Dynamic Batching (Token Batching) for Sequence Dataset with Variable Lengths
01 Sep 2023< 목차 >
Motivation
예를 들어 1000개의 text sequence 로 이루어진 corpus dataset을 생각해 보자. 만약 batch size가 20개라면 무작위로 50개의 batch chunk가 만들어 Queue에 넣게될 것이고 이를 다 순회하면 1 epoch 학습을 한 것이고, 다시 1000개의 sequence를 shuffle해서 batch chunk를 만들고… 를 end of training 시점까지 반복하게 된다.
하지만 이런 naive batching에는 몇 가지 문제가 있을 수 있는데 그 중 하나가 바로 너무 긴 문장이 짧은 문장들과 묶일 경우 batch tensor가 너무 커진다라는 것이다.
이 과정에서 짧은 문장들은 비효율적인 padding이 들어가고 input sequnece length에 quadratic으로 time, space complexity가 증가하는 일반적인 transformer 구조에서는 Out-Of-Memory (OOM)을 마주하는 상황이 생겨버린다.
그러면 batch size를 줄일 수 밖에 없다.
하지만 만약 비슷한 문장길이 끼리 묶을수만 있다면 어떻게 될까? 즉 문장이 길면 batch size를 줄이고 짧으면 늘리는 식으로 dynamic 하게 batch를 구성할 수 있다면? 이런 OOM 상황을 최대한 피할 수 있을 것이다.
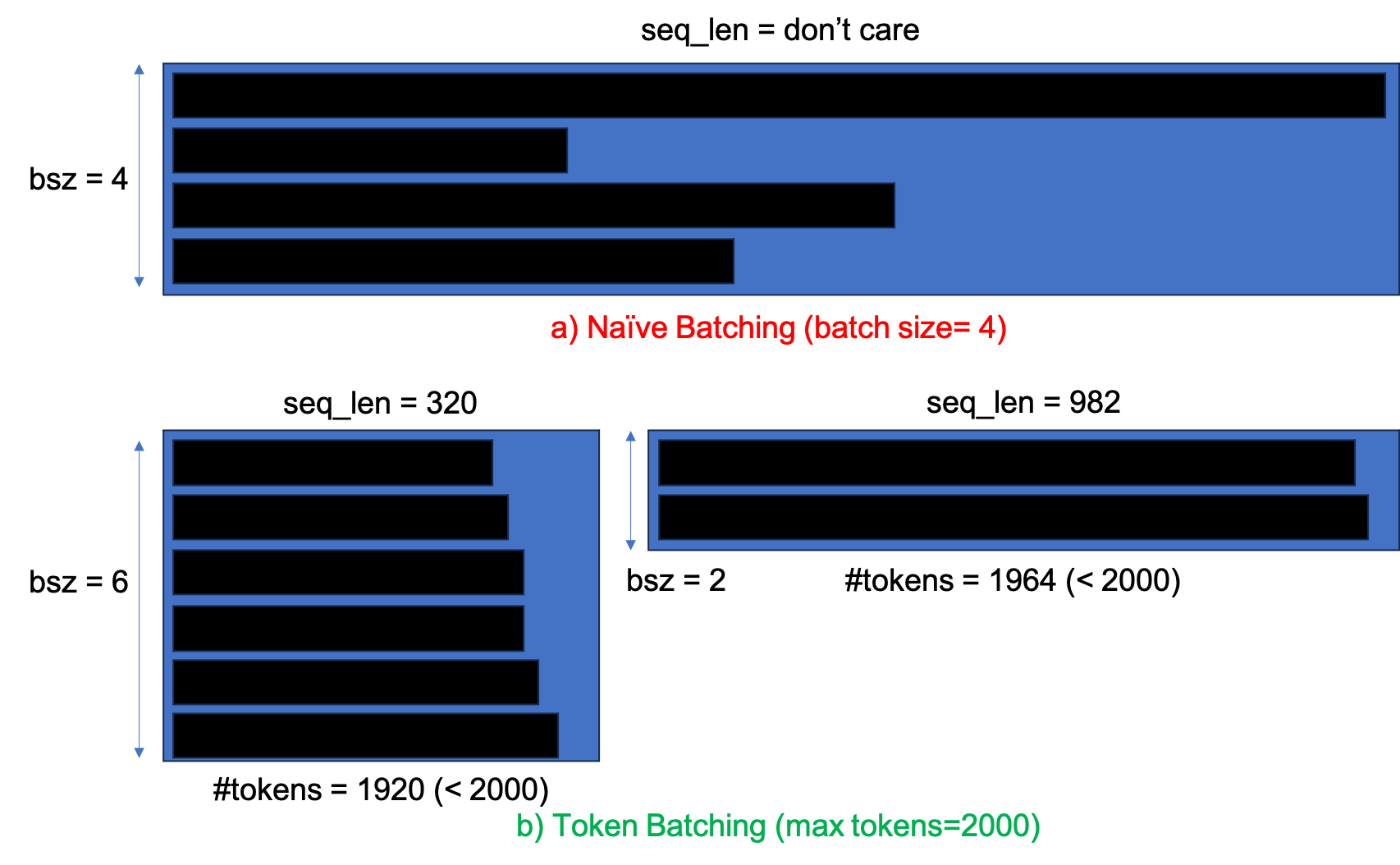 Fig.
Fig.
게다가 나의 경우 distributed training 환경에서 batch size를 키우면 total runtime이 오히려 증가하는 현상이 있었다. 보통 batch size를 키우면 실험이 더 빨리 끝날것으로 기대하는데 일반적이지는 않은 것이다.
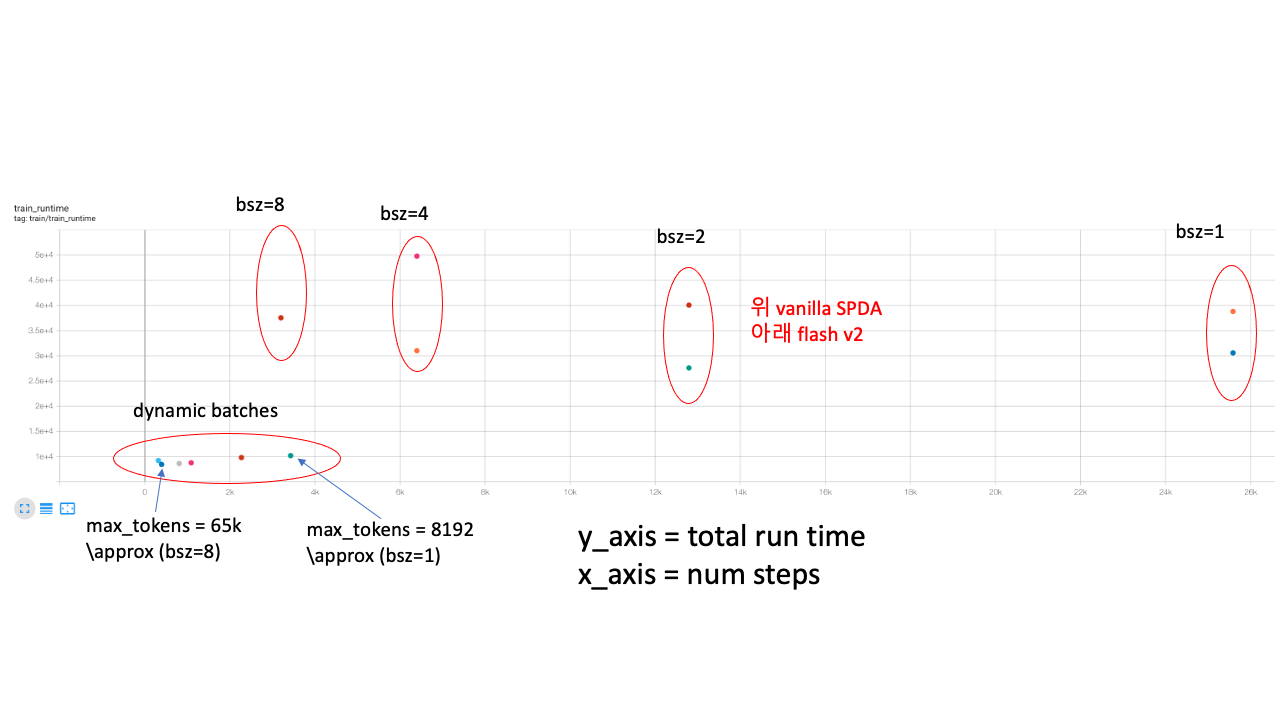 Fig.
