Implementation of Contrastive Loss (InfoNCE Loss)
22 Apr 2023< 목차 >
- Contrastive Loss (InfoNCE Loss)
- Some Details and Pesudo Code of SimCLR
- Chimera (for Speech Translation)
- References
이번 Post 에서는 Pytorch 로 Contrastive Loss 를 구현하는 방법에 대해서 알아보려고 합니다.
Contrastive Loss (InfoNCE Loss)
Contrastive Loss 혹은 InfoNCE Loss 는 Label (Annotation) 이 존재하지 않는 상황에서도 효과적으로 Representation 을 학습할 수 있게 해주는 Self-Supervised Learning (SSL) 에 주로 사용됩니다.
원래는 Representation Learning with Contrastive Predictive Coding 라는 paper 에서 제안되었으나 이후 SimCLR : A Simple Framework for Contrastive Learning of Visual Representations 같은 수많은 Representation Learning Paper 에서도 사용되게 되었습니다.
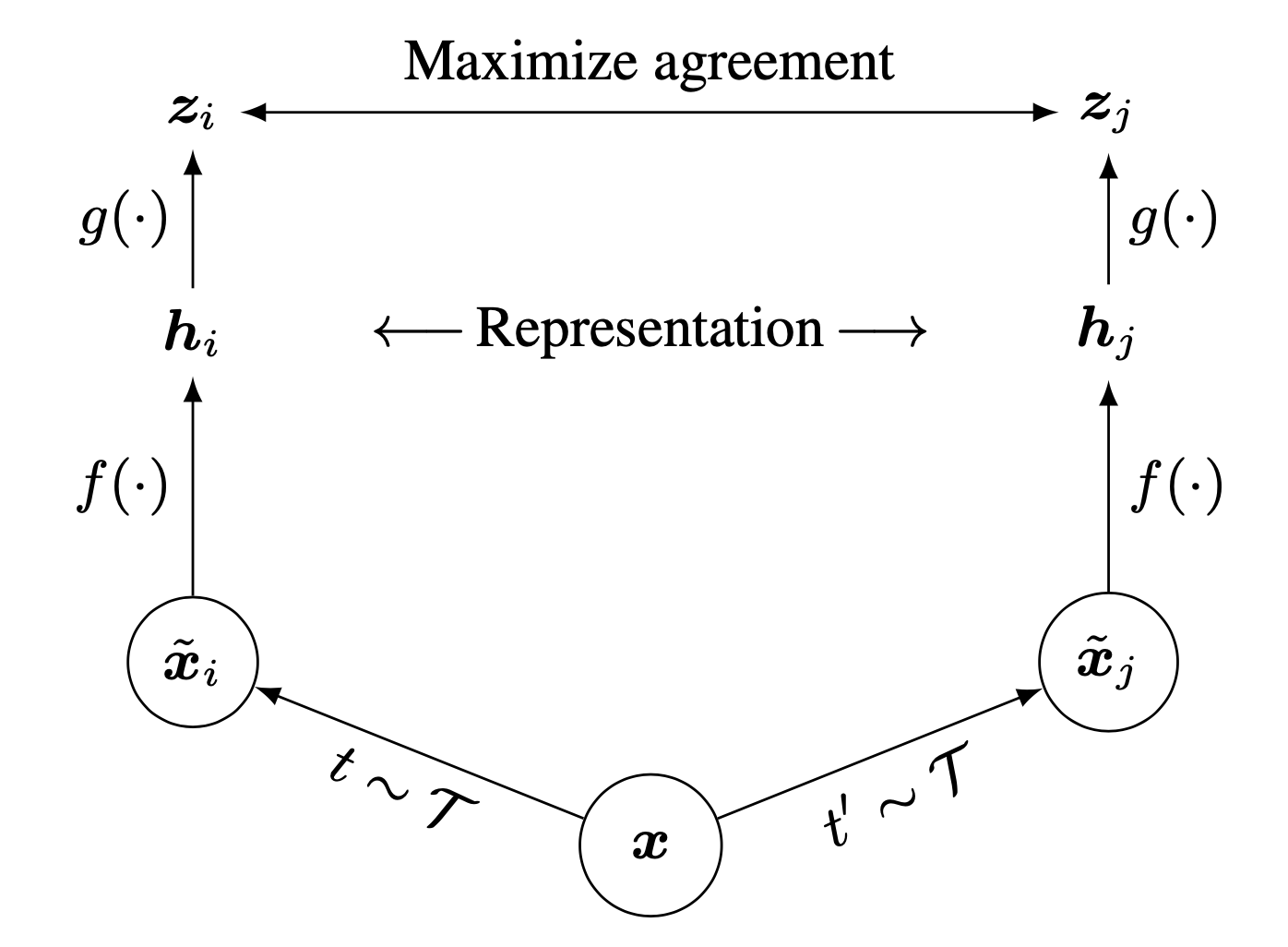 Fig. Main Figure of SimCLR. 어떤 Image Sample 은 Augmentation 이 되어도 여전히 같은 Image Class 로 분류되어야 하므로, 이 둘의 Representation 을 similar 하게 만드는 방향으로 학습이 된다.
Fig. Main Figure of SimCLR. 어떤 Image Sample 은 Augmentation 이 되어도 여전히 같은 Image Class 로 분류되어야 하므로, 이 둘의 Representation 을 similar 하게 만드는 방향으로 학습이 된다.
이를 수식으로 쓰면 아래와 같은데요,
\[L_{ctr} (i,j) = - \log \frac{ \exp ( sim(z_i,z_j) / \tau ) }{ \sum_{k=1}^{2N} 1_{[k \neq i]} \exp ( sim(z_i,z_k) / \tau )}\]이 때 \(z\) 는 Model 의 최종 output 으로 확률 분포로 normalize 되기 전의 logit 값 입니다.
