(WIP) Trivial (but critical) Training Techniques for Neural Networks
30 Jun 2023< 목차 >
- Standardizing Inputs and Outputs of NN
- Weight initialization
- Gradient Clipping
- More for Activations
- References
Machine Learning (ML) model을 학습할 때는 주의해야할 점이 많다. 고전 ML보다는 훨씬 깊은 층의 Neural Network (NN)를 쓰는 Deep Learning (DL)으로 갈수록 더더욱 그렇다. 예를 들어 ‘Weight Initiatlization 은 어떻게 해야하는지?’, ‘왜 feature normalization를 해줘야 하는지?’, ‘activation function은 어떤걸 쓰는게 좋은지?’나 gradient clipping, 학습된 weight의 distribution을 해석하는 방법 등등이 있겠다. 이들 대부분은 이미 많이 알려진 내용이지만 그럼에도 불구하고 대단히 중요한 내용들이다.
경험상 training에 실패하거나, 성공해도 model이 generalize를 못한다거나, model size가 커지고 precision이 달라져 문제가 생길 때마다 다시 이런것들을 찾게되어서 관련 내용들을 다시 정리하려고 한다.
 Fig. “왜 내 model이 학습이 잘 안됐을까?”를 알기 위한 기초적이면서도 매우 중요한 것들 (여기에 포함 안된 것도 많음)
Fig. “왜 내 model이 학습이 잘 안됐을까?”를 알기 위한 기초적이면서도 매우 중요한 것들 (여기에 포함 안된 것도 많음)
본 post는 Berkeley cs182와 Stanford cs231n를 기반으로 작성했으며, reference의 paper 등을 추가로 참고했음을 먼저 알린다.
Standardizing Inputs and Outputs of NN
먼저 normalization (or standardization)에 대한 얘기이다. 왜 NN layer의 input, output (model 중간 layer들의 activation)을 각 tensor의 statistic을 계산해서 scaling해줘야 할까?
그 이유는 Error Backpropagation 때문이다. Backpropagation은 objective function을 각 parameter에 대해서 미분 (derivative)하는 것을 효율적으로 수행해주는 algorithm일 뿐이므로, 결국에는 gradient based optimization을 할 때 gradient가 이상하게 계산되는 것을 막기 위함이 목적이라고 할 수 있다.
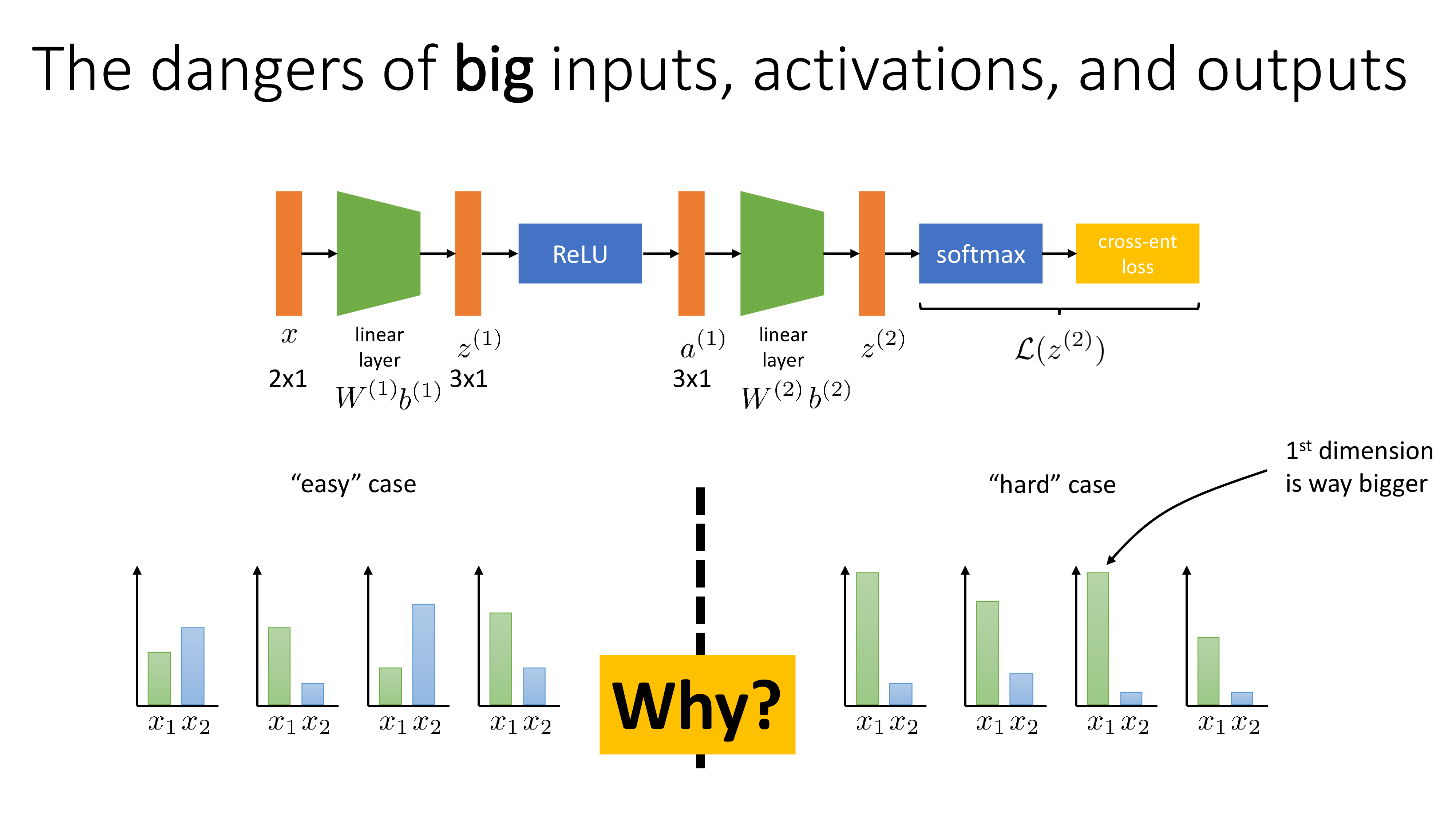 Fig.
Fig.
위 figure의 예시를 보면 easy case와 hard case의 각 feature가 가지는 scale이 다르다는걸 알 수 있다. hard case는 \(x_1\)이 normalize되어있지 않기 때문에 훨씬 큰 range 를 가지고 있다. 그리고 \(x_2\)의 값보다 훨씬 크다는 걸 알 수 있다. 이는 real world dataset에서 흔히 볼 수 있는 상황이라고 하는데, 가령 \(x_1\) feature가 kilometer 단위의 distance를 의미하고 \(x_2\)는 meter/sec 라던가 하는 경우 이럴 수 있다. (Sergey는 그럼에도 hard case를 적당히 잘 scale해주면 easy case와 같은 representation을 갖는다고 말한다.)
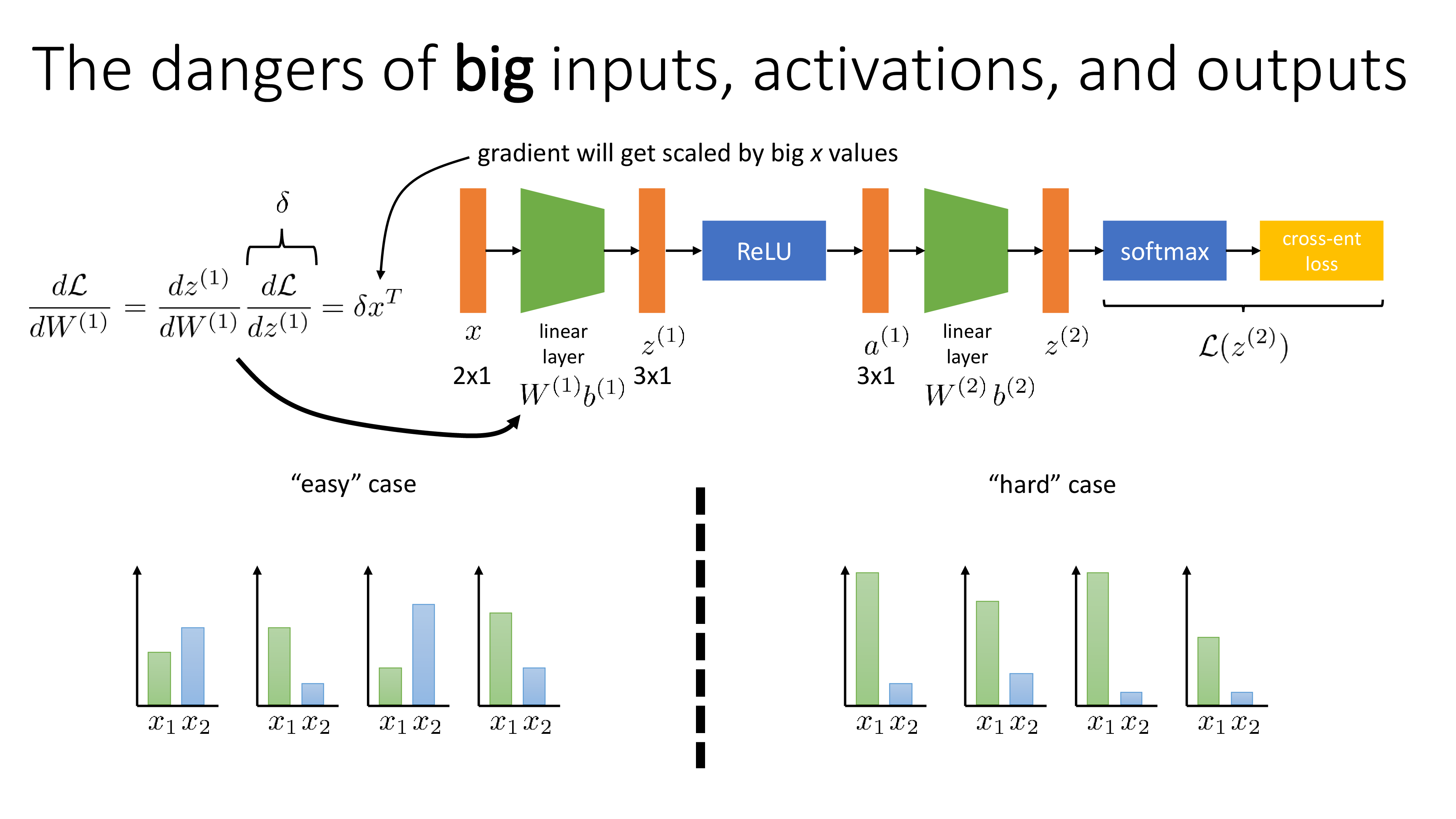 Fig.
Fig.
우리가 이렇게 scale이 다른 두 feature로 구성된 input을 NN에 feeding 해야한다고 치자. 먼저 첫 번째 linear layer를 backpropagation 철학에 따라 chain rule을 이용해 계산해보자. Last layer에서부터 전파된 upstream gradient와 local gradient를 곱하면 단순하게 구할 수 있는데, 아래의 외적 (outer product)를 구하면 된다.
\[\frac{d L}{d W^{(1)}} = \frac{d z^{(1)}}{d W^{(1)}} \frac{d L}{d z^{(1)}} = \delta x^T\]각 feature scale에 따라 실제로 얻는 gradient, \(\frac{d L}{d W^{(1)}}\)가 아래와 같을 수 있는데, 보면 정규화 되지 못한 input은 loss surface가 타원형 (ellipsoid)이 되는 것을 알 수 있고, 그에 따라서 gradient가 optimal point를 향하지 못하는 것을 알 수 있다.
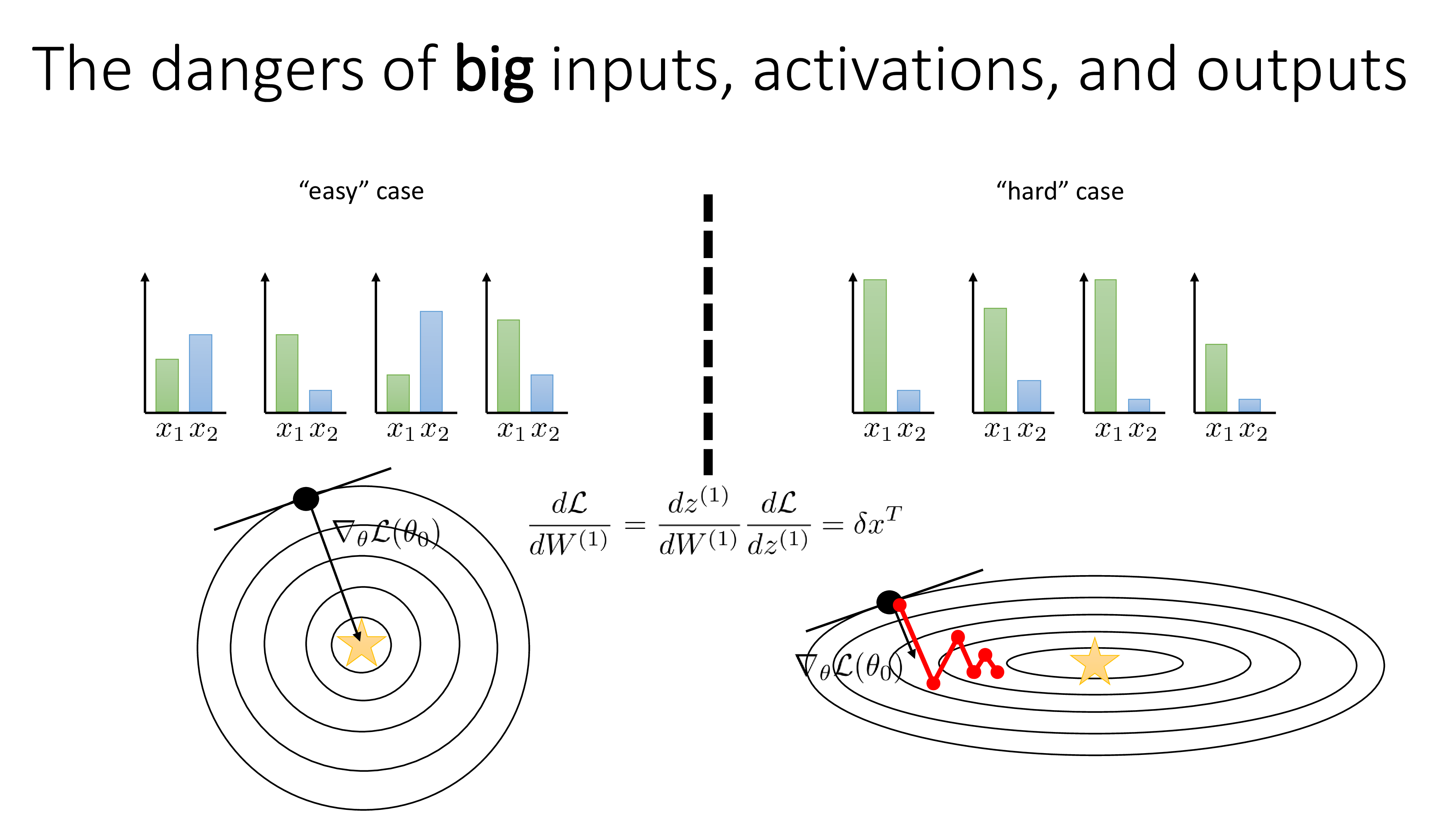 Fig.
Fig.
물론 이 문제를 해결하기 위해서 gradient를 rescaling 하고 momentum을 쓸 수도 있다. 즉 Adam optimizer같은 걸 쓰면 되는데, normalization (or standardization)을 통해서도 이를 해결할 수 있다. 하지만 이는 Computer Vision (CV)나 Natural Language Processing (NLP) 문제를 푸는 경우에는 괜찮을 수 있다고 한다.
 Fig.
Fig.
왜냐하면 image의 경우 모든 input이 RGB scale image라면 0~255사이로 정해져있고, gray scale image라면 0~1사이의 값을 갖게되며 NLP의 경우 one hot vector가 input이기 때문에 문제가 없다는 것이다. 그런데 만약 우리가 기상 예보를 하는 model을 만들고 싶다면 온도, 습도 등은 모두 scale이 다르기 때문에 꼭 이를 normalize해야 한다고 한다.
Standardizing Input Tensors
그래서 어떤값을 어떻게 scaling을 해줘야 할까?
먼저 NN의 input tensor를 standardization해보자. 정규화 (Normalization)과 표준화 (standardization)은 둘 다 input을 0과 1 사이의 값이 되도록 scaling해준다는 점에서는 같지만, normalization은 input의 min, max를 사용해서 scaling을 하는 반면 standardization은 그 input의 평균값 (mean)과 평균으로부터 얼마나 떨어져있는지를 의미하는 standard deviation (std)을 사용해 input의 statistics를 zero mean, unit variance 로 만드는 것이다.
