Gradient Clipping
23 Feb 2024< 목차 >
Motivation
얼마 전 Deepspeed에 아래와 같은 PR이 올라왔다. Gradient clipping coefficient가 제대로 적용되고 있지 않아서 bug fix를 했다는 것이다.
 Fig.
Fig.
오우 대체 뭔 소릴까..? 여태까지 내가 학습을 잘못하고 있었다는 걸까..?
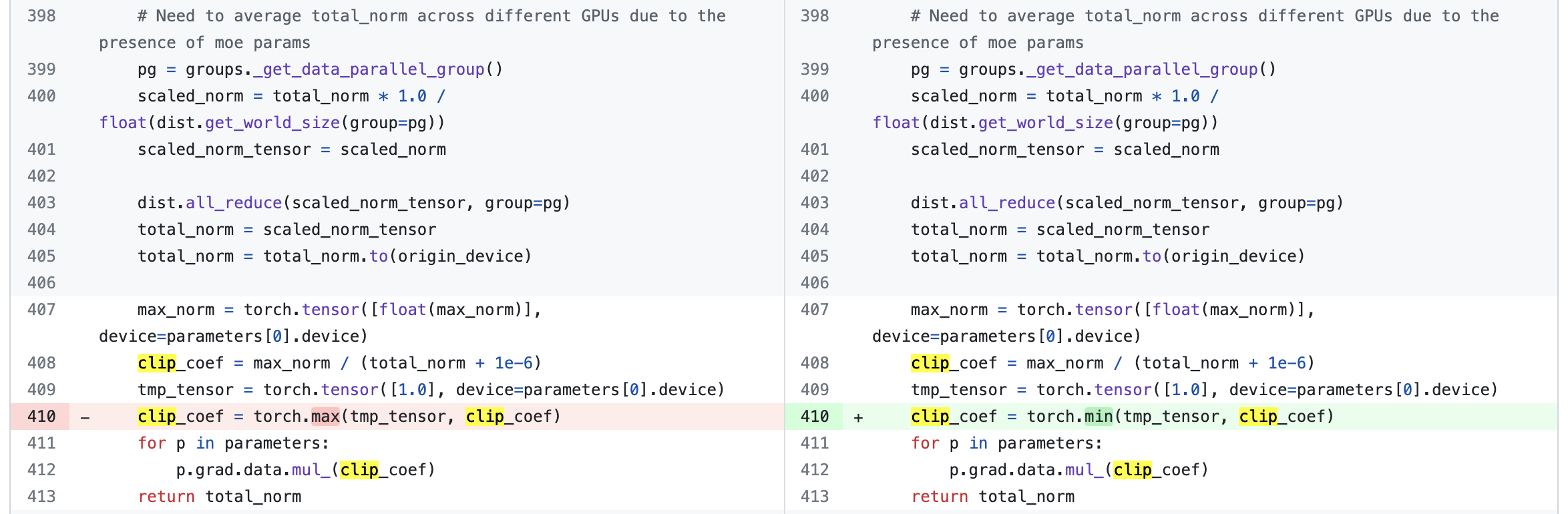 Fig.
Fig.
위의 고쳐진 line을 보면 torch.max가 torch.min으로 바뀐걸 알 수 있다. 아니 그러면 gradient clipping이 아니라 exploding을 하고 있었다는 건가? 검증을 하기 위해 gradient clipping logic을 recap해보자.