그리고 \(sim( \cdot )\) 은 두 vector 간의 similarity 값으로 주로 cosine similarity 를 사용하며, \(\tau\) 는 temperature 로 클수록 확률 분포의 entropy 를 줄이는 factor 입니다.
수식의 의미를 보면 원본 instance 를 서로 다른 방식으로 변형시킨 instance 들을 Model에 넣어 나온 vector 들끼리 서로 비슷한 출력을 내도록 한다 가 되는데요,
사실 이는 분류문제를 풀 때 사용되는 Cross Entropy (CE)와 크게 다르지 않습니다.
일반적으로 CE Loss 를 쓸 때는 어떤 instance x 와 이에 대한 정답 label 이 주어지는데요, 이 때 정답 label 은 one hot vector 가 사용되죠. 이는 즉 어떤 class에 해당하는 class vector 와 x 를 입력으로 했을 때 model 의 output vector 가 비슷해지도록 하게끔 강요하는 것이 되는데요, 다시 말해 두 vector 들을 dot product 를 계산해서 이를 높히는 방향으로 학습하는 것입니다.
즉 CE 는 아래의 Softmax 를 사용해서 먼저 확률 분포에 맞게 normalize 를 해준 뒤에
\[\begin{aligned} & Softmax (z) = \frac{ \exp (z) }{ \sum_{j \neq i}^{K} \exp (z_j) } & \\ \end{aligned}\]만약 이 Sample 의 정답이 2번재 class 였다면 아래처럼 정답 class 가 되는 겁니다.
\[\begin{aligned} & L_{CE} = - \log Softmax(z) \cdot \color{red}{label} \text{, where } (label = [0, 1, 0, \cdots, 0]) \\ & = - \log \frac{ \exp (z) }{ \sum_{j \neq i}^K \exp (z_j) } \cdot \color{red}{label} \text{, where } (label = [0, 1, 0, \cdots, 0]) & \\ \end{aligned}\]Contrastive Loss 는 label 이 없는 경우에 쓴다고 했는데, label 이 없으므로 마땅히 주어진 class vector 가 없는 상황에서 자기 자신을 변형해서 모델에 넣은것들을 서로가 자기 자신 (self) 을 정답 vector 로 써서 서로 끌어당긴다가 되는 것이므로 사실상 CE Loss 와 크게 다르지 않은 일을 한다고 볼 수 있습니다.
