Large Batch Training Difficulties
19 Dec 2023< 목차 >
- Motivation
- Measuring Gradient Noise Scale
- Solution Quality (Generalization Gap)
- Summary
- TBC) Understanding Optimization using Stochastic Differential Equations
- References
Motivation
Deep Learning (DL)을 할 때 large batch size로 training 할 수만 있다면 마다할 사람은 없을거다.
Resource만 된다면 말이다.
우리는 정해진 objective function 에 대해서 non-linear operator가 포함된 거대한 Neural Network (NN) model의 optimal solution을 close-form으로 찾을 수 없기 때문에 gradient descent라는 optimization algorithm을 통해 parameter를 iterative하게 update 하며 optimal solution을 찾아간다.
이 때 우리가 estimate한 gradient는 전체 sample들 중 일부를 사용해서 얻은 것으로 부정확한데 (noisy),
batch size를 키울 경우 이 값이 더욱 정교해진다.
하지만 이럴 경우 한 번에 보는 sample이 많아 그만큼 iteration 수가 줄어들게 되는데,
그렇기 때문에 이를 보상하기 위해서 step size (learning rate; LR)를 적당히 키워 학습하는 것이 일반적이다.
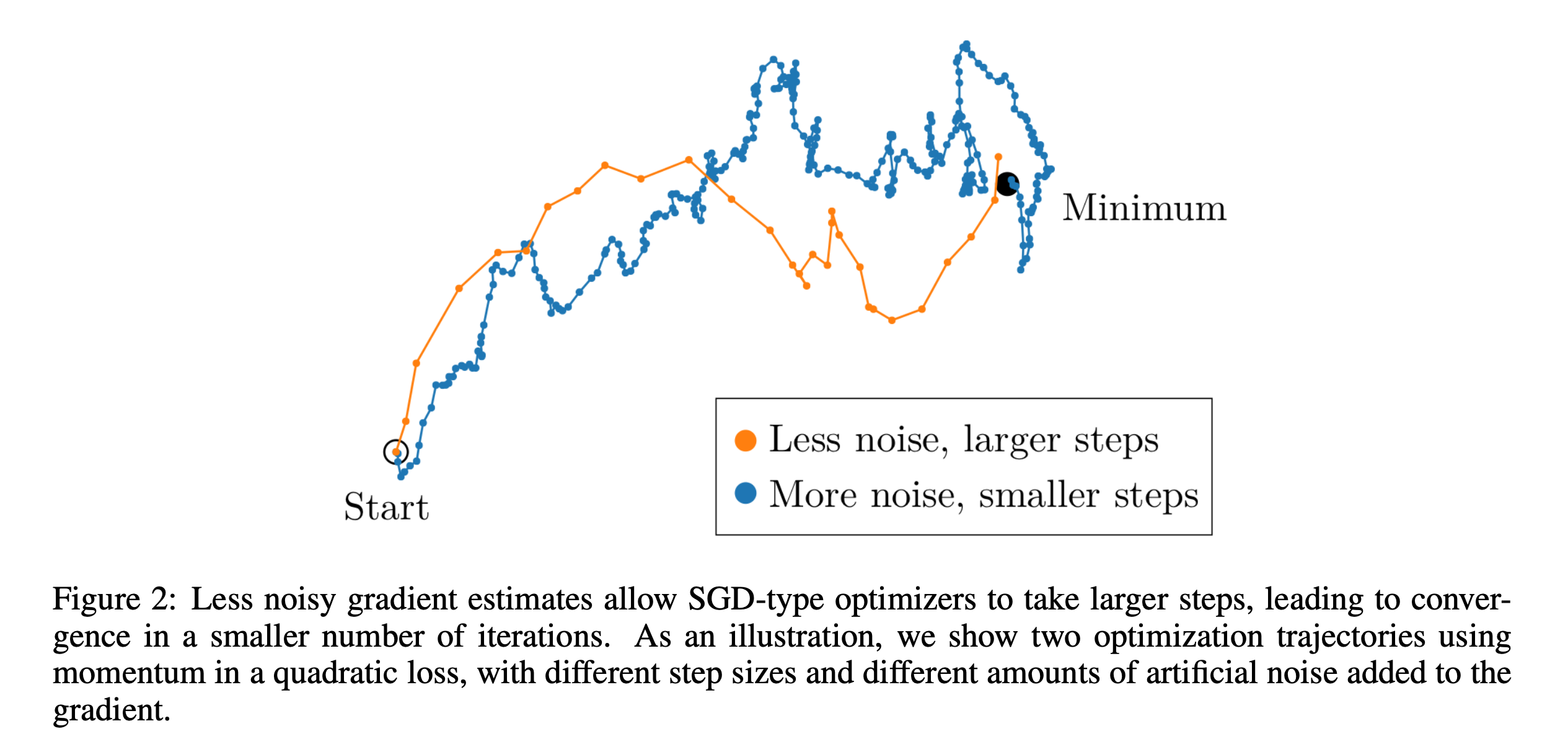 Fig.
Fig.
Batch size를 키움으로써 얻을 수 있는 이득은 크게 몇 가지가 있을 수 있는데, 그 중 하나가 바로 training time을 줄이는 것이다. 그 이유는 iteration 수가 줄어들기 때문이다. 하지만 이는 특정 지점에 도달할 때 까지만 유효한 이야기 일 수 있다. 우리가 한 개 node에 배치할 수 있는 최대 8개의 GPU device를 넘어 수십, 수백개의 node를 연결한 multi-node 상황에 놓여있다고 생각해보자. ZeRO-DP라는 method로 Data Parallelism (DP)처리를 해서 매우 많은 sample을 볼 수 있게 되었다. Device가 늘어날수록 batch size가 커져 너무 큰 지경에 이를 수 있다. 그래서 이게 뭐가 문제가 되는가? 크면 클수록 좋은게 아닌가?
아래 ZeRO-DP paper의 주석을 보자. Prior work 라고 언급된 것은 OpenAI에서 개발한 human level의 Dota2 를 play 하는 agent에 대한 technical report, Dota 2 with Large Scale Deep Reinforcement Learning이다.
 Fig.
Fig.
Dota2 라는 게임을 play하는 agent를 학습하면서 어떤 batch size가 가장 가성비가 좋은지?를 연구했었는데,
특정 지점을 지나면 더이상 device를 많이 쓰는 것이 같은 성능을 달성하기 위한 training time을 줄여주지 않는다는 것을 발견했다고 한다.
이는 또 다른 표현으로 slow convergence라고도 한다.
이게 무슨말일까?
Measuring Gradient Noise Scale
An Empirical Model of Large-Batch Training라는 paper는 OpenAI DOTA2 team이 OpenAI Five Agent를 학습하기 전 선행으로 한 연구이다.
여기서 어떻게하면 주어진 task에서 가장 효율적인 (가성비가 잘 나오는) batch size인 Critical Batch Size를 알 수 있는가? 라는 질문을 한다.
(OpenAI는 이미 2018~2019년 부터 large scale training에 진심이었다고 볼 수 있다. 하긴 이들이 만들고자 하는 것은 Artificial Generatl Intelligence (AGI)이기 때문에 효율적인 scale up을 위해 반드시 필요한 과정이었으리라 생각이 된다.)
아래의 figure를 보자.
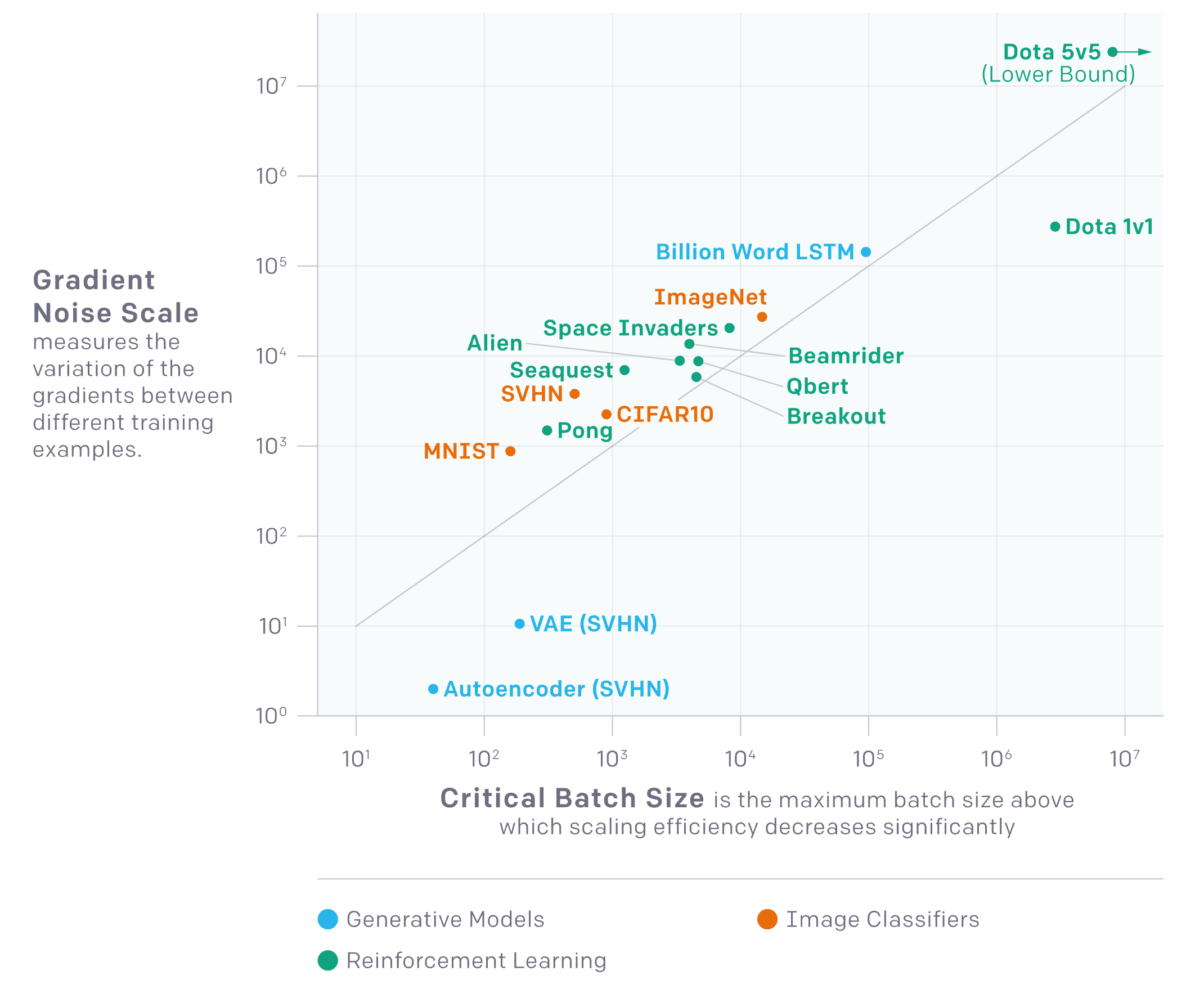 Fig.
