(WIP) Offline RL (corresponding to CS285 Lec 15 and 16)
08 Aug 2023< 목차 >
- Introduction
- Offline RL (Batch RL)
- Key Idea for Offline RL : Conservative Optimization
- Goal Conditioned BC Methods
- Outro
- References
These are the key resources I used to write this post.
Introduction
일반적인 Deep Learning (DL)은 일단 train dataset이 정해지면 (data distribution으로부터 i.i.d sampling 되었다고 가정) 그 dataset을 가지고 여러 epoch을 돌며 iterative optimization을 통해 Neural Network (NN)의 parameter를 최적화한다.
하지만 Reinforcement Learning (RL)은 매 optimization step마다 현재 내가 가지고있는 \(t\) 시점의current policy, \(\pi_{\theta_t}\)를 가지고 trajectory를 만들고 environment와의 interaction을 통해 각 state에서 이 action을 것이 어땠는가?에 대한 평가 (보상; reward)를 받아 학습한다.
즉 RL은 매 iteration마다 dataset을 다시 만들어야 한다고 볼 수 있는데, 이것이 RL 학습을 매우 비효율적으로 만든다.
RL에서는 '그래서 좋은 policy를 얻기까지 얼마나 많은 sampling 해야하는데?'를 sample efficiency라고 한다.
적게 필요할수록 efficient한거고 많이 필요할수록 inefficient한 것이지만 대부분의 RL은 이렇게 매 번 data를 sampling 해야하는 Online RL setting이다.
(하지만 sample efficient 하다고 해서 수렴하는데 실제로 걸리는 시간, total train wall clock이 항상 작은건 아니다)
Offline RL의 가장 큰 motivation은 매번 sampling 하기 싫다는 것이다.
즉 DL처럼 정해진 dataset을 가지고 data-driven으로 문제를 풀고싶다는 것.
Offline RL (Batch RL)
Offline RL을 하려면 일단 맨 처음에 trajectory들을 대거 sample해두고 이걸로 RL을 하면 되는데, 그러기 위해서는 어떠한 (optimal) policy로부터 trajectory를 sample해야한다.
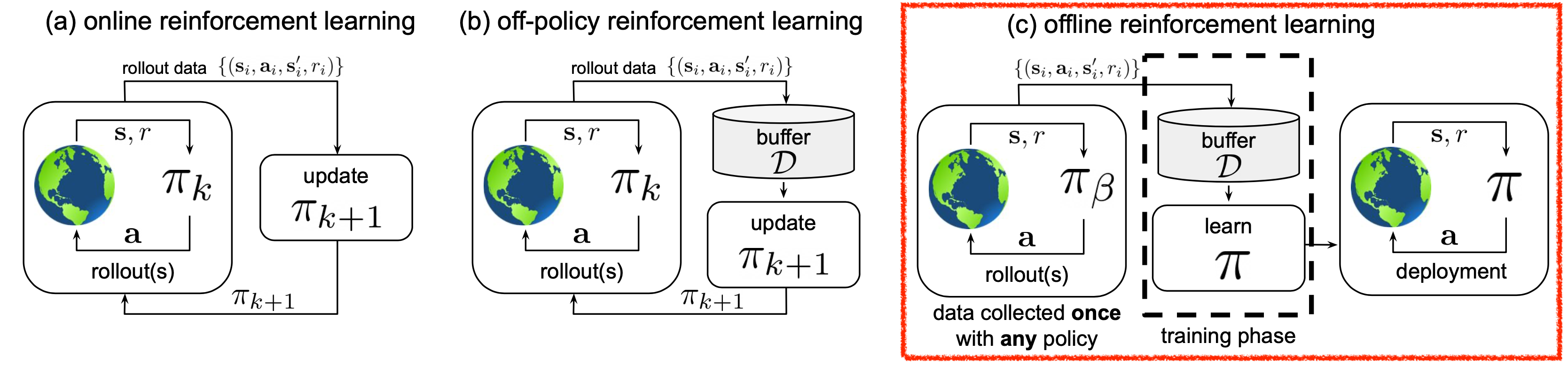 Fig. Offline RL은 online, off-policy RL과 다르게 environment와 interaction이 전혀 없이 맨처음에 모은 trajectory sample들만 가지고 한다.
Fig. Offline RL은 online, off-policy RL과 다르게 environment와 interaction이 전혀 없이 맨처음에 모은 trajectory sample들만 가지고 한다.
어떠한 policy는 실제로는 human expert의 data를 쓰거나 아니면 이미 잘 학습된 policy로부터 sampling된 trajectory를 쓸 수도 있다.
 Fig.
Fig.
하지만 human expert의 data가 있다면 policy를 학습하는 가장 쉬운 방법이 있지 않을까?
바로 주어진 state에서 expert의 action이 항상 맞다고 가정하고 그 action의 확률이 1이될때까지 학습하는 SL을 하면 되는데 이를 RL domain에서는 Behavior Cloning (BC)라고 부른다.
그럼 왜 굳이 어렵게 Offline RL을 해야할까?
Behavior Cloning (BC) vs Offline RL
BC는 human expert data를 그대로 모방하기때문에 Imitation Learning 이라고 하는 사람들도 있다.
하지만 엄밀히 말해서는 Imitation Learning이 좀 더 큰 개념이고 BC는 하위 개념이다.
Imitation Learning에는 expert data로 부터 reward function을 근사하고 (neural net으로) 이를 기반으로 policy를 학습하는
Inverse RL (IRL)이라는 것도 포함한다.
어쨌든, 만약 human expert data를 학습한다고 치면 BC와 Offline RL은 거의 동치일 수 있다. Actor만 있다면 말이다.
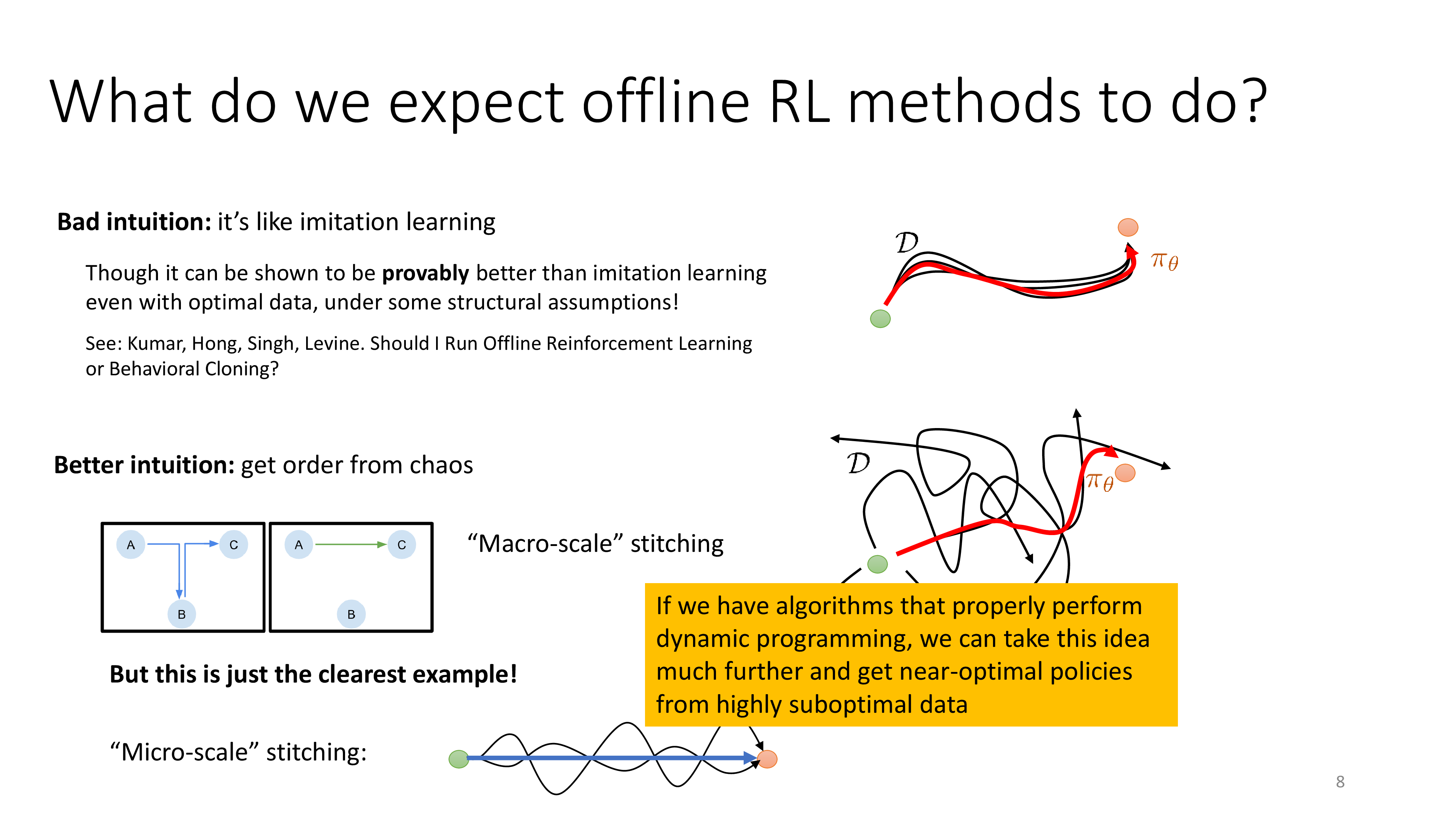 Fig. Offline RL을 BC만으로 보는것은 Bad intuition이다.
Fig. Offline RL을 BC만으로 보는것은 Bad intuition이다.
그런데 Offline RL에는 그 행동이 얼마나 좋았는지?를 environment가 reward로 알려주고,
동시에 Actor-Critic algorithm 처럼 이를 평가하는 (criticize) 모듈인 Value (Critic) Network가 있다.
그러니까 우리가 어떤 숙련된 사람에게 로봇을 조종시켜서 data를 수집했다고 치자.
아마 대부분은 good trajectory일 것이지만 아닌것도 많이 있을 것이며 AlphaGo에서 본 것 처럼 아무리 잘 하는 바둑기사보다도 더 바둑을 잘 두는 policy가 있을 수 있다.
즉 demonstration data는 sub-optimal일 가능성이 있다.
그런데 BC는 data가 100개 있을 경우 100개 모두 옳다는 식으로 학습이 될 것이다 (주어진 정답에 대해 maximum likelihood).
 Fig.
Fig.
그렇다면 결국 agent가 잘 학습돼봐야 할 수 있는일은 기껏해야 이를 모방하는 action 을 할 뿐이다.
 Fig.
Fig.
(물론 data가 무수히 많다면 더 뛰어난 action을 할 가능성이 있을 것 같다.)