이제 구현체를 살펴보려고 하는데요, PyTorch 공식 문서의 Loss 항목 을 보면 CE Loss 를 포함해 여러 Class 들이 있으나 Contrastive Loss 는 찾아볼 수가 없습니다.
그래서 open source 들을 참고해 어떻게 이를 직접 구현해야 하는지에 대해 알아보려고 합니다.
Some Details and Pesudo Code of SimCLR
우선 Contrastive Loss 를 사용해서 효과적으로 Representation 을 학습한 SimCLR 를 구현해볼 겁니다.
 Fig. 구현하고자 하는 Pseudo Code
Fig. 구현하고자 하는 Pseudo Code
위의 알고리즘이 어떻게 작동하는지 일러스트로 보고 구현체를 살펴봅시다. (link 참고)
먼저 어떤 input instance 에 대해서 서로 다른 Aumgentation Policy 를 통해 원본 이미지를 변환해줍니다.
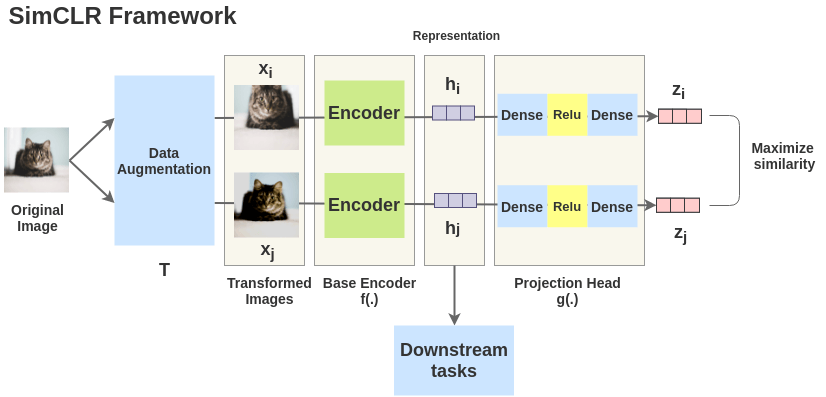
위의 그림에서 고양이 사진은 뒤집어져도, 확대해도 고양이 이기 때문에 두 logit 의 similarity 를 높히는게 (같은 class로 묶이게) 목적입니다.
그러기 위해서는 Pseudo code 에서 pairwise similarity 를 구하는 것 처럼 모든 batch sample N개 에 대해서 augmentation 을 2개씩 한 2N 개의 logit 을 구해서 각각의 cosine similarity 를 구해야 합니다.
이 때 similarity 는 pseudo code 처럼 cosine similarity 를 씁니다.
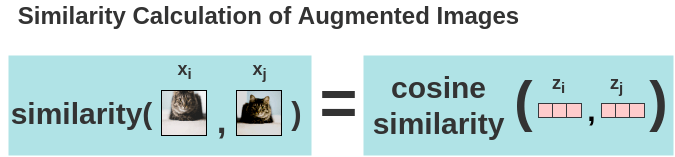
이렇게 모든 instance 들에 대해 similarity \(s_{i,j}\) 를 구하면 아래와 같은 similarity map 을 얻을 수 있습니다.

우리의 목표는 고양이끼리, 코끼리 끼리는 similarity 를 높게 하고, 고양이 <-> 코끼리 간에는 멀어지게 하는겁니다.
즉 위의 map 에서 diagonality 를 높히면 됩니다.
이 그림에서 첫 row 만 봅시다. (similarity 맵을 이렇게 2N * 2N 으로 생각해도 되고 아니면 N * N 으로만 생각해도 됩니다. 이해를 돕기 위해 2N * 2N 으로 생각하겠습니다.)

