Course Overview of CSC2541 (Topics in ML - Neural Net Training Dynamics)
01 Jan 2024< 목차 >
What's This?
본 post는 University of Toronto의 Associate Professor인 Roger Grosse의 lecture, Neural Net Training Dynamics에 대한 것이다. 새해 부터 재밌어 보이는 주제인 것 같아 syllabus나 introduction을 조금 살펴봤다. Lecturer는 뭘 하는 사람인가?
 Fig. Me?
Fig. Me?
Roger Grosse는 2014년에 MIT에서 Phd를 받고 현재 토론토대에서 교수로 재직중이며 Vector Institute의 founding member이자 Antrophic의 alignment team의 technical staff member중 한명이라고 한다. 지금까지의 연구 주제는 Neural Network (NN)의 training dynamics를 더 잘 이해하고 이를 바탕으로 training speed, generalization, automatic hyperparameter tuning등을 하는 것이었고, 지금은 Antrophic에서 이 연구들을 Reinforcement Learning from Human Feedback (RLHF)같은 alignment learning에 적용하는 일을 하는 것 같다. 지금의 main interests는 다음과 같다고 한다.
- AI system이 놀라운 (이상한) 행동을 했을 때 어떤 training example이 이에 기여했는지 밝혀낼 수 있을까?
- 언제 NN은 mesa-optimizers를 배울 수 있게 될까?
- 어떻게 완전히 신뢰할 수 없는 model로부터 신뢰할 만한 정보 (reliable information)를 뽑아낼 (elicit) 수 있을까?
Mesa-optimizer 같은 개념은 처음 들어보기에 잘 와닿지 않지만 이 사람은 human alignemd LLM을 만들고 분석하는 일을 하는 사람이고, 이 lecture (혹은 이분이 쓴 유사한 내용의 textbook)을 읽는것이 alignment learning이나 AI의 safety를 이해하는데 도움이 될 것이라고 했다는 것이다.
그래서 본 lecture에서 어떤 개념들에 대해 얘기하는지에 대해 알아보려고 했다. 각 chapter의 title들은 다음과 같은데, 언뜻 보기에는 optimization class같다는 생각이 들었다. Talyer approximation, second-order optimization, AdamW 등에 대해서 얘기하니 말이다.
- Chapter titles
- (1) A Toy Model: Linear Regression
- (2) Taylor Approximations
- (3) Metrics
- (4) Second-Order Optimization
- (5) Adaptive Gradient Methods, Normalization, and Weight Decay
- (6) Infinite Limits and Overparameterization
- (7) Stochastic Optimization and Scaling
- (8) Implicit Regularization and Bayesian Inference
- (9) Dynamical Systems and Momentum
- (10) Differentiable Games
- (11) Bilevel Optimization I
- (12) Bilevel Optimization II
그런데 lecturer는 이 class는 optimization class은 아니라고 한다. Optimization class들은 주어진 문제 상황에서 loss를 minimize 하는 solution을 제공하는 것이지, 어떻게 NN이 학습되는지?에 대한 얘기가 아니기 때문이다. 다만 optimization domain의 idea를 활용할 뿐이라고 한다.
Overview
이제 Lecture page에 있는 Overview를 제대로 읽어보자.
지난 10년 동안 NN은 시각, 언어 이해, 의학, 로봇공학, 게임 플레이 등 다양한 분야에서 놀라운 결과를 달성했다. 아마 누군가는 이러한 성공을 이룩하기 위해서는 이론적으로 존재한다고 여겨졌던 상당한 장애물을 극복해야 할 것으로 예상했을 것이다.
 Fig. Traditional issues for training NN.
Fig. Traditional issues for training NN.
아니 NN의 Optimization landscape는 non-convex하고, 매우 nonlinear하며, high-dimensional한데 대체 어떻게 이런 NN을 훈련이 되는걸까? 대부분의 경우 이런 NN model들은 data를 암기 (memorize)할 정도로 충분히 많은 parameter를 가지고 있는데 (이를 overparameterize라고 함), 그럼에도 불구하고 왜 일반화 (generalization)이 잘 되는걸까? 이러한 주제들은 실제 working하는 model들보다 더 단순한 model (simpler model)에 한해 ML comunity의 관심을 끌었지만, comunity의 태도는 일단 training하고 나중에 파헤쳐보자 였다 (train first and ask questions later). 분명히 이 접근법은 효과가 있었다.
 Fig. Empricial Deep Learning. Engineering같던 AI가 이제는 Reverse-Engineering이 되었다. 이미 잘 training돼서 working하는 model을 역으로 분석하는 것이다.
Fig. Empricial Deep Learning. Engineering같던 AI가 이제는 Reverse-Engineering이 되었다. 이미 잘 training돼서 working하는 model을 역으로 분석하는 것이다.
