(WIP) Differentiable Sampling for Discrete Distribution
23 Feb 2024< 목차 >
Introduction
Machine Learning (ML) model을 학습할 경우 종종 sampling이 필요할 때가 있다. 예를 들어 아래의 식은 Variational AutoEncoder (VAE)의 objective function인데, continuous distribution인 guassian distriubtion을 modeling하는 \(q_{\phi}\)로부터 noise vector를 sampling 해야하는데, 이는 미분이 불가능 (non differentiable) 하다는 것이 널리 알려져 있다.
\[\mathbb{E}_{q_{\phi}(z \vert x)} [ \log p_{\theta}(x \vert z) ] + D_{KL} (q_{\phi}(z \vert x) \parallel p(z))\]미분이 불가능하다는 것은 backpropagation을 할 때 local gradient를 계산할 수 없다는 것이고, 이는 upstream gradient와 곱해봐야 gradient가 없는 것이나 다름 없기 때문에 end-to-end training을 불가능하게 만든다. 그렇기 때문에 보통 VAE에서는 reparameterization trick 이라는 걸 쓴다. 이는 gaussian distribution에서 실제로 어떤 vector를 sampling 하는 것이 아니라 mean vector, \(q_{\phi}(\mu_z \vert x)\)를 뽑고 거기에 \(q_{\phi}(\sigma_z \vert x) \cdot \epsilon\)을 더해주면 되는데, 이 때 \(\epsilon\)이 stochastic하게 sampling되기 때문에 (\(\epsilon \sim \mathcal{N}(0,1)\)) \(\epsilon\)에는 gradient가 흐르지 않지만 이는 learnable parameter가 아니기 때문에 상관이 ㅇ벗으며 \(q_{\phi}\)에는 gradient가 안전하게 흐르게 된다.