첫 row 를 봤을 때 당연히 첫 번째 element 인 자기 자신간의 cosine similarity 는 1입니다. 목적은 나머지 3개에 대해 계산해서 고양이 끼리만 확률을 높히는건데요, 이는 아래처럼 계산하면 되겠습니다.
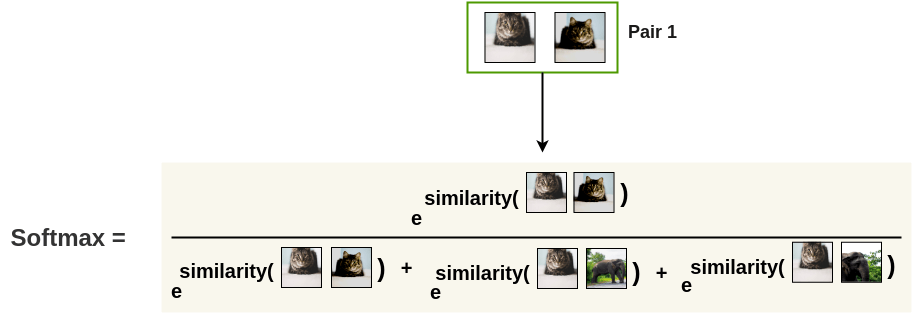
softmax 를 취했으니 기준이 되는 고양이와 나머지 세개의 instance 간의 유사도는 합이 1인 확률 분포가 됩니다. 같은 고양이에 대한 similarity 를 1에 가깝게 만드는 것은 cross entropy loss 가 정답에 대한 logit element 를 maximize` 하는 것과 같다고 생각하시면 됩니다.
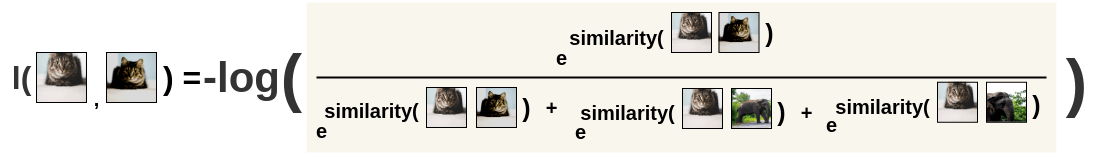
이걸 뒤집어서 한번 더 하시면 고양이 끼리에 대한 loss 계산이 끝납니다.


이제 이를 코끼리에 대해서도 해야겠죠?
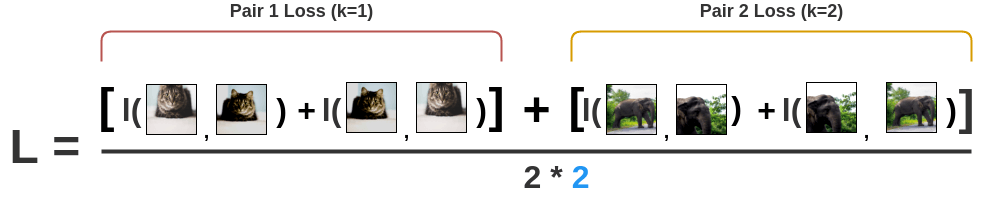
그러면 최종적인 loss 계산이 끝납니다.
Implementation
이제 SimCLR, Contrastive Loss 의 구현체를 살펴보죠. 이 Post 의 Reference 부분을 보시면 Contrastive Loss 를 구현하는 방법이 다양하지만 가장 직관적이고 간단한 버전을 준비해 봤습니다.
import torch
import torch.nn.functional as F
def compute_contrastive(input1, input2, temperature = 0.1):
b, _ = input1.size() # B, C
logits = F.cosine_similarity(
input1.float().unsqueeze(0), # 1, B, C
input2.float().unsqueeze(1), # B, 1, C
dim=-1
).type_as(input1)
logits /= temperature
target = torch.arange(b, device=input1.device)
loss = F.cross_entropy(logits, target, reduction="sum")
return loss
먼저 전체 batch 에 대해서 각각 따로 augmentation 를 해준 뒤에 나온 model output 들끼리 서로 cosine similarity 를 구해줍니다.
batch x channel 의 B, C 차원이므로 similarity map 이 B, B로 나올겁니다.