반면 Offline RL은 reward의 개념이 있기 때문에 그 안에서도 더 좋고 나쁨을 가려내고 optimal 만들어 낼 수 가 있다고 알려져 있다. 가령 아래와 같이 뒤죽박죽의 trajectory들 (demo)이 있을 때 (human expert가 만든 data여도 오류가 있을 수 있다고 생각하면 될듯)
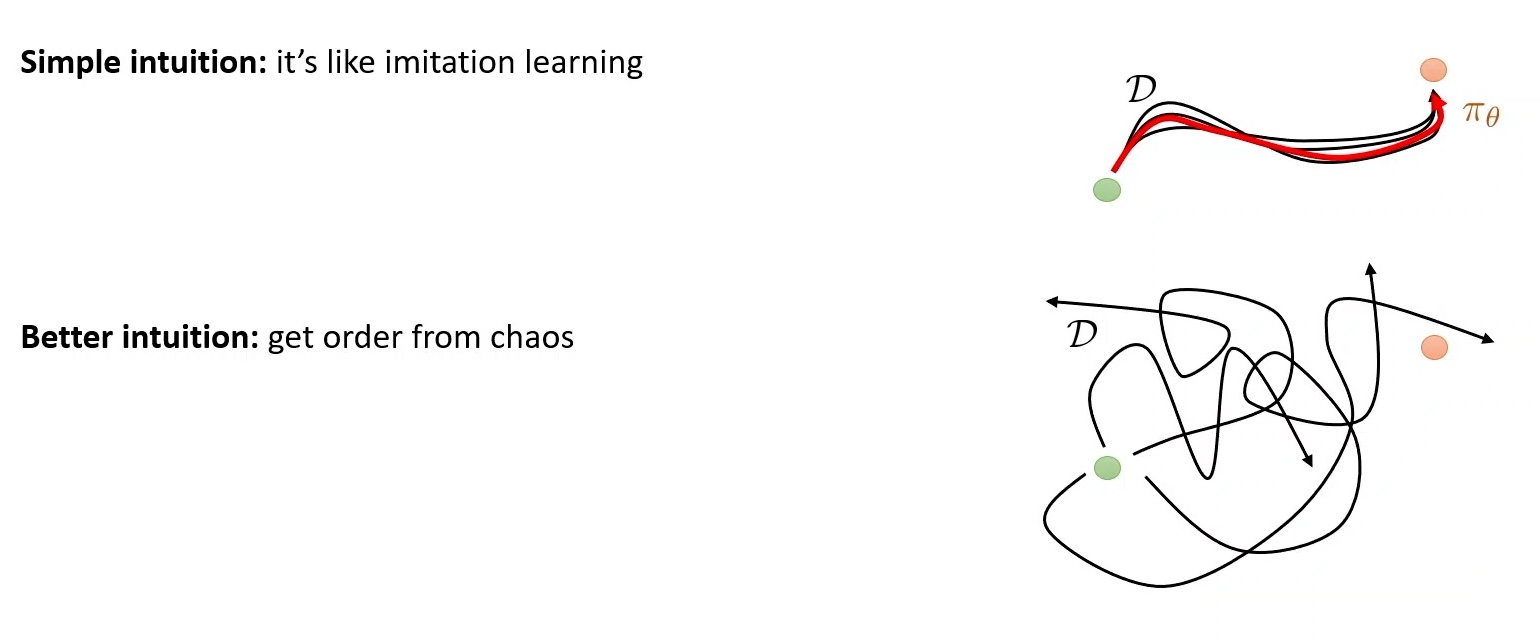 Fig.
Fig.
Offline RL은 수많은 sub-optimal trajecotry들 중에서 (안좋은 trajectory도 있는듯) optimal을 찾아낼 수가 있다는 것이다.
 Fig.
Fig.
이것이 바로 Offline RL이 작동하는 결정적인 차이가 된다.
 Fig.
Fig.
Offline RL이 BC 보다 좋을 수 있는 이유에 대해서 몇 가지 나열해보자면 다음과 같다.
- Reward, Value의 개념이 있음.
- Negative trajectory (실패한) 를 사용해 학습할 수 있음.
- …
여기서 Negative trajectory (실패한) 를 사용해 학습할 수 있음 부분은 예를 들어 우리가 user의 지시에 따라 action 하는 robot을 만들려고 할 때 이 robot data를 전문가가 붙어서 만들어 줄 수 있지만 (positive trajectory),
 Fig. RT-1이라는 robotics transformer는 BC로 학습된 것이다. 무려 17달 동안 13개의 robot으로 사람이 붙어 data를 만들었다는 것 같다.
Fig. RT-1이라는 robotics transformer는 BC로 학습된 것이다. 무려 17달 동안 13개의 robot으로 사람이 붙어 data를 만들었다는 것 같다.
아무래도 data가 적을 수 있으니 simulator를 통해서 data를 모아 이것도 같이 쓰자는 것이 된다.
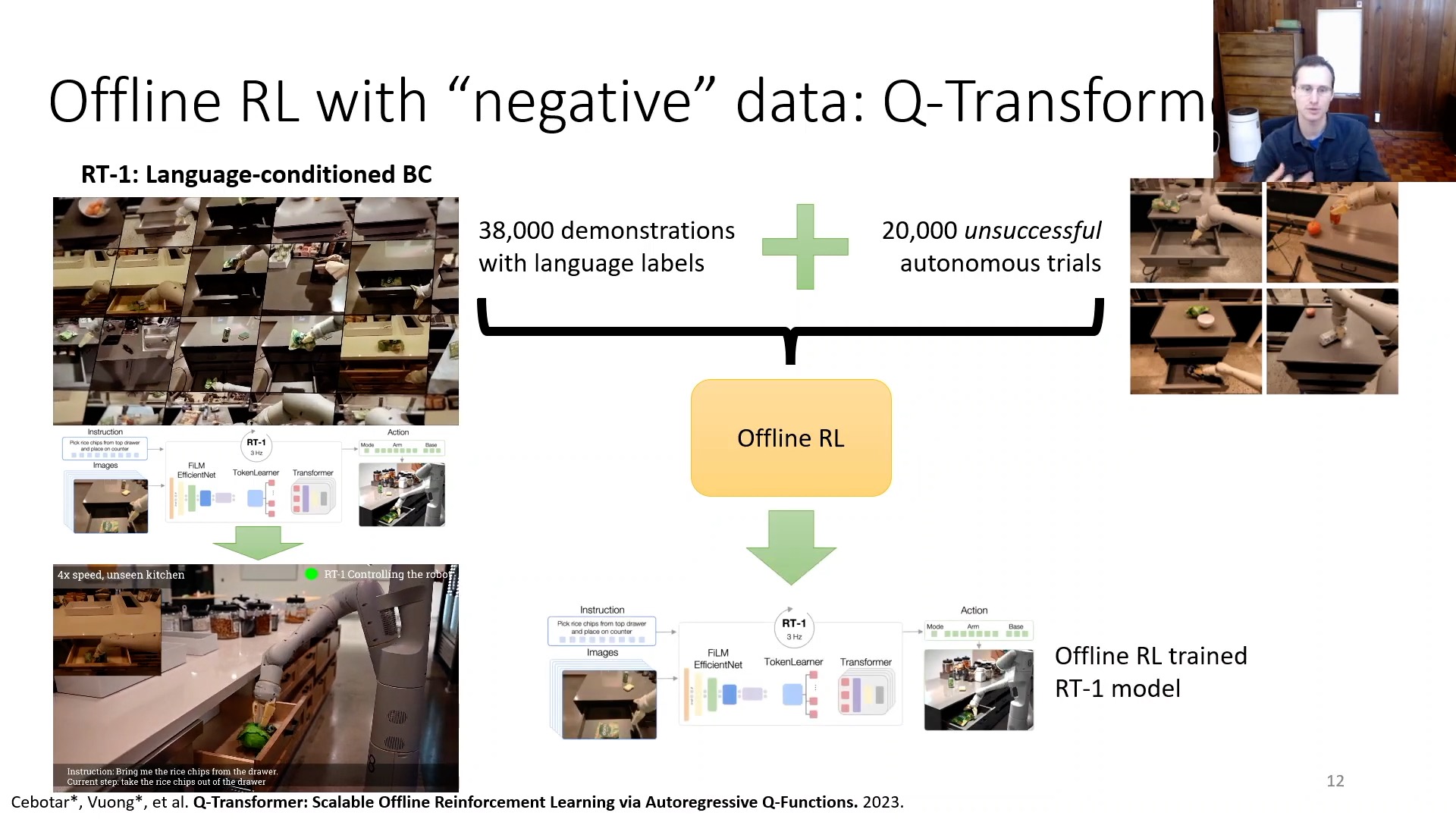 Fig. Offline RL은 좋지못한 trajectory도 같이 학습에 쓸 수 있다.
Fig. Offline RL은 좋지못한 trajectory도 같이 학습에 쓸 수 있다.
이는 아무래도 상대적으로 저질의 data가 될테지만, 좋고 나쁜 trajectory들 모두의 확률을 높히는 BC과 대비해 OffLine RL은 이를 구분지을 수 있기 때문에 negative data를 타산지석삼아 더 좋아질 가능성이 있는 것이다. 사실 offline RL의 mateiral들을 보다보면 극단적인 경우 goal state까지 아예 가지도 못하는 완전한 random policy로부터 trajectory들을 무수히 많이 뽑아서 학습하더라도 결국 near(?) optimal policy를 배우는 것이 가능하다. 이것이 잘 와닿지 않을 수도 있지만 Q-Learning을 생각해보면 되는데, 우리가 Deep Q-Learning (DQN)을 학습할 때에도 맨처음 Q-Network는 random initalization 되어있기 때문에 구린 action을 해서 transition을 만들어 replay buffer로 넣게 된다. 그리고 training iteration을 돌며 replay buffer에서 이런 구린 transition을 재평가 하며 학습을 해 나아간다.
이런 좋고 나쁜 혼돈의 (chaotic) trajectory들 속에서 좋은 transition 일부들만 떼어서 더 좋은 trajectory를 찾아낼 수 있기 때문에 Sergey는 이를 바느질 (stitching) 한다고 표현하기도 한다.
 Fig. 이 robot arm은 닫힌 서랍을 마주할 경우, 서랍을 열고 공을 꺼내고 지정된 곳으로 옮기도록 하습이 됐는데, 실제로는 한 번도 이 full trajectory를 학습한 적이 없다고 한다.
다만 수집한 offline data에 서랍을 여는 행위, 공만 집는행위 등이 있었고 그 외에 랜덤한 action도 있었을텐데 이를 stitching해서 배우는데 성공한 것이다.
Fig. 이 robot arm은 닫힌 서랍을 마주할 경우, 서랍을 열고 공을 꺼내고 지정된 곳으로 옮기도록 하습이 됐는데, 실제로는 한 번도 이 full trajectory를 학습한 적이 없다고 한다.
다만 수집한 offline data에 서랍을 여는 행위, 공만 집는행위 등이 있었고 그 외에 랜덤한 action도 있었을텐데 이를 stitching해서 배우는데 성공한 것이다.
Fig. Q-Transformer가 바로 Offline RL을 쓴 것이라고 할 수 있는데, BC보다 더 성능이 좋다.
이렇듯 BC는 human expert를 모방하는 행위만 할 뿐 이를 재평가해서 더 좋은 trajectory를 학습하려는 것은 아니기 때문에 human expert를 상회하는 performance를 내기가 어렵지만 Offline RL은 potential이 충분히 있는 method라고 생각할 수 있다.
Towards Generalized Agent
Offline RL을 해야하는 이유 중 또 하나로는 바로 Deep Learning의 일반적인 approach인 지도 학습 (Supervised Learning) 처럼 대량의, 다양한 data를 통해서 general agent를 만들기 위해서라고 할 수 있다.