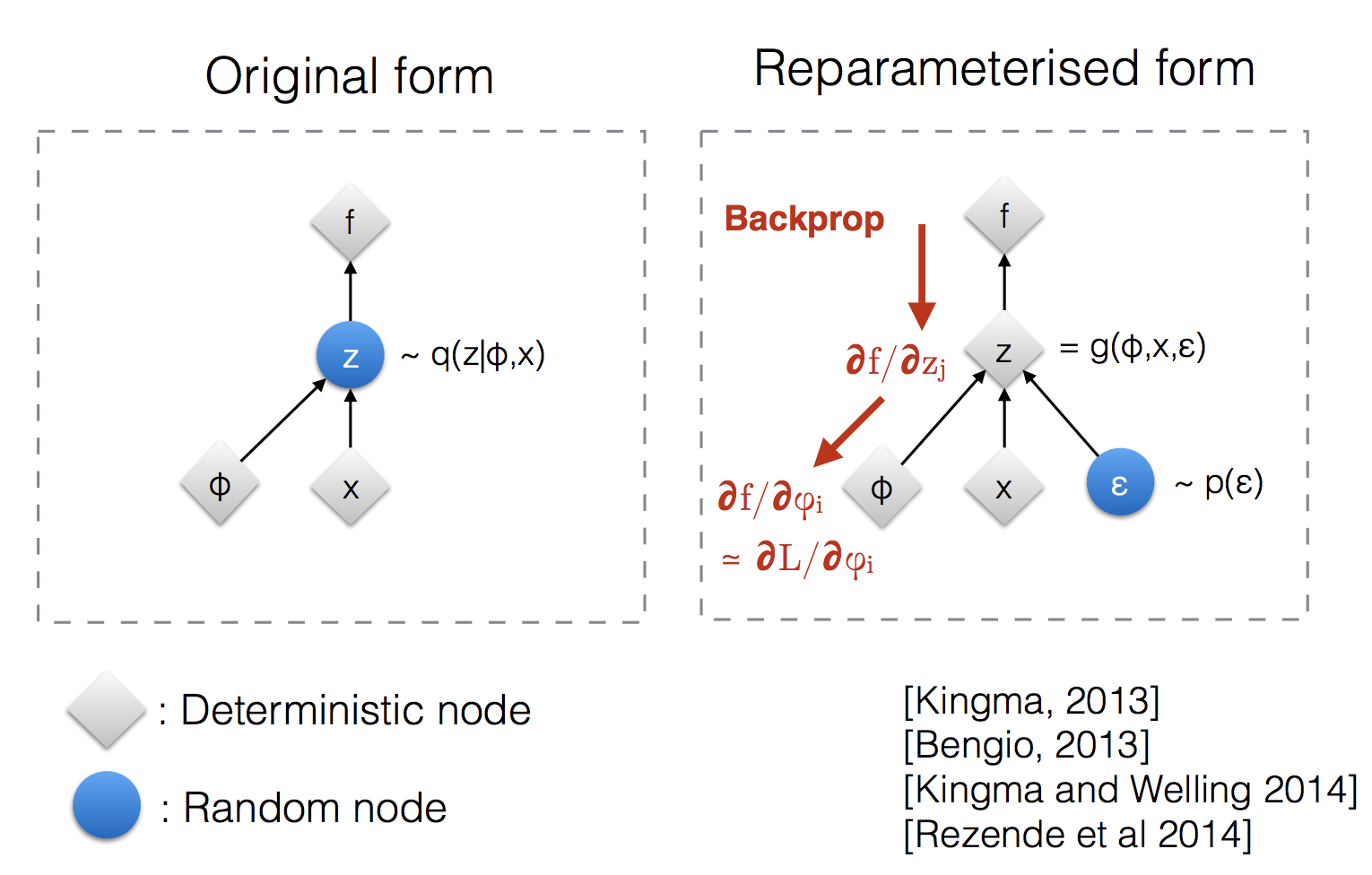 Fig.
Fig.
우리는 덧셈, 곱셈 operation에 대한 backprop rule을 알고 있기 때문에 이를 그대로 적용하면 정확한 gradient는 아닐 수 있지만 (?), 학습은 정상적으로 이루어진다. 구현은 다음과 같이 쉽게 할 수 있다.
import torch
import torch.nn as nn
input_dims, latent_dims = 784, 128
linear_mean = nn.Linear(input_dims, latent_dims).cuda()
linear_variance = nn.Linear(input_dims, latent_dims).cuda()
normal_dist = torch.distributions.Normal(0, 1)
input = torch.rand(1,784).cuda()
input.requires_grad = True
def reparam(x):
mu = linear_mean(x) # mean
sigma = torch.exp(linear_variance(x)) # variance, we should ensure it's positive value
z = mu + sigma * normal_dist.sample(mu.shape).cuda() # sampled with reparm trick
return z
reparam(input).sum().backward()
print(input.grad)
한 편 categorical distribution같은 경우에는 어떻게 이를 해야할까? 이런 distribution에서도 마찬가지로 sampling을 할 수 있어야 하고 (매 번 가장 큰 확률인 element가 뽑히지는 말아야 하며), 당연히 미분이 가능해야 할 것이다. 이 때 쓰는 gradient를 전파하는 방법이 여러 개가 있을 수 있는데, 바로 아래 figure의 (3,4,5)번이 대표적이다.