그 뒤에 temperature smoothing 을 해줄건지 정하고
target 에 대해서 cross entropy 를 계산해주면 됩니다.
이를 toy data에 대해서 forwarding 을 해봅시다.
device = "cuda" if torch.cuda.is_available() else "cpu"
input1 = torch.rand([4, 512]).to(device)
input2 = torch.rand([4, 512]).to(device)
def compute_contrastive(input1, input2, temperature = 0.1):
b, _ = input1.size # B, C
logits = F.cosine_similarity(
input1.float().unsqueeze(0), # 1, B, C
input2.float().unsqueeze(1), # B, 1, C
dim=-1
).type_as(input1)
logits /= temperature
target = torch.arange(b, device=input1.device)
print('logits : {}'.format(logits))
print('logits.size() : {}'.format(logits.size()))
print('target : {}'.format(target))
loss = F.cross_entropy(logits, target, reduction="sum")
return loss
(Pdb) compute_contrastive(input1, input2)
logits : tensor([[0.7441, 0.7224, 0.7438, 0.7262],
[0.7635, 0.7857, 0.7697, 0.7523],
[0.7574, 0.7301, 0.7583, 0.7455],
[0.7553, 0.7233, 0.7352, 0.7468]], device='cuda:0')
logits.size() : torch.Size([4, 4])
target : tensor([0, 1, 2, 3], device='cuda:0')
tensor(5.5004, device='cuda:0')
Torch의 cross entropy function 은 원래 target F.cross_entropy(logits, target) 에서 target 이 class label 에 대한 index 라면 그 batch instance 의 해당 label index 의 부분만 maximize 하는 방식이기 때문에 target 이 [0, 1, 2, 3] 면 diagonal 부분만 최대화 하는 것이기 때문에 우리가 원하는 바를 정확히 달성할 수 있는거죠.
좀더 구현체를 살펴보면 (link 참고) 아래처럼 되어있는데,
def forward(self, x):
b, c, h, w, device = *x.shape, x.device
transform_fn = self.augment if self.augment_both else noop
query_encoder = self.net
queries = query_encoder(transform_fn(x))
key_encoder = self.net if not self.use_momentum else self._get_key_encoder()
keys = key_encoder(self.augment(x))
if self.use_momentum:
keys = keys.detach()
queries, keys = map(flatten, (queries, keys))
project_fn = self._get_projection_fn(queries) if self.project_hidden else identity
queries, keys = map(project_fn, (queries, keys))
contrastive_loss(queries, keys)
def flatten(t):
return t.reshape(t.shape[0], -1)
Notation을 보시면 원래 instance 의 representation vector 들을 queries 라고 하고,
augmented input 에 대한 representation vector 들을 keys 라고 합니다.
원래는 한 instance 를 서로 다른 augmentation 을 취한 뒤에 계산해야 되는데 optional하게 구현이 되어 있습니다.
위의 코드에서 self.net 은 기본적으로는 ResNet 이 되겠습니다.
(그리고 Momentum 이 궁금하신 분들은 lucidrain 이 MoCo 에서 가져온 것 같으니 확인해 보시길 바랍니다.)
Chimera (for Speech Translation)
여기에 추가적으로 Speech Domain 에서 Contastive Loss 를 사용한 case 에 대해 알아보려고 합니다. Chimera 라는 논문에서 제안된 method 인데요, model output dimension 이 SimCLR 과는 좀 다른 부분이 있어 살펴보려고 합니다. 논문의 목적은 서로 다른 modality 의 representation 을 같은 공간에 mapping 시키는 것인데요, 자세한 사항은 논문을 읽어보시길 추천드리지만 몇 가지 핵심만 말씀드리자면
- Speech, Text 의 Representation 은
batch * time * channel으로B, T, C이다. - Speech, Text 는 같은 의미의 Sequence 여도 길이 (time, temporal resolution) 이 다르다.