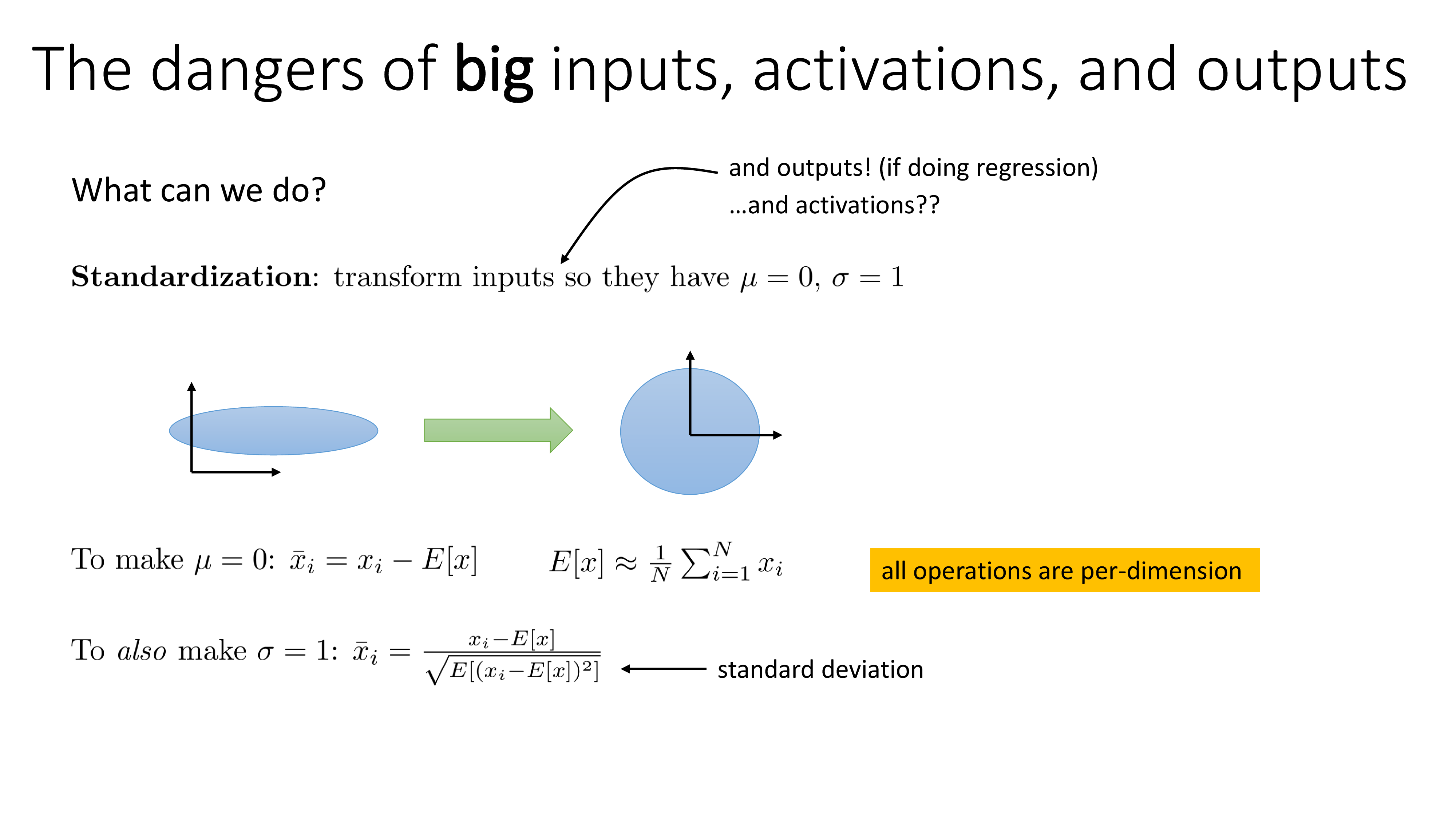 Fig.
Fig.
이는 input tensor의 모든 feature channel에 대해서 아래의 operation을 수행하면 된다.
\[\begin{aligned} & \mu = 0: \bar{x}_i = x_i - \mathbb{E}[x] = x_i - \frac{1}{N} \sum_{i=1}^N x_i & \\ & \sigma = 1: \bar{x}_i = \frac{x_i - \mathbb{E}[x]}{\sqrt{ \mathbb{E} [ (x_i - \mathbb{E}[x])^2 ] }} & \\ \end{aligned}\]Standardizing Activations
그런데 layer output도 standardizing 해야할까? 어떤 layer의 activation output은 다른 layer의 input일 것이므로 이는 괜찮은 option이며, classification이 아닌 regression task를 수행할 경우 output이 real value가 되기 마찬가지로 standardization이 필요할 것이다.
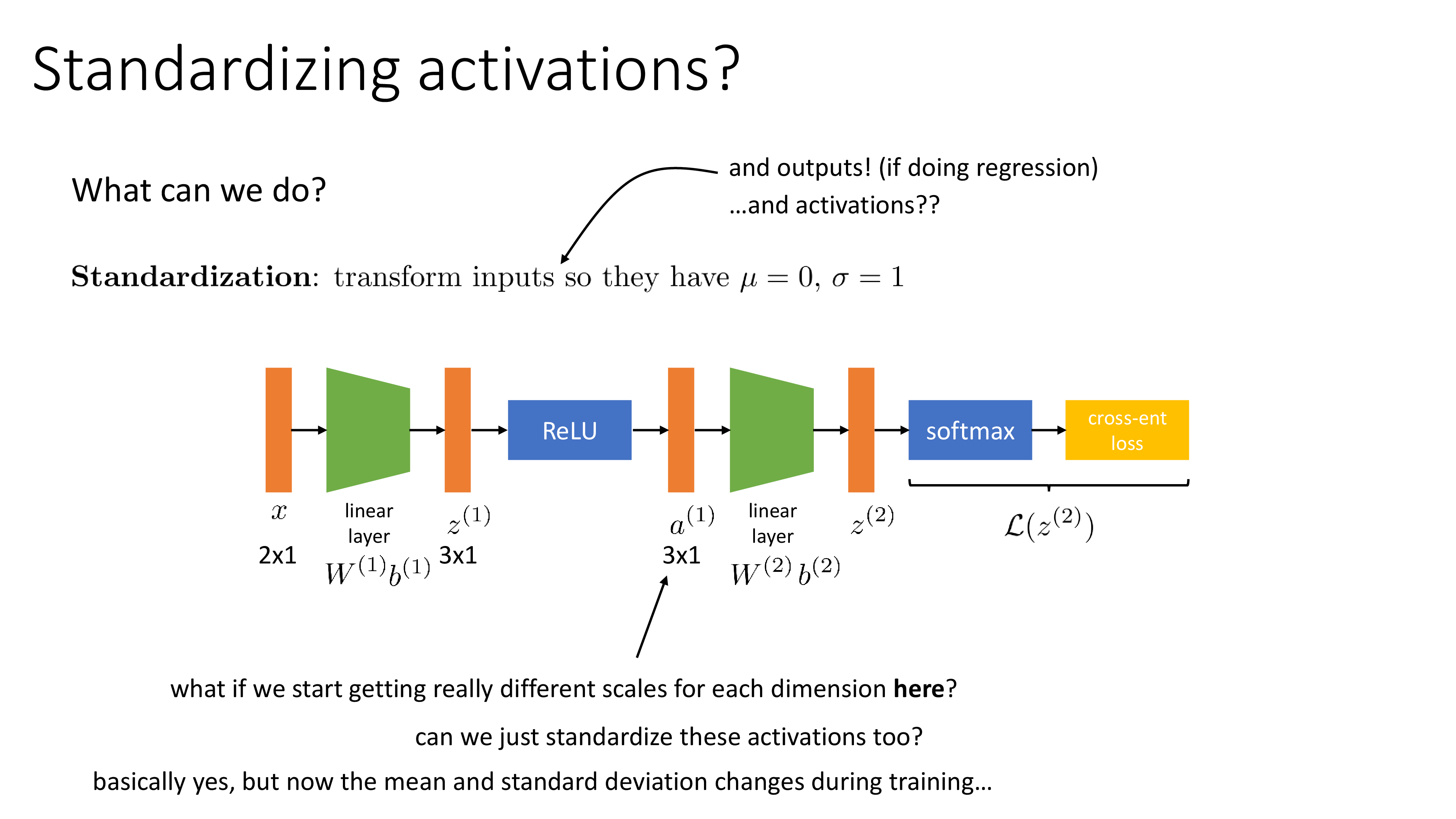 Fig.
Fig.
하지만 우리는 NN을 training하기 때문에 매 optimization step마다 weight and bias가 update될 것이다.
당연히 1st layer의 input은 관련이 없겠으나 매 iteration step마다 activation output들의 statistics는 변할 것이다.
즉, 우리는 매 step마다 mean, std를 다시 구해야 하는 것이다.
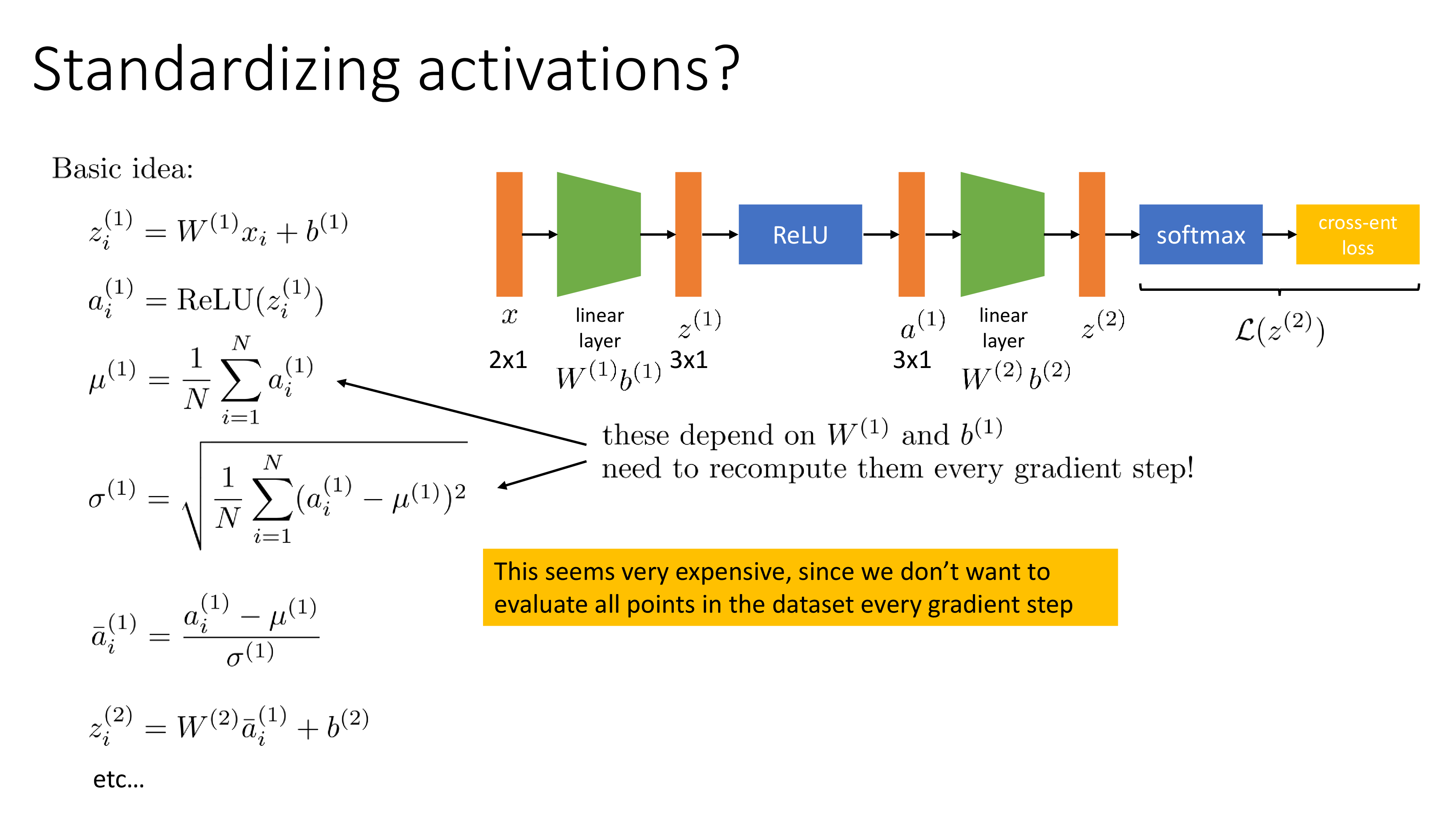 Fig.
Fig.
기본적인 idea는 위 figure의 수식과 같다.
activation마다 mean, std를 구하면 되는데 중요한 점은 모든 data sample을 다 봐야 한다는 것이다.
당연히 우리는 mini batch training을 할 것이기 때문에 이는 불가능하며,
mini batch 내에서 구한 mean, std를 사용한다.
 Fig.
Fig.
이것이 Batch Normalization (BN)의 기본적인 form이라고 할 수 있는데, real version은 여기에 \(\gamma, \beta\)를 추가로 곱해준다. 이 두 parameter는 input과 size가 같은데, 즉 \(\gamma\)는 elementwise 곱을 해주는 것이고 \(\beta\)는 bias로 단순히 더해지게 된다. 그리고 이 두 addtional parameter들은 learnable하다.
 Fig.
Fig.
굳이 mini-batch로 standardization을 한 뒤에 \(\gamma,\beta\)를 곱하는 이유는 mean을 빼주고 std로 나누기만 한다면 activation의 분포가 zero mean, unit variance를 를 갖게 될텐데 이는 우리가 원하는것이 아니기 때문이다. 우리는 모든 activation이 같은 scale을 가지길 원하는 것일 뿐 아예 bias가 사라지는 걸 원한는 것이 아니다. Sergey가 말하길 이 parameter를 빼더라도 여전히 training이 잘 된다고 하긴 하며, 사실 \(\beta\) term은 ReLU 다음 BN를 둘 경우 결국 그 다음 layer의 bias에 의해 무용지물 (redundant)하게 된다고 한다.
- ReLU -> BN -> Linear Layer with Bias
BN도 하나의 learnable parameter를 갖는 mapping function이므로 하나의 layer이며 학습할 수 있다.
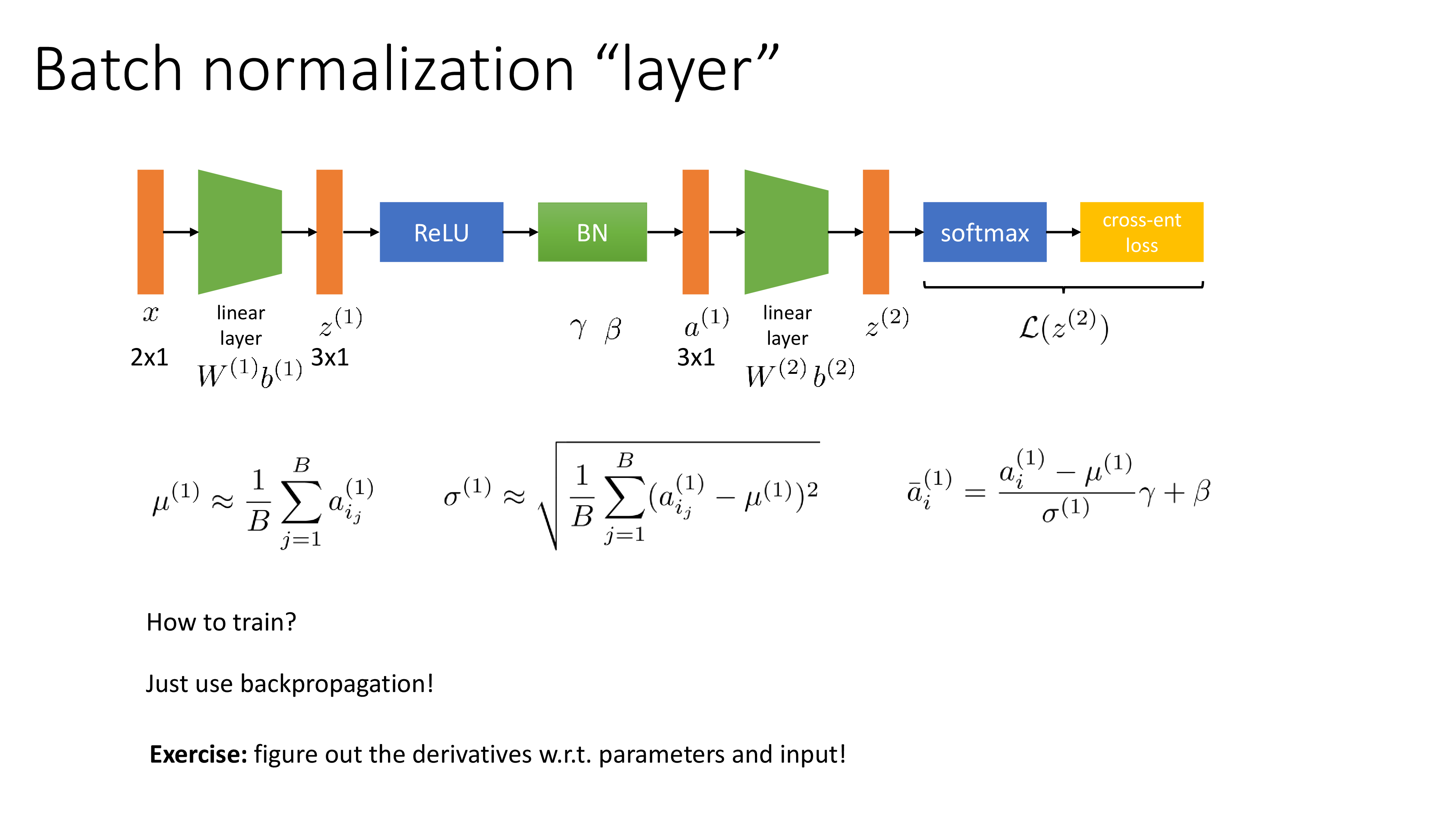 Fig.
