(WIP) Rethinking Weight Decay and LLM without Bias Term
06 Feb 2024< 목차 >
- Motivation
- L2 Regulairzation vs Bias Term
- L2 Regulairzation vs LayerNorm
- Transformer using Linear Layer without bias term
- References
Motivation
Transformer 구현체들을 보면 Deep Neural Network (DNN)의 특정 layer에는 weight decay를 적용하지 않는 구현을 종종 발견할 수 있다.
아래는 DeepSpeedExample의 RLHF를 위한 training code 일부인데,
optimizer에 parameter list를 넣어주고 parameter별로 weight decay, lr를 설정할 때 분기가 세 개로 나뉘는 걸 알 수 있다.
LoRA에 대해서 lr을 크게주는 것은 이 post의 주된 내용이 아니 거르도록 하고,
중요한 점은 bias, layernorm (혹은 batchnorm)에 대해서는 0.0의 weight decay를 준다는 것이다.
def get_optimizer_grouped_parameters(
model,
weight_decay,
lora_lr=5e-4,
no_decay_name_list=[
"bias",
"layer_norm.weight", "layernorm.weight",
"norm.weight", "ln_f.weight",
],
lora_name_list=["lora_right_weight", "lora_left_weight"],
):
optimizer_grouped_parameters = [
{
"params": [
p for n, p in model.named_parameters()
if (not any(nd in n.lower() for nd in no_decay_name_list)
and p.requires_grad and not any(nd in n.lower() for nd in lora_name_list))
],
"weight_decay":
weight_decay,
},
{
"params": [
p for n, p in model.named_parameters()
if (not any(nd in n.lower() for nd in no_decay_name_list)
and p.requires_grad and any(nd in n.lower() for nd in lora_name_list))
],
"weight_decay":
weight_decay,
"lr":
lora_lr
},
{
"params": [
p for n, p in model.named_parameters()
if (any(nd in n.lower()
for nd in no_decay_name_list) and p.requires_grad)
],
"weight_decay":
0.0,
},
]
non_empty_groups = []
for group in optimizer_grouped_parameters:
if group["params"]:
non_empty_groups.append(group)
return non_empty_groups
def get_optimizer(model, args)
# Split weights in two groups, one with weight decay and the other not.
optimizer_grouped_parameters = get_optimizer_grouped_parameters(
model, args.weight_decay, args.lora_learning_rate)
AdamOptimizer = DeepSpeedCPUAdam if args.offload else FusedAdam
optimizer = AdamOptimizer(optimizer_grouped_parameters,
lr=args.learning_rate,
betas=(0.9, 0.95))
retrun optimizer
왜 이럴까?
Googling을 하면 가장 먼저 발견하게 되는 근거는 바로 Google의 BERT 구현체가 이렇게 했기 때문이다. 몇몇 stackoverflow 등의 forum에 달린 답변을 보면 ‘명확한 근거는 없다. 단지 google의 선례가 있을 뿐’이라고 얘기한다. 또 하나의 근거는 Andrejy Karpathy의 minGPT에 달린 comment이다. 어떤 user가 ‘왜 bias, normalization layer에 no decay를 하는거죠?’라는 질문에 대한 답변으로 Karpathy는 아래와 같이 답변한다.
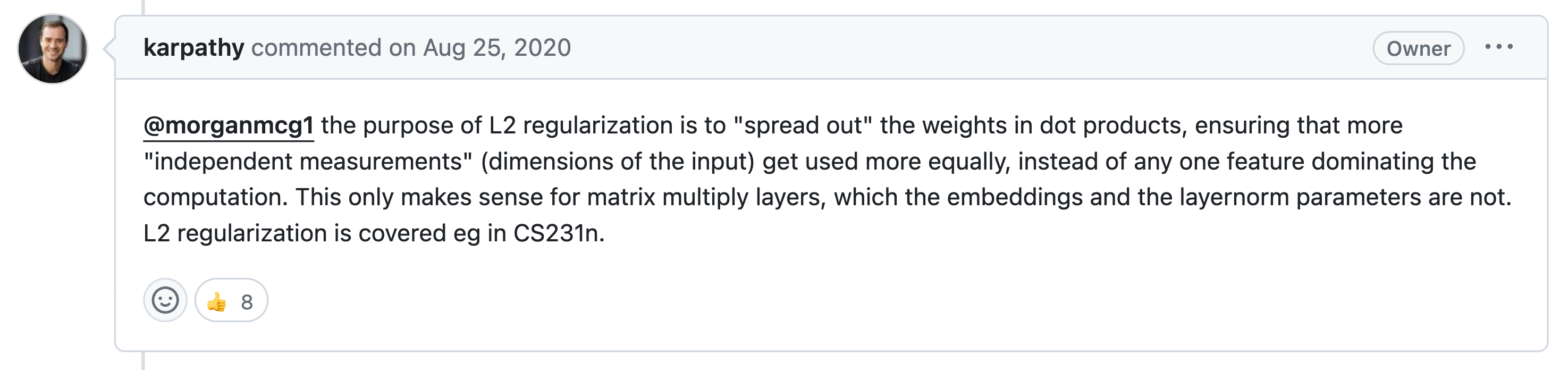 Fig.
