(WIP) Blockwise Ring Attention
15 Feb 2024< 목차 >
- Motivation
- Blockwise Parallel Transformer (BPT)
- Ring Attention
- DeepSpeed Ulysses (Sequence Parallel)
- References
Motivation
Blockwise Parallel Transformer (BPT)나 Ring Attention은 최근 pieter abbeel lab에서 제안된 Large World Model (LWM)를 이루는 핵심 module들이다. 핵심은 flash attention이나 memory efficient attention등에서 제안된 cumulative attention 이다.
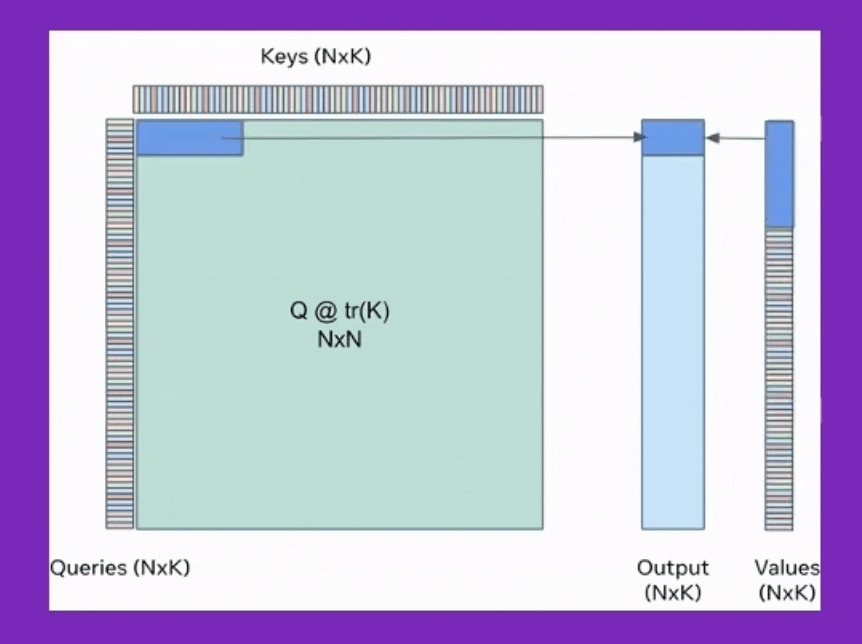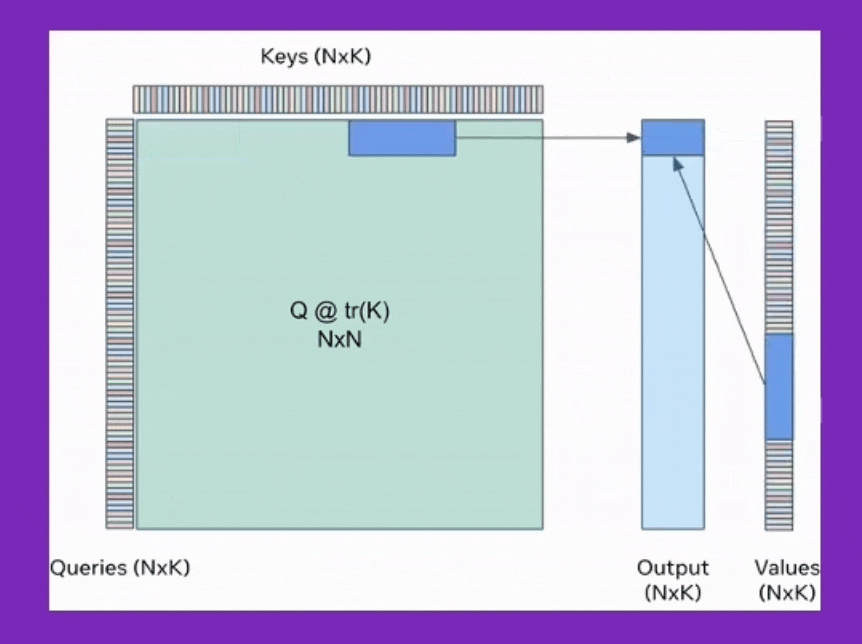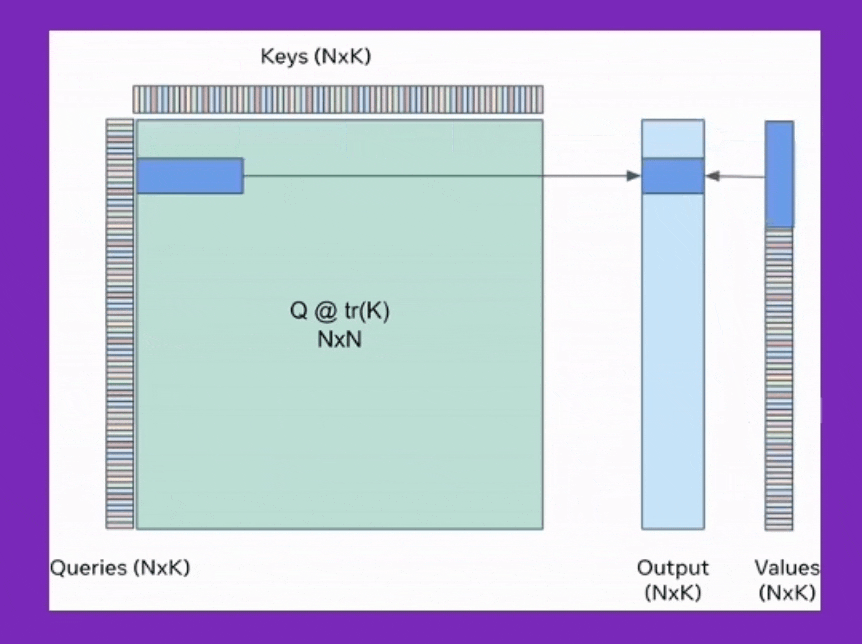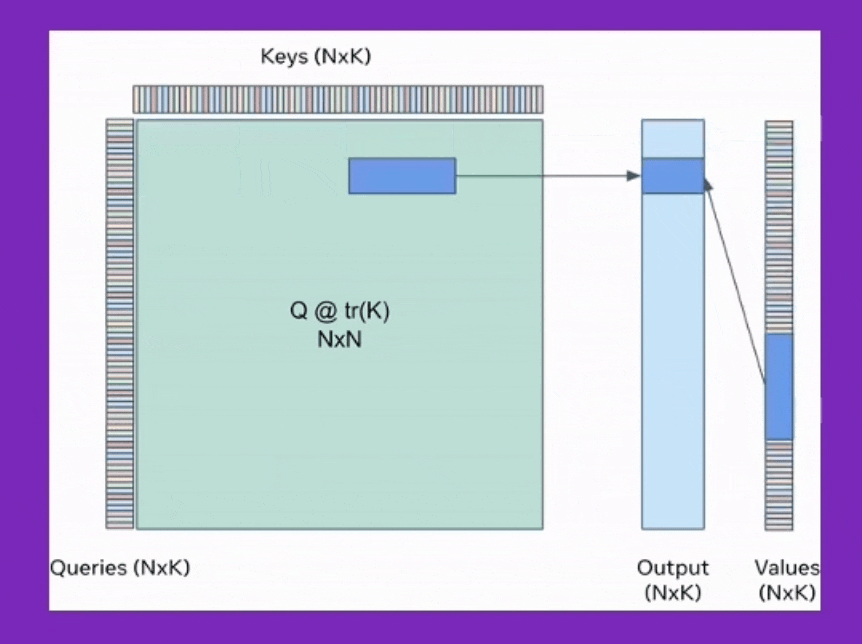
BPT는 이를 확장해서 Feed Forward Neural Network (FFN)에도 적용한 것이며, Ring attention은 이를 device간 communication을 통해 더욱 확장한 것이라고 볼 수 있는데, 어떻게보면 Transformer XL에서 제안된 hidden state를 cache하는 것과도 살짝 연관지어 생각할 수 있을 것 같다.