Fig.
이 또한 앞서 얘기한 것 처럼 input length가 길수록 computation cost overhead가 어마어마한데 짧은 sequence와 긴 sequence가 같이 batching되면 충분히 나올 수 있는 그림일 수 있다.
Facebook의 open-source library 중에는 sequence modeling 에 특화된 FAIRSEQ (Facbeook AI Research SEQuence)라는 library가 있는데, 이 library는 학습에 도움이 되는 feature를 많이 제공하고 그중 token 갯수 기준으로 batching을 하는 token batching (== dynamic batching)이라는 기능이 있다.
 Fig.
Fig.
이를 사용함으로써 얻을 수 있는 이득은 앞서 말한 것 처럼 비효율적으로 batch 구성이 되지 않고 비슷한 길이들끼리 묶이면서 sample들의 평균 길이가 짧으면 한번에 묶이는 sample 수가 대폭 증가하고 반대면 줄일 수 있다. 이렇게하면 한 batch sequence들의 padding이 최소한으로 들어가면서 더 효율적으로 loss계산을 할 수 있으므로 속도개선도 대폭 될 것이다. 하지만 우리가 huggingface transformers 같은 library를 쓴다거나 따로 trainer를 작성한다면 이를 따로 구현해줘야 한다.
 Fig. Huggingface Transformers는 model library지 학습을 위한 library가 아니다. (점차 발전하고 있으나) training shell scripts도 제대로 없고 모든 training code를 4000줄씩 한 python file에 넣어둔 점에서도 알 수 있는 부분. Source from link
Fig. Huggingface Transformers는 model library지 학습을 위한 library가 아니다. (점차 발전하고 있으나) training shell scripts도 제대로 없고 모든 training code를 4000줄씩 한 python file에 넣어둔 점에서도 알 수 있는 부분. Source from link
(좀 더 찾아보니 group_by_length 라는 이름으로 비슷한 구현이 있기는 하다만 조금 다르고 major한 feature도 아닌 것으로 보인다) 본 post에서는 torch dataloader의 구조를 제대로 파악하고 sampler라는 기능을 어떻게 사용해서 dynamic batching을 할 수 있는지 차례대로 알아보려고 한다.
Key References
3 Implementation
FAIRSEQ is implemented in PyTorch and it provides efficient batching, mixed precision training, multi-GPU as well as multi-machine training.
Batching. There are multiple strategies to batch input and output sequence pairs (Morishita et al., 2017).
FAIRSEQ minimizes padding within a mini-batch by grouping source and target sequences of similar length.
The content of each mini-batch stays the same throughout training, however mini- batches themselves are shuffled randomly every epoch.
When training on more than one GPU or machine, then the mini-batches for each worker are likely to differ in the average sentence length which results in more representative updates.
As a conclusion, the TRG and TRG SRC sorting methods, which are used by many NMT toolkits,
have a higher overall throughput when just measuring the number of words processed,
but for convergence speed and final model accuracy, it seems to be better to use SHUFFLE or SRC.
4.2 Training Setup
This section introduces the training implementations for the RM.
The learning rate is set to 5e-6 with a warmup over the first 10% steps.
We use a dynamic batch method instead of a fixed value, which balances the number of tokens in each batch as much as possible for a more efficient and stable training phase.
The batch size changes according to the number of tokens in a batch, with a maximum of 128 and a minimum of 4.
We fixed the training step to 1000, approximately 1.06 epoch for the whole training set.
We set βrm = 1, which represents LM loss weight to train our reward model for the entire experiment.
Implementation Details. The openchat-13b is based on the llama-2-13b (Touvron et al., 2023b).
We fine-tune the model for 5 epochs on the ShareGPT dataset using the AdamW optimizer with a sequence length of 4,096 tokens and an effective batch size of 200k tokens.
Given that the reward weight term in Eq. (6) (exp(rc/β)) remains constant within a class, we simplify the process by assigning a unit weight to Dexp and the weight of 0.1 to Dsub.
The AdamW optimizer’s hyperparameters are set as follows: β1 = 0.9, β2 = 0.95, ε = 10−5 , and weight decay of 0.1.
We employ a cosine learning rate schedule with a maximum learning rate of 6.7×10−5, which decays to 10% of the maximum value.
The hyperparameters remain consistent with the base model pretraining settings following Touvron et al. (2023b).
However, we scale the learning rate proportionally to the square root of the batch size, following the theoretical analysis provided by Granziol et al. (2020).
PyTorch DataLoader
Machine learning model을 학습하기 위해서는 주어진 dataset \(X = (x_1, x_2, \cdots, x_N)\)을 mini-batch sampling 해야 한다. 모든 dataset의 sample에 대해 gradient를 구하고 update하는 것은 불가능하고 비효율적이기 때문이다.
Pytorch framework을 사용해서 이를 구현하려면 세 가지를 핵심적으로 구현해줘야 한다.
- Dataset: csv, txt, json 등의 형태로 되어잇는 raw data file을 읽어서 전 처리를 하는 Pytorch Class
- Data Collator: DataLoader에 의해 data sample을 뽑을 때 model이 이해할 수 있는 형태로 가공해주는 rule을 정의해둔 함수.
- DataLoader: 위의 Dataset, Data Collator를 사용해 정해진 batch size만큼 data sample을 뽑아주는 것으로 data sample이 항상 같은 batch로 묶이는 것을 방지 하기 위해 shuffle을 한다거나 할 수 있음.
import totch
from torch.utils.data import Dataset, DataLoader
class CustomDataset(Dataset):
def __init__(dataset_file):
super().__init__()
def DataCollator(batch):
return batch
# Defaine dataset, collator and data loader
dataset = CustomDataset()
data_collator = DataCollator()
data_loader = DataLoader(
dataset,
batch_size=1,
shuffle=False,
sampler=None,
batch_sampler=None,
num_workers=0,
collate_fn=data_collator,
pin_memory=False,
drop_last=False,
timeout=0,
worker_init_fn=None,
*,
prefetch_factor=2,
persistent_workers=False
)
# Learning Algorithm
for batch in iter(data_loader):
x, y = batch
loss = CustomLoss(model(x), y)
loss.backward()
여기서 우리가 몇 가지 관심있게 봐야할 argument들이 있는데, 이는 다음과 같다.
