Rescent Advances in Deep Generative Model (2/4) - from DALL-E to DALL-E 2
30 Apr 2022< 목차 >
OpenAI 에서 2021 년 DALL-E에 이어 얼마 전 DALL-E 2 을 공개했습니다. 이 Model 의 Backbone 은 앞선 post 의 Diffusion Model 인데요, 여기에 CLIP Guidance 를 넣고 Upsampling 모듈을 추가한 것이 거의 전부라고 할 수 있습니다. 그 결과 Text 의 Semantic 정보를 거의 정확하게 이해하고 고퀄리티 이미지를 만들어 낼 수 있게 되었습니다.
Key Components
논문을 읽고나면 아래와같이 핵심 요소들을 정리할 수 있는데요, 먼저 DALL-E에 대해서 살펴보면
- 1.Discrete VAE 가 필요함 (미리 학습해놔야함)
- 학습된 VAE의 Encoder, Decoder를 얻을 수 있고 이 모듈들로 latent space상으로 이미지를 임베딩 하고 반대로 이미지 임베딩을 실제 이미지 픽셀값으로 복원해 줌
- 2.GPT와 같이 Autoregressive Transformer Decoder에 Image Embedding token들과 Text Embedding token들을 concat해서 입력으로 준다.
- Raw pixel의 이미지를 Discrete VAE의 Encoder에 태워서 나온 Discrete Vector들을 Image Embedding 으로 쓰고, Text Embedding은 토큰별로 one-hot 인코딩 된걸 쓰는 단순한 방식.
- 3.GPT 처럼 다음 토큰이 뭔지를 예측하는 단순한 Language Modeling 학습 방식처럼 (
[문장, 이미지 i번째 토큰]->[이미지 i+1 번째 토큰]예측) 모델을 학습함.- 다만 VAE가 들어갔기 때문에 Objective가 조금 더 복잡해졌을 뿐 다른건 없음.
와 같이 세 줄로 요약할 수 있겠습니다.
그리고 DALL-E 2사실 DALL-E 를 업그레이드 한 것이기 때문에 큰 틀은 다르지 않은데요, 이 중에서 핵심요소들은 다음과 같습니다.
- 1.VAE 말고
CLIP(마찬가지로 openai에서 개발함) 이라는 Text-Image Encoders 를 학습함. - 2.주어진 Text Caption 을 기반으로 Text Embedding을 만들고 이를 입력으로 Image Embedding 를 생성함.
- 이 때 CLIP Objective 를 사용해서 학습했기 때문에 Text Encoder 가 만들어낸 Text Embedding Vector도 충분히 이미지 정보를 갖고 있을 것 같으나, 이것만으로는 부족해서
Prior Model을 또 학습함.
- 이 때 CLIP Objective 를 사용해서 학습했기 때문에 Text Encoder 가 만들어낸 Text Embedding Vector도 충분히 이미지 정보를 갖고 있을 것 같으나, 이것만으로는 부족해서
- 3.
Diffusion decoder라는 현재 생성모델 쪽에서 핫한 방법론이 Image Embedding을 고퀄리티 이미지로 바꿔줌 (당연히 학습해야함)- 러프하게 이미지 생성모델은 VAE -> Flow-based model -> Diffusion model 순으로 발전했다고 생각하면 됨.
- Implicit Generative Model인 GAN은 별개로 아직 잘 나가고 있음.
- Diffusion model을 VAE와 비교해서 간단하게 생각해보면 VAE가 어떤 간단한 (가우시안) 분포에서 noise vector를
한 번샘플링하고 이를 디코더가 복원하면 새로운 이미지가 생성되는것인데, Diffusion Model은 이 작업을반복적으로한다고 생각하시면 됩니다. (그래서 고퀄리티인 대신 속도가 느리거나 한 단점이 있다고 하네요.)
- 러프하게 이미지 생성모델은 VAE -> Flow-based model -> Diffusion model 순으로 발전했다고 생각하면 됨.
DALL-E 1 을 이해하기 위해선 GPT-3 같은 AutoRegressive Model 에 대해서만 알고 있어도 되지만
DALL-E 2 를 제대로 이해하기 위해선 Diffusion 이나 Prior에 대해서 깊게 파봐야 하는데요,
이전 post 에서 Diffusion 에 대해 다뤘으므로 이를 참고해주시고 먼저 DALL-E 1 로 넘어가도록 하겠습니다.
DALL-E
Model Architecture and Implementation Details and Objective
DALL-E 는 GPT 를 이해하신다면 그렇게 크게 어려울 건 없습니다.
그냥 Transformer Decoder 라고 보면 되는데요, Text token 들만 AutoRegressive (AR) 하게 예측하던 GPT 와 달리 Image token 도 추가적으로 들어간다는 것 외에는 크게 다른점이 없습니다.
진입장벽을 낮추기 위해 별 거 없는 것 처럼 말씀드렸지만
사실 이렇게 Text, Image 두 개의 modality 를 결합해서 모델링하는 건
개념은 간단하지만 쉽지 않은 일이라고 합니다.
즉 이런 모델이 실제로 그럴싸한 결과물을 내려면 엄청난 Engineering이 필요합니다.
그리고 이런 기존에 있던 개념들을 결합해서 모델의 크기를 키워 (Scale Up)
엄청난 수준의 Engineering 을 특히 잘한다고 평가받는 곳이 바로 OpenAI 입니다.
DALL-E 는 Image token을 GPT에 잘 넣어줄 수 있도록 Discrete VAE의 Encoder, Decoder 모듈을 사용하는데요, 이를 그림으로 그려보면 아래와 같습니다.
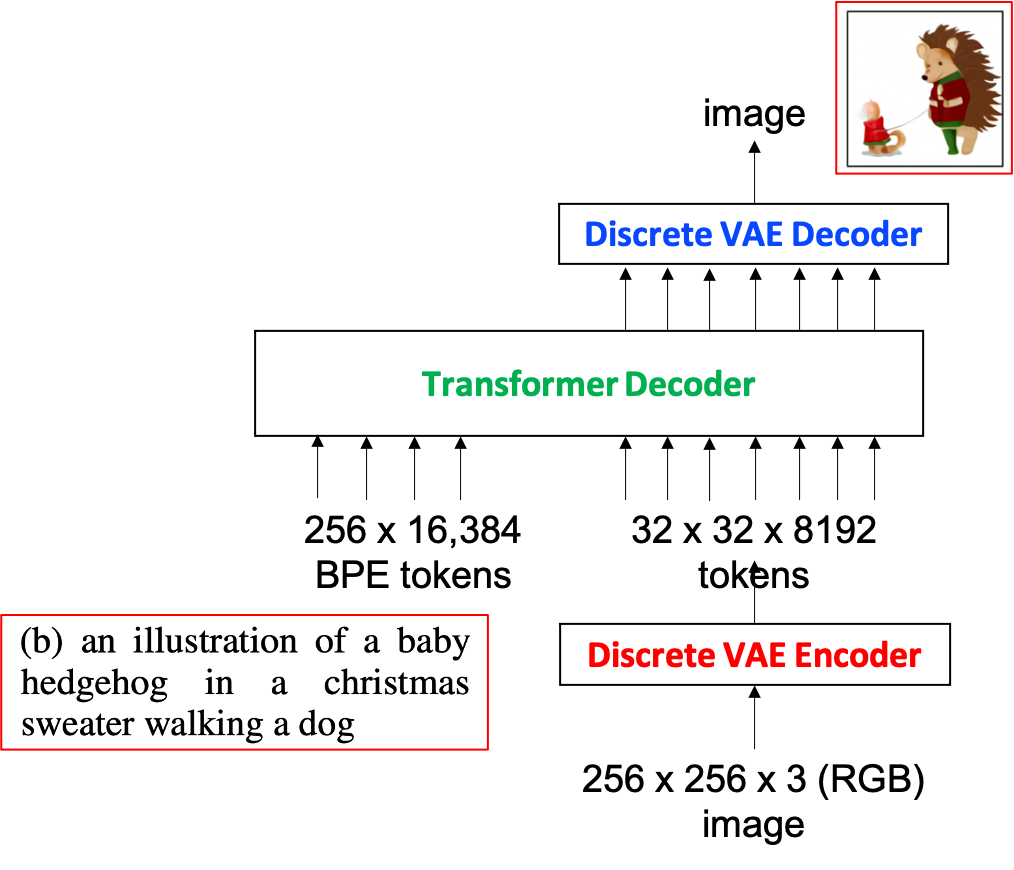 Fig. DALL-E Network Architecture
Fig. DALL-E Network Architecture
GPT-3와 다르게 이미지 임베딩 벡터가 들어가는 걸 볼 수 있습니다.
Discrete-VAE 의 모듈까지 추가한 Transformer Decoder Model, 즉 DALL-E 의 최종 Objective Function을 먼저 살펴보도록 하겠습니다.
\[\begin{aligned} \ln p_{\theta, \psi}(x, y) \geq \underset{z \sim q_{\phi}(z \mid x)}{\mathbb{E}}\left(\ln p_{\theta}(x \mid y, z)-\right.\left.\beta D_{\mathrm{KL}}\left(q_{\phi}(y, z \mid x), p_{\psi}(y, z)\right)\right) \end{aligned}\]DALL-E 를 학습하기 위해서는 위의 수식을 최대화 하면 되는데요, 어려워보여도 차근차근 살펴보면 VAE 같은 잠재 변수 모델에서 사용하던 Variational Inference (ELBO)와 크게 다를바가 없습니다.
머신러닝의 목적은 뭐였을까요?
주어진 데이터의 분포를 잘 설명하는 모수를 찾는 것이죠.
바로 Maximum likelihood 라고 할 수 있는데요, 여기에 더해 VAE같은 생성 모델은 잠재 변수 (latent vector) 를 넣어서 데이터의 분포를 모델링 하죠.
쉽게 말해서 우리가 가지고 있는 이미지 훈련 데이터 \(x_1, x_2, ...\) 를 나타내는 \(p(x)\) (전체 입력 이미지 데이터의 분포) 를 모델링 할 것을, \(p(x) = \int p(x,z) dz = \int p(x \vert z) p(z) dz\) 를 모델링 한다고 생각하는겁니다. 여기서 \(z\) 는 뭔지 모르지만 일단 이런게 끼어들어가 있을거라고 가정한겁니다.
적분식에 \(z\)가 들어갔지만 어차피 이를 적분하면 \(p(x)\) 이기 때문에 결국 똑같은 문제를 푸는거죠.
즉, 우리는 \(p(z)\) 와 \(p(x \vert z)\) 만 알면 우리가 바라던 \(p(x)\) 를 구할 수 있는 것이며 VAE 는 이를 풀기 위해 아래와 같은 수식을 유도해서 사용합니다.
위의 수식은 아래처럼 최종 정리할 수 있습니다.
\[\begin{aligned} &\log p\left(x_{i}\right)=\log \mathbb{E}_{z \sim q_{i}(z)}\left[\frac{p\left(x_{i} \mid z\right) p(z)}{q_{i}(z)}\right] \\ &\geq \mathbb{E}_{z \sim q_{i}(z)}\left[\log \frac{p\left(x_{i} \mid z\right) p(z)}{q_{i}(z)}\right]=\mathbb{E}_{z \sim q_{i}(z)}\left[\log p\left(x_{i} \mid z\right)+\log p(z)\right]-\mathbb{E}_{z \sim q_{i}(z)}\left[\log q_{i}(z)\right] \end{aligned}\]즉 우변을 최대화하는게 좌변을 최대화 하는거랑 같고, 여기에 Reparameterization Trick을 적용하고 이것저것 해주면 결국 아래의 수식이 나옵니다.
\[p_{\theta,\psi}(x) \geq \underset{z \sim q_{\phi}(z \mid x)}{\mathbb{E}} \left(\ln p_{\theta}(x \mid z)-\right.\left.\beta D_{\mathrm{KL}}\left(q_{\phi}(z \mid x), p(z)\right)\right)\] \[\hat{\theta}, \hat{\phi}=\operatorname{argmin}_{\theta, \phi}\left(-\sum_{i=1}^{N}\left[\operatorname{logp}_{\theta}\left(x_{i} \mid \mu_{\phi}\left(x_{i}\right)+\epsilon \sigma_{\phi}\left(x_{i}\right)\right)-D_{K L}\left(q_{\phi}\left(z \mid x_{i}\right) \| p(z)\right)\right]\right)\]이를 Evidence Lower Boundrary (ELBO) 라고 부르며 VAE는 이를 최적화하는걸로 학습됩니다.