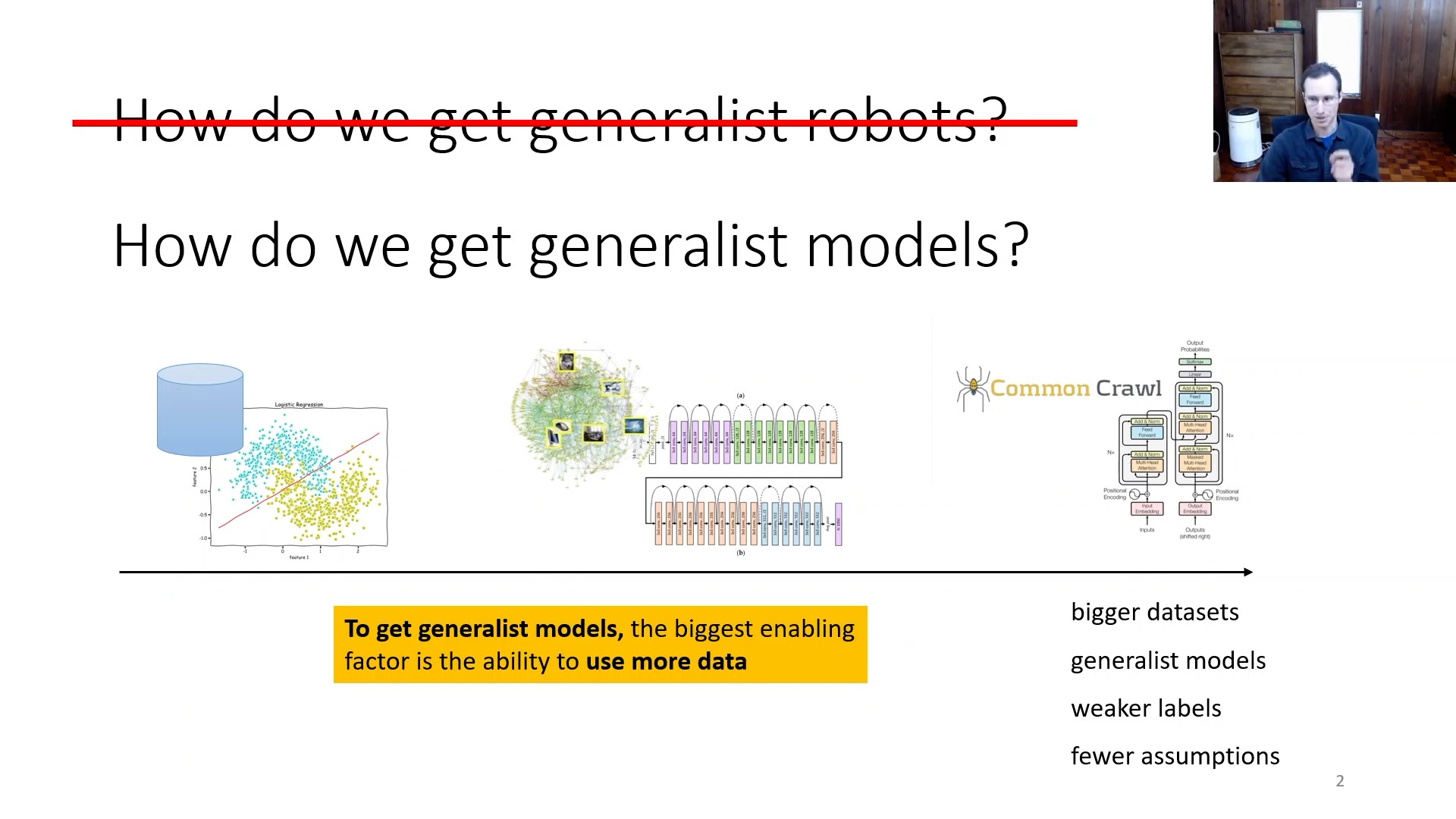 Fig.
Fig.
Deep Learning 분야의 trend가 점점 더
- Large sacle data로 pre-training 하기
- fine-tuning 으로 특정 task 강화하기
- multi-modal
- weak-label
- …
같은 방향으로 가고있기 때문에 Robotics 같은 분야도 이런 method들을 적용하기 위해서는 Offline RL이 잘 돼야 하는것이다.
When Offline RL?
그렇다면 언제? Offline RL을 할까? 실은 Online RL도 어떤 경우에는 나쁘지 않을 수 있다. 가령 Simulator에서 Trajectory를 뽑는데 (Roll-out) 걸리는 시간이 적다면? 즉 sampling이 over-head가 아니라면 Online RL을 쓰는것이 그냥 더 안전할 수 있다.
하지만 우리가 실제 Robot Arm을 Control하려고 한다고 치자. Simulator를 만들어서 학습할 수 도있겠으나 simulator에서 학습한 agent는 결국 real-world에서 잘 작동하지 않을수도 있기 때문에 어쩔수 없이 real-world에서 data를 모아야 한다고 치자. 이런 경우 Online RL을 할 수는 없는 노릇이다.
 Fig.
Fig.
또한 요즘 뜨고 있는 Large Language Model (LLM)의 경우에도 모든 sampling이 simulation 환경에서 돌아간다고 볼 수 있으나 model이 너무 크기때문에 Online으로 학습하기가 매우 부담스럽다. (하지만 현재 LLM은 Proximal Policy Optimization (PPO) 같은 method가 주류긴 하다)
어쨌든 이런 경우 Offline RL이 유망할 수 있는데, When Should We Prefer Offline Reinforcement Learning Over Behavioral Cloning? 같은 paper에서는 data의 형태와 문제 상황 (environment setting)등에 따라 BC 와 Offline RL 중 어떤것이 좋을지에 대해 얘기하기도 한다.
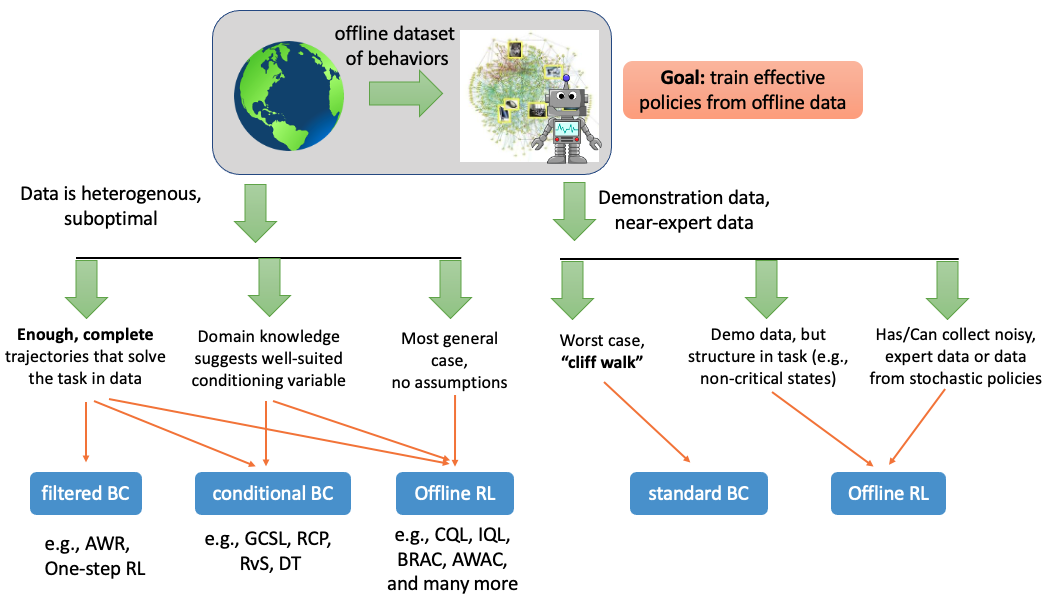 Fig.
Fig.
Can We Do just Off-Policy methods with Offline data?
앞서 Offline과 Online을 비교설명하기 위한 diagram에서 Off-Policy RL이라는 것도 있음을 눈치챘을 것이다.
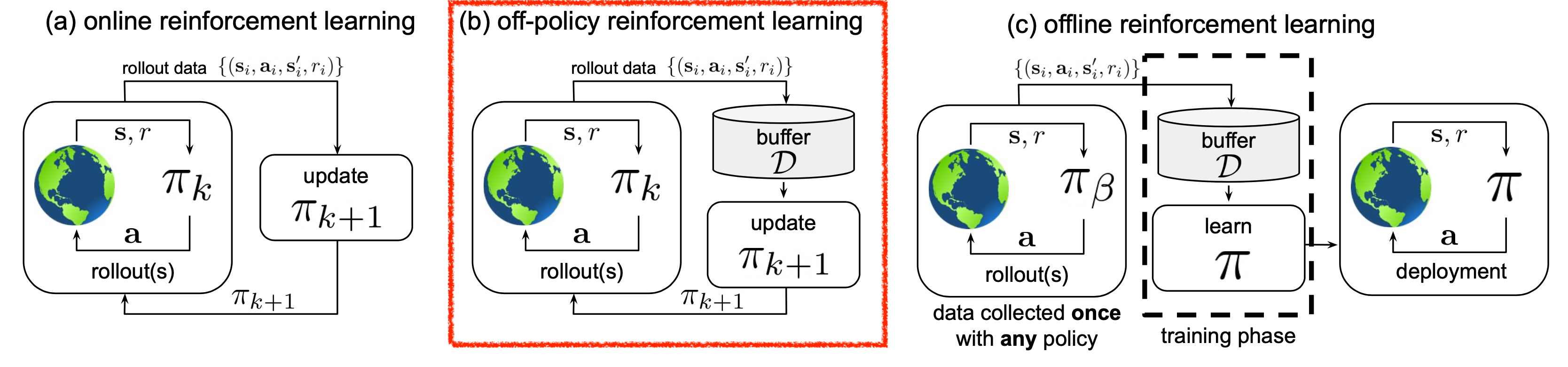 Fig.
Fig.
Off-Policy RL은 간단하게 말해서 내가 학습하고자 하는 sampled trajectory를 sampling한 policy와 현재 update하고자 하는 policy가 다른 것이다.
이와 반대되는 것은 On-Policy RL로 sampling한 policy와 update하고자 하는 policy가 같은것으로 gradient desecnet를 통해서 policy를 한 번 update하고 나면 policy가 변했으니 그전에 sampling 한 것은 의미가 없어지고 다시 sampling 해야 한다.
기본적으로 대부분의 Actor-Critic (policy-based) method들은 모두 On-Policy를 가정하고 만들어 졌다고 한다.
그러면 Offline RL은 Off-Policy RL과 동치일까?
누군가는 그렇다고 하기도 한다.
Offline RL을 다른 말로 하면 Batch RL, Fully Off-policy RL라고 할 수도 있으니 틀린 말은 아니다.
그러나 Offline RL도 어떤 human expert 가 만들어낸 (sampling한) trajectory 라는 것은 어떤 expert policy, \(\pi_{\text{expert}}\)가 뽑은 것일테고 내가 학습하고자 하는 policy는 서로 다른것이 되니까 Off-Policy라고 생각할 수도 있다만, Off-Policy RL은 예를 들어 100 step 정도 update된 policy를 update하는 데 100 step 전의 sample을 쓸 수 있는 방식이긴 하나 보통 step이 너무 경과하면 old sample은 버리고 envrioment와 interation해서 sampling하는 과정을 거치는데 반해 Offline RL은 그렇지 않다. 그러니까 기술적으로는 Fully Off-Policy RL가 맞는데 Off-Policy RL algorithm들로 offline setting training을 하면 잘 되지 않는다는 걸 바로 체감할 수 있다.