- batch_size
- sampler
- batch_sampler
- drop_last
Pytorch Sampler
Batch_size는 한 번의 iteration에 몇 개의 data를 sampling할 것이냐를 말하고 sampler는 이 sampling을 어떻게 할지?에 대한 rule이다. 보통 아래와같이 torch에서 기본적으로 제공해주는 sampler들이 존재하고,
from torch.utils.data import Sampler, RandomSampler, SequentialSampler
RandomSampler는 말 그대로 random seed에 따라 랜덤하게 sampling한다는 것을 의미하며 SequentialSampler는 data file이 정의된 대로 sampling을 해준다.
그러면 어떻게 해야 dynamic batching을 구현할 수 있을까?
우리는 batch_sampler를 유심히 봐야 한다.
실제로 sampler든 batch_sampler든 return을 하는 것은 input file의 데이터가 예를 들어 1000개이면 그 1000개 data들의 index가 0,1, …,1000 이렇게 정해져 있는 셈인데
sampler들은 이걸 shuffle하거나 하는 식으로 한 번 iteration에 (782,12,421,1,24 …) 하고 batch size만큼의 index들 (indices)를 리턴해주는 것 말고는 하는 일이 없다.
즉 아래와 같이 dynamic batching을 구현하기 위해서는 우선 비슷한 것들끼리 묶는 과정이 필요하고 그에 맞는 indices들을 리턴해주기만 하면 된다.
Fig.
다시 batch size 16인 경우의 간단한 경우를 생각해보자. data 개수가 1000개이므로
[
[124, ..., 11], # 16개 list
[932, ..., 41], # 16개 list
...
[351, ..., 24], # 16개 list
[29, ..., 88], # 8개 list
]
의 16개 짜리 index를 담은 List의 List를 우리가 가지고 있고 이에 맞는 data를 뽑아오기만 하면 된다.
이런 list를 random으로 할지, 순서대로 [1,2,3,4,…16] 할지를 RandomSampler, SequentialSampler가 하는 것이고
우리가 원하는것은 아래와 같이 16개로 무조건 묶는 것이 아니라 해당 배치의 총 Token 개수가 2000개가 되게 batch size에 구애받지 않고 최대한 효율적으로 dynamic 하게 묶는 것이기 때문이다.
[
[124, ..., 11], # 66개 List
[932, ..., 41], # 42개 list
...
[29, ..., 88], # 2개 list
]
즉 Padding을 최소화하면서 최대한 효율적으로 묶기를 원하기 때문에 우리가 구현해야 하는것은 다음의 두 가지다.
- 짧은 길이 순서로 data sample들의 index를 sorting하기
- 데이터 길이를 알고 있으므로 데이터를 순회하면서 token수가 2000개가 될 때까지 batch chunk를 구성하는 것을 반복하기
Dynamic Batching
Implementation
바로 구현에 들어가보자 (Open-source feature들도 여럿 썼다). 우선 아래처럼 몇 가지 library, package들을 import 해준다.
import random
import numpy as np
from typing import Optional, Tuple, List
try:
from collections.abc import Iterable
except ImportError:
from collections import Iterable
import torch
import torch.distributed as dist
from torch.utils.data import Dataset, DataLoader, Sampler, RandomSampler, SequentialSampler
from torch.utils.data.distributed import DistributedSampler
저는 어떤 dummy dataset을 만들어서 각 sampler의 결과물을 비교할것이기 때문에 randomness를 통제해야 함으로 다음을 정의한다.
def _reset_seeds(seed=1234):
torch.manual_seed(seed)
random.seed(seed)
np.random.seed(seed)
이제 아래와 같이 Random dataset을 정의하는데 여기서 주의할 점이 있다. 우리가 dynamic batching을 구현하기 위해서는 dataset sample들의 길이 정보를 반드시 알아야한다.
class RandomDataset(Dataset):
def __init__(
self,
num_data=200000,
min_len=128,
max_len=4096,
seed=2023,
):
super().__init__()
_reset_seeds(seed)
self.src_lens = list(np.random.randint(min_len, max_len, num_data))
self.samples = [np.random.rand(src_len) for src_len in self.src_lens]
def __len__(self):
return len(self.samples)
def __getitem__(self, idx):
return self.samples[idx], self.src_lens[idx]
이제 위의 simple dataset class를 상속받아 아래와 같이 dynamic batching dataset을 만들 것이다.
여기서 make_dynamic_sampler라는 batch sampler를 만드는 함수가 있는데,
앞서 얘기한 것 처럼 sorting을 하는 것과 이를 받아서 maximum token 개수로 묶어주는 batch_by_size라는 함수가 있다.
class RandomDatasetWithDynamicSampler(RandomDataset):
def __init__(
self,
num_data=200000,
min_len=128,
max_len=4096,
seed=2023,
):
super().__init__(num_data, min_len, max_len, seed)
self.max_target_length = max_len
def make_dynamic_sampler(self, max_tokens_per_batch=1024, **kwargs):
import numpy as np
sorted_indices = np.argsort(np.array(self.src_lens) * -1)
def num_tokens_fn(i):
return min(self.src_lens[i], self.max_target_length)
```
git clone https://github.com/facebookresearch/fairseq &&\
cd fairseq &&\
pip install -e . ## i recommend you to implement editable installation
```
from fairseq.data.data_utils import batch_by_size
# call fairseq cython function
batch_sampler: List[List[int]] = batch_by_size(
sorted_indices,
num_tokens_fn=num_tokens_fn,
num_tokens_vec=None,
max_tokens=max_tokens_per_batch,
max_sentences=None, # it means batch size
# required_batch_size_multiple=64,
required_batch_size_multiple=1,
fixed_shapes=None,
)
shuffled_batches = [batch_sampler[i] for i in np.random.permutation(range(len(batch_sampler)))]
# move the largest batch to the front to OOM quickly (uses an approximation for padding)
approximate_toks_per_batch = [max(self.src_lens[i] for i in batch) * len(batch) for batch in shuffled_batches]
largest_batch_idx = np.argmax(approximate_toks_per_batch)
shuffled_batches[0], shuffled_batches[largest_batch_idx] = (
shuffled_batches[largest_batch_idx],
shuffled_batches[0],
)
return shuffled_batches
여기서 batch_by_size라는 함수는 fairseq이라는 facebook의 library의 method를 호출해서 사용하도록 작성했다. 사실 for loop을 돌면서 max tokens를 충족할때까지 index들을 묶어서 하나의 list로 만들고… 이를 반복하면 되지만 cython으로 작성된 fairseq 구현체가 훨씬 좋기 때문에 이를 채택했다. 자세한 내용은 reference를 참고하길 바란다.
batch_by_size의 argument들이 나타내는 바는 아래와 같은데, num_tokens_fn가 존재하는 이유는 어떤 dataset은 실제로 input sequence의 length보다는 특정 feature extraction이후의 길이를 기준으로 sorting하는 것이 나을 수 있기 때문에 그것을 고려한 것일 수도 있고 아니면 transformer의 maximum length를 넘을 경우 (positional embedding때매 중요함)를 대비하기 위해서이다.
indices는 당연히 sorting된 것이어야겠으며 (그래야 차례차례 담을때 비슷한 길이끼리 묶임), max_tokens는 알 것이고, max_sentences는 batch size를 의미한다.
fairseq에서는 이 함수를 기본적으로 Call 하게 되어있기 때문에 max_tokens가 None이고 max_sentences가 None이 아니면 일반 Batch sampling이 되거나 둘 다 none이 아니면 max token 만큼씩 묶다가도 개수가 max_sentences를 넘으면 묶는것을 중단한다.