Fig.
당연히 error backpropagation 을 사용해서 chain rule을 사용하면 gradient를 구할 수 있다.
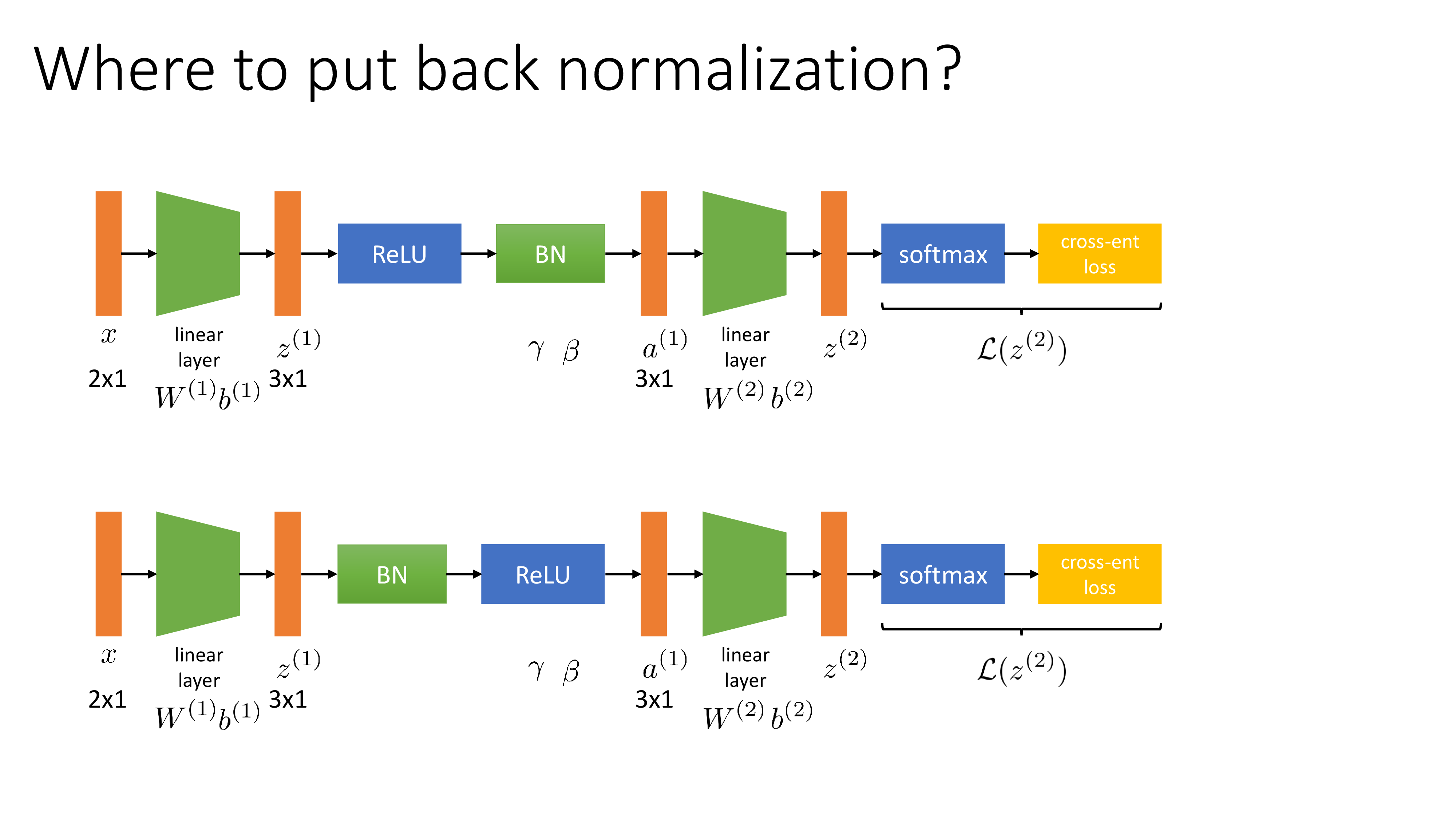 Fig.
Fig.
 Fig.
Fig.
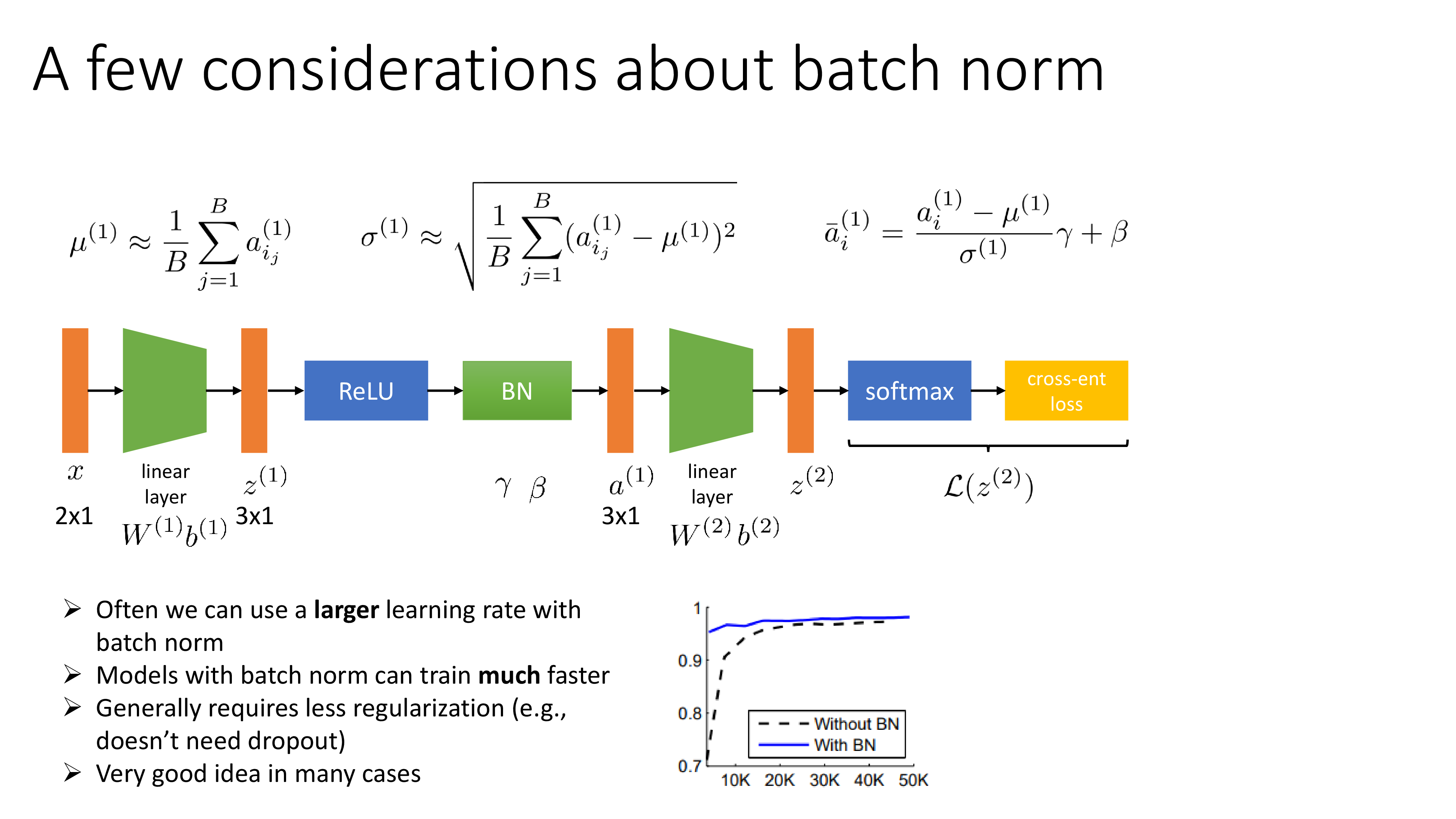 Fig.
Fig.
Linear Layer without Bias term
한 편, bias가 없는 linear layer들로 model을 구성하는 경우가 있다. Bias는 꼭 필요한 term일수도 있고 경우에 따라 아닐 수도 있는데, 예를 들어 우리가 layer 1개로 linear regression를 한다고 쳤을 때 true function이 \(y=3x+10\)이라고 했을 때, 실제로 trainable bias term이 존재하지 않는다면 우리는 이 function을 approximate할 수 없다. 즉 universal function approximator로서의 기능을 제대로 할 수 없는 것이다. 물론 \(y=20x\)정도 되는 function으로 근사했다 칠 수 있지만 error를 0으로 만드는 것은 불가능하다.
하지만 data가 zero centered 되어있다면?
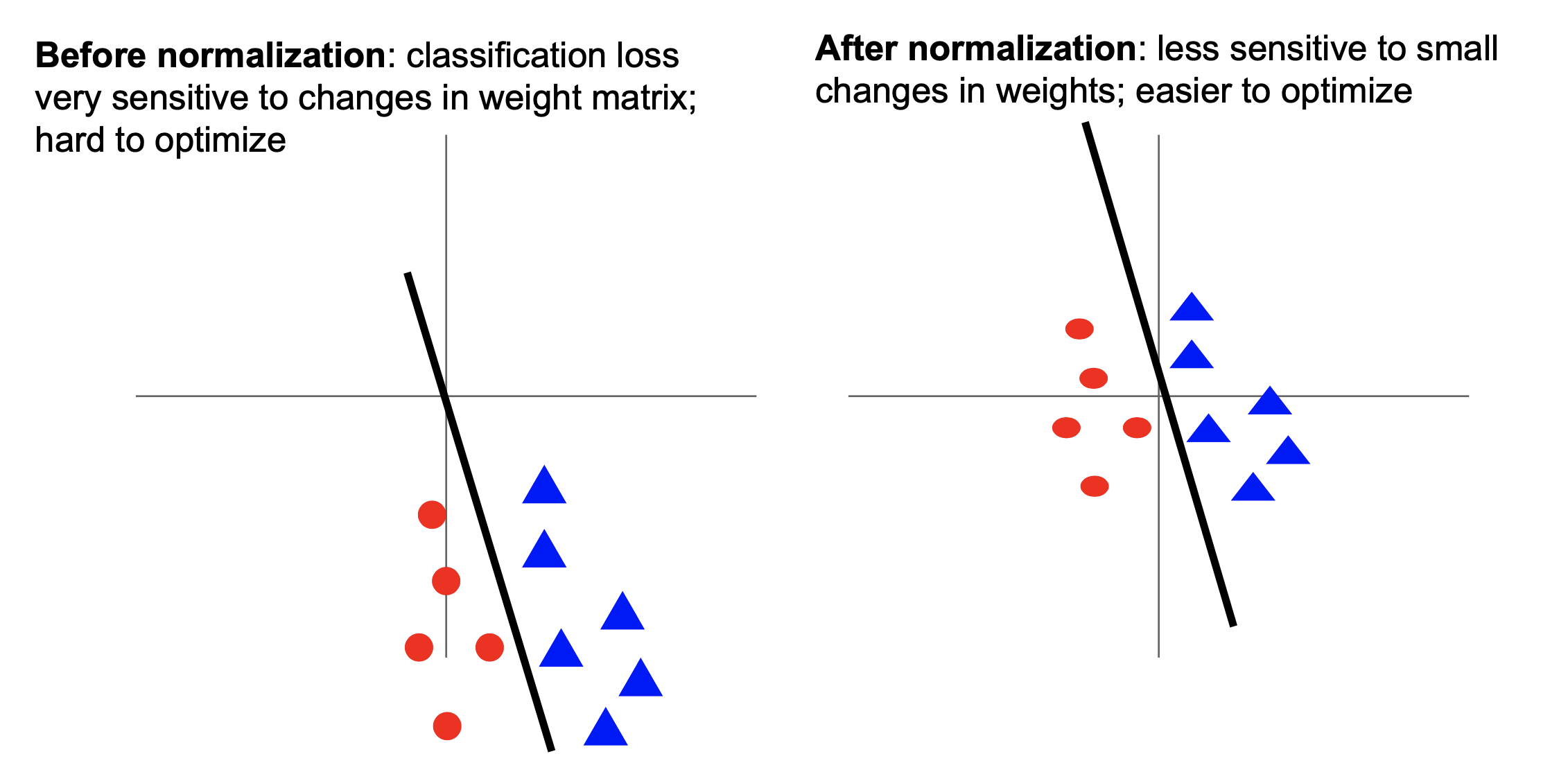
그래서 일반적으로 normalization layer를 포함하는 DL architecture의 경우 normalization layer 앞뒤로는 굳이 bias를 넣지 않는 경우도 있는 것 같다 (어차피 쓸모없음).
Weight initialization
그 다음은 weight initialization이다. NN을 학습할 때 random init point부터 시작해서 iterative optimization을 하면 optimal point으로 갈 수 있다. 무한히 많이 optimization을 하면 말이다. 그런데 무한히 많이 optimization을 하더라도 step size를 잘못 정하거나 하면 local minima에 빠질수도 있고 saddle point에 갖힐 수도 있다.
이런일을 최대한 겪지 않기 위해서는 어떻게 해야할까? 바로 시작점을 잘 잡는 것이다.
Init point를 잡는 몇 가지 중요한 철학은 아래 figure에 나와있다.
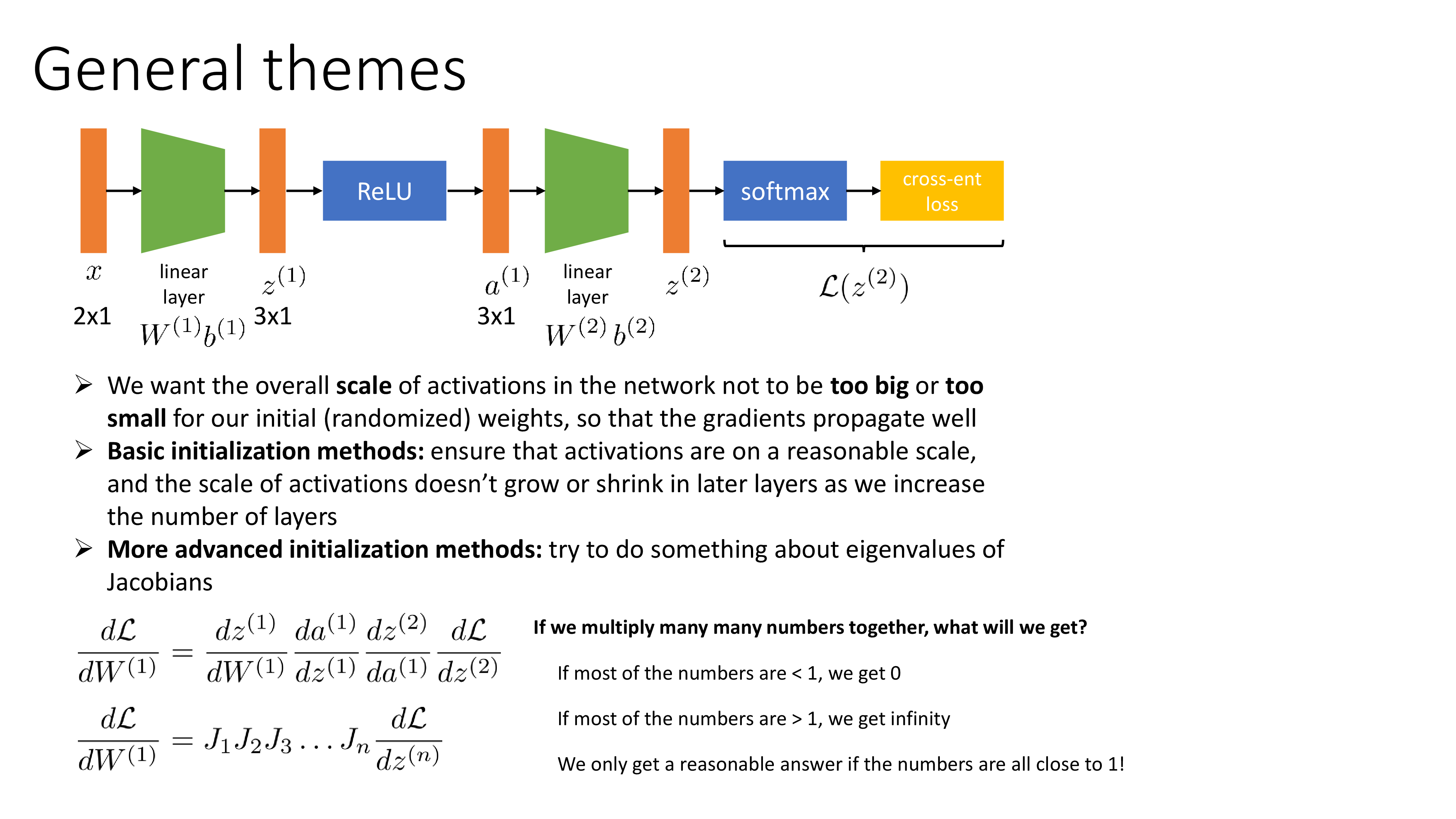 Fig.
