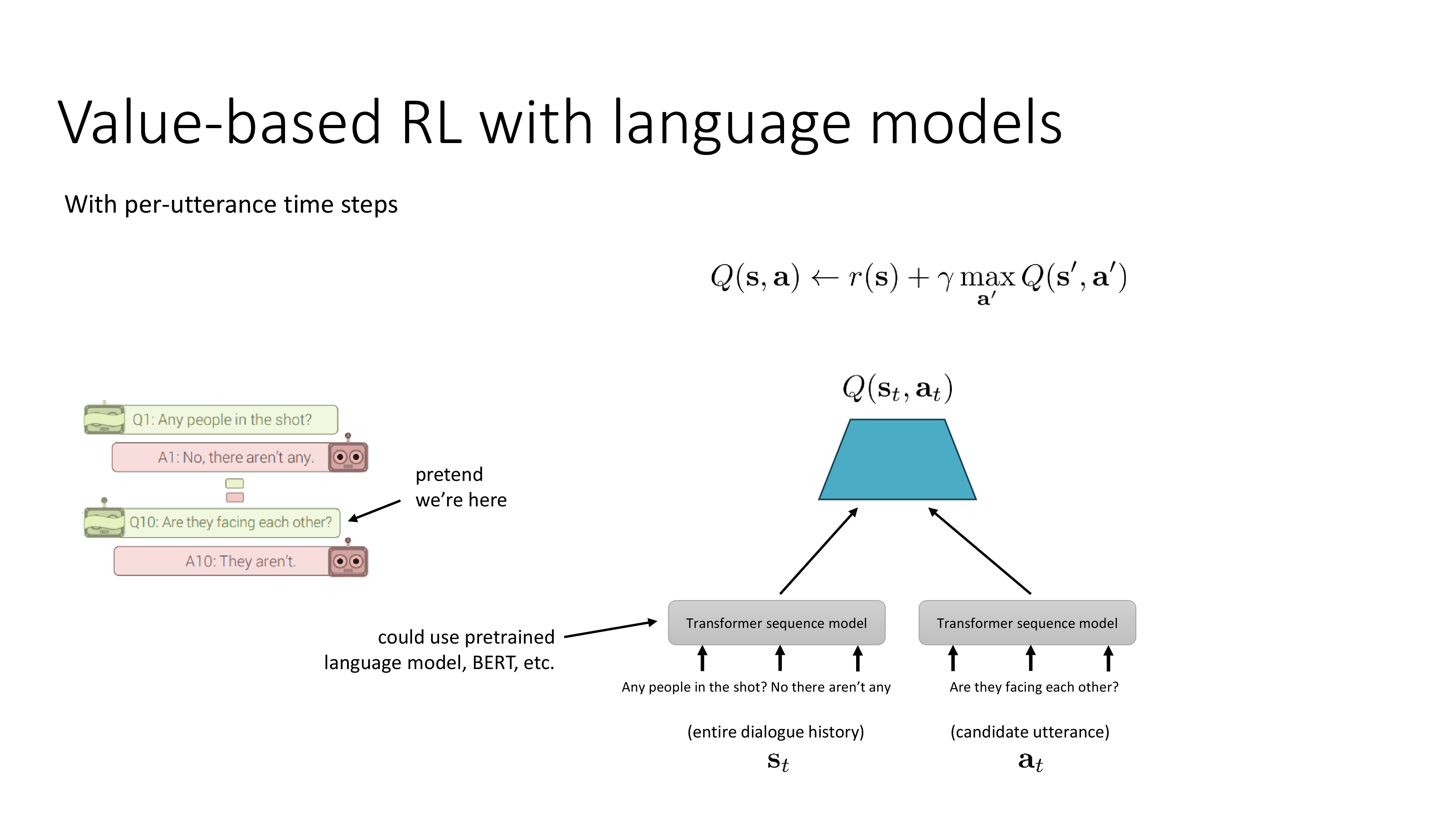 Fig.
Fig.