마지막으로 required_batch_size_multiple는 max_tokens로 묶을 때 예를들어 max_tokens이 2000이고 평균 sequence 길이가 100일 경우 batch size가 20이 되지만 required_batch_size_multiple가 예를 들어 8로 설정되어 있으면 8의 배수인 16이나 24가 될때까지 묶게 된다.
Yield mini-batches of indices bucketed by size. Batches may contain
sequences of different lengths.
Args:
indices (List[int]): ordered list of dataset indices
num_tokens_fn (callable): function that returns the number of tokens at
a given index
num_tokens_vec (List[int], optional): precomputed vector of the number
of tokens for each index in indices (to enable faster batch generation)
max_tokens (int, optional): max number of tokens in each batch
(default: None).
max_sentences (int, optional): max number of sentences in each
batch (default: None).
required_batch_size_multiple (int, optional): require batch size to
be less than N or a multiple of N (default: 1).
fixed_shapes (List[Tuple[int, int]], optional): if given, batches will
only be created with the given shapes. *max_sentences* and
*required_batch_size_multiple* will be ignored (default: None).
이제 마지막으로 collator를 작성해주는데, 이는 batch sampling이 될 때 적용되는 함수로 어차피 지금은 random set을 쓰고 있으니,
서로 다른 가변 길이의 sample들이 있을 때 padding을 붙혀 배치를 구성하는 기본 처리만 해준다.
def collator(batch):
sample_list = []
seq_len_list = []
for (sample, seq_len) in batch:
sample_list.append(torch.FloatTensor(sample))
seq_len_list.append(seq_len)
max_len = max(seq_len_list)
for i, sample in enumerate(sample_list):
diff = max_len-seq_len_list[i]
if diff!=0:
sample_list[i] = torch.cat((sample, torch.zeros(diff)), dim=0)
return torch.stack(sample_list, dim=0), seq_len_list
The Comparison between Dynamic Batching and Others
우리의 target은 얼마나 효율적으로 batching을 해서 평균 padding 수를 줄일 수 있느냐? 이다.
데이터 개수는 200000개, sample의 최소 길이는 128이고 최대는 4096이다.
먼저 128 batch를 가정하고 SequentialSampler를 써보자.
random_dataset = RandomDataset()
data_loader = DataLoader(
random_dataset,
batch_size=128,
shuffle=False,
sampler=SequentialSampler(random_dataset),
batch_sampler=None, # batch sampler and sampler is not compatible
num_workers=0,
collate_fn=collator,
pin_memory=False,
drop_last=False,
)
def plot_helper(data_loader):
print("total number of iteration: {}\n".format(len(data_loader)))
total_num_tokens = []
total_num_padding_tokens = []
for x in iter(data_loader):
B, T = x[0].size()
lens = x[1]
num_tokens = B*T
num_padding_tokens = num_tokens - sum(lens)
total_num_tokens.append(num_tokens)
total_num_padding_tokens.append(num_padding_tokens)
print("bsz: {}, min/max seq_lens in batch: {}, padding in batch: {:.2f}%({}/{})".format(
B,
(min(lens),max(lens)),
(num_padding_tokens)/(num_tokens)*100,
num_tokens,
num_padding_tokens,
)
)
print("avg padding in bathces: {:.2f}%({}/{})".format(
np.array(total_num_padding_tokens).sum()/np.array(total_num_tokens).sum()*100,
np.array(total_num_tokens).sum(),
np.array(total_num_padding_tokens).sum(),
)
)
plot_helper(data_loader)
total number of iteration: 1563
bsz: 128, min/max seq_lens in batch: (167, 4037), padding in batch: 50.69%(516736/261934)
bsz: 128, min/max seq_lens in batch: (157, 4084), padding in batch: 51.75%(522752/270537)
bsz: 128, min/max seq_lens in batch: (159, 4084), padding in batch: 46.72%(522752/244227)
bsz: 128, min/max seq_lens in batch: (149, 4086), padding in batch: 44.48%(523008/232638)
bsz: 128, min/max seq_lens in batch: (131, 4093), padding in batch: 51.38%(523904/269188)
...
bsz: 128, min/max seq_lens in batch: (130, 4049), padding in batch: 42.55%(518272/220545)
bsz: 128, min/max seq_lens in batch: (142, 4090), padding in batch: 49.68%(523520/260088)
bsz: 64, min/max seq_lens in batch: (208, 3992), padding in batch: 51.26%(255488/130958)
avg padding in bathces: 48.14%(813107328/391426144)
시종일관 50%대의 padding률을 보이며 모든 batch의 총 padding 비율을 봤을때도 꽤 비효율적이다. 그 다음은 RandomDataset 이다.
random_dataset = RandomDataset()
data_loader = DataLoader(
random_dataset,
batch_size=128,
shuffle=False,
sampler=RandomSampler(random_dataset),
batch_sampler=None, # batch sampler and sampler is not compatible
num_workers=0,
collate_fn=collator,
pin_memory=False,
drop_last=False,
)
plot_helper(data_loader)
total number of iteration: 1563
bsz: 128, min/max seq_lens in batch: (147, 4090), padding in batch: 52.26%(523520/273603)
bsz: 128, min/max seq_lens in batch: (191, 4079), padding in batch: 51.99%(522112/271458)
bsz: 128, min/max seq_lens in batch: (137, 4091), padding in batch: 47.26%(523648/247452)
bsz: 128, min/max seq_lens in batch: (155, 4090), padding in batch: 48.51%(523520/253972)
...
bsz: 128, min/max seq_lens in batch: (131, 4047), padding in batch: 47.54%(518016/246279)
bsz: 128, min/max seq_lens in batch: (128, 4026), padding in batch: 50.26%(515328/259025)
bsz: 64, min/max seq_lens in batch: (129, 4092), padding in batch: 44.85%(261888/117465)
avg padding in bathces: 48.14%(813069696/391388512)
마찬가지로 매우 비효율적인 모습을 볼 수 있다. 마지막으로 dynamic batching 이다.
random_dataset = RandomDatasetWithDynamicSampler()
dynamic_batch_sampler = random_dataset.make_dynamic_sampler(max_tokens_per_batch=500000)
data_loader = DataLoader(
random_dataset,
batch_size=1, # be careful of setting batch size larger than 1, it is not compatible with batch sampler
shuffle=False, # be careful of setting shuffle True, it is not compatible with batch sampler
sampler=None,
batch_sampler=dynamic_batch_sampler, # batch sampler and sampler is not compatible
num_workers=0,
collate_fn=collator,
pin_memory=False,
drop_last=False, # be careful of setting drop_last True, it is not compatible with batch sampler
)
plot_helper(data_loader)
이 때 주의해야할 점이 있는데, batch_sampler라는 것이 정의 되는 순간 아래의 argument들은 쓸 수 없다는 거싱다.