Fig.
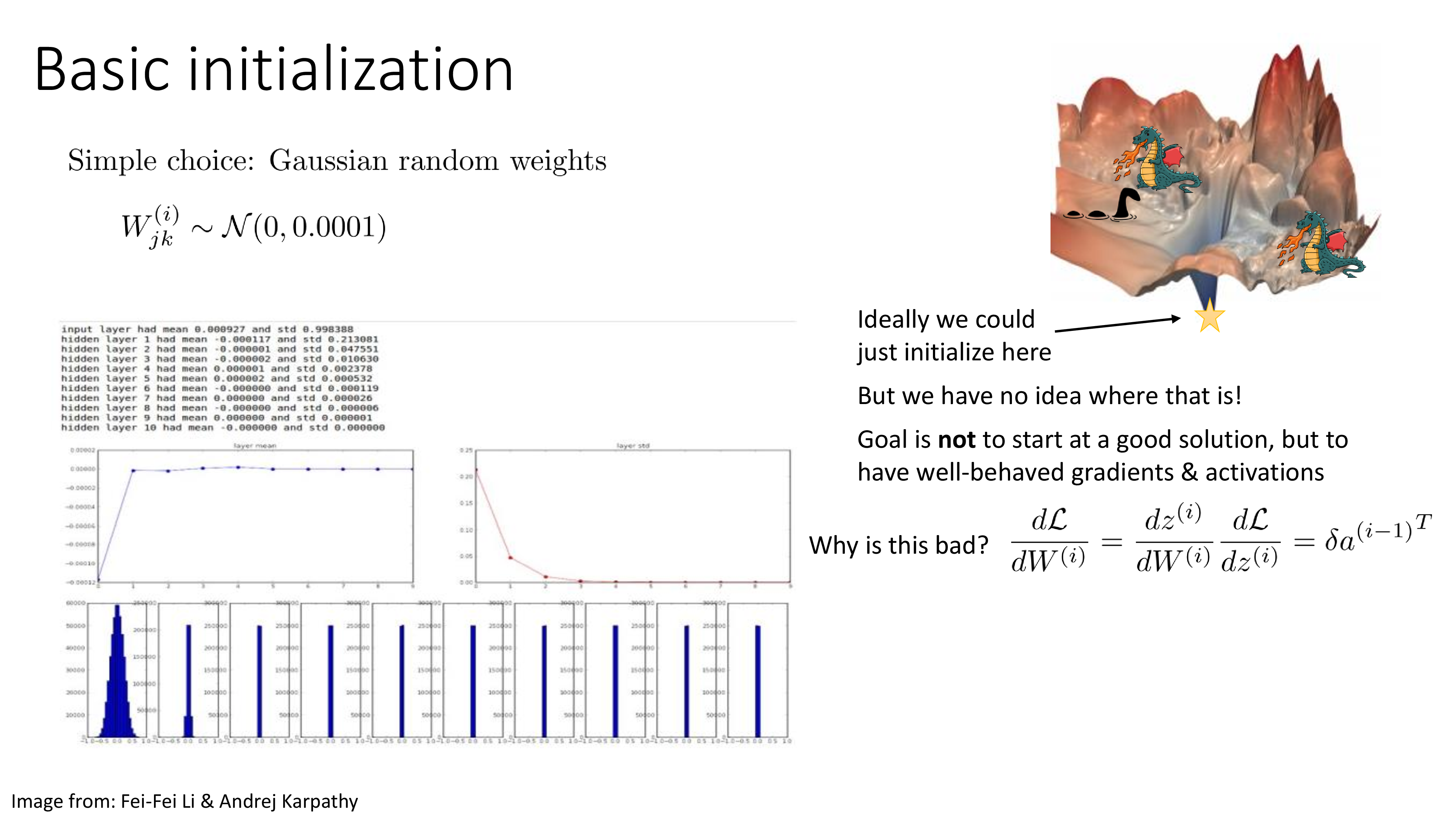 Fig.
Fig.
 Fig.
Fig.
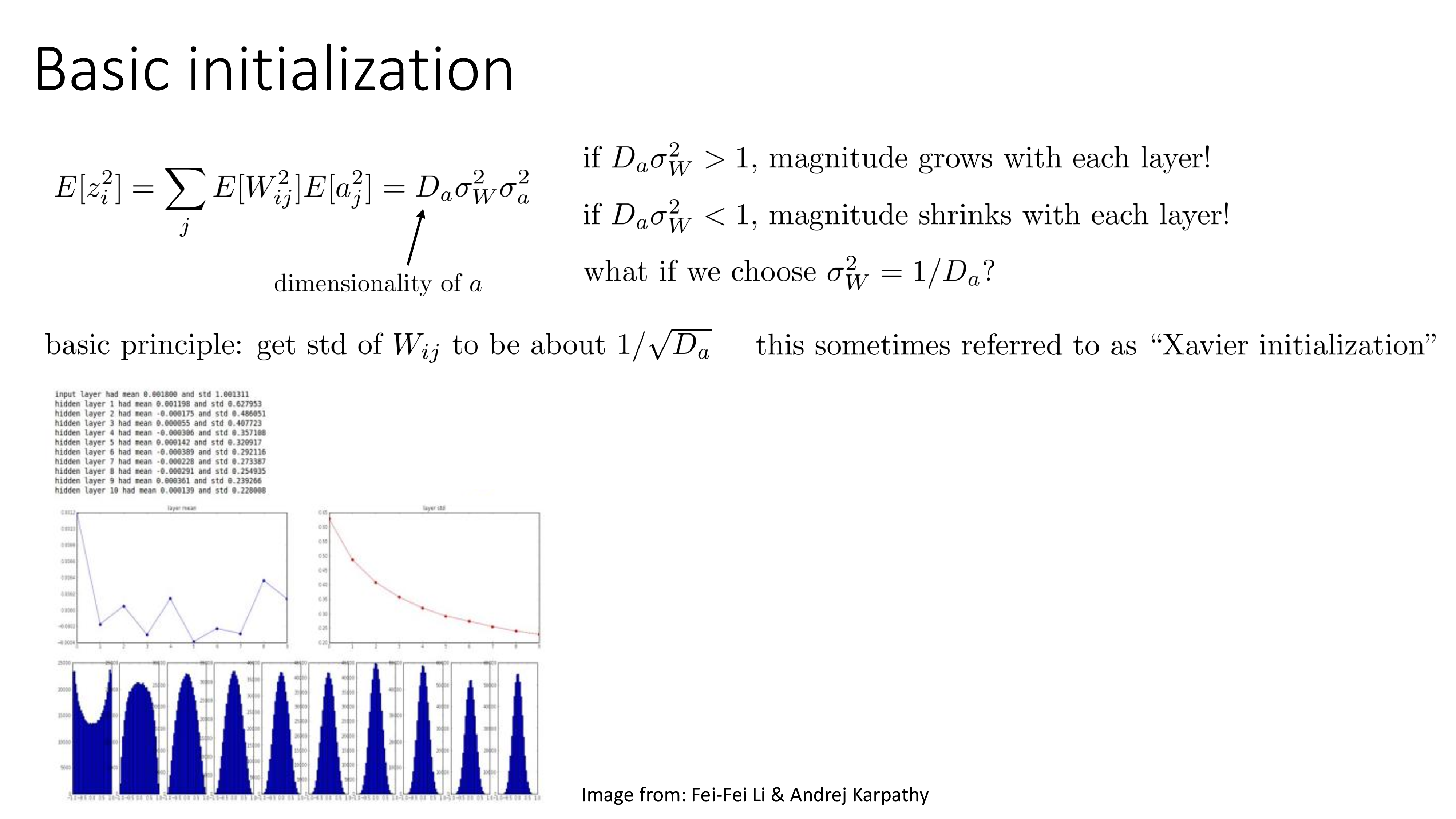 Fig.
Fig.
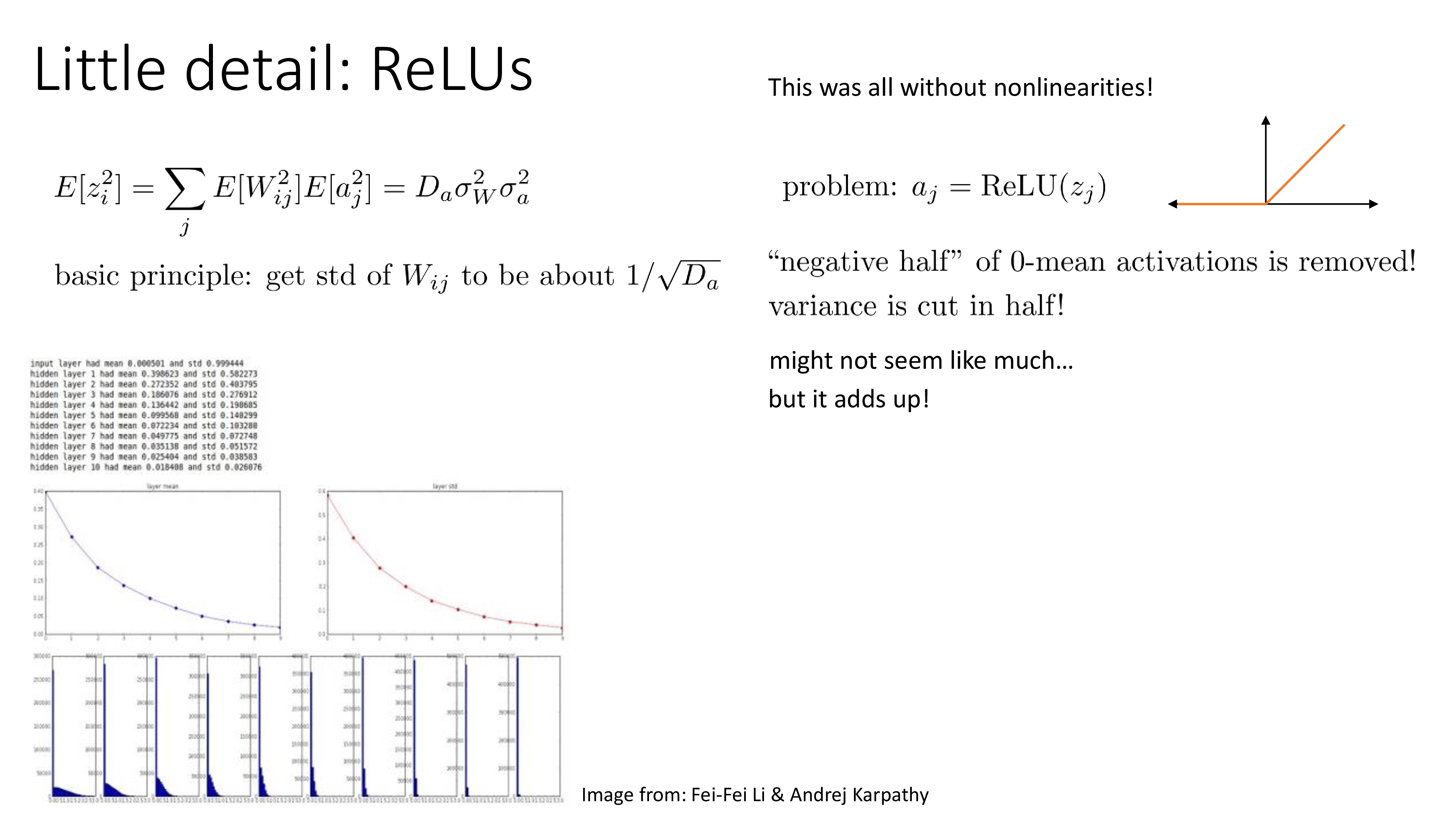 Fig.
Fig.
What happens if NN is initialized with 0?
Gradient Clipping
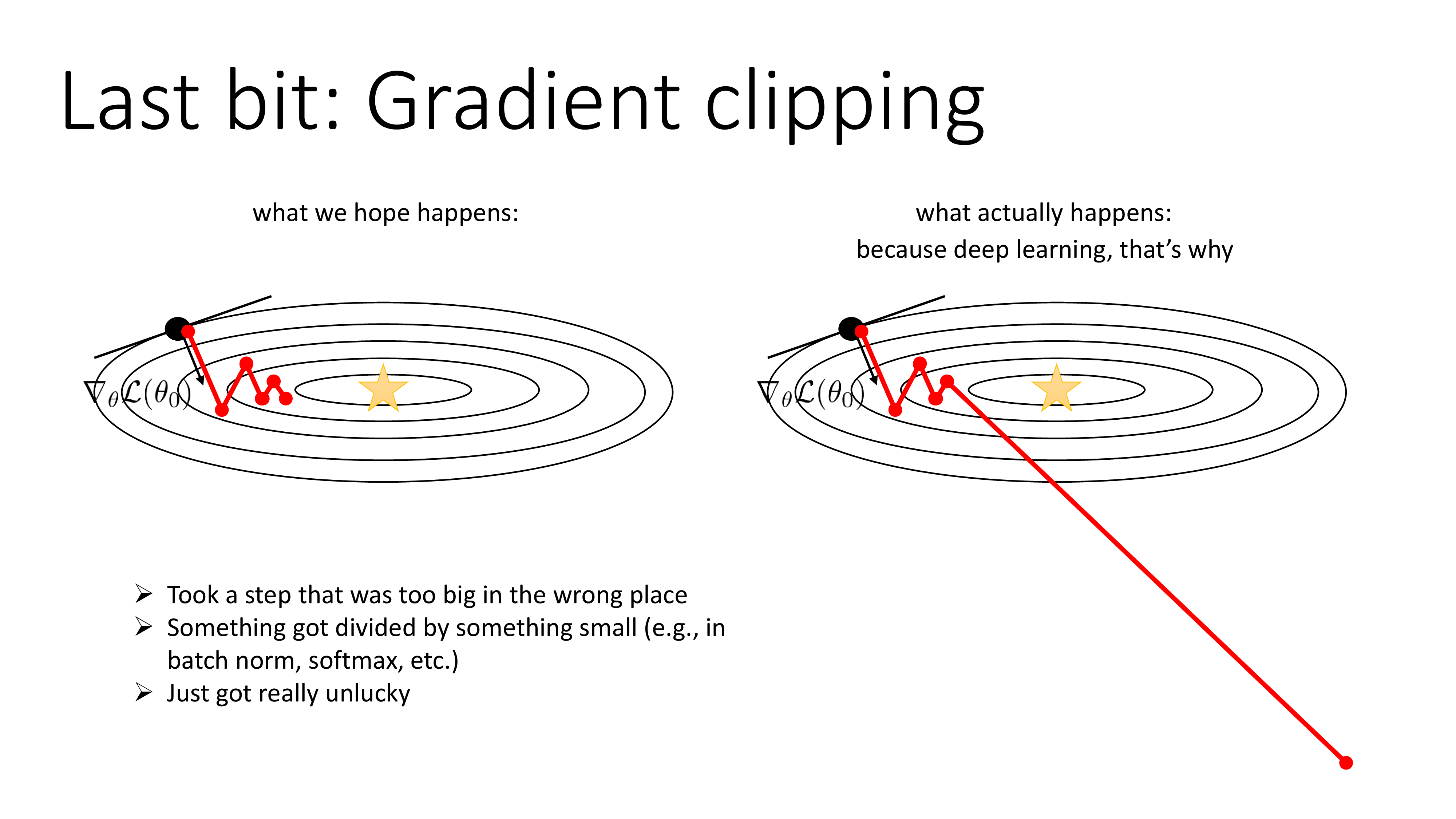 Fig.
Fig.
 Fig.
Fig.
More for Activations
Activation에 대해서 더 얘기해보자. 정확히는 activation function과 dead ReLU같은 현상에 대해서 말이다.
 Fig.
Fig.
 Fig.
Fig.