여기서 중요 모듈들은 아래의 세 개로 각각
- \(p(z)\) : prior, 가우시안 분포를 주로 씀.
- \(q_{\phi}\) : VAE encoder, 즉 이미지를 z 라는 벡터로 변환해줌.
- \(p_{\theta}\) : VAE decoder, z라는 벡터를 다시 이미지로 복원해줌.
입니다.
VAE를 간단하게 해석해보자면
실제 이미지들를 어떤 분포에 매핑시키고, 그 분포를 우리가 안다고 가정하면 분포로 부터
샘플링 한 noise vector를 decoder로 복원했을 때 전에 없던 이미지를 뽑아낼 수 있다.
다만 우리가 그 분포를 모델링하기 어려우니 우리가 알기 쉬운 가우시안 분포 같은걸로 모델링 하고 싶다.
입니다. (자세한 내용은 논문이나 저의 VAE post 를 참조)
자 여기에 입력 이미지 \(x\) 뿐만 아니라 이와 쌍을 이루는 텍스트 \(y\) 까지 끼워넣어보면 우리는 이렇게 나타낼 수 있을 텐데요,
\[\begin{aligned} && p(x,y) = \int p(x,y,z) dz && \\ && = \int p(x \vert y,z) p(y,z) dz && \\ \end{aligned}\]VAE 에서와 마찬가지로 우리는 \(p(y,z)\) 와 \(p(x \vert y,z)\) 를 잘 모델링하면 우리가 바라던 \(p(x,y)\) 를 모델링 할 수 있겠 됩니다.
\[\begin{aligned} \ln p_{\theta, \psi}(x, y) \geq \underset{z \sim q_{\phi}(z \mid x)}{\mathbb{E}}\left(\ln p_{\theta}(x \mid y, z)-\right.\left.\beta D_{\mathrm{KL}}\left(q_{\phi}(y, z \mid x), p_{\psi}(y, z)\right)\right) \end{aligned}\]DALL-E 논문에서도 본인들이 모델링 하려는게 아래의 x,y,z 의 결합 분포 (joint dist) 라고 얘기하는데요,
이게 바로 DALL-E 의 Objective Function 이며
각각의 모듈이 \(\theta,\phi\) 로 파라메터화 되어있으며 해당 component들은 아래와 같습니다.
- \(q_{\phi}\) :
VAE Encoder(이미지 -> latent vector로 바꿔줌)- \(q_{\phi} (y,z \mid x)\) : 이미지로부터 뽑은 1024개의 z 벡터와 텍스트 임베딩 벡터 y 를 나타냄.
- \(p_{\theta}\) : 주어진 latent space 상의 이미지 벡터 z 와 텍스트 임베딩 y로부터 이미지를 복원하는
VAE Decoder - \(p_{\psi}\) : 문장과 이미지 의 결합 분포로, Trasnformer Decoder로 모델링 함.
추론 시 최종적으로 원하는건 z,y 를 받아서 이미지 \(x\)를 뱉는 \(p_{\theta}(x \vert y,z)\) 겠죠?
위의 Objective를 사용해 모델을 학습하는 과정을 다시 풀어보자면, 아래와 같습니다.
- 1.우선 이미지와 쌍을 이루는 문장을 (최대 256개) 임베딩 벡터들로 만들고, 이미지 또한 VAE Encoder로 (32x32=1024개) 토큰으로 만든다.
- 2.그리고 이를 Transformer Decoder에 태워서 일반적인 Language Model 처럼 자기 자신의 다음 토큰을 예측하게 한다.
- (이걸 256(Text)+1024(Image) 토큰에 대해서 전부 수행하는 것)
- 3.마지막으로 이렇게 Transformer Decoder가 뱉은 1024개의 복원한 z 벡터를 VAE Decoder가 32x32 차원의 원래 이미지 사이즈로 디코딩하고 이를 원본 x와 비교해서 Backprop 한다.
학습이 다 끝나고 실제 추론시에는 어떤 모자를 쓴 웰시코기 사진 이라고 텍스트를 넣어주면 (마찬가지로 최대 256개 토큰까지 넣어줄 수 있음) Transformer Decoder가 (32x32=1024개)의 latent z 를 뱉고 이를 VAE Decoder가 받아서 실제 이미지를 반환해주는 겁니다.
Why Do we need Discrete VAE?
근데 왜 DALL-E는 Discrete VAE가 필요한 걸까요?
Fig. Discrete VAE가 필요한 DALL-E
그 이유는 바로 원본 이미지가 너무 고차원의 연속적인 (continuos) 벡터들이기 때문에 학습하기가 어려워서 입니다.
(즉 현재 Context 가 주어졌을 때 다음 Token 이 될 수 있는 Search Space 가 너무 큰 것)
Discrete VAE Encoder를 통과하기 전 후의 이미지 차원을 그림에서 보면 \(256 \times 256 \times 3\) 가 \(32 \times 32 \times 8192\) 가 되는걸 볼 수 있는데요, 이 때 Encoding된 32x32=1024개의 토큰은 각각 8192 차원의 Discrete 한 vector, 즉 one-hot vector가 되는 겁니다.
 Fig. Discretized Image. Source From Understanding VQ-VAE (DALL-E Explained Pt. 1)
Fig. Discretized Image. Source From Understanding VQ-VAE (DALL-E Explained Pt. 1)
즉 continuous 벡터가 discrete 벡터가 된건데요, 어떻게 이를 양자화 (quantization) 하는지는 VQ-VAE의 논문에 잘 설명되어 있습니다.
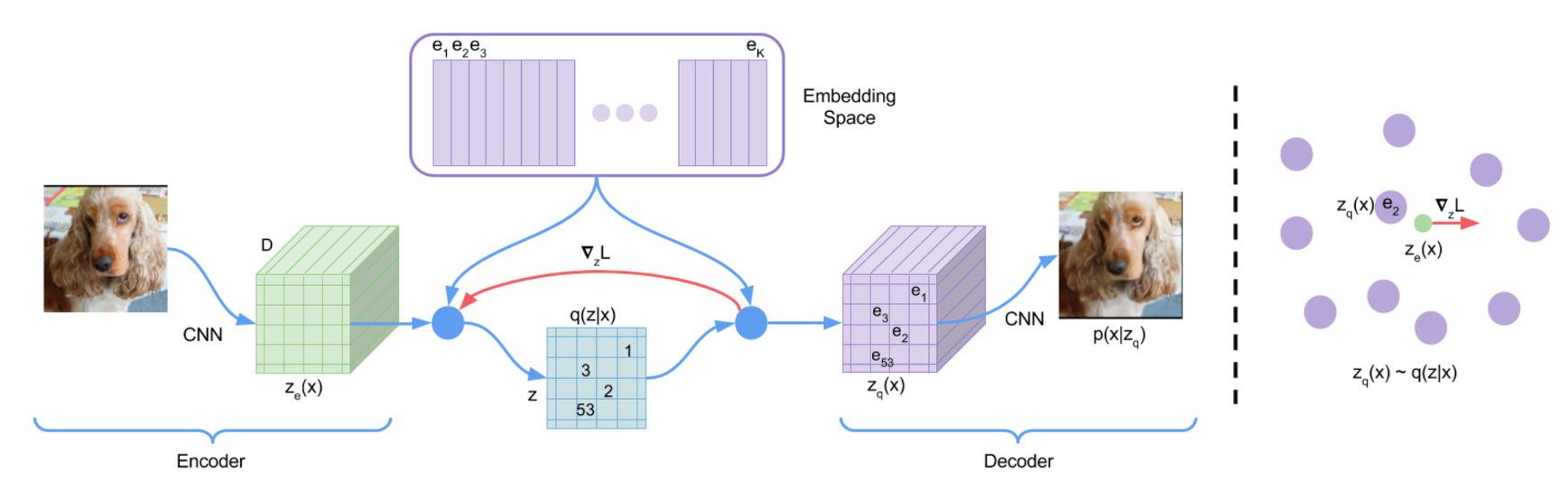 Fig. Vector Quantizaed Variational Auto-Encoder (VQ-VAE)
Fig. Vector Quantizaed Variational Auto-Encoder (VQ-VAE)
어떻게 벡터를 양자화 하는지에 대해서 간단하게만 설명드리면 아래와 같습니다.
- 1.Raw Image 가 CNN을 통과해서 압축됨.
- 2.정해진 사이즈의 Codebook을 통해 압축된 이미지의 각 토큰들이 특정 Codebook Entry로 매핑됨.
- 그림의 우측을 보면 알 수 있듯, CNN을 통과한 압축된 이미지의 어떤 토큰이 Codebook Space 에 떨어졌을 때 모든 entry들 중 가장 가까운 entry를 골라 그 값이 되는것 (가까운 다른 entry가 될 확률도 있긴 함(sampling))
- 3.Decoder가 양자화된 이미지를 기반으로 원본 이미지를 복원함.
- 1~3번을 학습하는 과정에서 이미지의 각 부분은 양자화 되는 과정을 배움. (즉 비슷한 질감, 형태를 나타내는 픽셀은 모두 비슷한 하나의 entry에 매핑되기 때문에 discrete space를 갖게 되는 것)
여기서 VQ-VAE는 2번의 entry를 고르는 sampling 과정이 전체 네트워크에 gradient를 흘리는데 지장을 주기 때문에 이를 해결하기 위해서 Straight Through Estimator 라는 방법을 사용하는데요,
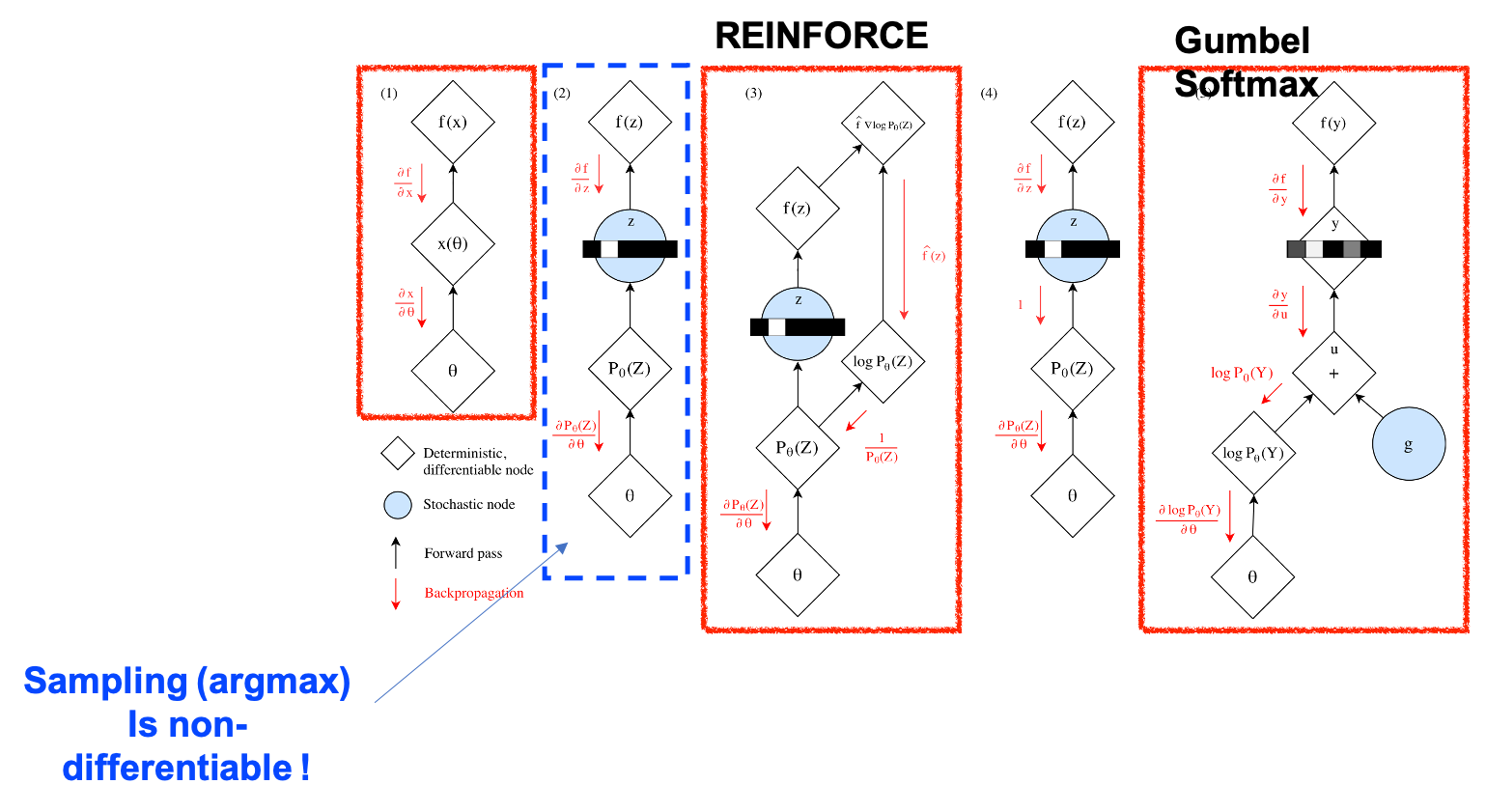 Fig. 미분 불가능한 (non-differentiable) 연산인 Sampling 연산이 네트워크에 들어갔을 때 gradient를 흘리 수 있는 방법은 다양하다. 1번은 일반적인 네트워크의 경우, 2번은 샘플링이 들어가 미분이 불가능해진 경우를 말하며, 3~5번은 2번의 문제를 해결한 방법들이다. 이 중에서 vq-vae에서 쓴 방법은 4번으로 sampling으로 선택된 token에 대해서 gradient를 그냥 1로 흘려주는 방법이고 마지막에 제시된 방법은 Gumbel-Softmax Trick 이다.