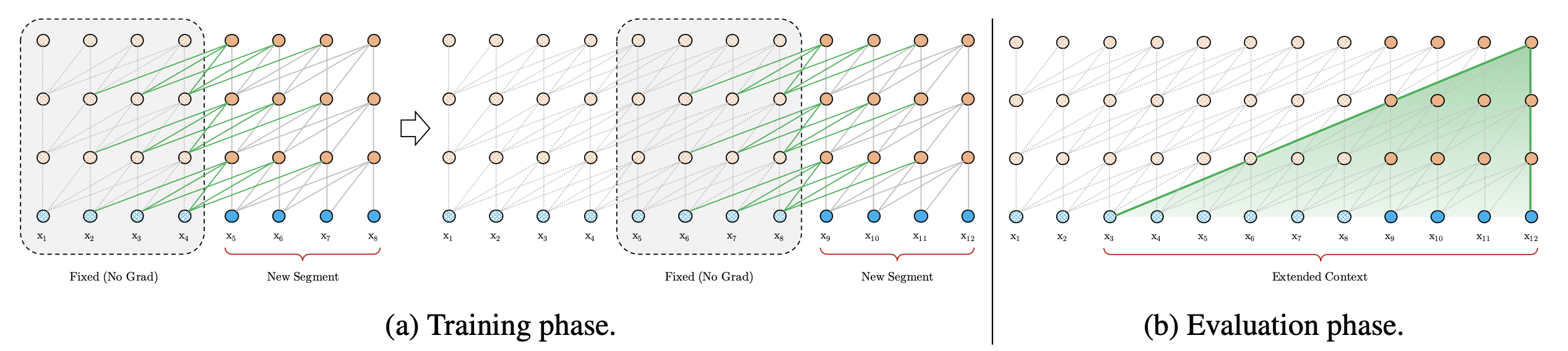 Fig.
Fig.
아무튼 inference시에도 Model Parallel (MP)를 하는데 여러 device가 필요하듯 LWM이나 google의 gemini의 주장대로 1M, 10M의 token 을 처리하기 위해서는 말도안되는 수의 device가 필요할 것으로 생각이 된다. (berkeley의 pieter abbeel lab은 꾸준히 google과 cowork을 했으며 ring attention이 TPU를 사용해 실험한 method이며 바로 gemini 1.5가 