Fig.
먼저 여기서 좌측의 Gradient Noise Scale이란 서로 다른 training sample 에 대한 gradient의 변화율을 measure한 것이다 (정확히는 network gradients의 Signal-to-Ratio (SNR) 라고 한다).
그리고 좌표 평면상에 놓여진 task들을 살펴보면 어려운 task일 수록 (5:5 AOS게임인 Dota2를 푸는 것이 MNIST 분류를 하는것 보다 어렵다) Gradient는 훨씬 더 noise하다는 걸 알 수 있고, 그에 따라서 Critical Batch Size라는 것이 매우 커진다는 걸 알 수 있다.
Critical batch size란 scaling efficiency가 확 떨어지기 직전의 어떤 순간, 즉 이 task를 푸는 데 있어 maximum batch size를 의미한다.
이 말은 예를 들어, MNIST같은건 아무리 device가 많아봐야 batch size를 키워봐야 낭비가 된다는 것으로 (redundant), 즉 더 많은 data를 병렬 처리하는 것이 아무런 득이 되지 않는 다는 것이다.
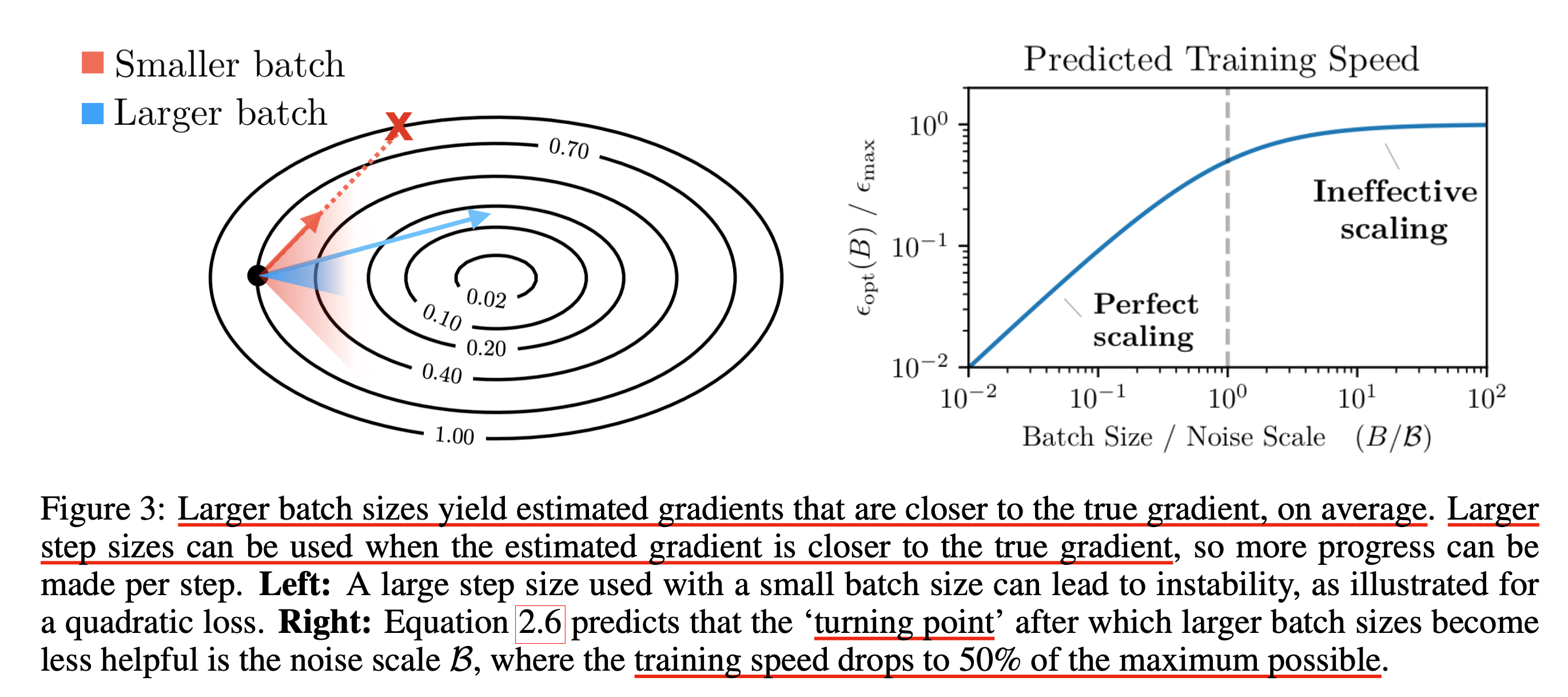 Fig.
Fig.
왜 그럴까? 직관적으로 task가 어렵지도 않은데, 많은 sample을 쓴것과 아닌것의 추정된 gradient가 비슷비슷하다는 것이다.
이 연구진들이 실험적으로 찾아낸 것은 바로 위의 figure에서 언급한 Ineffective한 scaling point를 찾는 것이다.
이 지점을 넘어가면 최대로 효율적으로 training할 경우의 50%정도나 training speed가 감소할 수 있다고 한다.
좀 더 nice한 figure를 보자.
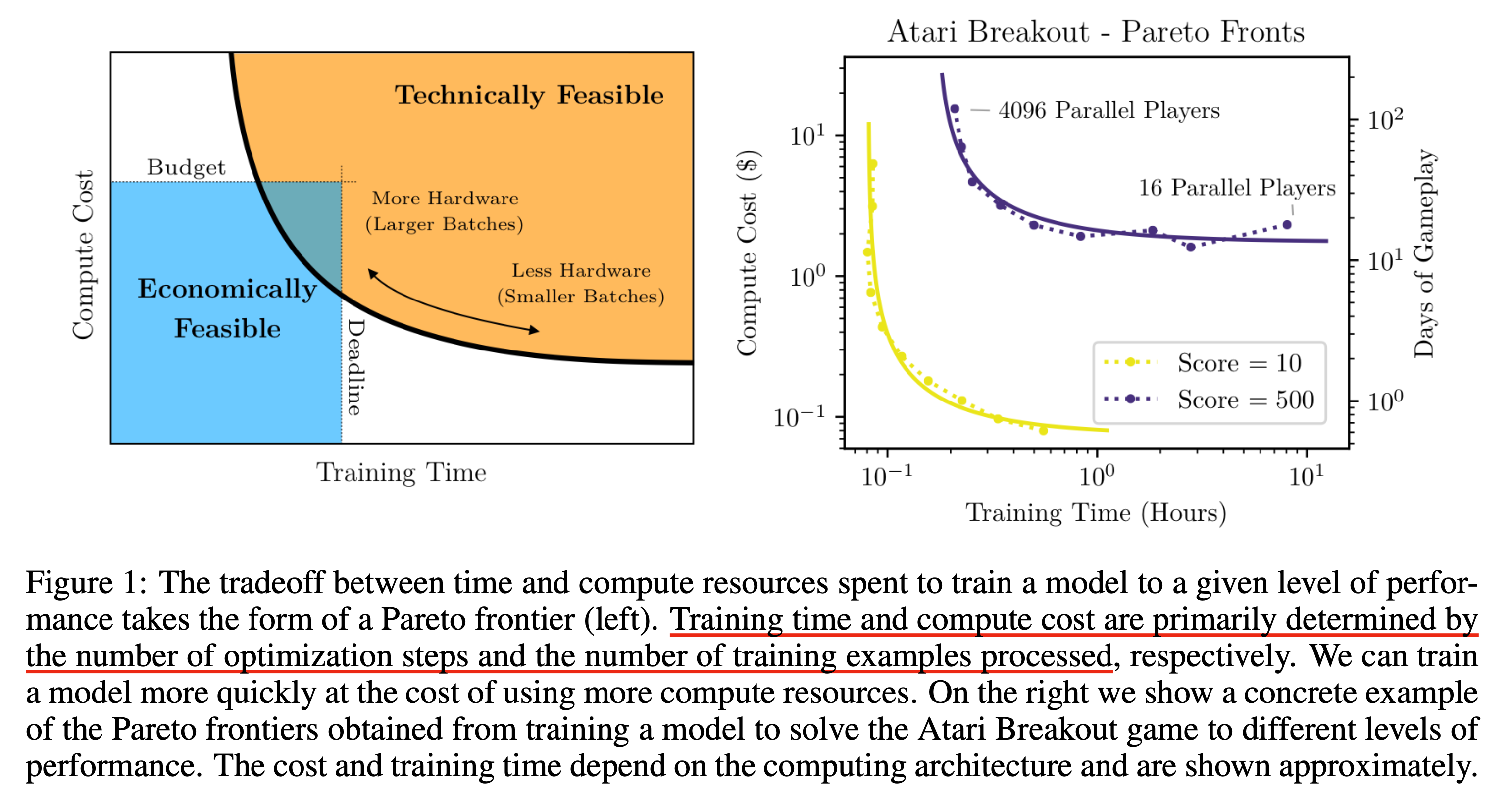 Fig.
