(WIP) Sequence Generation Techniques (Beam Search and Sampling)
01 Sep 2023< 목차 >
이번 post에서는 sequence generation model의 inference (decoding) 방식에 대해 알아보려고 합니다. 보통 목적에 따라 beam search (번역 모델은 beam search를 많이 씀)를 하거나 sampling (생성형 chatbot등은 sampling을 많이 씀)을 하는데 더 좋은 문장을 만들기 위해서는 어떻게 해야하는지? 효율적으로 빨리 만들려면 어떻게 해야하는지? 에 대해서 알아보도록 하겠습니다.
Beam Search
먼저 Beam search 입니다.
Beam search는 Facebook의 open-source library 중 sequence modeling 에 특화된 FAIRSEQ (Facbeook AI Research SEQuence)이라는 library에 있는 feature들을 위주로 설명드리려고 합니다.
Beam search에 필요한 기본 요소들을 요약하자면 다음과 같습니다.
class SequenceGenerator(nn.Module):
def __init__(
self,
models,
tgt_dict,
beam_size=1,
max_len_a=0,
max_len_b=200,
max_len=0,
min_len=1,
normalize_scores=True,
len_penalty=1.0,
unk_penalty=0.0,
temperature=1.0,
match_source_len=False,
no_repeat_ngram_size=0,
search_strategy=None,
eos=None,
symbols_to_strip_from_output=None,
lm_model=None,
lm_weight=1.0,
tokens_to_suppress=(),
):
(...)
def _generate(
self,
sample: Dict[str, Dict[str, Tensor]],
prefix_tokens: Optional[Tensor] = None,
constraints: Optional[Tensor] = None,
bos_token: Optional[int] = None,
):
- 생성될 sequence의 최소/최대 길이 관련
- max_len_a/b: ax + b, where x is the source length
- max_len
- min_len
- 빔 서치 관련
beam_size: 얼만큼 빔을 확장할것인지? 보통 빔서치 하는 동안 [batch_size * beam_size, seq_len] 형태를 유지normalize_scores: 빔 score를 생성된 sequence length의 길이로 normalize 할지? (보통 True)len_penalty: <1.0 이면 짧은 문장을 생성할 가능성이 높고 >1.0이면 더 긴 문장을 생성 (기본 1.0)- unk_penalty: <0 이면 unk token을 더 많이 생성할 가능성이 높고 >0이면 덜 생성 (기본 0.0)
-
temperature: 현재 state에서 vocab에 대한 prob을 더 uniform 하게 할지 (>1.0) 아니면 sharp하게 할지 (<1.0) (기본 1.0) prefix_tokens: 빔 서치를 시작할 때 무조건 이 token 부터 시작하도록 강제함 (LLM의 경우 Prompt)-
constraints: 빔 서치를 할 때 몇 가지 제약 사항을 포함하도록 강제함 no_repeat_ngram_size: encoder-decoder 계열이나 decoder-only 계열 등 nerual decoder가 들어가는 모델은 sequence 생성 시 같은 단어를 반복하는 (repetitive) 문제가 종종 있습니다. 이를 막기 위해서 각 hypothesis (빔)들의 현재까지 생성된 token들을 n-gram 으로 count해서 이미 count가 된 조합이 반복되려고 하면 해당 token의 확률을 강제로 0으로 만드는 일을 수행합니다. (n=3 이면 trigram, 기본 0)search_strategy: tmp- lm_weight: 빔 서치 시 Language Model (LM)을 fusion 하려고 할 때 LM의 vocab 확률에 얼만큼의 가중치를 줄 지
여기에 Transformer 계열의 model들을 추론 할 때 반드시 최적화 해야 하는 것이 있는데, 바로 Incremental Decoding입니다.
이는 빔 서치를 진행하면서 예를 들어 현재 11번 째 timestep의 token을 생성할 때 이전 10번째 까지 생성했던 [batch_size * beam_size, seq_len]의 matrix를 효율적으로 관리하는 기능인데요,
incremental decoding을 하는 이유는 beam search를 병렬적으로 할 수 있기 때문에 + 불필요한 연산을 막아 (K,V 연산) 효율을 높히기 위함 입니다.