Pytorch Naive Gradient Clipping
Gradient clipping은 Deep Neural Network (DNN)을 training하다보면 발생하는 gradient expoliding을 해결하기 위한 간단하면서도 효과적인 method이다. gradient exploding이 발생하는 이유는 아래 slide처럼 여러가지가 있을 수 있는데,
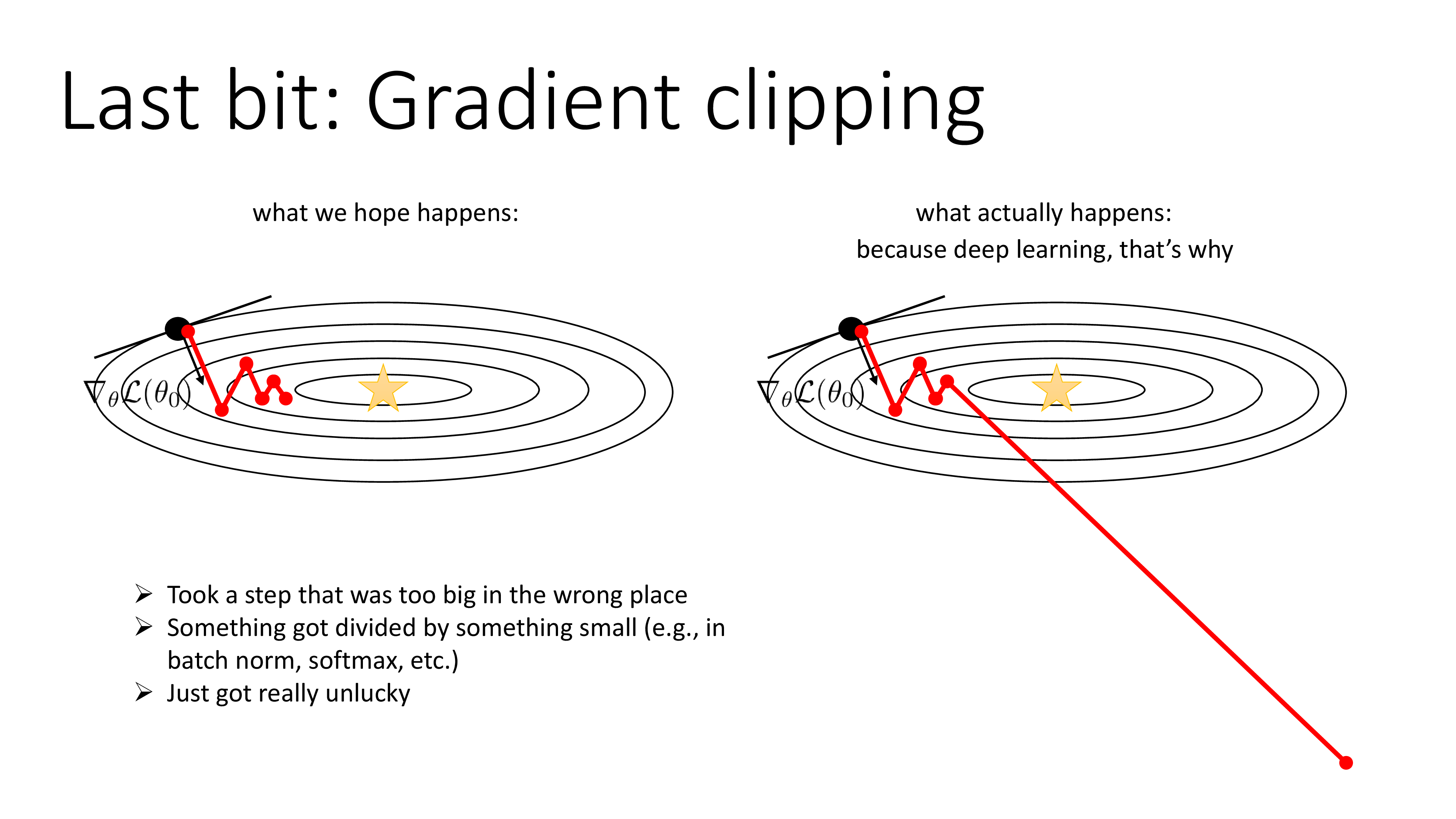 Fig. Source from cs182 by Sergey Levine
Fig. Source from cs182 by Sergey Levine
어쨌든 NN training은 model을 의인화 하여 training한다고 얘기하지만 사실은 optimization 에 관한 것이기 때문에 gradient가 exploding하면 model은 회복할 수 없을 정도로 망가져버린다. 그러므로 gradient vector (혹은 jacobian)가 일정 크기를 넘지 않도록 관리해주는 것이 중요한데, gradient clipping logic 은 아래처럼 매우 단순하다. 먼저 아래 pseudo code처럼 loss를 parameter, \(\theta\)에 대해 미분한 gradient의 크기 (norm)을 잰다.
 Fig.
Fig.
그리고 정해둔 thershold를 넘어가면 gradient의 크기를 scaling 해주는 것이 전부이다. 당연히 이런 중요한 training technique은 pytorch에 내장되어있는데, 이는 대충 아래처럼 단순화 할 수 있을 것 같다.
import torch
import torch.nn as nn
parameters = torch.nn.Parameter(torch.rand(3))
parameters.grad = torch.rand(3)
print('grad beforce clipping', parameters.grad)
max_norm = 1.0
norm_type = 2
def clip_grad_norm_(parameters, max_norm, norm_type=2, mpu=None):
if mpu:
raise NotImplementedError
if isinstance(parameters, torch.Tensor):
parameters = [parameters] # Ensure parameters is a list of Tensors
# Filter out parameters without gradients -> vector
grads = [p.grad for p in parameters if p.grad is not None]
# Calculate the norm of all gradients -> vector
total_norm = torch.norm(torch.stack([torch.norm(g, norm_type) for g in grads]), norm_type)
# Calculate the clip coefficient
clip_coef = max_norm / (total_norm + 1e-6)
# clip_coef_clamped = min(clip_coef, 1.0) # opt 1
clip_coef_clamped = torch.clamp(clip_coef, max=1.0) # opt 2. opt 1 == opt 2
print(f'''
total_norm: {total_norm}, max_norm = {max_norm}
clipping ? : {total_norm > max_norm}
clip_coef: {clip_coef}, clip_coef_clamped = {clip_coef_clamped}
''')
# Scale gradients by the clip coefficient
for g in grads:
g.mul_(clip_coef_clamped)
return total_norm
clip_grad_norm_(parameters, max_norm, norm_type)
print('after clipping', parameters.grad)
만약 parameter의 (p-)norm이 max norm을 넘지 않는다면, gradient와 곱해지는 clip coefficient가 1이 되기 때문에 당연히 gradient에 아무런 변화가 없다.