Fig.
위의 figure의 오른쪽 sub figure는 Atari 라는 어떤 콘솔 게임을 play하는 agent를 학습하는 task가 특정 점수를 달성하기 위해서는 어떤 얼만큼의 resource로 얼만큼의 training time을 써야 하는지를 의미한다.
Parallel player 가 작은 것이 batch size가 작은것이고 그 반대는 큰것이다.
여기서 먼저 알 수 잇는것은 매우 batch size가 작은 very small batch size의 경우에는 batch size를 2배 키우는 것에는 아무런 risk가 없다는 것인데, 다시 말해 computational cost를 추가로 들이지 않고도 training wall clock time을 반으로 줄일 수 있다는 것이다.
왜냐하면 batch size를 키운다는 것은 (GPU) chip을 2배나 더 쓴다는 것인데, 그 만큼 iteration 수도 절반이 되는데 성능이 거의 같기 때문이다.
반대로 very large batch size에서는 아무리 compute resource를 늘려도 training time은 줄어들지 않는다.
Bend의 중간 지점에서는 training time을 줄이기 위해서는 batch size를 단순히 늘리는걸 넘어 node수를 늘려줘야 한다는 걸 알 수 있다.
Gradient noise scale은 바로 이 bend (curve)를 예측하기 위한 metric이다.
한 편, 우리에게 주어진 budget (computing resource)와 time (deadline)이 주어져있다고 할 때, 경제적으로 그럴싸한 (Economically Feasible)한 구간에 이 technically feasibility를 의미하는 region이 안 들어올 수도 있다. 이 bend는 더 높은 점수를 달성하려고 할수록 (즉 더 높은 난이도의 task를 해결하려고 할 수록) 더 위로 이동하기 때문에 ecnomically feasible하지 않게 된다. 그러면 어떻게 해야 할까?
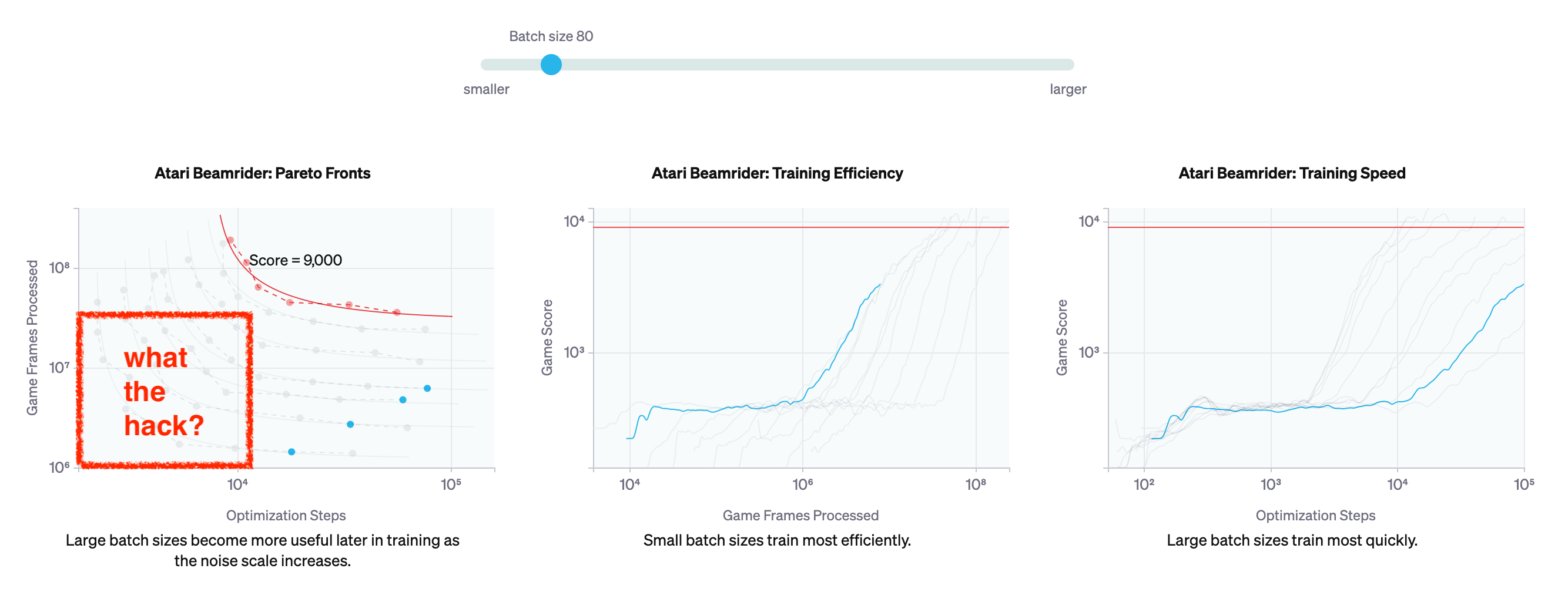 Fig. 가령 일정 수준 이상의 computing power를 쓰지 않으면 (batch size가 작으면), 영겁의 세월을 학습에 써야하거나 아예 그 성능에 도달하지 못할 수도 있다.
Fig. 가령 일정 수준 이상의 computing power를 쓰지 않으면 (batch size가 작으면), 영겁의 세월을 학습에 써야하거나 아예 그 성능에 도달하지 못할 수도 있다.
아마 budget과 time을 늘리면 될것같다 (…?)
Patterns in the gradient noise scale
일반적으로 gradient noise scale에는 몇 가지 패턴이 있다고 한다.
바로 학습이 진행되면서 noise scale이 수십 배 수준으로 증가한다는 것이다.
이미지 분류를 하는 경우에 대해서 생각해보자.
맨 처음에는 edge 같은 small-scale의 obvious feature를 학습하는 데 시간을 쓸 것이라고 한다.
NN 입장에서도 사물을 인식하는 것이 먼저라는 것은 직관적으로 받아들이기 쉬울 것이다.
그 다음엔 더 복잡한 intricate feature를 배우게 된다고 하는데, 점점 noise scale이 커지는 것이다.
연구진은 이런 현상이 여러 task, 여러 model에서도 비슷하게 나며,
더 powerful한 model이 더 큰 gradient noise scale을 갖게되고 이는 더 낮은 loss로 이어진다고 했는데 (아마 더 detail한 걸 배울 수 있는 capacity가 생기고 optimization space가 더 복잡해진다거나 하기 때문에 더 좋은 solution을 찾을 순 있겠지만 그만큼의 noise scale이?),
그러므로 우리가 large model을 학습할 때는 더 많은 병렬 처리를 해야한다고 얘기한다.
In DOTA2 Experiment
그래서 DOTA2 실험에서는 어떤 실험적인 결과가 있었는가? DOTA2는 MNIST와 비교도 안되는 어려운 task이다. 아래의 figure는 batch size에 따른 달성 가능한 skill 점수와 (높을수록 더 DOTA를 잘한다고 보면 된다), speed up 에 대한 관계를 나타낸다.