나왔으므로 gemini가 ring attention같은 method를 쓴 것은 확실할 것 같다)
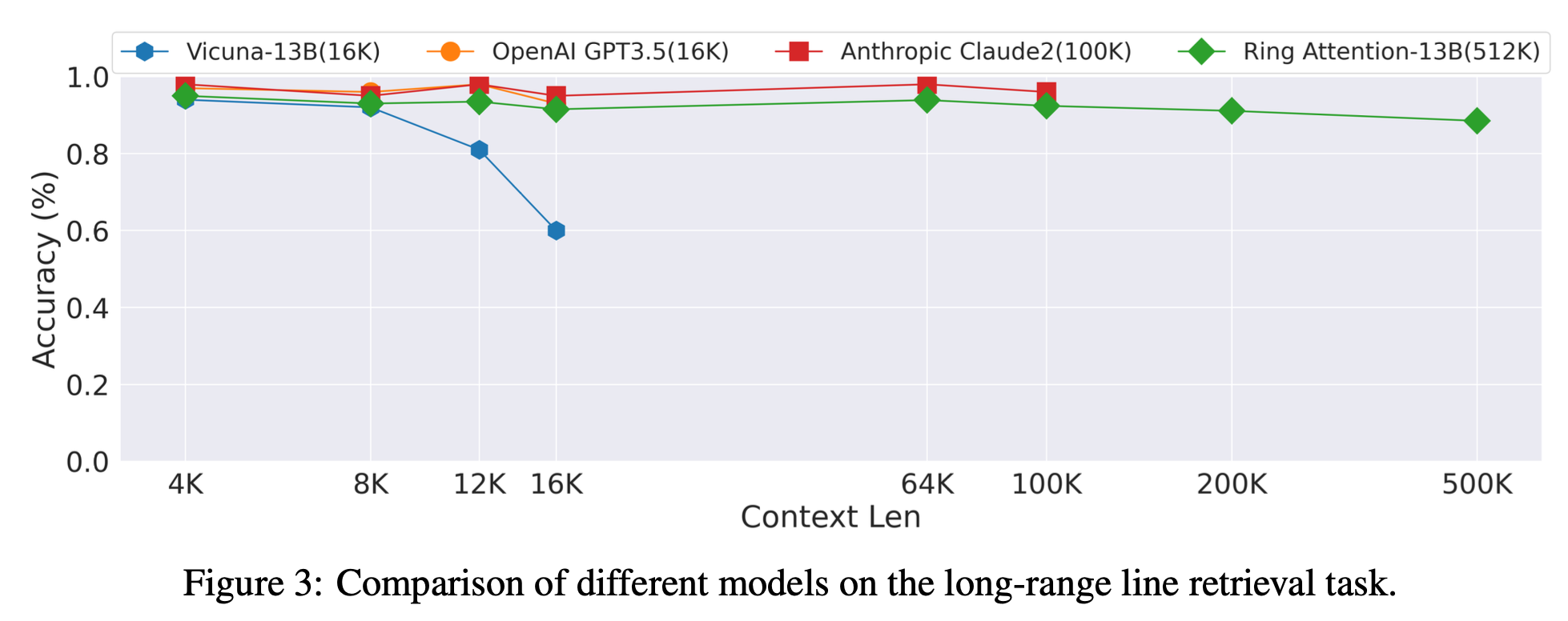 Fig. long context retrieval task에서 SOTA라고 주장하는 ring attention
Fig. long context retrieval task에서 SOTA라고 주장하는 ring attention
Blockwise Parallel Transformer (BPT)
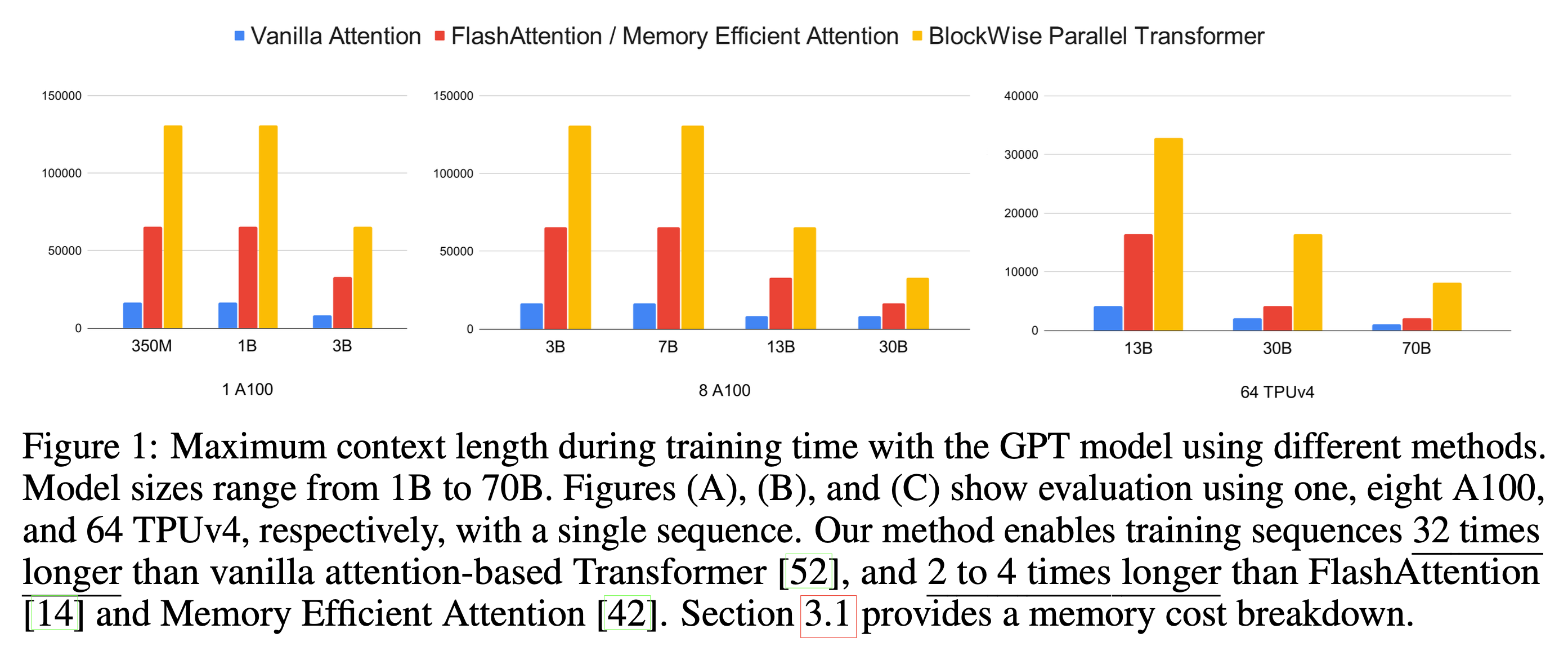 Fig.