Fig.
L2 regularization의 목적은 dot product의 weight을 분산시켜 어떤 하나의 feature가 모든 computation을 dominating하는걸 방지하기 위해 사요ㅕㅇ되는데, 이는 matrix multiplication을 수행하는 layer들에만 해당되는 내용이지 bias나 layernorm에는 해당이 안된다는 것이다.
직관적으로 bias에 L2 regularization을 적용한다고 치자. 그러면 bias는 0에 가까운 값을 가지도록 계속해서 penalty를 받을 것이다. 즉 각 hidden layer가 만드는 decision boundary가 모두 0부근에서 만들어지게 된다.
그다음으로 batchnorm이나 layernorm에 L2 regularization을 적용한다고 생각해보자. Layer의 output을 normalization 하는 것은 tensor를 zero centered가 되도록 rescaling하여 gradient가 수월하게 전파되게 하는 역할을 한다.
\[LN(x) = \frac{x- \mathbb{E}[x]}{\sqrt{ Var[x] + \epsilon}} \ast \gamma + \beta\]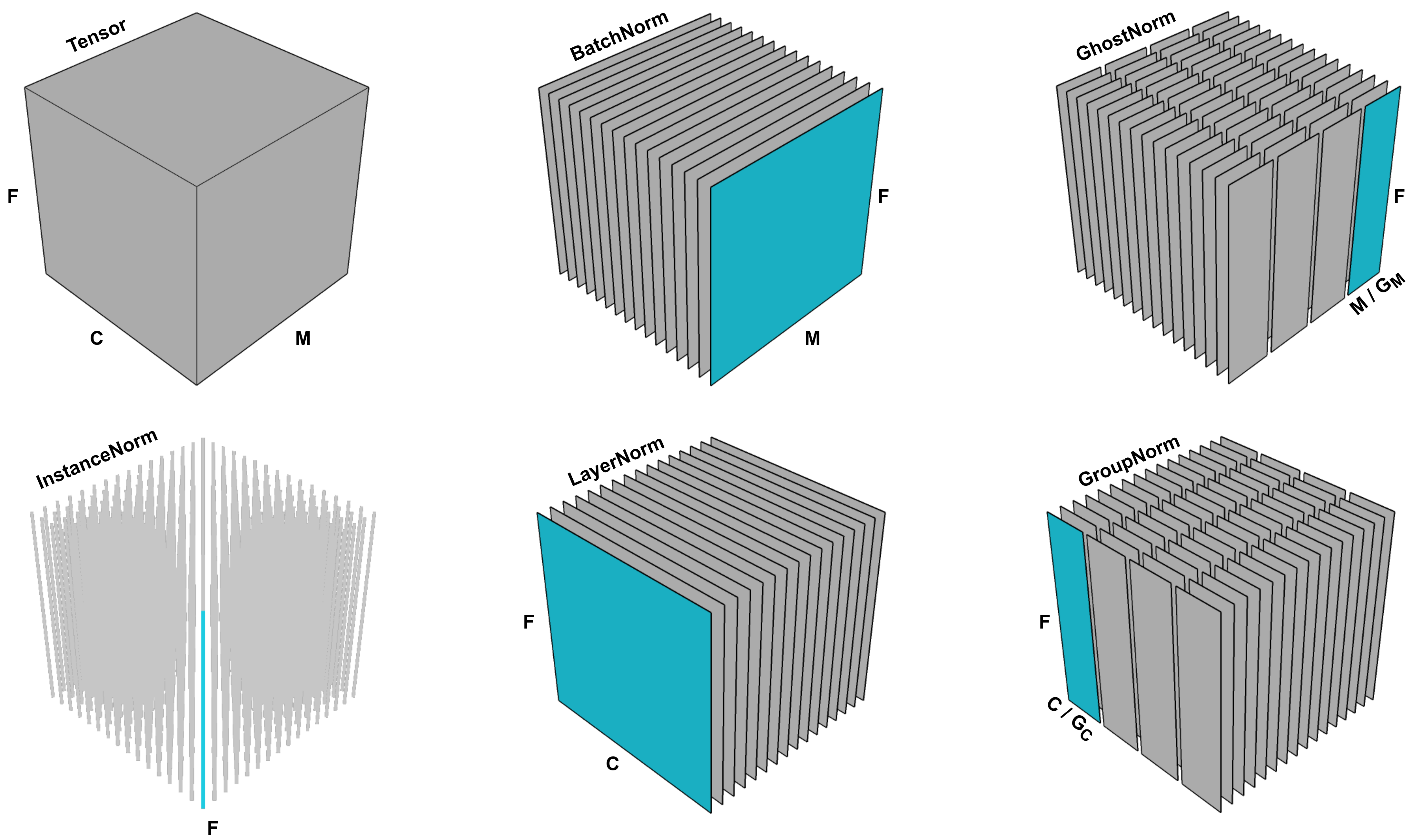 Fig. All Noramlization Layers for Computer Vision. Source from here
Fig. All Noramlization Layers for Computer Vision. Source from here
 Fig. Layer norm for Sequence Modeling (left). Source from here
Fig. Layer norm for Sequence Modeling (left). Source from here
L2 Regulairzation vs Bias Term
L2 Regulairzation vs LayerNorm
Revisit LayerNorm and It's Intuition
Transformer using Linear Layer without bias term
그런데 요즘 Large Language Model (LLM)들은 bias가 아예 없는 경우가 많다. 아래는 llama 구현체인데, bias가 아예 없이 modeling됐다는 것은 bias term이 0에 가까워지는 것 보다 더한 것이다. bias에 wegith decay를 하면 안된다고 했는데 어떻게 이게 가능한 것일까?