(post 아래에 어떻게 이를 효율적으로 관리할 수 있는지 말씀드리겠습니다)
 Fig. Fairseq Paper에서 언급된 Incremental Decoding
Fig. Fairseq Paper에서 언급된 Incremental Decoding
이 모든 것은 fairseq 내에서는 incremental_states 라는 List of Dictionary 로 관리되는데
incremental_states = torch.jit.annotate(
List[Dict[str, Dict[str, Optional[Tensor]]]],
[
torch.jit.annotate(Dict[str, Dict[str, Optional[Tensor]]], {})
for i in range(self.model.models_size)
],
)
fairseq 내의 모든 Model들은 그것이 Decoder-only model 이든 (gpt계열) 아니면 Encoder-Decoder 계열이든 각 Encoder, Decoder Module들이 상속을 하는 최상위 Abstract Class가 있습니다. 그렇기 때문에 이를 상속받는 모든 Class들은 각 model에 따라 디자인된 Incremental State를 관리하는 함수가 존재하게 되고 빔 서치 시 이를 호출하여 효율적으로 빔을 관리하게 됩니다.
from typing import Dict, Optional
from fairseq.incremental_decoding_utils import with_incremental_state
from fairseq.models import FairseqDecoder
from torch import Tensor
@with_incremental_state
class FairseqIncrementalDecoder(FairseqDecoder):
def __init__(self, dictionary):
super().__init__(dictionary)
def forward(
self, prev_output_tokens, encoder_out=None, incremental_state=None, **kwargs
):
raise NotImplementedError
def extract_features(
self, prev_output_tokens, encoder_out=None, incremental_state=None, **kwargs
):
raise NotImplementedError
def reorder_incremental_state(
self,
incremental_state: Dict[str, Dict[str, Optional[Tensor]]],
new_order: Tensor,
):
raise NotImplementedError
def reorder_incremental_state_scripting(
self,
incremental_state: Dict[str, Dict[str, Optional[Tensor]]],
new_order: Tensor,
):
raise NotImplementedError
def set_beam_size(self, beam_size):
raise NotImplementedError
이제 기본적인 빔 서치의 기본 요소들과 incremental decoding, ngram block 등 각종 technique 들에 대해 알아보도록 하겠습니다.
Beam Search Fundamentals
Incremental Decoding (KV Caching)
이제 Incremental Decoding에 대해 알아보도록 하겠습니다.
Fig. Fairseq Paper에서 언급된 Incremental Decoding
말씀드렸다시피 incremental decoding은 앞서 생성에 사용한 key value 를 caching해서 들고있다가 재사용 함으로써 불필요한 연산을 다시 하지 않는것이 목적입니다. 어떻게 이것이 가능할까요?
Transformer decoder-only model에 대해 생각해 보겠습니다. Decoder-only의 경우 transformer block 1개의 연산은 대충 pseudo code로 아래처럼 작성할 수 있습니다.
x # layer input. [bsz, time, channel]
attn_mask # padding mask + upper triangle mask. [bsz, num_head, time, time]
residual = x
x = prenorm1(x) # 1. normalization. [bsz, time, channel]
qkv = qkv_proj(x) # 2. qkv projection. [bsz, time, channel*3]
q, k, v = unroll(qkv) # 3. unroll. [bsz, time, num_head, channel/num_head]
x = scaled_dot_product_attention(q, k, v, attn_mask) # 4. attention. [bsz, time, num_head, channel/num_head]
x = reshape(x) # 5. reshape. [bsz, time, channel]
out = out_proj(x) # 6. output projection. [bsz, time, channel]
x += residual # 7. residual. [bsz, time, channel]
residual = x
x = prenorm2(x) # 8. normalization. [bsz, time, channel]
x = ffn1(x) # 9. feedforward 1. [bsz, time, 4*channel]
x = ffn2(x) # 10. feedforward 2. [bsz, time, channel]
x +=residual # 11. residual. [bsz, time, channel]
pre-norm의 경우를 가정했고 이를 block diagram 으로 나타내면 아래와 같습니다.
