(yet) Diffusion-based Video Generation
16 Feb 2024< 목차 >
tmp
오늘 Google이 Gemini pro 1.5를 발표하자마자 OpenAI에서는 Sora를 발표했다. Sora는 두가지 부분에서 충격적이었는데, 먼저 첫 번째는 자연스러운 controllable video generation이 가능하려면 2,3년은 더 필요할 줄 알았는데 오늘 그것이 가능하다는 걸 보여준 것이다. 이것이 1년전에 이미 만들어졌던 model일 수도 있다. 약 1~2주 전에 Google이 Lumiere라는 model의 demo를 공개했는데, 사실 이때도 너무 자연스러워서 놀라긴 했다. Diffusion based video generation은 물론 이번이 처음은 아니다 그전에도 많은 시도가 있었고 dall-e 2가 나오고 얼마 지나지 않아 2022년 학회에 참석중이었을 때 image-to-video, image-to-3d paper들이 나와 놀랐던 기억이 있다.
두 번째 충격적인 것은 Sora의 technical report에도 강조되어 있는 것인데, 바로 video generation이 AI가 물리적인 현실 세계 (physical world)를 연결시켜줄 것이라는 것이다. 즉 AI가 simulation이 가능하다는 것인데, 기억하기로는 2018년에 World Models이라는 paper가 나왔었다.
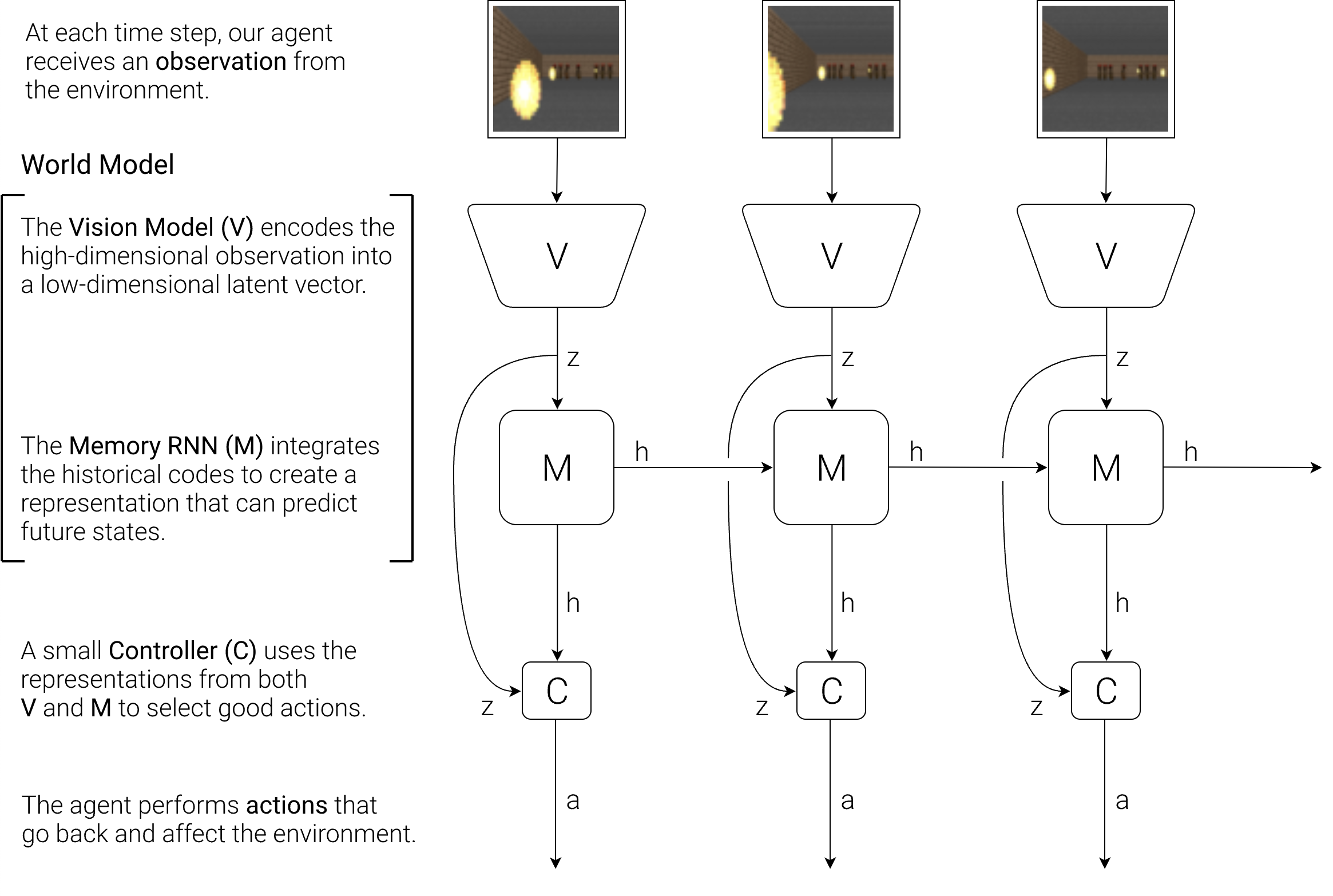 Fig.
Fig.
 Fig.
Fig.