Fig.
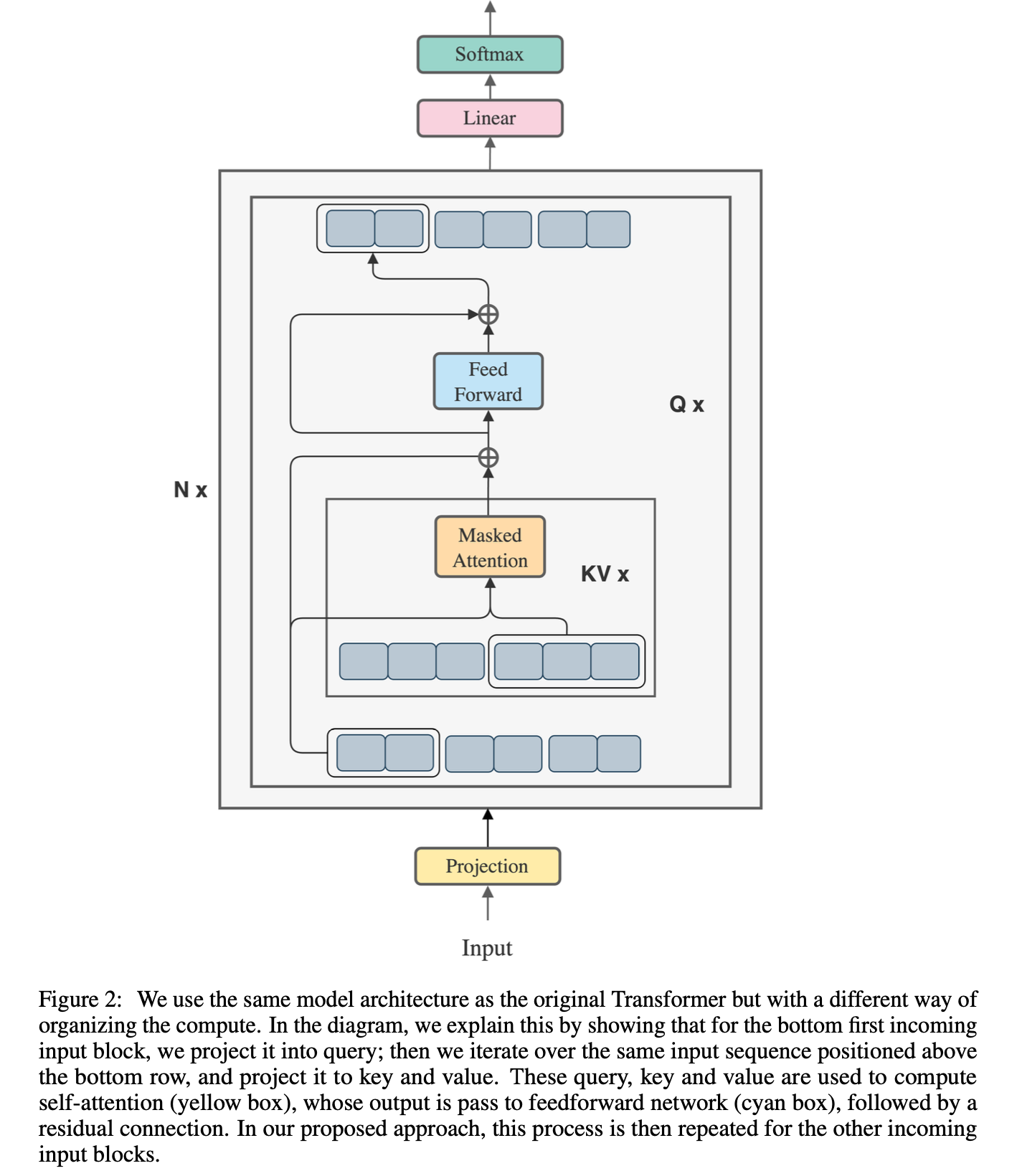 Fig.