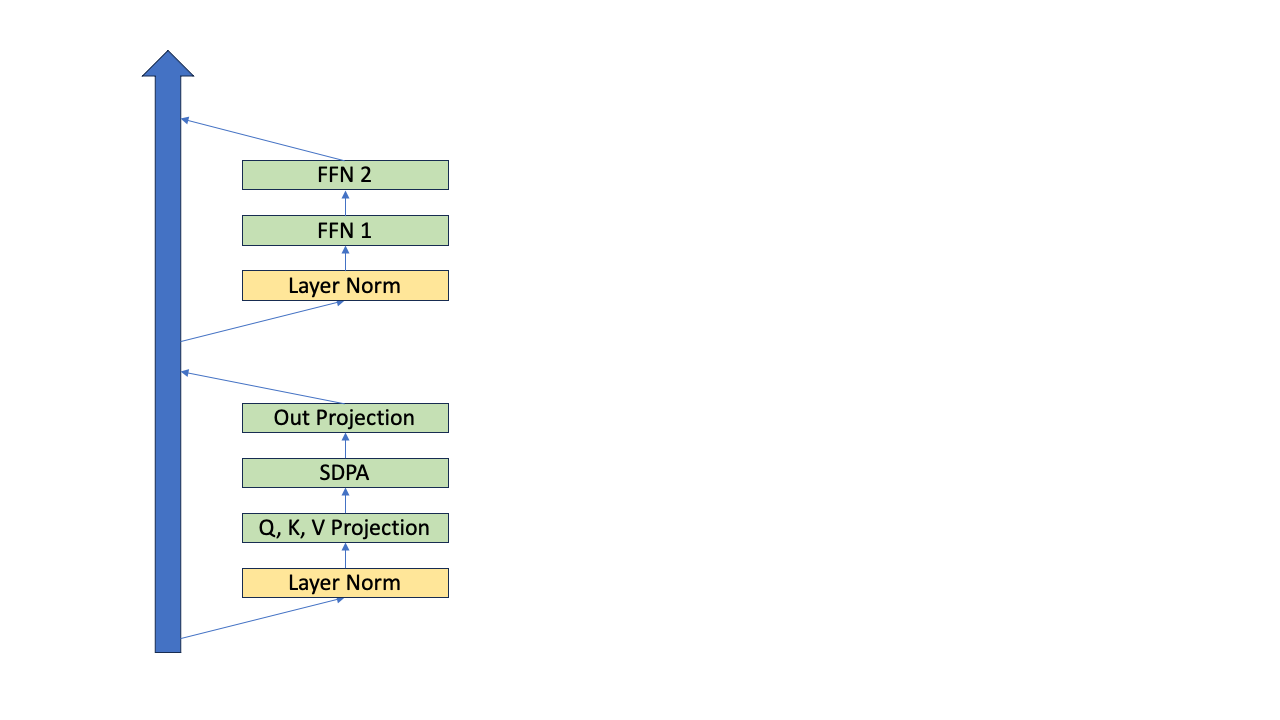 Fig.
Fig.
이제 4개의 token으로 이루어진 prompt (context)를 given으로, 5번째 token을 생성한다고 생각해 보겠습니다. 먼저 아래의 figure처럼 block (layer) input \(x\)를 \(q,k,v\) vector들로 선형 변환 해 줘야 합니다. (token이 4개니까 각각 4개의 vector들을 갖게 되겠죠)
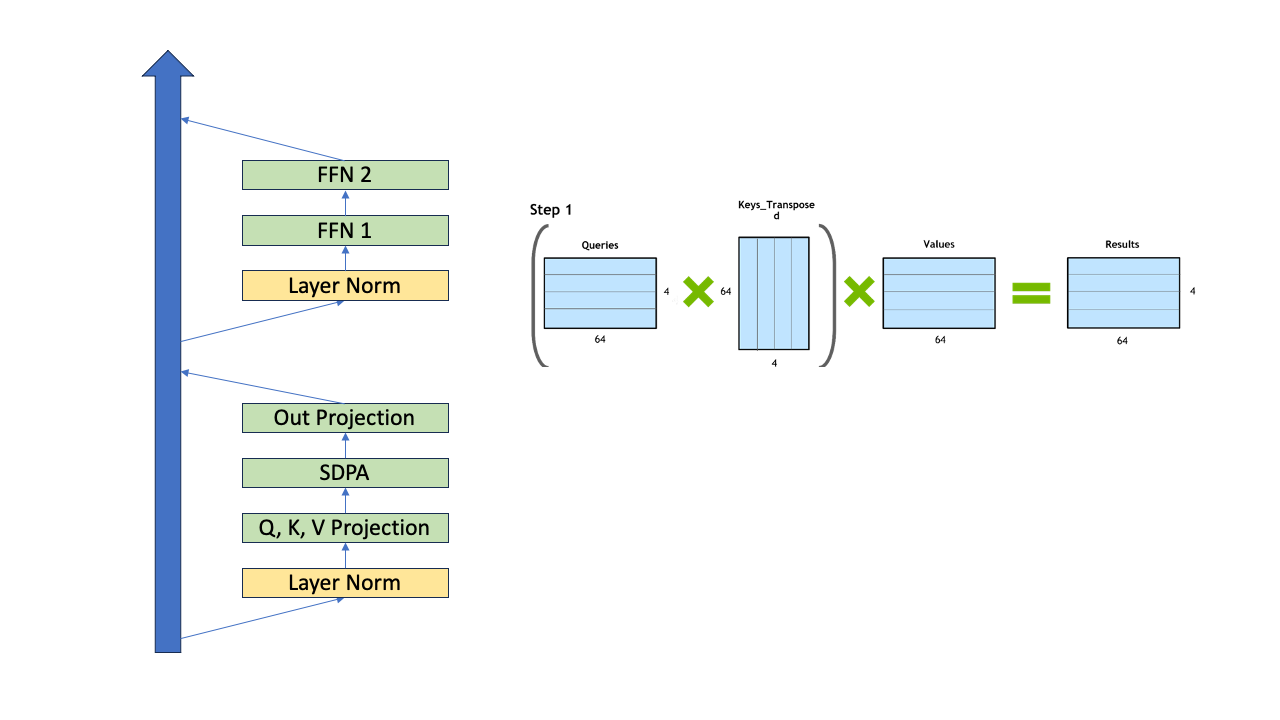 Fig.
Fig.