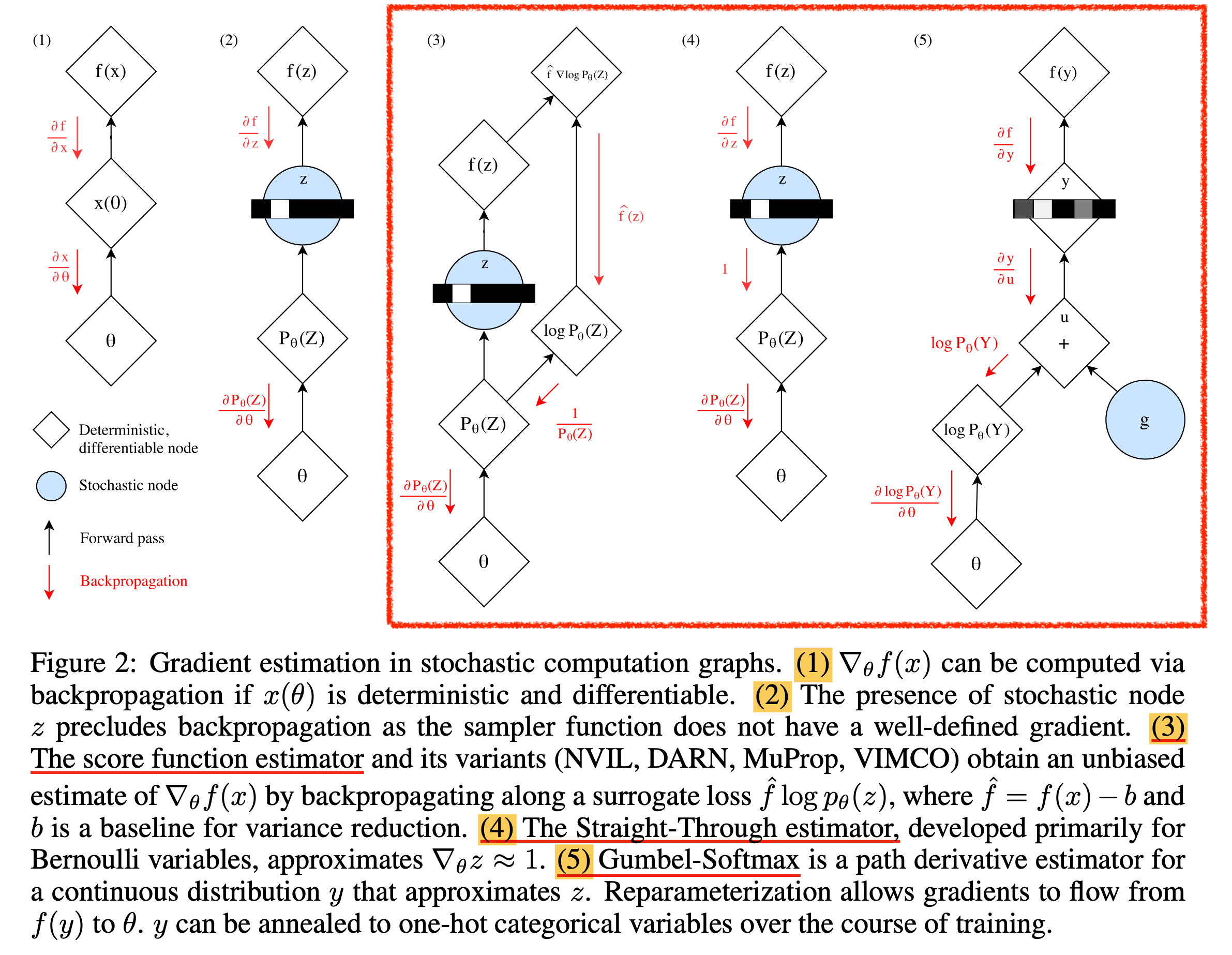 Fig.
Fig.
이는 Categorical Reparameterization with Gumbel-Softmax라는 paper의 figure로,
(1)번은 정상적인 computational graph를 표현한 것이며,
(2)번은 sampling을 할 경우 미분이 끝긴다는 걸 의미한다.
(3)번은 이제 Score Function estimator라고 쓰여있는데, 이를 다른 말로 REINFORCE라고도 한다.
REINFORCE는 원래 Reinforcement Learning (RL)의 policy gradient alogrithm 중 가장 naive한 approach인데,
이는 다음의 수학적 사실을 활용해 미분이 불가능한 reward function을 미분 가능하게 만든다.