Fig.
 Fig.
Fig.
Ring Attention
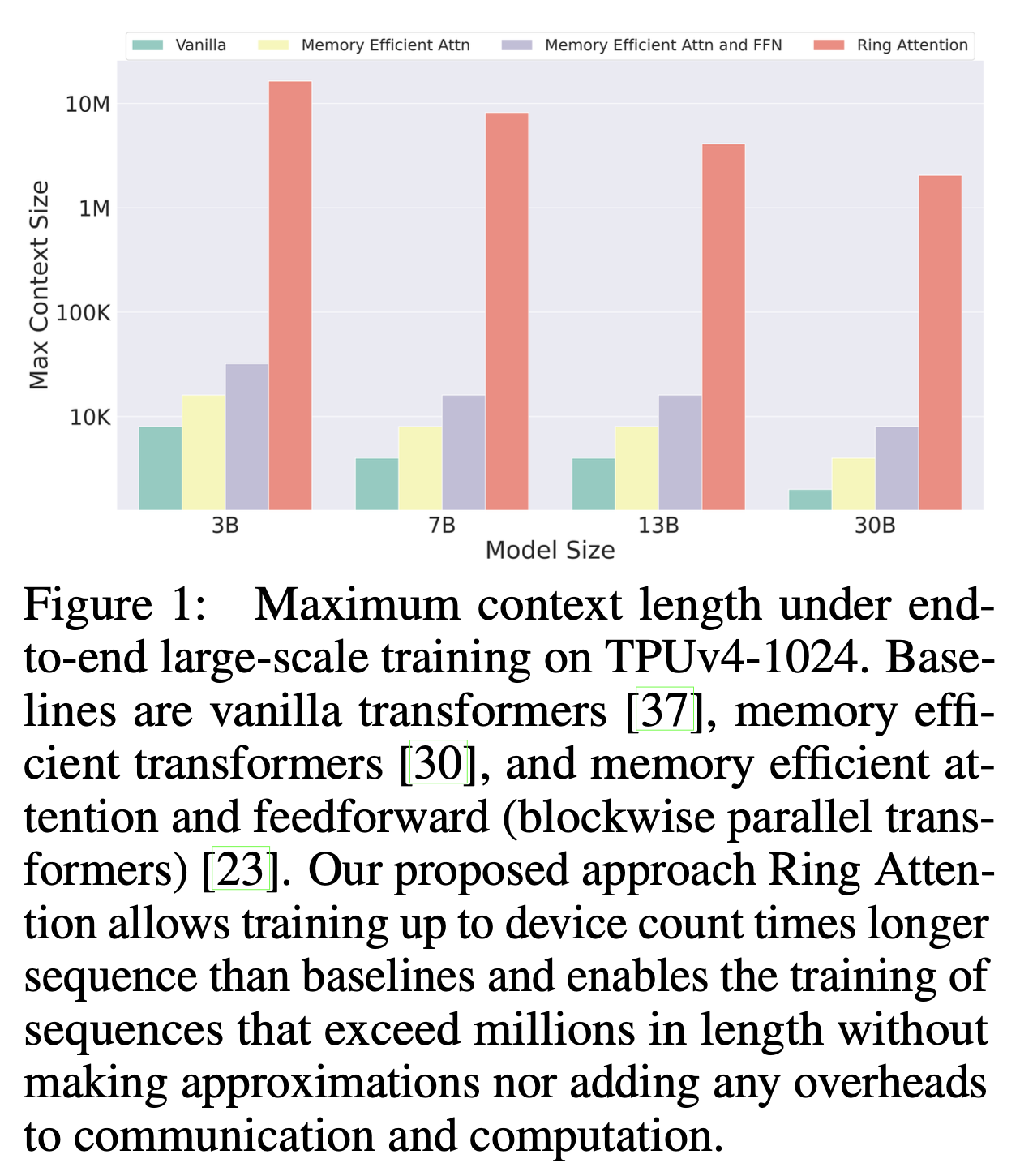 Fig.