Off-policy algortihm 중에는 DQN과 Soft Actor-Critic (SAC)이 유명하니, 이들 중 DQN에 대해서 조금 얘기해보도록 하자. (DQN에 대해서 잘 모르겠다면 이 blog 내 Q-iteration 관련 post를 살펴보면 좋을 것 같다)
 Fig. Offline RL은 CQL, IQL, ILQL 등 Q Function based를 많이 쓴다.
Fig. Offline RL은 CQL, IQL, ILQL 등 Q Function based를 많이 쓴다.
DQN은 현재 policy로 transition, \((s_t,a_t,r(s_t,a_t),s_{t+1})\)를 sampling해서 replay buffer에 저장한다. 여기서 어떤 state에서 action을 했을때 그 policy가 좋고 나쁘든간에 reward는 environment가 주는 것이므로 변하지도 않고 다시 reward를 environment와 interaction 해서 얻어야 할 필요는 없다. 그러므로 \(Q_{\phi}(s,a)\) network를 학습하기 위해서는 \(s_{t+1}\)에서 할 법한 action, \(a_{t+1}\)을 current policy로 sampling해서 traget Q value를 구하기만 하면 된다.
\[\begin{aligned} & Q_{\phi} (s_t,a_t) = r(s_t, a_t) + Q_{\text{target}} ( s_{t+1}, \color{red}{a_{t+1}} ) & \\ & \text{e.g. where transition is sample from } \pi_{0} \text{ but } a_{t+1} \text{ is sampled from } \color{red}{ \pi_{500} } & \\ \end{aligned}\]Offline data는 예를 들어 어떤 behavior policy (심하면 random policy)가 뽑은 무수히 많은 transition들을 뽑고, 한번 데이터를 뽑았으면 replay buffer를 update하는 것이 없는 (즉 environment와 interaction이 없음) 것만 제외하고는 Off-policy와 다른게 없으므로 DQN이 잘 작동해야 할 것 같다. 하지만 DQN을 Offline RL에 바로 쓸 수는 없다고 한다. 실제로 Offline RL에는 Q-function를 변형한 variants가 많긴 하지만 그냥 Vanilla DQN은 interaction이 없는 상황에서 매우 안좋은 성능을 낸다.
 Fig.
Fig.
왜일까?
Out Of Distribution (OOD) action
그 이유는 바로 out of distribution (OOD)인 action에 대해서 Q-Function 이 믿을만 하지 못한 값을 내뱉을 것이기 때문이다.
 Fig.
Fig.
만약 Q Network가 잘학습됐다고 치자. Deep Neural Network (DNN)이 잘하는 것은 training sample들을 보고 curve fitting을 해서 결국 unseen sample에 대한 prediction을 잘 수행하는 것이다. 현재 내가 수집한 offline batch data에 수많은 transition들이 있을텐데, 어떤 같은 state에 대해서도 수많은 action들에 대한 data sample들이 있을 것이다. Q Network를 학습하는 것은 regression을 하는 것이기 때문에 만약에 잘 학습이됐다면 아래의 blue curve를 얻을 수 있을 것이다.
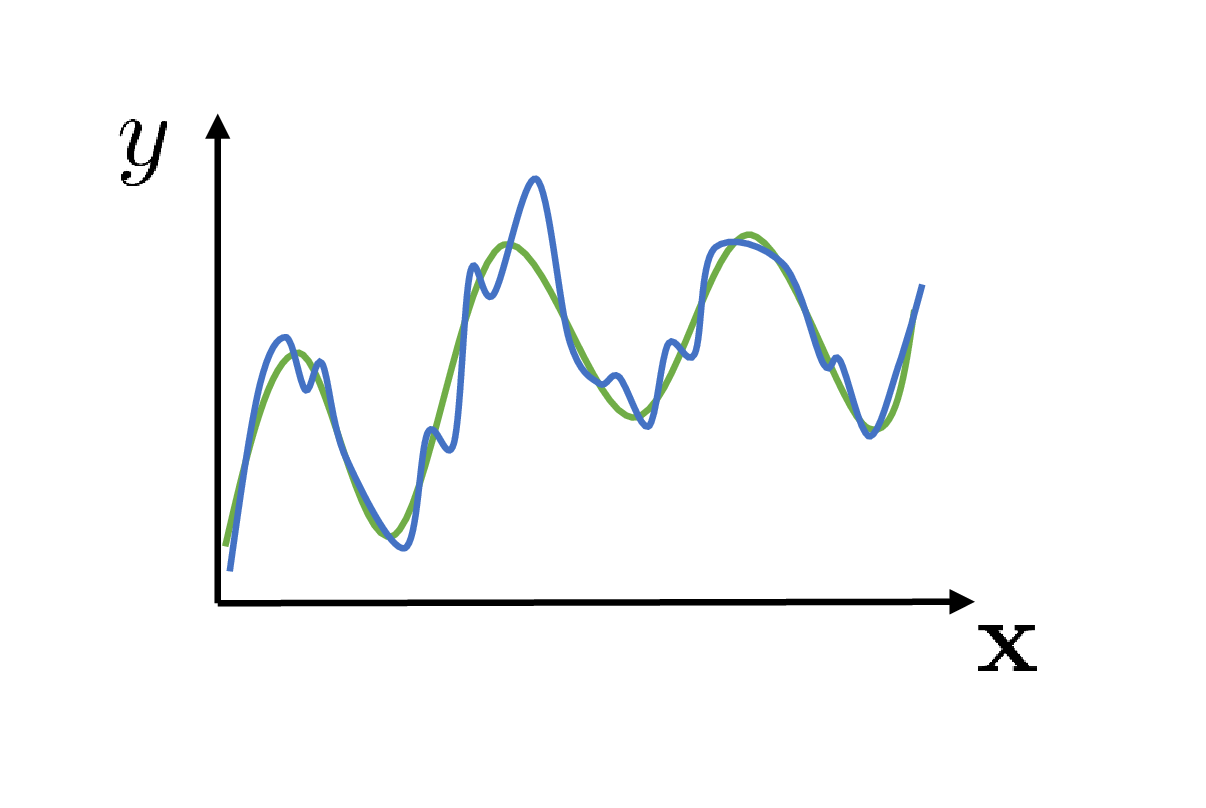 Fig.
Fig.
그런데 Q network가 policy를 산정하는 방법은 argmax를 하는 것이다. Agent는 아래처럼 continuous action space에 대해서 Q값이 max인 action의 확률을 1로 하는 greedy policy를 얻게 된다.
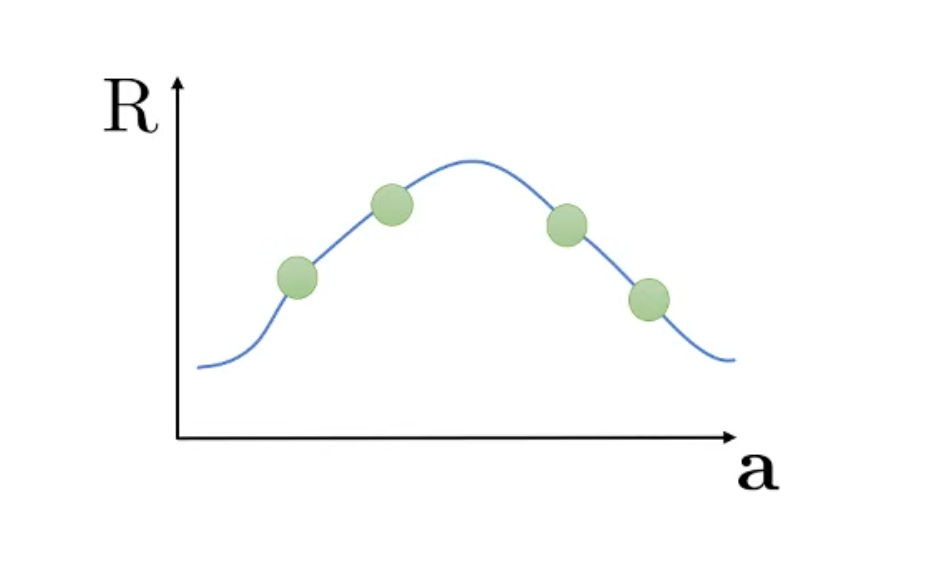 Fig.
Fig.
하지만 이 action은 우리가 실제로 해본 적이 없으므로 이게 좋은 것인지 나쁜 것인지 알 수 없다.
다만 Q Network가 그렇게 추정했을 뿐이다.
DQN같은 online method (online과 off-policy를 헷갈려선 안된다)들이 가능한 이유는 greedy policy가 가장 Q값이 커보이는 action을 고르게 된다면,
그 action을 실제로 고르게 되지만 그 action이 구리다면 결국에는 낮은 reward를 얻을 것이기 때문에 '해보고 아님 말고'가 되기 때문이다.
하지만 이렇게 ‘그 action은 안좋아요’라고 알려주기 위해서는 실제 이 action을 해본 transition을 replay buffer에 넣어야 하는데,
Offline setting은 environment와의 interaction이 일절 없다.
그러니까 trial and error가 불가능한 것이다.
 Fig.
Fig.
혹은 unseen action에 대해서 random에 가까운 값을 return할텐데, 이런 경우 유사한 action도 아예 엉뚱한 action이 bellman backup에 사용되어 network가 아예 맛이 가 버릴 수 있다.
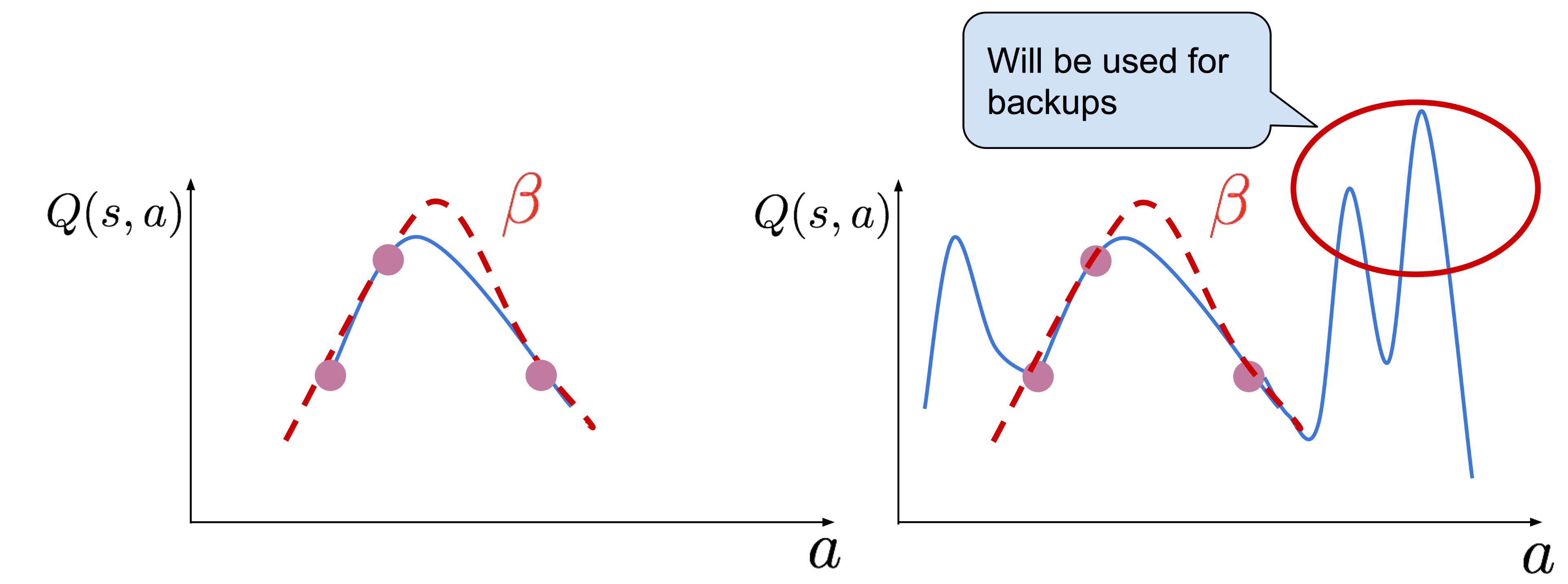 Fig.