예를 들어 우리가 probability distribution, \(p_{\theta}(z)\)에서 어떤 \(z\)를 뽑고 이를 통해 \(f(z)\)라는 loss를 계산했다고 치자. 그러면 \(\nabla_{\theta} \mathbb{E}_z [f(z)]\)는 다음과 같이 계산이 될 수 있다.
\[\begin{aligned} & \nabla_{\theta} \mathbb{E}_{z \sim p_{\theta}(z)} [f(z)] \\ & = \nabla_{\theta} \int p_{\theta}(z) f(z) dz \\ & = \int p_{\theta}(\tau) \nabla_{\theta} \log p_{\theta}(\tau) f(z) dz \\ & = \mathbb{E}_{z \sim p_{\theta}(z)} [ f(z) \nabla_{\theta} \log p_{\theta}(z)] \\ \end{aligned}\]그런데 여기서 문제는 이 gradient가 RL의 문제점을 그대로 떠안고 있다는 것이다. 즉 high variance하다는 것인데, expectation을 정확히 계산할 수 있어야 \(\theta\)에 정확한 gradient를 흘릴 수 있다. 혹은 이를 Monte Carlo (MC) sampling으로 몇 회 뽑는다고 하면 횟수를 늘려야 안정적으로 update를 할 수 있을 것이다.
(4)번은 sampling operation의 gradient를 1로 만드는 것으로,
Straight-Through estimator라고 불리우는데 이것 또한 단순하지만 좋은 gradient는 아닐 것이다.
마지막 (5)번은 Gumbel Softmax라고 불리우는데,
사실 이는 discrete distribution 판 reparameterization 이다.
아래 figure는 The Concrete Distribution: A Continuous Relaxation of Discrete Random Variables라는 paper의 figure인데,
앞서 언급한 gumbel softmax paper와 동시대에 나온 concurrent work이다.
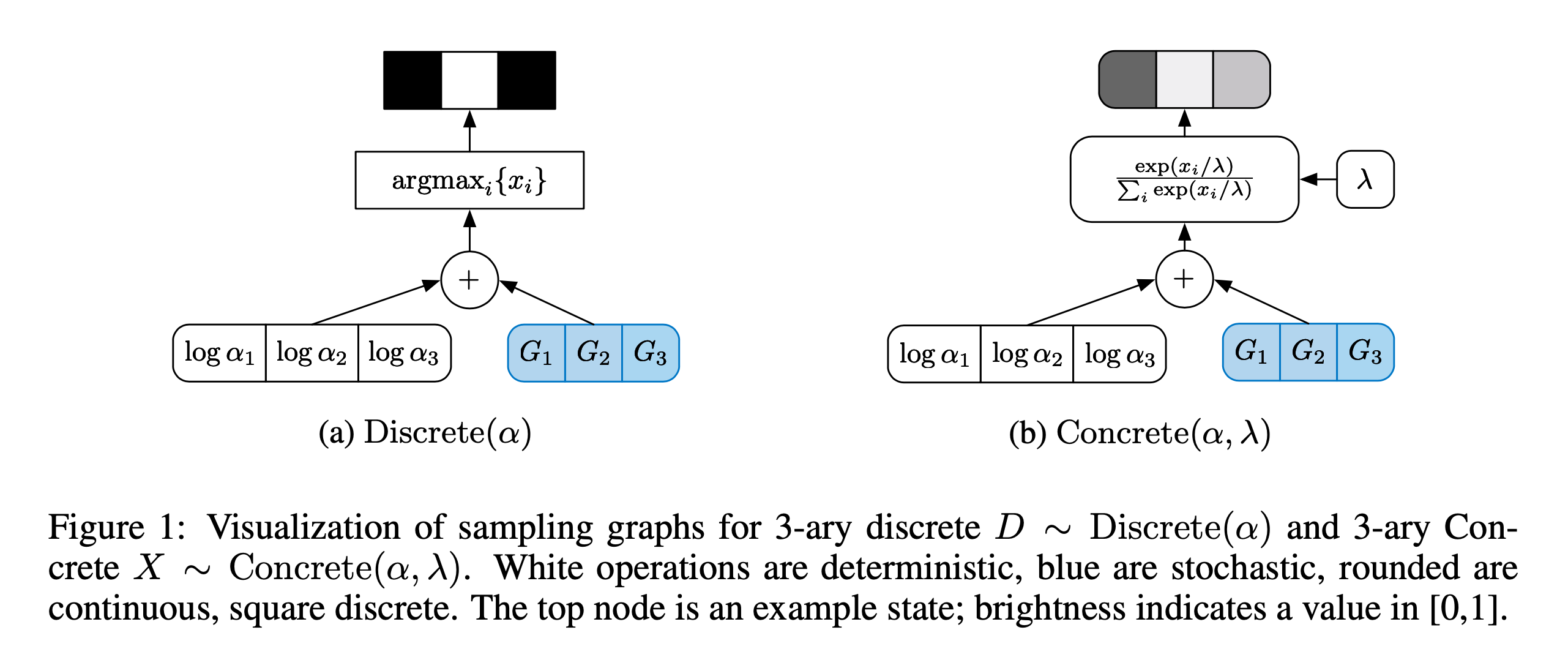 Fig.