Fig. 미분 불가능한 (non-differentiable) 연산인 Sampling 연산이 네트워크에 들어갔을 때 gradient를 흘리 수 있는 방법은 다양하다. 1번은 일반적인 네트워크의 경우, 2번은 샘플링이 들어가 미분이 불가능해진 경우를 말하며, 3~5번은 2번의 문제를 해결한 방법들이다. 이 중에서 vq-vae에서 쓴 방법은 4번으로 sampling으로 선택된 token에 대해서 gradient를 그냥 1로 흘려주는 방법이고 마지막에 제시된 방법은 Gumbel-Softmax Trick 이다.
DALL-E 논문에서 VQ-VAE 를 썼다는 말 대신에 Discrete-VAE를 썼다고 하는 이유는 VQ-VAE 를 학습하는 데 Gumbel Softmax Trick을 썼기 때문에 조금 변형이 있어서 그런 것 같습니다.
어쨌든 이런 식으로 학습을 할 경우 이미지의 각 픽셀들을 contiunous space이 아닌 discrete space에서 표현할 수 있게 돼 네트워크에 부담도 덜어주고 model이 이미지의 high-frequency detail 과 low-frequency structure를 모두 잘 파악하게 도와주게 됩니다.
However, using pixels directly as image tokens would require
an inordinate amount of memory for high-resolution images.
Likelihood objectives tend to prioritize modeling short-range
dependencies between pixels, so much of the modeling capacity would be spent
capturing high-frequency details instead of the low-frequency structure
that makes objects visually recognizable to us.
DALL-E 에서 말하는 이미지를 양자화 하는 이유
어쨌든 우리는 원래의 RGB 이미지를 그냥 GPT 에 넣어서 학습하기 어렵고 그러므로 이를 양자화해줄 Discrete VAE Encoder가 필요한 것인데 이를 또 GPT (Transformer Decoder)와 같이 학습하기 어렵기 때문에 DALL-E를 학습하는 과정은 2 단계로 나눠지게 됩니다.
- 1.Discrete VAE 학습 (Encoder, Decoder 둘 다 얻게됨)
- 2.Transformer Decoder를 Auto-Regressive 방식으로 LM 학습하듯이 학습.
그 밖에 논문을 읽어보시면 Sparse Transformer 를 사용했다거나 여러 종류의 Sparse Attention Mask들을 사용했다거나 하는 디테일이 있는데요,
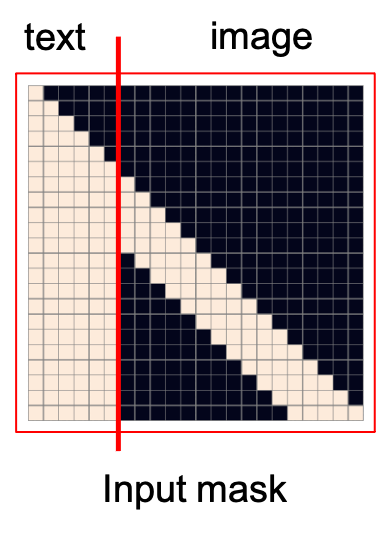 Fig. Transformer Decoder를 학습할 때, Text와 image를 모두 예측하게 된다. 이 때 이미지를 예측할 때는 Text의 정보는 모두 보게 된다. 이 그림은 여러가지 Sparse Attention mask들 중 Row attention mask를 나타낸다.
Fig. Transformer Decoder를 학습할 때, Text와 image를 모두 예측하게 된다. 이 때 이미지를 예측할 때는 Text의 정보는 모두 보게 된다. 이 그림은 여러가지 Sparse Attention mask들 중 Row attention mask를 나타낸다.
이는 생략하도록 하겠습니다.
DALL-E 2
Understanding How DALL-E 2 works in High-Level (Inference)
사실 이번 post의 핵심은 DALL-2 입니다.
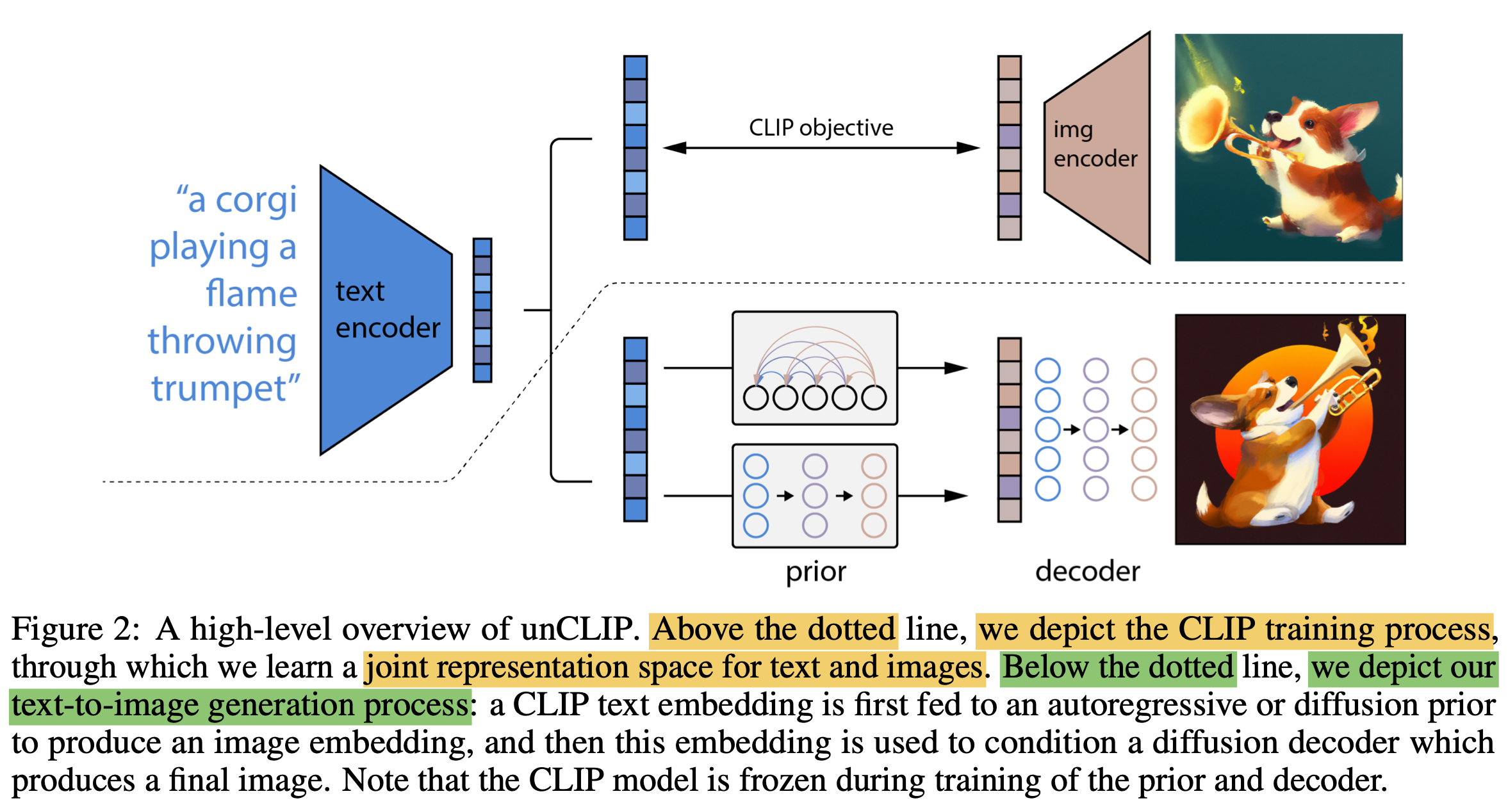 Fig. DALL-E 2 Network Architecture
Fig. DALL-E 2 Network Architecture
앞서 말씀드린 것 처럼 DALL-E 와 비교해보면 Prior Model이라는 게 추가됐고 Discrete VAE Decoder 대신 Diffusion Decoder가 이미지를 복원하고 CLIP Encoder 들이 추가됐습니다.
사실 DALL-E가 GPT와 크게 다르지 않았던것에 비해 DALL-E 2는 많은게 달라졌습니다 (갑자기 Diffusion Model을 쓰기 시작했습니다).
그렇기 때문에 새롭게 추가된 모듈들에 대해 알아보기 전에 먼저 추론시 어떻게 DALL-E 2가 이미지를 생성하는지?에 대해 얘기하고 넘어가보도록 합시다.
- 1.우선 DALL-E 2 에 “a corgi playing a flame throwing trumpet (불을 뿜는 트럼펫을 연주하는 웰시코기)” 같은 문장을 던져줍니다.
- 2.그러면
Text Encoder가 이 문장에서 Embedding Matrix를 뽑아줍니다. - 3.그리고
Prior라는 게 이 Text 정보를 Image 정보로 바꿔줍니다. - 4.마지막으로 3번의 Image Embedding 을 Decoding 하는데, 이 때 Decoder 가 바로
Diffusion Model이 됩니다.
이제 여기에 필요한 모듈들을 하나 하나 살펴보도록 하겠습니다.
CLIP (Contrastive Language-Image Pre-Training) Encoders
그 다음 알아볼 Module은 바로 CLIP 이라는 Text-Image Bi-modality를 학습하는 모델 입니다.