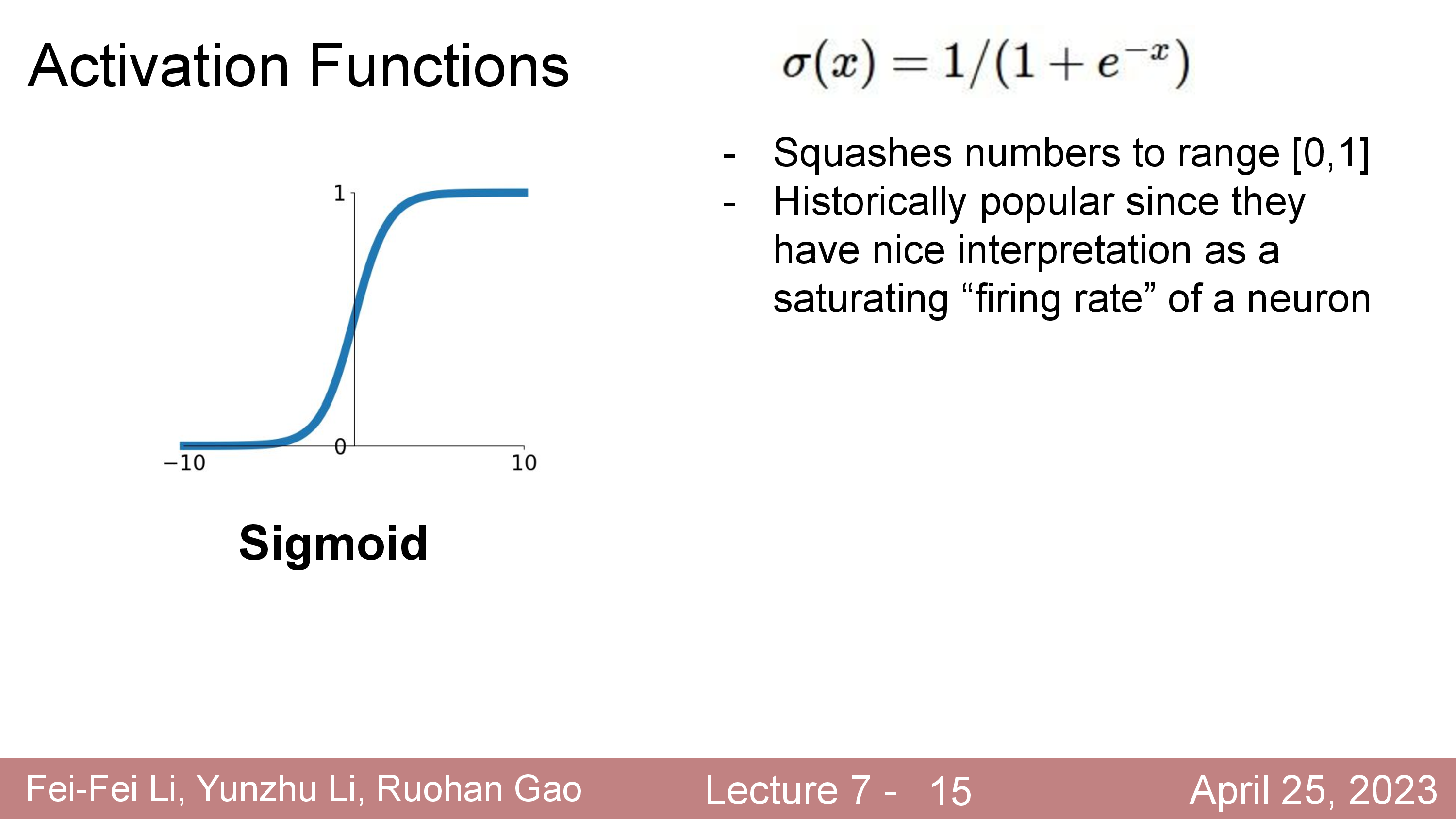 Fig.
Fig.
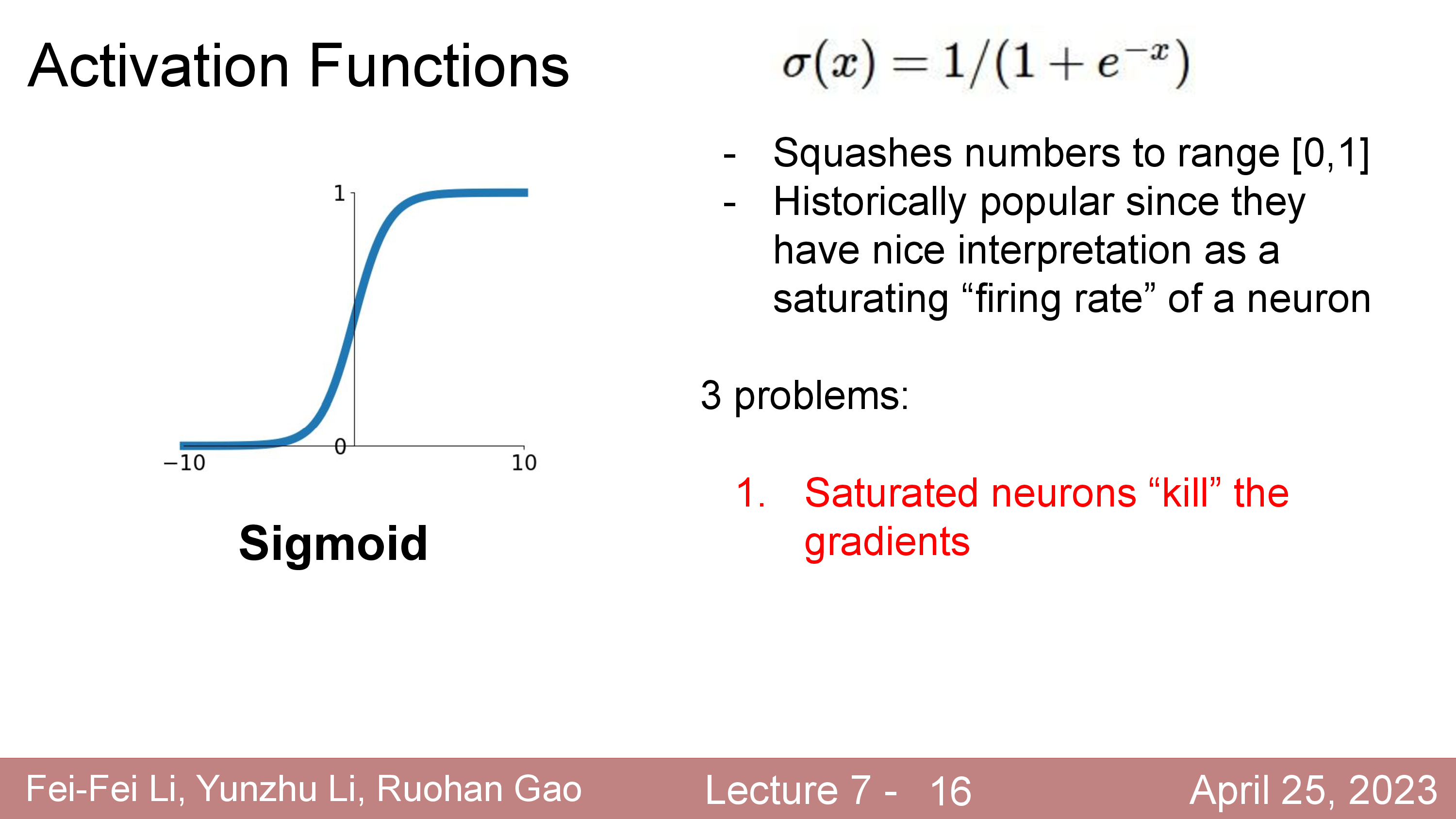 Fig.
Fig.
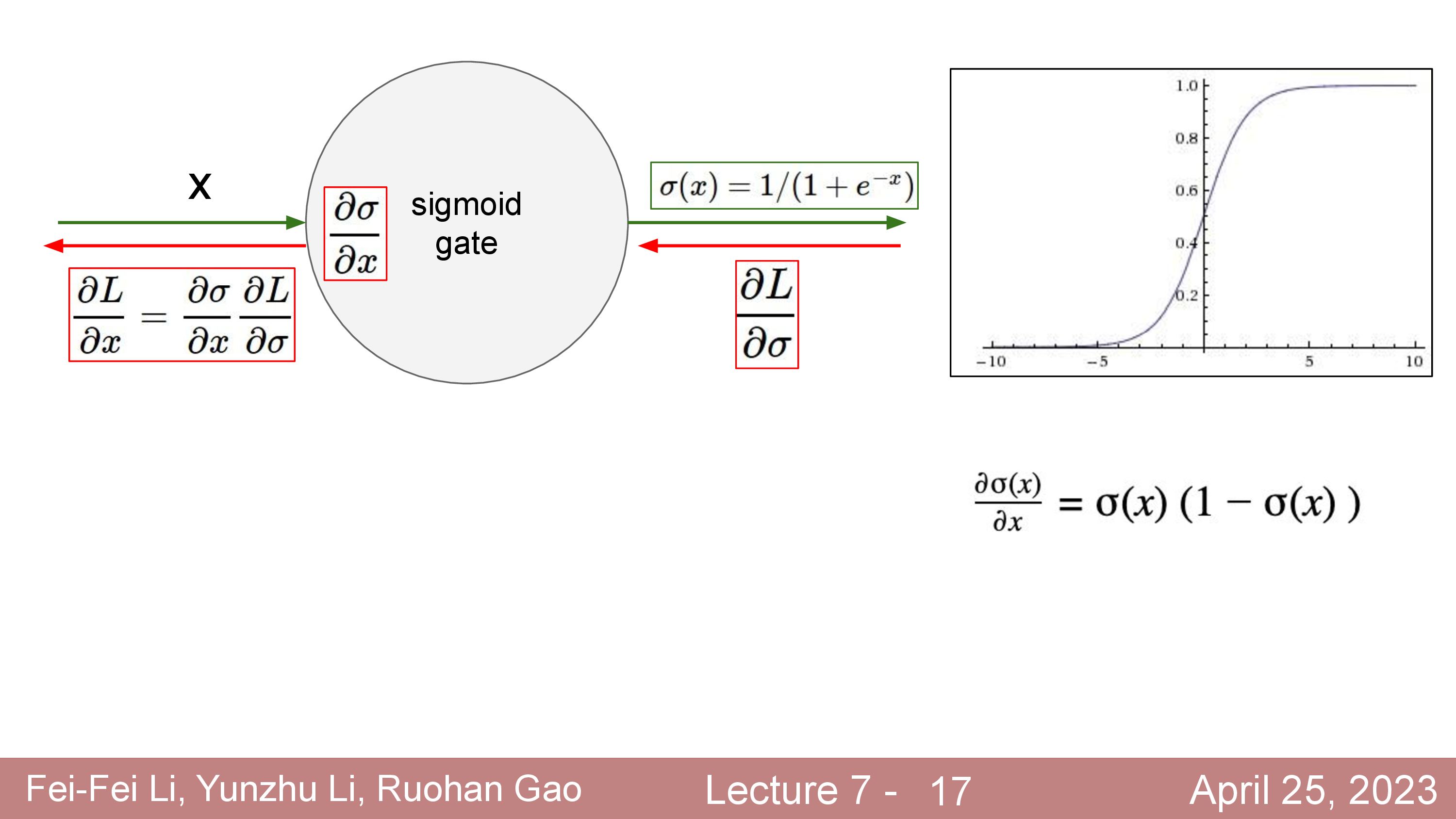 Fig.
Fig.
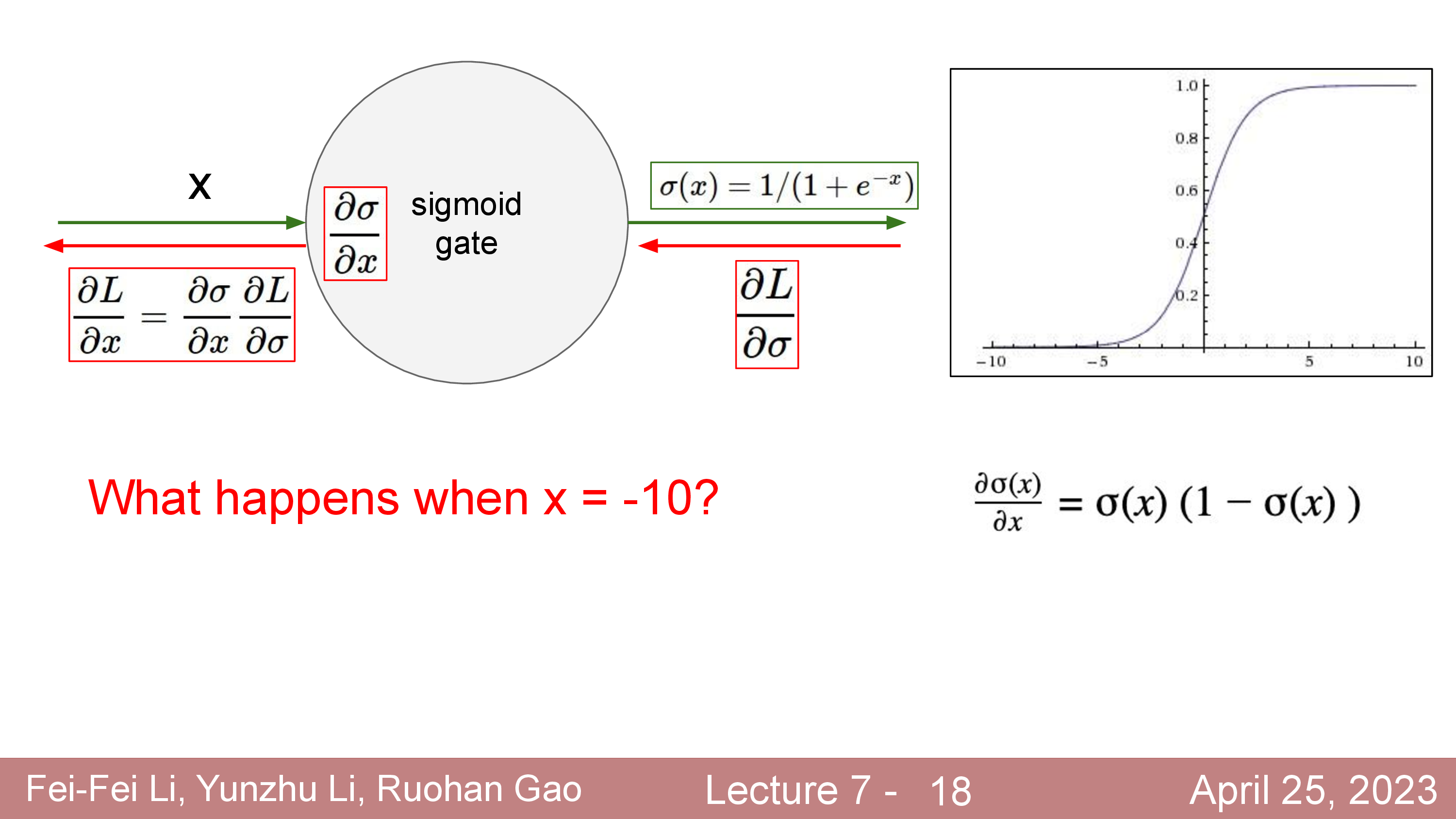 Fig.
Fig.
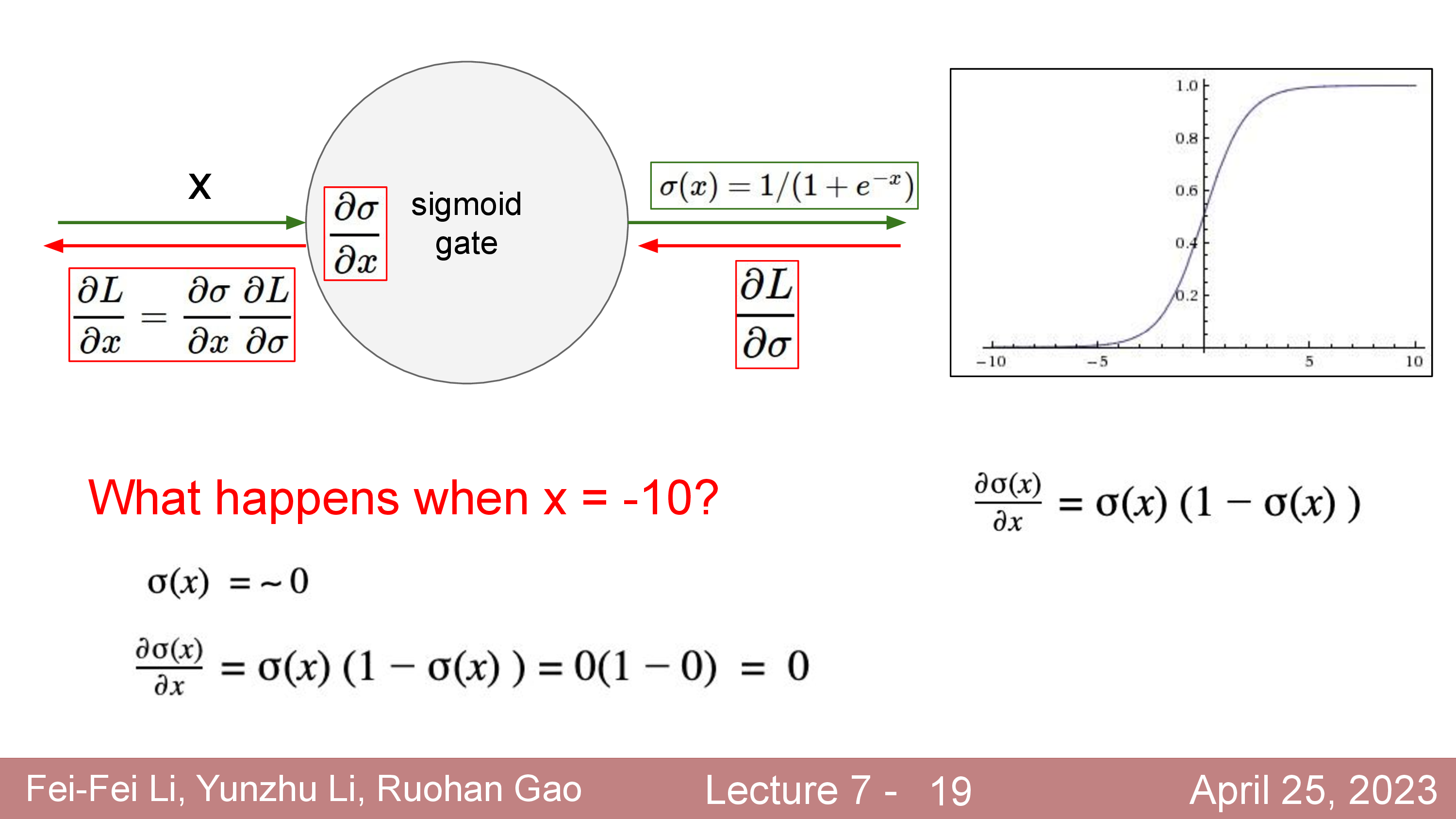 Fig.