Fig.
또 다른 말로 이를 behavior policy로부터 learned policy가 너무 멀어졌기 때문에 (deviate) 발생하는 일이라고도 하는데,
distributional shfit라고 얘기하기도 한다.
혹은 Sergey는 이 문제를 training된 DNN의 adversarial sample을 찾는 것으로 설명하기도 하는데,
adversarial sample이란 DNN이 가장 못할 것 같은, 즉 error를 가장 크게하는 sample을 찾는 것으로 Q-Learning의 max operator가 이런 일을 조장한다고 얘기한다.
 Fig.
Fig.
이는 결국 Q-Learning의 잘 알려진 문제점인 overestimation으로 이어지게 되는데, 이는 Q값이 계속 커지지만 (Q가 높은 action을 계속 선택함) reward는 전혀 커지지 않는 현상을 말하고 offline data sample을 million order로 늘려도 reward는 전혀 증가하지 않는다는 것을 확인할 수 있다. (half cheetah example)
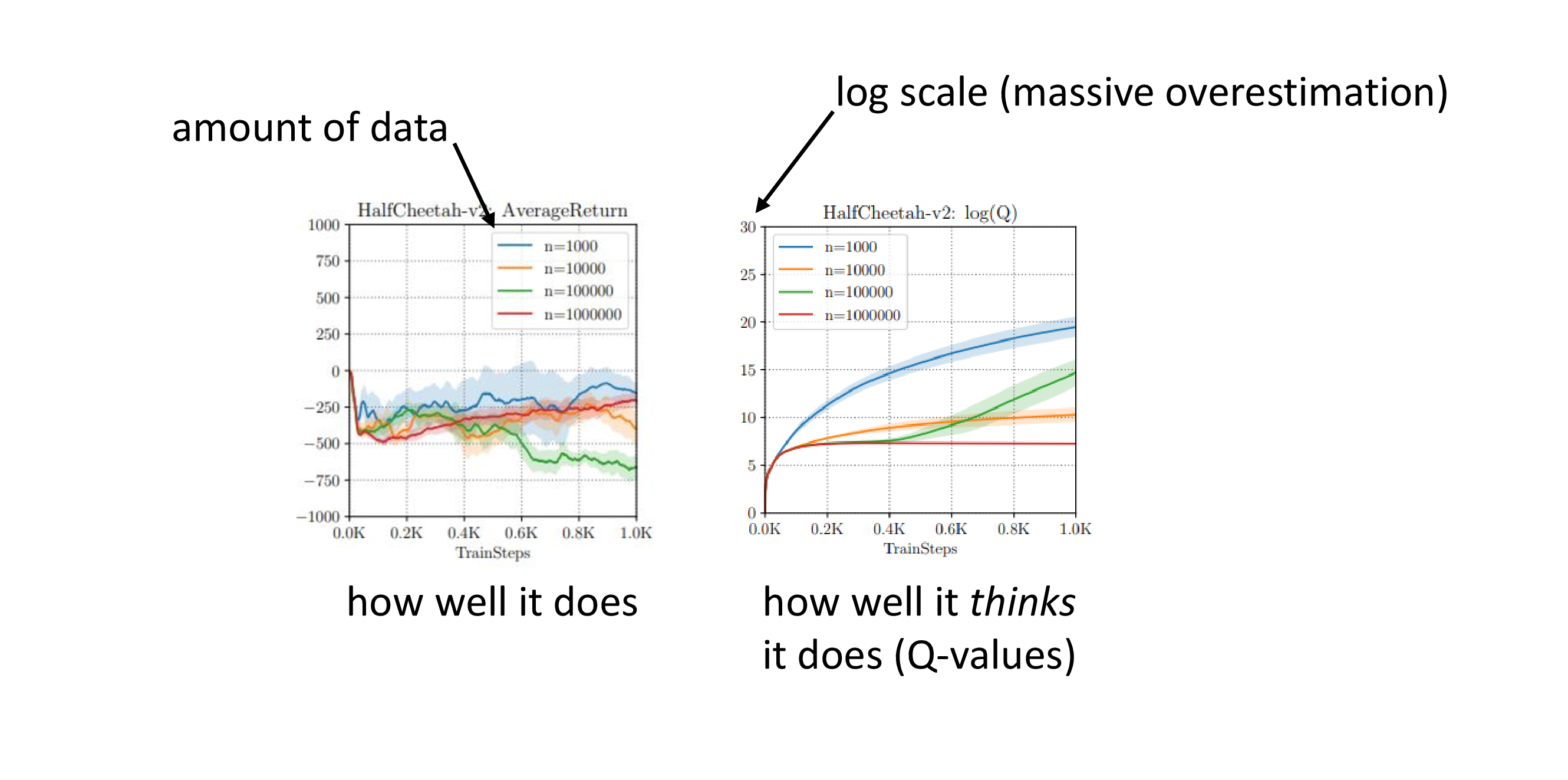 Fig.
Fig.
Key Idea for Offline RL : Conservative Optimization
어떻게 이 distributional shift 문제를 해결해야 할까?
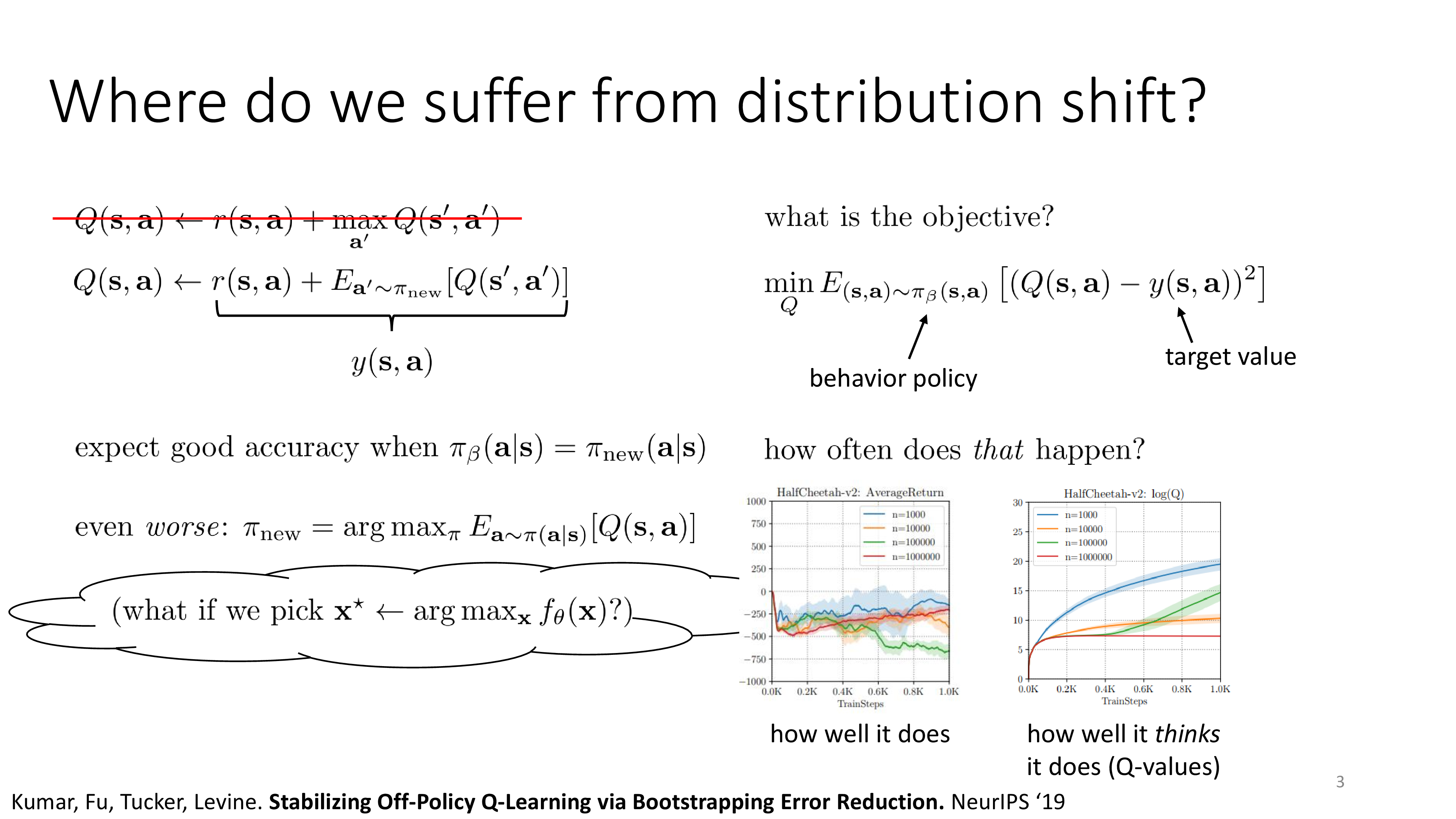 Fig.
Fig.
Key idea는 보수적으로 (conservative) optimization을 하는 것이다.
왜냐하면 우리는 어떤 state, \(s_t\)에 대해서 예를 들어 10개의 data point가 있으면 이 값들에 대해서는 믿을만 하지만 나머지 구간들에 대해서는 믿을 수 없다.
그래서 만약 우리가 behavior policy를 알고 있다면 current policy와의 divergence를 measure해서 낮은 수준으로 유지한다는 것이 핵심이다.
이는 behavior Q network와 current Q network사이의 divergence 를 minimize하면서 Q-Learning하는 것과 같은 말인데,
그 이유는 Q-Learning based method는 Q가 곧 policy이기 때문이다.
(가장 큰 Q값을 return하는 action의 확률이 1인 greedy policy)
만약 우리가 가지고 있는 data sample이 아래와 같다고 치자. Continuous action space를 가질 때 어떤 state에 대해 5개의 transition이 있는 셈이다.
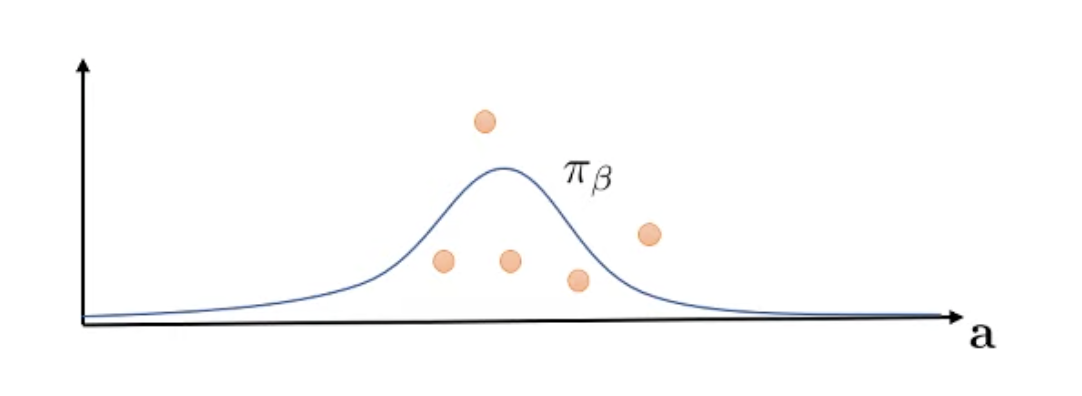 Fig.