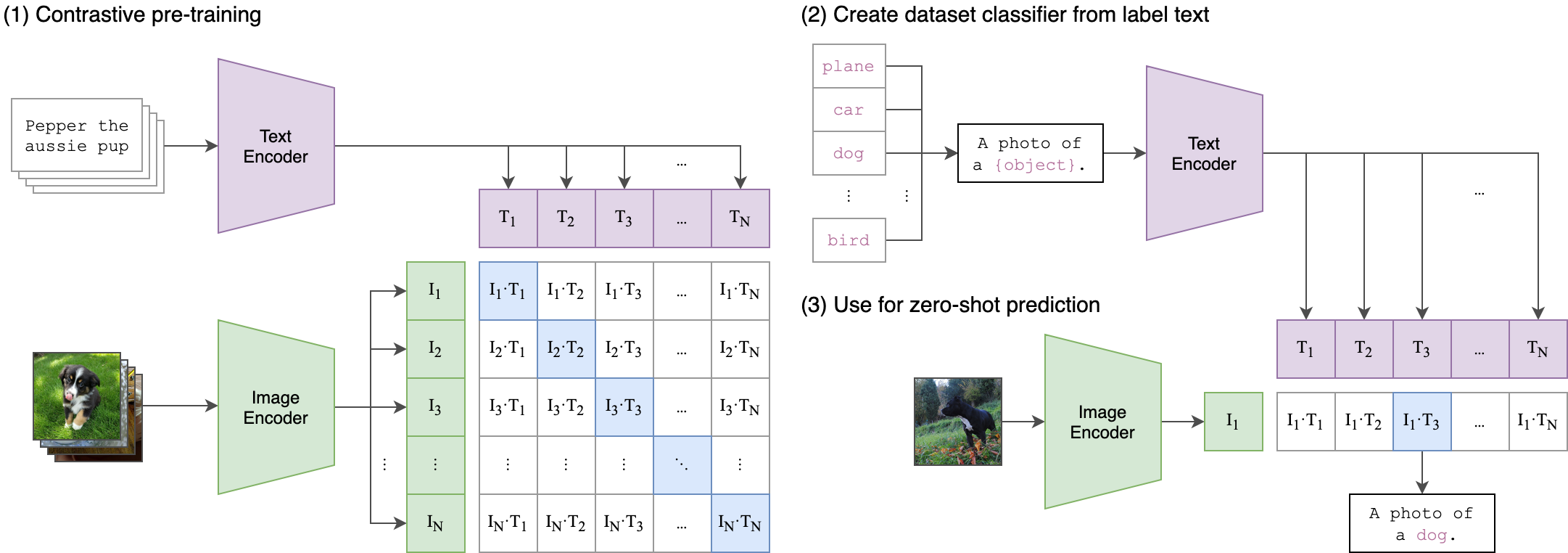 Fig. CLIP Network Architecture
Fig. CLIP Network Architecture
CLIP은 Text와 Image의 Joint embedding을 Contrastive Objective로 학습하는 방법론을 말합니다.
즉 이미지만 이용해서 SSL, Unsupervised 학습한 인코더는 이미지의 특징만 잘 잡을 뿐인데 비해 CLIP으로 학습하게 되면 이미지가 Semantic Information을 임베딩에 담을 수 있게 되는 겁니다.
위의 그림에서도 보실 수 있지만 이를 학습하기 위해서는 어떤 이미지가 있으면 이 설명할 Text Caption이 쌍으로 필요하고 이를 Contrastive Objective 로 학습하는데요,
여기서 Contrastive Objective 는 일반적으로 Annotation이 존재하지 않을 때 (즉 ground truth y 가 없을 때) self로 annotation을 만들어 학습하는 대표적인 Self-Supervised Learning 의 방법론 입니다.
Contrastive Loss를 직관적으로 이해하기 위해 아래의 그림을 보시면
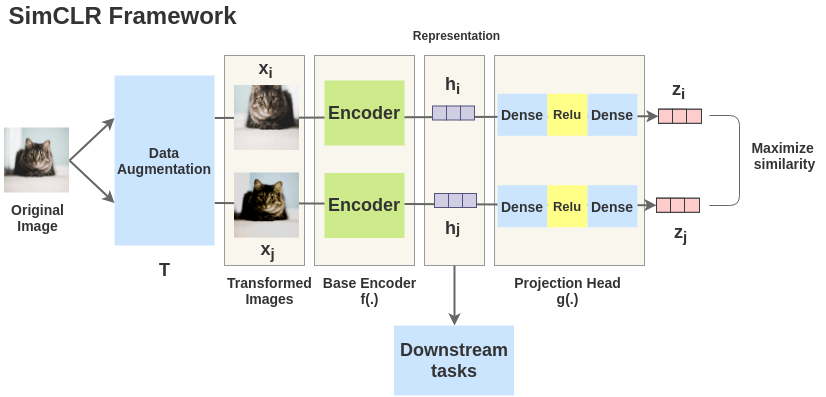 Fig. SimCLR Network Architecture. Source form Amit Chaudhary’s Blog
Fig. SimCLR Network Architecture. Source form Amit Chaudhary’s Blog
고양이라는 이미지를 뒤집어도 고양이가 되기 때문에 (즉 같은 class로 매핑돼야 할 이미지가 됨) 이 두개의 embedding vector를 가깝게 하는것이 Contrastive Learning의 목표입니다.
실제 배치를 구성하고 학습하기 위해서는 아래처럼 먼저 고양이, 코끼리 이미지가 있을때 이를 각각 Augmentation 해봅시다.
 Fig. SimCLR Batch. Source form Amit Chaudhary’s Blog
Fig. SimCLR Batch. Source form Amit Chaudhary’s Blog
그 다음으로 아래 처럼 같은 고양이 이미지끼리는 embedding vector가 가까워 지도록, 코끼리와는 멀어지도록 학습하면 되는데요,
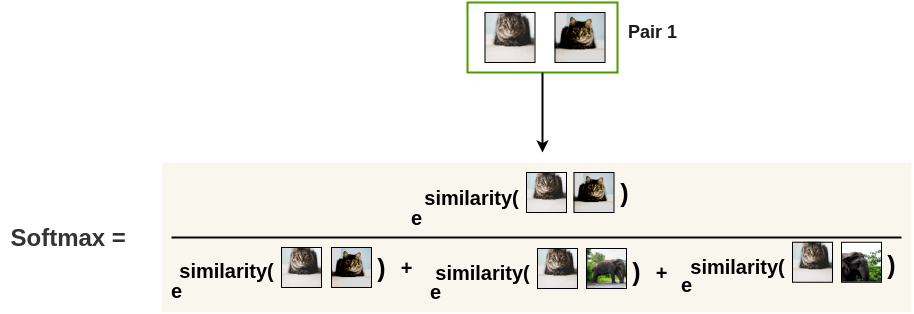 Fig. SimCLR Objective compared to Cross Entropy Objective. Source form Amit Chaudhary’s Blog
Fig. SimCLR Objective compared to Cross Entropy Objective. Source form Amit Chaudhary’s Blog
이는 직관적으로 생각해보면 Softmax를 취하고 Cross Entropy를 사용해서 Image Classification 문제를 푸는 것이 고양이 사진 vector와 고양이 class를 나타내는 one-hot vector 이 두 벡터를 가깝게 해주는 것이라고 할 때, Contrastive Objectvie는 고양이 이미지 각각이 서로의 class label 이 되어 서로를 끌어당긴다고 생각할 수 있겠습니다.
 Fig. SimCLR Result. Source form Amit Chaudhary’s Blog
Fig. SimCLR Result. Source form Amit Chaudhary’s Blog
실제 학습된 embedding vector는 위의 사진처럼 고양이 끼리는 유사한 벡터공간으로 매핑되고 코끼리는 코끼리 끼리 뭉치게 됩니다.
CLIP은 이런 방식을 통해서 (물론 CLIP은 이미지-텍스트 간 Pair-wise label이 필요합니다.) 이미지와 이를 설명하는 문장이 같은 곳에 매핑될 수 있도록 하는데요,
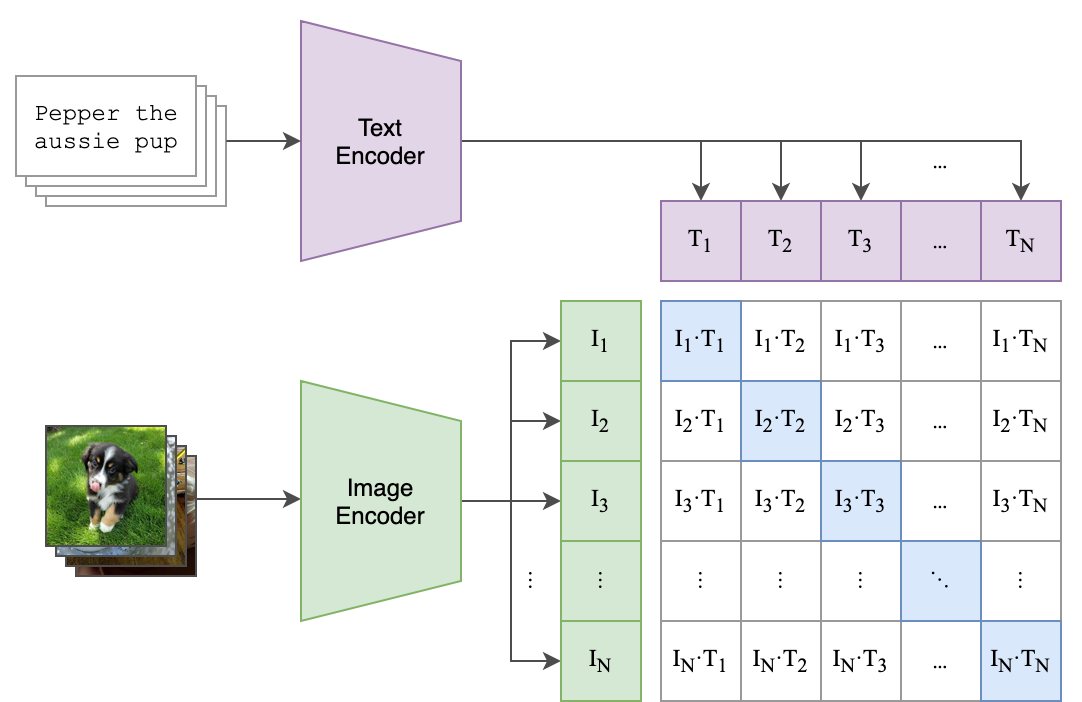 Fig. CLIP Network Architecture Recap
Fig. CLIP Network Architecture Recap
이렇게 학습할 경우 우리는 Text 정보에 이미지 정보까지 담고있는 Text Encoder 와 이미지 정보에 문장 정보까지 담는 Image Encoder 를 얻게 됩니다.
(CLIP의 Fine-tuning 단계는 pass)
GLIDE (Guided Language-to-Image Diffusion for Generation and Editing)
이제 거의 다 왔는데오, 우리는 이전 Post 에서 Diffusion Model 이 뭔지에 대해서 알아봤습니다.
하지만 DDPM 만으로 DALL-E 2 를 설명할 수 있는건 아니고 GLIDE 라는 모델도 추가적으로 이해해야 합니다.
DDPM 이 단순히 랜덤한 노이즈로부터 이미지를 만들어내는 것이라면 GLIDE는 어떤 Text 가 주어졌을 때 이에 해당하는 이미지를 만들어내는 Text Conditioned Generation 이 가능합니다.
Conditional-VAE (CVAE) 에서 처럼 당연히 지금의 생성모델도 Class Condition 해서 이미지를 만들어낼 만 하겠죠?
일단 GLIDE 논문에서의 term 을 갖다 쓰기 위해서 다시 Diffusion Model을 recap 해 봅시다.
\[q\left(x_{t} \mid x_{t-1}\right):=\mathcal{N}\left(x_{t} ; \sqrt{\alpha_{t}} x_{t-1},\left(1-\alpha_{t}\right) \mathcal{I}\right)\] \[p_{\theta}\left(x_{t-1} \mid x_{t}\right):=\mathcal{N}\left(\mu_{\theta}\left(x_{t}\right), \Sigma_{\theta}\left(x_{t}\right)\right)\] \[L_{\text {simple }}:=E_{t \sim[1, T], x_{0} \sim q\left(x_{0}\right), \epsilon \sim \mathcal{N}(0, \mathbf{I})}\left[\left\|\epsilon-\epsilon_{\theta}\left(x_{t}, t\right)\right\|^{2}\right]\](이제 익숙하시리라 생각이 됩니다.)