Fig.
먼저 logit vector가 있으면 gumbel noise를 더한 뒤 softmax를 해준다.
여기서 gumbel noise vector는 sampling 된 것이므로 stochasticity가 존재하며,
앞서 gaussian distribution의 reparam 처럼 logit vector에 sampling operator가 취해진 것이 아니므로 미분이 가능해야하는 부분에는 gradient가 여전히 흐르게 된다.
추가로 softmax를 계산할 때 \(\lambda\)라는 것이 추가되어 logit을 discount한 뒤 softmax하게 되는데,
이를 temperature라고 한다.
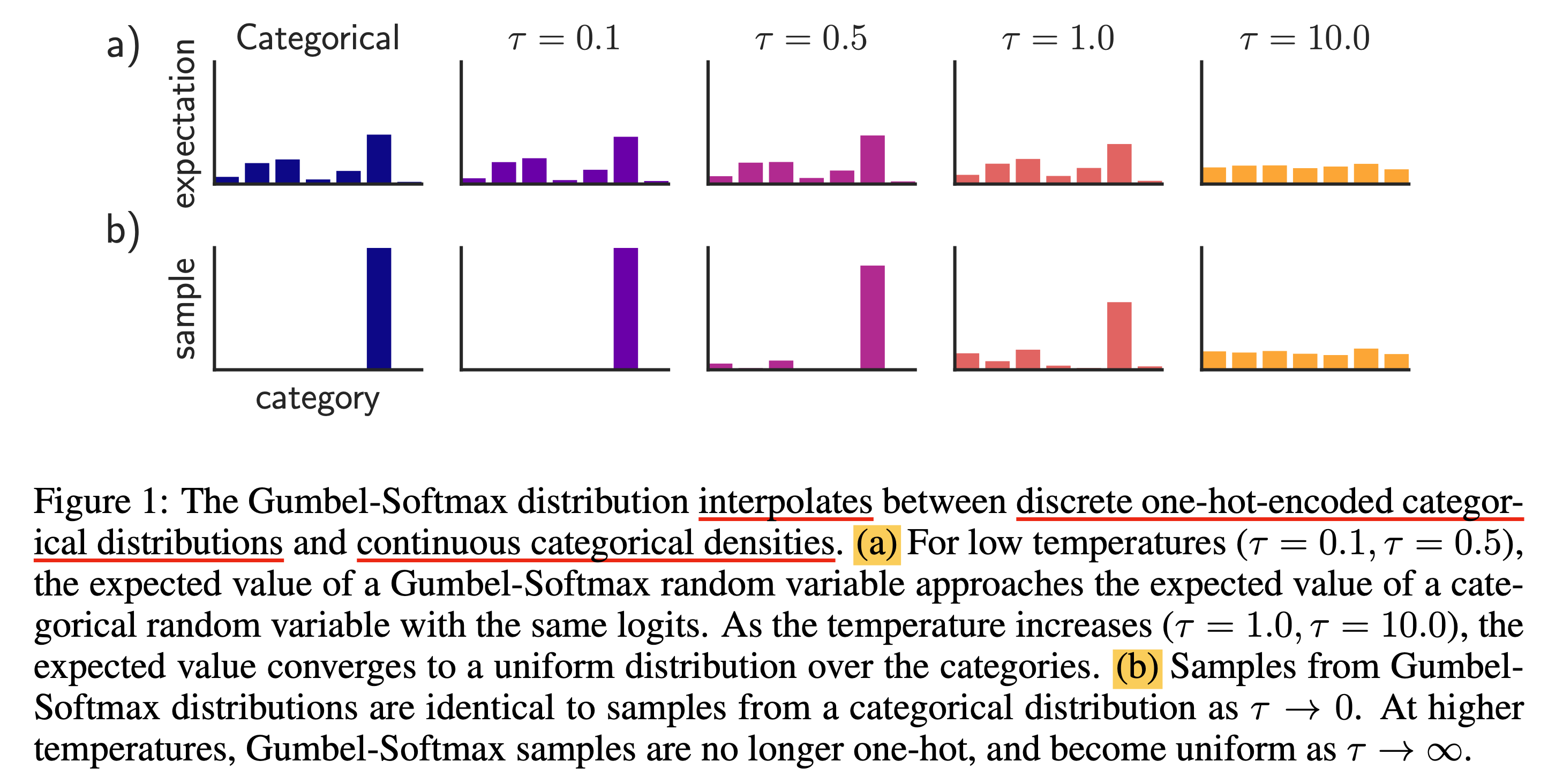 Fig.