Fig.
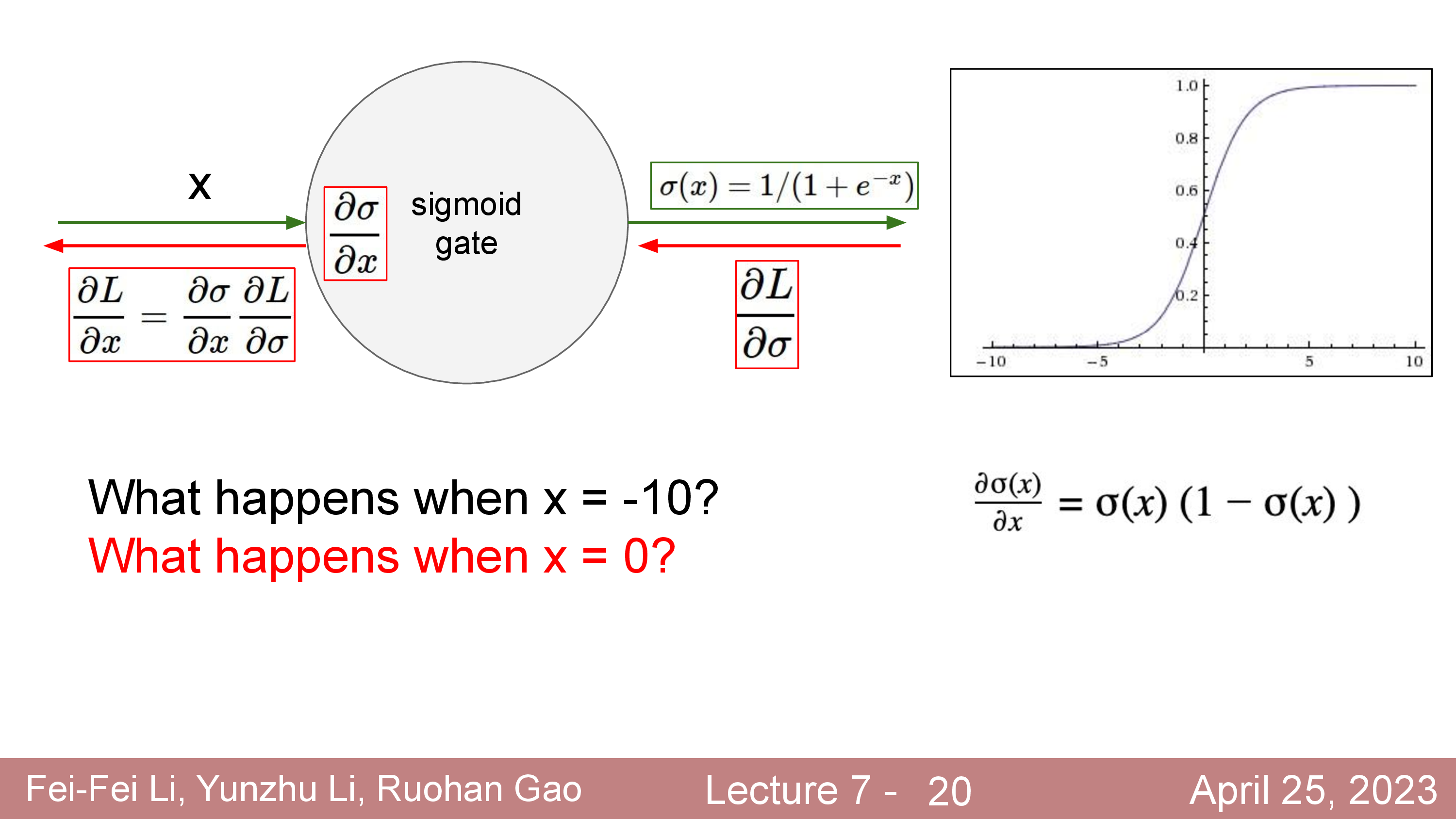 Fig.
Fig.
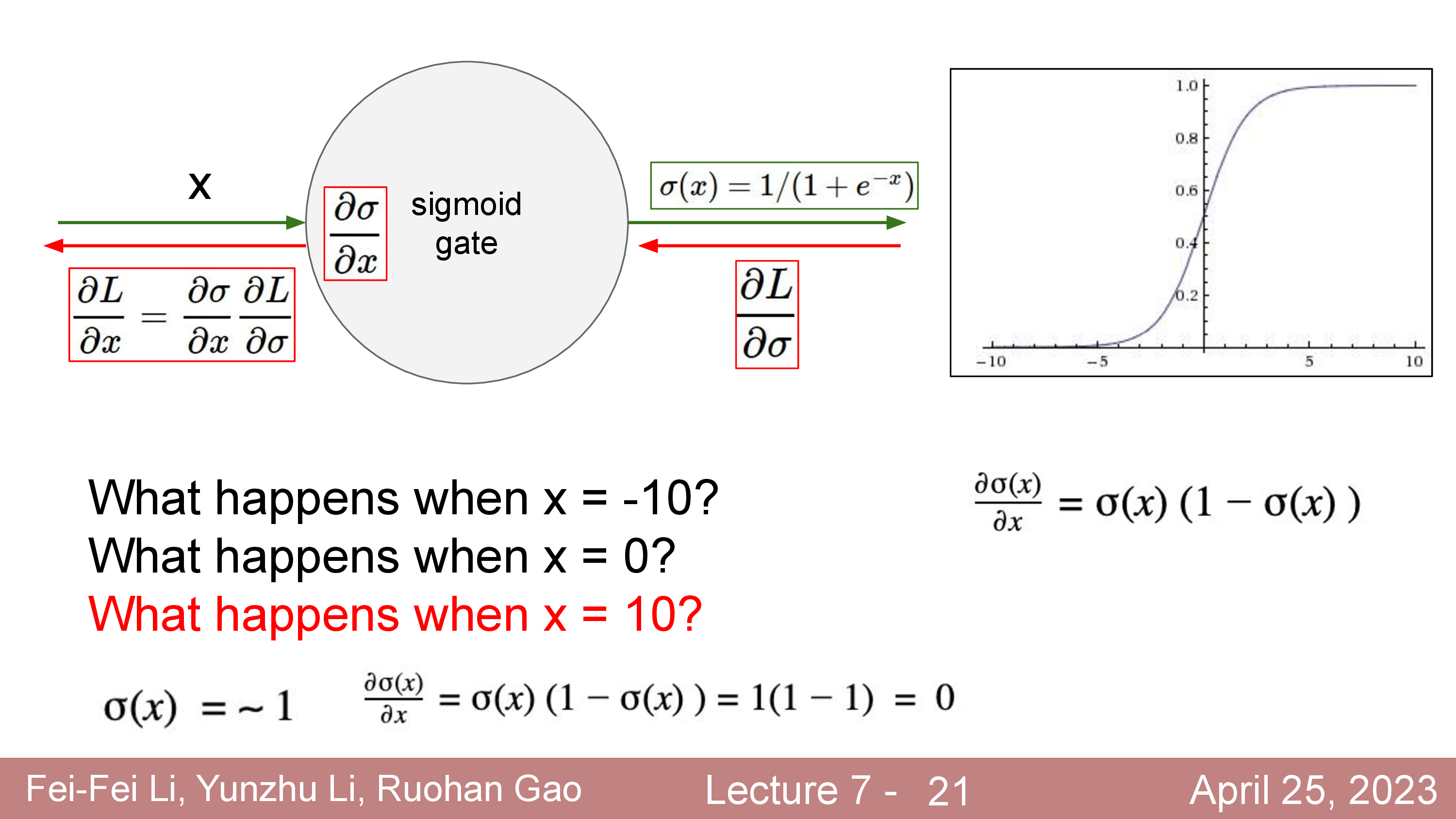 Fig.
Fig.
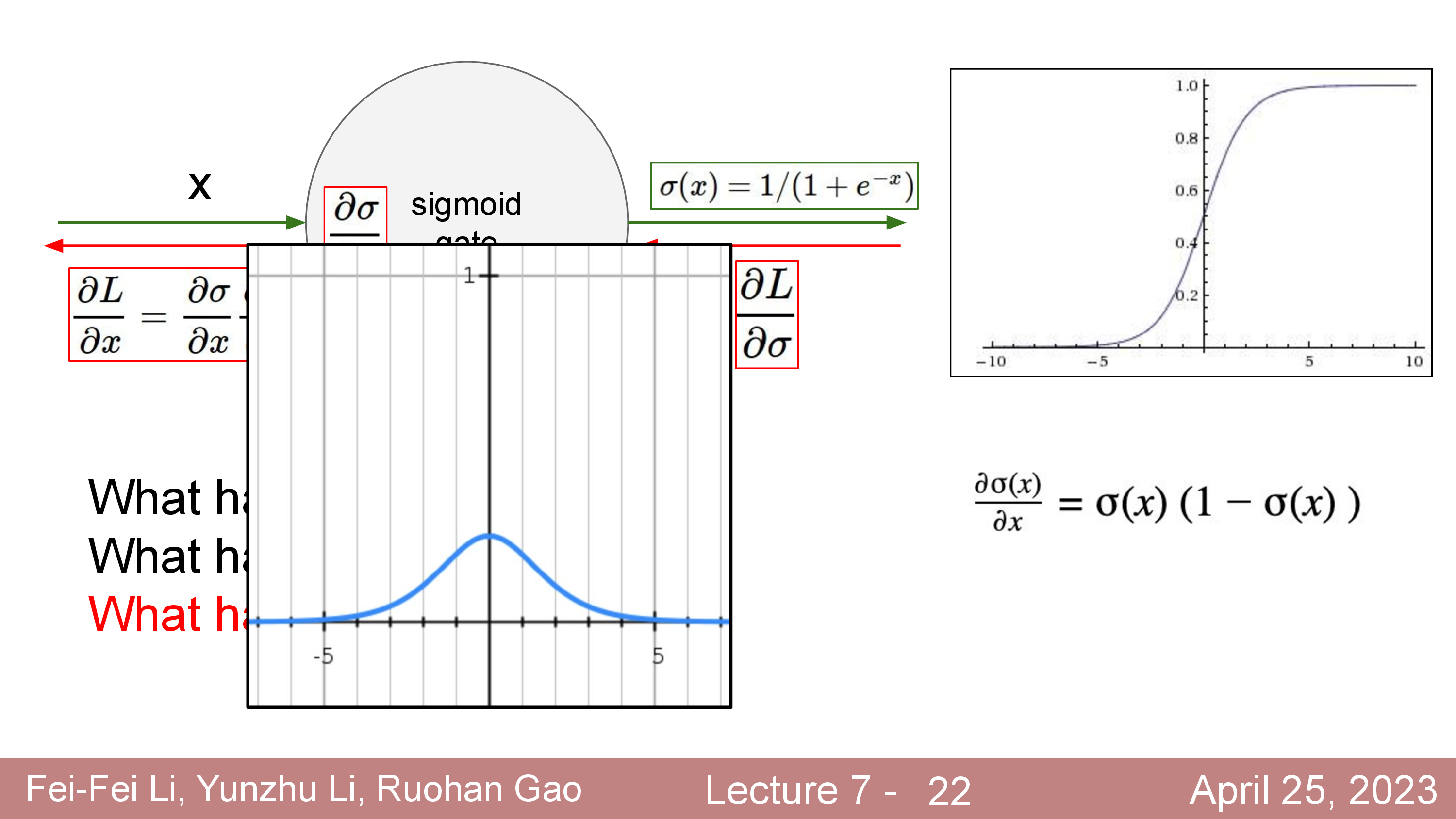 Fig.
Fig.
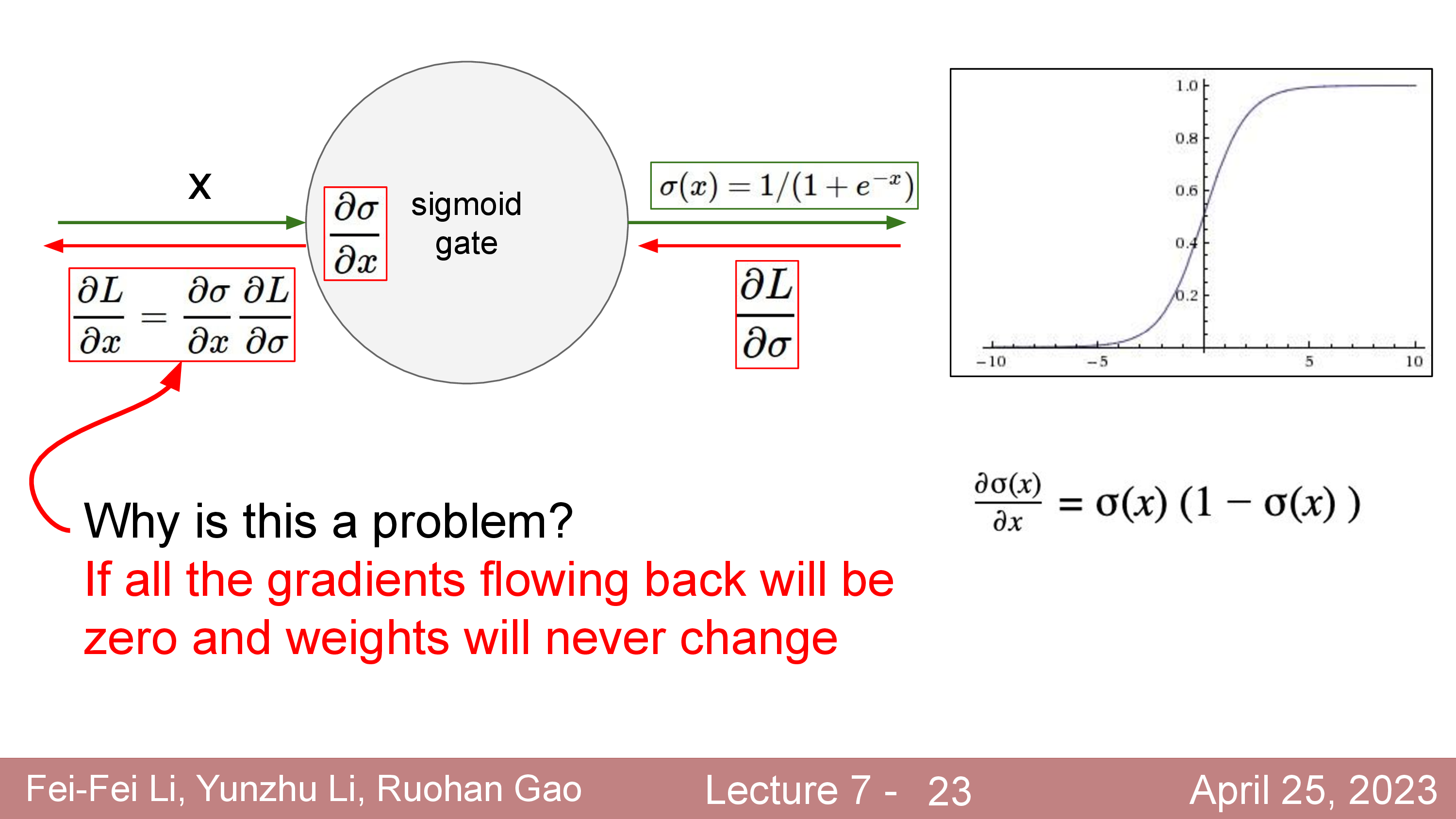 Fig.
Fig.
 Fig.
Fig.
 Fig.
Fig.
 Fig.
Fig.
 Fig.
Fig.
 Fig.
Fig.
 Fig.
Fig.
 Fig.
Fig.
 Fig.
Fig.
 Fig.
Fig.