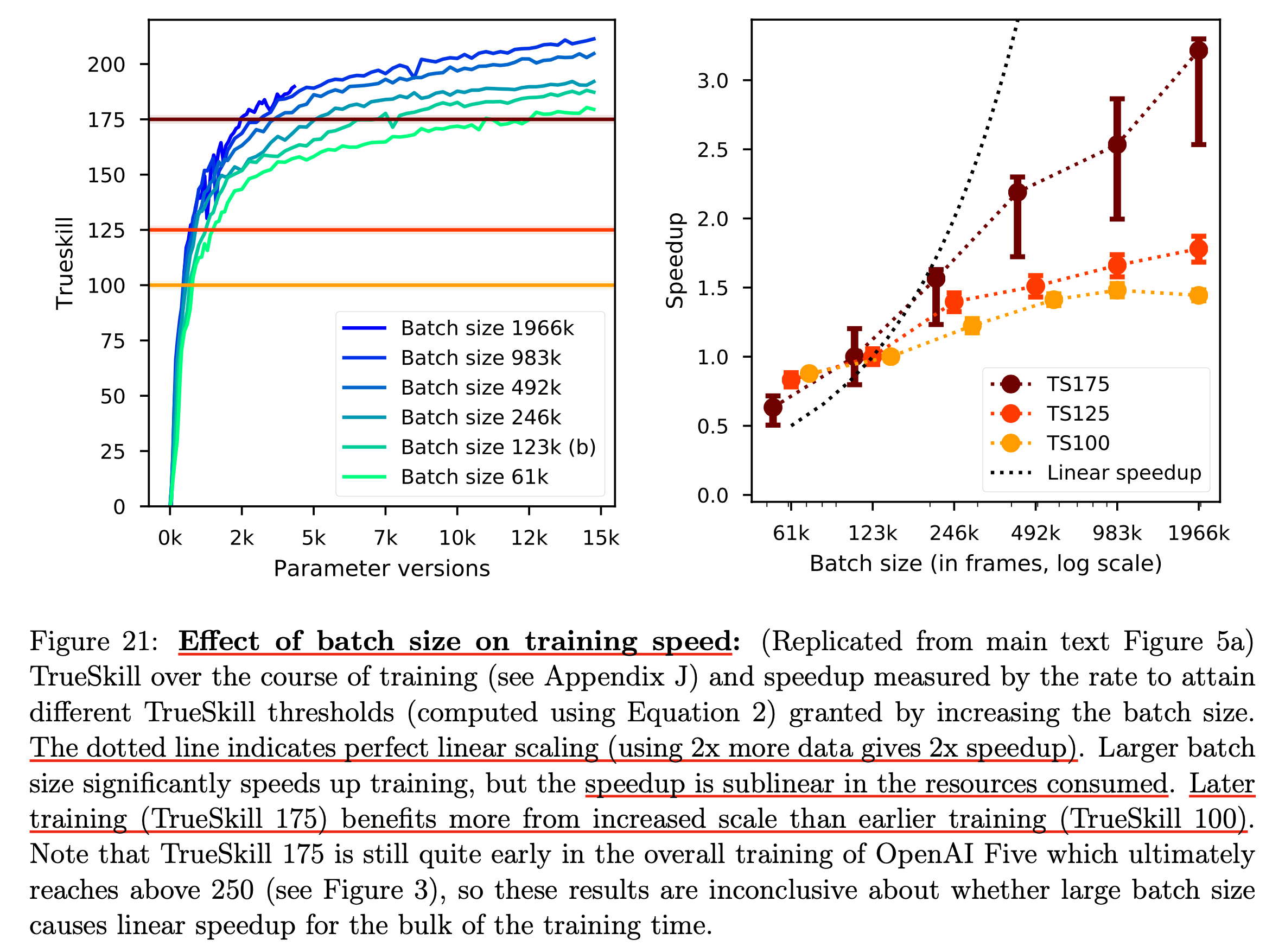 Fig.
Fig.
여깃 주목해야 할 점은 batch size가 클 수록 결국에 수렴하는 지점은 좋을 수 있지만 오른쪽의 speedup과 batch size의 관계가 linear하지 않다는 것이다. 즉 2배 computing resource를 더 쓰면 1/2배 시간이 줄어들어야 하는데 (speed up), 실제로는 batch size를 매우 크게 키우게 되면 점점 같은 성능에 도달하기 위해서 sublinear한 성능을 갖게 된다는 점이다. 그렇다는 말은 우리가 batch size를 키우면서 iteration이 반으로 줄어들게 될 텐데, 이를 늘려서 학습을 더 해줘야 한다는 것이다. 그럼에도 speed up은 있긴 있기 때문에 이득이 없지는 않다만 가성비가 안나온다는 것이다.
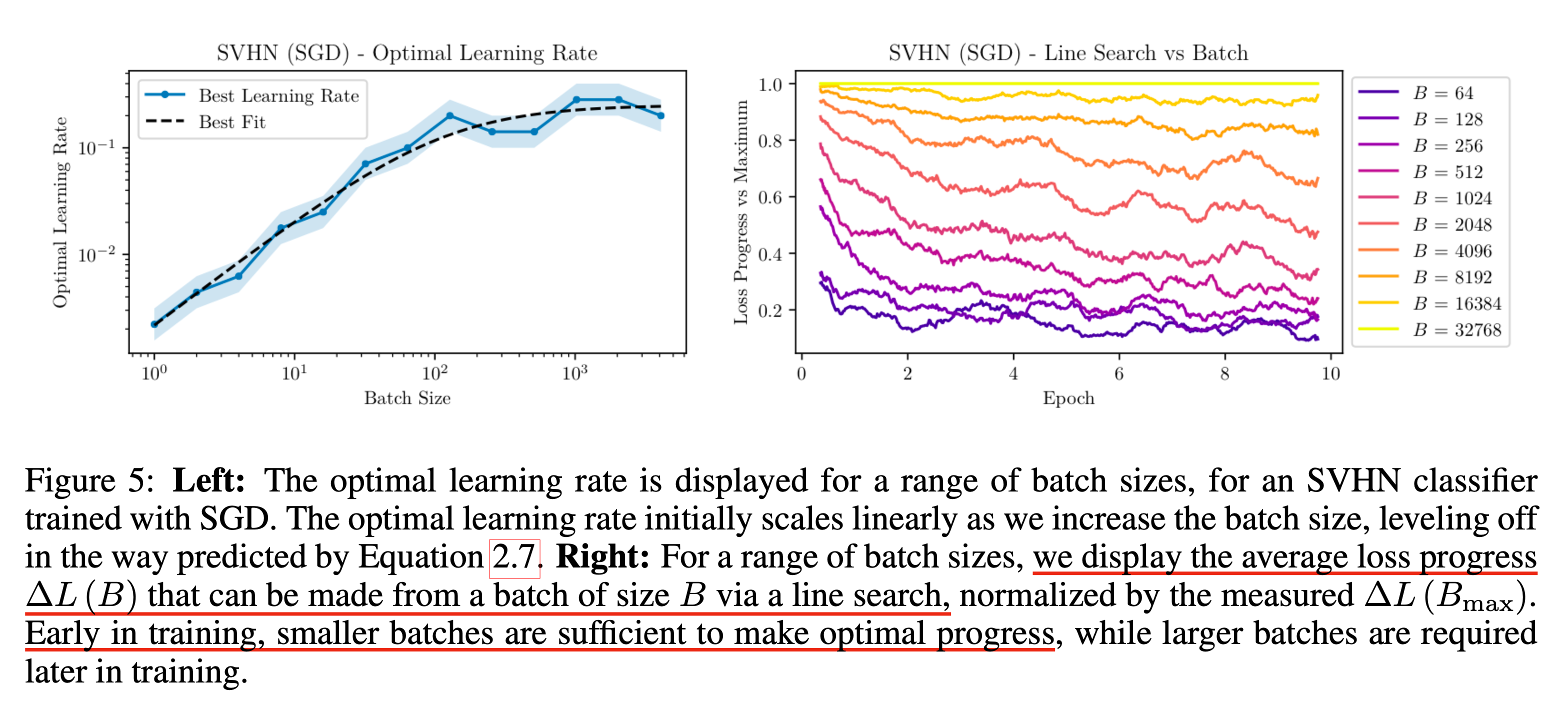 Fig. 오른쪽의 sub figure를 보면 Street View House Numbers (SVHN) dataset에 대한 분류 문제를 풀 때 학습 초기는 작은 batch size로도 충분하다는 걸 알 수 있다.
Fig. 오른쪽의 sub figure를 보면 Street View House Numbers (SVHN) dataset에 대한 분류 문제를 풀 때 학습 초기는 작은 batch size로도 충분하다는 걸 알 수 있다.
왜 그럴까?
앞서 설명한바에서 답을 알 수 있는데, 우리가 병렬처리를 많이한다 한들 학습 초기의 optimiation은 난이도가 쉽기 때문에 병렬처리를 한것에서 이득을 볼 수가 없는 것이다. 하지만 TS175 조차도 굉장히 학습 초반에 관한 것이며 (물론 resource가 한정되어있으니 scaling law?를 밝혀내기 위해 early phase만 가지고 한 것이다), pro level에 도달하기 위해서는 아무리 batch size를 키워도 아득한 시간만큼 학습을 해야 하는 것이다.