Fig.
Temperature가 높으면 sampling된 distribution이 uniform distribution 처럼 형성된다 (\(\tau \rightarrow \infty\)면 완전 uniform에 가까워진다). 반대로 temperature가 낮으면 sharp해지며 (\(\tau \rightarrow 0\)이면 one hot에 가까워진다), temperature가 1이면 일반 softmax distribution에서 sampling한 것 처럼 작동한다. (직관적으로 확률 분포를 의인화해서 온도가 높아지면 흐물흐물 풀어진다고 외워도 된다(?))
Implementation
Gumbel-Softmax
Gumbel softmax의 구현체는 torch.nn.functional.gumbel_softmax를 사용하면 된다. 이를 사용하면 stochastic하면서도 미분이 가능한 vector를 얻을 수 있게 된다. Hyperparam인 temperature를 잘 조절해가면서 학습에 사용하면 되는데, 일반적으로 high temperature에서 시작해 small but non-zero temperature로 annealing을 하면 된다.
logits = torch.randn(20, 32)
# Sample soft categorical using reparametrization trick:
F.gumbel_softmax(logits, tau=1, hard=False)
# Sample hard categorical using "Straight-through" trick:
F.gumbel_softmax(logits, tau=1, hard=True)
내부 구현은 아래처럼 되어있는데,
logit이 만약 2차원 matrix, \(z \in \mahtbb{R}^{B \times C}\)라고 하면 logit과 같은 size의 gumbel noise를 생성하여 더해주고 temperature로 나눠준 뒤 softmax를 취한 y_soft라는 vector를 return하게 된다.
이 때 당연히 softmax는 channel dim으로 이뤄진다.
def gumbel_softmax(logits: Tensor, tau: float = 1, hard: bool = False, eps: float = 1e-10, dim: int = -1) -> Tensor:
if has_torch_function_unary(logits):
return handle_torch_function(gumbel_softmax, (logits,), logits, tau=tau, hard=hard, eps=eps, dim=dim)
if eps != 1e-10:
warnings.warn("`eps` parameter is deprecated and has no effect.")
gumbels = -torch.empty_like(logits, memory_format=torch.legacy_contiguous_format).exponential_().log() # ~Gumbel(0,1)
gumbels = (logits + gumbels) / tau # ~Gumbel(logits,tau)
y_soft = gumbels.softmax(dim)
if hard:
# Straight through.
index = y_soft.max(dim, keepdim=True)[1]
y_hard = torch.zeros_like(logits, memory_format=torch.legacy_contiguous_format).scatter_(dim, index, 1.0)
ret = y_hard - y_soft.detach() + y_soft
else:
# Reparametrization trick.
ret = y_soft
return ret
여기서 option이 두개가 있는데,
hard=True인 경우 one-hot vector가 return되며,
hard=False인 경우 softmax normalized vector가 그대로 return된다.