class Attention(nn.Module):
"""Multi-head attention module."""
def __init__(self, args: ModelArgs):
...
self.wq = ColumnParallelLinear(
args.dim,
args.n_heads * self.head_dim,
bias=False,
gather_output=False,
init_method=lambda x: x,
)
self.wk = ColumnParallelLinear(
args.dim,
self.n_kv_heads * self.head_dim,
bias=False,
gather_output=False,
init_method=lambda x: x,
)
self.wv = ColumnParallelLinear(
args.dim,
self.n_kv_heads * self.head_dim,
bias=False,
gather_output=False,
init_method=lambda x: x,
)
self.wo = RowParallelLinear(
args.n_heads * self.head_dim,
args.dim,
bias=False,
input_is_parallel=True,
init_method=lambda x: x,
)
...
class FeedForward(nn.Module):
def __init__(
self,
dim: int,
hidden_dim: int,
multiple_of: int,
ffn_dim_multiplier: Optional[float],
):
...
self.w1 = ColumnParallelLinear(
dim, hidden_dim, bias=False, gather_output=False, init_method=lambda x: x
)
self.w2 = RowParallelLinear(
hidden_dim, dim, bias=False, input_is_parallel=True, init_method=lambda x: x
)
self.w3 = ColumnParallelLinear(
dim, hidden_dim, bias=False, gather_output=False, init_method=lambda x: x
)
...
Bias가 없다는 것은 기본적으로 linear regression을 한다고 할 때 절편이 없는 것이라고 생각할 수 있겠다. 예를 들어 data point들이 sampling된 function이 \(y=3x+10\)이라고 생각해 보자. 이 경우 bias term없이 slope term만으로는 어떻게해도 완벽하게 true function을 fitting할 수 없을 것이다. 하지만 DNN은 이런 layer가 매우 깊게 쌓여있기 때문에 가능할 수도 있을 것 같다.
사실 recent LLM들에 bias term이 왜 없는지에 대한 근거를 제대로 찾을 수는 없었다.
다만 google의 PaLM, alibaba group의 Qwen 등에서 training instability를 줄이기 위한 결정이었다는 문구를 찾을 수 있었다.
 Fig. from PaLM
Fig. from PaLM
 Fig. from Qwen
Fig. from Qwen
이것도 마찬가지로 BERT를 학습할 때 layernorm, bias에 L2 regularization을 걸어주지 않는 것 처럼 이론적 근거는 없지만, 생각해본 결과 google을 포함한 많은 group이 pre-training 시 loss가 터지는 것을 막기 위해 lower precision 중에서도 bf16 format을 쓰기 때문에 그런 것 같다. 왜냐하면 bf16은 fp32와 같은 dynamic range 를 표현할 수 있는 대신에 정밀도를 어느정도 포기한 format인데, 값이 커질수록 정밀도 차이가 야기하는 손해가 클 것인데 표현 가능한 범위가 모든 실수에 해당되는 bias가 크게 학습되어 더해지면 손실이 더 커지기 때문이다. 근데 이것이 사실이라면 bias가 커지지못하도록 regularization을 거는 것이 왜 안된다는걸까…? 좀 더 생각을 해봐야 할 것 같다.
References
- Papers
- Others (Blogs)
- Weight decay exclusions from minGPT issues
- Why not perform weight decay on layernorm/embedding?
- Exploring Weight Decay in Layer Normalization: Challenges and a Reparameterization Solution from Ohad Rubin
- When should you not use the bias in a layer?
- L2 Regularization versus Batch and Weight Normalization
- L2 Regularization and Batch Norm
- Codes