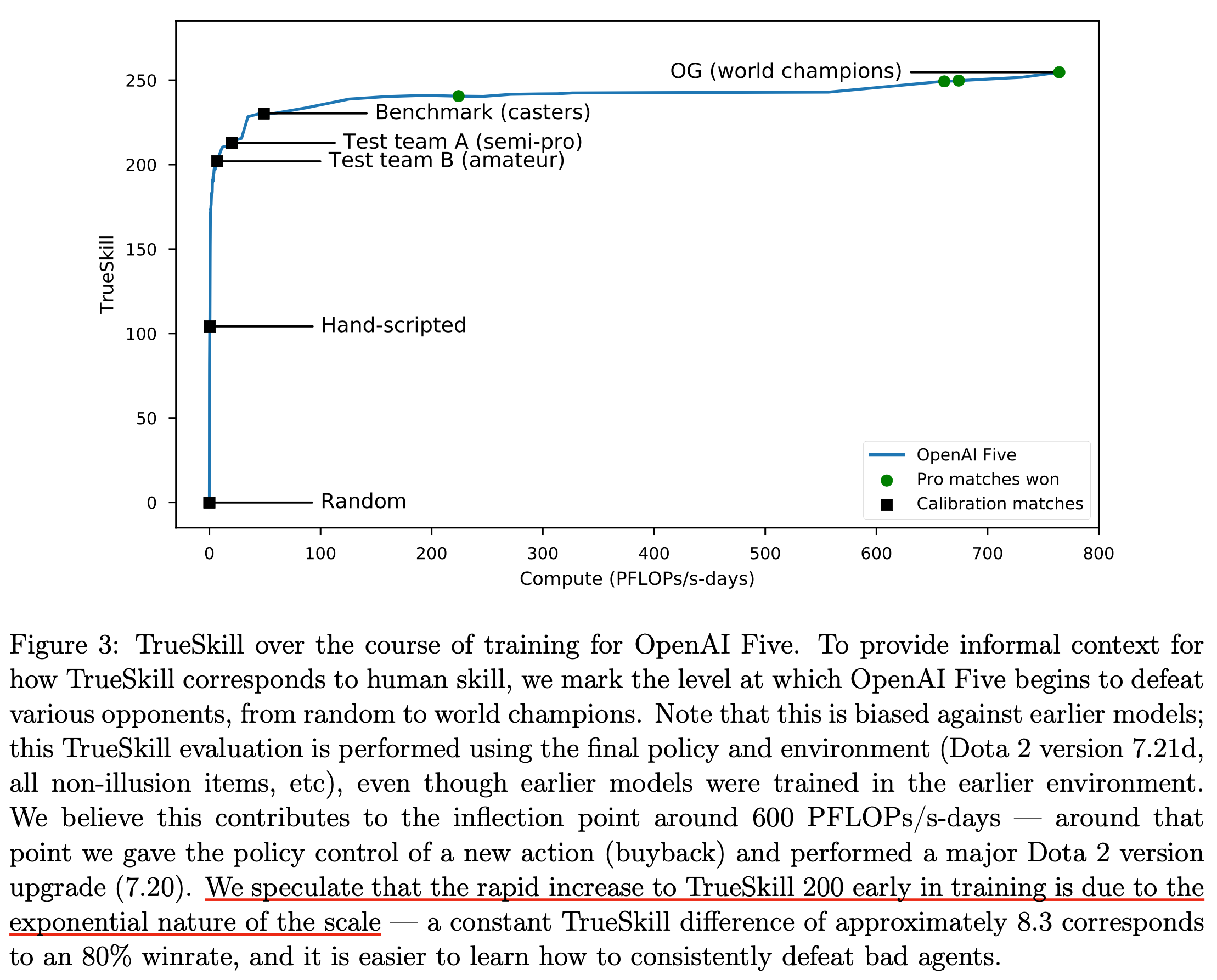 Fig.
Fig.
In LLM (PaLM)
Pathway LM (PaLM)에도 비슷한 언급이 있다. PaLM은 Google의 Large Language Model (LLM)인데, 이들도 학습을 할 때 early training phase에서는 더 낮은 batch size를 쓰다가 점점 batch size를 키우게 됐다고 한다.
 Fig. from PaLM
Fig. from PaLM
InstructGPT에서도 Proximal Policy Optimization (PPO)의 minibatch size를 정하는 데 있어 32가 가장 좋았지만 성능 감소를 감안하더라도 학습 효율을 위해 64를 골랐다고 한다.
 Fig. from InstructGPT
Fig. from InstructGPT
Measuring Effect of Batch Size according to Model and Task
다음은 Measuring the Effects of Data Parallelism on Neural Network Training의 실험 내용이다. 앞서 OpenAI의 paper처럼 task별로 critical batch size는 다르지만, 모두 일관되게 batch size가 커짐에 따라 필요한 optimization step 수가 linear하지만 중간에 이탈해서 sub linear 해지는 것을 볼 수 있다.
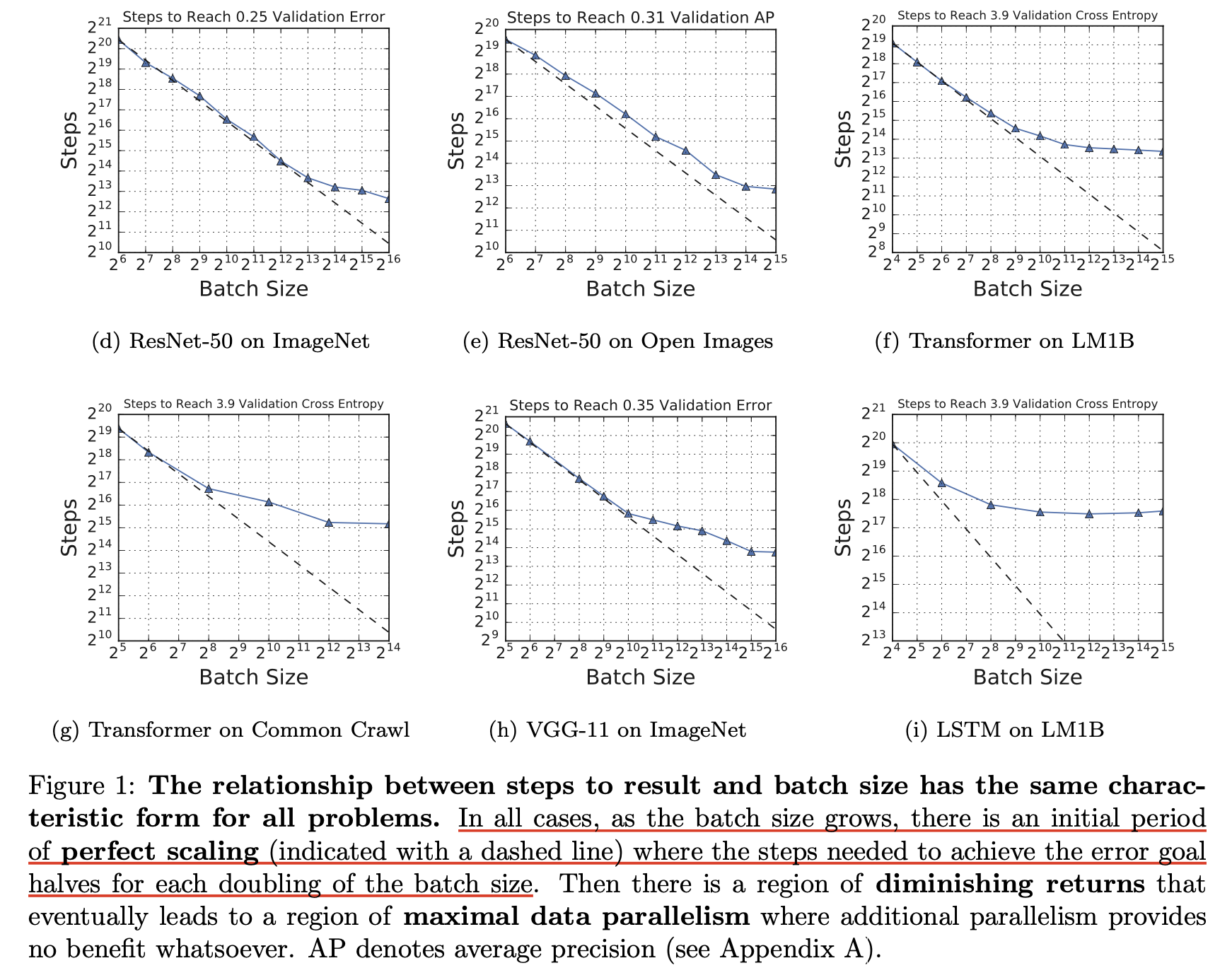 Fig.
Fig.
이 실험은 learning rate이 tuning이 안된게 아닌 것으로 보인다.
 Fig.
Fig.
그럼에도 불구하고 large batch size는 도움이 안된다는 것으로 보인다. 그리고 다음은 되게 중요한 observation 중 하나인데, 어떤 model들은 특히 더 scale up 하기가 좋은데 예를 들어 Transformer는 LSTM같은 architecture와 비교해서 훨 씬 더 좋았다.