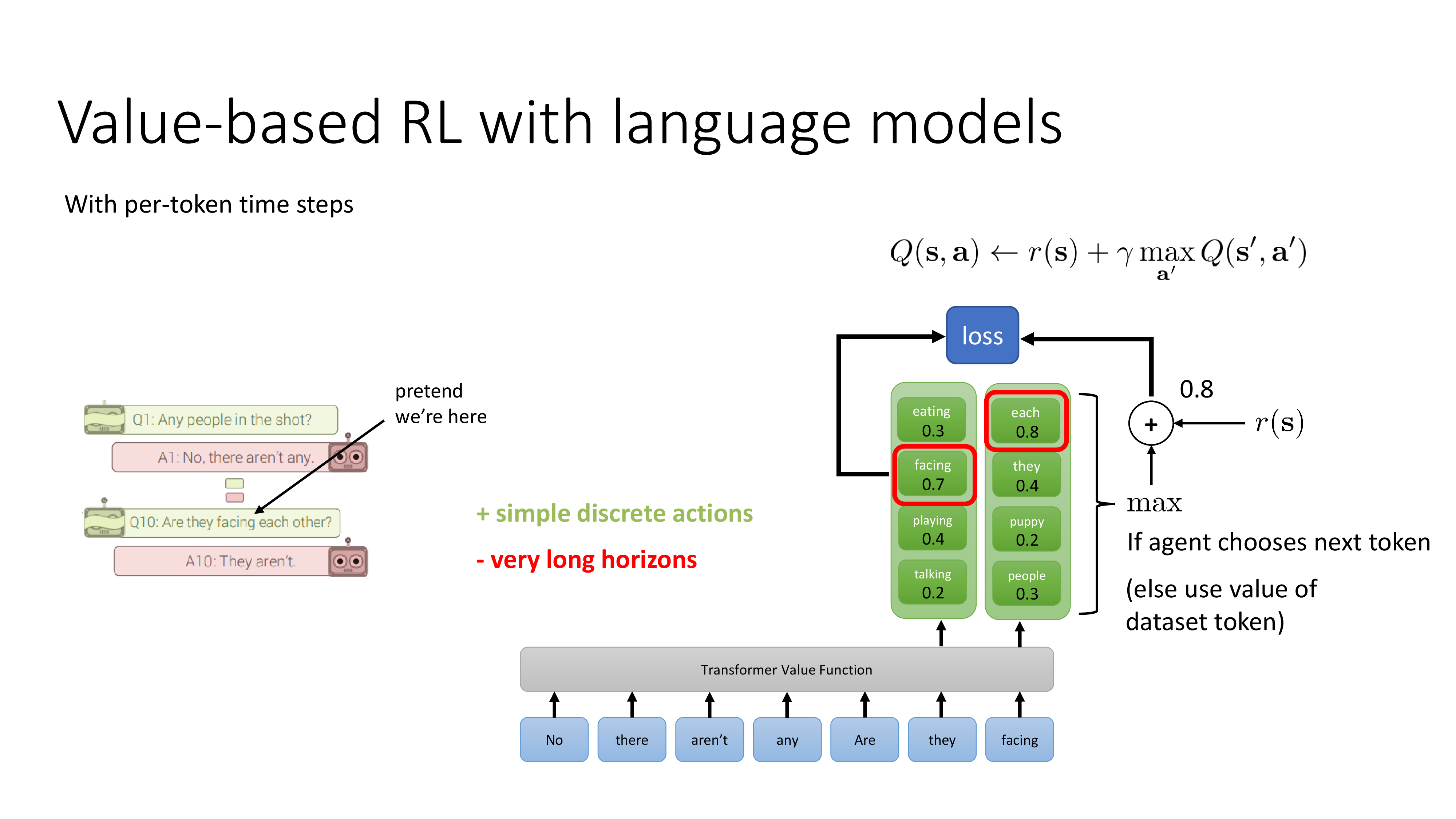 Fig.
Fig.