결과적으로 NN의 practical success는 우리가 그것들이 어떻게 작동하는지 이해하는 능력을 뛰어넘었다 (왜 잘되는지?에 대한 연구가 실사용 성능을 따라가지 못해 도태된 것). 이 class는 NN이 training될 때 도대체 무슨 일이 일어나는지?를 이해하기 위한 개념적 도구 (conceptual tools)를 개발하는 것에 관한 것이다. 일부 idea들은 수십 년 전에 확립되었으며 (그리고 compunity의 많은 사람들에 의해 잊혀졌을 수도 있음), 다른 것들은 오늘날에 이르러서야 이해되기 시작했다. 나는 (lecturer는) 비록 불완전할지라도 우리의 최신 이해 (model understanding)를 전달하려고 할 것이다.
이 class는 optimization에서 idea를 끌어오지만, optimization class는 아니다. 우선, optimization 연구는 optimization problem에 대한 정보와 특정 규범 (particular norm)에서의 빠른 수렴 (fast convergence)과 같은 잘 정의된 목표에서 시작하여 이를 달성할 수 있는 계획을 알아내는 규범적 (perspective)인 경우가 많다. Modern NN의 경우 분석은 종종 기술적 (descriptive)인데, 다시 말해서 이미 사용하고 있는 (training) procedure를 취하고 그것들이 작동하는 (것처럼 보이는) 이유를 파악하는 등 설명적인 경우가 많다는 것이다. 이러한 이해를 바탕으로 알고리즘을 개선할 수 있기를 바란다. (비꼬는건가?)
최적화 연구와의 또 다른 차이점은 목표가 단순히 유한한 training set에 맞추는 것이 아니라 일반화 (generalization) 한다는 것이다. NN이 엄청난 용량 (enormous capacity)에도 불구하고 generalize하는 이유는 training dynamics와 밀접한 관련이 있다. 따라서, optimization 분야에서 ideafmf 가져올 때는 loss function을 더 빨리 minimize할 수 있는지뿐만 아니라 generalization에 도움이 되는 방식으로 minimize할 수 있는지도 고려해야 한다.
이 class는 ImageNet에서 SOTA를 달성하기 위한 recipe를 제공하는 응용 수업 (practical class)이 아니다. 또한 이론만을 위한 것도 아님. 그보다는 특정 사례 (particular instance)에서 training에 영향을 미치는 factor를 추론하는 데 필요한 tool을 제공하는 것이 목표다.
NN의 training dynamics를 연구하는 또 다른 중요한 이유는 NN이 더 잘 training되도록 하는 것 외에도, 많은 최신 architecture들이 그 자체로 optimization을 수행할 수 있을 만큼 강력하기 때문이다 (앞서 얘기했던 mesa-optimizer 말하는 듯). 이는 MAML이나 Deep Equilibrium Models 에서처럼 architecture에 optimization을 명시적으로 구축하기 때문일 수 있다. 또는 GPT3의 경우처럼 많은 data에 대해 flexible architecture를 train한 결과 놀라운 추론 능력 (reasoning ability)를 발견할 수도 있다. 어느 쪽이든, NN architecture 자체가 무언가를 optimization하고 있다면, outer training procedure는 우리가 좋든 싫든 이 course에서 논의한 문제와 씨름하고 있는 것이다. 이 course에서 제시되는 solution을 조금이라도 이해하려면 problem들을 이해해야할 필요가 있다. 따라서 이 course에서는 지금까지 다룬 내용을 바탕으로 bilevel optimization을 이끌어 내는 것으로 마무리할 것임.
 Fig. 이 class가 정답을 제공해주진 않는다.
Fig. 이 class가 정답을 제공해주진 않는다.
Outro
이 lecture의 goal은 Bilevel Optimization인 것 같다. Bilevel optimization이란 말그대로 두 문제가 중첩되어 있는 상황에서 최적화를 하는 것을 말하는 것 같은데, outer optimization task를 upper-level optimization task라고 부르고 inner optimization task를 주로 lower-level optimization task라고 부른다고 한다. 이게 무슨 말일까? 아래 lecture slide중 일부를 보자.
 Fig.
Fig.
Bilevel optimization이란 inner objective의 optimal solution에 대해 정의된 outer objective를 최적화 하는 것을 말하는데, 여기서 outer variable ,\(\lambda\)의 예시로 learning rate 일커르는 hyperparmeter로 들고 model parameter, \(w\)를 inner variable로 든다. 그리고 이 때 inner objective는 (regularized) training loss가 되고 outer objective는 valid loss가 된다. 수식을 그대로 해석하면 현재 주어진 hyperparameter를 가지고 training loss를 최소화하는 optimal parameter를 가지고 validation loss를 최소화하는 hyperparameter를 찾겠다는 것이다. 두 variable이 서로 종속되어있는 (?) 관계처럼 보이고 해석이 맞는지 모르겠지만, 쉽게말하면 hyperparameter를 찾는것을 자동화하면서 결국 optimal parameter를 찾겠다는 것이다.