그렇다면 여기서 Reverse Process 에 이미지의 label 이나 caption y를 조건부로 걸어봅시다.
라고 쓸 수 있을텐데요 (여기서 Z는 constant), 즉 DDPM 이 reverse process 를 담당하는 모델만 있었던 데 반해 별도의 classifier \(\phi\) 가 추가돼서 이것 까지 학습하는 거죠.
이러면 앞선 DDPM 의 Inference 단계가 아래처럼 바뀌게 되는데요,
 Fig. DDPM 대비 조금 복잡해졌는데, 노이즈를 생성하고 Denoising 과정을 마찬가지로 T번 반복하는데, classifier의 Graident를 사용하는 것이 추가됐을 뿐이다.
Fig. DDPM 대비 조금 복잡해졌는데, 노이즈를 생성하고 Denoising 과정을 마찬가지로 T번 반복하는데, classifier의 Graident를 사용하는 것이 추가됐을 뿐이다.
여기에 Score-based Model 의 trick 등을 써서 잘 근사? 하면 (Denoising Diffusion Implicit Models (DDIM) 참고)
 Fig. Argorithm 1 과 다르게 이는 Stochastic Diffsuion Sampling Process 대신 DDIM 처럼 Deterministic Sampling 을 쓰기 위해 Score-Based Conditioning Trick 을 사용했다고 한다.
Fig. Argorithm 1 과 다르게 이는 Stochastic Diffsuion Sampling Process 대신 DDIM 처럼 Deterministic Sampling 을 쓰기 위해 Score-Based Conditioning Trick 을 사용했다고 한다.
가 된다고 합니다. (수식에서 classifier의 gradient를 사용하는데 이부분은 Score-based Model 을 봐야 합니다.)
하지만 여기서 DDPM의 저자인 Jonathan Ho 가 별도의 Classifier가 없이도 Class Condition Generation 이 가능하도록 잘 모델링해서 같은 해 NIPS workshop 에 또다른 논문을 출판했는데요, 바로 Classifier-Free Diffusion Guidance 입니다.
Classifier \(\phi\) 를 없애는 대신에 DDPM 의 Reverse model 에 바로 class 를 조건부로 주는데요, 이 때 그러면 condition 없이 생성할 때는 어떻게하냐? 의 해결책으로 그럴 때는 아무 의미도 없는 Null Label \(\emptyset\) 을 걸어주는 방식을 사용했다고 합니다.
그리고 실제 샘플링 시에는 아래의 수식을 썼다고 하는데요,
\[\hat{\epsilon}_{\theta}\left(x_{t} \mid y\right)=\epsilon_{\theta}\left(x_{t} \mid \emptyset\right)+s \cdot\left(\epsilon_{\theta}\left(x_{t} \mid y\right)-\epsilon_{\theta}\left(x_{t} \mid \emptyset\right)\right)\](During sampling, the output of the model is extrapolated further in the direction of \(\epsilon_{\theta}\left(x_{t} \mid y\right)\) and away from \(\epsilon_{\theta}\left(x_{t} \mid \emptyset\right)\) as follows)
수식이 앞서 살펴본 classifer 가 추가된 모델과 비슷하지만 이는 아래처럼 어떤 implicit classifier 가 DDPM의 Reverse Model 에 내재되어 있다는 가정을 수학적으로 풀어내서 얻은 것이라고 합니다.
우리는 단순히 이미지의 원핫 레이블 y 뿐 아니라 이미지의 caption 인 문장 c 를 쓸 것이기 때문에 다시 쓰면 아래와 같고,
이렇게 별도의 Classifier 없이 학습하는 방식이 그렇지 않은 방식보다 Text Condition Image Generation 문제를 굉장히 잘 풀게 해준다고 합니다.
자 거의 다 왔습니다.
앞서 Class Conditioned Diffusion Model 을 설명하기 이ㅜ해서 Classifier Free냐 아니냐에 대해 얘기했지만 이게 있느냐 없느냐보다 더 이미지 퀄리티를 좋게하는 방법이 있었으니 바로 앞서 살펴본 CLIP을 Classifer로 쓰는 방법 이 되겠습니다.
(당연히 이 논문이 CLIP을 쓴 최초의 생성모델은 아니고, GAN에 적용하거나 많은 시도가 있었고 꽤 잘됐다고 합니다)
별도의 Classifier가 있는 모델인데요, 이걸 CLIP 으로 쓰겠다는 겁니다.
\[\hat{\mu}_{\theta}\left(x_{t} \mid c\right)=\mu_{\theta}\left(x_{t} \mid c\right)+s \cdot \Sigma_{\theta}\left(x_{t} \mid c\right) \nabla_{x_{t}}\left(f\left(x_{t}\right) \cdot g(c)\right)\]여기서 \(f(x)\) 의 \(f\) 가 CLIP의 Image Encoder, \(x\) 가 이미지이고 \(g(c)\) 의 \(g\) 가 Text Encoder, \(c\)가 text, 즉 caption 입니다.
아까 Class-Guided Diffusion model 을 다시 봅시다.
이 수식은 Vanilla DDPM 의 Reverse Process 의 \(\mu(x_t)\) 에 noise 이미지 \(x_t\)가 \(y\) 로 분류될 확률의 gradient를 더해준 겁니다. 즉 해당이미지와 그에 해당하는 정답 label one-hot vector와의 Similarity 를 쓴 것이죠,
하지만 CLIP 을 Classifer로 쓰는 경우는 label one-hot vector 를 쓰는 것이 아닌 이미지와 그에 해당하는 정답 caption embedding vector와의 Similarity의 Gradient를 쓰게 된다는 차이가 있습니다.
이부분을 조금 곱씹어볼 필요가 있을 것 같습니다.
이 때 CLIP model은 pre-trained model을 써도 되지만
Fig. CLIP Network Architecture Recap
noisy image 에 대해서 튜닝을 좀 더 한 모델이 성능이 더 좋았기 때문에 GLIDE 의 저자들은 Training 시 CLIP Objective 와 Diffusion Model Objective 를 같이 섞어 쓴 것 같고, 논문의 묘사를 따라 Training Procedure를 그려보면 아래처럼 그릴 수 있을 것 같습니다.
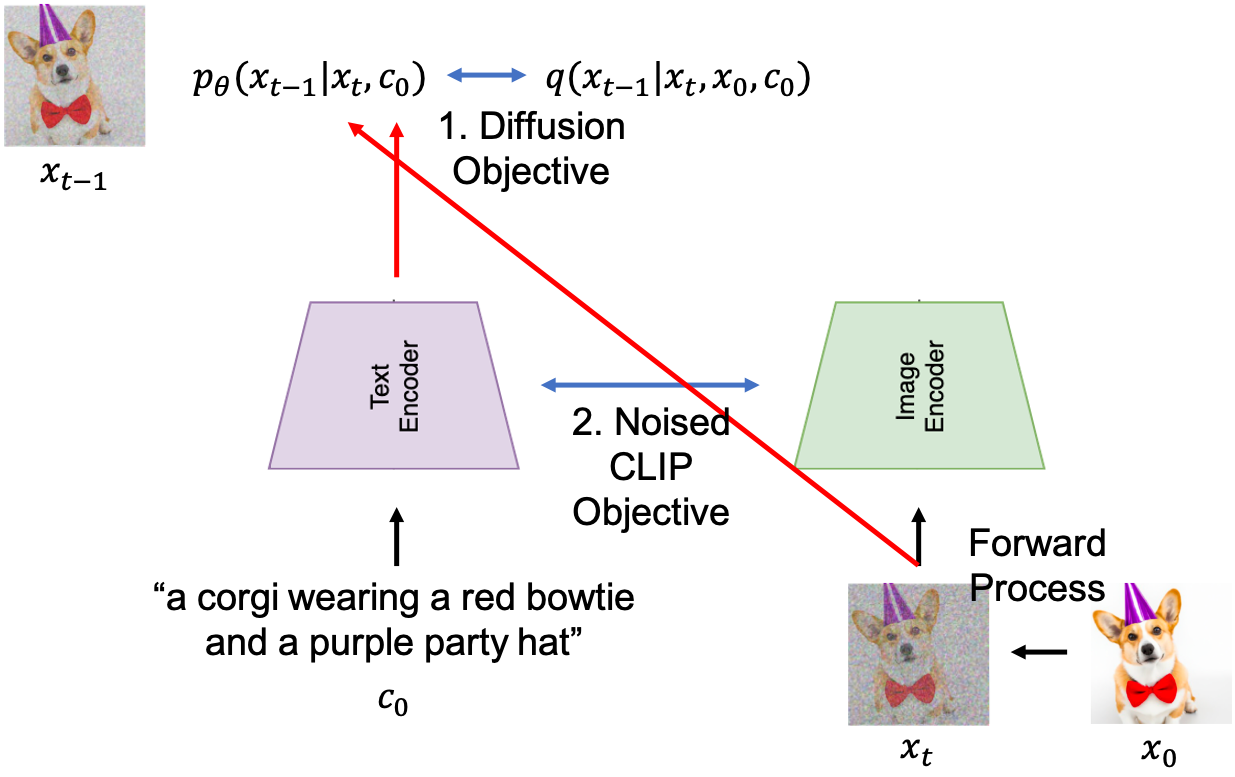 Fig. GLIDE Training Procedure using CLIP Classifier
Fig. GLIDE Training Procedure using CLIP Classifier
이렇게 학습된 Diffusion Model 은 DALL-E 1 처럼 Text 가 주어졌을 때 이미지를 만들어낼 수 있는데요,
 Fig. Text Conditioned Image Generation Example 1
Fig. Text Conditioned Image Generation Example 1
Inference 과정이 훨씬 오래걸리고 복잡한 만큼 다른 생성 모델들보다 더 정교한 이미지를 만들어 낸다고 저자들은 주장합니다.
 Fig. Text Conditioned Image Generation Example 2
Fig. Text Conditioned Image Generation Example 2
(GLIDE 뿐 아니라 요즘 나오는 생성모델들은 아래처럼 Text Guided Inpainting도 잘 해낸다는데 디테일은 논문을 참고해 주세요!)
 Fig. Inpainting Example 1
Fig. Inpainting Example 1
 Fig. Inpainting Example 2
Fig. Inpainting Example 2
Understanding How DALL-E 2 works in detail
돌고 돌아서 드디어 DALL-E 2로 왔습니다.
사실 DALL-E 2 라는 Title로 화제가 됐지만 논문의 제목은 Hierarchical Text-Conditional Image Generation with CLIP Latents 이고 모델의 이름은 unCLIP 입니다.
아키텍쳐 이름에서부터 우리가 앞서 알아본 CLIP latent를 reverse process로 디노이징 해 이미지를 만들어낸 다는 의미를 내포하고있는거죠.
다시 unCLIP 그림을 봅시다.