grad beforce clipping tensor([7.6175e-01, 4.9901e-04, 2.4826e-01])
total_norm: 0.8011820912361145, max_norm = 1.0
clipping ? : False
clip_coef: 1.2481541633605957, clip_coef_clamped = 1.0
after clipping tensor([7.6175e-01, 4.9901e-04, 2.4826e-01])
하지만 만약 이 coefficient가 1을 넘게되면 clip_coef_clamped이 1 이하가 되면서 rescaling이 되는 것을 볼 수 있다.
grad beforce clipping tensor([0.9344, 0.5794, 0.9206])
total_norm: 1.4340074062347412, max_norm = 1.0
clipping ? : True
clip_coef: 0.697346031665802, clip_coef_clamped = 0.697346031665802
after clipping tensor([0.6516, 0.4040, 0.6420])
Clip coefficient를 위와같이 계산하는 이유는 thresholding을 하는 것이 아래와 같기 때문이다.
\[\begin{aligned} & \parallel \hat{g} \parallel \geq threshold == \frac{\parallel \hat{g} \parallel}{threshold} \leq 1 \\ \end{aligned}\]Gradient clipping은 norm을 기준으로 scaling해주는 방법도 있고, 각 element를 특정 constant가 넘지 안도록 해주는 단순한 방법도 있다.
 Fig. Source from cs182 by Sergey Levine
Fig. Source from cs182 by Sergey Levine
찾아보면 다른 방법도 있겠으나 adaptive gradient-based optimization algorithm등에서도 scaling은 해주기 때문에 관심있는 사람들은 optimization algorithm 중에서 찾아보는 것이 더 좋을 것 같다. 그리고 threshold를 정하는 법은 사실 왕도가 없고 적당히 몇 epoch 학습을 해보면서 학습에 악영향을 끼치지 않을 healty gradient norm을 monitoring 하고 그 값을 사용하면 된다.
Deepspeed Gradient Clipping
그래서 Deepspeed 에서는 어떻게 grad clip이 구현되어있는가? 사실 주석에 써있듯이 torch.nn.utils.clip_grad.clip_grad_norm_를 adapt했기 때문에 별로 다를게 없다.
Fig.
먼저 PR이 되기 전 torch.max를 쓰는 경우를 생각해보자. 만약 max_norm이 1인데 total_norm이 1보다 작으면 clip_coef는 1보다 큰 값으로 계산된다 (왜냐면 역수이기 때문). 그런데 여기서 clip_coef과 max_norm=1 중에서 max인 값을 골라 gradient rescaling을 해주게 되는데, 이 경우 gradient를 의도치않게 키우게 된다. 반대로 total_norm이 1보다 큰 경우를 생각해보자. 그러면 clip_coef는 1보다 작아지는데 이 경우 max인 1값이 선택되어 gradient에 곱해지므로 아무런 변화가 생기지 않는다. 즉 gradient norm이 1보다 작을 때에는 gradient를 키우고 gradient norm이 1보다 클 때는 그냥 냅두는 일을 하고 있는 것이다.(…)
하지만 이 문제는 좀 찾아보니 사실 ZeRO를 쓰면 문제가 안된다는 것을 알 수 있었다.
 Fig.
Fig.
왜냐하면 이는 ZeRO를 쓰지 않을 경우, 즉 DDP만 하는 경우 사용되는 함수이기 때문이다. (this line 참고)
 Fig.
Fig.
ZeRO-3를 쓰는 경우는 backward propagation, optimizer step을 할 때 gradient를 모으는 등의 행위를 해야하기 때문에 이 logic이 따로 구현되어 있다.
 Fig.
Fig.
위 function은 gather된 gradient에 대해서 mixed precision 의 loss scaling과 gradient clipping을 한번에 해준다. 만약 bf16이라면 loss scaling은 필요없기 때문에 self.loss_scale=1로 영향을 주지 않을 것이다.
보통 ZeRO-3를 쓰는 경우에만 deepspeed를 쓰기 때문에 이번에는 문제 없이 넘어갔지만, opensource 를 쓰는 상황에서는 언제나 bug를 의심해야 한다는 것을 다시 깨달을 수 있었다.