- batch_size=1
- shuffle=False
- sampler=None
- drop_last=False
왜냐하면 예를 들어 drop last나 batch size같은 경우는 정말 의미가 없어서 인데, 마지막에 batch_size 예를 들어 8로 나눠떨어지지않은 남는 배치는 버릴것인가? 하는 drop_last는 사용자가 알아서 구현을 해줘야 하므로 이미 True인 것이나 다름없다. 이를 지켜주지 않으면 에러가 난다. (하지만 epoch마다 shuffle이 안되는 문제가 존재한다, 이는 알아서 해결해야하거나 믿고 가던가 해야한다.)
total number of iteration: 848
bsz: 160, min/max seq_lens in batch: (3121, 3125), padding in batch: 0.06%(500000/314)
bsz: 362, min/max seq_lens in batch: (1372, 1379), padding in batch: 0.25%(499198/1260)
bsz: 161, min/max seq_lens in batch: (3097, 3100), padding in batch: 0.05%(499100/239)
bsz: 233, min/max seq_lens in batch: (2137, 2141), padding in batch: 0.11%(498853/550)
bsz: 144, min/max seq_lens in batch: (3447, 3450), padding in batch: 0.05%(496800/224)
bsz: 173, min/max seq_lens in batch: (2877, 2881), padding in batch: 0.06%(498413/319)
bsz: 209, min/max seq_lens in batch: (2377, 2381), padding in batch: 0.07%(497629/326)
...
bsz: 130, min/max seq_lens in batch: (3832, 3835), padding in batch: 0.04%(498550/215)
bsz: 787, min/max seq_lens in batch: (619, 635), padding in batch: 1.30%(499745/6487)
bsz: 127, min/max seq_lens in batch: (3925, 3928), padding in batch: 0.04%(498856/178)
bsz: 131, min/max seq_lens in batch: (3807, 3810), padding in batch: 0.04%(499110/193)
bsz: 124, min/max seq_lens in batch: (4001, 4004), padding in batch: 0.03%(496496/161)
bsz: 168, min/max seq_lens in batch: (2973, 2976), padding in batch: 0.04%(499968/200)
bsz: 163, min/max seq_lens in batch: (3058, 3062), padding in batch: 0.07%(499106/326)
bsz: 137, min/max seq_lens in batch: (3628, 3630), padding in batch: 0.03%(497310/162)
avg padding in bathces: 0.19%(422494327/813143)
패딩율이 평균 1%도 안되는 모습과 함께 dataloader의 길이 자체도 반토막 난 걸 알 수 있다. 즉 한 Batch 내에서 최대한 padding없이 loss를 계산해 parameter를 update할 수 있음과 동시에 이 update횟수도 800회로 줄어들었기 때문에 훨씬 빠르게 학습할 수 있는 것이다.
In Real-World Dataset
Fairseq에서 dynamic batching을 함으로써 얼만큼의 성능 개선을 이뤄냈는지는 paper에 기재되어 있지 는다. 다만 Fairseq이 cite한 paper인 An Empirical Study of Mini-Batch Creation Strategies for Neural Machine Translation를 보면 얼만큼의 개선이 있었는지를 알 수 있는데, 해당 paper에서는 sorting방법과 batching 방법에 따른 성능 변화를 관찰한다.
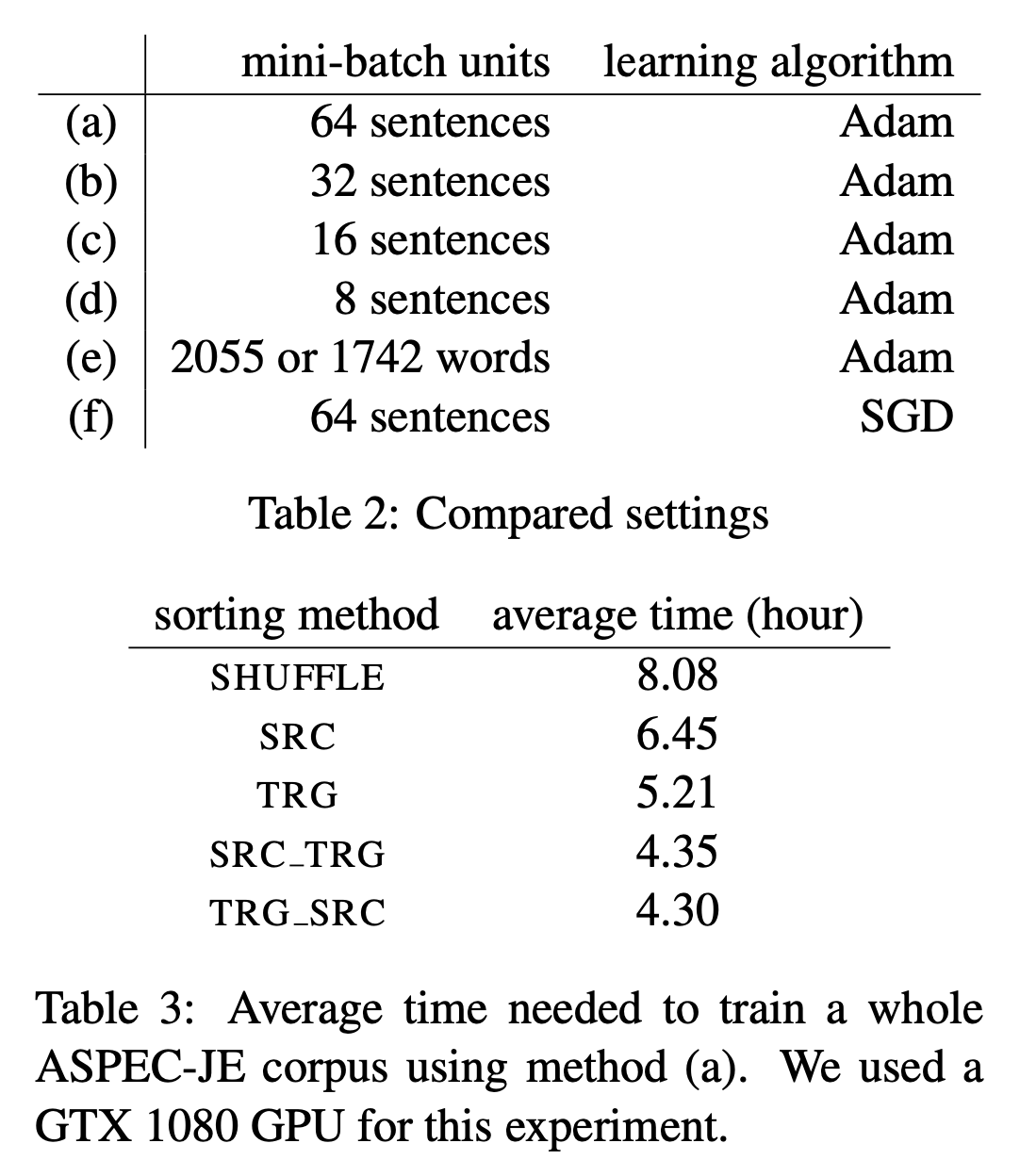 Table.
Table.
위의 table 에서 우리가 생각할 수 있는 일반적인 조합은 sentence batching + shuffle이 될 것이다.
여기서 word tokens batching + src (source) length 를 조합하면 바로 dynamic batching이 된다.
sorting method별로 학습에 걸린 (epoch은 당연히 같겠죠?) 시간을 평균낸 것을 보면 길이로 sorting한 것이 크면 2배 가까이 속도가 빨랐지만,
이는 평균을 낸 것이기 때문에 dynamic batching을 했냐 안했냐로 나누면 3~4배가량 속도 차이가 났을것으로 예상이 된다.
(참고로 나는 이를 적용해서 성능 loss는 없이 거의 3~4배 빠르게 실험을 했었다)
이렇게 다양한 조합을 했을 때 negative log likelihood 의 learning curve를 보면 아래와 같은데, tgt sentence 의 length를 기준으로 sorting했을 때 SGD를 사용한 경우를 제외하면 큰 차이가 없는 것을 볼 수 있다.