- ex) Speech :
[4, 320, 768] - Text :
[4, 50, 768]
- ex) Speech :
- 이를 맞추기 위해서 Memory Query 라는 Learnable Embedding 을 두고 이를 Multi Head Self-Attention (MHSA) 의 Query (Q) 로, 각 modality 의 representation 을 Key (K), Value (V) 로 사용해 Attention 해서
고정된 길이 (fixed length) 의 tensor 로 projection시켜서 사용합니다.- ex)
[4, 64(fixed), 512]
- ex)
- 각 Modality 의 같은 위치의 vector 를 같은 pair 로 보고 similarity 를 maximize 한다.
입니다.
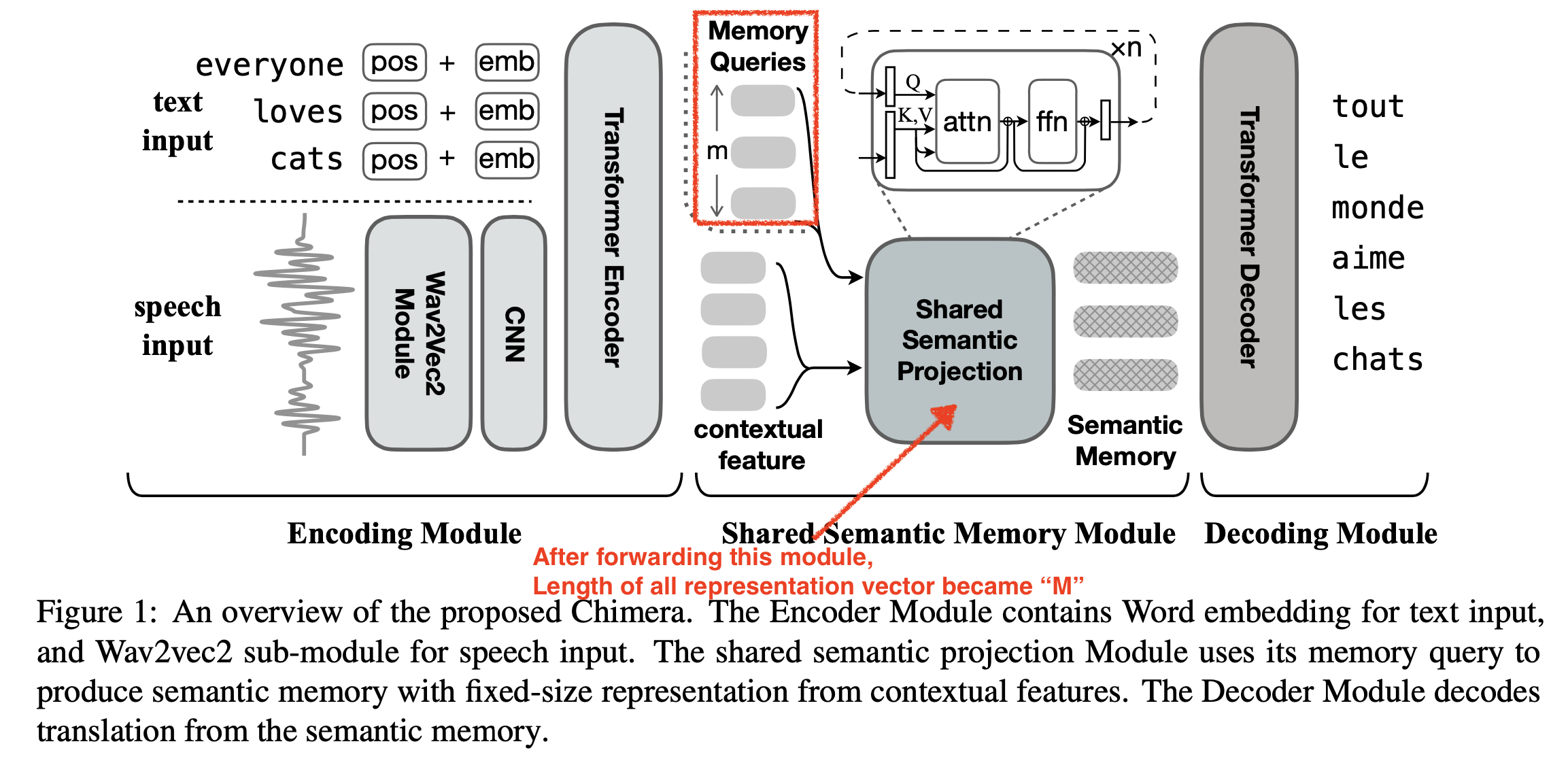 Fig.