 Fig.
Fig.
Bilevel optimization을 통해 궁극적으로 하고싶은 것은 위의 figure의 내용처럼 hyperparameter, optimizer, architecture search 등을 자동화 하는것들인 것 같다. (DARTS: Differentiable Architecture Search나 Self-Tuning Networks: Bilevel Optimization of Hyperparameters using Structured Best-Response Functions같은 paper에 이 내용이 자세히 서술되어 있는 것 같으니 읽어봐도 좋을 것 같다. 그리고 찾아보니 이 내용은 Meta-Learning에도 쓰이는 것 같다.)
 Fig. Rewriting Optimization Problem
Fig. Rewriting Optimization Problem
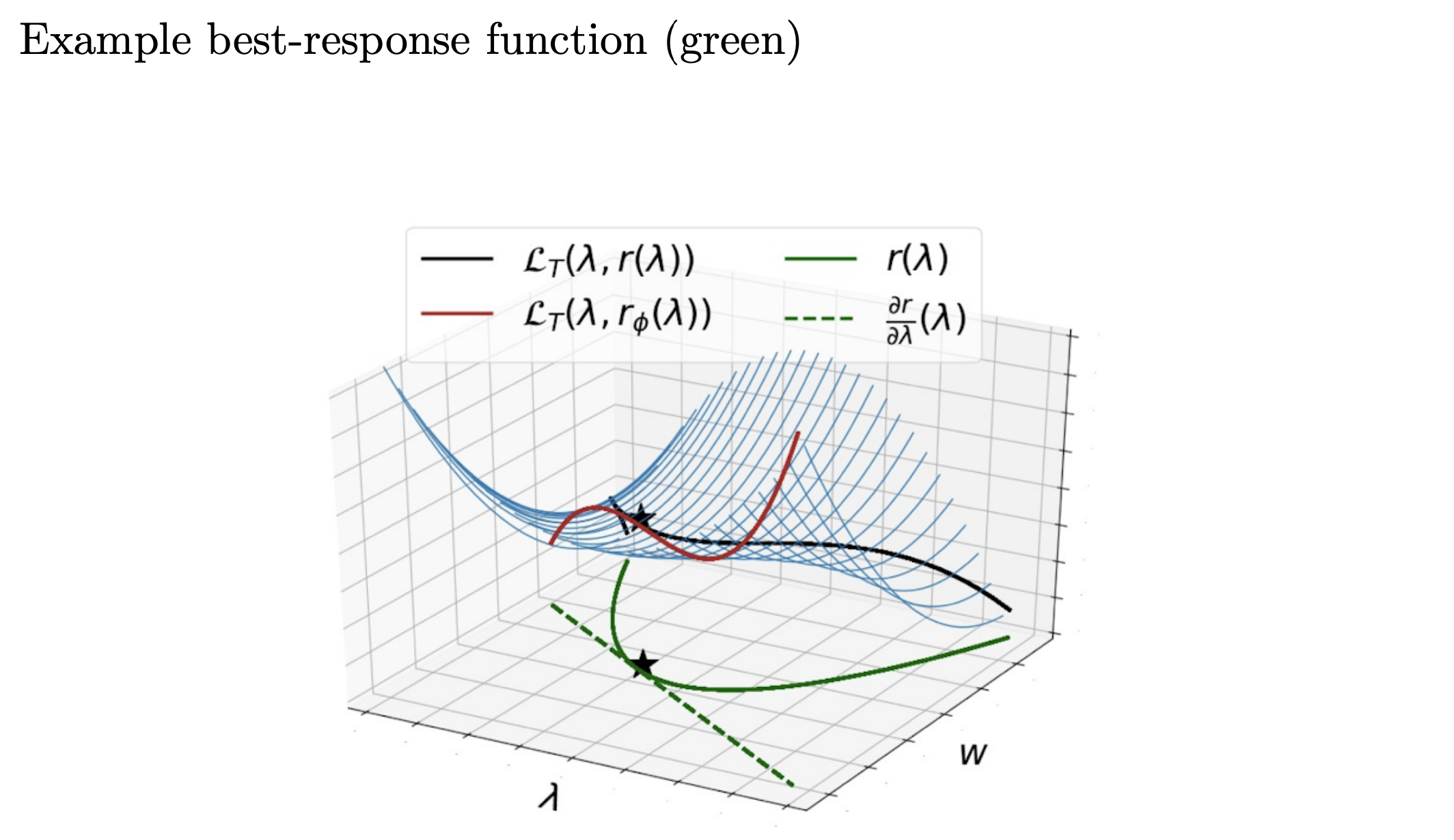 Fig. Example Best-Response Function
Fig. Example Best-Response Function
Mesa-optimizer에 대해서 조금 얘기만 하고 넘어가자면, ML system에서의 mesa-optimizer는 Risks from Learned Optimization in Advanced Machine Learning Systems에서 제안된 것 같다. 좀 더 보기 좋은 paper는 Transformers learn in-context by gradient descent인데, 요즘 핫한 LLM에 관련된 내용이다. In-context learning이라고 알려진 fewshot example을 model forward 하는 것 자체가 사실상 gradient descent 하는것과 같다는 sodyddlek.