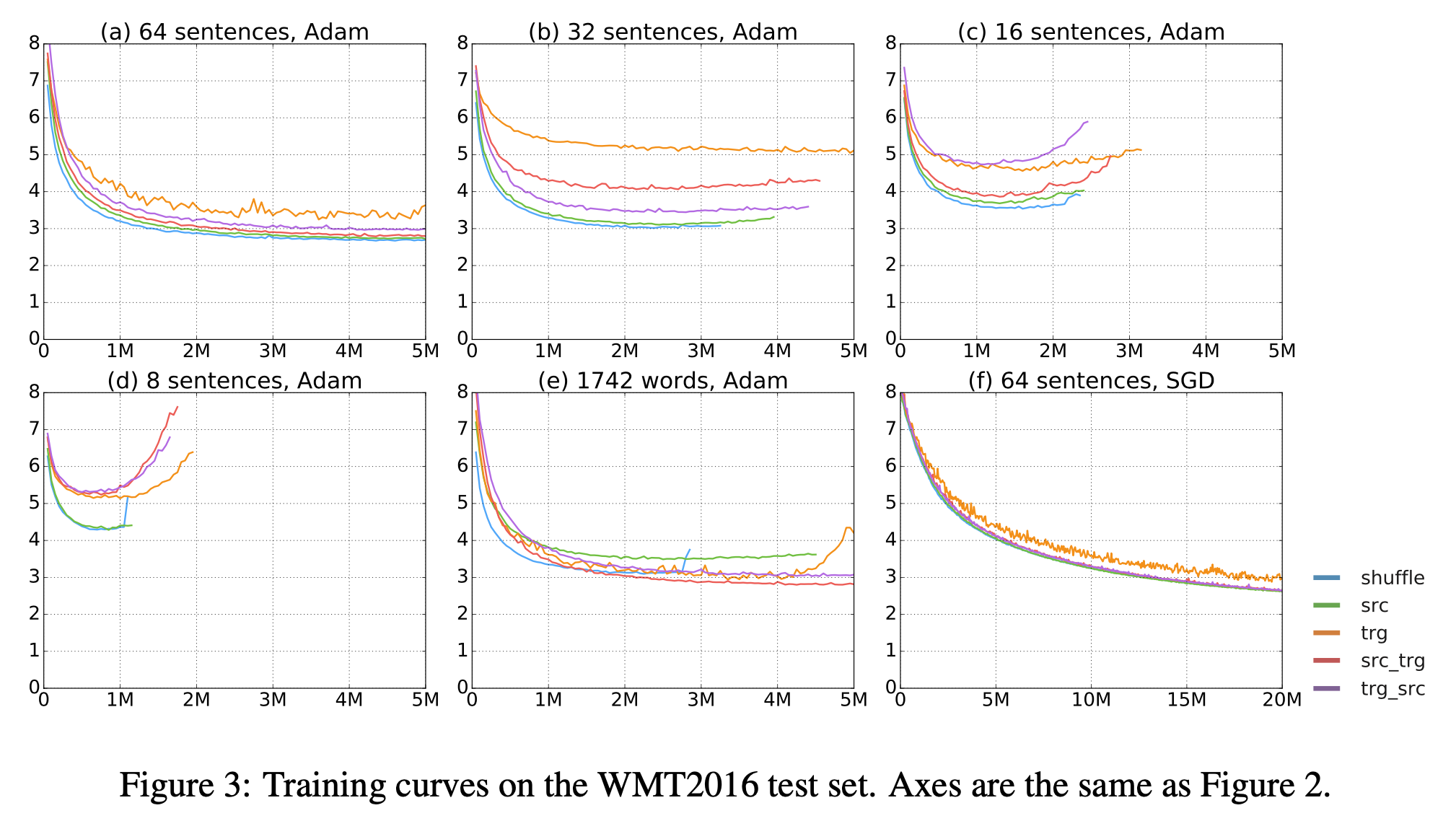 Fig.
Fig.
즉 dynamic batching을 해도 아무 상관이 없고 속도만 빨라지니 안 할 이유가 없는 것이다.
In Distributed Training
그럼 분산 학습을 할 때는 어떻게 dynamic batching을 구현해야 할까? Pytorch의 Sampler들 중에도 DistributedSampler라는 것이 있는데, 이것과 비슷한 방식으로 구현할 것이다. 마찬가지로 간단한 예제를 통해 설명하도록 하겠다.
 Fig. 먼저 15개의 sample이 있다고 가정해 본다. 실험 환경은 node가 2개이고 각 node는 4개 GPU를 가지고 있다.
Fig. 먼저 15개의 sample이 있다고 가정해 본다. 실험 환경은 node가 2개이고 각 node는 4개 GPU를 가지고 있다.
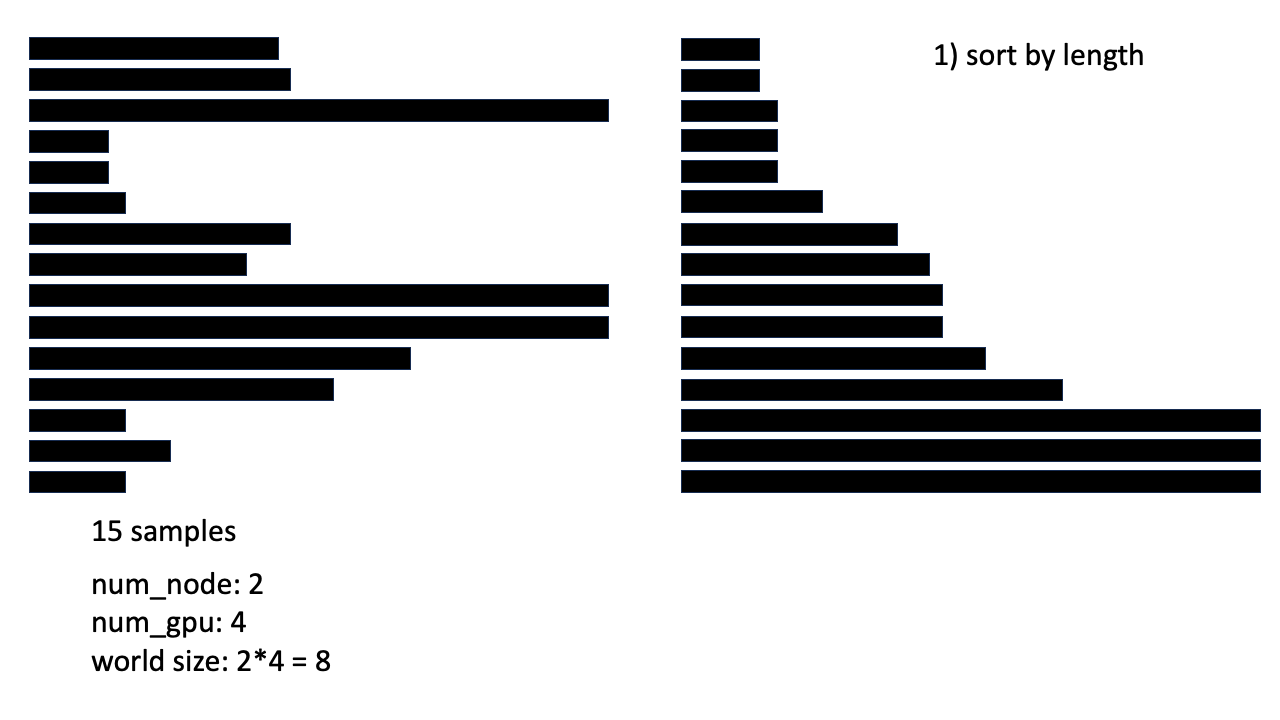 Fig. 먼저 sorting을 한다. (각 process에서 모두 동일하게 진행해준다)