그리고 query, key tensor들인 \(Q,K\)간의 dot product similarity 를 측정해서 (Scaled Dot Product Attention; SDPA), value tensor \(V\)와 곱해주면 (value vector들을 weighted sum하는 것) 각 timestep 별로의 output token에 대한 distribution을 얻을 수 있고 이 중에서 token을 고르면 됩니다 (greedy search면 확률이 가장 큰 값을 고름).
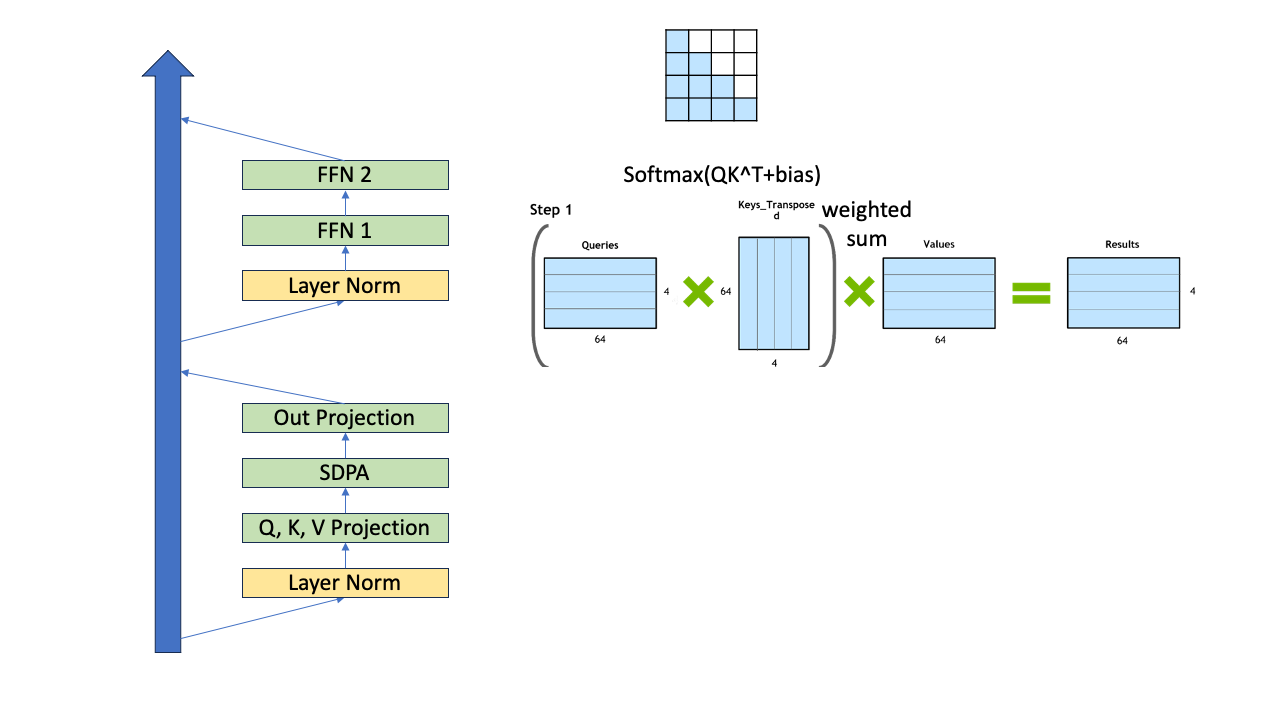 Fig.