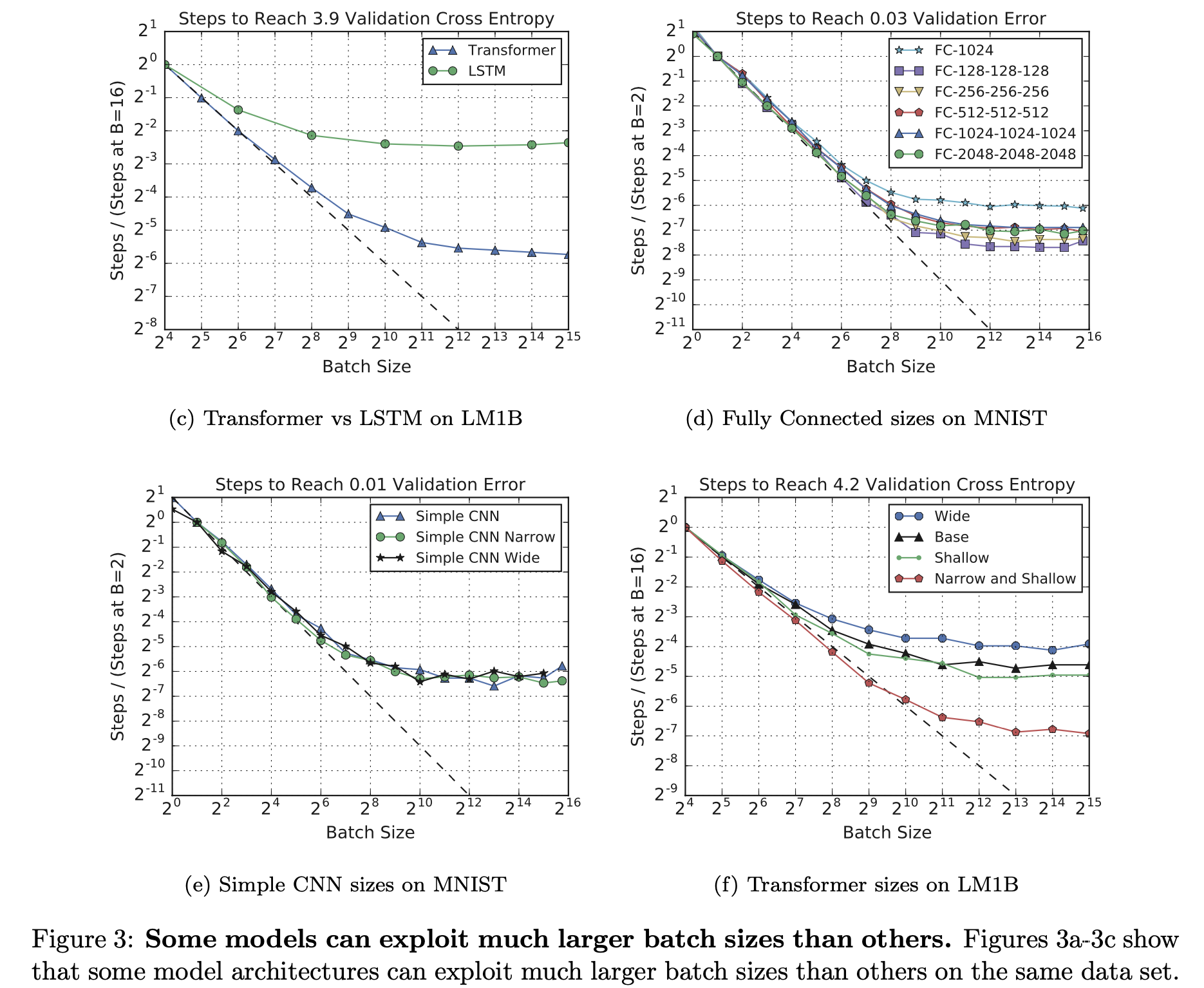 Fig.
Fig.
그래서 다들 Transformer를 쓰는것이라고 할 수 있겠다.
Solution Quality (Generalization Gap)
한 편, large batch size를 사용하는 것이 redundant한 것을 넘어서 실제로 수렴하는 지점이 다르지 않을까? 라는 생각이 들 수도 있다. 이번에는 아래 Large-Scale Deep Learning Optimizations: A Comprehensive Survey의 한 구절을 보자.
 Fig.
Fig.
실제로 batch size가 너무 커져서 어떤 특정 spot을 careful optimization scheme없이 넘기게 되면 test accuracy이 확 떨어질 수 있다는 것이다.
다시 말해서 train sample과 다른 새로운 sample들에 대해서 전혀 generalize를 못할 수도 있다는 것인데,
이를 paper에서는 generalization gap이라고 부른다.
저자들은 Batch size를 키우면 안정적인 학습 (stable training)을 위한 LR의 range 가 급격히 줄어든다고 paper는 주장하는데,
어떤 reference paper에 따르면 이것이 large batch method가 sharp minimizer에 빠지기 때문이라고 주장한다.
(하지만 이 이론이 딱 들어맞는지는 모르겠다. 왜 batch size를 키우는것만으로 sharp minima에 빠질 확률이 높아지고, 빠지면 다시 recover가 안되는지에 대해서 설득이 되지 않았는데, 아무래도 SGD에 가까울수록 variance가 커서 saddle point같은걸 탈출할 확률이 높다는 것과 같은 논지인 것 같다.)
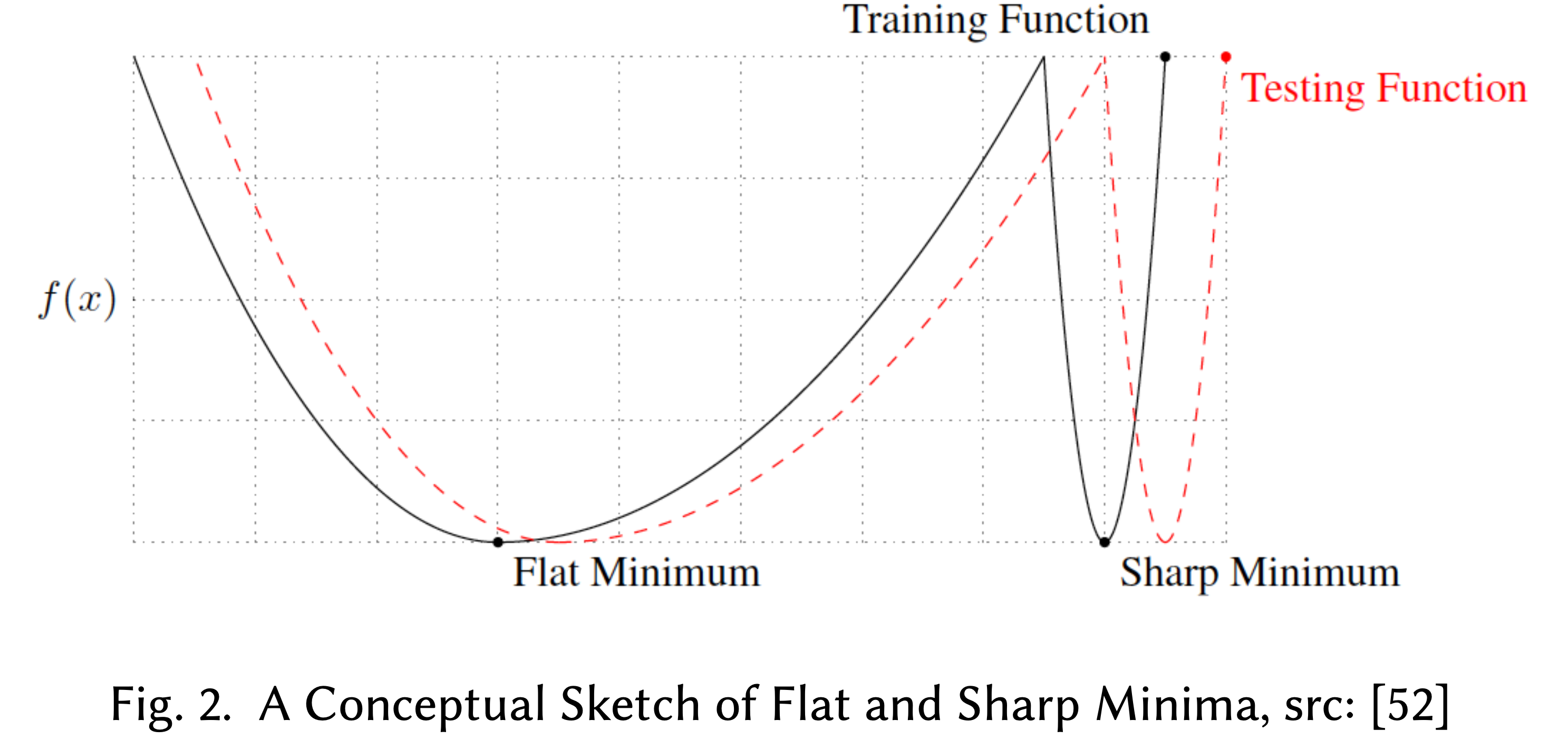 Fig. Sharp Minimizer. Source from here
Fig. Sharp Minimizer. Source from here
반면에 small batch method는 flat minima로 수렴하기 쉽다는 것이 알려져 있다고 한다. 위의 figure에서 직관적으로 flat minima는 test data point들에 대해서 objective function이 실제 training objective function과 다르다 해도 이들은 크게 다르지 않을 것이며, flat minima의 solution의 경우 이동한 objective function에도 잘 맞는 걸 볼 수 있다.
하지만 이를 반박하는 paper도 많은 것 같다. 앞서 얘기한 것 처럼 optimization step size를 늘리면 해결된다고 주장하는 이들도 있고, heuristic하게 warmup stage를 동반한 LR scaling을 하거나 layer별로 다르게 LR을 주는 것으로 해결이 가능하다고도 했다. Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour에 따르면 적어도 ImageNet에 대해서는 성능 감소 없이 large batch training을 이뤄냈다고 한다.
 Fig. Large batch size가 solution quality를 해치는가?에 대한 갑론을박.
Fig. Large batch size가 solution quality를 해치는가?에 대한 갑론을박.
In Gradient Noise Paper...
그렇다면 LR은 어떤식으로 키워줘야 할까? 앞선 OpenAI의 paper를 보면 이들은 Adam류의 optimizer를 쓸 때 적당히 batch size가 B일 때, 이에 비례하도록 \(B^\alpha\)만큼 LR을 키우면 된다고 한다. (여기서 \(\alpha\)의 범위는 \(0.5 \sim 1.0\))
 Fig.
Fig.
(이하 왜 task마다 \(\alpha\)가 좀 다른지에 대한 설명)
 Fig.
Fig.
Linear LR Scaling
또 다른 방법은 LR을 선형적으로 키워주는 것이다. 우리가 현재 batch size에서 K배 batch size를 키운다고 생각해보자. 가장 쉽게 생각할 수 있는 것은 learning rate를 그만큼 똑같이 곱해주는 것이다. 왜냐하면 plain SGD를 생각할 경우, k 번의 optimization step을 한 큐에 처리하는 것이나 다름 없기 때문에 (대신에 더 정교한 방향으로 한 step 갈 것) k배 크게 이동하는 것이 직관적으로 맞을 것이다.