Fig. 먼저 sorting을 한다. (각 process에서 모두 동일하게 진행해준다)
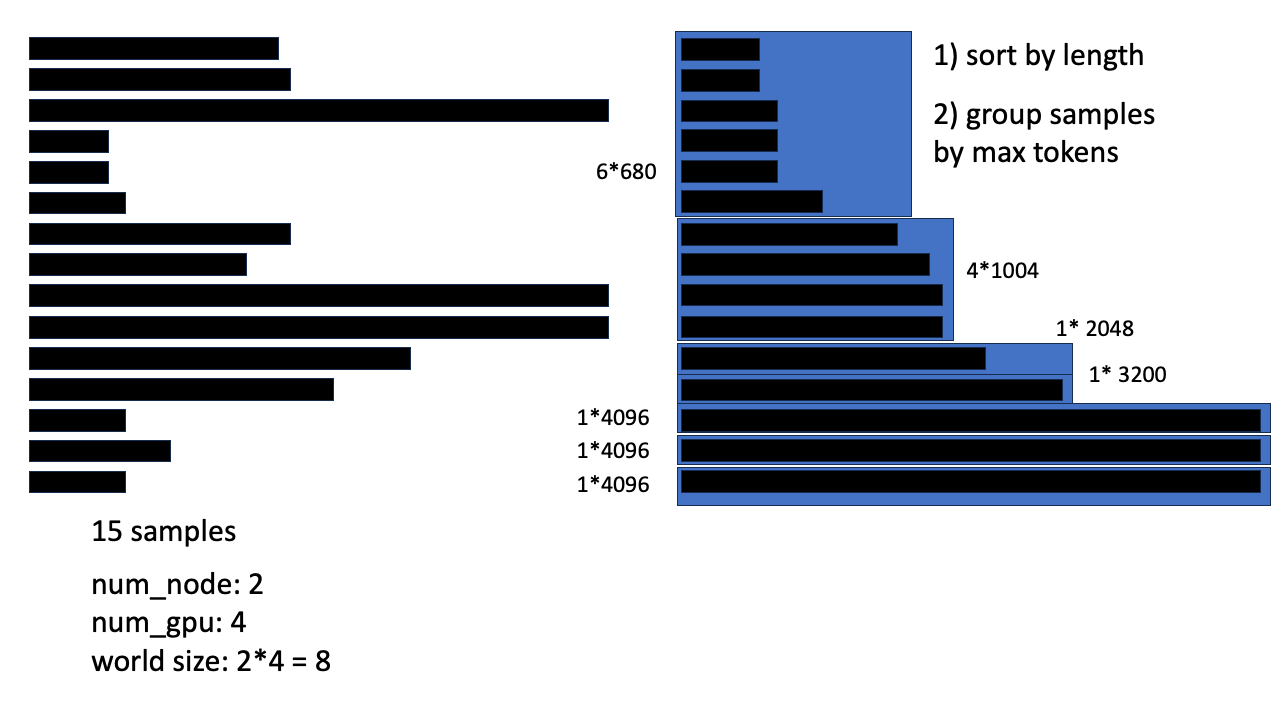 Fig. 그리고 dynamic 하게 각 sample들의 token 수의 합이 다 채워질 때 까지 chunking한다.
Fig. 그리고 dynamic 하게 각 sample들의 token 수의 합이 다 채워질 때 까지 chunking한다.
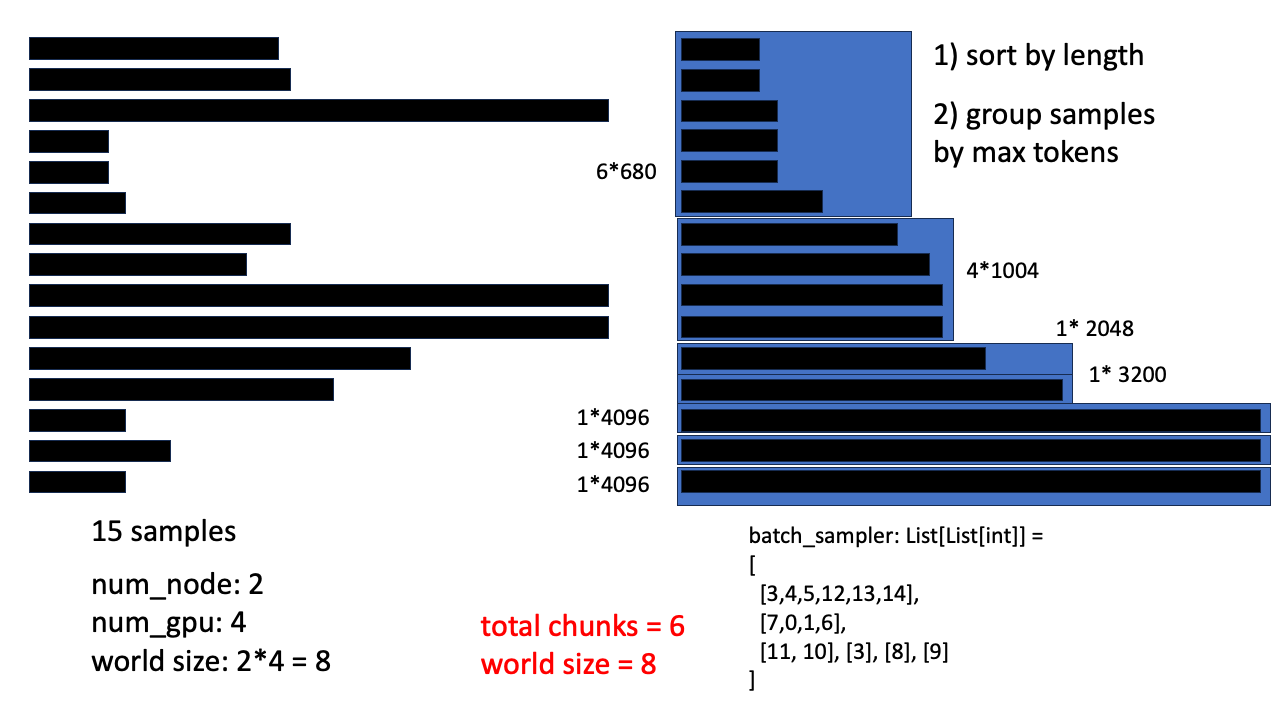 Fig. 만약 max tokens 수가 4096이라고 해보자, 그러면 batch sampler 를 구성했을 때 chunk 수가 6개이다. 이는 world size 8개와 딱 나눠떨어지는 수가 아니다.
Fig. 만약 max tokens 수가 4096이라고 해보자, 그러면 batch sampler 를 구성했을 때 chunk 수가 6개이다. 이는 world size 8개와 딱 나눠떨어지는 수가 아니다.