Fig.
이제 그러면 5번째 token을 생성한 겁니다 (context를 제외하면 첫 token을 만든 셈). 그러면 6번째 token은 어떻게 생성할 수 있을까요?
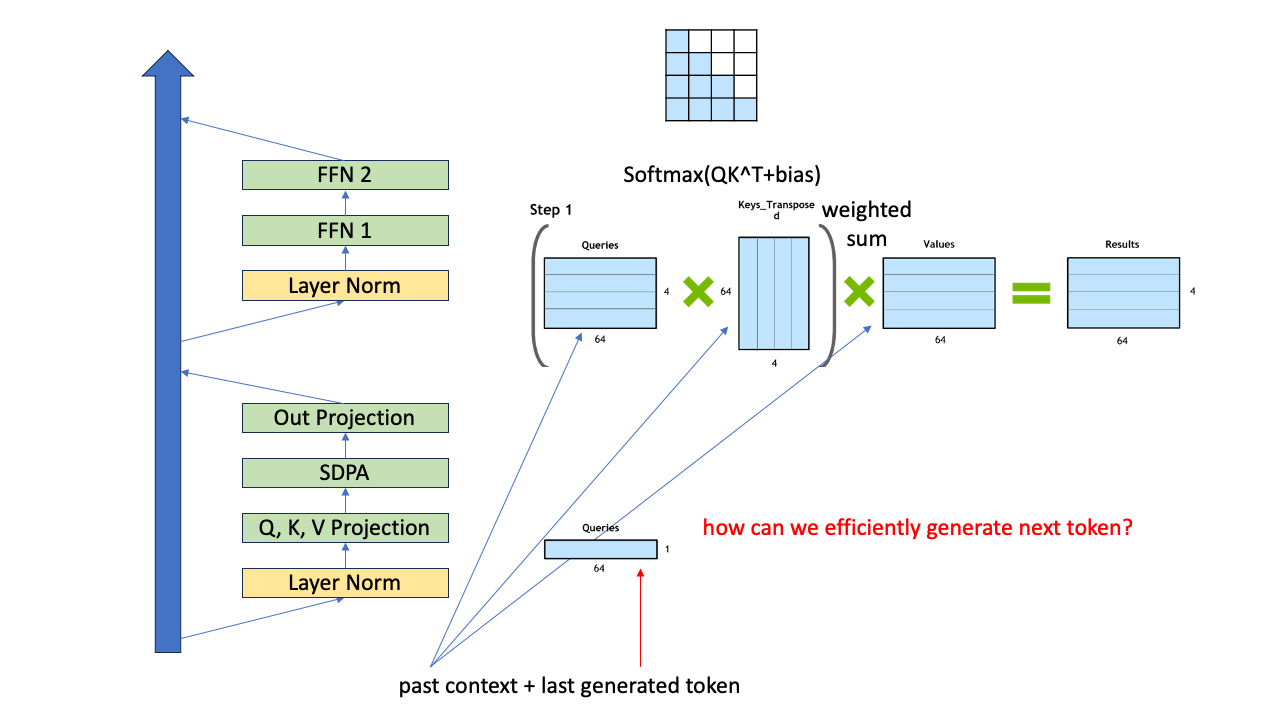 Fig.
Fig.