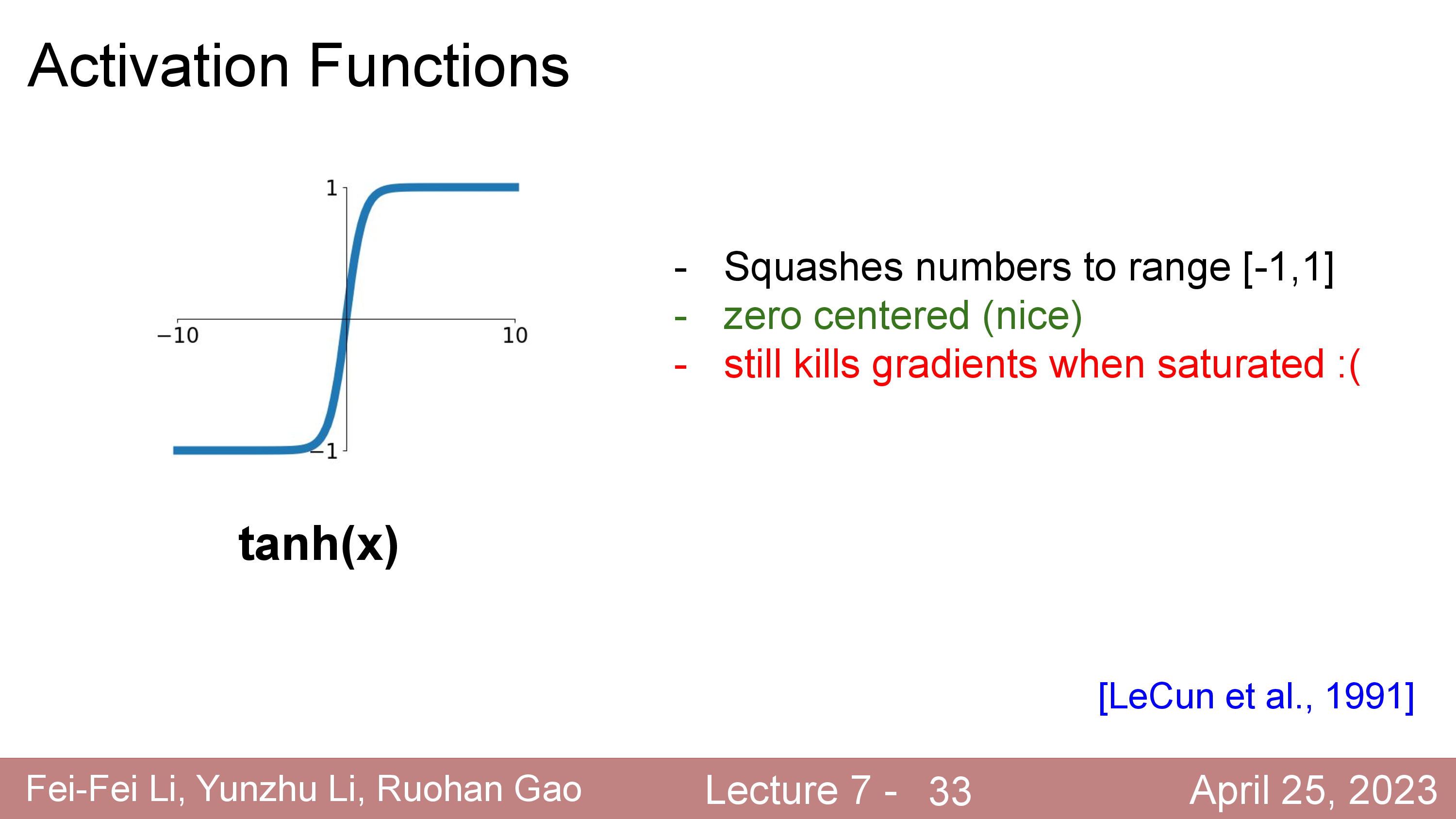 Fig.
Fig.
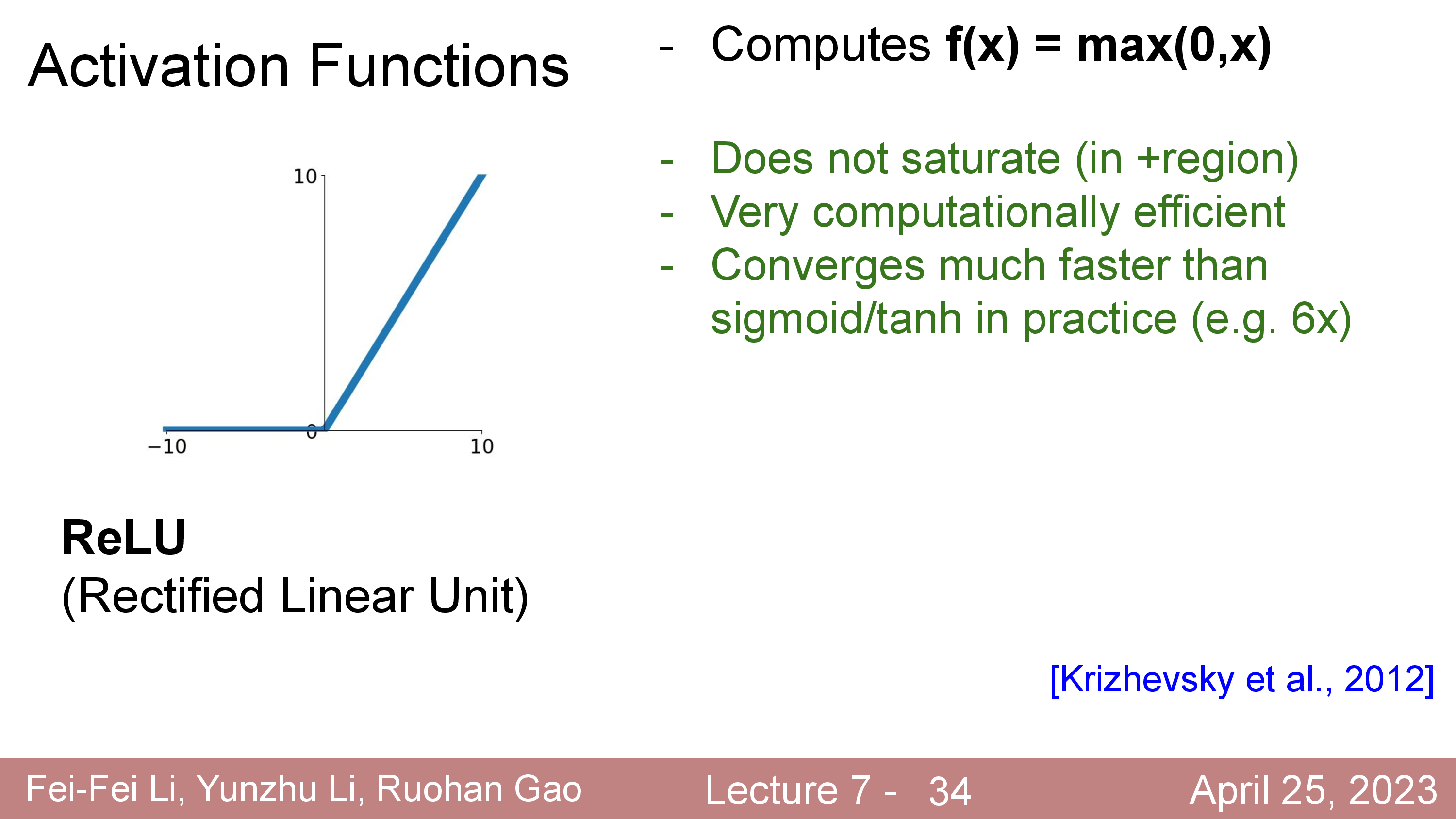 Fig.
Fig.
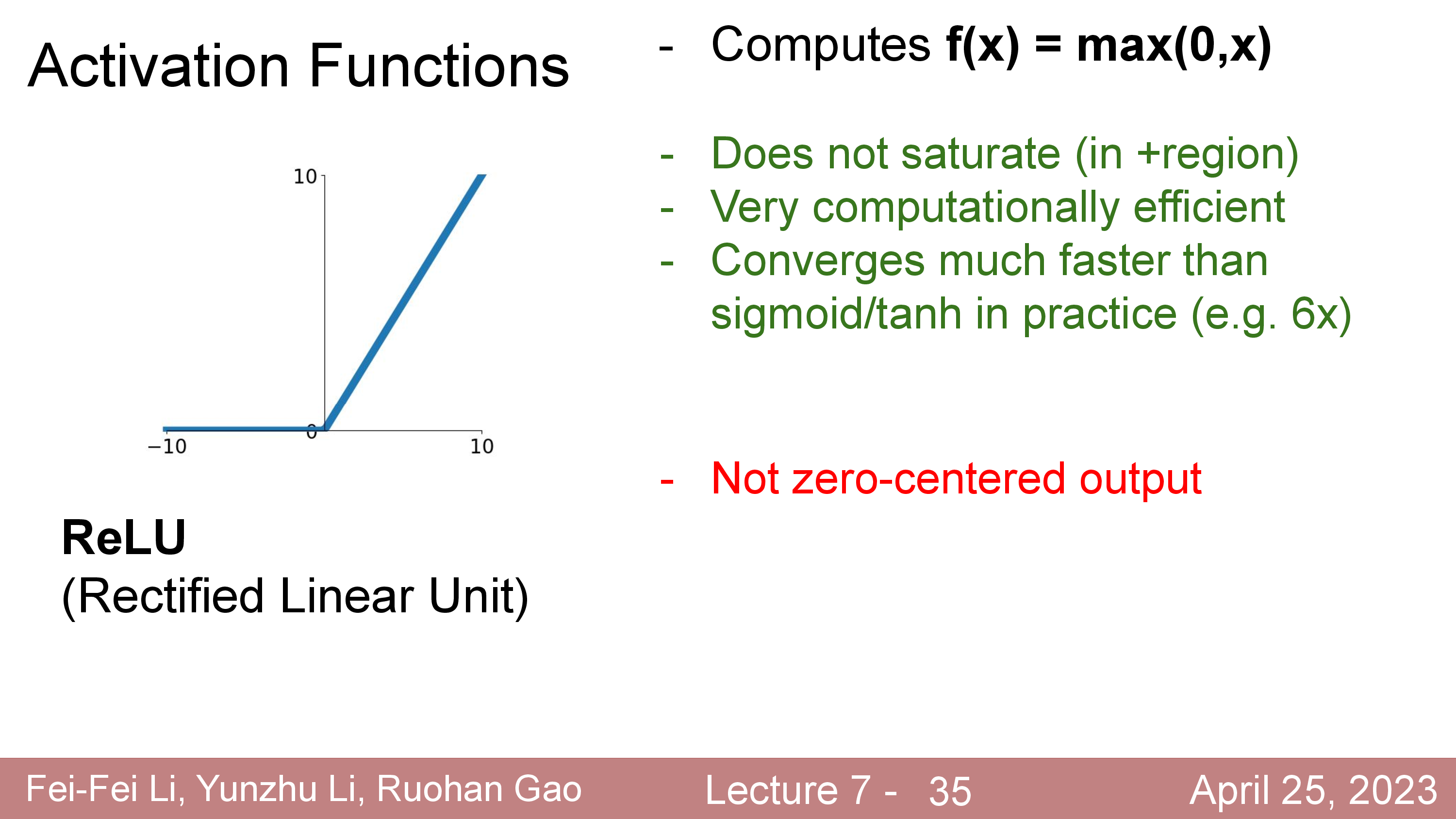 Fig.
Fig.
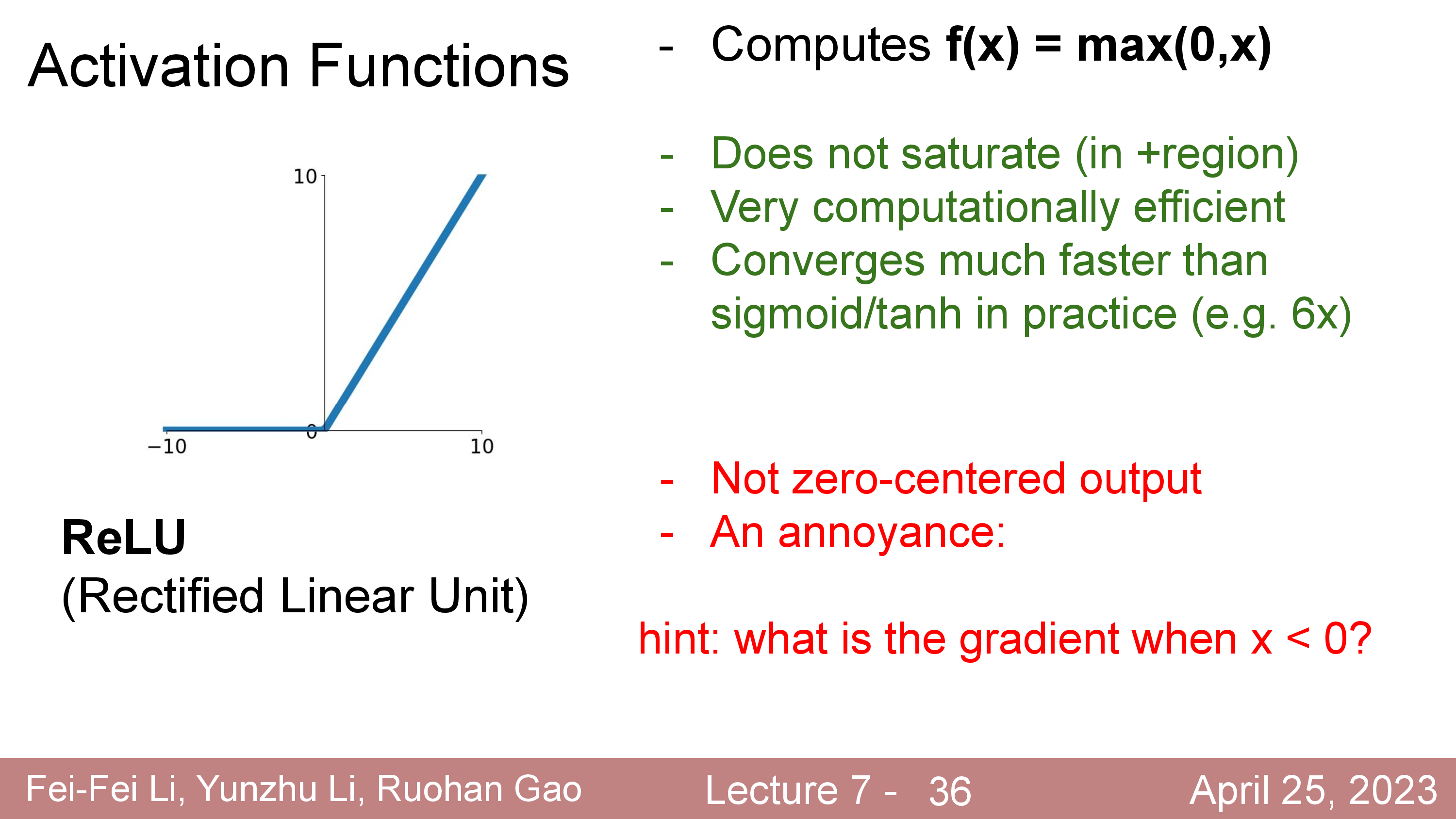 Fig.
Fig.
 Fig.
Fig.
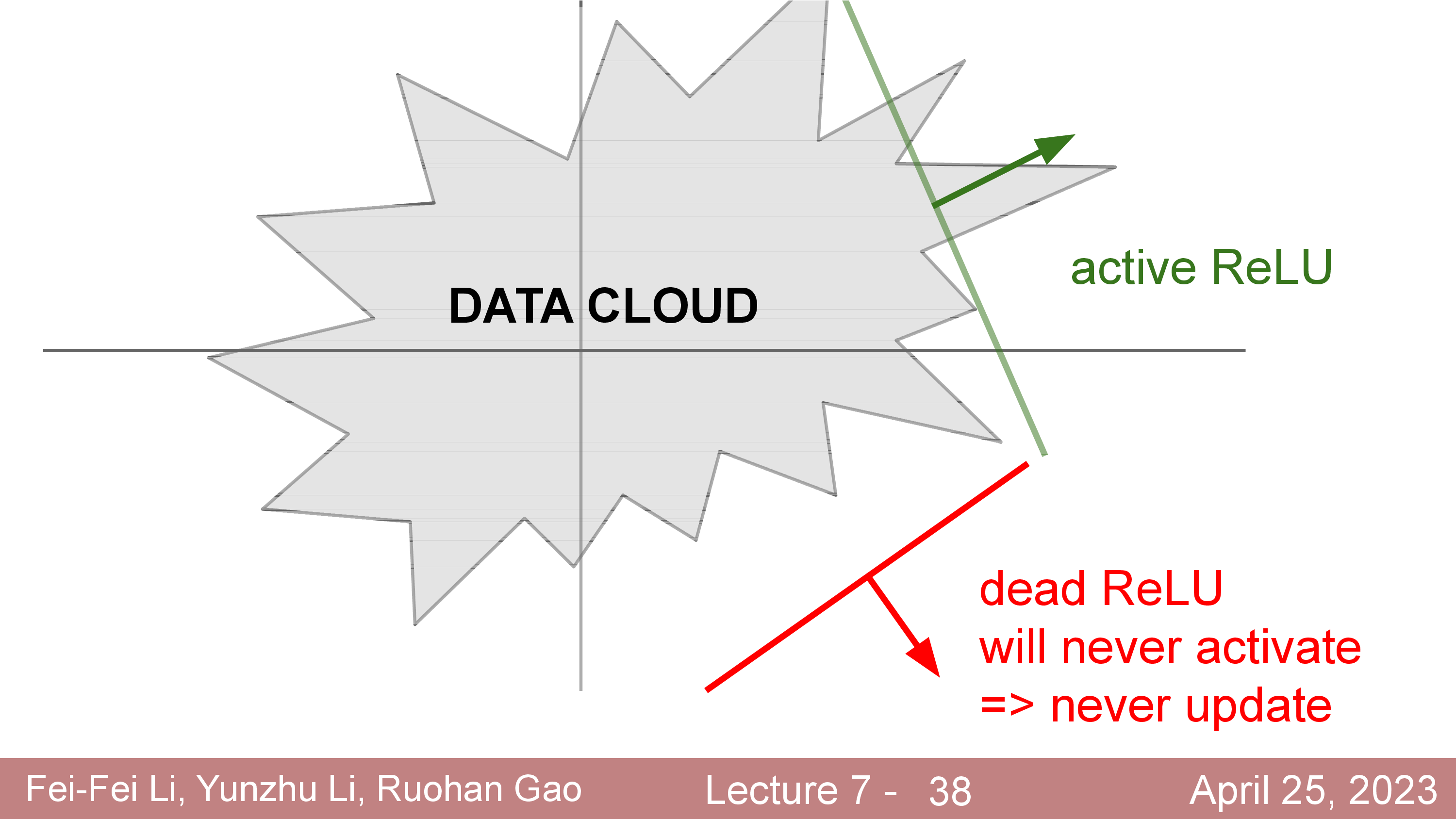 Fig.