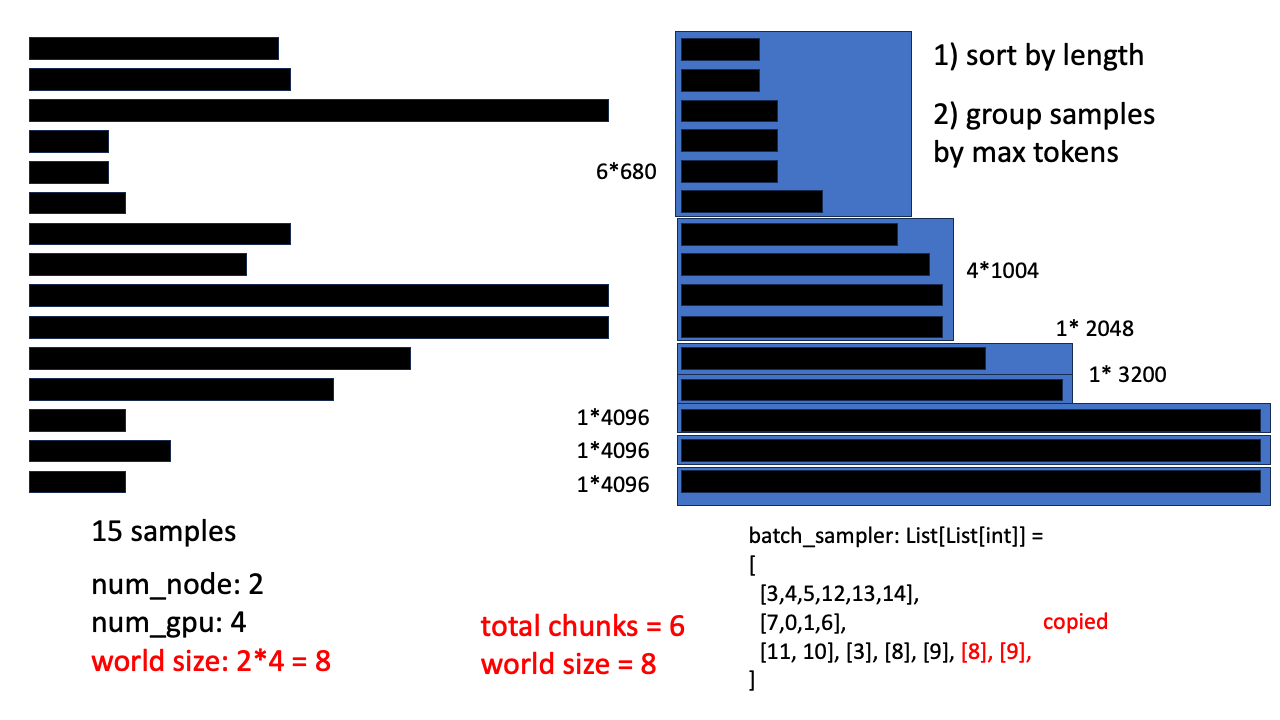 Fig. world size와 batch 갯수가 나눠떨이지지 않을 경우 모든 process가 동일한 연산을 하는 것이 아니다. 예를 들어 어떤 node는 batch input이 없는데 forward를 해야만 일을 수행한 것으로 치기 때문에 모든 GPU가 무한정 기다리게 될 수도 있다.
Fig. world size와 batch 갯수가 나눠떨이지지 않을 경우 모든 process가 동일한 연산을 하는 것이 아니다. 예를 들어 어떤 node는 batch input이 없는데 forward를 해야만 일을 수행한 것으로 치기 때문에 모든 GPU가 무한정 기다리게 될 수도 있다.
혹은 마지막에 drop_last 라는 것을 하면 딱 나눠떨어지지 않는 부분을 다 버리게 되는데 (위의 간단한 예시에서는 버리면 dataset이 0이 되어버리니 버릴 수 없겠죠?) 그렇게 해도 된다 이제 아까 했던 것 처럼 dynamic batching indices들을 모은다. 다시 얘기하지만 data shape은 List of List 이다
lengths = self._get_train_dataset_length()
assert lengths is not None
import numpy as np
sorted_indices = list(np.argsort(np.array(lengths) * -1))
batch_train_sampler = get_fairseq_style_dynamic_batching_indices(
sorted_indices = sorted_indices,
lengths = lengths,
max_length = self.max_length,
max_tokens = self.max_tokens,
)
이제 위의 DistributedSampler가 해주는 작업을 해주면 되는데, 일반적으로 분산 학습에서는 rank, node, world_size 같은 term을 사용한다. 예를 들어 아래처럼 되는 것이다.
- 한 node (PC)당 GPU가 8개
- node가 2개
- world_size는 8*2 = 16
- GPU 16개 별로 rank라는 이름이 붙는다 (0~15)
이제 아래의 코드처럼 sampler를 만들면 되는데, 각 GPU별로 rank가 다르기 때문에 서로 다른 indices들을 가져가게 되므로 중복없이 모든 dataset을 보며 loss를 계산하고 이를 모아서 학습하게 된다.
# batch sampler should be evenly divisible for distributed training (or it hangs at last )
rank = self.args.process_index
num_replicas=self.args.world_size
drop_last = self.args.dataloader_drop_last
이제 앞서 얘기한 것 처럼 dataset 길이가 rank수와 딱 맞아떨어지지 않으면 분산학습 환경에서는 보통 각 GPU가 다른 GPU들이 모든 일처리를 끝냈느냐? (loss를 계산했느냐?)를 기다리게 되는데, 특정 무한 loop에 빠지게 된다 (hang 걸림). 이를 Pytorch DataLoader의 drop_last와 비슷한 인자로 구현을 해주는데, 제가 알기로는 이렇게 dataset을 뻥튀기하거나 버리지 않아도 이를 해결할 방법이 있는 것으로 알고있지만 우선은 이런식으로 처리한다.
if drop_last and len(batch_train_sampler) % num_replicas != 0:
num_samples = math.ceil((len(batch_train_sampler) - num_replicas) / num_replicas)
else:
num_samples = math.ceil(len(batch_train_sampler) / num_replicas)
total_size = num_samples * num_replicas
if not drop_last:
batch_train_sampler += batch_train_sampler[: (total_size - len(batch_train_sampler))]
else:
batch_train_sampler = batch_train_sampler[: total_size]
assert total_size == len(batch_train_sampler)
위를 보시면 num_samples가 딱 batch_sampler의 list길이를 world size의 배수로 딱 맞아떨어지도록 뻥튀기를 한 값이고 이에 따라 꼬리를 자를지, 아니면 추가해줄지를 구현한 것이다. 이제 마지막으로 각 GPU에 indice들을 할당해주면 이로써 분산학습에 맞는 dynamic batching을 구현한 것이 된다.
# subsample data for each GPU
batch_train_sampler = batch_train_sampler[rank : total_size : num_replicas]
return DataLoader(
train_dataset,
batch_size=1, # if we want to use batch sampler, we should deactivate some options
shuffle=False, # if we want to use batch sampler, we should deactivate some options
sampler=None, # if we want to use batch sampler, we should deactivate some options
batch_sampler=batch_train_sampler,
collate_fn=data_collator,
drop_last=False, # if we want to use batch sampler, we should deactivate some options
num_workers=self.args.dataloader_num_workers,
pin_memory=self.args.dataloader_pin_memory,
)
enjoy your training
References
- Fairseq batch_by_size references
- Huggingface references
- Customize 4.28 version dynamic sample examples
- Customize 4.28 version _get_train_sampler
- fairseq batch_by_size (bbs) -> to huggingface style porting is from
- Pytorch Docs