4개의 token (맨 처음 context)에 방금 생성된 token 1개 을 추가해 5개에 대해서 앞서 했던것 처럼 똑같이 해도 됩니다. 하지만 여기서 중요한 점이 바로 앞선 4개에 token에 대한 \(q,k,v\) vector들은 다시 구하지 않아도 된다는 점 입니다. 왜 그럴까요?
사실 우리가 필요한 것은 방금 추가된 last token 1개와 context + 자기자신 에 대한 key와의 similarity 를 구하고 value vector들과 weighted sum을 하는 것이기 때문이죠.
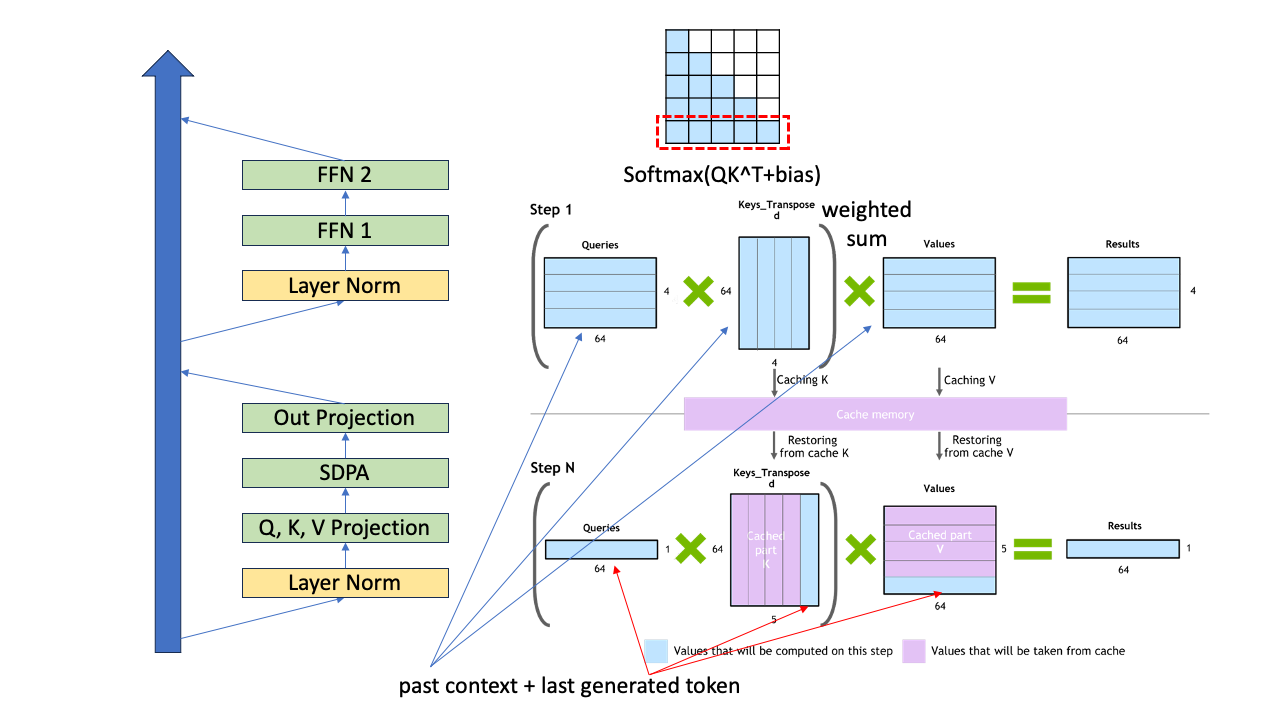 Fig.
Fig.
이렇게 해도 되는 이유는 층을 통과하면서 생성을 할 때 각 token들 자신의 query, key, value vector들은 자기 자신의 position 보다 앞선 token들은 참조하지 않기 때문에 5번째 token이 들어왔을때 여전히 4개의 token들끼리 연산한 결과를 써도 문제가 없기 때문입니다. 게다가 query는 6번째 token을 만드는데 필요하지도 않기 때문에 아예 다시 계산하지 않아도 됩니다. 왜냐면 우리는 5번째 token 을 query로 해서 그 위치에 대한 결과만 궁금하니까요.