Fig.
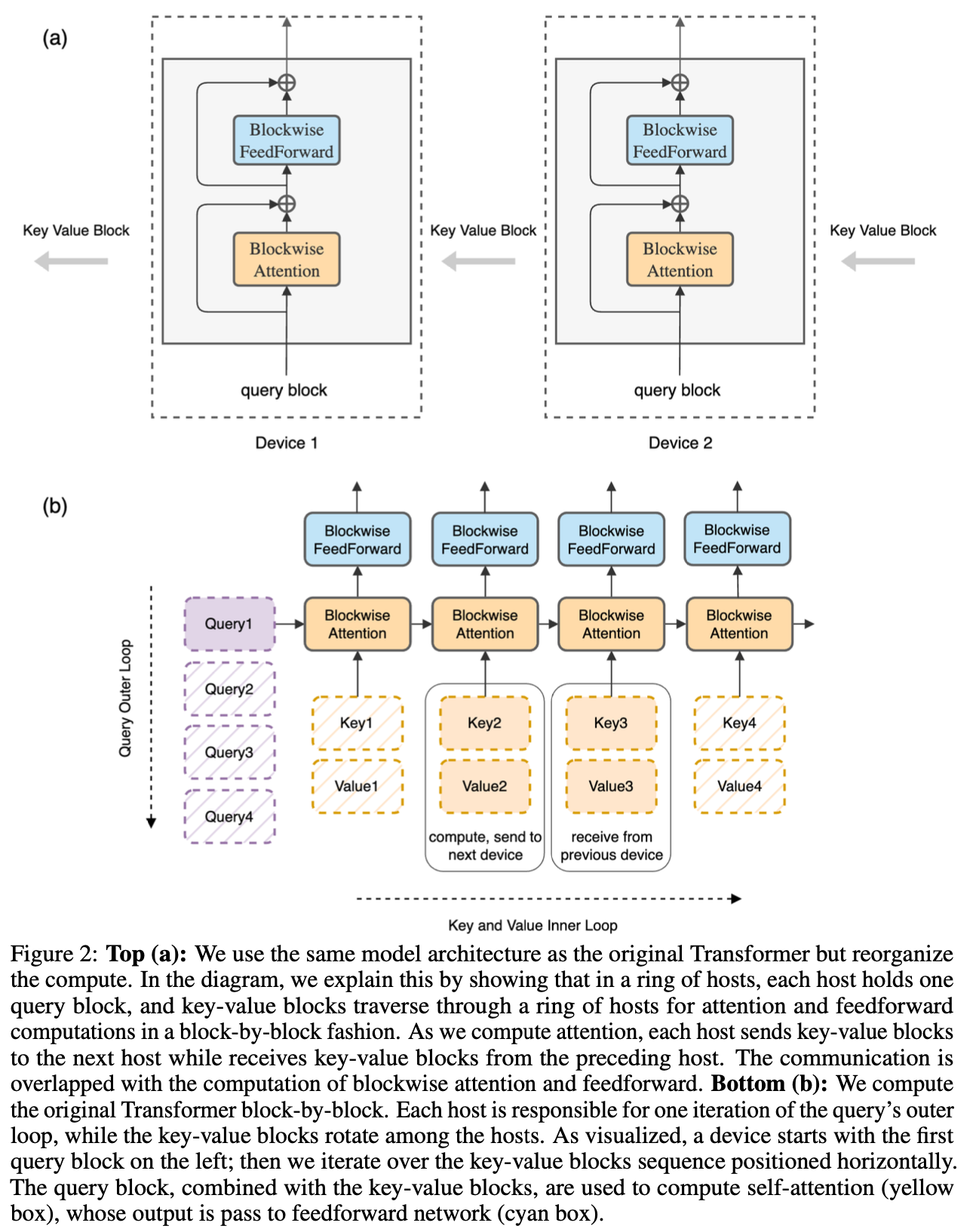 Fig.
Fig.