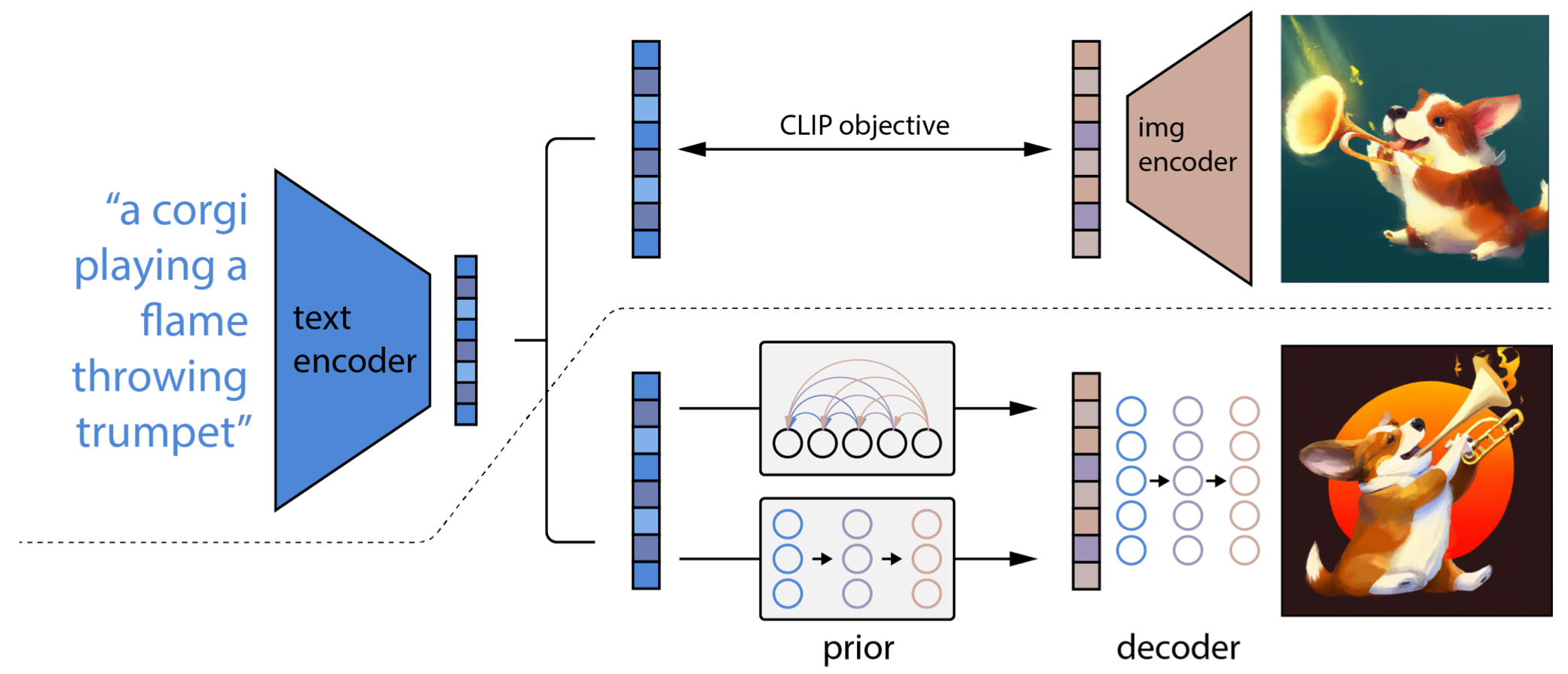 Fig. unCLIP Model
Fig. unCLIP Model
이 Figure 의 Caption 에는 unCLIP 하는 과정과 디테일 하나가 적혀있는데요,
- 1.CLIP
TextEmbedding 을 뽑는다. - 2.
AutoRegressive (AR)orDiffusionprior model로ImageEmbedding 을 만든다.- (여기서 전자 (former) 모델은 DALL-E 1 에서 처럼 Text 정보를 받아 Image latent를 뱉는 GPT 같은 모델일겁니다.)
- 3.이렇게 구한 Image Embedding 를
Diffusion Decoder가 복원한다. - 4.고 퀄리티 이미지를 위해 이미지 해상도를 64x64 -> 256x256 or 1024x1024 로 키워주는 Diffusion Upsampler 를 각각 학습함.
- (이 때 robustness 를 위해 이미지를 corrupt 했음.)
- 주의할 점은 CLIP model 은 Prior 와 Decoder 를 학습할 때는
frozen상태이다.
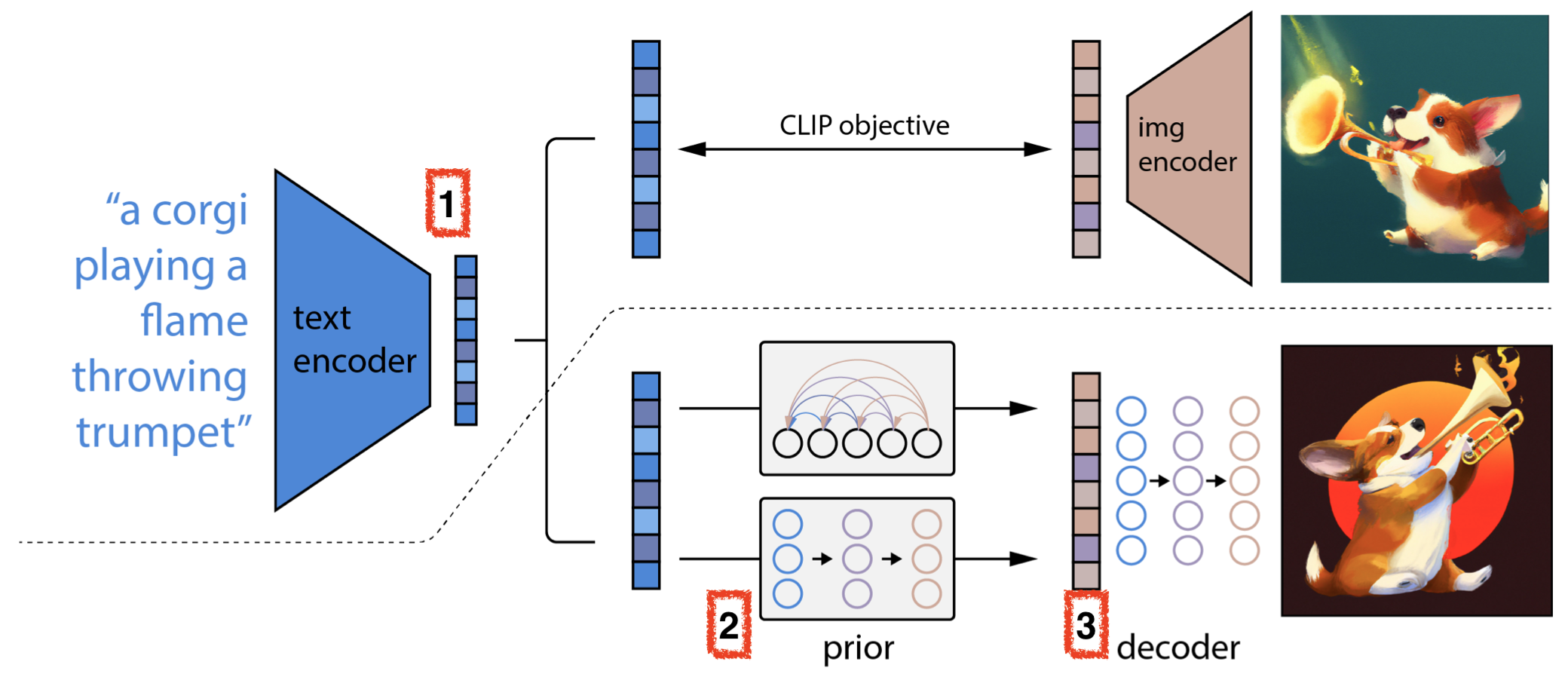 Fig. unCLIP Model Detail 1
Fig. unCLIP Model Detail 1
여기서 3번은 그냥 GLIDE 에서 묘사한 모델과 같고 1번은 CLIP Objective로 학습한 단순한 모델이니 넘어가면 2번만 잘 캐치하면 될 것 같죠?
근데 2번의 Prior가 좀 뜬금없이 추가 됐다는 느낌이 듭니다.
원래 GLIDE 논문에서 제시된 CLIP-Guided Diffusion Model 에는 Prior가 없었거든요.
아마 CLIP Objective로 학습하면서 Text Encoder가 Image 정보를 배우긴 하나 이걸로는 부족했기 때문에 아예 Image Embedding 을 생성해내도록 한 것 같습니다. 이게 필수는 아니지만 Image Diversity를 높혀주기도 하고 GLIDE에 비해 더 이미지 퀄리티가 좋았다고 합니다.
+) DDPM 이후의 모델들이 대부분 Diffusion Model 로 UNet 을 썼는데요,
논문에는 3.5 billion parameter GLIDE model 을 썼다고 하니
Diffusion Decoder 로는 UNet을 썼을 것 같습니다.
그리고 CLIP Image Encoder 로는 36층 짜리 트랜스포머, ViT 를 쓰고
Text Encoder 는 CLIP 페이퍼에 나온 것 처럼 24층 짜리 트랜스포머를 쓴 것 같습니다.
사실 Prior는 어디선가 툭 튀어나온건 아닌데요, 우리가 모델링 하고 싶은게 Text 를 주었을 때 이미지를 뽑는 모델이기 때문에
\[P(x \mid y)\]여기에 잠재 변수 \(z\) 를 추가해서 (이 latent가 CLIP latent인데요, 이미지 임베딩 벡터를 \(z_i\), 텍스트 임베딩 벡터를 \(z_t\)라는 Notation을 씁니다.) 표현하면
\[P(x \mid y) = P(x,z_i \mid y) = P(x \mid z_i, y) P(z_i \mid y)\]가 되는데 이 때 앞의 \(P(x \mid z_i, y)\) 가 우리가 주구장창 다뤘던 Reverse Process고 뒤의 \(P(z_i \mid y)\) 가 Prior가 되는 겁니다.
즉 수학적으로 모델링 할만 했다?는 거죠.
어쨌든 앞서 말한 것 처럼 CLIP Training 을 하면 각각의 인코더가 뱉는 \(z_t\) 와 \(z_i\)가 같은 Latnet Space에 매핑돼서 Prior 같은 중간다리는 필요 없어 보이지만 DALL-E 2 에서는 이걸 적용한게 더 좋았다고 하니 …
본 논문에서는 Prior로 두 모델을 써봤는데 더 efficient한 방법은 Diffusion Prior 였다고 합니다.
- AutoRegressive (AR) Prior : Transformer Decoder로 Autoregressive 하게 \(z_i\) 생성
- Diffusion Prior : 단순한 Gaussian Diffusion Model
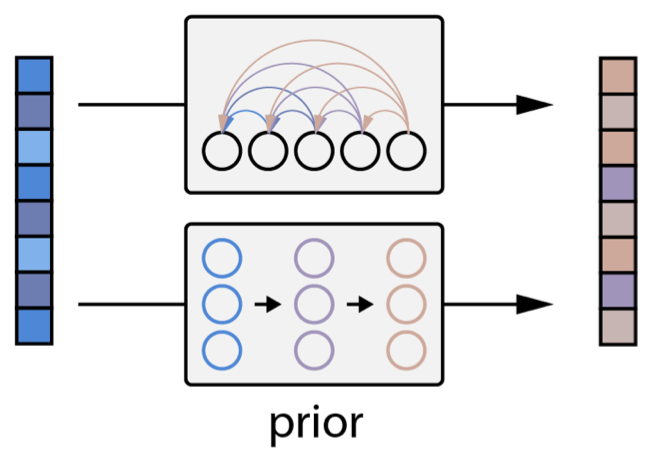 Fig. Two Different Prior Models
Fig. Two Different Prior Models
여기서 AR Prior는 단순히 DALL-E 1 에서 처럼 Text, Image Embedding token들을 sequence 로 생각해서 AutoRegressive (AR) 학습을 하는것인데요,
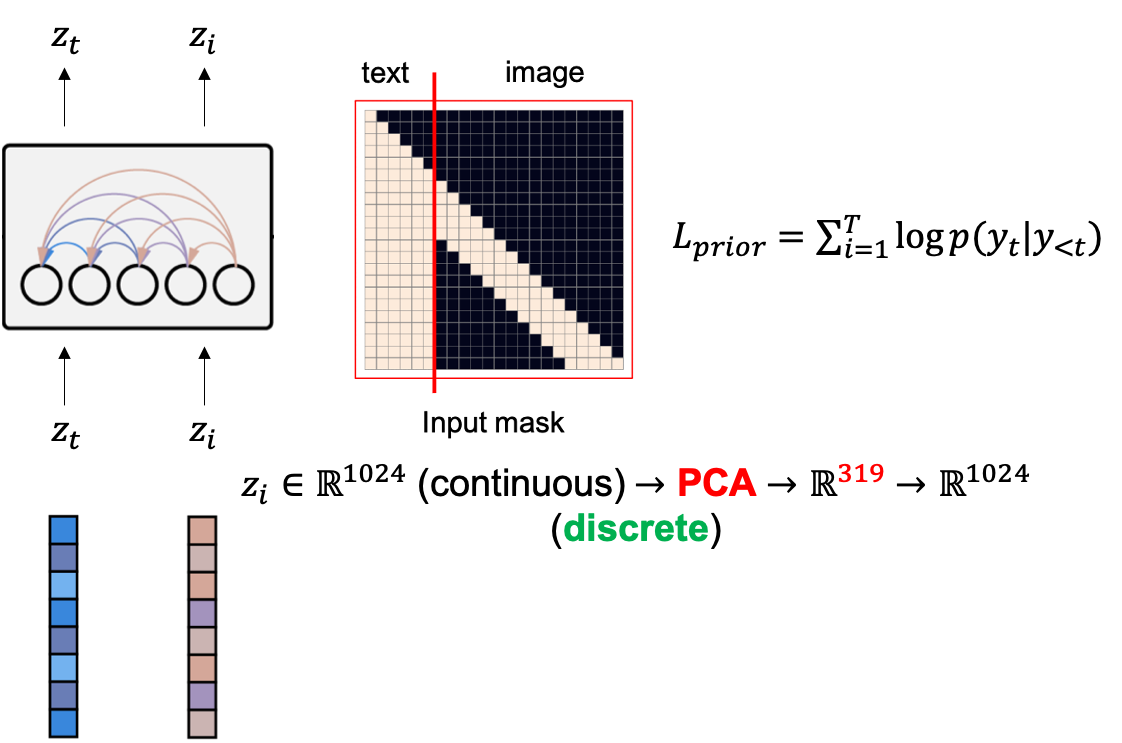 Fig. AutoRegressive (AR) Prior Diagram
Fig. AutoRegressive (AR) Prior Diagram
이 때 Image CLIP Embedding 은 continuous vector 이기 때문에 이를 바로 쓰지 않고 여기서 PCA 를 사용해 319개의 중요한 값들만 뽑은 뒤 다시 이를 Codebook 등을 통해 (논문에 묘사가 부족함) Discrete Token들로 만들어서 넣습니다.