Square Root LR Scaling
하지만 SGD에서 update 될 \(\Delta \theta\)의 co-variance matrix는 다음과 같다. (N개 sample에 대해 gradient의 평균을 구하던 원래의 case를 B배 batch size 키웠다고 생각하자.)
\[\Delta \theta \approx \frac{\alpha^2}{\vert B \vert} (\frac{1}{N} \sum_{n=1}^N g_n g_n^T)\]이 경우 서로다른 parameter들 간의 변화량을 의미하는 covariance를 동일하게 유지해주는 방법은 LR, \(\alpha\)를 square root 배 해주는 것일 수 있는데 이는 OpenAI에 서주장한 \(B^{\alpha}\)에 들어온다.
Layer-wise Adaptive Rate Scaling (LARS)
TBC. CPU Adam 같은걸 쓴다면 선택권이 없을 것으로 보여 pass.
Learning Rate Range Test (LRRT)
Learning Rate Range Test (LRRT)라는 method는 model이 diverge하지 않는 선에서 쓸 수 있는 가장 큰 LR을 찾는 method라고 한다. (이에 대한 MS Deepspeed team의 blog post를 참고하면 좋을 것 같다)
Device당 512 batch size를 갖는 경우에 대해 device를 4배로 늘려 2048 batch size를 쓰는 경우를 생각해보자. 이 경우 slow convergence 현상이 발생하는데, 앞서 말한 것 처럼 늘어난 batch 만큼 iteration 수가 줄어들겠으나 이런 setting으로는 baseline 과 같은 성능을 낼 수 없는 것을 말한다. 즉 LR을 키우거나 step수를 늘리거나… 해야 되는데, 이 경우에는 늘어난 batch size만큼 무지성으로 sqrt를 씌우지말고 실제로 어디가 upper bound인지 search를 한다.
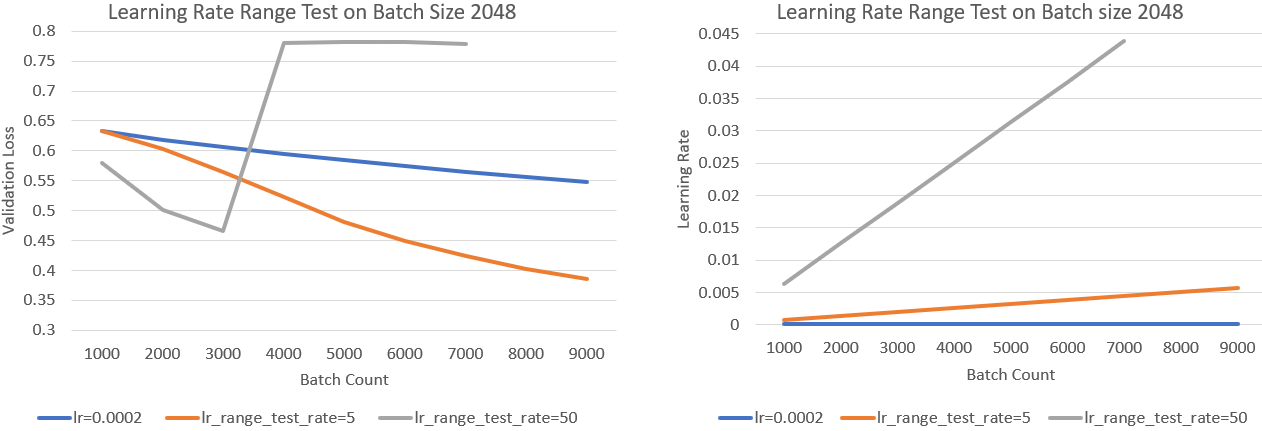
위 figure에서 왼쪽 sub figure는 첫 training batch 9000개에 대한 validation loss 를 의미한다. Grid search로 2048 batch size에 대한 best fixed lr을 0.0002로 찾았다고 치자. 이제 이를 기준으로 lr을 서서히 키우는데 변화율을 다르게 해서 관찰해보자. 너무 급격하게 키운 gray line은 중간에 발산했으나 적당히 증가시킨 orange line은 best fixed lr을 쓴 blue line보다 훨씬 loss가 잘 떨어지는 걸 볼 수 있다. 즉 이 model이 현재 batch size로는 최대 키울 수 있는 LR이 0.005정도이니 이 안에서 scheduling을 해주겠다는 매우 simple한 method이다.
(사실 training step이 경과할수록 parameter가 update되므로, 나중에 문제없는 lr이 초반에도 문제가 없다는 보장이 있는지는 모르겠다. 즉 0.005가 진짜 안전한지는 미지수인게 아닌지?)
Optimal effective LR do not always follow linear or square root scaling heuristics.
그런데 사실 이런 linear, sqrt scaling은 model이나 task에 따라 큰 의미가 없을 수도 있습니다. 아래의 figure는 Measuring the Effects of Data Parallelism on Neural Network Training.의 plot으로, Trasnformer를 common crawl dataset에 학습한 경우 같은 validation error에 도달하기 위해서 batch size가 증가에따라 LR scaling해주는 것이 sqrt scale도 못따라가는 것을 볼 수 있다.
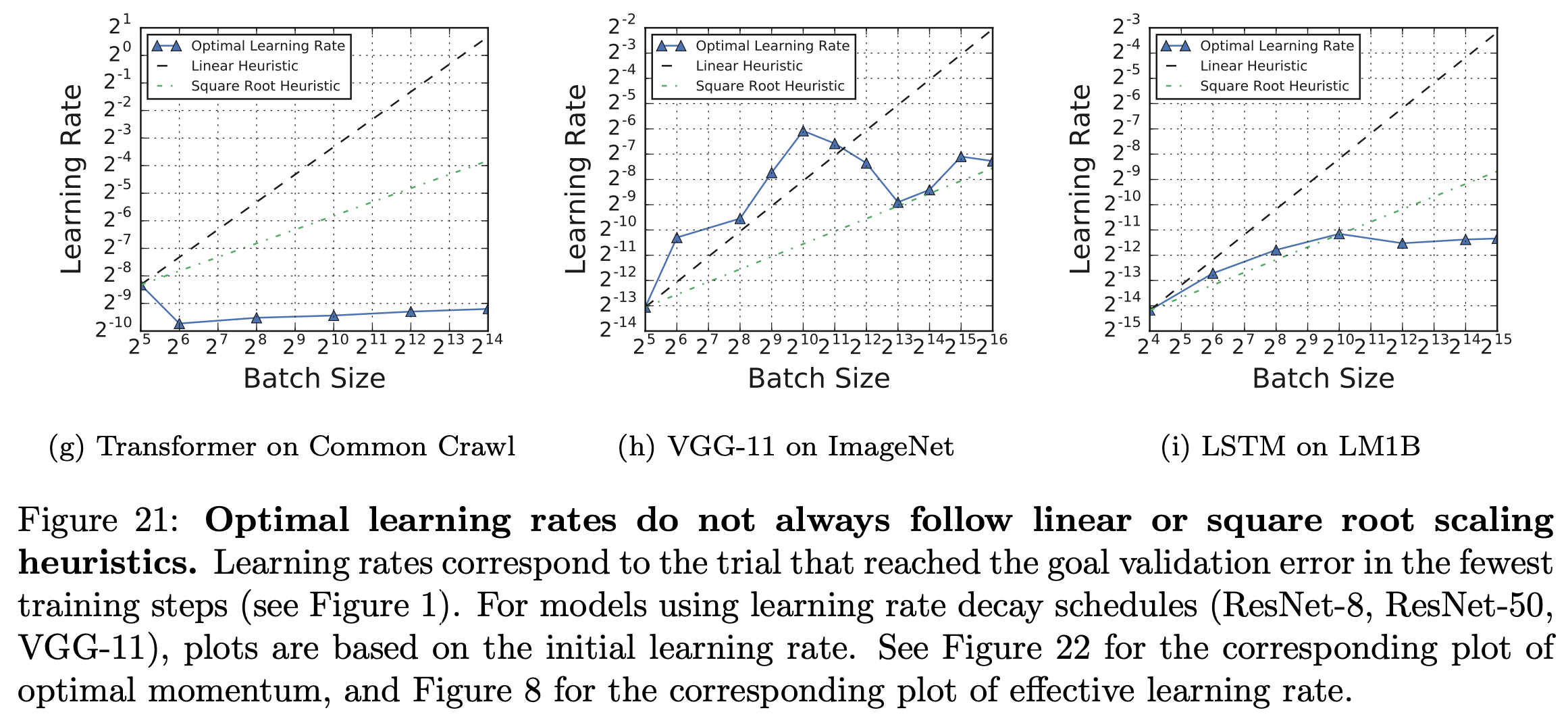 Fig.
Fig.
그리고 이 때의 optimal momentum은 아래의 plot에 대응한다.
 Fig.
Fig.
이 둘을 같은 plot에 표현하면 다음과 같다.