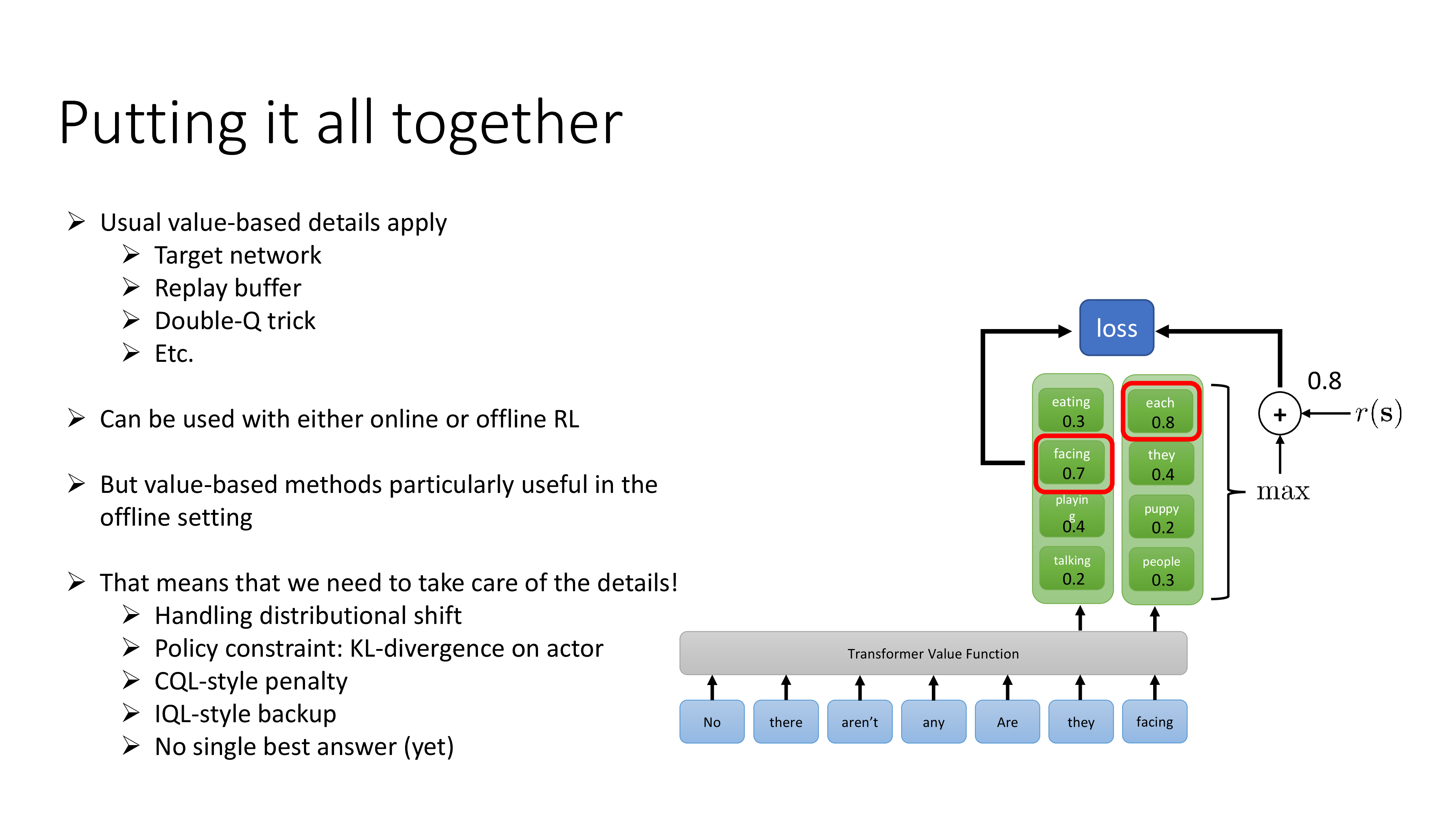 Fig.
Fig.