Diffusion Prior 는 Gaussian Diffusion Model 을 쓰는데 t번째 더럽혀진 이미지를 given 으로 \(\epsilon\)-prediction 을 하지는 않고 원본 이미지의 Image Embedding Vector 를 target 으로 하도록 학습됩니다.
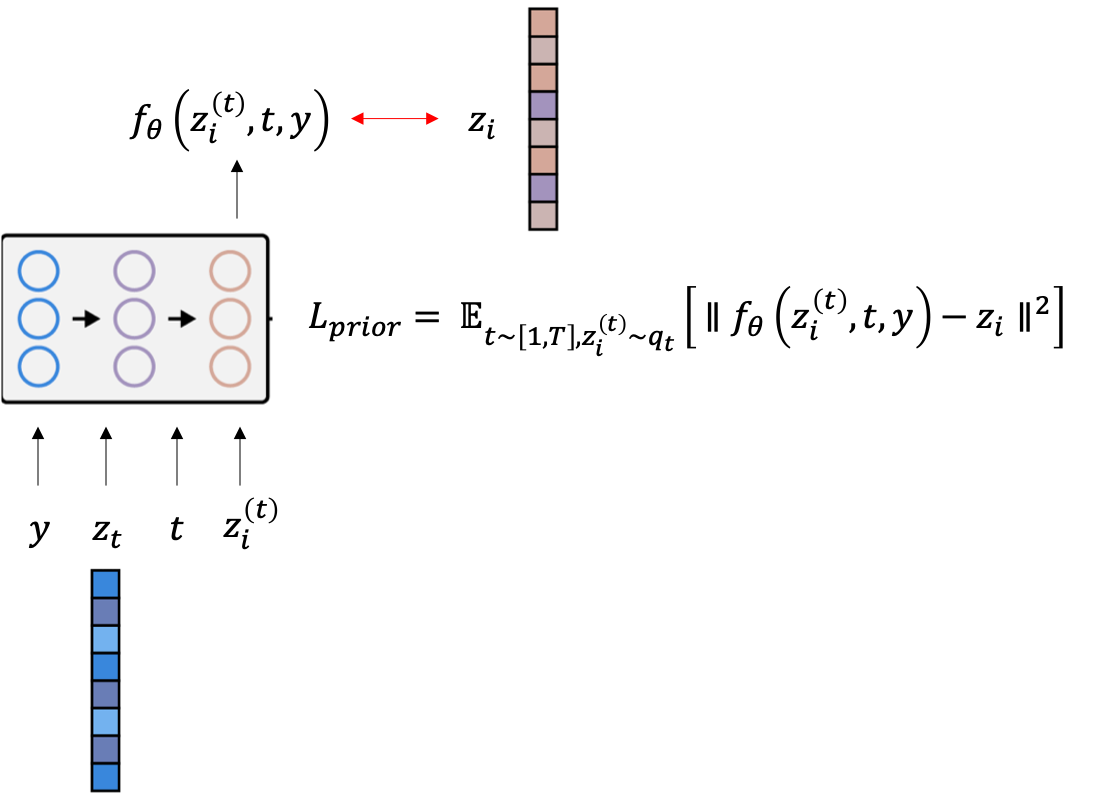 Fig. Diffusion Prior Diagram
Fig. Diffusion Prior Diagram
Diffusion Prior도 Transformer Decoder와 Causal Attention Mask를 쓴다고 되어있고
모델에 들어가는 Input은 순서대로
- Text token : \(y\)
- Text CLIP Embedding : \(z_t\)
- Embedding for the diffusion timestep : \(t\)
- Noised CLIP Image Embedding : \(z_i^{(t)}\)
이며 맨마지막 토큰과 \(z_i\) 를 비교하는 MSE Loss 를 Objective로 씁니다.
\[L_{\text{prior}} = \mathbb{E}_{t \sim [1,T], z_i^{(t)} \sim q_t} [ || f_{\theta}(z_i^{(t)},t,y) - z_i ||^2 ]\]다시 unCLIP 의 학습과정에 대해 생각해보자면 다음과 같이 쓸 수 있을 것 같습니다.
- 1.CLIP Pre-training
- CLIP은 Frozen 하고 아래의 모듈들을 동시에? 학습
- 2-1.(AR or Diffusion) Prior Training
- 2-2.Diffusion Decoder Training
- 이 때 Prior가 뽑은 Image Embedding 을 학습할 필요는 없고 아마 CLIP Image Embedding 을 조건부로 해서 학습할 듯 함. (추가적으로 이 때 text condition도 줄 수 있다고 함.)
- 2-3.upsampler Training
Experimental Results
 Fig. Figure 1
Fig. Figure 1
 Fig. Figure 3
Fig. Figure 3
 Fig. Figure 4
Fig. Figure 4
 Fig. Figure 5
Fig. Figure 5
 Fig. Figure 6
Fig. Figure 6
 Fig. Figure 7
Fig. Figure 7
 Fig. Figure 8
Fig. Figure 8
 Fig. Figure 9
Fig. Figure 9
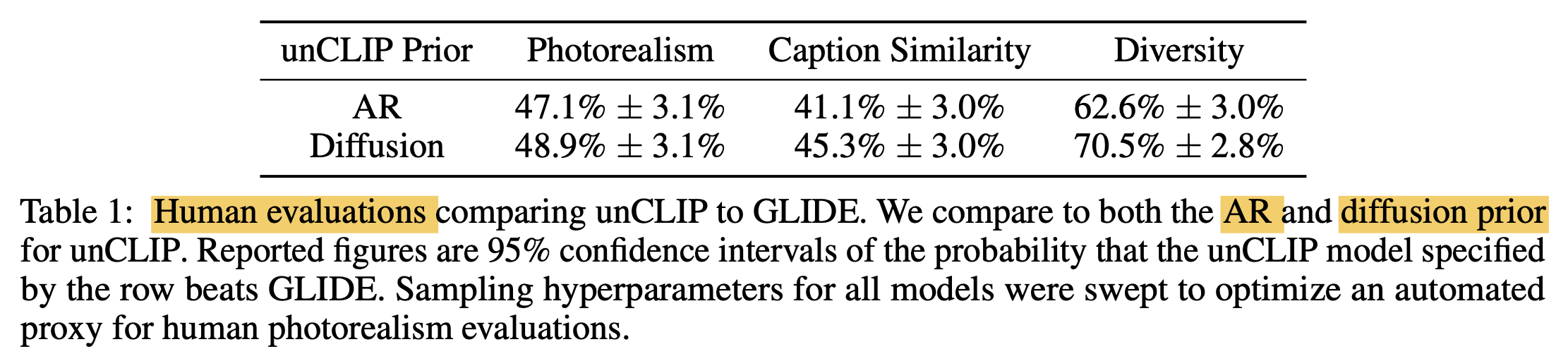 Fig. Table 1
Fig. Table 1
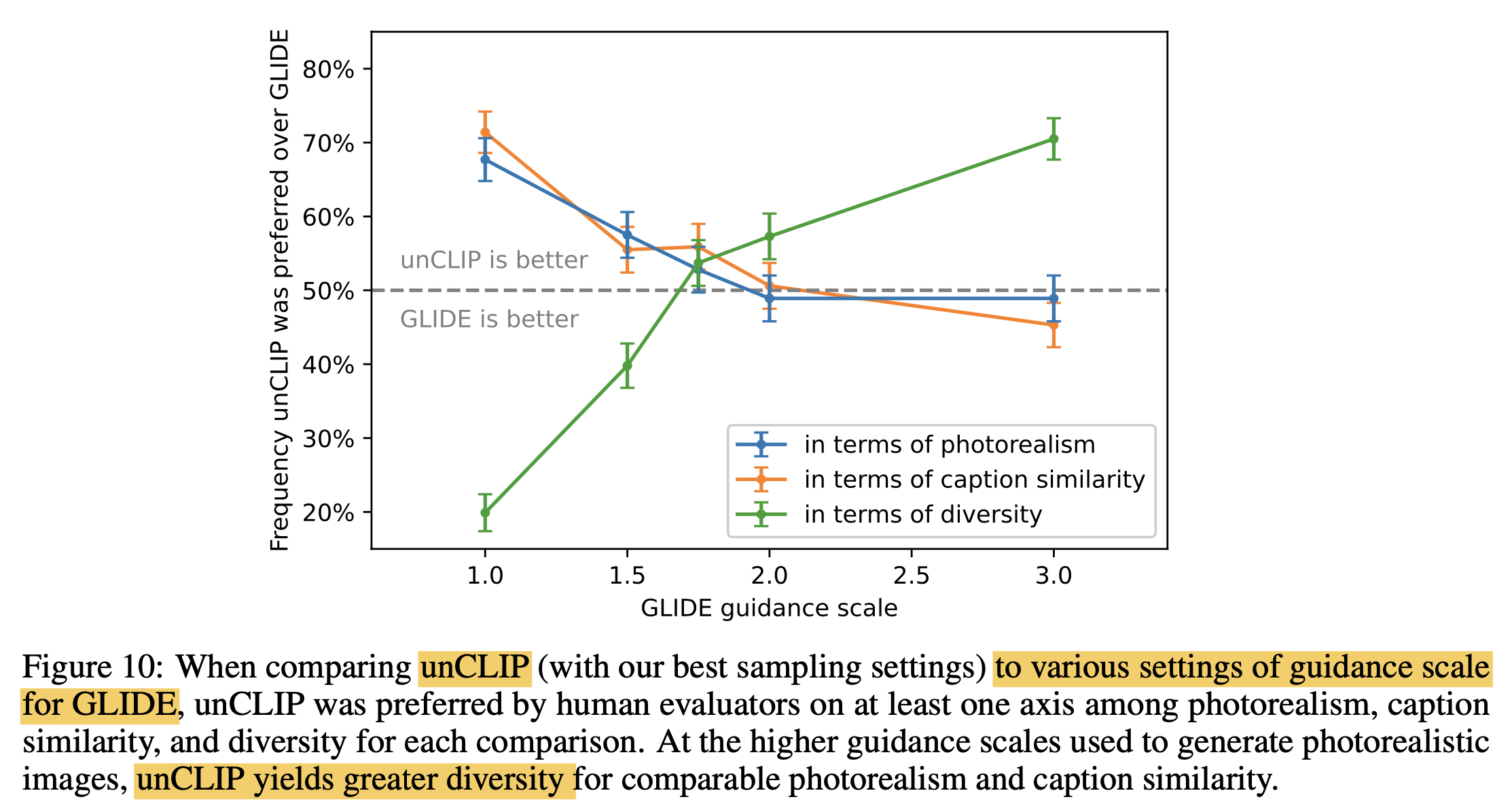 Fig. Figure 10
Fig. Figure 10
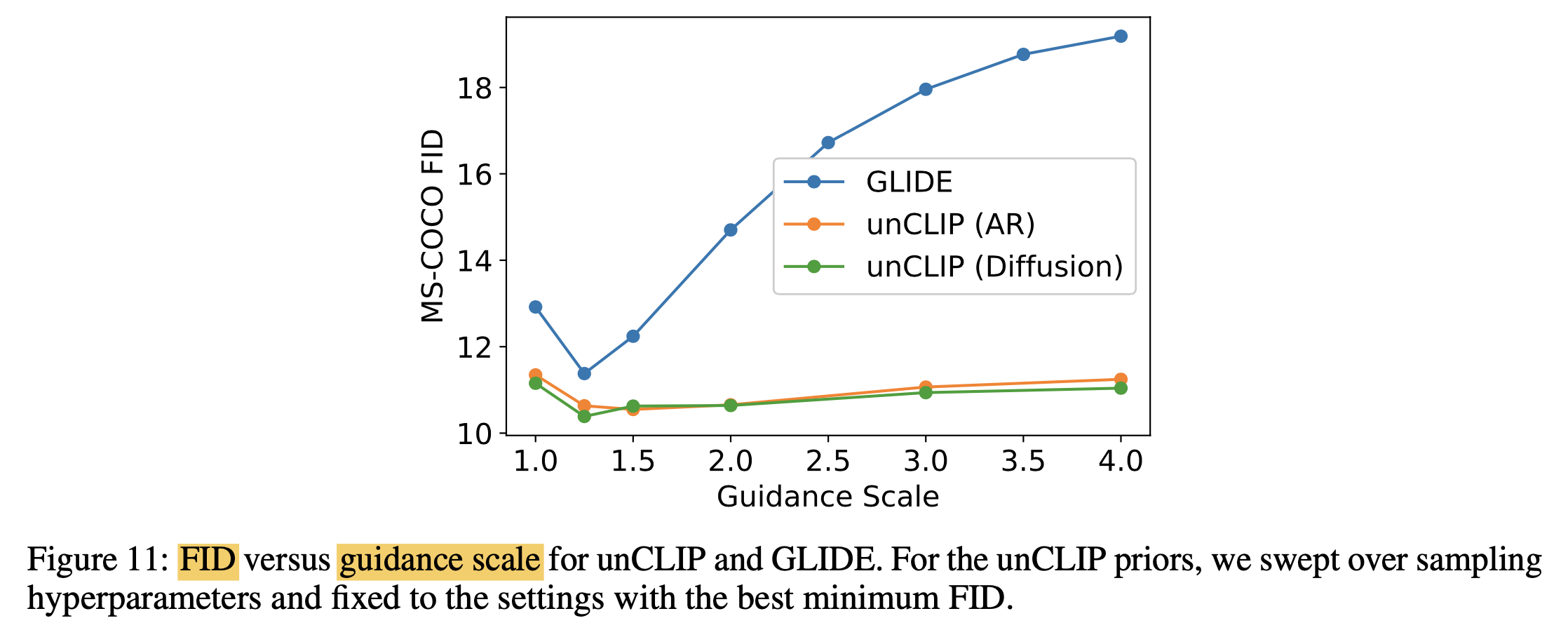 Fig. Figure 11
Fig. Figure 11