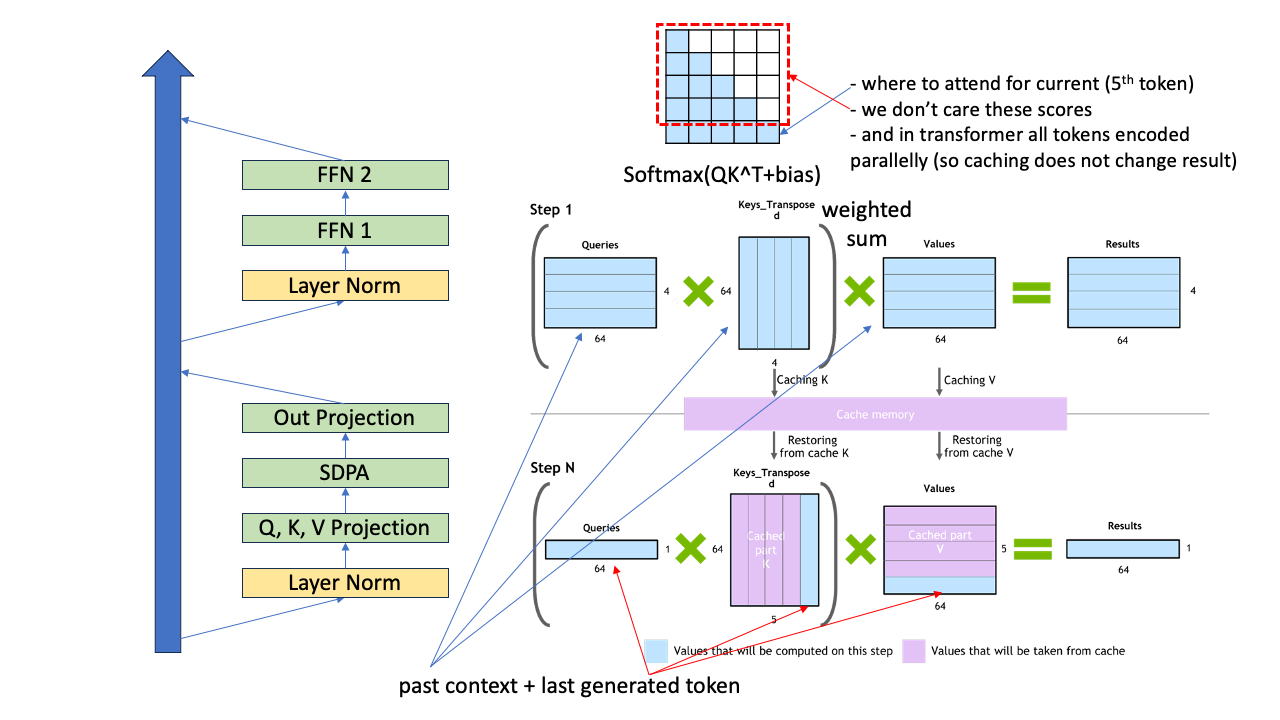 Fig.
Fig.
이런 식으로 전에 생성했던 \(k,v\) vector들을 gpu 메모리 어딘가에 저장하고 있으면 이걸 다시 꺼내 써도 결과에 전혀 영향이 없고 이 technique을 모든 층에 대해 적용해도 전혀 문제가 없으며 이를 바로 k-v caching이라고 얘기합니다.
Analysis
One-Step Further
 Fig.
Fig.
Ngram Block
Sequence generation을 할 때 model이 특정 단어를 Repetition하는 것은 꽤 흔한 현상입니다. 이를 방지하기 위해 ngram 을 count해서 현재 sample할 token들 중 중복이 될 가능성이 있는 candiadte의 확률을 아예 0으로 만들어버립니다.