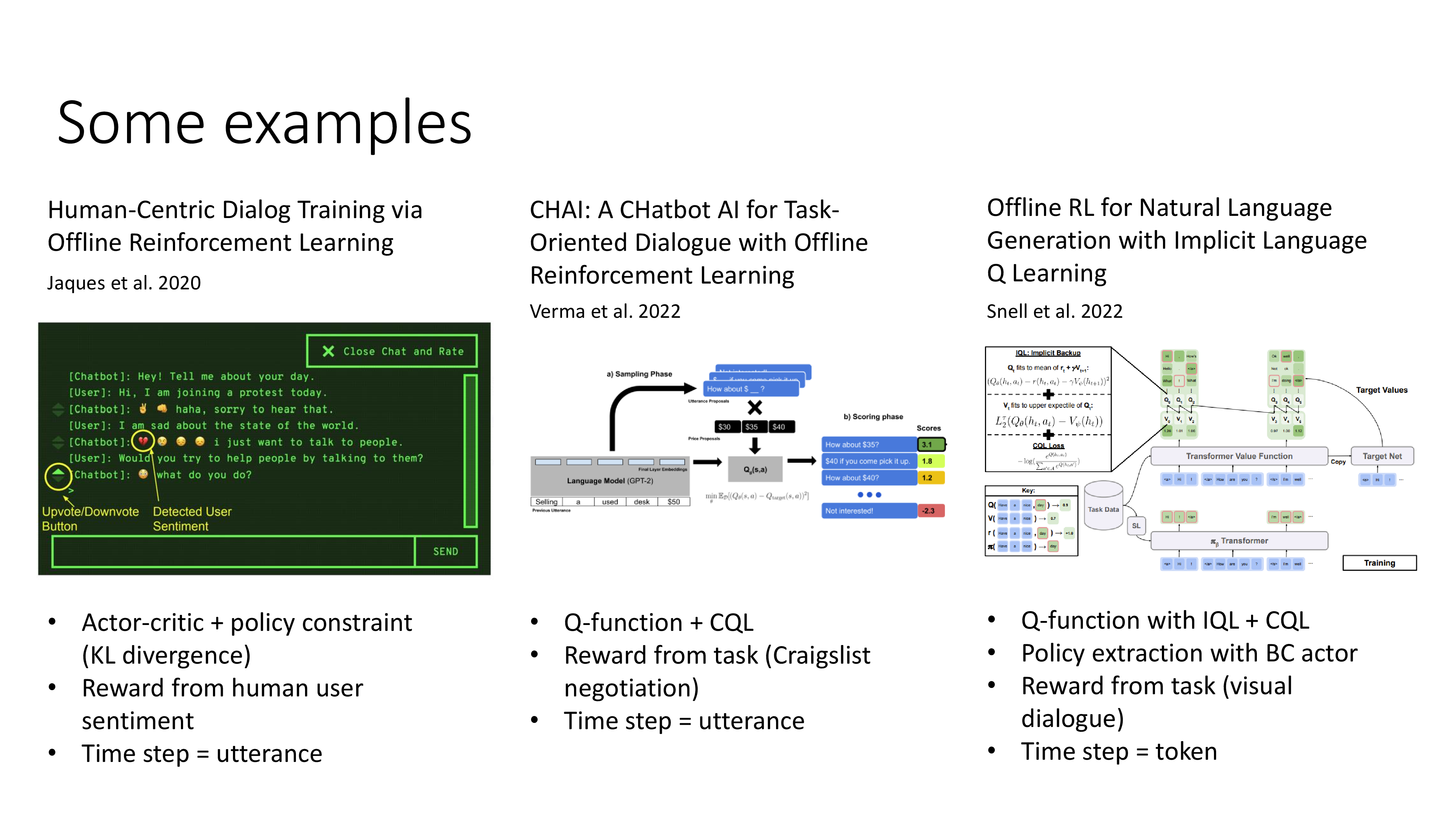 Fig.
Fig.