 Fig. Figure 12
Fig. Figure 12
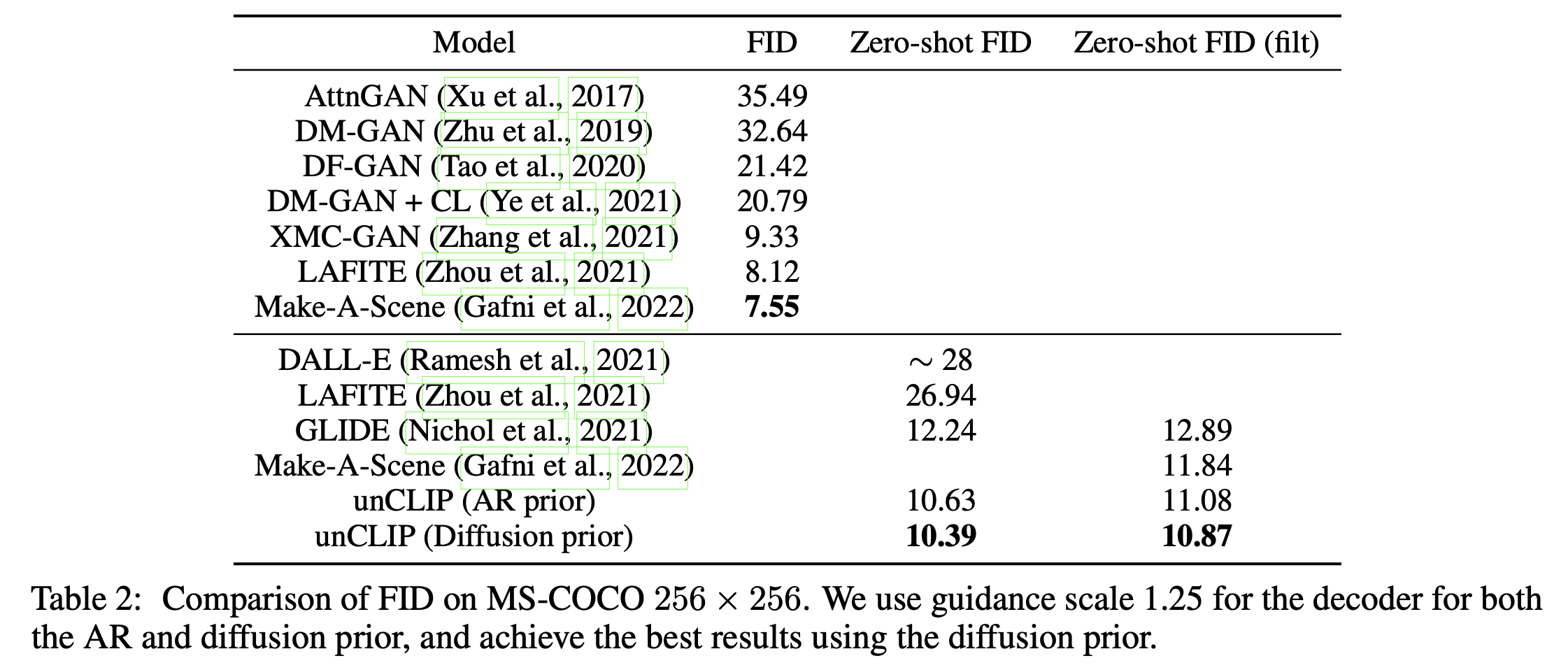 Fig. Table 2
Fig. Table 2
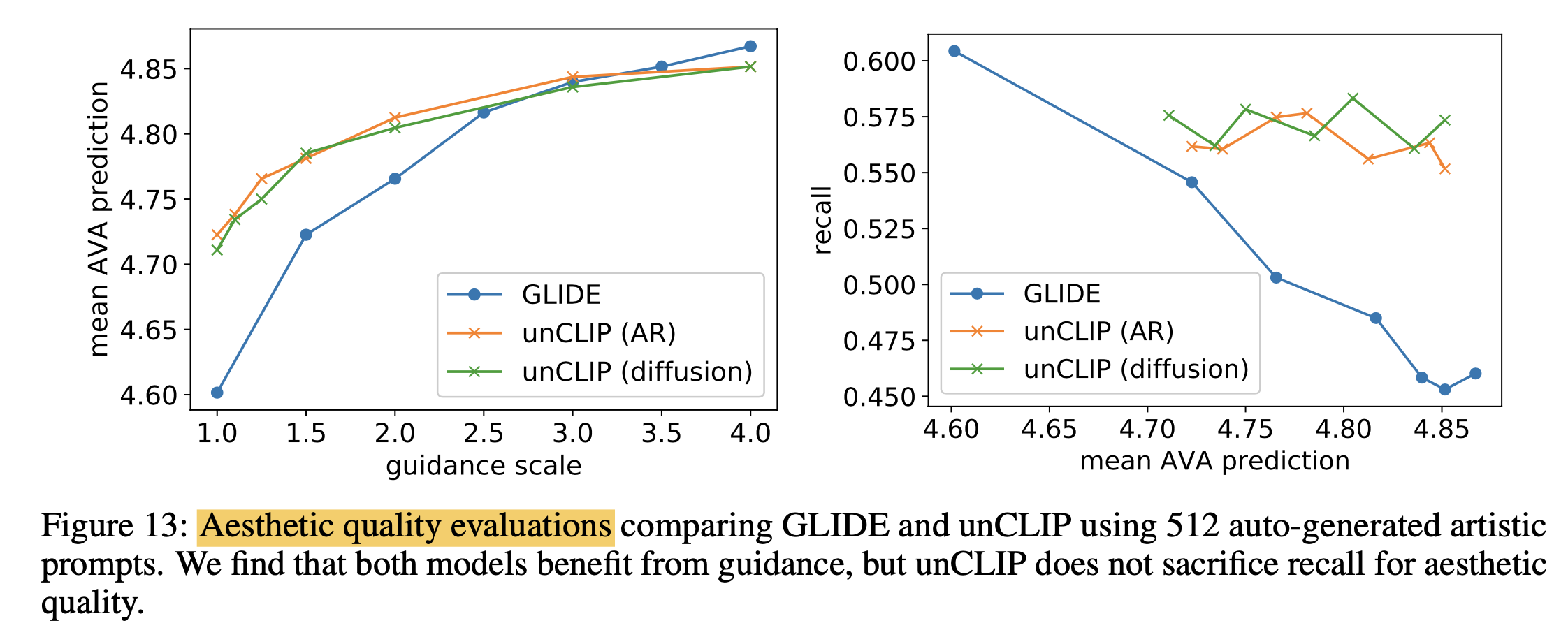 Fig. Figure 13
Fig. Figure 13
 Fig. Figure 14
Fig. Figure 14
 Fig. Figure 15
Fig. Figure 15
 Fig. Figure 16
Fig. Figure 16
 Fig. Figure 17
Fig. Figure 17
References
- Papers
- (DALL-E) Zero-Shot Text-to-Image Generation
- (DALL-E 2) Hierarchical Text-Conditional Image Generation with CLIP Latents
- Deep Unsupervised Learning using Nonequilibrium Thermodynamics
- Denoising Diffusion Probabilistic Models
- Denoising Diffusion Implicit Models
- (CLIP) Learning Transferable Visual Models From Natural Language Supervision
- Diffusion Models Beat GANs on Image Synthesis
- GLIDE, Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models
- Github (Codes)
- Blogs
- Diffusion Models as a kind of VAE from Angus Turner
- What are Diffusion Models? from lillian weng
- Generative Modeling by Estimating Gradients of the Data Distribution from Yang Song
- (OpenAI Blog) CLIP: Connecting Text and Images
- (OpenAI Blog) DALL·E: Creating Images from Text
- (OpenAI Blog) DALL·E 2
- Understanding VQ-VAE (DALL-E Explained Pt. 1)
- How is it so good ? (DALL-E Explained Pt. 2)
- DALL-E 2 vs Disco Diffusion
- Introduction to Diffusion Models for Machine Learning from AssemblyAI
- How DALL-E 2 Actually Works from AssemblyAI
- How diffusion models work: the math from scratch (AI summer School)
- How DALL·E 2 Works