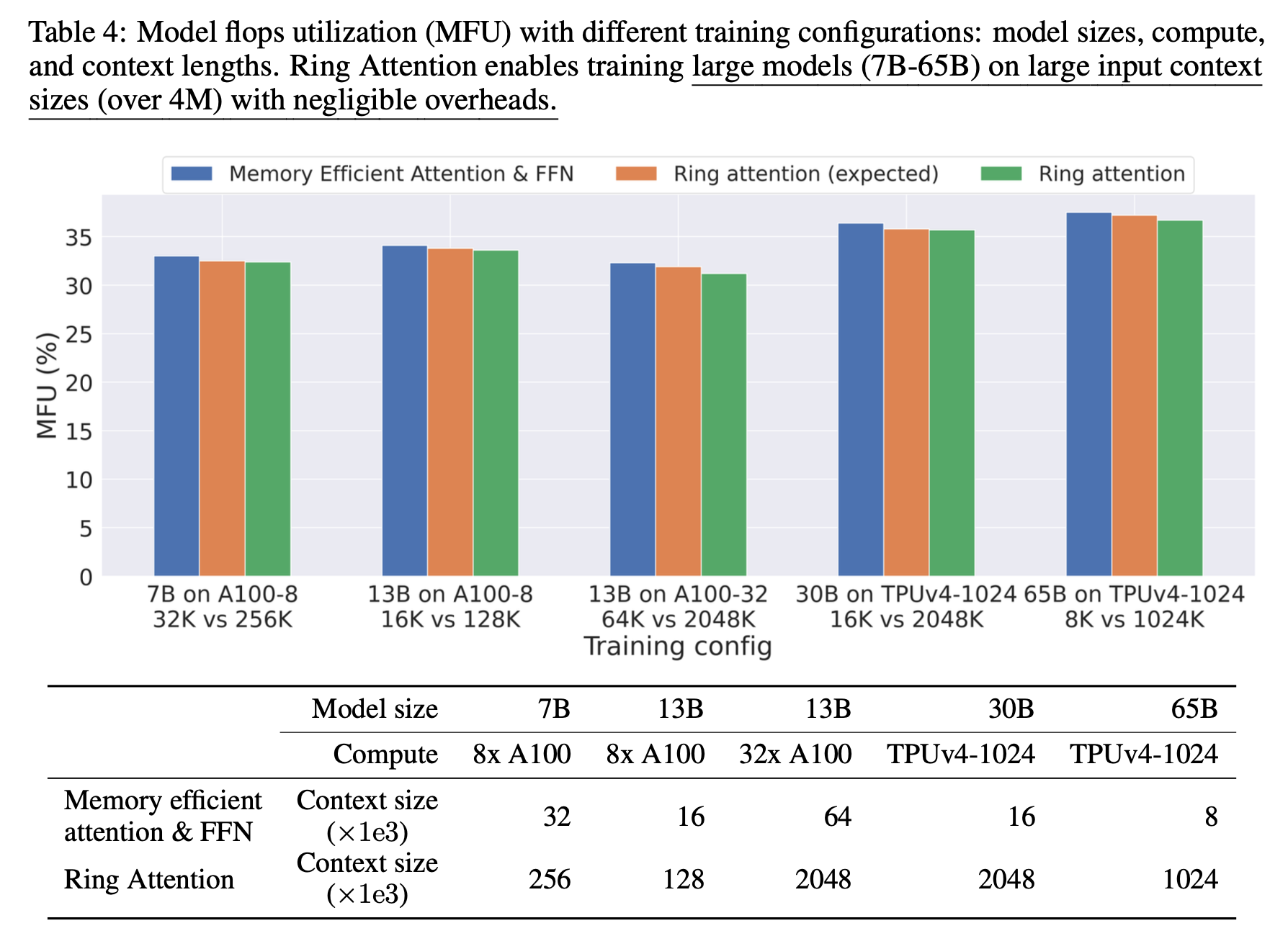 Fig.
Fig.
 Fig.
Fig.
DeepSpeed Ulysses (Sequence Parallel)
tmp
References
- Papers
- Blockwise Parallel Transformer for Large Context Models
- Ring Attention with Blockwise Transformers for Near-Infinite Context
- World Model on Million-Length Video and Language with RingAttention
- DeepSpeed Ulysses: System Optimizations for Enabling Training of Extreme Long Sequence Transformer Models
- Leave No Context Behind: Efficient Infinite Context Transformers with Infini-attention
- Code
- Blogs