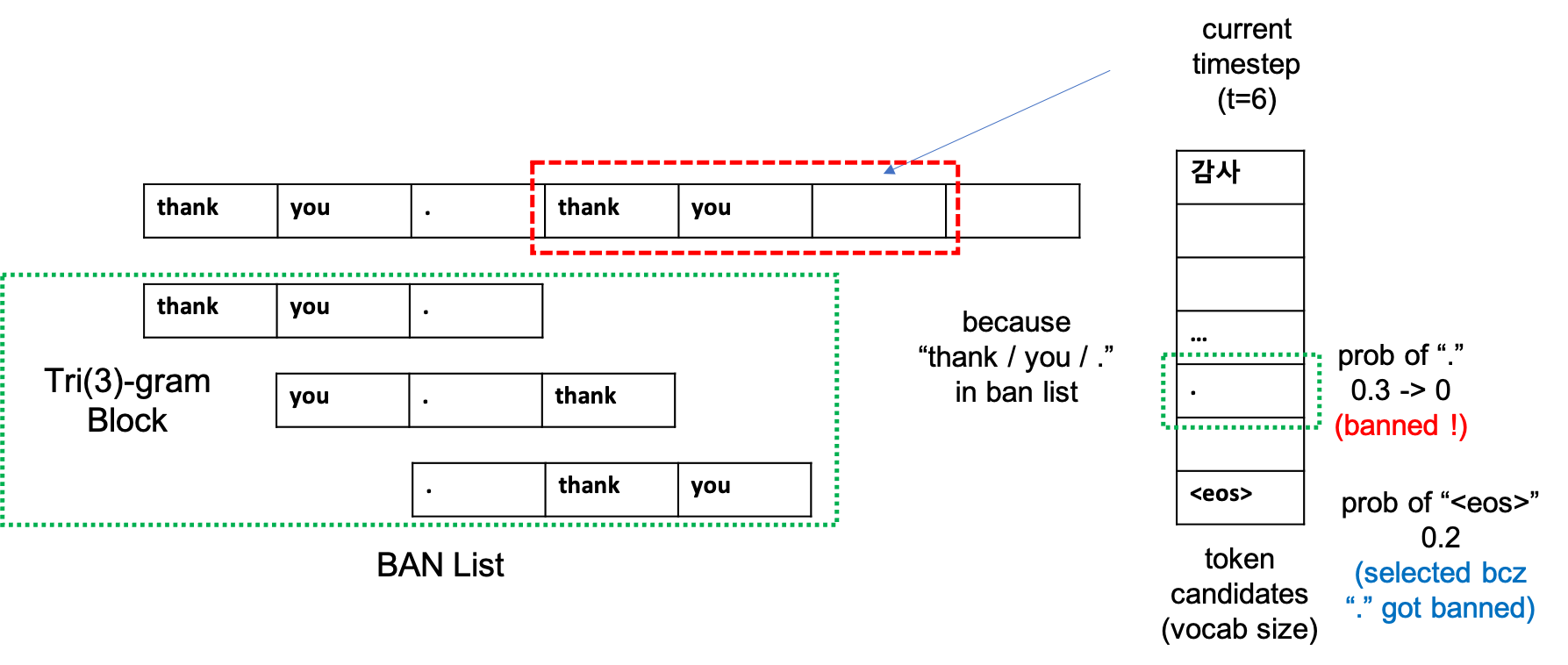
Fairseq에서는 이를 다음과 같이 구현하고 있는데요, 현재까지 만들어진 beam들, [beam_size * batch_size, time] 차원의 tokens을 given, 현재 timestep의 log probs, ([beam_size * batch_size, time, vocab_size])차원의 tensor를 repeat_ngram_blocker에 넣습니다.
lprobs, avg_attn_scores = self.model.forward_decoder(
tokens[:, : step + 1],
encoder_outs,
incremental_states,
self.temperature,
)
...
if self.repeat_ngram_blocker is not None:
lprobs = self.repeat_ngram_blocker(
tokens,
lprobs,
bsz,
beam_size,
step
)
NGramRepeatBlock class가 하는 일은 실제로 굉장히 단순한데요, 예를 들어
- beam_size = 5
- batch_size = 128
- step = 4 (현재 timestep)
- N of Ngram = 3
 Fig.
Fig.
 Fig.
Fig.
 Fig. Ngram Block Algorithm의 GPU version
Fig. Ngram Block Algorithm의 GPU version
Sampling
Top-k Sampling
Top-p Sampling
References
- Papers
- Blogs
- Understanding Incremental Decoding from Sam Shleifer
- Understanding incremental decoding in fairseq from Ankur Mohan
- Accelerated Inference for Large Transformer Models Using NVIDIA Triton Inference Server
- Transformer Inference Arithmetic
-
Large Transformer Model Inference Optimization of Lilian Weng
- How to generate text: using different decoding methods for language generation with Transformers from Patrick
- Generative LLM inference with Neuron
- fairseq