Fig.
당연히 이는 \(\color{blue}{\pi_{\beta}}\)로부터 sampling되었지만 실제로 curve fitting을 해보면 우리는 아래의 curve를 얻게 될 수 있다.
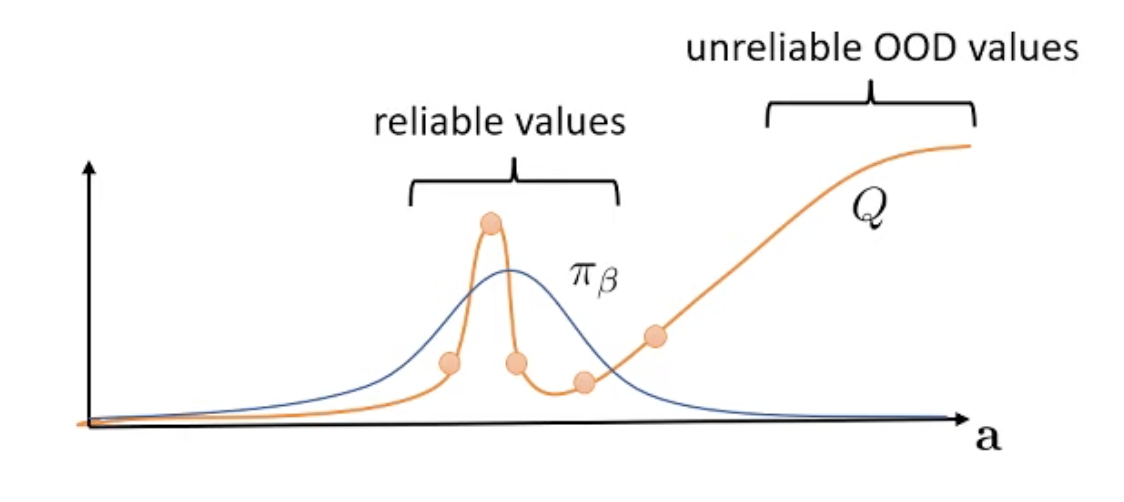 Fig.
Fig.
앞서 말했던 것 처럼 OOD sample에 대해 Q값이 크게 형성될 수 있는데, update하려는 current policy와 behavior policy간의 KL constraint를 걸어주면 아래와 같은 green curve를 얻을 수 있다.
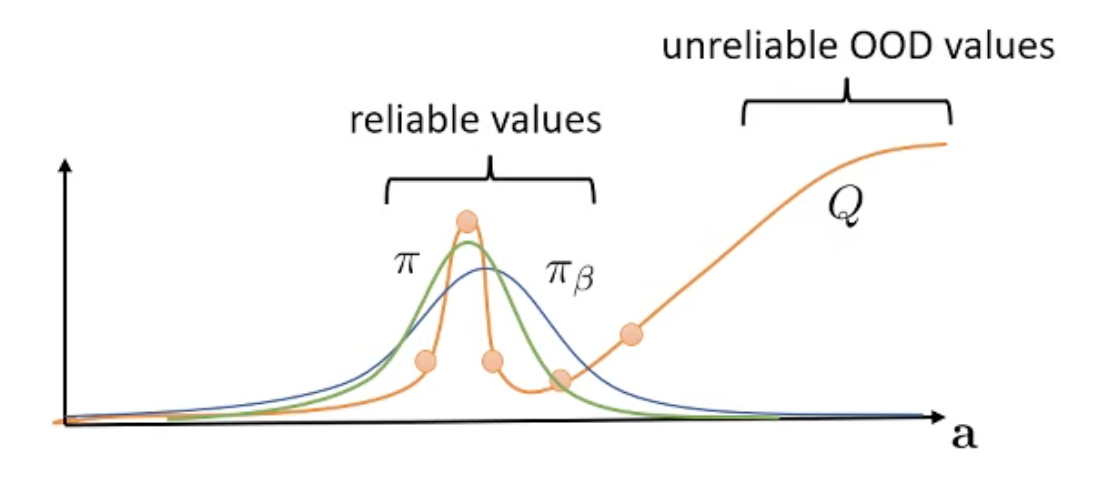 Fig.
Fig.
이런식으로 policy (or Q function)을 update 함으로써 Offline RL에 존재하는 distributional shift를 막는것이 핵심 idea라고 볼 수 있는데, 이러한 constrained optimization method는 advanced policy gradient methos (TRPO, PPO 등)에도 비슷하게 녹아있는 철학이다. (자세한 사항은 이 post 참고)
 Fig.
Fig.
하지만 이 method를 쓰는데 몇가지 문제가 있을 수 있다고 한는데, 첫 번째로 behavior policy가 어떻게 생겼는지 우리는 전혀 모른다는 것이다. 우리는 behavior policy가 만들어낸 sample만 가지고 있을 뿐이다. 생각해보면 expert demo를 모은다는 것은 우리가 직접 robot arm을 조작해서 trajectory를 수집한다는 것인데, 사람이 조작한 것을 가지고 어떤 state에서 어떤 action을 뽑는다는 policy혹은 Q function을 유추해 낼 수 있을까? 가지고 있는 sample로 BC을 해서 behavior policy를 approximate해서 KL constraint를 걸어주면 될지도 모르겠으나 좋아보이진 않는다.
두 번째로는 이런 idea가 너무 pessimistic하거나 충분히 pessimistic하지 않을 가능성을 모두 가지고 있다는 것이라고 한다.
아무튼 이런 idea를 적용한 Offline RL은 Actor-Ciritc based, Q-Learning based method 들이 모두 존재하고, 이를 model-based로 확장한 algorithm들도 존재하며 이들의 장단점은 아래와 같다고 한다. (robotics같은데서 Offline RL을 많이 시도하는 것 같은데 robotics에서는 dynamics를 학습하는 경우가 많기 때문인 듯 하다)
 Fig.
Fig.
이제 천천히 각 algorithm들에 대해서 알아보도록 하자.
Actor-Critic based Methods
먼저 Actor-Critic based method에 대해 알아보자. (이하 Sergey의 lecture slide)
 Fig.
Fig.
 Fig.
Fig.
2018, Advantage-Weighted Regression (AWR)
사실 model offline RL은 explicit policy constraint method를 쓰지 않는다.
대신 implicit policy constraint를 사용하는데, 이하의 내용은 Advantage-Weighted Regression (AWR) algorithm으로 2018년에 publish된 paper에서 소개되었다.
 Fig.
Fig.
이를 이해하기 위해서는 아래의 constraint optimization 수식을 통해 optimal policy, \(\color{red}{ \pi^{\ast} (a \vert s) }\)를 유도해야 한다.
여기서 \(Z(s)\)는 partition function이라고 하는데, \(\pi(a \vert s)\)를 \(\int \pi(a \vert s)=1\)이 되게 만들어주는 normalizer이다 (일딘 넘어가자).
 Fig.
Fig.
 Fig.
Fig.
2020, Advantage Weighted Actor-Critic (AWAC)
다음은 2020년에 제안된 Advantage Weighted Actor Critic (AWAC)이다. AWAC은 AWR에 Critic을 추가한 것이라고 볼 수 있는데, 먼저 behavior policy와의 KL constraint을 가지고 reward maximization을 하는 objective function으로부터 출발 한다는 것은 같다.
\[\begin{aligned} & \pi_{k+1}(a \vert s) = \arg \max_{\pi \in \Pi} \mathbb{E}_{a \sim \pi(a \vert s)} [ A^{\pi_k}(s,a) ] \\ & \text{s.t. } D_{KL} (\pi (\cdot \vert s) \parallel \pi_{\beta} (\cdot \vert s)) \leq \epsilon \\ & \int_a \pi (a \vert s) da = 1 \\ \end{aligned}\]asd
\[\begin{aligned} & \mathcal{L}(\pi, \lambda, \alpha) = \mathbb{E}_{a \sim \pi(\cdot \vert s)} [ A^{\pi_k}(s,a) ] \\ & + \lambda (\epsilon - D_{KL} (\pi (\cdot \vert s) \parallel \pi_{\beta} (\cdot \vert s)) ) \\ & + \alpha (\int_a \pi (a \vert s) - 1) \\ \end{aligned}\]이를 미분하면 다음을 얻게 된다.
\[\begin{aligned} & \frac{\partial \mathcal{L}}{\partial \pi} = A^{\pi_k}(s,a) - \lambda \log \pi_{\beta} (a \vert s) + \lambda \log \pi (a \vert s) + \lambda - \alpha \\ \end{aligned}\]이제 미분한 값을 0으로 놓고 solution을 구하게 되면 아래를 얻게 된다.
\[\pi^{\ast}(a \vert s) = \frac{1}{Z(s)} \pi_{\beta}(a \vert s) \exp (\frac{1}{\lambda} A^{\pi_k}(s,a))\]우리가 원하는 것은 parameterized Actor가 위에서 구한 optimal non-parametric solution이 되는 것이므로 아래의 KL divergence를 measure해서 minimize하면 된다.
\[\begin{aligned} & \arg \min_{\theta} \mathbb{E}_{\rho_{\pi_{\beta}}(s)} [D_{KL} (\pi^{\ast} (\cdot \vert s) \parallel \pi (\cdot \vert s))] \\ & \arg \min_{\theta} \mathbb{E}_{\rho_{\pi_{\beta}}(s)} [ \mathbb{E}_{\pi^{\ast}(\cdot \vert s)} [-\log \pi_{\theta}(\cdot \vert s)]] \\ \end{aligned}\] Fig.
Fig.
Q-Learning based Methods
2021, Implicit Q-Learning (IQL)
먼저 2021년에 publish된 Implicit Q-Learning (IQL)이다.
 Fig.
Fig.
 Fig.
Fig.
2020, Conservative Q-Learning (CQL)
그 다음은 2020년에 제안된 Conservative Q-Learning (CQL)이다. 말그대로 보수적으로 Q-Learning을 하겠다는 의미이다.
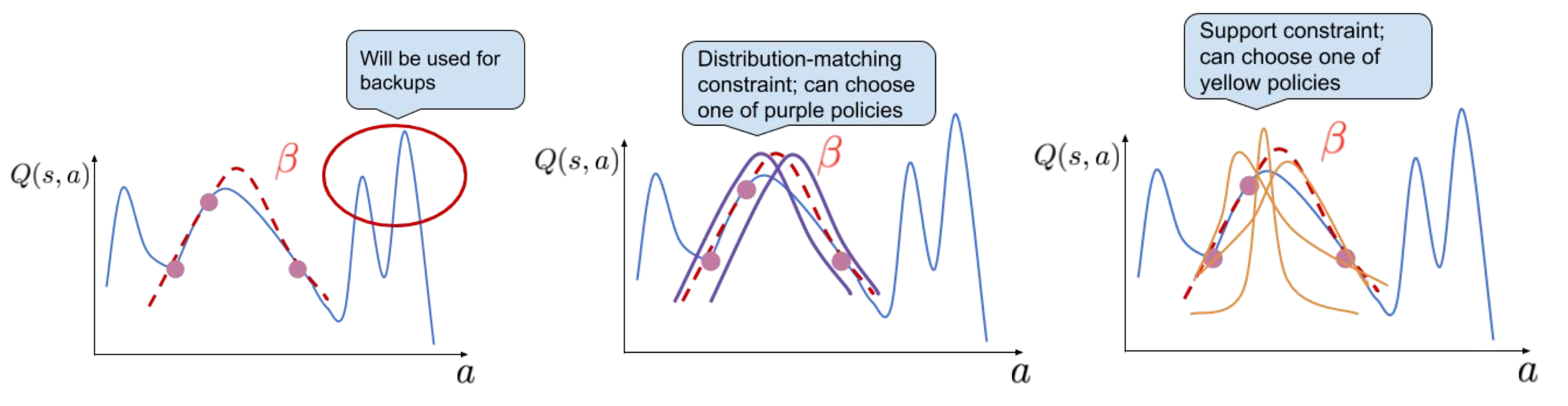 Fig.