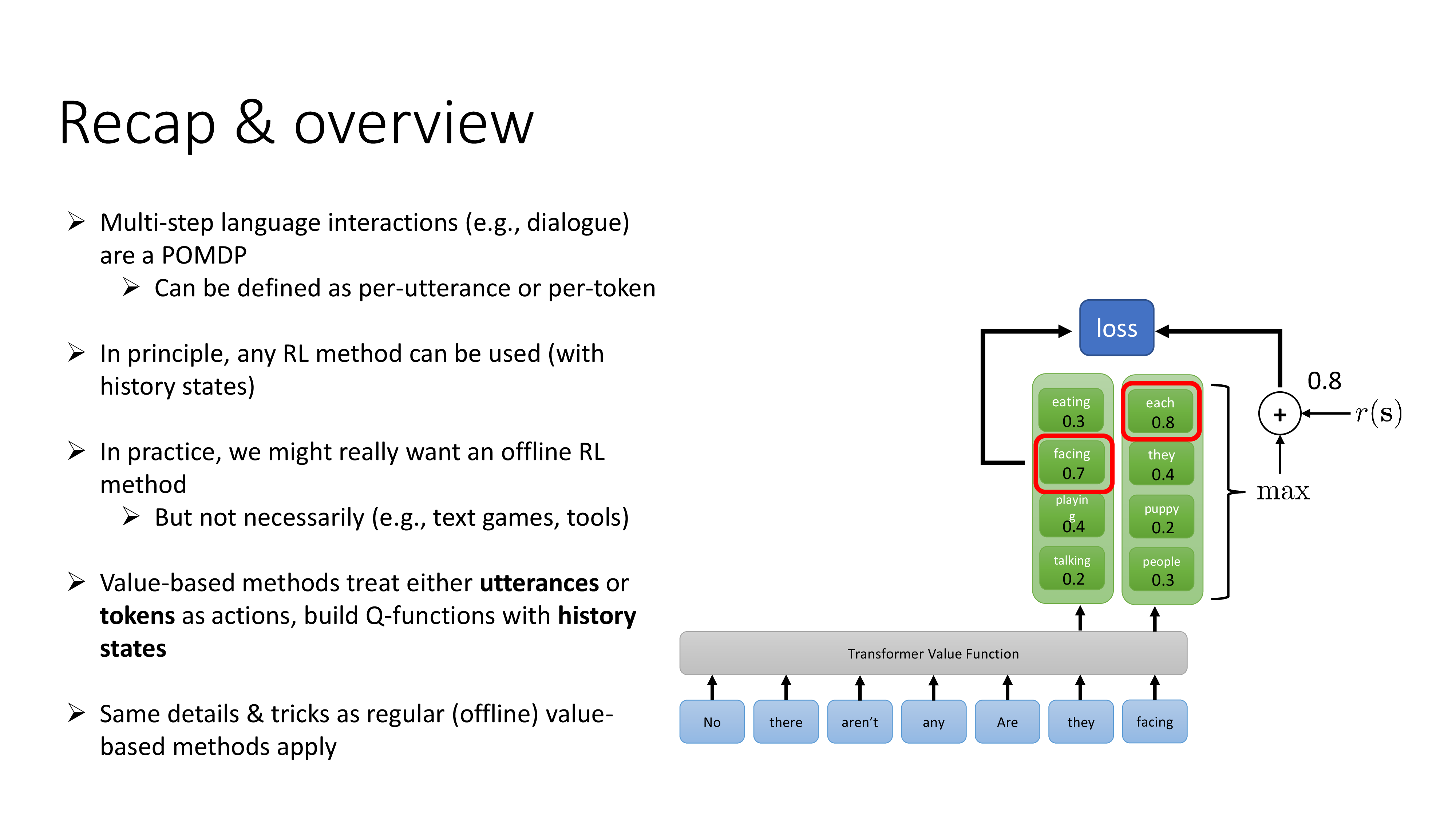 Fig.
Fig.