Fig.
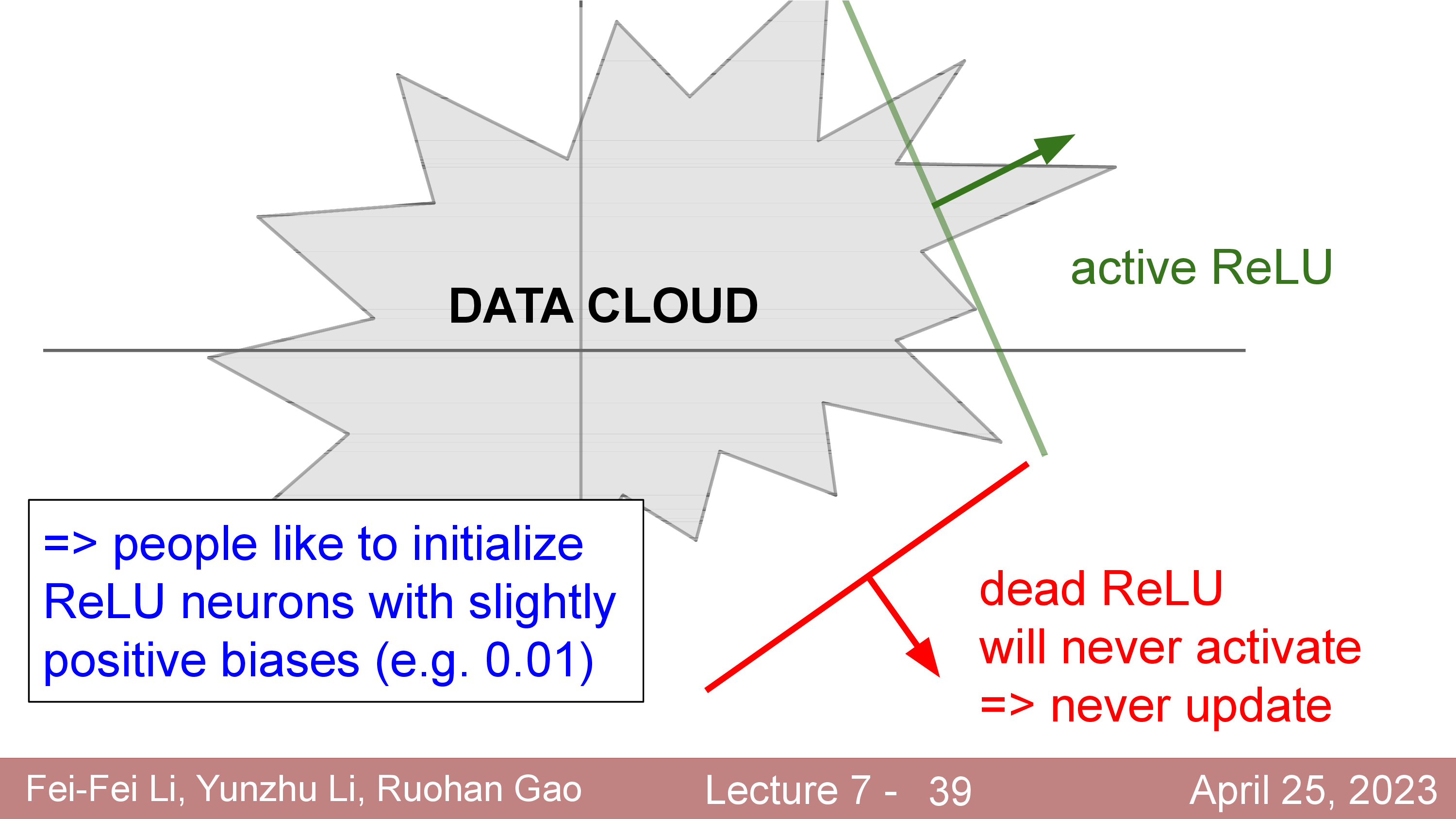 Fig.
Fig.
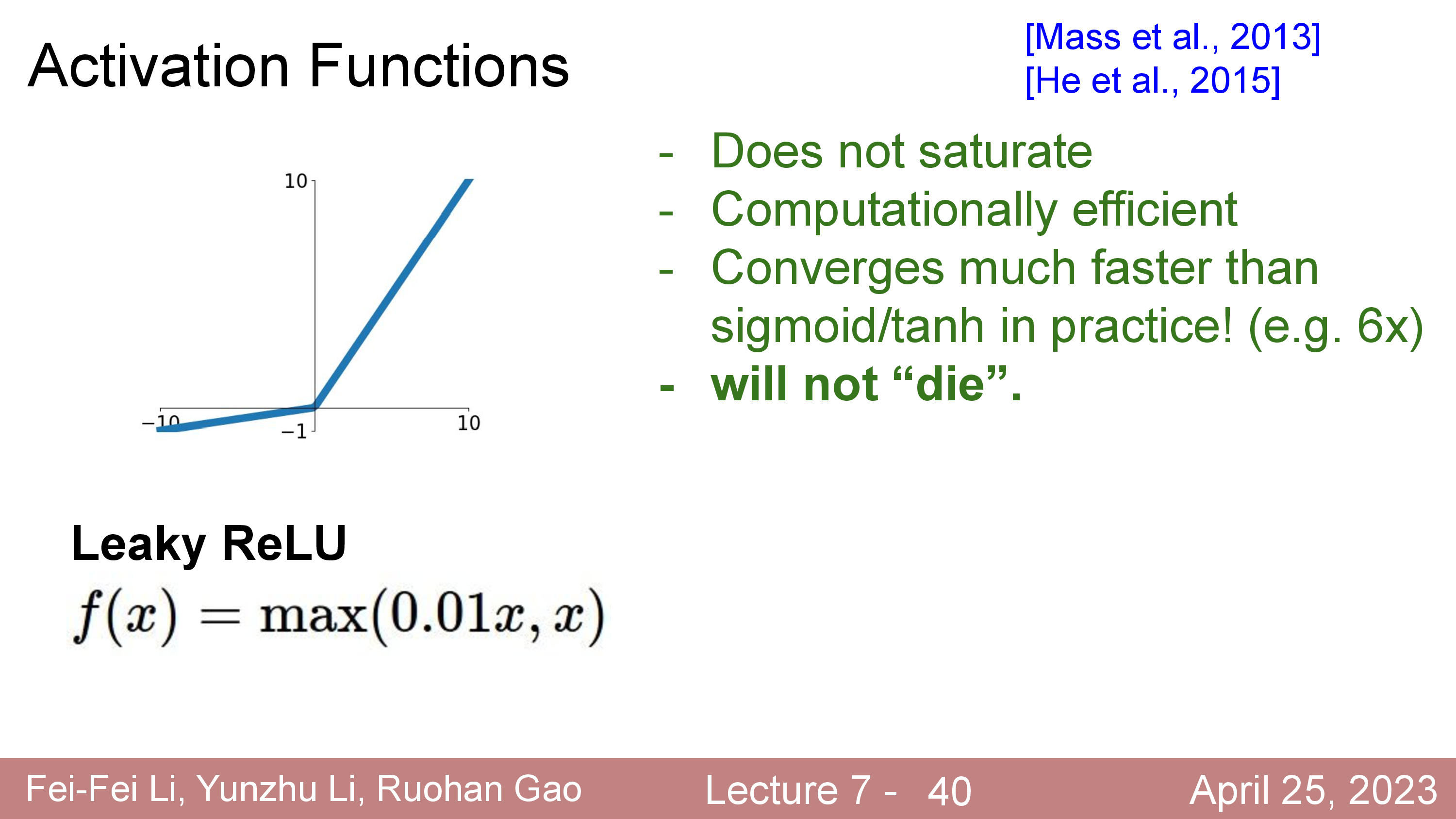 Fig.
Fig.
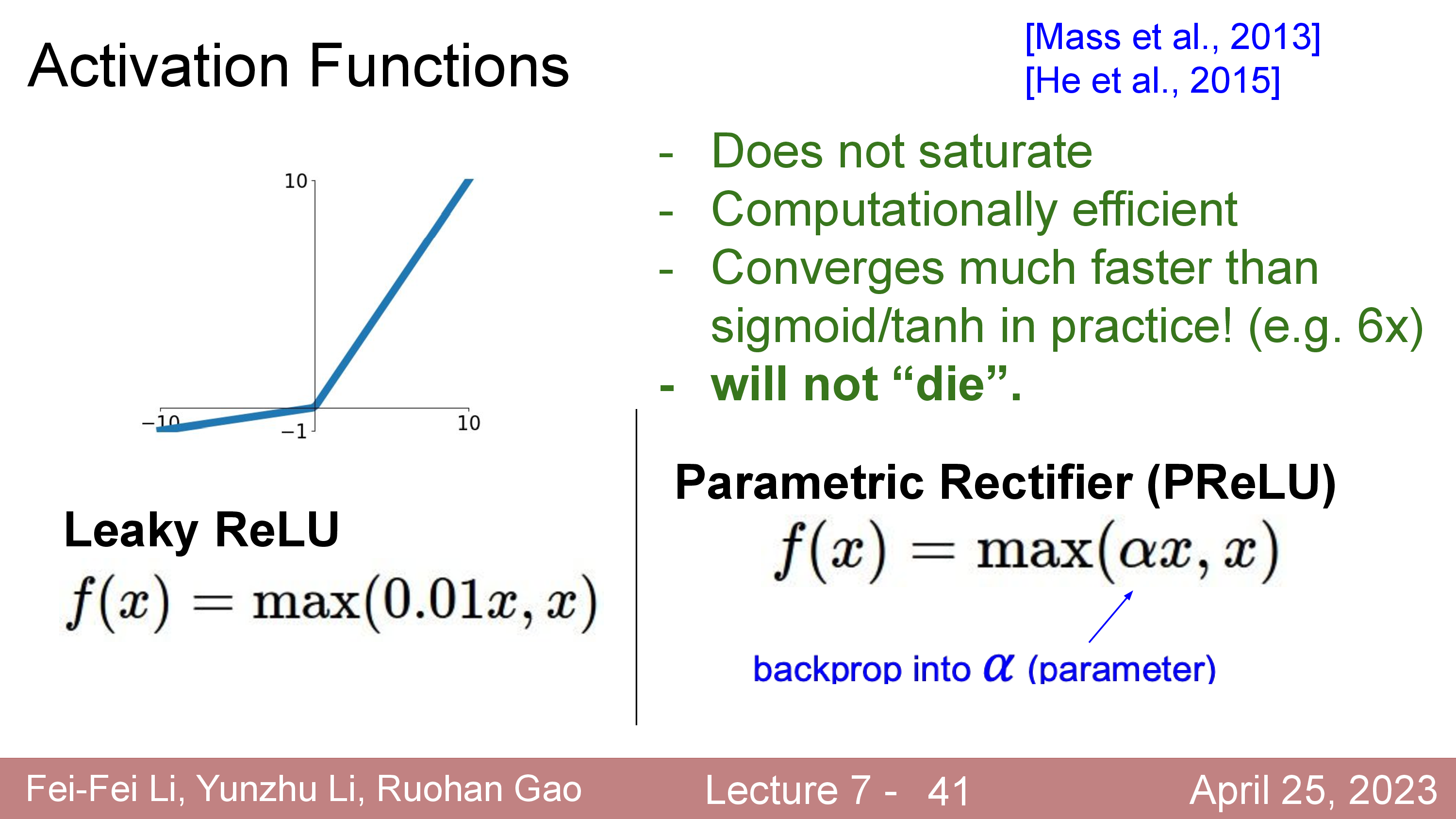 Fig.
Fig.
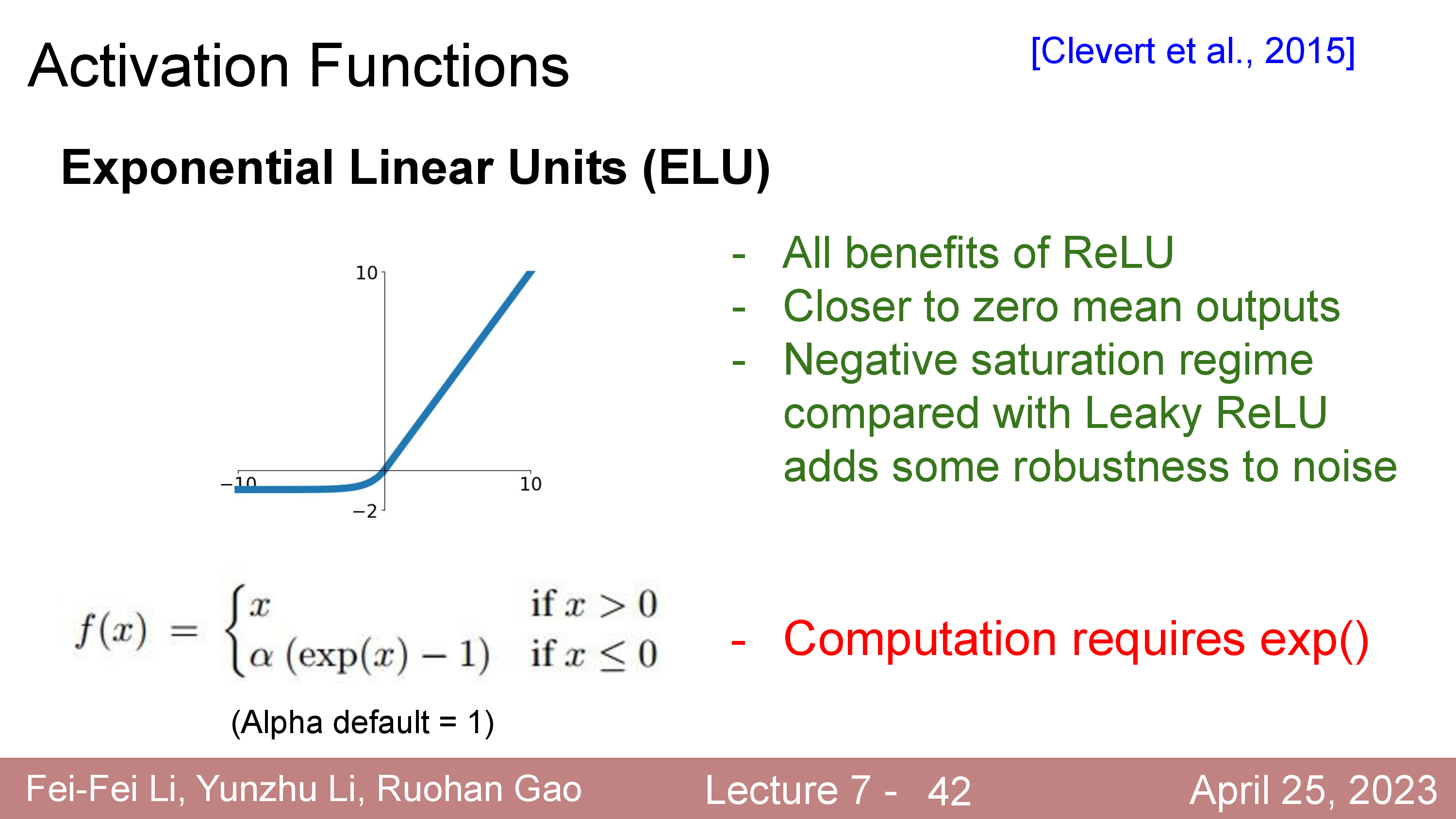 Fig.
Fig.
 Fig.
Fig.
 Fig.
Fig.
 Fig.
Fig.
Modern Activation Functions
한 편, 최근들어서는 sigmoid나 tanh, ReLU같은 activation function들은 잘 사용되지 않는다. 요즘 최신 model들은 Gaussian Error Linear Units (GELUs나 Sigmoid-Weighted Linear Units (SiLU)등을 사용한다.
References
- Lectures
- Others