Fig.
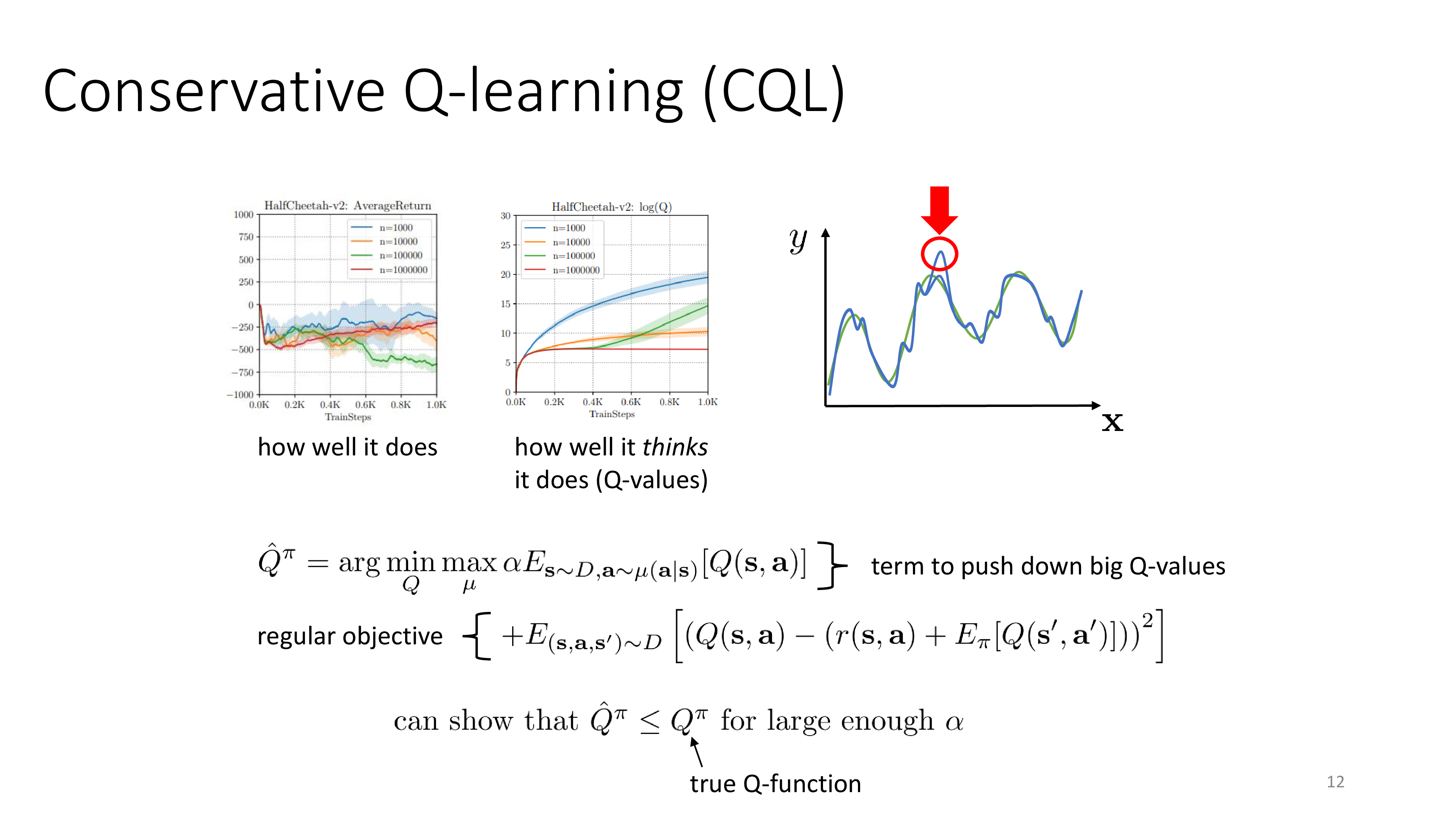 Fig.
Fig.
 Fig.
Fig.
 Fig.
Fig.
 Fig.
Fig.
Model-based Offline RL Methods
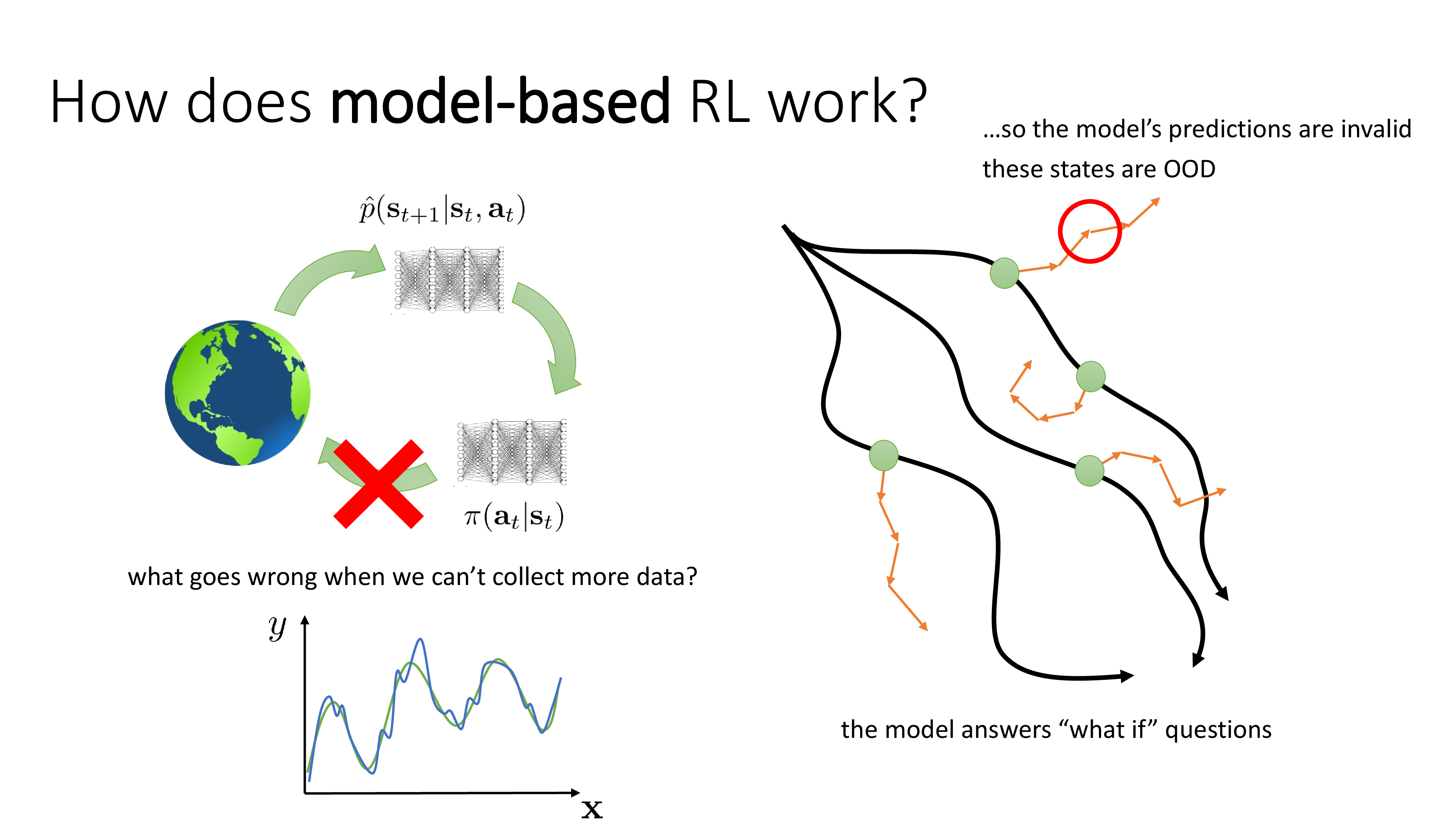 Fig.
Fig.
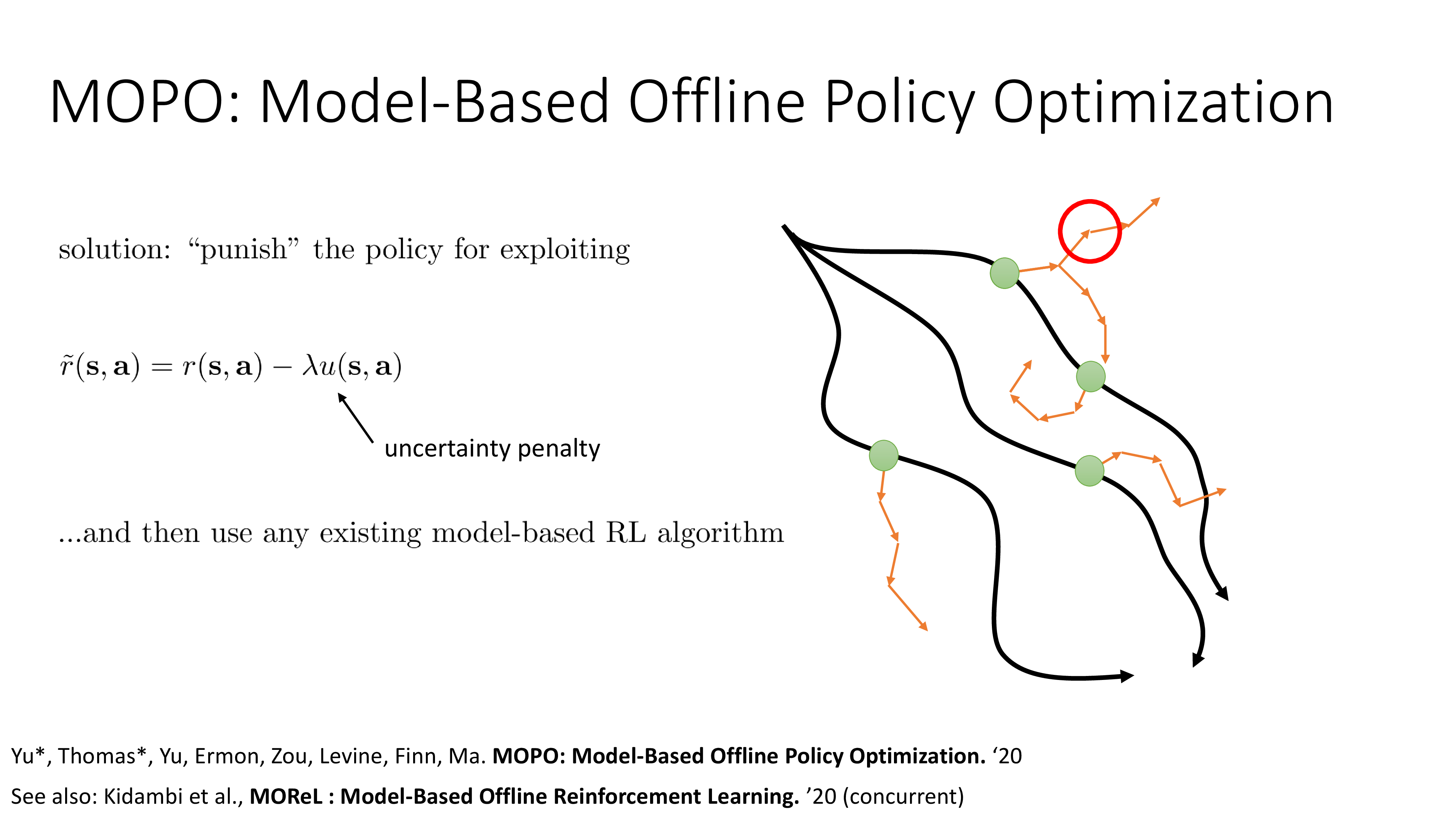 Fig.