이제 이 둘에 대해서 미분이 어떻게 되는지 알아보기 위해 gradient가 흐르는 random tensor를 만든 뒤 backprop을 해보자.
import torch
import torch.nn.functional as F
logits = torch.rand(2, 1, 10, requires_grad=True).cuda()
# Sample soft categorical using reparametrization trick:
soft_out = F.gumbel_softmax(logits, tau=1.0, hard=False, dim=-1)
soft_out.sum().backward()
print('soft_out', soft_out)
print('grad', logits.grad)
# Sample hard categorical using "Straight-through" trick:
logits.grad = None
hard_out = F.gumbel_softmax(logits, tau=1.0, hard=True, dim=-1)
hard_out.sum().backward()
print('hard_out', hard_out)
print('grad', logits.grad)
Routing from HF Mixtral
def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
""" """
batch_size, sequence_length, hidden_dim = hidden_states.shape
hidden_states = hidden_states.view(-1, hidden_dim)
# router_logits: (batch * sequence_length, n_experts)
router_logits = self.gate(hidden_states)
routing_weights = F.softmax(router_logits, dim=1, dtype=torch.float)
routing_weights, selected_experts = torch.topk(routing_weights, self.top_k, dim=-1)
routing_weights /= routing_weights.sum(dim=-1, keepdim=True)
# we cast back to the input dtype
routing_weights = routing_weights.to(hidden_states.dtype)
final_hidden_states = torch.zeros(
(batch_size * sequence_length, hidden_dim),
dtype=hidden_states.dtype,
device=hidden_states.device
)
# One hot encode the selected experts to create an expert mask
# this will be used to easily index which expert is going to be sollicitated
expert_mask = torch.nn.functional.one_hot(
selected_experts,
num_classes=self.num_experts
).permute(2, 1, 0)
# Loop over all available experts in the model and perform the computation on each expert
for expert_idx in range(self.num_experts):
expert_layer = self.experts[expert_idx]
idx, top_x = torch.where(expert_mask[expert_idx])
if top_x.shape[0] == 0:
continue
# in torch it is faster to index using lists than torch tensors
top_x_list = top_x.tolist()
idx_list = idx.tolist()
# Index the correct hidden states and compute the expert hidden state for
# the current expert. We need to make sure to multiply the output hidden
# states by `routing_weights` on the corresponding tokens (top-1 and top-2)
current_state = hidden_states[None, top_x_list].reshape(-1, hidden_dim)
current_hidden_states = expert_layer(current_state) * routing_weights[top_x_list, idx_list, None]
# However `index_add_` only support torch tensors for indexing so we'll use
# the `top_x` tensor here.
final_hidden_states.index_add_(0, top_x, current_hidden_states.to(hidden_states.dtype))
final_hidden_states = final_hidden_states.reshape(batch_size, sequence_length, hidden_dim)
return final_hidden_states, router_logits
Router from Megablocks
from megablocks.layers import common
from megablocks.layers.arguments import Arguments
import torch
# NOTE: To enable end-to-end benchmarking without convergence we
# support a flag to force the router to assign tokens uniformly
# across the experts. We do this with a custom autograd operation
# so that PyTorch still executes the full set of router operation.
class _UniformExpertAssignment(torch.autograd.Function):
@staticmethod
def forward(ctx, x, num_experts):
out = torch.arange(x.numel(), dtype=x.dtype, device=x.device)
out = torch.remainder(out, num_experts)
return out.view(x.shape)
_uniform_expert_assignment = _UniformExpertAssignment.apply
class LearnedRouter(torch.nn.Module):
def __init__(self, args : Arguments):
super().__init__()