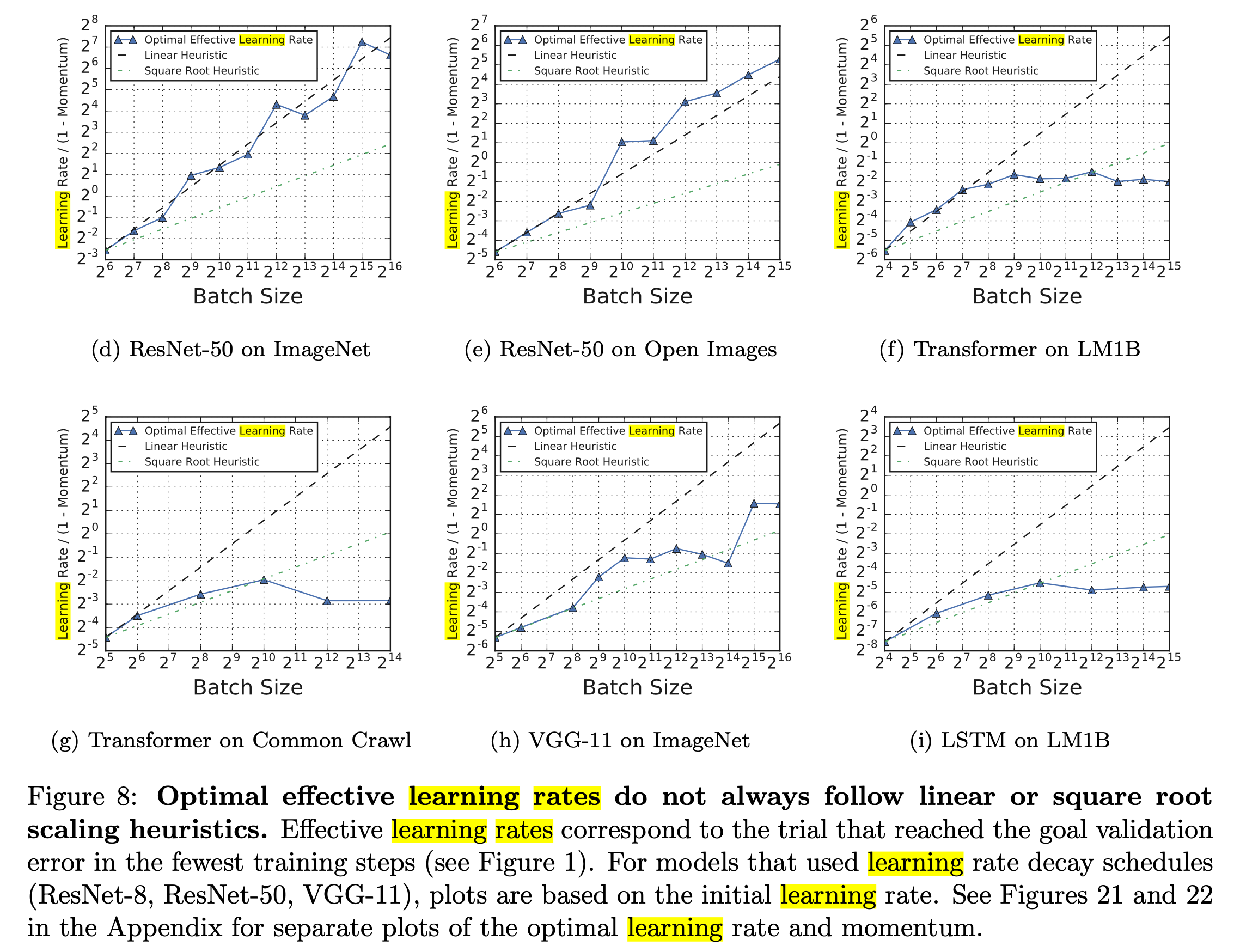 Fig.
Fig.
그럼 LR이나 momentum이 얼마나 sensitive한가? 이는 아래의 plot을 보면 또 알 수 있다.
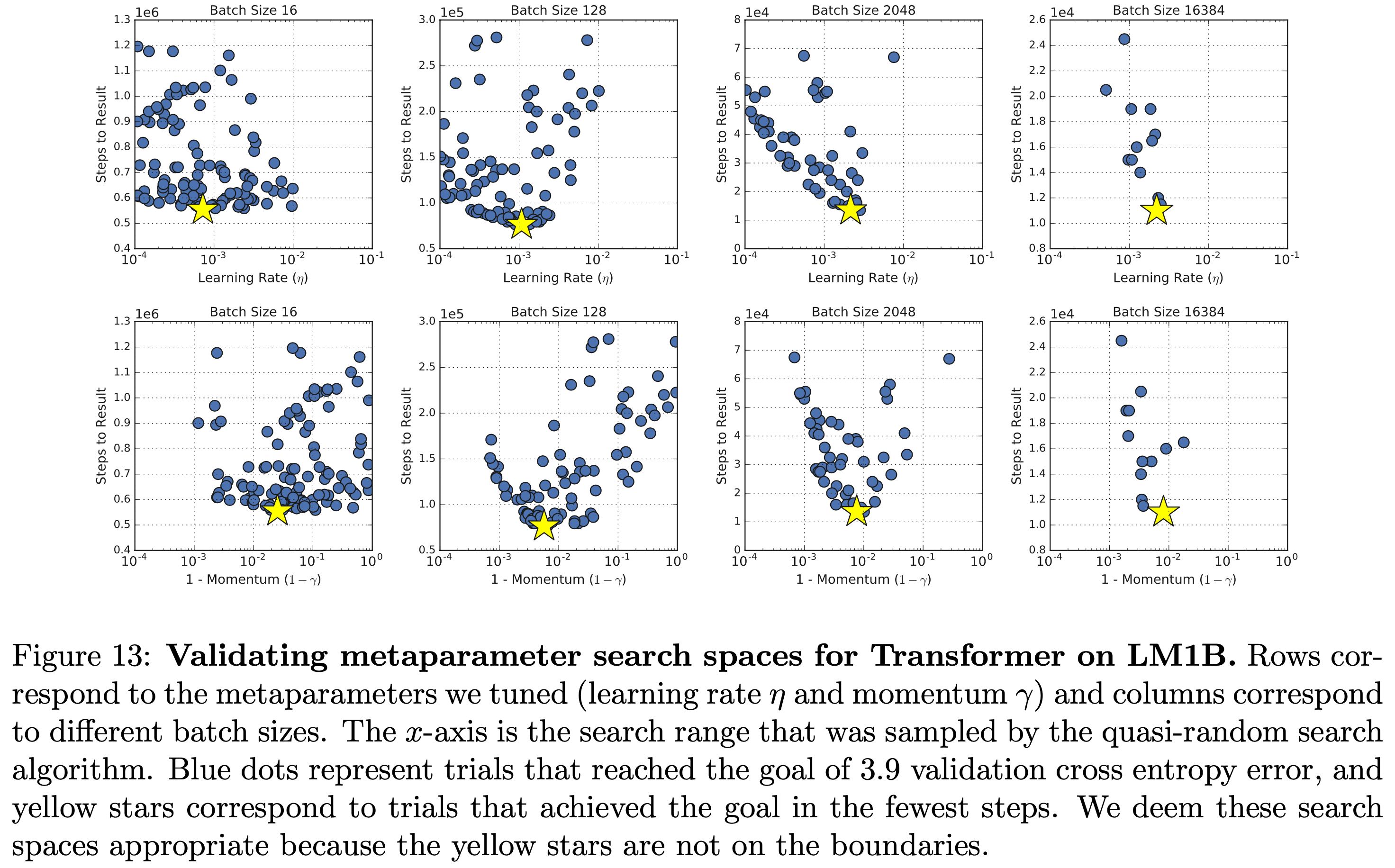 Fig.
Fig.
이런 empirical result들을 볼 때, LR은 결국 사람이 튜닝을 할 수 밖에 없는 것 같기도 하다.
Summary
Motivation에서 얘기했던 주석은 어떤 맥락에서 나왔는가?
Fig.
이는 Model Parallel (MP)의 효율성에 대해 얘기하다 나온 것이다. Paper에서는 ZeRO-DP가 communication overhead가 심한 MP 보다 훨씬 좋다고 주장하다가도 MP를 쓸 경우가 있다고 하는데, 그 중 하나가 바로 batch size가 너무 커서 효율이 나오지 않을 때 이다. (model이 작을때만 batch가 매우 클 수 있는가?)
 Fig.
Fig.
이럴경우 ZeRO + MP를 쓰는 방법도 탐색해보면 좋을 것 같다.
- conclusion
- batch size를 너무 키우는 것은 가성비면에서나 성능 면에서나 안좋을 수 있다.
- 그래도 키워야 하는 상황이 온다면, LR을 동일하게 scale-up 해주고 optimization step을 좀 더 가져가서 총 볼 수 있는 sample 수를 늘려야 한다.
- 근데 이와 별개로 solution quality는 나빠질 수도 있다.
- 그러므로 자신없으면 node를 적당히 나눠서 실험을 여러 개 돌리자.
- DP degree가 너무 높은 경우에는 ZeRO + MP도 고려해보자
TBC) Understanding Optimization using Stochastic Differential Equations
References
- Papers
- An Empirical Model of Large-Batch Training
- Dota 2 with Large Scale Deep Reinforcement Learning
- ZeRO: Memory Optimizations Toward Training Trillion Parameter Models
- Large-Scale Deep Learning Optimizations: A Comprehensive Survey
- Measuring the Effects of Data Parallelism on Neural Network Training.
- On Large-Batch Training for Deep Learning: Generalization Gap and Sharp Minima
- Others