Fig.
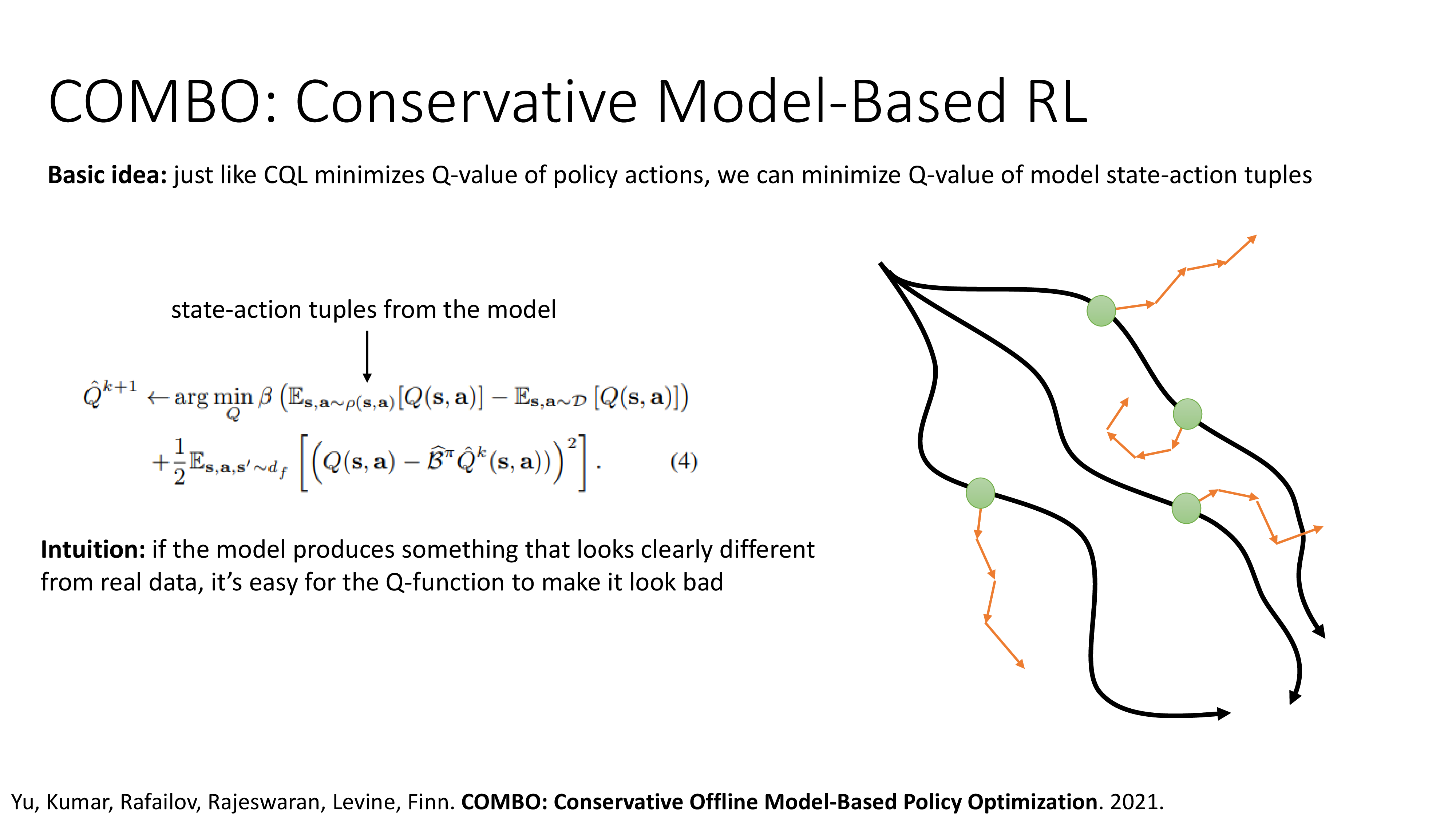 Fig.
Fig.
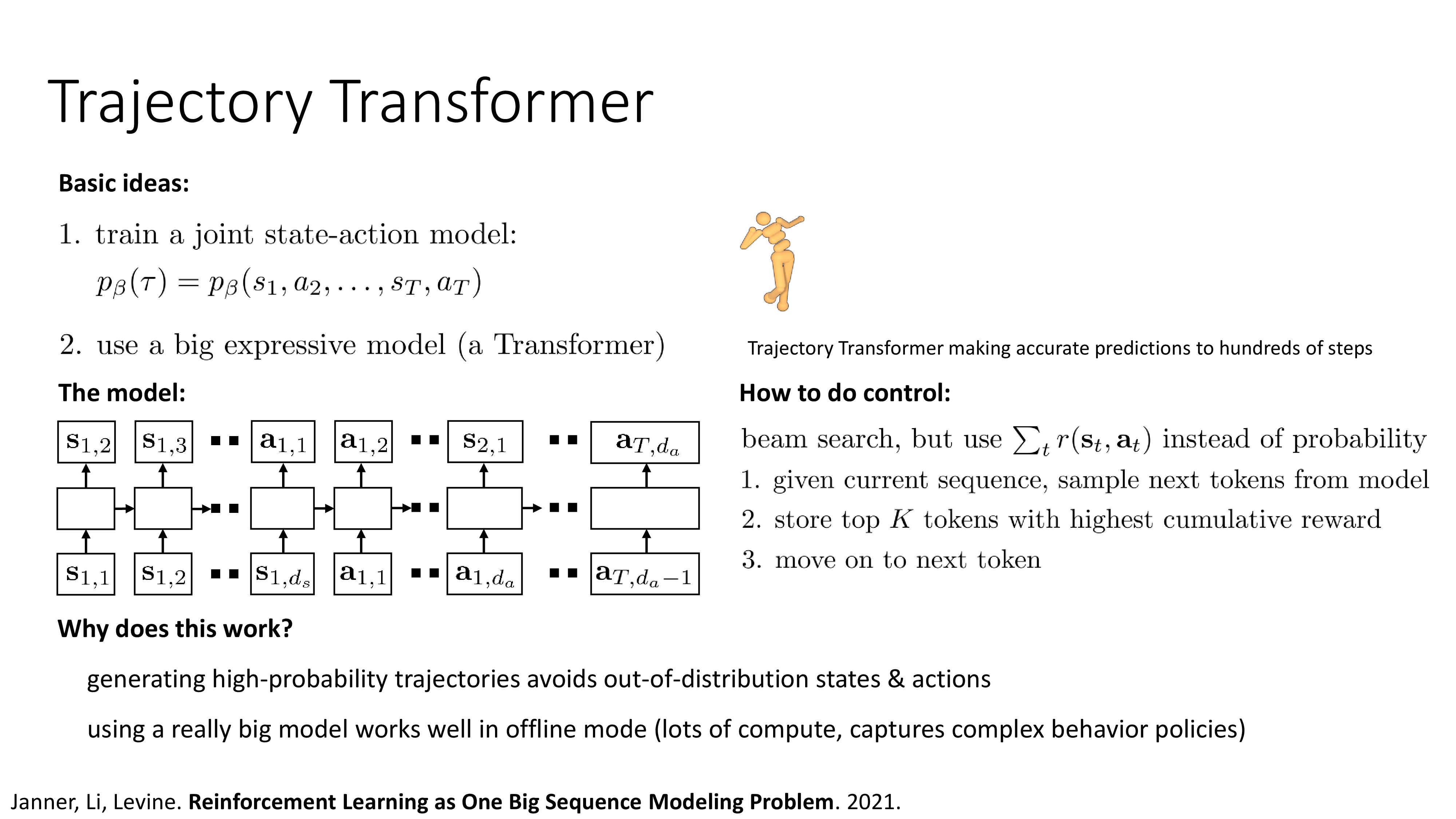 Fig.
Fig.
Goal Conditioned BC Methods
Can we do BC with suboptimal data?
앞서 BC가 가질 수 있는 한계에 대해서 얘기했다. 성능의 상한선이 demo를 한 policy나 expert를 넘지 못한다는 것이었는데, 그러므로 BC는 좋은 성능을 내기 위해서는 매우 detail하게 data를 수집하고 학습을 해야 한다고 한다. 그런데 suboptimal data를 가지고도 BC를 해도 될까?
2021, Decision Transformer and Trajectory Transformer
거의 비슷한 시기에 con-current work으로 Decision Transformer와 Trajectory Transformer가 나왔다. 둘 다 affiliation은 UCB이며 Deep RL의 쌍두마차인 Sergey와 Pieter가 각각 교신저자로 참여했다.
Outro
Takeaways, conclusions, future directions
 Fig.
Fig.
 Fig.
Fig.
How about Fine-tuning Offline trained model with Onlione RL method ?
그렇다면 Pre-training 을 Offline RL로 하고 Online RL로 fine-tuning하는 건 어떨까? Pre-Training for Robots: Offline RL Enables Learning New Tasks from a Handful of Trials에도 나와있듯 fine-tuning을 하면 성능이 잘 나온다고 하는데, pre-training에 썼던 trajectory와 새로 online으로 smapling한 trajectory의 비율을 잘 맞춰서 학습해야 제일 학습이 잘 되는 것 같다.
References
- Papers
- Videos (Tutorials, Lectures) and Others
- NeurIPS 2020 Tutorial on Offline RL
- CS285 from Sergey Levine
- Fall 2020 ver.
- Fall 2023 ver.
- CS224R from Chelsea Finn
- 10-703 from Katerina Fragkiadaki
- Imitation learning vs. offline reinforcement learning from Sergey Levine
- Data-Driven Reinforcement Learning: Deriving Common Sense from Past Experience from Sergey Levine
- The Bitterest of Lessons: The Role of Data and Optimization in Emergence
- Reinforcement Learning Pretraining for Reinforcement Learning Finetuning
- CS25 Stanford Seminar 2022 - Decision Transformer: Reinforcement Learning via Sequence Modeling from Aditya Grover
- Should I Use Offline RL or Imitation Learning?
-
Offline (Batch) Reinforcement Learning: A Review of Literature and Applications
- Towards Generalist Robots (CoRL 2023 workshop)
- 69. How many (new) samples do you need?: Zero! An introduction to Offline RL (KAIST 산업공학과 박준영)
- Others (Blogs)