self.args = args
# Learned router parameters.
#
# NOTE: This weight matrix is not parallelized with expert model
# parallelism. Each device needs the entire router weight matrix
# so that it can route its batch of data correctly.
self.layer = torch.nn.Linear(
args.hidden_size,
args.moe_num_experts,
bias=False,
dtype=common.dtype(args),
device=args.device)
args.init_method(self.layer.weight)
def jitter(self, x):
low = 1.0 - self.args.moe_jitter_eps
high = 1.0 + self.args.moe_jitter_eps
noise = torch.rand(x.size(), dtype=x.dtype, device=x.device)
return low + noise * (high - low)
def _top_k(self, scores):
if self.args.moe_top_k == 1:
return scores.max(dim=-1,keepdim=True)
return torch.topk(scores, self.args.moe_top_k, dim=-1)
def forward(self, x):
if self.training and self.args.moe_jitter_eps is not None:
x = x * self.jitter(x)
scores = self.layer(x.view(-1, x.shape[-1])).softmax(dim=-1)
expert_weights, expert_indices = self._top_k(scores)
if self.args.moe_normalize_expert_weights:
expert_weights = expert_weights / torch.norm(
expert_weights, p=self.args.moe_normalize_expert_weights,dim=-1, keepdim=True)
expert_indices = (
_uniform_expert_assignment(expert_indices, self.args.moe_num_experts)
if self.args.uniform_expert_assignment else expert_indices
)
return scores, expert_weights, expert_indices
Load Balancing Loss from HF Mixtral
def load_balancing_loss_func(
gate_logits: torch.Tensor, num_experts: torch.Tensor = None, top_k=2, attention_mask: Optional[torch.Tensor] = None
) -> float:
r"""
Computes auxiliary load balancing loss as in Switch Transformer - implemented in Pytorch.
See Switch Transformer (https://arxiv.org/abs/2101.03961) for more details. This function implements the loss
function presented in equations (4) - (6) of the paper. It aims at penalizing cases where the routing between
experts is too unbalanced.
Args:
gate_logits (Union[`torch.Tensor`, Tuple[torch.Tensor]):
Logits from the `gate`, should be a tuple of model.config.num_hidden_layers tensors of
shape [batch_size X sequence_length, num_experts].
attention_mask (`torch.Tensor`, None):
The attention_mask used in forward function
shape [batch_size X sequence_length] if not None.
num_experts (`int`, *optional*):
Number of experts
Returns:
The auxiliary loss.
"""
if gate_logits is None or not isinstance(gate_logits, tuple):
return 0
if isinstance(gate_logits, tuple):
compute_device = gate_logits[0].device
concatenated_gate_logits = torch.cat([layer_gate.to(compute_device) for layer_gate in gate_logits], dim=0)
routing_weights = torch.nn.functional.softmax(concatenated_gate_logits, dim=-1)
_, selected_experts = torch.topk(routing_weights, top_k, dim=-1)
expert_mask = torch.nn.functional.one_hot(selected_experts, num_experts)
if attention_mask is None:
# Compute the percentage of tokens routed to each experts
tokens_per_expert = torch.mean(expert_mask.float(), dim=0)
# Compute the average probability of routing to these experts
router_prob_per_expert = torch.mean(routing_weights, dim=0)
else:
batch_size, sequence_length = attention_mask.shape
num_hidden_layers = concatenated_gate_logits.shape[0] // (batch_size * sequence_length)
# Compute the mask that masks all padding tokens as 0 with the same shape of expert_mask
expert_attention_mask = (
attention_mask[None, :, :, None, None]
.expand((num_hidden_layers, batch_size, sequence_length, 2, num_experts))
.reshape(-1, 2, num_experts)
.to(compute_device)
)
# Compute the percentage of tokens routed to each experts
tokens_per_expert = torch.sum(expert_mask.float() * expert_attention_mask, dim=0) / torch.sum(
expert_attention_mask, dim=0
)
# Compute the mask that masks all padding tokens as 0 with the same shape of tokens_per_expert
router_per_expert_attention_mask = (
attention_mask[None, :, :, None]
.expand((num_hidden_layers, batch_size, sequence_length, num_experts))
.reshape(-1, num_experts)
.to(compute_device)
)
# Compute the average probability of routing to these experts
router_prob_per_expert = torch.sum(routing_weights * router_per_expert_attention_mask, dim=0) / torch.sum(
router_per_expert_attention_mask, dim=0
)
overall_loss = torch.sum(tokens_per_expert * router_prob_per_expert.unsqueeze(0))
return overall_loss * num_experts