Fig.
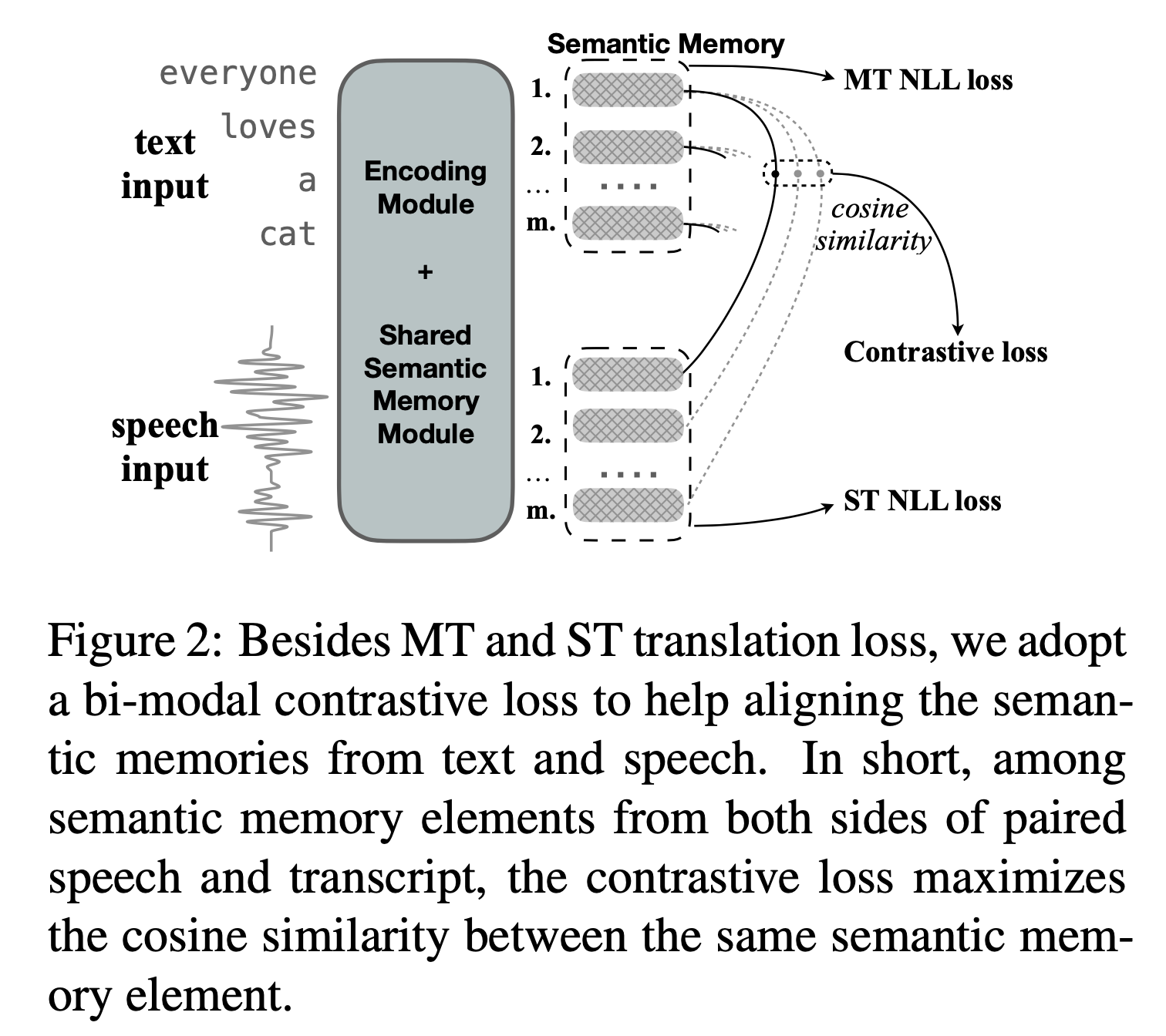 Fig.