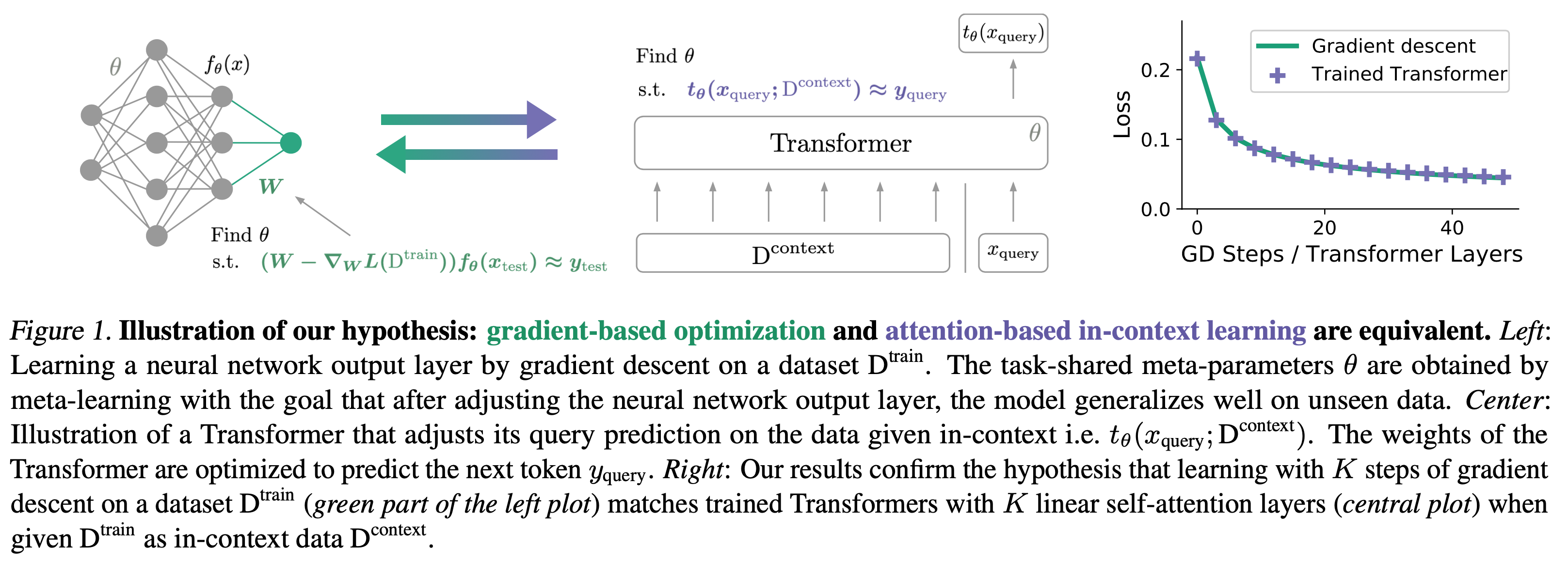
아무튼 이런 저런 재밌어보이는 내용을 다루는 것 같은데, slide들을 보니 class의 내용이 좀 어렵다. Optimization 관련한 내용이 많아서 그런지 수식도 많고…
얼마전에 살펴본 large batch training의 어려움과 sharp minima에 대한 내용들도 보이고, bilevel optimization, mesa-optimization 개념들이 재밌어 보여 더 알아보고 싶지만 제대로 볼 시간을 낼 수 있을지 모르겠다 (주말에 몰아봐야할 듯). 사실 이런 개념들 보다도 어떻게하면 alignment learning에 적용할 수 있다는지 그 내용이 궁금한데 lecture slides에는 일단 없다. 어떻게 lecture를 들으면 insight가 생길지…?는 사실 모르겠다.
아무튼 시간이 되면 lecture의 내용을 풀어 설명하는 시리즈를 연재해보도록 하겠다.