Fig.
아까 Computer Vision 의 SimCLR 의 경우, B, C 2차원 이었습니다만 지금은 B, T, C가 됐습니다.
이제 각 speech, text modality 의 batch pair 별로 각 time dim 만큼의 feature frame 들을 뽑고 이들끼리 pairwise similarity 를 재서 maximize 하면 됩니다.
Implementation
구현은 다음과 같이 하시면 됩니다.
최종 Model output 의 shape 이 B, T, C 이기 때문에
- B, T,
1, C - B,
1, T, C
로 unsqueeze 하고 이들 사이의 cosine similarity 를 계산하면 됩니다.
def compute_contrastive(
input1: torch.Tensor,
input2: torch.Tensor,
contrastive_temp: float = 1.0
):
assert input1.shape == input2.shape
batch_size, seqlen, _ = input1.shape
logits = F.cosine_similarity(
input1.float().unsqueeze(2), # B, T, 1, C
input2.float().unsqueeze(1), # B, 1, T, C
dim=-1
).type_as(input1)
logits /= contrastive_temp
target = torch.arange(seqlen)[None].repeat(batch_size, 1).to(logits.device)
print('logits.size() : {}'.format(logits.size()))
print('target.size() : {}'.format(target.size()))
print('target : {}'.format(target))
loss = F.cross_entropy(logits, target, reduction='sum')
return loss
toy data 를 feeding 해봅시다.
device = "cuda" if torch.cuda.is_available() else "cpu"
input1 = torch.rand([4, 64, 512]).to(device)
input2 = torch.rand([4, 64, 512]).to(device)
(Pdb) compute_contrastive(input1, input2)
logits.size() : torch.Size([4, 64, 64])
target.size() : torch.Size([4, 64])
target : tensor([[ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17,
18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35,
36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53,
54, 55, 56, 57, 58, 59, 60, 61, 62, 63],
[ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17,
18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35,
36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53,
54, 55, 56, 57, 58, 59, 60, 61, 62, 63],
[ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17,
18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35,
36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53,
54, 55, 56, 57, 58, 59, 60, 61, 62, 63],
[ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17,
18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35,
36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53,
54, 55, 56, 57, 58, 59, 60, 61, 62, 63]], device='cuda:0')
tensor(1064.6624, device='cuda:0')
target tensor 를 보시면 알 수 있듯 batch 별로 time dim 에 대해 similarity map 이 생겼으므로 이 loss 를 최소화 하면 되겠습니다.
References
- A Simple Framework for Contrastive Learning of Visual Representations
- SimCLR slides from Google Brain
- The Illustrated SimCLR Framework from Amit Chaudhary
- Chimera-ST/blob/main/fairseq/criterions/triplet_st_mt_contrastive.py
- Self-supervised learning tutorial: Implementing SimCLR with pytorch lightning from AI Summer School
- lucidrains/contrastive-learner
- TUTORIAL 13: SELF-SUPERVISED CONTRASTIVE LEARNING WITH SIMCLR
- sthalles/SimCLR
- SimCLR Code Review from 스님’s blog